Datasets:

File size: 10,269 Bytes
4dba939 7a6cc87 b208ea5 4dba939 b208ea5 7a6cc87 b208ea5 7a6cc87 b208ea5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 |
---
task_categories:
- visual-question-answering
language:
- en
---
# STRIDE-QA Dataset
[](https://arxiv.org/abs/2508.10427)
[](https://turingmotors.github.io/stride-qa/)
[](https://github.com/turingmotors/STRIDE-QA-Dataset)
[](https://huggingface.co/datasets/turing-motors/STRIDE-QA-Bench)
## 📦 Dataset
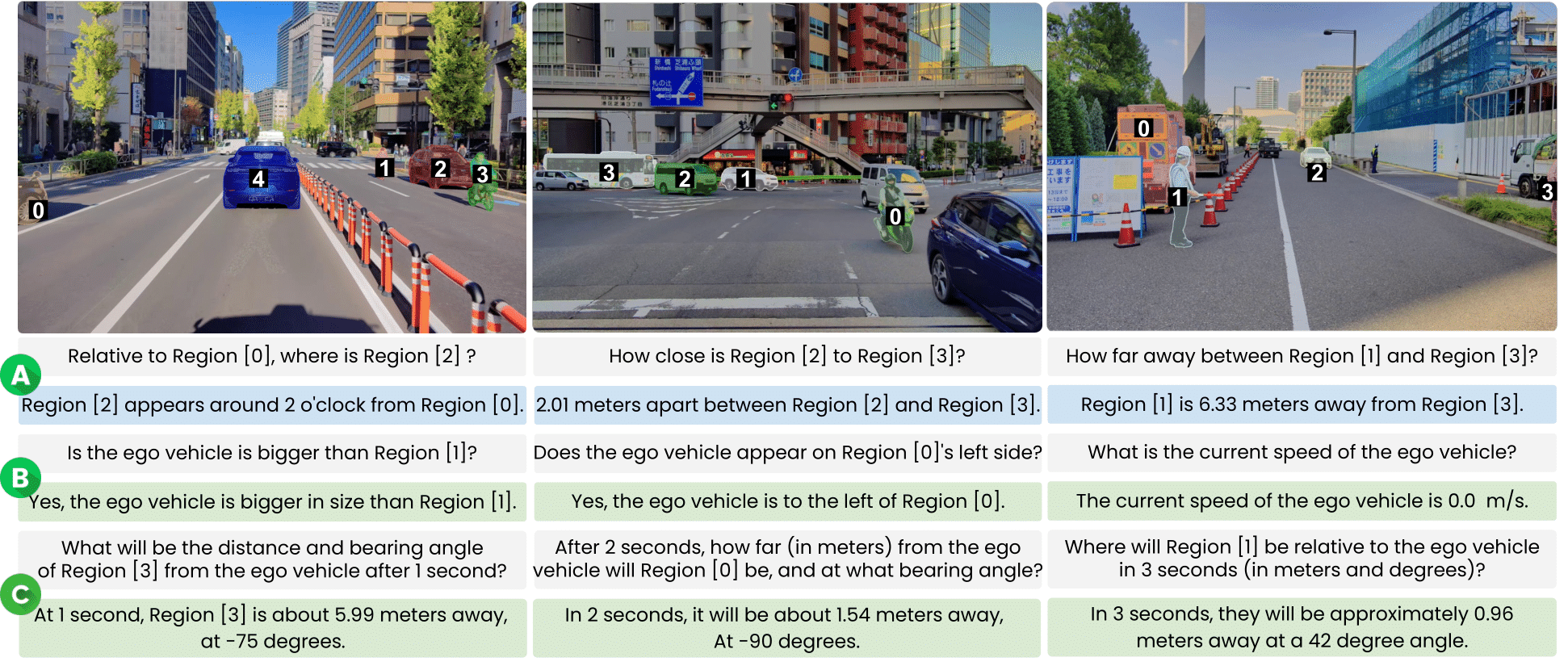
**STRIDE-QA** is a large-scale visual question answering (VQA) dataset for physically grounded spatiotemporal reasoning in autonomous driving. Constructed from 100 hours of multi-sensor driving data in Tokyo, it offers **16 M QA pairs** over **270 K frames** with dense annotations including 3D bounding boxes, segmentation masks, and multi-object tracks.
