
Ligeng Zhu commited on
Commit ·
ce989aa
1
Parent(s): dda6ee3
Initial commit
Browse files- .gitattributes +1 -0
- .gitignore +3 -0
- DeepSeek_V4.pdf +3 -0
- articles/01-23282743306-DeepSeek-V3-R1-的-Hosting-成本预估.md +40 -0
- articles/02-27181462601-DeepSeek-V3-R1-推理系统概览.md +95 -0
- articles/03-16445683081-计算DeepSeekV3训练的MFU.md +151 -0
- articles/04-27292649125-DeepSeek-V3-R1-推理效率分析(1):关于DeepSeek-V3-R1-Decoding吞吐极限的一些不负责任估计.md +203 -0
- articles/05-29841050824-DeepSeek-V3-R1-推理效率分析(2)-DeepSeek-满血版逆向工程分析.md +344 -0
- articles/06-29540042383-DeepSeek-V3-R1-推理效率分析(3):Decode-配置泛化讨论.md +511 -0
- download_zhihu_articles.py +267 -0
- source.md +14 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.pdf filter=lfs diff=lfs merge=lfs -text
|
.gitignore
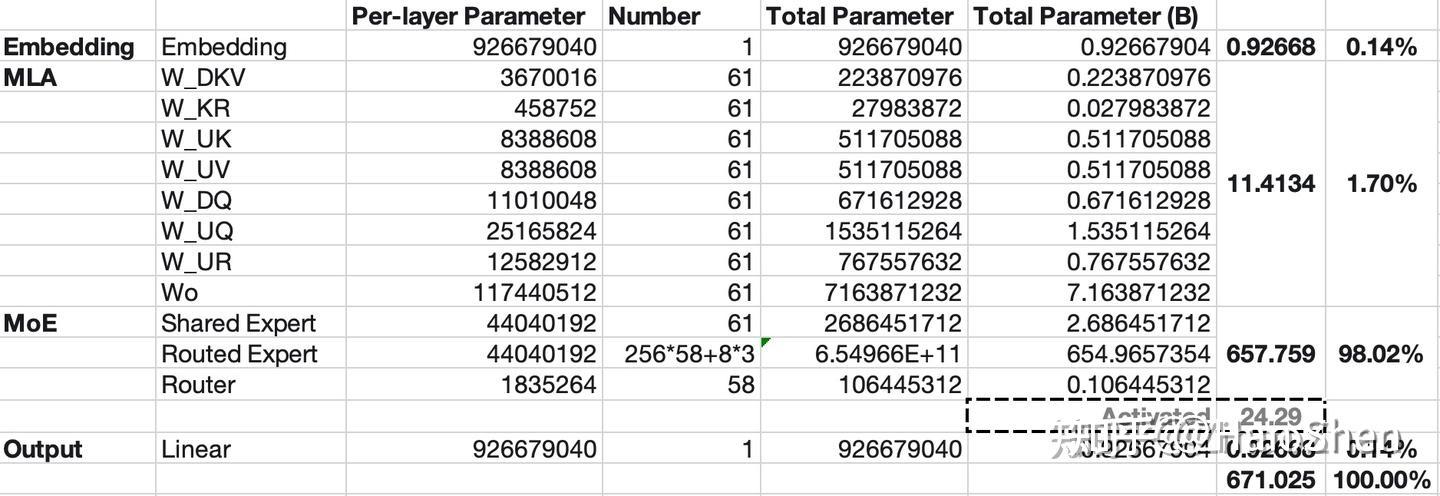
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
__pycache__/
|
| 3 |
+
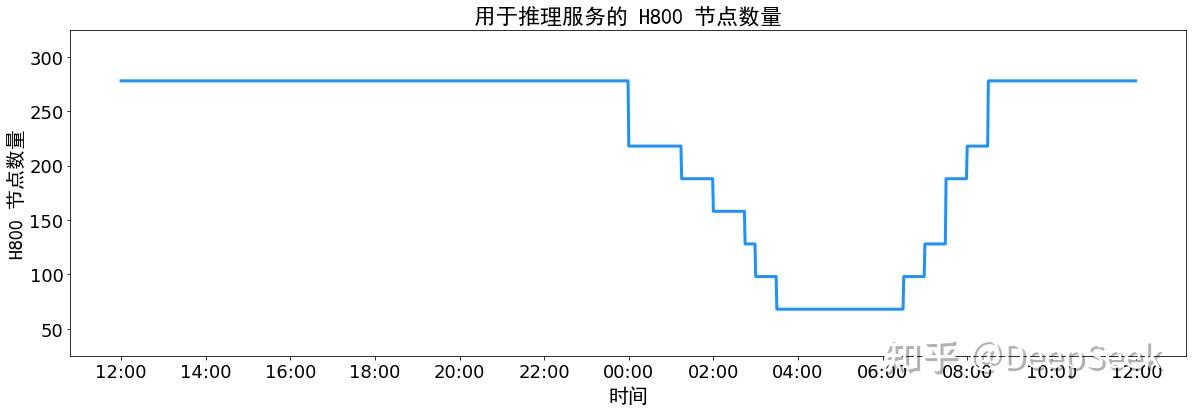
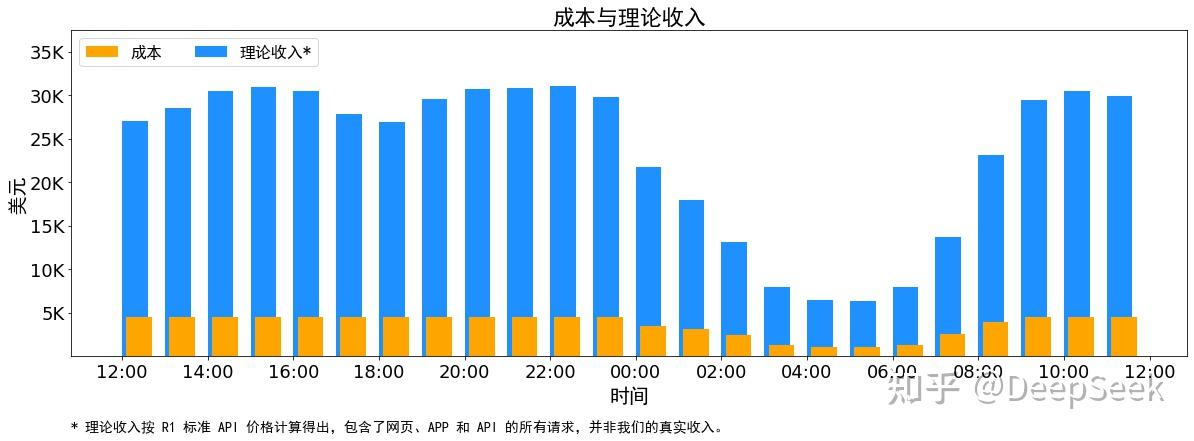
*.py[cod]
|
DeepSeek_V4.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a03dadae71894de1515da33e296f0df1dbeed3e7f4bf0badd087f9af77f29e9
|
| 3 |
+
size 4480407
|
articles/01-23282743306-DeepSeek-V3-R1-的-Hosting-成本预估.md
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
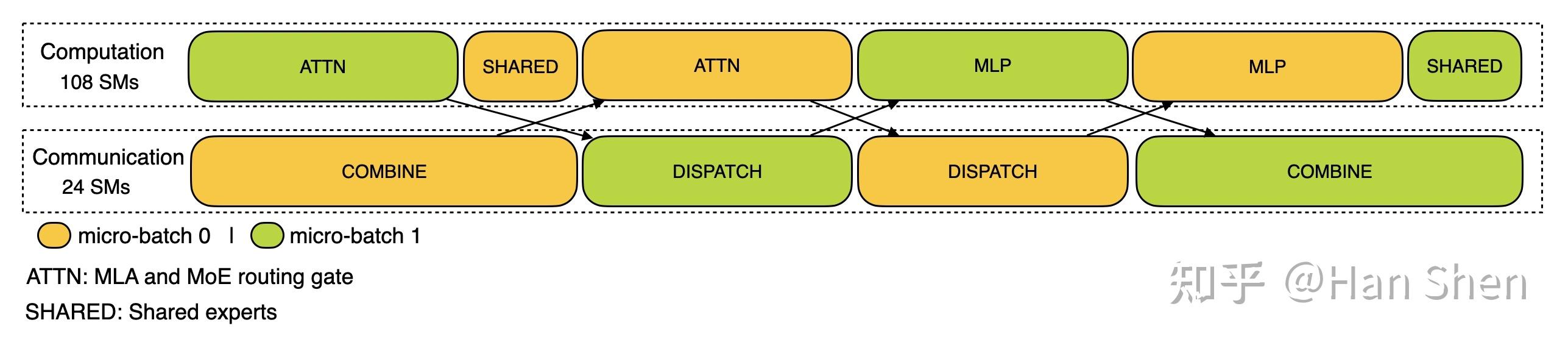
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DeepSeek-V3/R1 的 Hosting 成本预估"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/23282743306
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/23282743306
|
| 5 |
+
author: "Lyken"
|
| 6 |
+
published: 2025-02-12T13:13:14.000Z
|
| 7 |
+
modified: 2025-02-12T13:14:17.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DeepSeek-V3/R1 的 Hosting 成本预估
|
| 11 |
+
|
| 12 |
+
随着 deepseek-v3/r1 的爆火,各大 serving 厂商久旱逢甘霖终于是找到机会来宣传自家服务,在各大 MaaS 上线的如火如荼的时候,有人担忧厂商价格这么便宜(¥16 / Mtoken)真的能赚钱吗,会不会 V3/R1 的火热只是昙花一现
|
| 13 |
+
|
| 14 |
+
> 即便H800 GPU打满并且做出一流优化,H800每百万token的成本是约150元,昇腾是约300元 ... 如果满血版的DeepSeek R1每日输出1000亿token,那么每月的机器成本是4.5亿,亏损4亿!用户越多,亏损越多。
|
| 15 |
+
|
| 16 |
+
TLDR: 如果不优化直接用 TP / PP,那么部署是亏钱的,但如果优化的好,盈利点十分充裕 (>90%)
|
| 17 |
+
|
| 18 |
+
考虑到 serving throughput = latency \* batch-size
|
| 19 |
+
|
| 20 |
+
H100 / H800 的 throughput 很好预估,它们都是 80G 的卡,显存塞满的时候每一步 decoding 都需要把 GPU memory 挪到 L123 cache,那么预估 latency 是 **3.35TB/s / 80G = 42.88 token/s** 。在 SGLang 提供的 deployment 方案中[1],我们可以很容易的 observe 到 32 token/s + 的实际速率。
|
| 21 |
+
|
| 22 |
+
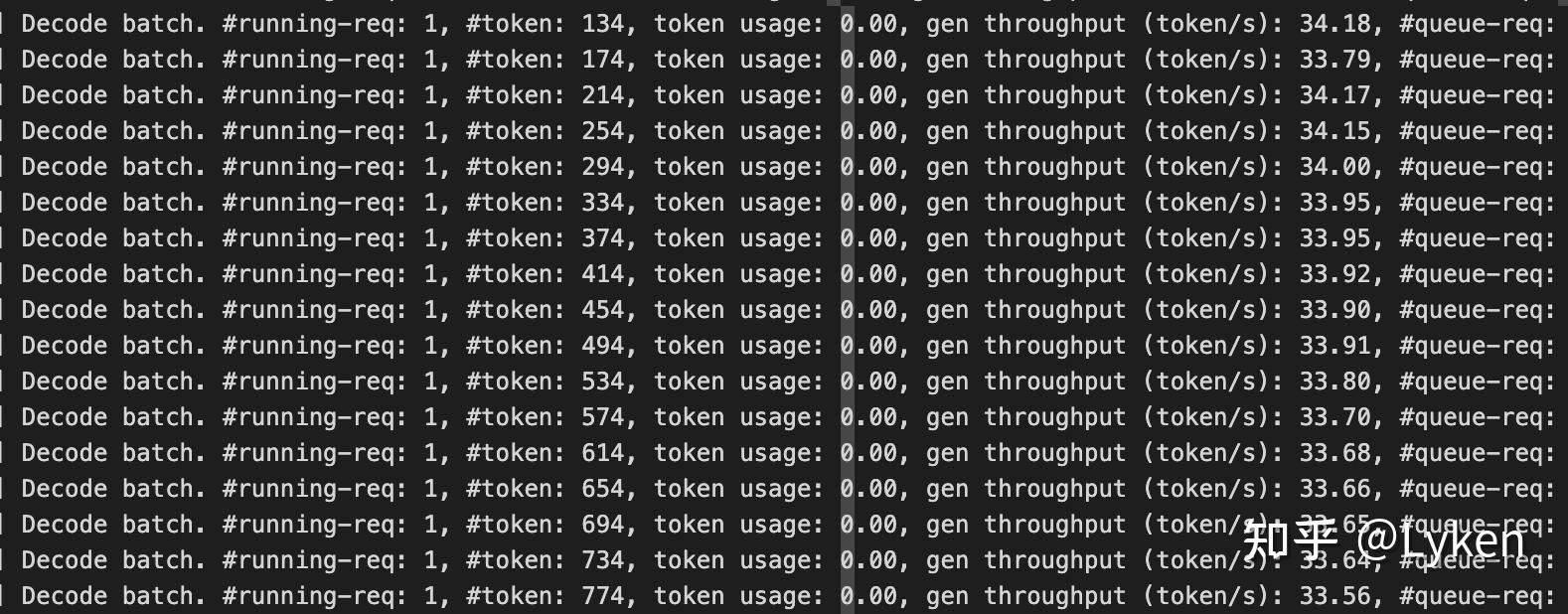
|
| 23 |
+
|
| 24 |
+
2x8H100 throughput with SGLang
|
| 25 |
+
|
| 26 |
+
接下来算 batch-size,参照 deepseek-v3[2] 论文 sec2.1.1 的信息,kvcache 需要缓存的是 **c\_t^{kv}** [d\_c, l] / **k\_t^{r}** [d\_h^{r}, l],那么每个 token 需要的缓存 kvcache 是
|
| 27 |
+
|
| 28 |
+
(dc+drh)⏟arch params∗N⏟seqlen∗L⏟#num layers\underbrace{(d\_c + d\_h^{r})}\_{\text{arch params}} \* \underbrace{N}\_{\text{seqlen}} \* \underbrace{L}\_{\text{#num layers}}
|
| 29 |
+
|
| 30 |
+
**(512 + 64) \* 5000 \* 61 = 167M**(假设每个输出为 5k seqlen)。参考 v3 论文 32 + 320 的配置,model weights 经过 shard 后占用可忽略,主要是每个 node 被 kvcache 占满。因此理论 batch size 可达到 80G / 167M = 479(考虑 overhead 向下取 400)。这样每张卡的理论 throughput 可达到 400 bs × 42.8 token/s = 17K token/s = 61M token/hour。H100 的租金为 $2/hour,**因此 offline batched hosting成本可低至 $0.03/M。**
|
| 31 |
+
|
| 32 |
+
考虑实际 throughput 30 token/s,bs 40,即 1.2K token/s = 4M token/hour,**比较实际的成本为 $0.5/M tokens = ¥3.7/M tokens**,**相比官方 API 16元的价格仍有利润空间**,更别说后面还有 MTP / fp4 等优化。
|
| 33 |
+
|
| 34 |
+
那回到一开始,为什么有一些 source 认为 hosting dsv3 需要高达 ¥150 / M token 的成本呢?因为他们采用的是 SGLang 现有的 out-of-box PP + TP ,并没有上 DeepSeek 介绍的 320 + 32 为 sparse experts 方案。现在 SGLang 在 2x8h800 上部署 single query 是 ~33 token/s,如果 batch-size 开到 12,那么 throughput ~ 400 token/s = 1.4M token/hour,机器的价格是 $32/h,算下来就是 $22.3 / M tokens ~= ¥150 / M token。而这个价格,离实际上的硬件最优利用率仍有很大距离。
|
| 35 |
+
|
| 36 |
+
[0]: 很多计算公式源于和 [Yixin Dong](https://link.zhihu.com/?target=https%3A//github.com/ubospica) 的讨论,他的 [XGrammar](https://link.zhihu.com/?target=https%3A//xgrammar.mlc.ai/) 是现在最好 LLM 的形式化输出插件,强烈推荐。
|
| 37 |
+
|
| 38 |
+
[1]: [https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek\_v3](https://link.zhihu.com/?target=https%3A//github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3)
|
| 39 |
+
|
| 40 |
+
[2]: [DeepSeek-V3 Technical Report](https://link.zhihu.com/?target=https%3A//arxiv.org/html/2412.19437v1%23S2)
|
articles/02-27181462601-DeepSeek-V3-R1-推理系统概览.md
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DeepSeek-V3 / R1 推理系统概览"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/27181462601
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/27181462601
|
| 5 |
+
author: "DeepSeek"
|
| 6 |
+
published: 2025-03-01T04:02:41.000Z
|
| 7 |
+
modified: 2025-03-01T04:02:41.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DeepSeek-V3 / R1 推理系统概览
|
| 11 |
+
|
| 12 |
+
**DeepSeek-V3 / R1 推理系统的优化目标是:更大的吞吐,更低的延迟。**
|
| 13 |
+
|
| 14 |
+
为了实现这两个目标,我们的方案是使用大规模跨节点专家并行(Expert Parallelism / EP)。首先 EP 使得 batch size 大大增加,从而提高 GPU 矩阵乘法的效率,提高吞吐。其次 EP 使得专家分散在不同的 GPU 上,每个 GPU 只需要计算很少的专家(因此更少的访存需求),从而降低延迟。
|
| 15 |
+
|
| 16 |
+
但 EP 同时也增加了系统的复杂性。复杂性主要体现在两个方面:
|
| 17 |
+
|
| 18 |
+
1. EP 引入跨节点的传输。为了优化吞吐,需要设计合适的计算流程使得传输和计算可以同步进行。
|
| 19 |
+
2. EP 涉及多个节点,因此天然需要 Data Parallelism(DP),不同的 DP 之间需要进行负载均衡。
|
| 20 |
+
|
| 21 |
+
因此,本文的主要内容是如何使用 EP 增大 batch size,如何隐藏传输的耗时,如何进行负载均衡。
|
| 22 |
+
|
| 23 |
+
### 大规模跨节点专家并行(Expert Parallelism / EP)
|
| 24 |
+
|
| 25 |
+
由于 DeepSeek-V3 / R1 的专家数量众多,并且每层 256 个专家中仅激活其中 8 个。模型的高度稀疏性决定了我们必须采用很大的 overall batch size,才能给每个专家提供足够的 expert batch size,从而实现更大的吞吐、更低的延时。需要大规模跨节点专家并行(Expert Parallelism / EP)。
|
| 26 |
+
|
| 27 |
+
我们采用多机多卡间的专家并行策略来达到以下目的:
|
| 28 |
+
|
| 29 |
+
- **Prefill**:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
|
| 30 |
+
- **Decode**:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
|
| 31 |
+
|
| 32 |
+
### 计算通信重叠
|
| 33 |
+
|
| 34 |
+
多机多卡的专家并行会引入比较大的通信开销,所以我们使用了双 batch 重叠来掩盖通信开销,提高整体吞吐。
|
| 35 |
+
|
| 36 |
+
对于 prefill 阶段,两个 batch 的计算和通信交错进行,一个 batch 在进行计算的时候可以去掩盖另一个 batch 的通信开销;
|
| 37 |
+
|
| 38 |
+
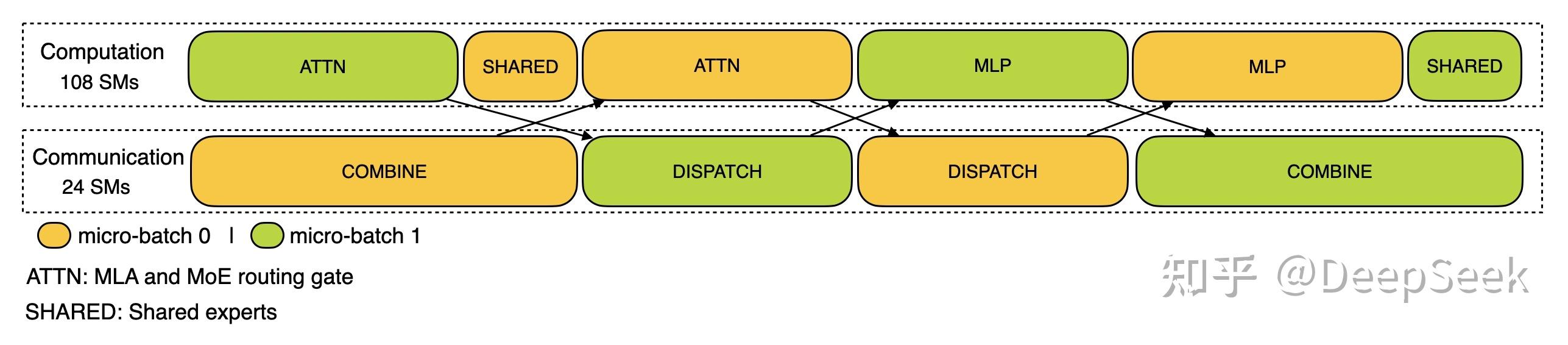
|
| 39 |
+
|
| 40 |
+
Prefill 阶段的双 batch 重叠
|
| 41 |
+
|
| 42 |
+
对于 decode 阶段,不同阶段的执行时间有所差别,所以我们把 attention 部分拆成了两个 stage,共计 5 个 stage 的流水线来实现计算和通信的重叠。
|
| 43 |
+
|
| 44 |
+
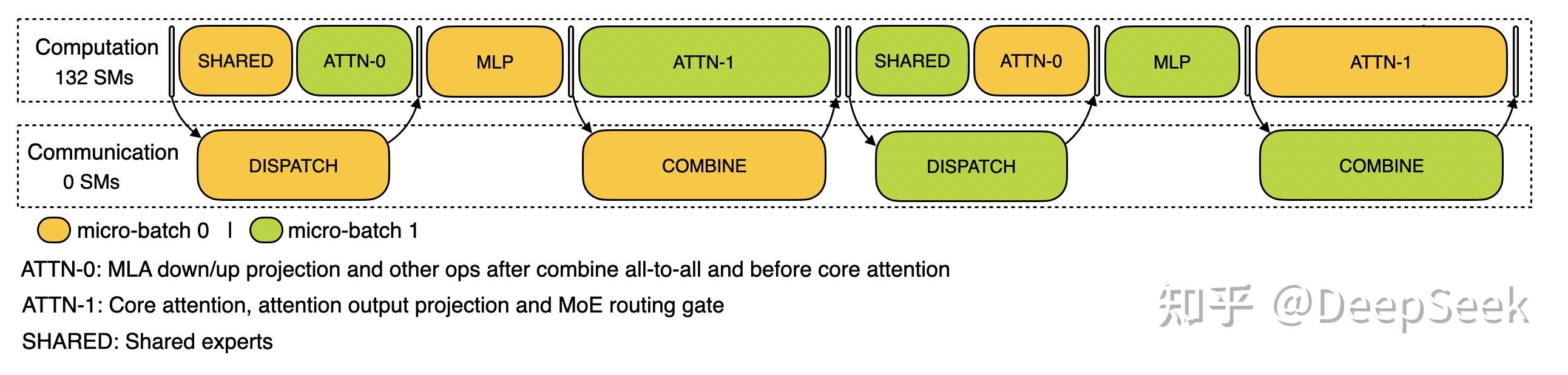
|
| 45 |
+
|
| 46 |
+
Decode 阶段的双 batch 重叠
|
| 47 |
+
|
| 48 |
+
关于更多双 batch 重叠的细节,可以参考我们的 profiling 数据的 GitHub 仓库:[https://github.com/deepseek-ai/profile-data](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/profile-data)。
|
| 49 |
+
|
| 50 |
+
### 尽可能地负载均衡
|
| 51 |
+
|
| 52 |
+
由于采用了很大规模的并行(包括数据并行和专家并行),如果某个 GPU 的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他 GPU 因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个 GPU 分配均衡的计算负载、通信负载。
|
| 53 |
+
|
| 54 |
+
1. **Prefill Load Balancer**
|
| 55 |
+
|
| 56 |
+
1. 核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致 core-attention 计算量、dispatch 发送量也不同
|
| 57 |
+
2. 优化目标:各 GPU 的计算量尽量相同(core-attention 计算负载均衡)、输入的 token 数量也尽量相同(dispatch 发送量负载均衡),避免部分 GPU 处理时间过长
|
| 58 |
+
|
| 59 |
+
2. **Decode Load Balancer**
|
| 60 |
+
|
| 61 |
+
1. 核心问题:不同数据并行(DP)实例上的请求数量、长度不同,导致 core-attention 计算量(与 KVCache 占用量相关)、dispatch 发送量不同
|
| 62 |
+
2. 优化目标:各 GPU 的 KVCache 占用量尽量相同(core-attention 计算负载均衡)、请求数量尽量相同(dispatch 发送量负载均衡)
|
| 63 |
+
|
| 64 |
+
3. **Expert-Parallel Load Balancer**
|
| 65 |
+
|
| 66 |
+
1. 核心问题:对于给定 MoE 模型,存在一些天然的高负载专家(expert),导致不同 GPU 的专家计算负载不均衡
|
| 67 |
+
2. 优化目标:每个 GPU 上的专家计算量均衡(即最小化所有 GPU 的 dispatch 接收量的最大值)
|
| 68 |
+
|
| 69 |
+
## 参考架构图
|
| 70 |
+
|
| 71 |
+
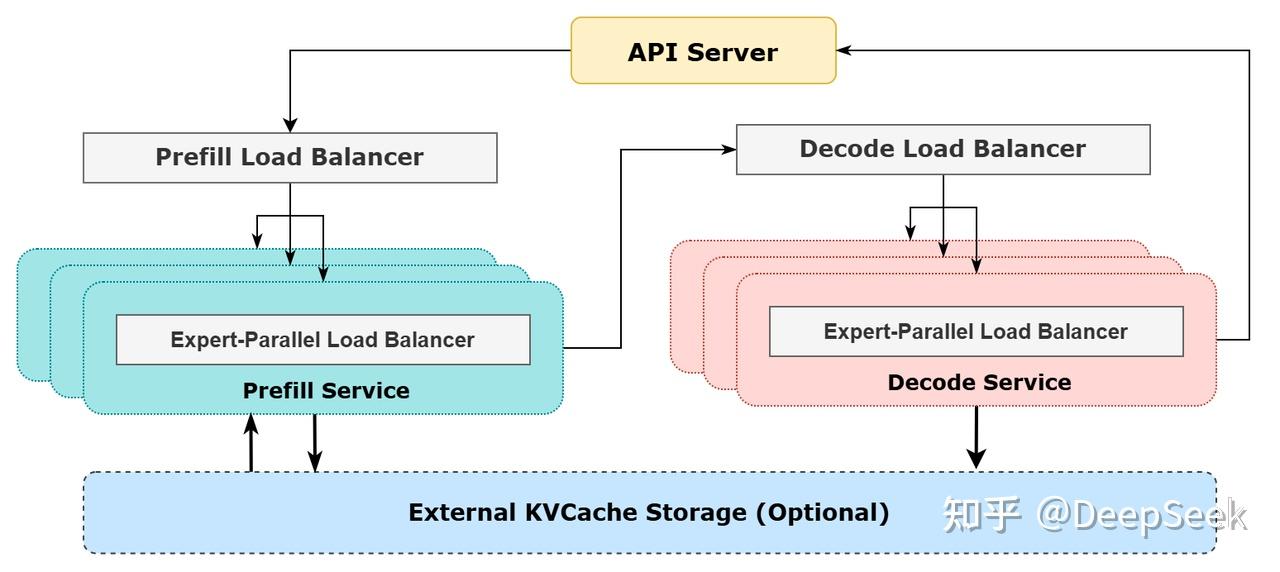
|
| 72 |
+
|
| 73 |
+
## 线上系统的实际统计数据
|
| 74 |
+
|
| 75 |
+
DeepSeek V3 和 R1 的所有服务均使用 H800 GPU,使用和训练一致的精度,即矩阵计算和 dispatch 传输采用和训练一致的 FP8 格式,core-attention 计算和 combine 传输采用和训练一致的 BF16,最大程度保证了服务效果。
|
| 76 |
+
|
| 77 |
+
另外,由于白天的服务负荷高,晚上的服务负荷低,因此我们实现了一套机制,在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。在最近的 24 小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU)。假定 GPU 租赁成本为 2 美金/小时,总成本为 $87,072/天。
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
**在 24 小时统计时段内,DeepSeek V3 和 R1:**
|
| 82 |
+
|
| 83 |
+
- 输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。
|
| 84 |
+
- 输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
|
| 85 |
+
- 平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
|
| 86 |
+
|
| 87 |
+
以上统计包括了网页、APP 和 API 的所有负载。如果所有 tokens 全部按照 DeepSeek R1 的定价[[1]](#ref_1)计算,理论上一天的总收入为 $562,027,成本利润率 545%。
|
| 88 |
+
|
| 89 |
+
> 当然我们实际上没有这么多收入,因为 V3 的定价更低,同时收费服务只占了一部分,另外夜间还会有折扣。
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
## 参考
|
| 94 |
+
|
| 95 |
+
1. [^](#ref_1_0)DeepSeek R1 的定价:$0.14 / 百万输入 tokens (缓存命中),$0.55 / 百万输入 tokens (缓存未命中),$2.19 / 百万输出 tokens。
|
articles/03-16445683081-计算DeepSeekV3训练的MFU.md
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "计算DeepSeekV3训练的MFU"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/16445683081
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/16445683081
|
| 5 |
+
author: "方佳瑞"
|
| 6 |
+
published: 2025-01-05T01:23:29.000Z
|
| 7 |
+
modified: 2025-01-27T07:45:45.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# 计算DeepSeekV3训练的MFU
|
| 11 |
+
|
| 12 |
+
> 本文利用公开信息推导得到DeepSeekV3训练时候的MFU为39%左右,相比V2的MFU提升大概60%,希望对后续技术讨论提供数据支撑。
|
| 13 |
+
|
| 14 |
+
自2024年12月发布以来,DeepSeekV3在人工智能领域引发了广泛关注。该模型不仅被国内三大顶会公众号上连篇累牍报道,更在海外社交媒体平台X等渠道引发热议。其关键因素之一在于突破性的训练成本控制——仅用557万美元便训练出了性能达到SOTA水平的模型。这一成就不仅引发业界对AI模型训练成本效益的重新思考,更延伸出对美国对华技术出口管制政策有效性的讨论,甚至影响到投资者对英伟达股价走势的判断。
|
| 15 |
+
|
| 16 |
+
神秘的幻方公司,加之某热点人物跳槽的花边,DeepSeekV3目前俨然成为舆论焦点,其影响力已远远超出技术领域,被置于中美科技博弈、中国创新实力等宏观议题中深入探讨。随着讨论不断发酵,从科技从业者到政策研究者,从资本市场到普通网民,越来越多群体加入这场大讨论,使得DeepSeekV3相关话题持续升温,形成了一场跨领域、多维度的全民热议。
|
| 17 |
+
|
| 18 |
+
低训练成本是DeepSeekV3独树一帜的特征,也是一时激起千层浪的根源。为什么DeepSeekV3能把成本打下来,网络上已经有大量的分析。
|
| 19 |
+
|
| 20 |
+
第一,是模型架构设计,通过采用MoE结构,尽管参数有671B但是激活只有37B。
|
| 21 |
+
|
| 22 |
+
第二,是高效的训练框架(幻方自研的HAI-LLM),创新性地采用了多种高超的工程优化技巧,包括流水线并行,FP8量化,通信计算隐藏等。推荐我的老同事朱小霖的回答:[如何评价 deepseek 上线的 deepseek-V3 模型?](https://www.zhihu.com/question/7837132971/answer/67345859891)
|
| 23 |
+
|
| 24 |
+
模型本身的作用是无可争议的,而训练框架的效率则成为学界和业界关注的焦点。然而,作为衡量训练框架运行效率的核心指标,**MFU(Model FLOPs Utilization)却长期被忽视——无论是在技术文献还是公众讨论中,都鲜少被提及,这是让人非常遗憾的。**基于此,本文试图通过公开数据,尝试对DeepSeekV3的训练MFU进行系统性测算,旨在为后续的学术研究和行业讨论提供一个可靠的基准参考。
|
| 25 |
+
|
| 26 |
+
⚠️ 本文可能纰漏,希望大家一起指点改正,集思广益,把MFU算精准。
|
| 27 |
+
|
| 28 |
+
技术报告和模型开源代码中已经包含了足够的信息,让我们能够计算出精确MFU。方法是计算每个token训练是需要的FLOP数目,然后乘以总的token数,除以总的GPU hours即可得到MFU。
|
| 29 |
+
|
| 30 |
+
问题的核心是每个token的FLOP数目,它主要包含了MLA部分和MoE部分,Embedding和LM head等非主干部分也占很小一部分。
|
| 31 |
+
|
| 32 |
+
## 1. 参数说明
|
| 33 |
+
|
| 34 |
+
dim = 7168
|
| 35 |
+
inter\_dim = 18432
|
| 36 |
+
moe\_inter\_dim = 2048
|
| 37 |
+
|
| 38 |
+
n\_layers = 61
|
| 39 |
+
n\_dense\_layers = 3
|
| 40 |
+
n\_heads = 128
|
| 41 |
+
|
| 42 |
+
n\_routed\_experts = 256
|
| 43 |
+
n\_shared\_experts = 1
|
| 44 |
+
n\_activated\_experts = 8
|
| 45 |
+
|
| 46 |
+
q\_lora\_rank = 1536
|
| 47 |
+
kv\_lora\_rank = 512
|
| 48 |
+
qk\_nope\_head\_dim = 128
|
| 49 |
+
qk\_rope\_head\_dim = 64
|
| 50 |
+
v\_head\_dim = 128
|
| 51 |
+
|
| 52 |
+
## 2. MLA的forward的FLOP
|
| 53 |
+
|
| 54 |
+
先规定:qk\_head\_dim = args.qk\_nope\_head\_dim + args.qk\_rope\_head\_dim
|
| 55 |
+
|
| 56 |
+
**2.1 Q down+up pro:**
|
| 57 |
+
|
| 58 |
+
flops = 2 \* *bs* \* *seq\_len* \* args.dim \* args.q\_lora\_rank
|
| 59 |
+
flops += 2 \* *bs* \* *seq\_len* \* args.q\_lora\_rank \* args.n\_heads \* args.qk\_head\_dim
