diff --git a/.gitattributes b/.gitattributes
index 21ae8588d5db87138d82f83eff34c9225403e235..8d46f2a4e5308b8972c736e6998008385436e48d 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -142,6 +142,8 @@ models/unet/zit_beyond_reality.safetensors filter=lfs diff=lfs merge=lfs -text
models/vae/ae.safetensors filter=lfs diff=lfs merge=lfs -text
models/vae/flux2-vae.safetensors filter=lfs diff=lfs merge=lfs -text
models/vae/wan_2.1_vae.safetensors filter=lfs diff=lfs merge=lfs -text
+custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/img/preview.jpg filter=lfs diff=lfs merge=lfs -text
+custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/posi_prompt.pth filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/FlashVSR1_1.safetensors filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/LQ_proj_in.safetensors filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/Prompt.safetensors filter=lfs diff=lfs merge=lfs -text
@@ -149,3 +151,7 @@ models/FlashVSR/TCDecoder.safetensors filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/Wan2.1_VAE.safetensors filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/Wan2_1-T2V-1_3B_FlashVSR_fp32.safetensors filter=lfs diff=lfs merge=lfs -text
models/FlashVSR/Wan2_1_FlashVSR_LQ_proj_model_bf16.safetensors filter=lfs diff=lfs merge=lfs -text
+models/FlashVSR-v1.1/LQ_proj_in.ckpt filter=lfs diff=lfs merge=lfs -text
+models/FlashVSR-v1.1/TCDecoder.ckpt filter=lfs diff=lfs merge=lfs -text
+models/FlashVSR-v1.1/Wan2.1_VAE.pth filter=lfs diff=lfs merge=lfs -text
+models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors filter=lfs diff=lfs merge=lfs -text
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/.gitignore b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..562f04eebd6e79906fd91fd86e8531df360221f6
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/.gitignore
@@ -0,0 +1,210 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[codz]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py.cover
+.hypothesis/
+.pytest_cache/
+cover/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+# For a library or package, you might want to ignore these files since the code is
+# intended to run in multiple environments; otherwise, check them in:
+# .python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# UV
+# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+#uv.lock
+
+# poetry
+# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
+#poetry.lock
+#poetry.toml
+
+# pdm
+# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
+# pdm recommends including project-wide configuration in pdm.toml, but excluding .pdm-python.
+# https://pdm-project.org/en/latest/usage/project/#working-with-version-control
+#pdm.lock
+#pdm.toml
+.pdm-python
+.pdm-build/
+
+# pixi
+# Similar to Pipfile.lock, it is generally recommended to include pixi.lock in version control.
+#pixi.lock
+# Pixi creates a virtual environment in the .pixi directory, just like venv module creates one
+# in the .venv directory. It is recommended not to include this directory in version control.
+.pixi
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.envrc
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# pytype static type analyzer
+.pytype/
+
+# Cython debug symbols
+cython_debug/
+
+# PyCharm
+# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
+# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
+# and can be added to the global gitignore or merged into this file. For a more nuclear
+# option (not recommended) you can uncomment the following to ignore the entire idea folder.
+#.idea/
+
+# Abstra
+# Abstra is an AI-powered process automation framework.
+# Ignore directories containing user credentials, local state, and settings.
+# Learn more at https://abstra.io/docs
+.abstra/
+
+# Visual Studio Code
+# Visual Studio Code specific template is maintained in a separate VisualStudioCode.gitignore
+# that can be found at https://github.com/github/gitignore/blob/main/Global/VisualStudioCode.gitignore
+# and can be added to the global gitignore or merged into this file. However, if you prefer,
+# you could uncomment the following to ignore the entire vscode folder
+# .vscode/
+
+# Ruff stuff:
+.ruff_cache/
+
+# PyPI configuration file
+.pypirc
+
+# Cursor
+# Cursor is an AI-powered code editor. `.cursorignore` specifies files/directories to
+# exclude from AI features like autocomplete and code analysis. Recommended for sensitive data
+# refer to https://docs.cursor.com/context/ignore-files
+.cursorignore
+.cursorindexingignore
+
+# Marimo
+marimo/_static/
+marimo/_lsp/
+__marimo__/
+
+# macOS
+.DS_Store
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/LICENSE b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..f288702d2fa16d3cdf0035b15a9fcbc552cd88e7
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/LICENSE
@@ -0,0 +1,674 @@
+ GNU GENERAL PUBLIC LICENSE
+ Version 3, 29 June 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+ Preamble
+
+ The GNU General Public License is a free, copyleft license for
+software and other kinds of works.
+
+ The licenses for most software and other practical works are designed
+to take away your freedom to share and change the works. By contrast,
+the GNU General Public License is intended to guarantee your freedom to
+share and change all versions of a program--to make sure it remains free
+software for all its users. We, the Free Software Foundation, use the
+GNU General Public License for most of our software; it applies also to
+any other work released this way by its authors. You can apply it to
+your programs, too.
+
+ When we speak of free software, we are referring to freedom, not
+price. Our General Public Licenses are designed to make sure that you
+have the freedom to distribute copies of free software (and charge for
+them if you wish), that you receive source code or can get it if you
+want it, that you can change the software or use pieces of it in new
+free programs, and that you know you can do these things.
+
+ To protect your rights, we need to prevent others from denying you
+these rights or asking you to surrender the rights. Therefore, you have
+certain responsibilities if you distribute copies of the software, or if
+you modify it: responsibilities to respect the freedom of others.
+
+ For example, if you distribute copies of such a program, whether
+gratis or for a fee, you must pass on to the recipients the same
+freedoms that you received. You must make sure that they, too, receive
+or can get the source code. And you must show them these terms so they
+know their rights.
+
+ Developers that use the GNU GPL protect your rights with two steps:
+(1) assert copyright on the software, and (2) offer you this License
+giving you legal permission to copy, distribute and/or modify it.
+
+ For the developers' and authors' protection, the GPL clearly explains
+that there is no warranty for this free software. For both users' and
+authors' sake, the GPL requires that modified versions be marked as
+changed, so that their problems will not be attributed erroneously to
+authors of previous versions.
+
+ Some devices are designed to deny users access to install or run
+modified versions of the software inside them, although the manufacturer
+can do so. This is fundamentally incompatible with the aim of
+protecting users' freedom to change the software. The systematic
+pattern of such abuse occurs in the area of products for individuals to
+use, which is precisely where it is most unacceptable. Therefore, we
+have designed this version of the GPL to prohibit the practice for those
+products. If such problems arise substantially in other domains, we
+stand ready to extend this provision to those domains in future versions
+of the GPL, as needed to protect the freedom of users.
