
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 1.61B 1.64B | node_id stringlengths 18 19 | number int64 5.6k 5.66k | title stringlengths 12 113 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone null | comments int64 0 15 | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 10 19.9k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app null | state_reason stringclasses 2
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5660/comments | https://api.github.com/repos/huggingface/datasets/issues/5660/events | https://github.com/huggingface/datasets/issues/5660 | 1,635,543,646 | I_kwDODunzps5hfGpe | 5,660 | integration with imbalanced-learn | {
"login": "tansaku",
"id": 30216,
"node_id": "MDQ6VXNlcjMwMjE2",
"avatar_url": "https://avatars.githubusercontent.com/u/30216?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tansaku",
"html_url": "https://github.com/tansaku",
"followers_url": "https://api.github.com/users/tansaku/follower... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2023-03-22T11:05:17 | 2023-03-22T11:05:17 | null | NONE | null | ### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I'v... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5660/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5659/comments | https://api.github.com/repos/huggingface/datasets/issues/5659/events | https://github.com/huggingface/datasets/issues/5659 | 1,635,447,540 | I_kwDODunzps5hevL0 | 5,659 | [Audio] Soundfile/libsndfile requirements too stringent for decoding mp3 files | {
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com... | [] | open | false | null | [] | null | 3 | 2023-03-22T10:07:33 | 2023-03-22T13:52:11 | null | CONTRIBUTOR | null | ### Describe the bug
I'm encountering several issues trying to load mp3 audio files using `datasets` on a TPU v4.
The PR https://github.com/huggingface/datasets/pull/5573 updated the audio loading logic to rely solely on the `soundfile`/`libsndfile` libraries for loading audio samples, regardless of their file t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5659/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5658/comments | https://api.github.com/repos/huggingface/datasets/issues/5658/events | https://github.com/huggingface/datasets/pull/5658 | 1,634,867,204 | PR_kwDODunzps5MmJe0 | 5,658 | docs: Update num_shards docs to mention num_proc on Dataset and DatasetDict | {
"login": "connor-henderson",
"id": 78612354,
"node_id": "MDQ6VXNlcjc4NjEyMzU0",
"avatar_url": "https://avatars.githubusercontent.com/u/78612354?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/connor-henderson",
"html_url": "https://github.com/connor-henderson",
"followers_url": "https://... | [] | open | false | null | [] | null | 0 | 2023-03-22T00:12:18 | 2023-03-22T00:14:05 | null | NONE | null | Closes #5653
@mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5658/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5658",
"html_url": "https://github.com/huggingface/datasets/pull/5658",
"diff_url": "https://github.com/huggingface/datasets/pull/5658.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5658.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5656/comments | https://api.github.com/repos/huggingface/datasets/issues/5656/events | https://github.com/huggingface/datasets/pull/5656 | 1,634,156,563 | PR_kwDODunzps5Mjxoo | 5,656 | Fix `fsspec.open` when using an HTTP proxy | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users... | [] | open | false | null | [] | null | 1 | 2023-03-21T15:23:29 | 2023-03-22T13:55:30 | null | CONTRIBUTOR | null | Most HTTP(S) downloads from this library support proxy automatically by reading the `HTTP_PROXY` environment variable (et al.) because `requests` is widely used. However, in some parts of the code, `fsspec` is used, which in turn uses `aiohttp` for HTTP(S) requests (as opposed to `requests`), which in turn doesn't supp... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5656/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5656",
"html_url": "https://github.com/huggingface/datasets/pull/5656",
"diff_url": "https://github.com/huggingface/datasets/pull/5656.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5656.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5655/comments | https://api.github.com/repos/huggingface/datasets/issues/5655/events | https://github.com/huggingface/datasets/pull/5655 | 1,634,030,017 | PR_kwDODunzps5MjWYy | 5,655 | Improve features decoding in to_iterable_dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | 3 | 2023-03-21T14:18:09 | 2023-03-22T16:31:24 | null | MEMBER | null | Following discussion at https://github.com/huggingface/datasets/pull/5589
Right now `to_iterable_dataset` on images/audio hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images/audios unnecessarily).
I fixed it by providing a generator that yields undecoded examples | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5655/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5655",
"html_url": "https://github.com/huggingface/datasets/pull/5655",
"diff_url": "https://github.com/huggingface/datasets/pull/5655.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5655.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5654/comments | https://api.github.com/repos/huggingface/datasets/issues/5654/events | https://github.com/huggingface/datasets/issues/5654 | 1,633,523,705 | I_kwDODunzps5hXZf5 | 5,654 | Offset overflow when executing Dataset.map | {
"login": "jan-pair",
"id": 118280608,
"node_id": "U_kgDOBwzRoA",
"avatar_url": "https://avatars.githubusercontent.com/u/118280608?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jan-pair",
"html_url": "https://github.com/jan-pair",
"followers_url": "https://api.github.com/users/jan-pair/... | [] | open | false | null | [] | null | 2 | 2023-03-21T09:33:27 | 2023-03-21T10:32:07 | null | NONE | null | ### Describe the bug
Hi, I'm trying to use `.map` method to cache multiple random crops from the image to speed up data processing during training, as the image size is too big.
