
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,900,197 | Evaluating the World Model Implicit in a Generative Model | Evaluating the World Model Implicit in a Generative Model | 0 | 2024-06-25T14:42:34 | https://aimodels.fyi/papers/arxiv/evaluating-world-model-implicit-generative-model | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Evaluating the World Model Implicit in a Generative Model](https://aimodels.fyi/papers/arxiv/evaluating-world-model-implicit-generative-model). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,900,196 | Scrolly2Reel: Retargeting Graphics for Social Media Using Narrative Beats | Scrolly2Reel: Retargeting Graphics for Social Media Using Narrative Beats | 0 | 2024-06-25T14:41:59 | https://aimodels.fyi/papers/arxiv/scrolly2reel-retargeting-graphics-social-media-using-narrative | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Scrolly2Reel: Retargeting Graphics for Social Media Using Narrative Beats](https://aimodels.fyi/papers/arxiv/scrolly2reel-retargeting-graphics-social-media-using-narrative). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi... | mikeyoung44 |
1,900,195 | VideoPrism: A Foundational Visual Encoder for Video Understanding | VideoPrism: A Foundational Visual Encoder for Video Understanding | 0 | 2024-06-25T14:41:24 | https://aimodels.fyi/papers/arxiv/videoprism-foundational-visual-encoder-video-understanding | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [VideoPrism: A Foundational Visual Encoder for Video Understanding](https://aimodels.fyi/papers/arxiv/videoprism-foundational-visual-encoder-video-understanding). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter]... | mikeyoung44 |
1,900,194 | Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers | Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers | 0 | 2024-06-25T14:40:50 | https://aimodels.fyi/papers/arxiv/should-ai-optimize-your-code-comparative-study | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers](https://aimodels.fyi/papers/arxiv/should-ai-optimize-your-code-comparative-study). If you like these kinds of analysis, you should... | mikeyoung44 |
1,900,193 | An Interactive Agent Foundation Model | An Interactive Agent Foundation Model | 0 | 2024-06-25T14:40:15 | https://aimodels.fyi/papers/arxiv/interactive-agent-foundation-model | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [An Interactive Agent Foundation Model](https://aimodels.fyi/papers/arxiv/interactive-agent-foundation-model). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twi... | mikeyoung44 |
1,900,192 | Foundation Models for Time Series Analysis: A Tutorial and Survey | Foundation Models for Time Series Analysis: A Tutorial and Survey | 0 | 2024-06-25T14:39:41 | https://aimodels.fyi/papers/arxiv/foundation-models-time-series-analysis-tutorial-survey | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Foundation Models for Time Series Analysis: A Tutorial and Survey](https://aimodels.fyi/papers/arxiv/foundation-models-time-series-analysis-tutorial-survey). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](htt... | mikeyoung44 |
1,900,191 | Depth Anything V2 | Depth Anything V2 | 0 | 2024-06-25T14:39:06 | https://aimodels.fyi/papers/arxiv/depth-anything-v2 | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Depth Anything V2](https://aimodels.fyi/papers/arxiv/depth-anything-v2). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44... | mikeyoung44 |
1,900,190 | Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning | Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning | 0 | 2024-06-25T14:38:31 | https://aimodels.fyi/papers/arxiv/diffusion-world-model-future-modeling-beyond-step | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning](https://aimodels.fyi/papers/arxiv/diffusion-world-model-future-modeling-beyond-step). If you like these kinds of analysis, you should subscribe to th... | mikeyoung44 |
1,900,189 | Are LLMs Naturally Good at Synthetic Tabular Data Generation? | Are LLMs Naturally Good at Synthetic Tabular Data Generation? | 0 | 2024-06-25T14:37:57 | https://aimodels.fyi/papers/arxiv/are-llms-naturally-good-at-synthetic-tabular | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Are LLMs Naturally Good at Synthetic Tabular Data Generation?](https://aimodels.fyi/papers/arxiv/are-llms-naturally-good-at-synthetic-tabular). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,900,187 | Large Language Models for Data Annotation: A Survey | Large Language Models for Data Annotation: A Survey | 0 | 2024-06-25T14:37:22 | https://aimodels.fyi/papers/arxiv/large-language-models-data-annotation-survey | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Large Language Models for Data Annotation: A Survey](https://aimodels.fyi/papers/arxiv/large-language-models-data-annotation-survey). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.c... | mikeyoung44 |
1,900,186 | Transparent Image Layer Diffusion using Latent Transparency | Transparent Image Layer Diffusion using Latent Transparency | 0 | 2024-06-25T14:36:48 | https://aimodels.fyi/papers/arxiv/transparent-image-layer-diffusion-using-latent-transparency | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Transparent Image Layer Diffusion using Latent Transparency](https://aimodels.fyi/papers/arxiv/transparent-image-layer-diffusion-using-latent-transparency). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](http... | mikeyoung44 |
1,900,154 | Four Courses that helped me to get into Gen AI | Getting Started with Generative AI: A Beginner’s Guide As a software engineer with 20... | 0 | 2024-06-25T14:20:24 | https://dev.to/rommik/four-courses-that-helped-me-to-get-into-gen-ai-5688 | genai, ai, learning, courses | ---
title: Four Courses that helped me to get into Gen AI
published: true
description:
tags: GenAI, AI, Learning, Courses
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/evxgzylcuqrrwnmpkn53.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-25 02:02 +0000
---
### Getting Star... | rommik |
1,900,185 | DataComp-LM: In search of the next generation of training sets for language models | DataComp-LM: In search of the next generation of training sets for language models | 0 | 2024-06-25T14:36:13 | https://aimodels.fyi/papers/arxiv/datacomp-lm-search-next-generation-training-sets | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [DataComp-LM: In search of the next generation of training sets for language models](https://aimodels.fyi/papers/arxiv/datacomp-lm-search-next-generation-training-sets). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi news... | mikeyoung44 |
1,900,184 | StreamBench: Towards Benchmarking Continuous Improvement of Language Agents | StreamBench: Towards Benchmarking Continuous Improvement of Language Agents | 0 | 2024-06-25T14:35:05 | https://aimodels.fyi/papers/arxiv/streambench-towards-benchmarking-continuous-improvement-language-agents | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [StreamBench: Towards Benchmarking Continuous Improvement of Language Agents](https://aimodels.fyi/papers/arxiv/streambench-towards-benchmarking-continuous-improvement-language-agents). If you like these kinds of analysis, you should subscribe to the [A... | mikeyoung44 |
1,900,183 | A Survey on Large Language Models for Recommendation | A Survey on Large Language Models for Recommendation | 0 | 2024-06-25T14:33:56 | https://aimodels.fyi/papers/arxiv/survey-large-language-models-recommendation | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [A Survey on Large Language Models for Recommendation](https://aimodels.fyi/papers/arxiv/survey-large-language-models-recommendation). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.c... | mikeyoung44 |