+
+ Finally, every program is threatened constantly by software patents.
+States should not allow patents to restrict development and use of
+software on general-purpose computers, but in those that do, we wish to
+avoid the special danger that patents applied to a free program could
+make it effectively proprietary. To prevent this, the GPL assures that
+patents cannot be used to render the program non-free.
+
+ The precise terms and conditions for copying, distribution and
+modification follow.
+
+ TERMS AND CONDITIONS
+
+ 0. Definitions.
+
+ "This License" refers to version 3 of the GNU General Public License.
+
+ "Copyright" also means copyright-like laws that apply to other kinds of
+works, such as semiconductor masks.
+
+ "The Program" refers to any copyrightable work licensed under this
+License. Each licensee is addressed as "you". "Licensees" and
+"recipients" may be individuals or organizations.
+
+ To "modify" a work means to copy from or adapt all or part of the work
+in a fashion requiring copyright permission, other than the making of an
+exact copy. The resulting work is called a "modified version" of the
+earlier work or a work "based on" the earlier work.
+
+ A "covered work" means either the unmodified Program or a work based
+on the Program.
+
+ To "propagate" a work means to do anything with it that, without
+permission, would make you directly or secondarily liable for
+infringement under applicable copyright law, except executing it on a
+computer or modifying a private copy. Propagation includes copying,
+distribution (with or without modification), making available to the
+public, and in some countries other activities as well.
+
+ To "convey" a work means any kind of propagation that enables other
+parties to make or receive copies. Mere interaction with a user through
+a computer network, with no transfer of a copy, is not conveying.
+
+ An interactive user interface displays "Appropriate Legal Notices"
+to the extent that it includes a convenient and prominently visible
+feature that (1) displays an appropriate copyright notice, and (2)
+tells the user that there is no warranty for the work (except to the
+extent that warranties are provided), that licensees may convey the
+work under this License, and how to view a copy of this License. If
+the interface presents a list of user commands or options, such as a
+menu, a prominent item in the list meets this criterion.
+
+ 1. Source Code.
+
+ The "source code" for a work means the preferred form of the work
+for making modifications to it. "Object code" means any non-source
+form of a work.
+
+ A "Standard Interface" means an interface that either is an official
+standard defined by a recognized standards body, or, in the case of
+interfaces specified for a particular programming language, one that
+is widely used among developers working in that language.
+
+ The "System Libraries" of an executable work include anything, other
+than the work as a whole, that (a) is included in the normal form of
+packaging a Major Component, but which is not part of that Major
+Component, and (b) serves only to enable use of the work with that
+Major Component, or to implement a Standard Interface for which an
+implementation is available to the public in source code form. A
+"Major Component", in this context, means a major essential component
+(kernel, window system, and so on) of the specific operating system
+(if any) on which the executable work runs, or a compiler used to
+produce the work, or an object code interpreter used to run it.
+
+ The "Corresponding Source" for a work in object code form means all
+the source code needed to generate, install, and (for an executable
+work) run the object code and to modify the work, including scripts to
+control those activities. However, it does not include the work's
+System Libraries, or general-purpose tools or generally available free
+programs which are used unmodified in performing those activities but
+which are not part of the work. For example, Corresponding Source
+includes interface definition files associated with source files for
+the work, and the source code for shared libraries and dynamically
+linked subprograms that the work is specifically designed to require,
+such as by intimate data communication or control flow between those
+subprograms and other parts of the work.
+
+ The Corresponding Source need not include anything that users
+can regenerate automatically from other parts of the Corresponding
+Source.
+
+ The Corresponding Source for a work in source code form is that
+same work.
+
+ 2. Basic Permissions.
+
+ All rights granted under this License are granted for the term of
+copyright on the Program, and are irrevocable provided the stated
+conditions are met. This License explicitly affirms your unlimited
+permission to run the unmodified Program. The output from running a
+covered work is covered by this License only if the output, given its
+content, constitutes a covered work. This License acknowledges your
+rights of fair use or other equivalent, as provided by copyright law.
+
+ You may make, run and propagate covered works that you do not
+convey, without conditions so long as your license otherwise remains
+in force. You may convey covered works to others for the sole purpose
+of having them make modifications exclusively for you, or provide you
+with facilities for running those works, provided that you comply with
+the terms of this License in conveying all material for which you do
+not control copyright. Those thus making or running the covered works
+for you must do so exclusively on your behalf, under your direction
+and control, on terms that prohibit them from making any copies of
+your copyrighted material outside their relationship with you.
+
+ Conveying under any other circumstances is permitted solely under
+the conditions stated below. Sublicensing is not allowed; section 10
+makes it unnecessary.
+
+ 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
+
+ No covered work shall be deemed part of an effective technological
+measure under any applicable law fulfilling obligations under article
+11 of the WIPO copyright treaty adopted on 20 December 1996, or
+similar laws prohibiting or restricting circumvention of such
+measures.
+
+ When you convey a covered work, you waive any legal power to forbid
+circumvention of technological measures to the extent such circumvention
+is effected by exercising rights under this License with respect to
+the covered work, and you disclaim any intention to limit operation or
+modification of the work as a means of enforcing, against the work's
+users, your or third parties' legal rights to forbid circumvention of
+technological measures.
+
+ 4. Conveying Verbatim Copies.
+
+ You may convey verbatim copies of the Program's source code as you
+receive it, in any medium, provided that you conspicuously and
+appropriately publish on each copy an appropriate copyright notice;
+keep intact all notices stating that this License and any
+non-permissive terms added in accord with section 7 apply to the code;
+keep intact all notices of the absence of any warranty; and give all
+recipients a copy of this License along with the Program.
+
+ You may charge any price or no price for each copy that you convey,
+and you may offer support or warranty protection for a fee.
+
+ 5. Conveying Modified Source Versions.
+
+ You may convey a work based on the Program, or the modifications to
+produce it from the Program, in the form of source code under the
+terms of section 4, provided that you also meet all of these conditions:
+
+ a) The work must carry prominent notices stating that you modified
+ it, and giving a relevant date.
+
+ b) The work must carry prominent notices stating that it is
+ released under this License and any conditions added under section
+ 7. This requirement modifies the requirement in section 4 to
+ "keep intact all notices".
+
+ c) You must license the entire work, as a whole, under this
+ License to anyone who comes into possession of a copy. This
+ License will therefore apply, along with any applicable section 7
+ additional terms, to the whole of the work, and all its parts,
+ regardless of how they are packaged. This License gives no
+ permission to license the work in any other way, but it does not
+ invalidate such permission if you have separately received it.
+
+ d) If the work has interactive user interfaces, each must display
+ Appropriate Legal Notices; however, if the Program has interactive
+ interfaces that do not display Appropriate Legal Notices, your
+ work need not make them do so.