|
| 60 |
+
|
| 61 |
+
**2.2 KV down proj:**
|
| 62 |
+
|
| 63 |
+
flops += 2 \* *bs* \* *seq\_len* \* args.dim \* (args.kv\_lora\_rank + args.qk\_rope\_head\_dim)
|
| 64 |
+
|
| 65 |
+
**2.3 KV up proj:**
|
| 66 |
+
|
| 67 |
+
flops += 2 \* *bs* \* *seq\_len* \* args.kv\_lora\_rank \* args.n\_heads \* (args.qk\_nope\_head\_dim + args.v\_head\_dim)
|
| 68 |
+
|
| 69 |
+
**2.4 score (Q x K^T): 由于是causal要/2**
|
| 70 |
+
|
| 71 |
+
flops += 2 \* *bs* \* *seq\_len* \* *seq\_len* \* args.n\_heads \* args.qk\_head\_dim / 2
|
| 72 |
+
|
| 73 |
+
**2.5 score x V**: **由于是causal要/2**
|
| 74 |
+
|
| 75 |
+
flops += 2 \* *bs* \* *seq\_len* \* *seq\_len* \* args.n\_heads \* args.v\_head\_dim / 2
|
| 76 |
+
|
| 77 |
+
**2.6 Wo:**
|
| 78 |
+
|
| 79 |
+
flops += 2 \* *bs* \* *seq\_len* \* args.n\_heads \* args.v\_head\_dim \* args.dim
|
| 80 |
+
|
| 81 |
+
## 3. MoE的forward FLOP
|
| 82 |
+
|
| 83 |
+
flops += 2 \* *bs* \* *seq\_len* \* args.dim \* args.moe\_inter\_dim \* 3
|
| 84 |
+
flops += *bs* \* *seq\_len* \* args.moe\_inter\_dim #matmul
|
| 85 |
+
|
| 86 |
+
## 4. MLP的forward FLOP
|
| 87 |
+
|
| 88 |
+
flops = 2 \* *bs* \* *seq\_len* \* args.dim \* args.inter\_dim \* 3
|
| 89 |
+
flops += *bs* \* *seq\_len* \* args.inter\_dim #matmul
|
| 90 |
+
|
| 91 |
+
## 5. lm head的forward FLOPS
|
| 92 |
+
|
| 93 |
+
这里只算一个head情况,先不考虑MTP
|
| 94 |
+
|
| 95 |
+
flops = 2 \* *bs* \* *seq\_len* \* args.dim \* args.vocab\_size
|
| 96 |
+
|
| 97 |
+
⚠️:这里没考虑 router 等模块的计算量。但是他们影响很小。
|
| 98 |
+
|
| 99 |
+
## 7. MFU计算
|
| 100 |
+
|
| 101 |
+
按照backward计算FLOP是forward的2倍来计算,注意这里不把attn反向的重计算当成有效flops。
|
| 102 |
+
|
| 103 |
+
V3总共有61层,前3层用MLP,后58层用MoE来计算。另外每个token激活9(1个share+8个router)MoE Expert。context length按照4K估算。H100\_peak\_bf16\_flops按照989.5 Tflops算(感谢评论区
|
| 104 |
+
|
| 105 |
+
[@Quokka](https://www.zhihu.com/people/157deec64cc5e062b2207aeece42f50f)
|
| 106 |
+
|
| 107 |
+
指正)
|
| 108 |
+
|
| 109 |
+
我们可以得到flops\_per\_1T\_tokens。然后按照如下公式可以算出MFU:
|
| 110 |
+
|
| 111 |
+
gpu\_hours = 2.664 \* 3600 / 1024
|
| 112 |
+
|
| 113 |
+
MFU = flops\_per\_1T\_tokens \* 14.8 / (gpu\_hours \* H100\_peak\_bf16\_flops)
|
| 114 |
+
|
| 115 |
+
代码我放在如下仓库中:
|
| 116 |
+
|
| 117 |
+
[https://github.com/feifeibear/DPSKV3MFU/blob/main/dpskv3\_flops.py](https://link.zhihu.com/?target=https%3A//github.com/feifeibear/DPSKV3MFU/blob/main/dpskv3_flops.py)
|
| 118 |
+
|
| 119 |
+
**计算得到的MFU是37.2%。**
|
| 120 |
+
|
| 121 |
+
[@菽陌松囿](https://www.zhihu.com/people/f2ee177a9cf9a5d252b0e6e687a337c4)
|
| 122 |
+
|
| 123 |
+
**提出**6ND+attn估算法:
|
| 124 |
+
|
| 125 |
+
按照2.4和2.5算attn\_flosp。
|
| 126 |
+
|
| 127 |
+
MFU\_ref = (37 *\* 6 + 3 \** attn\_flops *\* 61*) \* 14.8 / (gpu\_hours \* H100\_peak\_bf16\_flops)
|
| 128 |
+
|
| 129 |
+
**估算得到的MFU\_ref是40.0%**。笔者认为这一个偏高的估计,比如embedding层按参数算flops就不准确了,偏高很多。
|
| 130 |
+
|
| 131 |
+
⚠️
|
| 132 |
+
|
| 133 |
+
[@233](https://www.zhihu.com/people/de55655c466549f343ad2f175e593b9d)
|
| 134 |
+
|
| 135 |
+
大佬指出上述计算对H800峰值估算存在进制不一致问题。H100\_peak\_bf16\_flops=989.5 TFlops,其实是989.5\*1e12 Flops。
|
| 136 |
+
|
| 137 |
+
如果假设论文中的T,B,M都是以1000为单位的。**那么计算得到MFU为39.0%,**估算得到MFU是39.4%。
|
| 138 |
+
|
| 139 |
+
如果假设论文中的T,B,M都是以1024为单位的。**那么计算得到MFU为40.9%,**估算得到MFU是44.0%。
|
| 140 |
+
|
| 141 |
+
## **8. DeepSeek V3和V2的MFU对比**
|
| 142 |
+
|
| 143 |
+
我们顺便对比一下V3相比V2的MFU提升,鉴于两个模型应该是在同一个集群上训练,MFU的差异可以反应技术报告中框架优化的效果。简单期间,我们这次就用参数估算方法。
|
| 144 |
+
|
| 145 |
+
DeepSeek V3的MFU正比于37(B)\*14.8(T)/2.788M(GPU hours) = 196
|
| 146 |
+
|
| 147 |
+
与之对比,半年前在同一集群完成训练的DeepSeek V2的MFU正比于21(B)/0.1728M(GPU hours Per 1T tokens) = 121
|
| 148 |
+
|
| 149 |
+
DeepSeek的Infra团队半年内提效196/121 = 61%。
|
| 150 |
+
|
| 151 |
+
按照2美金一个 H800 GPU hours租金来算,2K卡集群的一个月租金为2000万RMB,DeepSeek Infra团队相当于**每个月赚1200万RMB**。
|
articles/04-27292649125-DeepSeek-V3-R1-推理效率分析(1):关于DeepSeek-V3-R1-Decoding吞吐极限的一些不负责任估计.md
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DeepSeek V3/R1 推理效率分析(1):关于DeepSeek V3/R1 Decoding吞吐极限的一些不负责任估计"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/27292649125
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/27292649125
|
| 5 |
+
author: "Han Shen"
|
| 6 |
+
published: 2025-03-01T14:38:21.000Z
|
| 7 |
+
modified: 2025-03-27T16:07:42.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DeepSeek V3/R1 推理效率分析(1):关于DeepSeek V3/R1 Decoding吞吐极限的一些不负责任估计
|
| 11 |
+
|
| 12 |
+
补充说明: 本系列按时间线分为
|
| 13 |
+
|
| 14 |
+
DeepSeek V3/R1 推理效率分析(1)
|
| 15 |
+
|
| 16 |
+
DeepSeek V3/R1 推理效率分析(2)
|
| 17 |
+
|
| 18 |
+
DeepSeek V3/R1 推理效率分析(3)
|
| 19 |
+
|
| 20 |
+
三篇连载,逐渐从一开始只是根据V3论文参数的一些粗略量级估计,到后来根据官方给出来的全部信息的逐步量化修正,也有一个时间上的发展过程。因此,估算精确性由粗逐渐精细(尤其是3,关心本话题的朋友强烈建议读到3),在第一篇讨论中有些关注到本文估算精确性的朋友,其实在后两篇中都有进一步的分析和修正,建议一起食用
|
| 21 |
+
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
经历了一周DeepSeek的打脸活动后,周六 DeepSeek终于开大放出来了自身的推理系统水平,[DeepSeek:DeepSeek-V3 / R1 推理系统概览](https://zhuanlan.zhihu.com/p/27181462601) 。在这个结论放出来之前,没有300多卡做充分实验(公司内部之前没有预判到大型分布式MoE推理的需求,社区的SGLang/vLLM引擎的scale out能力也还在建设中)的我们也做过一些不成熟的理论估计,为了对deepseek 的部署进行一定逆向工程的反推。
|
| 25 |
+
|
| 26 |
+
今天和同行朋友们交流的时候也帮忙纠正了很多计算上的错误得到更合理的答案。这里整理一下发出来供网友讨论一下,不预设正确立场,鼓励同行继续抓抓bug,也方便对DeepSeek当前的水平做一个理解。
|
| 27 |
+
|
| 28 |
+
评论区合理的纠错会及时更新。
|
| 29 |
+
|
| 30 |
+
Acknowledge:
|
| 31 |
+
|
| 32 |
+
> BatchSize的初版讨论由我和快手团队大模型推理的两个同学(Changcheng Tang & Xiangcheng Liu)讨论得到,Yuliang Liu review 了部分结论,计算和通信部分的上限预估经过了sambanova 的@mingran wang老师的review 和公式纠正,参考了@zarbot 老师的网络上限方法。
|
| 33 |
+
|
| 34 |
+
## DeepSeek V3 的网络结构参数
|
| 35 |
+
|
| 36 |
+
### **参数配置**
|
| 37 |
+
|
| 38 |
+
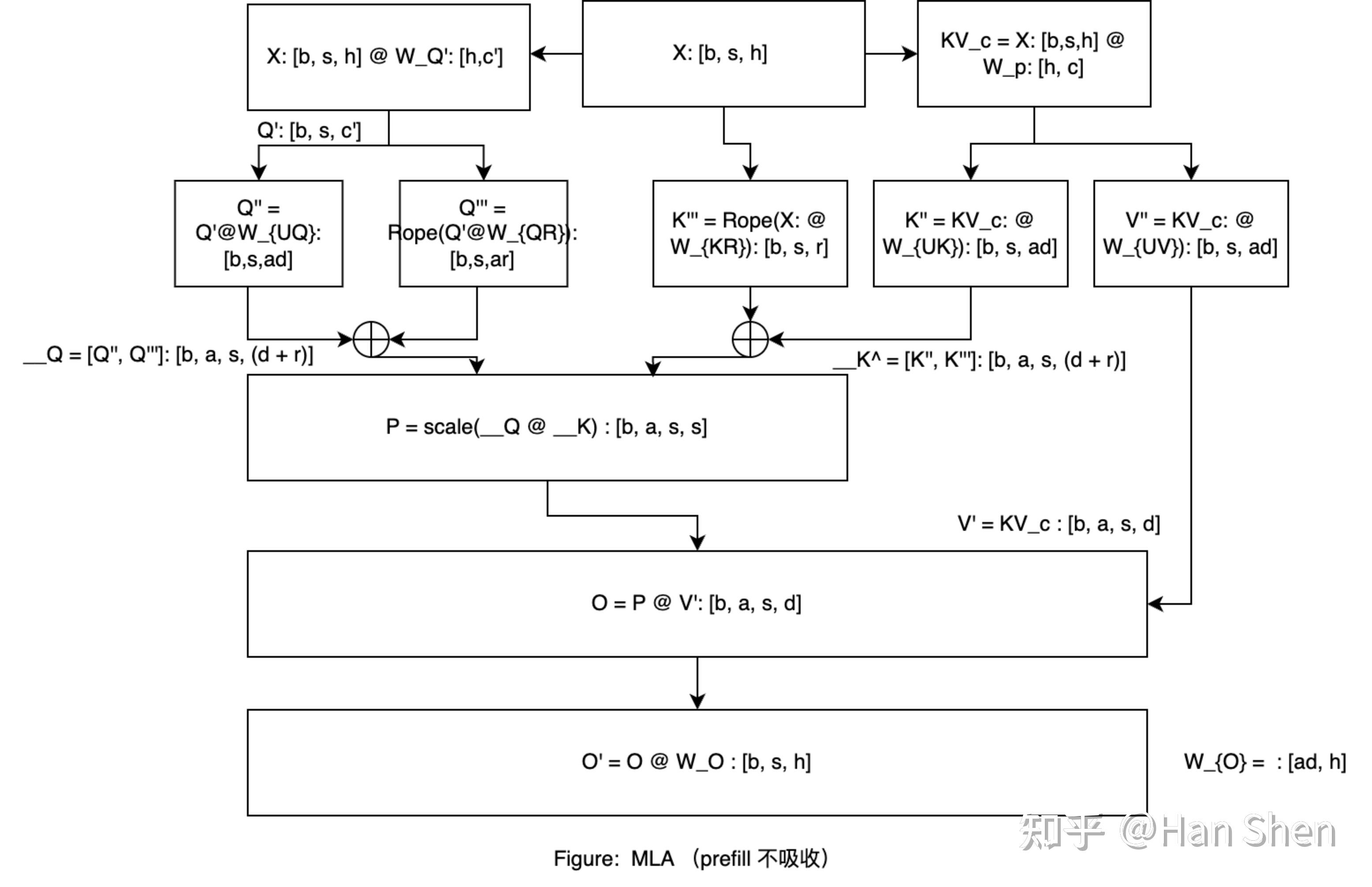
MLA
|
| 39 |
+
|
| 40 |
+
- nh=128,dh=128n\_{h}=128, d\_{h} =128
|
| 41 |
+
- KV压缩维度 dc=512d\_{c} =512 , Query压缩维度 dc′=1536d\_{c}' =1536 。 dhR=64d\_{h}^{R}=64
|
| 42 |
+
|
| 43 |
+
Expert
|
| 44 |
+
|
| 45 |
+
- 3个Gemm:Up gemm, Down gemm, Gate gemm: d\_h = 7168, d\_{expert} = 2048
|
| 46 |
+
|
| 47 |
+
DeepSeek-V3 总共包含 671B 个参数,其中每个 Token 激活了 37B;61层transformer layer,前3层非MoE,后58层FFN 拓展为 MoE,每个 MoE 层由 1 个共享专家和 256 个路由专家组成,h=2048。routered expert 每个token 激活8个expert,训练时每个token最多发送4个node以减少节点间通信。
|
| 48 |
+
|
| 49 |
+
### **推算Dense 部分和Sparse MoE部分参数**
|
| 50 |
+
|
| 51 |
+
单个Expert权重 7168\*2048\*3 = 44M,61层中3层非moe,58层moe,257\*58+3\*9个expert = 657 B,dense部分参数量为 671-657 = 14B,14B 在MLA部分占11.4B,其余部分是embedding、linear等权重。详细计算公式参考:[ZihaoZhao:DeepSeek-V3 (671B) 模型参数量分解计算](https://zhuanlan.zhihu.com/p/21455638257)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
DeepSeek-V3 参数分布
|
| 56 |
+
|
| 57 |
+
从per token 激活 37B 反推:37B - 44M *x* 61 x 9/1000 = 12.8B 差不多能和14B对上。
|
| 58 |
+
|
| 59 |
+
所以一个近似的权重值
|
| 60 |
+
|
| 61 |
+
- per expert 权重为44M=42MB
|
| 62 |
+
- dense 部分权重按14B=13GB
|
| 63 |
+
- expert 权重总量为 657B = 612GB。
|
| 64 |
+
|
| 65 |
+
### **平均Sequence 长度**
|
| 66 |
+
|
| 67 |
+
输入/输出sequence length 分布假设:
|
| 68 |
+
|
| 69 |
+
- DeepSeek V3 的平均输入/输出长度为:1k+1k (对齐 NVIDIA 官方测试标准)
|
| 70 |
+
- DeepSeek R1 **的**平均输入/输出长度为:1k+5k (与今天官方放出来的平均输出“平均每输出一个 token 的 KVCache 长度是 4989。” 基本吻合)
|
| 71 |
+
|
| 72 |
+
**尽量达到compute bound 的最佳设备数配置**
|
| 73 |
+
|
| 74 |
+
DeepSeek V3/R1最基本的实现是单机内做8卡TP,需要625GB 存放权重,因此入门门槛一般是H20 96Gx8 或者H800 80G x16。在这两种配置下,可用的kvcache容量非常小,导致attention QKV gemm的batchsize以及MoE部分的batchsize都非常低,MoE部分expert完全是memory bound乃至latency bound的,这对decoding做continous batching来提高硬件利用率来说非常不友好。因此,**打高batch size是一个提升吞吐的基本需求,而scale out到多机使得单卡权重降低是一个基本的提升batch size的手段。**
|
| 75 |
+
|
| 76 |
+
TP对MLA部分的KVCache 非常不友好,因为MLA将多个head 压缩到了同一个hidden向量,因此无法在TP节点内做head切分,意味着KVCache 各个卡的存储是冗余的。因此为了做scale out,基本的假设是Attention DP + MoE 部分TP/EP。考虑跨卡通信效率,Attention DP + MoE EP 是比较可行的。
|
| 77 |
+
|
| 78 |
+
DeepSeek V3论文中decode node采用的是40\*8 H800, Attention 4-way TP+SP + 80 way DP,MoE部分320-way EP。由于TP+SP一般在机内发生,不会是bound batch 或通信的主要瓶颈,**为了简单我们后文都假设并发配置为Attention DP+ MoE EP**。
|
| 79 |
+
|
| 80 |
+
现在想回答一个最基本问题:
|
| 81 |
+
|
| 82 |
+
**为了让MoE 部分的expert 达到计算bound,我们最少需要多少张 H800?**
|
| 83 |
+
|
| 84 |
+
> 避免估算复杂,假设无冗余expert,先不考虑shared expert 和前3层是dense的情况。
|
| 85 |
+
|
| 86 |
+
### **1. 先考虑显存约束**
|
| 87 |
+
|
| 88 |
+
- 单卡sequence length: s (decoding场景下往往是1)
|
| 89 |
+
- 单请求平均序列长度: s'
|
| 90 |
+
- 单卡MLA batchsize: b\_{mla}
|
| 91 |
+
- 单expert batchsize: b\_{ep}
|
| 92 |
+
- GPU 卡数:d
|
| 93 |
+
- expert 数目: n\_e
|
| 94 |
+
- 激活单卡占用:当 s' > 1000 时,基本上近似某个正比于b\_{mla}\*s' 的常量倍 C\_{constant\\_coefficient} \*b\_{mla}\*s' (主要跟MLA激活有关)。但现在SGLang激活显存管理做的不好,实测下假设s分布在1k~8k之间,激活不超过8G。**注:激活的量更小不会在数值上影响后续估算的量级。**
|
| 95 |
+
- 单token 的MLA kvcache storage size: (d\_c + d\_R)\*61 = 576 \* 61 = 34.3KB(FP8) (注:SGLang等框架目前只支持BF16 的kvcache size,上限推算还是按FP8 存)
|
| 96 |
+
- 假设 d\le n\_e ,平均每卡放置 \lceil n\_e/d \rceil 个expert。
|
| 97 |
+
|
| 98 |
+
于是权重守恒等式:
|
| 99 |
+
|
| 100 |
+
- 80 \* d- 14 \* d/1.024^3 - 612 = 34.3/1024/1024\*d\*b\_{mla}\* s' + C\_{constant\\_coefficient}\*b\_{mla}\*s'\*d
|
| 101 |
+
|
| 102 |
+
(67-(32.7\*10^{-6} + C\_{constant\\_coefficient})b\_{mla}s') d = 612,
|
| 103 |
+
|
| 104 |
+
带入激活的经验假设8G。
|
| 105 |
+
|
| 106 |
+
(59-(32.7\*10^{-6})b\_{mla}s') d = 612
|
| 107 |
+
|
| 108 |
+
**来看一下** d **与** b\_{mla} **的取值范围:**
|
| 109 |
+
|
| 110 |
+
1. 首先这个公式假设了expert无冗余存储(612G),因此 d\le 256
|
| 111 |
+
2. 其次需满足 59-(32.7\*10^{-6})b\_{mla}s')\ge 0 , 单卡存放token数需满足 b\_{mla}s' <=1.8 \* 10^6
|
| 112 |
+
|
| 113 |
+
- 注1: 即使激活为0,上限也是 2\*10^6 ;
|
| 114 |
+
- 注2: 根据条件1 有一个更紧的bound 59-(32.7\*10^{-6})b\_{mla}s')\ge 612/256 ,上限是 1.73\*10^6
|
| 115 |
+
- 都不影响我们估计数值的量级
|
| 116 |
+
|
| 117 |
+
对于DeepSeek V3: 平均 s' = 2000 , b\_{mla} <= 900,
|
| 118 |
+
|
| 119 |
+
对于DeepSeek R1: 平均 s' = 6000 , b\_{mla} <= 300,
|
| 120 |
+
|
| 121 |
+
3. 59d \ge 612, d\ge 11
|
| 122 |
+
|
| 123 |
+
**结论1:对于Q/K/V projection 矩阵,如果sequence length 比较长,在当前无论怎么scale H800设备,QKV 也无法达到FP8算力的饱和点。(从**[DeepEP](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/DeepGEMM)**的结果来看H800 当前矩阵乘法m\*n\*k规模下的FP8 经验饱和点m > 4096),而H200 141G 和MI300X 192G的大显存更能使QKVproj 逼近饱和点)**
|
| 124 |
+
|
| 125 |
+
### **2. 考虑MoE 达到Compute bound的约束**
|
| 126 |
+
|
| 127 |
+
再看MoE部分,MoE部分的总接收token数是 b\_{mla}\*d\*9 ,假设均衡,平均到每个expert的token数为 b\_{mla}\*9\*d/n\_e 。假设 moe gemm batchsize 的饱和点记为 b\_{ep\\_sat} 时,需满足
|
| 128 |
+
|
| 129 |
+
b\_{mla}\*9\*d/n\_{e} \ge b\_{ep\\_sat}
|
| 130 |
+
|
| 131 |
+
于是 d/n\_{e}\ge b\_{ep\\_sat}/b\_{mla}/9 。
|
| 132 |
+
|
| 133 |
+
对于DeepSeek V3: 平均s' = 2000,还按4096算饱和点, b\_{ep\\_sat} = 4096
|
| 134 |
+
|
| 135 |
+
对于 b\_{mla} = 900 , d \ge 0.5 \* 256 \approx 128
|
| 136 |
+
|
| 137 |
+
对于DeepSeek R1: 平均s' = 6000, b\_{ep\\_sat} = 4096
|
| 138 |
+
|
| 139 |
+
对于 b\_{mla} = 300,d \ge 1.51 \* 256 > 256 ,说明不可能达到理想饱和点了,此时若 d=256,b\_e <= 2700 ,当 d=128,b\_e <=1350 。
|
| 140 |
+
|
| 141 |
+
**结论2:对于H800来说,moe expert 设备数在V3 情况下,不需要特别大,d=128 和d=256 可能都是一个合理的设备配置。对于R1,d=256更有利于把moe 打饱和。对H20来说,由于** b\_{ep\\_sat} **足够小,设备数d可以比256小挺多就能达到compute bound;对于H200和MI300X,由于** b\_{mla} **比较大,也可以调小设备数d达到理想的compute bound。**
|
| 142 |
+
|
| 143 |
+
## **吞吐上限预估**
|
| 144 |
+
|
| 145 |
+
吞吐导向,我们希望batchsize 够大达到计算bound,那么整体极限不太可能bound在memory 带宽上,那么会bound在计算或者通信上:
|
| 146 |
+
|
| 147 |
+
1. **根据计算bound 假设计算上限:**
|
| 148 |
+
|
| 149 |
+
- 估计decoding 部分的 FLOPs:
|
| 150 |
+
|
| 151 |
+
对于decoding来说,非MLA的部分FLOPs数可以通过2\*N 方法来估计。MLA部分额外由于context window带来的Q@K和P@V的计算在s较大时也应该考虑在内:
|
| 152 |
+
|
| 153 |
+
一般decoding MLA 进行矩阵吸收:
|
| 154 |
+
|
| 155 |
+
- flops计算公式为 2 \* b\_{mla} s' n\_{head} (2\*d\_c + r) ,带入MLA的参数为 2 \* b\_{mla} s' 128 (512\*2 + 64) \approx 2.8\*10^5 b\_{mla}s' FLOPs
|
| 156 |
+
