

Update README.md
Browse files
README.md
CHANGED
|
@@ -13,7 +13,7 @@ Welcome to the official project page for **JoyAI-Image**.
|
|
| 13 |
|
| 14 |
## 🐶 JoyAI-Image
|
| 15 |
|
| 16 |
-
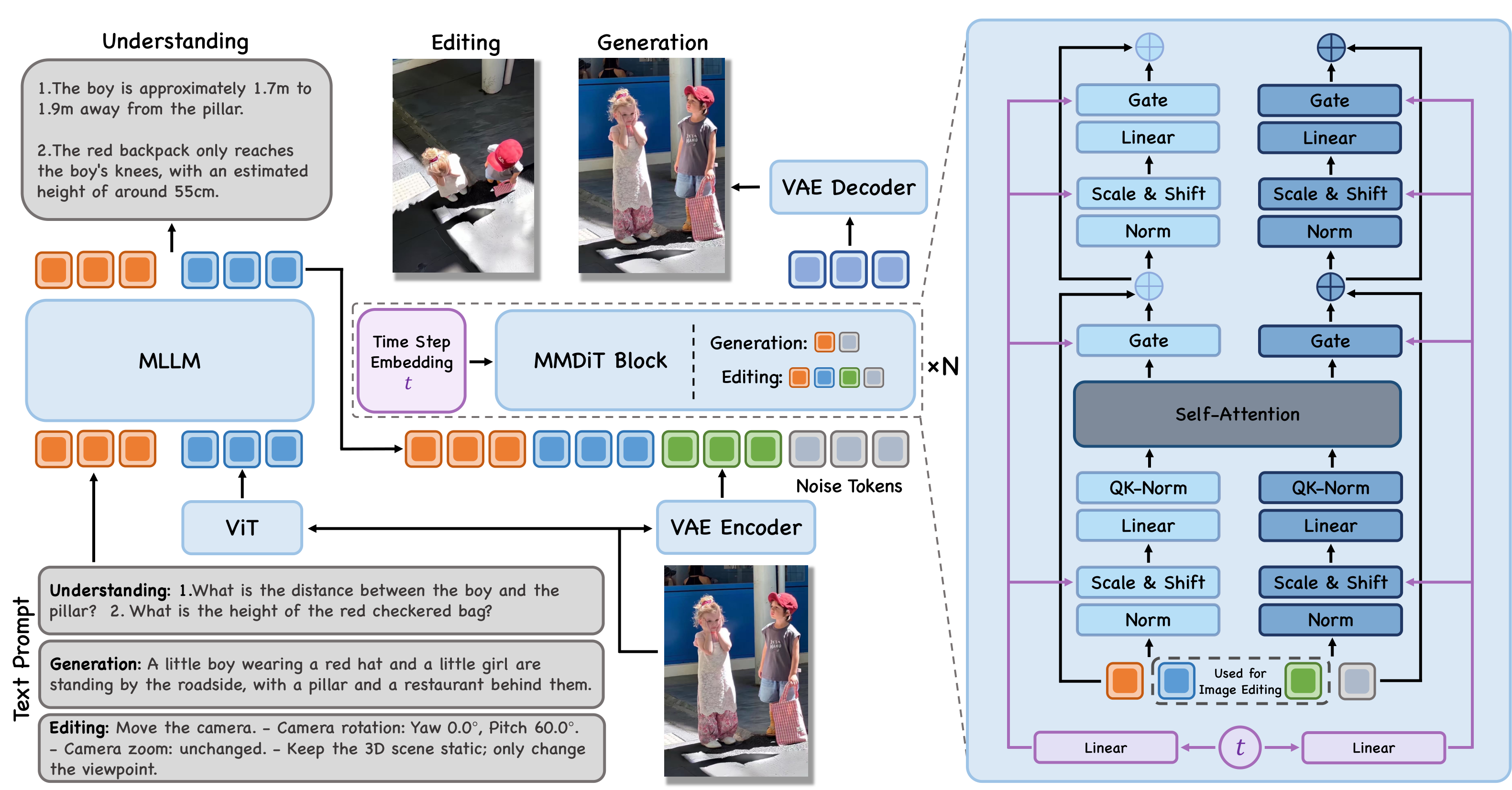
JoyAI-Image is a **unified multimodal foundation model** for image understanding, text-to-image generation, and instruction-guided image editing. It combines an 8B Multimodal Large Language Model (MLLM) with a 16B Multimodal Diffusion Transformer (MMDiT). A central principle of JoyAI-Image is the **closed-loop collaboration between understanding, generation, and editing**. Stronger spatial understanding improves grounded generation and
|
| 17 |
|
| 18 |
|
| 19 |
|
|
@@ -64,19 +64,18 @@ conda create -n joyai python=3.10 -y
|
|
| 64 |
conda activate joyai
|
| 65 |
|
| 66 |
pip install -e .