+
+ A compilation of a covered work with other separate and independent
+works, which are not by their nature extensions of the covered work,
+and which are not combined with it such as to form a larger program,
+in or on a volume of a storage or distribution medium, is called an
+"aggregate" if the compilation and its resulting copyright are not
+used to limit the access or legal rights of the compilation's users
+beyond what the individual works permit. Inclusion of a covered work
+in an aggregate does not cause this License to apply to the other
+parts of the aggregate.
+
+ 6. Conveying Non-Source Forms.
+
+ You may convey a covered work in object code form under the terms
+of sections 4 and 5, provided that you also convey the
+machine-readable Corresponding Source under the terms of this License,
+in one of these ways:
+
+ a) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by the
+ Corresponding Source fixed on a durable physical medium
+ customarily used for software interchange.
+
+ b) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by a
+ written offer, valid for at least three years and valid for as
+ long as you offer spare parts or customer support for that product
+ model, to give anyone who possesses the object code either (1) a
+ copy of the Corresponding Source for all the software in the
+ product that is covered by this License, on a durable physical
+ medium customarily used for software interchange, for a price no
+ more than your reasonable cost of physically performing this
+ conveying of source, or (2) access to copy the
+ Corresponding Source from a network server at no charge.
+
+ c) Convey individual copies of the object code with a copy of the
+ written offer to provide the Corresponding Source. This
+ alternative is allowed only occasionally and noncommercially, and
+ only if you received the object code with such an offer, in accord
+ with subsection 6b.
+
+ d) Convey the object code by offering access from a designated
+ place (gratis or for a charge), and offer equivalent access to the
+ Corresponding Source in the same way through the same place at no
+ further charge. You need not require recipients to copy the
+ Corresponding Source along with the object code. If the place to
+ copy the object code is a network server, the Corresponding Source
+ may be on a different server (operated by you or a third party)
+ that supports equivalent copying facilities, provided you maintain
+ clear directions next to the object code saying where to find the
+ Corresponding Source. Regardless of what server hosts the
+ Corresponding Source, you remain obligated to ensure that it is
+ available for as long as needed to satisfy these requirements.
+
+ e) Convey the object code using peer-to-peer transmission, provided
+ you inform other peers where the object code and Corresponding
+ Source of the work are being offered to the general public at no
+ charge under subsection 6d.
+
+ A separable portion of the object code, whose source code is excluded
+from the Corresponding Source as a System Library, need not be
+included in conveying the object code work.
+
+ A "User Product" is either (1) a "consumer product", which means any
+tangible personal property which is normally used for personal, family,
+or household purposes, or (2) anything designed or sold for incorporation
+into a dwelling. In determining whether a product is a consumer product,
+doubtful cases shall be resolved in favor of coverage. For a particular
+product received by a particular user, "normally used" refers to a
+typical or common use of that class of product, regardless of the status
+of the particular user or of the way in which the particular user
+actually uses, or expects or is expected to use, the product. A product
+is a consumer product regardless of whether the product has substantial
+commercial, industrial or non-consumer uses, unless such uses represent
+the only significant mode of use of the product.
+
+ "Installation Information" for a User Product means any methods,
+procedures, authorization keys, or other information required to install
+and execute modified versions of a covered work in that User Product from
+a modified version of its Corresponding Source. The information must
+suffice to ensure that the continued functioning of the modified object
+code is in no case prevented or interfered with solely because
+modification has been made.
+
+ If you convey an object code work under this section in, or with, or
+specifically for use in, a User Product, and the conveying occurs as
+part of a transaction in which the right of possession and use of the
+User Product is transferred to the recipient in perpetuity or for a
+fixed term (regardless of how the transaction is characterized), the
+Corresponding Source conveyed under this section must be accompanied
+by the Installation Information. But this requirement does not apply
+if neither you nor any third party retains the ability to install
+modified object code on the User Product (for example, the work has
+been installed in ROM).
+
+ The requirement to provide Installation Information does not include a
+requirement to continue to provide support service, warranty, or updates
+for a work that has been modified or installed by the recipient, or for
+the User Product in which it has been modified or installed. Access to a
+network may be denied when the modification itself materially and
+adversely affects the operation of the network or violates the rules and
+protocols for communication across the network.
+
+ Corresponding Source conveyed, and Installation Information provided,
+in accord with this section must be in a format that is publicly
+documented (and with an implementation available to the public in
+source code form), and must require no special password or key for
+unpacking, reading or copying.
+
+ 7. Additional Terms.
+
+ "Additional permissions" are terms that supplement the terms of this
+License by making exceptions from one or more of its conditions.
+Additional permissions that are applicable to the entire Program shall
+be treated as though they were included in this License, to the extent
+that they are valid under applicable law. If additional permissions
+apply only to part of the Program, that part may be used separately
+under those permissions, but the entire Program remains governed by
+this License without regard to the additional permissions.
+
+ When you convey a copy of a covered work, you may at your option
+remove any additional permissions from that copy, or from any part of
+it. (Additional permissions may be written to require their own
+removal in certain cases when you modify the work.) You may place
+additional permissions on material, added by you to a covered work,
+for which you have or can give appropriate copyright permission.
+
+ Notwithstanding any other provision of this License, for material you
+add to a covered work, you may (if authorized by the copyright holders of
+that material) supplement the terms of this License with terms:
+
+ a) Disclaiming warranty or limiting liability differently from the
+ terms of sections 15 and 16 of this License; or
+
+ b) Requiring preservation of specified reasonable legal notices or
+ author attributions in that material or in the Appropriate Legal
+ Notices displayed by works containing it; or
+
+ c) Prohibiting misrepresentation of the origin of that material, or
+ requiring that modified versions of such material be marked in
+ reasonable ways as different from the original version; or
+
+ d) Limiting the use for publicity purposes of names of licensors or
+ authors of the material; or
+
+ e) Declining to grant rights under trademark law for use of some
+ trade names, trademarks, or service marks; or
+
+ f) Requiring indemnification of licensors and authors of that
+ material by anyone who conveys the material (or modified versions of
+ it) with contractual assumptions of liability to the recipient, for
+ any liability that these contractual assumptions directly impose on
+ those licensors and authors.
+
+ All other non-permissive additional terms are considered "further
+restrictions" within the meaning of section 10. If the Program as you
+received it, or any part of it, contains a notice stating that it is
+governed by this License along with a term that is a further
+restriction, you may remove that term. If a license document contains
+a further restriction but permits relicensing or conveying under this
+License, you may add to a covered work material governed by the terms
+of that license document, provided that the further restriction does
+not survive such relicensing or conveying.
