
Update README.md
Browse files
README.md
CHANGED
|
@@ -3,3 +3,119 @@ base_model:
|
|
| 3 |
- google/gemma-3-1b-pt
|
| 4 |
pipeline_tag: feature-extraction
|
| 5 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
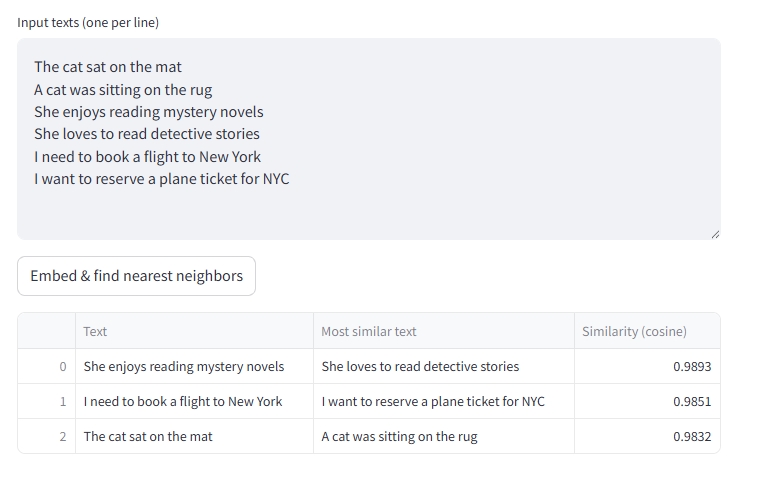
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
- google/gemma-3-1b-pt
|
| 4 |
pipeline_tag: feature-extraction
|
| 5 |
---
|
| 6 |
+
# Training Gemma-3-1B Embedding Model with LoRA
|
| 7 |
+
|
| 8 |
+
In our previous post, [Training a Query Fan-Out Model](https://dejan.ai/blog/training-a-query-fan-out-model/), we demonstrated how to generate millions of high-quality query reformulations without human labelling, by navigating the embedding space between a seed query and its target document and then decoding each intermediate vector back into text using a trained query decoder.
|
| 9 |
+
|
| 10 |
+
That decoder's success critically depends on having an embedding encoder whose latent geometry is fully under our control: off-the-shelf models (e.g. mxbai embed large) optimize for general semantic similarity, not for invertibility, so their embeddings cannot reliably be mapped back into meaningful queries.
|
| 11 |
+
|
| 12 |
+
To bridge that gap, this article introduces **Gemma-Embed**, a bespoke 256-dim embedding model built by fine-tuning `google/gemma-3-1b-pt` with LoRA adapters and contrastive objectives. By training our own encoder, we lock in a consistent, L2-normalized latent space that the subsequent query decoder can invert with high fidelity.
|
| 13 |
+
|
| 14 |
+
## Quick Recap of the Query Fan-Out Mission
|
| 15 |
+
|
| 16 |
+
- **Query Decoder**: Train a T5-based model to invert a fixed retrieval encoder (e.g. GTR) so that any embedding vector produces the original query. Achieved ~96% cosine similarity on reconstruction.
|
| 17 |
+
- **Latent Space Traversal**: For each (query, document) pair, interpolate in the embedding space, decode each point, and retain reformulations that improve retrieval metrics—yielding hundreds of thousands of synthetic examples.
|
| 18 |
+
- **Production Model (qsT5)**: Fine-tune T5 on that synthetic dataset (with and without pseudo-relevance feedback) to internalize traversal patterns—so at inference time it generates diverse, effective reformulations without any explicit vector arithmetic.
|
| 19 |
+
|
| 20 |
+
Together, these steps automate query fan-out, boost retrieval performance, and open the door to interpretable, language-agnostic search suggestions.
|
| 21 |
+
|
| 22 |
+
To power a query fan‑out decoder that inverts embeddings back to natural language queries, we need an embedding encoder whose latent geometry we control. Since no off‑the‑shelf Gemma‑3 embedding model exists, we fine‑tune `google/gemma‑3‑1b‑pt` with LoRA and contrastive objectives to produce high‑quality, L2‑normalized 256‑dim embeddings.
|
| 23 |
+
|
| 24 |
+
## Model Architecture
|
| 25 |
+
|
| 26 |
+
### Base Encoder
|
| 27 |
+
- `google/gemma-3-1b-pt` (1 B params)
|
| 28 |
+
|
| 29 |
+
### LoRA Adapters
|
| 30 |
+
- **Target modules**: `q_proj`, `v_proj`
|
| 31 |
+
- **Rank (r)**: 8
|
| 32 |
+
- **Alpha (α)**: 16
|
| 33 |
+
- **Dropout**: 0.05
|
| 34 |
+
|
| 35 |
+
### Projection Head
|
| 36 |
+
- **Input**: hidden_size (1024)
|
| 37 |
+
- **MLP**: Linear(1024→512) → ReLU → Linear(512→256)
|
| 38 |
+
- **L2 normalization**
|
| 39 |
+
|
| 40 |
+
## Data and Format
|
| 41 |
+
|
| 42 |
+
### Phase 1 – Unsupervised SimCSE
|
| 43 |
+
- **Source**: `text.txt` (wiki sentences or plain text logs)
|
| 44 |
+
- **Size**: 579,719 sentences
|
| 45 |
+
- **Format**: UTF‑8 plain text, one sequence per line
|
| 46 |
+
- **Sample lines**:
|
| 47 |
+
```
|
| 48 |
+
Breaking news: stock markets rally as central bank hints at rate cut.
|
| 49 |
+
How do I fine‑tune a large language model for embeddings?
|
| 50 |
+
The Northern Lights are visible tonight in high‑latitude regions.
