diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..955c68ac938e4ec763a4d51175c65c9989500b06 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+ckpts/clip_vit_l14_with_masks_6c17944 filter=lfs diff=lfs merge=lfs -text
+ckpts/owl2-b16-960-st-ngrams-curated-ft-lvisbase-ens-cold-weight-05_209b65b filter=lfs diff=lfs merge=lfs -text
+ckpts/owl2-l14-1008-st-ngrams-ft-lvisbase-ens-cold-weight-04_8ca674c filter=lfs diff=lfs merge=lfs -text
+images/scenic_design.jpg filter=lfs diff=lfs merge=lfs -text
+images/scenic_logo.jpg filter=lfs diff=lfs merge=lfs -text
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..797fbaaf978606e1991e51e05be7813862584c5e
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,32 @@
+# How to Contribute
+
+Scenic is a platform used for developing new methods and ideas by Google
+researchers, mostly around attention-based models for computer vision or
+multi-modal applications. We encourage forking the repository and continued
+development. We welcome suggestions and contributions to improving Scenic.
+There are a few small guidelines you need to follow.
+
+## Contributor License Agreement
+
+Contributions to this project must be accompanied by a Contributor License
+Agreement (CLA). You (or your employer) retain the copyright to your
+contribution; this simply gives us permission to use and redistribute your
+contributions as part of the project. Head over to
+ to see your current agreements on file or
+to sign a new one.
+
+You generally only need to submit a CLA once, so if you've already submitted one
+(even if it was for a different project), you probably don't need to do it
+again.
+
+## Code Reviews
+
+All submissions, including submissions by project members, require review. We
+use GitHub pull requests for this purpose. Consult
+[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
+information on using pull requests.
+
+## Community Guidelines
+
+This project follows
+[Google's Open Source Community Guidelines](https://opensource.google/conduct/).
diff --git a/IOU_test.py b/IOU_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..eeac3327d3bb17c7aa88d7022d4388e4c6975e0a
--- /dev/null
+++ b/IOU_test.py
@@ -0,0 +1,21 @@
+from owlv2_helper_functions import get_iou, boxes_filter
+
+boxes = [
+ (128.56, 4.57, 732.52, 476.05),
+ (569.65, 185.71, 740.31, 244.76),
+ (569.65, 185.71, 740.31, 244.76),
+ (569.65, 185.71, 740.31, 244.76),
+ (101.99, 99.00, 720.12, 88.63),
+ ]
+
+scores = [1.0, 0.99, 0.89, 1.0, 0.99]
+
+instances = ['cat', 'dog', 'dog', 'tiger', 'cat']
+
+
+
+pred_bboxes, pred_scores, instances = boxes_filter(boxes, scores, instances)
+
+print(pred_bboxes)
+print(pred_scores)
+print(instances)
\ No newline at end of file
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..d645695673349e3947e8e5ae42332d0ac3164cd7
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,202 @@
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4aa107e4a89900a7f3faa873e6b07282b1c1ff7a
--- /dev/null
+++ b/README.md
@@ -0,0 +1,217 @@
+# Scenic
+
+

+
+
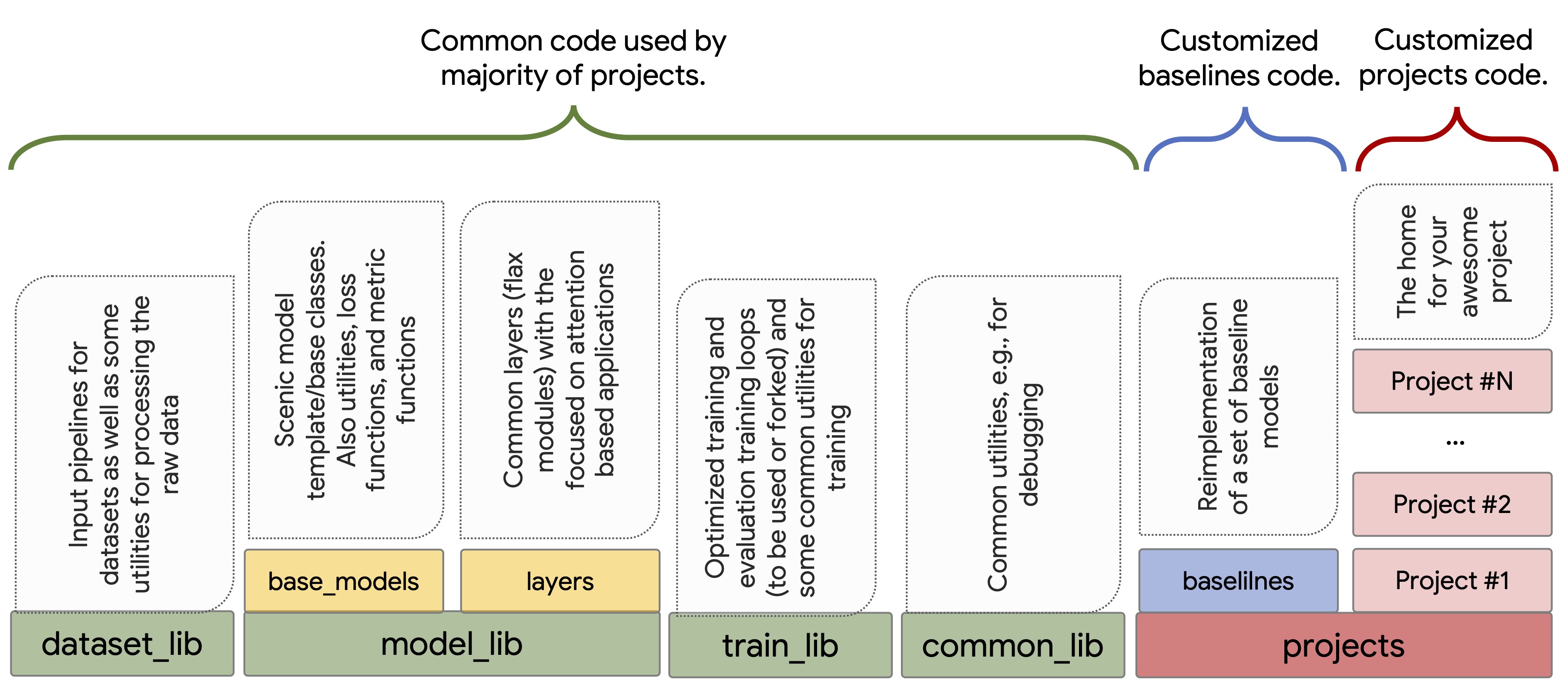
+
blah"
+ )
+
+ def test_strfmt(self):
+ data = {
+ "int": tf.constant(42, tf.uint8),
+ "float": tf.constant(3.14, tf.float32),
+ "vec": tf.range(3),
+ "empty_str": tf.constant(""),
+ "regex_problem1": tf.constant(r"no \replace pattern"),
+ "regex_problem2": tf.constant(r"yes \1 pattern"),
+ }
+ for out in self.tfrun(pp.get_strfmt("Nothing"), data):
+ self.assertEqual(out["text"], b"Nothing")
+ for out in self.tfrun(pp.get_strfmt("{int}"), data):
+ self.assertEqual(out["text"], b"42")
+ for out in self.tfrun(pp.get_strfmt("A{int}"), data):
+ self.assertEqual(out["text"], b"A42")
+ for out in self.tfrun(pp.get_strfmt("{int}A"), data):
+ self.assertEqual(out["text"], b"42A")
+ for out in self.tfrun(pp.get_strfmt("{int}{int}"), data):
+ self.assertEqual(out["text"], b"4242")
+ for out in self.tfrun(pp.get_strfmt("A{int}A{int}A"), data):
+ self.assertEqual(out["text"], b"A42A42A")
+ for out in self.tfrun(pp.get_strfmt("A{float}A"), data):
+ self.assertEqual(out["text"], b"A3.14A")
+ for out in self.tfrun(pp.get_strfmt("A{float}A{int}"), data):
+ self.assertEqual(out["text"], b"A3.14A42")
+ for out in self.tfrun(pp.get_strfmt("A{vec}A"), data):
+ self.assertEqual(out["text"], b"A[0 1 2]A")
+ for out in self.tfrun(pp.get_strfmt("A{empty_str}A"), data):
+ self.assertEqual(out["text"], b"AA")
+ for out in self.tfrun(pp.get_strfmt("{empty_str}"), data):
+ self.assertEqual(out["text"], b"")
+ for out in self.tfrun(pp.get_strfmt("A{regex_problem1}A"), data):
+ self.assertEqual(out["text"], br"Ano \replace patternA")
+ for out in self.tfrun(pp.get_strfmt("A{regex_problem2}A"), data):
+ self.assertEqual(out["text"], br"Ayes \1 patternA")
+
+
+@Registry.register("tokensets.sp_extra_tokens")
+def _get_sp_extra_tokens():
+ # For sentencepiece, adding these tokens will make them visible when decoding.
+ # If a token is not found (e.g. "" is not found in "mistral"), then it is
+ # added to the vocabulary, increasing the vocab_size accordingly.
+ return ["", "", ""]
+
+
+if __name__ == "__main__":
+ tf.test.main()
diff --git a/big_vision/pp/registry.py b/big_vision/pp/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5c7d996d756be16ba68a5fcb143f23129e1249d
--- /dev/null
+++ b/big_vision/pp/registry.py
@@ -0,0 +1,163 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Global Registry for big_vision pp ops.
+
+Author: Joan Puigcerver (jpuigcerver@)
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import ast
+import contextlib
+import functools
+
+
+def parse_name(string_to_parse):
+ """Parses input to the registry's lookup function.
+
+ Args:
+ string_to_parse: can be either an arbitrary name or function call
+ (optionally with positional and keyword arguments).
+ e.g. "multiclass", "resnet50_v2(filters_factor=8)".
+
+ Returns:
+ A tuple of input name, argument tuple and a keyword argument dictionary.
+ Examples:
+ "multiclass" -> ("multiclass", (), {})
+ "resnet50_v2(9, filters_factor=4)" ->
+ ("resnet50_v2", (9,), {"filters_factor": 4})
+
+ Author: Joan Puigcerver (jpuigcerver@)
+ """
+ expr = ast.parse(string_to_parse, mode="eval").body # pytype: disable=attribute-error
+ if not isinstance(expr, (ast.Attribute, ast.Call, ast.Name)):
+ raise ValueError(
+ "The given string should be a name or a call, but a {} was parsed from "
+ "the string {!r}".format(type(expr), string_to_parse))
+
+ # Notes:
+ # name="some_name" -> type(expr) = ast.Name
+ # name="module.some_name" -> type(expr) = ast.Attribute
+ # name="some_name()" -> type(expr) = ast.Call
+ # name="module.some_name()" -> type(expr) = ast.Call
+
+ if isinstance(expr, ast.Name):
+ return string_to_parse, (), {}
+ elif isinstance(expr, ast.Attribute):
+ return string_to_parse, (), {}
+
+ def _get_func_name(expr):
+ if isinstance(expr, ast.Attribute):
+ return _get_func_name(expr.value) + "." + expr.attr
+ elif isinstance(expr, ast.Name):
+ return expr.id
+ else:
+ raise ValueError(
+ "Type {!r} is not supported in a function name, the string to parse "
+ "was {!r}".format(type(expr), string_to_parse))
+
+ def _get_func_args_and_kwargs(call):
+ args = tuple([ast.literal_eval(arg) for arg in call.args])
+ kwargs = {
+ kwarg.arg: ast.literal_eval(kwarg.value) for kwarg in call.keywords
+ }
+ return args, kwargs
+
+ func_name = _get_func_name(expr.func)
+ func_args, func_kwargs = _get_func_args_and_kwargs(expr)
+
+ return func_name, func_args, func_kwargs
+
+
+class Registry(object):
+ """Implements global Registry.
+
+ Authors: Joan Puigcerver (jpuigcerver@), Alexander Kolesnikov (akolesnikov@)
+ """
+
+ _GLOBAL_REGISTRY = {}
+
+ @staticmethod
+ def global_registry():
+ return Registry._GLOBAL_REGISTRY
+
+ @staticmethod
+ def register(name, replace=False):
+ """Creates a function that registers its input."""
+
+ def _register(item):
+ if name in Registry.global_registry() and not replace:
+ raise KeyError("The name {!r} was already registered.".format(name))
+
+ Registry.global_registry()[name] = item
+ return item
+
+ return _register
+
+ @staticmethod
+ def lookup(lookup_string, kwargs_extra=None):
+ """Lookup a name in the registry."""
+
+ try:
+ name, args, kwargs = parse_name(lookup_string)
+ except ValueError as e:
+ raise ValueError(f"Error parsing:\n{lookup_string}") from e
+ if kwargs_extra:
+ kwargs.update(kwargs_extra)
+ item = Registry.global_registry()[name]
+ return functools.partial(item, *args, **kwargs)
+
+ @staticmethod
+ def knows(lookup_string):
+ try:
+ name, _, _ = parse_name(lookup_string)
+ except ValueError as e:
+ raise ValueError(f"Error parsing:\n{lookup_string}") from e
+ return name in Registry.global_registry()
+
+
+@contextlib.contextmanager
+def temporary_ops(**kw):
+ """Registers specified pp ops for use in a `with` block.
+
+ Example use:
+
+ with pp_registry.remporary_ops(
+ pow=lambda alpha: lambda d: {k: v**alpha for k, v in d.items()}):
+ pp = pp_builder.get_preprocess_fn("pow(alpha=2.0)|pow(alpha=0.5)")
+ features = pp(features)
+
+ Args:
+ **kw: Names are preprocess string function names to be used to specify the
+ preprocess function. Values are functions that can be called with params
+ (e.g. the `alpha` param in above example) and return functions to be used
+ to transform features.
+
+ Yields:
+ A context manager to be used in a `with` statement.
+ """
+ reg = Registry.global_registry()
+ kw = {f"preprocess_ops.{k}": v for k, v in kw.items()}
+ for k in kw:
+ assert k not in reg
+ for k, v in kw.items():
+ reg[k] = v
+ try:
+ yield
+ finally:
+ for k in kw:
+ del reg[k]
diff --git a/big_vision/pp/registry_test.py b/big_vision/pp/registry_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..2296e7de91ce0495bade59e8e65417384507e58e
--- /dev/null
+++ b/big_vision/pp/registry_test.py
@@ -0,0 +1,128 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Tests for registry."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from unittest import mock
+
+from absl.testing import absltest
+from big_vision.pp import registry
+
+
+class RegistryTest(absltest.TestCase):
+
+ def setUp(self):
+ super(RegistryTest, self).setUp()
+ # Mock global registry in each test to keep them isolated and allow for
+ # concurrent tests.
+ self.addCleanup(mock.patch.stopall)
+ self.global_registry = dict()
+ self.mocked_method = mock.patch.object(
+ registry.Registry, "global_registry",
+ return_value=self.global_registry).start()
+
+ def test_parse_name(self):
+ name, args, kwargs = registry.parse_name("f")
+ self.assertEqual(name, "f")
+ self.assertEqual(args, ())
+ self.assertEqual(kwargs, {})
+
+ name, args, kwargs = registry.parse_name("f()")
+ self.assertEqual(name, "f")
+ self.assertEqual(args, ())
+ self.assertEqual(kwargs, {})
+
+ name, args, kwargs = registry.parse_name("func(a=0,b=1,c='s')")
+ self.assertEqual(name, "func")
+ self.assertEqual(args, ())
+ self.assertEqual(kwargs, {"a": 0, "b": 1, "c": "s"})
+
+ name, args, kwargs = registry.parse_name("func(1,'foo',3)")
+ self.assertEqual(name, "func")
+ self.assertEqual(args, (1, "foo", 3))
+ self.assertEqual(kwargs, {})
+
+ name, args, kwargs = registry.parse_name("func(1,'2',a=3,foo='bar')")
+ self.assertEqual(name, "func")
+ self.assertEqual(args, (1, "2"))
+ self.assertEqual(kwargs, {"a": 3, "foo": "bar"})
+
+ name, args, kwargs = registry.parse_name("foo.bar.func(a=0,b=(1),c='s')")
+ self.assertEqual(name, "foo.bar.func")
+ self.assertEqual(kwargs, dict(a=0, b=1, c="s"))
+
+ with self.assertRaises(SyntaxError):
+ registry.parse_name("func(0")
+ with self.assertRaises(SyntaxError):
+ registry.parse_name("func(a=0,,b=0)")
+ with self.assertRaises(SyntaxError):
+ registry.parse_name("func(a=0,b==1,c='s')")
+ with self.assertRaises(ValueError):
+ registry.parse_name("func(a=0,b=undefined_name,c='s')")
+
+ def test_register(self):
+ # pylint: disable=unused-variable
+ @registry.Registry.register("func1")
+ def func1():
+ pass
+
+ self.assertLen(registry.Registry.global_registry(), 1)
+
+ def test_lookup_function(self):
+
+ @registry.Registry.register("func1")
+ def func1(arg1, arg2, arg3): # pylint: disable=unused-variable
+ return arg1, arg2, arg3
+
+ self.assertTrue(callable(registry.Registry.lookup("func1")))
+ self.assertEqual(registry.Registry.lookup("func1")(1, 2, 3), (1, 2, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(arg3=9)")(1, 2), (1, 2, 9))
+ self.assertEqual(
+ registry.Registry.lookup("func1(arg2=9,arg1=99)")(arg3=3), (99, 9, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(arg2=9,arg1=99)")(arg1=1, arg3=3),
+ (1, 9, 3))
+
+ self.assertEqual(
+ registry.Registry.lookup("func1(1)")(1, 2), (1, 1, 2))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1)")(arg3=3, arg2=2), (1, 2, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1, 2)")(3), (1, 2, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1, 2)")(arg3=3), (1, 2, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1, arg2=2)")(arg3=3), (1, 2, 3))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1, arg3=2)")(arg2=3), (1, 3, 2))
+ self.assertEqual(
+ registry.Registry.lookup("func1(1, arg3=2)")(3), (1, 3, 2))
+
+ with self.assertRaises(TypeError):
+ registry.Registry.lookup("func1(1, arg2=2)")(3)
+ with self.assertRaises(TypeError):
+ registry.Registry.lookup("func1(1, arg3=3)")(arg3=3)
+ with self.assertRaises(TypeError):
+ registry.Registry.lookup("func1(1, arg3=3)")(arg1=3)
+ with self.assertRaises(SyntaxError):
+ registry.Registry.lookup("func1(arg1=1, 3)")(arg2=3)
+
+
+if __name__ == "__main__":
+ absltest.main()
diff --git a/big_vision/pp/tokenizer.py b/big_vision/pp/tokenizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..681494e436aacd48d5d720e07d2df1a80c704eb2
--- /dev/null
+++ b/big_vision/pp/tokenizer.py
@@ -0,0 +1,103 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""The tokenizer API for big_vision, and central registration place."""
+import functools
+import importlib
+from typing import Protocol
+
+from absl import logging
+from big_vision.pp import registry
+import big_vision.utils as u
+import numpy as np
+
+
+class Tokenizer(Protocol):
+ """Just to unify on the API as we now have mmany different ones."""
+
+ def to_int(self, text, *, bos=False, eos=False):
+ """Tokenizes `text` into a list of integer tokens.
+
+ Args:
+ text: can be a single string, or a list of strings.
+ bos: Whether a beginning-of-sentence token should be prepended.
+ eos: Whether an end-of-sentence token should be appended.
+
+ Returns:
+ List or list-of-list of tokens.
+ """
+
+ def to_int_tf_op(self, text, *, bos=False, eos=False):
+ """Same as `to_int()`, but as TF ops to be used in pp."""
+
+ def to_str(self, tokens, *, stop_at_eos=True):
+ """Inverse of `to_int()`.
+
+ Args:
+ tokens: list of tokens, or list of lists of tokens.
+ stop_at_eos: remove everything that may come after the first EOS.
+
+ Returns:
+ A string (if `tokens` is a list of tokens), or a list of strings.
+ Note that most tokenizers strip select few control tokens like
+ eos/bos/pad/unk from the output string.
+ """
+
+ def to_str_tf_op(self, tokens, *, stop_at_eos=True):
+ """Same as `to_str()`, but as TF ops to be used in pp."""
+
+ @property
+ def pad_token(self):
+ """Token id of padding token."""
+
+ @property
+ def eos_token(self):
+ """Token id of end-of-sentence token."""
+
+ @property
+ def bos_token(self):
+ """Token id of beginning-of-sentence token."""
+
+ @property
+ def vocab_size(self):
+ """Returns the size of the vocabulary."""
+
+
+@functools.cache
+def get_tokenizer(name):
+ with u.chrono.log_timing(f"z/secs/tokenizer/{name}"):
+ if not registry.Registry.knows(f"tokenizers.{name}"):
+ raw_name, *_ = registry.parse_name(name)
+ logging.info("Tokenizer %s not registered, "
+ "trying import big_vision.pp.%s", name, raw_name)
+ importlib.import_module(f"big_vision.pp.{raw_name}")
+
+ return registry.Registry.lookup(f"tokenizers.{name}")()
+
+
+def get_extra_tokens(tokensets):
+ extra_tokens = []
+ for tokenset in tokensets:
+ extra_tokens.extend(registry.Registry.lookup(f"tokensets.{tokenset}")())
+ return list(np.unique(extra_tokens)) # Preserves order. Dups make no sense.
+
+
+@registry.Registry.register("tokensets.loc")
+def _get_loc1024(n=1024):
+ return [f"" for i in range(n)]
+
+
+@registry.Registry.register("tokensets.seg")
+def _get_seg(n=128):
+ return [f"" for i in range(n)]
diff --git a/big_vision/pp/utils.py b/big_vision/pp/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ee834560246549c71f0a6d9785694fd1507ca9b
--- /dev/null
+++ b/big_vision/pp/utils.py
@@ -0,0 +1,53 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Preprocessing utils."""
+
+from collections import abc
+
+
+def maybe_repeat(arg, n_reps):
+ if not isinstance(arg, abc.Sequence) or isinstance(arg, str):
+ arg = (arg,) * n_reps
+ return arg
+
+
+class InKeyOutKey(object):
+ """Decorator for preprocessing ops, which adds `inkey` and `outkey` arguments.
+
+ Note: Only supports single-input single-output ops.
+ """
+
+ def __init__(self, indefault="image", outdefault="image", with_data=False):
+ self.indefault = indefault
+ self.outdefault = outdefault
+ self.with_data = with_data
+
+ def __call__(self, orig_get_pp_fn):
+
+ def get_ikok_pp_fn(*args, key=None,
+ inkey=self.indefault, outkey=self.outdefault, **kw):
+
+ orig_pp_fn = orig_get_pp_fn(*args, **kw)
+ def _ikok_pp_fn(data):
+ # Optionally allow the function to get the full data dict as aux input.