+
+ If you add terms to a covered work in accord with this section, you
+must place, in the relevant source files, a statement of the
+additional terms that apply to those files, or a notice indicating
+where to find the applicable terms.
+
+ Additional terms, permissive or non-permissive, may be stated in the
+form of a separately written license, or stated as exceptions;
+the above requirements apply either way.
+
+ 8. Termination.
+
+ You may not propagate or modify a covered work except as expressly
+provided under this License. Any attempt otherwise to propagate or
+modify it is void, and will automatically terminate your rights under
+this License (including any patent licenses granted under the third
+paragraph of section 11).
+
+ However, if you cease all violation of this License, then your
+license from a particular copyright holder is reinstated (a)
+provisionally, unless and until the copyright holder explicitly and
+finally terminates your license, and (b) permanently, if the copyright
+holder fails to notify you of the violation by some reasonable means
+prior to 60 days after the cessation.
+
+ Moreover, your license from a particular copyright holder is
+reinstated permanently if the copyright holder notifies you of the
+violation by some reasonable means, this is the first time you have
+received notice of violation of this License (for any work) from that
+copyright holder, and you cure the violation prior to 30 days after
+your receipt of the notice.
+
+ Termination of your rights under this section does not terminate the
+licenses of parties who have received copies or rights from you under
+this License. If your rights have been terminated and not permanently
+reinstated, you do not qualify to receive new licenses for the same
+material under section 10.
+
+ 9. Acceptance Not Required for Having Copies.
+
+ You are not required to accept this License in order to receive or
+run a copy of the Program. Ancillary propagation of a covered work
+occurring solely as a consequence of using peer-to-peer transmission
+to receive a copy likewise does not require acceptance. However,
+nothing other than this License grants you permission to propagate or
+modify any covered work. These actions infringe copyright if you do
+not accept this License. Therefore, by modifying or propagating a
+covered work, you indicate your acceptance of this License to do so.
+
+ 10. Automatic Licensing of Downstream Recipients.
+
+ Each time you convey a covered work, the recipient automatically
+receives a license from the original licensors, to run, modify and
+propagate that work, subject to this License. You are not responsible
+for enforcing compliance by third parties with this License.
+
+ An "entity transaction" is a transaction transferring control of an
+organization, or substantially all assets of one, or subdividing an
+organization, or merging organizations. If propagation of a covered
+work results from an entity transaction, each party to that
+transaction who receives a copy of the work also receives whatever
+licenses to the work the party's predecessor in interest had or could
+give under the previous paragraph, plus a right to possession of the
+Corresponding Source of the work from the predecessor in interest, if
+the predecessor has it or can get it with reasonable efforts.
+
+ You may not impose any further restrictions on the exercise of the
+rights granted or affirmed under this License. For example, you may
+not impose a license fee, royalty, or other charge for exercise of
+rights granted under this License, and you may not initiate litigation
+(including a cross-claim or counterclaim in a lawsuit) alleging that
+any patent claim is infringed by making, using, selling, offering for
+sale, or importing the Program or any portion of it.
+
+ 11. Patents.
+
+ A "contributor" is a copyright holder who authorizes use under this
+License of the Program or a work on which the Program is based. The
+work thus licensed is called the contributor's "contributor version".
+
+ A contributor's "essential patent claims" are all patent claims
+owned or controlled by the contributor, whether already acquired or
+hereafter acquired, that would be infringed by some manner, permitted
+by this License, of making, using, or selling its contributor version,
+but do not include claims that would be infringed only as a
+consequence of further modification of the contributor version. For
+purposes of this definition, "control" includes the right to grant
+patent sublicenses in a manner consistent with the requirements of
+this License.
+
+ Each contributor grants you a non-exclusive, worldwide, royalty-free
+patent license under the contributor's essential patent claims, to
+make, use, sell, offer for sale, import and otherwise run, modify and
+propagate the contents of its contributor version.
+
+ In the following three paragraphs, a "patent license" is any express
+agreement or commitment, however denominated, not to enforce a patent
+(such as an express permission to practice a patent or covenant not to
+sue for patent infringement). To "grant" such a patent license to a
+party means to make such an agreement or commitment not to enforce a
+patent against the party.
+
+ If you convey a covered work, knowingly relying on a patent license,
+and the Corresponding Source of the work is not available for anyone
+to copy, free of charge and under the terms of this License, through a
+publicly available network server or other readily accessible means,
+then you must either (1) cause the Corresponding Source to be so
+available, or (2) arrange to deprive yourself of the benefit of the
+patent license for this particular work, or (3) arrange, in a manner
+consistent with the requirements of this License, to extend the patent
+license to downstream recipients. "Knowingly relying" means you have
+actual knowledge that, but for the patent license, your conveying the
+covered work in a country, or your recipient's use of the covered work
+in a country, would infringe one or more identifiable patents in that
+country that you have reason to believe are valid.
+
+ If, pursuant to or in connection with a single transaction or
+arrangement, you convey, or propagate by procuring conveyance of, a
+covered work, and grant a patent license to some of the parties
+receiving the covered work authorizing them to use, propagate, modify
+or convey a specific copy of the covered work, then the patent license
+you grant is automatically extended to all recipients of the covered
+work and works based on it.
+
+ A patent license is "discriminatory" if it does not include within
+the scope of its coverage, prohibits the exercise of, or is
+conditioned on the non-exercise of one or more of the rights that are
+specifically granted under this License. You may not convey a covered
+work if you are a party to an arrangement with a third party that is
+in the business of distributing software, under which you make payment
+to the third party based on the extent of your activity of conveying
+the work, and under which the third party grants, to any of the
+parties who would receive the covered work from you, a discriminatory
+patent license (a) in connection with copies of the covered work
+conveyed by you (or copies made from those copies), or (b) primarily
+for and in connection with specific products or compilations that
+contain the covered work, unless you entered into that arrangement,
+or that patent license was granted, prior to 28 March 2007.
+
+ Nothing in this License shall be construed as excluding or limiting
+any implied license or other defenses to infringement that may
+otherwise be available to you under applicable patent law.
+
+ 12. No Surrender of Others' Freedom.
+
+ If conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot convey a
+covered work so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you may
+not convey it at all. For example, if you agree to terms that obligate you
+to collect a royalty for further conveying from those to whom you convey
+the Program, the only way you could satisfy both those terms and this
+License would be to refrain entirely from conveying the Program.
+
+ 13. Use with the GNU Affero General Public License.
+
+ Notwithstanding any other provision of this License, you have
+permission to link or combine any covered work with a work licensed
+under version 3 of the GNU Affero General Public License into a single
+combined work, and to convey the resulting work. The terms of this
+License will continue to apply to the part which is the covered work,
+but the special requirements of the GNU Affero General Public License,
+section 13, concerning interaction through a network will apply to the
+combination as such.
