

Commit ·
6c599c3
1
Parent(s): d3a0ec4
image to image interface
Browse files
README.md
CHANGED
|
@@ -2,14 +2,18 @@
|
|
| 2 |
license: openrail++
|
| 3 |
tags:
|
| 4 |
- stable-diffusion
|
| 5 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
duplicated_from: stabilityai/stable-diffusion-2-1-base
|
| 7 |
---
|
| 8 |
|
| 9 |
# Stable Diffusion v2-1-base Model Card
|
| 10 |
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
|
| 11 |
|
| 12 |
-
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
|
| 13 |
|
| 14 |
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
|
| 15 |
- Use it with 🧨 [`diffusers`](#examples)
|
|
@@ -31,7 +35,7 @@ This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](http
|
|
| 31 |
year = {2022},
|
| 32 |
pages = {10684-10695}
|
| 33 |
}
|
| 34 |
-
|
| 35 |
|
| 36 |
## Examples
|
| 37 |
|
|
@@ -53,8 +57,8 @@ pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, to
|
|
| 53 |
pipe = pipe.to("cuda")
|
| 54 |
|
| 55 |
prompt = "a photo of an astronaut riding a horse on mars"
|
| 56 |
-
image = pipe(prompt).images[0]
|
| 57 |
-
|
| 58 |
image.save("astronaut_rides_horse.png")
|
| 59 |
```
|
| 60 |
|
|
@@ -64,7 +68,7 @@ image.save("astronaut_rides_horse.png")
|
|
| 64 |
|
| 65 |
# Uses
|
| 66 |
|
| 67 |
-
## Direct Use
|
| 68 |
The model is intended for research purposes only. Possible research areas and tasks include
|
| 69 |
|
| 70 |
- Safe deployment of models which have the potential to generate harmful content.
|
|
@@ -109,11 +113,11 @@ Using the model to generate content that is cruel to individuals is a misuse of
|
|
| 109 |
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
|
| 110 |
|
| 111 |
### Bias
|
| 112 |
-
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 113 |
-
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
| 114 |
-
which consists of images that are limited to English descriptions.
|
| 115 |
-
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 116 |
-
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 117 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 118 |
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
|
| 119 |
|
|
@@ -126,7 +130,7 @@ The model developers used the following dataset for training the model:
|
|
| 126 |
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
|
| 127 |
|
| 128 |
**Training Procedure**
|
| 129 |
-
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
| 130 |
|
| 131 |
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
|
| 132 |
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
|
|
@@ -148,7 +152,7 @@ The additional input channels of the U-Net which process this extra information
|
|
| 148 |
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
|
| 149 |
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
|
| 150 |
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
|
| 151 |
-
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
|
| 152 |
|
| 153 |
- **Hardware:** 32 x 8 x A100 GPUs
|
| 154 |
- **Optimizer:** AdamW
|
|
@@ -156,11 +160,11 @@ In addition to the textual input, it receives a `noise_level` as an input parame
|
|
| 156 |
- **Batch:** 32 x 8 x 2 x 4 = 2048
|
| 157 |
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
|
| 158 |
|
| 159 |
-
## Evaluation Results
|
| 160 |
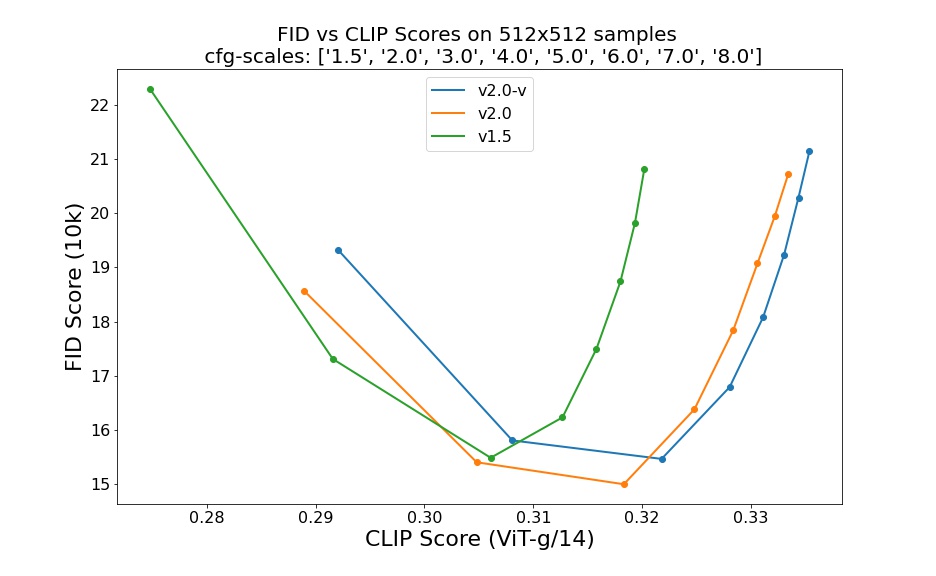
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 161 |
