---
license: apache-2.0
language:
- zh
- en
pipeline_tag: image-text-to-text
library_name: transformers
---

MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale



---
### News 🚀🚀
2026.05.21 🎉🎉 We are pleased to announce the release of MinerU2.5-Pro-2605, an updated version of our model.
- **Enhanced Layout Detection**
To address the category misclassification issues observed in the 2604 version during layout detection, we conducted a comprehensive data cleaning process. This has substantially reduced category errors in layout detection. Notably, the missed detection rate for the `image_block` category has been significantly reduced.
- **Improved Image Analysis**
To overcome the limitations of the 2604 version in image analysis, we constructed a large-scale training dataset for this task. As a result, the 2605 version demonstrates markedly enhanced recognition capabilities across a wide range of charts, flowcharts, and even seals.
- **Comparable Performance on OmniDocBench**
The 2605 version primarily focuses on enhancing user experience, with performance metrics showing only marginal differences compared to the 2604 version. A detailed comparison of the metrics is presented below:
MinerU2.5-Pro-2605 vs. MinerU2.5-Pro-2604 on OmniDocBench (v1.6_full)
| Model Version |
Overall↑ |
TextEdit↓ |
FormulaCDM↑ |
TableTEDS↑ |
TableTEDS-S↑ |
Read OrderEdit↓ |
| MinerU2.5-Pro-2605 |
95.72 |
0.036 |
97.15 |
93.62 |
96.01 |
0.123 |
| MinerU2.5-Pro-2604 |
95.69 |
0.036 |
97.29 |
93.42 |
95.92 |
0.120 |
### 🏆 Unmatched SOTA Performance
**MinerU2.5-Pro** is our latest document parsing model (PDF-to-Markdown) that establishes a new industry standard. By focusing entirely on data engineering without altering the original 1.2B-parameter architecture, it delivers exceptional results across the board:
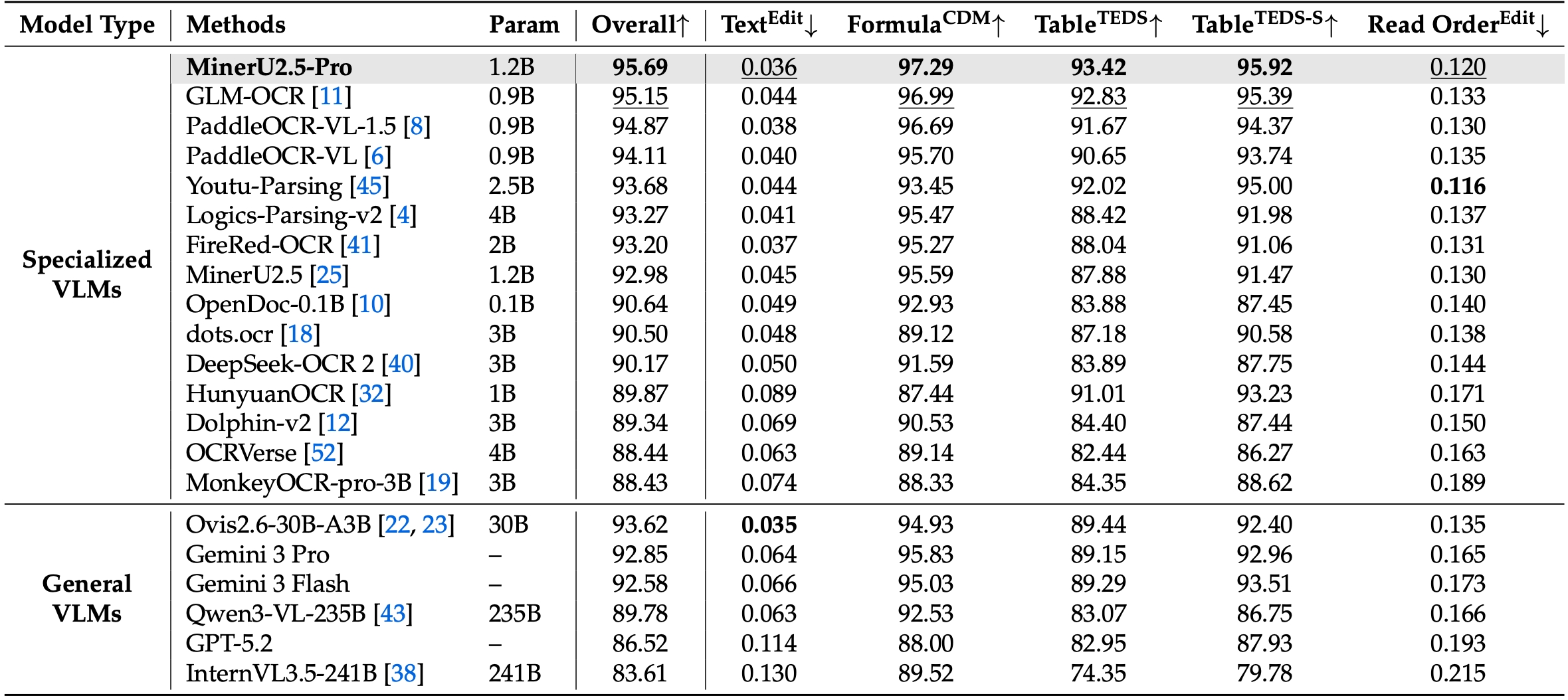
**1. Defeating Leading Models on OmniDocBench v1.6**
On the newly proposed, highly rigorous OmniDocBench v1.6, MinerU2.5-Pro achieves the absolute **SOTA overall score of 95.69**. It comprehensively outperforms both top-tier specialized OCR models (**GLM-OCR, PaddleOCR-VL-1.5**) and massive frontier VLMs (**Gemini 3 Pro, Qwen3-VL-235B**).
