
Update README.md
Browse files
README.md
CHANGED
|
@@ -4,117 +4,139 @@ language:
|
|
| 4 |
- en
|
| 5 |
- zh
|
| 6 |
base_model:
|
| 7 |
-
- Qwen/Qwen-Image
|
| 8 |
pipeline_tag: image-text-to-image
|
| 9 |
library_name: diffusers
|
| 10 |
---
|
| 11 |
-
|
| 12 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/layered/qwen-image-layered-logo.png" width="800"/>
|
| 13 |
-
<p>
|
| 14 |
-
<p align="center">  🤗 <a href="https://huggingface.co/Qwen/Qwen-Image-Layered">HuggingFace</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image-Layered">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2512.15603">Research Paper</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image-layered/">Blog</a>    |    🤗 <a href="https://huggingface.co/spaces/Qwen/Qwen-Image-Layered">Demo</a>   
|
| 15 |
-
</p>
|
| 16 |
|
| 17 |
-
|
| 18 |
-
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/layered/layered.JPG" width="1024"/>
|
| 19 |
-
<p>
|
| 20 |
|
| 21 |
-
|
| 22 |
-
We are excited to introduce **Qwen-Image-Layered**, a model capable of decomposing an image into multiple RGBA layers. This layered representation unlocks **inherent editability**: each layer can be independently manipulated without affecting other content. Meanwhile, such a layered representation naturally supports **high-fidelity elementary operations**-such as resizing, reposition, and recoloring. By physically isolating semantic or structural components into distinct layers, our approach enables high-fidelity and consistent editing.
|
| 23 |
|
| 24 |
-
|
| 25 |
|
| 26 |
-
|
| 27 |
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
|
|
|
| 33 |
|
|
|
|
| 34 |
|
| 35 |
-
|
| 36 |
-
from diffusers import QwenImageLayeredPipeline
|
| 37 |
-
import torch
|
| 38 |
-
from PIL import Image
|
| 39 |
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
output_image = output.images[0]
|
| 61 |
-
|
| 62 |
-
