
Improve model card metadata and README structure
Browse files
README.md
CHANGED
|
@@ -2,9 +2,22 @@
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: transformers
|
| 4 |
pipeline_tag: zero-shot-image-classification
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
tags:
|
|
|
|
|
|
|
| 6 |
- multimodal
|
| 7 |
- image-text-retrieval
|
|
|
|
| 8 |
- bilingual
|
| 9 |
- chinese
|
| 10 |
- english
|
|
@@ -12,30 +25,47 @@ tags:
|
|
| 12 |
- custom-code
|
| 13 |
---
|
| 14 |
|
| 15 |
-
# M2-Encoder-0.4B
|
| 16 |
|
| 17 |
-
|
| 18 |
|
| 19 |
-
|
| 20 |
|
| 21 |
-
-
|
| 22 |
-
- `AutoProcessor.from_pretrained(..., trust_remote_code=True)`
|
| 23 |
-
- `AutoModel.from_pretrained(..., trust_remote_code=True)`
|
| 24 |
-
- Zero-shot image-text retrieval and zero-shot image classification
|
| 25 |
|
| 26 |
-
##
|
| 27 |
|
| 28 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
-
|
| 31 |
|
| 32 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
|
| 34 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
### ModelScope-equivalent scoring
|
| 37 |
|
| 38 |
-
The original ModelScope sample computes probabilities from
|
| 39 |
|
| 40 |
```python
|
| 41 |
from transformers import AutoModel, AutoProcessor
|
|
@@ -61,16 +91,16 @@ print(probs)
|
|
| 61 |
### CLIP-style logits
|
| 62 |
|
| 63 |
`model(**inputs)` also returns `logits_per_image` and `logits_per_text`, which use the model's learned `logit_scale`.
|
| 64 |
-
Those logits are useful, but they are not the same computation as the raw dot product in the original ModelScope demo.
|
| 65 |
|
| 66 |
-
##
|
| 67 |
|
| 68 |
This repo also includes two ONNX exports:
|
| 69 |
|
| 70 |
- `onnx/text_encoder.onnx`
|
| 71 |
- `onnx/image_encoder.onnx`
|
| 72 |
|
| 73 |
-
|
| 74 |
|
| 75 |
```python
|
| 76 |
import importlib
|
|
@@ -132,48 +162,17 @@ image_embeds = image_session.run(
|
|
| 132 |
)[0]
|
| 133 |
```
|
| 134 |
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
`examples/run_onnx_inference.py`
|
| 138 |
-
|
| 139 |
-
```bash
|
| 140 |
-
python examples/run_onnx_inference.py \
|
| 141 |
-
--image pokemon.jpeg \
|
| 142 |
-
--text 杰尼龟 妙蛙种子 小火龙 皮卡丘
|
| 143 |
-
```
|
| 144 |
-
|
| 145 |
-
You can also download from the Hub first:
|
| 146 |
|
| 147 |
```bash
|
| 148 |
python examples/run_onnx_inference.py \
|
| 149 |
-
--repo-id malusama/M2-Encoder-0.4B \
|
| 150 |
--image pokemon.jpeg \
|
| 151 |
--text 杰尼龟 妙蛙种子 小火龙 皮卡丘
|
| 152 |
```
|
| 153 |
|
| 154 |
-
## Upload
|
| 155 |
-
|
| 156 |
-
Option 1:
|
| 157 |
-
|
| 158 |
-
```bash
|
| 159 |
-
python upload_to_hub.py --repo-id malusama/M2-Encoder-0.4B
|
| 160 |
-
```
|
| 161 |
-
|
| 162 |
-
Option 2:
|
| 163 |
-
|
| 164 |
-
```bash
|
| 165 |
-
huggingface-cli login
|
| 166 |
-
git init
|
| 167 |
-
git lfs install
|
| 168 |
-
git remote add origin https://huggingface.co/malusama/M2-Encoder-0.4B
|
| 169 |
-
git add .