+ if self.with_data:
+ data[key or outkey] = orig_pp_fn(data[key or inkey], data=data)
+ else:
+ data[key or outkey] = orig_pp_fn(data[key or inkey])
+ return data
+
+ return _ikok_pp_fn
+
+ return get_ikok_pp_fn
diff --git a/big_vision/pp/utils_test.py b/big_vision/pp/utils_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..beec18cef62a9638ed143229d7aedc5e218a70b6
--- /dev/null
+++ b/big_vision/pp/utils_test.py
@@ -0,0 +1,53 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Tests for preprocessing utils."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from big_vision.pp import utils
+import tensorflow.compat.v1 as tf
+
+
+class UtilsTest(tf.test.TestCase):
+
+ def test_maybe_repeat(self):
+ self.assertEqual((1, 1, 1), utils.maybe_repeat(1, 3))
+ self.assertEqual((1, 2), utils.maybe_repeat((1, 2), 2))
+ self.assertEqual([1, 2], utils.maybe_repeat([1, 2], 2))
+
+ def test_inkeyoutkey(self):
+ @utils.InKeyOutKey()
+ def get_pp_fn(shift, scale=0):
+ def _pp_fn(x):
+ return scale * x + shift
+ return _pp_fn
+
+ data = {"k_in": 2, "other": 3}
+ ppfn = get_pp_fn(1, 2, inkey="k_in", outkey="k_out") # pylint: disable=unexpected-keyword-arg
+ self.assertEqual({"k_in": 2, "k_out": 5, "other": 3}, ppfn(data))
+
+ data = {"k": 6, "other": 3}
+ ppfn = get_pp_fn(1, inkey="k", outkey="k") # pylint: disable=unexpected-keyword-arg
+ self.assertEqual({"k": 1, "other": 3}, ppfn(data))
+
+ data = {"other": 6, "image": 3}
+ ppfn = get_pp_fn(5, 2)
+ self.assertEqual({"other": 6, "image": 11}, ppfn(data))
+
+
+if __name__ == "__main__":
+ tf.test.main()
diff --git a/big_vision/requirements.txt b/big_vision/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9ae71db5ac26e2746864c37959dfd28cb9fe70bf
--- /dev/null
+++ b/big_vision/requirements.txt
@@ -0,0 +1,19 @@
+numpy>=1.26
+absl-py
+git+https://github.com/google/CommonLoopUtils
+distrax
+editdistance
+einops
+flax
+optax
+git+https://github.com/google/flaxformer
+git+https://github.com/akolesnikoff/panopticapi.git@mute
+overrides
+protobuf
+sentencepiece
+tensorflow-cpu
+tfds-nightly
+tensorflow-text
+tensorflow-gan
+psutil
+pycocoevalcap
diff --git a/big_vision/run_tpu.sh b/big_vision/run_tpu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..3c3da2e44e7d2829a00188f5e6177ea9d6e3ba4d
--- /dev/null
+++ b/big_vision/run_tpu.sh
@@ -0,0 +1,35 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+#!/bin/bash
+
+if [ ! -d "bv_venv" ]
+then
+ sudo apt-get update
+ sudo apt install -y python3-venv
+ python3 -m venv bv_venv
+ . bv_venv/bin/activate
+
+ pip install -U pip # Yes, really needed.
+ # NOTE: doesn't work when in requirements.txt -> cyclic dep
+ pip install "jax[tpu]>=0.4.25" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
+ pip install -r big_vision/requirements.txt
+else
+ . bv_venv/bin/activate
+fi
+
+if [ $# -ne 0 ]
+then
+ env TFDS_DATA_DIR=$TFDS_DATA_DIR BV_JAX_INIT=1 python3 -m "$@"
+fi
diff --git a/big_vision/sharding.py b/big_vision/sharding.py
new file mode 100644
index 0000000000000000000000000000000000000000..be76cb3a1f6b8bc0e494515bac2a54528a53494c
--- /dev/null
+++ b/big_vision/sharding.py
@@ -0,0 +1,197 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Big vision sharding utilities."""
+
+from absl import logging
+
+from big_vision.pp.registry import Registry
+import big_vision.utils as u
+import flax.linen as nn
+import jax
+import numpy as np
+
+
+NamedSharding = jax.sharding.NamedSharding
+P = jax.sharding.PartitionSpec
+
+
+def _replicated(mesh):
+ return NamedSharding(mesh, P())
+
+
+def _shard_along_axis(mesh, i, axis_name):
+ return NamedSharding(mesh, P(*((None,) * i + (axis_name,))))
+
+
+def infer_sharding(params, strategy, mesh):
+ """Infers `params` sharding based on strategy.
+
+ Args:
+ params: a pytree of arrays.
+ strategy: sharding strategy.
+ mesh: jax device mesh.
+
+ Returns:
+ A pytree with shardings, that has the same shape as the `tree` argument.
+ """
+ patterns, tactics = zip(*strategy)
+
+ x_with_names, tree_def = u.tree_flatten_with_names(params)
+ names = tree_def.unflatten(list(zip(*x_with_names))[0])
+
+ # Follows big_vision conventions: each variable is matched at most once,
+ # early patterns get matching priority.
+ mask_trees = u.make_mask_trees(params, patterns)
+
+ specs = jax.tree.map(lambda x: (None,) * x.ndim, params)
+
+ for mask_tree, tactic in zip(mask_trees, tactics):
+ for op_str in tactic.split("|"):
+ op = Registry.lookup(f"shardings.{op_str}")()
+ specs = jax.tree.map(
+ lambda x, n, match, spec, op=op: op(spec, mesh, n, x)
+ if match else spec,
+ params, names, mask_tree, specs,
+ is_leaf=lambda v: isinstance(v, nn.Partitioned))
+
+ # Two-level tree_map to prevent it from doing traversal inside the spec.
+ specs = jax.tree.map(lambda _, spec: P(*spec), nn.unbox(params), specs)
+ return jax.tree.map(lambda spec: NamedSharding(mesh, spec), specs)
+
+
+# Sharding rules
+#
+# Each rule needs to be added to the registry, can accept custom args, and
+# returns a function that updates the current spec. The arguments are:
+# 1. Variable name
+# 2. Variable itself (or placeholder with .shape and .dtype properties)
+# 3. The current sharing spec.
+
+
+@Registry.register("shardings.replicate")
+def replicate():
+ """Full replication sharding rule.
+
+ Note full replication is deafult, so this can be skipped and useful to
+ explicitly state in the config that certrain parameters are replicated.
+ TODO: can be generalized to support replication over a sub-mesh.
+
+ Returns:
+ A function that updates the sharding spec.
+ """
+ def _update_spec(cur_spec, mesh, name, x):
+ del x, mesh
+ if not all(axis is None for axis in cur_spec):
+ raise ValueError(f"Inconsistent sharding instructions: "
+ f"parameter {name} has spec {cur_spec}, "
+ f"so it can't be fully replicated.")
+ return cur_spec
+ return _update_spec
+
+
+@Registry.register("shardings.fsdp")
+def fsdp(axis, min_size_to_shard_mb=4):
+ """FSDP sharding rule.
+
+ Shards the largest dimension that is not sharded already and is divisible
+ by the total device count.
+
+ Args:
+ axis: mesh axis name for FSDP, or a collection of names.
+ min_size_to_shard_mb: minimal tensor size to bother with sharding.
+
+ Returns:
+ A function that updates the sharding spec.
+ """
+ axis = axis if isinstance(axis, str) else tuple(axis)
+ axis_tuple = axis if isinstance(axis, tuple) else (axis,)
+ def _update_spec(cur_spec, mesh, name, x):
+ shape = x.shape
+ axis_size = np.prod([mesh.shape[a] for a in axis_tuple])
+
+ if np.prod(shape) * x.dtype.itemsize <= min_size_to_shard_mb * (2 ** 20):
+ return cur_spec
+
+ # Partition along largest axis that is divisible and not taken.
+ idx = np.argsort(shape)[::-1]
+ for i in idx:
+ if shape[i] % axis_size == 0:
+ if cur_spec[i] is None:
+ return cur_spec[:i] + (axis,) + cur_spec[i+1:]
+
+ logging.info("Failed to apply `fsdp` rule to the parameter %s:%s, as all "
+ "its dimensions are not divisible by the requested axis: "
+ "%s:%i, or already occupied by other sharding rules: %s",
+ name, shape, axis, axis_size, cur_spec)
+ return cur_spec
+ return _update_spec
+
+
+@Registry.register("shardings.logical_partitioning")
+def logical_partitioning():
+ """Manual sharding based on Flax's logical partitioning annotations.
+
+ Uses logical sharding annotations added in model code with
+ `nn.with_logical_partitioning`. Respects logical to mesh name mapping rules
+ (typically defined in the dynamic context using
+ `with nn.logical_axis_rules(rules): ...`).
+
+ Returns:
+ A function that outputs the sharding spec of `nn.LogicallyPartitioned` boxed
+ specs.
+ """
+ def _update_spec(cur_spec, mesh, name, x):
+ del x, name, mesh
+ if isinstance(cur_spec, nn.LogicallyPartitioned):
+ return nn.logical_to_mesh_axes(cur_spec.names)
+ return cur_spec
+ return _update_spec
+
+
+@Registry.register("shardings.shard_dim")
+def shard_dim(axis, dim, ignore_ndim_error=False):
+ """Shards the given dimension along the given axis.
+
+ Args:
+ axis: mesh axis name for sharding.
+ dim: dimension to shard (can be negative).
+ ignore_ndim_error: if True, a warning error is logged instead of raising an
+ exception when the given dimension is not compatible with the number of
+ dimensions of the array.
+
+ Returns:
+ A function that updates the sharding spec.
+ """
+ def _update_spec(cur_spec, mesh, name, x):
+ del mesh, x
+ if np.abs(dim) >= len(cur_spec):
+ msg = f"Cannot shard_dim({axis}, {dim}): name={name} cur_spec={cur_spec}"
+ if ignore_ndim_error:
+ logging.warning(msg)
+ return cur_spec
+ else:
+ raise ValueError(msg)
+ pos_dim = dim
+ if pos_dim < 0:
+ pos_dim += len(cur_spec)
+ if cur_spec[pos_dim] is not None:
+ raise ValueError(
+ f"Already sharded: shard_dim({axis}, {dim}):"
+ f" name={name} cur_spec={cur_spec}"
+ )
+ new_spec = cur_spec[:pos_dim] + (axis,) + cur_spec[pos_dim + 1 :]
+ return new_spec
+
+ return _update_spec
diff --git a/big_vision/tools/download_tfds_datasets.py b/big_vision/tools/download_tfds_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..b64c33d51a7cb8df063d15e828e30b07007ff6b0
--- /dev/null
+++ b/big_vision/tools/download_tfds_datasets.py
@@ -0,0 +1,44 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Download and prepare TFDS datasets for the big_vision codebase.
+
+This python script covers cifar10, cifar100, oxford_iiit_pet
+and oxford_flowers10.
+
+If you want to integrate other public or custom datasets, please follow:
+https://www.tensorflow.org/datasets/catalog/overview
+"""
+
+from absl import app
+import tensorflow_datasets as tfds
+
+
+def main(argv):
+ if len(argv) > 1 and "download_tfds_datasets.py" in argv[0]:
+ datasets = argv[1:]
+ else:
+ datasets = [
+ "cifar10",
+ "cifar100",
+ "oxford_iiit_pet",
+ "oxford_flowers102",
+ "imagenet_v2",
+ ]
+ for d in datasets:
+ tfds.load(name=d, download=True)
+
+
+if __name__ == "__main__":
+ app.run(main)
diff --git a/big_vision/tools/eval_only.py b/big_vision/tools/eval_only.py
new file mode 100644
index 0000000000000000000000000000000000000000..abdde4a6c0aa656a2e8ec76ce645982a2a6723b3
--- /dev/null
+++ b/big_vision/tools/eval_only.py
@@ -0,0 +1,146 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Script that loads a model and only runs evaluators."""
+
+from functools import partial
+import importlib
+
+import os
+
+from absl import app
+from absl import flags
+from absl import logging
+import big_vision.evaluators.common as eval_common
+import big_vision.utils as u
+from clu import parameter_overview
+import flax
+import flax.jax_utils as flax_utils
+import jax
+import jax.numpy as jnp
+from ml_collections import config_flags
+from tensorflow.io import gfile
+
+
+config_flags.DEFINE_config_file(
+ "config", None, "Training configuration.", lock_config=True)
+
+flags.DEFINE_string("workdir", default=None, help="Work unit directory.")
+flags.DEFINE_boolean("cleanup", default=False,
+ help="Delete workdir (only) after successful completion.")
+
+# Adds jax flags to the program.
+jax.config.parse_flags_with_absl()
+
+
+def main(argv):
+ del argv
+
+ config = flags.FLAGS.config
+ workdir = flags.FLAGS.workdir
+ logging.info("Workdir: %s", workdir)
+
+ # Here we register preprocessing ops from modules listed on `pp_modules`.
+ for m in config.get("pp_modules", ["ops_general", "ops_image"]):
+ importlib.import_module(f"big_vision.pp.{m}")
+
+ # These functions do more stuff internally, for OSS release we mock them by
+ # trivial alternatives in order to minize disruptions in the code.
+ xid, wid = -1, -1
+ def write_note(note):
+ if jax.process_index() == 0:
+ logging.info("NOTE: %s", note)
+
+ mw = u.BigVisionMetricWriter(xid, wid, workdir, config)
+ u.chrono.inform(measure=mw.measure, write_note=write_note)
+
+ write_note(f"Initializing {config.model_name} model...")
+ assert config.get("model.reinit") is None, (
+ "I don't think you want any part of the model to be re-initialized.")
+ model_mod = importlib.import_module(f"big_vision.models.{config.model_name}")
+ model_kw = dict(config.get("model", {}))
+ if "num_classes" in config: # Make it work for regular + image_text.
+ model_kw["num_classes"] = config.num_classes
+ model = model_mod.Model(**model_kw)
+
+ # We want all parameters to be created in host RAM, not on any device, they'll
+ # be sent there later as needed, otherwise we already encountered two
+ # situations where we allocate them twice.
+ @partial(jax.jit, backend="cpu")
+ def init(rng):
+ input_shapes = config.get("init_shapes", [(1, 224, 224, 3)])
+ input_types = config.get("init_types", [jnp.float32] * len(input_shapes))
+ dummy_inputs = [jnp.zeros(s, t) for s, t in zip(input_shapes, input_types)]
+ things = flax.core.unfreeze(model.init(rng, *dummy_inputs))
+ return things.get("params", {})
+
+ with u.chrono.log_timing("z/secs/init"):
+ params_cpu = init(jax.random.PRNGKey(42))
+ if jax.process_index() == 0:
+ parameter_overview.log_parameter_overview(params_cpu, msg="init params")
+ num_params = sum(p.size for p in jax.tree.leaves(params_cpu))
+ mw.measure("num_params", num_params)
+
+ # The use-case for not loading an init is testing and debugging.
+ if config.get("model_init"):
+ write_note(f"Initialize model from {config.model_init}...")
+ params_cpu = model_mod.load(
+ params_cpu, config.model_init, config.get("model"),
+ **config.get("model_load", {}))
+ if jax.process_index() == 0:
+ parameter_overview.log_parameter_overview(params_cpu, msg="loaded params")
+
+ write_note("Replicating...")
+ params_repl = flax_utils.replicate(params_cpu)
+
+ def predict_fn(params, *a, **kw):
+ return model.apply({"params": params}, *a, **kw)
+
+ evaluators = eval_common.from_config(
+ config, {"predict": predict_fn, "model": model},
+ lambda s: write_note(f"Initializing evaluator: {s}..."),
+ lambda key, cfg: 1, # Ignore log_steps, always run.
+ )
+
+ # Allow running for multiple steps can be useful for couple cases:
+ # 1. non-deterministic evaluators
+ # 2. warmup when timing evaluators (eg compile cache etc).
+ for s in range(config.get("eval_repeats", 1)):
+ mw.step_start(s)
+ for (name, evaluator, _, prefix) in evaluators:
+ write_note(f"{name} evaluation step {s}...")
+ with u.profile(name, noop=name in config.get("no_profile", [])):
+ with u.chrono.log_timing(f"z/secs/eval/{name}"):
+ for key, value in evaluator.run(params_repl):
+ mw.measure(f"{prefix}{key}", value)
+ u.sync() # sync barrier to get correct measurements
+ u.chrono.flush_timings()
+ mw.step_end()
+
+ write_note("Done!")
+ mw.close()
+
+ # Make sure all hosts stay up until the end of main.
+ u.sync()
+
+ if workdir and flags.FLAGS.cleanup and jax.process_index() == 0:
+ gfile.rmtree(workdir)
+ try: # Only need this on the last work-unit, if already empty.
+ gfile.remove(os.path.join(workdir, ".."))
+ except tf.errors.OpError:
+ pass
+
+
+if __name__ == "__main__":
+ app.run(main)
diff --git a/big_vision/tools/lit_demo/README.md b/big_vision/tools/lit_demo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/big_vision/tools/lit_demo/build.js b/big_vision/tools/lit_demo/build.js
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/big_vision/tools/lit_demo/package.json b/big_vision/tools/lit_demo/package.json
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/big_vision/train.py b/big_vision/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..51f49cc75c59f27e6393c73b400420e2c89da9e0
--- /dev/null
+++ b/big_vision/train.py
@@ -0,0 +1,517 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Training loop example.
+
+This is a basic variant of a training loop, good starting point for fancy ones.
+"""
+# pylint: disable=consider-using-from-import
+# pylint: disable=logging-fstring-interpolation
+
+import functools
+import importlib
+import multiprocessing.pool
+import os
+
+from absl import app
+from absl import flags
+from absl import logging
+import big_vision.evaluators.common as eval_common
+import big_vision.input_pipeline as input_pipeline
+import big_vision.optax as bv_optax
+import big_vision.sharding as bv_sharding
+import big_vision.utils as u
+from clu import parameter_overview
+import flax.linen as nn
+import jax
+from jax.experimental import multihost_utils
+from jax.experimental.array_serialization import serialization as array_serial
+from jax.experimental.shard_map import shard_map
+import jax.numpy as jnp
+from ml_collections import config_flags
+import numpy as np
+import optax
+import tensorflow as tf
+
+from tensorflow.io import gfile
+
+
+config_flags.DEFINE_config_file(
+ "config", None, "Training configuration.", lock_config=True)
+
+flags.DEFINE_string("workdir", default=None, help="Work unit directory.")
+flags.DEFINE_boolean("cleanup", default=False,
+ help="Delete workdir (only) after successful completion.")
+
+# Adds jax flags to the program.
+jax.config.parse_flags_with_absl()
+# Transfer guard will fail the program whenever that data between a host and
+# a device is transferred implicitly. This often catches subtle bugs that
+# cause slowdowns and memory fragmentation. Explicit transfers are done
+# with jax.device_put and jax.device_get.
+jax.config.update("jax_transfer_guard", "disallow")
+# Fixes design flaw in jax.random that may cause unnecessary d2d comms.
+jax.config.update("jax_threefry_partitionable", True)
+
+
+NamedSharding = jax.sharding.NamedSharding
+P = jax.sharding.PartitionSpec
+
+
+def main(argv):
+ del argv
+
+ # This is needed on multihost systems, but crashes on non-TPU single-host.
+ if os.environ.get("BV_JAX_INIT"):
+ jax.distributed.initialize()
+
+ # Make sure TF does not touch GPUs.
+ tf.config.set_visible_devices([], "GPU")
+
+ config = flags.FLAGS.config
+
+################################################################################
+# #
+# Set up logging #
+# #
+################################################################################
+
+ # Set up work directory and print welcome message.
+ workdir = flags.FLAGS.workdir
+ logging.info(
+ f"\u001b[33mHello from process {jax.process_index()} holding "
+ f"{jax.local_device_count()}/{jax.device_count()} devices and "
+ f"writing to workdir {workdir}.\u001b[0m")
+ logging.info(f"The config:\n{config}")
+
+ save_ckpt_path = None
+ if workdir: # Always create if requested, even if we may not write into it.
+ gfile.makedirs(workdir)
+ save_ckpt_path = os.path.join(workdir, "checkpoint.bv")
+
+ # The pool is used to perform misc operations such as logging in async way.
+ pool = multiprocessing.pool.ThreadPool(1)
+
+ # Here we register preprocessing ops from modules listed on `pp_modules`.
+ for m in config.get("pp_modules", ["ops_general", "ops_image", "ops_text"]):
+ importlib.import_module(f"big_vision.pp.{m}")
+
+ # Setup up logging and experiment manager.
+ xid, wid = -1, -1
+ fillin = lambda s: s
+ def info(s, *a):
+ logging.info("\u001b[33mNOTE\u001b[0m: " + s, *a)
+ def write_note(note):
+ if jax.process_index() == 0:
+ info("%s", note)
+
+ mw = u.BigVisionMetricWriter(xid, wid, workdir, config)
+
+ # Allow for things like timings as early as possible!
+ u.chrono.inform(measure=mw.measure, write_note=write_note)
+
+################################################################################
+# #
+# Set up Mesh #
+# #
+################################################################################
+
+ # We rely on jax mesh_utils to organize devices, such that communication
+ # speed is the fastest for the last dimension, second fastest for the
+ # penultimate dimension, etc.
+ config_mesh = config.get("mesh", [("data", jax.device_count())])
+
+ # Sharding rules with default
+ sharding_rules = config.get("sharding_rules", [("act_batch", "data")])
+
+ write_note("Creating device mesh...")
+ mesh = u.create_device_mesh(
+ config_mesh,
+ allow_split_physical_axes=config.get("mesh_allow_split_physical_axes",
+ False))
+ repl_sharding = jax.sharding.NamedSharding(mesh, P())
+
+ # Consistent device order is important to ensure correctness of various train
+ # loop components, such as input pipeline, update step, evaluators. The
+ # order presribed by the `devices_flat` variable should be used throughout
+ # the program.
+ devices_flat = mesh.devices.flatten()
+
+################################################################################
+# #
+# Input Pipeline #
+# #
+################################################################################
+
+ write_note("Initializing train dataset...")
+ batch_size = config.input.batch_size
+ if batch_size % jax.device_count() != 0:
+ raise ValueError(f"Batch size ({batch_size}) must "
+ f"be divisible by device number ({jax.device_count()})")
+ info("Global batch size %d on %d hosts results in %d local batch size. With "
+ "%d dev per host (%d dev total), that's a %d per-device batch size.",
+ batch_size, jax.process_count(), batch_size // jax.process_count(),
+ jax.local_device_count(), jax.device_count(),
+ batch_size // jax.device_count())
+
+ train_ds, ntrain_img = input_pipeline.training(config.input)
+
+ total_steps = u.steps("total", config, ntrain_img, batch_size)
+ def get_steps(name, default=ValueError, cfg=config):
+ return u.steps(name, cfg, ntrain_img, batch_size, total_steps, default)
+
+ u.chrono.inform(total_steps=total_steps, global_bs=batch_size,
+ steps_per_epoch=ntrain_img / batch_size)
+
+ info("Running for %d steps, that means %f epochs",
+ total_steps, total_steps * batch_size / ntrain_img)
+
+ # Start input pipeline as early as possible.
+ n_prefetch = config.get("prefetch_to_device", 1)
+ train_iter = input_pipeline.start_global(train_ds, devices_flat, n_prefetch)
+
+################################################################################
+# #
+# Create Model & Optimizer #
+# #
+################################################################################
+
+ write_note("Creating model...")
+ model_mod = importlib.import_module(f"big_vision.models.{config.model_name}")
+ model = model_mod.Model(
+ num_classes=config.num_classes, **config.get("model", {}))
+
+ def init(rng):
+ batch = jax.tree.map(lambda x: jnp.zeros(x.shape, x.dtype.as_numpy_dtype),
+ train_ds.element_spec)
+ params = model.init(rng, batch["image"])["params"]
+
+ # Set bias in the head to a low value, such that loss is small initially.
+ if "init_head_bias" in config:
+ params["head"]["bias"] = jnp.full_like(params["head"]["bias"],
+ config["init_head_bias"])
+
+ return params
+
+ # This seed makes the Jax part of things (like model init) deterministic.
+ # However, full training still won't be deterministic, for example due to the
+ # tf.data pipeline not being deterministic even if we would set TF seed.
+ # See (internal link) for a fun read on what it takes.
