
Update README.md
Browse files
README.md
CHANGED
|
@@ -24,6 +24,45 @@ Code: https://github.com/yfzhang114/MME-RealWorld
|
|
| 24 |
Project page: https://mme-realworld.github.io/
|
| 25 |
|
| 26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
# MME-RealWorld Data Card
|
| 28 |
|
| 29 |
## Dataset details
|
|
@@ -47,34 +86,6 @@ We present MME-RealWord, a benchmark meticulously designed to address real-world
|
|
| 47 |
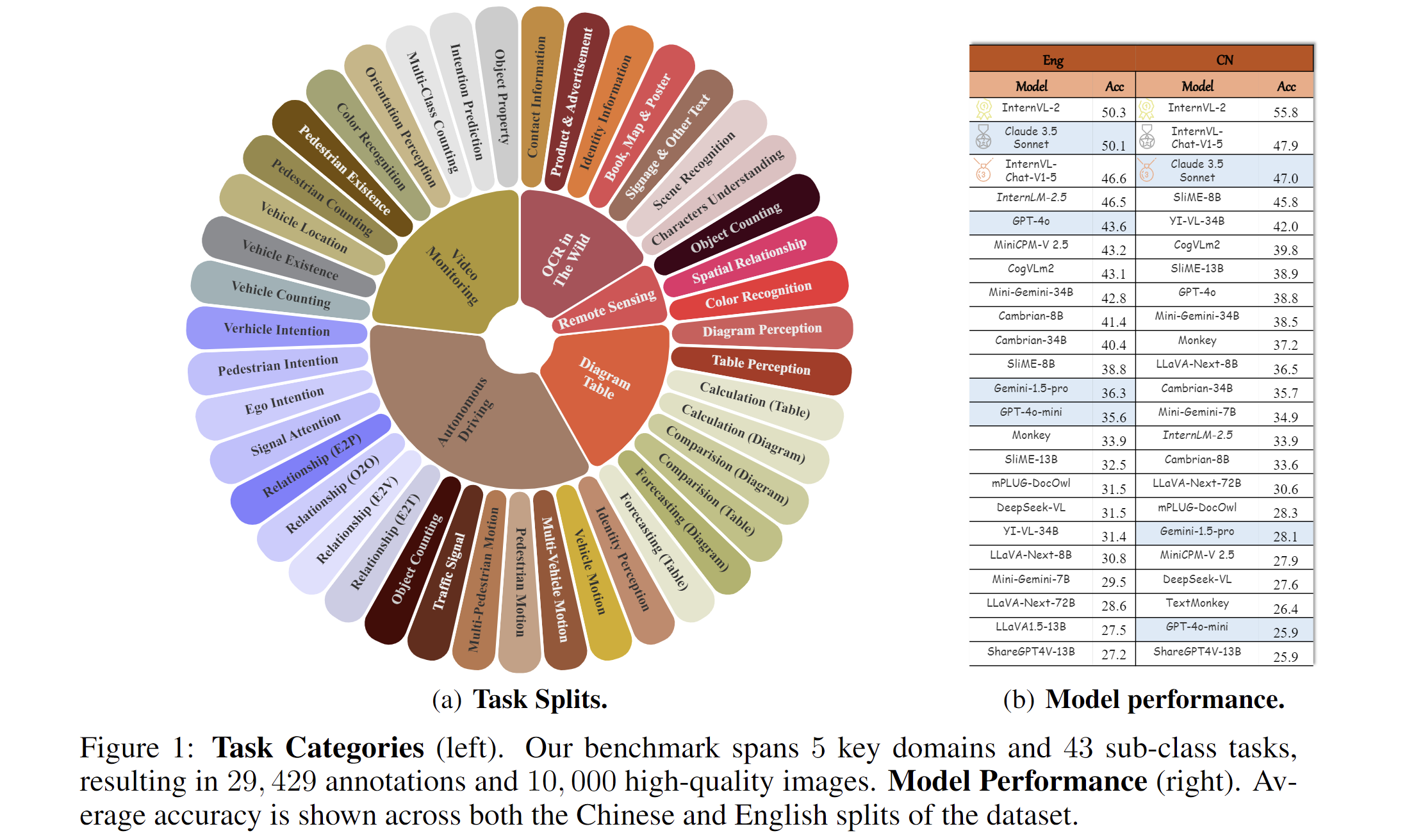
|
| 48 |
|
| 49 |
|
| 50 |
-
## How to use?
|
| 51 |
-
|
| 52 |
-
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
|
| 53 |
-
|
| 54 |
-
```
|
| 55 |
-
#!/bin/bash
|
| 56 |
-
|
| 57 |
-
# Navigate to the directory containing the split files
|
| 58 |
-
cd TARFILES
|
| 59 |
-
|
| 60 |
-
# Loop through each set of split files
|
| 61 |
-
for part in *.tar.gz.part_aa; do
|
| 62 |
-
# Extract the base name of the file
|
| 63 |
-
base_name=$(basename "$part" .tar.gz.part_aa)
|
| 64 |
-
|
| 65 |
-
# Merge the split files into a single archive
|
| 66 |
-
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
|
| 67 |
-
|
| 68 |
-
# Extract the merged archive
|
| 69 |
-
tar -xzf "${base_name}.tar.gz"
|
| 70 |
-
|
| 71 |
-
# Optional: Remove the temporary merged archive
|
| 72 |
-
rm "${base_name}.tar.gz"
|
| 73 |
-
done
|
| 74 |
-
|
| 75 |
-
```
|
| 76 |
-
|
| 77 |
-
|
| 78 |
|
| 79 |
|
| 80 |
|
|
|
|
| 24 |
Project page: https://mme-realworld.github.io/
|
| 25 |
|
| 26 |
|
| 27 |
+
## How to use?
|
| 28 |
+
|
| 29 |
+
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
#!/bin/bash
|
| 33 |
+
|
| 34 |
+
# Function to process each set of split files
|
| 35 |
+
process_files() {
|
| 36 |
+
local part="$1"
|
| 37 |
+
|
| 38 |
+
# Extract the base name of the file
|
| 39 |
+
local base_name=$(basename "$part" .tar.gz.part_aa)
|
| 40 |
+
|
| 41 |
+
# Merge the split files into a single archive
|
| 42 |
+
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
|
| 43 |
+
|
| 44 |
+
# Extract the merged archive
|
| 45 |
+
tar -xzf "${base_name}.tar.gz"
|
| 46 |
+
|
| 47 |
+
# Remove the individual split files
|
| 48 |
+
rm -rf "${base_name}".tar.gz.part_*
|
| 49 |
+
|
| 50 |
+
rm -rf "${base_name}.tar.gz"
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
export -f process_files
|
| 54 |
+
|
| 55 |
+
# Find all .tar.gz.part_aa files and process them in parallel
|
| 56 |
+
find . -name '*.tar.gz.part_aa' | parallel process_files
|
| 57 |
+
|
| 58 |
+
# Wait for all background jobs to finish
|
| 59 |
+
wait
|
| 60 |
+
|
| 61 |
+
# nohup bash unzip_file.sh >> unfold.log 2>&1 &
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
# MME-RealWorld Data Card
|
| 67 |
|
| 68 |
## Dataset details
|
|
|
|
| 86 |

|
| 87 |
|
| 88 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
|
| 90 |
|
| 91 |
|