+
+ 14. Revised Versions of this License.
+
+ The Free Software Foundation may publish revised and/or new versions of
+the GNU General Public License from time to time. Such new versions will
+be similar in spirit to the present version, but may differ in detail to
+address new problems or concerns.
+
+ Each version is given a distinguishing version number. If the
+Program specifies that a certain numbered version of the GNU General
+Public License "or any later version" applies to it, you have the
+option of following the terms and conditions either of that numbered
+version or of any later version published by the Free Software
+Foundation. If the Program does not specify a version number of the
+GNU General Public License, you may choose any version ever published
+by the Free Software Foundation.
+
+ If the Program specifies that a proxy can decide which future
+versions of the GNU General Public License can be used, that proxy's
+public statement of acceptance of a version permanently authorizes you
+to choose that version for the Program.
+
+ Later license versions may give you additional or different
+permissions. However, no additional obligations are imposed on any
+author or copyright holder as a result of your choosing to follow a
+later version.
+
+ 15. Disclaimer of Warranty.
+
+ THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
+APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
+HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
+OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
+THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
+IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
+ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
+
+ 16. Limitation of Liability.
+
+ IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
+WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
+THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
+GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
+USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
+DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
+PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
+EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
+SUCH DAMAGES.
+
+ 17. Interpretation of Sections 15 and 16.
+
+ If the disclaimer of warranty and limitation of liability provided
+above cannot be given local legal effect according to their terms,
+reviewing courts shall apply local law that most closely approximates
+an absolute waiver of all civil liability in connection with the
+Program, unless a warranty or assumption of liability accompanies a
+copy of the Program in return for a fee.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Programs
+
+ If you develop a new program, and you want it to be of the greatest
+possible use to the public, the best way to achieve this is to make it
+free software which everyone can redistribute and change under these terms.
+
+ To do so, attach the following notices to the program. It is safest
+to attach them to the start of each source file to most effectively
+state the exclusion of warranty; and each file should have at least
+the "copyright" line and a pointer to where the full notice is found.
+
+
+ Copyright (C)
+
+ This program is free software: you can redistribute it and/or modify
+ it under the terms of the GNU General Public License as published by
+ the Free Software Foundation, either version 3 of the License, or
+ (at your option) any later version.
+
+ This program is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ GNU General Public License for more details.
+
+ You should have received a copy of the GNU General Public License
+ along with this program. If not, see .
+
+Also add information on how to contact you by electronic and paper mail.
+
+ If the program does terminal interaction, make it output a short
+notice like this when it starts in an interactive mode:
+
+ Copyright (C)
+ This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
+ This is free software, and you are welcome to redistribute it
+ under certain conditions; type `show c' for details.
+
+The hypothetical commands `show w' and `show c' should show the appropriate
+parts of the General Public License. Of course, your program's commands
+might be different; for a GUI interface, you would use an "about box".
+
+ You should also get your employer (if you work as a programmer) or school,
+if any, to sign a "copyright disclaimer" for the program, if necessary.
+For more information on this, and how to apply and follow the GNU GPL, see
+.
+
+ The GNU General Public License does not permit incorporating your program
+into proprietary programs. If your program is a subroutine library, you
+may consider it more useful to permit linking proprietary applications with
+the library. If this is what you want to do, use the GNU Lesser General
+Public License instead of this License. But first, please read
+.
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README.md b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e77018407bf1f45ad5ae61f1017d4b569c624ab7
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README.md
@@ -0,0 +1,68 @@
+# ComfyUI-FlashVSR_Ultra_Fast
+Running FlashVSR on lower VRAM without any artifacts.
+**[[📃中文版本](./README_zh.md)]**
+
+## Changelog
+#### 2025-10-24
+- Added long video pipeline that significantly reduces VRAM usage when upscaling long videos.
+
+#### 2025-10-21
+- Initial this project, introducing features such as `tile_dit` to significantly reducing VRAM usage.
+
+#### 2025-10-22
+- Replaced `Block-Sparse-Attention` with `Sparse_Sage`, removing the need to compile any custom kernels.
+- Added support for running on RTX 50 series GPUs.
+
+## Preview
+
+
+## Usage
+- **mode:**
+`tiny` -> faster (default); `full` -> higher quality
+- **scale:**
+`4` is always better, unless you are low on VRAM then use `2`
+- **color_fix:**
+Use wavelet transform to correct the color of output video.
+- **tiled_vae:**
+Set to True for lower VRAM consumption during decoding at the cost of speed.
+- **tiled_dit:**
+Significantly reduces VRAM usage at the cost of speed.
+- **tile\_size, tile\_overlap**:
+How to split the input video.
+- **unload_dit:**
+Unload DiT before decoding to reduce VRAM peak at the cost of speed.
+
+## Installation
+
+#### nodes:
+
+```bash
+cd ComfyUI/custom_nodes
+git clone https://github.com/lihaoyun6/ComfyUI-FlashVSR_Ultra_Fast.git
+python -m pip install -r ComfyUI-FlashVSR_Ultra_Fast/requirements.txt
+```
+📢: For Turing or older GPU, please install `triton<3.3.0`:
+
+```bash
+# Windows
+python -m pip install -U triton-windows<3.3.0
+# Linux
+python -m pip install -U triton<3.3.0
+```
+
+#### models:
+
+- Download the entire `FlashVSR` folder with all the files inside it from [here](https://huggingface.co/JunhaoZhuang/FlashVSR) and put it in the `ComfyUI/models`
+
+```
+├── ComfyUI/models/FlashVSR
+| ├── LQ_proj_in.ckpt
+| ├── TCDecoder.ckpt
+| ├── diffusion_pytorch_model_streaming_dmd.safetensors
+| ├── Wan2.1_VAE.pth
+```
+
+## Acknowledgments
+- [FlashVSR](https://github.com/OpenImagingLab/FlashVSR) @OpenImagingLab
+- [Sparse_SageAttention](https://github.com/jt-zhang/Sparse_SageAttention_API) @jt-zhang
+- [ComfyUI](https://github.com/comfyanonymous/ComfyUI) @comfyanonymous
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README_zh.md b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README_zh.md
new file mode 100644
index 0000000000000000000000000000000000000000..4cd055db1aa5329b15d260d2f9e052e2c48579df
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/README_zh.md
@@ -0,0 +1,66 @@
+# ComfyUI-FlashVSR_Ultra_Fast
+在低显存环境下运行 FlashVSR,同时保持无伪影高质量输出。
+**[[📃English](./readme.md)]**
+
+## 更新日志
+#### 2025-10-24
+- 新增长视频管道, 可显著降低长视频放大的显存用量
+
+#### 2025-10-21
+- 项目首次发布, 引入了`tile_dit`等功能, 大幅度降低显存需求
+
+#### 2025-10-22
+- 使用`Sparse_SageAttention`替换了`Block-Sparse-Attention`, 无需编译安装任何自定义内核, 开箱即用.