The map function executes all iterations, and then returns the following error:
```bash
Traceback (most recent call last): ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5654/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5653/comments | https://api.github.com/repos/huggingface/datasets/issues/5653/events | https://github.com/huggingface/datasets/issues/5653 | 1,633,254,159 | I_kwDODunzps5hWXsP | 5,653 | Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented | {
"login": "RmZeta2718",
"id": 42400165,
"node_id": "MDQ6VXNlcjQyNDAwMTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/42400165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RmZeta2718",
"html_url": "https://github.com/RmZeta2718",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
},
{
"id": 19358928... | open | false | null | [] | null | 1 | 2023-03-21T05:25:35 | 2023-03-21T13:19:57 | null | NONE | null | ### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5653/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5652/comments | https://api.github.com/repos/huggingface/datasets/issues/5652/events | https://github.com/huggingface/datasets/pull/5652 | 1,632,546,073 | PR_kwDODunzps5MeVUR | 5,652 | Copy features | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | 6 | 2023-03-20T17:17:23 | 2023-03-22T15:00:00 | null | MEMBER | null | Some users (even internally at HF) are doing
```python
dset_features = dset.features
dset_features.pop(col_to_remove)
dset = dset.map(..., features=dset_features)
```
Right now this causes issues because it modifies the features dict in place before the map.
In this PR I modified `dset.features` to return a ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5652/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5652",
"html_url": "https://github.com/huggingface/datasets/pull/5652",
"diff_url": "https://github.com/huggingface/datasets/pull/5652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5652.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5651/comments | https://api.github.com/repos/huggingface/datasets/issues/5651/events | https://github.com/huggingface/datasets/issues/5651 | 1,631,967,509 | I_kwDODunzps5hRdkV | 5,651 | expanduser in save_to_disk | {
"login": "RmZeta2718",
"id": 42400165,
"node_id": "MDQ6VXNlcjQyNDAwMTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/42400165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RmZeta2718",
"html_url": "https://github.com/RmZeta2718",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 0 | 2023-03-20T12:02:18 | 2023-03-20T12:03:59 | null | NONE | null | ### Describe the bug
save_to_disk() does not expand `~`
1. `dataset = load_datasets("any dataset")`
2. `dataset.save_to_disk("~/data")`
3. a folder named "~" created in current folder
4. FileNotFoundError is raised, because the expanded path does not exist (`/home/<user>/data`)
related issue https://github.... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5651/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5650/comments | https://api.github.com/repos/huggingface/datasets/issues/5650/events | https://github.com/huggingface/datasets/issues/5650 | 1,630,336,919 | I_kwDODunzps5hLPeX | 5,650 | load_dataset can't work correct with my image data | {
"login": "WiNE-iNEFF",
"id": 41611046,
"node_id": "MDQ6VXNlcjQxNjExMDQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WiNE-iNEFF",
"html_url": "https://github.com/WiNE-iNEFF",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 10 | 2023-03-18T13:59:13 | 2023-03-22T12:41:48 | null | NONE | null | I have about 20000 images in my folder which divided into 4 folders with class names.
When i use load_dataset("my_folder_name", split="train") this function create dataset in which there are only 4 images, the remaining 19000 images were not added there. What is the problem and did not understand. Tried converting imag... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5650/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5649/comments | https://api.github.com/repos/huggingface/datasets/issues/5649/events | https://github.com/huggingface/datasets/issues/5649 | 1,630,173,460 | I_kwDODunzps5hKnkU | 5,649 | The index column created with .to_sql() is dependent on the batch_size when writing | {
"login": "lsb",
"id": 45281,
"node_id": "MDQ6VXNlcjQ1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lsb",
"html_url": "https://github.com/lsb",
"followers_url": "https://api.github.com/users/lsb/followers",
"following... | [] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2023-03-18T05:25:17 | 2023-03-20T13:16:12 | null | NONE | null | ### Describe the bug
It seems like the "index" column is designed to be unique? The values are only unique per batch. The SQL index is not a unique index.
This can be a problem, for instance, when building a faiss index on a dataset and then trying to match up ids with a sql export.
