

Update README.md
Browse files
README.md
CHANGED
|
@@ -3,9 +3,151 @@ datasets:
|
|
| 3 |
- letxbe/BoundingDocs
|
| 4 |
language:
|
| 5 |
- en
|
| 6 |
-
pipeline_tag: question-answering
|
| 7 |
tags:
|
| 8 |
- Visual-Question-Answering
|
| 9 |
- Question-Answering
|
| 10 |
- Document
|
| 11 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
- letxbe/BoundingDocs
|
| 4 |
language:
|
| 5 |
- en
|
| 6 |
+
pipeline_tag: visual-question-answering
|
| 7 |
tags:
|
| 8 |
- Visual-Question-Answering
|
| 9 |
- Question-Answering
|
| 10 |
- Document
|
| 11 |
+
license: apache-2.0
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
<div align="center">
|
| 16 |
+
|
| 17 |
+
<h1>DocExplainerV0: Visual Document QA with Bounding Box Localization</h1>
|
| 18 |
+
|
| 19 |
+
[](https://creativecommons.org/licenses/by/4.0/)
|
| 20 |
+
[]()
|
| 21 |
+
[](https://huggingface.co/letxbe/DocExplainerV0)
|
| 22 |
+
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
## Model description
|
| 26 |
+
|
| 27 |
+
DocExplainerV0 is a **first-step approach** to Visual Document Question Answering (VQA) with bounding box localization.
|
| 28 |
+
Unlike standard VLMs that only provide text-based answers, DocExplainerV0 adds **visual evidence through bounding boxes**, making model predictions more interpretable.
|
| 29 |
+
It is designed as a **plug-and-play module** to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
|
| 30 |
+
|
| 31 |
+
⚠️ **Important Note**:
|
| 32 |
+
This model is **not intended as a final solution**, but rather as a **baseline framework and proof of concept**. Its purpose is to highlight the gap between textual accuracy and spatial grounding in current VLMs, and to serve as a foundation for future research on interpretable document understanding.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
- **Authors:** Alessio Chen, Simone Giovannini, Andrea Gemelli, Fabio Coppini, Simone Marinai
|
| 36 |
+
- **Affiliations:** [Letxbe AI](https://letxbe.ai/), [University of Florence](https://www.unifi.it/it)
|
| 37 |
+
- **License:** CC-BY-4.0
|
| 38 |
+
- **Paper:** ["Towards Reliable and Interpretable Document Question Answering via VLMs"](https://arxiv.org/abs/2501.03403) by Alessio Chen et al.
|
| 39 |
+
|
| 40 |
+
<div align="center">
|
| 41 |
+
<img src="https://cdn.prod.website-files.com/655f447668b4ad1dd3d4b3d9/664cc272c3e176608bc14a4c_LOGO%20v0%20-%20LetXBebicolore.svg" alt="letxbe ai logo" width="200">
|
| 42 |
+
<img src="https://www.dinfo.unifi.it/upload/notizie/Logo_Dinfo_web%20(1).png" alt="Logo Unifi" width="200">
|
| 43 |
+
</div>
|
| 44 |
+
---
|
| 45 |
+
|
| 46 |
+
## Model Details
|
| 47 |
+
|
| 48 |
+
DocExplainerV0 is a fine-tuned SigLIP-based regressor that predicts bounding box coordinates for answer localization in document images. The system operates in a two-stage process:
|
| 49 |
+
|
| 50 |
+
1. **Question Answering**: Any VLM processes the document image and question to generate a textual answer.
|
| 51 |
+
2. **Bounding Box Explanation**: DocExplainerV0 takes the image, question, and generated answer to predict the coordinates of the supporting evidence.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
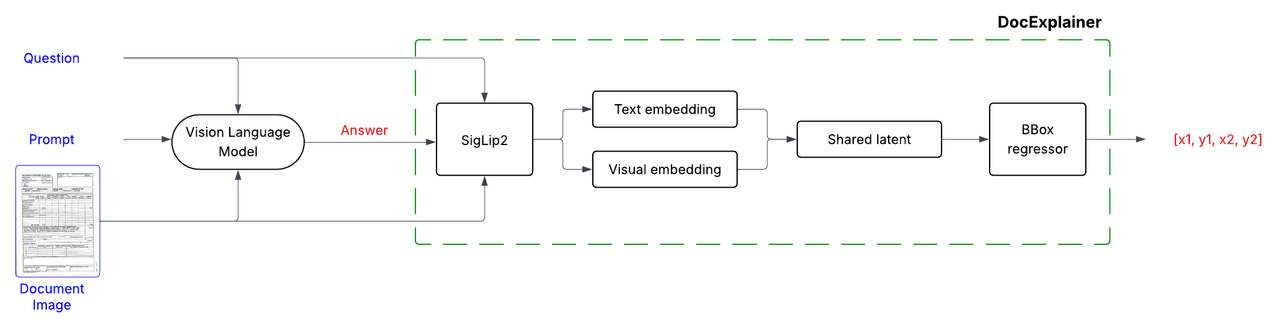
## Model Architecture
|
| 55 |
+
DocExplainerV0 builds on [SigLIP2](https://huggingface.co/google/siglip2-giant-opt-patch16-384) visual and text embeddings.