+ rng = jax.random.PRNGKey(u.put_cpu(config.get("seed", 0)))
+
+ write_note("Inferring parameter shapes...")
+ rng, rng_init = jax.random.split(rng)
+ params_shape = jax.eval_shape(init, rng_init)
+
+ write_note("Inferring optimizer state shapes...")
+ tx, sched_fns = bv_optax.make(config, nn.unbox(params_shape), sched_kw=dict(
+ total_steps=total_steps, batch_size=batch_size, data_size=ntrain_img))
+ opt_shape = jax.eval_shape(tx.init, params_shape)
+ # We jit this, such that the arrays are created on the CPU, not device[0].
+ sched_fns_cpu = [u.jit_cpu()(sched_fn) for sched_fn in sched_fns]
+
+ if jax.process_index() == 0:
+ num_params = sum(np.prod(p.shape) for p in jax.tree.leaves(params_shape))
+ mw.measure("num_params", num_params)
+
+################################################################################
+# #
+# Shard & Transfer #
+# #
+################################################################################
+
+ write_note("Inferring shardings...")
+ train_state_shape = {"params": params_shape, "opt": opt_shape}
+
+ strategy = config.get("sharding_strategy", [(".*", "replicate")])
+ with nn.logical_axis_rules(sharding_rules):
+ train_state_sharding = bv_sharding.infer_sharding(
+ train_state_shape, strategy=strategy, mesh=mesh)
+
+ write_note("Transferring train_state to devices...")
+ # RNG is always replicated
+ rng_init = u.reshard(rng_init, repl_sharding)
+
+ # Parameters and the optimizer are now global (distributed) jax arrays.
+ params = jax.jit(init, out_shardings=train_state_sharding["params"])(rng_init)
+ opt = jax.jit(tx.init, out_shardings=train_state_sharding["opt"])(params)
+
+ rng, rng_loop = jax.random.split(rng, 2)
+ rng_loop = u.reshard(rng_loop, repl_sharding)
+ del rng # not used anymore, so delete it.
+
+ # At this point we have everything we need to form a train state. It contains
+ # all the parameters that are passed and updated by the main training step.
+ # From here on, we have no need for Flax AxisMetadata (such as partitioning).
+ train_state = nn.unbox({"params": params, "opt": opt})
+ del params, opt # Delete to avoid memory leak or accidental reuse.
+
+ write_note("Logging parameter overview...")
+ parameter_overview.log_parameter_overview(
+ train_state["params"], msg="Init params",
+ include_stats="global", jax_logging_process=0)
+
+################################################################################
+# #
+# Update Step #
+# #
+################################################################################
+
+ @functools.partial(
+ jax.jit,
+ donate_argnums=(0,),
+ out_shardings=(train_state_sharding, repl_sharding))
+ def update_fn(train_state, rng, batch):
+ """Update step."""
+
+ images, labels = batch["image"], batch["labels"]
+
+ step_count = bv_optax.get_count(train_state["opt"], jittable=True)
+ rng = jax.random.fold_in(rng, step_count)
+
+ if config.get("mixup") and config.mixup.p:
+ # The shard_map below makes mixup run on every device independently and
+ # thus avoids unnecessary communication.
+ sharded_mixup_fn = shard_map(
+ u.get_mixup(rng, config.mixup.p),
+ mesh=jax.sharding.Mesh(devices_flat, ("data",)),
+ in_specs=P("data"), out_specs=(P(), P("data"), P("data")))
+ rng, (images, labels), _ = sharded_mixup_fn(images, labels)
+
+ # Get device-specific loss rng.
+ rng, rng_model = jax.random.split(rng, 2)
+
+ def loss_fn(params):
+ logits, _ = model.apply(
+ {"params": params}, images,
+ train=True, rngs={"dropout": rng_model})
+ return getattr(u, config.get("loss", "sigmoid_xent"))(
+ logits=logits, labels=labels)
+
+ params, opt = train_state["params"], train_state["opt"]
+ loss, grads = jax.value_and_grad(loss_fn)(params)
+ updates, opt = tx.update(grads, opt, params)
+ params = optax.apply_updates(params, updates)
+
+ measurements = {"training_loss": loss}
+ gs = jax.tree.leaves(bv_optax.replace_frozen(config.schedule, grads, 0.))
+ measurements["l2_grads"] = jnp.sqrt(sum([jnp.sum(g * g) for g in gs]))
+ ps = jax.tree.leaves(params)
+ measurements["l2_params"] = jnp.sqrt(sum([jnp.sum(p * p) for p in ps]))
+ us = jax.tree.leaves(updates)
+ measurements["l2_updates"] = jnp.sqrt(sum([jnp.sum(u * u) for u in us]))
+
+ return {"params": params, "opt": opt}, measurements
+
+################################################################################
+# #
+# Load Checkpoint #
+# #
+################################################################################
+
+ # Decide how to initialize training. The order is important.
+ # 1. Always resumes from the existing checkpoint, e.g. resumes a finetune job.
+ # 2. Resume from a previous checkpoint, e.g. start a cooldown training job.
+ # 3. Initialize model from something, e,g, start a fine-tuning job.
+ # 4. Train from scratch.
+ resume_ckpt_path = None
+ if save_ckpt_path and gfile.exists(f"{save_ckpt_path}-LAST"):
+ resume_ckpt_path = save_ckpt_path
+ elif config.get("resume"):
+ resume_ckpt_path = fillin(config.resume)
+
+ ckpt_mngr = None
+ if save_ckpt_path or resume_ckpt_path:
+ ckpt_mngr = array_serial.GlobalAsyncCheckpointManager()
+
+ if resume_ckpt_path:
+ write_note(f"Resuming training from checkpoint {resume_ckpt_path}...")
+ jax.tree.map(lambda x: x.delete(), train_state)
+ del train_state
+ shardings = {
+ **train_state_sharding,
+ "chrono": jax.tree.map(lambda _: repl_sharding,
+ u.chrono.save()),
+ }
+ loaded = u.load_checkpoint_ts(
+ resume_ckpt_path, tree=shardings, shardings=shardings)
+ train_state = {key: loaded[key] for key in train_state_sharding.keys()}
+
+ u.chrono.load(jax.device_get(loaded["chrono"]))
+ del loaded
+ elif config.get("model_init"):
+ write_note(f"Initialize model from {config.model_init}...")
+ # TODO: when updating the `load` API soon, do pass and request the
+ # full `train_state` from it. Examples where useful: VQVAE, BN.
+ train_state["params"] = model_mod.load(
+ train_state["params"], config.model_init, config.get("model"),
+ **config.get("model_load", {}))
+
+ # load has the freedom to return params not correctly sharded. Think of for
+ # example ViT resampling position embedings on CPU as numpy arrays.
+ train_state["params"] = u.reshard(
+ train_state["params"], train_state_sharding["params"])
+
+ parameter_overview.log_parameter_overview(
+ train_state["params"], msg="restored params",
+ include_stats="global", jax_logging_process=0)
+
+
+################################################################################
+# #
+# Setup Evals #
+# #
+################################################################################
+
+ # We do not jit/pmap this function, because it is passed to evaluator that
+ # does it later. We output as many intermediate tensors as possible for
+ # maximal flexibility. Later `jit` will prune out things that are not needed.
+ def eval_logits_fn(train_state, batch):
+ logits, out = model.apply({"params": train_state["params"]}, batch["image"])
+ return logits, out
+
+ def eval_loss_fn(train_state, batch):
+ logits, _ = model.apply({"params": train_state["params"]}, batch["image"])
+ loss_fn = getattr(u, config.get("loss", "sigmoid_xent"))
+ return {
+ "loss": loss_fn(logits=logits, labels=batch["labels"], reduction=False)
+ }
+
+ eval_fns = {
+ "predict": eval_logits_fn,
+ "loss": eval_loss_fn,
+ }
+
+ # Only initialize evaluators when they are first needed.
+ @functools.lru_cache(maxsize=None)
+ def evaluators():
+ return eval_common.from_config(
+ config, eval_fns,
+ lambda s: write_note(f"Init evaluator: {s}…\n{u.chrono.note}"),
+ lambda key, cfg: get_steps(key, default=None, cfg=cfg),
+ devices_flat,
+ )
+
+ # At this point we need to know the current step to see whether to run evals.
+ write_note("Inferring the first step number...")
+ first_step_device = bv_optax.get_count(train_state["opt"], jittable=True)
+ first_step = int(jax.device_get(first_step_device))
+ u.chrono.inform(first_step=first_step)
+
+ # Note that training can be pre-empted during the final evaluation (i.e.
+ # just after the final checkpoint has been written to disc), in which case we
+ # want to run the evals.
+ if first_step in (total_steps, 0):
+ write_note("Running initial or final evals...")
+ mw.step_start(first_step)
+ for (name, evaluator, _, prefix) in evaluators():
+ if config.evals[name].get("skip_first") and first_step != total_steps:
+ continue
+ write_note(f"{name} evaluation...\n{u.chrono.note}")
+ with u.chrono.log_timing(f"z/secs/eval/{name}"):
+ with mesh, nn.logical_axis_rules(sharding_rules):
+ for key, value in evaluator.run(train_state):
+ mw.measure(f"{prefix}{key}", value)
+
+################################################################################
+# #
+# Train Loop #
+# #
+################################################################################
+
+ prof = None # Keeps track of start/stop of profiler state.
+
+ write_note("Starting training loop, compiling the first step...")
+ for step, batch in zip(range(first_step + 1, total_steps + 1), train_iter):
+ mw.step_start(step)
+
+ with jax.profiler.StepTraceAnnotation("train_step", step_num=step):
+ with u.chrono.log_timing("z/secs/update0", noop=step > first_step + 1):
+ with mesh, nn.logical_axis_rules(sharding_rules):
+ train_state, measurements = update_fn(train_state, rng_loop, batch)
+
+ # On the first host, let's always profile a handful of early steps.
+ if jax.process_index() == 0:
+ prof = u.startstop_prof(prof, step, first_step, get_steps("log_training"))
+
+ # Report training progress
+ if (u.itstime(step, get_steps("log_training"), total_steps, host=0)
+ or u.chrono.warmup and jax.process_index() == 0):
+ for i, sched_fn_cpu in enumerate(sched_fns_cpu):
+ mw.measure(f"global_schedule{i if i else ''}",
+ sched_fn_cpu(u.put_cpu(step - 1)))
+ measurements = jax.device_get(measurements)
+ for name, value in measurements.items():
+ mw.measure(name, value)
+ u.chrono.tick(step)
+ for k in ("training_loss", "l2_grads", "l2_updates", "l2_params"):
+ if not np.isfinite(measurements.get(k, 0.0)):
+ raise RuntimeError(f"{k} became nan or inf somewhere within steps "
+ f"[{step - get_steps('log_training')}, {step}]")
+
+ # Checkpoint saving
+ keep_ckpt_steps = get_steps("keep_ckpt", None) or total_steps
+ if save_ckpt_path and (
+ (keep := u.itstime(step, keep_ckpt_steps, total_steps, first=False))
+ or u.itstime(step, get_steps("ckpt", None), total_steps, first=True)
+ ):
+ u.chrono.pause(wait_for=train_state)
+
+ # Copy because we add extra stuff to the checkpoint.
+ ckpt = {**train_state}
+
+ # To save chrono state correctly and safely in a multihost setup, we
+ # broadcast the state to all hosts and convert it to a global array.
+ with jax.transfer_guard("allow"):
+ chrono_ckpt = multihost_utils.broadcast_one_to_all(u.chrono.save())
+ chrono_shardings = jax.tree.map(lambda _: repl_sharding, chrono_ckpt)
+ ckpt = ckpt | {"chrono": u.reshard(chrono_ckpt, chrono_shardings)}
+
+ u.save_checkpoint_ts(ckpt_mngr, ckpt, save_ckpt_path, step, keep)
+ u.chrono.resume()
+
+ for (name, evaluator, log_steps, prefix) in evaluators():
+ if u.itstime(step, log_steps, total_steps, first=False, last=True):
+ u.chrono.pause(wait_for=train_state)
+ u.chrono.tick(step) # Record things like epoch number, core hours etc.
+ write_note(f"{name} evaluation...\n{u.chrono.note}")
+ with u.chrono.log_timing(f"z/secs/eval/{name}"):
+ with mesh, nn.logical_axis_rules(sharding_rules):
+ for key, value in evaluator.run(train_state):
+ mw.measure(f"{prefix}{key}", jax.device_get(value))
+ u.chrono.resume()
+ mw.step_end()
+
+ # Always give a chance to stop the profiler, no matter how things ended.
+ # TODO: can we also do this when dying of an exception like OOM?
+ if jax.process_index() == 0 and prof is not None:
+ u.startstop_prof(prof)
+
+ # Last note needs to happen before the pool's closed =)
+ write_note(f"Done!\n{u.chrono.note}")
+
+ pool.close()
+ pool.join()
+ mw.close()
+ if ckpt_mngr:
+ ckpt_mngr.wait_until_finished()
+
+ # Make sure all hosts stay up until the end of main.
+ u.sync()
+
+ u.maybe_cleanup_workdir(workdir, flags.FLAGS.cleanup, info)
+
+
+if __name__ == "__main__":
+ app.run(main)
diff --git a/big_vision/utils.py b/big_vision/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a954300f9ac7e4ccce27c38eb1367d3233451532
--- /dev/null
+++ b/big_vision/utils.py
@@ -0,0 +1,1478 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Utils very specific to this project, not generic."""
+
+import collections
+import contextlib
+import dataclasses
+import functools
+import io
+import json
+import multiprocessing
+import multiprocessing.pool
+import os
+import re
+import sys
+import time
+from typing import Mapping
+
+from absl import flags
+from absl import logging
+from big_vision.pp import registry as pp_registry
+import einops
+import flax
+import flax.jax_utils as flax_utils
+import jax
+from jax.experimental import mesh_utils
+from jax.experimental.array_serialization import serialization as array_serial
+import jax.numpy as jnp
+import ml_collections as mlc
+import numpy as np
+
+import tensorflow.io.gfile as gfile # pylint: disable=consider-using-from-import
+
+
+Registry = pp_registry.Registry
+
+
+# pylint: disable=logging-fstring-interpolation
+
+
+def pad_shard_unpad(wrapped, static_argnums=(0,), static_argnames=()):
+ """Wraps a function with code that pads, shards, then un-shards, un-pads.
+
+ Args:
+ wrapped: the function to be wrapped. Signature is `params, *args, *kwargs`.
+ static_argnums: indices of arguments to `wrapped` that should _not_ be
+ padded and sharded, but instead be forwarded as-is. The default is (0,)
+ because by far the most common use-case is to pass `params` first.
+ static_argnames: names of kwargs to `wrapped` that should _not_ be padded
+ and sharded, but instead be forwarded as-is.
+
+ Returns:
+ A new function that pads and shards its arguments before passing them to
+ the wrapped function, and un-shards and un-pads the returned pytree.
+
+ This is useful for calling a pmap'ed function with inputs that aren't
+ divisible by the number of devices. A typical use is:
+ @pad_shard_unpad
+ @jax.pmap
+ def forward(params, x): ...
+
+ Notes:
+ The padding is done in host-memory before being passed to the function, and
+ the values returned by the function are transferred back to host memory.
+
+ The returned function is augmented with a new keyword-only argument
+ `min_device_batch` that, if specified, forces padding inputs to at least
+ this size per device. This can be useful to avoid recompiles for the last
+ batch and reduce memory fragmentation.
+ """
+
+ def pad_shard_unpad_wrapper(*args, min_device_batch=None, **kw):
+ d = jax.local_device_count() # d = devices, b = batch
+
+ # Find the batch-sizes of all non-static arguments.
+ def get_bs(x):
+ batch_sizes = jax.tree.map(lambda y: y.shape[0], x)
+ return jax.tree.flatten(batch_sizes)[0]
+
+ bs_a = [get_bs(a) for i, a in enumerate(args) if i not in static_argnums]
+ bs_kw = [get_bs(v) for k, v in kw.items() if k not in static_argnames]
+ bs = set([n for b in (bs_a + bs_kw) for n in b])
+ assert len(bs) == 1, f"Inconsistent batch-sizes: {bs}"
+ b = bs.pop()
+
+ def pad(x):
+ _, *shape = x.shape
+ db, rest = divmod(b, d)
+ if rest:
+ x = np.concatenate([x, np.zeros((d - rest, *shape), x.dtype)], axis=0)
+ db += 1
+ if min_device_batch and db < min_device_batch:
+ x = np.concatenate(
+ [x, np.zeros((d * (min_device_batch - db), *shape), x.dtype)])
+ db = min_device_batch
+ return x.reshape(d, db, *shape)
+
+ def maybe_pad(x, actually_pad=True):
+ if not actually_pad: return x # For call-site convenience below.
+ return jax.tree.map(pad, x)
+
+ args = [maybe_pad(a, i not in static_argnums) for i, a in enumerate(args)]
+ kw = {k: maybe_pad(v, k not in static_argnames) for k, v in kw.items()}
+ out = wrapped(*args, **kw)
+
+ def unpad(x):
+ # Transfer back before cutting, to reduce on-device shape diversity.
+ return einops.rearrange(jax.device_get(x), "d b ... -> (d b) ...")[:b]
+ return jax.tree.map(unpad, out)
+
+ return pad_shard_unpad_wrapper
+
+
+def onehot(labels, num_classes, on_value=1.0, off_value=0.0):
+ x = (labels[..., None] == jnp.arange(num_classes)[None])
+ x = jax.lax.select(x, jnp.full(x.shape, on_value),
+ jnp.full(x.shape, off_value))
+ return x.astype(jnp.float32)
+
+
+def npload(fname):
+ """Loads `fname` and returns an np.ndarray or dict thereof."""
+ # Load the data; use local paths directly if possible:
+ if os.path.exists(fname):
+ loaded = np.load(fname, allow_pickle=False)
+ else:
+ # For other (remote) paths go via gfile+BytesIO as np.load requires seeks.
+ with gfile.GFile(fname, "rb") as f:
+ data = f.read()
+ loaded = np.load(io.BytesIO(data), allow_pickle=False)
+
+ # Support loading both single-array files (np.save) and zips (np.savez).
+ if isinstance(loaded, np.ndarray):
+ return loaded
+ else:
+ return dict(loaded)
+
+
+def load_checkpoint_np(npz, tree=None):
+ """Loads a jax pytree from a npz file.
+
+ Args:
+ npz: Either path to the checkpoint file (.npz), or a dict-like.
+ tree: deprecated, use None.
+ Bwd-compat for old format that only stored values: the pytree structure.
+
+ Returns:
+ A pytree that is the checkpoint.
+ """
+ if isinstance(npz, str): # If not already loaded, then load.
+ npz = npload(npz)
+ keys, values = zip(*list(npz.items()))
+ if tree:
+ checkpoint = tree.unflatten(values)
+ else:
+ checkpoint = recover_tree(keys, values)
+ return checkpoint
+
+
+def load_params(ckpt, **kw):
+ """Loads the parameters of a big_vision checkpoint, both old or new format.
+
+ Args:
+ ckpt: Path to the checkpoint (.npz, .ts) or dict-like.
+ **kw: forwarded to the underlying load function (_np or _ts).
+
+ Returns:
+ A pytree that is the checkpoint, potentially sharded.
+
+ Notes:
+ The `ckpt` string can contain an colon-separated "submodel" indicator, like
+ `img` in the example `/path/to/file.npz:img`.
+ This is used to load sub-parts of a model, for example the image load the
+ image encoder out of a two_tower (SigLIP) checkpoint, or distillation.
+ This way, ANY model that uses this function can load itself from a
+ checkpoint that contains multiple sub-models.
+ """
+ key = None # Whether we want to extract only a sub-key of the model.
+
+ if isinstance(ckpt, str): # Most common case of passing a checkpoint path.
+ # Potentially read out the sub-part to load from after the colon
+ # '/path/to/file:img/head' => '/path/to/file', 'img/head'
+ # 'gs://path/to/file' => 'gs://path/to/file', None
+ if match := re.match(r"^(.*?/.*?)(?::([\w/]+))?$", ckpt):
+ ckpt, key = match.groups()
+ else:
+ raise ValueError(f"Weird ckpt path: {ckpt} ; Maybe prepend ./ ?")
+
+ # Use the checkpoint filename to detect when we're loading old-style .npz
+ # checkpoints, as opposed to new-style tensorstore checkpoint folders.
+ if ".npz" in ckpt: # Not a perfect heuristic, but good enough.
+ checkpoint = load_checkpoint_np(ckpt, **kw)
+ checkpoint = jax.tree.map(recover_dtype, checkpoint)
+ if "params" in checkpoint:
+ # Checkpoint with optax state (after (internal link)).
+ params = checkpoint["params"]
+ elif "opt" in checkpoint:
+ # Checkpoint with Flax optimizer.
+ params = checkpoint["opt"]["target"]
+ else:
+ # When open-sourcing, we often shared only the params directly.
+ params = checkpoint
+ else:
+ # Here we're now loading new-style tensorstore checkpoints.
+ # We can be a more efficient and load params and `key` only right away.
+ regex = f"params/{key}($|/.*)" if key else "params/.*"
+ assert "regex" not in kw, "For a custom regex, use tsload directly."
+ kw["regex"] = regex
+ checkpoint = load_checkpoint_ts(ckpt, **kw)
+ params = checkpoint["params"]
+
+ if key is not None:
+ params = tree_get(params, key)
+
+ return params
+
+
+def prefetch_scalar(it, nprefetch=1, devices=None):
+ n_loc_dev = len(devices) if devices else jax.local_device_count()
+ repl_iter = (np.ones(n_loc_dev) * i for i in it)
+ return flax_utils.prefetch_to_device(repl_iter, nprefetch, devices)
+
+
+def sigmoid_xent(*, logits, labels, reduction=True):
+ # NOTE: This implementation is stable, see these two:
+ # (internal link)
+ # https://github.com/google/jax/issues/2140
+ log_p = jax.nn.log_sigmoid(logits)
+ log_not_p = jax.nn.log_sigmoid(-logits)
+ nll = -jnp.sum(labels * log_p + (1. - labels) * log_not_p, axis=-1)
+ return jnp.mean(nll) if reduction else nll
+
+
+def bidirectional_contrastive_loss(zimg, ztxt, t, mask=None, reduction=False):
+ """Bidirectional contrastive loss (e.g. for contrastive trainer/evaluator)."""
+ # BF.FB = BB
+ logits = jnp.dot(zimg, ztxt.T) * t
+
+ if mask is not None:
+ # Set to negative infinity where mask = 0. Masked examples will disappear
+ # under softmax, and be ignored by ncorrect (NINF will never win argmax).
+ exclude = jnp.logical_not(mask) # Now 1 if we don't want to keep.
+ exclude = jnp.logical_or(exclude[:, None], exclude[None, :])
+ logits = jnp.where(exclude, -jnp.inf, logits)
+
+ # Note: assumed t is in a good range e.g. already passed through exp/softplus.
+ l1 = -jnp.diag(jax.nn.log_softmax(logits, axis=1)) # NLL img->txt
+ l2 = -jnp.diag(jax.nn.log_softmax(logits, axis=0)) # NLL txt->img
+ l = 0.5 * (l1 + l2)
+
+ if mask is not None:
+ l = jnp.where(mask, l, 0)
+
+ redux = jnp.mean if reduction else lambda x: x
+ if reduction and mask is not None:
+ redux = lambda x: jnp.sum(x * mask) / (jnp.sum(mask) + 1e-8)
+
+ # Also return extra measurements.
