
Upload 921 files
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .github/ISSUE_TEMPLATE/bug_report.yml +91 -0
- .github/ISSUE_TEMPLATE/config.yml +1 -0
- .github/workflows/tests.yml +37 -0
- .gitignore +171 -0
- LICENSE +21 -0
- README.md +247 -0
- annotator/annotator_path.py +22 -0
- annotator/binary/__init__.py +14 -0
- annotator/canny/__init__.py +5 -0
- annotator/clip/__init__.py +39 -0
- annotator/clip_vision/config.json +171 -0
- annotator/clip_vision/merges.txt +0 -0
- annotator/clip_vision/preprocessor_config.json +19 -0
- annotator/clip_vision/tokenizer.json +0 -0
- annotator/clip_vision/tokenizer_config.json +34 -0
- annotator/clip_vision/vocab.json +0 -0
- annotator/color/__init__.py +20 -0
- annotator/hed/__init__.py +98 -0
- annotator/keypose/__init__.py +212 -0
- annotator/keypose/faster_rcnn_r50_fpn_coco.py +182 -0
- annotator/keypose/hrnet_w48_coco_256x192.py +169 -0
- annotator/lama/__init__.py +58 -0
- annotator/lama/config.yaml +157 -0
- annotator/lama/saicinpainting/__init__.py +0 -0
- annotator/lama/saicinpainting/training/__init__.py +0 -0
- annotator/lama/saicinpainting/training/data/__init__.py +0 -0
- annotator/lama/saicinpainting/training/data/masks.py +332 -0
- annotator/lama/saicinpainting/training/losses/__init__.py +0 -0
- annotator/lama/saicinpainting/training/losses/adversarial.py +177 -0
- annotator/lama/saicinpainting/training/losses/constants.py +152 -0
- annotator/lama/saicinpainting/training/losses/distance_weighting.py +126 -0
- annotator/lama/saicinpainting/training/losses/feature_matching.py +33 -0
- annotator/lama/saicinpainting/training/losses/perceptual.py +113 -0
- annotator/lama/saicinpainting/training/losses/segmentation.py +43 -0
- annotator/lama/saicinpainting/training/losses/style_loss.py +155 -0
- annotator/lama/saicinpainting/training/modules/__init__.py +31 -0
- annotator/lama/saicinpainting/training/modules/base.py +80 -0
- annotator/lama/saicinpainting/training/modules/depthwise_sep_conv.py +17 -0
- annotator/lama/saicinpainting/training/modules/fake_fakes.py +47 -0
- annotator/lama/saicinpainting/training/modules/ffc.py +485 -0
- annotator/lama/saicinpainting/training/modules/multidilated_conv.py +98 -0
- annotator/lama/saicinpainting/training/modules/multiscale.py +244 -0
- annotator/lama/saicinpainting/training/modules/pix2pixhd.py +669 -0
- annotator/lama/saicinpainting/training/modules/spatial_transform.py +49 -0
- annotator/lama/saicinpainting/training/modules/squeeze_excitation.py +20 -0
- annotator/lama/saicinpainting/training/trainers/__init__.py +29 -0
- annotator/lama/saicinpainting/training/trainers/base.py +293 -0
- annotator/lama/saicinpainting/training/trainers/default.py +175 -0
- annotator/lama/saicinpainting/training/visualizers/__init__.py +15 -0
- annotator/lama/saicinpainting/training/visualizers/base.py +73 -0
.github/ISSUE_TEMPLATE/bug_report.yml
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Bug Report
|
| 2 |
+
description: Create a report
|
| 3 |
+
title: "[Bug]: "
|
| 4 |
+
labels: ["bug-report"]
|
| 5 |
+
|
| 6 |
+
body:
|
| 7 |
+
- type: checkboxes
|
| 8 |
+
attributes:
|
| 9 |
+
label: Is there an existing issue for this?
|
| 10 |
+
description: Please search to see if an issue already exists for the bug you encountered, and that it hasn't been fixed in a recent build/commit.
|
| 11 |
+
options:
|
| 12 |
+
- label: I have searched the existing issues and checked the recent builds/commits of both this extension and the webui
|
| 13 |
+
required: true
|
| 14 |
+
- type: markdown
|
| 15 |
+
attributes:
|
| 16 |
+
value: |
|
| 17 |
+
*Please fill this form with as much information as possible, don't forget to fill "What OS..." and "What browsers" and *provide screenshots if possible**
|
| 18 |
+
- type: textarea
|
| 19 |
+
id: what-did
|
| 20 |
+
attributes:
|
| 21 |
+
label: What happened?
|
| 22 |
+
description: Tell us what happened in a very clear and simple way
|
| 23 |
+
validations:
|
| 24 |
+
required: true
|
| 25 |
+
- type: textarea
|
| 26 |
+
id: steps
|
| 27 |
+
attributes:
|
| 28 |
+
label: Steps to reproduce the problem
|
| 29 |
+
description: Please provide us with precise step by step information on how to reproduce the bug
|
| 30 |
+
value: |
|
| 31 |
+
1. Go to ....
|
| 32 |
+
2. Press ....
|
| 33 |
+
3. ...
|
| 34 |
+
validations:
|
| 35 |
+
required: true
|
| 36 |
+
- type: textarea
|
| 37 |
+
id: what-should
|
| 38 |
+
attributes:
|
| 39 |
+
label: What should have happened?
|
| 40 |
+
description: Tell what you think the normal behavior should be
|
| 41 |
+
validations:
|
| 42 |
+
required: true
|
| 43 |
+
- type: textarea
|
| 44 |
+
id: commits
|
| 45 |
+
attributes:
|
| 46 |
+
label: Commit where the problem happens
|
| 47 |
+
description: Which commit of the extension are you running on? Please include the commit of both the extension and the webui (Do not write *Latest version/repo/commit*, as this means nothing and will have changed by the time we read your issue. Rather, copy the **Commit** link at the bottom of the UI, or from the cmd/terminal if you can't launch it.)
|
| 48 |
+
value: |
|
| 49 |
+
webui:
|
| 50 |
+
controlnet:
|
| 51 |
+
validations:
|
| 52 |
+
required: true
|
| 53 |
+
- type: dropdown
|
| 54 |
+
id: browsers
|
| 55 |
+
attributes:
|
| 56 |
+
label: What browsers do you use to access the UI ?
|
| 57 |
+
multiple: true
|
| 58 |
+
options:
|
| 59 |
+
- Mozilla Firefox
|
| 60 |
+
- Google Chrome
|
| 61 |
+
- Brave
|
| 62 |
+
- Apple Safari
|
| 63 |
+
- Microsoft Edge
|
| 64 |
+
- type: textarea
|
| 65 |
+
id: cmdargs
|
| 66 |
+
attributes:
|
| 67 |
+
label: Command Line Arguments
|
| 68 |
+
description: Are you using any launching parameters/command line arguments (modified webui-user .bat/.sh) ? If yes, please write them below. Write "No" otherwise.
|
| 69 |
+
render: Shell
|
| 70 |
+
validations:
|
| 71 |
+
required: true
|
| 72 |
+
- type: textarea
|
| 73 |
+
id: extensions
|
| 74 |
+
attributes:
|
| 75 |
+
label: List of enabled extensions
|
| 76 |
+
description: Please provide a full list of enabled extensions or screenshots of your "Extensions" tab.
|
| 77 |
+
validations:
|
| 78 |
+
required: true
|
| 79 |
+
- type: textarea
|
| 80 |
+
id: logs
|
| 81 |
+
attributes:
|
| 82 |
+
label: Console logs
|
| 83 |
+
description: Please provide full cmd/terminal logs from the moment you started UI to the end of it, after your bug happened. If it's very long, provide a link to pastebin or similar service.
|
| 84 |
+
render: Shell
|
| 85 |
+
validations:
|
| 86 |
+
required: true
|
| 87 |
+
- type: textarea
|
| 88 |
+
id: misc
|
| 89 |
+
attributes:
|
| 90 |
+
label: Additional information
|
| 91 |
+
description: Please provide us with any relevant additional info or context.
|
.github/ISSUE_TEMPLATE/config.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: true
|
.github/workflows/tests.yml
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Run basic features tests on CPU
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
- push
|
| 5 |
+
- pull_request
|
| 6 |
+
|
| 7 |
+
jobs:
|
| 8 |
+
build:
|
| 9 |
+
runs-on: ubuntu-latest
|
| 10 |
+
steps:
|
| 11 |
+
- name: Checkout Code
|
| 12 |
+
uses: actions/checkout@v3
|
| 13 |
+
with:
|
| 14 |
+
repository: 'AUTOMATIC1111/stable-diffusion-webui'
|
| 15 |
+
path: 'stable-diffusion-webui'
|
| 16 |
+
ref: '5ab7f213bec2f816f9c5644becb32eb72c8ffb89'
|
| 17 |
+
|
| 18 |
+
- name: Checkout Code
|
| 19 |
+
uses: actions/checkout@v3
|
| 20 |
+
with:
|
| 21 |
+
repository: 'Mikubill/sd-webui-controlnet'
|
| 22 |
+
path: 'stable-diffusion-webui/extensions/sd-webui-controlnet'
|
| 23 |
+
|
| 24 |
+
- name: Set up Python 3.10
|
| 25 |
+
uses: actions/setup-python@v4
|
| 26 |
+
with:
|
| 27 |
+
python-version: 3.10.6
|
| 28 |
+
cache: pip
|
| 29 |
+
cache-dependency-path: |
|
| 30 |
+
**/requirements*txt
|
| 31 |
+
stable-diffusion-webui/requirements*txt
|
| 32 |
+
|
| 33 |
+
- run: |
|
| 34 |
+
pip install torch torchvision
|
| 35 |
+
curl -Lo stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_canny-fp16.safetensors https://huggingface.co/webui/ControlNet-modules-safetensors/resolve/main/control_canny-fp16.safetensors
|
| 36 |
+
cd stable-diffusion-webui && python launch.py --no-half --disable-opt-split-attention --use-cpu all --skip-torch-cuda-test --api --tests ./extensions/sd-webui-controlnet/tests
|
| 37 |
+
rm -fr stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_canny-fp16.safetensors
|
.gitignore
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea
|
| 161 |
+
*.pt
|
| 162 |
+
*.pth
|
| 163 |
+
*.ckpt
|
| 164 |
+
*.bin
|
| 165 |
+
*.safetensors
|
| 166 |
+
|
| 167 |
+
# Editor setting metadata
|
| 168 |
+
.idea/
|
| 169 |
+
.vscode/
|
| 170 |
+
detected_maps/
|
| 171 |
+
annotator/downloads/
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Kakigōri Maker
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ControlNet for Stable Diffusion WebUI
|
| 2 |
+
|
| 3 |
+
The WebUI extension for ControlNet and other injection-based SD controls.
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
This extension is for AUTOMATIC1111's [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui), allows the Web UI to add [ControlNet](https://github.com/lllyasviel/ControlNet) to the original Stable Diffusion model to generate images. The addition is on-the-fly, the merging is not required.
|
| 8 |
+
|
| 9 |
+
# Installation
|
| 10 |
+
|
| 11 |
+
1. Open "Extensions" tab.
|
| 12 |
+
2. Open "Install from URL" tab in the tab.
|
| 13 |
+
3. Enter `https://github.com/Mikubill/sd-webui-controlnet.git` to "URL for extension's git repository".
|
| 14 |
+
4. Press "Install" button.
|
| 15 |
+
5. Wait for 5 seconds, and you will see the message "Installed into stable-diffusion-webui\extensions\sd-webui-controlnet. Use Installed tab to restart".
|
| 16 |
+
6. Go to "Installed" tab, click "Check for updates", and then click "Apply and restart UI". (The next time you can also use these buttons to update ControlNet.)
|
| 17 |
+
7. Completely restart A1111 webui including your terminal. (If you do not know what is a "terminal", you can reboot your computer to achieve the same effect.)
|
| 18 |
+
8. Download models (see below).
|
| 19 |
+
9. After you put models in the correct folder, you may need to refresh to see the models. The refresh button is right to your "Model" dropdown.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
**Update from ControlNet 1.0 to 1.1:**
|
| 23 |
+
|
| 24 |
+
* If you are not sure, you can back up and remove the folder "stable-diffusion-webui\extensions\sd-webui-controlnet", and then start from the step 1 in the above Installation section.
|
| 25 |
+
|
| 26 |
+
* Or you can start from the step 6 in the above Install section.
|
| 27 |
+
|
| 28 |
+
# Download Models
|
| 29 |
+
|
| 30 |
+
Right now all the 14 models of ControlNet 1.1 are in the beta test.
|
| 31 |
+
|
| 32 |
+
Download the models from ControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
|
| 33 |
+
|
| 34 |
+
You need to download model files ending with ".pth" .
|
| 35 |
+
|
| 36 |
+
Put models in your "stable-diffusion-webui\extensions\sd-webui-controlnet\models". Now we have already included all "yaml" files. You only need to download "pth" files.
|
| 37 |
+
|
| 38 |
+
Do not right-click the filenames in HuggingFace website to download. Some users right-clicked those HuggingFace HTML websites and saved those HTML pages as PTH/YAML files. They are not downloading correct files. Instead, please click the small download arrow “↓” icon in HuggingFace to download.
|
| 39 |
+
|
| 40 |
+
Note: If you download models elsewhere, please make sure that yaml file names and model files names are same. Please manually rename all yaml files if you download from other sources. (Some models like "shuffle" needs the yaml file so that we know the outputs of ControlNet should pass a global average pooling before injecting to SD U-Nets.)
|
| 41 |
+
|
| 42 |
+
# New Features in ControlNet 1.1
|
| 43 |
+
|
| 44 |
+
### Perfect Support for All ControlNet 1.0/1.1 and T2I Adapter Models.
|
| 45 |
+
|
| 46 |
+
Now we have perfect support all available models and preprocessors, including perfect support for T2I style adapter and ControlNet 1.1 Shuffle. (Make sure that your YAML file names and model file names are same, see also YAML files in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".)
|
| 47 |
+
|
| 48 |
+
### Perfect Support for A1111 High-Res. Fix
|
| 49 |
+
|
| 50 |
+
Now if you turn on High-Res Fix in A1111, each controlnet will output two different control images: a small one and a large one. The small one is for your basic generating, and the big one is for your High-Res Fix generating. The two control images are computed by a smart algorithm called "super high-quality control image resampling". This is turned on by default, and you do not need to change any setting.
|
| 51 |
+
|
| 52 |
+
### Perfect Support for All A1111 Img2Img or Inpaint Settings and All Mask Types
|
| 53 |
+
|
| 54 |
+
Now ControlNet is extensively tested with A1111's different types of masks, including "Inpaint masked"/"Inpaint not masked", and "Whole picture"/"Only masked", and "Only masked padding"&"Mask blur". The resizing perfectly matches A1111's "Just resize"/"Crop and resize"/"Resize and fill". This means you can use ControlNet in nearly everywhere in your A1111 UI without difficulty!
|
| 55 |
+
|
| 56 |
+
### The New "Pixel-Perfect" Mode
|
| 57 |
+
|
| 58 |
+
Now if you turn on pixel-perfect mode, you do not need to set preprocessor (annotator) resolutions manually. The ControlNet will automatically compute the best annotator resolution for you so that each pixel perfectly matches Stable Diffusion.
|
| 59 |
+
|
| 60 |
+
### User-Friendly GUI and Preprocessor Preview
|
| 61 |
+
|
| 62 |
+
We reorganized some previously confusing UI like "canvas width/height for new canvas" and it is in the 📝 button now. Now the preview GUI is controlled by the "allow preview" option and the trigger button 💥. The preview image size is better than before, and you do not need to scroll up and down - your a1111 GUI will not be messed up anymore!
|
| 63 |
+
|
| 64 |
+
### Support for Almost All Upscaling Scripts
|
| 65 |
+
|
| 66 |
+
Now ControlNet 1.1 can support almost all Upscaling/Tile methods. ControlNet 1.1 support the script "Ultimate SD upscale" and almost all other tile-based extensions. Please do not confuse ["Ultimate SD upscale"](https://github.com/Coyote-A/ultimate-upscale-for-automatic1111) with "SD upscale" - they are different scripts. Note that the most recommended upscaling method is ["Tiled VAE/Diffusion"](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111) but we test as many methods/extensions as possible. Note that "SD upscale" is supported since 1.1.117, and if you use it, you need to leave all ControlNet images as blank (We do not recommend "SD upscale" since it is somewhat buggy and cannot be maintained - use the "Ultimate SD upscale" instead).
|
| 67 |
+
|
| 68 |
+
### More Control Modes (previously called Guess Mode)
|
| 69 |
+
|
| 70 |
+
We have fixed many bugs in previous 1.0’s Guess Mode and now it is called Control Mode
|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
Now you can control which aspect is more important (your prompt or your ControlNet):
|
| 75 |
+
|
| 76 |
+
* "Balanced": ControlNet on both sides of CFG scale, same as turning off "Guess Mode" in ControlNet 1.0
|
| 77 |
+
|
| 78 |
+
* "My prompt is more important": ControlNet on both sides of CFG scale, with progressively reduced SD U-Net injections (layer_weight*=0.825**I, where 0<=I <13, and the 13 means ControlNet injected SD 13 times). In this way, you can make sure that your prompts are perfectly displayed in your generated images.
|
| 79 |
+
|
| 80 |
+
* "ControlNet is more important": ControlNet only on the Conditional Side of CFG scale (the cond in A1111's batch-cond-uncond). This means the ControlNet will be X times stronger if your cfg-scale is X. For example, if your cfg-scale is 7, then ControlNet is 7 times stronger. Note that here the X times stronger is different from "Control Weights" since your weights are not modified. This "stronger" effect usually has less artifact and give ControlNet more room to guess what is missing from your prompts (and in the previous 1.0, it is called "Guess Mode").
|
| 81 |
+
|
| 82 |
+
<table width="100%">
|
| 83 |
+
<tr>
|
| 84 |
+
<td width="25%" style="text-align: center">Input (depth+canny+hed)</td>
|
| 85 |
+
<td width="25%" style="text-align: center">"Balanced"</td>
|
| 86 |
+
<td width="25%" style="text-align: center">"My prompt is more important"</td>
|
| 87 |
+
<td width="25%" style="text-align: center">"ControlNet is more important"</td>
|
| 88 |
+
</tr>
|
| 89 |
+
<tr>
|
| 90 |
+
<td width="25%" style="text-align: center"><img src="samples/cm1.png"></td>
|
| 91 |
+
<td width="25%" style="text-align: center"><img src="samples/cm2.png"></td>
|
| 92 |
+
<td width="25%" style="text-align: center"><img src="samples/cm3.png"></td>
|
| 93 |
+
<td width="25%" style="text-align: center"><img src="samples/cm4.png"></td>
|
| 94 |
+
</tr>
|
| 95 |
+
</table>
|
| 96 |
+
|
| 97 |
+
### Reference-Only Control
|
| 98 |
+
|
| 99 |
+
Now we have a `reference-only` preprocessor that does not require any control models. It can guide the diffusion directly using images as references.
|
| 100 |
+
|
| 101 |
+
(Prompt "a dog running on grassland, best quality, ...")
|
| 102 |
+
|
| 103 |
+

|
| 104 |
+
|
| 105 |
+
This method is similar to inpaint-based reference but it does not make your image disordered.
|
| 106 |
+
|
| 107 |
+
Many professional A1111 users know a trick to diffuse image with references by inpaint. For example, if you have a 512x512 image of a dog, and want to generate another 512x512 image with the same dog, some users will connect the 512x512 dog image and a 512x512 blank image into a 1024x512 image, send to inpaint, and mask out the blank 512x512 part to diffuse a dog with similar appearance. However, that method is usually not very satisfying since images are connected and many distortions will appear.
|
| 108 |
+
|
| 109 |
+
This `reference-only` ControlNet can directly link the attention layers of your SD to any independent images, so that your SD will read arbitary images for reference. You need at least ControlNet 1.1.153 to use it.
|
| 110 |
+
|
| 111 |
+
To use, just select `reference-only` as preprocessor and put an image. Your SD will just use the image as reference.
|
| 112 |
+
|
| 113 |
+
*Note that this method is as "non-opinioned" as possible. It only contains very basic connection codes, without any personal preferences, to connect the attention layers with your reference images. However, even if we tried best to not include any opinioned codes, we still need to write some subjective implementations to deal with weighting, cfg-scale, etc - tech report is on the way.*
|
| 114 |
+
|
| 115 |
+
More examples [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236).
|
| 116 |
+
|
| 117 |
+
# Technical Documents
|
| 118 |
+
|
| 119 |
+
See also the documents of ControlNet 1.1:
|
| 120 |
+
|
| 121 |
+
https://github.com/lllyasviel/ControlNet-v1-1-nightly#model-specification
|
| 122 |
+
|
| 123 |
+
# Default Setting
|
| 124 |
+
|
| 125 |
+
This is my setting. If you run into any problem, you can use this setting as a sanity check
|
| 126 |
+
|
| 127 |
+
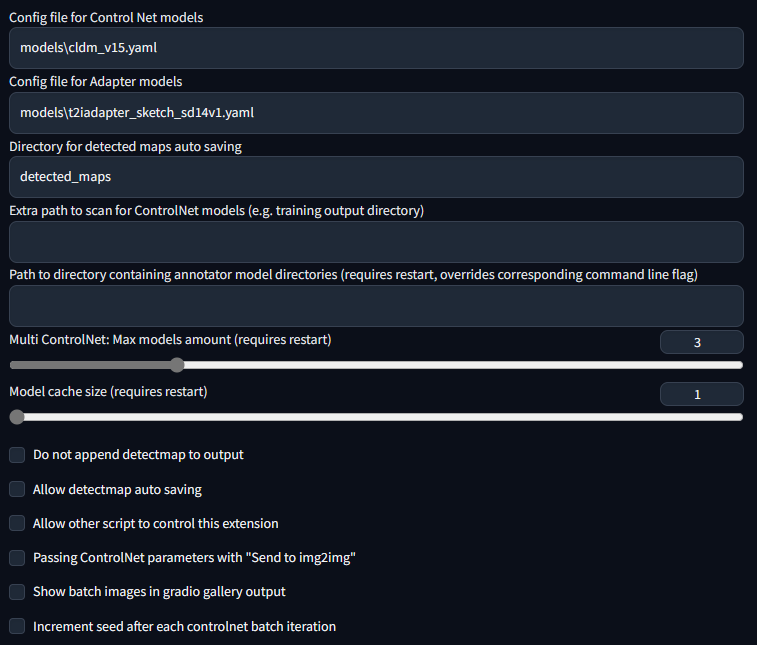
|
| 128 |
+
|
| 129 |
+
# Use Previous Models
|
| 130 |
+
|
| 131 |
+
### Use ControlNet 1.0 Models
|
| 132 |
+
|
| 133 |
+
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
|
| 134 |
+
|
| 135 |
+
You can still use all previous models in the previous ControlNet 1.0. Now, the previous "depth" is now called "depth_midas", the previous "normal" is called "normal_midas", the previous "hed" is called "softedge_hed". And starting from 1.1, all line maps, edge maps, lineart maps, boundary maps will have black background and white lines.
|
| 136 |
+
|
| 137 |
+
### Use T2I-Adapter Models
|
| 138 |
+
|
| 139 |
+
(From TencentARC/T2I-Adapter)
|
| 140 |
+
|
| 141 |
+
To use T2I-Adapter models:
|
| 142 |
+
|
| 143 |
+
1. Download files from https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
|
| 144 |
+
2. Put them in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".
|
| 145 |
+
3. Make sure that the file names of pth files and yaml files are consistent.
|
| 146 |
+
|
| 147 |
+
*Note that "CoAdapter" is not implemented yet.*
|
| 148 |
+
|
| 149 |
+
# Gallery
|
| 150 |
+
|
| 151 |
+
The below results are from ControlNet 1.0.
|
| 152 |
+
|
| 153 |
+
| Source | Input | Output |
|
| 154 |
+
|:-------------------------:|:-------------------------:|:-------------------------:|
|
| 155 |
+
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-source.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-gen.png?raw=true"> |
|
| 156 |
+
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.png?raw=true"> |
|
| 157 |
+
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_input.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_canny.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro-out.png?raw=true"> |
|
| 158 |
+
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_hed.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_gen.png?raw=true"> |
|
| 159 |
+
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-pose.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-gen.png?raw=true"> |
|
| 160 |
+
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-src.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-dep.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-out.png?raw=true"> |
|
| 161 |
+
|
| 162 |
+
The below examples are from T2I-Adapter.
|
| 163 |
+
|
| 164 |
+
From `t2iadapter_color_sd14v1.pth` :
|
| 165 |
+
|
| 166 |
+
| Source | Input | Output |
|
| 167 |
+
|:-------------------------:|:-------------------------:|:-------------------------:|
|
| 168 |
+
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947435-1164e7d8-d857-42f9-ab10-2d4a4b25f33a.png"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947557-5520d5f8-88b4-474d-a576-5c9cd3acac3a.png"> |
|
| 169 |
+
|
| 170 |
+
From `t2iadapter_style_sd14v1.pth` :
|
| 171 |
+
|
| 172 |
+
| Source | Input | Output |
|
| 173 |
+
|:-------------------------:|:-------------------------:|:-------------------------:|
|
| 174 |
+
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | (clip, non-image) | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222965711-7b884c9e-7095-45cb-a91c-e50d296ba3a2.png"> |
|
| 175 |
+
|
| 176 |
+
# Minimum Requirements
|
| 177 |
+
|
| 178 |
+
* (Windows) (NVIDIA: Ampere) 4gb - with `--xformers` enabled, and `Low VRAM` mode ticked in the UI, goes up to 768x832
|
| 179 |
+
|
| 180 |
+
# Multi-ControlNet
|
| 181 |
+
|
| 182 |
+
This option allows multiple ControlNet inputs for a single generation. To enable this option, change `Multi ControlNet: Max models amount (requires restart)` in the settings. Note that you will need to restart the WebUI for changes to take effect.
|
| 183 |
+
|
| 184 |
+
<table width="100%">
|
| 185 |
+
<tr>
|
| 186 |
+
<td width="25%" style="text-align: center">Source A</td>
|
| 187 |
+
<td width="25%" style="text-align: center">Source B</td>
|
| 188 |
+
<td width="25%" style="text-align: center">Output</td>
|
| 189 |
+
</tr>
|
| 190 |
+
<tr>
|
| 191 |
+
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448620-cd3ede92-8d3f-43d5-b771-32dd8417618f.png"></td>
|
| 192 |
+
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448619-beed9bdb-f6bb-41c2-a7df-aa3ef1f653c5.png"></td>
|
| 193 |
+
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448613-c99a9e04-0450-40fd-bc73-a9122cefaa2c.png"></td>
|
| 194 |
+
</tr>
|
| 195 |
+
</table>
|
| 196 |
+
|
| 197 |
+
# Control Weight/Start/End
|
| 198 |
+
|
| 199 |
+
Weight is the weight of the controlnet "influence". It's analogous to prompt attention/emphasis. E.g. (myprompt: 1.2). Technically, it's the factor by which to multiply the ControlNet outputs before merging them with original SD Unet.
|
| 200 |
+
|
| 201 |
+
Guidance Start/End is the percentage of total steps the controlnet applies (guidance strength = guidance end). It's analogous to prompt editing/shifting. E.g. \[myprompt::0.8\] (It applies from the beginning until 80% of total steps)
|
| 202 |
+
|
| 203 |
+
# Batch Mode
|
| 204 |
+
|
| 205 |
+
Put any unit into batch mode to activate batch mode for all units. Specify a batch directory for each unit, or use the new textbox in the img2img batch tab as a fallback. Although the textbox is located in the img2img batch tab, you can use it to generate images in the txt2img tab as well.
|
| 206 |
+
|
| 207 |
+
Note that this feature is only available in the gradio user interface. Call the APIs as many times as you want for custom batch scheduling.
|
| 208 |
+
|
| 209 |
+
# API and Script Access
|
| 210 |
+
|
| 211 |
+
This extension can accept txt2img or img2img tasks via API or external extension call. Note that you may need to enable `Allow other scripts to control this extension` in settings for external calls.
|
| 212 |
+
|
| 213 |
+
To use the API: start WebUI with argument `--api` and go to `http://webui-address/docs` for documents or checkout [examples](https://github.com/Mikubill/sd-webui-controlnet/blob/main/example/api_txt2img.ipynb).
|
| 214 |
+
|
| 215 |
+
To use external call: Checkout [Wiki](https://github.com/Mikubill/sd-webui-controlnet/wiki/API)
|
| 216 |
+
|
| 217 |
+
# Command Line Arguments
|
| 218 |
+
|
| 219 |
+
This extension adds these command line arguments to the webui:
|
| 220 |
+
|
| 221 |
+
```
|
| 222 |
+
--controlnet-dir <path to directory with controlnet models> ADD a controlnet models directory
|
| 223 |
+
--controlnet-annotator-models-path <path to directory with annotator model directories> SET the directory for annotator models
|
| 224 |
+
--no-half-controlnet load controlnet models in full precision
|
| 225 |
+
--controlnet-preprocessor-cache-size Cache size for controlnet preprocessor results
|
| 226 |
+
--controlnet-loglevel Log level for the controlnet extension
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
# MacOS Support
|
| 230 |
+
|
| 231 |
+
Tested with pytorch nightly: https://github.com/Mikubill/sd-webui-controlnet/pull/143#issuecomment-1435058285
|
| 232 |
+
|
| 233 |
+
To use this extension with mps and normal pytorch, currently you may need to start WebUI with `--no-half`.
|
| 234 |
+
|
| 235 |
+
# Archive of Deprecated Versions
|
| 236 |
+
|
| 237 |
+
The previous version (sd-webui-controlnet 1.0) is archived in
|
| 238 |
+
|
| 239 |
+
https://github.com/lllyasviel/webui-controlnet-v1-archived
|
| 240 |
+
|
| 241 |
+
Using this version is not a temporary stop of updates. You will stop all updates forever.
|
| 242 |
+
|
| 243 |
+
Please consider this version if you work with professional studios that requires 100% reproducing of all previous results pixel by pixel.