1,900,182 | Directly Fine-Tuning Diffusion Models on Differentiable Rewards | Directly Fine-Tuning Diffusion Models on Differentiable Rewards | 0 | 2024-06-25T14:32:47 | https://aimodels.fyi/papers/arxiv/directly-fine-tuning-diffusion-models-differentiable-rewards | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Directly Fine-Tuning Diffusion Models on Differentiable Rewards](https://aimodels.fyi/papers/arxiv/directly-fine-tuning-diffusion-models-differentiable-rewards). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter]... | mikeyoung44 |
1,900,181 | Common JavaScript "event Handler" Mistake | When i was dealing javacript click event i was doing this mistake see the blow javascript &... | 0 | 2024-06-25T14:32:34 | https://dev.to/sagar7170/common-javascript-event-handler-mistake-38ce | javascript, jquery, programming, coding |
When i was dealing javacript click event i was doing this mistake see the blow javascript & jquery code snippet
**javascript code example**
```
let name = 'herry';
document.getElementbByClassName('demo').addEventListener('click',function(){
name = "joy";
})
console.log(name) // herry
```
**jquery code example**... | sagar7170 |
1,900,180 | CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training | CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training | 0 | 2024-06-25T14:32:12 | https://aimodels.fyi/papers/arxiv/color-filter-conditional-loss-reduction-filtering-targeted | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training](https://aimodels.fyi/papers/arxiv/color-filter-conditional-loss-reduction-filtering-targeted). If you like these kinds of analysis, you should subscribe to the... | mikeyoung44 |
1,900,178 | Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference | Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference | 0 | 2024-06-25T14:31:04 | https://aimodels.fyi/papers/arxiv/inference-via-interpolation-contrastive-representations-provably-enable | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference](https://aimodels.fyi/papers/arxiv/inference-via-interpolation-contrastive-representations-provably-enable). If you like these kinds of analysis, you should... | mikeyoung44 |
1,900,177 | DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence | DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence | 0 | 2024-06-25T14:30:29 | https://aimodels.fyi/papers/arxiv/deepseek-coder-v2-breaking-barrier-closed-source | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence](https://aimodels.fyi/papers/arxiv/deepseek-coder-v2-breaking-barrier-closed-source). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi ne... | mikeyoung44 |
1,900,176 | Social Norms in Cinema: A Cross-Cultural Analysis of Shame, Pride and Prejudice | Social Norms in Cinema: A Cross-Cultural Analysis of Shame, Pride and Prejudice | 0 | 2024-06-25T14:29:55 | https://aimodels.fyi/papers/arxiv/social-norms-cinema-cross-cultural-analysis-shame | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Social Norms in Cinema: A Cross-Cultural Analysis of Shame, Pride and Prejudice](https://aimodels.fyi/papers/arxiv/social-norms-cinema-cross-cultural-analysis-shame). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsle... | mikeyoung44 |
1,900,128 | Harnessing IoT for Connected Innovations | The Internet of Things (IoT) has rapidly evolved from a futuristic concept to a fundamental aspect of... | 0 | 2024-06-25T13:59:19 | https://dev.to/sshamza/harnessing-iot-for-connected-innovations-52kj | The Internet of Things (IoT) has rapidly evolved from a futuristic concept to a fundamental aspect of modern technology. As more devices become interconnected, IoT is transforming various industries, improving efficiency, and enhancing our daily lives. This blog explores the current state of IoT, its applications, and ... | sshamza | |
1,900,174 | StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images | StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images | 0 | 2024-06-25T14:28:45 | https://aimodels.fyi/papers/arxiv/stablesemantics-synthetic-language-vision-dataset-semantic-representations | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images](https://aimodels.fyi/papers/arxiv/stablesemantics-synthetic-language-vision-dataset-semantic-representations). If you like these kinds of analysis,... | mikeyoung44 |
1,900,173 | How to Deploy Infisical to Manage Application Secrets on Koyeb | Infisical is an open-source secret management platform to securely store and manage secrets for both... | 0 | 2024-06-25T14:27:43 | https://www.koyeb.com/tutorials/how-to-deploy-infisical-to-manage-application-secrets-on-koyeb | webdev, tutorial, opensource, security | [Infisical](https://infisical.com/) is an open-source secret management platform to securely store and manage secrets for both users and applications. It integrates easily with many different application stacks and can replace environment variable-based secret workflows with simple API driven secret management. With ad... | alisdairbr |
1,900,172 | Neural Thermodynamic Integration: Free Energies from Energy-based Diffusion Models | Neural Thermodynamic Integration: Free Energies from Energy-based Diffusion Models | 0 | 2024-06-25T14:27:37 | https://aimodels.fyi/papers/arxiv/neural-thermodynamic-integration-free-energies-from-energy | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Neural Thermodynamic Integration: Free Energies from Energy-based Diffusion Models](https://aimodels.fyi/papers/arxiv/neural-thermodynamic-integration-free-energies-from-energy). If you like these kinds of analysis, you should subscribe to the [AImodel... | mikeyoung44 |
1,900,171 | Do you know how passive liveness detection is used in KYC verification | Passive liveness detection ensures the user is physically present during KYC verification. It... | 0 | 2024-06-25T14:26:52 | https://dev.to/miniailive/do-you-know-how-passive-liveness-detection-is-used-in-kyc-verification-934 | webdev, androiddev, ai, machinelearning | Passive liveness detection ensures the user is physically present during KYC verification. It enhances security by detecting spoofing attempts.
KYC (Know Your Customer) verification is crucial for financial institutions to confirm the identity of their clients. Passive liveness detection plays a significant role in th... | miniailive |
1,900,170 | AWS exam history | I passed my last AWS exam almost a month ago. Of course, I left the easiest one for the end; it was... | 0 | 2024-06-25T14:24:47 | https://dev.to/laszloczirok/aws-exam-history-46ma | I passed my last AWS exam almost a month ago. Of course, I left the easiest one for the end; it was lovely 😀
Thirteen exams, two years, and endless nights and weekends of revision — it is worth pausing momentarily, reflecting, and answering the inevitable questions.
Was it worth it? The answer is clearly yes. I hav... | laszloczirok | |
1,898,909 | A guide to React 19’s new Document Metadata feature | Written by Boemo Mmopelwa✏️ The recent release of React 19 introduced Document Metadata, a feature... | 0 | 2024-06-25T14:13:53 | https://blog.logrocket.com/guide-react-19-new-document-metadata-feature | react, webdev | **Written by [Boemo Mmopelwa](https://blog.logrocket.com/author/boemowamemmopelwa/)✏️**
The recent release of [React 19 introduced Document Metadata](https://react.dev/blog/2024/04/25/react-19#whats-new-in-react-19), a feature that manages meta tags and elements like titles and descriptions directly from React compone... | leemeganj |
1,900,124 | Let's Talk Version Control | Understanding Git can be really confusing. I have been using Git for quite some time, but I sometimes... | 0 | 2024-06-25T14:13:37 | https://dev.to/shavonharrisdev/lets-talk-version-control-25ce | github, git, development, developer | Understanding Git can be really confusing. I have been using Git for quite some time, but I sometimes found it difficult to explain. This guide aims to equip you with the essential language and concepts of version control so that you do not have that problem.