+ return redux(l), {
+ "ncorrect": redux(jnp.argmax(logits, axis=1) == jnp.arange(len(logits))),
+ }
+
+
+def softmax_xent(*, logits, labels, reduction=True, kl=False, axis=-1):
+ log_p = jax.nn.log_softmax(logits, axis=axis)
+ nll = -jnp.sum(labels * log_p, axis=axis)
+ if kl:
+ nll += jnp.sum(labels * jnp.log(jnp.clip(labels, 1e-8)), axis=axis)
+ return jnp.mean(nll) if reduction else nll
+
+
+def weighted_softmax_xent(*,
+ logits,
+ labels,
+ reduction=True,
+ weights=None,
+ label_smoothing=0.0,
+ normalize=True):
+ """Compute weighted cross entropy.
+
+ Args:
+ logits: [batch, length, num_classes] float array.
+ labels: categorical targets [batch, length] int array.
+ reduction: reduce across batch dim.
+ weights: None or array of shape [batch, length].
+ label_smoothing: label smoothing constant, used to determine the on and off
+ values.
+ normalize: normalize each "sentence" loss by the number of tokens in it.
+
+ Returns:
+ Tuple of scalar loss and batch normalizing factor.
+ """
+ if logits.ndim != labels.ndim + 1:
+ raise ValueError("Incorrect shapes. Got shape %s logits and %s targets" %
+ (str(logits.shape), str(labels.shape)))
+ vocab_size = logits.shape[-1]
+ confidence = 1.0 - label_smoothing
+ low_confidence = (1.0 - confidence) / (vocab_size - 1)
+ soft_targets = onehot(
+ labels, vocab_size, on_value=confidence, off_value=low_confidence)
+
+ loss = -jnp.sum(soft_targets * jax.nn.log_softmax(logits), axis=-1)
+
+ normalizing_factor = labels.shape[1]
+ if weights is not None:
+ loss = loss * weights
+ normalizing_factor = jnp.clip(weights.sum(axis=1), 2e-38)
+
+ loss = loss.sum(axis=1)
+ if normalize:
+ loss = loss / normalizing_factor
+
+ return loss.mean() if reduction else loss
+
+
+def accumulate_gradient(loss_and_grad_fn, params, images, labels, accum_steps):
+ """Accumulate gradient over multiple steps to save on memory."""
+ # See (internal link) for details and experiments.
+ if accum_steps and accum_steps > 1:
+ assert images.shape[0] % accum_steps == 0, (
+ f"Bad accum_steps {accum_steps} for batch size {images.shape[0]}")
+ step_size = images.shape[0] // accum_steps
+ l, g = loss_and_grad_fn(params, images[:step_size], labels[:step_size])
+ def acc_grad_and_loss(i, l_and_g):
+ imgs = jax.lax.dynamic_slice(images, (i*step_size, 0, 0, 0),
+ (step_size,) + images.shape[1:])
+ lbls = jax.lax.dynamic_slice(labels, (i*step_size, 0),
+ (step_size, labels.shape[1]))
+ li, gi = loss_and_grad_fn(params, imgs, lbls)
+ l, g = l_and_g
+ return (l + li, jax.tree.map(lambda x, y: x + y, g, gi))
+ l, g = jax.lax.fori_loop(1, accum_steps, acc_grad_and_loss, (l, g))
+ return jax.tree.map(lambda x: x / accum_steps, (l, g))
+ else:
+ return loss_and_grad_fn(params, images, labels)
+
+
+def itstime(step, every_n_steps, total_steps, host=None, last=True, first=True,
+ drop_close_to_last=0.25):
+ """Returns True if it's time to execute an action.
+
+ Args:
+ step: the current step representing "now".
+ every_n_steps: the action should run every this many steps.
+ total_steps: the step number of the last step of training.
+ host: host number. If provided, only run if we are this process.
+ last: whether to run on the last step or not.
+ first: whether to run on the first step or not.
+ drop_close_to_last: if a step would run, but is this close (in terms of
+ fraction of every_n_step) to the last one, skip.
+
+ Returns:
+ True if the action should be executed, False if not.
+ """
+
+ # This logic avoids running `itstime` "a few" steps before the last step.
+ # Canonical example: don't save checkpoint 2 steps before the last, and then
+ # at the last again; it's pointless and checkpoint timing will time out.
+ close_to_last = False
+ if drop_close_to_last and every_n_steps:
+ close_to_last = abs(step - total_steps) < drop_close_to_last * every_n_steps
+
+ is_host = host is None or jax.process_index() == host
+ is_step = every_n_steps and (step % every_n_steps == 0) and not close_to_last
+ is_last = every_n_steps and step == total_steps
+ is_first = every_n_steps and step == 1
+ return is_host and (is_step or (last and is_last) or (first and is_first))
+
+
+def checkpointing_timeout(writer, timeout):
+ # Make sure checkpoint writing is not a bottleneck
+ if writer is not None:
+ try:
+ # Note: `writer` is a multiprocessing.AsyncResult, and
+ # timeout is in seconds.
+ writer.get(timeout=timeout)
+ except multiprocessing.TimeoutError as e:
+ raise TimeoutError(
+ "Checkpoint writing seems to be a bottleneck. Make sure you do "
+ "not do something wrong, like writing checkpoints to a distant "
+ "cell. In a case you are OK with checkpoint writing being a "
+ "bottleneck, you can configure `ckpt_timeout` parameter") from e
+
+
+def hms(s):
+ """Format time in hours/minutes/seconds."""
+ if s < 60:
+ return f"{s:.0f}s"
+ m, s = divmod(s, 60)
+ if m < 60:
+ return f"{m:.0f}m{s:.0f}s"
+ h, m = divmod(m, 60)
+ if h < 25:
+ return f"{h:.0f}h{m:.0f}m" # Seconds intentionally omitted.
+ d, h = divmod(h, 24)
+ return f"{d:.0f}d{h:.0f}h{m:.0f}m" # Seconds intentionally omitted.
+
+
+class Chrono:
+ """Measures time and reports progress, hyper-specific to our train loops.
+
+ Some concepts:
+ 1. This differentiates between three "types" of time:
+ - training time: the time spent on actual training (fprop/bprop/update)
+ - program time: overall time the program runs, including all overheads
+ - pause time: the chronometer can be paused (eg during evals).
+ 2. This handles a "warmup": the first step is skipped for training time
+ purposes, as it includes significant compilation overheads, which distort
+ estimates.
+ 3. `accum`ulates (i.e. integrates) timings, and save/load them across
+ restarts.
+ """
+
+ def __init__(self):
+ self._timing_history = collections.defaultdict(list)
+ self._measure = None
+ self._write_note = None
+
+ self.program_start_time = time.monotonic()
+ self.train_start_time = None
+ self.train_start_step = None # When we started timing (after warmup)
+
+ self.prev_time = None
+ self.prev_step = None
+
+ self.pause_start = None
+ self.paused_time = 0
+
+ self.total_steps = None
+ self.global_bs = None
+ self.steps_per_epoch = None
+
+ self.warmup = 2 # How many calls to `tick` to skip.
+ self.load() # Inits accum integrators.
+ self.note = "Chrono n/a"
+
+ def inform(self, *, first_step=None, total_steps=None, global_bs=None,
+ steps_per_epoch=None, measure=None, write_note=None):
+ """Provide some extra info that's only known later in the program."""
+ # The pattern of `self.x = x or self.x` allows one to call `inform` various
+ # times with various subset of information (args), as they become available.
+ # Except for `first_step` which can be 0 so is a bit more verbose.
+ self.prev_step = first_step if first_step is not None else self.prev_step
+ self.total_steps = total_steps or self.total_steps
+ self.steps_per_epoch = steps_per_epoch or self.steps_per_epoch
+ self.global_bs = global_bs or self.global_bs
+ self._measure = measure or self._measure
+ self._write_note = write_note or self._write_note
+ if self.total_steps and self.prev_step is not None:
+ self.note = (f"Steps:{self.prev_step}/{self.total_steps} "
+ f"[{self.prev_step/self.total_steps:.1%}]")
+
+ def tick(self, step, measure=None, write_note=None):
+ """A chronometer tick."""
+ if step == self.prev_step: return # Can happen from evals for example.
+
+ measure = measure or self._measure
+ write_note = write_note or self._write_note
+
+ now = time.monotonic()
+ measure("uptime", now - self.program_start_time)
+ self.flush_timings()
+
+ # We do always count examples, regardless of the timing-related warmup that
+ # happens a few lines below.
+ ds = step - self.prev_step # Steps between ticks
+ self.prev_step = step
+ self.accum_examples_seen += ds * self.global_bs
+ measure("examples_seen", self.accum_examples_seen)
+ measure("progress", step / self.total_steps)
+ if self.steps_per_epoch:
+ measure("epoch", step / self.steps_per_epoch)
+
+ # We take the start as the second time `tick` is called, so we avoid
+ # measuring the overhead of compilation and don't include it in time
+ # estimates.
+ if self.warmup > 1:
+ self.warmup -= 1
+ write_note(self.note) # This can help debugging.
+ return
+ if self.warmup == 1:
+ self.train_start_time = self.prev_time = now
+ self.train_start_step = step
+ self.accum_program_time += now - self.program_start_time
+ self.paused_time = 0 # Drop pauses that happened before timing starts.
+ self.warmup = 0
+ write_note(self.note) # This can help debugging.
+ return
+
+ # Measurement with micro-timings of current training steps speed.
+ # Time between ticks (ignoring pause)
+ dt = now - self.prev_time - self.paused_time
+ ncores = jax.device_count() # Global device count
+ measure("img/sec/core", self.global_bs * ds / dt / ncores)
+
+ # Accumulate (integrate) times, good for plots.
+ self.accum_train_time += dt
+ self.accum_pause_time += self.paused_time
+ self.accum_program_time += dt + self.paused_time
+
+ # Convert to, and log as, core hours.
+ core_hours = self.accum_train_time * ncores / 60 / 60
+ devtype = jax.devices()[0].device_kind
+ measure(f"core_hours_{devtype}", core_hours)
+ measure("core_hours", core_hours) # For convenience as x-axis in sweeps.
+
+ # Progress note with "global" full-program average timings
+ # (eg in program-time minus warmup)
+ dt = now - self.train_start_time # Time elapsed since end of warmup.
+ steps_timed = step - self.train_start_step
+ steps_todo = self.total_steps - step
+ self.note = f"Steps:{step}/{self.total_steps} [{step/self.total_steps:.1%}]"
+ self.note += f"\nWalltime:{hms(self.accum_program_time)}"
+ self.note += f" ({hms(self.accum_pause_time)} eval)"
+ self.note += f"\nETA:{hms(dt / steps_timed*steps_todo)}"
+ self.note += f"\nTotal train time:{hms(dt / steps_timed*self.total_steps)}"
+ write_note(self.note)
+
+ log_memory(measure)
+
+ self.prev_time = now
+ self.paused_time = 0
+
+ def pause(self, wait_for=()):
+ assert self.pause_start is None, "Don't pause twice."
+ jax.block_until_ready(wait_for)
+ self.pause_start = time.monotonic()
+
+ def resume(self):
+ self.paused_time += time.monotonic() - self.pause_start
+ self.pause_start = None
+
+ def save(self):
+ return dict(
+ accum_program_time=self.accum_program_time,
+ accum_train_time=self.accum_train_time,
+ accum_pause_time=self.accum_pause_time,
+ accum_examples_seen=self.accum_examples_seen,
+ )
+
+ def load(self, ckpt={}): # pylint: disable=dangerous-default-value
+ self.accum_program_time = float(ckpt.get("accum_program_time", 0.0))
+ self.accum_train_time = float(ckpt.get("accum_train_time", 0.0))
+ self.accum_pause_time = float(ckpt.get("accum_pause_time", 0.0))
+ self.accum_examples_seen = int(ckpt.get("accum_examples_seen", 0))
+
+ @contextlib.contextmanager
+ def log_timing(self, name, *, noop=False):
+ """Use this when you time sth once per step and want instant flushing."""
+ t0 = time.monotonic()
+ yield
+ dt = time.monotonic() - t0
+ if not noop:
+ if self._measure: # So that timed things still work in colab.
+ self._measure(name, dt)
+ logging.info("TIMING[%s]: %s", name, dt)
+ logging.flush()
+
+ @contextlib.contextmanager
+ def log_timing_avg(self, name, *, noop=False):
+ """Use this when you time sth multiple times per step (eg in a loop)."""
+ t0 = time.monotonic()
+ yield
+ dt = time.monotonic() - t0
+ if not noop:
+ self._timing_history[name].append(dt)
+ logging.info("TIMING[%s]: avg %s current %s",
+ name, np.mean(self._timing_history[name]), dt)
+ logging.flush()
+
+ def flush_timings(self):
+ assert self._measure is not None
+ for name, times in self._timing_history.items():
+ self._measure(name, np.mean(times))
+ self._timing_history.clear()
+
+
+# Singleton to use from everywhere. https://stackoverflow.com/a/6760726/2366315
+chrono = Chrono()
+
+
+def log_memory(measure):
+ """Log a bunch of memory-related measurements."""
+ try:
+ import psutil
+ except ImportError:
+ psutil = None
+
+ if psutil is not None:
+ # Note that total != available + used, see psutil docs.
+ vmem = psutil.virtual_memory()
+ measure("y/hostmem/total", vmem.total)
+ measure("y/hostmem/available", vmem.available)
+ measure("y/hostmem/used", vmem.used)
+
+ # We show only device 0 and 1 to avoid spam. The reason to show two and not
+ # just one, if multiple are available, is because a frequent mistake is to
+ # create arrays on the default device, which is device 0.
+ for i, d in zip([0, 1], jax.local_devices()):
+ for k, v in (d.memory_stats() or {}).items():
+ measure(f"y/devmem/dev{i}/{k}", v)
+
+
+def _traverse_with_names(tree, with_inner_nodes=False):
+ """Traverses nested dicts/dataclasses and emits (leaf_name, leaf_val)."""
+ if dataclasses.is_dataclass(tree):
+ tree = flax.serialization.to_state_dict(tree)
+ # Don't output the non-leaf nodes. If the optimizer doesn't have a state
+ # the tree leaves can be Nones which was interpreted as a leaf by this
+ # function but not by the other functions (like jax.tree.map).
+ if tree is None:
+ return
+ elif isinstance(tree, Mapping):
+ keys = sorted(tree.keys())
+ for key in keys:
+ for path, v in _traverse_with_names(tree[key], with_inner_nodes):
+ yield (key + "/" + path).rstrip("/"), v
+ if with_inner_nodes:
+ yield "", tree
+ elif isinstance(tree, (list, tuple)):
+ for idx in range(len(tree)):
+ for path, v in _traverse_with_names(tree[idx], with_inner_nodes):
+ yield (str(idx) + "/" + path).rstrip("/"), v
+ if with_inner_nodes:
+ yield "", tree
+ else:
+ yield "", tree
+
+
+def tree_flatten_with_names(tree):
+ """Populates tree_flatten with leaf names.
+
+ This function populates output of tree_flatten with leaf names, using a
+ custom traversal that produces names is provided. The custom traversal does
+ NOT have to traverse tree in the same order as jax, as we take care of
+ automatically aligning jax' and custom traversals.
+
+ Args:
+ tree: python tree.
+
+ Returns:
+ A list of values with names: [(name, value), ...]
+ """
+ vals, tree_def = jax.tree.flatten(tree)
+
+ # "Fake" token tree that is use to track jax internal tree traversal and
+ # adjust our custom tree traversal to be compatible with it.
+ tokens = range(len(vals))
+ token_tree = tree_def.unflatten(tokens)
+ val_names, perm = zip(*_traverse_with_names(token_tree))
+ inv_perm = np.argsort(perm)
+
+ # Custom traverasal should visit the same number of leaves.
+ assert len(val_names) == len(vals)
+
+ return [(val_names[i], v) for i, v in zip(inv_perm, vals)], tree_def
+
+
+def tree_unflatten(names_and_vals):
+ """Reverses `tree_flatten_with_names(tree)[0]`."""
+ return recover_tree(*zip(*names_and_vals))
+
+
+def tree_map_with_names(f, tree, *rest):
+ """Like jax.tree.map but with a filter on the leaf path name.
+
+ Args:
+ f: A function with first parameter `name` (path-like "a/b/c") and remaining
+ parameters values of `tree` and `*rest` corresponding to the given `name`
+ Should return a new value for parameter `name`.
+ tree: The tree of parameters `f` should be applied to.
+ *rest: more trees of the exact same structure.
+
+ Returns:
+ A tree identical in structure to `tree` and `*rest` but with the leaves the
+ result of calling `f` on corresponding name/leaves in `tree` and `*rest`.
+ """
+ names_and_vals, tree_def = tree_flatten_with_names(tree)
+ names, vals = zip(*names_and_vals)
+ rest_vals = [list(zip(*tree_flatten_with_names(t)[0]))[1] for t in rest]
+ vals = [f(*name_and_vals) for name_and_vals in zip(names, vals, *rest_vals)]
+ return tree_def.unflatten(vals)
+
+
+def tree_map_with_regex(f, tree, regex_rules, not_f=lambda x: x, name=None):
+ """Apply jax-style tree_map based on regex rules.
+
+ Args:
+ f: a function that is being applied to every variable.
+ tree: jax tree of arrays.
+ regex_rules: a list of tuples `(pattern, args)`, where `pattern` is a regex
+ which used for variable matching and `args` are positional arguments
+ passed to `f`. If some variable is not matched, we apply `not_f` transform
+ which is id by default. If multiple patterns match, then only the first
+ rule is applied.
+ not_f: optional function which is applied to variables that do not match any
+ pattern.
+ name: a name of transform for logging purposes.
+
+ Returns:
+ a tree, transformed by `f` according to the given rules.
+ """
+ def _f(vname, v):
+ for pattern, arg in regex_rules:
+ if re.fullmatch(pattern, vname):
+ if name and jax.process_index() == 0:
+ logging.info("Applying %s to %s with %s due to `%s`",
+ name, vname, arg, pattern)
+ return f(v, arg)
+ return not_f(v)
+ return tree_map_with_names(_f, tree)
+
+
+def tree_get(tree, name):
+ """Get an entry of pytree by flattened key name, eg a/b/c, with nice error.
+
+ Args:
+ tree: the pytree to be queried.
+ name: the path to extract from the tree, see below for examples.
+
+ Returns:
+ A few examples:
+ tree = {'a': 1, 'b': {'c': 2, 'd': 3}}
+ tree_get(tree, 'a') == 1
+ tree_get(tree, 'b/c') == 2
+ tree_get(tree, 'b') == {'c': 2, 'd': 3}
+ """
+ flattened = dict(_traverse_with_names(tree, with_inner_nodes=True))
+ try:
+ return flattened[name]
+ except KeyError as e:
+ class Msg(str): # Reason: https://stackoverflow.com/a/70114007/2366315
+ def __repr__(self):
+ return str(self)
+ msg = "\n".join([name, "Available keys:", *flattened, ""])
+ # Turn into configdict to use its "did you mean?" error message!
+ msg = mlc.ConfigDict(flattened)._generate_did_you_mean_message(name, msg) # pylint: disable=protected-access
+ raise KeyError(Msg(msg)) from e
+
+
+def tree_replace(tree, replacements):
+ """Renames/removes (nested) keys.
+
+ Example usage:
+
+ tree = {'a': {'b': 2, 'c': 3}, 'c': 4}
+ replacements = {
+ 'a/b': 'a/b/x', # replaces 'a/b' with 'a/b/x'
+ '.*c': 'C', # replaces 'c' with 'C' ('a/c' is removed)
+ 'C': 'D', # replaces 'C' (which was 'c') with 'D'
+ '.*/c': None, # removes 'a/c'
+ }
+ tree2 = rename_remove(tree, replacements)
+ assert tree2 == {'D': 4, 'a': {'b': {'x': 2}}}
+
+ Args:
+ tree: A nested dictionary.
+ replacements: Rules specifying `regex` as keys and `replacement` as values
+ to be used with `m = re.match(regex, key)` and `m.expand(replacement)`
+ for every `key` independently.
+
+ Note that:
+ 1. If any rule matches with `replacement=None`, then the key is removed.
+ 2. The rules are applied in order. It's possible to have multiple
+ transformations on a single key.
+
+ Returns:
+ Updated `tree` according to rules defined in `replacements`.
+ """
+ replacements = {
+ re.compile(kk): vv for kk, vv in replacements.items()
+ }
+
+ def rename(k):
+ for kk, vv in replacements.items():
+ m = kk.match(k)
+ if m:
+ k = k[:m.start()] + m.expand(vv) + k[m.end():]
+ return k
+
+ def should_remove(k):
+ return any(vv is None and kk.match(k) for kk, vv in replacements.items())
+
+ names_and_vals, _ = tree_flatten_with_names(tree)
+ names_and_vals = [
+ (rename(k), v) for k, v in names_and_vals if not should_remove(k)
+ ]
+ return tree_unflatten(names_and_vals)
+
+
+def tree_compare(tree1, tree2):
+ """Returns `(tree1_only, tree2_only, dtype_shape_mismatch)`."""
+ tree1 = flax.traverse_util.flatten_dict(tree1, sep="/")
+ tree2 = flax.traverse_util.flatten_dict(tree2, sep="/")
+ return set(tree1) - set(tree2), set(tree2) - set(tree1), {
+ k: [(v.dtype, v.shape), (tree2[k].dtype, tree2[k].shape)]
+ for k, v in tree1.items()
+ if k in tree2 and (v.dtype != tree2[k].dtype or v.shape != tree2[k].shape)
+ }
+
+
+def tree_filter(tree, mask):
+ """Returns nested dict structure with only a subset of children."""
+ # TODO: The code below only works for nested-dict and only when they
+ # have same structure. Consider relax this.
+ if not isinstance(tree, dict):
+ assert isinstance(mask, bool), f"Mask leaves must be boolean! {mask}"
+ return tree
+ assert sorted(tree.keys()) == sorted(mask.keys()), (
+ f"Keys in tree and mask are not equal! {tree.keys()} != {mask.keys()}")
+ return {k: tree_filter(v, mask[k]) for k, v in tree.items()
+ if mask[k] is not False}
+
+
+def recover_dtype(a):
+ """Numpy's `save` stores bfloat16 type as "void" type, so we recover it."""
+ if hasattr(a, "dtype") and a.dtype.type is np.void:
+ assert a.itemsize == 2, "Unknown dtype!"
+ return a.view(jax.numpy.bfloat16)
+ else:
+ return a
+
+
+def recover_tree(keys, values):
+ """Recovers a tree as a nested dict from flat names and values.
+
+ This function is useful to analyze checkpoints that are saved by our programs
+ without need to access the exact source code of the experiment. In particular,
+ it can be used to extract an reuse various subtrees of the scheckpoint, e.g.
+ subtree of parameters.
+
+ Args:
+ keys: a list of keys, where '/' is used as separator between nodes.
+ values: a list of leaf values.
+
+ Returns:
+ A nested tree-like dict.
+ """
+ tree = {}
+ sub_trees = collections.defaultdict(list)
+ for k, v in zip(keys, values):
+ if "/" not in k:
+ tree[k] = v
+ else:
+ k_left, k_right = k.split("/", 1)
+ sub_trees[k_left].append((k_right, v))
+ for k, kv_pairs in sub_trees.items():
+ k_subtree, v_subtree = zip(*kv_pairs)
+ tree[k] = recover_tree(k_subtree, v_subtree)
+ return tree
+
+
+def tssave(mngr, pytree, path, on_commit=lambda *_, **__: None):
+ """Save pytree using jax tensorstore-based checkpoint manager.
+
+ NOTE: When overwriting an existing checkpoint with a different pytree, the
+ result is, counterintuitively, the union of both, not only the new one.