|
| 244 |
+
|
| 245 |
+
# Thanks
|
| 246 |
+
|
| 247 |
+
This implementation is inspired by kohya-ss/sd-webui-additional-networks
|
annotator/annotator_path.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from modules import shared
|
| 3 |
+
|
| 4 |
+
models_path = shared.opts.data.get('control_net_modules_path', None)
|
| 5 |
+
if not models_path:
|
| 6 |
+
models_path = getattr(shared.cmd_opts, 'controlnet_annotator_models_path', None)
|
| 7 |
+
if not models_path:
|
| 8 |
+
models_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'downloads')
|
| 9 |
+
|
| 10 |
+
if not os.path.isabs(models_path):
|
| 11 |
+
models_path = os.path.join(shared.data_path, models_path)
|
| 12 |
+
|
| 13 |
+
clip_vision_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'clip_vision')
|
| 14 |
+
# clip vision is always inside controlnet "extensions\sd-webui-controlnet"
|
| 15 |
+
# and any problem can be solved by removing controlnet and reinstall
|
| 16 |
+
|
| 17 |
+
models_path = os.path.realpath(models_path)
|
| 18 |
+
os.makedirs(models_path, exist_ok=True)
|
| 19 |
+
print(f'ControlNet preprocessor location: {models_path}')
|
| 20 |
+
# Make sure that the default location is inside controlnet "extensions\sd-webui-controlnet"
|
| 21 |
+
# so that any problem can be solved by removing controlnet and reinstall
|
| 22 |
+
# if users do not change configs on their own (otherwise users will know what is wrong)
|
annotator/binary/__init__.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def apply_binary(img, bin_threshold):
|
| 5 |
+
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
| 6 |
+
|
| 7 |
+
if bin_threshold == 0 or bin_threshold == 255:
|
| 8 |
+
# Otsu's threshold
|
| 9 |
+
otsu_threshold, img_bin = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
|
| 10 |
+
print("Otsu threshold:", otsu_threshold)
|
| 11 |
+
else:
|
| 12 |
+
_, img_bin = cv2.threshold(img_gray, bin_threshold, 255, cv2.THRESH_BINARY_INV)
|
| 13 |
+
|
| 14 |
+
return cv2.cvtColor(img_bin, cv2.COLOR_GRAY2RGB)
|
annotator/canny/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def apply_canny(img, low_threshold, high_threshold):
|
| 5 |
+
return cv2.Canny(img, low_threshold, high_threshold)
|
annotator/clip/__init__.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import CLIPProcessor, CLIPVisionModel
|
| 3 |
+
from modules import devices
|
| 4 |
+
import os
|
| 5 |
+
from annotator.annotator_path import clip_vision_path
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
remote_model_path = "https://huggingface.co/openai/clip-vit-large-patch14/resolve/main/pytorch_model.bin"
|
| 9 |
+
clip_path = clip_vision_path
|
| 10 |
+
print(f'ControlNet ClipVision location: {clip_path}')
|
| 11 |
+
|
| 12 |
+
clip_proc = None
|
| 13 |
+
clip_vision_model = None
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def apply_clip(img):
|
| 17 |
+
global clip_proc, clip_vision_model
|
| 18 |
+
|
| 19 |
+
if clip_vision_model is None:
|
| 20 |
+
modelpath = os.path.join(clip_path, 'pytorch_model.bin')
|
| 21 |
+
if not os.path.exists(modelpath):
|
| 22 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 23 |
+
load_file_from_url(remote_model_path, model_dir=clip_path)
|
| 24 |
+
|
| 25 |
+
clip_proc = CLIPProcessor.from_pretrained(clip_path)
|
| 26 |
+
clip_vision_model = CLIPVisionModel.from_pretrained(clip_path)
|
| 27 |
+
|
| 28 |
+
with torch.no_grad():
|
| 29 |
+
clip_vision_model = clip_vision_model.to(devices.get_device_for("controlnet"))
|
| 30 |
+
style_for_clip = clip_proc(images=img, return_tensors="pt")['pixel_values']
|
| 31 |
+
style_feat = clip_vision_model(style_for_clip.to(devices.get_device_for("controlnet")))['last_hidden_state']
|
| 32 |
+
|
| 33 |
+
return style_feat
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def unload_clip_model():
|
| 37 |
+
global clip_proc, clip_vision_model
|
| 38 |
+
if clip_vision_model is not None:
|
| 39 |
+
clip_vision_model.cpu()
|
annotator/clip_vision/config.json
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "clip-vit-large-patch14/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPModel"
|
| 5 |
+
],
|
| 6 |
+
"initializer_factor": 1.0,
|
| 7 |
+
"logit_scale_init_value": 2.6592,
|
| 8 |
+
"model_type": "clip",
|
| 9 |
+
"projection_dim": 768,
|
| 10 |
+
"text_config": {
|
| 11 |
+
"_name_or_path": "",
|
| 12 |
+
"add_cross_attention": false,
|
| 13 |
+
"architectures": null,
|
| 14 |
+
"attention_dropout": 0.0,
|
| 15 |
+
"bad_words_ids": null,
|
| 16 |
+
"bos_token_id": 0,
|
| 17 |
+
"chunk_size_feed_forward": 0,
|
| 18 |
+
"cross_attention_hidden_size": null,
|
| 19 |
+
"decoder_start_token_id": null,
|
| 20 |
+
"diversity_penalty": 0.0,
|
| 21 |
+
"do_sample": false,
|
| 22 |
+
"dropout": 0.0,
|
| 23 |
+
"early_stopping": false,
|
| 24 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 25 |
+
"eos_token_id": 2,
|
| 26 |
+
"finetuning_task": null,
|
| 27 |
+
"forced_bos_token_id": null,
|
| 28 |
+
"forced_eos_token_id": null,
|
| 29 |
+
"hidden_act": "quick_gelu",
|
| 30 |
+
"hidden_size": 768,
|
| 31 |
+
"id2label": {
|
| 32 |
+
"0": "LABEL_0",
|
| 33 |
+
"1": "LABEL_1"
|
| 34 |
+
},
|
| 35 |
+
"initializer_factor": 1.0,
|
| 36 |
+
"initializer_range": 0.02,
|
| 37 |
+
"intermediate_size": 3072,
|
| 38 |
+
"is_decoder": false,
|
| 39 |
+
"is_encoder_decoder": false,
|
| 40 |
+
"label2id": {
|
| 41 |
+
"LABEL_0": 0,
|
| 42 |
+
"LABEL_1": 1
|
| 43 |
+
},
|
| 44 |
+
"layer_norm_eps": 1e-05,
|
| 45 |
+
"length_penalty": 1.0,
|
| 46 |
+
"max_length": 20,
|
| 47 |
+
"max_position_embeddings": 77,
|
| 48 |
+
"min_length": 0,
|
| 49 |
+
"model_type": "clip_text_model",
|
| 50 |
+
"no_repeat_ngram_size": 0,
|
| 51 |
+
"num_attention_heads": 12,
|
| 52 |
+
"num_beam_groups": 1,
|
| 53 |
+
"num_beams": 1,
|
| 54 |
+
"num_hidden_layers": 12,
|
| 55 |
+
"num_return_sequences": 1,
|
| 56 |
+
"output_attentions": false,
|
| 57 |
+
"output_hidden_states": false,
|
| 58 |
+
"output_scores": false,
|
| 59 |
+
"pad_token_id": 1,
|
| 60 |
+
"prefix": null,
|
| 61 |
+
"problem_type": null,
|
| 62 |
+
"projection_dim" : 768,
|
| 63 |
+
"pruned_heads": {},
|
| 64 |
+
"remove_invalid_values": false,
|
| 65 |
+
"repetition_penalty": 1.0,
|
| 66 |
+
"return_dict": true,
|
| 67 |
+
"return_dict_in_generate": false,
|
| 68 |
+
"sep_token_id": null,
|
| 69 |
+
"task_specific_params": null,
|
| 70 |
+
"temperature": 1.0,
|
| 71 |
+
"tie_encoder_decoder": false,
|
| 72 |
+
"tie_word_embeddings": true,
|
| 73 |
+
"tokenizer_class": null,
|
| 74 |
+
"top_k": 50,
|
| 75 |
+
"top_p": 1.0,
|
| 76 |
+
"torch_dtype": null,
|
| 77 |
+
"torchscript": false,
|
| 78 |
+
"transformers_version": "4.16.0.dev0",
|
| 79 |
+
"use_bfloat16": false,
|
| 80 |
+
"vocab_size": 49408
|
| 81 |
+
},
|
| 82 |
+
"text_config_dict": {
|
| 83 |
+
"hidden_size": 768,
|
| 84 |
+
"intermediate_size": 3072,
|
| 85 |
+
"num_attention_heads": 12,
|
| 86 |
+
"num_hidden_layers": 12,
|
| 87 |
+
"projection_dim": 768
|
| 88 |
+
},
|
| 89 |
+
"torch_dtype": "float32",
|
| 90 |
+
"transformers_version": null,
|
| 91 |
+
"vision_config": {
|
| 92 |
+
"_name_or_path": "",
|
| 93 |
+
"add_cross_attention": false,
|
| 94 |
+
"architectures": null,
|
| 95 |
+
"attention_dropout": 0.0,
|
| 96 |
+
"bad_words_ids": null,
|
| 97 |
+
"bos_token_id": null,
|
| 98 |
+
"chunk_size_feed_forward": 0,
|
| 99 |
+
"cross_attention_hidden_size": null,
|
| 100 |
+
"decoder_start_token_id": null,
|
| 101 |
+
"diversity_penalty": 0.0,
|
| 102 |
+
"do_sample": false,
|
| 103 |
+
"dropout": 0.0,
|
| 104 |
+
"early_stopping": false,
|
| 105 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 106 |
+
"eos_token_id": null,
|
| 107 |
+
"finetuning_task": null,
|
| 108 |
+
"forced_bos_token_id": null,
|
| 109 |
+
"forced_eos_token_id": null,
|
| 110 |
+
"hidden_act": "quick_gelu",
|
| 111 |
+
"hidden_size": 1024,
|
| 112 |
+
"id2label": {
|
| 113 |
+
"0": "LABEL_0",
|
| 114 |
+
"1": "LABEL_1"
|
| 115 |
+
},
|
| 116 |
+
"image_size": 224,
|
| 117 |
+
"initializer_factor": 1.0,
|
| 118 |
+
"initializer_range": 0.02,
|
| 119 |
+
"intermediate_size": 4096,
|
| 120 |
+
"is_decoder": false,
|
| 121 |
+
"is_encoder_decoder": false,
|
| 122 |
+
"label2id": {
|
| 123 |
+
"LABEL_0": 0,
|
| 124 |
+
"LABEL_1": 1
|
| 125 |
+
},
|
| 126 |
+
"layer_norm_eps": 1e-05,
|
| 127 |
+
"length_penalty": 1.0,
|
| 128 |
+
"max_length": 20,
|
| 129 |
+
"min_length": 0,
|
| 130 |
+
"model_type": "clip_vision_model",
|
| 131 |
+
"no_repeat_ngram_size": 0,
|
| 132 |
+
"num_attention_heads": 16,
|
| 133 |
+
"num_beam_groups": 1,
|
| 134 |
+
"num_beams": 1,
|
| 135 |
+
"num_hidden_layers": 24,
|
| 136 |
+
"num_return_sequences": 1,
|
| 137 |
+
"output_attentions": false,
|
| 138 |
+
"output_hidden_states": false,
|
| 139 |
+
"output_scores": false,
|
| 140 |
+
"pad_token_id": null,
|
| 141 |
+
"patch_size": 14,
|
| 142 |
+
"prefix": null,
|
| 143 |
+
"problem_type": null,
|
| 144 |
+
"projection_dim" : 768,
|
| 145 |
+
"pruned_heads": {},
|
| 146 |
+
"remove_invalid_values": false,
|
| 147 |
+
"repetition_penalty": 1.0,
|
| 148 |
+
"return_dict": true,
|
| 149 |
+
"return_dict_in_generate": false,
|
| 150 |
+
"sep_token_id": null,
|
| 151 |
+
"task_specific_params": null,
|
| 152 |
+
"temperature": 1.0,
|
| 153 |
+
"tie_encoder_decoder": false,
|
| 154 |
+
"tie_word_embeddings": true,
|
| 155 |
+
"tokenizer_class": null,
|
| 156 |
+
"top_k": 50,
|
| 157 |
+
"top_p": 1.0,
|
| 158 |
+
"torch_dtype": null,
|
| 159 |
+
"torchscript": false,
|
| 160 |
+
"transformers_version": "4.16.0.dev0",
|
| 161 |
+
"use_bfloat16": false
|
| 162 |
+
},
|
| 163 |
+
"vision_config_dict": {
|
| 164 |
+
"hidden_size": 1024,
|
| 165 |
+
"intermediate_size": 4096,
|
| 166 |
+
"num_attention_heads": 16,
|
| 167 |
+
"num_hidden_layers": 24,
|
| 168 |
+
"patch_size": 14,
|
| 169 |
+
"projection_dim": 768
|
| 170 |
+
}
|
| 171 |
+
}
|
annotator/clip_vision/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
annotator/clip_vision/preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 224,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.48145466,
|
| 9 |
+
0.4578275,
|
| 10 |
+
0.40821073
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.26862954,
|
| 14 |
+
0.26130258,
|
| 15 |
+
0.27577711
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 224
|
| 19 |
+
}
|
annotator/clip_vision/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
annotator/clip_vision/tokenizer_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"unk_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"single_word": false,
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"__type": "AddedToken"
|
| 9 |
+
},
|
| 10 |
+
"bos_token": {
|
| 11 |
+
"content": "<|startoftext|>",
|
| 12 |
+
"single_word": false,
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"rstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"__type": "AddedToken"
|
| 17 |
+
},
|
| 18 |
+
"eos_token": {
|
| 19 |
+
"content": "<|endoftext|>",
|
| 20 |
+
"single_word": false,
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"normalized": true,
|
| 24 |
+
"__type": "AddedToken"
|
| 25 |
+
},
|
| 26 |
+
"pad_token": "<|endoftext|>",
|
| 27 |
+
"add_prefix_space": false,
|
| 28 |
+
"errors": "replace",
|
| 29 |
+
"do_lower_case": true,
|
| 30 |
+
"name_or_path": "openai/clip-vit-base-patch32",
|
| 31 |
+
"model_max_length": 77,
|
| 32 |
+
"special_tokens_map_file": "./special_tokens_map.json",
|
| 33 |
+
"tokenizer_class": "CLIPTokenizer"
|
| 34 |
+
}
|
annotator/clip_vision/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
annotator/color/__init__.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
|
| 3 |
+
def cv2_resize_shortest_edge(image, size):
|
| 4 |
+
h, w = image.shape[:2]
|
| 5 |
+
if h < w:
|
| 6 |
+
new_h = size
|
| 7 |
+
new_w = int(round(w / h * size))
|
| 8 |
+
else:
|
| 9 |
+
new_w = size
|
| 10 |
+
new_h = int(round(h / w * size))
|
| 11 |
+
resized_image = cv2.resize(image, (new_w, new_h), interpolation=cv2.INTER_AREA)
|
| 12 |
+
return resized_image
|
| 13 |
+
|
| 14 |
+
def apply_color(img, res=512):
|
| 15 |
+
img = cv2_resize_shortest_edge(img, res)
|
| 16 |
+
h, w = img.shape[:2]
|
| 17 |
+
|
| 18 |
+
input_img_color = cv2.resize(img, (w//64, h//64), interpolation=cv2.INTER_CUBIC)
|
| 19 |
+
input_img_color = cv2.resize(input_img_color, (w, h), interpolation=cv2.INTER_NEAREST)
|
| 20 |
+
return input_img_color
|
annotator/hed/__init__.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is an improved version and model of HED edge detection with Apache License, Version 2.0.
|
| 2 |
+
# Please use this implementation in your products
|
| 3 |
+
# This implementation may produce slightly different results from Saining Xie's official implementations,
|
| 4 |
+
# but it generates smoother edges and is more suitable for ControlNet as well as other image-to-image translations.
|
| 5 |
+
# Different from official models and other implementations, this is an RGB-input model (rather than BGR)
|
| 6 |
+
# and in this way it works better for gradio's RGB protocol
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import cv2
|
| 10 |
+
import torch
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
from einops import rearrange
|
| 14 |
+
import os
|
| 15 |
+
from modules import devices
|
| 16 |
+
from annotator.annotator_path import models_path
|
| 17 |
+
from annotator.util import safe_step, nms
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class DoubleConvBlock(torch.nn.Module):
|
| 21 |
+
def __init__(self, input_channel, output_channel, layer_number):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.convs = torch.nn.Sequential()
|
| 24 |
+
self.convs.append(torch.nn.Conv2d(in_channels=input_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
| 25 |
+
for i in range(1, layer_number):
|
| 26 |
+
self.convs.append(torch.nn.Conv2d(in_channels=output_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
|
| 27 |
+
self.projection = torch.nn.Conv2d(in_channels=output_channel, out_channels=1, kernel_size=(1, 1), stride=(1, 1), padding=0)
|
| 28 |
+
|
| 29 |
+
def __call__(self, x, down_sampling=False):
|
| 30 |
+
h = x
|
| 31 |
+
if down_sampling:
|
| 32 |
+
h = torch.nn.functional.max_pool2d(h, kernel_size=(2, 2), stride=(2, 2))
|
| 33 |
+
for conv in self.convs:
|
| 34 |
+
h = conv(h)
|
| 35 |
+
h = torch.nn.functional.relu(h)
|
| 36 |
+
return h, self.projection(h)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class ControlNetHED_Apache2(torch.nn.Module):
|
| 40 |
+
def __init__(self):
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.norm = torch.nn.Parameter(torch.zeros(size=(1, 3, 1, 1)))
|
| 43 |
+
self.block1 = DoubleConvBlock(input_channel=3, output_channel=64, layer_number=2)
|
| 44 |
+
self.block2 = DoubleConvBlock(input_channel=64, output_channel=128, layer_number=2)
|
| 45 |
+
self.block3 = DoubleConvBlock(input_channel=128, output_channel=256, layer_number=3)
|
| 46 |
+
self.block4 = DoubleConvBlock(input_channel=256, output_channel=512, layer_number=3)
|
| 47 |
+
self.block5 = DoubleConvBlock(input_channel=512, output_channel=512, layer_number=3)
|
| 48 |
+
|
| 49 |
+
def __call__(self, x):
|
| 50 |
+
h = x - self.norm
|
| 51 |
+
h, projection1 = self.block1(h)
|
| 52 |
+
h, projection2 = self.block2(h, down_sampling=True)
|
| 53 |
+
h, projection3 = self.block3(h, down_sampling=True)
|
| 54 |
+
h, projection4 = self.block4(h, down_sampling=True)
|
| 55 |
+
h, projection5 = self.block5(h, down_sampling=True)
|
| 56 |
+
return projection1, projection2, projection3, projection4, projection5
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
netNetwork = None
|
| 60 |
+
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetHED.pth"
|
| 61 |
+
modeldir = os.path.join(models_path, "hed")
|
| 62 |
+
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def apply_hed(input_image, is_safe=False):
|
| 66 |
+
global netNetwork
|
| 67 |
+
if netNetwork is None:
|
| 68 |
+
modelpath = os.path.join(modeldir, "ControlNetHED.pth")
|
| 69 |
+
old_modelpath = os.path.join(old_modeldir, "ControlNetHED.pth")
|
| 70 |
+
if os.path.exists(old_modelpath):
|
| 71 |
+
modelpath = old_modelpath
|
| 72 |
+
elif not os.path.exists(modelpath):
|
| 73 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 74 |
+
load_file_from_url(remote_model_path, model_dir=modeldir)
|
| 75 |
+
netNetwork = ControlNetHED_Apache2().to(devices.get_device_for("controlnet"))
|
| 76 |
+
netNetwork.load_state_dict(torch.load(modelpath, map_location='cpu'))
|
| 77 |
+
netNetwork.to(devices.get_device_for("controlnet")).float().eval()
|
| 78 |
+
|
| 79 |
+
assert input_image.ndim == 3
|
| 80 |
+
H, W, C = input_image.shape
|
| 81 |
+
with torch.no_grad():
|
| 82 |
+
image_hed = torch.from_numpy(input_image.copy()).float().to(devices.get_device_for("controlnet"))
|
| 83 |
+
image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
|
| 84 |
+
edges = netNetwork(image_hed)
|
| 85 |
+
edges = [e.detach().cpu().numpy().astype(np.float32)[0, 0] for e in edges]
|
| 86 |
+
edges = [cv2.resize(e, (W, H), interpolation=cv2.INTER_LINEAR) for e in edges]
|
| 87 |
+
edges = np.stack(edges, axis=2)
|
| 88 |
+
edge = 1 / (1 + np.exp(-np.mean(edges, axis=2).astype(np.float64)))
|
| 89 |
+
if is_safe:
|
| 90 |
+
edge = safe_step(edge)
|
| 91 |
+
edge = (edge * 255.0).clip(0, 255).astype(np.uint8)
|
| 92 |
+
return edge
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def unload_hed_model():
|
| 96 |
+
global netNetwork
|
| 97 |
+
if netNetwork is not None:
|
| 98 |
+
netNetwork.cpu()
|
annotator/keypose/__init__.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
from modules import devices
|
| 7 |
+
from annotator.annotator_path import models_path
|
| 8 |
+
|
| 9 |
+
import mmcv
|
| 10 |
+
from mmdet.apis import inference_detector, init_detector
|
| 11 |
+
from mmpose.apis import inference_top_down_pose_model
|
| 12 |
+
from mmpose.apis import init_pose_model, process_mmdet_results, vis_pose_result
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def preprocessing(image, device):
|
| 16 |
+
# Resize
|
| 17 |
+
scale = 640 / max(image.shape[:2])
|
| 18 |
+
image = cv2.resize(image, dsize=None, fx=scale, fy=scale)
|
| 19 |
+
raw_image = image.astype(np.uint8)
|
| 20 |
+
|
| 21 |
+
# Subtract mean values
|
| 22 |
+
image = image.astype(np.float32)
|
| 23 |
+
image -= np.array(
|
| 24 |
+
[
|
| 25 |
+
float(104.008),
|
| 26 |
+
float(116.669),
|
| 27 |
+
float(122.675),
|
| 28 |
+
]
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
# Convert to torch.Tensor and add "batch" axis
|
| 32 |
+
image = torch.from_numpy(image.transpose(2, 0, 1)).float().unsqueeze(0)
|
| 33 |
+
image = image.to(device)
|
| 34 |
+
|
| 35 |
+
return image, raw_image
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def imshow_keypoints(img,
|
| 39 |
+
pose_result,
|
| 40 |
+
skeleton=None,
|
| 41 |
+
kpt_score_thr=0.1,
|
| 42 |
+
pose_kpt_color=None,
|
| 43 |
+
pose_link_color=None,
|
| 44 |
+
radius=4,
|
| 45 |
+
thickness=1):
|
| 46 |
+
"""Draw keypoints and links on an image.
|
| 47 |
+
Args:
|
| 48 |
+
img (ndarry): The image to draw poses on.
|
| 49 |
+
pose_result (list[kpts]): The poses to draw. Each element kpts is
|
| 50 |
+
a set of K keypoints as an Kx3 numpy.ndarray, where each
|
| 51 |
+
keypoint is represented as x, y, score.
|
| 52 |
+
kpt_score_thr (float, optional): Minimum score of keypoints
|
| 53 |
+
to be shown. Default: 0.3.
|
| 54 |
+
pose_kpt_color (np.array[Nx3]`): Color of N keypoints. If None,
|
| 55 |
+
the keypoint will not be drawn.
|
| 56 |
+
pose_link_color (np.array[Mx3]): Color of M links. If None, the
|
| 57 |
+
links will not be drawn.
|
| 58 |
+
thickness (int): Thickness of lines.
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
img_h, img_w, _ = img.shape
|
| 62 |
+
img = np.zeros(img.shape)
|
| 63 |
+
|
| 64 |
+
for idx, kpts in enumerate(pose_result):
|
| 65 |
+
if idx > 1:
|
| 66 |
+
continue
|
| 67 |
+
kpts = kpts['keypoints']
|
| 68 |
+
# print(kpts)
|
| 69 |
+
kpts = np.array(kpts, copy=False)
|
| 70 |
+
|
| 71 |
+
# draw each point on image
|
| 72 |
+
if pose_kpt_color is not None:
|
| 73 |
+
assert len(pose_kpt_color) == len(kpts)
|
| 74 |
+
|
| 75 |
+
for kid, kpt in enumerate(kpts):
|
| 76 |
+
x_coord, y_coord, kpt_score = int(kpt[0]), int(kpt[1]), kpt[2]
|
| 77 |
+
|
| 78 |
+
if kpt_score < kpt_score_thr or pose_kpt_color[kid] is None:
|
| 79 |
+
# skip the point that should not be drawn
|
| 80 |
+
continue
|
| 81 |
+
|
| 82 |
+
color = tuple(int(c) for c in pose_kpt_color[kid])
|
| 83 |
+
cv2.circle(img, (int(x_coord), int(y_coord)),
|
| 84 |
+
radius, color, -1)
|
| 85 |
+
|
| 86 |
+
# draw links
|
| 87 |
+
if skeleton is not None and pose_link_color is not None:
|
| 88 |
+
assert len(pose_link_color) == len(skeleton)
|
| 89 |
+
|
| 90 |
+
for sk_id, sk in enumerate(skeleton):
|
| 91 |
+
pos1 = (int(kpts[sk[0], 0]), int(kpts[sk[0], 1]))
|
| 92 |
+
pos2 = (int(kpts[sk[1], 0]), int(kpts[sk[1], 1]))
|
| 93 |
+
|
| 94 |
+
if (pos1[0] <= 0 or pos1[0] >= img_w or pos1[1] <= 0 or pos1[1] >= img_h or pos2[0] <= 0
|
| 95 |
+
or pos2[0] >= img_w or pos2[1] <= 0 or pos2[1] >= img_h or kpts[sk[0], 2] < kpt_score_thr
|
| 96 |
+
or kpts[sk[1], 2] < kpt_score_thr or pose_link_color[sk_id] is None):
|
| 97 |
+
# skip the link that should not be drawn
|
| 98 |
+
continue
|
| 99 |
+
color = tuple(int(c) for c in pose_link_color[sk_id])
|
| 100 |
+
cv2.line(img, pos1, pos2, color, thickness=thickness)
|
| 101 |
+
|
| 102 |
+
return img
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
human_det, pose_model = None, None
|
| 106 |
+
det_model_path = "https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth"
|
| 107 |
+
pose_model_path = "https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth"
|
| 108 |
+
|
| 109 |
+
modeldir = os.path.join(models_path, "keypose")
|
| 110 |
+
old_modeldir = os.path.dirname(os.path.realpath(__file__))
|
| 111 |
+
|
| 112 |
+
det_config = 'faster_rcnn_r50_fpn_coco.py'
|
| 113 |
+
pose_config = 'hrnet_w48_coco_256x192.py'
|
| 114 |
+
|
| 115 |
+
det_checkpoint = 'faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
|
| 116 |
+
pose_checkpoint = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth'
|
| 117 |
+
det_cat_id = 1
|
| 118 |
+
bbox_thr = 0.2
|
| 119 |
+
|
| 120 |
+
skeleton = [
|
| 121 |
+
[15, 13], [13, 11], [16, 14], [14, 12], [11, 12], [5, 11], [6, 12], [5, 6], [5, 7], [6, 8],
|
| 122 |
+
[7, 9], [8, 10],
|
| 123 |
+
[1, 2], [0, 1], [0, 2], [1, 3], [2, 4], [3, 5], [4, 6]
|
| 124 |
+
]
|
| 125 |
+
|
| 126 |
+
pose_kpt_color = [
|
| 127 |
+
[51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255],
|
| 128 |
+
[0, 255, 0],
|
| 129 |
+
[255, 128, 0], [0, 255, 0], [255, 128, 0], [0, 255, 0], [255, 128, 0], [0, 255, 0],
|
| 130 |
+
[255, 128, 0],
|
| 131 |
+
[0, 255, 0], [255, 128, 0], [0, 255, 0], [255, 128, 0]
|
| 132 |
+
]
|
| 133 |
+
|
| 134 |
+
pose_link_color = [
|
| 135 |
+
[0, 255, 0], [0, 255, 0], [255, 128, 0], [255, 128, 0],
|
| 136 |
+
[51, 153, 255], [51, 153, 255], [51, 153, 255], [51, 153, 255], [0, 255, 0],
|
| 137 |
+
[255, 128, 0],
|
| 138 |
+
[0, 255, 0], [255, 128, 0], [51, 153, 255], [51, 153, 255], [51, 153, 255],
|
| 139 |
+
[51, 153, 255],
|
| 140 |
+
[51, 153, 255], [51, 153, 255], [51, 153, 255]
|
| 141 |
+
]
|
| 142 |
+
|
| 143 |
+
def find_download_model(checkpoint, remote_path):
|
| 144 |
+
modelpath = os.path.join(modeldir, checkpoint)
|
| 145 |
+
old_modelpath = os.path.join(old_modeldir, checkpoint)
|
| 146 |
+
|
| 147 |
+
if os.path.exists(old_modelpath):
|
| 148 |
+
modelpath = old_modelpath
|
| 149 |
+
elif not os.path.exists(modelpath):
|
| 150 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 151 |
+
load_file_from_url(remote_path, model_dir=modeldir)
|
| 152 |
+
|
| 153 |
+
return modelpath
|
| 154 |
+
|
| 155 |
+
def apply_keypose(input_image):
|
| 156 |
+
global human_det, pose_model
|
| 157 |
+
if netNetwork is None:
|
| 158 |
+
det_model_local = find_download_model(det_checkpoint, det_model_path)
|
| 159 |
+
hrnet_model_local = find_download_model(pose_checkpoint, pose_model_path)
|
| 160 |
+
det_config_mmcv = mmcv.Config.fromfile(det_config)
|
| 161 |
+
pose_config_mmcv = mmcv.Config.fromfile(pose_config)
|
| 162 |
+
human_det = init_detector(det_config_mmcv, det_model_local, device=devices.get_device_for("controlnet"))
|
| 163 |
+
pose_model = init_pose_model(pose_config_mmcv, hrnet_model_local, device=devices.get_device_for("controlnet"))
|
| 164 |
+
|
| 165 |
+
assert input_image.ndim == 3
|
| 166 |
+
input_image = input_image.copy()
|
| 167 |
+
with torch.no_grad():
|
| 168 |
+
image = torch.from_numpy(input_image).float().to(devices.get_device_for("controlnet"))
|
| 169 |
+
image = image / 255.0
|
| 170 |
+
mmdet_results = inference_detector(human_det, image)
|
| 171 |
+
|
| 172 |
+
# keep the person class bounding boxes.
|
| 173 |
+
person_results = process_mmdet_results(mmdet_results, det_cat_id)
|
| 174 |
+
|
| 175 |
+
return_heatmap = False
|
| 176 |
+
dataset = pose_model.cfg.data['test']['type']
|
| 177 |
+
|
| 178 |
+
# e.g. use ('backbone', ) to return backbone feature
|
| 179 |
+
output_layer_names = None
|
| 180 |
+
pose_results, _ = inference_top_down_pose_model(
|
| 181 |
+
pose_model,
|
| 182 |
+
image,
|
| 183 |
+
person_results,
|
| 184 |
+
bbox_thr=bbox_thr,
|
| 185 |
+
format='xyxy',
|
| 186 |
+
dataset=dataset,
|
| 187 |
+
dataset_info=None,
|
| 188 |
+
return_heatmap=return_heatmap,
|
| 189 |
+
outputs=output_layer_names
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
im_keypose_out = imshow_keypoints(
|
| 193 |
+
image,
|
| 194 |
+
pose_results,
|
| 195 |
+
skeleton=skeleton,
|
| 196 |
+
pose_kpt_color=pose_kpt_color,
|
| 197 |
+
pose_link_color=pose_link_color,
|
| 198 |
+
radius=2,
|
| 199 |
+
thickness=2
|
| 200 |
+
)
|
| 201 |
+
im_keypose_out = im_keypose_out.astype(np.uint8)
|
| 202 |
+
|
| 203 |
+
# image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
|
| 204 |
+
# edge = netNetwork(image_hed)[0]
|
| 205 |
+
# edge = (edge.cpu().numpy() * 255.0).clip(0, 255).astype(np.uint8)
|
| 206 |
+
return im_keypose_out
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def unload_hed_model():
|
| 210 |
+
global netNetwork
|
| 211 |
+
if netNetwork is not None:
|
| 212 |
+
netNetwork.cpu()
|
annotator/keypose/faster_rcnn_r50_fpn_coco.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
checkpoint_config = dict(interval=1)
|
| 2 |
+
# yapf:disable
|
| 3 |
+
log_config = dict(
|
| 4 |
+
interval=50,
|
| 5 |
+
hooks=[
|
| 6 |
+
dict(type='TextLoggerHook'),
|
| 7 |
+
# dict(type='TensorboardLoggerHook')
|
| 8 |
+
])
|
| 9 |
+
# yapf:enable
|
| 10 |
+
dist_params = dict(backend='nccl')
|
| 11 |
+
log_level = 'INFO'
|
| 12 |
+
load_from = None
|
| 13 |
+
resume_from = None
|
| 14 |
+
workflow = [('train', 1)]
|
| 15 |
+
# optimizer
|
| 16 |
+
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
|
| 17 |
+
optimizer_config = dict(grad_clip=None)
|
| 18 |
+
# learning policy
|
| 19 |
+
lr_config = dict(
|
| 20 |
+
policy='step',
|
| 21 |
+
warmup='linear',
|
| 22 |
+
warmup_iters=500,
|
| 23 |
+
warmup_ratio=0.001,
|
| 24 |
+
step=[8, 11])
|
| 25 |
+
total_epochs = 12
|
| 26 |
+
|
| 27 |
+
model = dict(
|
| 28 |
+
type='FasterRCNN',
|
| 29 |
+
pretrained='torchvision://resnet50',
|
| 30 |
+
backbone=dict(
|
| 31 |
+
type='ResNet',
|
| 32 |
+
depth=50,
|
| 33 |
+
num_stages=4,
|
| 34 |
+
out_indices=(0, 1, 2, 3),
|
| 35 |
+
frozen_stages=1,
|
| 36 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 37 |
+
norm_eval=True,
|
| 38 |
+
style='pytorch'),
|
| 39 |
+
neck=dict(
|
| 40 |
+
type='FPN',
|
| 41 |
+
in_channels=[256, 512, 1024, 2048],
|
| 42 |
+
out_channels=256,
|
| 43 |
+
num_outs=5),
|
| 44 |
+
rpn_head=dict(
|
| 45 |
+
type='RPNHead',
|
| 46 |
+
in_channels=256,
|
| 47 |
+
feat_channels=256,
|
| 48 |
+
anchor_generator=dict(
|
| 49 |
+
type='AnchorGenerator',
|
| 50 |
+
scales=[8],
|
| 51 |
+
ratios=[0.5, 1.0, 2.0],
|
| 52 |
+
strides=[4, 8, 16, 32, 64]),
|
| 53 |
+
bbox_coder=dict(
|
| 54 |
+
type='DeltaXYWHBBoxCoder',
|
| 55 |
+
target_means=[.0, .0, .0, .0],
|
| 56 |
+
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
| 57 |
+
loss_cls=dict(
|
| 58 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 59 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 60 |
+
roi_head=dict(
|
| 61 |
+
type='StandardRoIHead',
|
| 62 |
+
bbox_roi_extractor=dict(
|
| 63 |
+
type='SingleRoIExtractor',
|
| 64 |
+
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
| 65 |
+
out_channels=256,
|
| 66 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 67 |
+
bbox_head=dict(
|
| 68 |
+
type='Shared2FCBBoxHead',
|
| 69 |
+
in_channels=256,
|
| 70 |
+
fc_out_channels=1024,
|
| 71 |
+
roi_feat_size=7,
|
| 72 |
+
num_classes=80,
|
| 73 |
+
bbox_coder=dict(
|
| 74 |
+
type='DeltaXYWHBBoxCoder',
|
| 75 |
+
target_means=[0., 0., 0., 0.],
|
| 76 |
+
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
| 77 |
+
reg_class_agnostic=False,
|
| 78 |
+
loss_cls=dict(
|
| 79 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 80 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
|
| 81 |
+
# model training and testing settings
|
| 82 |
+
train_cfg=dict(
|
| 83 |
+
rpn=dict(
|
| 84 |
+
assigner=dict(
|
| 85 |
+
type='MaxIoUAssigner',
|
| 86 |
+
pos_iou_thr=0.7,
|
| 87 |
+
neg_iou_thr=0.3,
|
| 88 |
+
min_pos_iou=0.3,
|
| 89 |
+
match_low_quality=True,