|
| 170 |
-
git commit -m "Upload M2-Encoder HF export"
|
| 171 |
-
git push origin main
|
| 172 |
-
```
|
| 173 |
-
|
| 174 |
## Inference Endpoints
|
| 175 |
|
| 176 |
-
This repo
|
| 177 |
|
| 178 |
Example request body:
|
| 179 |
|
|
@@ -198,9 +197,34 @@ Example response fields:
|
|
| 198 |
- `probs`
|
| 199 |
- `logits_per_image` when `return_logits=true`
|
| 200 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 201 |
## Notes
|
| 202 |
|
| 203 |
-
- This is a Hugging Face remote-code adapter, not a native `transformers` implementation.
|
| 204 |
-
-
|
| 205 |
-
-
|
| 206 |
-
- The
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: transformers
|
| 4 |
pipeline_tag: zero-shot-image-classification
|
| 5 |
+
language:
|
| 6 |
+
- zh
|
| 7 |
+
- en
|
| 8 |
+
datasets:
|
| 9 |
+
- BM-6B
|
| 10 |
+
- ImageNet
|
| 11 |
+
- ImageNet-CN
|
| 12 |
+
- Flickr30K
|
| 13 |
+
- Flickr30K-CN
|
| 14 |
+
- COCO-CN
|
| 15 |
tags:
|
| 16 |
+
- onnx
|
| 17 |
+
- feature-extraction
|
| 18 |
- multimodal
|
| 19 |
- image-text-retrieval
|
| 20 |
+
- zero-shot-image-classification
|
| 21 |
- bilingual
|
| 22 |
- chinese
|
| 23 |
- english
|
|
|
|
| 25 |
- custom-code
|
| 26 |
---
|
| 27 |
|
| 28 |
+
# M2-Encoder-0.4B
|
| 29 |
|
| 30 |
+
`M2-Encoder-0.4B` is a Hugging Face export of the bilingual vision-language foundation model from the paper [M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining](https://arxiv.org/abs/2401.15896).
|
| 31 |
|
| 32 |
+
It supports Chinese-English image-text retrieval, zero-shot image classification, `transformers` remote-code loading, ONNXRuntime inference, and Hugging Face Inference Endpoints via the bundled `handler.py`.
|
| 33 |
|
| 34 |
+
This is the smallest published M2-Encoder variant and is the best starting point for CPU demos, Spaces, and lightweight retrieval services.
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
+
## Links
|
| 37 |
|
| 38 |
+
- Paper: https://arxiv.org/abs/2401.15896
|
| 39 |
+
- Official code: https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_Encoder
|
| 40 |
+
- ModelScope source model: `M2Cognition/M2-Encoder`
|
| 41 |
+
- Hugging Face repo: `malusama/M2-Encoder-0.4B`
|
| 42 |
+
- Hugging Face Space demo: https://huggingface.co/spaces/malusama/M2-Encoder-0.4B-Space
|
| 43 |
|
| 44 |
+
## At A Glance
|
| 45 |
|
| 46 |
+
| Item | Value |
|
| 47 |
+
| --- | --- |
|
| 48 |
+
| Variant | `M2-Encoder-0.4B` |
|
| 49 |
+
| Languages | Chinese, English |
|
| 50 |
+
| Embedding dimension | `768` |
|
| 51 |
+
| Image size | `224` |
|
| 52 |
+
| Main tasks | Image-text retrieval, zero-shot image classification, bilingual feature extraction |
|
| 53 |
+
| Weight format | `safetensors` |
|
| 54 |
+
| ONNX export | `onnx/text_encoder.onnx`, `onnx/image_encoder.onnx` |
|
| 55 |
|
| 56 |
+
## Files In This Repo
|
| 57 |
+
|
| 58 |
+
- `m2_encoder_0.4B.safetensors`: main `transformers` weight file
|
| 59 |
+
- `onnx/text_encoder.onnx`: text embedding encoder
|
| 60 |
+
- `onnx/image_encoder.onnx`: image embedding encoder
|
| 61 |
+
- `examples/run_onnx_inference.py`: runnable ONNX example
|
| 62 |
+
- `handler.py`: custom handler for Hugging Face Inference Endpoints
|
| 63 |
+
|
| 64 |
+
## Transformers Usage
|
| 65 |
|
| 66 |
### ModelScope-equivalent scoring
|
| 67 |
|
| 68 |
+
The original ModelScope sample computes probabilities from raw normalized embedding dot products:
|
| 69 |
|
| 70 |
```python
|
| 71 |
from transformers import AutoModel, AutoProcessor
|
|
|
|
| 91 |
### CLIP-style logits
|
| 92 |
|
| 93 |
`model(**inputs)` also returns `logits_per_image` and `logits_per_text`, which use the model's learned `logit_scale`.
