
Update README.md
Browse files
README.md
CHANGED
|
@@ -11,7 +11,7 @@ license: mit
|
|
| 11 |
[](https://linzhiqiu.github.io/papers/camerabench/)
|
| 12 |
[](https://huggingface.co/datasets/syCen/CameraBench)
|
| 13 |
|
| 14 |
-

|
| 15 |
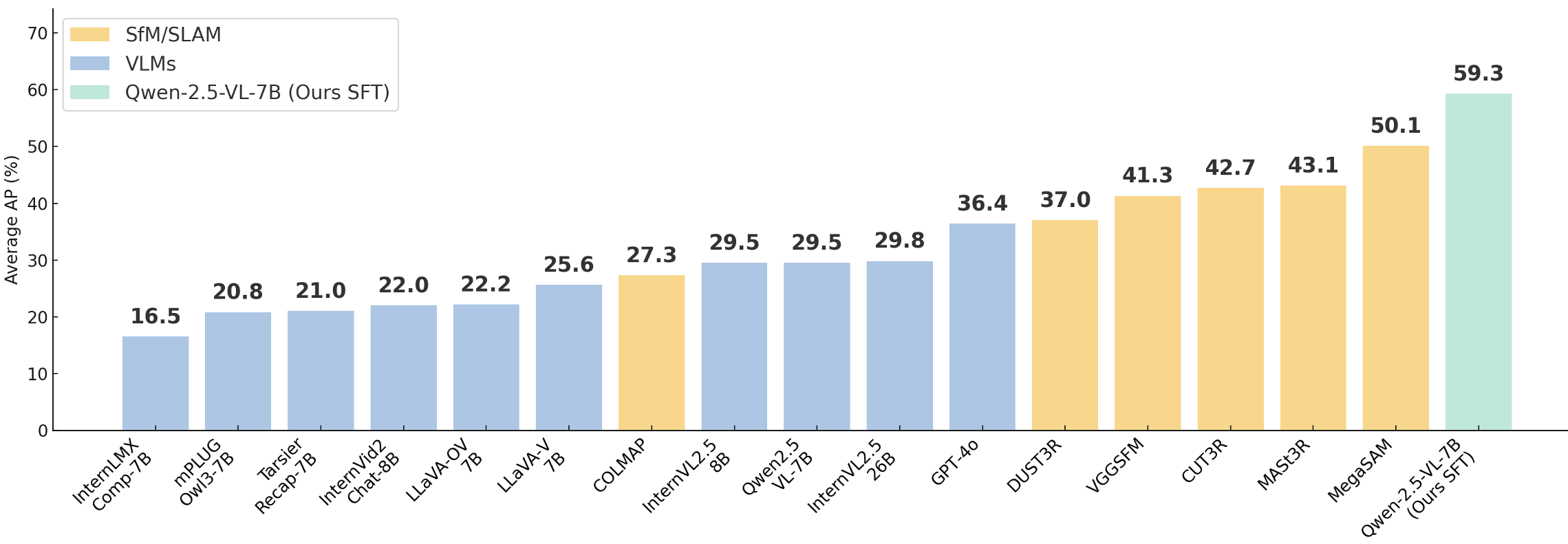
> **SfMs and VLMs performance on CameraBench**: Generative VLMs (evaluated with [VQAScore](https://linzhiqiu.github.io/papers/vqascore/)) trail classical SfM/SLAM in pure geometry, yet they outperform discriminative VLMs that rely on CLIPScore/ITMScore and—even better—capture scene‑aware semantic cues missed by SfM
|
| 16 |
> After simple supervised fine‑tuning (SFT) on ≈1,400 extra annotated clips, our 7B Qwen2.5‑VL doubles its AP, outperforming the current best MegaSAM.
|
| 17 |
|
|
|
|
| 11 |
[](https://linzhiqiu.github.io/papers/camerabench/)
|
| 12 |
[](https://huggingface.co/datasets/syCen/CameraBench)
|
| 13 |
|
| 14 |
+
|
| 15 |
> **SfMs and VLMs performance on CameraBench**: Generative VLMs (evaluated with [VQAScore](https://linzhiqiu.github.io/papers/vqascore/)) trail classical SfM/SLAM in pure geometry, yet they outperform discriminative VLMs that rely on CLIPScore/ITMScore and—even better—capture scene‑aware semantic cues missed by SfM
|
| 16 |
> After simple supervised fine‑tuning (SFT) on ≈1,400 extra annotated clips, our 7B Qwen2.5‑VL doubles its AP, outperforming the current best MegaSAM.
|
| 17 |
|