|
| 90 |
+
ignore_iof_thr=-1),
|
| 91 |
+
sampler=dict(
|
| 92 |
+
type='RandomSampler',
|
| 93 |
+
num=256,
|
| 94 |
+
pos_fraction=0.5,
|
| 95 |
+
neg_pos_ub=-1,
|
| 96 |
+
add_gt_as_proposals=False),
|
| 97 |
+
allowed_border=-1,
|
| 98 |
+
pos_weight=-1,
|
| 99 |
+
debug=False),
|
| 100 |
+
rpn_proposal=dict(
|
| 101 |
+
nms_pre=2000,
|
| 102 |
+
max_per_img=1000,
|
| 103 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 104 |
+
min_bbox_size=0),
|
| 105 |
+
rcnn=dict(
|
| 106 |
+
assigner=dict(
|
| 107 |
+
type='MaxIoUAssigner',
|
| 108 |
+
pos_iou_thr=0.5,
|
| 109 |
+
neg_iou_thr=0.5,
|
| 110 |
+
min_pos_iou=0.5,
|
| 111 |
+
match_low_quality=False,
|
| 112 |
+
ignore_iof_thr=-1),
|
| 113 |
+
sampler=dict(
|
| 114 |
+
type='RandomSampler',
|
| 115 |
+
num=512,
|
| 116 |
+
pos_fraction=0.25,
|
| 117 |
+
neg_pos_ub=-1,
|
| 118 |
+
add_gt_as_proposals=True),
|
| 119 |
+
pos_weight=-1,
|
| 120 |
+
debug=False)),
|
| 121 |
+
test_cfg=dict(
|
| 122 |
+
rpn=dict(
|
| 123 |
+
nms_pre=1000,
|
| 124 |
+
max_per_img=1000,
|
| 125 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 126 |
+
min_bbox_size=0),
|
| 127 |
+
rcnn=dict(
|
| 128 |
+
score_thr=0.05,
|
| 129 |
+
nms=dict(type='nms', iou_threshold=0.5),
|
| 130 |
+
max_per_img=100)
|
| 131 |
+
# soft-nms is also supported for rcnn testing
|
| 132 |
+
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
|
| 133 |
+
))
|
| 134 |
+
|
| 135 |
+
dataset_type = 'CocoDataset'
|
| 136 |
+
data_root = 'data/coco'
|
| 137 |
+
img_norm_cfg = dict(
|
| 138 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 139 |
+
train_pipeline = [
|
| 140 |
+
dict(type='LoadImageFromFile'),
|
| 141 |
+
dict(type='LoadAnnotations', with_bbox=True),
|
| 142 |
+
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
|
| 143 |
+
dict(type='RandomFlip', flip_ratio=0.5),
|
| 144 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 145 |
+
dict(type='Pad', size_divisor=32),
|
| 146 |
+
dict(type='DefaultFormatBundle'),
|
| 147 |
+
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
|
| 148 |
+
]
|
| 149 |
+
test_pipeline = [
|
| 150 |
+
dict(type='LoadImageFromFile'),
|
| 151 |
+
dict(
|
| 152 |
+
type='MultiScaleFlipAug',
|
| 153 |
+
img_scale=(1333, 800),
|
| 154 |
+
flip=False,
|
| 155 |
+
transforms=[
|
| 156 |
+
dict(type='Resize', keep_ratio=True),
|
| 157 |
+
dict(type='RandomFlip'),
|
| 158 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 159 |
+
dict(type='Pad', size_divisor=32),
|
| 160 |
+
dict(type='DefaultFormatBundle'),
|
| 161 |
+
dict(type='Collect', keys=['img']),
|
| 162 |
+
])
|
| 163 |
+
]
|
| 164 |
+
data = dict(
|
| 165 |
+
samples_per_gpu=2,
|
| 166 |
+
workers_per_gpu=2,
|
| 167 |
+
train=dict(
|
| 168 |
+
type=dataset_type,
|
| 169 |
+
ann_file=f'{data_root}/annotations/instances_train2017.json',
|
| 170 |
+
img_prefix=f'{data_root}/train2017/',
|
| 171 |
+
pipeline=train_pipeline),
|
| 172 |
+
val=dict(
|
| 173 |
+
type=dataset_type,
|
| 174 |
+
ann_file=f'{data_root}/annotations/instances_val2017.json',
|
| 175 |
+
img_prefix=f'{data_root}/val2017/',
|
| 176 |
+
pipeline=test_pipeline),
|
| 177 |
+
test=dict(
|
| 178 |
+
type=dataset_type,
|
| 179 |
+
ann_file=f'{data_root}/annotations/instances_val2017.json',
|
| 180 |
+
img_prefix=f'{data_root}/val2017/',
|
| 181 |
+
pipeline=test_pipeline))
|
| 182 |
+
evaluation = dict(interval=1, metric='bbox')
|
annotator/keypose/hrnet_w48_coco_256x192.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# _base_ = [
|
| 2 |
+
# '../../../../_base_/default_runtime.py',
|
| 3 |
+
# '../../../../_base_/datasets/coco.py'
|
| 4 |
+
# ]
|
| 5 |
+
evaluation = dict(interval=10, metric='mAP', save_best='AP')
|
| 6 |
+
|
| 7 |
+
optimizer = dict(
|
| 8 |
+
type='Adam',
|
| 9 |
+
lr=5e-4,
|
| 10 |
+
)
|
| 11 |
+
optimizer_config = dict(grad_clip=None)
|
| 12 |
+
# learning policy
|
| 13 |
+
lr_config = dict(
|
| 14 |
+
policy='step',
|
| 15 |
+
warmup='linear',
|
| 16 |
+
warmup_iters=500,
|
| 17 |
+
warmup_ratio=0.001,
|
| 18 |
+
step=[170, 200])
|
| 19 |
+
total_epochs = 210
|
| 20 |
+
channel_cfg = dict(
|
| 21 |
+
num_output_channels=17,
|
| 22 |
+
dataset_joints=17,
|
| 23 |
+
dataset_channel=[
|
| 24 |
+
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
|
| 25 |
+
],
|
| 26 |
+
inference_channel=[
|
| 27 |
+
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
|
| 28 |
+
])
|
| 29 |
+
|
| 30 |
+
# model settings
|
| 31 |
+
model = dict(
|
| 32 |
+
type='TopDown',
|
| 33 |
+
pretrained='https://download.openmmlab.com/mmpose/'
|
| 34 |
+
'pretrain_models/hrnet_w48-8ef0771d.pth',
|
| 35 |
+
backbone=dict(
|
| 36 |
+
type='HRNet',
|
| 37 |
+
in_channels=3,
|
| 38 |
+
extra=dict(
|
| 39 |
+
stage1=dict(
|
| 40 |
+
num_modules=1,
|
| 41 |
+
num_branches=1,
|
| 42 |
+
block='BOTTLENECK',
|
| 43 |
+
num_blocks=(4, ),
|
| 44 |
+
num_channels=(64, )),
|
| 45 |
+
stage2=dict(
|
| 46 |
+
num_modules=1,
|
| 47 |
+
num_branches=2,
|
| 48 |
+
block='BASIC',
|
| 49 |
+
num_blocks=(4, 4),
|
| 50 |
+
num_channels=(48, 96)),
|
| 51 |
+
stage3=dict(
|
| 52 |
+
num_modules=4,
|
| 53 |
+
num_branches=3,
|
| 54 |
+
block='BASIC',
|
| 55 |
+
num_blocks=(4, 4, 4),
|
| 56 |
+
num_channels=(48, 96, 192)),
|
| 57 |
+
stage4=dict(
|
| 58 |
+
num_modules=3,
|
| 59 |
+
num_branches=4,
|
| 60 |
+
block='BASIC',
|
| 61 |
+
num_blocks=(4, 4, 4, 4),
|
| 62 |
+
num_channels=(48, 96, 192, 384))),
|
| 63 |
+
),
|
| 64 |
+
keypoint_head=dict(
|
| 65 |
+
type='TopdownHeatmapSimpleHead',
|
| 66 |
+
in_channels=48,
|
| 67 |
+
out_channels=channel_cfg['num_output_channels'],
|
| 68 |
+
num_deconv_layers=0,
|
| 69 |
+
extra=dict(final_conv_kernel=1, ),
|
| 70 |
+
loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
|
| 71 |
+
train_cfg=dict(),
|
| 72 |
+
test_cfg=dict(
|
| 73 |
+
flip_test=True,
|
| 74 |
+
post_process='default',
|
| 75 |
+
shift_heatmap=True,
|
| 76 |
+
modulate_kernel=11))
|
| 77 |
+
|
| 78 |
+
data_cfg = dict(
|
| 79 |
+
image_size=[192, 256],
|
| 80 |
+
heatmap_size=[48, 64],
|
| 81 |
+
num_output_channels=channel_cfg['num_output_channels'],
|
| 82 |
+
num_joints=channel_cfg['dataset_joints'],
|
| 83 |
+
dataset_channel=channel_cfg['dataset_channel'],
|
| 84 |
+
inference_channel=channel_cfg['inference_channel'],
|
| 85 |
+
soft_nms=False,
|
| 86 |
+
nms_thr=1.0,
|
| 87 |
+
oks_thr=0.9,
|
| 88 |
+
vis_thr=0.2,
|
| 89 |
+
use_gt_bbox=False,
|
| 90 |
+
det_bbox_thr=0.0,
|
| 91 |
+
bbox_file='data/coco/person_detection_results/'
|
| 92 |
+
'COCO_val2017_detections_AP_H_56_person.json',
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
train_pipeline = [
|
| 96 |
+
dict(type='LoadImageFromFile'),
|
| 97 |
+
dict(type='TopDownGetBboxCenterScale', padding=1.25),
|
| 98 |
+
dict(type='TopDownRandomShiftBboxCenter', shift_factor=0.16, prob=0.3),
|
| 99 |
+
dict(type='TopDownRandomFlip', flip_prob=0.5),
|
| 100 |
+
dict(
|
| 101 |
+
type='TopDownHalfBodyTransform',
|
| 102 |
+
num_joints_half_body=8,
|
| 103 |
+
prob_half_body=0.3),
|
| 104 |
+
dict(
|
| 105 |
+
type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
|
| 106 |
+
dict(type='TopDownAffine'),
|
| 107 |
+
dict(type='ToTensor'),
|
| 108 |
+
dict(
|
| 109 |
+
type='NormalizeTensor',
|
| 110 |
+
mean=[0.485, 0.456, 0.406],
|
| 111 |
+
std=[0.229, 0.224, 0.225]),
|
| 112 |
+
dict(type='TopDownGenerateTarget', sigma=2),
|
| 113 |
+
dict(
|
| 114 |
+
type='Collect',
|
| 115 |
+
keys=['img', 'target', 'target_weight'],
|
| 116 |
+
meta_keys=[
|
| 117 |
+
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
|
| 118 |
+
'rotation', 'bbox_score', 'flip_pairs'
|
| 119 |
+
]),
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
val_pipeline = [
|
| 123 |
+
dict(type='LoadImageFromFile'),
|
| 124 |
+
dict(type='TopDownGetBboxCenterScale', padding=1.25),
|
| 125 |
+
dict(type='TopDownAffine'),
|
| 126 |
+
dict(type='ToTensor'),
|
| 127 |
+
dict(
|
| 128 |
+
type='NormalizeTensor',
|
| 129 |
+
mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225]),
|
| 131 |
+
dict(
|
| 132 |
+
type='Collect',
|
| 133 |
+
keys=['img'],
|
| 134 |
+
meta_keys=[
|
| 135 |
+
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
|
| 136 |
+
'flip_pairs'
|
| 137 |
+
]),
|
| 138 |
+
]
|
| 139 |
+
|
| 140 |
+
test_pipeline = val_pipeline
|
| 141 |
+
|
| 142 |
+
data_root = 'data/coco'
|
| 143 |
+
data = dict(
|
| 144 |
+
samples_per_gpu=32,
|
| 145 |
+
workers_per_gpu=2,
|
| 146 |
+
val_dataloader=dict(samples_per_gpu=32),
|
| 147 |
+
test_dataloader=dict(samples_per_gpu=32),
|
| 148 |
+
train=dict(
|
| 149 |
+
type='TopDownCocoDataset',
|
| 150 |
+
ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
|
| 151 |
+
img_prefix=f'{data_root}/train2017/',
|
| 152 |
+
data_cfg=data_cfg,
|
| 153 |
+
pipeline=train_pipeline,
|
| 154 |
+
dataset_info={{_base_.dataset_info}}),
|
| 155 |
+
val=dict(
|
| 156 |
+
type='TopDownCocoDataset',
|
| 157 |
+
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
|
| 158 |
+
img_prefix=f'{data_root}/val2017/',
|
| 159 |
+
data_cfg=data_cfg,
|
| 160 |
+
pipeline=val_pipeline,
|
| 161 |
+
dataset_info={{_base_.dataset_info}}),
|
| 162 |
+
test=dict(
|
| 163 |
+
type='TopDownCocoDataset',
|
| 164 |
+
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
|
| 165 |
+
img_prefix=f'{data_root}/val2017/',
|
| 166 |
+
data_cfg=data_cfg,
|
| 167 |
+
pipeline=test_pipeline,
|
| 168 |
+
dataset_info={{_base_.dataset_info}}),
|
| 169 |
+
)
|
annotator/lama/__init__.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/advimman/lama
|
| 2 |
+
|
| 3 |
+
import yaml
|
| 4 |
+
import torch
|
| 5 |
+
from omegaconf import OmegaConf
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
import os
|
| 10 |
+
from modules import devices
|
| 11 |
+
from annotator.annotator_path import models_path
|
| 12 |
+
from annotator.lama.saicinpainting.training.trainers import load_checkpoint
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LamaInpainting:
|
| 16 |
+
model_dir = os.path.join(models_path, "lama")
|
| 17 |
+
|
| 18 |
+
def __init__(self):
|
| 19 |
+
self.model = None
|
| 20 |
+
self.device = devices.get_device_for("controlnet")
|
| 21 |
+
|
| 22 |
+
def load_model(self):
|
| 23 |
+
remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetLama.pth"
|
| 24 |
+
modelpath = os.path.join(self.model_dir, "ControlNetLama.pth")
|
| 25 |
+
if not os.path.exists(modelpath):
|
| 26 |
+
from basicsr.utils.download_util import load_file_from_url
|
| 27 |
+
load_file_from_url(remote_model_path, model_dir=self.model_dir)
|
| 28 |
+
config_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'config.yaml')
|
| 29 |
+
cfg = yaml.safe_load(open(config_path, 'rt'))
|
| 30 |
+
cfg = OmegaConf.create(cfg)
|
| 31 |
+
cfg.training_model.predict_only = True
|
| 32 |
+
cfg.visualizer.kind = 'noop'
|
| 33 |
+
self.model = load_checkpoint(cfg, os.path.abspath(modelpath), strict=False, map_location='cpu')
|
| 34 |
+
self.model = self.model.to(self.device)
|
| 35 |
+
self.model.eval()
|
| 36 |
+
|
| 37 |
+
def unload_model(self):
|
| 38 |
+
if self.model is not None:
|
| 39 |
+
self.model.cpu()
|
| 40 |
+
|
| 41 |
+
def __call__(self, input_image):
|
| 42 |
+
if self.model is None:
|
| 43 |
+
self.load_model()
|
| 44 |
+
self.model.to(self.device)
|
| 45 |
+
color = np.ascontiguousarray(input_image[:, :, 0:3]).astype(np.float32) / 255.0
|
| 46 |
+
mask = np.ascontiguousarray(input_image[:, :, 3:4]).astype(np.float32) / 255.0
|
| 47 |
+
with torch.no_grad():
|
| 48 |
+
color = torch.from_numpy(color).float().to(self.device)
|
| 49 |
+
mask = torch.from_numpy(mask).float().to(self.device)
|
| 50 |
+
mask = (mask > 0.5).float()
|
| 51 |
+
color = color * (1 - mask)
|
| 52 |
+
image_feed = torch.cat([color, mask], dim=2)
|
| 53 |
+
image_feed = rearrange(image_feed, 'h w c -> 1 c h w')
|
| 54 |
+
result = self.model(image_feed)[0]
|
| 55 |
+
result = rearrange(result, 'c h w -> h w c')
|
| 56 |
+
result = result * mask + color * (1 - mask)
|
| 57 |
+
result *= 255.0
|
| 58 |
+
return result.detach().cpu().numpy().clip(0, 255).astype(np.uint8)
|
annotator/lama/config.yaml
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
run_title: b18_ffc075_batch8x15
|
| 2 |
+
training_model:
|
| 3 |
+
kind: default
|
| 4 |
+
visualize_each_iters: 1000
|
| 5 |
+
concat_mask: true
|
| 6 |
+
store_discr_outputs_for_vis: true
|
| 7 |
+
losses:
|
| 8 |
+
l1:
|
| 9 |
+
weight_missing: 0
|
| 10 |
+
weight_known: 10
|
| 11 |
+
perceptual:
|
| 12 |
+
weight: 0
|
| 13 |
+
adversarial:
|
| 14 |
+
kind: r1
|
| 15 |
+
weight: 10
|
| 16 |
+
gp_coef: 0.001
|
| 17 |
+
mask_as_fake_target: true
|
| 18 |
+
allow_scale_mask: true
|
| 19 |
+
feature_matching:
|
| 20 |
+
weight: 100
|
| 21 |
+
resnet_pl:
|
| 22 |
+
weight: 30
|
| 23 |
+
weights_path: ${env:TORCH_HOME}
|
| 24 |
+
|
| 25 |
+
optimizers:
|
| 26 |
+
generator:
|
| 27 |
+
kind: adam
|
| 28 |
+
lr: 0.001
|
| 29 |
+
discriminator:
|
| 30 |
+
kind: adam
|
| 31 |
+
lr: 0.0001
|
| 32 |
+
visualizer:
|
| 33 |
+
key_order:
|
| 34 |
+
- image
|
| 35 |
+
- predicted_image
|
| 36 |
+
- discr_output_fake
|
| 37 |
+
- discr_output_real
|
| 38 |
+
- inpainted
|
| 39 |
+
rescale_keys:
|
| 40 |
+
- discr_output_fake
|
| 41 |
+
- discr_output_real
|
| 42 |
+
kind: directory
|
| 43 |
+
outdir: /group-volume/User-Driven-Content-Generation/r.suvorov/inpainting/experiments/r.suvorov_2021-04-30_14-41-12_train_simple_pix2pix2_gap_sdpl_novgg_large_b18_ffc075_batch8x15/samples
|
| 44 |
+
location:
|
| 45 |
+
data_root_dir: /group-volume/User-Driven-Content-Generation/datasets/inpainting_data_root_large
|
| 46 |
+
out_root_dir: /group-volume/User-Driven-Content-Generation/${env:USER}/inpainting/experiments
|
| 47 |
+
tb_dir: /group-volume/User-Driven-Content-Generation/${env:USER}/inpainting/tb_logs
|
| 48 |
+
data:
|
| 49 |
+
batch_size: 15
|
| 50 |
+
val_batch_size: 2
|
| 51 |
+
num_workers: 3
|
| 52 |
+
train:
|
| 53 |
+
indir: ${location.data_root_dir}/train
|
| 54 |
+
out_size: 256
|
| 55 |
+
mask_gen_kwargs:
|
| 56 |
+
irregular_proba: 1
|
| 57 |
+
irregular_kwargs:
|
| 58 |
+
max_angle: 4
|
| 59 |
+
max_len: 200
|
| 60 |
+
max_width: 100
|
| 61 |
+
max_times: 5
|
| 62 |
+
min_times: 1
|
| 63 |
+
box_proba: 1
|
| 64 |
+
box_kwargs:
|
| 65 |
+
margin: 10
|
| 66 |
+
bbox_min_size: 30
|
| 67 |
+
bbox_max_size: 150
|
| 68 |
+
max_times: 3
|
| 69 |
+
min_times: 1
|
| 70 |
+
segm_proba: 0
|
| 71 |
+
segm_kwargs:
|
| 72 |
+
confidence_threshold: 0.5
|
| 73 |
+
max_object_area: 0.5
|
| 74 |
+
min_mask_area: 0.07
|
| 75 |
+
downsample_levels: 6
|
| 76 |
+
num_variants_per_mask: 1
|
| 77 |
+
rigidness_mode: 1
|
| 78 |
+
max_foreground_coverage: 0.3
|
| 79 |
+
max_foreground_intersection: 0.7
|
| 80 |
+
max_mask_intersection: 0.1
|
| 81 |
+
max_hidden_area: 0.1
|
| 82 |
+
max_scale_change: 0.25
|
| 83 |
+
horizontal_flip: true
|
| 84 |
+
max_vertical_shift: 0.2
|
| 85 |
+
position_shuffle: true
|
| 86 |
+
transform_variant: distortions
|
| 87 |
+
dataloader_kwargs:
|
| 88 |
+
batch_size: ${data.batch_size}
|
| 89 |
+
shuffle: true
|
| 90 |
+
num_workers: ${data.num_workers}
|
| 91 |
+
val:
|
| 92 |
+
indir: ${location.data_root_dir}/val
|
| 93 |
+
img_suffix: .png
|
| 94 |
+
dataloader_kwargs:
|
| 95 |
+
batch_size: ${data.val_batch_size}
|
| 96 |
+
shuffle: false
|
| 97 |
+
num_workers: ${data.num_workers}
|
| 98 |
+
visual_test:
|
| 99 |
+
indir: ${location.data_root_dir}/korean_test
|
| 100 |
+
img_suffix: _input.png
|
| 101 |
+
pad_out_to_modulo: 32
|
| 102 |
+
dataloader_kwargs:
|
| 103 |
+
batch_size: 1
|
| 104 |
+
shuffle: false
|
| 105 |
+
num_workers: ${data.num_workers}
|
| 106 |
+
generator:
|
| 107 |
+
kind: ffc_resnet
|
| 108 |
+
input_nc: 4
|
| 109 |
+
output_nc: 3
|
| 110 |
+
ngf: 64
|
| 111 |
+
n_downsampling: 3
|
| 112 |
+
n_blocks: 18
|
| 113 |
+
add_out_act: sigmoid
|
| 114 |
+
init_conv_kwargs:
|
| 115 |
+
ratio_gin: 0
|
| 116 |
+
ratio_gout: 0
|
| 117 |
+
enable_lfu: false
|
| 118 |
+
downsample_conv_kwargs:
|
| 119 |
+
ratio_gin: ${generator.init_conv_kwargs.ratio_gout}
|
| 120 |
+
ratio_gout: ${generator.downsample_conv_kwargs.ratio_gin}
|
| 121 |
+
enable_lfu: false
|
| 122 |
+
resnet_conv_kwargs:
|
| 123 |
+
ratio_gin: 0.75
|
| 124 |
+
ratio_gout: ${generator.resnet_conv_kwargs.ratio_gin}
|
| 125 |
+
enable_lfu: false
|
| 126 |
+
discriminator:
|
| 127 |
+
kind: pix2pixhd_nlayer
|
| 128 |
+
input_nc: 3
|
| 129 |
+
ndf: 64
|
| 130 |
+
n_layers: 4
|
| 131 |
+
evaluator:
|
| 132 |
+
kind: default
|
| 133 |
+
inpainted_key: inpainted
|
| 134 |
+
integral_kind: ssim_fid100_f1
|
| 135 |
+
trainer:
|
| 136 |
+
kwargs:
|
| 137 |
+
gpus: -1
|
| 138 |
+
accelerator: ddp
|
| 139 |
+
max_epochs: 200
|
| 140 |
+
gradient_clip_val: 1
|
| 141 |
+
log_gpu_memory: None
|
| 142 |
+
limit_train_batches: 25000
|
| 143 |
+
val_check_interval: ${trainer.kwargs.limit_train_batches}
|
| 144 |
+
log_every_n_steps: 1000
|
| 145 |
+
precision: 32
|
| 146 |
+
terminate_on_nan: false
|
| 147 |
+
check_val_every_n_epoch: 1
|
| 148 |
+
num_sanity_val_steps: 8
|
| 149 |
+
limit_val_batches: 1000
|
| 150 |
+
replace_sampler_ddp: false
|
| 151 |
+
checkpoint_kwargs:
|
| 152 |
+
verbose: true
|
| 153 |
+
save_top_k: 5
|
| 154 |
+
save_last: true
|
| 155 |
+
period: 1
|
| 156 |
+
monitor: val_ssim_fid100_f1_total_mean
|
| 157 |
+
mode: max
|
annotator/lama/saicinpainting/__init__.py
ADDED
|
File without changes
|
annotator/lama/saicinpainting/training/__init__.py
ADDED
|
File without changes
|
annotator/lama/saicinpainting/training/data/__init__.py
ADDED
|
File without changes
|
annotator/lama/saicinpainting/training/data/masks.py
ADDED
|
@@ -0,0 +1,332 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import random
|
| 3 |
+
import hashlib
|
| 4 |
+
import logging
|
| 5 |
+
from enum import Enum
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
# from annotator.lama.saicinpainting.evaluation.masks.mask import SegmentationMask
|
| 11 |
+
from annotator.lama.saicinpainting.utils import LinearRamp
|
| 12 |
+
|
| 13 |
+
LOGGER = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class DrawMethod(Enum):
|
| 17 |
+
LINE = 'line'
|
| 18 |
+
CIRCLE = 'circle'
|
| 19 |
+
SQUARE = 'square'
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def make_random_irregular_mask(shape, max_angle=4, max_len=60, max_width=20, min_times=0, max_times=10,
|
| 23 |
+
draw_method=DrawMethod.LINE):
|
| 24 |
+
draw_method = DrawMethod(draw_method)
|
| 25 |
+
|
| 26 |
+
height, width = shape
|
| 27 |
+
mask = np.zeros((height, width), np.float32)
|
| 28 |
+
times = np.random.randint(min_times, max_times + 1)
|
| 29 |
+
for i in range(times):
|
| 30 |
+
start_x = np.random.randint(width)
|
| 31 |
+
start_y = np.random.randint(height)
|
| 32 |
+
for j in range(1 + np.random.randint(5)):
|
| 33 |
+
angle = 0.01 + np.random.randint(max_angle)
|
| 34 |
+
if i % 2 == 0:
|
| 35 |
+
angle = 2 * 3.1415926 - angle
|
| 36 |
+
length = 10 + np.random.randint(max_len)
|
| 37 |
+
brush_w = 5 + np.random.randint(max_width)
|
| 38 |
+
end_x = np.clip((start_x + length * np.sin(angle)).astype(np.int32), 0, width)
|
| 39 |
+
end_y = np.clip((start_y + length * np.cos(angle)).astype(np.int32), 0, height)
|
| 40 |
+
if draw_method == DrawMethod.LINE:
|
| 41 |
+
cv2.line(mask, (start_x, start_y), (end_x, end_y), 1.0, brush_w)
|
| 42 |
+
elif draw_method == DrawMethod.CIRCLE:
|
| 43 |
+
cv2.circle(mask, (start_x, start_y), radius=brush_w, color=1., thickness=-1)
|
| 44 |
+
elif draw_method == DrawMethod.SQUARE:
|
| 45 |
+
radius = brush_w // 2
|
| 46 |
+
mask[start_y - radius:start_y + radius, start_x - radius:start_x + radius] = 1
|
| 47 |
+
start_x, start_y = end_x, end_y
|
| 48 |
+
return mask[None, ...]
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class RandomIrregularMaskGenerator:
|
| 52 |
+
def __init__(self, max_angle=4, max_len=60, max_width=20, min_times=0, max_times=10, ramp_kwargs=None,
|
| 53 |
+
draw_method=DrawMethod.LINE):
|
| 54 |
+
self.max_angle = max_angle
|
| 55 |
+
self.max_len = max_len
|
| 56 |
+
self.max_width = max_width
|
| 57 |
+
self.min_times = min_times
|
| 58 |
+
self.max_times = max_times
|
| 59 |
+
self.draw_method = draw_method
|
| 60 |
+
self.ramp = LinearRamp(**ramp_kwargs) if ramp_kwargs is not None else None
|
| 61 |
+
|
| 62 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 63 |
+
coef = self.ramp(iter_i) if (self.ramp is not None) and (iter_i is not None) else 1
|
| 64 |
+
cur_max_len = int(max(1, self.max_len * coef))
|
| 65 |
+
cur_max_width = int(max(1, self.max_width * coef))
|
| 66 |
+
cur_max_times = int(self.min_times + 1 + (self.max_times - self.min_times) * coef)
|
| 67 |
+
return make_random_irregular_mask(img.shape[1:], max_angle=self.max_angle, max_len=cur_max_len,
|
| 68 |
+
max_width=cur_max_width, min_times=self.min_times, max_times=cur_max_times,
|
| 69 |
+
draw_method=self.draw_method)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def make_random_rectangle_mask(shape, margin=10, bbox_min_size=30, bbox_max_size=100, min_times=0, max_times=3):
|
| 73 |
+
height, width = shape
|
| 74 |
+
mask = np.zeros((height, width), np.float32)
|
| 75 |
+
bbox_max_size = min(bbox_max_size, height - margin * 2, width - margin * 2)
|
| 76 |
+
times = np.random.randint(min_times, max_times + 1)
|
| 77 |
+
for i in range(times):
|
| 78 |
+
box_width = np.random.randint(bbox_min_size, bbox_max_size)
|
| 79 |
+
box_height = np.random.randint(bbox_min_size, bbox_max_size)
|
| 80 |
+
start_x = np.random.randint(margin, width - margin - box_width + 1)
|
| 81 |
+
start_y = np.random.randint(margin, height - margin - box_height + 1)
|
| 82 |
+
mask[start_y:start_y + box_height, start_x:start_x + box_width] = 1
|
| 83 |
+
return mask[None, ...]
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class RandomRectangleMaskGenerator:
|
| 87 |
+
def __init__(self, margin=10, bbox_min_size=30, bbox_max_size=100, min_times=0, max_times=3, ramp_kwargs=None):
|
| 88 |
+
self.margin = margin
|
| 89 |
+
self.bbox_min_size = bbox_min_size
|
| 90 |
+
self.bbox_max_size = bbox_max_size
|
| 91 |
+
self.min_times = min_times
|
| 92 |
+
self.max_times = max_times
|
| 93 |
+
self.ramp = LinearRamp(**ramp_kwargs) if ramp_kwargs is not None else None
|
| 94 |
+
|
| 95 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 96 |
+
coef = self.ramp(iter_i) if (self.ramp is not None) and (iter_i is not None) else 1
|
| 97 |
+
cur_bbox_max_size = int(self.bbox_min_size + 1 + (self.bbox_max_size - self.bbox_min_size) * coef)
|
| 98 |
+
cur_max_times = int(self.min_times + (self.max_times - self.min_times) * coef)
|
| 99 |
+
return make_random_rectangle_mask(img.shape[1:], margin=self.margin, bbox_min_size=self.bbox_min_size,
|
| 100 |
+
bbox_max_size=cur_bbox_max_size, min_times=self.min_times,
|
| 101 |
+
max_times=cur_max_times)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class RandomSegmentationMaskGenerator:
|
| 105 |
+
def __init__(self, **kwargs):
|
| 106 |
+
self.impl = None # will be instantiated in first call (effectively in subprocess)
|
| 107 |
+
self.kwargs = kwargs
|
| 108 |
+
|
| 109 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 110 |
+
if self.impl is None:
|
| 111 |
+
self.impl = SegmentationMask(**self.kwargs)
|
| 112 |
+
|
| 113 |
+
masks = self.impl.get_masks(np.transpose(img, (1, 2, 0)))
|
| 114 |
+
masks = [m for m in masks if len(np.unique(m)) > 1]
|
| 115 |
+
return np.random.choice(masks)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def make_random_superres_mask(shape, min_step=2, max_step=4, min_width=1, max_width=3):
|
| 119 |
+
height, width = shape
|
| 120 |
+
mask = np.zeros((height, width), np.float32)
|
| 121 |
+
step_x = np.random.randint(min_step, max_step + 1)
|
| 122 |
+
width_x = np.random.randint(min_width, min(step_x, max_width + 1))
|
| 123 |
+
offset_x = np.random.randint(0, step_x)
|
| 124 |
+
|
| 125 |
+
step_y = np.random.randint(min_step, max_step + 1)
|
| 126 |
+
width_y = np.random.randint(min_width, min(step_y, max_width + 1))
|
| 127 |
+
offset_y = np.random.randint(0, step_y)
|
| 128 |
+
|
| 129 |
+
for dy in range(width_y):
|
| 130 |
+
mask[offset_y + dy::step_y] = 1
|
| 131 |
+
for dx in range(width_x):
|
| 132 |
+
mask[:, offset_x + dx::step_x] = 1
|
| 133 |
+
return mask[None, ...]
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class RandomSuperresMaskGenerator:
|
| 137 |
+
def __init__(self, **kwargs):
|
| 138 |
+
self.kwargs = kwargs
|
| 139 |
+
|
| 140 |
+
def __call__(self, img, iter_i=None):
|
| 141 |
+
return make_random_superres_mask(img.shape[1:], **self.kwargs)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class DumbAreaMaskGenerator:
|
| 145 |
+
min_ratio = 0.1
|
| 146 |
+
max_ratio = 0.35
|
| 147 |
+
default_ratio = 0.225
|
| 148 |
+
|
| 149 |
+
def __init__(self, is_training):
|
| 150 |
+
#Parameters:
|
| 151 |
+
# is_training(bool): If true - random rectangular mask, if false - central square mask
|
| 152 |
+
self.is_training = is_training
|
| 153 |
+
|
| 154 |
+
def _random_vector(self, dimension):
|
| 155 |
+
if self.is_training:
|
| 156 |
+
lower_limit = math.sqrt(self.min_ratio)
|
| 157 |
+
upper_limit = math.sqrt(self.max_ratio)
|
| 158 |
+
mask_side = round((random.random() * (upper_limit - lower_limit) + lower_limit) * dimension)
|
| 159 |
+
u = random.randint(0, dimension-mask_side-1)
|
| 160 |
+
v = u+mask_side
|
| 161 |
+
else:
|
| 162 |
+
margin = (math.sqrt(self.default_ratio) / 2) * dimension
|
| 163 |
+
u = round(dimension/2 - margin)
|
| 164 |
+
v = round(dimension/2 + margin)
|
| 165 |
+
return u, v
|
| 166 |
+
|
| 167 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 168 |
+
c, height, width = img.shape
|
| 169 |
+
mask = np.zeros((height, width), np.float32)
|
| 170 |
+
x1, x2 = self._random_vector(width)
|
| 171 |
+
y1, y2 = self._random_vector(height)
|
| 172 |
+
mask[x1:x2, y1:y2] = 1
|
| 173 |
+
return mask[None, ...]
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class OutpaintingMaskGenerator:
|
| 177 |
+
def __init__(self, min_padding_percent:float=0.04, max_padding_percent:int=0.25, left_padding_prob:float=0.5, top_padding_prob:float=0.5,
|
| 178 |
+
right_padding_prob:float=0.5, bottom_padding_prob:float=0.5, is_fixed_randomness:bool=False):
|
| 179 |
+
"""
|
| 180 |
+
is_fixed_randomness - get identical paddings for the same image if args are the same
|
| 181 |
+
"""
|
| 182 |
+
self.min_padding_percent = min_padding_percent
|
| 183 |
+
self.max_padding_percent = max_padding_percent
|
| 184 |
+
self.probs = [left_padding_prob, top_padding_prob, right_padding_prob, bottom_padding_prob]
|
| 185 |
+
self.is_fixed_randomness = is_fixed_randomness
|
| 186 |
+
|
| 187 |
+
assert self.min_padding_percent <= self.max_padding_percent
|
| 188 |
+
assert self.max_padding_percent > 0
|
| 189 |
+
assert len([x for x in [self.min_padding_percent, self.max_padding_percent] if (x>=0 and x<=1)]) == 2, f"Padding percentage should be in [0,1]"
|
| 190 |
+
assert sum(self.probs) > 0, f"At least one of the padding probs should be greater than 0 - {self.probs}"
|
| 191 |
+
assert len([x for x in self.probs if (x >= 0) and (x <= 1)]) == 4, f"At least one of padding probs is not in [0,1] - {self.probs}"
|
| 192 |
+
if len([x for x in self.probs if x > 0]) == 1:
|
| 193 |
+
LOGGER.warning(f"Only one padding prob is greater than zero - {self.probs}. That means that the outpainting masks will be always on the same side")
|
| 194 |
+
|
| 195 |
+
def apply_padding(self, mask, coord):
|
| 196 |
+
mask[int(coord[0][0]*self.img_h):int(coord[1][0]*self.img_h),
|
| 197 |
+
int(coord[0][1]*self.img_w):int(coord[1][1]*self.img_w)] = 1
|
| 198 |
+
return mask
|
| 199 |
+
|
| 200 |
+
def get_padding(self, size):
|
| 201 |
+
n1 = int(self.min_padding_percent*size)
|
| 202 |
+
n2 = int(self.max_padding_percent*size)
|
| 203 |
+
return self.rnd.randint(n1, n2) / size
|
| 204 |
+
|
| 205 |
+
@staticmethod
|
| 206 |
+
def _img2rs(img):
|
| 207 |
+
arr = np.ascontiguousarray(img.astype(np.uint8))
|
| 208 |
+
str_hash = hashlib.sha1(arr).hexdigest()
|
| 209 |
+
res = hash(str_hash)%(2**32)
|
| 210 |
+
return res
|
| 211 |
+
|
| 212 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 213 |
+
c, self.img_h, self.img_w = img.shape
|
| 214 |
+
mask = np.zeros((self.img_h, self.img_w), np.float32)
|
| 215 |
+
at_least_one_mask_applied = False
|
| 216 |
+
|
| 217 |
+
if self.is_fixed_randomness:
|
| 218 |
+
assert raw_image is not None, f"Cant calculate hash on raw_image=None"
|
| 219 |
+
rs = self._img2rs(raw_image)
|
| 220 |
+
self.rnd = np.random.RandomState(rs)
|
| 221 |
+
else:
|
| 222 |
+
self.rnd = np.random
|
| 223 |
+
|
| 224 |
+
coords = [[
|
| 225 |
+
(0,0),
|
| 226 |
+
(1,self.get_padding(size=self.img_h))
|
| 227 |
+
],
|
| 228 |
+
[
|
| 229 |
+
(0,0),
|
| 230 |
+
(self.get_padding(size=self.img_w),1)
|
| 231 |
+
],
|
| 232 |
+
[
|
| 233 |
+
(0,1-self.get_padding(size=self.img_h)),
|
| 234 |
+
(1,1)
|
| 235 |
+
],
|
| 236 |
+
[
|
| 237 |
+
(1-self.get_padding(size=self.img_w),0),
|
| 238 |
+
(1,1)
|
| 239 |
+
]]
|
| 240 |
+
|
| 241 |
+
for pp, coord in zip(self.probs, coords):
|
| 242 |
+
if self.rnd.random() < pp:
|
| 243 |
+
at_least_one_mask_applied = True
|
| 244 |
+
mask = self.apply_padding(mask=mask, coord=coord)
|
| 245 |
+
|
| 246 |
+
if not at_least_one_mask_applied:
|
| 247 |
+
idx = self.rnd.choice(range(len(coords)), p=np.array(self.probs)/sum(self.probs))
|
| 248 |
+
mask = self.apply_padding(mask=mask, coord=coords[idx])
|
| 249 |
+
return mask[None, ...]