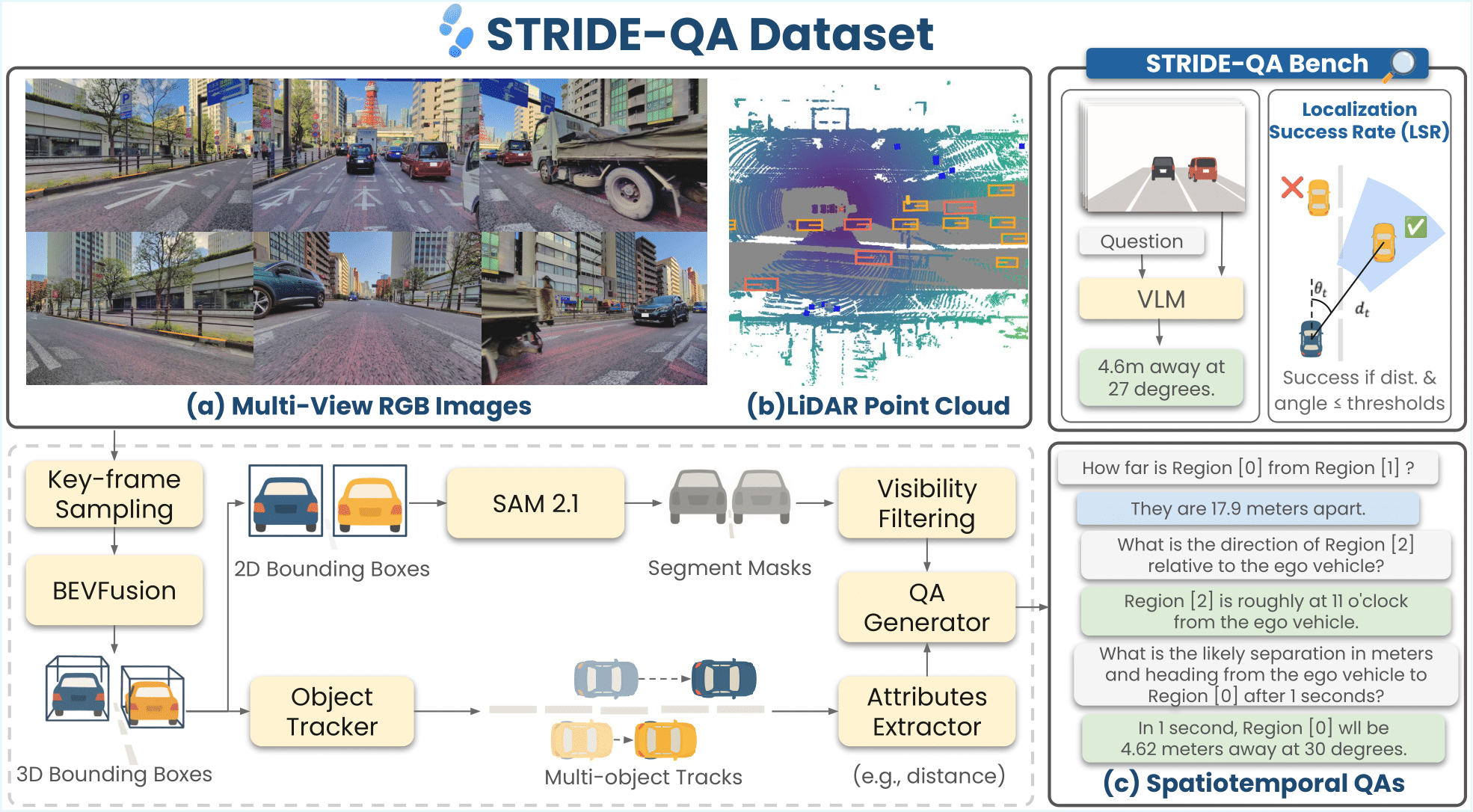
| Category | Description |
| --- | --- |
| **Object-centric Spatial QA** | Spatial relations between two surrounding agents (single frame). Includes qualitative (e.g., relative position) and quantitative (e.g., distance, angle) questions. |
| **Ego-centric Spatial QA** | Spatial relations between the ego vehicle and a surrounding agent (single frame). Covers distance, direction, and size comparisons. |
| **Ego-centric Spatiotemporal QA** | Short-term prediction using 4 context frames (2 Hz). Forecasts distance, heading angle, and velocity at t ∈ {1, 2, 3} s. |
| QA Category | Qualitative (train) | Qualitative (val) | Quantitative (train) | Quantitative (val) | Total (M) |
| --- | --- | --- | --- | --- | --- |
| Object-centric Spatial QA | 2.20 | 0.11 | 1.10 | 0.06 | 3.47 |
| Ego-centric Spatial QA | 3.10 | 0.16 | 4.33 | 0.23 | 7.82 |
| Ego-centric Spatiotemporal QA | – | – | 4.73 | 0.40 | 5.13 |
| **Total** | **5.30** | **0.28** | **10.17** | **0.69** | **16.43** |
### Data Format
This repository provides front camera images and JSONL annotations.