+
+ Args:
+ mngr: An instance of GlobalAsyncCheckpointManager.
+ pytree: What to store; any pytree of arrays.
+ path: Where to save the pytree. Creates subfolders as needed.
+ on_commit: A callback when writing is done, see `mngr.serialize`.
+ """
+ names, vals = zip(*tree_flatten_with_names(pytree)[0])
+
+ for name in names:
+ if "~" in name:
+ raise ValueError(f"Symbol '~' is not allowed in names. Found in {name}.")
+
+ gfile.makedirs(path)
+ with jax.transfer_guard("allow"):
+ names = [name.replace("/", "~") for name in names]
+ mngr.serialize_with_paths(
+ list(vals), [os.path.join(path, name) for name in names],
+ on_commit_callback=functools.partial(on_commit, array_names=names))
+
+
+def save_checkpoint_ts(mngr, checkpoint, path, step, keep=True):
+ """Preemption-safe saving of checkpoints using tssave."""
+ # The tensorstore checkpoint format is a folder with (potentially) many files.
+ # On some file-systems, operations on these (copy, rename, delete) are slow,
+ # so we implement a flow that's both robust to pre-emptions/crashes during
+ # checkpointing and makes minimal use of these slow operations.
+
+ # The logic goes as follows. It's infaillible :)
+ # (...if file move is atomic, which it is.)
+ # We always write the current checkpoint to a new folder, which contains the
+ # step number in its name. If we don't need to keep it indefinitely, we append
+ # "-tmp" to its name.
+ # After writing the next checkpoint, we remove the previous one if it had
+ # "-tmp" in its name.
+ # We also have a -LAST file that contains a pointer to the latest complete
+ # checkpoint. File operations are cheap to make atomic, that's why.
+
+ def _on_commit_callback(array_names): # Runs after writing ckpt is done.
+ with gfile.GFile(f"{path}-CUR", "w") as f:
+ f.write(curr)
+
+ last = ""
+ if gfile.exists(f"{path}-LAST"):
+ with gfile.GFile(f"{path}-LAST", "r") as f:
+ last = f.read().strip()
+
+ gfile.rename(f"{path}-CUR", f"{path}-LAST", overwrite=True)
+
+ if last.endswith("-tmp"):
+ # If pre-emption happens here, some old checkpoints may not be deleted.
+ multiprocessing.pool.ThreadPool().map(
+ gfile.rmtree,
+ [f"{path}-{last}/{name}" for name in array_names])
+ gfile.rmtree(f"{path}-{last}")
+
+ # NOTE: The jax checkpoint manager automatically waits for the previous save
+ # to be finished before writing again, so we don't need to do it here.
+
+ # Always write to path with step number in it.
+ curr = f"{step:09d}{'-tmp' if not keep else ''}"
+ tssave(mngr, checkpoint, f"{path}-{curr}", _on_commit_callback)
+
+
+def load_checkpoint_ts(path, **tsload_kw):
+ """Loads a big_vision checkpoint saved by `save_checkpoint_ts`."""
+ to_load = path
+
+ try:
+ # When passing a general path (not a specific step), get the last available.
+ with gfile.GFile(f"{path}-LAST", "r") as f:
+ to_load = f"{path}-{f.read().strip()}"
+ except Exception: # Differs based on backend, so blanket catch. pylint:disable=broad-exception-caught
+ pass
+
+ return tsload(to_load, **tsload_kw)
+
+
+def tsload(path, *, tree=None, shardings=None, regex=None):
+ """Loads tensorstore-based array-tree from disk.
+
+ If `tree` argument is provided, then array names to load and target structure
+ is derived from the tree. If `tree` is None, then array names to load are
+ derived from array filenames on the disk, and, optionally, `regex` is applied
+ to filter these names. The`tree` argument is then automatically derived from
+ array names with `recover_tree` util.
+
+ Arrays are loaded to CPU/TPU/GPU memory as specified by the `shardings`
+ argument, which is a pytree of CPU/TPU/GPU shardings (can be mixed within a
+ single pytree). `shardings` should a prefix tree of the `tree` argument. We
+ automatically broadcast `shardings` to a full `tree`. For example, a user can
+ specify `shardings=jax.sharding.SingleDeviceSharing(jax.devices('cpu')[0])`,
+ which will be broadcasted to a full tree.
+
+ Args:
+ path: a directory where the checkpoint arrays are stored.
+ tree: a target pytree, which defines array names to load and the target tree
+ structure. If tree is None, then `tree` is inferred from the names of
+ arrays stored on the disk.
+ shardings: a prefix pytree (with respect to `tree`) of the target shardings.
+ regex: regex to filter array names from the disk, if `tree` is not provided.
+
+ Returns:
+ A pytree of loaded arrays that has the same structure as `shardings` arg.
+ """
+ if (tree is not None) and (regex is not None):
+ raise ValueError("If tree is specified, regex filtering is not allowed.")
+
+ if tree is None:
+ # Some file-systems (gs://) list folders with a trailing /, get rid of it.
+ path_names = set([p.rstrip("/").replace("~", "/")
+ for p in gfile.listdir(path)])
+ regex = re.compile(regex) if regex is not None else re.compile(".*")
+ path_names = [p for p in path_names if regex.match(p)]
+ tree = recover_tree(path_names, [0] * len(path_names))
+
+ names_and_vals, tree_def = tree_flatten_with_names(tree)
+ names_to_load, _ = zip(*names_and_vals)
+
+ if shardings is None:
+ shardings = jax.sharding.SingleDeviceSharding(
+ jax.local_devices(backend="cpu")[0]
+ )
+ shardings = list(jax.tree.leaves(tree_broadcast(shardings, tree)))
+
+ names_to_load = [os.path.join(path, name.replace("/", "~"))
+ for name in names_to_load]
+ specs = [array_serial.get_tensorstore_spec(n) for n in names_to_load]
+ arrays = array_serial.run_deserialization(shardings, specs, concurrent_gb=64)
+ return tree_def.unflatten(arrays)
+
+
+def steps(prefix, config, data_size=None, batch_size=None, total_steps=None,
+ default=ValueError):
+ """Gets duration named `prefix` out of `config` and converts it to steps.
+
+ Using this function to access a configuration value that denotes some kind
+ of duration (eg training time, warmup, checkpoint frequency, ...) allows the
+ duration to be specified in terms of steps, epochs, examples, or percent of
+ training time, and converts any of these into steps, such that the training
+ code only deals with steps.
+ If the result is not an integer step number, it is rounded to the nearest one.
+
+ Args:
+ prefix: The name of the duration to query. The actual config fields can
+ then be one of `prefix_steps`, `prefix_examples`, or `prefix_epochs`.
+ config: The dictionary (config) from which to read the duration.
+ data_size: The total number of training examples in one epoch.
+ batch_size: The number of examples processed per step.
+ total_steps: The total number of training steps to run.
+ default: The default value to return when no duration of the name `prefix`
+ is found in the `config`. Set to `ValueError` (the default) to raise an
+ error instead of returning a default value.
+
+ Returns:
+ The number of steps from the config, or the default value.
+
+ Raises:
+ ValueError if there is no such duration in the config and no default is set.
+ """
+ # Be helpful and make sure only match one of the following suffixes.
+ suffixes = {"steps", "examples", "epochs", "percent"}
+ matches = {
+ f"{prefix}_{s}"
+ for s in suffixes
+ if (x := config.get(f"{prefix}_{s}")) is not None and x >= 0
+ }
+ # Note that steps=0 is also a valid value (e.g. to only run evaluators).
+ assert len(matches) <= 1, f"Only one of '{matches}' should be defined."
+
+ if f"{prefix}_steps" in matches:
+ return config[f"{prefix}_steps"]
+
+ def to_integer(x):
+ # Round to nearest but always executed at least one step unless explictily
+ # asked for 0. E.g. total_epochs=0 vs total_epochs=0.0001
+ return max(1, round(x)) if x else 0
+
+ if batch_size and f"{prefix}_examples" in matches:
+ return to_integer(config[f"{prefix}_examples"] / batch_size)
+
+ if batch_size and data_size and f"{prefix}_epochs" in matches:
+ steps_per_epoch = data_size / batch_size
+ return to_integer(config[f"{prefix}_epochs"] * steps_per_epoch)
+
+ if total_steps and f"{prefix}_percent" in matches:
+ pct = config[f"{prefix}_percent"]
+ assert 0.0 <= pct <= 1.0, ( # Be helpful, since it's not obvious.
+ f"Percents should lie in [0.0, 1.0], but {prefix}_percent is {pct}")
+ return to_integer(pct * total_steps)
+
+ if default is ValueError:
+ raise ValueError(
+ f"Cannot convert {prefix} to steps, due to missing batch_size "
+ f"({batch_size}), data_size ({data_size}), total_steps ({total_steps})"
+ ", or corresponding entry in config:\n" + "\n".join(config.keys()))
+
+ return default
+
+
+def create_learning_rate_schedule(
+ total_steps, batch_size=None, data_size=None,
+ base=1.0, decay_type="stair",
+ scale_with_batchsize=False, **kw):
+ """Creates learning rate schedule, see (internal link).
+
+ Args:
+ total_steps: The total number of steps to run.
+ batch_size: The global batch-size optionally used for scaling.
+ data_size: Number of examples in the training data (for epoch conversion).
+ base: The starting learning-rate (without warmup).
+ decay_type: 'linear' or 'cosine', 'rsqrt', 'stair'.
+ scale_with_batchsize: Whether or not to scale lr automatically.
+ **kw: extra arguments specific to individual decay_types. Also contains
+ declaration of `{warmup,cooldown}_{steps,epochs,examples}` that applies
+ on top of any/all decay_type.
+
+ Returns:
+ A function learning_rate(step): float -> {"learning_rate": float}.
+ """
+
+ def to_steps(name, default=0):
+ return steps(name, kw, data_size, batch_size, total_steps, default=default)
+
+ warmup_steps = to_steps("warmup")
+ cooldown_steps = to_steps("cooldown")
+
+ # Early catch hard to backtrack errors due to warmup_steps >= total_steps,
+ # but let it run for 0 and 1 steps used to eval and debug runs.
+ assert (total_steps <= 1) or (warmup_steps < total_steps), (
+ "warmup_steps is >= total_steps")
+
+ def step_fn(step):
+ """Step to learning rate function."""
+ lr = base
+
+ # This implements the linear scaling rule following
+ # Goyal et al. at arxiv.org/abs/1706.02677.
+ # The reference batch size in literature is 256, so we scale the lr to
+ # adjust to the literature lr when bach_size changes.
+ if scale_with_batchsize:
+ lr = lr * batch_size / 256.0
+
+ progress = (step - warmup_steps) / float(total_steps - warmup_steps)
+ progress = jnp.clip(progress, 0.0, 1.0)
+ if decay_type in ("linear", "polynomial"):
+ power = kw.get("power", 1)
+ zero = kw.get("end", kw.get("linear_end", 0))
+ lr = zero + (lr - zero) * (1.0 - progress) ** power
+ elif decay_type == "cosine":
+ lr = lr * 0.5 * (1. + jnp.cos(jnp.pi * progress))
+ elif decay_type == "rsqrt":
+ # See (internal link) for details, especially how to set timescale
+ # and shift in order to continue smoothly when changing batch-size.
+ t = to_steps("timescale", default=kw.get("timescale", 10_000))
+ shift = to_steps("shift", default=kw.get("shift", 0))
+ lr = jnp.where(
+ warmup_steps <= step,
+ lr / jnp.sqrt(1 + (step + shift - warmup_steps) / t), # In decay
+ lr / jnp.sqrt(1 + shift / t)) # In warmup.
+ elif decay_type == "stair":
+ i = jnp.searchsorted(jnp.array(kw.get("steps", [])), step + 1)
+ lr = lr * jnp.take(jnp.array([1.0] + list(kw.get("mults", []))), i)
+ else:
+ raise ValueError(f"Unknown lr type {decay_type}")
+
+ if warmup_steps:
+ lr = lr * jnp.minimum(1., step / warmup_steps)
+ if cooldown_steps:
+ lr = lr * jnp.minimum(1., (total_steps - step) / cooldown_steps)
+
+ return jnp.asarray(lr, dtype=jnp.float32)
+
+ return step_fn
+
+
+def get_mixup(rng, p):
+ """Perform mixup https://arxiv.org/abs/1710.09412."""
+ rng, rng_mixup = jax.random.split(rng)
+ a = jax.random.beta(rng_mixup, p, p)
+ a = jnp.maximum(a, 1.0 - a) # see (internal link) for the context.
+ def _mixup(*things, **more_things):
+ mix = lambda thing: a * thing + (1 - a) * jnp.roll(thing, shift=1, axis=0)
+ return rng, *jax.tree.map(mix, (things, more_things))
+ return _mixup
+
+
+# For backwards compatability with legacy code.
+def mixup(rng, *things, p, **more_things):
+ return get_mixup(rng, p)(*things, **more_things)
+
+
+def sync():
+ """Syncs hosts and empties async computation queue."""
+ x = reshard(np.ones(jax.device_count()),
+ jax.sharding.PositionalSharding(jax.devices()))
+ jax.jit(jnp.sum)(x).block_until_ready()
+
+
+def check_and_compile_patterns(patterns):
+ """Validates and compiles a list of param-patterns.
+
+ The validation consists of checking for common mistakes, currently only that
+ the pattern does not start with a slash, because unlike FLAX, our parameter
+ names don't start with a slash.
+
+ Args:
+ patterns: a single (string) pattern (regex), or a list of patterns.
+
+ Returns:
+ A list of compiled and verified regexes.
+ """
+ if isinstance(patterns, str):
+ patterns = [patterns]
+
+ assert isinstance(patterns, (list, tuple)), patterns
+
+ def check_and_compile(pattern):
+ assert not pattern.startswith("/"), (
+ f"Big vision parameter names never start with '/': '{pattern}")
+ return re.compile(pattern)
+
+ return list(map(check_and_compile, patterns))
+
+
+def make_mask_trees(tree, patterns, *, log=None):
+ """Returns a boolean mask tree for every pattern (only first match)."""
+ compiled_patterns = check_and_compile_patterns(patterns)
+
+ def matchfirst(name, _):
+ matches = []
+ for pattern in compiled_patterns:
+ matches.append(not any(matches) and bool(pattern.fullmatch(name)))
+ if log is not None and True in matches and jax.process_index() == 0:
+ logging.info("%s: %s - matched by %s", log, name,
+ patterns[matches.index(True)])
+ return np.array(matches)
+
+ multimask = tree_map_with_names(matchfirst, tree)
+ return [
+ jax.tree.map(lambda matches, i=idx: matches[i], multimask)
+ for idx in range(len(patterns))
+ ]
+
+
+@contextlib.contextmanager
+def profile(name, ttl=3 * 365 * 24 * 3600, noop=False):
+ if not noop:
+ sess = startstop_prof_at_steps(None, name=name, ttl=ttl)
+ yield
+ if not noop:
+ startstop_prof_at_steps(sess, name=name, ttl=ttl)
+
+
+def startstop_prof(sess, step=None, first_step=0,
+ log_steps=1, surround=10, **kw):
+ """Runs the profiler for `surround` steps around the next `log_steps`."""
+ first_log = first_step + log_steps - (first_step % log_steps)
+ # don't start before first!
+ start = max(first_log - surround//2, first_step + 1)
+ return startstop_prof_at_steps(sess, step, start, start + surround, **kw)
+
+
+def startstop_prof_at_steps(
+ sess, step=None, first_step=None, last_step=None,
+ name="steps", ttl=3 * 365 * 24 * 3600):
+ del sess, step, first_step, last_step, name, ttl
+ pass # TODO: implement using `jax.profiler` API. Needs workdir.
+
+
+# This is a very minimal variant for open-sourcing. Our internal code makes use
+# of multiple internal logging tools instead.
+class BigVisionMetricWriter:
+ """A class for logging metrics."""
+
+ def __init__(self, xid=-1, wid=-1, workdir=None, config=None):
+ self.step_start(0)
+ if jax.process_index() != 0: return # Only one host shall write stuff.
+
+ self.pool = multiprocessing.pool.ThreadPool(1) # 1 is important here.
+ self.fname = None
+ if workdir:
+ if xid != -1 and wid != -1:
+ self.fname = os.path.join(workdir,
+ f"big_vision_{xid}_{wid}_metrics.txt")
+ else:
+ self.fname = os.path.join(workdir, "big_vision_metrics.txt")
+ if config:
+ with gfile.GFile(os.path.join(workdir, "config.json"), "w") as f:
+ f.write(config.to_json())
+
+ def step_start(self, step):
+ self.step = step
+ self.step_metrics = {}
+
+ def measure(self, name, value):
+ """Logs the metric value."""
+ if jax.process_index() != 0: return # Only one host shall write stuff.
+
+ # Convenience for accepting scalar np/DeviceArrays, as well as N-d single
+ # scalars, like [[[123]]] or similar, avoiding silly mistakes.
+ value = np.array(value).squeeze()
+
+ # If the value is a scalar, we keep it in mind to append a line to the logs.
+ # If it has any structure, we instead just log its shape.
+ value = float(value) if value.ndim == 0 else value.shape
+
+ logging.info(f"\u001b[35m[{self.step}]\u001b[0m {name} = {value}")
+ logging.flush()
+ self.step_metrics[name] = value
+
+ return value # Just for convenience
+
+ def step_end(self):
+ """Ends a training step, write its full row."""
+ if not self.step_metrics: return
+
+ def write(metrics):
+ with gfile.GFile(self.fname, "a") as f:
+ f.write(json.dumps({"step": self.step, **metrics}) + "\n")
+
+ if self.fname:
+ self.pool.apply(lambda: None) # Potentially wait for past writes.
+ self.pool.apply_async(write, (self.step_metrics,))
+
+ def close(self):
+ self.step_end()
+ if jax.process_index() == 0:
+ self.pool.close()
+ self.pool.join()
+
+
+def maybe_cleanup_workdir(workdir, cleanup, info):
+ """Potentially removes workdirs at end of run for cleanup."""
+ if not workdir:
+ return
+
+ if not cleanup:
+ info("Logs/checkpoints are in %s", workdir)
+ elif jax.process_index() == 0:
+ gfile.rmtree(workdir)
+ try: # Only need this on the last work-unit, if already empty.
+ gfile.remove(os.path.join(workdir, ".."))
+ except tf.errors.OpError:
+ pass
+
+
+def tree_broadcast(prefix, target):
+ """Broadcasts a prefix tree to a full tree.
+
+ Input-output examples:
+ 1. prefix: {"x": 10, "y": 20}
+ target: {"x": {"a": 1, "b": 2}, "y": 3}
+
+ Result: {"x": {"a": 10, "b": 10}, "y": 20}
+
+ 2. prefix: 100
+ target: {"x": {"a": 1, "b": 2}, "y": 3}
+
+ Result: {"x": {"a": 100, "b": 100}, "y": 100}
+
+ 3. prefix: {"x": 10}
+ target: {"x": {"a": 1, "b": 2}, "y": 3}
+
+ Result: ValueError
+
+ Args:
+ prefix: prefix pytree.
+ target: boradcast target for a prefix tree.
+
+ Returns:
+ prefix tree broadcasted to a target tree.
+ """
+ def _broadcast(leaf, subtree):
+ return jax.tree.map(lambda _: leaf, subtree)
+ return jax.tree.map(_broadcast, prefix, target)
+
+
+def reshard(tree, shardings):
+ """Take an arbitrarily* sharded pytree and shard it according to `shardings`.
+
+ This is a no-op for tree elements which are already sharded as requested.
+
+ *Arrays that are fully addressable (for example, CPU arrays) are assumed to be
+ identical (i.e. replicated) across hosts.
+
+ *It does not work if an element of `tree` is not fully-addressable, unless its
+ sharding is already consistent with the target sharding.
+ If this is needed, please ping lbeyer@ or akolesnikov@.
+
+ Args:
+ tree: a pytree of arrays.
+ shardings: a (prefix) pytree of jax array shardings.
+ Returns:
+ A pytree of global jax arrays that follows provided shardings.
+ """
+ def _make_global_arr(x, shard, shape):
+ # Avoid unnecessary copies and transfers:
+ if hasattr(x, "sharding") and x.sharding.is_equivalent_to(shard, len(shape)): # pylint: disable=line-too-long
+ return x
+ if not getattr(x, "is_fully_addressable", True):
+ raise RuntimeError("Trying to reshard a non-fully-addressable array. "
+ "Please see the doc-comment for detailed explanation.")
+ x = jax.device_get(x) # Might be on local devices.
+ xs = [jax.device_put(x[s], device=d)
+ for d, s in shard.addressable_devices_indices_map(shape).items()]
+ return jax.make_array_from_single_device_arrays(shape, shard, xs)
+
+ shapes = jax.tree.map(np.shape, tree)
+ shardings = tree_broadcast(shardings, tree)
+ return jax.tree.map(_make_global_arr, tree, shardings, shapes)
+
+
+def put_cpu(x):
+ """Places array/pytree on a CPU device."""
+ return jax.device_put(x, jax.local_devices(backend="cpu")[0])
+
+
+def make_fsarray_from_local_slice(local_slice, global_devices):
+ """Create a fully-sharded global device array from local host arrays.
+
+ Args:
+ local_slice: Something convertible to a numpy array (eg also TF tensors)
+ that is this host's slice of the global array.
+ global_devices: The list of global devices. Needed for consistent ordering.
+
+ Returns:
+ The global on-device array which consists of all local slices stacked
+ together in the order consistent with the devices.
+ """
+ mesh = jax.sharding.Mesh(global_devices, ("devices",))
+ sharding = jax.sharding.NamedSharding(
+ mesh, jax.sharding.PartitionSpec("devices"))
+ local_ds = mesh.local_devices
+
+ x = np.asarray(memoryview(local_slice)) # No-copy: http://(internal link)
+ xs = jax.device_put(np.split(x, len(local_ds), axis=0), local_ds)
+
+ global_shape = (x.shape[0] * jax.process_count(), *x.shape[1:])
+ return jax.make_array_from_single_device_arrays(global_shape, sharding, xs)
+
+
+def get_local_slice_from_fsarray(global_array):
+ """Return numpy array for the host-local slice of fully-sharded array.
+
+ Args:
+ global_array: JAX array, globally sharded on devices across hosts.
+
+ Returns:
+ NumPy array that holds the part of `global_array` that is held by the
+ devices on the host that calls this function.
+ """
+ # For now, for simplicity, we only implement slicing along the first axis.
+ for shard in global_array.addressable_shards:
+ assert all(idx == slice(None) for idx in shard.index[1:]), (
+ f"global_array is sharded along non-first dimensions:\n{shard.index}")
+
+ # Get the shards back in the same order in which the global array was created
+ # in the first place. This makes sure it's consistent with other things in the
+ # batch, for example (assuming the whole batch is consistent).
+ m = {s.device: s for s in global_array.addressable_shards}
+ local_shards = [m[d] for d in global_array.sharding.mesh.local_devices]
+ return np.concatenate([jax.device_get(s.data) for s in local_shards], axis=0)
+
+
+def assert_local_slices_same(*global_arrays):
+ """Check whether all `global_arrays` have local slices at the same indices."""
+ slices = [
+ tuple(
+ tuple((idx.start, idx.end, idx.step) for idx in s.index)
+ for s in a.addressable_shards)
+ for a in global_arrays]
+ assert len(set(slices)) == 1, f"Not all slices are the same: {slices}"
+
+
+# TODO: remove this logic when the
+# issue is github fixed https://github.com/google/jax/issues/15600.