**2. Massive Leap from MinerU 2.5 via Data Engineering**
Compared to the previous MinerU 2.5 baseline, the overall score skyrocketed from **92.98 to 95.69**. This breakthrough was achieved not by scaling model parameters, but through meticulous data engineering—drastically expanding data scale, enriching distribution and difficulty diversity, and systematically elevating annotation quality.
**3. Exceptional Modality-Specific Breakthroughs**
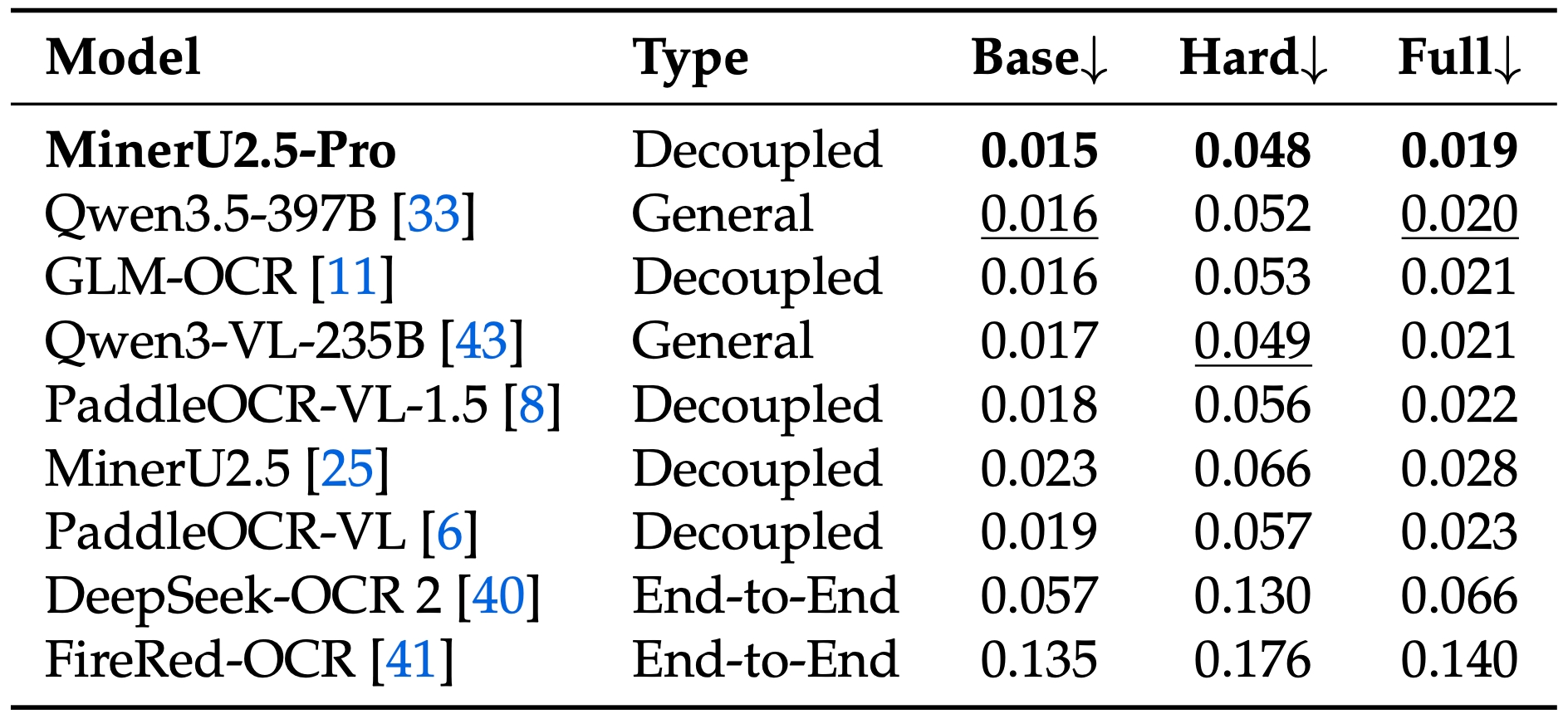
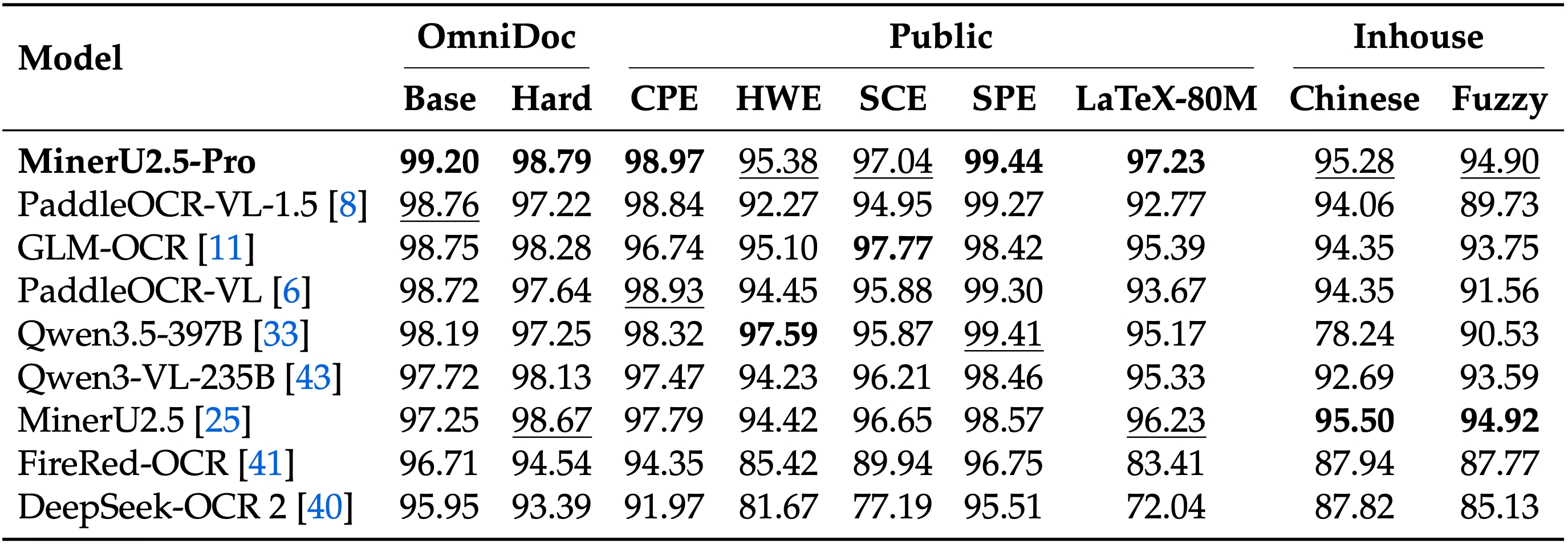
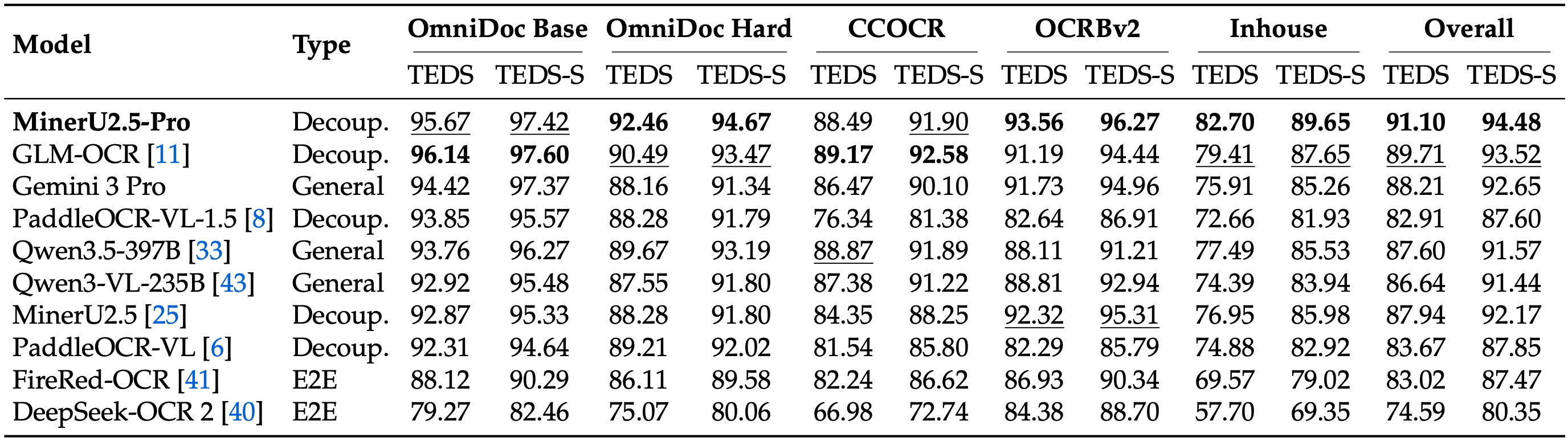
