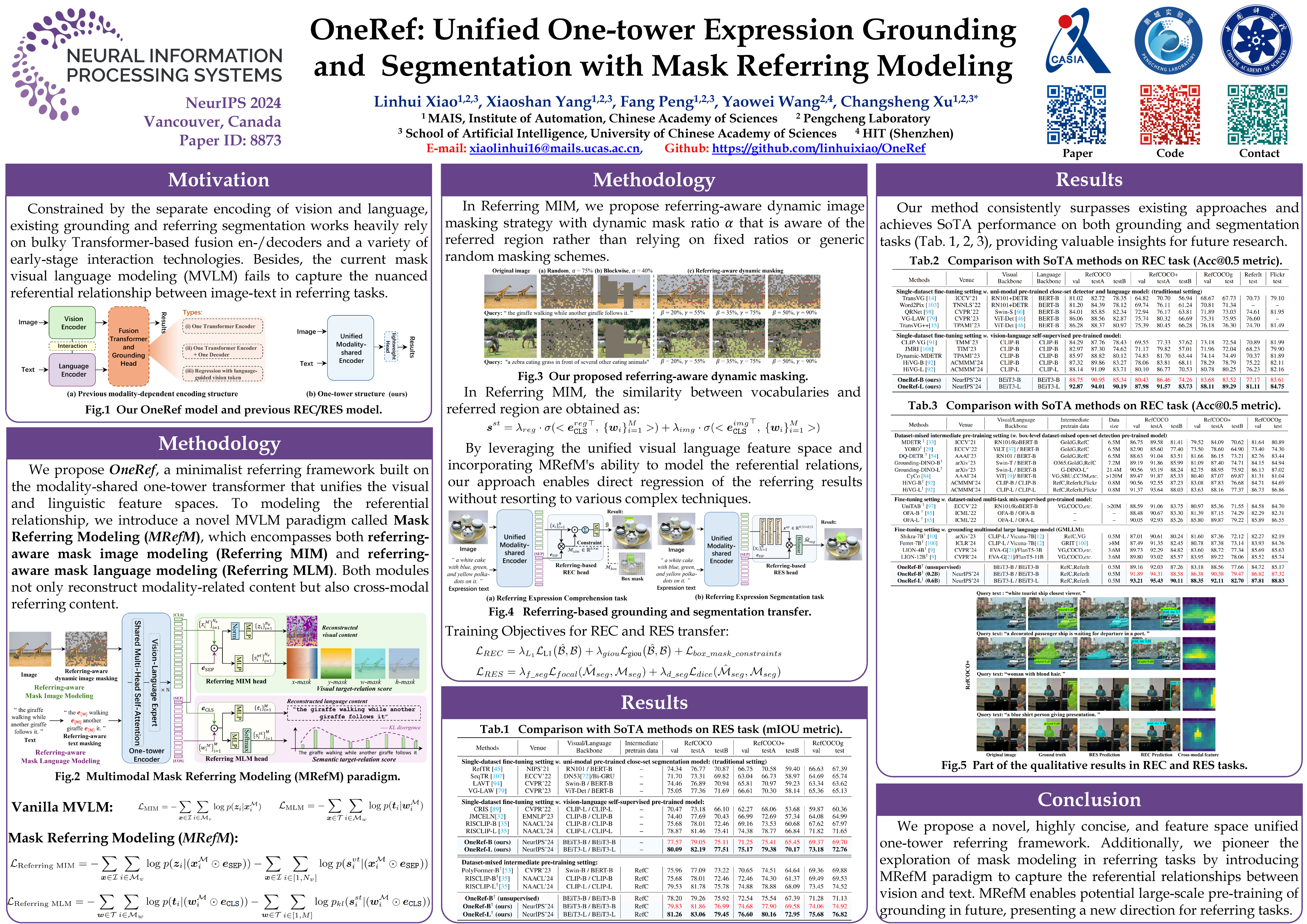
| Large model |
mixup_pretraining_large_unc+g, ~8.0 GB |
mixup_pretraining_large_referit, ~8.0 GB |
mixup_pretraining_large_flickr, ~8.0 GB |
### REC task: Ultimate performance prediction in our [Grounding Survey paper](https://arxiv.org/pdf/2412.20206)
### RES task: Single-dataset fine-tuning checkpoints download
### RES task: Mixup grounding pre-training checkpoints download
After downloading all of these checkpoints, you can save them in the following directory, allowing you to train and test
the five datasets at once and just using a single script.
```angular2html
|-- /finetuning_checkpoints (base or large model, rec or res task)
├── flickr
│ └── best_checkpoint.pth
├── gref_umd
│ └── best_checkpoint.pth
├── referit
│ └── best_checkpoint.pth
├── unc
│ └── best_checkpoint.pth
└── unc+
└── best_checkpoint.pth
|-- /mixup_grounding_pretraining (base or large model, rec or res task)
└── mixup
└── best_checkpoint.pth
```
### MRefM pretrained backbone checkpoints download
We propose our multimodal **Mask Referring Modeling (MRefM)** paradigm to enhance the model's referring comprehension ability.
Since MRefM aims to improve its general referring comprehension ability through pre-training, it mainly demonstrates its
performance gain under the mixed pre-training setting. In the experiment, the MRefM pre-training **for the REC task** is
mainly carried out through a mixture of the RefCOCO/+/g (short as RefC) and ReferIt datasets. To ensure a fair comparison,
the MRefM pre-training **for the RES task** is mainly carried out through a mixture of the RefC datasets.
For MRefM pre-training, the base model took 15 hours on 32 NVIDIA A100 GPUs, while the large model took 50 hours on
the same number of GPUs. We provide the MRefM pre-trained checkpoints at the following: All model are placed in [HuggingFace Page](https://huggingface.co/linhuixiao/OneRef/tree/main)
### Original BEiT-3 checkpoints download
In order to facilitate the reproducibility of the MRefM pre-training results and to achieve transferability in non-MRefM settings,
we also provide the original BEiT-3 model as follows. You can download it from the table below or from
the [BEiT-3 official repository](https://github.com/microsoft/unilm/tree/master/beit3).
## REC and RES Transfer Training and Evaluation
As shown below, we have provided complete evaluation, training, and pre-training scripts in the [train_and_eval_script](train_and_eval_script).
```angular2html
train_and_eval_script
├── eval_rec_mixup_grounding_pretraining_base.sh
├── eval_rec_mixup_grounding_pretraining_large.sh
├── eval_rec_single_dataset_finetuning_base.sh
├── eval_rec_single_dataset_finetuning_large.sh
├── eval_res_mixup_grounding_pretraining_base.sh
├── eval_res_mixup_grounding_pretraining_large.sh
├── eval_res_single_dataset_finetuning_base.sh
├── eval_res_single_dataset_finetuning_large.sh
├── MRefM_pretraining
│ ├── rec_mrefm_pretraining_base.sh
│ ├── rec_mrefm_pretraining_large.sh
│ ├── res_mrefm_pretraining_base.sh
│ └── res_mrefm_pretraining_large.sh
├── submit_for_multi_node_pretraining
│ ├── get_master_ip.sh
│ ├── master_ip.sh
│ └── train_and_eval_for_multi_node.sh
├── train_rec_mixup_grounding_pretraining_base.sh
├── train_rec_mixup_grounding_pretraining_large.sh
├── train_rec_single_dataset_finetuning_base.sh
├── train_rec_single_dataset_finetuning_large.sh
├── train_res_mixup_grounding_pretraining_base.sh
├── train_res_mixup_grounding_pretraining_large.sh