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
class MixedMaskGenerator:
|
| 253 |
+
def __init__(self, irregular_proba=1/3, irregular_kwargs=None,
|
| 254 |
+
box_proba=1/3, box_kwargs=None,
|
| 255 |
+
segm_proba=1/3, segm_kwargs=None,
|
| 256 |
+
squares_proba=0, squares_kwargs=None,
|
| 257 |
+
superres_proba=0, superres_kwargs=None,
|
| 258 |
+
outpainting_proba=0, outpainting_kwargs=None,
|
| 259 |
+
invert_proba=0):
|
| 260 |
+
self.probas = []
|
| 261 |
+
self.gens = []
|
| 262 |
+
|
| 263 |
+
if irregular_proba > 0:
|
| 264 |
+
self.probas.append(irregular_proba)
|
| 265 |
+
if irregular_kwargs is None:
|
| 266 |
+
irregular_kwargs = {}
|
| 267 |
+
else:
|
| 268 |
+
irregular_kwargs = dict(irregular_kwargs)
|
| 269 |
+
irregular_kwargs['draw_method'] = DrawMethod.LINE
|
| 270 |
+
self.gens.append(RandomIrregularMaskGenerator(**irregular_kwargs))
|
| 271 |
+
|
| 272 |
+
if box_proba > 0:
|
| 273 |
+
self.probas.append(box_proba)
|
| 274 |
+
if box_kwargs is None:
|
| 275 |
+
box_kwargs = {}
|
| 276 |
+
self.gens.append(RandomRectangleMaskGenerator(**box_kwargs))
|
| 277 |
+
|
| 278 |
+
if segm_proba > 0:
|
| 279 |
+
self.probas.append(segm_proba)
|
| 280 |
+
if segm_kwargs is None:
|
| 281 |
+
segm_kwargs = {}
|
| 282 |
+
self.gens.append(RandomSegmentationMaskGenerator(**segm_kwargs))
|
| 283 |
+
|
| 284 |
+
if squares_proba > 0:
|
| 285 |
+
self.probas.append(squares_proba)
|
| 286 |
+
if squares_kwargs is None:
|
| 287 |
+
squares_kwargs = {}
|
| 288 |
+
else:
|
| 289 |
+
squares_kwargs = dict(squares_kwargs)
|
| 290 |
+
squares_kwargs['draw_method'] = DrawMethod.SQUARE
|
| 291 |
+
self.gens.append(RandomIrregularMaskGenerator(**squares_kwargs))
|
| 292 |
+
|
| 293 |
+
if superres_proba > 0:
|
| 294 |
+
self.probas.append(superres_proba)
|
| 295 |
+
if superres_kwargs is None:
|
| 296 |
+
superres_kwargs = {}
|
| 297 |
+
self.gens.append(RandomSuperresMaskGenerator(**superres_kwargs))
|
| 298 |
+
|
| 299 |
+
if outpainting_proba > 0:
|
| 300 |
+
self.probas.append(outpainting_proba)
|
| 301 |
+
if outpainting_kwargs is None:
|
| 302 |
+
outpainting_kwargs = {}
|
| 303 |
+
self.gens.append(OutpaintingMaskGenerator(**outpainting_kwargs))
|
| 304 |
+
|
| 305 |
+
self.probas = np.array(self.probas, dtype='float32')
|
| 306 |
+
self.probas /= self.probas.sum()
|
| 307 |
+
self.invert_proba = invert_proba
|
| 308 |
+
|
| 309 |
+
def __call__(self, img, iter_i=None, raw_image=None):
|
| 310 |
+
kind = np.random.choice(len(self.probas), p=self.probas)
|
| 311 |
+
gen = self.gens[kind]
|
| 312 |
+
result = gen(img, iter_i=iter_i, raw_image=raw_image)
|
| 313 |
+
if self.invert_proba > 0 and random.random() < self.invert_proba:
|
| 314 |
+
result = 1 - result
|
| 315 |
+
return result
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def get_mask_generator(kind, kwargs):
|
| 319 |
+
if kind is None:
|
| 320 |
+
kind = "mixed"
|
| 321 |
+
if kwargs is None:
|
| 322 |
+
kwargs = {}
|
| 323 |
+
|
| 324 |
+
if kind == "mixed":
|
| 325 |
+
cl = MixedMaskGenerator
|
| 326 |
+
elif kind == "outpainting":
|
| 327 |
+
cl = OutpaintingMaskGenerator
|
| 328 |
+
elif kind == "dumb":
|
| 329 |
+
cl = DumbAreaMaskGenerator
|
| 330 |
+
else:
|
| 331 |
+
raise NotImplementedError(f"No such generator kind = {kind}")
|
| 332 |
+
return cl(**kwargs)
|
annotator/lama/saicinpainting/training/losses/__init__.py
ADDED
|
File without changes
|
annotator/lama/saicinpainting/training/losses/adversarial.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple, Dict, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class BaseAdversarialLoss:
|
| 9 |
+
def pre_generator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 10 |
+
generator: nn.Module, discriminator: nn.Module):
|
| 11 |
+
"""
|
| 12 |
+
Prepare for generator step
|
| 13 |
+
:param real_batch: Tensor, a batch of real samples
|
| 14 |
+
:param fake_batch: Tensor, a batch of samples produced by generator
|
| 15 |
+
:param generator:
|
| 16 |
+
:param discriminator:
|
| 17 |
+
:return: None
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 21 |
+
generator: nn.Module, discriminator: nn.Module):
|
| 22 |
+
"""
|
| 23 |
+
Prepare for discriminator step
|
| 24 |
+
:param real_batch: Tensor, a batch of real samples
|
| 25 |
+
:param fake_batch: Tensor, a batch of samples produced by generator
|
| 26 |
+
:param generator:
|
| 27 |
+
:param discriminator:
|
| 28 |
+
:return: None
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
def generator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 32 |
+
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
| 33 |
+
mask: Optional[torch.Tensor] = None) \
|
| 34 |
+
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 35 |
+
"""
|
| 36 |
+
Calculate generator loss
|
| 37 |
+
:param real_batch: Tensor, a batch of real samples
|
| 38 |
+
:param fake_batch: Tensor, a batch of samples produced by generator
|
| 39 |
+
:param discr_real_pred: Tensor, discriminator output for real_batch
|
| 40 |
+
:param discr_fake_pred: Tensor, discriminator output for fake_batch
|
| 41 |
+
:param mask: Tensor, actual mask, which was at input of generator when making fake_batch
|
| 42 |
+
:return: total generator loss along with some values that might be interesting to log
|
| 43 |
+
"""
|
| 44 |
+
raise NotImplemented()
|
| 45 |
+
|
| 46 |
+
def discriminator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 47 |
+
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
| 48 |
+
mask: Optional[torch.Tensor] = None) \
|
| 49 |
+
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 50 |
+
"""
|
| 51 |
+
Calculate discriminator loss and call .backward() on it
|
| 52 |
+
:param real_batch: Tensor, a batch of real samples
|
| 53 |
+
:param fake_batch: Tensor, a batch of samples produced by generator
|
| 54 |
+
:param discr_real_pred: Tensor, discriminator output for real_batch
|
| 55 |
+
:param discr_fake_pred: Tensor, discriminator output for fake_batch
|
| 56 |
+
:param mask: Tensor, actual mask, which was at input of generator when making fake_batch
|
| 57 |
+
:return: total discriminator loss along with some values that might be interesting to log
|
| 58 |
+
"""
|
| 59 |
+
raise NotImplemented()
|
| 60 |
+
|
| 61 |
+
def interpolate_mask(self, mask, shape):
|
| 62 |
+
assert mask is not None
|
| 63 |
+
assert self.allow_scale_mask or shape == mask.shape[-2:]
|
| 64 |
+
if shape != mask.shape[-2:] and self.allow_scale_mask:
|
| 65 |
+
if self.mask_scale_mode == 'maxpool':
|
| 66 |
+
mask = F.adaptive_max_pool2d(mask, shape)
|
| 67 |
+
else:
|
| 68 |
+
mask = F.interpolate(mask, size=shape, mode=self.mask_scale_mode)
|
| 69 |
+
return mask
|
| 70 |
+
|
| 71 |
+
def make_r1_gp(discr_real_pred, real_batch):
|
| 72 |
+
if torch.is_grad_enabled():
|
| 73 |
+
grad_real = torch.autograd.grad(outputs=discr_real_pred.sum(), inputs=real_batch, create_graph=True)[0]
|
| 74 |
+
grad_penalty = (grad_real.view(grad_real.shape[0], -1).norm(2, dim=1) ** 2).mean()
|
| 75 |
+
else:
|
| 76 |
+
grad_penalty = 0
|
| 77 |
+
real_batch.requires_grad = False
|
| 78 |
+
|
| 79 |
+
return grad_penalty
|
| 80 |
+
|
| 81 |
+
class NonSaturatingWithR1(BaseAdversarialLoss):
|
| 82 |
+
def __init__(self, gp_coef=5, weight=1, mask_as_fake_target=False, allow_scale_mask=False,
|
| 83 |
+
mask_scale_mode='nearest', extra_mask_weight_for_gen=0,
|
| 84 |
+
use_unmasked_for_gen=True, use_unmasked_for_discr=True):
|
| 85 |
+
self.gp_coef = gp_coef
|
| 86 |
+
self.weight = weight
|
| 87 |
+
# use for discr => use for gen;
|
| 88 |
+
# otherwise we teach only the discr to pay attention to very small difference
|
| 89 |
+
assert use_unmasked_for_gen or (not use_unmasked_for_discr)
|
| 90 |
+
# mask as target => use unmasked for discr:
|
| 91 |
+
# if we don't care about unmasked regions at all
|
| 92 |
+
# then it doesn't matter if the value of mask_as_fake_target is true or false
|
| 93 |
+
assert use_unmasked_for_discr or (not mask_as_fake_target)
|
| 94 |
+
self.use_unmasked_for_gen = use_unmasked_for_gen
|
| 95 |
+
self.use_unmasked_for_discr = use_unmasked_for_discr
|
| 96 |
+
self.mask_as_fake_target = mask_as_fake_target
|
| 97 |
+
self.allow_scale_mask = allow_scale_mask
|
| 98 |
+
self.mask_scale_mode = mask_scale_mode
|
| 99 |
+
self.extra_mask_weight_for_gen = extra_mask_weight_for_gen
|
| 100 |
+
|
| 101 |
+
def generator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 102 |
+
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
| 103 |
+
mask=None) \
|
| 104 |
+
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 105 |
+
fake_loss = F.softplus(-discr_fake_pred)
|
| 106 |
+
if (self.mask_as_fake_target and self.extra_mask_weight_for_gen > 0) or \
|
| 107 |
+
not self.use_unmasked_for_gen: # == if masked region should be treated differently
|
| 108 |
+
mask = self.interpolate_mask(mask, discr_fake_pred.shape[-2:])
|
| 109 |
+
if not self.use_unmasked_for_gen:
|
| 110 |
+
fake_loss = fake_loss * mask
|
| 111 |
+
else:
|
| 112 |
+
pixel_weights = 1 + mask * self.extra_mask_weight_for_gen
|
| 113 |
+
fake_loss = fake_loss * pixel_weights
|
| 114 |
+
|
| 115 |
+
return fake_loss.mean() * self.weight, dict()
|
| 116 |
+
|
| 117 |
+
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 118 |
+
generator: nn.Module, discriminator: nn.Module):
|
| 119 |
+
real_batch.requires_grad = True
|
| 120 |
+
|
| 121 |
+
def discriminator_loss(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 122 |
+
discr_real_pred: torch.Tensor, discr_fake_pred: torch.Tensor,
|
| 123 |
+
mask=None) \
|
| 124 |
+
-> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 125 |
+
|
| 126 |
+
real_loss = F.softplus(-discr_real_pred)
|
| 127 |
+
grad_penalty = make_r1_gp(discr_real_pred, real_batch) * self.gp_coef
|
| 128 |
+
fake_loss = F.softplus(discr_fake_pred)
|
| 129 |
+
|
| 130 |
+
if not self.use_unmasked_for_discr or self.mask_as_fake_target:
|
| 131 |
+
# == if masked region should be treated differently
|
| 132 |
+
mask = self.interpolate_mask(mask, discr_fake_pred.shape[-2:])
|
| 133 |
+
# use_unmasked_for_discr=False only makes sense for fakes;
|
| 134 |
+
# for reals there is no difference beetween two regions
|
| 135 |
+
fake_loss = fake_loss * mask
|
| 136 |
+
if self.mask_as_fake_target:
|
| 137 |
+
fake_loss = fake_loss + (1 - mask) * F.softplus(-discr_fake_pred)
|
| 138 |
+
|
| 139 |
+
sum_discr_loss = real_loss + grad_penalty + fake_loss
|
| 140 |
+
metrics = dict(discr_real_out=discr_real_pred.mean(),
|
| 141 |
+
discr_fake_out=discr_fake_pred.mean(),
|
| 142 |
+
discr_real_gp=grad_penalty)
|
| 143 |
+
return sum_discr_loss.mean(), metrics
|
| 144 |
+
|
| 145 |
+
class BCELoss(BaseAdversarialLoss):
|
| 146 |
+
def __init__(self, weight):
|
| 147 |
+
self.weight = weight
|
| 148 |
+
self.bce_loss = nn.BCEWithLogitsLoss()
|
| 149 |
+
|
| 150 |
+
def generator_loss(self, discr_fake_pred: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 151 |
+
real_mask_gt = torch.zeros(discr_fake_pred.shape).to(discr_fake_pred.device)
|
| 152 |
+
fake_loss = self.bce_loss(discr_fake_pred, real_mask_gt) * self.weight
|
| 153 |
+
return fake_loss, dict()
|
| 154 |
+
|
| 155 |
+
def pre_discriminator_step(self, real_batch: torch.Tensor, fake_batch: torch.Tensor,
|
| 156 |
+
generator: nn.Module, discriminator: nn.Module):
|
| 157 |
+
real_batch.requires_grad = True
|
| 158 |
+
|
| 159 |
+
def discriminator_loss(self,
|
| 160 |
+
mask: torch.Tensor,
|
| 161 |
+
discr_real_pred: torch.Tensor,
|
| 162 |
+
discr_fake_pred: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 163 |
+
|
| 164 |
+
real_mask_gt = torch.zeros(discr_real_pred.shape).to(discr_real_pred.device)
|
| 165 |
+
sum_discr_loss = (self.bce_loss(discr_real_pred, real_mask_gt) + self.bce_loss(discr_fake_pred, mask)) / 2
|
| 166 |
+
metrics = dict(discr_real_out=discr_real_pred.mean(),
|
| 167 |
+
discr_fake_out=discr_fake_pred.mean(),
|
| 168 |
+
discr_real_gp=0)
|
| 169 |
+
return sum_discr_loss, metrics
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def make_discrim_loss(kind, **kwargs):
|
| 173 |
+
if kind == 'r1':
|
| 174 |
+
return NonSaturatingWithR1(**kwargs)
|
| 175 |
+
elif kind == 'bce':
|
| 176 |
+
return BCELoss(**kwargs)
|
| 177 |
+
raise ValueError(f'Unknown adversarial loss kind {kind}')
|
annotator/lama/saicinpainting/training/losses/constants.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
weights = {"ade20k":
|
| 2 |
+
[6.34517766497462,
|
| 3 |
+
9.328358208955224,
|
| 4 |
+
11.389521640091116,
|
| 5 |
+
16.10305958132045,
|
| 6 |
+
20.833333333333332,
|
| 7 |
+
22.22222222222222,
|
| 8 |
+
25.125628140703515,
|
| 9 |
+
43.29004329004329,
|
| 10 |
+
50.5050505050505,
|
| 11 |
+
54.6448087431694,
|
| 12 |
+
55.24861878453038,
|
| 13 |
+
60.24096385542168,
|
| 14 |
+
62.5,
|
| 15 |
+
66.2251655629139,
|
| 16 |
+
84.74576271186442,
|
| 17 |
+
90.90909090909092,
|
| 18 |
+
91.74311926605505,
|
| 19 |
+
96.15384615384616,
|
| 20 |
+
96.15384615384616,
|
| 21 |
+
97.08737864077669,
|
| 22 |
+
102.04081632653062,
|
| 23 |
+
135.13513513513513,
|
| 24 |
+
149.2537313432836,
|
| 25 |
+
153.84615384615384,
|
| 26 |
+
163.93442622950818,
|
| 27 |
+
166.66666666666666,
|
| 28 |
+
188.67924528301887,
|
| 29 |
+
192.30769230769232,
|
| 30 |
+
217.3913043478261,
|
| 31 |
+
227.27272727272725,
|
| 32 |
+
227.27272727272725,
|
| 33 |
+
227.27272727272725,
|
| 34 |
+
303.03030303030306,
|
| 35 |
+
322.5806451612903,
|
| 36 |
+
333.3333333333333,
|
| 37 |
+
370.3703703703703,
|
| 38 |
+
384.61538461538464,
|
| 39 |
+
416.6666666666667,
|
| 40 |
+
416.6666666666667,
|
| 41 |
+
434.7826086956522,
|
| 42 |
+
434.7826086956522,
|
| 43 |
+
454.5454545454545,
|
| 44 |
+
454.5454545454545,
|
| 45 |
+
500.0,
|
| 46 |
+
526.3157894736842,
|
| 47 |
+
526.3157894736842,
|
| 48 |
+
555.5555555555555,
|
| 49 |
+
555.5555555555555,
|
| 50 |
+
555.5555555555555,
|
| 51 |
+
555.5555555555555,
|
| 52 |
+
555.5555555555555,
|
| 53 |
+
555.5555555555555,
|
| 54 |
+
555.5555555555555,
|
| 55 |
+
588.2352941176471,
|
| 56 |
+
588.2352941176471,
|
| 57 |
+
588.2352941176471,
|
| 58 |
+
588.2352941176471,
|
| 59 |
+
588.2352941176471,
|
| 60 |
+
666.6666666666666,
|
| 61 |
+
666.6666666666666,
|
| 62 |
+
666.6666666666666,
|
| 63 |
+
666.6666666666666,
|
| 64 |
+
714.2857142857143,
|
| 65 |
+
714.2857142857143,
|
| 66 |
+
714.2857142857143,
|
| 67 |
+
714.2857142857143,
|
| 68 |
+
714.2857142857143,
|
| 69 |
+
769.2307692307693,
|
| 70 |
+
769.2307692307693,
|
| 71 |
+
769.2307692307693,
|
| 72 |
+
833.3333333333334,
|
| 73 |
+
833.3333333333334,
|
| 74 |
+
833.3333333333334,
|
| 75 |
+
833.3333333333334,
|
| 76 |
+
909.090909090909,
|
| 77 |
+
1000.0,
|
| 78 |
+
1111.111111111111,
|
| 79 |
+
1111.111111111111,
|
| 80 |
+
1111.111111111111,
|
| 81 |
+
1111.111111111111,
|
| 82 |
+
1111.111111111111,
|
| 83 |
+
1250.0,
|
| 84 |
+
1250.0,
|
| 85 |
+
1250.0,
|
| 86 |
+
1250.0,
|
| 87 |
+
1250.0,
|
| 88 |
+
1428.5714285714287,
|
| 89 |
+
1428.5714285714287,
|
| 90 |
+
1428.5714285714287,
|
| 91 |
+
1428.5714285714287,
|
| 92 |
+
1428.5714285714287,
|
| 93 |
+
1428.5714285714287,
|
| 94 |
+
1428.5714285714287,
|
| 95 |
+
1666.6666666666667,
|
| 96 |
+
1666.6666666666667,
|
| 97 |
+
1666.6666666666667,
|
| 98 |
+
1666.6666666666667,
|
| 99 |
+
1666.6666666666667,
|
| 100 |
+
1666.6666666666667,
|
| 101 |
+
1666.6666666666667,
|
| 102 |
+
1666.6666666666667,
|
| 103 |
+
1666.6666666666667,
|
| 104 |
+
1666.6666666666667,
|
| 105 |
+
1666.6666666666667,
|
| 106 |
+
2000.0,
|
| 107 |
+
2000.0,
|
| 108 |
+
2000.0,
|
| 109 |
+
2000.0,
|
| 110 |
+
2000.0,
|
| 111 |
+
2000.0,
|
| 112 |
+
2000.0,
|
| 113 |
+
2000.0,
|
| 114 |
+
2000.0,
|
| 115 |
+
2000.0,
|
| 116 |
+
2000.0,
|
| 117 |
+
2000.0,
|
| 118 |
+
2000.0,
|
| 119 |
+
2000.0,
|
| 120 |
+
2000.0,
|
| 121 |
+
2000.0,
|
| 122 |
+
2000.0,
|
| 123 |
+
2500.0,
|
| 124 |
+
2500.0,
|
| 125 |
+
2500.0,
|
| 126 |
+
2500.0,
|
| 127 |
+
2500.0,
|
| 128 |
+
2500.0,
|
| 129 |
+
2500.0,
|
| 130 |
+
2500.0,
|
| 131 |
+
2500.0,
|
| 132 |
+
2500.0,
|
| 133 |
+
2500.0,
|
| 134 |
+
2500.0,
|
| 135 |
+
2500.0,
|
| 136 |
+
3333.3333333333335,
|
| 137 |
+
3333.3333333333335,
|
| 138 |
+
3333.3333333333335,
|
| 139 |
+
3333.3333333333335,
|
| 140 |
+
3333.3333333333335,
|
| 141 |
+
3333.3333333333335,
|
| 142 |
+
3333.3333333333335,
|
| 143 |
+
3333.3333333333335,
|
| 144 |
+
3333.3333333333335,
|
| 145 |
+
3333.3333333333335,
|
| 146 |
+
3333.3333333333335,
|
| 147 |
+
3333.3333333333335,
|
| 148 |
+
3333.3333333333335,
|
| 149 |
+
5000.0,
|
| 150 |
+
5000.0,
|
| 151 |
+
5000.0]
|
| 152 |
+
}
|
annotator/lama/saicinpainting/training/losses/distance_weighting.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchvision
|
| 5 |
+
|
| 6 |
+
from annotator.lama.saicinpainting.training.losses.perceptual import IMAGENET_STD, IMAGENET_MEAN
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def dummy_distance_weighter(real_img, pred_img, mask):
|
| 10 |
+
return mask
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_gauss_kernel(kernel_size, width_factor=1):
|
| 14 |
+
coords = torch.stack(torch.meshgrid(torch.arange(kernel_size),
|
| 15 |
+
torch.arange(kernel_size)),
|
| 16 |
+
dim=0).float()
|
| 17 |
+
diff = torch.exp(-((coords - kernel_size // 2) ** 2).sum(0) / kernel_size / width_factor)
|
| 18 |
+
diff /= diff.sum()
|
| 19 |
+
return diff
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class BlurMask(nn.Module):
|
| 23 |
+
def __init__(self, kernel_size=5, width_factor=1):
|
| 24 |
+
super().__init__()
|
| 25 |
+
self.filter = nn.Conv2d(1, 1, kernel_size, padding=kernel_size // 2, padding_mode='replicate', bias=False)
|
| 26 |
+
self.filter.weight.data.copy_(get_gauss_kernel(kernel_size, width_factor=width_factor))
|
| 27 |
+
|
| 28 |
+
def forward(self, real_img, pred_img, mask):
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
result = self.filter(mask) * mask
|
| 31 |
+
return result
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class EmulatedEDTMask(nn.Module):
|
| 35 |
+
def __init__(self, dilate_kernel_size=5, blur_kernel_size=5, width_factor=1):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.dilate_filter = nn.Conv2d(1, 1, dilate_kernel_size, padding=dilate_kernel_size// 2, padding_mode='replicate',
|
| 38 |
+
bias=False)
|
| 39 |
+
self.dilate_filter.weight.data.copy_(torch.ones(1, 1, dilate_kernel_size, dilate_kernel_size, dtype=torch.float))
|
| 40 |
+
self.blur_filter = nn.Conv2d(1, 1, blur_kernel_size, padding=blur_kernel_size // 2, padding_mode='replicate', bias=False)
|
| 41 |
+
self.blur_filter.weight.data.copy_(get_gauss_kernel(blur_kernel_size, width_factor=width_factor))
|
| 42 |
+
|
| 43 |
+
def forward(self, real_img, pred_img, mask):
|
| 44 |
+
with torch.no_grad():
|
| 45 |
+
known_mask = 1 - mask
|
| 46 |
+
dilated_known_mask = (self.dilate_filter(known_mask) > 1).float()
|
| 47 |
+
result = self.blur_filter(1 - dilated_known_mask) * mask
|
| 48 |
+
return result
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class PropagatePerceptualSim(nn.Module):
|
| 52 |
+
def __init__(self, level=2, max_iters=10, temperature=500, erode_mask_size=3):
|
| 53 |
+
super().__init__()
|
| 54 |
+
vgg = torchvision.models.vgg19(pretrained=True).features
|
| 55 |
+
vgg_avg_pooling = []
|
| 56 |
+
|
| 57 |
+
for weights in vgg.parameters():
|
| 58 |
+
weights.requires_grad = False
|
| 59 |
+
|
| 60 |
+
cur_level_i = 0
|
| 61 |
+
for module in vgg.modules():
|
| 62 |
+
if module.__class__.__name__ == 'Sequential':
|
| 63 |
+
continue
|
| 64 |
+
elif module.__class__.__name__ == 'MaxPool2d':
|
| 65 |
+
vgg_avg_pooling.append(nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
|
| 66 |
+
else:
|
| 67 |
+
vgg_avg_pooling.append(module)
|
| 68 |
+
if module.__class__.__name__ == 'ReLU':
|
| 69 |
+
cur_level_i += 1
|
| 70 |
+
if cur_level_i == level:
|
| 71 |
+
break
|
| 72 |
+
|
| 73 |
+
self.features = nn.Sequential(*vgg_avg_pooling)
|
| 74 |
+
|
| 75 |
+
self.max_iters = max_iters
|
| 76 |
+
self.temperature = temperature
|
| 77 |
+
self.do_erode = erode_mask_size > 0
|
| 78 |
+
if self.do_erode:
|
| 79 |
+
self.erode_mask = nn.Conv2d(1, 1, erode_mask_size, padding=erode_mask_size // 2, bias=False)
|
| 80 |
+
self.erode_mask.weight.data.fill_(1)
|
| 81 |
+
|
| 82 |
+
def forward(self, real_img, pred_img, mask):
|
| 83 |
+
with torch.no_grad():
|
| 84 |
+
real_img = (real_img - IMAGENET_MEAN.to(real_img)) / IMAGENET_STD.to(real_img)
|
| 85 |
+
real_feats = self.features(real_img)
|
| 86 |
+
|
| 87 |
+
vertical_sim = torch.exp(-(real_feats[:, :, 1:] - real_feats[:, :, :-1]).pow(2).sum(1, keepdim=True)
|
| 88 |
+
/ self.temperature)
|
| 89 |
+
horizontal_sim = torch.exp(-(real_feats[:, :, :, 1:] - real_feats[:, :, :, :-1]).pow(2).sum(1, keepdim=True)
|
| 90 |
+
/ self.temperature)
|
| 91 |
+
|
| 92 |
+
mask_scaled = F.interpolate(mask, size=real_feats.shape[-2:], mode='bilinear', align_corners=False)
|
| 93 |
+
if self.do_erode:
|
| 94 |
+
mask_scaled = (self.erode_mask(mask_scaled) > 1).float()
|
| 95 |
+
|
| 96 |
+
cur_knowness = 1 - mask_scaled
|
| 97 |
+
|
| 98 |
+
for iter_i in range(self.max_iters):
|
| 99 |
+
new_top_knowness = F.pad(cur_knowness[:, :, :-1] * vertical_sim, (0, 0, 1, 0), mode='replicate')
|
| 100 |
+
new_bottom_knowness = F.pad(cur_knowness[:, :, 1:] * vertical_sim, (0, 0, 0, 1), mode='replicate')
|
| 101 |
+
|
| 102 |
+
new_left_knowness = F.pad(cur_knowness[:, :, :, :-1] * horizontal_sim, (1, 0, 0, 0), mode='replicate')
|
| 103 |
+
new_right_knowness = F.pad(cur_knowness[:, :, :, 1:] * horizontal_sim, (0, 1, 0, 0), mode='replicate')
|
| 104 |
+
|
| 105 |
+
new_knowness = torch.stack([new_top_knowness, new_bottom_knowness,
|
| 106 |
+
new_left_knowness, new_right_knowness],
|
| 107 |
+
dim=0).max(0).values
|
| 108 |
+
|
| 109 |
+
cur_knowness = torch.max(cur_knowness, new_knowness)
|
| 110 |
+
|
| 111 |
+
cur_knowness = F.interpolate(cur_knowness, size=mask.shape[-2:], mode='bilinear')
|
| 112 |
+
result = torch.min(mask, 1 - cur_knowness)
|
| 113 |
+
|
| 114 |
+
return result
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def make_mask_distance_weighter(kind='none', **kwargs):
|
| 118 |
+
if kind == 'none':
|
| 119 |
+
return dummy_distance_weighter
|
| 120 |
+
if kind == 'blur':
|
| 121 |
+
return BlurMask(**kwargs)
|
| 122 |
+
if kind == 'edt':
|
| 123 |
+
return EmulatedEDTMask(**kwargs)
|
| 124 |
+
if kind == 'pps':
|
| 125 |
+
return PropagatePerceptualSim(**kwargs)
|
| 126 |
+
raise ValueError(f'Unknown mask distance weighter kind {kind}')
|
annotator/lama/saicinpainting/training/losses/feature_matching.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def masked_l2_loss(pred, target, mask, weight_known, weight_missing):
|
| 8 |
+
per_pixel_l2 = F.mse_loss(pred, target, reduction='none')
|
| 9 |
+
pixel_weights = mask * weight_missing + (1 - mask) * weight_known
|
| 10 |
+
return (pixel_weights * per_pixel_l2).mean()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def masked_l1_loss(pred, target, mask, weight_known, weight_missing):
|
| 14 |
+
per_pixel_l1 = F.l1_loss(pred, target, reduction='none')
|
| 15 |
+
pixel_weights = mask * weight_missing + (1 - mask) * weight_known
|
| 16 |
+
return (pixel_weights * per_pixel_l1).mean()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def feature_matching_loss(fake_features: List[torch.Tensor], target_features: List[torch.Tensor], mask=None):
|
| 20 |
+
if mask is None:
|
| 21 |
+
res = torch.stack([F.mse_loss(fake_feat, target_feat)
|
| 22 |
+
for fake_feat, target_feat in zip(fake_features, target_features)]).mean()
|
| 23 |
+
else:
|
| 24 |
+
res = 0
|
| 25 |
+
norm = 0
|
| 26 |
+
for fake_feat, target_feat in zip(fake_features, target_features):
|
| 27 |
+
cur_mask = F.interpolate(mask, size=fake_feat.shape[-2:], mode='bilinear', align_corners=False)
|
| 28 |
+
error_weights = 1 - cur_mask
|
| 29 |
+
cur_val = ((fake_feat - target_feat).pow(2) * error_weights).mean()
|
| 30 |
+
res = res + cur_val
|
| 31 |
+
norm += 1
|
| 32 |
+
res = res / norm
|
| 33 |
+
return res
|
annotator/lama/saicinpainting/training/losses/perceptual.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchvision
|
| 5 |
+
|
| 6 |
+
# from models.ade20k import ModelBuilder
|
| 7 |
+
from annotator.lama.saicinpainting.utils import check_and_warn_input_range
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
IMAGENET_MEAN = torch.FloatTensor([0.485, 0.456, 0.406])[None, :, None, None]
|
| 11 |
+
IMAGENET_STD = torch.FloatTensor([0.229, 0.224, 0.225])[None, :, None, None]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class PerceptualLoss(nn.Module):
|
| 15 |
+
def __init__(self, normalize_inputs=True):
|
| 16 |
+
super(PerceptualLoss, self).__init__()
|
| 17 |
+
|
| 18 |
+
self.normalize_inputs = normalize_inputs
|
| 19 |
+
self.mean_ = IMAGENET_MEAN
|
| 20 |
+
self.std_ = IMAGENET_STD
|
| 21 |
+
|
| 22 |
+
vgg = torchvision.models.vgg19(pretrained=True).features
|
| 23 |
+
vgg_avg_pooling = []
|
| 24 |
+
|
| 25 |
+
for weights in vgg.parameters():
|
| 26 |
+
weights.requires_grad = False
|
| 27 |
+
|
| 28 |
+
for module in vgg.modules():
|
| 29 |
+
if module.__class__.__name__ == 'Sequential':
|
| 30 |
+
continue
|
| 31 |
+
elif module.__class__.__name__ == 'MaxPool2d':
|
| 32 |
+
vgg_avg_pooling.append(nn.AvgPool2d(kernel_size=2, stride=2, padding=0))
|
| 33 |
+
else:
|
| 34 |
+
vgg_avg_pooling.append(module)
|
| 35 |
+
|
| 36 |
+
self.vgg = nn.Sequential(*vgg_avg_pooling)
|
| 37 |
+
|
| 38 |
+
def do_normalize_inputs(self, x):
|
| 39 |
+
return (x - self.mean_.to(x.device)) / self.std_.to(x.device)
|
| 40 |
+
|
| 41 |
+
def partial_losses(self, input, target, mask=None):
|
| 42 |
+
check_and_warn_input_range(target, 0, 1, 'PerceptualLoss target in partial_losses')
|
| 43 |
+
|
| 44 |
+
# we expect input and target to be in [0, 1] range
|
| 45 |
+
losses = []
|
| 46 |
+
|
| 47 |
+
if self.normalize_inputs:
|
| 48 |
+
features_input = self.do_normalize_inputs(input)
|
| 49 |
+
features_target = self.do_normalize_inputs(target)
|
| 50 |
+
else:
|
| 51 |
+
features_input = input
|
| 52 |
+
features_target = target
|
| 53 |
+
|
| 54 |
+
for layer in self.vgg[:30]:
|
| 55 |
+
|
| 56 |
+
features_input = layer(features_input)
|
| 57 |
+
features_target = layer(features_target)
|
| 58 |
+
|
| 59 |
+
if layer.__class__.__name__ == 'ReLU':
|
| 60 |
+
loss = F.mse_loss(features_input, features_target, reduction='none')
|
| 61 |
+
|
| 62 |
+
if mask is not None:
|
| 63 |
+
cur_mask = F.interpolate(mask, size=features_input.shape[-2:],
|
| 64 |
+
mode='bilinear', align_corners=False)
|
| 65 |
+
loss = loss * (1 - cur_mask)
|
| 66 |
+
|
| 67 |
+
loss = loss.mean(dim=tuple(range(1, len(loss.shape))))
|
| 68 |
+
losses.append(loss)
|
| 69 |
+
|
| 70 |
+
return losses
|
| 71 |
+
|
| 72 |
+
def forward(self, input, target, mask=None):
|
| 73 |
+
losses = self.partial_losses(input, target, mask=mask)
|
| 74 |
+
return torch.stack(losses).sum(dim=0)
|
| 75 |
+
|
| 76 |
+
def get_global_features(self, input):
|
| 77 |
+
check_and_warn_input_range(input, 0, 1, 'PerceptualLoss input in get_global_features')
|
| 78 |
+
|
| 79 |
+
if self.normalize_inputs:
|
| 80 |
+
features_input = self.do_normalize_inputs(input)
|
| 81 |
+
else:
|
| 82 |
+
features_input = input
|
| 83 |
+
|
| 84 |
+
features_input = self.vgg(features_input)
|
| 85 |
+
return features_input
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class ResNetPL(nn.Module):
|
| 89 |
+
def __init__(self, weight=1,
|
| 90 |
+
weights_path=None, arch_encoder='resnet50dilated', segmentation=True):
|
| 91 |
+
super().__init__()
|
| 92 |
+
self.impl = ModelBuilder.get_encoder(weights_path=weights_path,
|
| 93 |
+
arch_encoder=arch_encoder,
|
| 94 |
+
arch_decoder='ppm_deepsup',
|
| 95 |
+
fc_dim=2048,
|
| 96 |
+
segmentation=segmentation)
|
| 97 |
+
self.impl.eval()
|
| 98 |
+
for w in self.impl.parameters():
|
| 99 |
+
w.requires_grad_(False)
|
| 100 |
+
|
| 101 |
+
self.weight = weight
|
| 102 |
+
|
| 103 |
+
def forward(self, pred, target):
|
| 104 |
+
pred = (pred - IMAGENET_MEAN.to(pred)) / IMAGENET_STD.to(pred)
|
| 105 |
+
target = (target - IMAGENET_MEAN.to(target)) / IMAGENET_STD.to(target)
|
| 106 |
+
|
| 107 |
+
pred_feats = self.impl(pred, return_feature_maps=True)
|
| 108 |
+
target_feats = self.impl(target, return_feature_maps=True)
|
| 109 |
+
|
| 110 |
+
result = torch.stack([F.mse_loss(cur_pred, cur_target)
|
| 111 |
+
for cur_pred, cur_target
|
| 112 |
+
in zip(pred_feats, target_feats)]).sum() * self.weight
|
| 113 |
+
return result
|
annotator/lama/saicinpainting/training/losses/segmentation.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from .constants import weights as constant_weights
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class CrossEntropy2d(nn.Module):
|
| 9 |
+
def __init__(self, reduction="mean", ignore_label=255, weights=None, *args, **kwargs):
|
| 10 |
+
"""
|
| 11 |
+
weight (Tensor, optional): a manual rescaling weight given to each class.
