

Update README.md
Browse files
README.md
CHANGED
|
@@ -27,7 +27,7 @@ license: apache-2.0
|
|
| 27 |
DocExplainer is a an approach to Document Visual Question Answering (Document VQA) with bounding box localization.
|
| 28 |
Unlike standard VLMs that only provide text-based answers, DocExplainer adds **visual evidence through bounding boxes**, making model predictions more interpretable.
|
| 29 |
It is designed as a **plug-and-play module** to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
|
| 30 |
-
|
| 31 |
- **Authors:** Alessio Chen, Simone Giovannini, Andrea Gemelli, Fabio Coppini, Simone Marinai
|
| 32 |
- **Affiliations:** [Letxbe AI](https://letxbe.ai/), [University of Florence](https://www.unifi.it/it)
|
| 33 |
- **License:** CC-BY-4.0
|
|
@@ -41,21 +41,21 @@ It is designed as a **plug-and-play module** to be combined with existing Vision
|
|
| 41 |
|
| 42 |
## Model Details
|
| 43 |
|
| 44 |
-
DocExplainer is a fine-tuned
|
| 45 |
|
| 46 |
-
1. **Question Answering**: Any VLM
|
| 47 |
2. **Bounding Box Explanation**: DocExplainer takes the image, question, and generated answer to predict the coordinates of the supporting evidence.
|
| 48 |
|
| 49 |
|
| 50 |
## Model Architecture
|
| 51 |
-
DocExplainer builds on [SigLIP2](https://huggingface.co/google/siglip2-giant-opt-patch16-384) visual and text embeddings.
|
| 52 |
|
| 53 |
-
![https://i.postimg.cc/
|
| 54 |
|
| 55 |
## Training Procedure
|
| 56 |
- Visual and textual embeddings from SigLiP2 are projected into a shared latent space, fused via fully connected layers.
|
| 57 |
- A regression head outputs normalized coordinates `[x1, y1, x2, y2]`.
|
| 58 |
-
- **Backbone**: SigLiP2 (frozen).
|
| 59 |
- **Loss Function**: Smooth L1 (Huber loss) applied to normalized coordinates in [0,1].
|
| 60 |
|
| 61 |
#### Training Setup
|
|
|
|
| 27 |
DocExplainer is a an approach to Document Visual Question Answering (Document VQA) with bounding box localization.
|
| 28 |
Unlike standard VLMs that only provide text-based answers, DocExplainer adds **visual evidence through bounding boxes**, making model predictions more interpretable.
|
| 29 |
It is designed as a **plug-and-play module** to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
|
| 30 |
+
|
| 31 |
- **Authors:** Alessio Chen, Simone Giovannini, Andrea Gemelli, Fabio Coppini, Simone Marinai
|
| 32 |
- **Affiliations:** [Letxbe AI](https://letxbe.ai/), [University of Florence](https://www.unifi.it/it)
|
| 33 |
- **License:** CC-BY-4.0
|
|
|
|
| 41 |
|
| 42 |
## Model Details
|
| 43 |
|
| 44 |
+
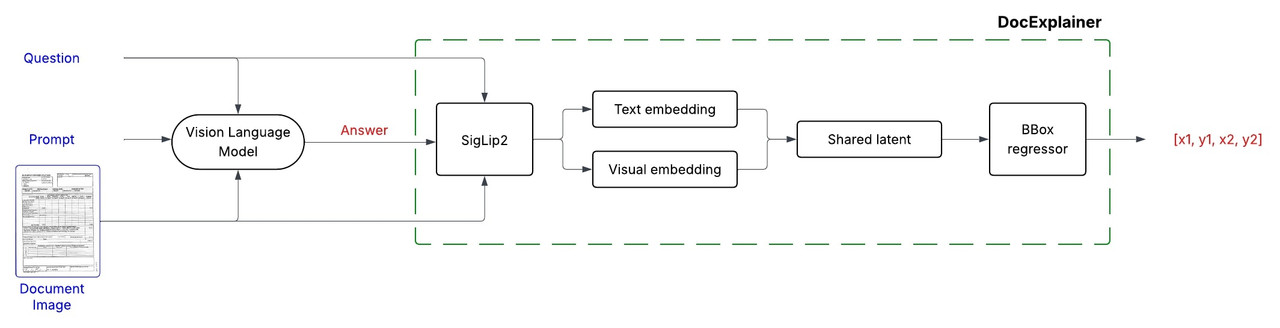
DocExplainer is a fine-tuned [SigLIP2 Giant](https://huggingface.co/google/siglip2-giant-opt-patch16-384)-based regressor that predicts bounding box coordinates for answer localization in document images. The system operates in a two-stage process:
|
| 45 |
|
| 46 |
+
1. **Question Answering**: Any VLM is used as a black box component to generate a textual answer given in input a document image and question.
|
| 47 |
2. **Bounding Box Explanation**: DocExplainer takes the image, question, and generated answer to predict the coordinates of the supporting evidence.
|
| 48 |
|
| 49 |
|
| 50 |
## Model Architecture
|
| 51 |
+
DocExplainer builds on [SigLIP2 Giant](https://huggingface.co/google/siglip2-giant-opt-patch16-384) visual and text embeddings.
|
| 52 |
|
| 53 |
+
|
| 54 |
|
| 55 |
## Training Procedure
|
| 56 |
- Visual and textual embeddings from SigLiP2 are projected into a shared latent space, fused via fully connected layers.
|
| 57 |
- A regression head outputs normalized coordinates `[x1, y1, x2, y2]`.
|
| 58 |
+
- **Backbone**: SigLiP2 Giant (frozen).
|
| 59 |
- **Loss Function**: Smooth L1 (Huber loss) applied to normalized coordinates in [0,1].
|
| 60 |
|
| 61 |
#### Training Setup
|