## What is Git?
Imagine you're writing a novel collaborati... | shavonharrisdev |
1,900,143 | Need Help with Nodemailer Access Issues on Outlook and Gmail | Of course! Here is the updated paragraph with the additional information: Hello everyone, I'm... | 0 | 2024-06-25T14:12:17 | https://dev.to/manandhiscomputer/need-help-with-nodemailer-access-issues-on-outlook-and-gmail-4clf | webdev, node, security, authentication |
Of course! Here is the updated paragraph with the additional information:
Hello everyone,
I'm currently facing an issue with using Nodemailer to send emails through Outlook and Gmail. It appears that both services have strict security policies that block access by less secure apps like Nodemailer by default. I've tr... | manandhiscomputer |
1,900,142 | Streamlining the design-to-code workflow is a constant battle for web developers. | PixelFree Studio emerges as a revolutionary platform aiming to bridge the gap between designers and... | 0 | 2024-06-25T14:12:09 | https://dev.to/precinctplatforms/streamlining-the-design-to-code-workflow-is-a-constant-battle-for-web-developers-5ng | webdev, angular, node, react |
[PixelFree Studio](https://pixelfreestudio.com/?rl=vc-Marketing) emerges as a revolutionary platform aiming to bridge the gap between designers and developers by fostering a seamless transition from mockup to functional code. This article delves into PixelFree Studio's functionalities, exploring its potential to enhan... | precinctplatforms |
1,900,141 | Discover Joyful Learning at Tinker Tots Preschool and Daycare - The Best Playgroup in Jagatpur! | Finding the right playgroup in Jagatpur for your child can be a daunting task. With so many options... | 0 | 2024-06-25T14:11:56 | https://dev.to/tinkertots1/discover-joyful-learning-at-tinker-tots-preschool-and-daycare-the-best-playgroup-in-jagatpur-1822 | preschool, playgroupinjagatput, playgroup, playgroupeducation | Finding the right [playgroup in Jagatpur](https://tinkertots.in/preschool-in-jagatpur/) for your child can be a daunting task. With so many options available, it's essential to choose a place that offers more than just basic care. At Tinker Tots Preschool and Daycare, we provide a nurturing environment where children c... | tinkertots1 |
1,900,140 | Serverless Front End Development: Benefits And Challenges | by Hannah Kalio Serverless architectures have come to light as an appealing option for enterprises... | 0 | 2024-06-25T14:11:11 | https://blog.openreplay.com/serverless-front-end-development--benefits-and-challenges/ |
by [Hannah Kalio](https://blog.openreplay.com/authors/hannah-kalio)
<blockquote><em>
Serverless architectures have come to light as an appealing option for enterprises looking for more effective ways to develop and implement online applications. Serverless architectures provide unmatched flexibility and agility by ... | asayerio_techblog | |
1,900,137 | Maximizing User Experience - The Importance Of Pre-Caching | by Chisom Kanu Have you ever visited a website that takes forever to load, leaving you staring at... | 0 | 2024-06-25T14:05:39 | https://blog.openreplay.com/maximizing-user-experience--the-importance-of-pre-caching/ |
by [Chisom Kanu](https://blog.openreplay.com/authors/chisom-kanu)
<blockquote><em>
Have you ever visited a website that takes forever to load, leaving you staring at your screen in frustration? In today's world, users expect websites to load fast. This is where pre-caching comes in—a way to improve the user experi... | asayerio_techblog | |
1,900,136 | API Development and Monitoring with FastAPI and Apitally | In today's digital world, creating and keeping up effective APIs is really important for the success... | 0 | 2024-06-25T14:05:27 | https://developer-service.blog/api-development-and-monitoring-with-fastapi-and-apitally/ | python, fastapi, apitally, monitoring | In today's digital world, creating and keeping up effective APIs is really important for the success of web applications.
FastAPI has become a favorite among developers because of its high speed and easy-to-use design when building APIs.
Working together with FastAPI is Apitally, a tool that makes monitoring and anal... | devasservice |
1,900,134 | see the next WordCamps - meetings around the globe - central.wordcamp.org | Upcoming WordCamps Uganda Website Projects Competition 2024 Kampala, Uganda 5 July, 2024 July,... | 0 | 2024-06-25T14:03:24 | https://dev.to/linomanzz/see-the-next-wordcamps-meetings-around-the-globe-centralwordcamporg-2egb | Upcoming WordCamps
Uganda Website Projects Competition 2024 Kampala, Uganda 5 July, 2024
July, 2024
WordCamp Whitley Bay, UK Whitley Bay, UK 12 July, 2024
WordCamp Cape Town, Western Cape, South Africa Cape Town, Western Cape, South Africa 1 August–2 August, 2024
WordCamp Rio de Janeiro, RJ, Brazil Rio de Janeiro,... | linomanzz | |
1,900,117 | What Does SPF Stand For? | Sun Protection Factor (SPF) is a crucial component of any sunscreen product, but many people don't... | 0 | 2024-06-25T13:39:51 | https://dev.to/ayushi_sharma_e8b2cfdb906/what-does-spf-stand-for-4bel | Sun Protection Factor (SPF) is a crucial component of any sunscreen product, but many people don't fully understand what it signifies or how it works. Knowing the answer to "What does SPF stand for?" can help you make informed choices about protecting your skin from the sun's harmful effects.
Understanding SPF
[SPF st... | ayushi_sharma_e8b2cfdb906 | |
1,900,133 | WordCamp Europe 2024 13 – 15 June 2024 Torino Italy | WordCamp Europe 2024 :: 13 – 15 June 2024 Torino, Italy "Sustainable Open Source is the Future ::... | 0 | 2024-06-25T14:03:03 | https://dev.to/linomanzz/wordcamp-europe-2024-13-15-june-2024-torino-italy-36e2 | WordCamp Europe 2024 :: 13 – 15 June 2024 Torino, Italy "Sustainable Open Source is the Future :: WordCamp Europe kicks off in just two days! Don't miss out
Dive into the schedule to plan your days: https://europe.wordcamp.org/2024/schedule/
#WordPress #WCEU
https://europe.wordcamp.org/2024/
Schedule
08.30 Regis... | linomanzz | |
1,900,126 | Código limpo e boas práticas de programação: Simplificando para o futuro. | Na era da tecnologia em constante evolução, escrever um código limpo e seguir boas práticas de... | 0 | 2024-06-25T14:02:51 | https://dev.to/womakerscode/codigo-limpo-e-boas-praticas-de-programacao-simplificando-para-o-futuro-ni4 | java, cleancode | Na era da tecnologia em constante evolução, escrever um código limpo e seguir boas práticas de programação não é apenas uma vantagem, mas uma necessidade para o desenvolvimento de software sustentável e de qualidade. Clean Code se refere ao código que não apenas funciona corretamente, mas que também é fácil de entender... | anafbarreto |
1,900,131 | Strategic Pricing For Your Tech Services | by Joyce Nkwocha How do you set good prices for your work? Too high, you lose clients; too low, you... | 0 | 2024-06-25T14:01:37 | https://blog.openreplay.com/strategic-pricing-for-your-tech-services/ |
by [Joyce Nkwocha](https://blog.openreplay.com/authors/joyce-nkwocha)
<blockquote><em>
How do you set good prices for your work? Too high, you lose clients; too low, you lose money. This article provides everything you need to avoid these traps and master the art of strategic pricing. You'll learn how to set fair ... | asayerio_techblog | |
1,900,130 | Create alternative of Next Auth | Below is a fully functional example of how you can create an authentication system in a Next.js... | 0 | 2024-06-25T14:01:22 | https://dev.to/nadim_ch0wdhury/create-alternative-of-next-auth-i29 | Below is a fully functional example of how you can create an authentication system in a Next.js application without using NextAuth. This example uses JWT (JSON Web Tokens) for authentication and cookie-based session management.
