---
language: zh
license: cc-by-nc-4.0
tags:
- speech
- conversational-speech
- chinese
pretty_name: SmoothConv
---

# SmoothConv
**SmoothConv** is a high-quality Chinese multi-channel conversational speech dataset with **expert human annotations**, developed by [ASLP@NPU](https://www.npu-aslp.org) and QualiaLabs as part of the SmoothConv–DuplexConv corpus family.



**Companion dataset:** [**DuplexConv**](https://huggingface.co/datasets/qualialabsAI/DuplexConv) on HuggingFace (2,000 hours, LLM-assisted annotation). SmoothConv and DuplexConv are constructed from the same underlying conversational sources. SmoothConv provides high-fidelity human annotations for benchmarking and supervised training; DuplexConv offers large-scale annotations for Speech LLM pre-training and data-driven modeling.
## Dataset Overview
SmoothConv contains **100 hours** of naturally occurring **multi-party Chinese conversations** recorded in **multi-channel** environments across **Tutoring** and **Social Chat** scenarios. Unlike corpora dominated by read speech or scripted interactions, it captures realistic conversational dynamics, including overlapping speech, backchannels, interruptions, pauses, and turn transitions.
The dataset is **manually annotated by trained experts** and provides fine-grained conversational labels, making it suitable for turn-taking modeling, overlap and interruption detection, full-duplex spoken dialogue systems, conversational speech understanding, and Speech LLM research.
| Metric | Value |
| :--- | :---: |
| **Total Duration** | 100.53 hours |
| **Audio Files** | 2,503 |
| **Mean Duration** | 144.59 sec |
| **Duration Range** | 60.0 – 634.7 sec |
| **Language** | Chinese (zh) |
| **Domains** | Tutoring, Social Chat |
| **Annotation** | Expert human annotation |
## Domains & Directory Layout
After download, each conversation is stored under a **top-level folder** whose name indicates the scenario. Match the folder prefix to the domain:
| Scenario | Folder prefix | Example |
| :--- | :--- | :--- |
| **Tutoring** | starts with `edu` or `Edu` | `Edu_20240101_001/` |
| **Social Chat** | starts with `none_Edu` | `none_Edu_20240101_001/` |
Within each folder you will find paired multi-channel audio (`.wav`) and annotation (`.json`) files. The same naming convention applies to both SmoothConv and DuplexConv.
## Dataset Statistics
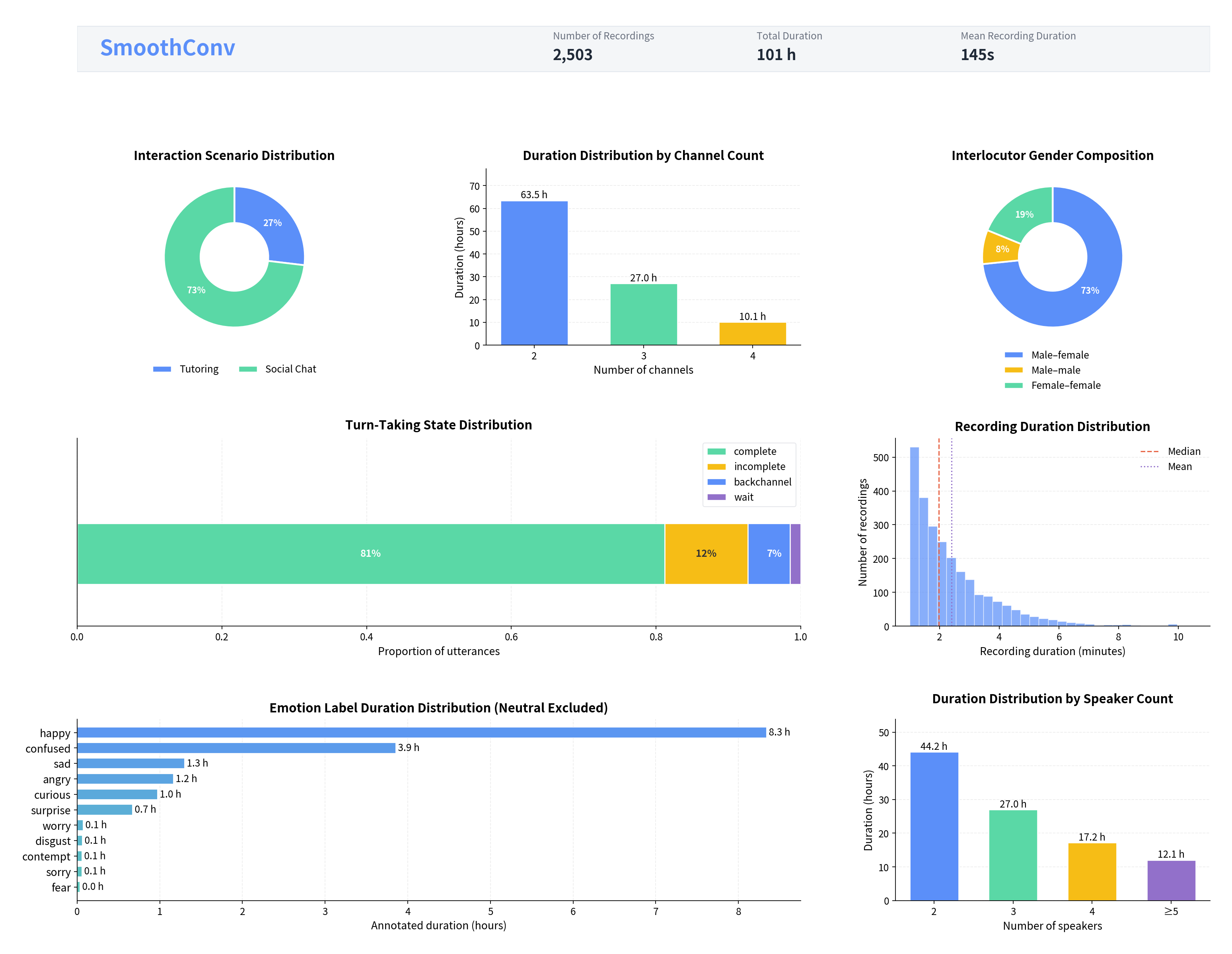
Turn-taking labels include **complete**, **incomplete**, **backchannel**, and **wait**.