+def jit_cpu(**extra_kwargs):
+ def _decorator(fun):
+ def _wrapped(*args, **kwargs):
+ sh = jax.sharding.SingleDeviceSharding(
+ jax.local_devices(backend="cpu")[0]
+ )
+ return jax.jit(fun, **extra_kwargs, out_shardings=sh)(*args, **kwargs)
+ return _wrapped
+ return _decorator
+
+
+def create_device_mesh(
+ config_mesh,
+ *,
+ allow_split_physical_axes=False,
+):
+ """Returns a JAX device mesh.
+
+ Args:
+ config_mesh: A list of tuples of (axis_name, axis_size). It is advised to
+ sort the axis in increasing order of network communication intensity.
+ allow_split_physical_axes: Whether to allow splitting physical axes.
+ """
+ devices = jax.devices()
+ mesh_axes, mesh_size = tuple(zip(*config_mesh))
+ # Because jax.utils do not support `-1` shape size.
+ mesh_size = np.array(devices).reshape(mesh_size).shape
+ device_mesh = mesh_utils.create_device_mesh(
+ mesh_size,
+ devices=devices,
+ allow_split_physical_axes=allow_split_physical_axes)
+ return jax.sharding.Mesh(device_mesh, mesh_axes)
diff --git a/big_vision/utils_test.py b/big_vision/utils_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..20680ee689262ef10e7a69d0446cc35f0fcf08bf
--- /dev/null
+++ b/big_vision/utils_test.py
@@ -0,0 +1,360 @@
+# Copyright 2024 Big Vision Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Tests for utils."""
+
+from functools import partial
+import os
+
+from absl.testing import parameterized
+from big_vision import utils
+import chex
+import flax
+import jax
+from jax.experimental.array_serialization import serialization as array_serial
+import jax.numpy as jnp
+import numpy as np
+import tensorflow as tf
+
+from tensorflow.io import gfile
+
+
+NDEV = 4
+
+
+def setUpModule():
+ chex.set_n_cpu_devices(NDEV)
+
+
+class PadShardUnpadTest(chex.TestCase, tf.test.TestCase):
+ BATCH_SIZES = [NDEV, NDEV + 1, NDEV - 1, 5 * NDEV, 5 * NDEV + 1, 5 * NDEV - 1]
+ DTYPES = [np.float32, np.uint8, jax.numpy.bfloat16, np.int32]
+
+ def tearDown(self):
+ chex.clear_trace_counter()
+ super().tearDown()
+
+ @parameterized.product(dtype=DTYPES, bs=BATCH_SIZES)
+ def test_basics(self, dtype, bs):
+ # Just tests that basic calling works without exploring caveats.
+ @partial(utils.pad_shard_unpad, static_argnums=())
+ def add(a, b):
+ return a + b
+
+ x = jnp.arange(bs, dtype=dtype)
+ y = add(x, 10 * x)
+ chex.assert_type(y.dtype, x.dtype)
+ np.testing.assert_allclose(np.float64(y), np.float64(x + 10*x))
+
+ @parameterized.parameters(DTYPES)
+ def test_min_device_batch_avoids_recompile(self, dtype):
+ @partial(utils.pad_shard_unpad, static_argnums=())
+ @jax.jit
+ @chex.assert_max_traces(n=1)
+ def add(a, b):
+ return a + b
+
+ chex.clear_trace_counter()
+
+ for bs in self.BATCH_SIZES:
+ x = jnp.arange(bs, dtype=dtype)
+ y = add(x, 10 * x, min_device_batch=9) # pylint: disable=unexpected-keyword-arg
+ chex.assert_type(y.dtype, x.dtype)
+ np.testing.assert_allclose(np.float64(y), np.float64(x + 10*x))
+
+ @parameterized.product(dtype=DTYPES, bs=BATCH_SIZES)
+ def test_static_argnum(self, dtype, bs):
+ @partial(utils.pad_shard_unpad, static_argnums=(1,))
+ def add(a, b):
+ return a + b
+
+ x = jnp.arange(bs, dtype=dtype)
+ y = add(x, dtype(10))
+ chex.assert_type(y.dtype, x.dtype)
+ np.testing.assert_allclose(np.float64(y), np.float64(x + 10))
+
+ @parameterized.product(dtype=DTYPES, bs=BATCH_SIZES)
+ def test_static_argnames(self, dtype, bs):
+ # In this test, leave static_argnums at the default value too, in order to
+ # test the default/most canonical path where `params` are the first arg.
+ @partial(utils.pad_shard_unpad, static_argnames=('b',))
+ def add(params, a, *, b):
+ return params * a + b
+
+ x = jnp.arange(bs, dtype=dtype)
+ y = add(dtype(5), x, b=dtype(10))
+ chex.assert_type(y.dtype, x.dtype)
+ np.testing.assert_allclose(np.float64(y), np.float64(5 * x + 10))
+
+
+class TreeTest(tf.test.TestCase):
+
+ def setUp(self):
+ super().setUp()
+
+ self.d1 = {'w1': 1, 'w2': 2, 'w34': (3, 4)}
+ self.d1_flat = [1, 2]
+ self.d1_flat_jax = jax.tree.flatten(self.d1)[0]
+ self.d1_named_flat = [('w1', 1), ('w2', 2), ('w34/0', 3), ('w34/1', 4)]
+ self.d1_named_flat_jax = [('w1', 1), ('w2', 2), ('w34/0', 3), ('w34/1', 4)]
+
+ self.d2 = {'conv1': {'kernel': 0, 'bias': 1},
+ 'conv2': {'kernel': 2, 'bias': 3}}
+ self.d2_flat = [1, 0, 3, 2]
+ self.d2_flat_jax = jax.tree.flatten(self.d2)[0]
+ self.d2_named_flat = [('conv1/bias', 1), ('conv1/kernel', 0),
+ ('conv2/bias', 3), ('conv2/kernel', 2)]
+ self.d2_named_flat_jax = [('conv1/bias', 1), ('conv1/kernel', 0),
+ ('conv2/bias', 3), ('conv2/kernel', 2)]
+ self.d2_named_flat_inner = [
+ ('conv1/bias', 1), ('conv1/kernel', 0), ('conv1', self.d2['conv1']),
+ ('conv2/bias', 3), ('conv2/kernel', 2), ('conv2', self.d2['conv2']),
+ ('', self.d2),
+ ]
+
+ # This is a very important testcase that checks whether we correctly
+ # recover jax' traversal order, even though our custom traversal may not
+ # be consistent with jax' traversal order. In particular, jax traverses
+ # FlaxStruct in the order of attribute definition, while our custom
+ # traversal is alphabetical.
+ @flax.struct.dataclass
+ class FlaxStruct():
+ v3: float
+ v2: int
+ v1: str
+ self.d3 = {'a': 0, 'flax': FlaxStruct(2.0, 1, 's')}
+ self.d3_flat = [0, 1, 2.0, 's']
+ self.d3_flat_jax = jax.tree.flatten(self.d3)[0]
+ self.d3_named_flat = [
+ ('a', 0), ('flax/v1', 's'), ('flax/v2', 1), ('flax/v3', 2.0)]
+ self.d3_named_flat_jax = [
+ ('a', 0), ('flax/v3', 2.0), ('flax/v2', 1), ('flax/v1', 's')]
+
+ def test_traverse_with_names(self):
+ names_and_vals = list(utils._traverse_with_names(self.d1))
+ self.assertEqual(names_and_vals, self.d1_named_flat)
+
+ names_and_vals = list(utils._traverse_with_names(self.d2))
+ self.assertEqual(names_and_vals, self.d2_named_flat)
+
+ names_and_vals = list(utils._traverse_with_names(
+ self.d2, with_inner_nodes=True))
+ self.assertEqual(names_and_vals, self.d2_named_flat_inner)
+
+ names_and_vals = list(utils._traverse_with_names(self.d3))
+ self.assertEqual(names_and_vals, self.d3_named_flat)
+
+ def test_tree_flatten_with_names(self):
+ names_and_vals = utils.tree_flatten_with_names(self.d1)[0]
+ self.assertEqual(names_and_vals, self.d1_named_flat_jax)
+ self.assertEqual([x for _, x in names_and_vals], self.d1_flat_jax)
+
+ names_and_vals = utils.tree_flatten_with_names(self.d2)[0]
+ self.assertEqual(names_and_vals, self.d2_named_flat_jax)
+ self.assertEqual([x for _, x in names_and_vals], self.d2_flat_jax)
+
+ names_and_vals = utils.tree_flatten_with_names(self.d3)[0]
+ self.assertEqual(names_and_vals, self.d3_named_flat_jax)
+ self.assertEqual([x for _, x in names_and_vals], self.d3_flat_jax)
+
+ def test_tree_map_with_names(self):
+ d1 = utils.tree_map_with_names(
+ lambda name, x: -x if 'w2' in name else x, self.d1)
+ self.assertEqual(d1, {'w1': 1, 'w2': -2, 'w34': (3, 4)})
+
+ d1 = utils.tree_map_with_names(
+ lambda name, x1, x2: x1 + x2 if 'w2' in name else x1, self.d1, self.d1)
+ self.assertEqual(d1, {'w1': 1, 'w2': 4, 'w34': (3, 4)})
+
+ def test_recover_tree(self):
+ keys = ['a/b', 'a/c/x', 'a/c/y', 'd']
+ values = [0, 1, 2, 3]
+ self.assertEqual(utils.recover_tree(keys, values),
+ {'a': {'b': 0, 'c': {'x': 1, 'y': 2}}, 'd': 3})
+
+ def test_make_mask_trees(self):
+ F, T = False, True # pylint: disable=invalid-name
+ tree = {'a': {'b': 0, 'x': 1}, 'b': {'x': 2, 'y': 3}}
+ msk1 = {'a': {'b': F, 'x': T}, 'b': {'x': T, 'y': F}}
+ msk2 = {'a': {'b': F, 'x': F}, 'b': {'x': F, 'y': T}}
+ # Note that 'b' matches '^b' only and not '.*/b'.
+ # Also note that "b/x" is matched by rule 1 only (because it comes first).
+ self.assertEqual(
+ utils.make_mask_trees(tree, ('.*/x', 'b/.*')), [msk1, msk2])
+
+ def test_tree_get(self):
+ tree = {'a': {'b': 0, 'x': 1}, 'b': {'x': 2, 'y': 3}}
+ self.assertEqual(utils.tree_get(tree, 'a/b'), 0)
+ self.assertEqual(utils.tree_get(tree, 'a/x'), 1)
+ self.assertEqual(utils.tree_get(tree, 'b/x'), 2)
+ self.assertEqual(utils.tree_get(tree, 'b/y'), 3)
+ self.assertEqual(utils.tree_get(tree, 'a'), tree['a'])
+ self.assertEqual(utils.tree_get(tree, 'b'), tree['b'])
+
+ def test_tree_replace(self):
+ tree = {'a': {'b': 2, 'c': 3}, 'c': 4}
+ replacements = {
+ 'a/b': 'a/b/x', # replaces 'a/b' with 'a/b/x'
+ '.*c': 'C', # replaces 'c' with 'C' ('a/c' is removed)
+ 'C': 'D', # replaces 'C' (which was 'c') with 'D'
+ '.*/c': None, # removes 'a/c'
+ }
+ tree2 = utils.tree_replace(tree, replacements)
+ self.assertEqual(tree2, {'D': 4, 'a': {'b': {'x': 2}}})
+
+ def test_tree_compare(self):
+ tree1_only, tree2_only, dtype_shape_mismatch = utils.tree_compare(
+ {'a': {'b': jnp.array(2), 'c': jnp.array(3)}},
+ {'a': {'B': jnp.array(2), 'c': jnp.array(3.)}},
+ )
+ self.assertEqual(tree1_only, {'a/b'})
+ self.assertEqual(tree2_only, {'a/B'})
+ self.assertEqual(
+ dtype_shape_mismatch,
+ {'a/c': [(jnp.dtype('int32'), ()), (jnp.dtype('float32'), ())]})
+
+
+class StepConversionTest(parameterized.TestCase, tf.test.TestCase):
+
+ @parameterized.named_parameters(
+ ('nice_steps', 1000, None, None, dict(foo_steps=3), 3),
+ ('nice_epochs', 1000, 100, None, dict(foo_epochs=3), 30),
+ ('nice_examples', None, 100, None, dict(foo_examples=300), 3),
+ ('nice_percent', None, None, 10, dict(foo_percent=0.30), 3),
+ ('ignore_neg', 1000, 100, 10, dict(foo_steps=-1, foo_epochs=-1,
+ foo_examples=-1, foo_percent=0.30), 3),
+ ('zero_steps', None, None, 10, dict(foo_percent=0.0), 0),
+ ('offbyone_steps', 1001, None, None, dict(foo_steps=3), 3),
+ ('offbyone_epochs', 1001, 100, None, dict(foo_epochs=3), 30),
+ ('offbyone_examples', None, 101, None, dict(foo_examples=300), 3),
+ ('offbyone_percent', None, None, 11, dict(foo_percent=0.30), 3),
+ )
+ def test_steps(self, data_size, batch_size, total, cfg, expected):
+ # Correct default usage:
+ step = utils.steps('foo', cfg, data_size=data_size, batch_size=batch_size,
+ total_steps=total)
+ self.assertEqual(step, expected)
+
+ # Inexitent entry:
+ with self.assertRaises(ValueError):
+ step = utils.steps('bar', cfg, data_size=data_size, batch_size=batch_size,
+ total_steps=total)
+ step = utils.steps('bar', cfg, data_size=data_size, batch_size=batch_size,
+ total_steps=total, default=1234)
+ self.assertEqual(step, 1234)
+
+
+class CreateLearningRateScheduleTest(parameterized.TestCase, tf.test.TestCase):
+
+ @parameterized.named_parameters(
+ ('linear', 'linear', {}, 13, .5),
+ ('polynomial', 'polynomial', {'end': .1, 'power': 2}, 13, .325),
+ ('cosine', 'cosine', {}, 13, .5),
+ ('rsqrt', 'rsqrt', {'timescale': 1}, 13, 0.3333333),
+ ('stair_5', 'stair', {'steps': [10], 'mults': [.5]}, 5, 1.),
+ ('stair_10', 'stair', {'steps': [10], 'mults': [.5]}, 10, .5),
+ ('warmup_before', 'rsqrt', {'timescale': 1}, 3, .6),
+ ('cooldown_after', 'rsqrt', {'timescale': 1}, 20, .05),
+ )
+ def test_schedule(self, decay_type, extra_kwargs, step, expected_lr):
+ lr_fn = utils.create_learning_rate_schedule(
+ total_steps=21,
+ batch_size=512,
+ base=.5,
+ decay_type=decay_type,
+ scale_with_batchsize=True,
+ warmup_steps=5,
+ cooldown_steps=5,
+ **extra_kwargs)
+ lr = lr_fn(step)
+ self.assertAlmostEqual(lr, expected_lr)
+
+
+class CheckpointTest(tf.test.TestCase):
+
+ def setup(self):
+ gacm = array_serial.GlobalAsyncCheckpointManager()
+
+ save_path = os.path.join(self.create_tempdir('workdir'), 'checkpoint.bv')
+ x = utils.put_cpu(np.array([1, 2, 3, 4]))
+ y = utils.put_cpu(np.array([5, 6, 7, 8]))
+ ckpt = {'x': x, 'y': {'z': y}}
+
+ sharding = jax.sharding.SingleDeviceSharding(
+ jax.local_devices(backend='cpu')[0]
+ )
+ shardings = jax.tree.map(lambda _: sharding, ckpt)
+
+ return gacm, save_path, ckpt, shardings
+
+ def test_save_and_load(self):
+ gacm, save_path, ckpt, shardings = self.setup()
+ step = 100
+ utils.save_checkpoint_ts(gacm, ckpt, save_path, step, keep=True)
+ gacm.wait_until_finished()
+ ckpt_loaded = utils.load_checkpoint_ts(save_path,
+ tree=ckpt, shardings=shardings)
+ chex.assert_trees_all_equal(ckpt_loaded, ckpt)
+
+ save_path_step = f'{save_path}-{step:09d}'
+ ckpt_loaded_step = utils.tsload(save_path_step, shardings=shardings)
+ chex.assert_trees_all_equal(ckpt_loaded_step, ckpt)
+
+ def test_save_and_partial_load(self):
+ gacm, save_path, ckpt, shardings = self.setup()
+ utils.save_checkpoint_ts(gacm, ckpt, save_path, step=100)
+ gacm.wait_until_finished()
+ _ = shardings.pop('x'), ckpt.pop('x')
+ ckpt_loaded = utils.load_checkpoint_ts(save_path,
+ tree=ckpt, shardings=shardings)
+ chex.assert_trees_all_equal(ckpt_loaded, ckpt)
+
+ def test_save_and_cpu_load(self):
+ gacm, save_path, ckpt, _ = self.setup()
+ utils.save_checkpoint_ts(gacm, ckpt, save_path, step=100)
+ gacm.wait_until_finished()
+ ckpt_loaded = utils.load_checkpoint_ts(save_path)
+ chex.assert_trees_all_equal(ckpt_loaded, ckpt)
+
+ def test_save_and_partial_cpu_load(self):
+ gacm, save_path, ckpt, _ = self.setup()
+ utils.save_checkpoint_ts(gacm, ckpt, save_path, step=100)
+ gacm.wait_until_finished()
+ ckpt.pop('y')
+ ckpt_loaded = utils.load_checkpoint_ts(save_path, regex='x.*')
+ chex.assert_trees_all_equal(ckpt_loaded, ckpt)
+
+ def test_keep_deletes(self):
+ def x(tree, factor): # x as in "times" for multiplying.
+ return jax.tree.map(lambda a: a * factor, tree)
+
+ gacm, save_path, ckpt, _ = self.setup()
+ utils.save_checkpoint_ts(gacm, ckpt, save_path, step=100, keep=False)
+ utils.save_checkpoint_ts(gacm, x(ckpt, 2), save_path, step=200, keep=True)
+ utils.save_checkpoint_ts(gacm, x(ckpt, 3), save_path, step=300, keep=False)
+ gacm.wait_until_finished()
+ ckpt_loaded_200 = utils.tsload(f'{save_path}-{200:09d}')
+ chex.assert_trees_all_equal(ckpt_loaded_200, x(ckpt, 2))
+ ckpt_loaded_300 = utils.tsload(f'{save_path}-{300:09d}-tmp')
+ chex.assert_trees_all_equal(ckpt_loaded_300, x(ckpt, 3))
+ ckpt_loaded_last = utils.load_checkpoint_ts(save_path)
+ chex.assert_trees_all_equal(ckpt_loaded_last, x(ckpt, 3))
+ with self.assertRaises(Exception): # Can different types depending on fs.