### 1. Install Dependencies
First, install the required dependencies:
```bash
npm install... | nadim_ch0wdhury | |
1,895,078 | When did you Really get the Hang of Programming? | I do not know when or if I have ever gotten a true hang of programming, but I truly felt like I got a... | 0 | 2024-06-25T14:00:00 | https://dev.to/anitaolsen/when-did-you-really-get-the-hang-of-programming-2nc7 | discuss, programming | I do not know when or if I have ever gotten a true hang of programming, but I truly felt like I got a hang on something when I made [my games](https://olsenanita.com/) from the Game Development courses on [CodeCombat](https://codecombat.com/user/anitaolsen):
** is a tool that calculates a person's age based on their date of birth and the current date. You simply input your birth date and the calculator will determine how old you are in years, months, and days. It is a convenient way to quickly find out someone's age wit... | agecalculator |
1,900,122 | Unlocking Efficiency: Understanding Medical Revenue Services | Effective management of medical revenue services is essential for the smooth operation and financial... | 0 | 2024-06-25T13:47:06 | https://dev.to/oliviamitchel/unlocking-efficiency-understanding-medical-revenue-services-4gce | Effective management of [medical revenue services](https://meddatsys.com/) is essential for the smooth operation and financial stability of healthcare practices. These services streamline the revenue cycle, ensuring timely and accurate reimbursement for medical services provided. This post explores the intricacies of t... | oliviamitchel | |
1,900,121 | Unleashing Real-Time Data: Setting Up Kafka on EC2 and Connecting from Your Local Machine | This blog post will show you how to install Apache Kafka on an Amazon EC2 instance and connect to it... | 0 | 2024-06-25T13:46:36 | https://dev.to/rajat-nayak/unleashing-real-time-data-setting-up-kafka-on-ec2-and-connecting-from-your-local-machine-4mca | This blog post will show you how to install Apache Kafka on an Amazon EC2 instance and connect to it locally to take use of the potential of real-time data. We will guide you through every step of the process, including setting up Kafka on the cloud and managing data streams using a producer and consumer. By the end, y... | rajat-nayak | |
1,900,120 | Programming Trending Topics in 2024: What Developers Need to Know | The field of programming is constantly evolving, driven by technological advancements and the... | 0 | 2024-06-25T13:45:28 | https://dev.to/markwilliams21/programming-trending-topics-in-2024-what-developers-need-to-know-51mc | The field of programming is constantly evolving, driven by technological advancements and the ever-changing demands of the industry. As we move through 2024, several trends are shaping the landscape of software development. Here, we delve into some of the most prominent programming trends that developers should be awar... | markwilliams21 | |
1,900,118 | Supply Chain Security in Mobile App Development: Why is it Important? 📲 | Supply Chain Security in Mobile App Development: Why is it important? Supply chain... | 0 | 2024-06-25T13:39:51 | https://dev.to/bytehide/supply-chain-security-in-mobile-app-development-why-is-it-important-afd | mobile, development, coding, cybersecurity | ## Supply Chain Security in Mobile App Development: Why is it important?
Supply chain security. Sounds like something only big corporations need to worry about, right? Wrong. In today’s connected world, every mobile app developer needs to be on top of their game.
After all, a single vulnerability in your supply chain... | bytehide |
1,890,307 | MongoDB database cloud migration | I gave a talk on how Woovi migrated from the cloud to our servers, here are the slides:... | 0 | 2024-06-25T13:37:51 | https://dev.to/woovi/mongodb-database-cloud-migration-14ea | mongodb, cloud, migration, nocloud | I gave a talk on how Woovi migrated from the cloud to our servers, here are the slides: [https://speakerdeck.com/sibelius/no-cloud-how-woovi-moved-from-aws-to-its-own-servers](https://speakerdeck.com/sibelius/no-cloud-how-woovi-moved-from-aws-to-its-own-servers)
In this article, we are going to cover three approaches ... | sibelius |
1,900,105 | Going Pro | Take your career seriously. I've encountered many engineers who don't. They only think about... | 0 | 2024-06-25T13:35:12 | https://open.substack.com/pub/sethorell/p/going-pro | career, success, achievement, ambition | Take your career seriously.
I've encountered many engineers who don't. They only think about improving from 9 to 5 at their job (and I know some who don't think about improving at all). A few are even explicit about it. They say "Want me to get better at coding [or architecture or management]? Pay me to do it." Essent... | setho |
1,900,114 | Building a Mock Data Generator with Google Sheets, Gemini AI & ToolJet ⚙️ | Introduction This tutorial will guide you through the process of building an AI-driven... | 0 | 2024-06-25T13:33:12 | https://blog.tooljet.com/building-a-mock-data-generator-with-google-sheets-gemini-ai-tooljet/ | googlesheets, ai, javascript, lowcode | ## Introduction
This tutorial will guide you through the process of building an AI-driven Mock Data Generator using [ToolJet](https://github.com/ToolJet/ToolJet), a low-code visual app builder, and the Gemini API, a powerful natural language processing API. We'll also use ToolJet's build-in integration with Google Shee... | amanregu |
1,900,112 | LaabamOne: Streamline Textile Distribution & Boost Sales | Efficient management and seamless operations are vital for success in the competitive textile... | 0 | 2024-06-25T13:27:36 | https://dev.to/laabamone/laabamone-streamline-textile-distribution-boost-sales-12fh | erpsoftware, textileerpsoftware | Efficient management and seamless operations are vital for success in the competitive textile distribution industry. LaabamOne offers a comprehensive ERP solution designed specifically for wholesale textile distributors, providing tools to streamline operations, enhance decision-making, and boost sales. Here's how Laab... | laabamone |
1,892,985 | The Magical World of Machine Learning at Hogwarts (Part #3) | 🌟✨ Greetings, young wizards and witches, to the enchanting realm of machine learning! I am Professor... | 0 | 2024-06-25T13:26:52 | https://dev.to/gerryleonugroho/the-magical-world-of-machine-learning-at-hogwarts-part-3-km2 | machinelearning, ai, beginners, algorithms | 🌟✨ Greetings, young **wizards and witches**, to the enchanting realm of **machine learning**! I am Professor Leo, a cherished confidant of the illustrious Albus Dumbledore and your guide on this mystical odyssey through the marvels of **machine learning**. My son, **Gemika Haziq Nugroho**, is just like you — a **burge... | gerryleonugroho |
1,900,111 | Escaping untrusted input and form validation. | As in my last post, I explained how to create a new note using a form and request methods, but I... | 0 | 2024-06-25T13:25:58 | https://dev.to/ghulam_mujtaba_247/escaping-untrusted-input-and-form-validation-mlf | webdev, beginners, programming, php | As in my last post, I explained how to create a new note using a form and request methods, but I didn't store the data in a database table.
## Diving in code
Today, I learned how to get input from users using forms and store it in a database, as well as how to validate forms to ensure the data is correct and secure.