- 因此 Decoding部分计算量约为 2 \* 37 \* b\_{mla} \* s d + 61\*2.8\*10^{-4}b\_{mla}s'd = (74s + 170.8\*10^{-4}s')b\_{mla}d GFLOPs
|
| 157 |
+
- H800 FP8 聚合算力 1978d TFLOPS, H20 FP8聚合算力 296d TFLOPS
|
| 158 |
+
|
| 159 |
+
对DeepSeek V3 s = 1, s' = 2000, 则total FLOPs 为 108 b\_{mla}d ,H800 单卡吞吐上限为18300 tokens/s, H20单卡吞吐上限为2740 tokens/s
|
| 160 |
+
|
| 161 |
+
对R1 s = 1, s' = 6000, 则total FLOPs为 176 b\_{mla}d ,H800 单卡吞吐上限约为11000 tokens/s, H20单卡吞吐上限为1681 tokens/s
|
| 162 |
+
|
| 163 |
+
**2. 根据网络 bound 假设计算上限:**(zarbot算法)
|
| 164 |
+
|
| 165 |
+
单token 通信量 7168B,50GB/s 跨机RDMA 带宽,单次dispatch 61层+9expert 一共通信量~4MB。zarbot在这里考虑了allreduce ,得到通信总量8MB所以单卡最大吞吐6000的结论,但实际上DP+EP的并行DP部分没有通信,dp阶段不需发送,实际上是 dispatch + combine 也是 8MB,如果combine为BF16,为12MB,因此50GB/s(实际达到40GB/s)的RDMA带宽最多能打单卡5000(FP8)/3333(BF16) 左右tokens/s 。
|
| 166 |
+
|
| 167 |
+
**讨论:**
|
| 168 |
+
|
| 169 |
+
> zarbot这里9个expert的算法考虑是decode为了极致的latency需求做了EP320,那么单node 只有8 experts,通信量可能还是按9 experts去估计更合适(减少hop数,考虑均衡性)
|
| 170 |
+
> 考虑如果按最省节点间带宽的做法来通信,如训练一般可以假设per token最多发给4个node,这里可以先通信再在设备内duplicate,因此这里只需要考虑4个node的传输量,再精确一点,前3层transformer不是MoE,那么单次dispatch通信量为58层\*4 expert 约1.6MB。如果combine也是FP8,为3.2MB,如果combine为BF16,为4.8MB,50GB/s的RDMA带宽(按40GB/s实际带宽算),combine(FP8)上限单卡12800 tokens/s,combine (BF16) 8500 tokens/s。这种情况下可以提高通信带宽的上限。
|
| 171 |
+
|
| 172 |
+
因此联合考虑计算和通信两者,在不开启MTP的情况下,R1的 EP256 H800 FP8单卡吞吐的上限在3300(combine BF16)-5000(combine FP8) tokens/s,H20 的上限在1600 tokens/s 左右。
|
| 173 |
+
|
| 174 |
+
> 注意:
|
| 175 |
+
> 1. 网络约束较好估计实测网络带宽上线,这里如果是被算力约束,还是需要考虑到MFU的损耗, 打个6-7折是一个比较现实的估计,H20 在1000 tokens/s 更合适)。
|
| 176 |
+
> 2. 对H800 是网络带宽的约束的前提是H800 的算力上限足够高。如果网络带宽算力翻倍或考虑到H800 的MFU极低,那么实际上是有可能被算力先bound的。总的来说,被水管最细的通道bound上限是主要原则。
|
| 177 |
+
|
| 178 |
+
## **满足 latency约束**
|
| 179 |
+
|
| 180 |
+
假设latency 约束为10ms,按expert 单iter极限访存量与聚合带宽来估算, 需满足 (671+14\*(d-1))/1.024^3/(3300d) \le 0.01 ,d\ge 31 因此一个基本的要求就是,**极限的latency需求需要靠多台机器降低expert访存压力。**
|
| 181 |
+
|
| 182 |
+
考虑业界MaaS普遍的output per user 20tokens/s的SLO,当打满batch时,等价访存为80GB全load一次的时间,最小为80GB/3350 = 24ms。如果bs较大到达到计算bound区,这个时间会往上涨。考虑到bs较小时, expert 矩阵单次访存只有 7168\*2048 = 14M,经验上 MBU最多达到50%,估计load完一次也需要24ms~50ms(我们实测单机或两机不同长度bs=1的TPOT介于35ms~50ms之间)。
|
| 183 |
+
|
| 184 |
+
这里就会有一个访存bound - 计算bound之间的tradeoff,先通过scale out把bs=1的latency打的足够低,然后再找到一个甜点区的设备数,使得在TPOT latency 满足50ms 约束下,batch打的尽可能高。
|
| 185 |
+
|
| 186 |
+
## 总结
|
| 187 |
+
|
| 188 |
+
回顾一下DeepSeek 推理系统的水平,
|
| 189 |
+
|
| 190 |
+
> 输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
|
| 191 |
+
> 平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
|
| 192 |
+
|
| 193 |
+
平均单卡吞吐达到了1.85k tokens/s,达到我们刚才算的3300(combine BF16,根据DeepEP所述) tokens/s的56%,同时保证平均输出20-22 tokens/s,考虑我们上一节说的latency 约束, 在延迟约束下能达到理论吞吐的56%,我认为已经是一个非常好的系统水平了(如果没有做MTP的话)!
|
| 194 |
+
|
| 195 |
+
而在设计中去tradeoff 延迟和吞吐还有很多的细节可以去讨论,比如是否可以让单卡的expert更多一些从而提升network bound的上限,也许还有更多的调参可能性。
|
| 196 |
+
|
| 197 |
+
reference:
|
| 198 |
+
|
| 199 |
+
[zarbot: 谈谈微信+DeepSeek](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s/TGzU5oA4hEOvqFJYzBaRSw)
|
| 200 |
+
|
| 201 |
+
————————
|
| 202 |
+
|
| 203 |
+
欢迎评论区友好学术讨论,抓到计算中的错误来完善这个理论推导。对喷非所愿,喷就是你对 :D
|
articles/05-29841050824-DeepSeek-V3-R1-推理效率分析(2)-DeepSeek-满血版逆向工程分析.md
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DeepSeek V3/R1 推理效率分析(2): DeepSeek 满血版逆向工程分析"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/29841050824
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/29841050824
|
| 5 |
+
author: "Han Shen"
|
| 6 |
+
published: 2025-03-12T15:28:18.000Z
|
| 7 |
+
modified: 2025-03-24T03:35:02.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DeepSeek V3/R1 推理效率分析(2): DeepSeek 满血版逆向工程分析
|
| 11 |
+
|
| 12 |
+
3.21 update: 官方放出来了decoding.json,从moe layer 来看单moe层双microbatch 714 \* 2 = 1.4 ms 左右,端到端在87ms~96ms左右,效率比mtp=1 略高,overlap和逐层profiling方法是一样的,具体数值不再更新。
|
| 13 |
+
|
| 14 |
+
3.16 update: 更新 Decode 部分 bmm的profiling 数值。
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
## 1. 前言
|
| 19 |
+
|
| 20 |
+
之前的一些“不负责任”的[定性估计](https://zhuanlan.zhihu.com/p/27292649125)意外地受到了挺多同学的关注,很多同学在评论区也提出了相关的疑问。尽管从“估计上限”这个目标来说,上次的分析完成了它的使命(避免了一些天方夜谭的数字上限,变成打工人的索命KPI),但是对于已经放出来timeline的DeepSeek R1性能估计来说还是太糙了。方法论上存在以下几个问题:
|
| 21 |
+
|
| 22 |
+
**a) 上界可达性:**
|
| 23 |
+
|
| 24 |
+
> 联合考虑计算和通信两者,在不开启MTP的情况下,R1的 EP256 H800 FP8单卡吞吐的上限在3300(combine BF16)-5000(combine FP8) tokens/s,H20 的上限在1600 tokens/s 左右。
|
| 25 |
+
|
| 26 |
+
记单卡吞吐为 TT ,之前用了一个naive 的吞吐估计方法——Toverall=min(Tnet,Tcompute)T\_{overall} = min(T\_{net}, T\_{compute}) 。尽管这样取出来的最小值一定是最终吞吐的上界,但不一定是一个“可达上界”: TnetT\_{net} 是一个相对紧且实际的bound,但是用 TcomputeT\_{compute} 不应该直接取峰值算力折合吞吐 TcomputepeakT\_{compute}^{peak} ,它的实际取值往往和MFU及overlap设计有关:
|
| 27 |
+
|
| 28 |
+
- 对于H800, 如果网络通信无法完全掩盖计算(即 Tcompute=Tcomputepeak∗MFU<TnetT\_{compute} = T\_{compute}^{peak} \* MFU < T\_{net} ),那么 TnetT\_{net} 是不可达的,此时可达上界取决于 TcomputeT\_{compute} 。
|
| 29 |
+
- 对于H20, 尽管有 Tcomputepeak<TnetT\_{compute}^{peak} < T\_{net} ,然而也需要考虑MFU的折损,实际可达的吞吐只能是 Tcomputepeak∗MFUT\_{compute}^{peak}\*MFU , MFU主要取决于非通信算子的实现效率。
|
| 30 |
+
|
| 31 |
+
**b) Expert 饱和点的计算**
|
| 32 |
+
|
| 33 |
+
上次饱和点估计时使用到了 bmla∗9∗d/ne≥bep\_satb\_{mla} \* 9 \* d / n\_e \ge b\_{ep\\_sat} ,这里取饱和点的时候用的是dense gemm估计的一个batch值(来源于我之前BF16 gemm的经验外推),有以下几个问题:
|
| 34 |
+
|
| 35 |
+
- 一方面是没有测过完整的FP8 gemm 测试曲线,对饱和点可能有较大偏差;
|
| 36 |
+
- 另一方面没有考虑group gemm对TFLOPS的提升——使用 bep\_sat=4096b\_{ep\\_sat} = 4096 假设的是单个expert gemm就能打满GPU 算力,显然忽略了当gemm尺寸较小时group gemm对SM利用率(从而对整体TFLOPS)表现的提升。这样算出来的结果会导致设备数 dd 的估计偏大,无法实现很多同行最关心的问题——更少的卡数组EP是否能达到同样效果的讨论。
|
| 37 |
+
- 考虑Group Gemm, bep\_satb\_{ep\\_sat} 应该是一个与 group\_numbergroup\\_number 、 m\_per\_groupm\\_per\\_group 相关的值,与等式左边的 d/n\_e 相关。
|
| 38 |
+
|
| 39 |
+
针对上述问题,本着自己挖坑自己埋的操守,本文希望结合DeepSeek放出来的所有公开信息:[FlashMLA](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/FlashMLA)、[DeepEP](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/DeepEP)、[DeepGemm](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/DeepGEMM)、[Profile-data](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/profile-data%3Ftab%3Dreadme-ov-file),及[DeepSeek V3/R1 推理系统概览](https://zhuanlan.zhihu.com/p/27181462601),对DeepSeek EP144 做一个比较完备的逆向工程 :D。笔者水平有限,如有错漏欢迎指出。
|
| 40 |
+
|
| 41 |
+
> 注:这里不再区分V3和R1,而是使用[DeepSeek V3/R1 推理系统概览](https://zhuanlan.zhihu.com/p/27181462601)里的平均分布来统称“满血版”。既然要对齐官方,这里相对之前做估计的时候的粗糙假设修正了两个地方:
|
| 42 |
+
> 1. 考虑shared expert 每个设备都存放副本,而不是EP320 一样shared expert 冗余分布在独立节点
|
| 43 |
+
> 2. 考虑专家冗余,prefill与decode 都为 256 个路由专家+32个冗余专家
|
| 44 |
+
|
| 45 |
+
## 2. DeepSeek 满血版逆向工程分析
|
| 46 |
+
|
| 47 |
+
DeepSeek 官方放出来的关键数据
|
| 48 |
+
|
| 49 |
+
- **Prefill**:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
|
| 50 |
+
- **Decode**:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
|
| 51 |
+
- 输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存��
|
| 52 |
+
- 输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
|
| 53 |
+
- 平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
|
| 54 |
+
|
| 55 |
+
## 2.1 平均 P/D 长度
|
| 56 |
+
|
| 57 |
+
这里按
|
| 58 |
+
|
| 59 |
+
[@天阿西吧](https://www.zhihu.com/people/98fbb29dec79005c2a71ac6bff0d88f7)
|
| 60 |
+
|
| 61 |
+
在之前评论区提到的算法:
|
| 62 |
+
|
| 63 |
+
> 假设P代表sequence的平均输入长度,D代表sequence的平均输出长度,那对于每一个输出token的平均KVcache的长度约等于P+D/2=4989; 再加上P/D=608B/168B;P的取值大概为4383,D的取值大概为1210。
|
| 64 |
+
|
| 65 |
+
因此 \bar P = 4383, \bar D = 1210 ,attention kvcache平均长度为 s' = 4989 \approx 5000
|
| 66 |
+
|
| 67 |
+
## 2.2 平均 P/D 实例数
|
| 68 |
+
|
| 69 |
+
为了达到P/D 的消费均衡,来看一下4节点的Prefill instance和18 节点的Decode instance配比:
|
| 70 |
+
|
| 71 |
+
设prefill node 为 x 组,decode node 为 y 组,平均意义上 4x + 18y = 226.75
|
| 72 |
+
|
| 73 |
+
- 从输入总吞吐量来反推,并发度约为 (608-342)\*10^9 / 24 / 3600 /(73.7\*43.7\%\*1000) = 96 nodes
|
| 74 |
+
- 从输出总吞吐反推, 168B/24/3600/14.8/1000 = 131 nodes ,那么可以估计出平均意义上P/D组建的集群配置为 x \approx 24, y \approx 7
|
| 75 |
+
|
| 76 |
+
即平均 24组prefill实例与7组decode实例,能比较均衡地支持DeepSeek所需线上负载。
|
| 77 |
+
|
| 78 |
+
## **2.3 Prefill 分析**
|
| 79 |
+
|
| 80 |
+
根据 prefill的[timeline](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/profile-data/blob/main/prefill.json) setting,prefill 用的4k的prompt,每卡16k tokens做2 microbatch。因此可以推断单个microbatch的b=2, s=4096。因为prefill overlap的方式两个microbatch 负载均衡,这里先只考虑单个microbatch的。
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
DP-32, EP-32 prefill 2-microbatch overlap timeline
|
| 85 |
+
|
| 86 |
+
## 2.3.1 prefill 单microbatch 单层profiling
|
| 87 |
+
|
| 88 |
+
**核心计算部分**
|
| 89 |
+
|
| 90 |
+
给一个之前画的比较糙的prefill MLA 示意图, 符号和[这里](https://zhuanlan.zhihu.com/p/27292649125)定义的不太一样,有一点abuse大家能看明白就行:
|
| 91 |
+
|
| 92 |
+
c' = 1536,r = 64, a/n\_{head} = 128, d = 128, h = 7168
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
- **QKV projection**
|
| 97 |
+
- X@(Concat(W\_Q', W\_p,W\_{KR})): [b\*s, 7168] @ [7168, 2112] = 2\*2\*4096\*7168\*2112/10^9 = 248 GFLOPs
|
| 98 |
+
- Q' @Concat(W\_{UQ}, W\_{QR}): [b\*s, 1536] @ [1536, 24576] = 2\*2\*4096\*1536\*24576/10^9 = 618.5 GFLOPs
|
| 99 |
+
- KV @ Concat(W\_{UK}, W\_{UV}): \\ [b\*s, 512] @ [512, 128\*128\*2] = 2\*2\*4096\*512\*32768/10^9 = 274 GFLOPs
|
| 100 |
+
- **MLA(MHA) Attention:**
|
| 101 |
+
- Q^T @ K: 2 \* b\*s\*s\*n\_{head}\*(d+r)/2(causal) = 2 \* 2 \* 4096 \* 4096 \* 128 \* 196 /10^9 / 2= 841.5 GFLOPs
|
| 102 |
+
- P@V: 2 \* b\*s\*s\*n\_{head}\*(d)/2(causal) = 2 \* 2 \* 4096 \* 4096 \* 128 \* 128 /10^9/2 = 550 GFLOPs
|
| 103 |
+
- **O Projection**
|
| 104 |
+
- [b\*s, 128\*128] @ [128\*128, 7168] = 2 \* 2 \* 4096 \* 16384\*7168/10^9 = 1924 GFLOPs
|
| 105 |
+
- **Router Gemm**
|
| 106 |
+
- group\\_number=9, m\\_per\\_group = b\*s \* 8 \* 32/ (256+32) = 7281
|
| 107 |
+
- Up \& Gate\ Gemm: 9 \* [7281, 7168] @ [7168, 4096] = 2 \* 9 \* 7281 \* 7168 \* 4096 / 10^9 = 3848 GFLOPs
|
| 108 |
+
- Down\ Gemm: 9 \* [7281, 2048] @ [2048, 7168] = 2 \* 9 \* 7281 \* 7168 \* 2048 / 10^9 = 1924 GFLOPs
|
| 109 |
+
- **Shared Gemm**
|
| 110 |
+
- Up\&Gate\ Gemm: [2 \* 4096, 7168] @ [7168, 4096] = 2 \* 8192 \* 7168 \* 4096 / 10^9 = 481 GFLOPs
|
| 111 |
+
- Down\ Gemm: [2 \* 4096, 2048] @ [2048, 7168] = 2 \* 8192 \* 7168 \* 2048 / 10^9 = 241 GFLOPs
|
| 112 |
+
|
| 113 |
+
**网络通信部分**
|
| 114 |
+
|
| 115 |
+
由于只有4台机器,网络上限的估计符合我们之前谈到的intra-device deduplication的传输方式,这里总共4个节点,所以最多每个token往外发3个副本,因此通信量:
|
| 116 |
+
|
| 117 |
+
- **Dispatch(单层)**
|
| 118 |
+
- (2\*4096\*7168\*3/1024/1024) = 168 MB
|
| 119 |
+
- **Combine (单层)**
|
| 120 |
+
- (2\*2\*4096\*7168\*3/1024/1024) = 336 MB
|
| 121 |
+
|
| 122 |
+
得到计算量和通信量之后,我们对prefill.json 的timeline 时间进行分析:
|
| 123 |
+
|
| 124 |
+

|
| 125 |
+
|
| 126 |
+
prefill timeline overlap 真实情况
|
| 127 |
+
|
| 128 |
+
**单层单microbatch 耗时与TFLOPS分布**
|
| 129 |
+
|
| 130 |
+
这里为了overlap 计算普遍采用了108 个 SM core,通信采用24个SM core。Gemm计算相比独占牺牲了10%~20%的MFU。
|
| 131 |
+
|
| 132 |
+
| | | | |
|
| 133 |
+
| --- | --- | --- | --- |
|
| 134 |
+
| | 浮点计算数(GFLOPs) | Duration(us) | TFLOPS |
|
| 135 |
+
| Dense Gemm & MLA |
|
| 136 |
+
| X@(Concat(W\_Q', W\_p,W\_{KR}))[7168,2112] | 248 | 268 | 925.5 |
|
| 137 |
+
| Q' @Concat(W\_{UQ}, W\_{QR}) [1536,24576] | 618.5 | 922 | 670.8 |
|
| 138 |
+
| KV @ Concat(W\_{UK}, W{UV} [512,32768] | 274 | 533 | 515.7 |
|
| 139 |
+
| MHA Attention | 1392 | 2683 | 519 |
|
| 140 |
+
| O Projection [16384,7168] | 1924 | 1652 | 1164.7 |
|
| 141 |
+
| Expert Gemm |
|
| 142 |
+
| Shared Up&Gate[7168, 4096] | 481.04 | 439 | 1095 |
|
| 143 |
+
| Shared Down[2048, 7168] | 240.5 | 306 | 786 |
|
| 144 |
+
| Routed Up&Gate[7168, 4096] | 3848.3 | 3534 | 1089 |