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Training Procedure
|
| 60 |
+
- Visual and textual embeddings from SigLiP2 are projected into a shared latent space, fused via fully connected layers.
|
| 61 |
+
- A regression head outputs normalized coordinates `[x1, y1, x2, y2]`.
|
| 62 |
+
- **Backbone**: SigLiP2 (frozen).
|
| 63 |
+
- **Loss Function**: Smooth L1 (Huber loss) applied to normalized coordinates in [0,1].
|
| 64 |
+
|
| 65 |
+
#### Training Setup
|
| 66 |
+
- **Dataset**: [BoundingDocs v2.0](https://huggingface.co/datasets/letxbe/BoundingDocs)
|
| 67 |
+
- **Epochs**: 20
|
| 68 |
+
- **Optimizer**: AdamW (default settings)
|
| 69 |
+
- **Hardware**: 1 × NVIDIA L40S-1-48G GPU
|
| 70 |
+
- **Model Selection**: Best checkpoint chosen by highest mean IoU on the validation split.
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## Quick Start
|
| 75 |
+
|
| 76 |
+
Here is a simple example of how to use `DocExplainer` to get an answer and its corresponding bounding box from a document image.
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
from PIL import Image
|
| 80 |
+
import requests
|
| 81 |
+
from transformers import AutoModel
|
| 82 |
+
|
| 83 |
+
# Load example document image
|
| 84 |
+
url = "https://datasets-server.huggingface.co/cached-assets/letxbe/BoundingDocs/--/47db6d2b6af0aadfd082591a8445d0f47c3b8d61/--/default/test/7/doc_images/image-1d100e9.jpg"
|
| 85 |
+
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
|
| 86 |
+
question = "What is the invoice number?"
|
| 87 |
+
answer = "3Y8M2d-846" # generate it with any VLM
|
| 88 |
+
|
| 89 |
+
explainer = AutoModel.from_pretrained("letxbe/DocExplainerv0", trust_remote_code=True)
|
| 90 |
+
bbox = explainer.predict(image, answer)
|
| 91 |
+
print(f"Bounding box: {bbox}") # [x1, y1, x2, y2]
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
<table>
|
| 96 |
+
<tr>
|
| 97 |
+
<td width="50%" valign="top">
|
| 98 |
+
Example Output:
|
| 99 |
+
|
| 100 |
+
**Question**: What is the invoice number? <br>
|
| 101 |
+
**Answer**: 3Y8M2d-846<br><br>
|
| 102 |
+
**Predicted BBox**: [0.6353235244750977, 0.03685223311185837, 0.8617828488349915, 0.058749228715896606] <br>
|
| 103 |
+
</td>
|
| 104 |
+
<td width="50%" valign="top">
|
| 105 |
+
Visualized Answer Location:
|
| 106 |
+
<img src="https://i.postimg.cc/0NmBM0b1/invoice-explained.png" alt="Invoice with predicted bounding box" width="100%">
|
| 107 |
+
</td>
|
| 108 |
+
</tr>
|
| 109 |
+
</table>
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
## Performance
|
| 115 |
+
Evaluated on [BoundingDocs v2.0](https://huggingface.co/datasets/letxbe/BoundingDocs) dataset:
|
| 116 |
+
### Full DocExplainer Pipeline
|
| 117 |
+
|
| 118 |
+
| VLM Model | ANLS ↑| IoU ↑ |
|
| 119 |
+
| --------------- | ----- | ----- |
|
| 120 |
+
| SmolVLM2-2.2b | 0.572 | 0.175 |
|
| 121 |
+
| qwen2.5-vl-7b | 0.689 | 0.188 |
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
### VLM-only Baseline (for comparison)
|
| 125 |
+
| VLM Model | ANLS ↑| IoU ↑ |
|
| 126 |
+
| --------------- | ----- | ----- |
|
| 127 |
+
| SmolVLM2-2.2b | 0.561 | 0.011 |
|
| 128 |
+
| qwen2.5-vl-7b | 0.720 | 0.038 |
|
| 129 |
+
| Claude Sonnet 4 | 0.737 | 0.031 |
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
## Limitations
|
| 137 |
+
- **Prototype only**: Intended as a first approach, not a production-ready solution.
|
| 138 |
+
- **Dataset constraints**: Current evaluation is limited to cases where an answer fits in a single bounding box. Answers requiring reasoning over multiple regions or not fully captured by OCR cannot be properly evaluated.
|
| 139 |
+
|
| 140 |
+
## Citation
|
| 141 |
+
If you use this model in your research, please cite:
|
| 142 |
+
```
|
| 143 |
+
bibtex@misc{docexplainer2024,
|
| 144 |
+
title={DocExplainer: Visual Document QA with Bounding Box Localization},
|
| 145 |
+
author={[Your Name]},
|
| 146 |
+
year={2024},
|
| 147 |
+
url={}
|
| 148 |
+
}
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
|