... | ghulam_mujtaba_247 |
1,900,110 | Essential Video Conferencing Features for Productive One-on-One Meetings | Remember those pre-pandemic days when catching up with colleagues over a coffee was the norm? Times... | 0 | 2024-06-25T13:24:14 | https://dev.to/digitalsamba/essential-video-conferencing-features-for-productive-one-on-one-meetings-3l36 | videoconferencing, webdev, programming, opensource | Remember those pre-pandemic days when catching up with colleagues over a coffee was the norm? Times have changed, and video calls have become the new standard for team check-ins, particularly with so many of us working remotely these days. However, let's be honest: these virtual meetings can sometimes become... well, a... | digitalsamba |
1,900,109 | HTTP Methods and Common Error Codes | Understanding HTTP methods and error codes is crucial for anyone involved in web development or... | 0 | 2024-06-25T13:21:46 | https://dev.to/rahulvijayvergiya/http-methods-and-common-error-codes-12d5 | api, webdev, website, microservices | Understanding HTTP methods and error codes is crucial for anyone involved in web development or interacting with web services. By grasping the purpose and implications of each method and common error codes, developers can build more robust applications, diagnose and troubleshoot issues effectively, and ensure seamless ... | rahulvijayvergiya |
1,900,108 | ss | function printDuplicateCharacters(str) { // Step 1: Initialize an empty object to store... | 0 | 2024-06-25T13:21:06 | https://dev.to/shivam_sahu_704d021337aec/ss-o51 | ```
function printDuplicateCharacters(str) {
// Step 1: Initialize an empty object to store character counts
let charCount = {};
// Step 2: Iterate through the string to count each character
for (let i = 0; i < str.length; i++) {
let char = str[i];
if (charCount[char]) {
cha... | shivam_sahu_704d021337aec | |
1,900,107 | WHAT IS HTTP ?! | HTTP (HyperText Transfer Protocol) it is a way that the server communicates with the client (usually... | 0 | 2024-06-25T13:21:04 | https://dev.to/1hamzabek/what-is-http--587o | network, webdev, programming, beginners | HTTP (HyperText Transfer Protocol) it is a way that the server communicates with the client (usually web browser) , it's fundamental protocol of the internet , and the foundation of data communication for the **World Wide Web**.
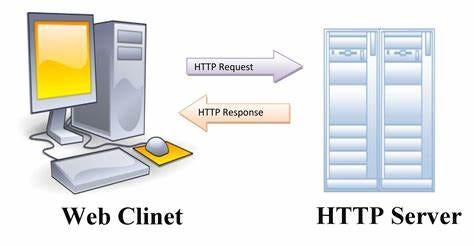... | 1hamzabek |
1,894,803 | Error Handling with Angular Interceptors | Introduction In this article I'll tackle the challenge of building a robust error handling... | 27,664 | 2024-06-25T13:20:45 | https://dev.to/cezar-plescan/error-handling-with-angular-interceptors-2548 | angular, tutorial, interceptor, refactoring | ## Introduction
In this article I'll tackle the challenge of building a robust error handling in our user profile form application. I'll look beyond simple validation errors and dive into a wider array of issues that can arise during the HTTP communication with the backend server. What if there's no network connection... | cezar-plescan |
1,900,104 | Seeding MongoDB for Different Development Environments | Seeding a MongoDB database involves populating it with initial data, which is essential for various... | 0 | 2024-06-25T13:15:07 | https://dev.to/platform_engineers/seeding-mongodb-for-different-development-environments-23ll | Seeding a MongoDB database involves populating it with initial data, which is essential for various purposes such as testing, demonstration, and proof of concept. This process can be automated using Node.js and the Faker library. In this blog, we will explore how to seed a MongoDB database for different development env... | shahangita | |
1,900,103 | Mastering the PMP Exam: Essential Tips for Success | Last month, I attended my first PMI chapter meeting, where I was seated with two other members next... | 0 | 2024-06-25T13:08:59 | https://dev.to/sumusiriwardana/mastering-the-pmp-exam-essential-tips-for-success-3j86 | projectmanagement, pmp, projectmanager, learning | Last month, I attended my first PMI chapter meeting, where I was seated with two other members next to me, one who had earned her PMP a year ago and another who was still preparing for the exam. As we introduced ourselves, our conversation naturally flowed into our experiences with the PMP exam, study processes, and re... | sumusiriwardana |
1,899,357 | For Engineers in a Hurry: A Guide for Implementing Security | Introduction I’m sure that, when trying to be a solopreneur or create your own side... | 27,848 | 2024-06-25T13:07:53 | https://dev.to/llxd/for-engineers-in-a-hurry-a-guide-for-implementing-security-1o8m | tutorial, webdev, javascript, react | ## Introduction
I’m sure that, when trying to be a solopreneur or create your own side projects, time constraints can be a big problem. Most of the time, we have to overlook things and do them as quickly as possible to meet the deadlines.
Unfortunately, security is one of those things that takes a lot of time to pro... | llxd |
1,900,102 | Five Must-Have Programming Tools That Will Make You Love Coding and Reduce Overtime | As a "CV Engineer," I diligently copy and paste code, but I never expected that today's tools would... | 0 | 2024-06-25T13:05:19 | https://dev.to/lunamiller/five-must-have-programming-tools-that-will-make-you-love-coding-and-reduce-overtime-24ei | webdev, php, programming, ai | As a "CV Engineer," I diligently copy and paste code, but I never expected that today's tools would become so convenient. Here are a few tools that have significantly improved my efficiency and reduced my overtime hours.
### [Fronty](https://fronty.com/)
A front-end engineer often needs to convert web designs into us... | lunamiller |
1,900,064 | Streamlining Development Workflow: Automating Tasks with GitHub Actions | During the entire development process, from code to deployment, we encounter many repeated... | 0 | 2024-06-25T13:04:24 | https://dev.to/olucasandrade/streamlining-development-workflow-automating-tasks-with-github-actions-58dg | github, cicd, git, automation |
![Github Actions Icon]()
During the entire development process, from code to deployment, we encounter many repeated processes: updating snapshots, running unit tests, deploying to staging, completing production deployments... all these types of processes will inevitably become part of every task developed, without e... | olucasandrade |
1,900,091 | Buy CogniCare Pro Review: An In-Depth Look at CogniCare Pro, CogniCare Pro Supplement, and How to Buy and Purchase CogniCare Pro | In today's fast-paced world, cognitive health is of paramount importance. With numerous supplements... | 0 | 2024-06-25T13:02:24 | https://dev.to/tushar_balchandani_1d6215/buy-cognicare-pro-review-an-in-depth-look-at-cognicare-pro-cognicare-pro-supplement-and-how-to-buy-and-purchase-cognicare-pro-3cmk | cognicarepro, cognicareproreview, buycognicarepro, cognicareprosupplement |

In today's fast-paced world, cognitive health is of paramount importance. With numerous supplements flooding the market, it can be challenging to find the right one that truly delivers on its promises. This article... | tushar_balchandani_1d6215 |
1,899,985 | Constructing Key Pages for Your E-Commerce Site: Shop, Cart, and Product Pages | Check this post in my web notes! And the final result is over here! We continue building our... | 27,540 | 2024-06-25T13:01:49 | https://webcraft-notes.com/blog/constructing-key-pages-for-your-ecommerce-site | vue, nuxt, javascript, tutorial |

> Check [this post](https://webcraft-notes.com/blog/constructing-key-pages-for-your-ecommerce-site) in my [web notes](https://webcraft-notes.com/blog/)!