|
| 94 |
+
Those logits are useful, but they are not the same computation as the raw dot product used in the original ModelScope demo.
|
| 95 |
|
| 96 |
+
## ONNXRuntime Usage
|
| 97 |
|
| 98 |
This repo also includes two ONNX exports:
|
| 99 |
|
| 100 |
- `onnx/text_encoder.onnx`
|
| 101 |
- `onnx/image_encoder.onnx`
|
| 102 |
|
| 103 |
+
Minimal example:
|
| 104 |
|
| 105 |
```python
|
| 106 |
import importlib
|
|
|
|
| 162 |
)[0]
|
| 163 |
```
|
| 164 |
|
| 165 |
+
Runnable script:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 166 |
|
| 167 |
```bash
|
| 168 |
python examples/run_onnx_inference.py \
|
|
|
|
| 169 |
--image pokemon.jpeg \
|
| 170 |
--text 杰尼龟 妙蛙种子 小火龙 皮卡丘
|
| 171 |
```
|
| 172 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 173 |
## Inference Endpoints
|
| 174 |
|
| 175 |
+
This repo includes a `handler.py` for Hugging Face Inference Endpoints custom deployments.
|
| 176 |
|
| 177 |
Example request body:
|
| 178 |
|
|
|
|
| 197 |
- `probs`
|
| 198 |
- `logits_per_image` when `return_logits=true`
|
| 199 |
|
| 200 |
+
## Evaluation Summary
|
| 201 |
+
|
| 202 |
+
According to the official project README and paper, the M2-Encoder series is trained on the bilingual BM-6B corpus and evaluated on:
|
| 203 |
+
|
| 204 |
+
- ImageNet
|
| 205 |
+
- ImageNet-CN
|
| 206 |
+
- Flickr30K
|
| 207 |
+
- Flickr30K-CN
|
| 208 |
+
- COCO-CN
|
| 209 |
+
|
| 210 |
+
The official project reports that the M2-Encoder family sets strong bilingual retrieval and zero-shot classification results, and that the 10B variant reaches 88.5 top-1 on ImageNet and 80.7 top-1 on ImageNet-CN in the zero-shot setting. See the paper for exact cross-variant comparisons.
