
File size: 3,888 Bytes
6bb558e aad3928 6bb558e aad3928 e33891c aad3928 e33891c aad3928 e33891c 8ada5ec e33891c 6bb558e 8ada5ec 6bb558e e33891c ed00805 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
---
license: mit
size_categories:
- 10K<n<100K
---
Dataset for the evaluation of data-unlearning techniques using KLOM (KL-divergence of Margins).
# How KLOM works:
KLOM works by:
1. training N models (original models)
2. Training N fully-retrained models (oracles) on forget set F
3. unlearning forget set F from the original models
4. Comparing the outputs of the unlearned models from the retrained models on different points
(specifically, computing the KL divergence between the distribution of _margins_ of oracle models and distribution of _margins_ of the unlearned models)
Originally proposed in the work Attribute-to-Delete: Machine Unlearning via Datamodel Matching (https://arxiv.org/abs/2410.23232), described in detail in E.1.
**Outline of how KLOM works:**
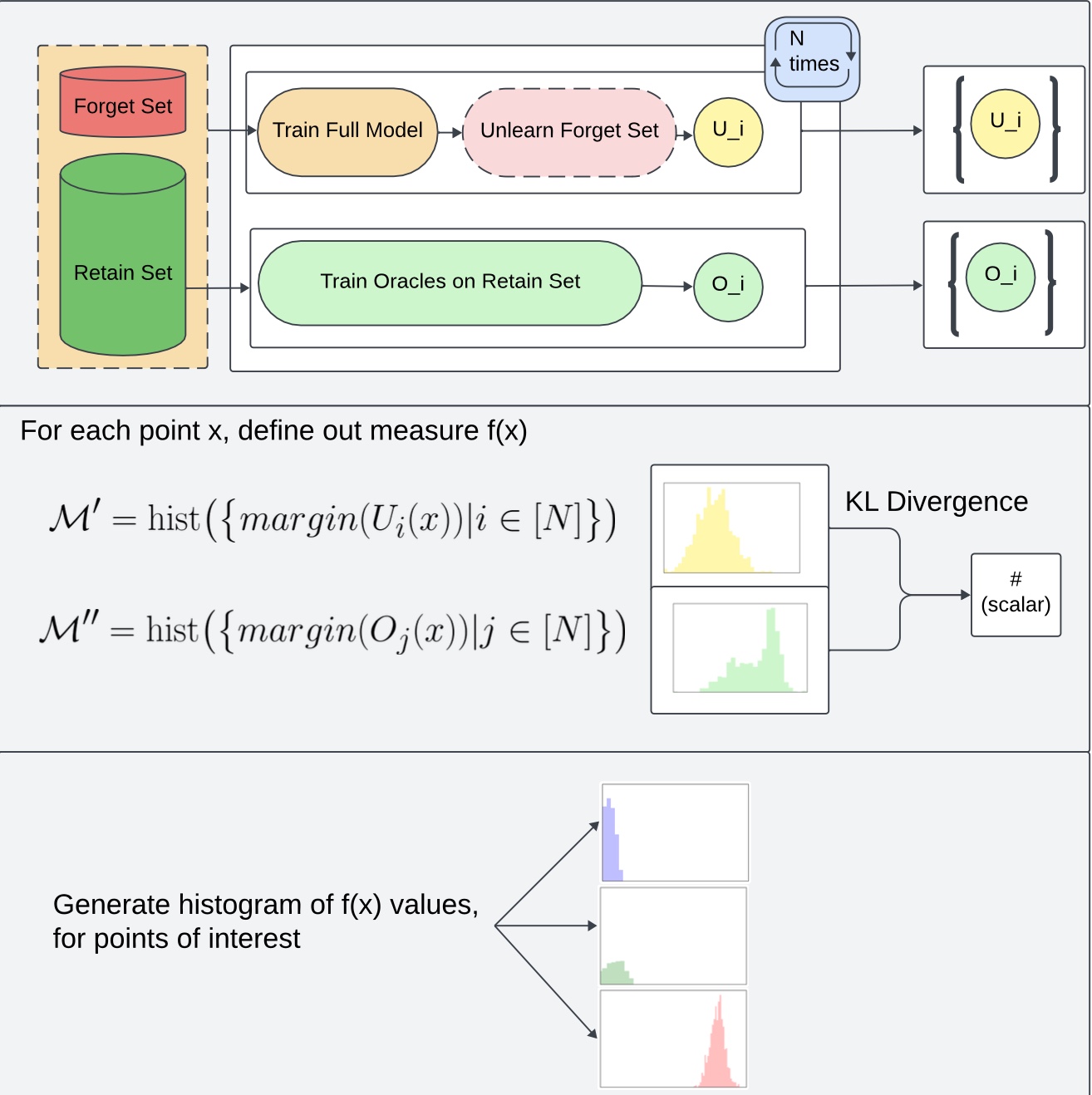
**Algorithm Description:**

# Structure of Data
The overal structure is as follows:
```
full_models
├── CIFAR10
├── CIFAR10_augmented
└── LIVING17
oracles
└── CIFAR10
├── forget_set_1
├── forget_set_2
├── forget_set_3
├── forget_set_4
├── forget_set_5
├── forget_set_6
├── forget_set_7
├── forget_set_8
├── forget_set_9
└── forget_set_10
```
Each folder has
* train_logits_##.pt - logits at the end of training for model `##` for validation points
* val_logits_##.pt - logits at the end of training for model `##` for train points
* `##__val_margins_#.npy` - margins of model `##` at epoch `#` (this is derived from logits)
* `sd_##____epoch_#.pt` - model `##` checkpoint at epoch `#`
# How to download
Create script `download_folder.sh`
```
#!/bin/bash
REPO_URL=https://huggingface.co/datasets/royrin/KLOM-models
TARGET_DIR=KLOM-models # name it what you wish
FOLDER=$1 # e.g., "oracles/CIFAR10/forget_set_3"
mkdir -p $TARGET_DIR
git clone --filter=blob:none --no-checkout $REPO_URL $TARGET_DIR
cd $TARGET_DIR
git sparse-checkout init --cone
git sparse-checkout set $FOLDER
git checkout main
```
Example how to run script:
```
bash download_folder.sh oracles/CIFAR10/forget_set_3
```
## How forget sets generated
We have 10 different forget sets: sets 1,2,3 are random forget sets of sizes 10,100,1000 respectively; sets 4-9 correspond to semantically coherent subpopulations of examples (e.g., all dogs facing a similar direction) identified using clustering methods.
Specifically, we take a $n \times n$ datamodel matrix constructed by concatenating ``train x train`` datamodels ($n=50,000$). Next, we compute the top principal components (PCs) of the influence matrix and construct the following forget sets:
* Forget set 1: 10 random samples
* Forget set 2: 100 random samples
* Forget set 3: 500 random samples
* Forget set 4: 10 samples with the highest projection onto the 1st PC
* Forget set 5: 100 samples with the highest projection onto the 1st PC
* Forget set 6: 250 samples with the highest projection onto the 1st PC and 250 with lowest projection
* Forget set 7: 10 samples with the highest projection onto the 2nd PC
* Forget set 8: 100 samples with the highest projection onto the 2nd PC
* Forget set 9: 250 samples with the highest projection onto the 2nd PC and 250 with the lowest projection.
* Forget set 10: 100 samples closest in CLIP image space to training example 6 (a cassowary)
\paragraph{ImageNet Living-17.} We use three different forget sets:
* Forget set 1 is random of size 500;
* Forget sets 2 and 3 correspond to 200 examples from a certain subpopulation (corresponding to a single original ImageNet class) within the Living-17 superclass.
|