+- 支持在 RTX50 系列显卡上运行.
+
+## 预览
+
+
+## 使用说明
+- **mode(模式):**
+ `tiny` → 更快(默认);`full` → 更高质量
+- **scale(放大倍数):**
+ 通常使用 `4` 效果更好;如果显存不足,可使用 `2`
+- **color_fix(颜色修正):**
+ 使用小波变换方法修正输出视频的颜色偏差。
+- **tiled_vae(VAE分块解码):**
+ 启用后可显著降低显存占用,但会降低解码速度。
+- **tiled_dit(DiT分块计算):**
+ 大幅减少显存占用,但会降低推理速度。
+- **tile_size / tile_overlap(分块大小与重叠):**
+ 控制输入视频在推理时的分块方式。
+- **unload_dit(卸载DiT模型):**
+ 解码前卸载 DiT 模型以降低显存峰值,但会略微降低速度。
+
+## 安装步骤
+
+#### 安装节点:
+```bash
+cd ComfyUI/custom_nodes
+git clone https://github.com/lihaoyun6/ComfyUI-FlashVSR_Ultra_Fast.git
+python -m pip install -r ComfyUI-FlashVSR_Ultra_Fast/requirements.txt
+```
+📢: 要在RTX20系或更早的GPU上运行, 请安装`triton<3.3.0`:
+
+```bash
+# Windows
+python -m pip install -U triton-windows<3.3.0
+# Linux
+python -m pip install -U triton<3.3.0
+```
+
+#### 模型下载:
+- 从[这里](https://huggingface.co/JunhaoZhuang/FlashVSR)下载整个`FlashVSR`文件夹和它里面的所有文件, 并将其放到`ComfyUI/models`目录中。
+
+```
+├── ComfyUI/models/FlashVSR
+| ├── LQ_proj_in.ckpt
+| ├── TCDecoder.ckpt
+| ├── diffusion_pytorch_model_streaming_dmd.safetensors
+| ├── Wan2.1_VAE.pth
+```
+
+## 致谢
+- [FlashVSR](https://github.com/OpenImagingLab/FlashVSR) @OpenImagingLab
+- [Sparse_SageAttention](https://github.com/jt-zhang/Sparse_SageAttention_API) @jt-zhang
+- [ComfyUI](https://github.com/comfyanonymous/ComfyUI) @comfyanonymous
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e96bd6ab3db650f769ae7886e0c13515752bd16
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/__init__.py
@@ -0,0 +1,3 @@
+from .nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
+
+__all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"]
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/img/preview.jpg b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/img/preview.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..04912119ed4702b9849c25f8e0ebab7181ae8e4d
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/img/preview.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ad7cc28a6c911472d5653b7c90aa8ca0737c42f34fa82b5f093e48af53039c0e
+size 775988
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/nodes.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/nodes.py
new file mode 100644
index 0000000000000000000000000000000000000000..37e9b3e654367121b1d1d8a93bd7e425bcc2a9fc
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/nodes.py
@@ -0,0 +1,553 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+
+import os,gc
+import math
+import torch
+import folder_paths
+import comfy.utils
+
+import numpy as np
+import torch.nn.functional as F
+
+from einops import rearrange
+from huggingface_hub import snapshot_download
+from .src import ModelManager, FlashVSRFullPipeline, FlashVSRTinyPipeline, FlashVSRTinyLongPipeline
+from .src.models.TCDecoder import build_tcdecoder
+from .src.models.utils import clean_vram, get_device_list, Buffer_LQ4x_Proj, Causal_LQ4x_Proj
+from .src.models import wan_video_dit
+
+device_choices = get_device_list()
+
+def log(message:str, message_type:str='normal'):
+ if message_type == 'error':
+ message = '\033[1;41m' + message + '\033[m'
+ elif message_type == 'warning':
+ message = '\033[1;31m' + message + '\033[m'
+ elif message_type == 'finish':
+ message = '\033[1;32m' + message + '\033[m'
+ elif message_type == 'info':
+ message = '\033[1;33m' + message + '\033[m'
+ else:
+ message = message
+ print(f"{message}")
+
+def model_downlod(model_name="JunhaoZhuang/FlashVSR"):
+ model_dir = os.path.join(folder_paths.models_dir, model_name.split("/")[-1])
+ if not os.path.exists(model_dir):
+ log(f"Downloading model '{model_name}' from huggingface...", message_type='info')
+ snapshot_download(repo_id=model_name, local_dir=model_dir, local_dir_use_symlinks=False, resume_download=True)
+
+def tensor2video(frames: torch.Tensor):
+ video_squeezed = frames.squeeze(0)
+ video_permuted = rearrange(video_squeezed, "C F H W -> F H W C")
+ video_final = (video_permuted.float() + 1.0) / 2.0
+ return video_final
+
+def largest_8n1_leq(n): # 8n+1
+ return 0 if n < 1 else ((n - 1)//8)*8 + 1
+
+def next_8n5(n): # next 8n+5
+ return 21 if n < 21 else ((n - 5 + 7) // 8) * 8 + 5
+
+def compute_scaled_and_target_dims(w0: int, h0: int, scale: int = 4, multiple: int = 128):
+ if w0 <= 0 or h0 <= 0:
+ raise ValueError("invalid original size")
+
+ sW, sH = w0 * scale, h0 * scale
+ tW = max(multiple, (sW // multiple) * multiple)
+ tH = max(multiple, (sH // multiple) * multiple)
+ return sW, sH, tW, tH
+
+def tensor_upscale_then_center_crop(frame_tensor: torch.Tensor, scale: int, tW: int, tH: int) -> torch.Tensor:
+ h0, w0, c = frame_tensor.shape
+ tensor_bchw = frame_tensor.permute(2, 0, 1).unsqueeze(0) # HWC -> CHW -> BCHW
+
+ sW, sH = w0 * scale, h0 * scale
+ upscaled_tensor = F.interpolate(tensor_bchw, size=(sH, sW), mode='bicubic', align_corners=False)
+
+ l = max(0, (sW - tW) // 2)
+ t = max(0, (sH - tH) // 2)
+ cropped_tensor = upscaled_tensor[:, :, t:t + tH, l:l + tW]
+
+ return cropped_tensor.squeeze(0)
+
+def prepare_input_tensor(image_tensor: torch.Tensor, device, scale: int = 4, dtype=torch.bfloat16):
+ N0, h0, w0, _ = image_tensor.shape
+
+ multiple = 128
+ sW, sH, tW, tH = compute_scaled_and_target_dims(w0, h0, scale=scale, multiple=multiple)
+ num_frames_with_padding = N0 + 4
+ F = largest_8n1_leq(num_frames_with_padding)
+
+ if F == 0:
+ raise RuntimeError(f"Not enough frames after padding. Got {num_frames_with_padding}.")