|
| 12 |
+
If given, has to be a Tensor of size "nclasses"
|
| 13 |
+
"""
|
| 14 |
+
super(CrossEntropy2d, self).__init__()
|
| 15 |
+
self.reduction = reduction
|
| 16 |
+
self.ignore_label = ignore_label
|
| 17 |
+
self.weights = weights
|
| 18 |
+
if self.weights is not None:
|
| 19 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 20 |
+
self.weights = torch.FloatTensor(constant_weights[weights]).to(device)
|
| 21 |
+
|
| 22 |
+
def forward(self, predict, target):
|
| 23 |
+
"""
|
| 24 |
+
Args:
|
| 25 |
+
predict:(n, c, h, w)
|
| 26 |
+
target:(n, 1, h, w)
|
| 27 |
+
"""
|
| 28 |
+
target = target.long()
|
| 29 |
+
assert not target.requires_grad
|
| 30 |
+
assert predict.dim() == 4, "{0}".format(predict.size())
|
| 31 |
+
assert target.dim() == 4, "{0}".format(target.size())
|
| 32 |
+
assert predict.size(0) == target.size(0), "{0} vs {1} ".format(predict.size(0), target.size(0))
|
| 33 |
+
assert target.size(1) == 1, "{0}".format(target.size(1))
|
| 34 |
+
assert predict.size(2) == target.size(2), "{0} vs {1} ".format(predict.size(2), target.size(2))
|
| 35 |
+
assert predict.size(3) == target.size(3), "{0} vs {1} ".format(predict.size(3), target.size(3))
|
| 36 |
+
target = target.squeeze(1)
|
| 37 |
+
n, c, h, w = predict.size()
|
| 38 |
+
target_mask = (target >= 0) * (target != self.ignore_label)
|
| 39 |
+
target = target[target_mask]
|
| 40 |
+
predict = predict.transpose(1, 2).transpose(2, 3).contiguous()
|
| 41 |
+
predict = predict[target_mask.view(n, h, w, 1).repeat(1, 1, 1, c)].view(-1, c)
|
| 42 |
+
loss = F.cross_entropy(predict, target, weight=self.weights, reduction=self.reduction)
|
| 43 |
+
return loss
|
annotator/lama/saicinpainting/training/losses/style_loss.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torchvision.models as models
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class PerceptualLoss(nn.Module):
|
| 7 |
+
r"""
|
| 8 |
+
Perceptual loss, VGG-based
|
| 9 |
+
https://arxiv.org/abs/1603.08155
|
| 10 |
+
https://github.com/dxyang/StyleTransfer/blob/master/utils.py
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
|
| 14 |
+
super(PerceptualLoss, self).__init__()
|
| 15 |
+
self.add_module('vgg', VGG19())
|
| 16 |
+
self.criterion = torch.nn.L1Loss()
|
| 17 |
+
self.weights = weights
|
| 18 |
+
|
| 19 |
+
def __call__(self, x, y):
|
| 20 |
+
# Compute features
|
| 21 |
+
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
|
| 22 |
+
|
| 23 |
+
content_loss = 0.0
|
| 24 |
+
content_loss += self.weights[0] * self.criterion(x_vgg['relu1_1'], y_vgg['relu1_1'])
|
| 25 |
+
content_loss += self.weights[1] * self.criterion(x_vgg['relu2_1'], y_vgg['relu2_1'])
|
| 26 |
+
content_loss += self.weights[2] * self.criterion(x_vgg['relu3_1'], y_vgg['relu3_1'])
|
| 27 |
+
content_loss += self.weights[3] * self.criterion(x_vgg['relu4_1'], y_vgg['relu4_1'])
|
| 28 |
+
content_loss += self.weights[4] * self.criterion(x_vgg['relu5_1'], y_vgg['relu5_1'])
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
return content_loss
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class VGG19(torch.nn.Module):
|
| 35 |
+
def __init__(self):
|
| 36 |
+
super(VGG19, self).__init__()
|
| 37 |
+
features = models.vgg19(pretrained=True).features
|
| 38 |
+
self.relu1_1 = torch.nn.Sequential()
|
| 39 |
+
self.relu1_2 = torch.nn.Sequential()
|
| 40 |
+
|
| 41 |
+
self.relu2_1 = torch.nn.Sequential()
|
| 42 |
+
self.relu2_2 = torch.nn.Sequential()
|
| 43 |
+
|
| 44 |
+
self.relu3_1 = torch.nn.Sequential()
|
| 45 |
+
self.relu3_2 = torch.nn.Sequential()
|
| 46 |
+
self.relu3_3 = torch.nn.Sequential()
|
| 47 |
+
self.relu3_4 = torch.nn.Sequential()
|
| 48 |
+
|
| 49 |
+
self.relu4_1 = torch.nn.Sequential()
|
| 50 |
+
self.relu4_2 = torch.nn.Sequential()
|
| 51 |
+
self.relu4_3 = torch.nn.Sequential()
|
| 52 |
+
self.relu4_4 = torch.nn.Sequential()
|
| 53 |
+
|
| 54 |
+
self.relu5_1 = torch.nn.Sequential()
|
| 55 |
+
self.relu5_2 = torch.nn.Sequential()
|
| 56 |
+
self.relu5_3 = torch.nn.Sequential()
|
| 57 |
+
self.relu5_4 = torch.nn.Sequential()
|
| 58 |
+
|
| 59 |
+
for x in range(2):
|
| 60 |
+
self.relu1_1.add_module(str(x), features[x])
|
| 61 |
+
|
| 62 |
+
for x in range(2, 4):
|
| 63 |
+
self.relu1_2.add_module(str(x), features[x])
|
| 64 |
+
|
| 65 |
+
for x in range(4, 7):
|
| 66 |
+
self.relu2_1.add_module(str(x), features[x])
|
| 67 |
+
|
| 68 |
+
for x in range(7, 9):
|
| 69 |
+
self.relu2_2.add_module(str(x), features[x])
|
| 70 |
+
|
| 71 |
+
for x in range(9, 12):
|
| 72 |
+
self.relu3_1.add_module(str(x), features[x])
|
| 73 |
+
|
| 74 |
+
for x in range(12, 14):
|
| 75 |
+
self.relu3_2.add_module(str(x), features[x])
|
| 76 |
+
|
| 77 |
+
for x in range(14, 16):
|
| 78 |
+
self.relu3_2.add_module(str(x), features[x])
|
| 79 |
+
|
| 80 |
+
for x in range(16, 18):
|
| 81 |
+
self.relu3_4.add_module(str(x), features[x])
|
| 82 |
+
|
| 83 |
+
for x in range(18, 21):
|
| 84 |
+
self.relu4_1.add_module(str(x), features[x])
|
| 85 |
+
|
| 86 |
+
for x in range(21, 23):
|
| 87 |
+
self.relu4_2.add_module(str(x), features[x])
|
| 88 |
+
|
| 89 |
+
for x in range(23, 25):
|
| 90 |
+
self.relu4_3.add_module(str(x), features[x])
|
| 91 |
+
|
| 92 |
+
for x in range(25, 27):
|
| 93 |
+
self.relu4_4.add_module(str(x), features[x])
|
| 94 |
+
|
| 95 |
+
for x in range(27, 30):
|
| 96 |
+
self.relu5_1.add_module(str(x), features[x])
|
| 97 |
+
|
| 98 |
+
for x in range(30, 32):
|
| 99 |
+
self.relu5_2.add_module(str(x), features[x])
|
| 100 |
+
|
| 101 |
+
for x in range(32, 34):
|
| 102 |
+
self.relu5_3.add_module(str(x), features[x])
|
| 103 |
+
|
| 104 |
+
for x in range(34, 36):
|
| 105 |
+
self.relu5_4.add_module(str(x), features[x])
|
| 106 |
+
|
| 107 |
+
# don't need the gradients, just want the features
|
| 108 |
+
for param in self.parameters():
|
| 109 |
+
param.requires_grad = False
|
| 110 |
+
|
| 111 |
+
def forward(self, x):
|
| 112 |
+
relu1_1 = self.relu1_1(x)
|
| 113 |
+
relu1_2 = self.relu1_2(relu1_1)
|
| 114 |
+
|
| 115 |
+
relu2_1 = self.relu2_1(relu1_2)
|
| 116 |
+
relu2_2 = self.relu2_2(relu2_1)
|
| 117 |
+
|
| 118 |
+
relu3_1 = self.relu3_1(relu2_2)
|
| 119 |
+
relu3_2 = self.relu3_2(relu3_1)
|
| 120 |
+
relu3_3 = self.relu3_3(relu3_2)
|
| 121 |
+
relu3_4 = self.relu3_4(relu3_3)
|
| 122 |
+
|
| 123 |
+
relu4_1 = self.relu4_1(relu3_4)
|
| 124 |
+
relu4_2 = self.relu4_2(relu4_1)
|
| 125 |
+
relu4_3 = self.relu4_3(relu4_2)
|
| 126 |
+
relu4_4 = self.relu4_4(relu4_3)
|
| 127 |
+
|
| 128 |
+
relu5_1 = self.relu5_1(relu4_4)
|
| 129 |
+
relu5_2 = self.relu5_2(relu5_1)
|
| 130 |
+
relu5_3 = self.relu5_3(relu5_2)
|
| 131 |
+
relu5_4 = self.relu5_4(relu5_3)
|
| 132 |
+
|
| 133 |
+
out = {
|
| 134 |
+
'relu1_1': relu1_1,
|
| 135 |
+
'relu1_2': relu1_2,
|
| 136 |
+
|
| 137 |
+
'relu2_1': relu2_1,
|
| 138 |
+
'relu2_2': relu2_2,
|
| 139 |
+
|
| 140 |
+
'relu3_1': relu3_1,
|
| 141 |
+
'relu3_2': relu3_2,
|
| 142 |
+
'relu3_3': relu3_3,
|
| 143 |
+
'relu3_4': relu3_4,
|
| 144 |
+
|
| 145 |
+
'relu4_1': relu4_1,
|
| 146 |
+
'relu4_2': relu4_2,
|
| 147 |
+
'relu4_3': relu4_3,
|
| 148 |
+
'relu4_4': relu4_4,
|
| 149 |
+
|
| 150 |
+
'relu5_1': relu5_1,
|
| 151 |
+
'relu5_2': relu5_2,
|
| 152 |
+
'relu5_3': relu5_3,
|
| 153 |
+
'relu5_4': relu5_4,
|
| 154 |
+
}
|
| 155 |
+
return out
|
annotator/lama/saicinpainting/training/modules/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
from annotator.lama.saicinpainting.training.modules.ffc import FFCResNetGenerator
|
| 4 |
+
from annotator.lama.saicinpainting.training.modules.pix2pixhd import GlobalGenerator, MultiDilatedGlobalGenerator, \
|
| 5 |
+
NLayerDiscriminator, MultidilatedNLayerDiscriminator
|
| 6 |
+
|
| 7 |
+
def make_generator(config, kind, **kwargs):
|
| 8 |
+
logging.info(f'Make generator {kind}')
|
| 9 |
+
|
| 10 |
+
if kind == 'pix2pixhd_multidilated':
|
| 11 |
+
return MultiDilatedGlobalGenerator(**kwargs)
|
| 12 |
+
|
| 13 |
+
if kind == 'pix2pixhd_global':
|
| 14 |
+
return GlobalGenerator(**kwargs)
|
| 15 |
+
|
| 16 |
+
if kind == 'ffc_resnet':
|
| 17 |
+
return FFCResNetGenerator(**kwargs)
|
| 18 |
+
|
| 19 |
+
raise ValueError(f'Unknown generator kind {kind}')
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def make_discriminator(kind, **kwargs):
|
| 23 |
+
logging.info(f'Make discriminator {kind}')
|
| 24 |
+
|
| 25 |
+
if kind == 'pix2pixhd_nlayer_multidilated':
|
| 26 |
+
return MultidilatedNLayerDiscriminator(**kwargs)
|
| 27 |
+
|
| 28 |
+
if kind == 'pix2pixhd_nlayer':
|
| 29 |
+
return NLayerDiscriminator(**kwargs)
|
| 30 |
+
|
| 31 |
+
raise ValueError(f'Unknown discriminator kind {kind}')
|
annotator/lama/saicinpainting/training/modules/base.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import abc
|
| 2 |
+
from typing import Tuple, List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
|
| 7 |
+
from annotator.lama.saicinpainting.training.modules.depthwise_sep_conv import DepthWiseSeperableConv
|
| 8 |
+
from annotator.lama.saicinpainting.training.modules.multidilated_conv import MultidilatedConv
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class BaseDiscriminator(nn.Module):
|
| 12 |
+
@abc.abstractmethod
|
| 13 |
+
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
|
| 14 |
+
"""
|
| 15 |
+
Predict scores and get intermediate activations. Useful for feature matching loss
|
| 16 |
+
:return tuple (scores, list of intermediate activations)
|
| 17 |
+
"""
|
| 18 |
+
raise NotImplemented()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_conv_block_ctor(kind='default'):
|
| 22 |
+
if not isinstance(kind, str):
|
| 23 |
+
return kind
|
| 24 |
+
if kind == 'default':
|
| 25 |
+
return nn.Conv2d
|
| 26 |
+
if kind == 'depthwise':
|
| 27 |
+
return DepthWiseSeperableConv
|
| 28 |
+
if kind == 'multidilated':
|
| 29 |
+
return MultidilatedConv
|
| 30 |
+
raise ValueError(f'Unknown convolutional block kind {kind}')
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_norm_layer(kind='bn'):
|
| 34 |
+
if not isinstance(kind, str):
|
| 35 |
+
return kind
|
| 36 |
+
if kind == 'bn':
|
| 37 |
+
return nn.BatchNorm2d
|
| 38 |
+
if kind == 'in':
|
| 39 |
+
return nn.InstanceNorm2d
|
| 40 |
+
raise ValueError(f'Unknown norm block kind {kind}')
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def get_activation(kind='tanh'):
|
| 44 |
+
if kind == 'tanh':
|
| 45 |
+
return nn.Tanh()
|
| 46 |
+
if kind == 'sigmoid':
|
| 47 |
+
return nn.Sigmoid()
|
| 48 |
+
if kind is False:
|
| 49 |
+
return nn.Identity()
|
| 50 |
+
raise ValueError(f'Unknown activation kind {kind}')
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class SimpleMultiStepGenerator(nn.Module):
|
| 54 |
+
def __init__(self, steps: List[nn.Module]):
|
| 55 |
+
super().__init__()
|
| 56 |
+
self.steps = nn.ModuleList(steps)
|
| 57 |
+
|
| 58 |
+
def forward(self, x):
|
| 59 |
+
cur_in = x
|
| 60 |
+
outs = []
|
| 61 |
+
for step in self.steps:
|
| 62 |
+
cur_out = step(cur_in)
|
| 63 |
+
outs.append(cur_out)
|
| 64 |
+
cur_in = torch.cat((cur_in, cur_out), dim=1)
|
| 65 |
+
return torch.cat(outs[::-1], dim=1)
|
| 66 |
+
|
| 67 |
+
def deconv_factory(kind, ngf, mult, norm_layer, activation, max_features):
|
| 68 |
+
if kind == 'convtranspose':
|
| 69 |
+
return [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
| 70 |
+
min(max_features, int(ngf * mult / 2)),
|
| 71 |
+
kernel_size=3, stride=2, padding=1, output_padding=1),
|
| 72 |
+
norm_layer(min(max_features, int(ngf * mult / 2))), activation]
|
| 73 |
+
elif kind == 'bilinear':
|
| 74 |
+
return [nn.Upsample(scale_factor=2, mode='bilinear'),
|
| 75 |
+
DepthWiseSeperableConv(min(max_features, ngf * mult),
|
| 76 |
+
min(max_features, int(ngf * mult / 2)),
|
| 77 |
+
kernel_size=3, stride=1, padding=1),
|
| 78 |
+
norm_layer(min(max_features, int(ngf * mult / 2))), activation]
|
| 79 |
+
else:
|
| 80 |
+
raise Exception(f"Invalid deconv kind: {kind}")
|
annotator/lama/saicinpainting/training/modules/depthwise_sep_conv.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
class DepthWiseSeperableConv(nn.Module):
|
| 5 |
+
def __init__(self, in_dim, out_dim, *args, **kwargs):
|
| 6 |
+
super().__init__()
|
| 7 |
+
if 'groups' in kwargs:
|
| 8 |
+
# ignoring groups for Depthwise Sep Conv
|
| 9 |
+
del kwargs['groups']
|
| 10 |
+
|
| 11 |
+
self.depthwise = nn.Conv2d(in_dim, in_dim, *args, groups=in_dim, **kwargs)
|
| 12 |
+
self.pointwise = nn.Conv2d(in_dim, out_dim, kernel_size=1)
|
| 13 |
+
|
| 14 |
+
def forward(self, x):
|
| 15 |
+
out = self.depthwise(x)
|
| 16 |
+
out = self.pointwise(out)
|
| 17 |
+
return out
|
annotator/lama/saicinpainting/training/modules/fake_fakes.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from kornia import SamplePadding
|
| 3 |
+
from kornia.augmentation import RandomAffine, CenterCrop
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class FakeFakesGenerator:
|
| 7 |
+
def __init__(self, aug_proba=0.5, img_aug_degree=30, img_aug_translate=0.2):
|
| 8 |
+
self.grad_aug = RandomAffine(degrees=360,
|
| 9 |
+
translate=0.2,
|
| 10 |
+
padding_mode=SamplePadding.REFLECTION,
|
| 11 |
+
keepdim=False,
|
| 12 |
+
p=1)
|
| 13 |
+
self.img_aug = RandomAffine(degrees=img_aug_degree,
|
| 14 |
+
translate=img_aug_translate,
|
| 15 |
+
padding_mode=SamplePadding.REFLECTION,
|
| 16 |
+
keepdim=True,
|
| 17 |
+
p=1)
|
| 18 |
+
self.aug_proba = aug_proba
|
| 19 |
+
|
| 20 |
+
def __call__(self, input_images, masks):
|
| 21 |
+
blend_masks = self._fill_masks_with_gradient(masks)
|
| 22 |
+
blend_target = self._make_blend_target(input_images)
|
| 23 |
+
result = input_images * (1 - blend_masks) + blend_target * blend_masks
|
| 24 |
+
return result, blend_masks
|
| 25 |
+
|
| 26 |
+
def _make_blend_target(self, input_images):
|
| 27 |
+
batch_size = input_images.shape[0]
|
| 28 |
+
permuted = input_images[torch.randperm(batch_size)]
|
| 29 |
+
augmented = self.img_aug(input_images)
|
| 30 |
+
is_aug = (torch.rand(batch_size, device=input_images.device)[:, None, None, None] < self.aug_proba).float()
|
| 31 |
+
result = augmented * is_aug + permuted * (1 - is_aug)
|
| 32 |
+
return result
|
| 33 |
+
|
| 34 |
+
def _fill_masks_with_gradient(self, masks):
|
| 35 |
+
batch_size, _, height, width = masks.shape
|
| 36 |
+
grad = torch.linspace(0, 1, steps=width * 2, device=masks.device, dtype=masks.dtype) \
|
| 37 |
+
.view(1, 1, 1, -1).expand(batch_size, 1, height * 2, width * 2)
|
| 38 |
+
grad = self.grad_aug(grad)
|
| 39 |
+
grad = CenterCrop((height, width))(grad)
|
| 40 |
+
grad *= masks
|
| 41 |
+
|
| 42 |
+
grad_for_min = grad + (1 - masks) * 10
|
| 43 |
+
grad -= grad_for_min.view(batch_size, -1).min(-1).values[:, None, None, None]
|
| 44 |
+
grad /= grad.view(batch_size, -1).max(-1).values[:, None, None, None] + 1e-6
|
| 45 |
+
grad.clamp_(min=0, max=1)
|
| 46 |
+
|
| 47 |
+
return grad
|
annotator/lama/saicinpainting/training/modules/ffc.py
ADDED
|
@@ -0,0 +1,485 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fast Fourier Convolution NeurIPS 2020
|
| 2 |
+
# original implementation https://github.com/pkumivision/FFC/blob/main/model_zoo/ffc.py
|
| 3 |
+
# paper https://proceedings.neurips.cc/paper/2020/file/2fd5d41ec6cfab47e32164d5624269b1-Paper.pdf
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
from annotator.lama.saicinpainting.training.modules.base import get_activation, BaseDiscriminator
|
| 11 |
+
from annotator.lama.saicinpainting.training.modules.spatial_transform import LearnableSpatialTransformWrapper
|
| 12 |
+
from annotator.lama.saicinpainting.training.modules.squeeze_excitation import SELayer
|
| 13 |
+
from annotator.lama.saicinpainting.utils import get_shape
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class FFCSE_block(nn.Module):
|
| 17 |
+
|
| 18 |
+
def __init__(self, channels, ratio_g):
|
| 19 |
+
super(FFCSE_block, self).__init__()
|
| 20 |
+
in_cg = int(channels * ratio_g)
|
| 21 |
+
in_cl = channels - in_cg
|
| 22 |
+
r = 16
|
| 23 |
+
|
| 24 |
+
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
|
| 25 |
+
self.conv1 = nn.Conv2d(channels, channels // r,
|
| 26 |
+
kernel_size=1, bias=True)
|
| 27 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 28 |
+
self.conv_a2l = None if in_cl == 0 else nn.Conv2d(
|
| 29 |
+
channels // r, in_cl, kernel_size=1, bias=True)
|
| 30 |
+
self.conv_a2g = None if in_cg == 0 else nn.Conv2d(
|
| 31 |
+
channels // r, in_cg, kernel_size=1, bias=True)
|
| 32 |
+
self.sigmoid = nn.Sigmoid()
|
| 33 |
+
|
| 34 |
+
def forward(self, x):
|
| 35 |
+
x = x if type(x) is tuple else (x, 0)
|
| 36 |
+
id_l, id_g = x
|
| 37 |
+
|
| 38 |
+
x = id_l if type(id_g) is int else torch.cat([id_l, id_g], dim=1)
|
| 39 |
+
x = self.avgpool(x)
|
| 40 |
+
x = self.relu1(self.conv1(x))
|
| 41 |
+
|
| 42 |
+
x_l = 0 if self.conv_a2l is None else id_l * \
|
| 43 |
+
self.sigmoid(self.conv_a2l(x))
|
| 44 |
+
x_g = 0 if self.conv_a2g is None else id_g * \
|
| 45 |
+
self.sigmoid(self.conv_a2g(x))
|
| 46 |
+
return x_l, x_g
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class FourierUnit(nn.Module):
|
| 50 |
+
|
| 51 |
+
def __init__(self, in_channels, out_channels, groups=1, spatial_scale_factor=None, spatial_scale_mode='bilinear',
|
| 52 |
+
spectral_pos_encoding=False, use_se=False, se_kwargs=None, ffc3d=False, fft_norm='ortho'):
|
| 53 |
+
# bn_layer not used
|
| 54 |
+
super(FourierUnit, self).__init__()
|
| 55 |
+
self.groups = groups
|
| 56 |
+
|
| 57 |
+
self.conv_layer = torch.nn.Conv2d(in_channels=in_channels * 2 + (2 if spectral_pos_encoding else 0),
|
| 58 |
+
out_channels=out_channels * 2,
|
| 59 |
+
kernel_size=1, stride=1, padding=0, groups=self.groups, bias=False)
|
| 60 |
+
self.bn = torch.nn.BatchNorm2d(out_channels * 2)
|
| 61 |
+
self.relu = torch.nn.ReLU(inplace=True)
|
| 62 |
+
|
| 63 |
+
# squeeze and excitation block
|
| 64 |
+
self.use_se = use_se
|
| 65 |
+
if use_se:
|
| 66 |
+
if se_kwargs is None:
|
| 67 |
+
se_kwargs = {}
|
| 68 |
+
self.se = SELayer(self.conv_layer.in_channels, **se_kwargs)
|
| 69 |
+
|
| 70 |
+
self.spatial_scale_factor = spatial_scale_factor
|
| 71 |
+
self.spatial_scale_mode = spatial_scale_mode
|
| 72 |
+
self.spectral_pos_encoding = spectral_pos_encoding
|
| 73 |
+
self.ffc3d = ffc3d
|
| 74 |
+
self.fft_norm = fft_norm
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
batch = x.shape[0]
|
| 78 |
+
|
| 79 |
+
if self.spatial_scale_factor is not None:
|
| 80 |
+
orig_size = x.shape[-2:]
|
| 81 |
+
x = F.interpolate(x, scale_factor=self.spatial_scale_factor, mode=self.spatial_scale_mode, align_corners=False)
|
| 82 |
+
|
| 83 |
+
r_size = x.size()
|
| 84 |
+
# (batch, c, h, w/2+1, 2)
|
| 85 |
+
fft_dim = (-3, -2, -1) if self.ffc3d else (-2, -1)
|
| 86 |
+
ffted = torch.fft.rfftn(x, dim=fft_dim, norm=self.fft_norm)
|
| 87 |
+
ffted = torch.stack((ffted.real, ffted.imag), dim=-1)
|
| 88 |
+
ffted = ffted.permute(0, 1, 4, 2, 3).contiguous() # (batch, c, 2, h, w/2+1)
|
| 89 |
+
ffted = ffted.view((batch, -1,) + ffted.size()[3:])
|
| 90 |
+
|
| 91 |
+
if self.spectral_pos_encoding:
|
| 92 |
+
height, width = ffted.shape[-2:]
|
| 93 |
+
coords_vert = torch.linspace(0, 1, height)[None, None, :, None].expand(batch, 1, height, width).to(ffted)
|
| 94 |
+
coords_hor = torch.linspace(0, 1, width)[None, None, None, :].expand(batch, 1, height, width).to(ffted)
|
| 95 |
+
ffted = torch.cat((coords_vert, coords_hor, ffted), dim=1)
|
| 96 |
+
|
| 97 |
+
if self.use_se:
|
| 98 |
+
ffted = self.se(ffted)
|
| 99 |
+
|
| 100 |
+
ffted = self.conv_layer(ffted) # (batch, c*2, h, w/2+1)
|
| 101 |
+
ffted = self.relu(self.bn(ffted))
|
| 102 |
+
|
| 103 |
+
ffted = ffted.view((batch, -1, 2,) + ffted.size()[2:]).permute(
|
| 104 |
+
0, 1, 3, 4, 2).contiguous() # (batch,c, t, h, w/2+1, 2)
|
| 105 |
+
ffted = torch.complex(ffted[..., 0], ffted[..., 1])
|
| 106 |
+
|
| 107 |
+
ifft_shape_slice = x.shape[-3:] if self.ffc3d else x.shape[-2:]
|
| 108 |
+
output = torch.fft.irfftn(ffted, s=ifft_shape_slice, dim=fft_dim, norm=self.fft_norm)
|
| 109 |
+
|
| 110 |
+
if self.spatial_scale_factor is not None:
|
| 111 |
+
output = F.interpolate(output, size=orig_size, mode=self.spatial_scale_mode, align_corners=False)
|
| 112 |
+
|
| 113 |
+
return output
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class SeparableFourierUnit(nn.Module):
|
| 117 |
+
|
| 118 |
+
def __init__(self, in_channels, out_channels, groups=1, kernel_size=3):
|
| 119 |
+
# bn_layer not used
|
| 120 |
+
super(SeparableFourierUnit, self).__init__()
|
| 121 |
+
self.groups = groups
|
| 122 |
+
row_out_channels = out_channels // 2
|
| 123 |
+
col_out_channels = out_channels - row_out_channels
|
| 124 |
+
self.row_conv = torch.nn.Conv2d(in_channels=in_channels * 2,
|
| 125 |
+
out_channels=row_out_channels * 2,
|
| 126 |
+
kernel_size=(kernel_size, 1), # kernel size is always like this, but the data will be transposed
|
| 127 |
+
stride=1, padding=(kernel_size // 2, 0),
|
| 128 |
+
padding_mode='reflect',
|
| 129 |
+
groups=self.groups, bias=False)
|
| 130 |
+
self.col_conv = torch.nn.Conv2d(in_channels=in_channels * 2,
|
| 131 |
+
out_channels=col_out_channels * 2,
|
| 132 |
+
kernel_size=(kernel_size, 1), # kernel size is always like this, but the data will be transposed
|
| 133 |
+
stride=1, padding=(kernel_size // 2, 0),
|
| 134 |
+
padding_mode='reflect',
|
| 135 |
+
groups=self.groups, bias=False)
|
| 136 |
+
self.row_bn = torch.nn.BatchNorm2d(row_out_channels * 2)
|
| 137 |
+
self.col_bn = torch.nn.BatchNorm2d(col_out_channels * 2)
|
| 138 |
+
self.relu = torch.nn.ReLU(inplace=True)
|
| 139 |
+
|
| 140 |
+
def process_branch(self, x, conv, bn):
|
| 141 |
+
batch = x.shape[0]
|
| 142 |
+
|
| 143 |
+
r_size = x.size()
|
| 144 |
+
# (batch, c, h, w/2+1, 2)
|
| 145 |
+
ffted = torch.fft.rfft(x, norm="ortho")
|
| 146 |
+
ffted = torch.stack((ffted.real, ffted.imag), dim=-1)
|
| 147 |
+
ffted = ffted.permute(0, 1, 4, 2, 3).contiguous() # (batch, c, 2, h, w/2+1)
|
| 148 |
+
ffted = ffted.view((batch, -1,) + ffted.size()[3:])
|
| 149 |
+
|
| 150 |
+
ffted = self.relu(bn(conv(ffted)))
|
| 151 |
+
|
| 152 |
+
ffted = ffted.view((batch, -1, 2,) + ffted.size()[2:]).permute(
|
| 153 |
+
0, 1, 3, 4, 2).contiguous() # (batch,c, t, h, w/2+1, 2)
|
| 154 |
+
ffted = torch.complex(ffted[..., 0], ffted[..., 1])
|
| 155 |
+
|
| 156 |
+
output = torch.fft.irfft(ffted, s=x.shape[-1:], norm="ortho")
|
| 157 |
+
return output
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def forward(self, x):
|
| 161 |
+
rowwise = self.process_branch(x, self.row_conv, self.row_bn)
|
| 162 |
+
colwise = self.process_branch(x.permute(0, 1, 3, 2), self.col_conv, self.col_bn).permute(0, 1, 3, 2)
|
| 163 |
+
out = torch.cat((rowwise, colwise), dim=1)
|
| 164 |
+
return out
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class SpectralTransform(nn.Module):
|
| 168 |
+
|
| 169 |
+
def __init__(self, in_channels, out_channels, stride=1, groups=1, enable_lfu=True, separable_fu=False, **fu_kwargs):
|
| 170 |
+
# bn_layer not used
|
| 171 |
+
super(SpectralTransform, self).__init__()
|
| 172 |
+
self.enable_lfu = enable_lfu
|
| 173 |
+
if stride == 2:
|
| 174 |
+
self.downsample = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
|
| 175 |
+
else:
|
| 176 |
+
self.downsample = nn.Identity()
|
| 177 |
+
|
| 178 |
+
self.stride = stride
|
| 179 |
+
self.conv1 = nn.Sequential(
|
| 180 |
+
nn.Conv2d(in_channels, out_channels //
|
| 181 |
+
2, kernel_size=1, groups=groups, bias=False),
|
| 182 |
+
nn.BatchNorm2d(out_channels // 2),
|
| 183 |
+
nn.ReLU(inplace=True)
|
| 184 |
+
)
|
| 185 |
+
fu_class = SeparableFourierUnit if separable_fu else FourierUnit
|
| 186 |
+
self.fu = fu_class(
|
| 187 |
+
out_channels // 2, out_channels // 2, groups, **fu_kwargs)
|
| 188 |
+
if self.enable_lfu:
|
| 189 |
+
self.lfu = fu_class(
|
| 190 |
+
out_channels // 2, out_channels // 2, groups)
|
| 191 |
+
self.conv2 = torch.nn.Conv2d(
|
| 192 |
+
out_channels // 2, out_channels, kernel_size=1, groups=groups, bias=False)
|
| 193 |
+
|
| 194 |
+
def forward(self, x):
|
| 195 |
+
|
| 196 |
+
x = self.downsample(x)
|
| 197 |
+
x = self.conv1(x)
|
| 198 |
+
output = self.fu(x)
|
| 199 |
+
|
| 200 |
+
if self.enable_lfu:
|
| 201 |
+
n, c, h, w = x.shape
|
| 202 |
+
split_no = 2
|
| 203 |
+
split_s = h // split_no
|
| 204 |
+
xs = torch.cat(torch.split(
|
| 205 |
+
x[:, :c // 4], split_s, dim=-2), dim=1).contiguous()
|
| 206 |
+
xs = torch.cat(torch.split(xs, split_s, dim=-1),
|
| 207 |
+
dim=1).contiguous()
|
| 208 |
+
xs = self.lfu(xs)
|
| 209 |
+
xs = xs.repeat(1, 1, split_no, split_no).contiguous()
|
| 210 |
+
else:
|
| 211 |
+
xs = 0
|
| 212 |
+
|
| 213 |
+
output = self.conv2(x + output + xs)
|
| 214 |
+
|
| 215 |
+
return output
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
class FFC(nn.Module):
|
| 219 |
+
|
| 220 |
+
def __init__(self, in_channels, out_channels, kernel_size,
|
| 221 |
+
ratio_gin, ratio_gout, stride=1, padding=0,
|
| 222 |
+
dilation=1, groups=1, bias=False, enable_lfu=True,
|
| 223 |
+
padding_type='reflect', gated=False, **spectral_kwargs):
|
| 224 |
+
super(FFC, self).__init__()
|
| 225 |
+
|
| 226 |
+
assert stride == 1 or stride == 2, "Stride should be 1 or 2."