* 📊 **Table Parsing:** Evaluated across 5 diverse table benchmarks, MinerU2.5-Pro dominates the leaderboard. It outperforms the 2nd place model by **1.39 points** and surpasses the original MinerU by **3.06 points** (with Table TEDS jumping specifically by **+5.54** on OmniDocBench).
* 🧮 **Formulas & Text:** Achieves SOTA levels with Dense Formula parsing (CDM) reaching **97.29** (+1.70), and Text Edit Distance dropping to an industry-best **0.036**.
**4. ✨ New Practical Capabilities**
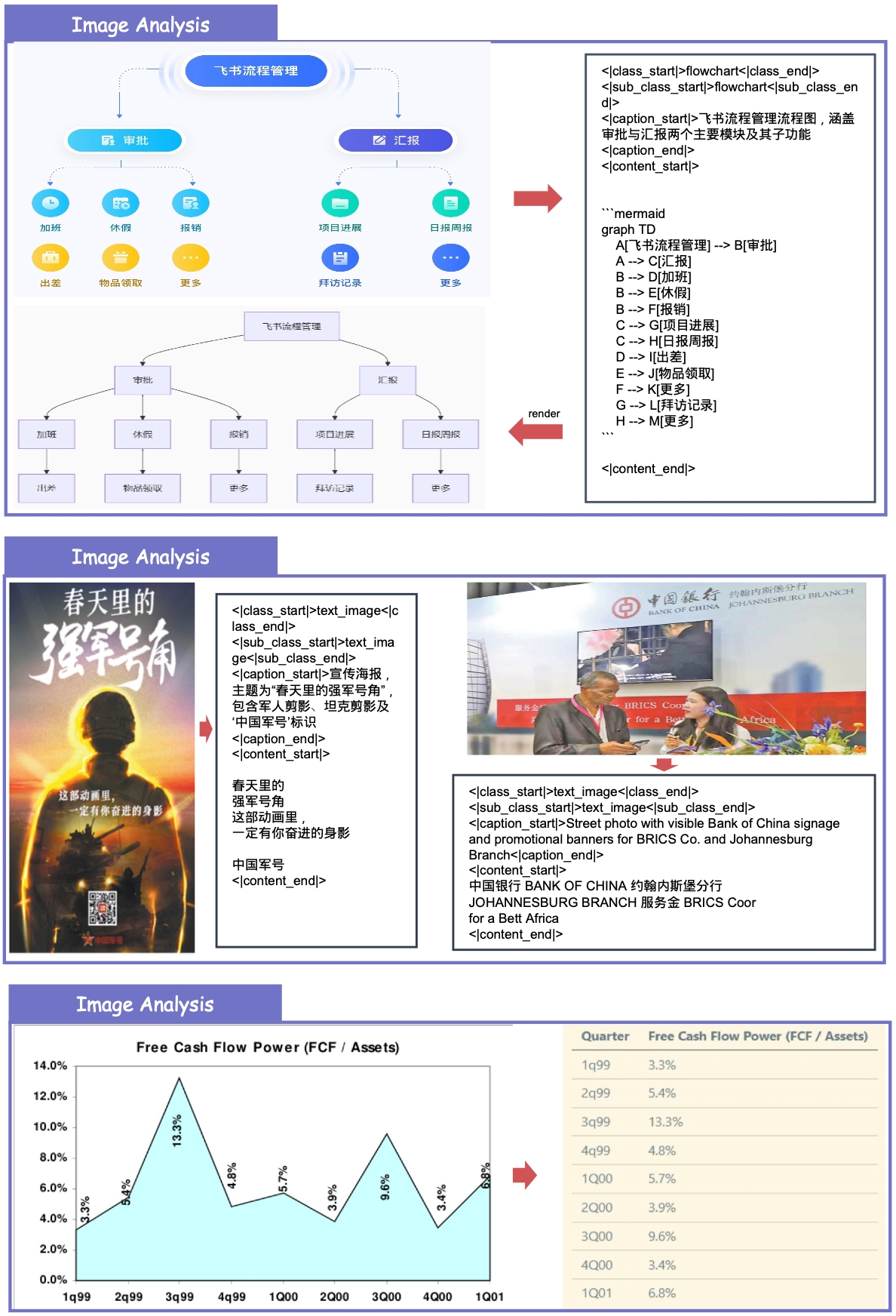
