
Commit ·
d6b2804
1
Parent(s): 5041213
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,12 +1,95 @@
|
|
| 1 |
# SecureBERT: A Domain-Specific Language Model for Cybersecurity
|
| 2 |
SecureBERT is a domain-specific language model based on RoBERTa which is trained on a huge amount of cybersecurity data and fine-tuned/tweaked to understand/represent cybersecurity textual data.
|
| 3 |
|
| 4 |
-
See details at [GitHub Repo](https://github.com/ehsanaghaei/SecureBERT/blob/main/README.md)
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
https://
|
| 9 |
|
| 10 |
** The paper has been accepted and presented in "EAI SecureComm 2022 - 18th EAI International Conference on Security and Privacy in Communication Networks".**
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# SecureBERT: A Domain-Specific Language Model for Cybersecurity
|
| 2 |
SecureBERT is a domain-specific language model based on RoBERTa which is trained on a huge amount of cybersecurity data and fine-tuned/tweaked to understand/represent cybersecurity textual data.
|
| 3 |
|
|
|
|
| 4 |
|
| 5 |
+
[SecureBERT](https://arxiv.org/pdf/2204.02685) is a domain-specific language model to represent cybersecurity textual data which is trained on a large amount of in-domain text crawled from online resources. ***See the presentation on [YouTube](https://www.youtube.com/watch?v=G8WzvThGG8c&t=8s)***
|
| 6 |
+
|
| 7 |
+
See details at [GitHub Repo](https://github.com/ehsanaghaei/SecureBERT/blob/main/README.md)
|
| 8 |
|
| 9 |
** The paper has been accepted and presented in "EAI SecureComm 2022 - 18th EAI International Conference on Security and Privacy in Communication Networks".**
|
| 10 |
|
| 11 |
+
|
| 12 |
+
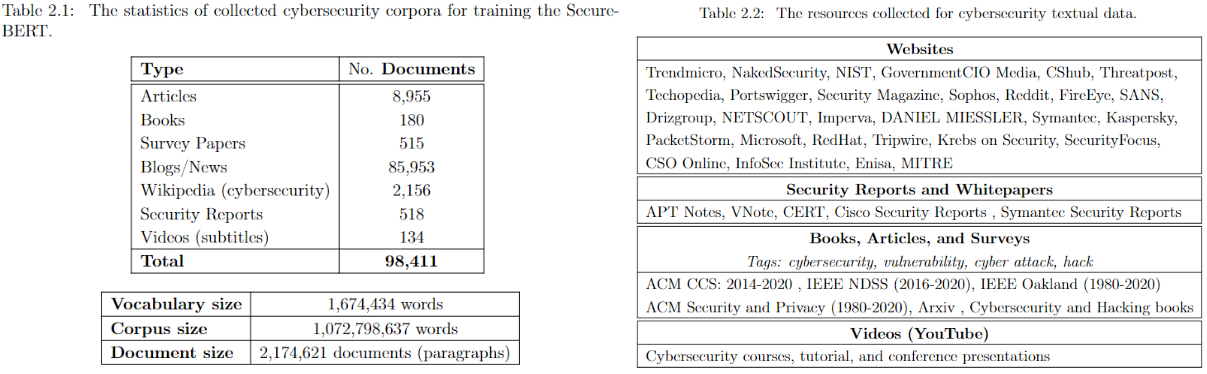
|
| 13 |
+
|
| 14 |
+
## SecureBERT can be used as the base model for any downstream task including text classification, NER, Seq-to-Seq, QA, etc.
|
| 15 |
+
* SecureBERT has demonstrated significantly higher performance in predicting masked words within the text when compared to existing models like RoBERTa (base and large), SciBERT, and SecBERT.
|
| 16 |
+
* SecureBERT has also demonstrated promising performance in preserving general English language understanding (representation).
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# How to use SecureBERT
|
| 21 |
+
SecureBERT has been uploaded to [Huggingface](https://huggingface.co/ehsanaghaei/SecureBERT) framework. You may use the code below
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
from transformers import RobertaTokenizer, RobertaModel
|
| 25 |
+
import torch
|
| 26 |
+
|
| 27 |
+
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
|
| 28 |
+
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
|
| 29 |
+
|
| 30 |
+
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
|
| 31 |
+
outputs = model(**inputs)
|
| 32 |
+
|
| 33 |
+
last_hidden_states = outputs.last_hidden_state
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
Or just clone the repo:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
git lfs install
|
| 41 |
+
git clone https://huggingface.co/ehsanaghaei/SecureBERT
|
| 42 |
+
# if you want to clone without large files – just their pointers
|
| 43 |
+
# prepend your git clone with the following env var:
|
| 44 |
+
GIT_LFS_SKIP_SMUDGE=1
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Fill Mask
|
| 48 |
+
SecureBERT has been trained on MLM. Use the code below to predict the masked word within the given sentences:
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
#!pip install transformers
|
| 52 |
+
#!pip install torch
|
| 53 |
+
#!pip install tokenizers
|
| 54 |
+
|
| 55 |
+
import torch
|
| 56 |
+
import transformers
|
| 57 |
+
from transformers import RobertaTokenizer, RobertaTokenizerFast
|
| 58 |
+
|
| 59 |
+
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
|
| 60 |
+
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT")
|
| 61 |
+
|
| 62 |
+
def predict_mask(sent, tokenizer, model, topk =10, print_results = True):
|
| 63 |
+
token_ids = tokenizer.encode(sent, return_tensors='pt')
|
| 64 |
+
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero()
|
| 65 |
+
masked_pos = [mask.item() for mask in masked_position]
|
| 66 |
+
words = []
|
| 67 |
+
with torch.no_grad():
|
| 68 |
+
output = model(token_ids)
|
| 69 |
+
|
| 70 |
+
last_hidden_state = output[0].squeeze()
|
| 71 |
+
|
| 72 |
+
list_of_list = []
|
| 73 |
+
for index, mask_index in enumerate(masked_pos):
|
| 74 |
+
mask_hidden_state = last_hidden_state[mask_index]
|
| 75 |
+
idx = torch.topk(mask_hidden_state, k=topk, dim=0)[1]
|
| 76 |
+
words = [tokenizer.decode(i.item()).strip() for i in idx]
|
| 77 |
+
words = [w.replace(' ','') for w in words]
|
| 78 |
+
list_of_list.append(words)
|
| 79 |
+
if print_results:
|
| 80 |
+
print("Mask ", "Predictions : ", words)
|
| 81 |
+
|
| 82 |
+
best_guess = ""
|
| 83 |
+
for j in list_of_list:
|
| 84 |
+
best_guess = best_guess + "," + j[0]
|
| 85 |
+
|
| 86 |
+
return words
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
while True:
|
| 90 |
+
sent = input("Text here: \t")
|
| 91 |
+
print("SecureBERT: ")
|
| 92 |
+
predict_mask(sent, tokenizer, model)
|
| 93 |
+
|
| 94 |
+
print("===========================\n")
|
| 95 |
+
```
|