
Update four-model benchmark report
Browse files
README.md
CHANGED
|
@@ -1,106 +1,32 @@
|
|
| 1 |
---
|
| 2 |
license: gpl-3.0
|
| 3 |
pretty_name: Calculator
|
| 4 |
-
size_categories:
|
| 5 |
-
- 10K<n<100K
|
| 6 |
-
task_categories:
|
| 7 |
-
- text-generation
|
| 8 |
-
language:
|
| 9 |
-
- en
|
| 10 |
-
configs:
|
| 11 |
-
- config_name: default
|
| 12 |
-
data_files:
|
| 13 |
-
- split: train
|
| 14 |
-
path: data/train-*
|
| 15 |
-
- split: validation
|
| 16 |
-
path: data/validation-*
|
| 17 |
-
- split: test
|
| 18 |
-
path: data/test-*
|
| 19 |
---
|
| 20 |
|
| 21 |
-
# Arithmetic Expression Dataset
|
| 22 |
|
| 23 |
-
|
|
|
|
| 24 |
|
| 25 |
-
|
| 26 |
|
| 27 |
-
|
| 28 |
-
-
|
| 29 |
-
- curly braces: `{}`
|
| 30 |
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
The dataset is balanced across reduction depths from 1 to 15 and is intended for SLMs that learn structured mathematical reasoning from examples.
|
| 34 |
-
|
| 35 |
-
## Content
|
| 36 |
-
|
| 37 |
-
Each sample contains:
|
| 38 |
-
|
| 39 |
-
- `expression` — the original arithmetic expression
|
| 40 |
-
- `prompt` — the input prompt for the model
|
| 41 |
-
- `completion` — the target answer in `<think> ... </think>` and `<answer> ... </answer>` format
|
| 42 |
-
- `answer` — the final numeric result
|
| 43 |
-
- `steps` — the number of reduction steps
|
| 44 |
-
- `text` — the full formatted training sample
|
| 45 |
-
|
| 46 |
-
## Counts
|
| 47 |
-
|
| 48 |
-
- Train examples: 15000
|
| 49 |
-
- Validation examples: 750
|
| 50 |
-
- Test examples: 3000
|
| 51 |
-
- Total examples: 18750
|
| 52 |
-
|
| 53 |
-
Each step from 1 to 15 appears exactly:
|
| 54 |
-
|
| 55 |
-
- 1000 times in train
|
| 56 |
-
- 50 times in validation
|
| 57 |
-
- 200 times in test
|
| 58 |
-
|
| 59 |
-
The symbol-length distribution:
|
| 60 |
-
|
| 61 |
-

|
| 62 |
-
|
| 63 |
-
## Example
|
| 64 |
-
|
| 65 |
-
```text
|
| 66 |
-
### Expression
|
| 67 |
-