|
| 67 |
-
```
|
| 68 |
|
| 69 |
> **Note on Flash Attention**: `flash-attn >= 2.8.0` is listed as a dependency for best performance.
|
| 70 |
|
| 71 |
#### Core Dependencies
|
| 72 |
|
| 73 |
-
| Package
|
| 74 |
-
|---------|---------|---------|
|
| 75 |
-
| `torch`
|
| 76 |
-
| `transformers` | >= 4.57.0, < 4.58.0 | Text encoder
|
| 77 |
-
| `diffusers`
|
| 78 |
-
| `flash-attn`
|
| 79 |
-
|
| 80 |
|
| 81 |
### 2. Inference
|
| 82 |
|
|
@@ -108,40 +107,139 @@ python inference.py \
|
|
| 108 |
|
| 109 |
### CLI Reference (`inference.py`)
|
| 110 |
|
| 111 |
-
| Argument
|
| 112 |
-
|----------
|
| 113 |
-
| `--ckpt-root`
|
| 114 |
-
| `--prompt`
|
| 115 |
-
| `--image`
|
| 116 |
-
| `--output`
|
| 117 |
-
| `--steps`
|
| 118 |
-
| `--guidance-scale` | float | 5.0
|
| 119 |
-
| `--seed`
|
| 120 |
-
| `--neg-prompt`
|
| 121 |
-
| `--basesize`
|
| 122 |
-
| `--config`
|
| 123 |
-
| `--rewrite-prompt` | flag
|
| 124 |
-
| `--rewrite-model`
|
| 125 |
-
| `--hsdp-shard-dim` | int
|
| 126 |
|
| 127 |
### CLI Reference (`inference_und.py`)
|
| 128 |
|
| 129 |
-
| Argument
|
| 130 |
-
|----------
|
| 131 |
-
| `--ckpt-root`
|
| 132 |
-
| `--image`
|
| 133 |
-
| `--prompt`
|
| 134 |
-
| `--max-new-tokens` | int
|
| 135 |
-
| `--temperature`
|
| 136 |
-
| `--top-p`
|
| 137 |
-
| `--top-k`
|
| 138 |
-
| `--output`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 140 |
|
| 141 |
## License Agreement
|
| 142 |
|
| 143 |
-
JoyAI-Image is licensed under Apache 2.0.
|
| 144 |
|
| 145 |
## ☎�� We're Hiring!
|
| 146 |
-
We are actively hiring Research Scientists, Engineers, and Interns to join us in building next-generation generative foundation models and bringing them into real-world applications. If you’re interested, please send your resume to: huanghaoyang.ocean@jd.com
|
| 147 |
|
|
|
|
|
|
| 13 |
|
| 14 |
## 🐶 JoyAI-Image
|
| 15 |
|
| 16 |
+
JoyAI-Image is a **unified multimodal foundation model** for image understanding, text-to-image generation, and instruction-guided image editing. It combines an 8B Multimodal Large Language Model (MLLM) with a 16B Multimodal Diffusion Transformer (MMDiT). A central principle of JoyAI-Image is the **closed-loop collaboration between understanding, generation, and editing**. Stronger spatial understanding improves grounded generation and controllable editing through better scene parsing, relational grounding, and instruction decomposition, while generative transformations such as viewpoint changes provide complementary evidence for spatial reasoning.
|
| 17 |
|
| 18 |

|
| 19 |
|
|
|
|
| 64 |
conda activate joyai
|
| 65 |
|
| 66 |
pip install -e .
|
| 67 |
+
````
|
| 68 |
|
| 69 |
> **Note on Flash Attention**: `flash-attn >= 2.8.0` is listed as a dependency for best performance.