for i, image in enumerate(output_image):
|
| 63 |
-
image.save(f"{i}.png")
|
| 64 |
-
```
|
| 65 |
|
|
|
|
| 66 |
|
| 67 |
-
|
| 68 |
-
### Layered Decomposition in Application
|
| 69 |
-
Given an image, Qwen-Image-Layered can decompose it into several RGBA layers:
|
| 70 |
-

|
| 71 |
|
| 72 |
-
|
| 73 |
|
| 74 |
-
|
| 75 |
-
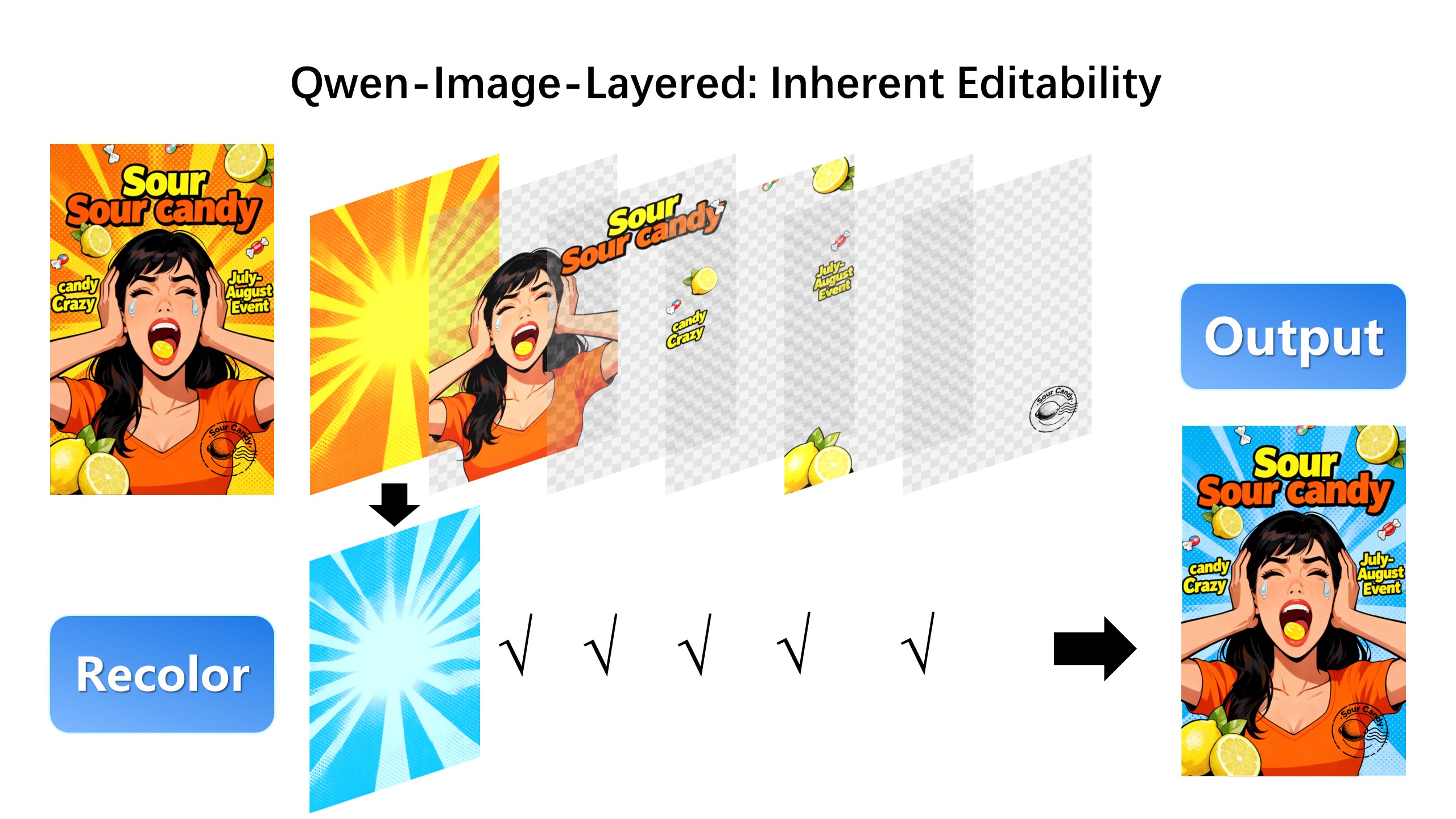
|
| 76 |
|
| 77 |
-
|
| 78 |
-
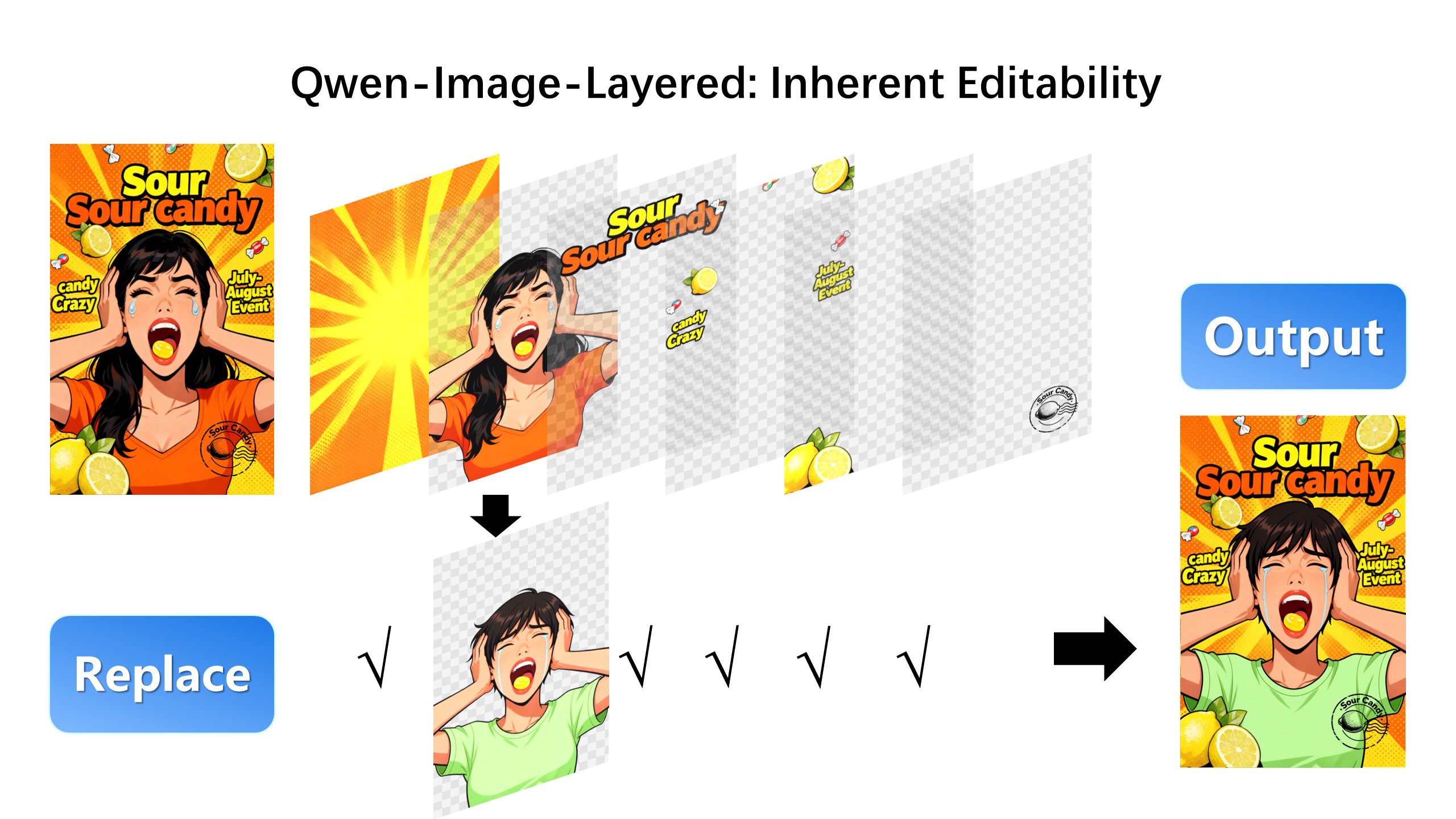
|
| 79 |
|
| 80 |
-
|
| 81 |
-
|
|
|
|
| 82 |
|
| 83 |
-
|
| 84 |
-
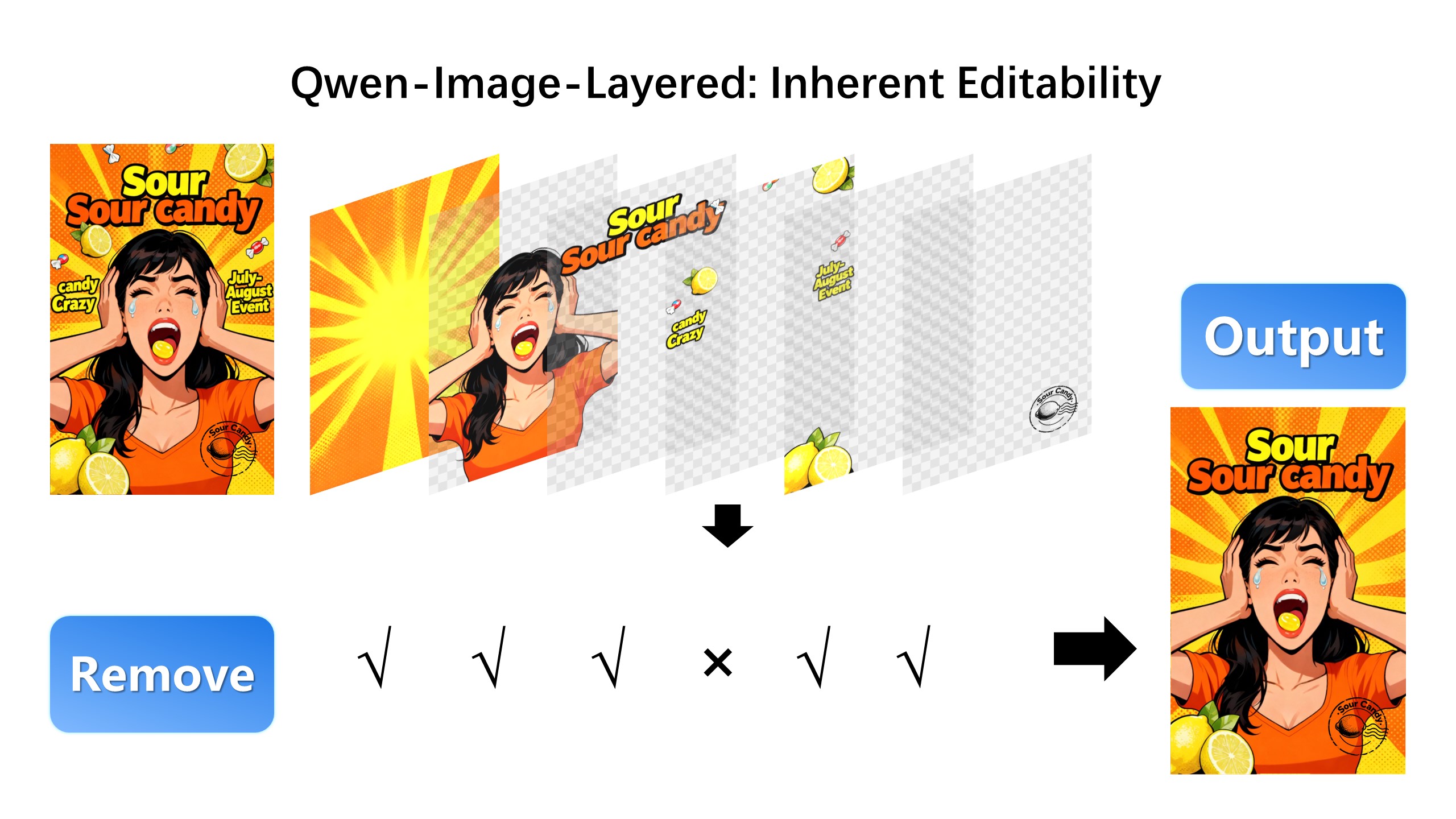
|
| 85 |
|
| 86 |
-
|
| 87 |
-
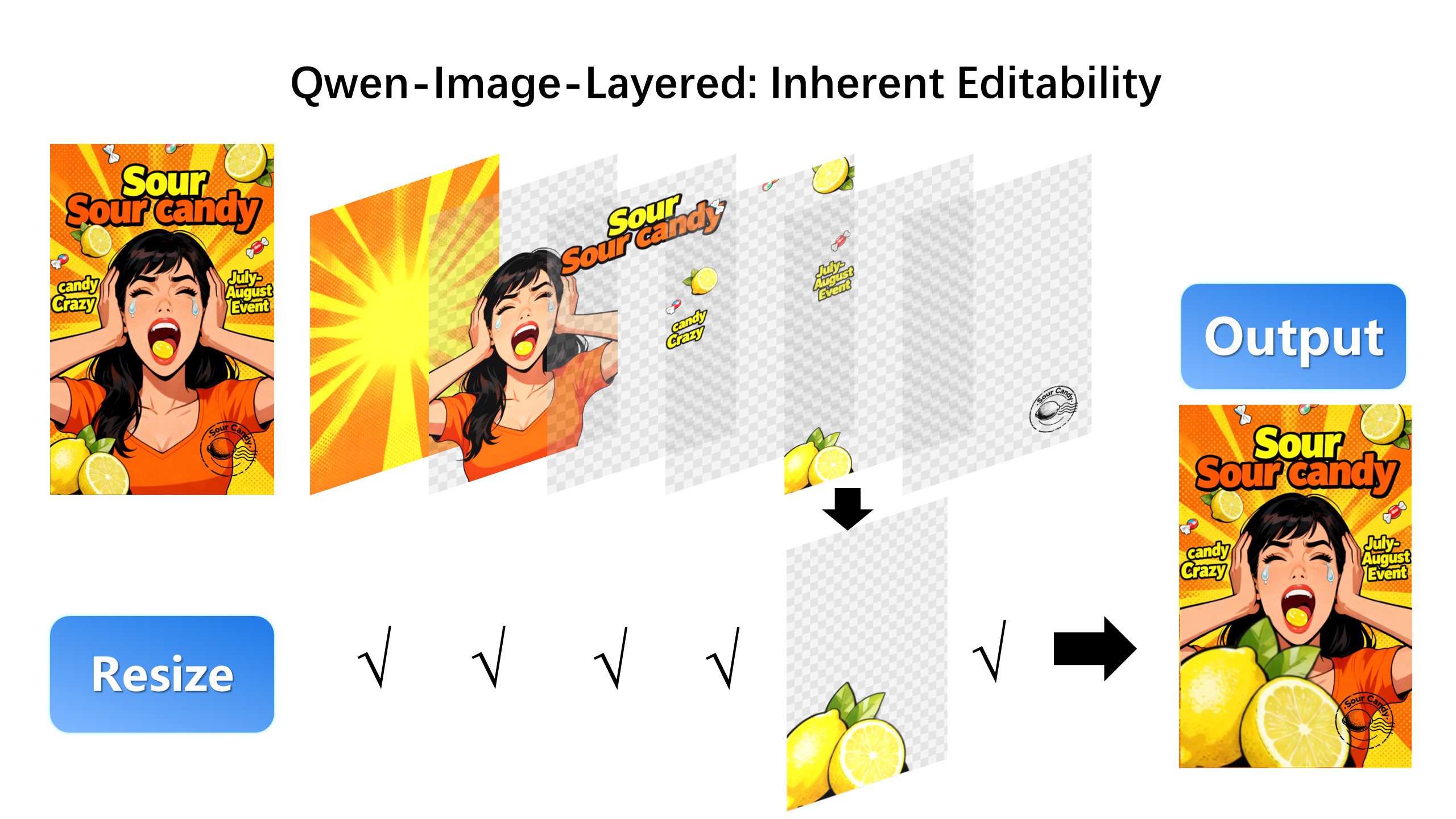
|
| 88 |
|
| 89 |
-
|
| 90 |
-
|
|
|
|
|
|
|
| 91 |
|
| 92 |
-
|
| 93 |
-
Qwen-Image-Layered is not limited to a fixed number of layers. The model supports variable-layer decomposition. For example, we can decompose an image into either 3 or 8 layers as needed:
|
| 94 |
|
| 95 |
-
|
| 96 |
|
| 97 |
-
|
| 98 |
|
| 99 |
-
|
| 100 |
|
|
