---
license: mit
pipeline_tag: image-to-3d
tags:
- 3d
- gaussian-splatting
- voxel-aligned
- novel-view-synthesis
datasets:
- lhmd/re10k_torch
- lhmd/acid_torch
---
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
Weijie Wang*
·
Yeqing Chen*
·
Zeyu Zhang
·
Hengyu Liu
·
Haoxiao Wang
·
Zhiyuan Feng
·
Wenkang Qin
·
Feng Chen
·
Zheng Zhu
·
Donny Y. Chen
·
Bohan Zhuang
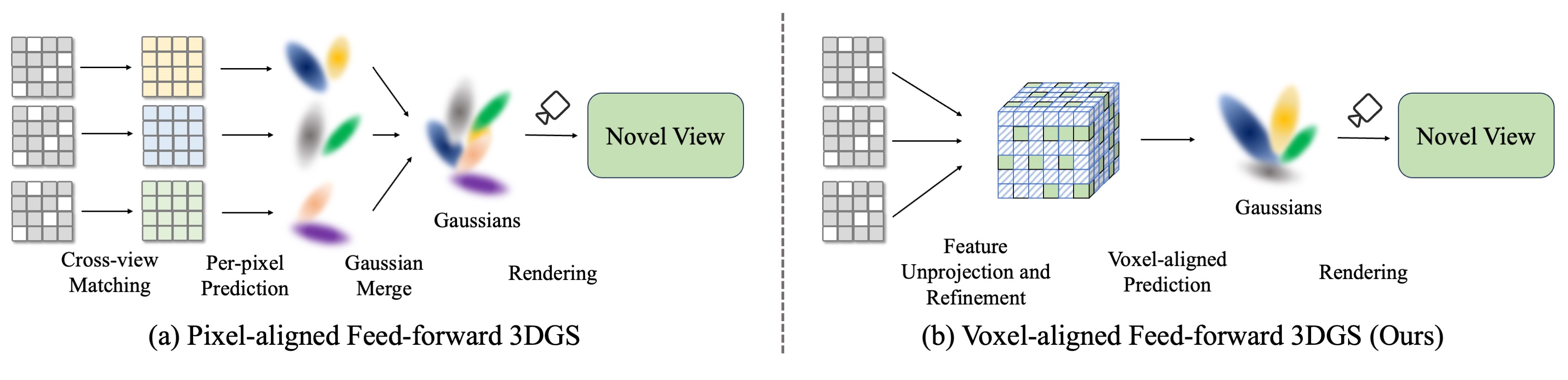
Pixel-aligned feed-forward 3DGS methods suffer from two primary limitations: 1) 2D feature matching struggles to effectively resolve the multi-view alignment problem, and 2) the Gaussian density is constrained and cannot be adaptively controlled according to scene complexity. We propose VolSplat, a method that directly regresses Gaussians from 3D features based on a voxel-aligned prediction strategy. This approach achieves adaptive control over scene complexity and resolves the multi-view alignment challenge.
## Updates
- **2026-03-11 Update:** Since the dataset links of RE10K and ACID are frequently broken, we provide preprocessed data on HuggingFace ([RE10K](https://huggingface.co/datasets/lhmd/re10k_torch) and [ACID](https://huggingface.co/datasets/lhmd/acid_torch)).
- **2025-12-21 Update:** Release our training/evaluation code and model checkpoints. We are working on a more powerful version of VolSplat. Stay tuned!
- **2025-09-23 Update:** Release our paper on arXiv.