|
| 70 |
|
| 71 |
#### Core Dependencies
|
| 72 |
|
| 73 |
+
| Package | Version | Purpose |
|
| 74 |
+
| -------------- | ------------------- | --------------------- |
|
| 75 |
+
| `torch` | >= 2.8 | PyTorch |
|
| 76 |
+
| `transformers` | >= 4.57.0, < 4.58.0 | Text encoder |
|
| 77 |
+
| `diffusers` | >= 0.34.0 | Pipeline utilities |
|
| 78 |
+
| `flash-attn` | >= 2.8.0 | Fast attention kernel |
|
|
|
|
| 79 |
|
| 80 |
### 2. Inference
|
| 81 |
|
|
|
|
| 107 |
|
| 108 |
### CLI Reference (`inference.py`)
|
| 109 |
|
| 110 |
+
| Argument | Type | Default | Description |
|
| 111 |
+
| ------------------ | ----- | ------------- | ------------------------------------------------------------ |
|
| 112 |
+
| `--ckpt-root` | str | *required* | Checkpoint root |
|
| 113 |
+
| `--prompt` | str | *required* | Edit instruction or T2I prompt |
|
| 114 |
+
| `--image` | str | None | Input image path (required for editing, omit for T2I) |
|
| 115 |
+
| `--output` | str | `example.png` | Output image path |
|
| 116 |
+
| `--steps` | int | 50 | Denoising steps |
|
| 117 |
+
| `--guidance-scale` | float | 5.0 | Classifier-free guidance scale |
|
| 118 |
+
| `--seed` | int | 42 | Random seed for reproducibility |
|
| 119 |
+
| `--neg-prompt` | str | `""` | Negative prompt |
|
| 120 |
+
| `--basesize` | int | 1024 | Bucket base size for input image resizing (256/512/768/1024) |
|
| 121 |
+
| `--config` | str | auto | Config path; defaults to `<ckpt-root>/infer_config.py` |
|
| 122 |
+
| `--rewrite-prompt` | flag | off | Enable LLM-based prompt rewriting |
|
| 123 |
+
| `--rewrite-model` | str | `gpt-5` | Model name for prompt rewriting |
|
| 124 |
+
| `--hsdp-shard-dim` | int | 1 | FSDP shard dimension for multi-GPU (set to GPU count) |
|
| 125 |
|
| 126 |
### CLI Reference (`inference_und.py`)
|
| 127 |
|
| 128 |
+
| Argument | Type | Default | Description |
|
| 129 |
+
| ------------------ | ----- | ---------------------------------- | ------------------------------------------------------------------------ |
|
| 130 |
+
| `--ckpt-root` | str | *required* | Checkpoint root containing `text_encoder/` |
|
| 131 |
+
| `--image` | str | *required* | Input image path, or comma-separated paths for multiple images |
|
| 132 |
+
| `--prompt` | str | `"Describe this image in detail."` | User question or instruction. When omitted, defaults to image captioning |
|
| 133 |
+
| `--max-new-tokens` | int | 2048 | Maximum number of tokens to generate |
|
| 134 |
+
| `--temperature` | float | 0.7 | Sampling temperature. Use `0` for greedy decoding |
|
| 135 |
+
| `--top-p` | float | 0.8 | Top-p (nucleus) sampling threshold |
|
| 136 |
+
| `--top-k` | int | 50 | Top-k sampling threshold |
|
| 137 |
+
| `--output` | str | None | Optional output file to save the response text |
|
| 138 |
+
|
| 139 |
+
### Spatial Editing Reference
|
| 140 |
+
|
| 141 |
+
JoyAI-Image supports three spatial editing prompt patterns: **Object Move**, **Object Rotation**, and **Camera Control**. For the most stable behavior, we recommend following the prompt templates below as closely as possible.
|
| 142 |
+
|
| 143 |
+
#### 1. Object Move
|
| 144 |
+
|
| 145 |
+
Use this pattern when you want to move a target object into a specified region.
|
| 146 |
+
|
| 147 |
+
**Prompt template:**
|
| 148 |
+
|
| 149 |
+
```text
|
| 150 |
+
Move the <object> into the red box and finally remove the red box.