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
|
| 162 |
|
| 163 |
-
|
| 164 |
|
| 165 |
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
| 166 |
|
|
@@ -185,4 +189,4 @@ Based on that information, we estimate the following CO2 emissions using the [Ma
|
|
| 185 |
pages = {10684-10695}
|
| 186 |
}
|
| 187 |
|
| 188 |
-
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
|
|
|
| 2 |
license: openrail++
|
| 3 |
tags:
|
| 4 |
- stable-diffusion
|
| 5 |
+
- image-to-image
|
| 6 |
+
widget:
|
| 7 |
+
- src: >-
|
| 8 |
+
https://huggingface.co/datasets/mishig/sample_images/resolve/main/canny-edge.jpg
|
| 9 |
+
prompt: Girl with Pearl Earring
|
| 10 |
duplicated_from: stabilityai/stable-diffusion-2-1-base
|
| 11 |
---
|
| 12 |
|
| 13 |
# Stable Diffusion v2-1-base Model Card
|
| 14 |
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
|
| 15 |
|
| 16 |
+
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
|
| 17 |
|
| 18 |
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
|
| 19 |
- Use it with 🧨 [`diffusers`](#examples)
|
|
|
|
| 35 |
year = {2022},
|
| 36 |
pages = {10684-10695}
|
| 37 |
}
|
| 38 |
+
|
| 39 |
|
| 40 |
## Examples
|
| 41 |
|
|
|
|
| 57 |
pipe = pipe.to("cuda")
|
| 58 |
|
| 59 |
prompt = "a photo of an astronaut riding a horse on mars"
|
| 60 |
+
image = pipe(prompt).images[0]
|
| 61 |
+
|
| 62 |
image.save("astronaut_rides_horse.png")
|
| 63 |
```
|
| 64 |
|
|
|
|
| 68 |
|
| 69 |
# Uses
|
| 70 |
|
| 71 |
+
## Direct Use
|
| 72 |
The model is intended for research purposes only. Possible research areas and tasks include
|
| 73 |
|
| 74 |
- Safe deployment of models which have the potential to generate harmful content.
|
|
|
|
| 113 |
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
|
| 114 |
|
| 115 |
### Bias
|
| 116 |
+
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 117 |
+
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
| 118 |
+
which consists of images that are limited to English descriptions.
|
| 119 |
+
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 120 |
+
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 121 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 122 |
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
|
| 123 |
|
|
|
|
| 130 |
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
|
| 131 |
|
| 132 |
**Training Procedure**
|
| 133 |
+
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
| 134 |
|
| 135 |
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
|
| 136 |
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
|
|
|
|
| 152 |
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
|
| 153 |
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
|
| 154 |
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
|
| 155 |
+
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
|
| 156 |
|
| 157 |
- **Hardware:** 32 x 8 x A100 GPUs
|
| 158 |
- **Optimizer:** AdamW
|
|
|
|
| 160 |
- **Batch:** 32 x 8 x 2 x 4 = 2048
|
| 161 |
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
|
| 162 |
|
| 163 |
+
## Evaluation Results
|
| 164 |
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 165 |
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
|
| 166 |
|
| 167 |
+

|
| 168 |
|
| 169 |
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
| 170 |
|
|
|
|
| 189 |
pages = {10684-10695}
|
| 190 |
}
|
| 191 |
|
| 192 |
+
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|