### Steps to reproduce the ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5649/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5648/comments | https://api.github.com/repos/huggingface/datasets/issues/5648/events | https://github.com/huggingface/datasets/issues/5648 | 1,629,253,719 | I_kwDODunzps5hHHBX | 5,648 | flatten_indices doesn't work with pandas format | {
"login": "alialamiidrissi",
"id": 14365168,
"node_id": "MDQ6VXNlcjE0MzY1MTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alialamiidrissi",
"html_url": "https://github.com/alialamiidrissi",
"followers_url": "https://api... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 1 | 2023-03-17T12:44:25 | 2023-03-21T13:12:03 | null | NONE | null | ### Describe the bug
Hi,
I noticed that `flatten_indices` throws an error when the batch format is `pandas`. This is probably due to the fact that flatten_indices uses map internally which doesn't accept dataframes as the transformation function output
### Steps to reproduce the bug
tabular_data = pd.DataFrame(np.r... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5648/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5647/comments | https://api.github.com/repos/huggingface/datasets/issues/5647/events | https://github.com/huggingface/datasets/issues/5647 | 1,628,225,544 | I_kwDODunzps5hDMAI | 5,647 | Make all print statements optional | {
"login": "gagan3012",
"id": 49101362,
"node_id": "MDQ6VXNlcjQ5MTAxMzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gagan3012",
"html_url": "https://github.com/gagan3012",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2023-03-16T20:30:07 | 2023-03-16T20:30:07 | null | NONE | null | ### Feature request
Make all print statements optional to speed up the development
### Motivation
Im loading multiple tiny datasets and all the print statements make the loading slower
### Your contribution
I can help contribute | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5647/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5646/comments | https://api.github.com/repos/huggingface/datasets/issues/5646/events | https://github.com/huggingface/datasets/pull/5646 | 1,627,838,762 | PR_kwDODunzps5MOqjj | 5,646 | Allow self as key in `Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-16T16:17:03 | 2023-03-16T17:21:58 | 2023-03-16T17:14:50 | CONTRIBUTOR | null | Fix #5641 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5646/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5646",
"html_url": "https://github.com/huggingface/datasets/pull/5646",
"diff_url": "https://github.com/huggingface/datasets/pull/5646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5646.patch",
"merged_at": "2023-03-16T17:14... | true |
https://api.github.com/repos/huggingface/datasets/issues/5645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5645/comments | https://api.github.com/repos/huggingface/datasets/issues/5645/events | https://github.com/huggingface/datasets/issues/5645 | 1,627,108,278 | I_kwDODunzps5g-7O2 | 5,645 | Datasets map and select(range()) is giving dill error | {
"login": "Tanya-11",
"id": 90728105,
"node_id": "MDQ6VXNlcjkwNzI4MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tanya-11",
"html_url": "https://github.com/Tanya-11",
"followers_url": "https://api.github.com/users/Tan... | [] | closed | false | null | [] | null | 2 | 2023-03-16T10:01:28 | 2023-03-17T04:24:51 | 2023-03-17T04:24:51 | NONE | null | ### Describe the bug
I'm using Huggingface Datasets library to load the dataset in google colab
When I do,
> data = train_dataset.select(range(10))
or
> train_datasets = train_dataset.map(
> process_data_to_model_inputs,
> batched=True,
> batch_size=batch_size,
> remove_columns... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5645/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5644/comments | https://api.github.com/repos/huggingface/datasets/issues/5644/events | https://github.com/huggingface/datasets/pull/5644 | 1,626,204,046 | PR_kwDODunzps5MJHUi | 5,644 | Allow direct cast from binary to Audio/Image | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-15T20:02:54 | 2023-03-16T14:20:44 | 2023-03-16T14:12:55 | CONTRIBUTOR | null | To address https://github.com/huggingface/datasets/discussions/5593.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5644/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5644",
"html_url": "https://github.com/huggingface/datasets/pull/5644",
"diff_url": "https://github.com/huggingface/datasets/pull/5644.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5644.patch",
"merged_at": "2023-03-16T14:12... | true |
https://api.github.com/repos/huggingface/datasets/issues/5643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5643/comments | https://api.github.com/repos/huggingface/datasets/issues/5643/events | https://github.com/huggingface/datasets/pull/5643 | 1,626,160,220 | PR_kwDODunzps5MI9zO | 5,643 | Support PyArrow arrays as column values in `from_dict` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-15T19:32:40 | 2023-03-16T17:23:06 | 2023-03-16T17:15:40 | CONTRIBUTOR | null | For consistency with `pa.Table.from_pydict`, which supports both Python lists and PyArrow arrays as column values.
"Fixes" https://discuss.huggingface.co/t/pyarrow-lib-floatarray-did-not-recognize-python-value-type-when-inferring-an-arrow-data-type/33417 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5643/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5643",
"html_url": "https://github.com/huggingface/datasets/pull/5643",
"diff_url": "https://github.com/huggingface/datasets/pull/5643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5643.patch",
"merged_at": "2023-03-16T17:15... | true |
https://api.github.com/repos/huggingface/datasets/issues/5642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5642/comments | https://api.github.com/repos/huggingface/datasets/issues/5642/events | https://github.com/huggingface/datasets/pull/5642 | 1,626,043,177 | PR_kwDODunzps5MIjw9 | 5,642 | Bump hfh to 0.11.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 6 | 2023-03-15T18:26:07 | 2023-03-20T12:34:09 | 2023-03-20T12:26:58 | MEMBER | null | to fix errors like
```
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/...