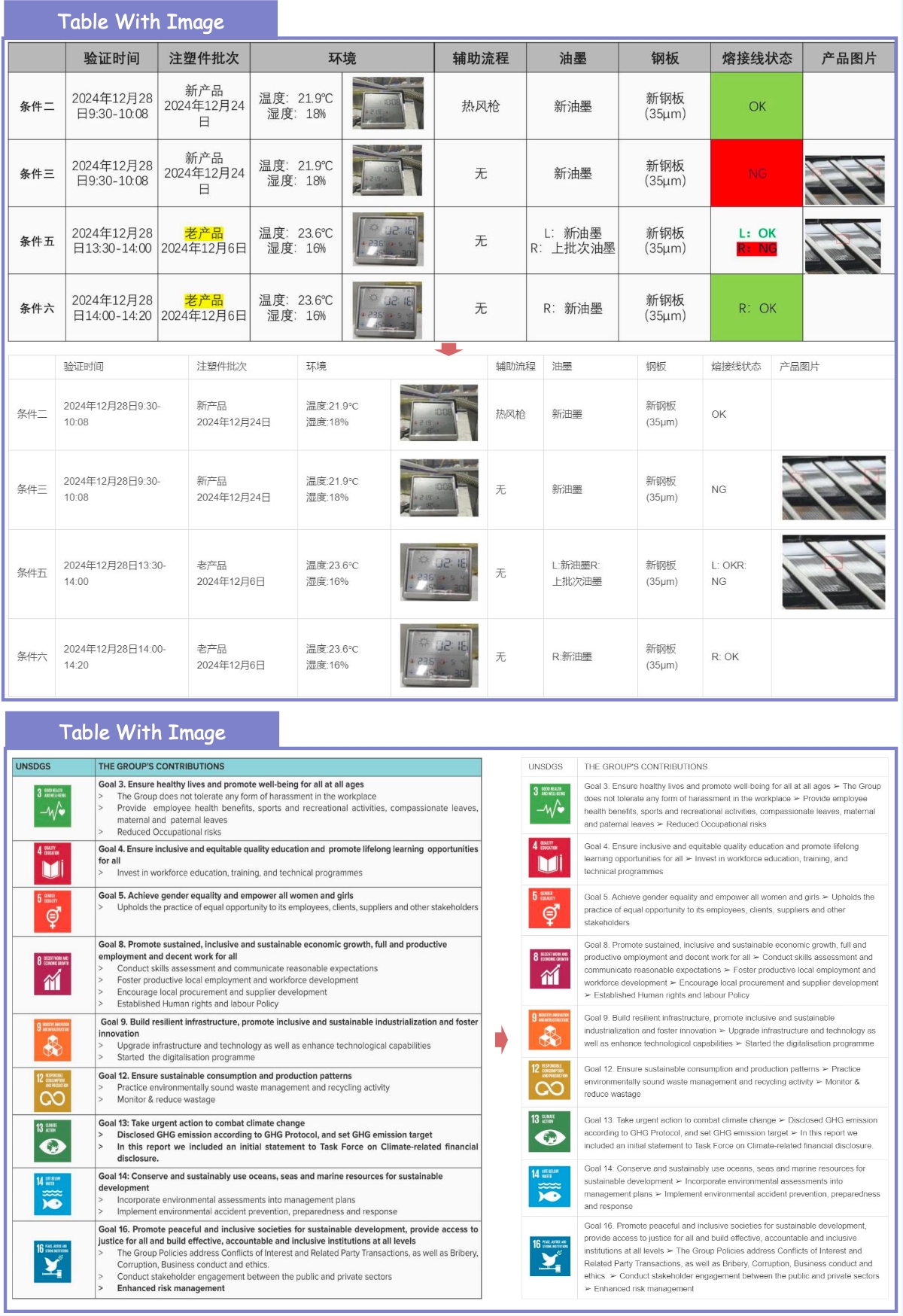
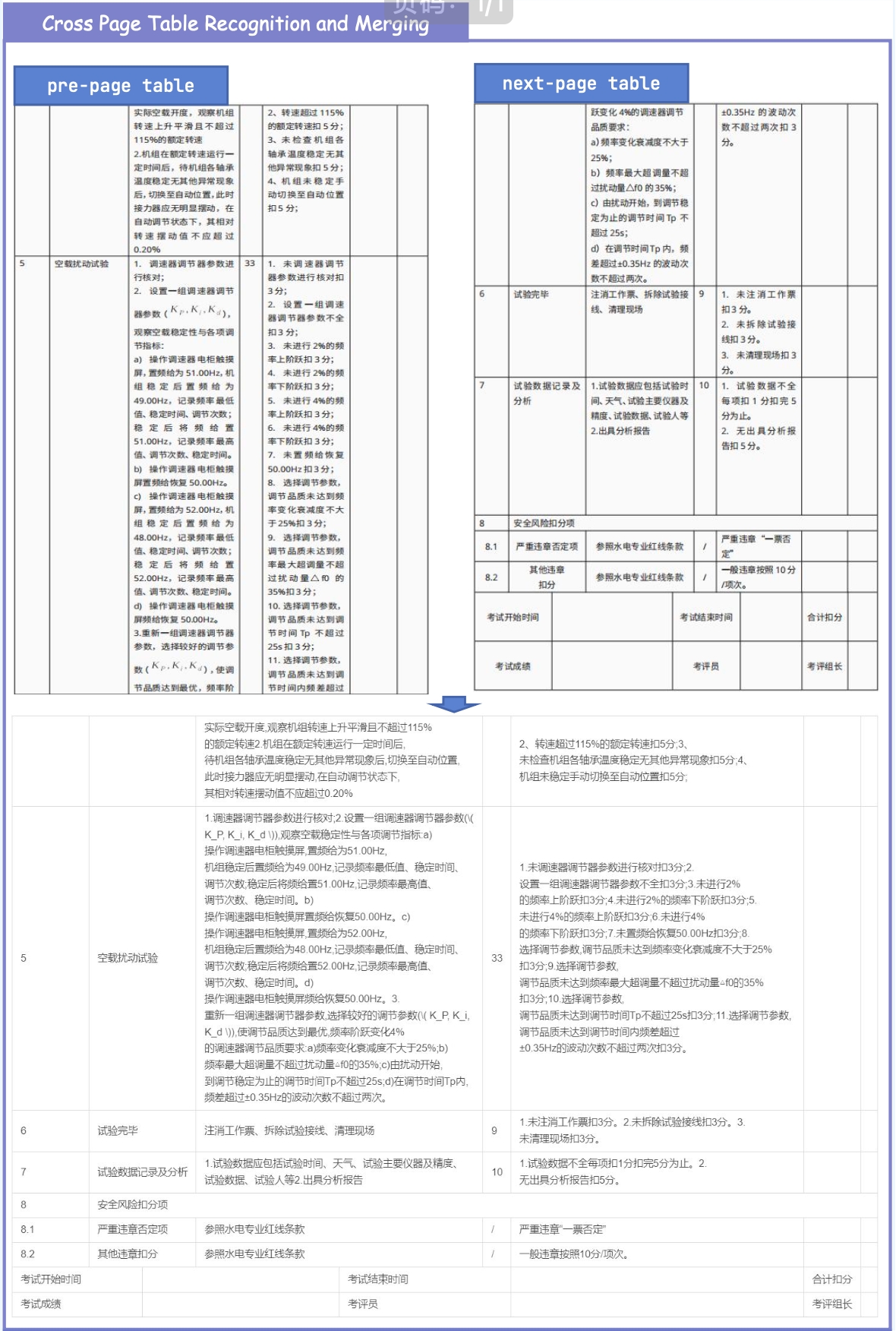
Beyond metric improvements, MinerU2.5-Pro now natively supports: **Image & Chart Parsing**, **Truncated Paragraph Merging**, **Cross-Page Table Merging** and **In-Table Image Recognition**.