|
| 227 |
+
self.stride = stride
|
| 228 |
+
|
| 229 |
+
in_cg = int(in_channels * ratio_gin)
|
| 230 |
+
in_cl = in_channels - in_cg
|
| 231 |
+
out_cg = int(out_channels * ratio_gout)
|
| 232 |
+
out_cl = out_channels - out_cg
|
| 233 |
+
#groups_g = 1 if groups == 1 else int(groups * ratio_gout)
|
| 234 |
+
#groups_l = 1 if groups == 1 else groups - groups_g
|
| 235 |
+
|
| 236 |
+
self.ratio_gin = ratio_gin
|
| 237 |
+
self.ratio_gout = ratio_gout
|
| 238 |
+
self.global_in_num = in_cg
|
| 239 |
+
|
| 240 |
+
module = nn.Identity if in_cl == 0 or out_cl == 0 else nn.Conv2d
|
| 241 |
+
self.convl2l = module(in_cl, out_cl, kernel_size,
|
| 242 |
+
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
| 243 |
+
module = nn.Identity if in_cl == 0 or out_cg == 0 else nn.Conv2d
|
| 244 |
+
self.convl2g = module(in_cl, out_cg, kernel_size,
|
| 245 |
+
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
| 246 |
+
module = nn.Identity if in_cg == 0 or out_cl == 0 else nn.Conv2d
|
| 247 |
+
self.convg2l = module(in_cg, out_cl, kernel_size,
|
| 248 |
+
stride, padding, dilation, groups, bias, padding_mode=padding_type)
|
| 249 |
+
module = nn.Identity if in_cg == 0 or out_cg == 0 else SpectralTransform
|
| 250 |
+
self.convg2g = module(
|
| 251 |
+
in_cg, out_cg, stride, 1 if groups == 1 else groups // 2, enable_lfu, **spectral_kwargs)
|
| 252 |
+
|
| 253 |
+
self.gated = gated
|
| 254 |
+
module = nn.Identity if in_cg == 0 or out_cl == 0 or not self.gated else nn.Conv2d
|
| 255 |
+
self.gate = module(in_channels, 2, 1)
|
| 256 |
+
|
| 257 |
+
def forward(self, x):
|
| 258 |
+
x_l, x_g = x if type(x) is tuple else (x, 0)
|
| 259 |
+
out_xl, out_xg = 0, 0
|
| 260 |
+
|
| 261 |
+
if self.gated:
|
| 262 |
+
total_input_parts = [x_l]
|
| 263 |
+
if torch.is_tensor(x_g):
|
| 264 |
+
total_input_parts.append(x_g)
|
| 265 |
+
total_input = torch.cat(total_input_parts, dim=1)
|
| 266 |
+
|
| 267 |
+
gates = torch.sigmoid(self.gate(total_input))
|
| 268 |
+
g2l_gate, l2g_gate = gates.chunk(2, dim=1)
|
| 269 |
+
else:
|
| 270 |
+
g2l_gate, l2g_gate = 1, 1
|
| 271 |
+
|
| 272 |
+
if self.ratio_gout != 1:
|
| 273 |
+
out_xl = self.convl2l(x_l) + self.convg2l(x_g) * g2l_gate
|
| 274 |
+
if self.ratio_gout != 0:
|
| 275 |
+
out_xg = self.convl2g(x_l) * l2g_gate + self.convg2g(x_g)
|
| 276 |
+
|
| 277 |
+
return out_xl, out_xg
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class FFC_BN_ACT(nn.Module):
|
| 281 |
+
|
| 282 |
+
def __init__(self, in_channels, out_channels,
|
| 283 |
+
kernel_size, ratio_gin, ratio_gout,
|
| 284 |
+
stride=1, padding=0, dilation=1, groups=1, bias=False,
|
| 285 |
+
norm_layer=nn.BatchNorm2d, activation_layer=nn.Identity,
|
| 286 |
+
padding_type='reflect',
|
| 287 |
+
enable_lfu=True, **kwargs):
|
| 288 |
+
super(FFC_BN_ACT, self).__init__()
|
| 289 |
+
self.ffc = FFC(in_channels, out_channels, kernel_size,
|
| 290 |
+
ratio_gin, ratio_gout, stride, padding, dilation,
|
| 291 |
+
groups, bias, enable_lfu, padding_type=padding_type, **kwargs)
|
| 292 |
+
lnorm = nn.Identity if ratio_gout == 1 else norm_layer
|
| 293 |
+
gnorm = nn.Identity if ratio_gout == 0 else norm_layer
|
| 294 |
+
global_channels = int(out_channels * ratio_gout)
|
| 295 |
+
self.bn_l = lnorm(out_channels - global_channels)
|
| 296 |
+
self.bn_g = gnorm(global_channels)
|
| 297 |
+
|
| 298 |
+
lact = nn.Identity if ratio_gout == 1 else activation_layer
|
| 299 |
+
gact = nn.Identity if ratio_gout == 0 else activation_layer
|
| 300 |
+
self.act_l = lact(inplace=True)
|
| 301 |
+
self.act_g = gact(inplace=True)
|
| 302 |
+
|
| 303 |
+
def forward(self, x):
|
| 304 |
+
x_l, x_g = self.ffc(x)
|
| 305 |
+
x_l = self.act_l(self.bn_l(x_l))
|
| 306 |
+
x_g = self.act_g(self.bn_g(x_g))
|
| 307 |
+
return x_l, x_g
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
class FFCResnetBlock(nn.Module):
|
| 311 |
+
def __init__(self, dim, padding_type, norm_layer, activation_layer=nn.ReLU, dilation=1,
|
| 312 |
+
spatial_transform_kwargs=None, inline=False, **conv_kwargs):
|
| 313 |
+
super().__init__()
|
| 314 |
+
self.conv1 = FFC_BN_ACT(dim, dim, kernel_size=3, padding=dilation, dilation=dilation,
|
| 315 |
+
norm_layer=norm_layer,
|
| 316 |
+
activation_layer=activation_layer,
|
| 317 |
+
padding_type=padding_type,
|
| 318 |
+
**conv_kwargs)
|
| 319 |
+
self.conv2 = FFC_BN_ACT(dim, dim, kernel_size=3, padding=dilation, dilation=dilation,
|
| 320 |
+
norm_layer=norm_layer,
|
| 321 |
+
activation_layer=activation_layer,
|
| 322 |
+
padding_type=padding_type,
|
| 323 |
+
**conv_kwargs)
|
| 324 |
+
if spatial_transform_kwargs is not None:
|
| 325 |
+
self.conv1 = LearnableSpatialTransformWrapper(self.conv1, **spatial_transform_kwargs)
|
| 326 |
+
self.conv2 = LearnableSpatialTransformWrapper(self.conv2, **spatial_transform_kwargs)
|
| 327 |
+
self.inline = inline
|
| 328 |
+
|
| 329 |
+
def forward(self, x):
|
| 330 |
+
if self.inline:
|
| 331 |
+
x_l, x_g = x[:, :-self.conv1.ffc.global_in_num], x[:, -self.conv1.ffc.global_in_num:]
|
| 332 |
+
else:
|
| 333 |
+
x_l, x_g = x if type(x) is tuple else (x, 0)
|
| 334 |
+
|
| 335 |
+
id_l, id_g = x_l, x_g
|
| 336 |
+
|
| 337 |
+
x_l, x_g = self.conv1((x_l, x_g))
|
| 338 |
+
x_l, x_g = self.conv2((x_l, x_g))
|
| 339 |
+
|
| 340 |
+
x_l, x_g = id_l + x_l, id_g + x_g
|
| 341 |
+
out = x_l, x_g
|
| 342 |
+
if self.inline:
|
| 343 |
+
out = torch.cat(out, dim=1)
|
| 344 |
+
return out
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class ConcatTupleLayer(nn.Module):
|
| 348 |
+
def forward(self, x):
|
| 349 |
+
assert isinstance(x, tuple)
|
| 350 |
+
x_l, x_g = x
|
| 351 |
+
assert torch.is_tensor(x_l) or torch.is_tensor(x_g)
|
| 352 |
+
if not torch.is_tensor(x_g):
|
| 353 |
+
return x_l
|
| 354 |
+
return torch.cat(x, dim=1)
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
class FFCResNetGenerator(nn.Module):
|
| 358 |
+
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
| 359 |
+
padding_type='reflect', activation_layer=nn.ReLU,
|
| 360 |
+
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True),
|
| 361 |
+
init_conv_kwargs={}, downsample_conv_kwargs={}, resnet_conv_kwargs={},
|
| 362 |
+
spatial_transform_layers=None, spatial_transform_kwargs={},
|
| 363 |
+
add_out_act=True, max_features=1024, out_ffc=False, out_ffc_kwargs={}):
|
| 364 |
+
assert (n_blocks >= 0)
|
| 365 |
+
super().__init__()
|
| 366 |
+
|
| 367 |
+
model = [nn.ReflectionPad2d(3),
|
| 368 |
+
FFC_BN_ACT(input_nc, ngf, kernel_size=7, padding=0, norm_layer=norm_layer,
|
| 369 |
+
activation_layer=activation_layer, **init_conv_kwargs)]
|
| 370 |
+
|
| 371 |
+
### downsample
|
| 372 |
+
for i in range(n_downsampling):
|
| 373 |
+
mult = 2 ** i
|
| 374 |
+
if i == n_downsampling - 1:
|
| 375 |
+
cur_conv_kwargs = dict(downsample_conv_kwargs)
|
| 376 |
+
cur_conv_kwargs['ratio_gout'] = resnet_conv_kwargs.get('ratio_gin', 0)
|
| 377 |
+
else:
|
| 378 |
+
cur_conv_kwargs = downsample_conv_kwargs
|
| 379 |
+
model += [FFC_BN_ACT(min(max_features, ngf * mult),
|
| 380 |
+
min(max_features, ngf * mult * 2),
|
| 381 |
+
kernel_size=3, stride=2, padding=1,
|
| 382 |
+
norm_layer=norm_layer,
|
| 383 |
+
activation_layer=activation_layer,
|
| 384 |
+
**cur_conv_kwargs)]
|
| 385 |
+
|
| 386 |
+
mult = 2 ** n_downsampling
|
| 387 |
+
feats_num_bottleneck = min(max_features, ngf * mult)
|
| 388 |
+
|
| 389 |
+
### resnet blocks
|
| 390 |
+
for i in range(n_blocks):
|
| 391 |
+
cur_resblock = FFCResnetBlock(feats_num_bottleneck, padding_type=padding_type, activation_layer=activation_layer,
|
| 392 |
+
norm_layer=norm_layer, **resnet_conv_kwargs)
|
| 393 |
+
if spatial_transform_layers is not None and i in spatial_transform_layers:
|
| 394 |
+
cur_resblock = LearnableSpatialTransformWrapper(cur_resblock, **spatial_transform_kwargs)
|
| 395 |
+
model += [cur_resblock]
|
| 396 |
+
|
| 397 |
+
model += [ConcatTupleLayer()]
|
| 398 |
+
|
| 399 |
+
### upsample
|
| 400 |
+
for i in range(n_downsampling):
|
| 401 |
+
mult = 2 ** (n_downsampling - i)
|
| 402 |
+
model += [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
| 403 |
+
min(max_features, int(ngf * mult / 2)),
|
| 404 |
+
kernel_size=3, stride=2, padding=1, output_padding=1),
|
| 405 |
+
up_norm_layer(min(max_features, int(ngf * mult / 2))),
|
| 406 |
+
up_activation]
|
| 407 |
+
|
| 408 |
+
if out_ffc:
|
| 409 |
+
model += [FFCResnetBlock(ngf, padding_type=padding_type, activation_layer=activation_layer,
|
| 410 |
+
norm_layer=norm_layer, inline=True, **out_ffc_kwargs)]
|
| 411 |
+
|
| 412 |
+
model += [nn.ReflectionPad2d(3),
|
| 413 |
+
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 414 |
+
if add_out_act:
|
| 415 |
+
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 416 |
+
self.model = nn.Sequential(*model)
|
| 417 |
+
|
| 418 |
+
def forward(self, input):
|
| 419 |
+
return self.model(input)
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
class FFCNLayerDiscriminator(BaseDiscriminator):
|
| 423 |
+
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, max_features=512,
|
| 424 |
+
init_conv_kwargs={}, conv_kwargs={}):
|
| 425 |
+
super().__init__()
|
| 426 |
+
self.n_layers = n_layers
|
| 427 |
+
|
| 428 |
+
def _act_ctor(inplace=True):
|
| 429 |
+
return nn.LeakyReLU(negative_slope=0.2, inplace=inplace)
|
| 430 |
+
|
| 431 |
+
kw = 3
|
| 432 |
+
padw = int(np.ceil((kw-1.0)/2))
|
| 433 |
+
sequence = [[FFC_BN_ACT(input_nc, ndf, kernel_size=kw, padding=padw, norm_layer=norm_layer,
|
| 434 |
+
activation_layer=_act_ctor, **init_conv_kwargs)]]
|
| 435 |
+
|
| 436 |
+
nf = ndf
|
| 437 |
+
for n in range(1, n_layers):
|
| 438 |
+
nf_prev = nf
|
| 439 |
+
nf = min(nf * 2, max_features)
|
| 440 |
+
|
| 441 |
+
cur_model = [
|
| 442 |
+
FFC_BN_ACT(nf_prev, nf,
|
| 443 |
+
kernel_size=kw, stride=2, padding=padw,
|
| 444 |
+
norm_layer=norm_layer,
|
| 445 |
+
activation_layer=_act_ctor,
|
| 446 |
+
**conv_kwargs)
|
| 447 |
+
]
|
| 448 |
+
sequence.append(cur_model)
|
| 449 |
+
|
| 450 |
+
nf_prev = nf
|
| 451 |
+
nf = min(nf * 2, 512)
|
| 452 |
+
|
| 453 |
+
cur_model = [
|
| 454 |
+
FFC_BN_ACT(nf_prev, nf,
|
| 455 |
+
kernel_size=kw, stride=1, padding=padw,
|
| 456 |
+
norm_layer=norm_layer,
|
| 457 |
+
activation_layer=lambda *args, **kwargs: nn.LeakyReLU(*args, negative_slope=0.2, **kwargs),
|
| 458 |
+
**conv_kwargs),
|
| 459 |
+
ConcatTupleLayer()
|
| 460 |
+
]
|
| 461 |
+
sequence.append(cur_model)
|
| 462 |
+
|
| 463 |
+
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
| 464 |
+
|
| 465 |
+
for n in range(len(sequence)):
|
| 466 |
+
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
| 467 |
+
|
| 468 |
+
def get_all_activations(self, x):
|
| 469 |
+
res = [x]
|
| 470 |
+
for n in range(self.n_layers + 2):
|
| 471 |
+
model = getattr(self, 'model' + str(n))
|
| 472 |
+
res.append(model(res[-1]))
|
| 473 |
+
return res[1:]
|
| 474 |
+
|
| 475 |
+
def forward(self, x):
|
| 476 |
+
act = self.get_all_activations(x)
|
| 477 |
+
feats = []
|
| 478 |
+
for out in act[:-1]:
|
| 479 |
+
if isinstance(out, tuple):
|
| 480 |
+
if torch.is_tensor(out[1]):
|
| 481 |
+
out = torch.cat(out, dim=1)
|
| 482 |
+
else:
|
| 483 |
+
out = out[0]
|
| 484 |
+
feats.append(out)
|
| 485 |
+
return act[-1], feats
|
annotator/lama/saicinpainting/training/modules/multidilated_conv.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import random
|
| 4 |
+
from annotator.lama.saicinpainting.training.modules.depthwise_sep_conv import DepthWiseSeperableConv
|
| 5 |
+
|
| 6 |
+
class MultidilatedConv(nn.Module):
|
| 7 |
+
def __init__(self, in_dim, out_dim, kernel_size, dilation_num=3, comb_mode='sum', equal_dim=True,
|
| 8 |
+
shared_weights=False, padding=1, min_dilation=1, shuffle_in_channels=False, use_depthwise=False, **kwargs):
|
| 9 |
+
super().__init__()
|
| 10 |
+
convs = []
|
| 11 |
+
self.equal_dim = equal_dim
|
| 12 |
+
assert comb_mode in ('cat_out', 'sum', 'cat_in', 'cat_both'), comb_mode
|
| 13 |
+
if comb_mode in ('cat_out', 'cat_both'):
|
| 14 |
+
self.cat_out = True
|
| 15 |
+
if equal_dim:
|
| 16 |
+
assert out_dim % dilation_num == 0
|
| 17 |
+
out_dims = [out_dim // dilation_num] * dilation_num
|
| 18 |
+
self.index = sum([[i + j * (out_dims[0]) for j in range(dilation_num)] for i in range(out_dims[0])], [])
|
| 19 |
+
else:
|
| 20 |
+
out_dims = [out_dim // 2 ** (i + 1) for i in range(dilation_num - 1)]
|
| 21 |
+
out_dims.append(out_dim - sum(out_dims))
|
| 22 |
+
index = []
|
| 23 |
+
starts = [0] + out_dims[:-1]
|
| 24 |
+
lengths = [out_dims[i] // out_dims[-1] for i in range(dilation_num)]
|
| 25 |
+
for i in range(out_dims[-1]):
|
| 26 |
+
for j in range(dilation_num):
|
| 27 |
+
index += list(range(starts[j], starts[j] + lengths[j]))
|
| 28 |
+
starts[j] += lengths[j]
|
| 29 |
+
self.index = index
|
| 30 |
+
assert(len(index) == out_dim)
|
| 31 |
+
self.out_dims = out_dims
|
| 32 |
+
else:
|
| 33 |
+
self.cat_out = False
|
| 34 |
+
self.out_dims = [out_dim] * dilation_num
|
| 35 |
+
|
| 36 |
+
if comb_mode in ('cat_in', 'cat_both'):
|
| 37 |
+
if equal_dim:
|
| 38 |
+
assert in_dim % dilation_num == 0
|
| 39 |
+
in_dims = [in_dim // dilation_num] * dilation_num
|
| 40 |
+
else:
|
| 41 |
+
in_dims = [in_dim // 2 ** (i + 1) for i in range(dilation_num - 1)]
|
| 42 |
+
in_dims.append(in_dim - sum(in_dims))
|
| 43 |
+
self.in_dims = in_dims
|
| 44 |
+
self.cat_in = True
|
| 45 |
+
else:
|
| 46 |
+
self.cat_in = False
|
| 47 |
+
self.in_dims = [in_dim] * dilation_num
|
| 48 |
+
|
| 49 |
+
conv_type = DepthWiseSeperableConv if use_depthwise else nn.Conv2d
|
| 50 |
+
dilation = min_dilation
|
| 51 |
+
for i in range(dilation_num):
|
| 52 |
+
if isinstance(padding, int):
|
| 53 |
+
cur_padding = padding * dilation
|
| 54 |
+
else:
|
| 55 |
+
cur_padding = padding[i]
|
| 56 |
+
convs.append(conv_type(
|
| 57 |
+
self.in_dims[i], self.out_dims[i], kernel_size, padding=cur_padding, dilation=dilation, **kwargs
|
| 58 |
+
))
|
| 59 |
+
if i > 0 and shared_weights:
|
| 60 |
+
convs[-1].weight = convs[0].weight
|
| 61 |
+
convs[-1].bias = convs[0].bias
|
| 62 |
+
dilation *= 2
|
| 63 |
+
self.convs = nn.ModuleList(convs)
|
| 64 |
+
|
| 65 |
+
self.shuffle_in_channels = shuffle_in_channels
|
| 66 |
+
if self.shuffle_in_channels:
|
| 67 |
+
# shuffle list as shuffling of tensors is nondeterministic
|
| 68 |
+
in_channels_permute = list(range(in_dim))
|
| 69 |
+
random.shuffle(in_channels_permute)
|
| 70 |
+
# save as buffer so it is saved and loaded with checkpoint
|
| 71 |
+
self.register_buffer('in_channels_permute', torch.tensor(in_channels_permute))
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
if self.shuffle_in_channels:
|
| 75 |
+
x = x[:, self.in_channels_permute]
|
| 76 |
+
|
| 77 |
+
outs = []
|
| 78 |
+
if self.cat_in:
|
| 79 |
+
if self.equal_dim:
|
| 80 |
+
x = x.chunk(len(self.convs), dim=1)
|
| 81 |
+
else:
|
| 82 |
+
new_x = []
|
| 83 |
+
start = 0
|
| 84 |
+
for dim in self.in_dims:
|
| 85 |
+
new_x.append(x[:, start:start+dim])
|
| 86 |
+
start += dim
|
| 87 |
+
x = new_x
|
| 88 |
+
for i, conv in enumerate(self.convs):
|
| 89 |
+
if self.cat_in:
|
| 90 |
+
input = x[i]
|
| 91 |
+
else:
|
| 92 |
+
input = x
|
| 93 |
+
outs.append(conv(input))
|
| 94 |
+
if self.cat_out:
|
| 95 |
+
out = torch.cat(outs, dim=1)[:, self.index]
|
| 96 |
+
else:
|
| 97 |
+
out = sum(outs)
|
| 98 |
+
return out
|
annotator/lama/saicinpainting/training/modules/multiscale.py
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Tuple, Union, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
from annotator.lama.saicinpainting.training.modules.base import get_conv_block_ctor, get_activation
|
| 8 |
+
from annotator.lama.saicinpainting.training.modules.pix2pixhd import ResnetBlock
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class ResNetHead(nn.Module):
|
| 12 |
+
def __init__(self, input_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
| 13 |
+
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True)):
|
| 14 |
+
assert (n_blocks >= 0)
|
| 15 |
+
super(ResNetHead, self).__init__()
|
| 16 |
+
|
| 17 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 18 |
+
|
| 19 |
+
model = [nn.ReflectionPad2d(3),
|
| 20 |
+
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
| 21 |
+
norm_layer(ngf),
|
| 22 |
+
activation]
|
| 23 |
+
|
| 24 |
+
### downsample
|
| 25 |
+
for i in range(n_downsampling):
|
| 26 |
+
mult = 2 ** i
|
| 27 |
+
model += [conv_layer(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
|
| 28 |
+
norm_layer(ngf * mult * 2),
|
| 29 |
+
activation]
|
| 30 |
+
|
| 31 |
+
mult = 2 ** n_downsampling
|
| 32 |
+
|
| 33 |
+
### resnet blocks
|
| 34 |
+
for i in range(n_blocks):
|
| 35 |
+
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
| 36 |
+
conv_kind=conv_kind)]
|
| 37 |
+
|
| 38 |
+
self.model = nn.Sequential(*model)
|
| 39 |
+
|
| 40 |
+
def forward(self, input):
|
| 41 |
+
return self.model(input)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class ResNetTail(nn.Module):
|
| 45 |
+
def __init__(self, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
| 46 |
+
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
| 47 |
+
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True), add_out_act=False, out_extra_layers_n=0,
|
| 48 |
+
add_in_proj=None):
|
| 49 |
+
assert (n_blocks >= 0)
|
| 50 |
+
super(ResNetTail, self).__init__()
|
| 51 |
+
|
| 52 |
+
mult = 2 ** n_downsampling
|
| 53 |
+
|
| 54 |
+
model = []
|
| 55 |
+
|
| 56 |
+
if add_in_proj is not None:
|
| 57 |
+
model.append(nn.Conv2d(add_in_proj, ngf * mult, kernel_size=1))
|
| 58 |
+
|
| 59 |
+
### resnet blocks
|
| 60 |
+
for i in range(n_blocks):
|
| 61 |
+
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
| 62 |
+
conv_kind=conv_kind)]
|
| 63 |
+
|
| 64 |
+
### upsample
|
| 65 |
+
for i in range(n_downsampling):
|
| 66 |
+
mult = 2 ** (n_downsampling - i)
|
| 67 |
+
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2), kernel_size=3, stride=2, padding=1,
|
| 68 |
+
output_padding=1),
|
| 69 |
+
up_norm_layer(int(ngf * mult / 2)),
|
| 70 |
+
up_activation]
|
| 71 |
+
self.model = nn.Sequential(*model)
|
| 72 |
+
|
| 73 |
+
out_layers = []
|
| 74 |
+
for _ in range(out_extra_layers_n):
|
| 75 |
+
out_layers += [nn.Conv2d(ngf, ngf, kernel_size=1, padding=0),
|
| 76 |
+
up_norm_layer(ngf),
|
| 77 |
+
up_activation]
|
| 78 |
+
out_layers += [nn.ReflectionPad2d(3),
|
| 79 |
+
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 80 |
+
|
| 81 |
+
if add_out_act:
|
| 82 |
+
out_layers.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 83 |
+
|
| 84 |
+
self.out_proj = nn.Sequential(*out_layers)
|
| 85 |
+
|
| 86 |
+
def forward(self, input, return_last_act=False):
|
| 87 |
+
features = self.model(input)
|
| 88 |
+
out = self.out_proj(features)
|
| 89 |
+
if return_last_act:
|
| 90 |
+
return out, features
|
| 91 |
+
else:
|
| 92 |
+
return out
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class MultiscaleResNet(nn.Module):
|
| 96 |
+
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=2, n_blocks_head=2, n_blocks_tail=6, n_scales=3,
|
| 97 |
+
norm_layer=nn.BatchNorm2d, padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
| 98 |
+
up_norm_layer=nn.BatchNorm2d, up_activation=nn.ReLU(True), add_out_act=False, out_extra_layers_n=0,
|
| 99 |
+
out_cumulative=False, return_only_hr=False):
|
| 100 |
+
super().__init__()
|
| 101 |
+
|
| 102 |
+
self.heads = nn.ModuleList([ResNetHead(input_nc, ngf=ngf, n_downsampling=n_downsampling,
|
| 103 |
+
n_blocks=n_blocks_head, norm_layer=norm_layer, padding_type=padding_type,
|
| 104 |
+
conv_kind=conv_kind, activation=activation)
|
| 105 |
+
for i in range(n_scales)])
|
| 106 |
+
tail_in_feats = ngf * (2 ** n_downsampling) + ngf
|
| 107 |
+
self.tails = nn.ModuleList([ResNetTail(output_nc,
|
| 108 |
+
ngf=ngf, n_downsampling=n_downsampling,
|
| 109 |
+
n_blocks=n_blocks_tail, norm_layer=norm_layer, padding_type=padding_type,
|
| 110 |
+
conv_kind=conv_kind, activation=activation, up_norm_layer=up_norm_layer,
|
| 111 |
+
up_activation=up_activation, add_out_act=add_out_act,
|
| 112 |
+
out_extra_layers_n=out_extra_layers_n,
|
| 113 |
+
add_in_proj=None if (i == n_scales - 1) else tail_in_feats)
|
| 114 |
+
for i in range(n_scales)])
|
| 115 |
+
|
| 116 |
+
self.out_cumulative = out_cumulative
|
| 117 |
+
self.return_only_hr = return_only_hr
|
| 118 |
+
|
| 119 |
+
@property
|
| 120 |
+
def num_scales(self):
|
| 121 |
+
return len(self.heads)
|
| 122 |
+
|
| 123 |
+
def forward(self, ms_inputs: List[torch.Tensor], smallest_scales_num: Optional[int] = None) \
|
| 124 |
+
-> Union[torch.Tensor, List[torch.Tensor]]:
|
| 125 |
+
"""
|
| 126 |
+
:param ms_inputs: List of inputs of different resolutions from HR to LR
|
| 127 |
+
:param smallest_scales_num: int or None, number of smallest scales to take at input
|
| 128 |
+
:return: Depending on return_only_hr:
|
| 129 |
+
True: Only the most HR output
|
| 130 |
+
False: List of outputs of different resolutions from HR to LR
|
| 131 |
+
"""
|
| 132 |
+
if smallest_scales_num is None:
|
| 133 |
+
assert len(self.heads) == len(ms_inputs), (len(self.heads), len(ms_inputs), smallest_scales_num)
|
| 134 |
+
smallest_scales_num = len(self.heads)
|
| 135 |
+
else:
|
| 136 |
+
assert smallest_scales_num == len(ms_inputs) <= len(self.heads), (len(self.heads), len(ms_inputs), smallest_scales_num)
|
| 137 |
+
|
| 138 |
+
cur_heads = self.heads[-smallest_scales_num:]
|
| 139 |
+
ms_features = [cur_head(cur_inp) for cur_head, cur_inp in zip(cur_heads, ms_inputs)]
|
| 140 |
+
|
| 141 |
+
all_outputs = []
|
| 142 |
+
prev_tail_features = None
|
| 143 |
+
for i in range(len(ms_features)):
|
| 144 |
+
scale_i = -i - 1
|
| 145 |
+
|
| 146 |
+
cur_tail_input = ms_features[-i - 1]
|
| 147 |
+
if prev_tail_features is not None:
|
| 148 |
+
if prev_tail_features.shape != cur_tail_input.shape:
|
| 149 |
+
prev_tail_features = F.interpolate(prev_tail_features, size=cur_tail_input.shape[2:],
|
| 150 |
+
mode='bilinear', align_corners=False)
|
| 151 |
+
cur_tail_input = torch.cat((cur_tail_input, prev_tail_features), dim=1)
|
| 152 |
+
|
| 153 |
+
cur_out, cur_tail_feats = self.tails[scale_i](cur_tail_input, return_last_act=True)
|
| 154 |
+
|
| 155 |
+
prev_tail_features = cur_tail_feats
|
| 156 |
+
all_outputs.append(cur_out)
|
| 157 |
+
|
| 158 |
+
if self.out_cumulative:
|
| 159 |
+
all_outputs_cum = [all_outputs[0]]
|
| 160 |
+
for i in range(1, len(ms_features)):
|
| 161 |
+
cur_out = all_outputs[i]
|
| 162 |
+
cur_out_cum = cur_out + F.interpolate(all_outputs_cum[-1], size=cur_out.shape[2:],
|
| 163 |
+
mode='bilinear', align_corners=False)
|
| 164 |
+
all_outputs_cum.append(cur_out_cum)
|
| 165 |
+
all_outputs = all_outputs_cum
|
| 166 |
+
|
| 167 |
+
if self.return_only_hr:
|
| 168 |
+
return all_outputs[-1]
|
| 169 |
+
else:
|
| 170 |
+
return all_outputs[::-1]
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class MultiscaleDiscriminatorSimple(nn.Module):
|
| 174 |
+
def __init__(self, ms_impl):
|
| 175 |
+
super().__init__()
|
| 176 |
+
self.ms_impl = nn.ModuleList(ms_impl)
|
| 177 |
+
|
| 178 |
+
@property
|
| 179 |
+
def num_scales(self):
|
| 180 |
+
return len(self.ms_impl)
|
| 181 |
+
|
| 182 |
+
def forward(self, ms_inputs: List[torch.Tensor], smallest_scales_num: Optional[int] = None) \
|
| 183 |
+
-> List[Tuple[torch.Tensor, List[torch.Tensor]]]:
|
| 184 |
+
"""
|
| 185 |
+
:param ms_inputs: List of inputs of different resolutions from HR to LR
|
| 186 |
+
:param smallest_scales_num: int or None, number of smallest scales to take at input
|
| 187 |
+
:return: List of pairs (prediction, features) for different resolutions from HR to LR
|
| 188 |
+
"""
|
| 189 |
+
if smallest_scales_num is None:
|
| 190 |
+
assert len(self.ms_impl) == len(ms_inputs), (len(self.ms_impl), len(ms_inputs), smallest_scales_num)
|
| 191 |
+
smallest_scales_num = len(self.heads)
|
| 192 |
+
else:
|
| 193 |
+
assert smallest_scales_num == len(ms_inputs) <= len(self.ms_impl), \
|
| 194 |
+
(len(self.ms_impl), len(ms_inputs), smallest_scales_num)
|
| 195 |
+
|
| 196 |
+
return [cur_discr(cur_input) for cur_discr, cur_input in zip(self.ms_impl[-smallest_scales_num:], ms_inputs)]
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
class SingleToMultiScaleInputMixin:
|
| 200 |
+
def forward(self, x: torch.Tensor) -> List:
|
| 201 |
+
orig_height, orig_width = x.shape[2:]
|
| 202 |
+
factors = [2 ** i for i in range(self.num_scales)]
|
| 203 |
+
ms_inputs = [F.interpolate(x, size=(orig_height // f, orig_width // f), mode='bilinear', align_corners=False)
|
| 204 |
+
for f in factors]
|
| 205 |
+
return super().forward(ms_inputs)
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class GeneratorMultiToSingleOutputMixin:
|
| 209 |
+
def forward(self, x):
|
| 210 |
+
return super().forward(x)[0]
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
class DiscriminatorMultiToSingleOutputMixin:
|
| 214 |
+
def forward(self, x):
|
| 215 |
+
out_feat_tuples = super().forward(x)
|
| 216 |
+
return out_feat_tuples[0][0], [f for _, flist in out_feat_tuples for f in flist]
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
class DiscriminatorMultiToSingleOutputStackedMixin:
|
| 220 |
+
def __init__(self, *args, return_feats_only_levels=None, **kwargs):
|
| 221 |
+
super().__init__(*args, **kwargs)
|
| 222 |
+
self.return_feats_only_levels = return_feats_only_levels
|
| 223 |
+
|
| 224 |
+
def forward(self, x):
|
| 225 |
+
out_feat_tuples = super().forward(x)
|
| 226 |
+
outs = [out for out, _ in out_feat_tuples]
|
| 227 |
+
scaled_outs = [outs[0]] + [F.interpolate(cur_out, size=outs[0].shape[-2:],
|
| 228 |
+
mode='bilinear', align_corners=False)
|
| 229 |
+
for cur_out in outs[1:]]
|
| 230 |
+
out = torch.cat(scaled_outs, dim=1)