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
### Phase 2 – Supervised Paraphrase Contrastive
|
| 54 |
+
- **Source**: `triplets.csv`
|
| 55 |
+
- **Columns**: `a_ids,a_mask,p_ids,p_mask,n_ids,n_mask` (token IDs & masks)
|
| 56 |
+
- **Size**: user‑provided paraphrase pairs (e.g., ParaNMT ~3.6 M, QuoraQP ~400 k, PAWS ~60 k)
|
| 57 |
+
- **Format**: CSV with header. Each row:
|
| 58 |
+
```
|
| 59 |
+
a_ids,a_mask,p_ids,p_mask,n_ids,n_mask
|
| 60 |
+
102 345 ... ,1 1 ... ,203 456 ... ,1 1 ... ,307 523 ... ,1 1 ...
|
| 61 |
+
```
|
| 62 |
+
- Original text pairs stored in scripts folder for reference.
|
| 63 |
+
|
| 64 |
+
### Phase 3 – In‑Domain Self‑Contrast
|
| 65 |
+
- **Source**: `queries.db`
|
| 66 |
+
```sql
|
| 67 |
+
CREATE TABLE queries (
|
| 68 |
+
query_id INTEGER PRIMARY KEY AUTOINCREMENT,
|
| 69 |
+
query TEXT UNIQUE NOT NULL
|
| 70 |
+
);
|
| 71 |
+
```
|
| 72 |
+
- **Size**: 7,129,444 unique queries
|
| 73 |
+
- **Pretokenized**: `pretokenized_queries.pt`
|
| 74 |
+
- **Tensors**: `input_ids` (7,129,444 × 128), `attention_mask` (7,129,444 × 128)
|
| 75 |
+
- **File size**: ~13.5 GB
|
| 76 |
+
- **Sample queries**:
|
| 77 |
+
```sql
|
| 78 |
+
SELECT query FROM queries LIMIT 5;
|
| 79 |
+
How to bake sourdough at home?
|
| 80 |
+
Weather tomorrow in Sydney
|
| 81 |
+
Best restaurants near me open now
|
| 82 |
+
convert 1 mile to kilometers
|
| 83 |
+
streamlit file uploader example
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
## Training Pipeline
|
| 87 |
+
|
| 88 |
+
| Phase | Objective | Loss | Batch | Epochs | LR | Data Size |
|
| 89 |
+
|-------|-----------|------|-------|--------|----|-----------|
|
| 90 |
+
| 1 | Unsupervised SimCSE | InfoNCE (τ=0.05) | 12 | 1 | 1e‑5 | 579,719 sentences |
|
| 91 |
+
| 2 | Supervised Triplet Contrastive | TripletMarginLoss(0.2) | 12 | 3 | 1e‑5 | ~4 M triplets |
|
| 92 |
+
| 3 | In‑Domain Self‑Contrast | InfoNCE (τ=0.05) | 64 | 1 | 1e‑5 | 7,129,444 queries |
|
| 93 |
+
|
| 94 |
+
## File Layout
|
| 95 |
+
|
| 96 |
+
```
|
| 97 |
+
train-gemma/
|
| 98 |
+
├── text.txt
|
| 99 |
+
├── triplets.csv
|
| 100 |
+
├── queries.db
|
| 101 |
+
├── pretokenized_queries.pt
|
| 102 |
+
├── scripts/
|
| 103 |
+
│ ├── train_stage_1.py
|
| 104 |
+
│ ├── train_stage_2.py
|
| 105 |
+
│ ├── pretokenize_queries.py
|
| 106 |
+
│ └── train_stage_3.py
|
| 107 |
+
├��─ stage1_simcse/final/
|
| 108 |
+
├── phase2_triplet_amp/final/
|
| 109 |
+
└── phase3_self_contrast/final/
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
## Sample Data Sizes
|
| 113 |
+
|
| 114 |
+
- **text.txt**: 579,719 lines (~50 MB)
|
| 115 |
+
- **triplets.csv**: depends on sources (~500 MB for 4 M rows)
|
| 116 |
+
- **queries.db**: ~200 MB SQLite file
|
| 117 |
+
- **pretokenized_queries.pt**: 13.5 GB
|
| 118 |
+
|
| 119 |
+
## Inference Test
|
| 120 |
+
|
| 121 |
+
|