> And the final result is over... | webcraft-notes |
1,899,762 | Flutter's Essential Toolkit: Top Tools for Every Developer | Top Flutter app development tools to consider. | 0 | 2024-06-25T13:01:24 | https://dev.to/harsh8088/flutters-essential-toolkit-top-tools-for-every-developer-nk8 | flutter, dart, tools, ide | ---
title: Flutter's Essential Toolkit: Top Tools for Every Developer
published: true
description: Top Flutter app development tools to consider.
tags: flutter, dart, tools, ide
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/grsmyqb0d38m7wf8hhha.png
# Use a ratio of 100:42 for best results.
# pub... | harsh8088 |
1,900,096 | The Perfect Pair: Disposable Vapes and Nic Salts for Every Vaper | Disposable vapes provide a cost-effective alternative upfront compared to traditional vape setups, as... | 0 | 2024-06-25T12:57:16 | https://dev.to/adnan_jahanian/the-perfect-pair-disposable-vapes-and-nic-salts-for-every-vaper-54c2 | Disposable vapes provide a cost-effective alternative upfront compared to traditional vape setups, as users avoid the need to purchase additional components like batteries or e-liquids. Additionally, their pre-filled cartridges ensure unparalleled convenience by eliminating the need for refilling or recharging. This si... | adnan_jahanian | |
1,900,100 | Dotfiles: The Developer Secret to the Perfect Setup | What Are Dotfiles? 📁 Dotfiles are configuration files for Unix-like systems that start... | 0 | 2024-06-25T12:59:57 | https://dev.to/codejourney/dotfiles-the-developer-secret-to-the-perfect-setup-4dll | dotfiles, customization, linux | ## What Are Dotfiles? 📁
Dotfiles are configuration files for Unix-like systems that start with a dot (.). They are usually hidden in your home folder and silently monitor the behavior of applications and the shell. Think of them as the DNA of your development environment.
Common examples are:
- `.bashrc` or `.zshrc`... | codejourney |
1,900,099 | React-complex-grid-builder | Hello,Developers! 🚀 Excited to share a new milestone in my journey as a Full Stack Developer!... | 0 | 2024-06-25T12:59:17 | https://dev.to/arnav2001/react-complex-grid-builder-3ejc | fullstack, nextjs, npm, react | Hello,Developers!
🚀 Excited to share a new milestone in my journey as a Full Stack Developer! 🚀
Recently, I encountered a challenge where I needed to build a dynamic grid with divs of varying sizes. The goal was to ensure that as soon as new data is added on the backend, a new item seamlessly appears in the grid. A... | arnav2001 |
1,899,800 | TailwindCSS Dark Mode. Free UI/UX design course | Dark mode Psst! Press shift + D to toggle dark/light mode on most websites. For some time... | 25,935 | 2024-06-25T12:59:00 | https://dev.to/keepcoding/tailwindcss-dark-mode-free-uiux-design-course-3eb4 | tailwindcss, learning, html, ui | ## Dark mode
_Psst!
Press shift + D to toggle dark/light mode on most websites._
For some time now, dark mode has ceased to be just a fashionable novelty, and has become a mandatory functionality of good design.
Thanks to Tailwind, the implementation of dark mode in our project is child's play.
![Image description]... | keepcoding |
1,900,098 | Explosive Growth in the Sapphire Technology Market: Innovations and Trends Shaping the Future | Infinium Global Research recently released a comprehensive report on the sapphire technology market,... | 0 | 2024-06-25T12:58:20 | https://dev.to/prathmeshkinfinium/explosive-growth-in-the-sapphire-technology-market-innovations-and-trends-shaping-the-future-ee5 |
Infinium Global Research recently released a comprehensive report on the sapphire technology market, offering detailed analysis of global and regional segments and sub-segments. The study evaluates the influence of drivers, constraints, and macroeconomic indicators on both short-term and long-term aspects of the globa... | prathmeshkinfinium | |
1,900,097 | Automotive Suspension Market Sees Unprecedented Growth Amid Surge in Vehicle Demand and Technological Advancements | Infinium Global Research recently released a comprehensive report on the automotive suspension... | 0 | 2024-06-25T12:57:42 | https://dev.to/prathmeshkinfinium/automotive-suspension-market-sees-unprecedented-growth-amid-surge-in-vehicle-demand-and-technological-advancements-4a6l | Infinium Global Research recently released a comprehensive report on the automotive suspension market, offering detailed analysis of global and regional segments. The study delves into the influence of drivers, constraints, and macroeconomic factors on both short-term and long-term perspectives of the market. Emphasizi... | prathmeshkinfinium | |
1,900,040 | Using ModSecurity in Nginx project — maintaining protection on WordPress | ModSecurity, one of the world’s most popular web app firewalls (WAF), helps prevent various types of... | 0 | 2024-06-25T12:56:42 | https://dev.to/ispmanager/using-modsecurity-in-nginx-project-maintaining-protection-on-wordpress-31d3 | nginx, security, webdev, tutorial |
ModSecurity, one of the world’s most popular web app firewalls (WAF), helps prevent various types of attacks on web applications. Such attacks include SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF). ModSecurity is a module for servers such as Apache, Nginx, and IIS.
An alternative to... | ispmanager_com |
1,900,095 | Global ANPR System Market Sees Robust Growth Driven by Advancements in AI and Traffic Management Solutions | Infinium Global Research recently published a comprehensive report on the ANPR system market,... | 0 | 2024-06-25T12:52:27 | https://dev.to/prathmeshkinfinium/global-anpr-system-market-sees-robust-growth-driven-by-advancements-in-ai-and-traffic-management-solutions-361h | Infinium Global Research recently published a comprehensive report on the ANPR system market, offering detailed analysis of global and regional segments. The study emphasizes the influence of drivers, restraints, and macroeconomic indicators on both short-term and long-term perspectives of the ANPR system market. The r... | prathmeshkinfinium | |
1,900,094 | Armoured Vehicle Market Surges: Industry Sees Robust Growth Amid Rising Defense Investments and Technological Advancements | A recent report from Infinium Global Research delves deep into the armoured vehicle market, offering... | 0 | 2024-06-25T12:51:46 | https://dev.to/prathmeshkinfinium/armoured-vehicle-market-surges-industry-sees-robust-growth-amid-rising-defense-investments-and-technological-advancements-1bne | A recent report from Infinium Global Research delves deep into the armoured vehicle market, offering a thorough analysis of its global and regional segments and sub-segments. The study assesses the influence of drivers, constraints, and macro indicators on both short-term and long-term aspects of the global and regiona... | prathmeshkinfinium | |
1,900,093 | Why Non-VOIP Numbers are Essential for Secure Online Verification | Online security is a big deal these days. With so many services requiring phone number verifications,... | 0 | 2024-06-25T12:48:57 | https://dev.to/legitsms/why-non-voip-numbers-are-essential-for-secure-online-verification-58f0 | nonvoipnumber, nonvoipusfreenumber, nonvoipphonenumber | Online security is a big deal these days. With so many services requiring phone number verifications, it's important to keep your personal information safe. That's where non-VOIP numbers come in. This guide will explore why non-VOIP numbers are essential for secure online verifications, how to set them up, and their be... | legitsms |
1,900,081 | Venture Capital: Strategic Pros and Cons | Understanding Venture Capital Financing Venture capital (VC) is a form of private equity where... | 0 | 2024-06-25T12:28:37 | https://dev.to/linda0609/venture-capital-strategic-pros-and-cons-2k7g | investment, research | Understanding Venture Capital Financing