---
### 💡 How We Achieved It: The Data Engine
Current SOTA models (regardless of architecture) consistently fail on the same set of complex layouts. We realized the true bottleneck is **training data deficiency and annotation noise**. To fix this, we built a novel Data Engine:
1. **Difficulty & Diversity-Aware Scaling:** We expanded the training corpus from under 10M to **65.5M pages**, heavily targeting long-tail hard samples while controlling distribution shifts.
2. **Solving the "Annotation Paradox":** Complex tables and dense formulas usually suffer from noisy automatic labels. We generated ultra-reliable annotations using **Cross-Model Consistency Verification (CMCV)** and an iterative **Judge-and-Refine** pipeline.
3. **3-Stage Progressive Training:** We maximized data utility by matching data quality tiers to a structured training pipeline: Large-scale Pre-training ➡️ High-quality Hard-Sample Fine-Tuning ➡️ GRPO Format Alignment.
**Bottom Line:** MinerU2.5-Pro proves that systematic data engineering is the ultimate lever for document parsing, providing the most accurate structural extraction available today for LLM data pipelines and advanced RAG systems.
# 1. Quick Start
For convenience, we provide `mineru-vl-utils`, a Python package that simplifies the process of sending requests and handling responses from MinerU2.5-Pro Vision-Language Model. Here we give some examples to use MinerU2.5-Pro. For more information and usages, please refer to [mineru-vl-utils](https://github.com/opendatalab/mineru-vl-utils/tree/main).
📌 We strongly recommend using vllm for inference, as the `vllm-async-engine` can achieve a concurrent inference speed of **2.12 fps** on one A100.
## 1.1. Install packages
```bash
# For `transformers` backend
pip install "mineru-vl-utils[transformers]"
# For `vllm-engine` and `vllm-async-engine` backend
pip install "mineru-vl-utils[vllm]"
```
## 1.2. `transformers` Example
```python
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from PIL import Image
from mineru_vl_utils import MinerUClient
# for transformers>=4.56.0
model = Qwen2VLForConditionalGeneration.from_pretrained(
"opendatalab/MinerU2.5-Pro-2604-1.2B", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"opendatalab/MinerU2.5-Pro-2604-1.2B", use_fast=True
)
client = MinerUClient(
backend="transformers", model=model, processor=processor,
image_analysis=False # default False, set True to enable image/chart analysis
)
print(client.two_step_extract(Image.open("/path/to/page.png")))
```
## 1.3. `vllm-engine` Example (Recommended!)
```python
from vllm import LLM
from PIL import Image
from mineru_vl_utils import MinerUClient
from mineru_vl_utils import MinerULogitsProcessor # if vllm>=0.10.1
llm = LLM(
model="opendatalab/MinerU2.5-Pro-2604-1.2B",
logits_processors=[MinerULogitsProcessor] # if vllm>=0.10.1
)
client = MinerUClient(
backend="vllm-engine", vllm_llm=llm,
image_analysis=False # default False, set True to enable image/chart analysis
)
print(client.two_step_extract(Image.open("/path/to/page.png")))
```
## 1.4. JSON result to Markdown (enable truncated paragraph merging)
```python
from mineru_vl_utils.post_process import json2md
# ... omit client initialize
content_list = client.two_step_extract(Image.open("path/to/page.png"))
md_res = json2md(content_list)
```
🚧 Cross-Page Table Merging: Currently under integration. Stay tuned!
