

Update README.md
Browse files
README.md
CHANGED
|
@@ -8,130 +8,69 @@ pipeline_tag: text-to-image
|
|
| 8 |
base_model:
|
| 9 |
- Qwen/Qwen-Image
|
| 10 |
---
|
| 11 |
-
<p align="center">
|
| 12 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_logo.png" width="400"/>
|
| 13 |
-
<p>
|
| 14 |
-
<p align="center">
|
| 15 |
-
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image/">Blog</a>   
|
| 16 |
-
<br>
|
| 17 |
-
🖥️ <a href="https://huggingface.co/spaces/Qwen/qwen-image">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  
|
| 18 |
-
</p>
|
| 19 |
|
| 20 |
-
<
|
| 21 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/merge3.jpg" width="1600"/>
|
| 22 |
-
<p>
|
| 23 |
|
| 24 |
-
|
| 25 |
-
We are thrilled to release **Qwen-Image**, an image generation foundation model in the Qwen series that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.
|
| 26 |
|
| 27 |
-
 of Qwen-Image!
|
| 31 |
-
- 2025.08.04: We released Qwen-Image weights! Check at [huggingface](https://huggingface.co/Qwen/Qwen-Image) and [Modelscope](https://modelscope.cn/models/Qwen/Qwen-Image)!
|
| 32 |
-
- 2025.08.04: We released Qwen-Image! Check our [blog](https://qwenlm.github.io/blog/qwen-image) for more details!
|
| 33 |
|
|
|
|
| 34 |
|
| 35 |
-
##
|
| 36 |
|
| 37 |
-
|
| 38 |
-
```
|
| 39 |
-
pip install git+https://github.com/huggingface/diffusers
|
| 40 |
-
```
|
| 41 |
|
| 42 |
-
|
| 43 |
|
| 44 |
-
|
| 45 |
-
from diffusers import DiffusionPipeline
|
| 46 |
-
import torch
|
| 47 |
|
| 48 |
-
|
| 49 |
|
| 50 |
-
# Load the pipeline
|
| 51 |
-
if torch.cuda.is_available():
|
| 52 |
-
torch_dtype = torch.bfloat16
|
| 53 |
-
device = "cuda"
|
| 54 |
-
else:
|
| 55 |
-
torch_dtype = torch.float32
|
| 56 |
-
device = "cpu"
|
| 57 |
|
| 58 |
-
|
| 59 |
-
pipe = pipe.to(device)
|
| 60 |
|
| 61 |
-
|
| 62 |
-
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
|
| 63 |
-
"zh": "超清,4K,电影级构图" # for chinese prompt,
|
| 64 |
-
}
|
| 65 |
|
| 66 |
-
|
| 67 |
-
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
|
| 68 |
|
| 69 |
-
|
| 70 |
|
|
|
|
| 71 |
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
"16:9": (1664, 928),
|
| 76 |
-
"9:16": (928, 1664),
|
| 77 |
-
"4:3": (1472, 1140),
|
| 78 |
-
"3:4": (1140, 1472),
|
| 79 |
-
"3:2": (1584, 1056),
|
| 80 |
-
"2:3": (1056, 1584),
|
| 81 |
-
}
|
| 82 |
|
| 83 |
-
|
| 84 |
|
| 85 |
-
|
| 86 |
-
prompt=prompt + positive_magic["en"],
|
| 87 |
-
negative_prompt=negative_prompt,
|
| 88 |
-
width=width,
|
| 89 |
-
height=height,
|
| 90 |
-
num_inference_steps=50,
|
| 91 |
-
true_cfg_scale=4.0,
|
| 92 |
-
generator=torch.Generator(device="cuda").manual_seed(42)
|
| 93 |
-
).images[0]
|
| 94 |
|
| 95 |
-
|
|
|
|
| 96 |
```
|
| 97 |
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
One of its standout capabilities is high-fidelity text rendering across diverse images. Whether it’s alphabetic languages like English or logographic scripts like Chinese, Qwen-Image preserves typographic details, layout coherence, and contextual harmony with stunning accuracy. Text isn’t just overlaid—it’s seamlessly integrated into the visual fabric.
|
| 101 |
-
|
| 102 |
-

|
| 103 |
-
|
| 104 |
-
Beyond text, Qwen-Image excels at general image generation with support for a wide range of artistic styles. From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, the model adapts fluidly to creative prompts, making it a versatile tool for artists, designers, and storytellers.
|
| 105 |
-
|
| 106 |
-

|
| 107 |
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
But Qwen-Image doesn’t just create or edit—it understands. It supports a suite of image understanding tasks, including object detection, semantic segmentation, depth and edge (Canny) estimation, novel view synthesis, and super-resolution. These capabilities, while technically distinct, can all be seen as specialized forms of intelligent image editing, powered by deep visual comprehension.
|
| 113 |
-
|
| 114 |
-

|
| 115 |
-
|
| 116 |
-
Together, these features make Qwen-Image not just a tool for generating pretty pictures, but a comprehensive foundation model for intelligent visual creation and manipulation—where language, layout, and imagery converge.