+
+ frames = []
+ for i in range(F):
+ frame_idx = min(i, N0 - 1)
+ frame_slice = image_tensor[frame_idx].to(device)
+ tensor_chw = tensor_upscale_then_center_crop(frame_slice, scale=scale, tW=tW, tH=tH).to('cpu').to(dtype) * 2.0 - 1.0
+ frames.append(tensor_chw)
+ del frame_slice
+
+ vid_stacked = torch.stack(frames, 0)
+ vid_final = vid_stacked.permute(1, 0, 2, 3).unsqueeze(0)
+
+ del vid_stacked
+ clean_vram()
+
+ return vid_final, tH, tW, F
+
+def calculate_tile_coords(height, width, tile_size, overlap):
+ coords = []
+
+ stride = tile_size - overlap
+ num_rows = math.ceil((height - overlap) / stride)
+ num_cols = math.ceil((width - overlap) / stride)
+
+ for r in range(num_rows):
+ for c in range(num_cols):
+ y1 = r * stride
+ x1 = c * stride
+
+ y2 = min(y1 + tile_size, height)
+ x2 = min(x1 + tile_size, width)
+
+ if y2 - y1 < tile_size:
+ y1 = max(0, y2 - tile_size)
+ if x2 - x1 < tile_size:
+ x1 = max(0, x2 - tile_size)
+
+ coords.append((x1, y1, x2, y2))
+
+ return coords
+
+def create_feather_mask(size, overlap):
+ H, W = size
+ mask = torch.ones(1, 1, H, W)
+ ramp = torch.linspace(0, 1, overlap)
+
+ mask[:, :, :, :overlap] = torch.minimum(mask[:, :, :, :overlap], ramp.view(1, 1, 1, -1))
+ mask[:, :, :, -overlap:] = torch.minimum(mask[:, :, :, -overlap:], ramp.flip(0).view(1, 1, 1, -1))
+
+ mask[:, :, :overlap, :] = torch.minimum(mask[:, :, :overlap, :], ramp.view(1, 1, -1, 1))
+ mask[:, :, -overlap:, :] = torch.minimum(mask[:, :, -overlap:, :], ramp.flip(0).view(1, 1, -1, 1))
+
+ return mask
+
+def init_pipeline(model, mode, device, dtype, alt_vae="none"):
+ model_downlod(model_name="JunhaoZhuang/"+model)
+ model_path = os.path.join(folder_paths.models_dir, model)
+ if not os.path.exists(model_path):
+ raise RuntimeError(f'Model directory does not exist!\nPlease save all weights to "{model_path}"')
+ ckpt_path = os.path.join(model_path, "diffusion_pytorch_model_streaming_dmd.safetensors")
+ if not os.path.exists(ckpt_path):
+ raise RuntimeError(f'"diffusion_pytorch_model_streaming_dmd.safetensors" does not exist!\nPlease save it to "{model_path}"')
+ if alt_vae != "none":
+ vae_path = folder_paths.get_full_path_or_raise("vae", alt_vae)
+ if not os.path.exists(vae_path):
+ raise RuntimeError(f'"{alt_vae}" does not exist!')
+ else:
+ vae_path = os.path.join(model_path, "Wan2.1_VAE.pth")
+ if not os.path.exists(vae_path):
+ raise RuntimeError(f'"Wan2.1_VAE.pth" does not exist!\nPlease save it to "{model_path}"')
+ lq_path = os.path.join(model_path, "LQ_proj_in.ckpt")
+ if not os.path.exists(lq_path):
+ raise RuntimeError(f'"LQ_proj_in.ckpt" does not exist!\nPlease save it to "{model_path}"')
+ tcd_path = os.path.join(model_path, "TCDecoder.ckpt")
+ if not os.path.exists(tcd_path):
+ raise RuntimeError(f'"TCDecoder.ckpt" does not exist!\nPlease save it to "{model_path}"')
+ current_dir = os.path.dirname(os.path.abspath(__file__))
+ prompt_path = os.path.join(current_dir, "posi_prompt.pth")
+
+ mm = ModelManager(torch_dtype=dtype, device="cpu")
+ if mode == "full":
+ mm.load_models([ckpt_path, vae_path])
+ pipe = FlashVSRFullPipeline.from_model_manager(mm, device=device)
+ pipe.vae.model.encoder = None
+ pipe.vae.model.conv1 = None
+ else:
+ mm.load_models([ckpt_path])
+ if mode == "tiny":
+ pipe = FlashVSRTinyPipeline.from_model_manager(mm, device=device)
+ else:
+ pipe = FlashVSRTinyLongPipeline.from_model_manager(mm, device=device)
+ multi_scale_channels = [512, 256, 128, 128]
+ pipe.TCDecoder = build_tcdecoder(new_channels=multi_scale_channels, device=device, dtype=dtype, new_latent_channels=16+768)
+ mis = pipe.TCDecoder.load_state_dict(torch.load(tcd_path, map_location=device), strict=False)
+ pipe.TCDecoder.clean_mem()
+
+ if model == "FlashVSR":
+ pipe.denoising_model().LQ_proj_in = Buffer_LQ4x_Proj(in_dim=3, out_dim=1536, layer_num=1).to(device, dtype=dtype)
+ else:
+ pipe.denoising_model().LQ_proj_in = Causal_LQ4x_Proj(in_dim=3, out_dim=1536, layer_num=1).to(device, dtype=dtype)
+ pipe.denoising_model().LQ_proj_in.load_state_dict(torch.load(lq_path, map_location="cpu"), strict=True)
+ pipe.denoising_model().LQ_proj_in.to(device)
+ pipe.to(device, dtype=dtype)
+ pipe.enable_vram_management(num_persistent_param_in_dit=None)
+ pipe.init_cross_kv(prompt_path=prompt_path)
+ pipe.load_models_to_device(["dit","vae"])
+ pipe.offload_model()
+
+ return pipe
+
+class cqdm:
+ def __init__(self, iterable=None, total=None, desc="Processing"):
+ self.desc = desc
+ self.pbar = None
+ self.iterable = None
+ self.total = total
+
+ if iterable is not None:
+ try:
+ self.total = len(iterable)
+ self.iterable = iter(iterable)
+ except TypeError:
+ if self.total is None:
+ raise ValueError("Total must be provided for iterables with no length.")