## Supported Tasks
- Turn-taking modeling
- Overlap and interruption detection
- Full-duplex spoken dialogue systems
- Conversational speech understanding
- Speech Language Models (Speech LLMs)
## Annotation Format
Each audio file is paired with a JSON annotation file. The top-level object contains an **`instances`** list; each element describes one annotated segment.
### Top-level structure
| Field | Type | Description |
| :--- | :--- | :--- |
| `instances` | `list` | List of annotated segments in the conversation |
### `instances[i]` — per-segment annotation
| Field | Type | Description |
| :--- | :--- | :--- |
| `id` | `str` | Unique segment identifier (UUID) |
| `channelIndex` | `int` | Audio channel index (0-based) |
| `start` | `float` | Segment start time in **seconds** |
| `end` | `float` | Segment end time in **seconds** |
| `text` | `str` | Human-annotated transcript; inline tags mark events (e.g. ``, `<噪声>`, ``) |
| `attributes` | `dict` | Speaker, turn, paralinguistic, and scene attributes (see below) |
### `instances[i].attributes`
| Field | Type | Description |
| :--- | :--- | :--- |
| `speaker` | `str` | Speaker ID (e.g. `A1`, `B1`); `unknown` if unidentifiable |
| `turn` | `str` | Turn-taking state: `complete`, `incomplete`, `backchannel`, `wait` |
| `other_turn` | `list` (optional) | Co-occurring interaction cues, e.g. `pause`, `unknown turn` |
| `gender` | `str` | Speaker gender |
| `age` | `str` | Speaker age group (e.g. `adult`, `child`) |
| `emotion` | `str` | Emotion label for the segment |
| `speech event` | `list` | Paralinguistic / non-speech events (e.g. `nonespeech event`, `echo`, `shouting`) |
| `这段数据是在什么环境` | `str` | Scene / environment description |
### Example segment
```json
{
"id": "0d0687e7-b2e5-4b91-834b-f3e8988e7a4a",
"channelIndex": 0,
"start": 0.702,
"end": 5.146,
"attributes": {
"speaker": "A1",
"turn": "complete",
"gender": "male",
"age": "adult",
"emotion": "neutral",
"speech event": ["nonespeech event"],
"这段数据是在什么环境": "unknown"
},
"text": "春风花草香迟日江山丽日出江花红胜火"
}
```
## Usage
```python
import json
from datasets import load_dataset
ds = load_dataset("qualialabsAI/SmoothConv")
# Load annotation for a sample
with open("path/to/annotation.json", "r", encoding="utf-8") as f:
anno = json.load(f)
for seg in anno["instances"]:
print(seg["channelIndex"], seg["start"], seg["end"], seg["text"])
```
## Ethics Statement
- **Informed consent.** Conversations were recorded with the knowledge and consent of participants. Personal identifiers have been removed or anonymized prior to release.
- **Privacy protection.** For academic and research use only. Do not attempt to re-identify speakers or reconstruct private information.
- **Intended use.** Research on spoken dialogue, turn-taking, and speech understanding—not for unauthorized surveillance, impersonation, or deceptive content generation.
- **Limitations & bias.** Human annotations may contain errors; account for domain and demographic bias in experiments.
- **Responsible use.** Report suspected misuse to [jimz@qualialabs.ai](mailto:jimz@qualialabs.ai).
## License
[CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/)
## Citation
```bibtex
@article{wang2026duoconv,
title = {DuoConv: Large-Scale Chinese Full-Duplex Speech Datasets for Conversational AI},
author = {Chengyou Wang and Chunjiang He and Zhou Zhu and Lei Xie},
journal = {arXiv preprint arXiv:0000.00000},
year = {2026},
note = {Placeholder; paper forthcoming}
}
```
## Contact
[jimz@qualialabs.ai](mailto:jimz@qualialabs.ai)