+ _ = utils.tsload(f'{save_path}-{100:09d}')
+ # Test that ckpt@100 was deleted
+ self.assertFalse(gfile.exists(f'{save_path}-{100:09d}-tmp'))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git a/build/lib/scenic/__init__.py b/build/lib/scenic/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/build/lib/scenic/app.py b/build/lib/scenic/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/build/lib/scenic/main.py b/build/lib/scenic/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/ckpts/clip_vit_l14_with_masks_6c17944 b/ckpts/clip_vit_l14_with_masks_6c17944
new file mode 100644
index 0000000000000000000000000000000000000000..215495e23ca242ae84b6ea1dc4a756c3a2ac602c
--- /dev/null
+++ b/ckpts/clip_vit_l14_with_masks_6c17944
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:26bb25bb66e747705143a35f76f5294114746e531436949d96933019cd17b2e6
+size 1048576
diff --git a/ckpts/owl2-b16-960-st-ngrams-curated-ft-lvisbase-ens-cold-weight-05_209b65b b/ckpts/owl2-b16-960-st-ngrams-curated-ft-lvisbase-ens-cold-weight-05_209b65b
new file mode 100644
index 0000000000000000000000000000000000000000..21d2912d4b08d035e8b5d16f2852288f3a67b559
--- /dev/null
+++ b/ckpts/owl2-b16-960-st-ngrams-curated-ft-lvisbase-ens-cold-weight-05_209b65b
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a05870e6eaf244a52382fb6935b955ca7e6e873181a0583d552a8330d228b900
+size 1048576
diff --git a/ckpts/owl2-l14-1008-st-ngrams-ft-lvisbase-ens-cold-weight-04_8ca674c b/ckpts/owl2-l14-1008-st-ngrams-ft-lvisbase-ens-cold-weight-04_8ca674c
new file mode 100644
index 0000000000000000000000000000000000000000..8e95f93bff54a951abaec26cad050ec874249a7d
--- /dev/null
+++ b/ckpts/owl2-l14-1008-st-ngrams-ft-lvisbase-ens-cold-weight-04_8ca674c
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7a276d61fb7c1ec7bbf68fa7d5d34a8032b6aa4f15170c1125208f77133b9c17
+size 1048576
diff --git a/images/scenic_design.jpg b/images/scenic_design.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f330bf75c9a8433a833ca288a41c0f219a9d8ffb
--- /dev/null
+++ b/images/scenic_design.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1b341d7d1fa31b679c346834e568221da3616196040d302fd65aa7d417010ee6
+size 668643
diff --git a/images/scenic_logo.jpg b/images/scenic_logo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..76fbd8bfa116986e38b96293a7d4c7132589ad88
--- /dev/null
+++ b/images/scenic_logo.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1e74593754532c72b37f9c16b386609d794467e2baf0c5532266e69e8c0c954b
+size 163943
diff --git a/images/scenic_logo.pdf b/images/scenic_logo.pdf
new file mode 100644
index 0000000000000000000000000000000000000000..c22604a5800abf0712331c3d6e85543315b7ef7b
Binary files /dev/null and b/images/scenic_logo.pdf differ
diff --git a/images/scenic_logo.png b/images/scenic_logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..9fb1f0d03dc18fcbab60a6b01073e1997be6b81e
Binary files /dev/null and b/images/scenic_logo.png differ
diff --git a/owlv2_helper.py b/owlv2_helper.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb8768be029d2f4233d610d8756363885ba7fdb0
--- /dev/null
+++ b/owlv2_helper.py
@@ -0,0 +1,155 @@
+import os
+from matplotlib import pyplot as plt
+import skimage
+from skimage import io as skimage_io
+import numpy as np
+import re
+import cv2
+
+
+def rescale_detection_box(boxes, image):
+ h_img, w_img, _ = image.shape
+ size = max(h_img, w_img)
+
+ pad_h = size - h_img
+ pad_w = size - w_img
+
+ recovered_boxes = []
+ for box in boxes:
+ cx, cy, w, h = box
+ cx = cx * size
+ cy = cy * size
+ w = w * size
+ h = h * size
+
+ # if cx < 0 or cx > w_img or cy < 0 or cy > h_img:
+ # continue;
+
+ x1 = cx - w / 2
+ y1 = cy - h / 2
+ x2 = cx + w / 2
+ y2 = cy + h / 2
+ recovered_boxes.append((x1, y1, x2, y2))
+ return recovered_boxes
+
+
+
+
+def read_images(image_dir):
+ images = []
+ filenames = [p for p in os.listdir(image_dir) if os.path.splitext(p)[-1].lower() in [".png", ".jpg", ".jpeg",]]
+ filenames.sort(key=lambda p: os.path.splitext(p)[0])
+ for filename in filenames:
+ file_path = os.path.join(image_dir, filename)
+ image_uint8 = skimage_io.imread(file_path)
+ image = image_uint8.astype(np.float32) / 255.0
+ images.append(image)
+ return images, filenames
+
+
+
+
+def preprocess_images(images, model_input_size):
+ processed_images = []
+ for image in images:
+ # Pad image to square
+ h, w, d = image.shape
+ size = max(h, w)
+ image_padded = np.pad(image, ((0, size - h), (0, size - w), (0, 0)), constant_values=0.5)
+ # Resize image to fit model's input size
+ image_resized = skimage.transform.resize(
+ image_padded,
+ (model_input_size, model_input_size),
+ anti_aliasing=True,
+ )
+ processed_images.append(image_resized)
+ # Shape: (b, h, w, d)
+ return np.array(processed_images, dtype=np.float32)
+
+
+
+
+def too_small(bbox, threshold=400):
+ x1, y1, x2, y2 = bbox
+ width = max(0, x2 - x1)
+ height = max(0, y2 - y1)
+ area = width * height
+ # Return True if area is too small
+ return area < threshold
+
+
+def too_large(bbox, image, threshold=0.9):
+ x1, y1, x2, y2 = bbox
+
+ bbox_width = x2 - x1
+ bbox_height = y2 - y1
+ bbox_area = bbox_width * bbox_height
+
+ image_height, image_width = image.shape[:2]
+ image_area = image_width * image_height
+
+ area_ratio = bbox_area / image_area
+ return area_ratio >= threshold
+
+
+
+
+def plot_bboxes_on_orig_image(image, boxes, output_path):
+ plt.clf()
+ plt.imshow(image)
+ plt.axis('off')
+
+ for box in boxes:
+ x1, y1, x2, y2 = box
+ plt.plot(
+ [x1, x2, x2, x1, x1],
+ [y1, y1, y2, y2, y1],
+ linewidth=0.8, alpha=0.6
+ )
+
+ plt.savefig(output_path, bbox_inches='tight', pad_inches=0.1, dpi=300)
+ plt.close()
+ print(f" Done! Visualization saved to {output_path}")
+
+
+
+
+def compute_iou(box1, box2):
+ x1_inter = max(box1[0], box2[0])
+ y1_inter = max(box1[1], box2[1])
+ x2_inter = min(box1[2], box2[2])
+ y2_inter = min(box1[3], box2[3])
+ inter_width = max(0, x2_inter - x1_inter)
+ inter_height = max(0, y2_inter - y1_inter)
+ inter_area = inter_width * inter_height
+ box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])
+ box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1])
+ union_area = box1_area + box2_area - inter_area
+ return inter_area / union_area if union_area > 0 else 0
+
+
+
+
+def remove_overlapping_bboxes(bboxes, iou_threshold=0.7):
+ if not bboxes:
+ return []
+ bboxes = sorted(bboxes, key=lambda x: (x[2] - x[0]) * (x[3] - x[1]), reverse=True)
+ keep = []
+ for bbox in bboxes:
+ should_keep = True
+ for kept_bbox in keep:
+ if compute_iou(bbox, kept_bbox) > iou_threshold:
+ should_keep = False
+ break
+ if should_keep:
+ keep.append(bbox)
+ return keep
+
+
+
+
+def get_centroid(bbox):
+ x1, y1, x2, y2 = bbox
+ cx = (x1 + x2) / 2
+ cy = (y1 + y2) / 2
+ return (int(cx), int(cy))
\ No newline at end of file
diff --git a/owlv2_helper_functions.py b/owlv2_helper_functions.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbf991db19325bfe6e777daba431b4877e3daa4e
--- /dev/null
+++ b/owlv2_helper_functions.py
@@ -0,0 +1,290 @@
+import os
+from matplotlib import pyplot as plt
+import skimage
+from skimage import io as skimage_io
+import numpy as np
+import re
+
+
+def rescale_detection_box(boxes, image):
+ h_img, w_img, _ = image.shape
+ size = max(h_img, w_img)
+
+ pad_h = size - h_img
+ pad_w = size - w_img
+
+ recovered_boxes = []
+ for box in boxes:
+ cx, cy, w, h = box
+ cx = cx * size
+ cy = cy * size
+ w = w * size
+ h = h * size
+
+ # if cx < 0 or cx > w_img or cy < 0 or cy > h_img:
+ # continue;
+
+ x1 = cx - w / 2
+ y1 = cy - h / 2
+ x2 = cx + w / 2
+ y2 = cy + h / 2
+ recovered_boxes.append((x1, y1, x2, y2))
+ return recovered_boxes
+
+
+
+def plot_boxes_on_image(image, text_queries,
+ scores, boxes, labels,
+ filename, score_threshold,
+ output_dir):
+
+ colors = ['red', 'green', 'blue', 'orange', 'purple', 'pink', 'cyan', 'magenta', 'lightblue', 'darkorange', 'darkgreen', 'darkred', 'lavender', 'brown', 'gray', 'black']
+
+ # 显示原始图片
+ plt.clf()
+ plt.imshow(image)
+ plt.axis('off')
+
+ # 绘制边界框
+ for score, box, label in zip(scores, boxes, labels):
+ if score < score_threshold:
+ continue;
+
+ x1, y1, x2, y2 = box
+ # print(f"box coord: {[x1, y1, x2, y2]}")
+ plt.plot(
+ [x1, x2, x2, x1, x1], [y1, y1, y2, y2, y1],
+ color=colors[label], linewidth=0.6, alpha=0.6
+ )
+ plt.text(
+ x1, y2 + 0.015,
+ f'{text_queries[label]}: {score:1.2f}',
+ ha='left', va='top', color=colors[label], fontsize=6,
+ bbox={'facecolor': 'white', 'edgecolor': colors[label], 'boxstyle': 'square,pad=.3', 'alpha': 0.5}
+ )
+ # 保存图片到指定路径 OUTPUT_DIR
+ output_path = os.path.join(output_dir, filename)
+ plt.savefig(output_path, bbox_inches='tight', pad_inches=0.1, dpi=300)
+ print(f"Image with boxes saved to {output_path}")
+
+
+
+def image_based_plot_boxes_on_image(image, text_queries, scores, boxes, filename,output_dir):
+ colors = ['red', 'green', 'blue', 'orange', 'cyan', 'magenta', 'lightblue', 'darkorange', 'lavender']
+
+ plt.clf()
+ plt.imshow(image)
+ plt.axis('off')
+ for score, box, text_query, color in zip(scores, boxes, text_queries, colors):
+ x1, y1, x2, y2 = box
+ plt.plot(
+ [x1, x2, x2, x1, x1],
+ [y1, y1, y2, y2, y1],
+ color=color, linewidth=1
+ )
+ plt.text(
+ x1, y2 + 0.015,
+ f'{text_query}: {score:1.2f}',
+ ha='left', va='top', color=color, fontsize=6,
+ bbox={'facecolor': 'white', 'edgecolor': color, 'boxstyle': 'square,pad=.3','alpha': 0.5}
+ )
+ output_path = os.path.join(output_dir, filename)
+ plt.savefig(output_path, bbox_inches='tight', pad_inches=0.1, dpi=300)
+ print(f"Image with boxes saved to {output_path}")
+
+
+
+def get_iou(bbox1, bbox2):
+ # 分别解包 bbox1 和 bbox2 的坐标
+ x1_min, y1_min, x1_max, y1_max = bbox1
+ x2_min, y2_min, x2_max, y2_max = bbox2
+
+ # 计算交集的顶点坐标
+ inter_x_min = max(x1_min, x2_min)
+ inter_y_min = max(y1_min, y2_min)
+ inter_x_max = min(x1_max, x2_max)
+ inter_y_max = min(y1_max, y2_max)
+
+ # 计算交集的宽度和高度(确保为非负值)
+ inter_width = max(0, inter_x_max - inter_x_min)
+ inter_height = max(0, inter_y_max - inter_y_min)
+ inter_area = inter_width * inter_height
+
+ # 计算每个边界框的面积
+ area1 = (x1_max - x1_min) * (y1_max - y1_min)
+ area2 = (x2_max - x2_min) * (y2_max - y2_min)
+
+ # 计算并集面积
+ union_area = area1 + area2 - inter_area
+
+ # 计算 IOU
+ iou = inter_area / union_area if union_area > 0 else 0
+ return iou
+
+
+
+
+def read_images(image_dir):
+ images = []
+ filenames = sorted(os.listdir(image_dir))
+ for filename in filenames:
+ file_path = os.path.join(image_dir, filename)
+ image_uint8 = skimage_io.imread(file_path)
+ image = image_uint8.astype(np.float32) / 255.0
+ images.append(image)
+ return images, filenames
+
+
+
+def preprocess_images(images, model_input_size):
+ processed_images = []
+ for image in images:
+ # Pad image to square
+ h, w, d = image.shape
+ size = max(h, w)
+ image_padded = np.pad(image, ((0, size - h), (0, size - w), (0, 0)), constant_values=0.5,)
+ # Resize image to fit model's input size
+ image_resized = skimage.transform.resize(
+ image_padded,
+ (model_input_size, model_input_size),
+ anti_aliasing=True,
+ )
+ processed_images.append(image_resized)
+ # Shape: (b, h, w, d)
+ return np.array(processed_images, dtype=np.float32)
+
+
+
+def prepare_images(image_dir, model_input_size):
+ filenames = sorted(os.listdir(image_dir))
+
+ images = []
+ for filename in filenames:
+ file_path = os.path.join(image_dir, filename)
+ image_uint8 = skimage_io.imread(file_path)
+ image = image_uint8.astype(np.float32) / 255.0
+
+ # Pad image to square
+ h, w, d = image.shape
+ size = max(h, w)
+ image_padded = np.pad(
+ image, ((0, size - h), (0, size - w), (0, 0)), constant_values=0.5
+ )
+
+ # Resize image to fit model's input size
+ image_resized = skimage.transform.resize(
+ image_padded,
+ (model_input_size, model_input_size),
+ anti_aliasing=True,
+ )
+ images.append(image_resized)
+
+ # Shape: (b, h, w, d)
+ return np.array(images, dtype=np.float32), filenames
+
+
+
+def plot_bbox_on_image(image, boxes, objectnesses, threshold, output_file):
+ fig, ax = plt.subplots(1, 1, figsize=(8, 8))
+ ax.imshow(image, extent=(0, 1, 1, 0))
+ ax.set_axis_off()
+
+ for i, (box, objectness) in enumerate(zip(boxes, objectnesses)):
+ if objectness < threshold:
+ continue
+
+ index = i
+ cx, cy, w, h = box
+ ax.plot(
+ [cx - w / 2, cx + w / 2, cx + w / 2, cx - w / 2, cx - w / 2],
+ [cy - h / 2, cy - h / 2, cy + h / 2, cy + h / 2, cy - h / 2],
+ color='lime',
+ )
+
+ ax.text(
+ cx - w / 2 + 0.015,
+ cy + h / 2 - 0.015,
+ f'Index {i}: {objectness:1.2f}',
+ ha='left',
+ va='bottom',
+ color='black',
+ bbox={
+ 'facecolor': 'white',
+ 'edgecolor': 'lime',
+ 'boxstyle': 'square,pad=.3',
+ },
+ )
+
+ ax.set_xlim(0, 1)
+ ax.set_ylim(1, 0)
+ ax.set_title(f'Top objects by objectness')
+
+ # 保存图片到指定路径
+ plt.savefig(output_file, bbox_inches='tight', dpi=300)
+ plt.close() # 关闭图像以释放内存
+ print(f"结果图片已保存到: {output_file}")
+ return index
+
+
+def top_object_index(objectnesses, threshold):
+ for i, objectness in enumerate(objectnesses):
+ if objectness < threshold:
+ continue
+ else:
+ return i
+
+
+
+
+def boxes_filter(pred_bboxes, raw_bboxes, pred_scores, instances):
+ # Step 1: Filter by pred_scores
+ filtered_indices = [i for i, score in enumerate(pred_scores) if score >= 0.97]
+
+ pred_bboxes = [pred_bboxes[i] for i in filtered_indices]
+ raw_bboxes = [raw_bboxes[i] for i in filtered_indices]
+ pred_scores = [pred_scores[i] for i in filtered_indices]
+ instances = [instances[i] for i in filtered_indices]
+
+ # Step 2: Filter by IoU
+ keep_indices = set(range(len(pred_bboxes)))
+ for i in range(len(pred_bboxes)):
+ if i not in keep_indices:
+ continue
+ for j in range(i + 1, len(pred_bboxes)):
+ if j not in keep_indices:
+ continue
+ iou = get_iou(pred_bboxes[i], pred_bboxes[j])
+ if iou > 0.9:
+ if pred_scores[i] >= pred_scores[j]:
+ keep_indices.discard(j)
+ else:
+ keep_indices.discard(i)
+
+ pred_bboxes = [pred_bboxes[i] for i in sorted(keep_indices)]
+ raw_bboxes = [raw_bboxes[i] for i in sorted(keep_indices)]
+ pred_scores = [pred_scores[i] for i in sorted(keep_indices)]
+ instances = [instances[i] for i in sorted(keep_indices)]
+
+ # Step 3: Filter by duplicate instances
+ instance_map = {}
+ for i in range(len(instances)):
+ instance = instances[i]
+ if instance not in instance_map or pred_scores[i] > pred_scores[instance_map[instance]]:
+ instance_map[instance] = i
+
+ unique_indices = sorted(instance_map.values())
+ pred_bboxes = [pred_bboxes[i] for i in unique_indices]
+ raw_bboxes = [raw_bboxes[i] for i in unique_indices]
+ pred_scores = [pred_scores[i] for i in unique_indices]
+ instances = [instances[i] for i in unique_indices]
+
+ return pred_bboxes, raw_bboxes, pred_scores, instances
+
+
+
+def format_string(input_string: str) -> str:
+ # 大写 转 小写
+ lowercased = input_string.lower()
+ # 空格 转 下划线
+ transformed = re.sub(r"\s+", "_", lowercased) # \s+ 匹配一个或多个空白字符
+ return transformed
\ No newline at end of file
diff --git a/owlv2_img_embeding.py b/owlv2_img_embeding.py
new file mode 100644
index 0000000000000000000000000000000000000000..170312b227e391d4069e3d8d008dc3c81ad8cd5d
--- /dev/null
+++ b/owlv2_img_embeding.py
@@ -0,0 +1,180 @@
+import os
+import sys
+import json
+
+# pip install ott-jax==0.2.0
+import jax
+import numpy as np
+import tensorflow as tf
+from scipy.special import expit as sigmoid
+
+import skimage
+from skimage import io as skimage_io
+from skimage import transform as skimage_transform
+import matplotlib as mpl
+from matplotlib import pyplot as plt
+
+sys.path.append('/home/netzone22/bohanliu_2025/VisionModels/Scenic_OWLv2/big_vision')
+tf.config.experimental.set_visible_devices([], 'GPU')
+
+from scenic.projects.owl_vit import configs
+from scenic.projects.owl_vit import models
+
+# from owlv2_helper_functions import prepare_images
+from owlv2_helper_functions import read_images, preprocess_images
+from owlv2_helper_functions import plot_bbox_on_image, image_based_plot_boxes_on_image
+from owlv2_helper_functions import top_object_index
+from owlv2_helper_functions import rescale_detection_box
+from owlv2_helper_functions import get_iou, boxes_filter
+
+
+
+"""
+Prepare OWLv2 pretrained model
+"""
+config = configs.owl_v2_clip_l14.get_config(init_mode='canonical_checkpoint')
+module = models.TextZeroShotDetectionModule(
+ body_configs=config.model.body,
+ objectness_head_configs=config.model.objectness_head,
+ normalize=config.model.normalize,
+ box_bias=config.model.box_bias)
+variables = module.load_variables(config.init_from.checkpoint_path)
+
+
+
+
+"""
+Wrapped model components
+"""
+import functools
+
+image_embedder = jax.jit(
+ functools.partial(module.apply, variables, train=False, method=module.image_embedder))
+
+objectness_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.objectness_predictor))
+
+box_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.box_predictor))
+
+class_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.class_predictor))
+
+
+
+
+"""
+Detect the main object on instances' images
+"""
+INSTANCE_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_instances'
+INSTANCE_DETECTION = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_instances_detections'
+
+model_input_size = config.dataset_configs.input_size
+images, source_images_names = read_images(INSTANCE_DIR)
+source_images = preprocess_images(images, model_input_size)
+
+
+instances, query_embeddings, indexes = [], [], []
+for source_image, source_image_name in zip(source_images, source_images_names):
+ feature_map = image_embedder(source_image[None, ...])
+ b, h, w, d = feature_map.shape
+ image_features = feature_map.reshape(b, h * w, d)
+
+ objectnesses = objectness_predictor(image_features)['objectness_logits']
+ bboxes = box_predictor(image_features=image_features, feature_map=feature_map)['pred_boxes']
+ all_class_embeddings = class_predictor(image_features=image_features)['class_embeddings']
+
+ # Remove batch dimension
+ objectnesses = np.array(objectnesses[0])
+ bboxes = np.array(bboxes[0])
+ all_class_embeddings = np.array(all_class_embeddings[0])
+
+ top_k = 1
+ objectnesses = sigmoid(objectnesses)
+ objectness_threshold = np.partition(objectnesses, -top_k)[-top_k]
+
+ index = top_object_index(objectnesses, objectness_threshold)
+ query_embedding = all_class_embeddings[index]
+
+ indexes.append(index)
+ instances.append(source_image_name.split('_')[0])
+ query_embeddings.append(query_embedding)
+
+ # Plot instance detection
+ output_file = os.path.join(INSTANCE_DETECTION, source_image_name)
+ plot_bbox_on_image(source_image, bboxes, objectnesses, objectness_threshold, output_file)
+
+
+
+
+# IMAGE_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/data_sample'
+# OUTPUT_DIR = '/home/netzone22/bohanliu_2025/VisionModels/Scenic_OWLv2/bliu75_output/test_output/batch_results'
+IMAGE_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_video08'
+OUTPUT_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_video08_detect'
+
+digital_twins = {}
+
+images, target_images_names = read_images(IMAGE_DIR)
+target_images = preprocess_images(images, model_input_size)
+h, w, d = images[0].shape
+size = max(h, w)
+
+for target_image, target_image_name, image in zip(target_images, target_images_names, images):
+
+ feature_map = image_embedder(target_image[None, ...])
+ b, h, w, d = feature_map.shape
+ image_features = feature_map.reshape(b, h * w, d)
+ all_bboxes = box_predictor(image_features=image_features, feature_map=feature_map)['pred_boxes']
+
+ pred_scores, pred_bboxes = [], []
+ for i, query_embedding in enumerate(query_embeddings):
+ target_class_predictions = class_predictor(
+ image_features=feature_map.reshape(b, h * w, d),
+ query_embeddings=query_embedding[None, None, ...], # [batch, queries, d]
+ )
+
+ # Remove batch dimension and convert to numpy:
+ logits = np.array(target_class_predictions['pred_logits'][0])
+ bboxes = np.array(all_bboxes[0])
+
+ top_ind = np.argmax(logits[:, 0], axis=0)
+ score = logits[top_ind, 0]
+ bbox = bboxes[top_ind]
+
+ pred_bboxes.append(bbox)
+ pred_scores.append(score)
+
+ instances_dup = instances[:]
+ pred_scores = sigmoid(pred_scores)
+ rescaled_bboxes = rescale_detection_box(pred_bboxes, image)
+
+ rescaled_bboxes, pred_bboxes, pred_scores, instances_dup = boxes_filter(rescaled_bboxes, pred_bboxes, pred_scores, instances_dup)
+
+
+ count = {}
+ for instance_name in instances_dup:
+ count[instance_name] = 0
+
+ digital_twins[target_image_name] = {}
+ for instance_i, (instance_name, instance_box, instance_raw_box, instance_score) in enumerate(zip(instances_dup, rescaled_bboxes, pred_bboxes, pred_scores)):
+ x1, y1, x2, y2 = map(float, instance_box)
+ cx, cy, box_w, box_h = map(float, instance_raw_box)
+ x = round(instance_score, 2)
+
+ digital_twins[target_image_name][f'{instance_name}_{count[instance_name]}'] = {
+ 'detection_label': instance_name,
+ 'detection_box': [x1, y1, x2, y2],
+ 'detection_centroid': [cx*size, cy*size],
+ 'detection_score': round(float(instance_score), 2),
+ }
+ count[instance_name] += 1
+
+
+ image_based_plot_boxes_on_image(image, instances_dup, pred_scores, rescaled_bboxes, target_image_name, OUTPUT_DIR)
+
+
+JSON_OUT_PATH = "/home/netzone22/bohanliu_2025/DT_SPR_video08_detection.json"
+if not os.path.exists(JSON_OUT_PATH):
+ os.makedirs(JSON_OUT_PATH)
+with open(JSON_OUT_PATH, "w", encoding="utf-8") as json_f:
+ json.dump(digital_twins, json_f, indent=4)
\ No newline at end of file
diff --git a/owlv2_img_embeding_2.py b/owlv2_img_embeding_2.py
new file mode 100644
index 0000000000000000000000000000000000000000..96fb0da8cf201cdef78cb47ae0bdaff1724f0642
--- /dev/null
+++ b/owlv2_img_embeding_2.py
@@ -0,0 +1,148 @@
+import os
+import sys
+import json
+
+# pip install ott-jax==0.2.0
+import jax
+import numpy as np
+import tensorflow as tf
+from scipy.special import expit as sigmoid
+
+import skimage
+from skimage import io as skimage_io
+from skimage import transform as skimage_transform
+import matplotlib as mpl
+from matplotlib import pyplot as plt
+
+sys.path.append('/home/netzone22/bohanliu_2025/VisionModels/Scenic_OWLv2/big_vision')
+tf.config.experimental.set_visible_devices([], 'GPU')
+
+from scenic.projects.owl_vit import configs
+from scenic.projects.owl_vit import models
+
+# from owlv2_helper_functions import prepare_images
+from owlv2_helper_functions import read_images, preprocess_images
+from owlv2_helper_functions import plot_bbox_on_image, image_based_plot_boxes_on_image, plot_boxes_on_image
+from owlv2_helper_functions import top_object_index
+from owlv2_helper_functions import rescale_detection_box
+
+
+
+
+"""
+Prepare OWLv2 pretrained model
+"""
+config = configs.owl_v2_clip_l14.get_config(init_mode='canonical_checkpoint')
+module = models.TextZeroShotDetectionModule(
+ body_configs=config.model.body,
+ objectness_head_configs=config.model.objectness_head,
+ normalize=config.model.normalize,
+ box_bias=config.model.box_bias)
+variables = module.load_variables(config.init_from.checkpoint_path)
+
+
+
+
+"""
+Wrapped model components
+"""
+import functools
+
+image_embedder = jax.jit(
+ functools.partial(module.apply, variables, train=False, method=module.image_embedder))
+objectness_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.objectness_predictor))
+box_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.box_predictor))
+class_predictor = jax.jit(
+ functools.partial(module.apply, variables, method=module.class_predictor))
+
+
+
+
+"""
+Detect the main object on instances' images
+"""
+INSTANCE_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_instances_0'
+INSTANCE_DETECTION = '/home/netzone22/bohanliu_2025/DT_SPR/DT_SPR_instances_detections_0'
+
+model_input_size = config.dataset_configs.input_size
+images, source_images_names = read_images(INSTANCE_DIR)
+source_images = preprocess_images(images, model_input_size)
+
+feature_map = image_embedder(source_images)
+b, h, w, d = feature_map.shape
+image_features = feature_map.reshape(b, h * w, d)
+
+objectnesses = objectness_predictor(image_features)['objectness_logits']
+bboxes = box_predictor(image_features=image_features, feature_map=feature_map)['pred_boxes']
+source_class_embeddings = class_predictor(image_features=image_features)['class_embeddings']
+
+# print(f"Debug: source instance detection")
+# print(f" Source images features shape: {image_features.shape}")
+# print(f" objectnesses shape: {objectnesses.shape}")
+# print(f" bboxes shape: {bboxes.shape}")
+# print(f" source_class_embeddings shape: {source_class_embeddings.shape}")
+
+objectnesses = sigmoid(objectnesses)
+top_objectnesses = np.max(objectnesses, axis=1)
+
+instances, query_embeddings, indexes = [], [], []
+for i in range(len(source_images_names)):
+ index = top_object_index(objectnesses[i], top_objectnesses[i])
+ query_embedding = source_class_embeddings[index]
+
+ indexes.append(index)
+ instances.append(source_images_names[i].split('_')[0])
+ query_embeddings.append(query_embedding)
+
+ output_file = os.path.join(INSTANCE_DETECTION, source_images_names[i])
+ plot_bbox_on_image(source_images[i], bboxes[i], objectnesses[i], top_objectnesses[i], output_file)
+
+
+
+
+
+IMAGE_DIR = '/home/netzone22/bohanliu_2025/DT_SPR/data_sample'
+OUTPUT_DIR = '/home/netzone22/bohanliu_2025/VisionModels/Scenic_OWLv2/bliu75_output/test_output/batch_results'
+
+images, target_images_names = read_images(IMAGE_DIR)
+target_images = preprocess_images(images, model_input_size)
+
+for target_image, target_image_name, image in zip(target_images, target_images_names, images):
+
+ feature_map = image_embedder(target_image[None, ...])