|
| 145 |
+
| Routed Down[2048, 7168] | 1924 | 2381 | 808 |
|
| 146 |
+
| Communication |
|
| 147 |
+
| | 通信量(MegaBytes) | Duration(us) | Bandwidth(GB/s) |
|
| 148 |
+
| Dispatch notify | | 743 | |
|
| 149 |
+
| Dispatch Alltoall | 168 | 4326 | 38 |
|
| 150 |
+
| Cache notify | | 788 | |
|
| 151 |
+
| Combine Alltoall | 336 | 8845 | 37 |
|
| 152 |
+
| Others:In total 3004 us |
|
| 153 |
+
| Attn part: add & LayerNorm & Rope | | 549 | |
|
| 154 |
+
| Attn part: Attn BF16-to-FP8 to O projection | | 232 | |
|
| 155 |
+
| Gate part: router gate & prepare shared gemm | | 529 | |
|
| 156 |
+
| Expert part: prepare router gemm | | 728 | |
|
| 157 |
+
| Expert part: Swiglu | | 314 | |
|
| 158 |
+
| Expert part: Combine reduce | | 594 | |
|
| 159 |
+
|
| 160 |
+
主要计算耗时12.7ms
|
| 161 |
+
|
| 162 |
+
| | | | | |
|
| 163 |
+
| --- | --- | --- | --- | --- |
|
| 164 |
+
| | GFLOPs | Duration(us) | Model TFLOPS | MFU |
|
| 165 |
+
| Gemms + Attn (SM 108) | 10950 | 12718 | 861 | 44% |
|
| 166 |
+
| Gemms + Attn + MemoryOps (SM 108) | ~10950 | 15722 | 696 | 35% |
|
| 167 |
+
|
| 168 |
+
## 2.3.2 prefill 单卡吞吐分析
|
| 169 |
+
|
| 170 |
+
**prefill timeline 吞吐分析**
|
| 171 |
+
|
| 172 |
+
从2.3.1 的 timeline 看,整个prefill 单次forward的总时长约为2118ms,对应单次forward 吞吐为 4\*4096/2.118 = 7735 tokens/s ,
|
| 173 |
+
|
| 174 |
+
而理论值
|
| 175 |
+
|
| 176 |
+
- 通信带宽按38GB/s来算, T\_{net} = 2\*4096\*38/((168+336)\*58/1024) = 10900 tokens/s
|
| 177 |
+
- 算力峰值来看, T\_{compute}^{peak} = 2\*4096\*1978\*1000/12341/61 = 21524 tokens/s ,实际达到 T\_{compute} = T\_{compute}^{peak} \* MFU = 21524 \* 0.35 =7533 tokens/s ,说明MFU 低的时候, T\_{compute} 成为了bound 吞吐的紧上界。
|
| 178 |
+
|
| 179 |
+
**prefill 线上平均吞吐分析**
|
| 180 |
+
|
| 181 |
+
根据线上数据,prefill 的单卡吞吐大约为 73.7k \* (1-56.3%) / 8 = 4025 tokens/s。
|
| 182 |
+
|
| 183 |
+
**结论:**可以看出,deepseek的峰值吞吐在***负载均衡下***能达到7735 tokens/s,之前平均数据得到的4k tokens/s是一个考虑到了全天波峰波谷没有打满/或者负载不均衡无法完全overlap的值。
|
| 184 |
+
|
| 185 |
+
## 2.4 Decode 分析
|
| 186 |
+
|
| 187 |
+
由于DeepSeek 官方尚未发布EP144 的decoding timeline,decoding部分的profiling数据来源于DeepGemm、FlashMLA的实测与少量估计:
|
| 188 |
+
|
| 189 |
+
让我们假设per GPU b\_{mla} 约为[profile\_data](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/profile-data) 里的128。于是每个micro-batch 的 b\_{mla} = 64 。
|
| 190 |
+
|
| 191 |
+
根据DP144-EP144,expert 部分的router expert 平均接收到 64\*144\*8/(256 + 32) = 256 tokens ,即 m\\_per\\_group= 256 ,单卡 group\\_number = (256+32)/144 = 2 。
|
| 192 |
+
|
| 193 |
+
## 2.4.1 decode 单microbatch 单层profiling
|
| 194 |
+
|
| 195 |
+
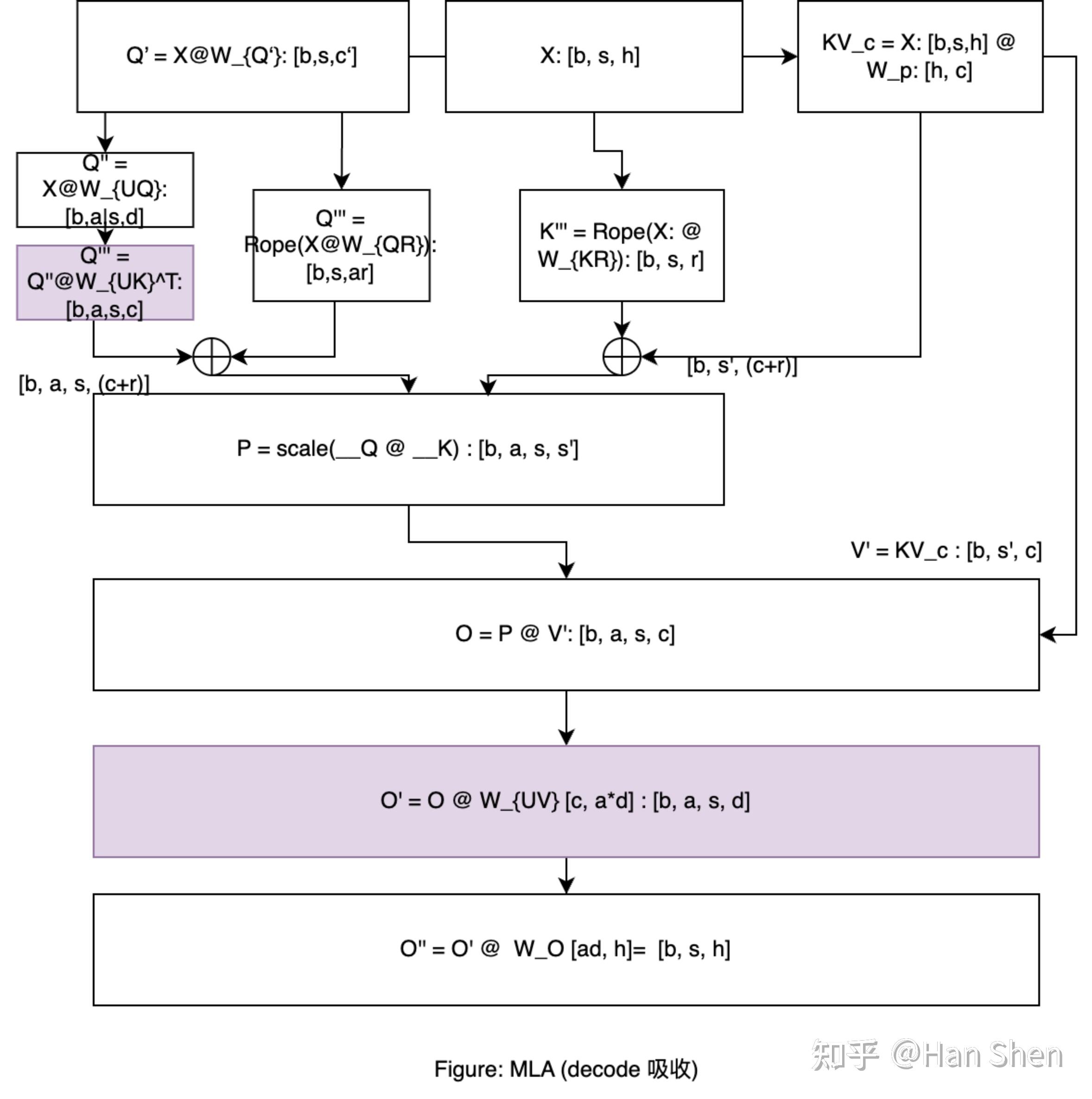
考虑 MLA 吸收矩阵,稍微和prefill不太一样:**(此处更新了一下吸收部分的示意,根据[sglang](https://link.zhihu.com/?target=https%3A//github.com/sgl-project/sglang/blob/e1a5e7e47ddc35e55f87a0e66e4306bff62cdef6/python/sglang/srt/models/deepseek_v2.py%23L684) 的实现,确认紫色部分为bmm,不是吸收后的普通linear,bmm 的实现目前使用torch.bmm 的bf16 gemm 来进行模拟,乘上一个1.7的折扣系数来近似fp8 bmm的性能,据此更新了之后profiling的数据)**
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
**核心计算部分**
|
| 200 |
+
|
| 201 |
+
- **QKV projection**
|
| 202 |
+
- X@(Concat(W\_Q', W\_p,W\_{KR})): [b\*s, 7168] @ [7168, 2112] = 2\*64\*7168\*2112/10^9 = 1.94 GFLOPs
|
| 203 |
+
- Q'' = Q' @Concat(W\_{Qf}, W\_{QR}): [b\*s, 1536] @ [1536, 24576] = 2\*64\*1536\*24576/10^9 = 4.83 GFLOPs
|
| 204 |
+
- Q''' = bmm (Q'', W\_{UK}^T): bmm([128, b\*s, 128], [128, 128, 512]) = 2 \* 128 \* 64 \* 1 \* 128 \* 512 / 10^9 = 1.07 GFLOPs
|
| 205 |
+
- **MLA/MQA Attention**
|
| 206 |
+
- Q^T @ K: 2 \* b\*s\*s'\*n\_{head}\*(c+r) = 2 \* 64\* 5000 \* 128 \* 576 /10^9 = 47.2 GFLOPs
|
| 207 |
+
- O=P@V: 2 \* b\*s\*s'\*n\_{head}\*(c) = 2 \* 64 \* 5000 \* 128 \* 512 /10^9 = 41.9 GFLOPs
|
| 208 |
+
- **O Projection**
|
| 209 |
+
- O' = bmm(PV, W\_{UV}): [n\_{head}, b\*s, c] @ [n\_{head}, c, d] = 2 \*n\_{head} \* b \* s \* c \* d = 2 \* 128 \* 64 \* 1 \* 512 \* 128 /10^9 = 1.1 GFLOPs
|
| 210 |
+
- O' Projection: [b\*s, 128\*128] @ [128\*128, 7168] = 2 \* 64 \* 16384\*7168/10^9 = 15 GFLOPs
|
| 211 |
+
- **Router Gemm**
|
| 212 |
+
- group\\_number=2, m\_{per\\_expert}= b\*s \* 8 \* d/ (256+32) = 256
|
| 213 |
+
- Up\&Gate\ Gemm: 2 \* [256, 7168] @ [7168, 4096] = 2 \* 2 \* 256 \* 7168 \* 4096 / 10^9 = 30 GFLOPs
|
| 214 |
+
- Down\ Gemm: 2 \* [256, 2048] @ [2048, 7168] = 2 \* 2\* 256 \* 7168 \* 2048 / 10^9 = 15 GFLOPs
|
| 215 |
+
- **Shared Gemm**
|
| 216 |
+
- Up\&Gate\ Gemm: [64, 7168] @ [7168, 4096] = 2 \* 64 \* 7168 \* 4096 / 10^9 = 3.76 GFLOPs
|
| 217 |
+
- Down\ Gemm: [64, 2048] @ [2048, 7168] = 2 \* 64 \* 7168 \* 2048 / 10^9 = 1.88 GFLOPs
|
| 218 |
+
|
| 219 |
+
**网络通信部分**
|
| 220 |
+
|
| 221 |
+
由于decode 节点数不会太小,我们先假设会有8台以上机器。网络上限的估计按通信最不友好的方式,往另外8个节点法,所以最多每个token往外发8个副本,因此通信量:
|
| 222 |
+
|
| 223 |
+
- **Dispatch(单层)**
|
| 224 |
+
- (64\*8\*7168/1024/1024) = 3.5 MB
|
| 225 |
+
- **Combine (单层)**
|
| 226 |
+
- (2\*64\*7168\*8/1024/1024) = 7 MB
|
| 227 |
+
|
| 228 |
+
访存密集算子的耗时根据2.3里prefill 的耗时按token数等比折算(在带宽bound下相对合理), 比如对于router gate & prepare shared gemm: 529/9/7281\*2\*256 = 4.13 ;
|
| 229 |
+
|
| 230 |
+
ContextLen 按DeepSeek 实际 s' = P+D/2 \approx 5000 带入
|
| 231 |
+
|
| 232 |
+
| | | | |
|
| 233 |
+
| --- | --- | --- | --- |
|
| 234 |
+
| | 浮点计算数(GFLOPs) | Duration(us) | TFLOPS |
|
| 235 |
+
| Dense Gemm |
|
| 236 |
+
| X@(Concat(W\_Q', W\_p,W\_{KR}))[7168,2112] | 1.94 | 10 | 190 |
|
| 237 |
+
| Q' @Concat(W\_{UQ}, W\_{QR})[1536,24576] | 4.83 | 17 | 280 |
|
| 238 |
+
| Q''' = bmm(Q'', W\_{UK}^T) bmm([128, bs, 128], [128, 512, 128]) | 1.07 | 10 | 112 |
|
| 239 |
+
| MLA/MQA Attention | 89.1 | 196 | 462 |
|
| 240 |
+
| O' = bmm(PV, W\_{UV}) bmm([128, bs, 512], [128, 512, 128]) | 1.1 | 8 | 132 |
|
| 241 |
+
| O Projection[16384,7168] | 15 | 46 | 326 |
|
| 242 |
+
| Expert Gemm |
|
| 243 |
+
| Shared Up&Gate[7168, 4096] | 3.76 | 14 | 270 |
|
| 244 |
+
| Shared Down[2048, 7168] | 1.88 | 7 | 258 |
|
| 245 |
+
| Routed Up&Gate[7168, 4096] | 30 | 33 | 898 |
|
| 246 |
+
| Routed Down[2048, 7168] | 15 | 20 | 753 |
|
| 247 |
+
| Communication |
|
| 248 |
+
| | 通信量(MegaBytes) | Duration(us) | Bandwidth(GB/s) |
|
| 249 |
+
| Dispatch Alltoall | 3.5 | 88 | 39 |
|
| 250 |
+
| Combine Alltoall | 7 | 175 | 39 |
|
| 251 |
+
| Others: In total 23us (估) |
|
| 252 |
+
| Attn part: add & LayerNorm & Rope | | 4.29 | |
|
| 253 |
+
| Attn part: Attn BF16-to-FP8 to O projection | | 1.81 | |
|
| 254 |
+
| Gate part: router gate & prepare shared gemm | | 4.13 | |
|
| 255 |
+
| Expert part: prepare router gemm | | 5.69 | |
|
| 256 |
+
| Expert part: router swiglu | | 2.45 | |
|
| 257 |
+
| Expert part: Combine reduce | | 4.64 | |
|
| 258 |
+
|
| 259 |
+
主要计算耗时350us
|
| 260 |
+
|
| 261 |
+
| | | | | |
|
| 262 |
+
| --- | --- | --- | --- | --- |
|
| 263 |
+
| | GFLOPs | Duration(us) | Model TFLOPS | MFU |
|
| 264 |
+
| Gemms + Attn (SM 132) | 164 | 361 | 454 | 23% |
|
| 265 |
+
| Gemms + Attn + MemoryOps (SM 132) | ~164 | 384 | 427 | 21.5% |
|
| 266 |
+
|
| 267 |
+
## 2.4.2 decode 单卡吞吐分析
|
| 268 |
+
|
| 269 |
+
**decode timeline 吞吐分析**
|
| 270 |
+
|
| 271 |
+
由于没有完整的timeline,我们对decode 整个耗时进行一次拆解:
|
| 272 |
+
|
| 273 |
+
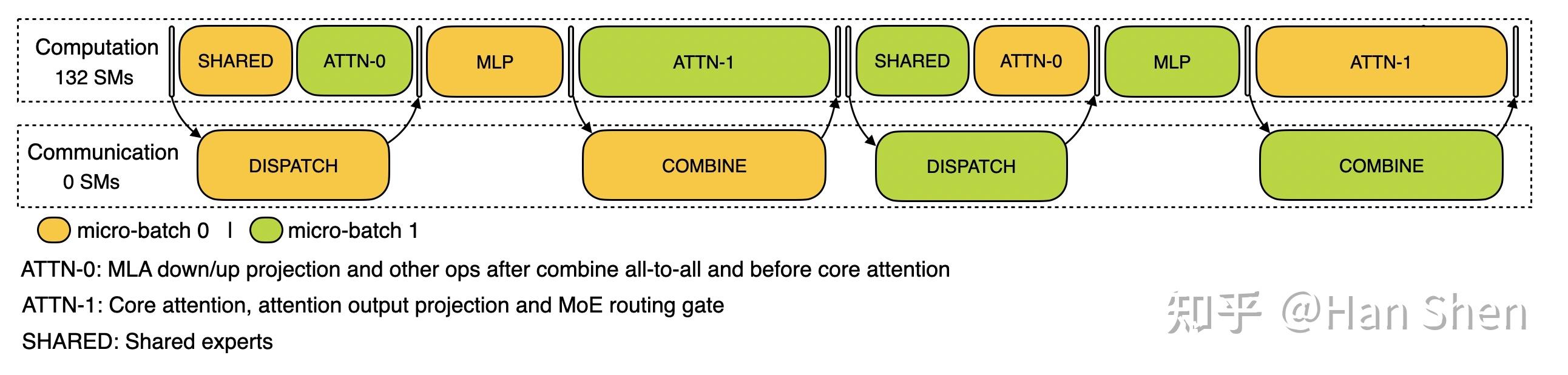
|
| 274 |
+
|
| 275 |
+
DP-144, EP-144 decode 2-microbatch overlap timeline
|
| 276 |
+
|
| 277 |
+
- **Shared + Attn0**
|
| 278 |
+
- Shared + MLA QKV gemm + AfterCombineReduce + BeforeCoreAttention, 10+17+10+14+7+4.1+4.6+4.29 = 71 us < 88us。这部分没有完全藏住通信,因此88us
|
| 279 |
+
- **MLP 部分**
|
| 280 |
+
- Prepare + Router Gemm + SwiGlu: 5.69 + 33 + 20 + 2.45 = 61 us
|
| 281 |
+
- **Attn1**
|
| 282 |
+
- Core attention + O projection + Routing gate: 196 + 8 + 46 + 1.81 + 4.13 = 255 us > 174us,盖住了combine,因此约255us
|
| 283 |
+
|
| 284 |
+
因此单层forward时间约为88+71+255 = 414, 前三层没有通信 384 us差不多,于是单iter forward 时间(包括2个microbatch)约为
|
| 285 |
+
|
| 286 |
+
(384\*3 +414\*58)\*2 = 50ms
|
| 287 |
+
|
| 288 |
+
**这意味着TPOT 大约在50ms,也就是per user 平均 20 tokens/s 左右的延迟**,同时单卡吞吐约为 64\*2\*1000/50=2560 tokens/s 。
|
| 289 |
+
|
| 290 |
+
**decode 线上平均吞吐分析**
|
| 291 |
+
|
| 292 |
+
根据线上数据,decode 的单卡吞吐大约为 14.8 \* 1000 / 8 = 1850 tokens/s,实际单卡并发数为 per GPU
|
| 293 |
+
|
| 294 |
+
b\_{mla}=1850/21=88 左右。
|
| 295 |
+
|
| 296 |
+
**结论:**可以看出,deepseek的峰值吞吐在***负载均衡下***能达到2560 tokens/s,之前平均数据得到的1850 tokens/s是一个考虑到了全天波峰波谷没有打满的值。
|
| 297 |
+
|
| 298 |
+
## 2.5 Overlap 方式的选择
|
| 299 |
+
|
| 300 |
+
从官方的pipeline 示意图我们可以发现,prefill 和decode 用到了不一样的overlap策略,其中prefill 部分匀出了24个SM core 进行通信,而decode 部分并没有消耗SM。
|
| 301 |
+
|
| 302 |
+
我们先忽略为了追求延迟在decode 引入IBGDA实现上的差异,先看看如果想要讲通信与计算overlap,我们怎么设计:
|
| 303 |
+
|
| 304 |
+
> 笔者推测,引入IBGDA主要是在小传输量下达到更低的延迟,在DeepEP里体现为更高的等效带宽,不影响overlap分析。
|
| 305 |
+
|
| 306 |
+
对于prefill来说,Gemm计算密集型的算子占据主导,因此可以基本忽略memory-bound的算子开销。可以先画出蓝色部分的单microbatch 时序依赖图。剩下的工作时如何将 dispatch (dispatch notify + alltoall ~ 5ms) 与combine(cache notify + alltoall ~ 9.6ms)带来的bubble填满。我们很容易的发现,QKV + Core Attention.+ O projection的计算时间约为6ms,而MLP 计算时间约为5.9ms,两者正好与dispatch 的耗时相近且依赖错开。于是很自然地构造出下面双batch overlap方式:为了尽量填满combine,将shared expert计算挪到了与combine overlap的位置。
|
| 307 |
+
|
| 308 |
+
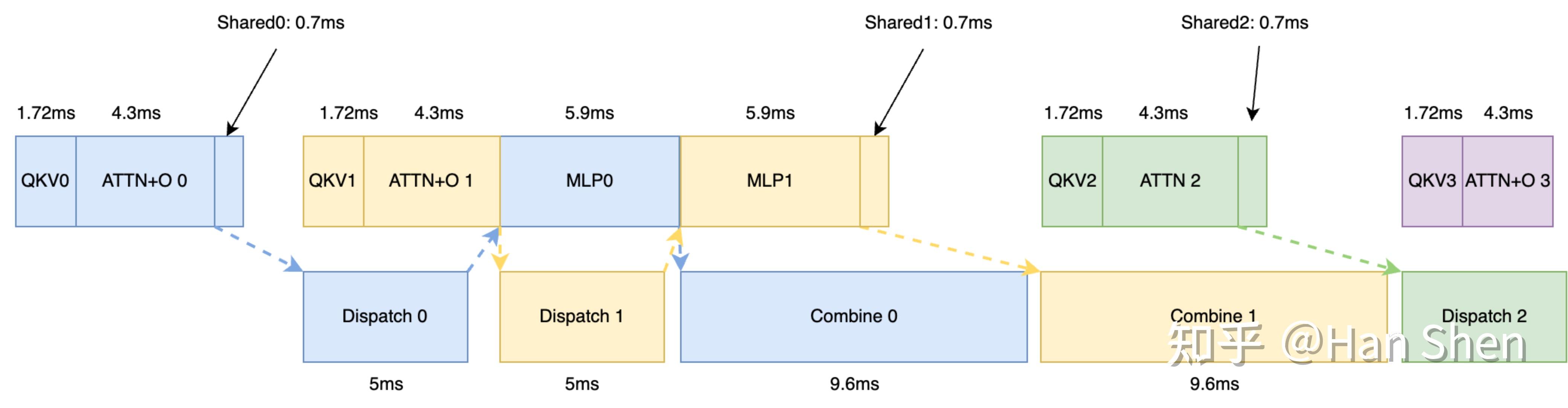
|
| 309 |
+
|
| 310 |
+
Prefill overlap 示意
|
| 311 |
+
|
| 312 |
+
由于decode gemm算子都相对较小,这里无法忽略memory bound的算子开销,
|
| 313 |
+
|
| 314 |
+
我们用以下符号来表示:
|
| 315 |
+
|
| 316 |
+
**QKV(**QKV Attn part: add & LayerNorm & Rope + QKV gemm) = 10 + 17 + 10 + 4.29 = 41.3us
|
| 317 |
+
|
| 318 |
+
**ATTN + O + Gate(**Core MLA Attention + O projection + Routing gate): 196 + 8 + 46 = 250us
|
| 319 |
+
|
| 320 |
+
**Shared(**Prepare + Shared expert gemms): 4.13 + 14 + 7 = 25.1 us
|
| 321 |
+
|
| 322 |
+
> 注:因为Gate耗时较小,这里还是加到Shared里了
|
| 323 |
+
|
| 324 |
+
**MLP(** Prepare + Router Gemms + SwiGlu**):** 5.69 + 33 + 20 +2.45 = 61us
|
| 325 |
+
|
| 326 |
+
对于decode来说,也是先画出单microbatch的时序依赖,如下图蓝色模块。
|
| 327 |
+
|
| 328 |
+
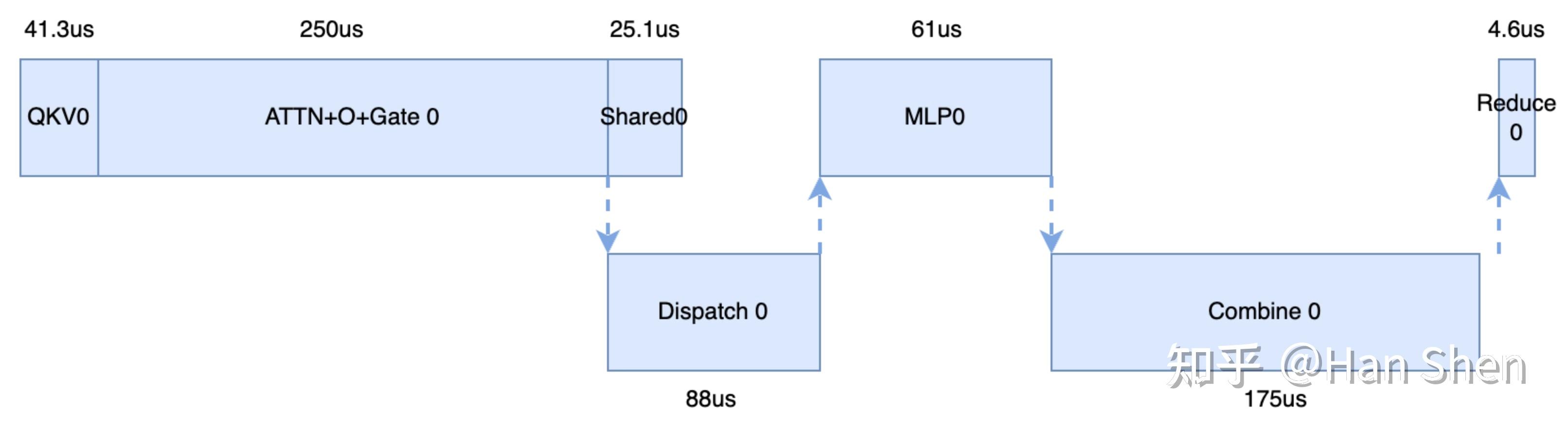
|
| 329 |
+
|
| 330 |
+
我们发现由于MLA Core Attention 的计算在decode部分占据了主导部分,不能再继续把MLA Core Attention 与Dispatch overlap了,而是应该尽量让Core Attention 与Combine 进行overlap。于是易得下面的overlap方式,与官方给出的overlap 方式一致。
|
| 331 |
+
|
| 332 |
+

|
| 333 |
+
|
| 334 |
+
## 3. 结论
|
| 335 |
+
|
| 336 |
+
至此,我们对DeepSeek 放出来的信息做了一个相对完备的拆解。本来寄希望��在本文里完成更多泛化性讨论的,但是工作量实在是有点大,阅读起来也会相对困难,如有关心的朋友,请等等下一篇 TAT。
|
| 337 |
+
|
| 338 |
+
## 4. 参考材料
|
| 339 |
+
|
| 340 |
+
- [FlashMLA](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/FlashMLA)
|
| 341 |
+
- [DeepEP](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/DeepEP)
|
| 342 |
+
- [DeepGemm](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/DeepGEMM)
|
| 343 |
+
- [Profile-data](https://link.zhihu.com/?target=https%3A//github.com/deepseek-ai/profile-data%3Ftab%3Dreadme-ov-file)
|
| 344 |
+
- [DeepSeek V3/R1 推理系统概览](https://zhuanlan.zhihu.com/p/27181462601)
|
articles/06-29540042383-DeepSeek-V3-R1-推理效率分析(3):Decode-配置泛化讨论.md
ADDED
|
@@ -0,0 +1,511 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DeepSeek V3/R1 推理效率分析(3):Decode 配置泛化讨论"
|
| 3 |
+
source: https://zhuanlan.zhihu.com/p/29540042383
|
| 4 |
+
fetched_url: https://zhuanlan.zhihu.com/p/29540042383
|
| 5 |
+
author: "Han Shen"
|
| 6 |
+
published: 2025-03-17T04:46:09.000Z
|
| 7 |
+
modified: 2025-08-30T15:03:25.000Z
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# DeepSeek V3/R1 推理效率分析(3):Decode 配置泛化讨论
|
| 11 |
+
|
| 12 |
+
## 1. 前言
|
| 13 |
+
|
| 14 |
+
经过了 [DeepSeek 逆向分析](https://zhuanlan.zhihu.com/p/29841050824) 之后,我们已经有了充足的数据和方法论来回答以下问题:
|
| 15 |
+
|
| 16 |
+
- 不同的 DP-EP 数会对吞吐产生什么影响?