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
**Rules:**
|
| 154 |
+
|
| 155 |
+
* Replace `<object>` with a clear description of the target object to be moved.
|
| 156 |
+
* The **red box** indicates the target destination in the image.
|
| 157 |
+
* The phrase **"finally remove the red box"** means the guidance box should not appear in the final edited result.
|
| 158 |
+
|
| 159 |
+
**Example:**
|
| 160 |
+
|
| 161 |
+
```text
|
| 162 |
+
Move the apple into the red box and finally remove the red box.
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
#### 2. Object Rotation
|
| 166 |
+
|
| 167 |
+
Use this pattern when you want to rotate an object to a specific canonical view.
|
| 168 |
+
|
| 169 |
+
**Prompt template:**
|
| 170 |
+
|
| 171 |
+
```text
|
| 172 |
+
Rotate the <object> to show the <view> side view.
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
**Supported `<view>` values:**
|
| 176 |
+
|
| 177 |
+
* `front`
|
| 178 |
+
* `right`
|
| 179 |
+
* `left`
|
| 180 |
+
* `rear`
|
| 181 |
+
* `front right`
|
| 182 |
+
* `front left`
|
| 183 |
+
* `rear right`
|
| 184 |
+
* `rear left`
|
| 185 |
+
|
| 186 |
+
**Rules:**
|
| 187 |
+
|
| 188 |
+
* Replace `<object>` with a clear description of the object to rotate.
|
| 189 |
+
* Replace `<view>` with one of the supported directions above.
|
| 190 |
+
* This instruction is intended to change the **object orientation**, while keeping the object identity and surrounding scene as consistent as possible.
|
| 191 |
+
|
| 192 |
+
**Examples:**
|
| 193 |
+
|
| 194 |
+
```text
|
| 195 |
+
Rotate the chair to show the front side view.
|
| 196 |
+
Rotate the car to show the rear left side view.
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
#### 3. Camera Control
|
| 200 |
+
|
| 201 |
+
Use this pattern when you want to change only the camera viewpoint while keeping the 3D scene itself unchanged.
|
| 202 |
+
|
| 203 |
+
**Prompt template:**
|
| 204 |
|
| 205 |
+
```text
|
| 206 |
+
Move the camera.
|
| 207 |
+
- Camera rotation: Yaw {y_rotation}°, Pitch {p_rotation}°.
|
| 208 |
+
- Camera zoom: in/out/unchanged.
|
| 209 |
+
- Keep the 3D scene static; only change the viewpoint.
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
**Rules:**
|
| 213 |
+
|
| 214 |
+
* `{y_rotation}` specifies the yaw rotation angle in degrees.
|
| 215 |
+
* `{p_rotation}` specifies the pitch rotation angle in degrees.
|
| 216 |
+
* `Camera zoom` must be one of:
|
| 217 |
+
|
| 218 |
+
* `in`
|
| 219 |
+
* `out`
|
| 220 |
+
* `unchanged`
|
| 221 |
+
* The last line is important: it explicitly tells the model to preserve the 3D scene content and geometry, and only adjust the camera viewpoint.
|
| 222 |
+
|
| 223 |
+
**Examples:**
|
| 224 |
+
|
| 225 |
+
```text
|
| 226 |
+
Move the camera.
|
| 227 |
+
- Camera rotation: Yaw 45°, Pitch 0°.
|
| 228 |
+
- Camera zoom: in.
|
| 229 |
+
- Keep the 3D scene static; only change the viewpoint.
|
| 230 |
+
```
|
| 231 |
+
|
| 232 |
+
```text
|
| 233 |
+
Move the camera.
|
| 234 |
+
- Camera rotation: Yaw -90°, Pitch 20°.
|
| 235 |
+
- Camera zoom: unchanged.
|
| 236 |
+
- Keep the 3D scene static; only change the viewpoint.
|
| 237 |
+
```
|
| 238 |
|
| 239 |
## License Agreement
|
| 240 |
|
| 241 |
+
JoyAI-Image is licensed under Apache 2.0.
|
| 242 |
|
| 243 |
## ☎�� We're Hiring!
|
|
|
|
| 244 |
|
| 245 |
+
We are actively hiring Research Scientists, Engineers, and Interns to join us in building next-generation generative foundation models and bringing them into real-world applications. If you’re interested, please send your resume to: [huanghaoyang.ocean@jd.com](mailto:huanghaoyang.ocean@jd.com)
|