|
| 231 |
+
if self.return_feats_only_levels is not None:
|
| 232 |
+
feat_lists = [out_feat_tuples[i][1] for i in self.return_feats_only_levels]
|
| 233 |
+
else:
|
| 234 |
+
feat_lists = [flist for _, flist in out_feat_tuples]
|
| 235 |
+
feats = [f for flist in feat_lists for f in flist]
|
| 236 |
+
return out, feats
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class MultiscaleDiscrSingleInput(SingleToMultiScaleInputMixin, DiscriminatorMultiToSingleOutputStackedMixin, MultiscaleDiscriminatorSimple):
|
| 240 |
+
pass
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
class MultiscaleResNetSingle(GeneratorMultiToSingleOutputMixin, SingleToMultiScaleInputMixin, MultiscaleResNet):
|
| 244 |
+
pass
|
annotator/lama/saicinpainting/training/modules/pix2pixhd.py
ADDED
|
@@ -0,0 +1,669 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# original: https://github.com/NVIDIA/pix2pixHD/blob/master/models/networks.py
|
| 2 |
+
import collections
|
| 3 |
+
from functools import partial
|
| 4 |
+
import functools
|
| 5 |
+
import logging
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
|
| 11 |
+
from annotator.lama.saicinpainting.training.modules.base import BaseDiscriminator, deconv_factory, get_conv_block_ctor, get_norm_layer, get_activation
|
| 12 |
+
from annotator.lama.saicinpainting.training.modules.ffc import FFCResnetBlock
|
| 13 |
+
from annotator.lama.saicinpainting.training.modules.multidilated_conv import MultidilatedConv
|
| 14 |
+
|
| 15 |
+
class DotDict(defaultdict):
|
| 16 |
+
# https://stackoverflow.com/questions/2352181/how-to-use-a-dot-to-access-members-of-dictionary
|
| 17 |
+
"""dot.notation access to dictionary attributes"""
|
| 18 |
+
__getattr__ = defaultdict.get
|
| 19 |
+
__setattr__ = defaultdict.__setitem__
|
| 20 |
+
__delattr__ = defaultdict.__delitem__
|
| 21 |
+
|
| 22 |
+
class Identity(nn.Module):
|
| 23 |
+
def __init__(self):
|
| 24 |
+
super().__init__()
|
| 25 |
+
|
| 26 |
+
def forward(self, x):
|
| 27 |
+
return x
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class ResnetBlock(nn.Module):
|
| 31 |
+
def __init__(self, dim, padding_type, norm_layer, activation=nn.ReLU(True), use_dropout=False, conv_kind='default',
|
| 32 |
+
dilation=1, in_dim=None, groups=1, second_dilation=None):
|
| 33 |
+
super(ResnetBlock, self).__init__()
|
| 34 |
+
self.in_dim = in_dim
|
| 35 |
+
self.dim = dim
|
| 36 |
+
if second_dilation is None:
|
| 37 |
+
second_dilation = dilation
|
| 38 |
+
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, activation, use_dropout,
|
| 39 |
+
conv_kind=conv_kind, dilation=dilation, in_dim=in_dim, groups=groups,
|
| 40 |
+
second_dilation=second_dilation)
|
| 41 |
+
|
| 42 |
+
if self.in_dim is not None:
|
| 43 |
+
self.input_conv = nn.Conv2d(in_dim, dim, 1)
|
| 44 |
+
|
| 45 |
+
self.out_channnels = dim
|
| 46 |
+
|
| 47 |
+
def build_conv_block(self, dim, padding_type, norm_layer, activation, use_dropout, conv_kind='default',
|
| 48 |
+
dilation=1, in_dim=None, groups=1, second_dilation=1):
|
| 49 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 50 |
+
|
| 51 |
+
conv_block = []
|
| 52 |
+
p = 0
|
| 53 |
+
if padding_type == 'reflect':
|
| 54 |
+
conv_block += [nn.ReflectionPad2d(dilation)]
|
| 55 |
+
elif padding_type == 'replicate':
|
| 56 |
+
conv_block += [nn.ReplicationPad2d(dilation)]
|
| 57 |
+
elif padding_type == 'zero':
|
| 58 |
+
p = dilation
|
| 59 |
+
else:
|
| 60 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 61 |
+
|
| 62 |
+
if in_dim is None:
|
| 63 |
+
in_dim = dim
|
| 64 |
+
|
| 65 |
+
conv_block += [conv_layer(in_dim, dim, kernel_size=3, padding=p, dilation=dilation),
|
| 66 |
+
norm_layer(dim),
|
| 67 |
+
activation]
|
| 68 |
+
if use_dropout:
|
| 69 |
+
conv_block += [nn.Dropout(0.5)]
|
| 70 |
+
|
| 71 |
+
p = 0
|
| 72 |
+
if padding_type == 'reflect':
|
| 73 |
+
conv_block += [nn.ReflectionPad2d(second_dilation)]
|
| 74 |
+
elif padding_type == 'replicate':
|
| 75 |
+
conv_block += [nn.ReplicationPad2d(second_dilation)]
|
| 76 |
+
elif padding_type == 'zero':
|
| 77 |
+
p = second_dilation
|
| 78 |
+
else:
|
| 79 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 80 |
+
conv_block += [conv_layer(dim, dim, kernel_size=3, padding=p, dilation=second_dilation, groups=groups),
|
| 81 |
+
norm_layer(dim)]
|
| 82 |
+
|
| 83 |
+
return nn.Sequential(*conv_block)
|
| 84 |
+
|
| 85 |
+
def forward(self, x):
|
| 86 |
+
x_before = x
|
| 87 |
+
if self.in_dim is not None:
|
| 88 |
+
x = self.input_conv(x)
|
| 89 |
+
out = x + self.conv_block(x_before)
|
| 90 |
+
return out
|
| 91 |
+
|
| 92 |
+
class ResnetBlock5x5(nn.Module):
|
| 93 |
+
def __init__(self, dim, padding_type, norm_layer, activation=nn.ReLU(True), use_dropout=False, conv_kind='default',
|
| 94 |
+
dilation=1, in_dim=None, groups=1, second_dilation=None):
|
| 95 |
+
super(ResnetBlock5x5, self).__init__()
|
| 96 |
+
self.in_dim = in_dim
|
| 97 |
+
self.dim = dim
|
| 98 |
+
if second_dilation is None:
|
| 99 |
+
second_dilation = dilation
|
| 100 |
+
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, activation, use_dropout,
|
| 101 |
+
conv_kind=conv_kind, dilation=dilation, in_dim=in_dim, groups=groups,
|
| 102 |
+
second_dilation=second_dilation)
|
| 103 |
+
|
| 104 |
+
if self.in_dim is not None:
|
| 105 |
+
self.input_conv = nn.Conv2d(in_dim, dim, 1)
|
| 106 |
+
|
| 107 |
+
self.out_channnels = dim
|
| 108 |
+
|
| 109 |
+
def build_conv_block(self, dim, padding_type, norm_layer, activation, use_dropout, conv_kind='default',
|
| 110 |
+
dilation=1, in_dim=None, groups=1, second_dilation=1):
|
| 111 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 112 |
+
|
| 113 |
+
conv_block = []
|
| 114 |
+
p = 0
|
| 115 |
+
if padding_type == 'reflect':
|
| 116 |
+
conv_block += [nn.ReflectionPad2d(dilation * 2)]
|
| 117 |
+
elif padding_type == 'replicate':
|
| 118 |
+
conv_block += [nn.ReplicationPad2d(dilation * 2)]
|
| 119 |
+
elif padding_type == 'zero':
|
| 120 |
+
p = dilation * 2
|
| 121 |
+
else:
|
| 122 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 123 |
+
|
| 124 |
+
if in_dim is None:
|
| 125 |
+
in_dim = dim
|
| 126 |
+
|
| 127 |
+
conv_block += [conv_layer(in_dim, dim, kernel_size=5, padding=p, dilation=dilation),
|
| 128 |
+
norm_layer(dim),
|
| 129 |
+
activation]
|
| 130 |
+
if use_dropout:
|
| 131 |
+
conv_block += [nn.Dropout(0.5)]
|
| 132 |
+
|
| 133 |
+
p = 0
|
| 134 |
+
if padding_type == 'reflect':
|
| 135 |
+
conv_block += [nn.ReflectionPad2d(second_dilation * 2)]
|
| 136 |
+
elif padding_type == 'replicate':
|
| 137 |
+
conv_block += [nn.ReplicationPad2d(second_dilation * 2)]
|
| 138 |
+
elif padding_type == 'zero':
|
| 139 |
+
p = second_dilation * 2
|
| 140 |
+
else:
|
| 141 |
+
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
|
| 142 |
+
conv_block += [conv_layer(dim, dim, kernel_size=5, padding=p, dilation=second_dilation, groups=groups),
|
| 143 |
+
norm_layer(dim)]
|
| 144 |
+
|
| 145 |
+
return nn.Sequential(*conv_block)
|
| 146 |
+
|
| 147 |
+
def forward(self, x):
|
| 148 |
+
x_before = x
|
| 149 |
+
if self.in_dim is not None:
|
| 150 |
+
x = self.input_conv(x)
|
| 151 |
+
out = x + self.conv_block(x_before)
|
| 152 |
+
return out
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
class MultidilatedResnetBlock(nn.Module):
|
| 156 |
+
def __init__(self, dim, padding_type, conv_layer, norm_layer, activation=nn.ReLU(True), use_dropout=False):
|
| 157 |
+
super().__init__()
|
| 158 |
+
self.conv_block = self.build_conv_block(dim, padding_type, conv_layer, norm_layer, activation, use_dropout)
|
| 159 |
+
|
| 160 |
+
def build_conv_block(self, dim, padding_type, conv_layer, norm_layer, activation, use_dropout, dilation=1):
|
| 161 |
+
conv_block = []
|
| 162 |
+
conv_block += [conv_layer(dim, dim, kernel_size=3, padding_mode=padding_type),
|
| 163 |
+
norm_layer(dim),
|
| 164 |
+
activation]
|
| 165 |
+
if use_dropout:
|
| 166 |
+
conv_block += [nn.Dropout(0.5)]
|
| 167 |
+
|
| 168 |
+
conv_block += [conv_layer(dim, dim, kernel_size=3, padding_mode=padding_type),
|
| 169 |
+
norm_layer(dim)]
|
| 170 |
+
|
| 171 |
+
return nn.Sequential(*conv_block)
|
| 172 |
+
|
| 173 |
+
def forward(self, x):
|
| 174 |
+
out = x + self.conv_block(x)
|
| 175 |
+
return out
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class MultiDilatedGlobalGenerator(nn.Module):
|
| 179 |
+
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3,
|
| 180 |
+
n_blocks=3, norm_layer=nn.BatchNorm2d,
|
| 181 |
+
padding_type='reflect', conv_kind='default',
|
| 182 |
+
deconv_kind='convtranspose', activation=nn.ReLU(True),
|
| 183 |
+
up_norm_layer=nn.BatchNorm2d, affine=None, up_activation=nn.ReLU(True),
|
| 184 |
+
add_out_act=True, max_features=1024, multidilation_kwargs={},
|
| 185 |
+
ffc_positions=None, ffc_kwargs={}):
|
| 186 |
+
assert (n_blocks >= 0)
|
| 187 |
+
super().__init__()
|
| 188 |
+
|
| 189 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 190 |
+
resnet_conv_layer = functools.partial(get_conv_block_ctor('multidilated'), **multidilation_kwargs)
|
| 191 |
+
norm_layer = get_norm_layer(norm_layer)
|
| 192 |
+
if affine is not None:
|
| 193 |
+
norm_layer = partial(norm_layer, affine=affine)
|
| 194 |
+
up_norm_layer = get_norm_layer(up_norm_layer)
|
| 195 |
+
if affine is not None:
|
| 196 |
+
up_norm_layer = partial(up_norm_layer, affine=affine)
|
| 197 |
+
|
| 198 |
+
model = [nn.ReflectionPad2d(3),
|
| 199 |
+
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
| 200 |
+
norm_layer(ngf),
|
| 201 |
+
activation]
|
| 202 |
+
|
| 203 |
+
identity = Identity()
|
| 204 |
+
### downsample
|
| 205 |
+
for i in range(n_downsampling):
|
| 206 |
+
mult = 2 ** i
|
| 207 |
+
|
| 208 |
+
model += [conv_layer(min(max_features, ngf * mult),
|
| 209 |
+
min(max_features, ngf * mult * 2),
|
| 210 |
+
kernel_size=3, stride=2, padding=1),
|
| 211 |
+
norm_layer(min(max_features, ngf * mult * 2)),
|
| 212 |
+
activation]
|
| 213 |
+
|
| 214 |
+
mult = 2 ** n_downsampling
|
| 215 |
+
feats_num_bottleneck = min(max_features, ngf * mult)
|
| 216 |
+
|
| 217 |
+
### resnet blocks
|
| 218 |
+
for i in range(n_blocks):
|
| 219 |
+
if ffc_positions is not None and i in ffc_positions:
|
| 220 |
+
model += [FFCResnetBlock(feats_num_bottleneck, padding_type, norm_layer, activation_layer=nn.ReLU,
|
| 221 |
+
inline=True, **ffc_kwargs)]
|
| 222 |
+
model += [MultidilatedResnetBlock(feats_num_bottleneck, padding_type=padding_type,
|
| 223 |
+
conv_layer=resnet_conv_layer, activation=activation,
|
| 224 |
+
norm_layer=norm_layer)]
|
| 225 |
+
|
| 226 |
+
### upsample
|
| 227 |
+
for i in range(n_downsampling):
|
| 228 |
+
mult = 2 ** (n_downsampling - i)
|
| 229 |
+
model += deconv_factory(deconv_kind, ngf, mult, up_norm_layer, up_activation, max_features)
|
| 230 |
+
model += [nn.ReflectionPad2d(3),
|
| 231 |
+
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 232 |
+
if add_out_act:
|
| 233 |
+
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 234 |
+
self.model = nn.Sequential(*model)
|
| 235 |
+
|
| 236 |
+
def forward(self, input):
|
| 237 |
+
return self.model(input)
|
| 238 |
+
|
| 239 |
+
class ConfigGlobalGenerator(nn.Module):
|
| 240 |
+
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3,
|
| 241 |
+
n_blocks=3, norm_layer=nn.BatchNorm2d,
|
| 242 |
+
padding_type='reflect', conv_kind='default',
|
| 243 |
+
deconv_kind='convtranspose', activation=nn.ReLU(True),
|
| 244 |
+
up_norm_layer=nn.BatchNorm2d, affine=None, up_activation=nn.ReLU(True),
|
| 245 |
+
add_out_act=True, max_features=1024,
|
| 246 |
+
manual_block_spec=[],
|
| 247 |
+
resnet_block_kind='multidilatedresnetblock',
|
| 248 |
+
resnet_conv_kind='multidilated',
|
| 249 |
+
resnet_dilation=1,
|
| 250 |
+
multidilation_kwargs={}):
|
| 251 |
+
assert (n_blocks >= 0)
|
| 252 |
+
super().__init__()
|
| 253 |
+
|
| 254 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 255 |
+
resnet_conv_layer = functools.partial(get_conv_block_ctor(resnet_conv_kind), **multidilation_kwargs)
|
| 256 |
+
norm_layer = get_norm_layer(norm_layer)
|
| 257 |
+
if affine is not None:
|
| 258 |
+
norm_layer = partial(norm_layer, affine=affine)
|
| 259 |
+
up_norm_layer = get_norm_layer(up_norm_layer)
|
| 260 |
+
if affine is not None:
|
| 261 |
+
up_norm_layer = partial(up_norm_layer, affine=affine)
|
| 262 |
+
|
| 263 |
+
model = [nn.ReflectionPad2d(3),
|
| 264 |
+
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
| 265 |
+
norm_layer(ngf),
|
| 266 |
+
activation]
|
| 267 |
+
|
| 268 |
+
identity = Identity()
|
| 269 |
+
|
| 270 |
+
### downsample
|
| 271 |
+
for i in range(n_downsampling):
|
| 272 |
+
mult = 2 ** i
|
| 273 |
+
model += [conv_layer(min(max_features, ngf * mult),
|
| 274 |
+
min(max_features, ngf * mult * 2),
|
| 275 |
+
kernel_size=3, stride=2, padding=1),
|
| 276 |
+
norm_layer(min(max_features, ngf * mult * 2)),
|
| 277 |
+
activation]
|
| 278 |
+
|
| 279 |
+
mult = 2 ** n_downsampling
|
| 280 |
+
feats_num_bottleneck = min(max_features, ngf * mult)
|
| 281 |
+
|
| 282 |
+
if len(manual_block_spec) == 0:
|
| 283 |
+
manual_block_spec = [
|
| 284 |
+
DotDict(lambda : None, {
|
| 285 |
+
'n_blocks': n_blocks,
|
| 286 |
+
'use_default': True})
|
| 287 |
+
]
|
| 288 |
+
|
| 289 |
+
### resnet blocks
|
| 290 |
+
for block_spec in manual_block_spec:
|
| 291 |
+
def make_and_add_blocks(model, block_spec):
|
| 292 |
+
block_spec = DotDict(lambda : None, block_spec)
|
| 293 |
+
if not block_spec.use_default:
|
| 294 |
+
resnet_conv_layer = functools.partial(get_conv_block_ctor(block_spec.resnet_conv_kind), **block_spec.multidilation_kwargs)
|
| 295 |
+
resnet_conv_kind = block_spec.resnet_conv_kind
|
| 296 |
+
resnet_block_kind = block_spec.resnet_block_kind
|
| 297 |
+
if block_spec.resnet_dilation is not None:
|
| 298 |
+
resnet_dilation = block_spec.resnet_dilation
|
| 299 |
+
for i in range(block_spec.n_blocks):
|
| 300 |
+
if resnet_block_kind == "multidilatedresnetblock":
|
| 301 |
+
model += [MultidilatedResnetBlock(feats_num_bottleneck, padding_type=padding_type,
|
| 302 |
+
conv_layer=resnet_conv_layer, activation=activation,
|
| 303 |
+
norm_layer=norm_layer)]
|
| 304 |
+
if resnet_block_kind == "resnetblock":
|
| 305 |
+
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
| 306 |
+
conv_kind=resnet_conv_kind)]
|
| 307 |
+
if resnet_block_kind == "resnetblock5x5":
|
| 308 |
+
model += [ResnetBlock5x5(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
| 309 |
+
conv_kind=resnet_conv_kind)]
|
| 310 |
+
if resnet_block_kind == "resnetblockdwdil":
|
| 311 |
+
model += [ResnetBlock(ngf * mult, padding_type=padding_type, activation=activation, norm_layer=norm_layer,
|
| 312 |
+
conv_kind=resnet_conv_kind, dilation=resnet_dilation, second_dilation=resnet_dilation)]
|
| 313 |
+
make_and_add_blocks(model, block_spec)
|
| 314 |
+
|
| 315 |
+
### upsample
|
| 316 |
+
for i in range(n_downsampling):
|
| 317 |
+
mult = 2 ** (n_downsampling - i)
|
| 318 |
+
model += deconv_factory(deconv_kind, ngf, mult, up_norm_layer, up_activation, max_features)
|
| 319 |
+
model += [nn.ReflectionPad2d(3),
|
| 320 |
+
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 321 |
+
if add_out_act:
|
| 322 |
+
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 323 |
+
self.model = nn.Sequential(*model)
|
| 324 |
+
|
| 325 |
+
def forward(self, input):
|
| 326 |
+
return self.model(input)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
def make_dil_blocks(dilated_blocks_n, dilation_block_kind, dilated_block_kwargs):
|
| 330 |
+
blocks = []
|
| 331 |
+
for i in range(dilated_blocks_n):
|
| 332 |
+
if dilation_block_kind == 'simple':
|
| 333 |
+
blocks.append(ResnetBlock(**dilated_block_kwargs, dilation=2 ** (i + 1)))
|
| 334 |
+
elif dilation_block_kind == 'multi':
|
| 335 |
+
blocks.append(MultidilatedResnetBlock(**dilated_block_kwargs))
|
| 336 |
+
else:
|
| 337 |
+
raise ValueError(f'dilation_block_kind could not be "{dilation_block_kind}"')
|
| 338 |
+
return blocks
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
class GlobalGenerator(nn.Module):
|
| 342 |
+
def __init__(self, input_nc, output_nc, ngf=64, n_downsampling=3, n_blocks=9, norm_layer=nn.BatchNorm2d,
|
| 343 |
+
padding_type='reflect', conv_kind='default', activation=nn.ReLU(True),
|
| 344 |
+
up_norm_layer=nn.BatchNorm2d, affine=None,
|
| 345 |
+
up_activation=nn.ReLU(True), dilated_blocks_n=0, dilated_blocks_n_start=0,
|
| 346 |
+
dilated_blocks_n_middle=0,
|
| 347 |
+
add_out_act=True,
|
| 348 |
+
max_features=1024, is_resblock_depthwise=False,
|
| 349 |
+
ffc_positions=None, ffc_kwargs={}, dilation=1, second_dilation=None,
|
| 350 |
+
dilation_block_kind='simple', multidilation_kwargs={}):
|
| 351 |
+
assert (n_blocks >= 0)
|
| 352 |
+
super().__init__()
|
| 353 |
+
|
| 354 |
+
conv_layer = get_conv_block_ctor(conv_kind)
|
| 355 |
+
norm_layer = get_norm_layer(norm_layer)
|
| 356 |
+
if affine is not None:
|
| 357 |
+
norm_layer = partial(norm_layer, affine=affine)
|
| 358 |
+
up_norm_layer = get_norm_layer(up_norm_layer)
|
| 359 |
+
if affine is not None:
|
| 360 |
+
up_norm_layer = partial(up_norm_layer, affine=affine)
|
| 361 |
+
|
| 362 |
+
if ffc_positions is not None:
|
| 363 |
+
ffc_positions = collections.Counter(ffc_positions)
|
| 364 |
+
|
| 365 |
+
model = [nn.ReflectionPad2d(3),
|
| 366 |
+
conv_layer(input_nc, ngf, kernel_size=7, padding=0),
|
| 367 |
+
norm_layer(ngf),
|
| 368 |
+
activation]
|
| 369 |
+
|
| 370 |
+
identity = Identity()
|
| 371 |
+
### downsample
|
| 372 |
+
for i in range(n_downsampling):
|
| 373 |
+
mult = 2 ** i
|
| 374 |
+
|
| 375 |
+
model += [conv_layer(min(max_features, ngf * mult),
|
| 376 |
+
min(max_features, ngf * mult * 2),
|
| 377 |
+
kernel_size=3, stride=2, padding=1),
|
| 378 |
+
norm_layer(min(max_features, ngf * mult * 2)),
|
| 379 |
+
activation]
|
| 380 |
+
|
| 381 |
+
mult = 2 ** n_downsampling
|
| 382 |
+
feats_num_bottleneck = min(max_features, ngf * mult)
|
| 383 |
+
|
| 384 |
+
dilated_block_kwargs = dict(dim=feats_num_bottleneck, padding_type=padding_type,
|
| 385 |
+
activation=activation, norm_layer=norm_layer)
|
| 386 |
+
if dilation_block_kind == 'simple':
|
| 387 |
+
dilated_block_kwargs['conv_kind'] = conv_kind
|
| 388 |
+
elif dilation_block_kind == 'multi':
|
| 389 |
+
dilated_block_kwargs['conv_layer'] = functools.partial(
|
| 390 |
+
get_conv_block_ctor('multidilated'), **multidilation_kwargs)
|
| 391 |
+
|
| 392 |
+
# dilated blocks at the start of the bottleneck sausage
|
| 393 |
+
if dilated_blocks_n_start is not None and dilated_blocks_n_start > 0:
|
| 394 |
+
model += make_dil_blocks(dilated_blocks_n_start, dilation_block_kind, dilated_block_kwargs)
|
| 395 |
+
|
| 396 |
+
# resnet blocks
|
| 397 |
+
for i in range(n_blocks):
|
| 398 |
+
# dilated blocks at the middle of the bottleneck sausage
|
| 399 |
+
if i == n_blocks // 2 and dilated_blocks_n_middle is not None and dilated_blocks_n_middle > 0:
|
| 400 |
+
model += make_dil_blocks(dilated_blocks_n_middle, dilation_block_kind, dilated_block_kwargs)
|
| 401 |
+
|
| 402 |
+
if ffc_positions is not None and i in ffc_positions:
|
| 403 |
+
for _ in range(ffc_positions[i]): # same position can occur more than once
|
| 404 |
+
model += [FFCResnetBlock(feats_num_bottleneck, padding_type, norm_layer, activation_layer=nn.ReLU,
|
| 405 |
+
inline=True, **ffc_kwargs)]
|
| 406 |
+
|
| 407 |
+
if is_resblock_depthwise:
|
| 408 |
+
resblock_groups = feats_num_bottleneck
|
| 409 |
+
else:
|
| 410 |
+
resblock_groups = 1
|
| 411 |
+
|
| 412 |
+
model += [ResnetBlock(feats_num_bottleneck, padding_type=padding_type, activation=activation,
|
| 413 |
+
norm_layer=norm_layer, conv_kind=conv_kind, groups=resblock_groups,
|
| 414 |
+
dilation=dilation, second_dilation=second_dilation)]
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
# dilated blocks at the end of the bottleneck sausage
|
| 418 |
+
if dilated_blocks_n is not None and dilated_blocks_n > 0:
|
| 419 |
+
model += make_dil_blocks(dilated_blocks_n, dilation_block_kind, dilated_block_kwargs)
|
| 420 |
+
|
| 421 |
+
# upsample
|
| 422 |
+
for i in range(n_downsampling):
|
| 423 |
+
mult = 2 ** (n_downsampling - i)
|
| 424 |
+
model += [nn.ConvTranspose2d(min(max_features, ngf * mult),
|
| 425 |
+
min(max_features, int(ngf * mult / 2)),
|
| 426 |
+
kernel_size=3, stride=2, padding=1, output_padding=1),
|
| 427 |
+
up_norm_layer(min(max_features, int(ngf * mult / 2))),
|
| 428 |
+
up_activation]
|
| 429 |
+
model += [nn.ReflectionPad2d(3),
|
| 430 |
+
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
|
| 431 |
+
if add_out_act:
|
| 432 |
+
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 433 |
+
self.model = nn.Sequential(*model)
|
| 434 |
+
|
| 435 |
+
def forward(self, input):
|
| 436 |
+
return self.model(input)
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
class GlobalGeneratorGated(GlobalGenerator):
|
| 440 |
+
def __init__(self, *args, **kwargs):
|
| 441 |
+
real_kwargs=dict(
|
| 442 |
+
conv_kind='gated_bn_relu',
|
| 443 |
+
activation=nn.Identity(),
|
| 444 |
+
norm_layer=nn.Identity
|
| 445 |
+
)
|
| 446 |
+
real_kwargs.update(kwargs)
|
| 447 |
+
super().__init__(*args, **real_kwargs)
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
class GlobalGeneratorFromSuperChannels(nn.Module):
|
| 451 |
+
def __init__(self, input_nc, output_nc, n_downsampling, n_blocks, super_channels, norm_layer="bn", padding_type='reflect', add_out_act=True):
|
| 452 |
+
super().__init__()
|
| 453 |
+
self.n_downsampling = n_downsampling
|
| 454 |
+
norm_layer = get_norm_layer(norm_layer)
|
| 455 |
+
if type(norm_layer) == functools.partial:
|
| 456 |
+
use_bias = (norm_layer.func == nn.InstanceNorm2d)
|
| 457 |
+
else:
|
| 458 |
+
use_bias = (norm_layer == nn.InstanceNorm2d)
|
| 459 |
+
|
| 460 |
+
channels = self.convert_super_channels(super_channels)
|
| 461 |
+
self.channels = channels
|
| 462 |
+
|
| 463 |
+
model = [nn.ReflectionPad2d(3),
|
| 464 |
+
nn.Conv2d(input_nc, channels[0], kernel_size=7, padding=0, bias=use_bias),
|
| 465 |
+
norm_layer(channels[0]),
|
| 466 |
+
nn.ReLU(True)]
|
| 467 |
+
|
| 468 |
+
for i in range(n_downsampling): # add downsampling layers
|
| 469 |
+
mult = 2 ** i
|
| 470 |
+
model += [nn.Conv2d(channels[0+i], channels[1+i], kernel_size=3, stride=2, padding=1, bias=use_bias),
|
| 471 |
+
norm_layer(channels[1+i]),
|
| 472 |
+
nn.ReLU(True)]
|
| 473 |
+
|
| 474 |
+
mult = 2 ** n_downsampling
|
| 475 |
+
|
| 476 |
+
n_blocks1 = n_blocks // 3
|
| 477 |
+
n_blocks2 = n_blocks1
|
| 478 |
+
n_blocks3 = n_blocks - n_blocks1 - n_blocks2
|
| 479 |
+
|
| 480 |
+
for i in range(n_blocks1):
|
| 481 |
+
c = n_downsampling
|
| 482 |
+
dim = channels[c]
|
| 483 |
+
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer)]
|
| 484 |
+
|
| 485 |
+
for i in range(n_blocks2):
|
| 486 |
+
c = n_downsampling+1
|
| 487 |
+
dim = channels[c]
|
| 488 |
+
kwargs = {}
|
| 489 |
+
if i == 0:
|
| 490 |
+
kwargs = {"in_dim": channels[c-1]}
|
| 491 |
+
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer, **kwargs)]
|
| 492 |
+
|
| 493 |
+
for i in range(n_blocks3):
|
| 494 |
+
c = n_downsampling+2
|
| 495 |
+
dim = channels[c]
|
| 496 |
+
kwargs = {}
|
| 497 |
+
if i == 0:
|
| 498 |
+
kwargs = {"in_dim": channels[c-1]}
|
| 499 |
+
model += [ResnetBlock(dim, padding_type=padding_type, norm_layer=norm_layer, **kwargs)]
|
| 500 |
+
|
| 501 |
+
for i in range(n_downsampling): # add upsampling layers
|
| 502 |
+
mult = 2 ** (n_downsampling - i)
|
| 503 |
+
model += [nn.ConvTranspose2d(channels[n_downsampling+3+i],
|
| 504 |
+
channels[n_downsampling+3+i+1],
|
| 505 |
+
kernel_size=3, stride=2,
|
| 506 |
+
padding=1, output_padding=1,
|
| 507 |
+
bias=use_bias),
|
| 508 |
+
norm_layer(channels[n_downsampling+3+i+1]),
|
| 509 |
+
nn.ReLU(True)]
|
| 510 |
+
model += [nn.ReflectionPad2d(3)]
|
| 511 |
+
model += [nn.Conv2d(channels[2*n_downsampling+3], output_nc, kernel_size=7, padding=0)]
|
| 512 |
+
|
| 513 |
+
if add_out_act:
|
| 514 |
+
model.append(get_activation('tanh' if add_out_act is True else add_out_act))
|
| 515 |
+
self.model = nn.Sequential(*model)
|
| 516 |
+
|
| 517 |
+
def convert_super_channels(self, super_channels):
|
| 518 |
+
n_downsampling = self.n_downsampling
|
| 519 |
+
result = []
|
| 520 |
+
cnt = 0
|
| 521 |
+
|
| 522 |
+
if n_downsampling == 2:
|
| 523 |
+
N1 = 10
|
| 524 |
+
elif n_downsampling == 3:
|
| 525 |
+
N1 = 13
|
| 526 |
+
else:
|
| 527 |
+
raise NotImplementedError
|
| 528 |
+
|
| 529 |
+
for i in range(0, N1):
|
| 530 |
+
if i in [1,4,7,10]:
|
| 531 |
+
channel = super_channels[cnt] * (2 ** cnt)
|
| 532 |
+
config = {'channel': channel}
|
| 533 |
+
result.append(channel)
|
| 534 |
+
logging.info(f"Downsample channels {result[-1]}")
|
| 535 |
+
cnt += 1
|
| 536 |
+
|
| 537 |
+
for i in range(3):
|
| 538 |
+
for counter, j in enumerate(range(N1 + i * 3, N1 + 3 + i * 3)):
|
| 539 |
+
if len(super_channels) == 6:
|
| 540 |
+
channel = super_channels[3] * 4
|
| 541 |
+
else:
|
| 542 |
+
channel = super_channels[i + 3] * 4
|
| 543 |
+
config = {'channel': channel}
|
| 544 |
+
if counter == 0:
|
| 545 |
+
result.append(channel)
|
| 546 |
+
logging.info(f"Bottleneck channels {result[-1]}")
|
| 547 |
+
cnt = 2
|
| 548 |
+
|
| 549 |
+
for i in range(N1+9, N1+21):
|
| 550 |
+
if i in [22, 25,28]:
|
| 551 |
+
cnt -= 1
|
| 552 |
+
if len(super_channels) == 6:
|
| 553 |
+
channel = super_channels[5 - cnt] * (2 ** cnt)
|
| 554 |
+
else:
|
| 555 |
+
channel = super_channels[7 - cnt] * (2 ** cnt)
|
| 556 |
+
result.append(int(channel))
|
| 557 |
+
logging.info(f"Upsample channels {result[-1]}")
|
| 558 |
+
return result
|
| 559 |
+
|
| 560 |
+
def forward(self, input):
|
| 561 |
+
return self.model(input)
