
x54-729 commited on
Commit ·
6f4ea21
1
Parent(s): 32b8973
update readme
Browse files
README.md
CHANGED
|
@@ -121,18 +121,23 @@ print(response)
|
|
| 121 |
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
|
| 122 |
|
| 123 |
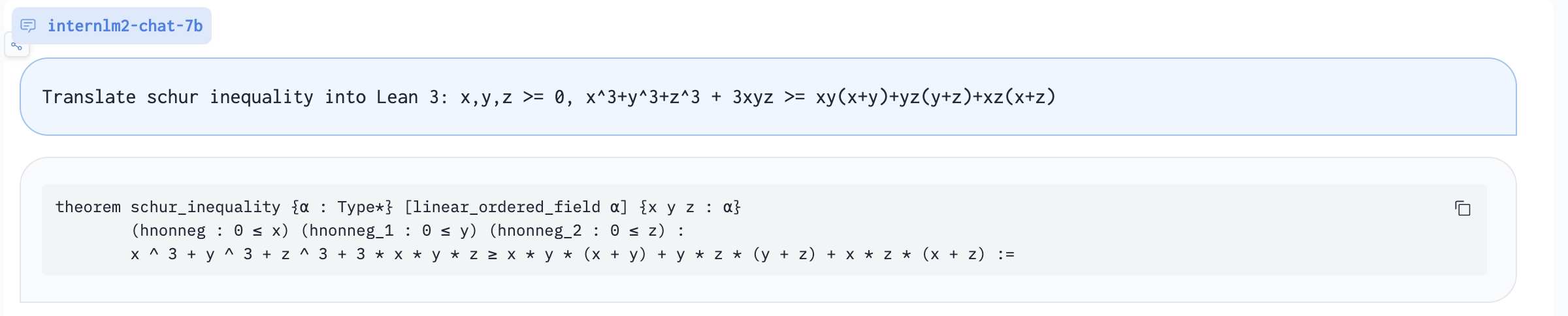
Translate proof problem to Lean:
|
|
|
|
| 124 |
|
| 125 |
|
| 126 |
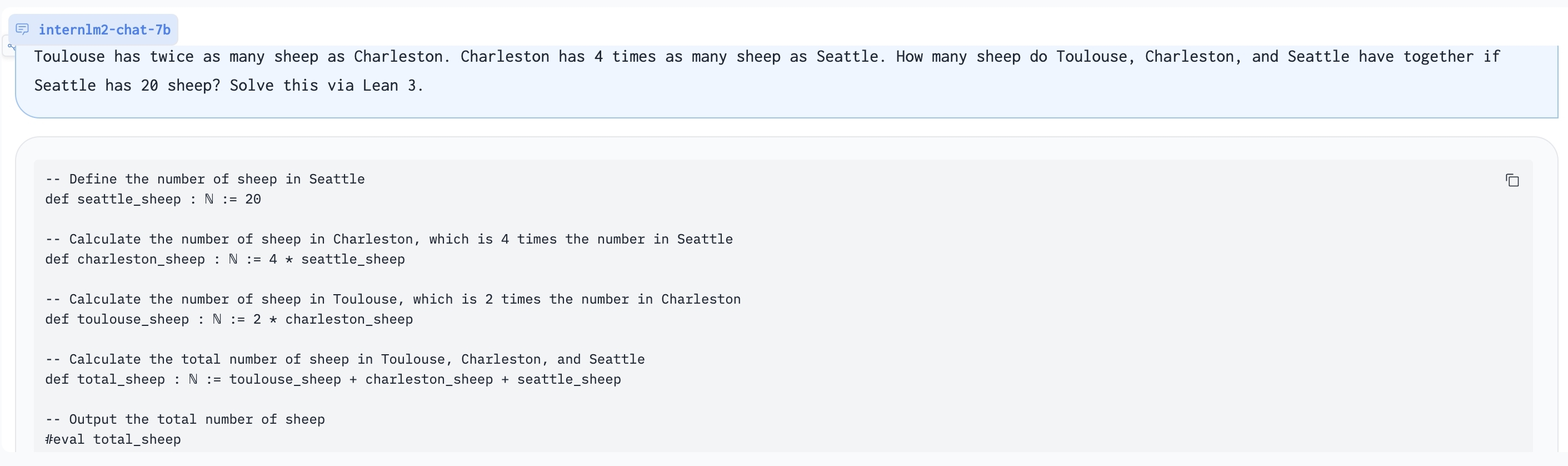
Using Lean 3 to solve GSM8K problem:
|
|
|
|
| 127 |
|
| 128 |
|
| 129 |
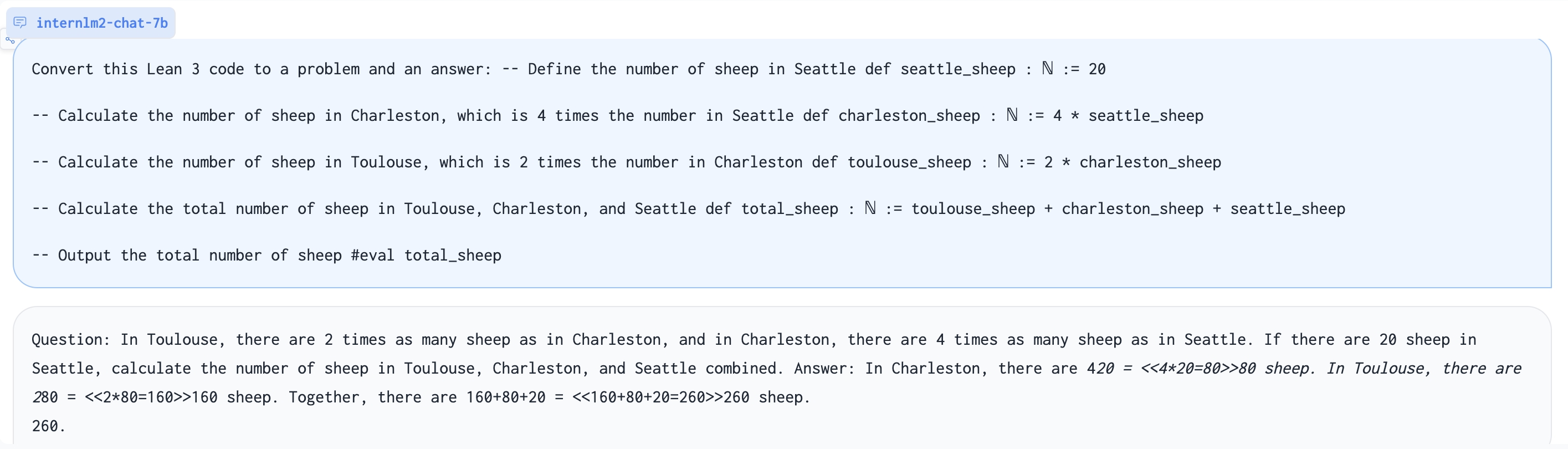
Generate problem based on Lean 3 code:
|
|
|
|
| 130 |
|
| 131 |
|
| 132 |
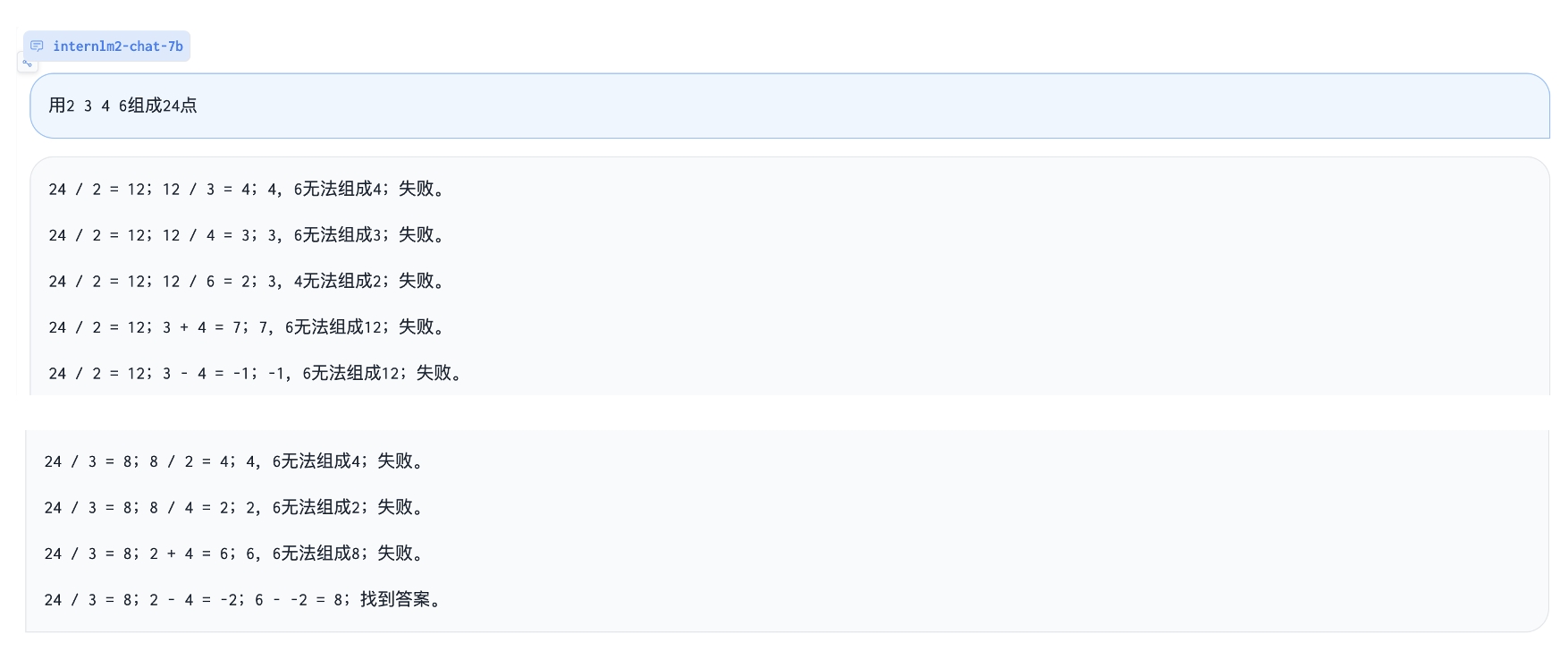
Play 24 point game:
|
|
|
|
| 133 |
|
| 134 |
|
| 135 |
Augment a harder math problem:
|
|
|
|
| 136 |

|
| 137 |
|
| 138 |
| Description | Query |
|
|
|
|
| 121 |
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
|
| 122 |
|
| 123 |
Translate proof problem to Lean:
|
| 124 |
+
|
| 125 |

|
| 126 |
|
| 127 |
Using Lean 3 to solve GSM8K problem:
|
| 128 |
+
|
| 129 |

|
| 130 |
|
| 131 |
Generate problem based on Lean 3 code:
|
| 132 |
+
|
| 133 |

|
| 134 |
|
| 135 |
Play 24 point game:
|
| 136 |
+
|
| 137 |

|
| 138 |
|
| 139 |
Augment a harder math problem:
|
| 140 |
+
|
| 141 |

|
| 142 |
|
| 143 |
| Description | Query |
|