#### Directory Structure
```bash
STRIDE-QA-Dataset/
├── train/
│ ├── images/
│ └── annotations/
│ ├── ego_centric_spatial_qa/
│ ├── ego_centric_spatiotemporal_qa/
│ └── object_centric_spatial_qa/
└── val/
├── images/
└── annotations/
├── ego_centric_spatial_qa/
├── ego_centric_spatiotemporal_qa/
└── object_centric_spatial_qa/
```
#### Data Fields
The dataset is provided in `.jsonl.gz`. Each line in the JSONL file represents a single sample with the following fields:
| Field | Type | Description |
| --- | --- | --- |
| `id` | `str` | Unique sample ID. |
| `split` | `str` | Dataset split (`train` or `val`). |
| `category` | `str` | QA category type. |
| `image` | `str` | File name of the key frame used in the prompt. |
| `images` | `list[str]` | File names for the four consecutive image frames. Only available in Ego-centric Spatiotemporal QA category. |
| `conversations` | `list[dict]` | Dialogue in VILA format (`"from": "human"` / `"gpt"`). |
| `image_info` | `dict` | Image metadata (height, width, dataset, landmark, file_path). |
| `token_info` | `dict` | Sample and sample data tokens for nuScenes reference. |
| `qa_info` | `list[dict]` | Metadata for each QA turn (type, category, class, token). |
| `bbox` | `list[list[float]]` | Bounding boxes \[x₁, y₁, x₂, y₂] for referenced regions. |
| `rle` | `list[dict]` | COCO-style run-length masks for regions. |
| `region` | `list[list[int]]` | Region tags mentioned in the prompt. |
#### Example Records
##### Object-centric Spatial QA
```json
{
"id": "0004143dce0d1445",
"split": "val",
"category": "object_centric_spatial_qa",
"image": "0004143dce0d1445.jpg",
"conversations": [
{
"from": "human",
"value": "Is Region [3] taller than Region [0]?"
},
{
"from": "gpt",
"value": "No, Region [3] is not taller than Region [0]."
}
// ... more QA pairs ...
],
"image_info": {
"height": 1860,
"width": 2880,
"dataset": "STRIDE-QA",
"landmark": "outdoor",
"file_path": "0004143dce0d1445.jpg"
},
"token_info": {
"sample_token": "a2950b1d20375897e99b633a981e4dfe",
"sample_data_token": "4aba804904f3a1a2d3271b1fe8a6fc92"
},
"qa_info": [
{
"type": "qualitative",
"category": "tall_predicate",
"class": ["car", "large_vehicle"],
"token": {
"obj_A": {
"instance_token": "c7238672f1bfcc08929f99729f842948",
"sample_annotation_token": "a8189cdb160a525e2f798e739849fe8b"
},
"obj_B": {
"instance_token": "4941cec428bd732ff3e54ee43fbcc0e1",
"sample_annotation_token": "bac4d2c0ae8d029e406961655bf82ee9"
}
}
}
// ... more qa_info entries ...
],
"bbox": [
[0.0, 101.39, 881.81, 1657.32]
// ... more bounding boxes ...
],
"rle": [
{
"size": [1860, 2880],
"counts": "o7\\W12jhN^b0VW1b]OjhN^b0VW1..."
}
// ... more RLE masks ...
],
"region": [
[3, 0]
// ... more region tags ...
]
}
```
##### Ego-centric Spatial QA
```json
{
"id": "0004143dce0d1445",
"split": "val",
"category": "ego_centric_spatial_qa",
"image": "0004143dce0d1445.jpg",
"conversations": [
{
"from": "human",
"value": "Is the ego vehicle bigger than Region [0]?"
},
{
"from": "gpt",
"value": "Incorrect, the ego vehicle is not larger than Region [0]."
}
// ... more QA pairs ...