|
| 17 |
+
- 其他硬件运行Dpsk V3/R1的表现将会如何?
|
| 18 |
+
|
| 19 |
+
因为 Prefill 相对简单,本文只讨论 Decode 的泛化。
|
| 20 |
+
|
| 21 |
+
**TL;DR**
|
| 22 |
+
|
| 23 |
+
在笔者攥写本文期间,zarbot 大佬发布了一套DeepSeek V3 的理论估计方法([DeepSeek-V3/R1推理效率分析(v0.17)](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s/214lYyKmL3XmPUHnnTrbXg%3Fpoc_token%3DHP_h1mejDBJ27hrIlHk_43343NcCObXhDLUXleo-) ),并且在每天高速迭代中(太卷啦!)。笔者认为非常适合跨硬件平台进行性能的估算。虽然纯理论估计在mm/group mm/bmm/attention MFU 以及overlap 方式的估计上会有一些误差,但是为了做跨平台的估计在没有对应实现的时候,理论估计还是非常有用的,非常推荐。
|
| 24 |
+
|
| 25 |
+
本文和zarbot 的行文思路的区别在于,笔者致力于整合现有性能测试库(DeepGemm、FlashMLA和torch),做一套可以直接测试进行精准性能分析的模拟器,并且对overlap做了精细的建模,得到的结果应该相对来说比较准确。全部代码开源在[这里](https://link.zhihu.com/?target=https%3A//github.com/shenh10/DeepSeek_Simulator)。如果非Hopper 硬件想要尝试使用这个工具,可以试图将自己的算子测试库按格式接入测试脚本,就可以得到自动化模拟的结果了。
|
| 26 |
+
|
| 27 |
+
**测试硬件:**
|
| 28 |
+
|
| 29 |
+
- H800 80G
|
| 30 |
+
- H20 96G
|
| 31 |
+
|
| 32 |
+
**并行方式:**
|
| 33 |
+
|
| 34 |
+
- Attention DP , MoE EP
|
| 35 |
+
- Attention TP+DP, MoE EP
|
| 36 |
+
|
| 37 |
+
**Overlap 方式:**
|
| 38 |
+
|
| 39 |
+
- two-mircobatch overlapping (DeepSeek 官方)
|
| 40 |
+
- single-batch compute-communication overlapping
|
| 41 |
+
|
| 42 |
+
**结果:**
|
| 43 |
+
|
| 44 |
+
完整实验结果和分析见第4节。
|
| 45 |
+
|
| 46 |
+
## 2. H800 DP-EP 方案的泛化
|
| 47 |
+
|
| 48 |
+
**权重守恒等式的修正**
|
| 49 |
+
|
| 50 |
+
- per GPU batchsize为 b\_{mla}^{PerGPU}
|
| 51 |
+
- per microbatch 的batch size为 b\_{mla}
|
| 52 |
+
- 每层多出32个expert,计42MB \* 32 \* 58 = 78G
|
| 53 |
+
- 总shared expert 多出42MB \*58(d-1) = 2.38(d-1) GB
|
| 54 |
+
- 根据FlashMLA,使用BF16 kvcache 而不是FP8 kvcache,因此单token存储成本是34.3\*2 = 68.6KB。
|
| 55 |
+
- 修正H800 权重公式 80 \* d- 13 \* d/1.024^3 - 612 - 78 - 2.38(d-1) = 34.3\*2/1024/1024\*d\*b\_{mla}^{PerGPU}\* s' + C\_{constant\\_coefficient}\*b\_{mla}^{PerGPU}\*s'\*d ,化简可得 (56.6-(65.4\*10^{-6})b\_{mla}^{PerGPU}s') d = 688 。因此可以根据d来得到对 b\_{mla}^{PerGPU} 上限的估计。
|
| 56 |
+
|
| 57 |
+
通过对H800 设备数 d 的枚举,我们来看看 b\_{mla} 取不同值时的可选配置。因为
|
| 58 |
+
|
| 59 |
+
- 使用FP8 kvcache能有效打高 b\_{mla} ,值得估计一下FP8 kvcache的吞吐表现 (我们假设可以忽略FlashMLA 进行FP8 dequant的性能影响,直接用FlashMLA BF16 Attention的性能来近似)
|
| 60 |
+
- 或者可以采用microbatch-1或者microbatch-2的两种不同的overlap pipeline方式(见后文)
|
| 61 |
+
|
| 62 |
+
我们取到小于" b\_{mla}^{PerGPU\\_max} (FP8) No activation" 的最大2的次幂作为单microbatch b\_{mla} 的上界。最终在估计性能时只需要把实际部署上取不到的 b\_{mla} 配置忽略即可。(为了清晰只能多传一些截图代替富文本表格,放在这里吐槽一万遍知乎
|
| 63 |
+
|
| 64 |
+
[@知乎小管家](https://www.zhihu.com/people/3d198a56310c02c4a83efb9f4a4c027e)
|
| 65 |
+
|
| 66 |
+
对表格格式及表格内无法输入公式的菜鸡支持)
|
| 67 |
+
|
| 68 |
+
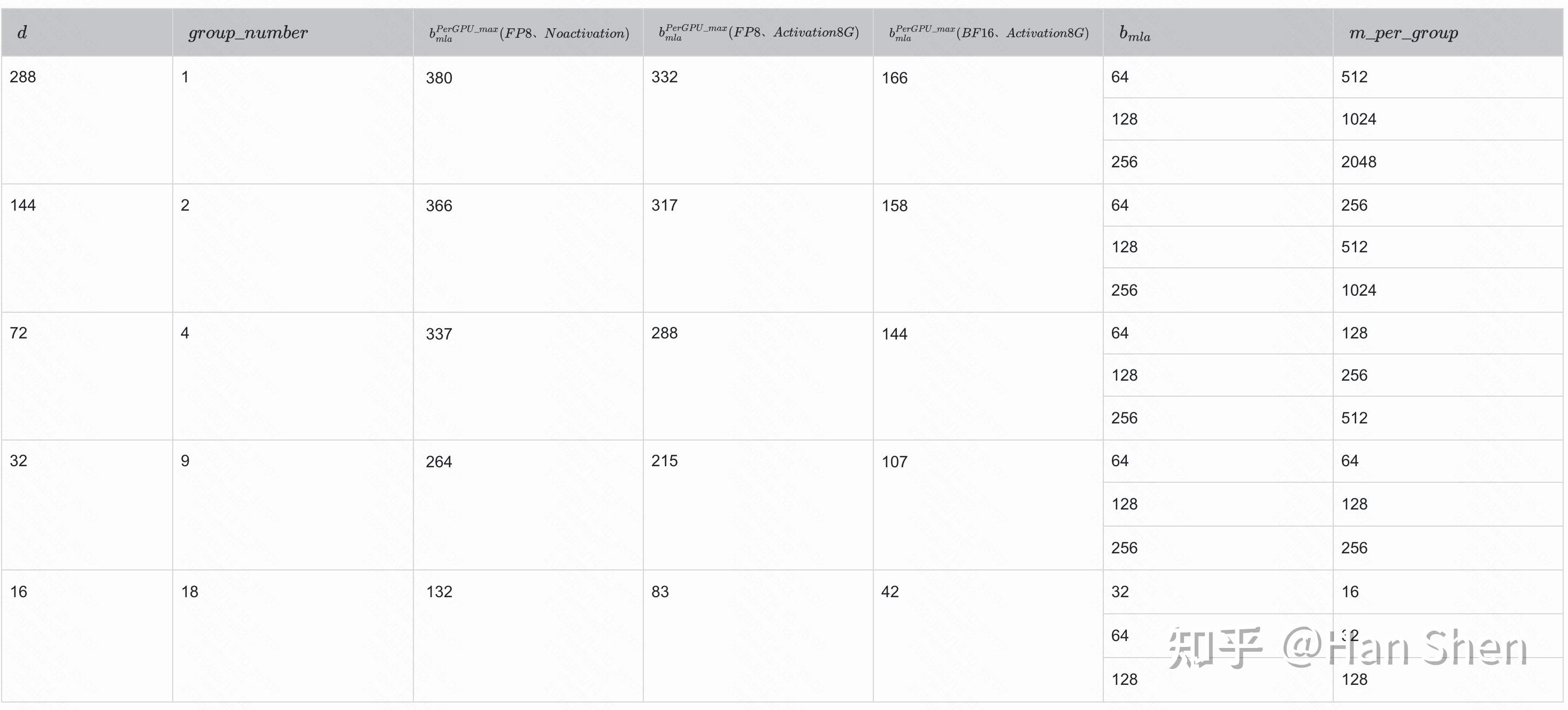
|
| 69 |
+
|
| 70 |
+
## 2.1 不同 shape 下 Dense Gemm 的性能分布
|
| 71 |
+
|
| 72 |
+
从 DeepGemm Dense Gemm的性能曲线来看,FP8 的峰值算力只能达到1400 TFLOPS,对应70% MFU,饱和点相对BF16 要早。
|
| 73 |
+
|
| 74 |
+
因为显存约束, b\_{mla} 的取值在 256 以内,只能达到最左4个点的TFLOPS。这时随着 b\_{mla} TFLOPS基本是线性增大的,实现上加速比不同shape略有差异。
|
| 75 |
+
|
| 76 |
+
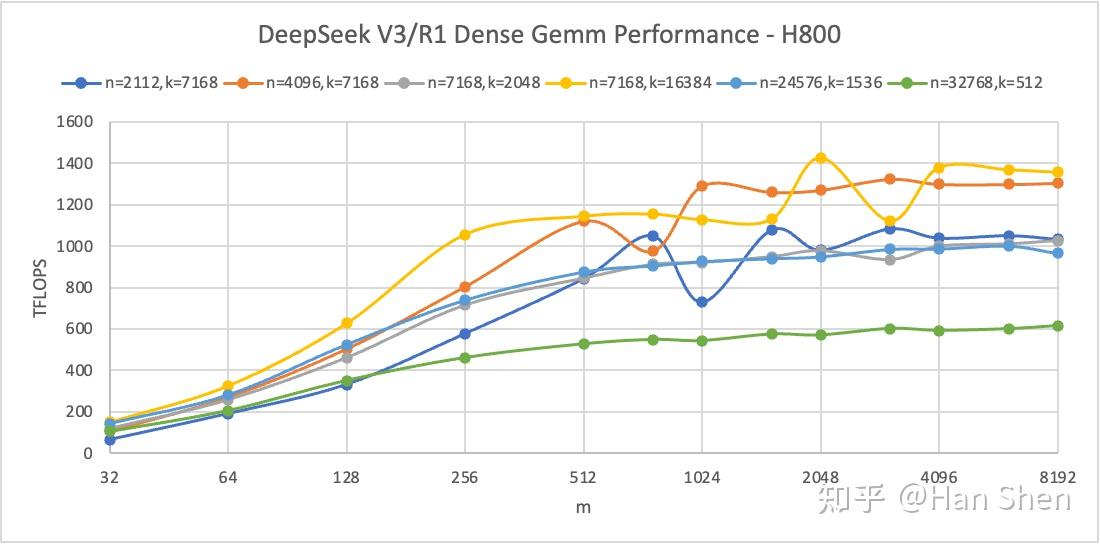
|
| 77 |
+
|
| 78 |
+
Dense Gemm 的特点是计算效率只与 b\_{mla} 有关,与设备数 d 无关。于是可以得到decoding 部分的dense gemm性能表现:
|
| 79 |
+
|
| 80 |
+

|
| 81 |
+
|
| 82 |
+
## 2.2 不同batch 下的 MLA Attention 性能分布
|
| 83 |
+
|
| 84 |
+
从FlashMLA测试结果来看,峰值算力基本就达到了500+TFLOPS了,笔者没来得及仔细研究FlashMLA的实现,可能和[ChiveArchitect:不同规格的芯片跑 Deepseek 671B 的单卡吞吐估算](https://zhuanlan.zhihu.com/p/28963593305) 提到的残血warp pipeline 有关。
|
| 85 |
+
|
| 86 |
+

|
| 87 |
+
|
| 88 |
+
## 2.3 不同设备数对 AlltoAll 通信的影响
|
| 89 |
+
|
| 90 |
+
这里通信值���讨论一下。假设
|
| 91 |
+
|
| 92 |
+
- 对H800 而言ConnectX-7 理论带宽50GB/s,实测带宽为39GB/s。拓扑上为PerGPUPerNIC的配置。
|
| 93 |
+
- 我们考虑的AlltoAll一直是bound在inter-device 通信上。对H800 而言,机内的通信带宽NVLINK 160GB/s / 7 = 29 GB/s < 40GB/s(机间带宽),因此存在极端情况,如果设备数只有2台以内,有可能会bound在节点内AlltoAll。但因为相对小概率(7个expert在机内,1个expert在跨机),所以暂时忽略不计。这里有两个延伸讨论:
|
| 94 |
+
|
| 95 |
+
- 如果网卡升级到下一代如ConnectX-8(实测估计80GB/s)而机内还是160GB/s,存在机内AlltoAll 会比机间(节点数较小时)慢的情况,此时对Expert locality要求会放松,需要平衡设计机内和机间的通信量达到AlltoAll的最优。这里暂时不在讨论范围内。
|
| 96 |
+
- 对于其他卡型比如PCIE卡,无论是PCIE switch还是AMD CPU直连,都很容易让机内的卡间AlltoAll成为全局瓶颈,这种情况吞吐好不了,建议大家升级网络(:D),不在本文的讨论范围之内。
|
| 97 |
+
|
| 98 |
+
- 那么在不同设备数 16 ~ 288 取值时,通信部分的发送量可能和设备数d相关,因为intra-device parallelism 假设下,如果节点数只有4,那么每个token 最多往其他节点发3个duplication,同理节点数为2时最多发1个duplication。
|
| 99 |
+
|
| 100 |
+
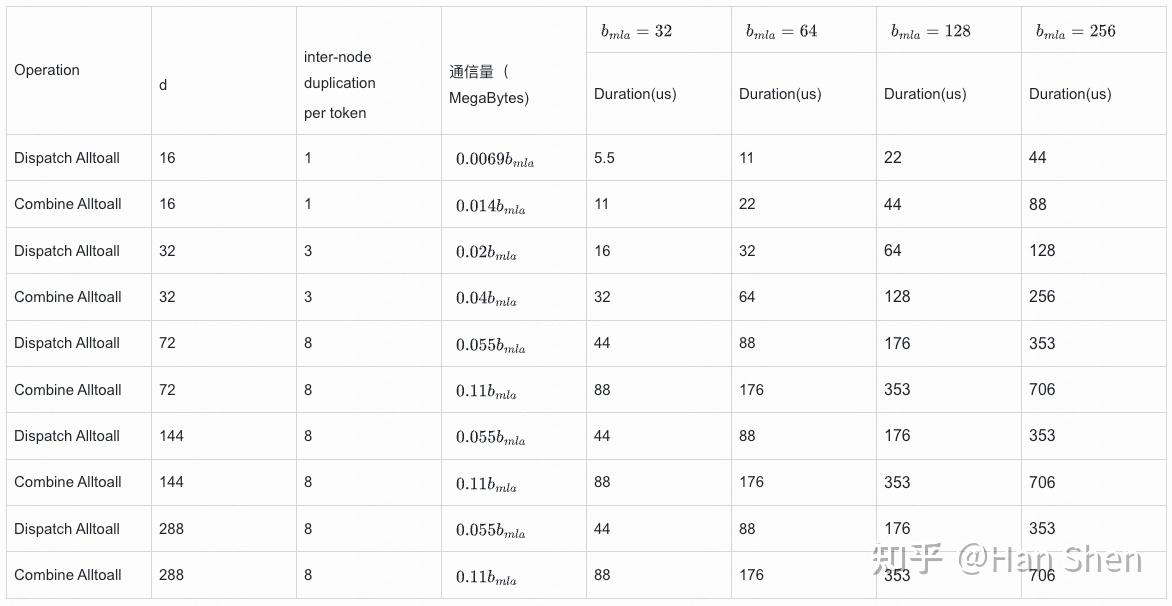
|
| 101 |
+
|
| 102 |
+
## 2.4 不同设备数与batch尺寸对 Router Expert Gemm计算的影响
|
| 103 |
+
|
| 104 |
+
group\\_number=\lceil288/d\rceil, m\\_per\\_group = b\_{mla}\* 8 \* d/ (256+32) = b\_{mla}\* d/36
|
| 105 |
+
|
| 106 |
+
可组合参数太长,这里放部分数据示意:
|
| 107 |
+
|
| 108 |
+
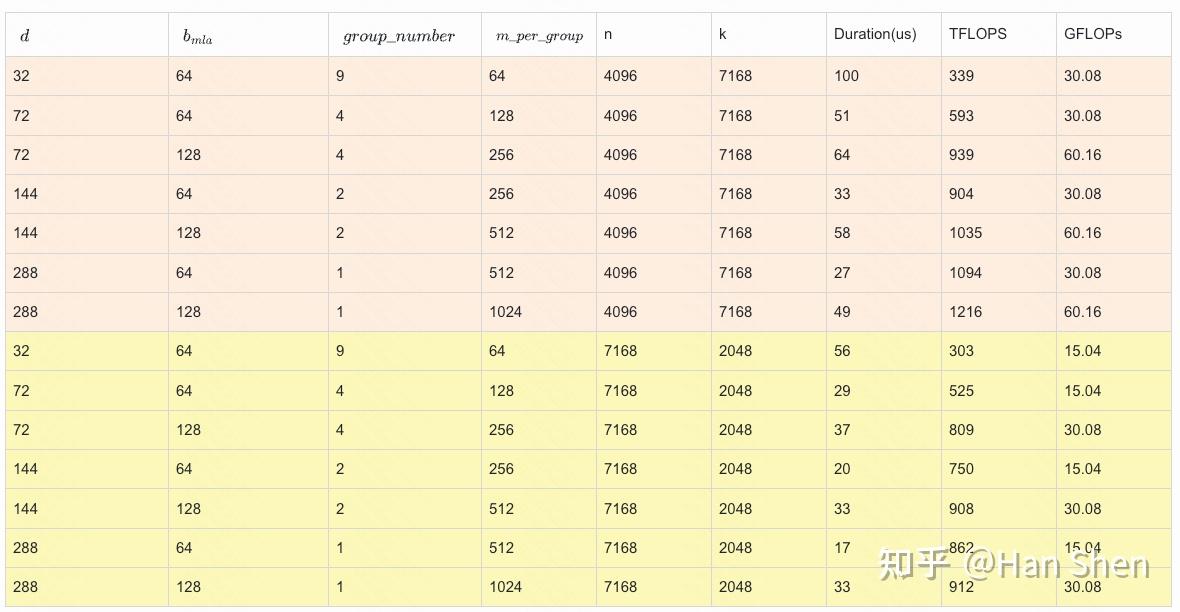
|
| 109 |
+
|
| 110 |
+
可以看到一些趋势:当设备数越小时,需要较大的per GPU b\_{mla} 才有足够per expert token数把 group gemm 打到计算bound。当总GFLOPs一样时, m\\_per\\_group 越大计算密度越高,TFLOPS越高。
|
| 111 |
+
|
| 112 |
+
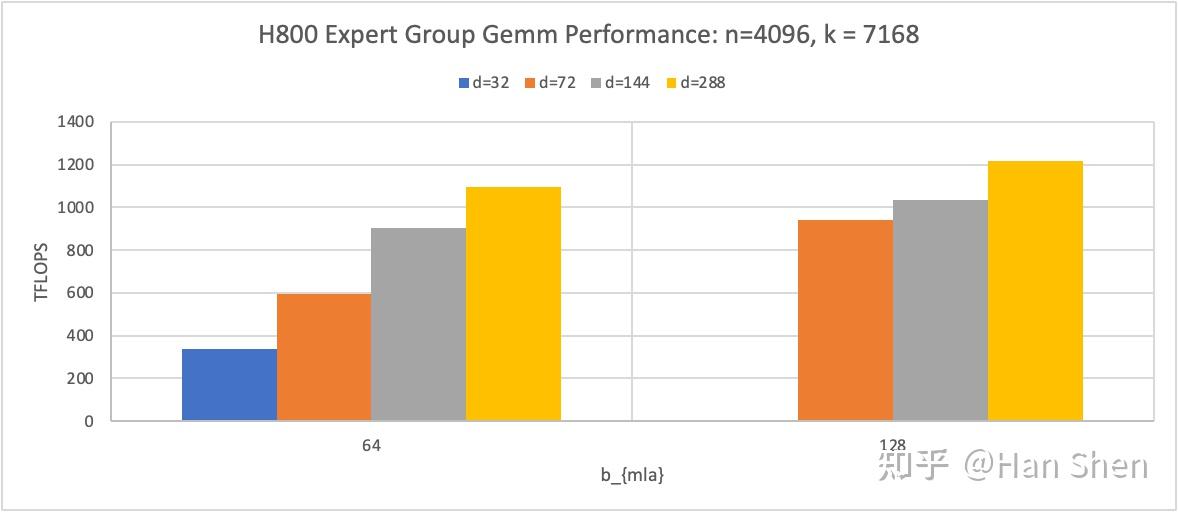
|
| 113 |
+
|
| 114 |
+
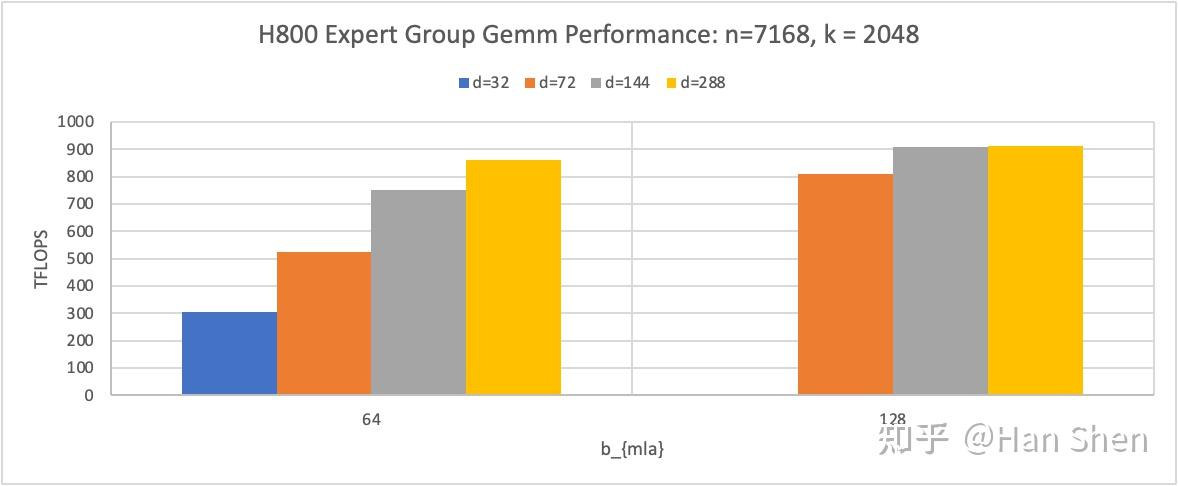
|
| 115 |
+
|
| 116 |
+
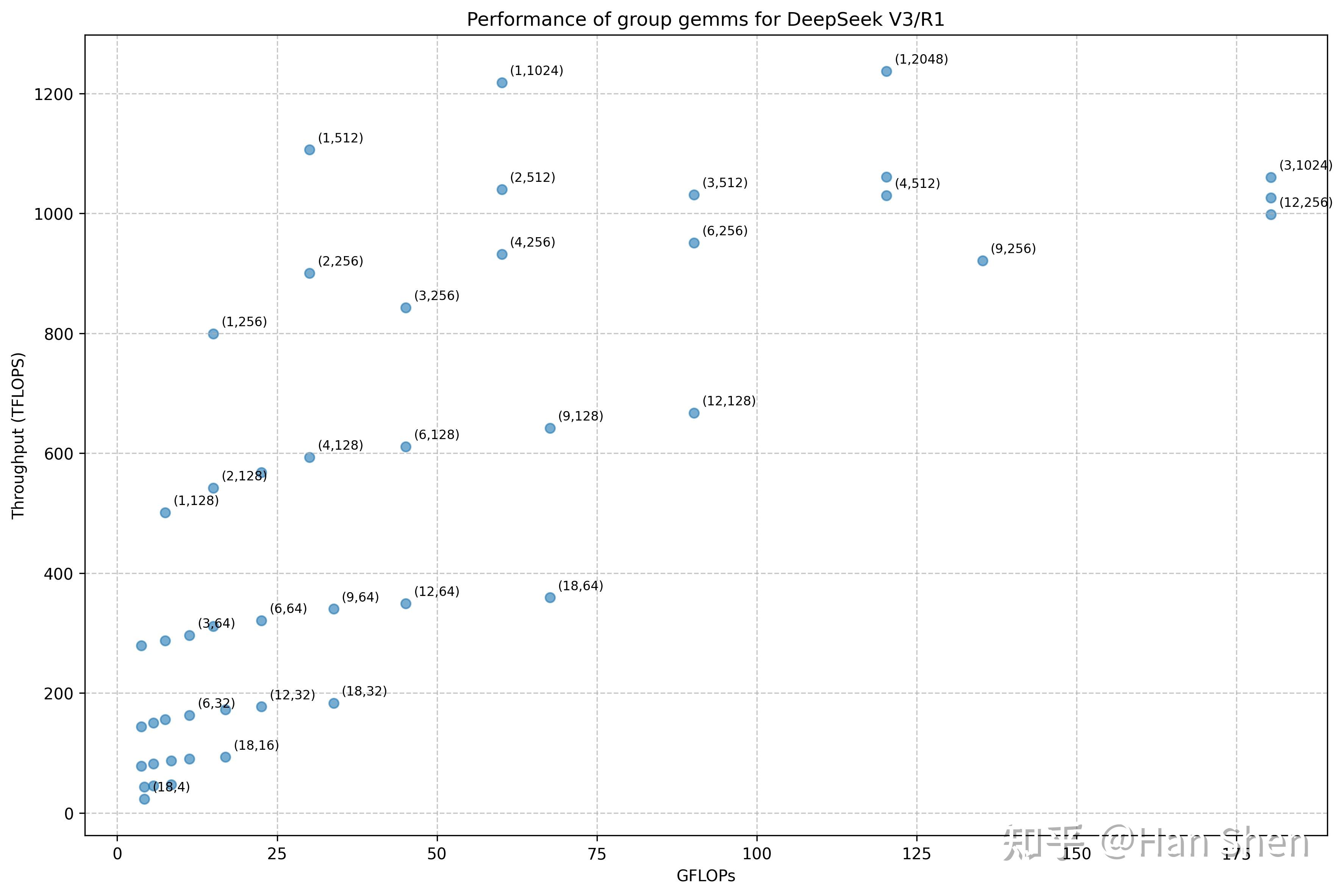
|
| 117 |
+
|
| 118 |
+
n=4096, k=7168 不同(num\_group、m\_per\_group) 下的TFLOPS表现
|
| 119 |
+
|
| 120 |
+
## 2.5 不同batch 对 Memory Ops 的影响
|
| 121 |
+
|
| 122 |
+
这里直接拿prefill的经验值来使用。理想情况下对不同的卡型,可以用带宽比来折算延时。然而这部分的计算还是小量切琐碎,之后估计的时候会逐渐忽略掉这些算子(后面的数据证明,是否考虑这些 memory-bound op 对数量级的影响非常微小)。
|
| 123 |
+
|
| 124 |
+
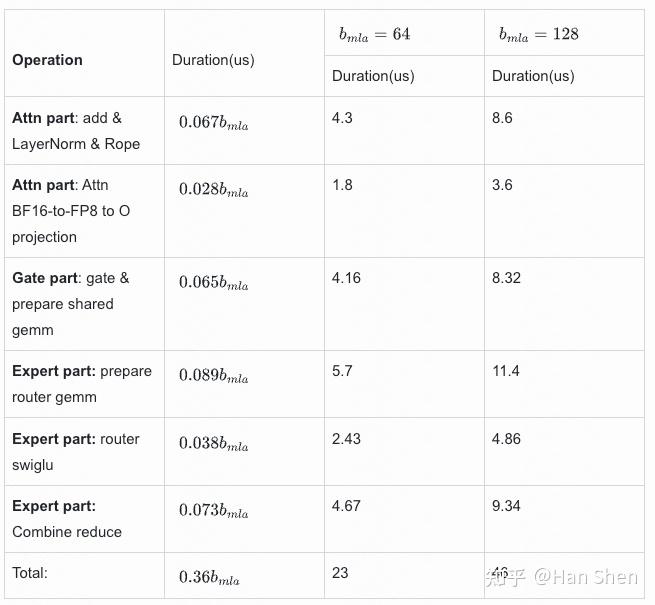
|
| 125 |
+
|
| 126 |
+
## 2.6 整合算子组件,构建 Pipeline
|
| 127 |
+
|
| 128 |
+
将各个部分的耗时wrap up在一起,我们可以得到下面的表格。
|
| 129 |
+
|
| 130 |
+
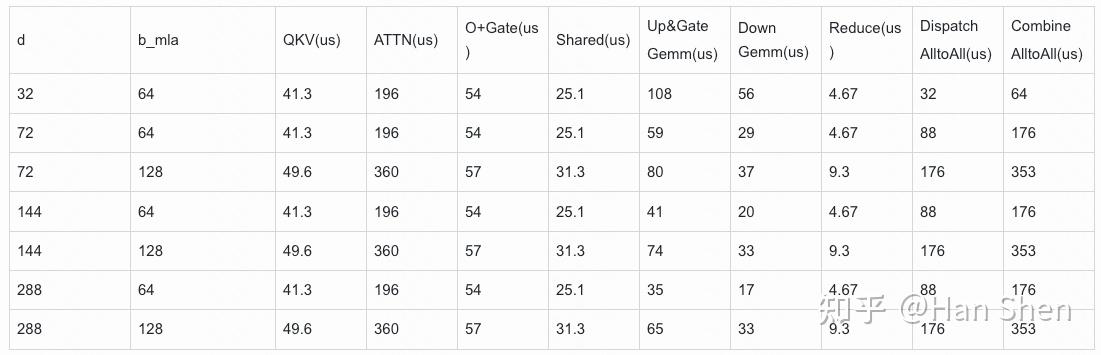
|
| 131 |
+
|
| 132 |
+
于是该如何组建pipeline呢?