```
(e.g. from this [failing CI](https://github.com/huggingface/datasets/actions/runs/4428956210/jobs/7769160997))
0.11.0 is the current mini... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5642/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5642",
"html_url": "https://github.com/huggingface/datasets/pull/5642",
"diff_url": "https://github.com/huggingface/datasets/pull/5642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5642.patch",
"merged_at": "2023-03-20T12:26... | true |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"login": "alialamiidrissi",
"id": 14365168,
"node_id": "MDQ6VXNlcjE0MzY1MTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alialamiidrissi",
"html_url": "https://github.com/alialamiidrissi",
"followers_url": "https://api... | [] | closed | false | null | [] | null | 0 | 2023-03-15T17:16:40 | 2023-03-16T17:14:51 | 2023-03-16T17:14:51 | NONE | null | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5640/comments | https://api.github.com/repos/huggingface/datasets/issues/5640/events | https://github.com/huggingface/datasets/pull/5640 | 1,625,896,057 | PR_kwDODunzps5MID3I | 5,640 | Less zip false positives | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 6 | 2023-03-15T16:48:59 | 2023-03-16T13:47:37 | 2023-03-16T13:40:12 | MEMBER | null | `zipfile.is_zipfile` return false positives for some Parquet files. It causes errors when loading certain parquet datasets, where some files are considered ZIP files by `zipfile.is_zipfile`
This is a known issue: https://github.com/python/cpython/issues/72680
At first I wanted to rely only on magic numbers, but t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5640/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5640",
"html_url": "https://github.com/huggingface/datasets/pull/5640",
"diff_url": "https://github.com/huggingface/datasets/pull/5640.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5640.patch",
"merged_at": "2023-03-16T13:40... | true |
https://api.github.com/repos/huggingface/datasets/issues/5639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5639/comments | https://api.github.com/repos/huggingface/datasets/issues/5639/events | https://github.com/huggingface/datasets/issues/5639 | 1,625,737,098 | I_kwDODunzps5g5seK | 5,639 | Parquet file wrongly recognized as zip prevents loading a dataset | {
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 0 | 2023-03-15T15:20:45 | 2023-03-16T13:40:14 | 2023-03-16T13:40:14 | CONTRIBUTOR | null | ### Describe the bug
When trying to `load_dataset_builder` for `HuggingFaceGECLM/StackExchange_Mar2023`, extraction fails, because parquet file [devops-00000-of-00001-22fe902fd8702892.parquet](https://huggingface.co/datasets/HuggingFaceGECLM/StackExchange_Mar2023/resolve/1f8c9a2ab6f7d0f9ae904b8b922e4384592ae1a5/data... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5639/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5638/comments | https://api.github.com/repos/huggingface/datasets/issues/5638/events | https://github.com/huggingface/datasets/issues/5638 | 1,625,564,471 | I_kwDODunzps5g5CU3 | 5,638 | xPath to implement all operations for Path | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 5 | 2023-03-15T13:47:11 | 2023-03-17T13:21:12 | 2023-03-17T13:21:12 | MEMBER | null | ### Feature request
Current xPath implementation is a great extension of Path in order to work with remote objects. However some methods such as `mkdir` are not implemented correctly. It should instead rely on `fsspec` methods, instead of defaulting do `Path` methods which only work locally.
### Motivation
I'm using... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5638/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5638/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5637/comments | https://api.github.com/repos/huggingface/datasets/issues/5637/events | https://github.com/huggingface/datasets/issues/5637 | 1,625,295,691 | I_kwDODunzps5g4AtL | 5,637 | IterableDataset with_format does not support 'device' keyword for jax | {
"login": "Lime-Cakes",
"id": 91322985,
"node_id": "MDQ6VXNlcjkxMzIyOTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/91322985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Lime-Cakes",
"html_url": "https://github.com/Lime-Cakes",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 2 | 2023-03-15T11:04:12 | 2023-03-16T18:30:59 | null | NONE | null | ### Describe the bug
As seen here: https://huggingface.co/docs/datasets/use_with_jax dataset.with_format() supports the keyword 'device', to put data on a specific device when loaded as jax. However, when called on an IterableDataset, I got the error `TypeError: with_format() got an unexpected keyword argument 'devi... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5637/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5636/comments | https://api.github.com/repos/huggingface/datasets/issues/5636/events | https://github.com/huggingface/datasets/pull/5636 | 1,623,721,577 | PR_kwDODunzps5MAunR | 5,636 | Fix CI: ignore C901 ("some_func" is to complex) in `ruff` | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-03-14T15:29:11 | 2023-03-14T16:37:06 | 2023-03-14T16:29:52 | CONTRIBUTOR | null | idk if I should have added this ignore to `ruff` too, but I added :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5636/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5636",
"html_url": "https://github.com/huggingface/datasets/pull/5636",
"diff_url": "https://github.com/huggingface/datasets/pull/5636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5636.patch",
"merged_at": "2023-03-14T16:29... | true |
https://api.github.com/repos/huggingface/datasets/issues/5635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5635/comments | https://api.github.com/repos/huggingface/datasets/issues/5635/events | https://github.com/huggingface/datasets/pull/5635 | 1,623,682,558 | PR_kwDODunzps5MAmLU | 5,635 | Pass custom metadata filename to Image/Audio folders | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | 4 | 2023-03-14T15:08:16 | 2023-03-22T17:50:31 | null | CONTRIBUTOR | null | This is a quick fix.