├── train_res_single_dataset_finetuning_base.sh
└── train_res_single_dataset_finetuning_large.sh
```
You only need to modify the corresponding paths (change ```$/path_to_split```, ``` $/path_to_image_data```, ``` $/path_to_output``` to your own file directory),
and then execute the corresponding scripts with the ```bash``` command to test and train the relevant models.
1. Training on RefCOCO with single dataset finetuning setting.
```
CUDA_VISIBLE_DEVICES=3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=5 --master_port 28887 --use_env train_clip_vg.py --num_workers 32 --epochs 120 --batch_size 64 --lr 0.00025 --lr_scheduler cosine --aug_crop --aug_scale --aug_translate --imsize 224 --max_query_len 77 --sup_type full --dataset unc --data_root $/path_to_image_data --split_root $/path_to_split --output_dir $/path_to_output/output_v01/unc;
```
Please refer to [train_and_eval_script/train_rec_single_dataset_finetuning_base.sh](train_and_eval_script/train_rec_single_dataset_finetuning_base.sh) for training commands on other datasets.
2. Evaluation on RefCOCO.
```
CUDA_VISIBLE_DEVICES=2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=6 --master_port 28888 --use_env eval.py --num_workers 2 --batch_size 128 --dataset unc --imsize 224 --max_query_len 77 --data_root $/path_to_image_data --split_root $/path_to_split --eval_model $/path_to_output/output_v01/unc/best_checkpoint.pth --eval_set val --output_dir $/path_to_output/output_v01/unc;
```
Please refer to [train_and_eval_script/eval_rec_single_dataset_finetuning_base.sh](train_and_eval_script/eval_rec_single_dataset_finetuning_base.sh) for evaluation commands on other splits or datasets.
3. We strongly recommend to use the ```bash``` commands to training or testing with different datasets and splits,
which will significant reduce the training workforce. such as:
```
bash train_and_eval_script/train_rec_single_dataset_finetuning_base.sh
```
**It should be noted that**, due to the limited number of data samples in the single-dataset setting, MRefM did not yield significant improvements in performance. To streamline the training process and facilitate the reproducibility of our work, we provide a training process without MRefM pre-training specifically for the single-dataset scenario.
## MRefM Pre-training
### 1. One-node Pre-training
Single-node means that only one multi-card server is needed. You just need to run the following command. This training is not much different from the fine-tuning training.
CUDA_VISIBLE_DEVICES=3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=5 --master_port 28887 --use_env train_clip_vg.py --num_workers 32 --epochs 120 --batch_size 64 --lr 0.00025 --lr_scheduler cosine --aug_crop --aug_scale --aug_translate --imsize 224 --max_query_len 77 --sup_type full --dataset unc --data_root $/path_to_image_data --split_root $/path_to_split --output_dir $/path_to_output/output_v01/unc;
Or using the bash command as follows:
```angular2html
bash train_and_eval_script/MRefM_pretraining/rec_mrefm_pretraining_base.sh
```
### 2. Multi-node Pre-training
Multi-node training means that multiple multi-card servers are required. You need to use the scripts in the [train_and_eval_script/submit_for_multi_node_pretraining](train_and_eval_script/submit_for_multi_node_pretraining) directory to start the process on multiple servers. For detailed operations, you can refer to the relevant tutorials.
## Results
### 1. REC task
REC Single-dataset Fine-tuning SoTA Result Table