|
| 133 |
+
|
| 134 |
+
## **2.6.1 Two-mircobatch overlapping**
|
| 135 |
+
|
| 136 |
+
第一种沿用deepseek采用的overlap方案。这个方案的前提假设是ATTN 占据了整个计算部分的主要耗时:
|
| 137 |
+
|
| 138 |
+
| | | |
|
| 139 |
+
| --- | --- | --- |
|
| 140 |
+
| 模块 | GFLOPs | 浮点计算量占比 |
|
| 141 |
+
| MLA Attention | 1.39b\_{mla} | 50% |
|
| 142 |
+
| O Projection | 0.234 b\_{mla} | 8% |
|
| 143 |
+
| Routed Up&Gate | 0.47 b\_{mla} | 17% |
|
| 144 |
+
| Routed Down | 0.235 b\_{mla} | 8% |
|
| 145 |
+
|
| 146 |
+
并且Combine 的时间开销也比较长。于是我们希望较长的ATTN可以和Combine overlap起来,而自然地,Dispatch 和QKV + Shared 这些小算子进行overlap。
|
| 147 |
+
|
| 148 |
+
**案例1:**d=72, b\_{mla} = 64 :
|
| 149 |
+
|
| 150 |
+
单层microbatch forwad 时间为250+88+88=426us,不包含通信开销为41.3+250+25.1+88+4.67=409 us,TPOT = 51.9ms,单卡吞吐2468 tokens/s
|
| 151 |
+
|
| 152 |
+
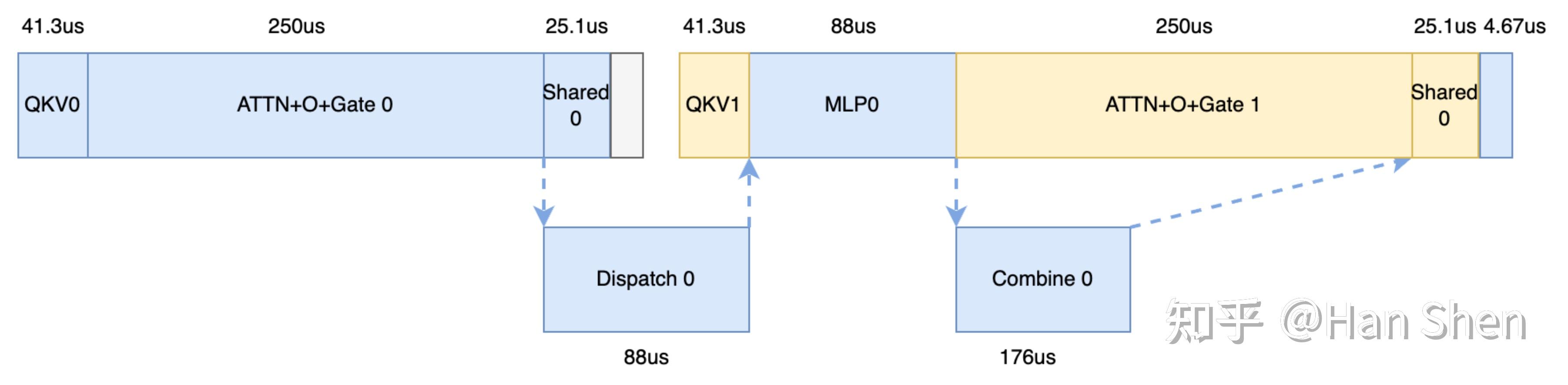
|
| 153 |
+
|
| 154 |
+
## **2.6.2 Single-batch** compute-communication **overlapping**
|
| 155 |
+
|
| 156 |
+
双microbatch带来的副作用是:
|
| 157 |
+
|
| 158 |
+
- 拆分microbatch降低了计算密度
|
| 159 |
+
- TPOT 需要等双microbatch 完全算完,延迟上并不是非常占优。
|
| 160 |
+
|
| 161 |
+
这里可以考虑的另一个overlap方法是在单batch内做Down gemm+combine的overlapping。
|
| 162 |
+
|
| 163 |
+
**案例2:** d=32, b\_{mla} = 64
|
| 164 |
+
|
| 165 |
+
双microbatch的做法:critcal path 上通信基本被掩盖,完全由计算和访存开销组成,单层microbatch forward 时间为 41.3+250+25.1+164+4.67=485us , TPOT = 485 \* 2 \* 61/1000 = 59 ms ,单卡吞吐为2169 tokens/s。
|
| 166 |
+
|
| 167 |
+
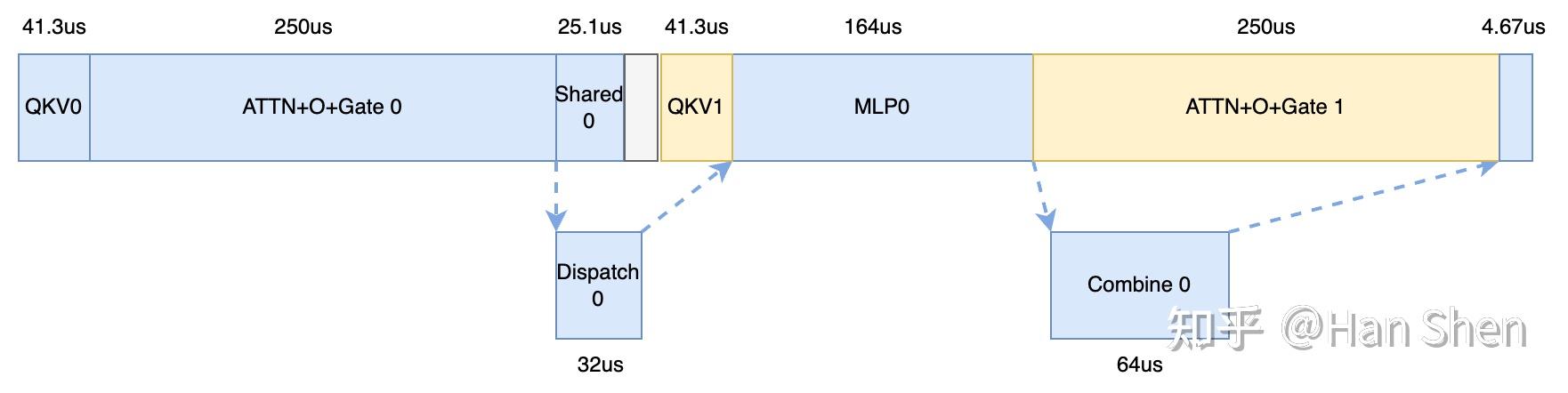
|
| 168 |
+
|
| 169 |
+
如果做单microbatch呢?
|
| 170 |
+
|
| 171 |
+
假设通过合适的tiling 使得Combine的计算与Down Gemm的通信overlap,(O+Gate 和Dispatch的overlap 算子不好写先假设无法overlap),这个work的前提是Combine与Down Gemm计算相仿。比如这个配置下Down gemm 56us,Combine 64us,能overlap不少 ,这样通信也能被隐藏,单层microbatch forwad 时间为 41.3+250+32+108+64+4.67=500us , TPOT = (500\*58+485\*3)/1000 = 30ms ,单卡吞吐为2133 tokens/s。于是我们可以看到**牺牲3%吞吐,获得了TPOT接近减半**。**这种overlap方式在Combine 与Down Gemm 数量级相仿的时候可以考虑!**
|
| 172 |
+
|
| 173 |
+
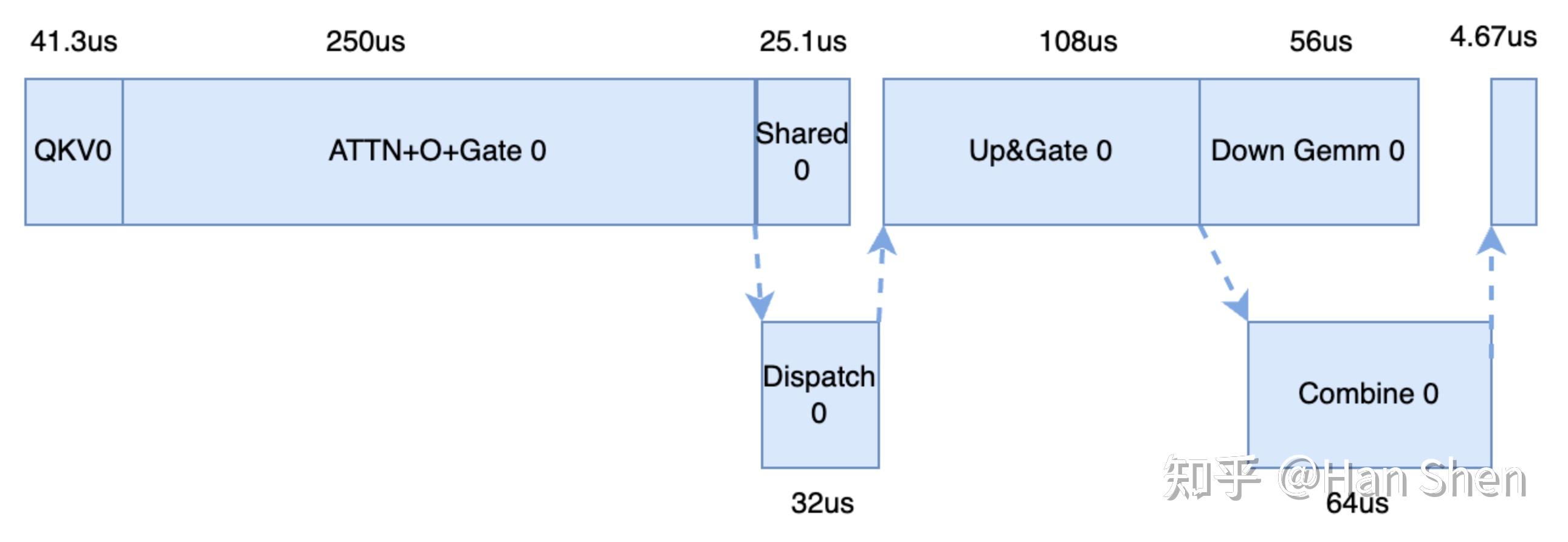
|
| 174 |
+
|
| 175 |
+
**案例3** d=32, b\_{mla} = 128
|
| 176 |
+
|
| 177 |
+
由于2-microbatch实际上 b\_{mla}^{PerGPU} = 128 ,我们看如果做单microbatch 128是什么结果:
|
| 178 |
+
|
| 179 |
+
单层microbatch forwad 时间为 49.6+417+64+121+128+9.34=789us ,不包含通信开销为 49.6+417+31.3+121+60+9.34=688us , TPOT = (789\*58+688\*3)/1000 = 48ms ,单卡吞吐为2667 tokens/s,远大于two-microbatch的2169 tokens/s 且TPOT 更小!
|
| 180 |
+
|
| 181 |
+
这里根本的原因在于:**由于Dispatch/Combine的耗时并不算特别大,引入部分可以接受的bubble,避免了2-batch的计算密度降低与延迟上的牺牲。如果Combine较长,我们将会明显看到吞吐下降。**
|
| 182 |
+
|
| 183 |
+
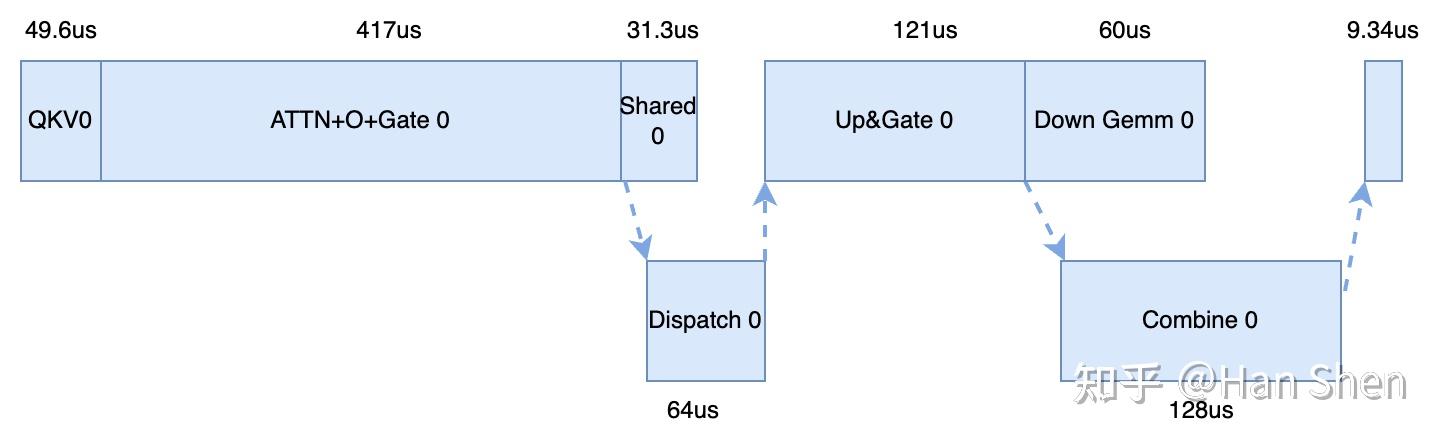
|
| 184 |
+
|
| 185 |
+
## 2.6.3 一般性规律
|
| 186 |
+
|
| 187 |
+
通过对流水排布的分析,我们很容易总结出下述公式:
|
| 188 |
+
|
| 189 |
+
**1) two-mircobatch overlapping**
|
| 190 |
+
|
| 191 |
+
单层同步时间 t\_{moe\\_layer} = 2\*(max(t\_{Dispatch}, t\_{Shared} + t\_{Reduce} + t\_{QKV}) + t\_{MLP} + max(t\_{Attn+O+Gate}, t\_{Combine}))
|
| 192 |
+
|
| 193 |
+
t\_{dense\\_layer} = 2\* ( t\_{Shared} + t\_{Reduce} + t\_{QKV} + t\_{MLP} + t\_{Attn+O+Gate})
|
| 194 |
+
|
| 195 |
+
TPOT=t\_{moe\\_layer} \* 58 + t\_{dense\\_layer} \* 3
|
| 196 |
+
|
| 197 |
+
T\_{overall} = b\_{mla} \* 2 / TPOT
|
| 198 |
+
|
| 199 |
+
**2) Single-batch compute-communication overlapping**
|
| 200 |
+
|
| 201 |
+
t\_{dense\\_layer} = t\_{Shared} + t\_{Reduce} + t\_{QKV} + t\_{MLP} + t\_{Attn+O+Gate}
|
| 202 |
+
|
| 203 |
+
t\_{moe\\_layer} = max(t\_{Dispatch},t\_{Shared}) + t\_{Reduce} + t\_{QKV} + t\_{Up\&Gate} + max(t\_{Down}, t\_{Combine})+ t\_{Attn+O+Gate}
|
| 204 |
+
|
| 205 |
+
TPOT=t\_{moe\\_layer} \* 58 + t\_{dense\\_layer} \* 3
|
| 206 |
+
|
| 207 |
+
T\_{overall} = b\_{mla} / TPOT
|
| 208 |
+
|
| 209 |
+
## 2.7 H800 吞吐数据示意
|
| 210 |
+
|
| 211 |
+
于是我们可以得到H800 的部分吞吐数据了!(这里遍历的 d/b\_{mla} 组合不全,后文会放更多配置的估计 )
|
| 212 |
+
|
| 213 |
+
**1) two-mircobatch overlapping**
|
| 214 |
+
|
| 215 |
+
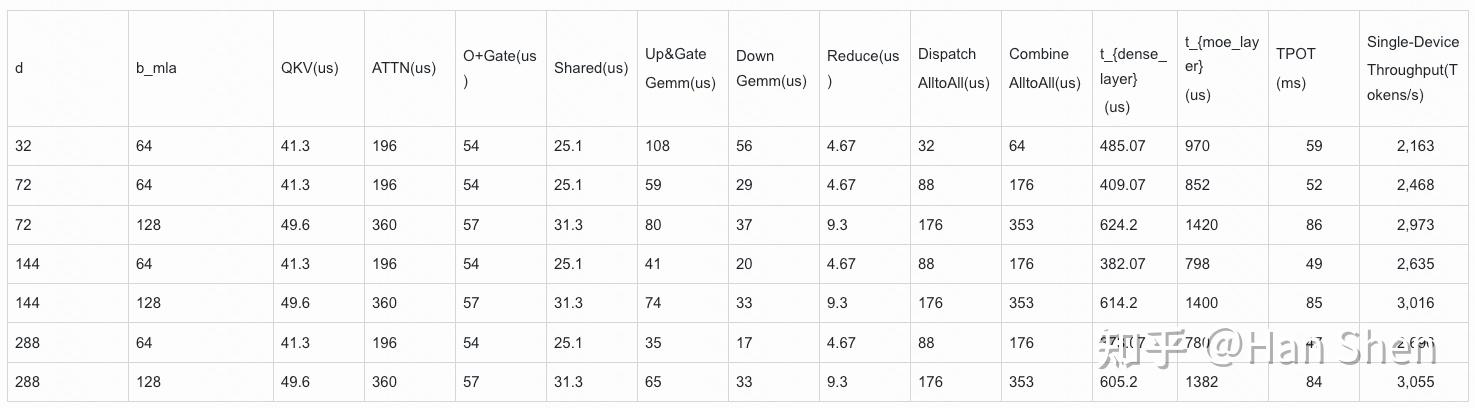
|
| 216 |
+
|
| 217 |
+
**2) single-batch compute-communication overlapping**
|
| 218 |
+
|
| 219 |
+
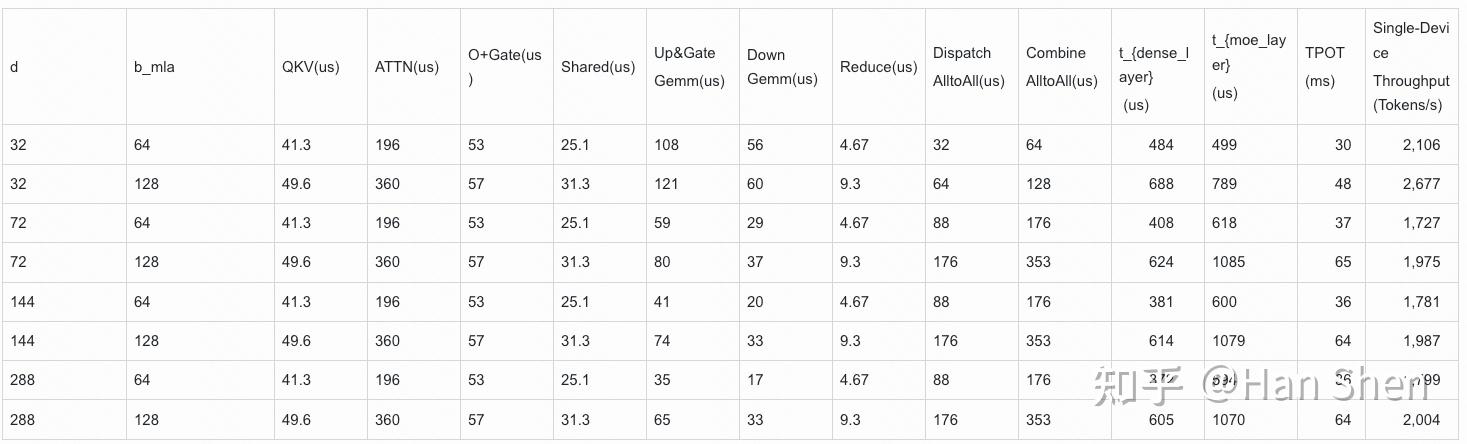
|
| 220 |
+
|
| 221 |
+
在估算的过程中,计算memory-op 耗时还是一个很麻烦的事情,在overlap 示意中画出来能更直观的说明overlap的效率,但他们的占比确实是足够小到可以忽略。于是,我们来看看如果只考虑Gemm+Attention+AlltoAll,估出来的数据有多大偏差?