Calculate: {([20 - 9] - 3) * ({[8 + {{2 * 18} - (12 * 19)}] - {(15 * 13) - 12}} + 11)}
|
| 68 |
-
|
| 69 |
-
### Answer
|
| 70 |
-
<think>
|
| 71 |
-
Start: {([20 - 9] - 3) * ({[8 + {{2 * 18} - (12 * 19)}] - {(15 * 13) - 12}} + 11)}
|
| 72 |
-
1. (20 - 9) = 11
|
| 73 |
-
2. (11 - 3) = 8
|
| 74 |
-
3. (2 * 18) = 36
|
| 75 |
-
4. (12 * 19) = 228
|
| 76 |
-
5. (36 - 228) = -192
|
| 77 |
-
6. (8 + -192) = -184
|
| 78 |
-
7. (15 * 13) = 195
|
| 79 |
-
8. (195 - 12) = 183
|
| 80 |
-
9. (-184 - 183) = -367
|
| 81 |
-
10. (-367 + 11) = -356
|
| 82 |
-
11. (8 * -356) = -2848
|
| 83 |
-
</think>
|
| 84 |
-
<answer>-2848</answer>
|
| 85 |
-
```
|
| 86 |
-
|
| 87 |
-
## Evaluation on Qwen2.5-Math
|
| 88 |
-
|
| 89 |
-
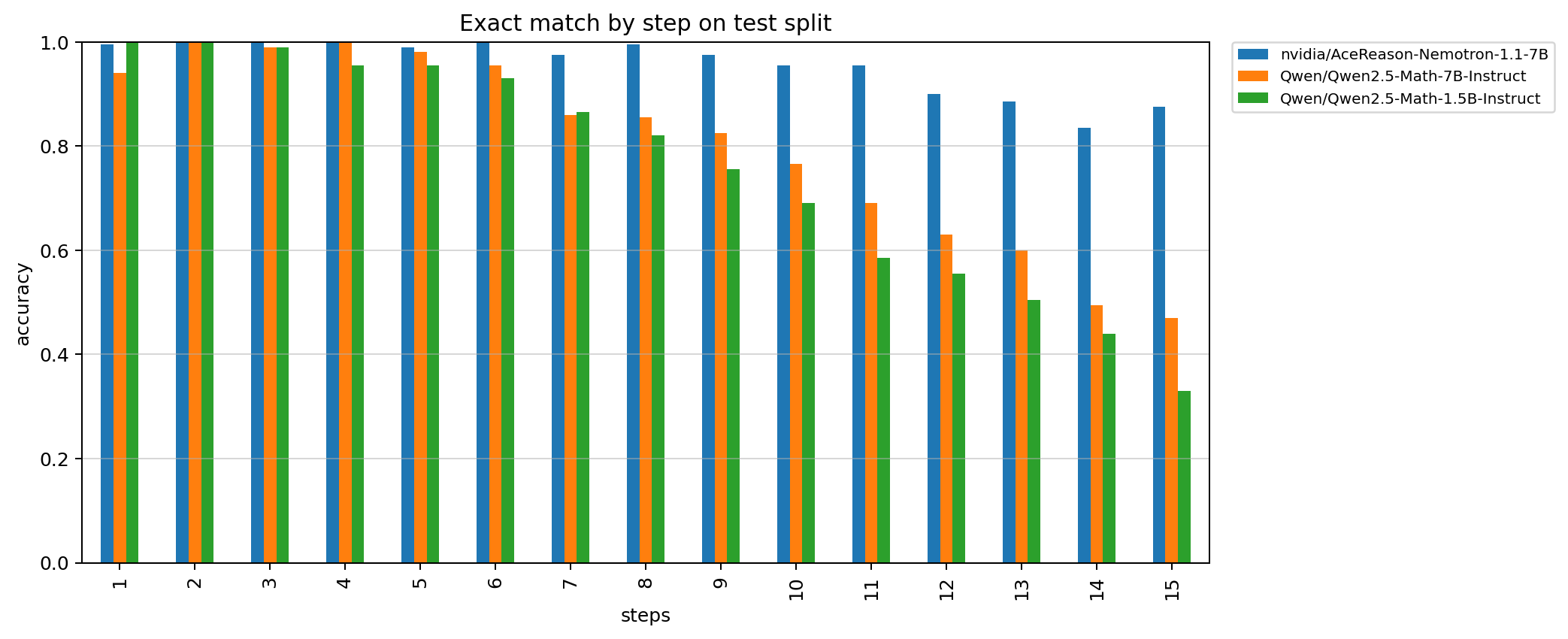
We used this dataset to evaluate the mathematical abilities of models from the `Qwen2.5-Math` family. The plot shows that the accuracy of models without integrated calculation tools decreases approximately quadratically:
|
| 90 |
-
|
| 91 |
-

|
| 92 |
-
|
| 93 |
-
We propose a weighted accuracy metric where results for problems requiring more steps are weighted by the square of the step count:
|
| 94 |
|
| 95 |
$$
|
| 96 |
-
\text{weighted\_score} = \frac{\
|
| 97 |
-
$$
|
| 98 |
-
|
| 99 |
-
Comparison table:
|
| 100 |
|
| 101 |
| model_id | overall_acc | weighted_score |
|
| 102 |
|---|---|---|
|
| 103 |
-
|
|
| 104 |
| Qwen/Qwen2.5-Math-7B-Instruct | 0.803667 | 0.651044 |
|
|
|
|
|
|
|
|
|
|
| 105 |
|
|
|
|
| 106 |
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: gpl-3.0
|
| 3 |
pretty_name: Calculator
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
---
|
| 5 |
|
| 6 |
+
# Arithmetic Expression Dataset
|
| 7 |
|
| 8 |
+
Source code and reproducible evaluation pipeline:
|
| 9 |
+
[calculator-benchmark](https://github.com/pymlex/calculator-benchmark) on GitHub.
|
| 10 |
|
| 11 |
+
## Evaluation across four models
|
| 12 |
|
| 13 |
+
Models: `Qwen2.5-Math-1.5B`, `Qwen2.5-Math-7B`,
|
| 14 |
+
`AceReason-Nemotron-1.1-7B`, `MathGLM-2B`.