|
|
| 101 |
|
| 102 |
-
|
|
|
|
|
|
|
| 103 |
|
| 104 |
-
|
| 105 |
|
| 106 |
-
|
| 107 |
|
| 108 |
-
|
|
|
|
|
|
|
|
|
|
| 109 |
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
```
|
|
|
|
| 4 |
- en
|
| 5 |
- zh
|
| 6 |
base_model:
|
| 7 |
+
- Qwen/Qwen-Image-Layered
|
| 8 |
pipeline_tag: image-text-to-image
|
| 9 |
library_name: diffusers
|
| 10 |
---
|
| 11 |
+
# Qwen-Image-Layered
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
+
## Model Introduction
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
This model is trained based on the model [Qwen/Qwen-Image-Layered](https://modelscope.cn/models/Qwen/Qwen-Image-Layered) using the dataset [artplus/PrismLayersPro](https://modelscope.cn/datasets/artplus/PrismLayersPro), enabling text-controlled extraction of segmented layers.
|
|
|
|
| 16 |
|
| 17 |
+
For more details about training strategies and implementation, feel free to check our [technical blog](https://modelscope.cn/learn/4938).
|
| 18 |
|
| 19 |
+
## Usage Tips
|
| 20 |
|
| 21 |
+
* The model architecture has been changed from multi-image output to single-image output, producing only the layer relevant to the provided text description.
|
| 22 |
+
* The model was trained exclusively on English text, but retains Chinese language understanding capabilities inherited from the base model.
|
| 23 |
+
* The native training resolution is 1024x1024; however, inference at other resolutions is supported.
|
| 24 |
+
* The model struggles to separate multiple entities that are heavily occluded or overlapping, such as the cartoon skeleton head and hat in the examples.
|
| 25 |
+
* The model excels at decomposing poster-like graphics but performs poorly on photographic images, especially those involving complex lighting and shadows.
|
| 26 |
+
* The model supports negative prompts—users can specify content they wish to exclude via negative prompt descriptions.