|
| 562 |
+
|
| 563 |
+
|
| 564 |
+
# Defines the PatchGAN discriminator with the specified arguments.
|
| 565 |
+
class NLayerDiscriminator(BaseDiscriminator):
|
| 566 |
+
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d,):
|
| 567 |
+
super().__init__()
|
| 568 |
+
self.n_layers = n_layers
|
| 569 |
+
|
| 570 |
+
kw = 4
|
| 571 |
+
padw = int(np.ceil((kw-1.0)/2))
|
| 572 |
+
sequence = [[nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
|
| 573 |
+
nn.LeakyReLU(0.2, True)]]
|
| 574 |
+
|
| 575 |
+
nf = ndf
|
| 576 |
+
for n in range(1, n_layers):
|
| 577 |
+
nf_prev = nf
|
| 578 |
+
nf = min(nf * 2, 512)
|
| 579 |
+
|
| 580 |
+
cur_model = []
|
| 581 |
+
cur_model += [
|
| 582 |
+
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=2, padding=padw),
|
| 583 |
+
norm_layer(nf),
|
| 584 |
+
nn.LeakyReLU(0.2, True)
|
| 585 |
+
]
|
| 586 |
+
sequence.append(cur_model)
|
| 587 |
+
|
| 588 |
+
nf_prev = nf
|
| 589 |
+
nf = min(nf * 2, 512)
|
| 590 |
+
|
| 591 |
+
cur_model = []
|
| 592 |
+
cur_model += [
|
| 593 |
+
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw),
|
| 594 |
+
norm_layer(nf),
|
| 595 |
+
nn.LeakyReLU(0.2, True)
|
| 596 |
+
]
|
| 597 |
+
sequence.append(cur_model)
|
| 598 |
+
|
| 599 |
+
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
| 600 |
+
|
| 601 |
+
for n in range(len(sequence)):
|
| 602 |
+
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
| 603 |
+
|
| 604 |
+
def get_all_activations(self, x):
|
| 605 |
+
res = [x]
|
| 606 |
+
for n in range(self.n_layers + 2):
|
| 607 |
+
model = getattr(self, 'model' + str(n))
|
| 608 |
+
res.append(model(res[-1]))
|
| 609 |
+
return res[1:]
|
| 610 |
+
|
| 611 |
+
def forward(self, x):
|
| 612 |
+
act = self.get_all_activations(x)
|
| 613 |
+
return act[-1], act[:-1]
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
class MultidilatedNLayerDiscriminator(BaseDiscriminator):
|
| 617 |
+
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, multidilation_kwargs={}):
|
| 618 |
+
super().__init__()
|
| 619 |
+
self.n_layers = n_layers
|
| 620 |
+
|
| 621 |
+
kw = 4
|
| 622 |
+
padw = int(np.ceil((kw-1.0)/2))
|
| 623 |
+
sequence = [[nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
|
| 624 |
+
nn.LeakyReLU(0.2, True)]]
|
| 625 |
+
|
| 626 |
+
nf = ndf
|
| 627 |
+
for n in range(1, n_layers):
|
| 628 |
+
nf_prev = nf
|
| 629 |
+
nf = min(nf * 2, 512)
|
| 630 |
+
|
| 631 |
+
cur_model = []
|
| 632 |
+
cur_model += [
|
| 633 |
+
MultidilatedConv(nf_prev, nf, kernel_size=kw, stride=2, padding=[2, 3], **multidilation_kwargs),
|
| 634 |
+
norm_layer(nf),
|
| 635 |
+
nn.LeakyReLU(0.2, True)
|
| 636 |
+
]
|
| 637 |
+
sequence.append(cur_model)
|
| 638 |
+
|
| 639 |
+
nf_prev = nf
|
| 640 |
+
nf = min(nf * 2, 512)
|
| 641 |
+
|
| 642 |
+
cur_model = []
|
| 643 |
+
cur_model += [
|
| 644 |
+
nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw),
|
| 645 |
+
norm_layer(nf),
|
| 646 |
+
nn.LeakyReLU(0.2, True)
|
| 647 |
+
]
|
| 648 |
+
sequence.append(cur_model)
|
| 649 |
+
|
| 650 |
+
sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
|
| 651 |
+
|
| 652 |
+
for n in range(len(sequence)):
|
| 653 |
+
setattr(self, 'model'+str(n), nn.Sequential(*sequence[n]))
|
| 654 |
+
|
| 655 |
+
def get_all_activations(self, x):
|
| 656 |
+
res = [x]
|
| 657 |
+
for n in range(self.n_layers + 2):
|
| 658 |
+
model = getattr(self, 'model' + str(n))
|
| 659 |
+
res.append(model(res[-1]))
|
| 660 |
+
return res[1:]
|
| 661 |
+
|
| 662 |
+
def forward(self, x):
|
| 663 |
+
act = self.get_all_activations(x)
|
| 664 |
+
return act[-1], act[:-1]
|
| 665 |
+
|
| 666 |
+
|
| 667 |
+
class NLayerDiscriminatorAsGen(NLayerDiscriminator):
|
| 668 |
+
def forward(self, x):
|
| 669 |
+
return super().forward(x)[0]
|
annotator/lama/saicinpainting/training/modules/spatial_transform.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from kornia.geometry.transform import rotate
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class LearnableSpatialTransformWrapper(nn.Module):
|
| 8 |
+
def __init__(self, impl, pad_coef=0.5, angle_init_range=80, train_angle=True):
|
| 9 |
+
super().__init__()
|
| 10 |
+
self.impl = impl
|
| 11 |
+
self.angle = torch.rand(1) * angle_init_range
|
| 12 |
+
if train_angle:
|
| 13 |
+
self.angle = nn.Parameter(self.angle, requires_grad=True)
|
| 14 |
+
self.pad_coef = pad_coef
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
if torch.is_tensor(x):
|
| 18 |
+
return self.inverse_transform(self.impl(self.transform(x)), x)
|
| 19 |
+
elif isinstance(x, tuple):
|
| 20 |
+
x_trans = tuple(self.transform(elem) for elem in x)
|
| 21 |
+
y_trans = self.impl(x_trans)
|
| 22 |
+
return tuple(self.inverse_transform(elem, orig_x) for elem, orig_x in zip(y_trans, x))
|
| 23 |
+
else:
|
| 24 |
+
raise ValueError(f'Unexpected input type {type(x)}')
|
| 25 |
+
|
| 26 |
+
def transform(self, x):
|
| 27 |
+
height, width = x.shape[2:]
|
| 28 |
+
pad_h, pad_w = int(height * self.pad_coef), int(width * self.pad_coef)
|
| 29 |
+
x_padded = F.pad(x, [pad_w, pad_w, pad_h, pad_h], mode='reflect')
|
| 30 |
+
x_padded_rotated = rotate(x_padded, angle=self.angle.to(x_padded))
|
| 31 |
+
return x_padded_rotated
|
| 32 |
+
|
| 33 |
+
def inverse_transform(self, y_padded_rotated, orig_x):
|
| 34 |
+
height, width = orig_x.shape[2:]
|
| 35 |
+
pad_h, pad_w = int(height * self.pad_coef), int(width * self.pad_coef)
|
| 36 |
+
|
| 37 |
+
y_padded = rotate(y_padded_rotated, angle=-self.angle.to(y_padded_rotated))
|
| 38 |
+
y_height, y_width = y_padded.shape[2:]
|
| 39 |
+
y = y_padded[:, :, pad_h : y_height - pad_h, pad_w : y_width - pad_w]
|
| 40 |
+
return y
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
if __name__ == '__main__':
|
| 44 |
+
layer = LearnableSpatialTransformWrapper(nn.Identity())
|
| 45 |
+
x = torch.arange(2* 3 * 15 * 15).view(2, 3, 15, 15).float()
|
| 46 |
+
y = layer(x)
|
| 47 |
+
assert x.shape == y.shape
|
| 48 |
+
assert torch.allclose(x[:, :, 1:, 1:][:, :, :-1, :-1], y[:, :, 1:, 1:][:, :, :-1, :-1])
|
| 49 |
+
print('all ok')
|
annotator/lama/saicinpainting/training/modules/squeeze_excitation.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class SELayer(nn.Module):
|
| 5 |
+
def __init__(self, channel, reduction=16):
|
| 6 |
+
super(SELayer, self).__init__()
|
| 7 |
+
self.avg_pool = nn.AdaptiveAvgPool2d(1)
|
| 8 |
+
self.fc = nn.Sequential(
|
| 9 |
+
nn.Linear(channel, channel // reduction, bias=False),
|
| 10 |
+
nn.ReLU(inplace=True),
|
| 11 |
+
nn.Linear(channel // reduction, channel, bias=False),
|
| 12 |
+
nn.Sigmoid()
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
def forward(self, x):
|
| 16 |
+
b, c, _, _ = x.size()
|
| 17 |
+
y = self.avg_pool(x).view(b, c)
|
| 18 |
+
y = self.fc(y).view(b, c, 1, 1)
|
| 19 |
+
res = x * y.expand_as(x)
|
| 20 |
+
return res
|
annotator/lama/saicinpainting/training/trainers/__init__.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import torch
|
| 3 |
+
from annotator.lama.saicinpainting.training.trainers.default import DefaultInpaintingTrainingModule
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_training_model_class(kind):
|
| 7 |
+
if kind == 'default':
|
| 8 |
+
return DefaultInpaintingTrainingModule
|
| 9 |
+
|
| 10 |
+
raise ValueError(f'Unknown trainer module {kind}')
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def make_training_model(config):
|
| 14 |
+
kind = config.training_model.kind
|
| 15 |
+
kwargs = dict(config.training_model)
|
| 16 |
+
kwargs.pop('kind')
|
| 17 |
+
kwargs['use_ddp'] = config.trainer.kwargs.get('accelerator', None) == 'ddp'
|
| 18 |
+
|
| 19 |
+
logging.info(f'Make training model {kind}')
|
| 20 |
+
|
| 21 |
+
cls = get_training_model_class(kind)
|
| 22 |
+
return cls(config, **kwargs)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def load_checkpoint(train_config, path, map_location='cuda', strict=True):
|
| 26 |
+
model = make_training_model(train_config).generator
|
| 27 |
+
state = torch.load(path, map_location=map_location)
|
| 28 |
+
model.load_state_dict(state, strict=strict)
|
| 29 |
+
return model
|
annotator/lama/saicinpainting/training/trainers/base.py
ADDED
|
@@ -0,0 +1,293 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import logging
|
| 3 |
+
from typing import Dict, Tuple
|
| 4 |
+
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import pytorch_lightning as ptl
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
# from torch.utils.data import DistributedSampler
|
| 11 |
+
|
| 12 |
+
# from annotator.lama.saicinpainting.evaluation import make_evaluator
|
| 13 |
+
# from annotator.lama.saicinpainting.training.data.datasets import make_default_train_dataloader, make_default_val_dataloader
|
| 14 |
+
# from annotator.lama.saicinpainting.training.losses.adversarial import make_discrim_loss
|
| 15 |
+
# from annotator.lama.saicinpainting.training.losses.perceptual import PerceptualLoss, ResNetPL
|
| 16 |
+
from annotator.lama.saicinpainting.training.modules import make_generator #, make_discriminator
|
| 17 |
+
# from annotator.lama.saicinpainting.training.visualizers import make_visualizer
|
| 18 |
+
from annotator.lama.saicinpainting.utils import add_prefix_to_keys, average_dicts, set_requires_grad, flatten_dict, \
|
| 19 |
+
get_has_ddp_rank
|
| 20 |
+
|
| 21 |
+
LOGGER = logging.getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def make_optimizer(parameters, kind='adamw', **kwargs):
|
| 25 |
+
if kind == 'adam':
|
| 26 |
+
optimizer_class = torch.optim.Adam
|
| 27 |
+
elif kind == 'adamw':
|
| 28 |
+
optimizer_class = torch.optim.AdamW
|
| 29 |
+
else:
|
| 30 |
+
raise ValueError(f'Unknown optimizer kind {kind}')
|
| 31 |
+
return optimizer_class(parameters, **kwargs)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def update_running_average(result: nn.Module, new_iterate_model: nn.Module, decay=0.999):
|
| 35 |
+
with torch.no_grad():
|
| 36 |
+
res_params = dict(result.named_parameters())
|
| 37 |
+
new_params = dict(new_iterate_model.named_parameters())
|
| 38 |
+
|
| 39 |
+
for k in res_params.keys():
|
| 40 |
+
res_params[k].data.mul_(decay).add_(new_params[k].data, alpha=1 - decay)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def make_multiscale_noise(base_tensor, scales=6, scale_mode='bilinear'):
|
| 44 |
+
batch_size, _, height, width = base_tensor.shape
|
| 45 |
+
cur_height, cur_width = height, width
|
| 46 |
+
result = []
|
| 47 |
+
align_corners = False if scale_mode in ('bilinear', 'bicubic') else None
|
| 48 |
+
for _ in range(scales):
|
| 49 |
+
cur_sample = torch.randn(batch_size, 1, cur_height, cur_width, device=base_tensor.device)
|
| 50 |
+
cur_sample_scaled = F.interpolate(cur_sample, size=(height, width), mode=scale_mode, align_corners=align_corners)
|
| 51 |
+
result.append(cur_sample_scaled)
|
| 52 |
+
cur_height //= 2
|
| 53 |
+
cur_width //= 2
|
| 54 |
+
return torch.cat(result, dim=1)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class BaseInpaintingTrainingModule(ptl.LightningModule):
|
| 58 |
+
def __init__(self, config, use_ddp, *args, predict_only=False, visualize_each_iters=100,
|
| 59 |
+
average_generator=False, generator_avg_beta=0.999, average_generator_start_step=30000,
|
| 60 |
+
average_generator_period=10, store_discr_outputs_for_vis=False,
|
| 61 |
+
**kwargs):
|
| 62 |
+
super().__init__(*args, **kwargs)
|
| 63 |
+
LOGGER.info('BaseInpaintingTrainingModule init called')
|
| 64 |
+
|
| 65 |
+
self.config = config
|
| 66 |
+
|
| 67 |
+
self.generator = make_generator(config, **self.config.generator)
|
| 68 |
+
self.use_ddp = use_ddp
|
| 69 |
+
|
| 70 |
+
if not get_has_ddp_rank():
|
| 71 |
+
LOGGER.info(f'Generator\n{self.generator}')
|
| 72 |
+
|
| 73 |
+
# if not predict_only:
|
| 74 |
+
# self.save_hyperparameters(self.config)
|
| 75 |
+
# self.discriminator = make_discriminator(**self.config.discriminator)
|
| 76 |
+
# self.adversarial_loss = make_discrim_loss(**self.config.losses.adversarial)
|
| 77 |
+
# self.visualizer = make_visualizer(**self.config.visualizer)
|
| 78 |
+
# self.val_evaluator = make_evaluator(**self.config.evaluator)
|
| 79 |
+
# self.test_evaluator = make_evaluator(**self.config.evaluator)
|
| 80 |
+
#
|
| 81 |
+
# if not get_has_ddp_rank():
|
| 82 |
+
# LOGGER.info(f'Discriminator\n{self.discriminator}')
|
| 83 |
+
#
|
| 84 |
+
# extra_val = self.config.data.get('extra_val', ())
|
| 85 |
+
# if extra_val:
|
| 86 |
+
# self.extra_val_titles = list(extra_val)
|
| 87 |
+
# self.extra_evaluators = nn.ModuleDict({k: make_evaluator(**self.config.evaluator)
|
| 88 |
+
# for k in extra_val})
|
| 89 |
+
# else:
|
| 90 |
+
# self.extra_evaluators = {}
|
| 91 |
+
#
|
| 92 |
+
# self.average_generator = average_generator
|
| 93 |
+
# self.generator_avg_beta = generator_avg_beta
|
| 94 |
+
# self.average_generator_start_step = average_generator_start_step
|
| 95 |
+
# self.average_generator_period = average_generator_period
|
| 96 |
+
# self.generator_average = None
|
| 97 |
+
# self.last_generator_averaging_step = -1
|
| 98 |
+
# self.store_discr_outputs_for_vis = store_discr_outputs_for_vis
|
| 99 |
+
#
|
| 100 |
+
# if self.config.losses.get("l1", {"weight_known": 0})['weight_known'] > 0:
|
| 101 |
+
# self.loss_l1 = nn.L1Loss(reduction='none')
|
| 102 |
+
#
|
| 103 |
+
# if self.config.losses.get("mse", {"weight": 0})['weight'] > 0:
|
| 104 |
+
# self.loss_mse = nn.MSELoss(reduction='none')
|
| 105 |
+
#
|
| 106 |
+
# if self.config.losses.perceptual.weight > 0:
|
| 107 |
+
# self.loss_pl = PerceptualLoss()
|
| 108 |
+
#
|
| 109 |
+
# # if self.config.losses.get("resnet_pl", {"weight": 0})['weight'] > 0:
|
| 110 |
+
# # self.loss_resnet_pl = ResNetPL(**self.config.losses.resnet_pl)
|
| 111 |
+
# # else:
|
| 112 |
+
# # self.loss_resnet_pl = None
|
| 113 |
+
#
|
| 114 |
+
# self.loss_resnet_pl = None
|
| 115 |
+
|
| 116 |
+
self.visualize_each_iters = visualize_each_iters
|
| 117 |
+
LOGGER.info('BaseInpaintingTrainingModule init done')
|
| 118 |
+
|
| 119 |
+
def configure_optimizers(self):
|
| 120 |
+
discriminator_params = list(self.discriminator.parameters())
|
| 121 |
+
return [
|
| 122 |
+
dict(optimizer=make_optimizer(self.generator.parameters(), **self.config.optimizers.generator)),
|
| 123 |
+
dict(optimizer=make_optimizer(discriminator_params, **self.config.optimizers.discriminator)),
|
| 124 |
+
]
|
| 125 |
+
|
| 126 |
+
def train_dataloader(self):
|
| 127 |
+
kwargs = dict(self.config.data.train)
|
| 128 |
+
if self.use_ddp:
|
| 129 |
+
kwargs['ddp_kwargs'] = dict(num_replicas=self.trainer.num_nodes * self.trainer.num_processes,
|
| 130 |
+
rank=self.trainer.global_rank,
|
| 131 |
+
shuffle=True)
|
| 132 |
+
dataloader = make_default_train_dataloader(**self.config.data.train)
|
| 133 |
+
return dataloader
|
| 134 |
+
|
| 135 |
+
def val_dataloader(self):
|
| 136 |
+
res = [make_default_val_dataloader(**self.config.data.val)]
|
| 137 |
+
|
| 138 |
+
if self.config.data.visual_test is not None:
|
| 139 |
+
res = res + [make_default_val_dataloader(**self.config.data.visual_test)]
|
| 140 |
+
else:
|
| 141 |
+
res = res + res
|
| 142 |
+
|
| 143 |
+
extra_val = self.config.data.get('extra_val', ())
|
| 144 |
+
if extra_val:
|
| 145 |
+
res += [make_default_val_dataloader(**extra_val[k]) for k in self.extra_val_titles]
|
| 146 |
+
|
| 147 |
+
return res
|
| 148 |
+
|
| 149 |
+
def training_step(self, batch, batch_idx, optimizer_idx=None):
|
| 150 |
+
self._is_training_step = True
|
| 151 |
+
return self._do_step(batch, batch_idx, mode='train', optimizer_idx=optimizer_idx)
|
| 152 |
+
|
| 153 |
+
def validation_step(self, batch, batch_idx, dataloader_idx):
|
| 154 |
+
extra_val_key = None
|
| 155 |
+
if dataloader_idx == 0:
|
| 156 |
+
mode = 'val'
|
| 157 |
+
elif dataloader_idx == 1:
|
| 158 |
+
mode = 'test'
|
| 159 |
+
else:
|
| 160 |
+
mode = 'extra_val'
|
| 161 |
+
extra_val_key = self.extra_val_titles[dataloader_idx - 2]
|
| 162 |
+
self._is_training_step = False
|
| 163 |
+
return self._do_step(batch, batch_idx, mode=mode, extra_val_key=extra_val_key)
|
| 164 |
+
|
| 165 |
+
def training_step_end(self, batch_parts_outputs):
|
| 166 |
+
if self.training and self.average_generator \
|
| 167 |
+
and self.global_step >= self.average_generator_start_step \
|
| 168 |
+
and self.global_step >= self.last_generator_averaging_step + self.average_generator_period:
|
| 169 |
+
if self.generator_average is None:
|
| 170 |
+
self.generator_average = copy.deepcopy(self.generator)
|
| 171 |
+
else:
|
| 172 |
+
update_running_average(self.generator_average, self.generator, decay=self.generator_avg_beta)
|
| 173 |
+
self.last_generator_averaging_step = self.global_step
|
| 174 |
+
|
| 175 |
+
full_loss = (batch_parts_outputs['loss'].mean()
|
| 176 |
+
if torch.is_tensor(batch_parts_outputs['loss']) # loss is not tensor when no discriminator used
|
| 177 |
+
else torch.tensor(batch_parts_outputs['loss']).float().requires_grad_(True))
|
| 178 |
+
log_info = {k: v.mean() for k, v in batch_parts_outputs['log_info'].items()}
|
| 179 |
+
self.log_dict(log_info, on_step=True, on_epoch=False)
|
| 180 |
+
return full_loss
|
| 181 |
+
|
| 182 |
+
def validation_epoch_end(self, outputs):
|
| 183 |
+
outputs = [step_out for out_group in outputs for step_out in out_group]
|
| 184 |
+
averaged_logs = average_dicts(step_out['log_info'] for step_out in outputs)
|
| 185 |
+
self.log_dict({k: v.mean() for k, v in averaged_logs.items()})
|
| 186 |
+
|
| 187 |
+
pd.set_option('display.max_columns', 500)
|
| 188 |
+
pd.set_option('display.width', 1000)
|
| 189 |
+
|
| 190 |
+
# standard validation
|
| 191 |
+
val_evaluator_states = [s['val_evaluator_state'] for s in outputs if 'val_evaluator_state' in s]
|
| 192 |
+
val_evaluator_res = self.val_evaluator.evaluation_end(states=val_evaluator_states)
|
| 193 |
+
val_evaluator_res_df = pd.DataFrame(val_evaluator_res).stack(1).unstack(0)
|
| 194 |
+
val_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
| 195 |
+
LOGGER.info(f'Validation metrics after epoch #{self.current_epoch}, '
|
| 196 |
+
f'total {self.global_step} iterations:\n{val_evaluator_res_df}')
|
| 197 |
+
|
| 198 |
+
for k, v in flatten_dict(val_evaluator_res).items():
|
| 199 |
+
self.log(f'val_{k}', v)
|
| 200 |
+
|
| 201 |
+
# standard visual test
|
| 202 |
+
test_evaluator_states = [s['test_evaluator_state'] for s in outputs
|
| 203 |
+
if 'test_evaluator_state' in s]
|
| 204 |
+
test_evaluator_res = self.test_evaluator.evaluation_end(states=test_evaluator_states)
|
| 205 |
+
test_evaluator_res_df = pd.DataFrame(test_evaluator_res).stack(1).unstack(0)
|
| 206 |
+
test_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
| 207 |
+
LOGGER.info(f'Test metrics after epoch #{self.current_epoch}, '
|
| 208 |
+
f'total {self.global_step} iterations:\n{test_evaluator_res_df}')
|
| 209 |
+
|
| 210 |
+
for k, v in flatten_dict(test_evaluator_res).items():
|
| 211 |
+
self.log(f'test_{k}', v)
|
| 212 |
+
|
| 213 |
+
# extra validations
|
| 214 |
+
if self.extra_evaluators:
|
| 215 |
+
for cur_eval_title, cur_evaluator in self.extra_evaluators.items():
|
| 216 |
+
cur_state_key = f'extra_val_{cur_eval_title}_evaluator_state'
|
| 217 |
+
cur_states = [s[cur_state_key] for s in outputs if cur_state_key in s]
|
| 218 |
+
cur_evaluator_res = cur_evaluator.evaluation_end(states=cur_states)
|
| 219 |
+
cur_evaluator_res_df = pd.DataFrame(cur_evaluator_res).stack(1).unstack(0)
|
| 220 |
+
cur_evaluator_res_df.dropna(axis=1, how='all', inplace=True)
|
| 221 |
+
LOGGER.info(f'Extra val {cur_eval_title} metrics after epoch #{self.current_epoch}, '
|
| 222 |
+
f'total {self.global_step} iterations:\n{cur_evaluator_res_df}')
|
| 223 |
+
for k, v in flatten_dict(cur_evaluator_res).items():
|
| 224 |
+
self.log(f'extra_val_{cur_eval_title}_{k}', v)
|
| 225 |
+
|
| 226 |
+
def _do_step(self, batch, batch_idx, mode='train', optimizer_idx=None, extra_val_key=None):
|
| 227 |
+
if optimizer_idx == 0: # step for generator
|
| 228 |
+
set_requires_grad(self.generator, True)
|
| 229 |
+
set_requires_grad(self.discriminator, False)
|
| 230 |
+
elif optimizer_idx == 1: # step for discriminator
|
| 231 |
+
set_requires_grad(self.generator, False)
|
| 232 |
+
set_requires_grad(self.discriminator, True)
|
| 233 |
+
|
| 234 |
+
batch = self(batch)
|
| 235 |
+
|
| 236 |
+
total_loss = 0
|
| 237 |
+
metrics = {}
|
| 238 |
+
|
| 239 |
+
if optimizer_idx is None or optimizer_idx == 0: # step for generator
|
| 240 |
+
total_loss, metrics = self.generator_loss(batch)
|
| 241 |
+
|
| 242 |
+
elif optimizer_idx is None or optimizer_idx == 1: # step for discriminator
|
| 243 |
+
if self.config.losses.adversarial.weight > 0:
|
| 244 |
+
total_loss, metrics = self.discriminator_loss(batch)
|
| 245 |
+
|
| 246 |
+
if self.get_ddp_rank() in (None, 0) and (batch_idx % self.visualize_each_iters == 0 or mode == 'test'):
|
| 247 |
+
if self.config.losses.adversarial.weight > 0:
|
| 248 |
+
if self.store_discr_outputs_for_vis:
|
| 249 |
+
with torch.no_grad():
|
| 250 |
+
self.store_discr_outputs(batch)
|
| 251 |
+
vis_suffix = f'_{mode}'
|
| 252 |
+
if mode == 'extra_val':
|
| 253 |
+
vis_suffix += f'_{extra_val_key}'
|
| 254 |
+
self.visualizer(self.current_epoch, batch_idx, batch, suffix=vis_suffix)
|
| 255 |
+
|
| 256 |
+
metrics_prefix = f'{mode}_'
|
| 257 |
+
if mode == 'extra_val':
|
| 258 |
+
metrics_prefix += f'{extra_val_key}_'
|
| 259 |
+
result = dict(loss=total_loss, log_info=add_prefix_to_keys(metrics, metrics_prefix))
|
| 260 |
+
if mode == 'val':
|
| 261 |
+
result['val_evaluator_state'] = self.val_evaluator.process_batch(batch)
|
| 262 |
+
elif mode == 'test':
|
| 263 |
+
result['test_evaluator_state'] = self.test_evaluator.process_batch(batch)
|
| 264 |
+
elif mode == 'extra_val':
|
| 265 |
+
result[f'extra_val_{extra_val_key}_evaluator_state'] = self.extra_evaluators[extra_val_key].process_batch(batch)
|
| 266 |
+
|
| 267 |
+
return result
|
| 268 |
+
|
| 269 |
+
def get_current_generator(self, no_average=False):
|
| 270 |
+
if not no_average and not self.training and self.average_generator and self.generator_average is not None:
|
| 271 |
+
return self.generator_average
|
| 272 |
+
return self.generator
|
| 273 |
+
|
| 274 |
+
def forward(self, batch: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
|
| 275 |
+
"""Pass data through generator and obtain at leas 'predicted_image' and 'inpainted' keys"""
|
| 276 |
+
raise NotImplementedError()
|
| 277 |
+
|
| 278 |
+
def generator_loss(self, batch) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 279 |
+
raise NotImplementedError()
|
| 280 |
+
|
| 281 |
+
def discriminator_loss(self, batch) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
|
| 282 |
+
raise NotImplementedError()
|
| 283 |
+
|
| 284 |
+
def store_discr_outputs(self, batch):
|
| 285 |
+
out_size = batch['image'].shape[2:]
|
| 286 |
+
discr_real_out, _ = self.discriminator(batch['image'])
|
| 287 |
+
discr_fake_out, _ = self.discriminator(batch['predicted_image'])
|
| 288 |
+
batch['discr_output_real'] = F.interpolate(discr_real_out, size=out_size, mode='nearest')
|
| 289 |
+
batch['discr_output_fake'] = F.interpolate(discr_fake_out, size=out_size, mode='nearest')
|
| 290 |
+
batch['discr_output_diff'] = batch['discr_output_real'] - batch['discr_output_fake']
|
| 291 |
+
|
| 292 |
+
def get_ddp_rank(self):
|
| 293 |
+
return self.trainer.global_rank if (self.trainer.num_nodes * self.trainer.num_processes) > 1 else None
|
annotator/lama/saicinpainting/training/trainers/default.py
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from omegaconf import OmegaConf
|
| 6 |
+
|
| 7 |
+
# from annotator.lama.saicinpainting.training.data.datasets import make_constant_area_crop_params
|
| 8 |
+
from annotator.lama.saicinpainting.training.losses.distance_weighting import make_mask_distance_weighter
|
| 9 |
+
from annotator.lama.saicinpainting.training.losses.feature_matching import feature_matching_loss, masked_l1_loss
|
| 10 |
+
# from annotator.lama.saicinpainting.training.modules.fake_fakes import FakeFakesGenerator
|
| 11 |
+
from annotator.lama.saicinpainting.training.trainers.base import BaseInpaintingTrainingModule, make_multiscale_noise
|
| 12 |
+
from annotator.lama.saicinpainting.utils import add_prefix_to_keys, get_ramp
|
| 13 |
+
|
| 14 |
+
LOGGER = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def make_constant_area_crop_batch(batch, **kwargs):
|
| 18 |
+
crop_y, crop_x, crop_height, crop_width = make_constant_area_crop_params(img_height=batch['image'].shape[2],
|
| 19 |
+
img_width=batch['image'].shape[3],
|
| 20 |
+
**kwargs)
|
| 21 |
+
batch['image'] = batch['image'][:, :, crop_y : crop_y + crop_height, crop_x : crop_x + crop_width]
|
| 22 |
+
batch['mask'] = batch['mask'][:, :, crop_y: crop_y + crop_height, crop_x: crop_x + crop_width]
|
| 23 |
+
return batch
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class DefaultInpaintingTrainingModule(BaseInpaintingTrainingModule):
|
| 27 |
+
def __init__(self, *args, concat_mask=True, rescale_scheduler_kwargs=None, image_to_discriminator='predicted_image',
|
| 28 |
+
add_noise_kwargs=None, noise_fill_hole=False, const_area_crop_kwargs=None,
|
| 29 |
+
distance_weighter_kwargs=None, distance_weighted_mask_for_discr=False,
|
| 30 |
+
fake_fakes_proba=0, fake_fakes_generator_kwargs=None,
|
| 31 |
+
**kwargs):
|
| 32 |
+
super().__init__(*args, **kwargs)
|
| 33 |
+
self.concat_mask = concat_mask
|
| 34 |
+
self.rescale_size_getter = get_ramp(**rescale_scheduler_kwargs) if rescale_scheduler_kwargs is not None else None
|
| 35 |
+
self.image_to_discriminator = image_to_discriminator
|
| 36 |
+
self.add_noise_kwargs = add_noise_kwargs
|
| 37 |
+
self.noise_fill_hole = noise_fill_hole
|
| 38 |
+
self.const_area_crop_kwargs = const_area_crop_kwargs
|
| 39 |
+
self.refine_mask_for_losses = make_mask_distance_weighter(**distance_weighter_kwargs) \
|
| 40 |
+
if distance_weighter_kwargs is not None else None
|
| 41 |
+
self.distance_weighted_mask_for_discr = distance_weighted_mask_for_discr
|
| 42 |
+
|
| 43 |
+
self.fake_fakes_proba = fake_fakes_proba
|
| 44 |
+
if self.fake_fakes_proba > 1e-3:
|
| 45 |
+
self.fake_fakes_gen = FakeFakesGenerator(**(fake_fakes_generator_kwargs or {}))
|
| 46 |
+
|
| 47 |
+
def forward(self, batch):
|
| 48 |
+
if self.training and self.rescale_size_getter is not None:
|
| 49 |
+
cur_size = self.rescale_size_getter(self.global_step)
|
| 50 |
+
batch['image'] = F.interpolate(batch['image'], size=cur_size, mode='bilinear', align_corners=False)
|
| 51 |
+
batch['mask'] = F.interpolate(batch['mask'], size=cur_size, mode='nearest')
|
| 52 |
+
|
| 53 |
+
if self.training and self.const_area_crop_kwargs is not None:
|
| 54 |
+
batch = make_constant_area_crop_batch(batch, **self.const_area_crop_kwargs)
|
| 55 |
+
|
| 56 |
+
img = batch['image']
|
| 57 |
+
mask = batch['mask']
|
| 58 |
+
|
| 59 |
+
masked_img = img * (1 - mask)
|
| 60 |
+
|
| 61 |
+
if self.add_noise_kwargs is not None:
|
| 62 |
+
noise = make_multiscale_noise(masked_img, **self.add_noise_kwargs)
|
| 63 |
+
if self.noise_fill_hole:
|
| 64 |
+
masked_img = masked_img + mask * noise[:, :masked_img.shape[1]]
|
| 65 |
+
masked_img = torch.cat([masked_img, noise], dim=1)
|
| 66 |
+
|
| 67 |
+
if self.concat_mask:
|
| 68 |
+
masked_img = torch.cat([masked_img, mask], dim=1)
|
| 69 |
+
|
| 70 |
+
batch['predicted_image'] = self.generator(masked_img)
|
| 71 |
+
batch['inpainted'] = mask * batch['predicted_image'] + (1 - mask) * batch['image']
|
| 72 |
+
|
| 73 |
+
if self.fake_fakes_proba > 1e-3:
|
| 74 |
+
if self.training and torch.rand(1).item() < self.fake_fakes_proba:
|
| 75 |
+
batch['fake_fakes'], batch['fake_fakes_masks'] = self.fake_fakes_gen(img, mask)
|
| 76 |
+
batch['use_fake_fakes'] = True
|
| 77 |
+
else:
|
| 78 |
+
batch['fake_fakes'] = torch.zeros_like(img)
|
| 79 |
+
batch['fake_fakes_masks'] = torch.zeros_like(mask)
|
| 80 |
+
batch['use_fake_fakes'] = False
|
| 81 |
+
|
| 82 |
+
batch['mask_for_losses'] = self.refine_mask_for_losses(img, batch['predicted_image'], mask) \
|
| 83 |
+
if self.refine_mask_for_losses is not None and self.training \
|
| 84 |
+
else mask
|
| 85 |
+
|
| 86 |
+
return batch
|
| 87 |
+
|
| 88 |
+
def generator_loss(self, batch):
|
| 89 |
+
img = batch['image']
|
| 90 |
+
predicted_img = batch[self.image_to_discriminator]
|
| 91 |
+
original_mask = batch['mask']
|
| 92 |
+
supervised_mask = batch['mask_for_losses']
|
| 93 |
+
|
| 94 |
+
# L1
|
| 95 |
+
l1_value = masked_l1_loss(predicted_img, img, supervised_mask,
|
| 96 |
+
self.config.losses.l1.weight_known,
|
| 97 |
+
self.config.losses.l1.weight_missing)
|
| 98 |
+
|
| 99 |
+
total_loss = l1_value
|
| 100 |
+
metrics = dict(gen_l1=l1_value)
|
| 101 |
+
|
| 102 |
+
# vgg-based perceptual loss
|
| 103 |
+
if self.config.losses.perceptual.weight > 0:
|
| 104 |
+
pl_value = self.loss_pl(predicted_img, img, mask=supervised_mask).sum() * self.config.losses.perceptual.weight
|
| 105 |
+
total_loss = total_loss + pl_value
|
| 106 |
+
metrics['gen_pl'] = pl_value
|
| 107 |
+
|
| 108 |
+
# discriminator
|
| 109 |
+
# adversarial_loss calls backward by itself
|
| 110 |
+
mask_for_discr = supervised_mask if self.distance_weighted_mask_for_discr else original_mask
|
| 111 |
+
self.adversarial_loss.pre_generator_step(real_batch=img, fake_batch=predicted_img,
|
| 112 |
+
generator=self.generator, discriminator=self.discriminator)
|
| 113 |
+
discr_real_pred, discr_real_features = self.discriminator(img)
|
| 114 |
+
discr_fake_pred, discr_fake_features = self.discriminator(predicted_img)
|
| 115 |
+
adv_gen_loss, adv_metrics = self.adversarial_loss.generator_loss(real_batch=img,
|
| 116 |
+
fake_batch=predicted_img,
|
| 117 |
+
discr_real_pred=discr_real_pred,
|
| 118 |
+
discr_fake_pred=discr_fake_pred,
|
| 119 |
+
mask=mask_for_discr)
|
| 120 |
+
total_loss = total_loss + adv_gen_loss
|
| 121 |
+
metrics['gen_adv'] = adv_gen_loss
|
| 122 |
+
metrics.update(add_prefix_to_keys(adv_metrics, 'adv_'))
|
| 123 |
+
|
| 124 |
+
# feature matching
|
| 125 |
+
if self.config.losses.feature_matching.weight > 0:
|
| 126 |
+
need_mask_in_fm = OmegaConf.to_container(self.config.losses.feature_matching).get('pass_mask', False)
|
| 127 |
+
mask_for_fm = supervised_mask if need_mask_in_fm else None
|
| 128 |
+
fm_value = feature_matching_loss(discr_fake_features, discr_real_features,
|
| 129 |
+
mask=mask_for_fm) * self.config.losses.feature_matching.weight
|
| 130 |
+
total_loss = total_loss + fm_value
|
| 131 |
+
metrics['gen_fm'] = fm_value
|
| 132 |
+
|
| 133 |
+
if self.loss_resnet_pl is not None:
|
| 134 |
+
resnet_pl_value = self.loss_resnet_pl(predicted_img, img)
|
| 135 |
+
total_loss = total_loss + resnet_pl_value
|
| 136 |
+
metrics['gen_resnet_pl'] = resnet_pl_value
|
| 137 |
+
|
| 138 |
+
return total_loss, metrics
|
| 139 |
+
|
| 140 |
+
def discriminator_loss(self, batch):
|
| 141 |
+
total_loss = 0
|
| 142 |
+
metrics = {}
|
| 143 |
+
|
| 144 |
+
predicted_img = batch[self.image_to_discriminator].detach()
|
| 145 |
+
self.adversarial_loss.pre_discriminator_step(real_batch=batch['image'], fake_batch=predicted_img,
|
| 146 |
+
generator=self.generator, discriminator=self.discriminator)
|
| 147 |
+
discr_real_pred, discr_real_features = self.discriminator(batch['image'])
|
| 148 |
+
discr_fake_pred, discr_fake_features = self.discriminator(predicted_img)
|
| 149 |
+
adv_discr_loss, adv_metrics = self.adversarial_loss.discriminator_loss(real_batch=batch['image'],
|
| 150 |
+
fake_batch=predicted_img,
|
| 151 |
+
discr_real_pred=discr_real_pred,
|
| 152 |
+
discr_fake_pred=discr_fake_pred,
|
| 153 |
+
mask=batch['mask'])
|
| 154 |
+
total_loss = total_loss + adv_discr_loss
|
| 155 |
+
metrics['discr_adv'] = adv_discr_loss
|
| 156 |
+
metrics.update(add_prefix_to_keys(adv_metrics, 'adv_'))
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
if batch.get('use_fake_fakes', False):
|
| 160 |
+
fake_fakes = batch['fake_fakes']
|
| 161 |
+
self.adversarial_loss.pre_discriminator_step(real_batch=batch['image'], fake_batch=fake_fakes,
|
| 162 |
+
generator=self.generator, discriminator=self.discriminator)
|
| 163 |
+
discr_fake_fakes_pred, _ = self.discriminator(fake_fakes)
|
| 164 |
+
fake_fakes_adv_discr_loss, fake_fakes_adv_metrics = self.adversarial_loss.discriminator_loss(
|
| 165 |
+
real_batch=batch['image'],
|
| 166 |
+
fake_batch=fake_fakes,
|
| 167 |
+
discr_real_pred=discr_real_pred,
|
| 168 |
+
discr_fake_pred=discr_fake_fakes_pred,
|
| 169 |
+
mask=batch['mask']
|
| 170 |
+
)
|
| 171 |
+
total_loss = total_loss + fake_fakes_adv_discr_loss
|
| 172 |
+
metrics['discr_adv_fake_fakes'] = fake_fakes_adv_discr_loss
|
| 173 |
+
metrics.update(add_prefix_to_keys(fake_fakes_adv_metrics, 'adv_'))
|
| 174 |
+
|
| 175 |
+
return total_loss, metrics
|
annotator/lama/saicinpainting/training/visualizers/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
from annotator.lama.saicinpainting.training.visualizers.directory import DirectoryVisualizer
|
| 4 |
+
from annotator.lama.saicinpainting.training.visualizers.noop import NoopVisualizer
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def make_visualizer(kind, **kwargs):
|
| 8 |
+
logging.info(f'Make visualizer {kind}')
|
| 9 |
+
|
| 10 |
+
if kind == 'directory':
|
| 11 |
+
return DirectoryVisualizer(**kwargs)
|
| 12 |
+
if kind == 'noop':
|
| 13 |
+
return NoopVisualizer()
|
| 14 |
+
|
| 15 |
+
raise ValueError(f'Unknown visualizer kind {kind}')
|
annotator/lama/saicinpainting/training/visualizers/base.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import abc
|
| 2 |
+
from typing import Dict, List
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from skimage import color
|
| 7 |
+
from skimage.segmentation import mark_boundaries
|
| 8 |
+
|
| 9 |
+
from . import colors
|
| 10 |
+
|
| 11 |
+
COLORS, _ = colors.generate_colors(151) # 151 - max classes for semantic segmentation
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class BaseVisualizer:
|
| 15 |
+
@abc.abstractmethod
|
| 16 |
+
def __call__(self, epoch_i, batch_i, batch, suffix='', rank=None):
|
| 17 |
+
"""
|
| 18 |
+
Take a batch, make an image from it and visualize
|
| 19 |
+
"""
|
| 20 |
+
raise NotImplementedError()
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def visualize_mask_and_images(images_dict: Dict[str, np.ndarray], keys: List[str],
|
| 24 |
+
last_without_mask=True, rescale_keys=None, mask_only_first=None,
|
| 25 |
+
black_mask=False) -> np.ndarray:
|
| 26 |
+
mask = images_dict['mask'] > 0.5
|
| 27 |
+
result = []
|
| 28 |
+
for i, k in enumerate(keys):
|
| 29 |
+
img = images_dict[k]
|
| 30 |
+
img = np.transpose(img, (1, 2, 0))
|
| 31 |
+
|
| 32 |
+
if rescale_keys is not None and k in rescale_keys:
|
| 33 |
+
img = img - img.min()
|
| 34 |
+
img /= img.max() + 1e-5
|
| 35 |
+
if len(img.shape) == 2:
|
| 36 |
+
img = np.expand_dims(img, 2)
|
| 37 |
+
|
| 38 |
+
if img.shape[2] == 1:
|
| 39 |
+
img = np.repeat(img, 3, axis=2)
|
| 40 |
+
elif (img.shape[2] > 3):
|
| 41 |
+
img_classes = img.argmax(2)
|
| 42 |
+
img = color.label2rgb(img_classes, colors=COLORS)
|
| 43 |
+
|
| 44 |
+
if mask_only_first:
|
| 45 |
+
need_mark_boundaries = i == 0
|
| 46 |
+
else:
|
| 47 |
+
need_mark_boundaries = i < len(keys) - 1 or not last_without_mask
|
| 48 |
+
|
| 49 |
+
if need_mark_boundaries:
|
| 50 |
+
if black_mask:
|
| 51 |
+
img = img * (1 - mask[0][..., None])
|
| 52 |
+
img = mark_boundaries(img,
|
| 53 |
+
mask[0],
|
| 54 |
+
color=(1., 0., 0.),
|
| 55 |
+
outline_color=(1., 1., 1.),
|
| 56 |
+
mode='thick')
|
| 57 |
+
result.append(img)
|
| 58 |
+
return np.concatenate(result, axis=1)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def visualize_mask_and_images_batch(batch: Dict[str, torch.Tensor], keys: List[str], max_items=10,
|
| 62 |
+
last_without_mask=True, rescale_keys=None) -> np.ndarray:
|
| 63 |
+
batch = {k: tens.detach().cpu().numpy() for k, tens in batch.items()
|
| 64 |
+
if k in keys or k == 'mask'}
|
| 65 |
+
|
| 66 |
+
batch_size = next(iter(batch.values())).shape[0]
|
| 67 |
+
items_to_vis = min(batch_size, max_items)
|
| 68 |
+
result = []
|
| 69 |
+
for i in range(items_to_vis):
|
| 70 |
+
cur_dct = {k: tens[i] for k, tens in batch.items()}
|
| 71 |
+
result.append(visualize_mask_and_images(cur_dct, keys, last_without_mask=last_without_mask,
|
| 72 |
+
rescale_keys=rescale_keys))
|
| 73 |
+
return np.concatenate(result, axis=0)
|