Venture capital (VC) is a form of private equity where investors allocate their capital to nascent business ideas showing strong potential for growth. [Investment research services](Understanding Venture Capital Financing
Venture capital (VC) is a form of private equity where i... | linda0609 |
1,900,092 | Backup Bluehost Emails | Users can take backup Bluehost emails via email client but in this way, they need to configure... | 0 | 2024-06-25T12:48:34 | https://dev.to/jackera/backup-bluehost-emails-1jcj | Users can take backup Bluehost emails via email client but in this way, they need to configure Bluehost account with email client. However, third part tool like **Mail Backup Tool** enable you to directly save Bluehost emails without any configuration. The software can download emails into multiple file formats such as... | jackera | |
1,900,090 | Revolutionizing the Road: Automotive Virtual Assistant Market Accelerates into the Future | In a recent publication by Infinium Global Research, the automotive virtual assistant market is... | 0 | 2024-06-25T12:46:17 | https://dev.to/prathmeshkinfinium/revolutionizing-the-road-automotive-virtual-assistant-market-accelerates-into-the-future-d8l |
In a recent publication by Infinium Global Research, the automotive virtual assistant market is thoroughly examined, offering a detailed analysis of global and regional segments and sub-segments. The report delves into the impacts of drivers, constraints, and macro indicators on both short-term and long-term aspects o... | prathmeshkinfinium | |
1,900,089 | Revolutionizing Convenience: Automotive Power Liftgate Market Surges with Innovative Solutions | Infinium Global Research recently released a comprehensive report on the automotive power liftgate... | 0 | 2024-06-25T12:44:48 | https://dev.to/prathmeshkinfinium/revolutionizing-convenience-automotive-power-liftgate-market-surges-with-innovative-solutions-5bc9 | Infinium Global Research recently released a comprehensive report on the automotive power liftgate market, offering detailed analysis of global and regional segments. The study evaluates the influence of drivers, constraints, and macro indicators on both short-term and long-term perspectives of the automotive power lif... | prathmeshkinfinium | |
1,900,088 | Surprising Influencer Marketing Statistics | Influencer marketing is an ever-evolving domain that leverages the social capital of individuals to... | 0 | 2024-06-25T12:41:07 | https://dev.to/k_jaksoftware_00e3ee8700c/surprising-influencer-marketing-statistics-hil | seoservices, seoexpert, digitalmarketing, socialmediamarketing | Influencer marketing is an ever-evolving domain that leverages the social capital of individuals to promote brands, products, or SEO services. With the exponential growth of social media platforms, influencers have become pivotal in shaping consumer opinions and behaviors. The statistics surrounding influencer marketin... | k_jaksoftware_00e3ee8700c |
1,900,086 | Discover Villa Plots in Nowluru with Amaravati Ventures! | Experience Luxurious Living. Explore our range of open and villa plots for sale in Nowluru, where... | 0 | 2024-06-25T12:39:54 | https://dev.to/digital_market_e985a4c41f/discover-villa-plots-in-nowluru-with-amaravati-ventures-11g5 | realestate, ventures, openplots, plotsforsale | **Experience Luxurious Living.**
Explore our range of open and villa plots for sale in Nowluru, where sophistication meets serene landscapes. Enjoy luxurious living surrounded by tranquil settings and breathtaking views.
**Premier Open Plots in Nowluru.**
Our exclusive [open plots in Nowluru](http://amaravativentures... | digital_market_e985a4c41f |
1,896,339 | MLOps: To Build or Buy? Navigating the Decision for Your Organization | The rapid evolution of artificial intelligence (AI) and machine learning (ML) technologies has... | 0 | 2024-06-25T12:39:00 | https://dev.to/craftworkai/mlops-to-build-or-buy-navigating-the-decision-for-your-organization-dj0 | mlops, machinelearning, ai | The rapid evolution of artificial intelligence (AI) and machine learning (ML) technologies has transformed numerous industries, offering unprecedented capabilities in data analysis, prediction, and automation. However, deploying AI/ML models in production environments remains a complex challenge. This is where MLOps (M... | larkmullins-craftworkai |
1,900,085 | Integrating Stripe Payments with Discord for Automatic User Addition and Subscription Management | Hello Dev.to community, I'm currently working on a project that involves integrating Stripe with... | 0 | 2024-06-25T12:38:19 | https://dev.to/kamal_antaal_a6dc8ee71f15/integrating-stripe-payments-with-discord-for-automatic-user-addition-and-subscription-management-1fc | Hello Dev.to community,
I'm currently working on a project that involves integrating Stripe with Discord for managing subscriptions and user access. Here are the main requirements I'm trying to achieve:
1. Stripe Integration: I need to create a button on my website that redirects users to a Stripe checkout page.
2. ... | kamal_antaal_a6dc8ee71f15 | |
1,900,079 | Build a real-time voting app with WebSockets, React & TypeScript 🔌⚡️ | TL;DR WebSockets allow your app to have “real time” features, where updates are instant... | 0 | 2024-06-25T12:35:33 | https://wasp-lang.dev/blog/2023/08/09/build-real-time-voting-app-websockets-react-typescript | websockets, react, typescript, tutorial | ## TL;DR
WebSockets allow your app to have “real time” features, where updates are instant because they’re passed on an open, two-way channel.
This is different from CRUD apps, which usually use HTTP requests that must establish a connection, send a request, receive a response, and then close the connection.
![real... | vincanger |
1,900,084 | A Beginner's Guide to Understanding the Benefits of Spay and Neuter Clinics | If you're a pet owner, you've likely heard about the importance of spaying and neutering your pets.... | 0 | 2024-06-25T12:34:04 | https://dev.to/graceah/a-beginners-guide-to-understanding-the-benefits-of-spay-and-neuter-clinics-51n8 | If you're a pet owner, you've likely heard about the importance of spaying and neutering your pets. Spay and neuter clinics provide essential services that benefit not only your pets but also the broader community. Understanding the advantages of these procedures can help you make informed decisions about your pet's he... | graceah | |
1,900,083 | String methods in JavaScript.! part(1). | String methods in javascript JavaScript String malumot turida quyidagi string metodlari mavjud, va... | 0 | 2024-06-25T12:31:55 | https://dev.to/samandarhodiev/string-methods-in-javascript-part1-73j | **String methods in javascript**
JavaScript String malumot turida quyidagi string metodlari mavjud, va ularni birma-bir ko'ribchiqamiz.!
`String length
String charAt()
String charCodeAt()
String at()
String [ ]
String slice()
String substring()
String substr()
String toUpperCase()
String toLowerCase()
String concat(... | samandarhodiev | |
1,900,080 | Streamline Your Workflow with OneChannelAdmin: Enhance Efficiency Today! | A post by onechanneladmin | 0 | 2024-06-25T12:26:58 | https://dev.to/onechanneladmin_c80ff8dc4/streamline-your-workflow-with-onechanneladmin-enhance-efficiency-today-5chl | webdev, programming, seo, react |
[](https://onechanneladmin.com/)
| onechanneladmin_c80ff8dc4 |
1,900,078 | Cloud-based Tax Software vs. Tax Software Hosting Solutions | The speed at which technology generates digital solutions is impressive. The tax preparation industry... | 0 | 2024-06-25T12:26:04 | https://dev.to/him_tyagi/cloud-based-tax-software-vs-tax-software-hosting-solutions-2a02 | webdev, javascript, beginners, programming | The speed at which technology generates digital solutions is impressive. The tax preparation industry has witnessed considerable transformations thanks to technological advancements, particularly in adopting digital solutions.