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
## License Agreement
|
| 120 |
-
|
| 121 |
-
Qwen-Image is licensed under Apache 2.0.
|
| 122 |
|
| 123 |
## Citation
|
| 124 |
|
| 125 |
-
We kindly encourage citation of our work if you find it useful.
|
| 126 |
-
|
| 127 |
```bibtex
|
| 128 |
-
@
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
archivePrefix={arXiv},
|
| 134 |
-
primaryClass={cs.CV},
|
| 135 |
-
url={https://arxiv.org/abs/2508.02324},
|
| 136 |
}
|
| 137 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
base_model:
|
| 9 |
- Qwen/Qwen-Image
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
+
<h1 align="center">TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows</h1>
|
|
|
|
|
|
|
| 13 |
|
| 14 |
+
<div align="center">
|
|
|
|
| 15 |
|
| 16 |
+
[](https://zhenglin-cheng.com/twinflow) 
|
| 17 |
+
[](https://huggingface.co/inclusionAI/TwinFlow) 
|
| 18 |
+
[](https://github.com/inclusionAI/TwinFlow) 
|
| 19 |
+
<a href="https://arxiv.org/abs/2512.05150" target="_blank"><img src="https://img.shields.io/badge/Paper-b5212f.svg?logo=arxiv" height="21px"></a>
|
| 20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
</div>
|
| 23 |
|
| 24 |
+
## News
|
| 25 |
|
| 26 |
+
- We release **TwinFlow-Qwen-Image-v1.0**! And we are also working on **Z-Image-Turbo to make it more faster**!
|
|
|
|
|
|
|
|
|
|
| 27 |
|
| 28 |
+
## TwinFlow
|
| 29 |
|
| 30 |
+
Checkout 2-NFE visualization of TwinFlow-Qwen-Image 👇
|
|
|
|
|
|
|
| 31 |
|
| 32 |
+

|
| 33 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
|
| 35 |
+
### Overview
|
|
|
|
| 36 |
|
| 37 |
+
We introduce TwinFlow, a framework that realizes high-quality 1-step and few-step generation without the pipeline bloat.
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
+
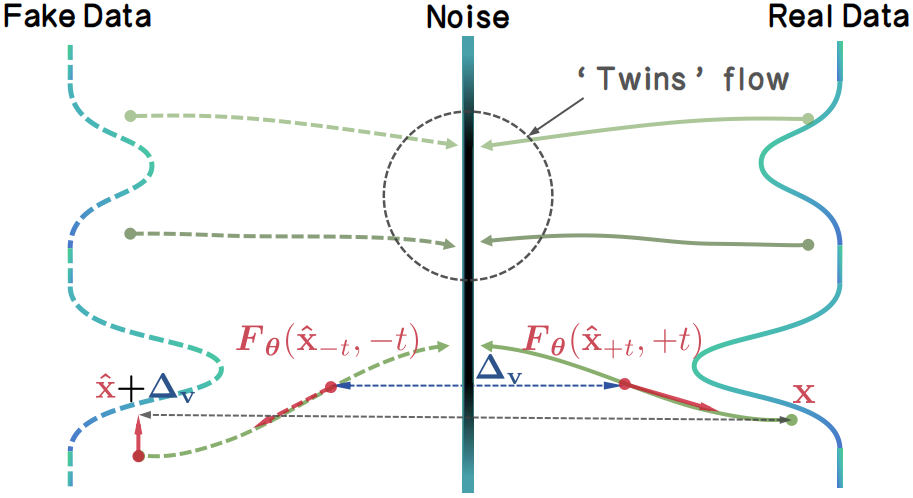
Instead of relying on external discriminators or frozen teachers, TwinFlow creates an internal "twin trajectory". By extending the time interval to $t\in[−1,1]$, we utilize the negative time branch to map noise to "fake" data, creating a self-adversarial signal directly within the model.
|
|
|
|
| 40 |
|
| 41 |
+
Then, the model can rectify itself by minimizing the difference of the velocity fields between real trajectory and fake trajectory, i.e. the $\Delta_\mathrm{v}$. The rectification performs distribution matching as velocity matching, which gradually transforms the model into a 1-step/few-step generator.
|
| 42 |
|
| 43 |
+
|
| 44 |
|
| 45 |
+
Key Advantages:
|
| 46 |
+
- **One-model Simplicity.** We eliminate the need for any auxiliary networks. The model learns to rectify its own flow field, acting as the generator, fake/real score. No extra GPU memory is wasted on frozen teachers or discriminators during training.
|
| 47 |
+
- **Scalability on Large Models.** TwinFlow is **easy to scale on 20B full-parameter training** due to the one-model simplicity. In contrast, methods like VSD, SiD, and DMD/DMD2 require maintaining three separate models for distillation, which not only significantly increases memory consumption—often leading OOM, but also introduces substantial complexity when scaling to large-scale training regimes.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
|
| 49 |
+
### Inference Demo
|
| 50 |
|
| 51 |
+
Install the latest diffusers:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 52 |
|
| 53 |
+
```bash
|
| 54 |
+
pip install git+https://github.com/huggingface/diffusers
|
| 55 |
```
|
| 56 |
|
| 57 |
+
Run inference demo `inference.py`:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |
+
```python
|
| 60 |
+
python inference.py
|
| 61 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
| 63 |
## Citation
|
| 64 |
|
|
|
|
|
|
|
| 65 |
```bibtex
|
| 66 |
+
@article{cheng2025twinflow,
|
| 67 |
+
title={TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows},
|
| 68 |
+
author={Cheng, Zhenglin and Sun, Peng and Li, Jianguo and Lin, Tao},
|
| 69 |
+
journal={arXiv preprint arXiv:2512.05150},
|
| 70 |
+
year={2025}
|
|
|
|
|
|
|
|
|
|
| 71 |
}
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
## Acknowledgement
|
| 75 |
+
|
| 76 |
+
TwinFlow is built upon [RCGM](https://github.com/LINs-lab/RCGM) and [UCGM](https://github.com/LINs-lab/UCGM), with much support from [InclusionAI](https://github.com/inclusionAI).
|