|
| 27 |
|
| 28 |
+
## Demo Examples
|
| 29 |
|
| 30 |
+
**Some images contain white text on light backgrounds. ModelScope users should click the "☀︎" icon in the top-right corner to switch to dark mode for better visibility.**
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
+
### Example 1
|
| 33 |
+
|
| 34 |
+
<div style="display: flex; justify-content: space-between;">
|
| 35 |
+
|
| 36 |
+
<div style="width: 30%;">
|
| 37 |
+
|
| 38 |
+
|Input Image|
|
| 39 |
+
|-|
|
| 40 |
+
||
|
| 41 |
+
|
| 42 |
+
</div>
|
| 43 |
+
|
| 44 |
+
<div style="width: 66%;">
|
| 45 |
+
|
| 46 |
+
|Prompt|Output Image|Prompt|Output Image|
|
| 47 |
+
|-|-|-|-|
|
| 48 |
+
|A solid, uniform color with no distinguishable features or objects||Text 'TRICK'||
|
| 49 |
+
|Cloud||Text 'TRICK OR TREAT'||
|
| 50 |
+
|A cartoon skeleton character wearing a purple hat and holding a gift box||Text 'TRICK OR'||
|
| 51 |
+
|A purple hat and a head||A gift box||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 52 |
|
| 53 |
+
</div>
|
| 54 |
|
| 55 |
+
</div>
|
|
|
|
|
|
|
|
|
|
| 56 |
|
| 57 |
+
### Example 2
|
| 58 |
|
| 59 |
+
<div style="display: flex; justify-content: space-between;">
|
|
|
|
| 60 |
|
| 61 |
+
<div style="width: 30%;">
|
|
|
|
| 62 |
|
| 63 |
+
|Input Image|
|
| 64 |
+
|-|
|
| 65 |
+
||
|
| 66 |
|
| 67 |
+
</div>
|
|
|
|
| 68 |
|
| 69 |
+
<div style="width: 66%;">
|
|
|
|
| 70 |
|
| 71 |
+
|Prompt|Output Image|Prompt|Output Image|
|
| 72 |
+
|-|-|-|-|
|
| 73 |
+
|Blue sky, white clouds, a garden with colorful flowers||Colorful, intricate floral wreath||
|
| 74 |
+
|Girl, wreath, kitten||Girl, kitten||
|
| 75 |
|
| 76 |
+
</div>
|
|
|
|
| 77 |
|
| 78 |
+
</div>
|
| 79 |
|
| 80 |
+
### Example 3
|
| 81 |
|
| 82 |
+
<div style="display: flex; justify-content: space-between;">
|
| 83 |
|
| 84 |
+
<div style="width: 30%;">
|
| 85 |
|
| 86 |
+
|Input Image|
|
| 87 |
+
|-|
|
| 88 |
+
||
|
| 89 |
|
| 90 |
+
</div>
|
| 91 |
|
| 92 |
+
<div style="width: 66%;">
|
| 93 |
|
| 94 |
+
|Prompt|Output Image|Prompt|Output Image|
|
| 95 |
+
|-|-|-|-|
|
| 96 |
+
|A clear blue sky and a turbulent sea||Text "The Life I Long For"||
|
| 97 |
+
|A seagull||Text "Life"||
|
| 98 |
|
| 99 |
+
</div>
|
| 100 |
+
|
| 101 |
+
</div>
|
| 102 |
+
|
| 103 |
+
## Inference Code
|
| 104 |
+
|
| 105 |
+
Install DiffSynth-Studio:
|
| 106 |
+
|
| 107 |
+
```
|
| 108 |
+
git clone https://github.com/modelscope/DiffSynth-Studio.git
|
| 109 |
+
cd DiffSynth-Studio
|
| 110 |
+
pip install -e .
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
Model inference:
|
| 114 |
+
|
| 115 |
+
```python
|
| 116 |
+
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
|
| 117 |
+
from PIL import Image
|
| 118 |
+
import torch, requests
|
| 119 |
+
pipe = QwenImagePipeline.from_pretrained(
|
| 120 |
+
torch_dtype=torch.bfloat16,
|
| 121 |
+
device="cuda",
|
| 122 |
+
model_configs=[
|
| 123 |
+
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-Layered-Control", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors"),
|
| 124 |
+
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors"),
|
| 125 |
+
ModelConfig(model_id="Qwen/Qwen-Image-Layered", origin_file_pattern="vae/diffusion_pytorch_model.safetensors"),
|
| 126 |
+
],
|
| 127 |
+
processor_config=ModelConfig(model_id="Qwen/Qwen-Image-Edit", origin_file_pattern="processor/"),
|
| 128 |
+
)
|
| 129 |
+
prompt = "A cartoon skeleton character wearing a purple hat and holding a gift box"
|
| 130 |
+
input_image = requests.get("https://modelscope.oss-cn-beijing.aliyuncs.com/resource/images/trick_or_treat.png", stream=True).raw
|
| 131 |
+
input_image = Image.open(input_image).convert("RGBA").resize((1024, 1024))
|
| 132 |
+
input_image.save("image_input.png")
|
| 133 |
+
images = pipe(
|
| 134 |
+
prompt,
|
| 135 |
+
seed=0,
|
| 136 |
+
num_inference_steps=30, cfg_scale=4,
|
| 137 |
+
height=1024, width=1024,
|
| 138 |
+
layer_input_image=input_image,
|
| 139 |
+
layer_num=0,
|
| 140 |
+
)
|
| 141 |
+
images[0].save("image.png")
|
| 142 |
```
|