Cloud-based tax software and [tax software hosting](https://www.acecloudhosting.com/tax-sof... | him_tyagi |
1,900,077 | What Is old Gmail Account? | What exactly is an old Gmail account? Well, it’s quite simple. An old Gmail account refers to a Gmail... | 0 | 2024-06-25T12:26:00 | https://dev.to/buyusaseller56/what-is-old-gmail-account-1dck | webdev, javascript, beginners, programming | What exactly is an old Gmail account? Well, it’s quite simple. An old Gmail account refers to a Gmail email address that has been in existence for a considerable period of time. These accounts have weathered the test of time, accumulating history and credibility along the way.
But what sets apart an old [Gmail account... | buyusaseller56 |
1,900,076 | Food deals in SG | The bright food court in Singapore provides a number of meals outlets has many offers and discounts... | 0 | 2024-06-25T12:24:24 | https://dev.to/sophia_hemsworth_c14c52b4/food-deals-in-sg-4jab | The bright food court in Singapore provides a number of meals outlets has many offers and discounts for counterpart fans. Major platforms that offer half-price and exclusive deals can also be accessed here, including Chope, Eatigo, Burpple - where everyone belonging to any category of food or restaurants will find some... | sophia_hemsworth_c14c52b4 | |
1,900,075 | What next after CISM? | Achieving your CISM certification is a significant milestone in your career. Now wondering what to do... | 0 | 2024-06-25T12:22:12 | https://dev.to/shivamchamoli18/what-next-after-cism-52l5 | cism, certificationtraining, cybersecurity, infosectrain | Achieving your [CISM certification](https://www.infosectrain.com/courses/cism-certification-training/) is a significant milestone in your career. Now wondering what to do after earning your cism certification? With your newfound expertise in information security management, countless opportunities await. Whether you're... | shivamchamoli18 |
1,900,063 | Top 4 Delivery Scripts to Start a Profitable Delivery Business | In today’s fast-paced digital world, the demand for efficient delivery services has skyrocketed.... | 0 | 2024-06-25T12:17:39 | https://dev.to/merrygomez12148/top-4-delivery-scripts-to-start-a-profitable-delivery-business-1lbn | deliveryscript, lalamoveclone, getirclone, gopuffclone |

In today’s fast-paced digital world, the demand for efficient delivery services has skyrocketed. From groceries to packages, customers now expect quick, reliable, and seamless delivery experiences. If you’re an ent... | merrygomez12148 |
1,900,062 | What is GraphQl? | Order What You Want: Imagine you’re at a restaurant. With GraphQL, you can order exactly what you... | 0 | 2024-06-25T12:16:58 | https://dev.to/sameer472/what-is-graphql-1bec | Order What You Want: Imagine you’re at a restaurant. With GraphQL, you can order exactly what you want from the menu, and you get just that. You don’t get a whole meal if you only wanted a drink.
Hope you get what I am trying to say. So basically GraphQl is a query Lanuage for API. GraphQL provides a complete and unde... | sameer472 | |
1,900,061 | How Can We Improve Mockingbird for Better Developer Experience? | Hello DEV community! I’ve been working on Mockingbird, a tool designed to enhance API development... | 0 | 2024-06-25T12:16:49 | https://dev.to/ozkeisar/how-can-we-improve-mockingbird-for-better-developer-experience-3i9d | discuss, javascript, typescript, api |
Hello DEV community!
I’ve been working on [Mockingbird](https://github.com/ozkeisar/mockingbird), a tool designed to enhance API development workflows by providing features like multiple responses for each route, presets for easy scenario switching, Git integration, and more. My goal is to make Mockingbird a seamles... | ozkeisar |
1,900,060 | Unlock Your Potential at the Paramedical Sciences College in Coimbatore | If you are passionate about healthcare and eager to make a difference in people's lives, the... | 0 | 2024-06-25T12:15:53 | https://dev.to/sreeabirami_123/unlock-your-potential-at-the-paramedical-sciences-college-in-coimbatore-4a5f | If you are passionate about healthcare and eager to make a difference in people's lives, the [Paramedical Sciences College in Coimbatore](https://www.sreeabiramiinstitutions.com/) is your ideal destination. As a premier institution under the esteemed Sree Abirami Institution, our college is dedicated to providing excep... | sreeabirami_123 | |
1,888,202 | About Spring AMQP | The discussion is based on following library Spring Framework 6.1.8 Spring Boot 3.3.0 Spring AMQP... | 0 | 2024-06-25T12:13:03 | https://dev.to/saladlam/about-spring-amqp-6dm | spring, springboot | The discussion is based on following library
- Spring Framework 6.1.8
- Spring Boot 3.3.0
- Spring AMQP 3.1.5
# Components
| Class | Function |
| - | - |
| RabbitAdmin | Exchange, queue and binding operation |
| Queue | Represent definition of queue |
| RabbitConnectionDetails | Connection information |
| RabbitConn... | saladlam |
1,900,058 | Make czy Zapier i dla czego warto wybrać n8n | Make czy Zapier? Żaden z nich? Poznaj najefektywniejsze narzędzie, którym jest n8n. Pokażę Ci... | 0 | 2024-06-25T12:12:57 | https://dev.to/kuzry/make-czy-zapier-i-dla-czego-warto-wybrac-n8n-42bc | Make czy Zapier? Żaden z nich? Poznaj najefektywniejsze narzędzie, którym jest n8n. Pokażę Ci funkcje, ceny i cechy każdego z nich.
Make, Zapier i n8n to popularne narzędzia do tworzenia automatyzacji, które pozwalają łączyć ze sobą aplikacje i usługi w celu tworzenia połączeń pomiędzy nimi. Chociaż wszystkie te narzę... | kuzry | |
1,900,057 | Raj Yog in Kundali: An Astrological Perspective | Introduction Raj Yog in kundli, often regarded as the pinnacle of auspicious yogas in... | 0 | 2024-06-25T12:12:53 | https://dev.to/mjvedicmeet/raj-yog-in-kundali-an-astrological-perspective-8hg | ## **Introduction**
Raj Yog in kundli, often regarded as the pinnacle of auspicious yogas in **[Vedic astrology](https://vedicmeet.com/topics/astrology/)**, signifies power, authority, and immense success. Imagine unlocking a secret pathway that leads to unparalleled prosperity and happiness. This is what Raj Yog prom... | mjvedicmeet | |
1,900,048 | How to create a flexible Dev Environment with Vagrant and Docker | Today we're discussing how you can create a fully automated, virtualized development environment. One... | 0 | 2024-06-25T12:11:51 | https://rolfstreefkerk.com/article/how-to-create-a-flexible-dev-environment-with-vagrant-and-docker | devops, productivity, docker, laravel |
Today we're discussing how you can create a fully automated, virtualized development environment. One that's customizable, and ready to use in minutes.
In this article, I'll show you how to set up such an environment using PHP and Laravel, though the principles can be applied to your preferred tech stack.
We'll div... | rolfstreefkerk |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.