],
"image_info": {
"height": 1860,
"width": 2880,
"dataset": "STRIDE-QA",
"landmark": "outdoor",
"file_path": "0004143dce0d1445.jpg"
},
"token_info": {
"sample_token": "a2950b1d20375897e99b633a981e4dfe",
"sample_data_token": "4aba804904f3a1a2d3271b1fe8a6fc92"
},
"qa_info": [
{
"type": "qualitative",
"category": "ego_big_predicate",
"class": ["ego_vehicle", "large_vehicle"],
"token": {
"ego": {
"instance_token": null,
"sample_annotation_token": null
},
"other": {
"instance_token": "4941cec428bd732ff3e54ee43fbcc0e1",
"sample_annotation_token": "bac4d2c0ae8d029e406961655bf82ee9"
}
}
}
// ... more qa_info entries ...
],
"bbox": [
[0.0, 101.39, 881.81, 1657.32]
// ... more bounding boxes ...
],
"rle": [
{
"size": [1860, 2880],
"counts": "o7\\W12jhN^b0VW1b]OjhN^b0VW1..."
}
// ... more RLE masks ...
],
"region": [
[99, 0]
// ... more region tags ...
]
}
```
##### Ego-centric Spatio-temporal QA
```json
{
"id": "0004143dce0d1445",
"split": "val",
"category": "ego_centric_spatiotemporal_qa",
"images": [
"31ee9bcfc3ed9dec.jpg",
"f6db1dee9bddc641.jpg",
"c76385f109139ea8.jpg",
"0004143dce0d1445.jpg"
],
"conversations": [
{
"from": "human",
"value": "Can you give me an estimate of the distance between the ego vehicle and Region [0]?"
},
{
"from": "gpt",
"value": "The ego vehicle and Region [0] are 3.27 meters apart from each other."
}
// ... more QA pairs ...
],
"image_info": {
"height": 1860,
"width": 2880,
"dataset": "STRIDE-QA",
"landmark": "outdoor",
"file_path": "0004143dce0d1445.jpg"
},
"token_info": {
"current": {
"sample_token": "a2950b1d20375897e99b633a981e4dfe",
"sample_data_token": "4aba804904f3a1a2d3271b1fe8a6fc92"
},
"prev_1": {
"sample_token": "93f455351c376fb32dc6315c3d0c53e2",
"sample_data_token": "0ec22aef72d02da0f26763b22ec7afe3"
}
// ... prev_2, prev_3 ...
},
"qa_info": [
{
"category": "target_distance_t0",
"target": {
"instance_token": "4941cec428bd732ff3e54ee43fbcc0e1",
"sample_annotation_token": "bac4d2c0ae8d029e406961655bf82ee9",
"class": "large_vehicle",
"region_id": 0
},
"state": {
"ego": {
"speed_mps": 4.38
},
"target": {
"speed_mps": 6.42,
"distance_m": 3.27,
"bearing_deg": 18.58,
"clock_position": 11
},
"after_t_seconds": 0
}
}
// ... more qa_info entries ...
],
"bbox": {
"current": [
[0.0, 101.39, 881.81, 1657.32]
// ... more bounding boxes ...
],
"prev_1": [
[0.0, 0.0, 802.30, 1860.0]
// ... more bounding boxes ...
]
// ... prev_2, prev_3 ...
},
"rle": {
"current": [
{
"size": [1860, 2880],
"counts": "o7\\W12jhN^b0VW1b]OjhN^b0VW1..."
}
// ... more RLE masks ...
]
// ... prev_1, prev_2, prev_3 ...
}
}
```
## 📄 License
STRIDE-QA-Dataset is released under the [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.en).
## 📚 Citation
```bibtex
@misc{strideqa2025,
title={STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes},
author={Keishi Ishihara and Kento Sasaki and Tsubasa Takahashi and Daiki Shiono and Yu Yamaguchi},
year={2025},
eprint={2508.10427},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.10427},
}
```
## 🤝 Acknowledgements
This dataset was developed as part of the project JPNP20017, which is subsidized by the New Energy and Industrial Technology Development Organization (NEDO), Japan.
We would like to acknowledge the use of the following open-source repositories:
- [SpatialRGPT](https://github.com/AnjieCheng/SpatialRGPT?tab=readme-ov-file) for building dataset generation pipeline
- [SAM 2.1](https://github.com/facebookresearch/sam2) for segmentation mask generation
- [dashcam-anonymizer](https://github.com/varungupta31/dashcam_anonymizer) for anonymization
## 🔏 Privacy Protection
To ensure privacy protection, human faces and license plates in the images were anonymized using the [Dashcam Anonymizer](https://github.com/varungupta31/dashcam_anonymizer). |