

Update README.md
Browse files
README.md
CHANGED
|
@@ -14,18 +14,18 @@ license: apache-2.0
|
|
| 14 |
|
| 15 |
<div align="center">
|
| 16 |
|
| 17 |
-
<h1>
|
| 18 |
|
| 19 |
[](https://creativecommons.org/licenses/by/4.0/)
|
| 20 |
<!-- []() -->
|
| 21 |
-
[](https://huggingface.co/letxbe/
|
| 22 |
|
| 23 |
</div>
|
| 24 |
|
| 25 |
## Model description
|
| 26 |
|
| 27 |
-
|
| 28 |
-
Unlike standard VLMs that only provide text-based answers,
|
| 29 |
It is designed as a **plug-and-play module** to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
|
| 30 |
|
| 31 |
⚠️ **Important Note**:
|
|
@@ -45,14 +45,14 @@ This model is **not intended as a final solution**, but rather as a **baseline f
|
|
| 45 |
|
| 46 |
## Model Details
|
| 47 |
|
| 48 |
-
|
| 49 |
|
| 50 |
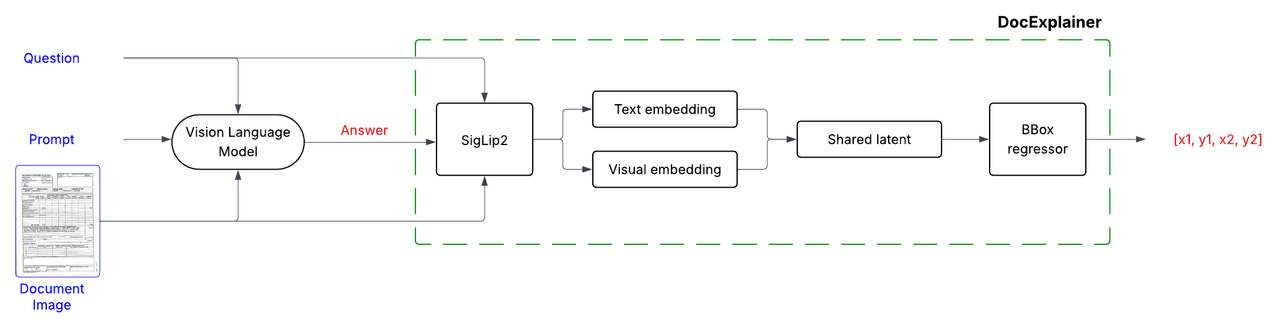
1. **Question Answering**: Any VLM processes the document image and question to generate a textual answer.
|
| 51 |
-
2. **Bounding Box Explanation**:
|
| 52 |
|
| 53 |
|
| 54 |
## Model Architecture
|
| 55 |
-
|
| 56 |
|
| 57 |
|
| 58 |
|
|
@@ -140,9 +140,9 @@ answer = json.loads(decoded_output)['content']
|
|
| 140 |
print(f"Answer: {answer}")
|
| 141 |
|
| 142 |
# -----------------------
|
| 143 |
-
# 2. Load
|
| 144 |
# -----------------------
|
| 145 |
-
explainer = AutoModel.from_pretrained("letxbe/
|
| 146 |
bbox = explainer.predict(image, answer)
|
| 147 |
print(f"Predicted bounding box (normalized): {bbox}")
|
| 148 |
```
|
|
|
|
| 14 |
|
| 15 |
<div align="center">
|
| 16 |
|
| 17 |
+
<h1>DocExplainer: Visual Document QA with Bounding Box Localization</h1>
|
| 18 |
|
| 19 |
[](https://creativecommons.org/licenses/by/4.0/)
|
| 20 |
<!-- []() -->
|
| 21 |
+
[](https://huggingface.co/letxbe/DocExplainer)
|
| 22 |
|
| 23 |
</div>
|
| 24 |
|
| 25 |
## Model description
|
| 26 |
|
| 27 |
+
DocExplainer is a **first-step approach** to Visual Document Question Answering with bounding box localization.
|
| 28 |
+
Unlike standard VLMs that only provide text-based answers, DocExplainer adds **visual evidence through bounding boxes**, making model predictions more interpretable.
|
| 29 |
It is designed as a **plug-and-play module** to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
|
| 30 |
|
| 31 |
⚠️ **Important Note**:
|
|
|
|
| 45 |
|
| 46 |
## Model Details
|
| 47 |
|
| 48 |
+
DocExplainer is a fine-tuned SigLIP-based regressor that predicts bounding box coordinates for answer localization in document images. The system operates in a two-stage process:
|
| 49 |
|
| 50 |
1. **Question Answering**: Any VLM processes the document image and question to generate a textual answer.
|
| 51 |
+
2. **Bounding Box Explanation**: DocExplainer takes the image, question, and generated answer to predict the coordinates of the supporting evidence.
|
| 52 |
|
| 53 |
|
| 54 |
## Model Architecture
|
| 55 |
+
DocExplainer builds on [SigLIP2](https://huggingface.co/google/siglip2-giant-opt-patch16-384) visual and text embeddings.
|
| 56 |
|
| 57 |

|
| 58 |
|
|
|
|
| 140 |
print(f"Answer: {answer}")
|
| 141 |
|
| 142 |
# -----------------------
|
| 143 |
+
# 2. Load DocExplainer for bounding box prediction
|
| 144 |
# -----------------------
|
| 145 |
+
explainer = AutoModel.from_pretrained("letxbe/DocExplainer", trust_remote_code=True)
|
| 146 |
bbox = explainer.predict(image, answer)
|
| 147 |
print(f"Predicted bounding box (normalized): {bbox}")
|
| 148 |
```
|