REC Dataset-mixed Pretraining SoTA Result Table

### 2. RES task
RES Single-dataset Fine-tuning and Dataset-mixed Pretraining SoTA Result Table (mIoU)

RES Single-dataset Fine-tuning and Dataset-mixed Pretraining SoTA Result Table (oIoU)

### 3. Our model also has significant energy efficiency advantages.
Comparison of the computational cost in REC task.
## Methods

** An Illustration of our multimodal Mask Referring Modeling (MRefM) paradigm, which
includes Referring-aware mask image modeling and Referring-aware mask language modeling.
**

** An Illustration of the referring-based grounding and segmentation transfer.
**

** Illustrations of random masking (MAE) [27], block-wise masking (BEiT) [4], and our
referring-aware dynamic masking. α denotes the entire masking ratio, while β and γ denote the
masking ratio beyond and within the referred region.
**
## Visualization

** Qualitative results on the RefCOCO-val dataset.
**

** Qualitative results on the RefCOCO+-val dataset.
**

** Qualitative results on the RefCOCOg-val dataset.
**
Each example shows two different query texts. From left to right: the original input image, the ground truth with
box and segmentation mask (in green), the RES prediction of OneRef (in cyan), the REC prediction
of OneRef (in cyan), and the cross-modal feature.
## Contacts
Email: .
Any kind discussions are welcomed!
## Acknowledgement
Our model is related to [BEiT-3](https://github.com/microsoft/unilm/tree/master/beit3) and
[MAE](https://github.com/facebookresearch/mae). Thanks for their great work!
We also thank the great previous work including [TransVG](https://github.com/linhuixiao/TransVG),
[DETR](https://github.com/facebookresearch/detr), [CLIP](https://github.com/openai/CLIP),
[CLIP-VG](https://github.com/linhuixiao/CLIP-VG), etc.
Thanks [Microsoft](https://github.com/microsoft/unilm) for their awesome models.
## Star History
[](https://star-history.com/#linhuixiao/OneRef&Date)