Now it requires to pass data via `data_files` parameters and include a required metadata file there and pass its filename as `metadata_filename` parameter.
For example, with the structure like:
```
data
images_dir/
im1.jpg
im2.jpg
...
metadata_dir/
meta_file... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5635/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5635/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5635",
"html_url": "https://github.com/huggingface/datasets/pull/5635",
"diff_url": "https://github.com/huggingface/datasets/pull/5635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5635.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5634/comments | https://api.github.com/repos/huggingface/datasets/issues/5634/events | https://github.com/huggingface/datasets/issues/5634 | 1,622,424,174 | I_kwDODunzps5gtDpu | 5,634 | Not all progress bars are showing up when they should for downloading dataset | {
"login": "garlandz-db",
"id": 110427462,
"node_id": "U_kgDOBpT9Rg",
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/garlandz-db",
"html_url": "https://github.com/garlandz-db",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 2 | 2023-03-13T23:04:18 | 2023-03-21T01:59:59 | null | NONE | null | ### Describe the bug
During downloading the rotten tomatoes dataset, not all progress bars are displayed properly. This might be related to [this ticket](https://github.com/huggingface/datasets/issues/5117) as it raised the same concern but its not clear if the fix solves this issue too.
ipywidgets
<img width=... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5634/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"login": "eerio",
"id": 11250555,
"node_id": "MDQ6VXNlcjExMjUwNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eerio",
"html_url": "https://github.com/eerio",
"followers_url": "https://api.github.com/users/eerio/follow... | [] | closed | false | null | [] | null | 1 | 2023-03-13T13:14:44 | 2023-03-13T17:54:19 | 2023-03-13T17:54:19 | NONE | null | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5632/comments | https://api.github.com/repos/huggingface/datasets/issues/5632/events | https://github.com/huggingface/datasets/issues/5632 | 1,621,177,391 | I_kwDODunzps5goTQv | 5,632 | Dataset cannot convert too large dictionnary | {
"login": "MaraLac",
"id": 108518627,
"node_id": "U_kgDOBnfc4w",
"avatar_url": "https://avatars.githubusercontent.com/u/108518627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MaraLac",
"html_url": "https://github.com/MaraLac",
"followers_url": "https://api.github.com/users/MaraLac/foll... | [] | open | false | null | [] | null | 1 | 2023-03-13T10:14:40 | 2023-03-16T15:28:57 | null | NONE | null | ### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of m... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5632/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"login": "ErfanMoosaviMonazzah",
"id": 79091831,
"node_id": "MDQ6VXNlcjc5MDkxODMx",
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ErfanMoosaviMonazzah",
"html_url": "https://github.com/ErfanMoosaviMonazzah",
"followers_url... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 1 | 2023-03-12T17:21:43 | 2023-03-13T18:13:02 | null | NONE | null | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (curren... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5630/comments | https://api.github.com/repos/huggingface/datasets/issues/5630/events | https://github.com/huggingface/datasets/pull/5630 | 1,620,327,510 | PR_kwDODunzps5L1ahF | 5,630 | adds early exit if url is `PathLike` | {
"login": "vvvm23",
"id": 44398246,
"node_id": "MDQ6VXNlcjQ0Mzk4MjQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/44398246?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvvm23",
"html_url": "https://github.com/vvvm23",
"followers_url": "https://api.github.com/users/vvvm23/fo... | [] | open | false | null | [] | null | 1 | 2023-03-12T11:23:28 | 2023-03-15T11:58:38 | null | NONE | null | Closes #4864
Should fix errors thrown when attempting to load `json` dataset using `pathlib.Path` in `data_files` argument. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5630/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5630",
"html_url": "https://github.com/huggingface/datasets/pull/5630",
"diff_url": "https://github.com/huggingface/datasets/pull/5630.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5630.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5629/comments | https://api.github.com/repos/huggingface/datasets/issues/5629/events | https://github.com/huggingface/datasets/issues/5629 | 1,619,921,247 | I_kwDODunzps5gjglf | 5,629 | load_dataset gives "403" error when using Financial phrasebank | {
"login": "Jimchoo91",
"id": 67709789,
"node_id": "MDQ6VXNlcjY3NzA5Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/67709789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jimchoo91",
"html_url": "https://github.com/Jimchoo91",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 1 | 2023-03-11T07:46:39 | 2023-03-13T18:27:26 | null | NONE | null | When I try to load this dataset, I receive the following error:
ConnectionError: Couldn't reach https://www.researchgate.net/profile/Pekka_Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip (error 403)
Has this been seen before? Thanks. The website loads ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5629/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5629/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5628/comments | https://api.github.com/repos/huggingface/datasets/issues/5628/events | https://github.com/huggingface/datasets/pull/5628 | 1,619,641,810 | PR_kwDODunzps5LzVKi | 5,628 | add kwargs to index search | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | [] | closed | false | null | [] | null | 1 | 2023-03-10T21:24:58 | 2023-03-15T14:48:47 | 2023-03-15T14:46:04 | CONTRIBUTOR | null | This PR proposes to add kwargs to index search methods.