|
|
|
|
| 15 |
|
| 16 |
+
Weighted score:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
$$
|
| 19 |
+
\text{weighted\_score} = \frac{\sum_{s=1}^{15} (\text{mean}(\text{correct}_s) \cdot s^2)}{\sum_{s=1}^{15} s^2}
|
| 20 |
+
$$
|
|
|
|
|
|
|
| 21 |
|
| 22 |
| model_id | overall_acc | weighted_score |
|
| 23 |
|---|---|---|
|
| 24 |
+
| nvidia/AceReason-Nemotron-1.1-7B | 0.955667 | 0.912847 |
|
| 25 |
| Qwen/Qwen2.5-Math-7B-Instruct | 0.803667 | 0.651044 |
|
| 26 |
+
| Qwen/Qwen2.5-Math-1.5B-Instruct | 0.758333 | 0.571052 |
|
| 27 |
+
|
| 28 |
+
|
| 29 |
|
| 30 |
+
|
| 31 |
|
| 32 |
+
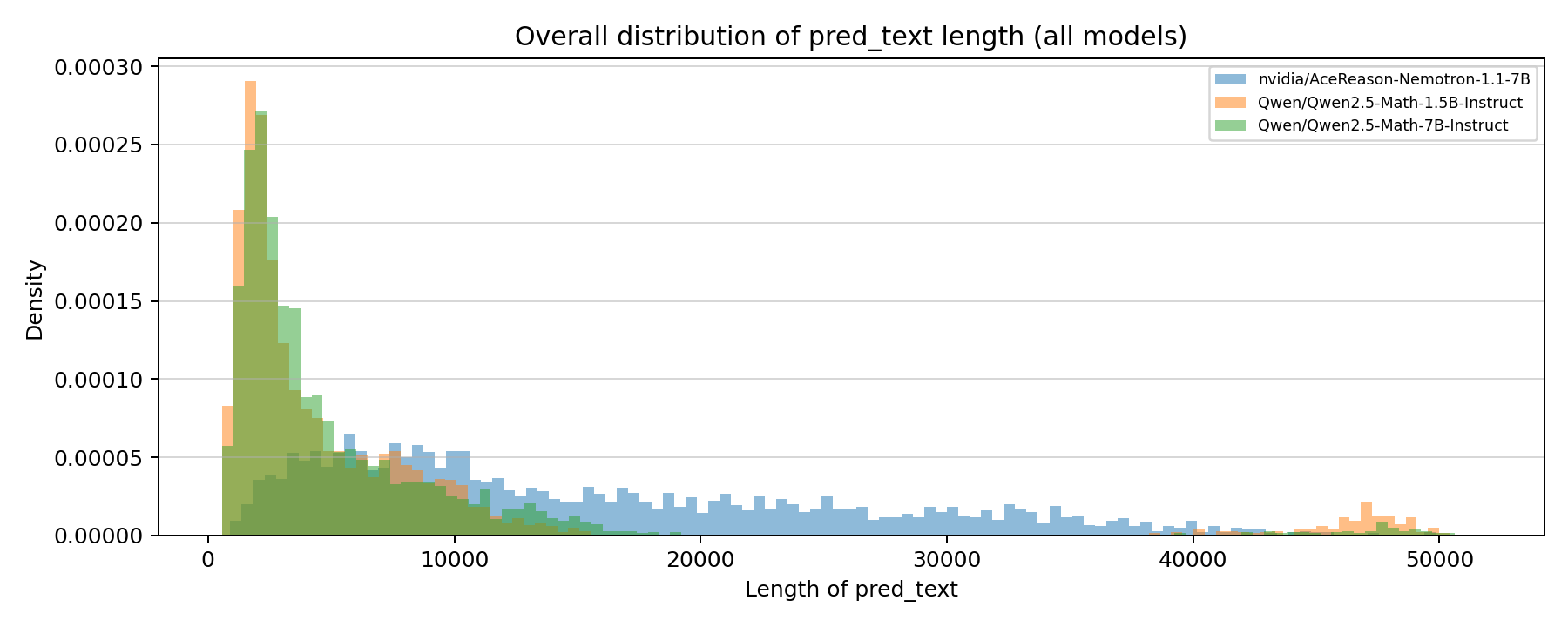
Per-model CSV files are attached in this dataset repository root.
|