|
| 211 |
+
|
| 212 |
+
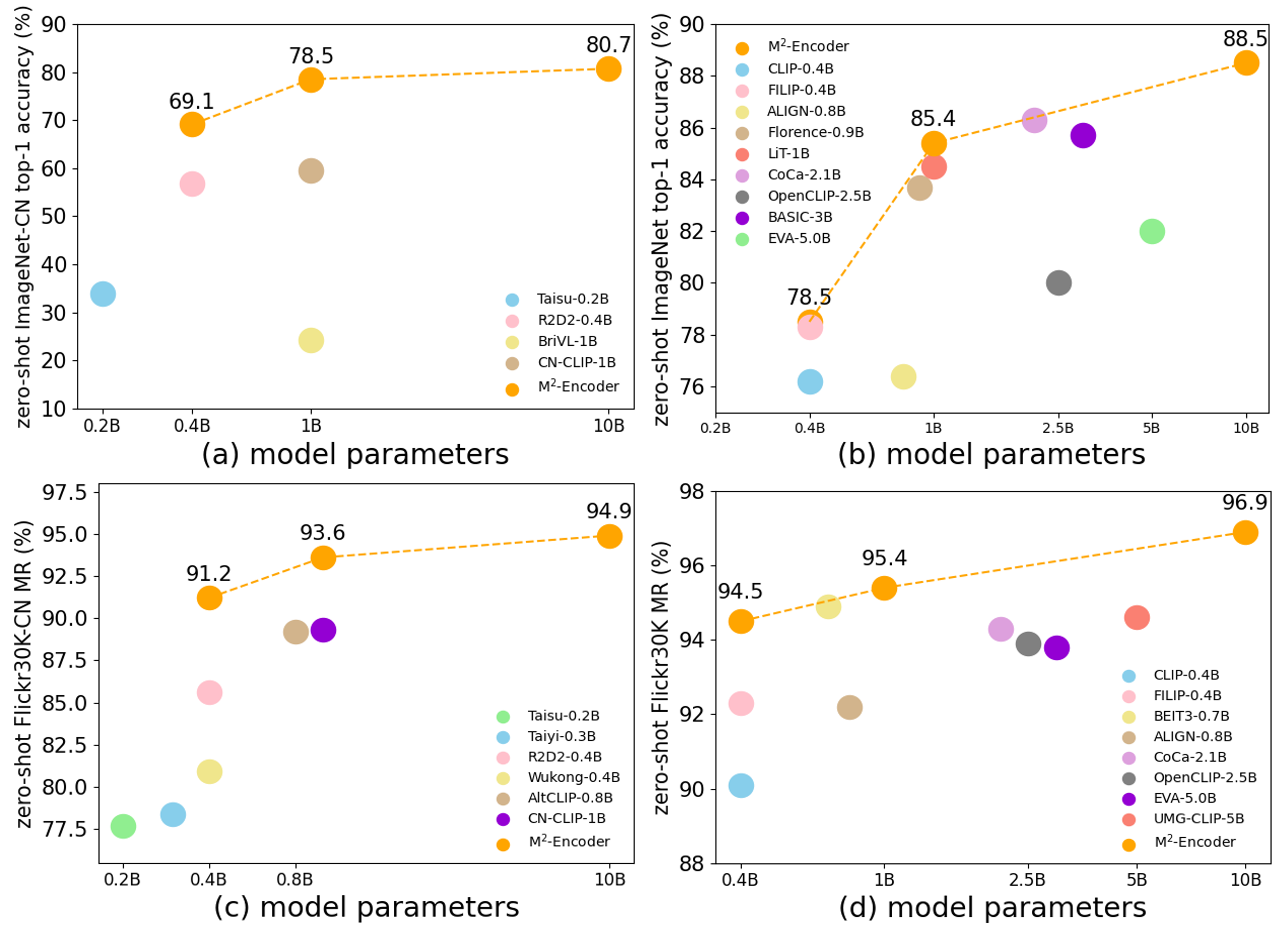
|
| 213 |
+
|
| 214 |
## Notes
|
| 215 |
|
| 216 |
+
- This is a Hugging Face remote-code adapter, not a native `transformers` implementation merged upstream.
|
| 217 |
+
- `trust_remote_code=True` is required for `AutoModel` and `AutoProcessor`.
|
| 218 |
+
- This repo is intended for retrieval, classification, and embedding use cases, not text generation.
|
| 219 |
+
- The Hub export has been numerically checked against the official implementation for the published demo workflow.
|
| 220 |
+
|
| 221 |
+
## Citation
|
| 222 |
+
|
| 223 |
+
```bibtex
|
| 224 |
+
@misc{guo2024m2encoder,
|
| 225 |
+
title={M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining},
|
| 226 |
+
author={Qingpei Guo and Furong Xu and Hanxiao Zhang and Wang Ren and Ziping Ma and Lin Ju and Jian Wang and Jingdong Chen and Ming Yang},
|
| 227 |
+
year={2024},
|
| 228 |
+
url={https://arxiv.org/abs/2401.15896}
|
| 229 |
+
}
|
| 230 |
+
```
|