This is particularly useful for setting the timeout of a query on elasticsearch.
A typical use case would be:
```python
dset.add_elasticsearch_index("filename", es_client=es_client)
scores, examples = dset.get_nearest_examples("filename", "my_name-train_2... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5628/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5628/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5628",
"html_url": "https://github.com/huggingface/datasets/pull/5628",
"diff_url": "https://github.com/huggingface/datasets/pull/5628.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5628.patch",
"merged_at": "2023-03-15T14:46... | true |
https://api.github.com/repos/huggingface/datasets/issues/5627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5627/comments | https://api.github.com/repos/huggingface/datasets/issues/5627/events | https://github.com/huggingface/datasets/issues/5627 | 1,619,336,609 | I_kwDODunzps5ghR2h | 5,627 | Unable to load AutoTrain-generated dataset from the hub | {
"login": "ijmiller2",
"id": 8560151,
"node_id": "MDQ6VXNlcjg1NjAxNTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8560151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ijmiller2",
"html_url": "https://github.com/ijmiller2",
"followers_url": "https://api.github.com/users/ij... | [] | open | false | null | [] | null | 2 | 2023-03-10T17:25:58 | 2023-03-11T15:44:42 | null | NONE | null | ### Describe the bug
DatasetGenerationError: An error occurred while generating the dataset -> ValueError: Couldn't cast ... because column names don't match
```
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5627/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5626/comments | https://api.github.com/repos/huggingface/datasets/issues/5626/events | https://github.com/huggingface/datasets/pull/5626 | 1,619,252,984 | PR_kwDODunzps5LyBT4 | 5,626 | Support streaming datasets with numpy.load | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-03-10T16:33:39 | 2023-03-21T06:36:05 | 2023-03-21T06:28:54 | MEMBER | null | Support streaming datasets with `numpy.load`.
See: https://huggingface.co/datasets/qgallouedec/gia_dataset/discussions/1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5626/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5626",
"html_url": "https://github.com/huggingface/datasets/pull/5626",
"diff_url": "https://github.com/huggingface/datasets/pull/5626.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5626.patch",
"merged_at": "2023-03-21T06:28... | true |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 2 | 2023-03-10T13:21:48 | 2023-03-11T10:35:39 | null | CONTRIBUTOR | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset scri... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"login": "lithafnium",
"id": 8939967,
"node_id": "MDQ6VXNlcjg5Mzk5Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lithafnium",
"html_url": "https://github.com/lithafnium",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 1 | 2023-03-09T14:47:18 | 2023-03-09T16:49:29 | 2023-03-09T16:49:29 | NONE | null | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5623/comments | https://api.github.com/repos/huggingface/datasets/issues/5623/events | https://github.com/huggingface/datasets/pull/5623 | 1,616,712,665 | PR_kwDODunzps5Lpb4q | 5,623 | Remove set_access_token usage + fail tests if FutureWarning | {
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Waupli... | [] | closed | false | null | [] | null | 6 | 2023-03-09T08:46:01 | 2023-03-09T15:39:00 | 2023-03-09T15:31:59 | CONTRIBUTOR | null | `set_access_token` is deprecated and will be removed in `huggingface_hub>=0.14`.
This PR removes it from the tests (it was not used in `datasets` source code itself). FYI, it was not needed since `set_access_token` was just setting git credentials and `datasets` doesn't seem to use git anywhere.
