

Published March 27, 2026
TRL v1: Post-Training Library That Holds When the Field Invalidates Its Own Assumptions

Published October 23, 2025
Building the Open Agent Ecosystem Together: Introducing OpenEnv

Published on August 7, 2025
Vision Language Model Alignment in TRL ⚡️

Published on June 3, 2025
NO GPU left behind: Unlocking Efficiency with Co-located vLLM in TRL

Published on May 25, 2025
🐯 Liger GRPO meets TRL

Published on January 28, 2025
Open-R1: a fully open reproduction of DeepSeek-R1

Published on July 10, 2024
Preference Optimization for Vision Language Models with TRL

Published on June 12, 2024
Putting RL back in RLHF

Published on September 29, 2023
Finetune Stable Diffusion Models with DDPO via TRL

Published on August 8, 2023
Fine-tune Llama 2 with DPO

Published on April 5, 2023
StackLLaMA: A hands-on guide to train LLaMA with RLHF

Published on March 9, 2023
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
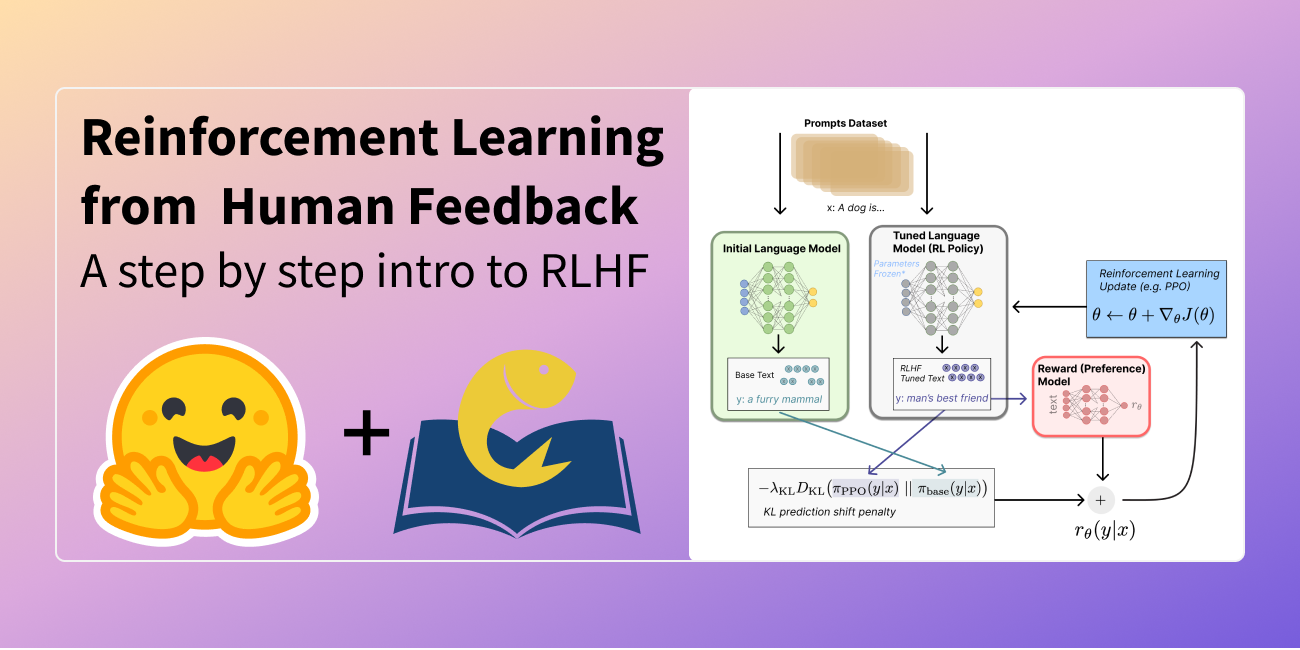
Published on December 9, 2022
Illustrating Reinforcement Learning from Human Feedback
.png)