# 2. Performance
## 2.1. End-to-End Document Parsing on OmniDocBench v1.6
## 2.2. Text Recognition
## 2.3. Formula Recognition
## 2.4. Table Recognition
# 3. Showcase
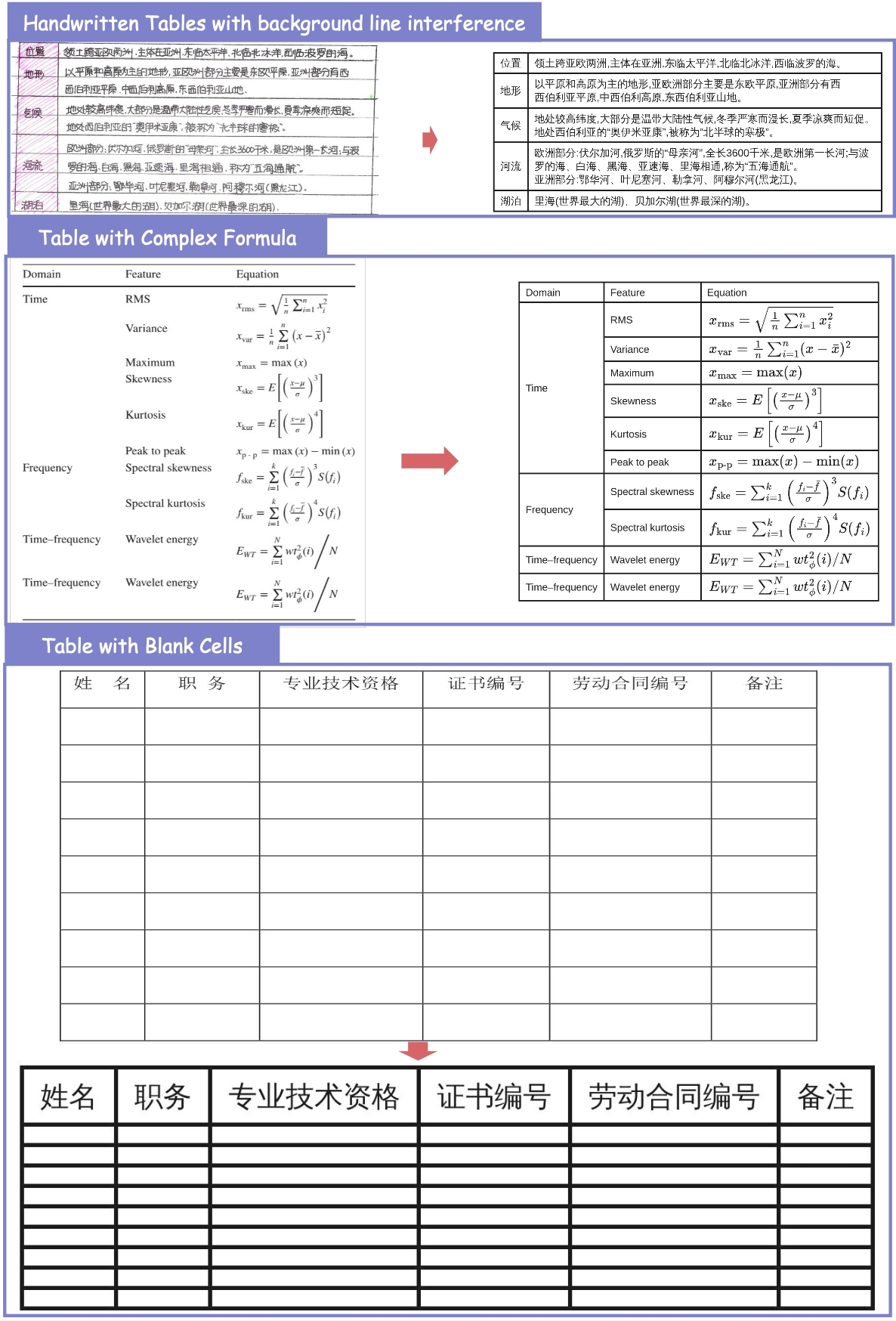
## 3.1. Basic Parsing Capability


## 3.2. Extra Supported Features

# 4. Acknowledgement & Citation
We would like to thank [Qwen Team](https://github.com/QwenLM), [vLLM](https://github.com/vllm-project/vllm), [OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), [UniMERNet](https://github.com/opendatalab/UniMERNet), [DocLayout-YOLO](https://github.com/opendatalab/DocLayout-YOLO) for providing valuable code and models. We also appreciate everyone's contribution to this open-source project!
If you find our work useful in your research, please consider giving a star ⭐ and citation 📝 :
```BibTeX
@misc{wang2026mineru25propushinglimitsdatacentric,
title={MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale},
author={Bin, Wang and Tianyao, He and Linke, Ouyang and Fan, Wu and Zhiyuan, Zhao and Tao, Chu and Yuan, Qu and Zhenjiang, Jin and Weijun, Zeng and Ziyang, Miao and Bangrui, Xu and Junbo, Niu and others},
year={2026},
eprint={2604.04771},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.04771},
}
```