In the future, us... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5623/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5623",
"html_url": "https://github.com/huggingface/datasets/pull/5623",
"diff_url": "https://github.com/huggingface/datasets/pull/5623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5623.patch",
"merged_at": "2023-03-09T15:31... | true |
https://api.github.com/repos/huggingface/datasets/issues/5622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5622/comments | https://api.github.com/repos/huggingface/datasets/issues/5622/events | https://github.com/huggingface/datasets/pull/5622 | 1,615,190,942 | PR_kwDODunzps5LkSj8 | 5,622 | Update README template to better template | {
"login": "emiltj",
"id": 54767532,
"node_id": "MDQ6VXNlcjU0NzY3NTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/54767532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emiltj",
"html_url": "https://github.com/emiltj",
"followers_url": "https://api.github.com/users/emiltj/fo... | [] | closed | false | null | [] | null | 3 | 2023-03-08T12:30:23 | 2023-03-11T05:07:38 | 2023-03-11T05:07:38 | NONE | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5622/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5622",
"html_url": "https://github.com/huggingface/datasets/pull/5622",
"diff_url": "https://github.com/huggingface/datasets/pull/5622.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5622.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5621/comments | https://api.github.com/repos/huggingface/datasets/issues/5621/events | https://github.com/huggingface/datasets/pull/5621 | 1,615,029,615 | PR_kwDODunzps5LjwD8 | 5,621 | Adding Oracle Cloud to docs | {
"login": "ahosler",
"id": 29129502,
"node_id": "MDQ6VXNlcjI5MTI5NTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/29129502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahosler",
"html_url": "https://github.com/ahosler",
"followers_url": "https://api.github.com/users/ahosle... | [] | closed | false | null | [] | null | 2 | 2023-03-08T10:22:50 | 2023-03-11T00:57:18 | 2023-03-11T00:49:56 | CONTRIBUTOR | null | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5621/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5621",
"html_url": "https://github.com/huggingface/datasets/pull/5621",
"diff_url": "https://github.com/huggingface/datasets/pull/5621.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5621.patch",
"merged_at": "2023-03-11T00:49... | true |
https://api.github.com/repos/huggingface/datasets/issues/5620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5620/comments | https://api.github.com/repos/huggingface/datasets/issues/5620/events | https://github.com/huggingface/datasets/pull/5620 | 1,613,460,520 | PR_kwDODunzps5LefAf | 5,620 | Bump pyarrow to 8.0.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 12 | 2023-03-07T13:31:53 | 2023-03-08T14:01:27 | 2023-03-08T13:54:22 | MEMBER | null | Fix those for Pandas 2.0 (tested [here](https://github.com/huggingface/datasets/actions/runs/4346221280/jobs/7592010397) with pandas==2.0.0.rc0):
```python
=========================== short test summary info ============================
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_to_parquet_in_memory... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5620/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5620",
"html_url": "https://github.com/huggingface/datasets/pull/5620",
"diff_url": "https://github.com/huggingface/datasets/pull/5620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5620.patch",
"merged_at": "2023-03-08T13:54... | true |
https://api.github.com/repos/huggingface/datasets/issues/5619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5619/comments | https://api.github.com/repos/huggingface/datasets/issues/5619/events | https://github.com/huggingface/datasets/pull/5619 | 1,613,439,709 | PR_kwDODunzps5LeaYP | 5,619 | unpin fsspec | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2023-03-07T13:22:41 | 2023-03-07T13:47:01 | 2023-03-07T13:39:02 | MEMBER | null | close https://github.com/huggingface/datasets/issues/5618 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5619/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5619",
"html_url": "https://github.com/huggingface/datasets/pull/5619",
"diff_url": "https://github.com/huggingface/datasets/pull/5619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5619.patch",
"merged_at": "2023-03-07T13:39... | true |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 0 | 2023-03-07T08:41:51 | 2023-03-07T13:39:03 | 2023-03-07T13:39:03 | MEMBER | null | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5617/comments | https://api.github.com/repos/huggingface/datasets/issues/5617/events | https://github.com/huggingface/datasets/pull/5617 | 1,612,947,422 | PR_kwDODunzps5LcvI- | 5,617 | Fix CI by temporarily pinning fsspec < 2023.3.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-03-07T08:18:20 | 2023-03-07T08:44:55 | 2023-03-07T08:37:28 | MEMBER | null | As a hotfix for our CI, temporarily pin `fsspec`:
Fix #5616.