|
| 222 |
+
|
| 223 |
+
**1) two-mircobatch overlapping**
|
| 224 |
+
|
| 225 |
+
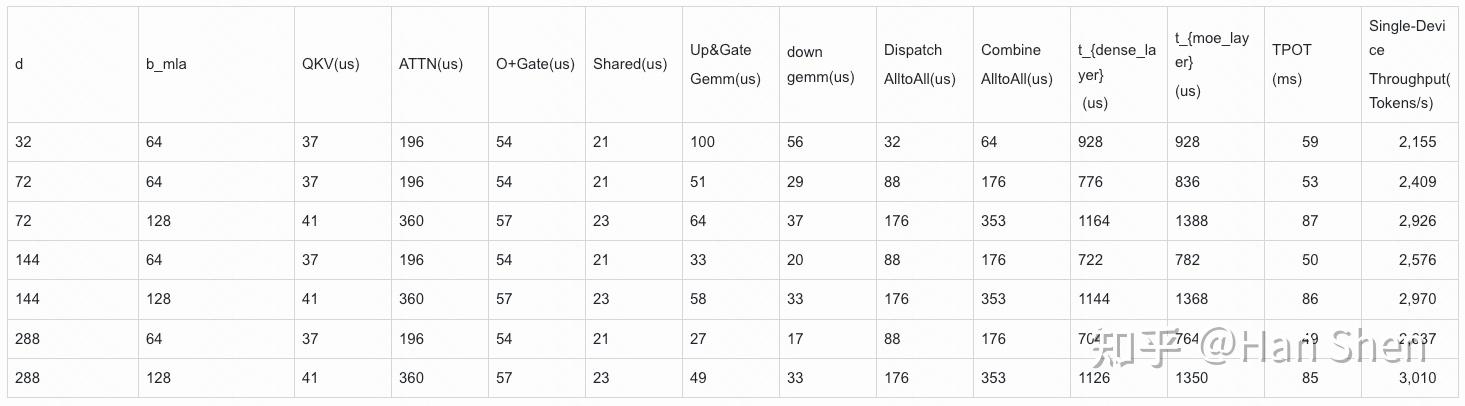
|
| 226 |
+
|
| 227 |
+
**2) single-batch comp-comm overlapping**
|
| 228 |
+
|
| 229 |
+
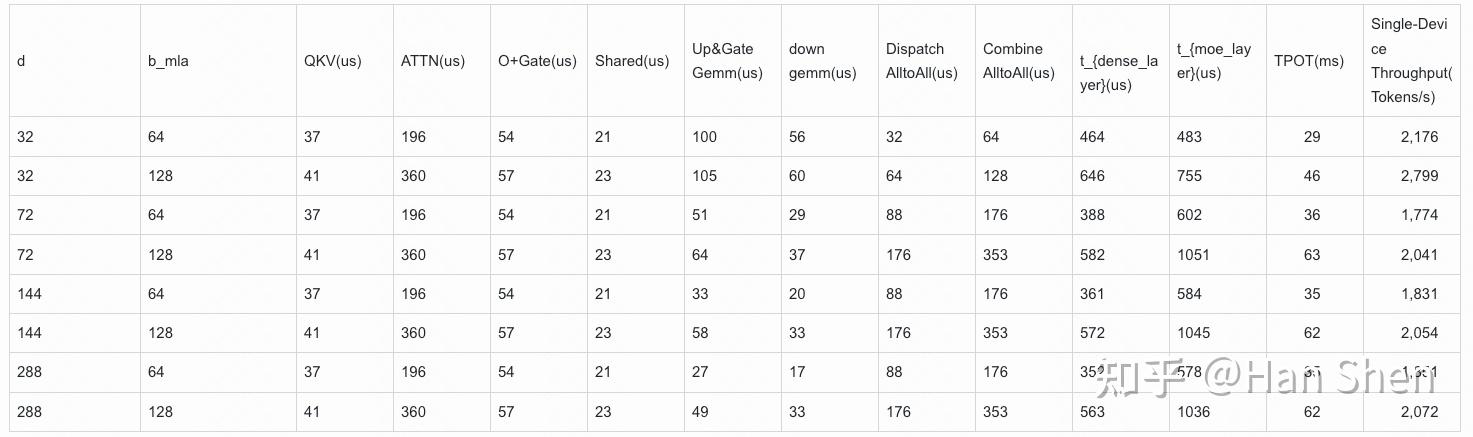
|
| 230 |
+
|
| 231 |
+
对比前后的数据,我们可以看到用Gemm+Attention+AlltoAll 基本能代表模型的延迟和吞吐真实值了!**之后的计算估计我们都抛弃对memory op的计算,使用近似的估法,这样更能往通用的模拟上简化**。
|
| 232 |
+
|
| 233 |
+
## 3. 跨硬件泛化
|
| 234 |
+
|
| 235 |
+
## 3.1 满足latency 需求的算力需求
|
| 236 |
+
|
| 237 |
+
single-layer and single-microbatch 计算部分总FLOPs: 2.79b\_{mla}GFLOPs
|
| 238 |
+
|
| 239 |
+
| | | |
|
| 240 |
+
| --- | --- | --- |
|
| 241 |
+
| 模块 | GFLOPs | 浮点计算量占比 |
|
| 242 |
+
| MLA Attention | 1.39b\_{mla} | 50% |
|
| 243 |
+
| O Projection | 0.234 b\_{mla} | 8% |
|
| 244 |
+
| Routed Up&Gate | 0.47 b\_{mla} | 17% |
|
| 245 |
+
| Routed Down | 0.235 b\_{mla} | 8% |
|
| 246 |
+
|
| 247 |
+
我们知道MLA Attention 使用BF16 计算,其他Gemm使用FP8计算,因此假设MFU=100%,为了满足20 tokens/s 的需求,我们需要
|
| 248 |
+
|
| 249 |
+
- 对H800
|
| 250 |
+
|
| 251 |
+
(1.39 \* b\_{mla} /1024/ 989 + (2.79-1.39) \* b\_{mla} / 1024 / 1978) \* 1000 \* 61 <= 50
|
| 252 |
+
|
| 253 |
+
易得 b\_{mla} <= 397 ,单卡吞吐最高 7940 tokens/s
|
| 254 |
+
|
| 255 |
+
- 对H20
|
| 256 |
+
|
| 257 |
+
(1.39 \* b\_{mla} /1024/ 148 + (2.79-1.39) \* b\_{mla} / 1024 / 296) \* 1000 \* 61 <= 50
|
| 258 |
+
|
| 259 |
+
易得 b\_{mla} <= 59 单卡吞吐最高 1180 tokens/s (注意这里和[第一次吞吐粗略估计](https://zhuanlan.zhihu.com/p/27292649125) 估计的理论上限不一样的原因是考虑了MLA 是BF16实现)
|
| 260 |
+
|
| 261 |
+
而我们看一下两个卡型的最高 b\_{mla} 取值,且用 kv\\_utility = min(b\_{mla}^{latency\\_bound}, b\_{mla}^{peak}) / b\_{mla}^{peak} 来衡量kvcache显存的有效利用率。
|
| 262 |
+
|
| 263 |
+
```
|
| 264 |
+
GPU Type: H800-80
|
| 265 |
+
Device number: (16, 24, 32, 48, 72, 96, 144, 288)
|
| 266 |
+
Max batch size per GPU: (133, 220, 264, 308, 337, 352, 366, 381)
|
| 267 |
+
|
| 268 |
+
GPU Type: H20-96
|
| 269 |
+
Device number: (16, 24, 32, 48, 72, 96, 144, 288)
|
| 270 |
+
Max batch size per GPU: (231, 318, 362, 406, 435, 449, 464, 478)
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
很容易得到
|
| 274 |
+
|
| 275 |
+
| Device Number | H800 kv utilization (FP8 kvcache) | H20 kv utilization (FP8 kvcache) | H20 kv utilization (BF16 kvcache) |
|
| 276 |
+
| --- | --- | --- | --- |
|
| 277 |
+
| 16 | 100% | 26% | 52% |
|
| 278 |
+
| 24 | 100% | 19% | 38% |
|
| 279 |
+
| 32 | 100% | 16% | 32% |
|
| 280 |
+
| 48 | 100% | 15% | 30% |
|
| 281 |
+
| 72 | 100% | 14% | 28% |
|
| 282 |
+
| 96 | 100% | 13% | 26% |
|
| 283 |
+
| 144 | 100% | 13% | 26% |
|
| 284 |
+
| 288 | 100% | 12% | 24% |
|
| 285 |
+
|
| 286 |
+
从上表可得,在latency 约束下,Scale H20 换取kvcache收益根本没有用,显存一开始就无法得到有效利用!
|
| 287 |
+
|
| 288 |
+
因此,**对于低算力卡型,我们需要考虑TP来放松延迟约束,从而换取更好的scale吞吐效果。**
|
| 289 |
+
|
| 290 |
+
因为Attention + O projection 占据了58%的计算,我们主要考虑对 Attention 和 O projection 矩阵进行TP切分。
|
| 291 |
+
|
| 292 |
+
## **3.2 MLA(TP-DP) + MoE EP**
|
| 293 |
+
|
| 294 |
+
因为MoE expert的计算shape相对较小,不是很建议做TP,另外为了建模简单与通信的高效,我们只考虑在机内进行Attention 部分 TP 切分。
|
| 295 |
+
|
| 296 |
+
MLA 切分主要对Q矩阵进行head维切分,对矩阵形状的影响主要是 Concat(W\_Q', W\_p,W\_{KR}): [h, c' + c + r], [7168, 2112] \\ Concat(W\_{UQ}, W\_{QR}): [c', a/N\*(d+r)] = [1536, 128/N\*192] \\ W\_{UK} \& W\_{UV}: 2 \* [c, a/N\*d] = 2 \* [512, 128/N\*128]\\ O: [a/N\*d, h] = [128/N\*128, 7168]
|
| 297 |
+
|
| 298 |
+
我们先来看看做了TP 之后对显存有效利用率的影响。我们将3.1节的算力矩阵列出:
|
| 299 |
+
|
| 300 |
+
| | | | | | |
|
| 301 |
+
| --- | --- | --- | --- | --- | --- |
|
| 302 |
+
| 模块 | GFLOPs(\*b\_mla) | TP=1 | TP=2 | TP=4 | TP=8 |
|
| 303 |
+
| MLA Attention | 1.39 | 1.39 | 0.70 | 0.35 | 0.17 |
|
| 304 |
+
| O Projection | 0.23 | 0.23 | 0.12 | 0.06 | 0.03 |
|
| 305 |
+
| Routed Up&Gate | 0.47 | 0.47 | 0.47 | 0.47 | 0.47 |
|
| 306 |
+
| Routed Down | 0.24 | 0.24 | 0.24 | 0.24 | 0.24 |
|
| 307 |
+
| Others | 0.46 | 0.46 | 0.46 | 0.46 | 0.46 |
|
| 308 |
+
| Total | 2.79 | 2.79 | 1.98 | 1.57 | 1.37 |
|
| 309 |
+
|
| 310 |
+
更新后的算力上限,当TP=8时,
|
| 311 |
+
|
| 312 |
+
- H800
|
| 313 |
+
|
| 314 |
+
(0.17 \* b\_{mla} /1024/ 989 + (1.37-0.17) \* b\_{mla} / 1024 / 1978) \* 1000 \* 61 <= 50 ,可以看到有效提升batchsize 上限从 b\_{mla} = 397 到 b\_{mla} = 1077 。
|
| 315 |
+
|
| 316 |
+
- H20
|
| 317 |
+
|
| 318 |
+
(0.17 \* b\_{mla} /1024/ 148 + (1.37-0.17) \* b\_{mla} / 1024 / 296) \* 1000 \* 61 <= 50 ,可以看到有效提升batchsize 上限从 b\_{mla} = 59 到 b\_{mla} = 161 。
|
| 319 |
+
|
| 320 |
+
## **3.2.1 更新显存守恒公式**
|
| 321 |
+
|
| 322 |
+
修正权重公式:
|
| 323 |
+
|
| 324 |
+
14B 的dense权重中MLA 部分参数量约
|
| 325 |
+
|
| 326 |
+
(7168\*2112+1536\*24576+512\*32768+16384\*7168)\*61 = 11.4B
|
| 327 |
+
|
| 328 |
+
考虑单卡 tp MLA 部分总参数量
|
| 329 |
+
|
| 330 |
+
(7168\*2112+1536\*24576/tp+512\*32768/tp+16384\*7168/tp)\*61
|
| 331 |
+
|
| 332 |
+
于是d个设备的MLA 总权重为
|
| 333 |
+
|
| 334 |
+
(0.86 + 9.77/tp)\*d , 其中d = tp \* dp
|
| 335 |
+
|
| 336 |
+
于是得到新的权重守恒公式
|
| 337 |
+
|
| 338 |
+
C \* d- (2.42 + 0.86+9.77/tp)d - 612 - 78 - 2.38(d-1) = 34.3 \* 2 /1024/1024\*d\*b\_{mla}^{PerGPU\\_max}\* s'
|
| 339 |
+
|
| 340 |
+
于是可以得到新的显存利用率
|
| 341 |
+
|
| 342 |
+
```
|
| 343 |
+
DeepSeek-Simulator - DEBUG - GPU Type: H20-96
|
| 344 |
+
DeepSeek-Simulator - DEBUG - TP= 1
|
| 345 |
+
DeepSeek-Simulator - DEBUG - Device Number: [16, 24, 32, 48, 72, 96, 144, 288]
|
| 346 |
+
DeepSeek-Simulator - DEBUG - Max batch size per GPU: [231, 318, 362, 406, 435, 449, 464, 478]
|
| 347 |
+
DeepSeek-Simulator - DEBUG - TP= 2
|
| 348 |
+
DeepSeek-Simulator - DEBUG - Device Number: [16, 24, 32, 48, 72, 96, 144, 288]
|
| 349 |
+
DeepSeek-Simulator - DEBUG - Max batch size per GPU: [240, 328, 371, 415, 444, 459, 473, 488]
|
| 350 |
+
DeepSeek-Simulator - DEBUG - TP= 4
|
| 351 |
+
DeepSeek-Simulator - DEBUG - Device Number: [16, 24, 32, 48, 72, 96, 144, 288]
|
| 352 |
+
DeepSeek-Simulator - DEBUG - Max batch size per GPU: [245, 332, 376, 420, 449, 463, 478, 493]
|
| 353 |
+
DeepSeek-Simulator - DEBUG - TP= 8
|
| 354 |
+
DeepSeek-Simulator - DEBUG - Device Number: [16, 24, 32, 48, 72, 96, 144, 288]
|
| 355 |
+
DeepSeek-Simulator - DEBUG - Max batch size per GPU: [247, 335, 378, 422, 451, 466, 480, 495]
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
| Device Number | H20 kv utilization (FP8 kvcache) | H20 kv utilization (BF16 kvcache) |
|
| 359 |
+
| --- | --- | --- |
|
| 360 |
+
| 16 | 65% | 100% |
|
| 361 |
+
| 24 | 48% | 96% |
|
| 362 |
+
| 32 | 43% | 86% |
|
| 363 |
+
| 48 | 38% | 76% |
|
| 364 |
+
| 72 | 36% | 72% |
|
| 365 |
+
| 96 | 35% | 70% |
|
| 366 |
+
| 144 | 34% | 68% |
|
| 367 |
+
| 288 | 33% | 66% |
|
| 368 |
+
|
| 369 |
+
## 3.2.1 更新 token 分发公式
|
| 370 |
+
|
| 371 |
+
开启TP 后,一个TP组内共享token。因此在计算MoE EP部分的token时,需要去除TP组间冗余。
|
| 372 |
+
|
| 373 |
+
- Router Expert 计算
|
| 374 |
+
|
| 375 |
+
num\\_groups = \lceil 288/d\rceil
|
| 376 |
+
|
| 377 |
+
m\\_per\\_group = \frac{b\_{mla} \* topk \* dp}{288},其中d = dp\*tp
|
| 378 |
+
|
| 379 |
+
- Router AlltoAll 发送量
|
| 380 |
+
|
| 381 |
+
同一个tp组内的alltoall 可以平摊到每张卡上,相当于每个卡只需要负责发送 b\_{mla}/tp 个token的激活。因此
|
| 382 |
+
|
| 383 |
+
Dispatch 通信量: b\_{mla}/tp\*min(num\\_node-1, topk)\*7168
|
| 384 |
+
|
| 385 |
+
Combine 通信量: b\_{mla}/tp\*min(num\\_node-1, topk)\*7168 \* 2
|
| 386 |
+
|
| 387 |
+
## 3.2.3 更新通信与Pipeline
|
| 388 |
+
|
| 389 |
+
引入了Attention TP 需要在O projection 之后做AllReduce,BF16 通信量 \frac{2\*(tp-1)\*(2b\_{mla} \* 7168)}{tp} ,假设NVLINK单向带宽为160GB/s,则不同tp下的AllReduce 耗时为(us):
|
| 390 |
+
|
| 391 |
+
| b\_{mla} | tp=2 | tp=4 | tp=8 |
|
| 392 |
+
| --- | --- | --- | --- |
|
| 393 |
+
| 8 | 1 | 1 | 1 |
|
| 394 |
+
| 16 | 1 | 2 | 2 |
|
| 395 |
+
| 32 | 3 | 4 | 5 |
|
| 396 |
+
| 64 | 5 | 8 | 9 |
|
| 397 |
+
| 128 | 11 | 16 | 19 |
|
| 398 |
+
| 256 | 21 | 32 | 37 |
|
| 399 |
+
|
| 400 |
+
这里考虑到通信量较小时为纯latency bound,可以取一个经验下限如5us。
|
| 401 |
+
|
| 402 |
+
再来看一下O projection gemm在H800上的的性能,我们发现AllReduce的耗时在 b\_{mla} 较大且tp较大的时候已经比O gemm 的计算耗时大了,在这种情况下可以考虑将Ogemm与AllReduce 进行overlap。但是当 b\_{mla} 较小时为延迟bound,不值得做overlap。在这种高速互联下,我们假设AllReduce 的通信不overlap也能接受(对比AlltoAll小得多)。
|
| 403 |
+
|
| 404 |
+
| b\_{mla} | tp=2 | tp=4 | tp=8 |
|
| 405 |
+
| --- | --- | --- | --- |
|
| 406 |
+
| 8 | 31 | 17 | 9 |
|
| 407 |
+
| 16 | 30 | 16 | 9 |
|
| 408 |
+
| 32 | 26 | 14 | 8 |
|
| 409 |
+
| 64 | 25 | 14 | 7 |
|
| 410 |
+
| 128 | 26 | 14 | 8 |
|
| 411 |
+
| 256 | 31 | 17 | 11 |
|
| 412 |
+
|
| 413 |
+
为了建模简单,我们假设不做AllReduce 的overlap。
|
| 414 |
+
|
| 415 |
+
- **single-batch compute-communication overlapping**
|
| 416 |
+
|
| 417 |
+
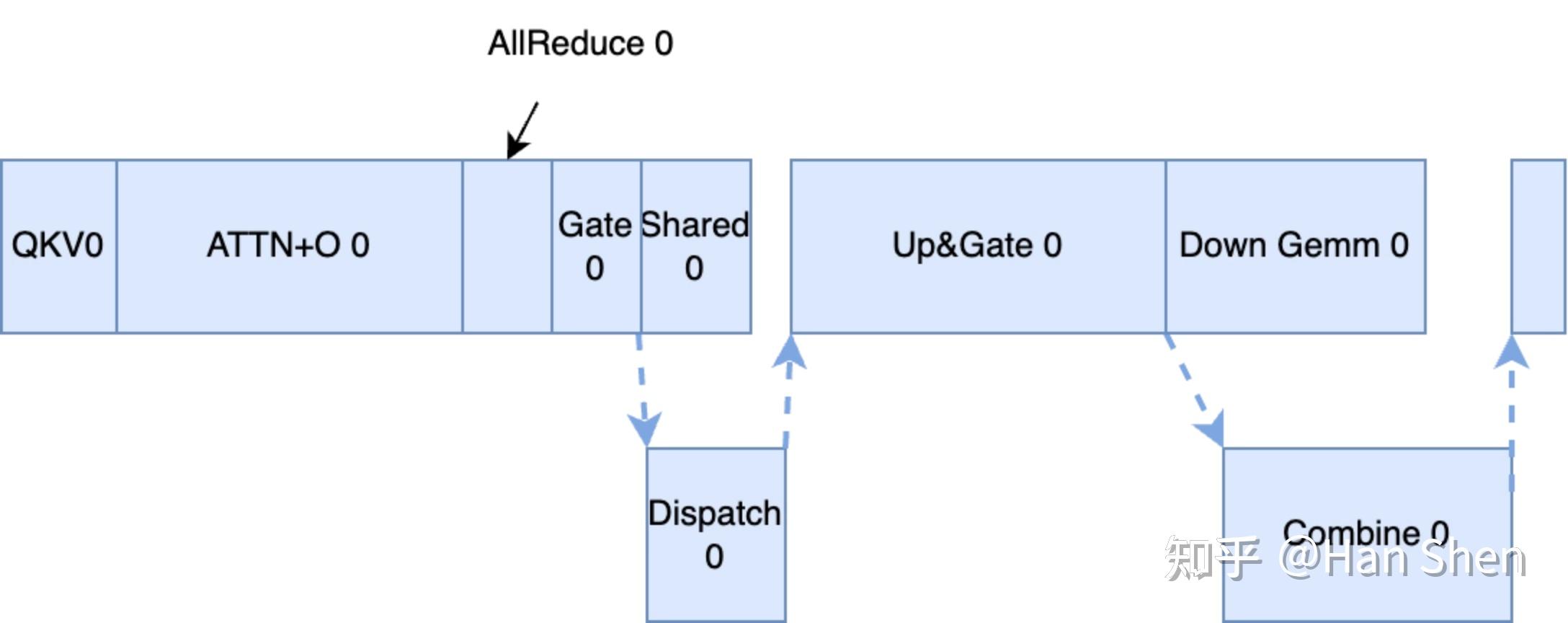
|
| 418 |
+
|
| 419 |
+
- **two-mircobatch overlapping**
|
| 420 |
+
|
| 421 |
+

|
| 422 |
+
|
| 423 |
+
更新overlap公式,注意**这里引入有效吞吐的概念,因为tp > 1,同一个tp组内实际上处理的时同样的数据,折合到单卡需要除以tp数。**
|
| 424 |
+
|
| 425 |
+
**1) two-mircobatch overlapping**
|
| 426 |
+
|
| 427 |
+
单层同步时间 t\_{moe\\_layer} = 2\*(max(t\_{Dispatch}, t\_{Shared} + t\_{Reduce} + t\_{QKV}) + t\_{MLP} + max(t\_{Attn+O} + t\_{AllReduce} + t\_{Gate}, t\_{Combine}))
|
| 428 |
+
|
| 429 |
+
t\_{dense\\_layer} = 2\* ( t\_{Shared} + t\_{Reduce} + t\_{QKV} + t\_{MLP} + t\_{Attn+O} + t\_{AllReduce} + t\_{Gate})
|
| 430 |
+
|
| 431 |
+
因此
|
| 432 |
+
|
| 433 |
+
TPOT=t\_{moe\\_layer} \* 58 + t\_{dense\\_layer} \* 3
|
| 434 |
+
|
| 435 |
+
T\_{overall\\_effective} = b\_{mla} / tp \* 2 / TPOT
|
| 436 |
+
|
| 437 |
+
**2) Single-batch compute-communication overlapping**
|
| 438 |
+
|
| 439 |
+
t\_{dense\\_layer} = t\_{Shared} + t\_{Reduce} + t\_{QKV} + t\_{MLP} + t\_{Attn+O} + t\_{AllReduce} + t\_{Gate}
|
| 440 |
+
|
| 441 |
+
t\_{moe\\_layer} = max(t\_{Dispatch},t\_{Shared}) + t\_{Reduce} + t\_{QKV} + t\_{Up\&Gate} + max(t\_{Down}, t\_{Combine})+ t\_{Attn+O} + t\_{AllReduce} + t\_{Gate}
|
| 442 |
+
|
| 443 |
+
因此
|
| 444 |
+
|
| 445 |
+
TPOT=t\_{moe\\_layer} \* 58 + t\_{dense\\_layer} \* 3
|
| 446 |
+
|
| 447 |
+
T\_{overall\\_effective} = b\_{mla} / tp / TPOT
|
| 448 |
+
|
| 449 |
+
## 4. H800 与H20 结果汇总
|
| 450 |
+
|
| 451 |
+
测试环境:
|
| 452 |
+
|
| 453 |
+
- CUDA-12.6
|
| 454 |
+
- PyTorch 2.4
|
| 455 |
+
- Python 3.10
|
| 456 |
+
|
| 457 |
+
我们分别为两种不同的流水线方式生成Attention DP + MoE EP和Attention TP+DP + MoE EP 的仿真结果。
|
| 458 |
+
|
| 459 |
+
- 黄色标注出了**各个设备卡数**下基本满足**20 tokens/s 左右用户延迟**的最佳吞吐结果
|
| 460 |
+
- 橙色表示在所有设备数下搜索出的基本满足**20 tokens/s 左右用户延迟**最好线上配置
|
| 461 |
+
- 绿色表示忽略延迟约束的FP8 kvcache 最大吞吐
|
| 462 |
+
- 蓝色表示忽略延迟约束的BF16 kvcache 最大吞吐
|
| 463 |
+
|
| 464 |
+
完整测试结果见[这里](https://link.zhihu.com/?target=https%3A//github.com/shenh10/DeepSeek_Simulator/tree/main/results)。
|
| 465 |
+
|
| 466 |
+
## 4.1 H800 实验结果
|
| 467 |
+
|
| 468 |
+
观察测试数据,我们发现
|
| 469 |
+
|
| 470 |
+
- DP-EP 是获得最佳离线吞吐表现的方案,开启Attention TP 会损害吞吐。
|
| 471 |
+
- H800 (BF16 kvcache)最佳离线吞吐为单卡2844 tokens/s,由two-mircobatch overlapping的 DP288-EP288 - b\_{mla}64 方案得到
|
| 472 |
+
- H800 (FP8 kvcache)最佳离线吞吐为单卡3121 tokens/s,由two-mircobatch overlapping的 DP288-EP288- b\_{mla}128 方案,或者DP48-EP48- b\_{mla} 128 方案得到
|
| 473 |
+
- H800 (FP8 kvcache)最佳线上吞吐(满足20 tokens/s 左右用户延迟)为2909 tokens/s, 由single-batch compute-communication overlapping的DP24-EP24- b\_{mla}128 方案得到。
|
| 474 |
+
- H800 (BF16 kvcache)最佳线上吞吐(满足20 tokens/s 左右用户延迟)为2844 tokens/s,由two-mircobatch overlapping的DP288-EP288- b\_{mla}64 方案得到。
|
| 475 |
+
|
| 476 |
+
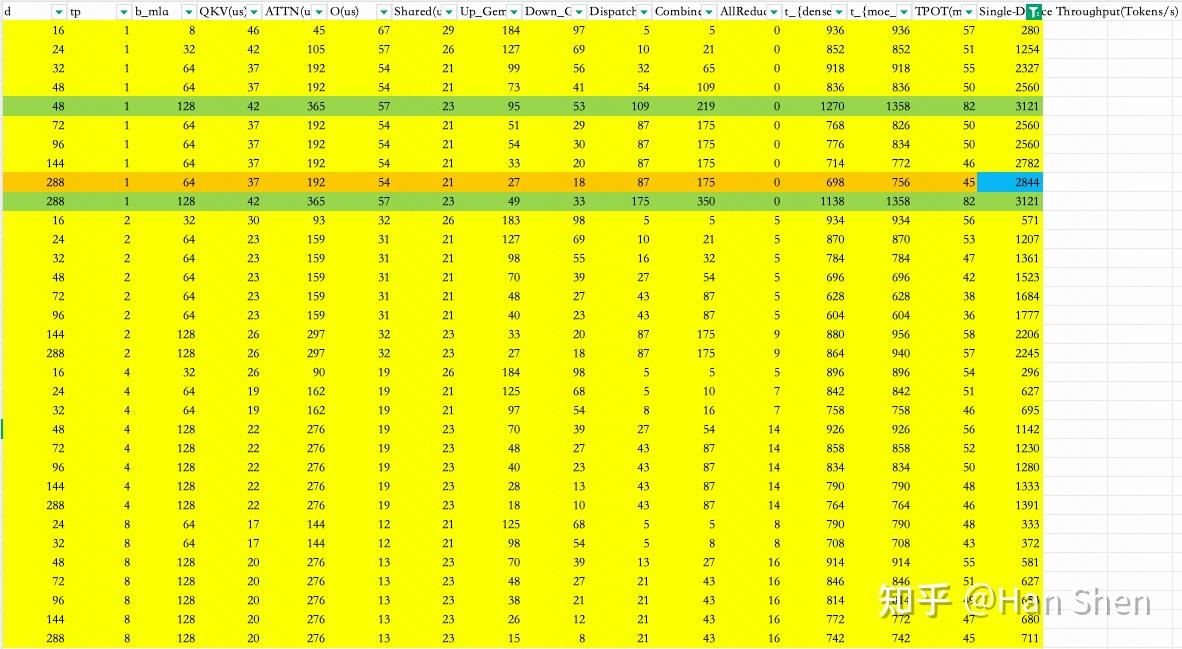
|
| 477 |
+
|
| 478 |
+
Two-Microbatch-Overlapping best configs - H800
|
| 479 |
+
|
| 480 |
+
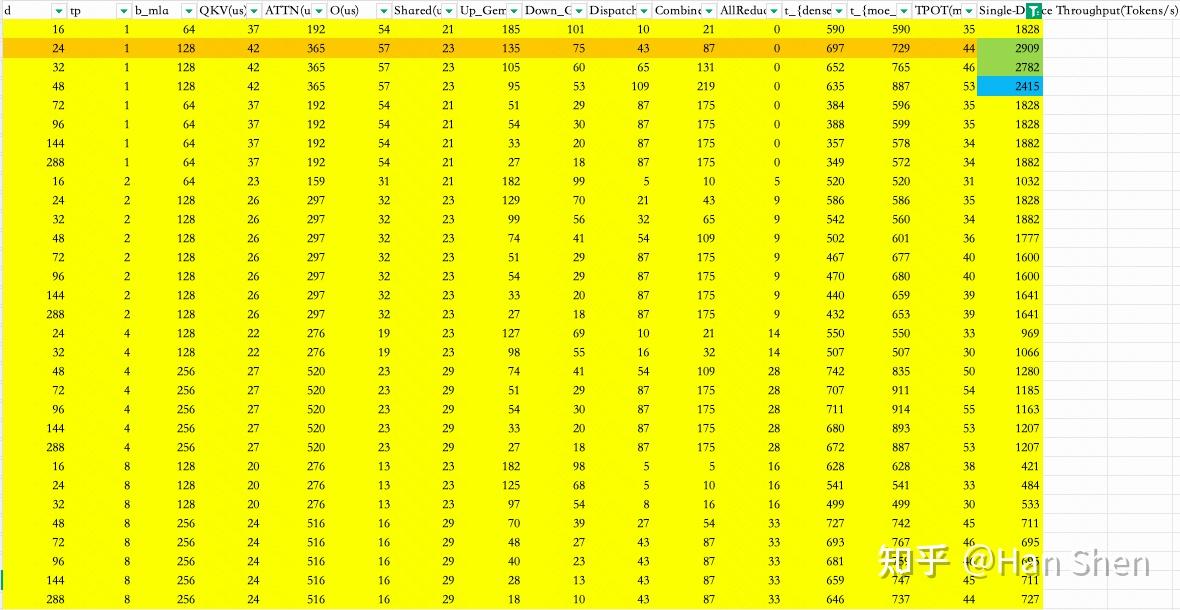
|
| 481 |
+
|
| 482 |
+
Single-batch-Overlapping best configs - H800
|
| 483 |
+
|
| 484 |
+
我们如预期中发现,当d<= 32时,single-batch comp-compute overlapping 比 two-mircobatch overlapping 有更好的吞吐表现:D ,**这个结果其实是非常鼓励无法做高并发的同行去实现的。**
|
| 485 |
+
|
| 486 |
+
除了官方的E144 实现之外,我们发现继续走EP288 吞吐上的边际收益相对有限了,读者可以参考[这里](https://link.zhihu.com/?target=https%3A//github.com/shenh10/DeepSeek_Simulator/tree/main/results)的完整测试结果来选择自己合适的配置。对于FP8 kvcache 与 single-batch compute-communication overlapping 的实现,前者需要自己尝试撸FP8 kvcache的 MLA算子,后者需要写DownGemm与Combine AlltoAll的overlapping,需要具备一定的infra 开发能力(但不难)。
|
| 487 |
+
|
| 488 |
+
## 4.2 H20 实验结果
|
| 489 |
+
|
| 490 |
+
观察测试数据,我们发现
|
| 491 |
+
|
| 492 |
+
- DP-EP 是获得最佳离线吞吐表现的方案,开启Attention TP 会损害吞吐。但对于H20这类低算力卡型,开启Attention TP有利于在同等节点数下达到更好的TPOT,从而满足SLO要求。需要注意的是,**TP数开得过多,会影响等效单卡吞吐,使得overall 吞吐下降**。实验测试下比较合适的线上配置为开启TP=2。
|
| 493 |
+
- H20 (BF16 kvcache)最佳离线吞吐为单卡969 tokens/s,由two-mircobatch overlapping的 DP72-EP72 - b\_{mla}64 方案得到
|
| 494 |
+
- H20 (FP8 kvcache)最佳离线吞吐为单卡980 tokens/s,由two-mircobatch overlapping的 DP72-EP72- b\_{mla}128 方案得到。
|
| 495 |
+
- H20 (FP8 kvcache/BF16 kvcache)最佳线上吞吐(满足20 tokens/s 左右用户延迟)为820 tokens/s, 由single-batch compute-communication overlapping的 DP48-EP48- b\_{mla}32 方案或TP2-DP24-EP48- b\_{mla}64 方案得到。