## Method
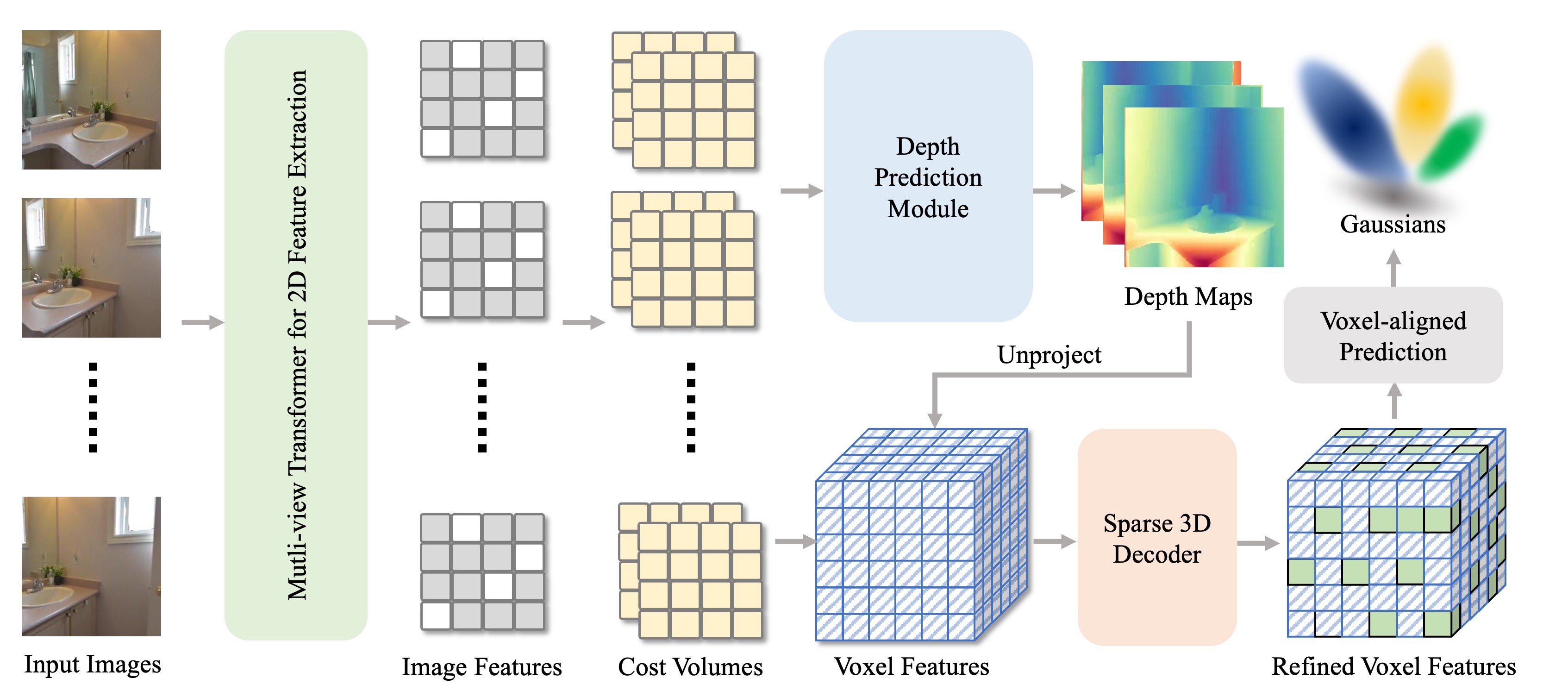
Overview of VolSplat. Given multi-view images as input, we first extract 2D features for each image using a Transformer-based network and construct per-view cost volumes with plane sweeping. Depth Prediction Module then estimates a depth map for each view, which is used to unproject the 2D features into 3D space to form a voxel feature grid. Subsequently, we employ a sparse 3D decoder to refine these features in 3D space and predict the parameters of a 3D Gaussian for each occupied voxel. Finally, novel views are rendered from the predicted 3D Gaussians.
## Installation
Our code is developed and tested with **PyTorch 2.4.0**, **CUDA 12.1**, and **Python 3.10**.
```bash
conda create -n volsplat python=3.10
conda activate volsplat
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 xformers==0.0.27.post2 --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
# Install MinkowskiEngine
# For easier installation, we made some modifications based on https://github.com/Julie-tang00/Common-envs-issues/blob/main/Cuda12-MinkowskiEngine and included it directly in our project.
conda install -c conda-forge openblas
pip install ninja
cd MinkowskiEngine
python setup.py install
cd ..
```
## Model Zoo
Our pre-trained models and baseline models are hosted on [Hugging Face](https://huggingface.co/lhmd/VolSplat). Please download the required models to the `./models `directory. To facilitate reproduction and comparison, we also provide pretrained weights from the baseline methods trained using same input views.
| Model | Download |
| --------------------------------- | ------------------------------------------------------------ |
| volsplat-re10k-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/volsplat-re10k-256x256.ckpt) |
| pixelsplat-re10k-baseline-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/pixelsplat-re10k-baseline-256x256.ckpt) |
| mvsplat-re10k-baseline-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/mvsplat-re10k-baseline-256x256.ckpt) |
| transplat-re10k-baseline-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/transplat-re10k-baseline-256x256.ckpt) |
| depthsplat-re10k-baseline-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/depthsplat-re10k-baseline-256x256.ckpt) |
| ggn-re10k-baseline-256x256 | [download](https://huggingface.co/lhmd/VolSplat/resolve/main/ggn-re10k-baseline-256x256.ckpt) |
## Datasets
### RealEstate10K / ACID
Please refer to [ZPressor](https://github.com/ziplab/ZPressor?tab=readme-ov-file#datasets) for dataset format and preprocessed versions of the datasets.
We also provide preprocessed data on HuggingFace ([RE10K](https://huggingface.co/datasets/lhmd/re10k_torch) and [ACID](https://huggingface.co/datasets/lhmd/acid_torch)).
### Scannet
For Scannet, we follow [FreeSplat](https://github.com/wangys16/FreeSplat) to train and evaluate on the 256x256 resolution.