Until root cause is fixed, see:
- #5614 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5617/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5617/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5617",
"html_url": "https://github.com/huggingface/datasets/pull/5617",
"diff_url": "https://github.com/huggingface/datasets/pull/5617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5617.patch",
"merged_at": "2023-03-07T08:37... | true |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 0 | 2023-03-07T08:06:39 | 2023-03-07T08:37:29 | 2023-03-07T08:37:29 | MEMBER | null | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"login": "zsaladin",
"id": 6466389,
"node_id": "MDQ6VXNlcjY0NjYzODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zsaladin",
"html_url": "https://github.com/zsaladin",
"followers_url": "https://api.github.com/users/zsala... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | 1 | 2023-03-07T01:52:00 | 2023-03-09T15:24:05 | 2023-03-09T15:23:54 | NONE | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5614/comments | https://api.github.com/repos/huggingface/datasets/issues/5614/events | https://github.com/huggingface/datasets/pull/5614 | 1,611,896,357 | PR_kwDODunzps5LZOTd | 5,614 | Fix archive fs test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 4 | 2023-03-06T17:28:09 | 2023-03-07T13:27:50 | 2023-03-07T13:20:57 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5614/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5614/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5614",
"html_url": "https://github.com/huggingface/datasets/pull/5614",
"diff_url": "https://github.com/huggingface/datasets/pull/5614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5614.patch",
"merged_at": "2023-03-07T13:20... | true |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | {
"login": "adampauls",
"id": 1243668,
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adampauls",
"html_url": "https://github.com/adampauls",
"followers_url": "https://api.github.com/users/ad... | [] | open | false | null | [] | null | 2 | 2023-03-06T17:14:41 | 2023-03-07T00:58:03 | null | NONE | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | reopened | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/... | [] | open | false | null | [] | null | 1 | 2023-03-06T12:03:24 | 2023-03-14T17:20:25 | null | MEMBER | null | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 2 | 2023-03-06T11:21:57 | 2023-03-22T15:48:30 | null | NONE | null | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5611",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"login": "gromzhu",
"id": 15223544,
"node_id": "MDQ6VXNlcjE1MjIzNTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gromzhu",
"html_url": "https://github.com/gromzhu",
"followers_url": "https://api.github.com/users/gromzh... | [] | open | false | null | [] | null | 0 | 2023-03-06T05:26:49 | 2023-03-06T05:37:10 | null | NONE | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | 2 | 2023-03-05T05:27:15 | 2023-03-14T19:31:53 | null | NONE | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/follower... | [] | closed | false | null | [] | null | 2 | 2023-03-05T00:14:45 | 2023-03-12T00:02:57 | 2023-03-12T00:02:57 | NONE | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Fix outdated `verification_mode` values | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-03-03T19:50:29 | 2023-03-09T17:34:13 | 2023-03-09T17:27:07 | CONTRIBUTOR | null | ~I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not co... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5607",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"merged_at": "2023-03-09T17:27... | true |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | open | false | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [
{
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://a... | null | 3 | 2023-03-03T16:17:10 | 2023-03-06T11:33:20 | null | CONTRIBUTOR | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/... | [] | closed | false | null | [] | null | 3 | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"merged_at": "2023-03-03T21:50... | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"login": "sentialx",
"id": 11065386,
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sentialx",
"html_url": "https://github.com/sentialx",
"followers_url": "https://api.github.com/users/sen... | [] | open | false | null | [] | null | 1 | 2023-03-03T09:52:08 | 2023-03-14T15:30:32 | null | NONE | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
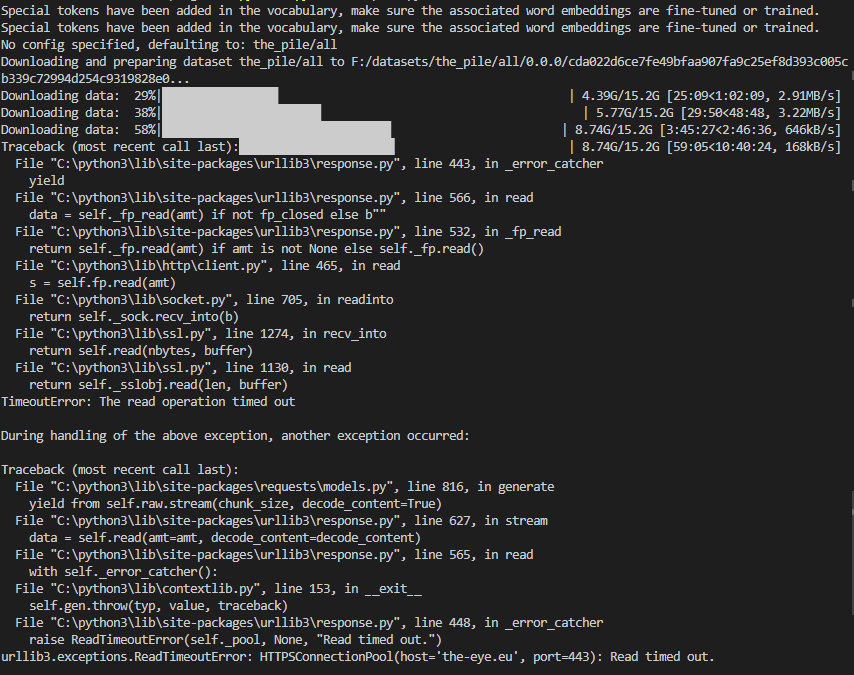
Here are the downloaded files:
,
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"login": "salahiguiliz",
"id": 76955987,
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salahiguiliz",
"html_url": "https://github.com/salahiguiliz",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 1 | 2023-03-02T11:00:27 | 2023-03-13T17:59:35 | 2023-03-13T17:59:35 | NONE | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | null | null | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.