+ b, h, w, d = feature_map.shape
+ target_boxes = box_predictor(image_features=feature_map.reshape(b, h * w, d), feature_map=feature_map)['pred_boxes']
+
+ target_class_predictions = class_predictor(
+ image_features=feature_map.reshape(b, h * w, d),
+ query_embeddings=query_embedding[None, ...], # [batch, queries, d]
+ )
+
+ logits = np.array(target_class_predictions['pred_logits'][0])
+ raw_boxes = np.array(target_boxes[0])
+
+ top_ind = np.argmax(logits[:, 0], axis=0)
+ score = sigmoid(logits[top_ind, 0])
+
+ # labels = np.argmax(target_class_predictions['pred_logits'][0], axis=-1)
+ # scores = sigmoid(np.max(logits, axis=-1))
+
+ boxes = rescale_detection_box(raw_boxes, image)
+ boxes = boxes[top_ind]
+
+ score = np.array([score])
+ boxes = np.array([boxes])
+
+ image_based_plot_boxes_on_image(image, instances, score, boxes, target_image_name, OUTPUT_DIR)
+
+ print(f"Debug: traget instance detection")
+ # print(f" target_class_predictions' keys: {target_class_predictions.keys()}")
+ print(f" target_logits: {logits.shape}")
+ print(logits)
+ # print(f" target_scores: {scores.shape}")
+ # print(f" target_labels: {labels.shape}")
+ # print(f" target_boxes shape: {raw_boxes.shape}")
+
+ # plot_boxes_on_image(image, instances, scores, boxes, labels, target_image_name, 0.5, OUTPUT_DIR)
diff --git a/owlv2_inference.py b/owlv2_inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8ed9fa343c89d5c8b7c1dbd95b2a6dd106dad28
--- /dev/null
+++ b/owlv2_inference.py
@@ -0,0 +1,176 @@
+import os
+import sys
+import json
+
+# pip install ott-jax==0.2.0
+import jax
+import numpy as np
+import tensorflow as tf
+from scipy.special import expit as sigmoid
+
+import skimage
+from skimage import io as skimage_io
+from skimage import transform as skimage_transform
+import matplotlib as mpl
+from matplotlib import pyplot as plt
+
+sys.path.append('/home/netzone22/bohanliu_2025/VisionModels/Scenic_OWLv2/big_vision')
+tf.config.experimental.set_visible_devices([], 'GPU')
+
+from scenic.projects.owl_vit import configs
+from scenic.projects.owl_vit import models
+
+from owlv2_helper_functions import plot_boxes_on_image, rescale_detection_box
+from owlv2_helper_functions import format_string
+
+
+
+# IMAGE_DIR = '/home/netzone22/bohanliu_2025/HALO/case28/case_28'
+# OUTPUT_DIR = '/home/netzone22/bohanliu_2025/HALO/case28/case_28_detection'
+# JOSN_IN = '/home/netzone22/bohanliu_2025/structured_prompt.json'
+# JSON_OUT = '/home/netzone22/bohanliu_2025/HALO/case28/case_28_detection.json'
+
+
+# IMAGE_DIR = '/home/netzone22/bohanliu_2025/HALO_test/single_image'
+# OUTPUT_DIR = '/home/netzone22/bohanliu_2025/HALO_test/single_image/detection'
+# JOSN_IN = '/home/netzone22/bohanliu_2025/structured_prompt.json'
+# JSON_OUT = '/home/netzone22/bohanliu_2025/HALO_test/single_image/detection.json'
+
+INSTANCE = 'machine'
+IMAGE_DIR = f'/home/netzone22/bohanliu_2025/HALO_test/semantic/{INSTANCE}'
+OUTPUT_DIR = f'/home/netzone22/bohanliu_2025/HALO_test/semantic_output/{INSTANCE}/detection'
+JOSN_IN = f'/home/netzone22/bohanliu_2025/HALO_test/semantic_output/{INSTANCE}/structured_prompt.json'
+JSON_OUT = f'/home/netzone22/bohanliu_2025/HALO_test/semantic_output/{INSTANCE}/metadata.json'
+
+
+THRESHOLD = 0.12
+
+TEXT = []
+with open(JOSN_IN, 'r') as file:
+ prompts = json.load(file)
+
+for target_obj in prompts['target_obj']:
+ TEXT.append(format_string(target_obj))
+if prompts['spacial_info'] == True:
+ for referred_obj in prompts['referred_obj'].keys():
+ TEXT.append(format_string(referred_obj))
+print(f"\nQueries: {TEXT}\n")
+
+
+
+### Choose config
+# config = configs.owl_v2_clip_b16.get_config(init_mode='canonical_checkpoint')
+config = configs.owl_v2_clip_l14.get_config(init_mode='canonical_checkpoint')
+
+
+### Load the model and variables
+module = models.TextZeroShotDetectionModule(
+ body_configs=config.model.body,
+ objectness_head_configs=config.model.objectness_head,
+ normalize=config.model.normalize,
+ box_bias=config.model.box_bias)
+
+variables = module.load_variables(config.init_from.checkpoint_path)
+
+
+
+### Prepare text queries
+text_queries = TEXT # ['machine', 'human']
+tokenized_queries = np.array([
+ module.tokenize(q, config.dataset_configs.max_query_length)
+ for q in text_queries
+])
+# Pad tokenized queries to avoid recompilation if number of queries changes:
+tokenized_queries = np.pad(
+ tokenized_queries,
+ pad_width=((0, 100 - len(text_queries)), (0, 0)),
+ constant_values=0)
+
+
+
+### Prepare image
+jitted = jax.jit(module.apply, static_argnames=('train',))
+digital_twins = {}
+# filenames = sorted(tf.io.gfile.listdir(IMAGE_DIR))
+
+extensions = {".jpg", ".jpeg", ".png"}
+filenames = sorted([
+ file
+ for file in tf.io.gfile.listdir(IMAGE_DIR)
+ if any(file.lower().endswith(ext) for ext in extensions)
+])
+
+for i, filename in enumerate(filenames):
+ file_path = os.path.join(IMAGE_DIR, filename)
+ image_uint8 = skimage_io.imread(file_path)
+ image = image_uint8.astype(np.float32) / 255.0
+ # Pad to square with gray pixels on bottom and right:
+ h, w, _ = image.shape
+ # print(f"original img: {h} x {w}")
+ size = max(h, w)
+ image_padded = np.pad(image, ((0, size - h), (0, size - w), (0, 0)), constant_values=0.5)
+ # Resize to model input size:
+ input_image = skimage.transform.resize(
+ image_padded,
+ (config.dataset_configs.input_size, config.dataset_configs.input_size),
+ anti_aliasing=True
+ )
+
+
+ ### Get predictions
+ # This will take a minute on the first execution due to model compilation.
+ # Subsequent executions will be faster.
+ # jitted = jax.jit(module.apply, static_argnames=('train',))
+
+ # Note: The model expects a batch dimension.
+ predictions = jitted(
+ variables,
+ input_image[None, ...],
+ tokenized_queries[None, ...],
+ train=False)
+ # Remove batch dimension and convert to numpy:
+ predictions = jax.tree_util.tree_map(lambda x: np.array(x[0]), predictions)
+ # print(predictions.keys())
+
+ ### Plot prediction
+ score_threshold = THRESHOLD # 0.1
+
+ logits = predictions['pred_logits'][..., :len(text_queries)] # Remove padding.
+ scores = sigmoid(np.max(logits, axis=-1))
+ labels = np.argmax(predictions['pred_logits'], axis=-1)
+ raw_boxes = predictions['pred_boxes']
+ boxes = rescale_detection_box(raw_boxes, image)
+
+
+
+ ### Write results into JSON file.
+ digital_twins[filename] = {}
+
+ count = {}
+ for label in labels:
+ count[text_queries[label]] = 0
+
+ for score, raw_box, box, label in zip(scores, raw_boxes, boxes, labels):
+ if score < score_threshold:
+ continue;
+
+ # x1, y1, x2, y2 = box
+ x1, y1, x2, y2 = map(float, box)
+ cx, cy, box_w, box_h = map(float, raw_box)
+ x = round(score, 2)
+
+ digital_twins[filename][f'{text_queries[label]}_{count[text_queries[label]]}'] = {
+ 'detection_label': text_queries[label],
+ 'detection_box': [x1, y1, x2, y2],
+ 'detection_centroid': [cx*size, cy*size],
+ 'detection_score': round(float(score), 2),
+ }
+ count[text_queries[label]]+=1
+
+ if not os.path.exists(OUTPUT_DIR):
+ os.makedirs(OUTPUT_DIR)
+ plot_boxes_on_image(image, text_queries, scores, boxes, labels, filename, score_threshold, OUTPUT_DIR)
+
+
+with open(JSON_OUT, "w", encoding="utf-8") as json_f:
+ json.dump(digital_twins, json_f, indent=4)
diff --git a/pylintrc b/pylintrc
new file mode 100644
index 0000000000000000000000000000000000000000..98037fc9c3181c961927ee0034afa8ef616e32e6
--- /dev/null
+++ b/pylintrc
@@ -0,0 +1,372 @@
+[MASTER]
+
+# Specify a configuration file.
+#rcfile=
+
+# Python code to execute, usually for sys.path manipulation such as
+# pygtk.require().
+#init-hook=
+
+# Add files or directories to the blacklist. They should be base names, not
+# paths.
+ignore=CVS
+
+# Pickle collected data for later comparisons.
+persistent=yes
+
+# List of plugins (as comma separated values of python modules names) to load,
+# usually to register additional checkers.
+load-plugins=
+
+# Use multiple processes to speed up Pylint.
+jobs=1
+
+# Allow loading of arbitrary C extensions. Extensions are imported into the
+# active Python interpreter and may run arbitrary code.
+unsafe-load-any-extension=no
+
+# A comma-separated list of package or module names from where C extensions may
+# be loaded. Extensions are loading into the active Python interpreter and may
+# run arbitrary code
+extension-pkg-whitelist=
+
+
+[MESSAGES CONTROL]
+
+# Only show warnings with the listed confidence levels. Leave empty to show
+# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED
+confidence=
+
+# Enable the message, report, category or checker with the given id(s). You can
+# either give multiple identifier separated by comma (,) or put this option
+# multiple time. See also the "--disable" option for examples.
+enable=use-symbolic-message-instead,useless-supression,fixme
+
+# Disable the message, report, category or checker with the given id(s). You
+# can either give multiple identifiers separated by comma (,) or put this
+# option multiple times (only on the command line, not in the configuration
+# file where it should appear only once).You can also use "--disable=all" to
+# disable everything first and then reenable specific checks. For example, if
+# you want to run only the similarities checker, you can use "--disable=all
+# --enable=similarities". If you want to run only the classes checker, but have
+# no Warning level messages displayed, use"--disable=all --enable=classes
+# --disable=W"
+
+disable=
+ attribute-defined-outside-init,
+ duplicate-code,
+ # invalid-name,
+ # missing-docstring,
+ protected-access,
+ too-few-public-methods,
+ # handled by black
+ format
+
+
+[REPORTS]
+
+# Set the output format. Available formats are text, parseable, colorized, msvs
+# (visual studio) and html. You can also give a reporter class, eg
+# mypackage.mymodule.MyReporterClass.
+output-format=text
+
+# Put messages in a separate file for each module / package specified on the
+# command line instead of printing them on stdout. Reports (if any) will be
+# written in a file name "pylint_global.[txt|html]".
+files-output=no
+
+# Tells whether to display a full report or only the messages
+reports=no
+
+# Python expression which should return a note less than 10 (10 is the highest
+# note). You have access to the variables errors warning, statement which
+# respectively contain the number of errors / warnings messages and the total
+# number of statements analyzed. This is used by the global evaluation report
+# (RP0004).
+evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
+
+# Template used to display messages. This is a python new-style format string
+# used to format the message information. See doc for all details
+#msg-template=
+
+
+[LOGGING]
+
+# Logging modules to check that the string format arguments are in logging
+# function parameter format
+logging-modules=logging
+
+
+[MISCELLANEOUS]
+
+# List of note tags to take in consideration, separated by a comma.
+notes=FIXME,XXX,TODO
+
+
+[SIMILARITIES]
+
+# Minimum lines number of a similarity.
+min-similarity-lines=4
+
+# Ignore comments when computing similarities.
+ignore-comments=yes
+
+# Ignore docstrings when computing similarities.
+ignore-docstrings=yes
+
+# Ignore imports when computing similarities.
+ignore-imports=no
+
+
+[VARIABLES]
+
+# Tells whether we should check for unused import in __init__ files.
+init-import=no
+
+# A regular expression matching the name of dummy variables (i.e. expectedly
+# not used).
+dummy-variables-rgx=_$|dummy
+
+# List of additional names supposed to be defined in builtins. Remember that
+# you should avoid defining new builtins when possible.
+additional-builtins=
+
+# List of strings which can identify a callback function by name. A callback
+# name must start or end with one of those strings.
+callbacks=cb_,_cb
+
+
+[FORMAT]
+
+# Maximum number of characters on a single line.
+max-line-length=80
+
+# Regexp for a line that is allowed to be longer than the limit.
+ignore-long-lines=^\s*(# )??$
+
+# Allow the body of an if to be on the same line as the test if there is no
+# else.
+single-line-if-stmt=no
+
+# List of optional constructs for which whitespace checking is disabled
+no-space-check=trailing-comma,dict-separator
+
+# Maximum number of lines in a module
+max-module-lines=2000
+
+# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
+# tab).
+indent-string=' '
+
+# Number of spaces of indent required inside a hanging or continued line.
+indent-after-paren=4
+
+# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
+expected-line-ending-format=
+
+
+[BASIC]
+
+# List of builtins function names that should not be used, separated by a comma
+bad-functions=map,filter,input
+
+# Good variable names which should always be accepted, separated by a comma
+good-names=i,j,k,ex,Run,_
+
+# Bad variable names which should always be refused, separated by a comma
+bad-names=foo,bar,baz,toto,tutu,tata
+
+# Colon-delimited sets of names that determine each other's naming style when
+# the name regexes allow several styles.
+name-group=
+
+# Include a hint for the correct naming format with invalid-name
+include-naming-hint=no
+
+# Regular expression matching correct function names
+function-rgx=[a-z_][a-z0-9_]{2,30}$
+
+# Naming hint for function names
+function-name-hint=[a-z_][a-z0-9_]{2,30}$
+
+# Regular expression matching correct variable names
+variable-rgx=[a-z_][a-z0-9_]{2,30}$
+
+# Naming hint for variable names
+variable-name-hint=[a-z_][a-z0-9_]{2,30}$
+
+# Regular expression matching correct constant names
+const-rgx=(([A-Z_][A-Z0-9_]*)|(__.*__))$
+
+# Naming hint for constant names
+const-name-hint=(([A-Z_][A-Z0-9_]*)|(__.*__))$
+
+# Regular expression matching correct attribute names
+attr-rgx=[a-z_][a-z0-9_]{2,}$
+
+# Naming hint for attribute names
+attr-name-hint=[a-z_][a-z0-9_]{2,}$
+
+# Regular expression matching correct argument names
+argument-rgx=[a-z_][a-z0-9_]{2,30}$
+
+# Naming hint for argument names
+argument-name-hint=[a-z_][a-z0-9_]{2,30}$
+
+# Regular expression matching correct class attribute names
+class-attribute-rgx=([A-Za-z_][A-Za-z0-9_]{2,30}|(__.*__))$
+
+# Naming hint for class attribute names
+class-attribute-name-hint=([A-Za-z_][A-Za-z0-9_]{2,30}|(__.*__))$
+
+# Regular expression matching correct inline iteration names
+inlinevar-rgx=[A-Za-z_][A-Za-z0-9_]*$
+
+# Naming hint for inline iteration names
+inlinevar-name-hint=[A-Za-z_][A-Za-z0-9_]*$
+
+# Regular expression matching correct class names
+class-rgx=[A-Z_][a-zA-Z0-9]+$
+
+# Naming hint for class names
+class-name-hint=[A-Z_][a-zA-Z0-9]+$
+
+# Regular expression matching correct module names
+module-rgx=(([a-z_][a-z0-9_]*)|([A-Z][a-zA-Z0-9]+))$
+
+# Naming hint for module names
+module-name-hint=(([a-z_][a-z0-9_]*)|([A-Z][a-zA-Z0-9]+))$
+
+# Regular expression matching correct method names
+method-rgx=[a-z_][a-z0-9_]{2,}$
+
+# Naming hint for method names
+method-name-hint=[a-z_][a-z0-9_]{2,}$
+
+# Regular expression which should only match function or class names that do
+# not require a docstring.
+no-docstring-rgx=__.*__
+
+# Minimum line length for functions/classes that require docstrings, shorter
+# ones are exempt.
+docstring-min-length=-1
+
+# List of decorators that define properties, such as abc.abstractproperty.
+property-classes=abc.abstractproperty
+
+
+[TYPECHECK]
+
+# Tells whether missing members accessed in mixin class should be ignored. A
+# mixin class is detected if its name ends with "mixin" (case insensitive).
+ignore-mixin-members=yes
+
+# List of module names for which member attributes should not be checked
+# (useful for modules/projects where namespaces are manipulated during runtime
+# and thus existing member attributes cannot be deduced by static analysis
+ignored-modules=
+
+# List of classes names for which member attributes should not be checked
+# (useful for classes with attributes dynamically set).
+ignored-classes=SQLObject, optparse.Values, thread._local, _thread._local
+
+# List of members which are set dynamically and missed by pylint inference
+# system, and so shouldn't trigger E1101 when accessed. Python regular
+# expressions are accepted.
+generated-members=REQUEST,acl_users,aq_parent
+
+# List of decorators that create context managers from functions, such as
+# contextlib.contextmanager.
+contextmanager-decorators=contextlib.contextmanager
+
+
+[SPELLING]
+
+# Spelling dictionary name. Available dictionaries: none. To make it working
+# install python-enchant package.
+spelling-dict=
+
+# List of comma separated words that should not be checked.
+spelling-ignore-words=
+
+# A path to a file that contains private dictionary; one word per line.
+spelling-private-dict-file=
+
+# Tells whether to store unknown words to indicated private dictionary in
+# --spelling-private-dict-file option instead of raising a message.
+spelling-store-unknown-words=no
+
+
+[DESIGN]
+
+# Maximum number of arguments for function / method
+max-args=10
+
+# Argument names that match this expression will be ignored. Default to name
+# with leading underscore
+ignored-argument-names=_.*
+
+# Maximum number of locals for function / method body
+max-locals=25
+
+# Maximum number of return / yield for function / method body
+max-returns=11
+
+# Maximum number of branch for function / method body
+max-branches=26
+
+# Maximum number of statements in function / method body
+max-statements=100
+
+# Maximum number of parents for a class (see R0901).
+max-parents=7
+
+# Maximum number of attributes for a class (see R0902).
+max-attributes=11
+
+# Minimum number of public methods for a class (see R0903).
+min-public-methods=2
+
+# Maximum number of public methods for a class (see R0904).
+max-public-methods=25
+
+
+[CLASSES]
+
+# List of method names used to declare (i.e. assign) instance attributes.
+defining-attr-methods=__init__,__new__,setUp,__post_init__
+
+# List of valid names for the first argument in a class method.
+valid-classmethod-first-arg=cls
+
+# List of valid names for the first argument in a metaclass class method.
+valid-metaclass-classmethod-first-arg=mcs
+
+# List of member names, which should be excluded from the protected access
+# warning.
+exclude-protected=_asdict,_fields,_replace,_source,_make
+
+
+[IMPORTS]
+
+# Deprecated modules which should not be used, separated by a comma
+deprecated-modules=regsub,TERMIOS,Bastion,rexec
+
+# Create a graph of every (i.e. internal and external) dependencies in the
+# given file (report RP0402 must not be disabled)
+import-graph=
+
+# Create a graph of external dependencies in the given file (report RP0402 must
+# not be disabled)
+ext-import-graph=
+
+# Create a graph of internal dependencies in the given file (report RP0402 must
+# not be disabled)
+int-import-graph=
+
+
+[EXCEPTIONS]
+
+# Exceptions that will emit a warning when being caught. Defaults to
+# "Exception"
+overgeneral-exceptions=Exception
diff --git a/scenic.egg-info/PKG-INFO b/scenic.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..e33311b418782a60e7e5517671cab875d3b4c3c2
--- /dev/null
+++ b/scenic.egg-info/PKG-INFO
@@ -0,0 +1,254 @@
+Metadata-Version: 2.1
+Name: scenic
+Version: 0.0.1
+Summary: A Jax Library for Computer Vision Research and Beyond.
+Home-page: http://github.com/google-research/scenic
+Author: Scenic Authors
+Author-email: no-reply@google.com
+License: Apache 2.0
+Keywords: Scenic
+Classifier: Development Status :: 1 - Beta
+Classifier: Intended Audience :: Developers
+Classifier: Intended Audience :: Science/Research
+Classifier: License :: OSI Approved :: Apache Software License
+Classifier: Programming Language :: Python
+Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
+Description-Content-Type: text/markdown
+License-File: LICENSE
+Requires-Dist: absl-py>=1.0.0
+Requires-Dist: numpy>=1.12
+Requires-Dist: jax>=0.4.3
+Requires-Dist: jaxlib>=0.4.3
+Requires-Dist: flax>=0.4.0
+Requires-Dist: ml-collections>=0.1.1
+Requires-Dist: tensorflow>=2.7
+Requires-Dist: immutabledict>=2.2.1
+Requires-Dist: clu>=0.0.6
+Requires-Dist: tensorflow-datasets
+Requires-Dist: optax@ git+https://github.com/google-deepmind/optax.git@main
+Provides-Extra: testing
+Requires-Dist: pytest; extra == "testing"
+Requires-Dist: shapely; extra == "testing"
+Requires-Dist: ott-jax>=0.2.0; extra == "testing"
+Requires-Dist: sklearn; extra == "testing"
+Requires-Dist: lingvo==0.12.6; extra == "testing"
+Requires-Dist: seaborn>=0.11.2; extra == "testing"
+Requires-Dist: dmvr@ git+https://github.com/google-deepmind/dmvr.git ; extra == "testing"
+
+# Scenic
+
+
+
+
+