|
| 496 |
+
|
| 497 |
+
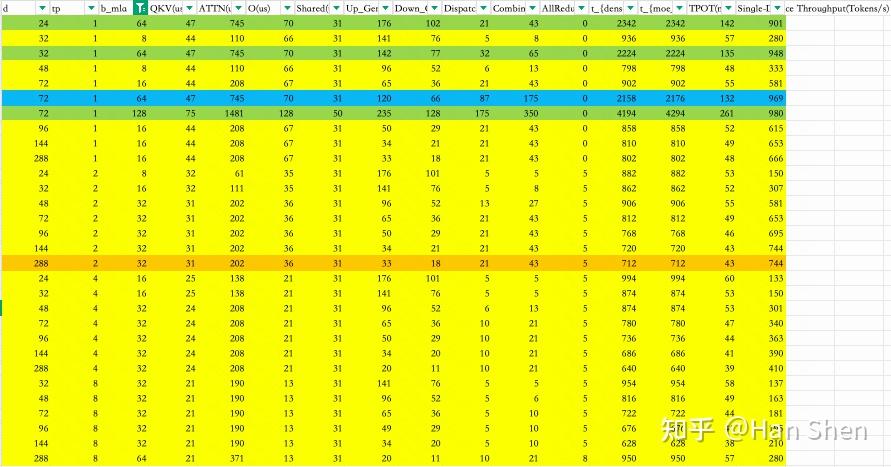
|
| 498 |
+
|
| 499 |
+
Two-Microbatch-Overlapping best configs - H20
|
| 500 |
+
|
| 501 |
+
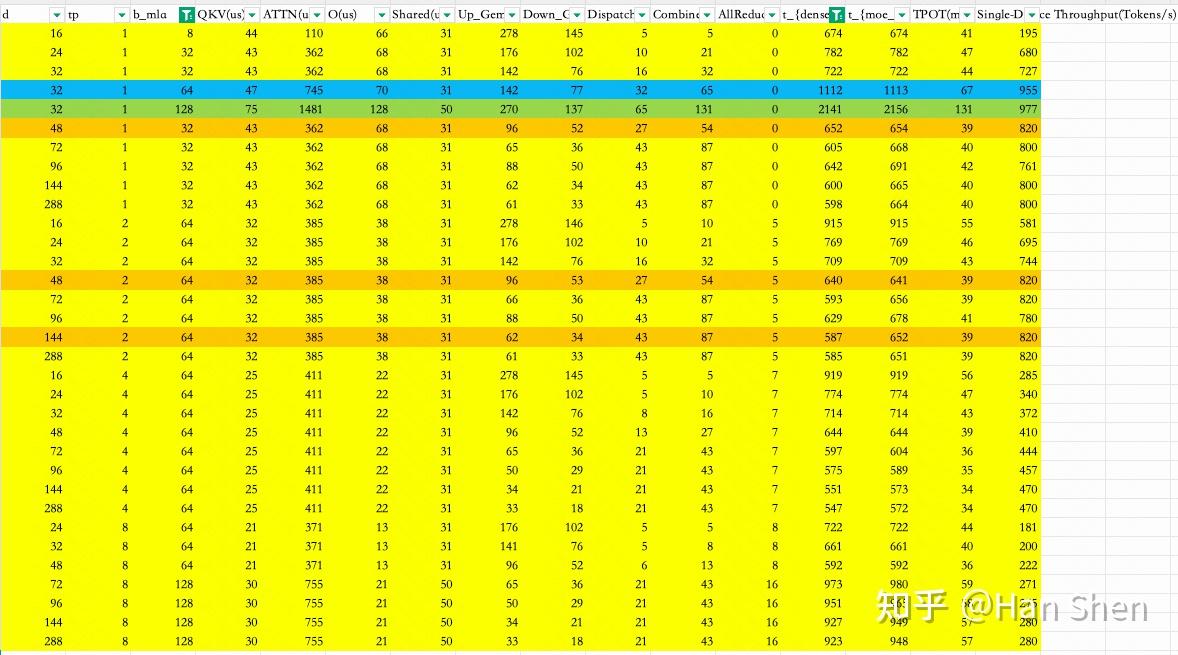
|
| 502 |
+
|
| 503 |
+
Single-batch-Overlapping best configs - H20
|
| 504 |
+
|
| 505 |
+
## 5. 结论
|
| 506 |
+
|
| 507 |
+
通过一系列分析,笔者终于完成了整个系列的目标——对DeepSeek R1的部署方案的推广泛化。我在分析的过程中发现我们可以自己实现小实例组的Single-batch-Overlapping,也可以选择FP8 kvcache 提升小实例组的吞吐,组合出更多样的部署方案搜索空间。我们惊喜的发现,官方的配置并不是唯一的选择,也并不需要DP144-EP144那么大的实例组才能达到较好的线上服务效果,tradeoff一定的吞吐我们可以让部署变得更为灵活和简单。
|
| 508 |
+
|
| 509 |
+
此外,我们发现H20 的吞吐效率大约是H800 30%,MaaS 老板们可以根据这个数据来判断一下TCO的收益:D 。因为手上没有异构硬件,我相信这套工具可以比较容易地适配到具备基础算子库的芯片厂商,从而得到较好的真实数据模拟,欢迎搞芯片的同学继续后面的工作。
|
| 510 |
+
|
| 511 |
+
还是老规矩,文章涉及大量计算,如有错漏欢迎同行指出:D。
|
download_zhihu_articles.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""Download Zhihu zhuanlan articles listed in source.md as Markdown."""
|
| 3 |
+
|
| 4 |
+
from __future__ import annotations
|
| 5 |
+
|
| 6 |
+
import html
|
| 7 |
+
import itertools
|
| 8 |
+
import json
|
| 9 |
+
import re
|
| 10 |
+
import shutil
|
| 11 |
+
import signal
|
| 12 |
+
import subprocess
|
| 13 |
+
import tempfile
|
| 14 |
+
import time
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
from typing import Any
|
| 17 |
+
|
| 18 |
+
import requests
|
| 19 |
+
import websocket
|
| 20 |
+
from bs4 import BeautifulSoup
|
| 21 |
+
from markdownify import markdownify as md
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
ROOT = Path(__file__).resolve().parent
|
| 25 |
+
SOURCE_FILE = ROOT / "source.md"
|
| 26 |
+
OUTPUT_DIR = ROOT / "articles"
|
| 27 |
+
CHROME = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
|
| 28 |
+
REMOTE_PORT = 9227
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def extract_zhihu_urls(text: str) -> list[str]:
|
| 32 |
+
urls = re.findall(r"https?://[^\s)]+", text)
|
| 33 |
+
seen: set[str] = set()
|
| 34 |
+
result: list[str] = []
|
| 35 |
+
for url in urls:
|
| 36 |
+
if "zhihu.com" not in url or "/p/" not in url:
|
| 37 |
+
continue
|
| 38 |
+
clean_url = url.rstrip("。.,,)")
|
| 39 |
+
if clean_url not in seen:
|
| 40 |
+
seen.add(clean_url)
|
| 41 |
+
result.append(clean_url)
|
| 42 |
+
return result
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def article_id(url: str) -> str:
|
| 46 |
+
match = re.search(r"/p/(\d+)", url)
|
| 47 |
+
if not match:
|
| 48 |
+
raise ValueError(f"Cannot find article id in {url}")
|
| 49 |
+
return match.group(1)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def safe_filename(value: str, fallback: str) -> str:
|
| 53 |
+
value = re.sub(r"[\\/:*?\"<>|\s]+", "-", value.strip())
|
| 54 |
+
value = re.sub(r"-+", "-", value).strip("-.")
|
| 55 |
+
return (value or fallback)[:80]
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class ChromeCDP:
|
| 59 |
+
def __init__(self, port: int = REMOTE_PORT) -> None:
|
| 60 |
+
self.port = port
|
| 61 |
+
self.profile_dir = Path(tempfile.mkdtemp(prefix="zhihu-chrome-"))
|
| 62 |
+
self.process: subprocess.Popen[bytes] | None = None
|
| 63 |
+
self.ws: websocket.WebSocket | None = None
|
| 64 |
+
self.counter = itertools.count(1)
|
| 65 |
+
|
| 66 |
+
def __enter__(self) -> "ChromeCDP":
|
| 67 |
+
self.process = subprocess.Popen(
|
| 68 |
+
[
|
| 69 |
+
CHROME,
|
| 70 |
+
f"--remote-debugging-port={self.port}",
|
| 71 |
+
"--remote-allow-origins=*",
|
| 72 |
+
f"--user-data-dir={self.profile_dir}",
|
| 73 |
+
"--no-first-run",
|
| 74 |
+
"--no-default-browser-check",
|
| 75 |
+
"about:blank",
|
| 76 |
+
],
|
| 77 |
+
stdout=subprocess.DEVNULL,
|
| 78 |
+
stderr=subprocess.DEVNULL,
|
| 79 |
+
)
|
| 80 |
+
for _ in range(100):
|
| 81 |
+
try:
|
| 82 |
+
requests.get(f"http://127.0.0.1:{self.port}/json/version", timeout=1)
|
| 83 |
+
break
|
| 84 |
+
except requests.RequestException:
|
| 85 |
+
time.sleep(0.2)
|
| 86 |
+
else:
|
| 87 |
+
raise RuntimeError("Chrome remote debugging endpoint did not start")
|
| 88 |
+
return self
|
| 89 |
+
|
| 90 |
+
def __exit__(self, *_: object) -> None:
|
| 91 |
+
try:
|
| 92 |
+
if self.ws:
|
| 93 |
+
self.ws.close()
|
| 94 |
+
finally:
|
| 95 |
+
if self.process:
|
| 96 |
+
self.process.send_signal(signal.SIGTERM)
|
| 97 |
+
try:
|
| 98 |
+
self.process.wait(timeout=10)
|
| 99 |
+
except subprocess.TimeoutExpired:
|
| 100 |
+
self.process.kill()
|
| 101 |
+
shutil.rmtree(self.profile_dir, ignore_errors=True)
|
| 102 |
+
|
| 103 |
+
def open_tab(self, url: str) -> None:
|
| 104 |
+
response = requests.put(f"http://127.0.0.1:{self.port}/json/new?{url}", timeout=5)
|
| 105 |
+
response.raise_for_status()
|
| 106 |
+
tab = response.json()
|
| 107 |
+
self.ws = websocket.create_connection(tab["webSocketDebuggerUrl"], timeout=20)
|
| 108 |
+
self.command("Runtime.enable")
|
| 109 |
+
self.command("Page.enable")
|
| 110 |
+
|
| 111 |
+
def close_tab(self) -> None:
|
| 112 |
+
if self.ws:
|
| 113 |
+
self.ws.close()
|
| 114 |
+
self.ws = None
|
| 115 |
+
|
| 116 |
+
def command(self, method: str, params: dict[str, Any] | None = None) -> dict[str, Any]:
|
| 117 |
+
if not self.ws:
|
| 118 |
+
raise RuntimeError("No active Chrome tab")
|
| 119 |
+
command_id = next(self.counter)
|
| 120 |
+
self.ws.send(json.dumps({"id": command_id, "method": method, "params": params or {}}))
|
| 121 |
+
while True:
|
| 122 |
+
message = json.loads(self.ws.recv())
|
| 123 |
+
if message.get("id") == command_id:
|
| 124 |
+
return message
|
| 125 |
+
|
| 126 |
+
def evaluate(self, expression: str) -> Any:
|
| 127 |
+
last_result: dict[str, Any] | None = None
|
| 128 |
+
for _ in range(8):
|
| 129 |
+
result = self.command(
|
| 130 |
+
"Runtime.evaluate",
|
| 131 |
+
{"expression": expression, "awaitPromise": True, "returnByValue": True},
|
| 132 |
+
)
|
| 133 |
+
last_result = result
|
| 134 |
+
error = result.get("error", {})
|
| 135 |
+
if error.get("message") == "Execution context was destroyed.":
|
| 136 |
+
time.sleep(1)
|
| 137 |
+
continue
|
| 138 |
+
break
|
| 139 |
+
else:
|
| 140 |
+
result = last_result or {}
|
| 141 |
+
payload = result.get("result", {}).get("result", {})
|
| 142 |
+
if "value" in payload:
|
| 143 |
+
return payload["value"]
|
| 144 |
+
if "unserializableValue" in payload:
|
| 145 |
+
return payload["unserializableValue"]
|
| 146 |
+
if result.get("result", {}).get("exceptionDetails"):
|
| 147 |
+
raise RuntimeError(json.dumps(result["result"]["exceptionDetails"], ensure_ascii=False))
|
| 148 |
+
raise RuntimeError("CDP evaluation returned no value: " + json.dumps(result, ensure_ascii=False)[:1000])
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
EXTRACT_SCRIPT = r"""
|
| 152 |
+
(async () => {
|
| 153 |
+
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
|
| 154 |
+
for (let i = 0; i < 80; i++) {
|
| 155 |
+
if (document.querySelector('.Post-RichText')) break;
|
| 156 |
+
await sleep(500);
|
| 157 |
+
}
|
| 158 |
+
window.scrollTo(0, document.body.scrollHeight);
|
| 159 |
+
await sleep(1200);
|
| 160 |
+
const content = document.querySelector('.Post-RichText');
|
| 161 |
+
const title = document.querySelector('.Post-Title, h1')?.innerText?.trim() || document.title.replace(/ - 知乎$/, '').trim();
|
| 162 |
+
const author = document.querySelector('.AuthorInfo-name, .Post-Author meta[itemprop="name"]')?.innerText?.trim()
|
| 163 |
+
|| document.querySelector('.Post-Author meta[itemprop="name"]')?.content?.trim()
|
| 164 |
+
|| '';
|
| 165 |
+
const published = document.querySelector('meta[itemprop="datePublished"]')?.content || '';
|
| 166 |
+
const modified = document.querySelector('meta[itemprop="dateModified"]')?.content || '';
|
| 167 |
+
return JSON.stringify({
|
| 168 |
+
ok: Boolean(content),
|
| 169 |
+
url: location.href,
|
| 170 |
+
title,
|
| 171 |
+
author,
|
| 172 |
+
published,
|
| 173 |
+
modified,
|
| 174 |
+
contentHtml: content ? content.outerHTML : '',
|
| 175 |
+
pageText: document.body.innerText.slice(0, 800),
|
| 176 |
+
});
|
| 177 |
+
})()
|
| 178 |
+
"""
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def clean_article_html(content_html: str, base_url: str) -> str:
|
| 182 |
+
soup = BeautifulSoup(content_html, "html.parser")
|
| 183 |
+
for tag in soup.select("script, style, noscript, button, svg"):
|
| 184 |
+
tag.decompose()
|
| 185 |
+
for tag in soup.select("a.RichContent-EntityWord"):
|
| 186 |
+
tag.unwrap()
|
| 187 |
+
for image in soup.find_all("img"):
|
| 188 |
+
src = image.get("data-original") or image.get("data-actualsrc") or image.get("src")
|
| 189 |
+
if src:
|
| 190 |
+
image["src"] = html.unescape(src)
|
| 191 |
+
for attr in list(image.attrs):
|
| 192 |
+
if attr not in {"src", "alt", "title"}:
|
| 193 |
+
del image[attr]
|
| 194 |
+
for anchor in soup.find_all("a"):
|
| 195 |
+
href = anchor.get("href")
|
| 196 |
+
if href and href.startswith("//"):
|
| 197 |
+
anchor["href"] = "https:" + href
|
| 198 |
+
elif href and href.startswith("/"):
|
| 199 |
+
anchor["href"] = "https://www.zhihu.com" + href
|
| 200 |
+
return str(soup)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def html_to_markdown(content_html: str) -> str:
|
| 204 |
+
markdown = md(
|
| 205 |
+
content_html,
|
| 206 |
+
heading_style="ATX",
|
| 207 |
+
bullets="-",
|
| 208 |
+
strip=["span"],
|
| 209 |
+
)
|
| 210 |
+
markdown = re.sub(r"\n{3,}", "\n\n", markdown)
|
| 211 |
+
markdown = re.sub(r"[ \t]+\n", "\n", markdown)
|
| 212 |
+
return markdown.strip()
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def make_markdown(data: dict[str, str], source_url: str, article_markdown: str) -> str:
|
| 216 |
+
lines = [
|
| 217 |
+
"---",
|
| 218 |
+
f"title: {json.dumps(data.get('title', ''), ensure_ascii=False)}",
|
| 219 |
+
f"source: {source_url}",
|
| 220 |
+
f"fetched_url: {data.get('url', source_url)}",
|
| 221 |
+
]
|
| 222 |
+
if data.get("author"):
|
| 223 |
+
lines.append(f"author: {json.dumps(data['author'], ensure_ascii=False)}")
|
| 224 |
+
if data.get("published"):
|
| 225 |
+
lines.append(f"published: {data['published']}")
|
| 226 |
+
if data.get("modified"):
|
| 227 |
+
lines.append(f"modified: {data['modified']}")
|
| 228 |
+
lines.extend(["---", "", f"# {data.get('title', '').strip()}", "", article_markdown, ""])
|
| 229 |
+
return "\n".join(lines)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
def download_one(browser: ChromeCDP, index: int, url: str) -> Path:
|
| 233 |
+
browser.open_tab(url)
|
| 234 |
+
try:
|
| 235 |
+
time.sleep(3)
|
| 236 |
+
raw = browser.evaluate(EXTRACT_SCRIPT)
|
| 237 |
+
data = json.loads(raw)
|
| 238 |
+
if not data.get("ok"):
|
| 239 |
+
raise RuntimeError(f"Could not find article content. Page starts with: {data.get('pageText', '')!r}")
|
| 240 |
+
cleaned_html = clean_article_html(data["contentHtml"], url)
|
| 241 |
+
article_markdown = html_to_markdown(cleaned_html)
|
| 242 |
+
if len(article_markdown) < 100:
|
| 243 |
+
raise RuntimeError("Extracted article is unexpectedly short")
|
| 244 |
+
aid = article_id(url)
|
| 245 |
+
filename = f"{index:02d}-{aid}-{safe_filename(data.get('title', ''), aid)}.md"
|
| 246 |
+
path = OUTPUT_DIR / filename
|
| 247 |
+
path.write_text(make_markdown(data, url, article_markdown), encoding="utf-8")
|
| 248 |
+
return path
|
| 249 |
+
finally:
|
| 250 |
+
browser.close_tab()
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
def main() -> None:
|
| 254 |
+
if not Path(CHROME).exists():
|
| 255 |
+
raise SystemExit(f"Chrome not found: {CHROME}")
|
| 256 |
+
urls = extract_zhihu_urls(SOURCE_FILE.read_text(encoding="utf-8"))
|
| 257 |
+
if not urls:
|
| 258 |
+
raise SystemExit("No Zhihu article URLs found in source.md")
|
| 259 |
+
OUTPUT_DIR.mkdir(exist_ok=True)
|
| 260 |
+
with ChromeCDP() as browser:
|
| 261 |
+
for index, url in enumerate(urls, start=1):
|
| 262 |
+
path = download_one(browser, index, url)
|
| 263 |
+
print(f"saved {path}")
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
if __name__ == "__main__":
|
| 267 |
+
main()
|
source.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DeepSeek V3/R1 hosting 成本估算
|
| 2 |
+
* https://zhuanlan.zhihu.com/p/23282743306
|
| 3 |
+
* https://zhuanlan.zhihu.com/p/27181462601
|
| 4 |
+
* https://zhuanlan.zhihu.com/p/16445683081
|
| 5 |
+
|
| 6 |
+
DeepSeek V3/R1 推理效率分析
|
| 7 |
+
* https://zhuanlan.zhihu.com/p/27292649125
|
| 8 |
+
* https://zhuanlan.zhihu.com/p/29841050824
|
| 9 |
+
* https://zhuanlan.zhihu.com/p/29540042383
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
DeepSeek V3 tech-report
|
| 13 |
+
* https://arxiv.org/html/2412.19437
|
| 14 |
+
|