## Training
### Preparation
Before training, you need to download the pre-trained [UniMatch](https://github.com/autonomousvision/unimatch) and [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2) weights
```
wget https://s3.eu-central-1.amazonaws.com/avg-projects/unimatch/pretrained/gmflow-scale1-things-e9887eda.pth -P pretrained
wget https://huggingface.co/depth-anything/Depth-Anything-V2-Base/resolve/main/depth_anything_v2_vitb.pth -P pretrained
```
### RealEstate10K
Run the following command to train on RealEstate10K:
```bash
python -m src.main +experiment=re10k \
data_loader.train.batch_size=1 \
'dataset.roots'='["datasets/re10k"]' \
dataset.test_chunk_interval=10 \
dataset.num_context_views=6 \
trainer.max_steps=150000 \
model.encoder.num_scales=2 \
model.encoder.upsample_factor=2 \
model.encoder.lowest_feature_resolution=4 \
model.encoder.monodepth_vit_type=vitb \
output_dir=outputs/re10k-256x256 \
wandb.project=VolSplat \
checkpointing.pretrained_monodepth=pretrained/pretrained_weights/depth_anything_v2_vitb.pth \
checkpointing.pretrained_mvdepth=pretrained/pretrained_weights/gmflow-scale1-things-e9887eda.pth
```
### ScanNet
To train on ScanNet, we fine-tune the model pre-trained on RealEstate10K.
```bash
python -m src.main +experiment=scannet \
data_loader.train.batch_size=1 \
'dataset.roots'='["datasets/scannet"]' \
dataset.image_shape=[256,256] \
trainer.max_steps=100000 \
trainer.val_check_interval=0.9 \
train.eval_model_every_n_val=40 \
checkpointing.every_n_train_steps=2000 \
model.encoder.num_scales=2 \
model.encoder.upsample_factor=2 \
model.encoder.lowest_feature_resolution=4 \
model.encoder.monodepth_vit_type=vitb \
output_dir=outputs/scannet-256x256 \
wandb.project=VolSplat \
checkpointing.pretrained_model=models/volsplat-re10k-256x256.ckpt
```
## Evaluation
Ensure pre-trained or downloaded models are located in `/models`.
### RealEstate10K
```bash
python -m src.main +experiment=re10k \
data_loader.train.batch_size=1 \
'dataset.roots'='["datasets/re10k"]' \
dataset.test_chunk_interval=10 \
dataset/view_sampler=evaluation \
dataset.view_sampler.num_context_views=6 \
dataset.view_sampler.index_path=assets/re10k_evaluation/evaluation_index_re10k.json \
trainer.max_steps=150000 \
model.encoder.num_scales=2 \
model.encoder.upsample_factor=2 \
model.encoder.lowest_feature_resolution=4 \
model.encoder.monodepth_vit_type=vitb \
mode=test \
test.save_video=false \
test.save_depth_concat_img=false \
test.save_image=false \
test.save_gt_image=false \
test.save_input_images=false \
test.save_video=false \
test.save_gaussian=false \
checkpointing.pretrained_model=models/volsplat-re10k-256x256.ckpt \
output_dir=outputs/volsplat-re10k-256x256-test
```
### ACID
We use the model trained on RealEstate10K (zero-shot) to evaluate on ACID.
```bash
python -m src.main +experiment=acid \
data_loader.train.batch_size=1 \
'dataset.roots'='["datasets/acid"]' \
dataset.test_chunk_interval=10 \
dataset/view_sampler=evaluation \
dataset.view_sampler.num_context_views=6 \
dataset.view_sampler.index_path=assets/acid_evaluation/evaluation_index_acid.json \
trainer.max_steps=150000 \
model.encoder.num_scales=2 \
model.encoder.upsample_factor=2 \
model.encoder.lowest_feature_resolution=4 \
model.encoder.monodepth_vit_type=vitb \
mode=test \
test.save_video=false \
test.save_depth_concat_img=false \
test.save_image=false \
test.save_gt_image=false \
test.save_input_images=false \
test.save_video=false \
test.save_gaussian=false \
checkpointing.pretrained_model=models/volsplat-re10k-256x256.ckpt \
output_dir=outputs/volsplat-acid-256x256-test
```
## Citation
If you find our work useful for your research, please consider citing us:
```bibtex
@article{wang2025volsplat,
title={VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction},
author={Wang, Weijie and Chen, Yeqing and Zhang, Zeyu and Liu, Hengyu and Wang, Haoxiao and Feng, Zhiyuan and Qin, Wenkang and Chen, Feng and Zhu, Zheng and Chen, Donny Y. and Zhuang, Bohan},
journal={arXiv preprint arXiv:2509.19297},
year={2025}
}
```
## Contact
If you have any questions, please create an issue on this repository or contact at wangweijie@zju.edu.cn.
## Acknowledgements
This project is developed with [DepthSplat](https://github.com/cvg/depthsplat) and [MinkowskiEngine](https://github.com/NVIDIA/MinkowskiEngine). We thank the original authors for their excellent work.