+
+ elif self.total is not None:
+ pass
+
+ else:
+ raise ValueError("Either iterable or total must be provided.")
+
+ def __iter__(self):
+ if self.iterable is None:
+ raise TypeError(f"'{type(self).__name__}' object is not iterable. Did you mean to use it with a 'with' statement?")
+ if self.pbar is None:
+ self.pbar = comfy.utils.ProgressBar(self.total)
+ return self
+
+ def __next__(self):
+ if self.iterable is None:
+ raise TypeError("Cannot call __next__ on a non-iterable cqdm object.")
+ try:
+ val = next(self.iterable)
+ if self.pbar:
+ self.pbar.update(1)
+ return val
+ except StopIteration:
+ raise
+
+ def __enter__(self):
+ if self.pbar is None:
+ self.pbar = comfy.utils.ProgressBar(self.total)
+ return self.pbar
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ pass
+
+ def __len__(self):
+ return self.total
+
+def flashvsr(pipe, frames, scale, color_fix, tiled_vae, tiled_dit, tile_size, tile_overlap, unload_dit, sparse_ratio, kv_ratio, local_range, seed, force_offload):
+ _frames = frames
+ _device = pipe.device
+ dtype = pipe.torch_dtype
+
+ add = next_8n5(frames.shape[0]) - frames.shape[0]
+ padding_frames = frames[-1:, :, :, :].repeat(add, 1, 1, 1)
+ _frames = torch.cat([frames, padding_frames], dim=0)
+
+ if tiled_dit:
+ N, H, W, C = _frames.shape
+
+ final_output_canvas = torch.zeros(
+ (N, H * scale, W * scale, C),
+ dtype=torch.float16,
+ device="cpu"
+ )
+ weight_sum_canvas = torch.zeros_like(final_output_canvas)
+ tile_coords = calculate_tile_coords(H, W, tile_size, tile_overlap)
+ latent_tiles_cpu = []
+
+ for i, (x1, y1, x2, y2) in enumerate(cqdm(tile_coords, desc="Processing Tiles")):
+ log(f"[FlashVSR] Processing tile {i+1}/{len(tile_coords)}: coords ({x1},{y1}) to ({x2},{y2})", message_type='info')
+ input_tile = _frames[:, y1:y2, x1:x2, :]
+
+ LQ_tile, th, tw, F = prepare_input_tensor(input_tile, _device, scale=scale, dtype=dtype)
+ if not isinstance(pipe, FlashVSRTinyLongPipeline):
+ LQ_tile = LQ_tile.to(_device)
+
+ output_tile_gpu = pipe(
+ prompt="", negative_prompt="", cfg_scale=1.0, num_inference_steps=1, seed=seed, tiled=tiled_vae,
+ LQ_video=LQ_tile, num_frames=F, height=th, width=tw, is_full_block=False, if_buffer=True,
+ topk_ratio=sparse_ratio*768*1280/(th*tw), kv_ratio=kv_ratio, local_range=local_range,
+ color_fix=color_fix, unload_dit=unload_dit, force_offload=force_offload
+ )
+
+ processed_tile_cpu = tensor2video(output_tile_gpu).to("cpu")
+
+ mask_nchw = create_feather_mask(
+ (processed_tile_cpu.shape[1], processed_tile_cpu.shape[2]),
+ tile_overlap * scale
+ ).to("cpu")
+ mask_nhwc = mask_nchw.permute(0, 2, 3, 1)
+ out_x1, out_y1 = x1 * scale, y1 * scale
+
+ tile_H_scaled = processed_tile_cpu.shape[1]
+ tile_W_scaled = processed_tile_cpu.shape[2]
+ out_x2, out_y2 = out_x1 + tile_W_scaled, out_y1 + tile_H_scaled
+ final_output_canvas[:, out_y1:out_y2, out_x1:out_x2, :] += processed_tile_cpu * mask_nhwc
+ weight_sum_canvas[:, out_y1:out_y2, out_x1:out_x2, :] += mask_nhwc
+
+ del LQ_tile, output_tile_gpu, processed_tile_cpu, input_tile
+ clean_vram()
+
+ weight_sum_canvas[weight_sum_canvas == 0] = 1.0
+ final_output = final_output_canvas / weight_sum_canvas
+ else:
+ log("[FlashVSR] Preparing frames...")
+ LQ, th, tw, F = prepare_input_tensor(_frames, _device, scale=scale, dtype=dtype)
+ if not isinstance(pipe, FlashVSRTinyLongPipeline):
+ LQ = LQ.to(_device)
+ log(f"[FlashVSR] Processing {frames.shape[0]} frames...", message_type='info')
+
+ video = pipe(
+ prompt="", negative_prompt="", cfg_scale=1.0, num_inference_steps=1, seed=seed, tiled=tiled_vae,
+ progress_bar_cmd=cqdm, LQ_video=LQ, num_frames=F, height=th, width=tw, is_full_block=False, if_buffer=True,
+ topk_ratio=sparse_ratio*768*1280/(th*tw), kv_ratio=kv_ratio, local_range=local_range,
+ color_fix = color_fix, unload_dit=unload_dit, force_offload=force_offload
+ )
+
+ final_output = tensor2video(video).to('cpu')
+
+ del video, LQ
+ clean_vram()
+
+ log("[FlashVSR] Done.", message_type='info')
+ if frames.shape[0] == 1:
+ final_output = final_output.to(_device)
+ stacked_image_tensor = torch.median(final_output, dim=0).values.unsqueeze(0).float().to('cpu')
+ del final_output
+ clean_vram()
+ return stacked_image_tensor
+
+ return final_output[:frames.shape[0], :, :, :]
+
+class FlashVSRNodeInitPipe:
+ @classmethod
+ def INPUT_TYPES(cls):
+ return {
+ "required": {
+ "model": (["FlashVSR", "FlashVSR-v1.1"], {
+ "default": "FlashVSR-v1.1",
+ "tooltip": "Model version."
+ }),
+ "mode": (["tiny", "tiny-long", "full"], {
+ "default": "tiny",
+ "tooltip": 'Using "tiny-long" mode can significantly reduce VRAM used with long video input.'
+ }),
+ "alt_vae": (["none"] + folder_paths.get_filename_list("vae"), {
+ "default": "none",
+ "tooltip": 'Replaces the built-in VAE, only available in "full" mode.'
+ }),
+ "force_offload": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Offload all weights to CPU after running a workflow to free up VRAM."
+ }),
+ "precision": (["fp16", "bf16"], {
+ "default": "bf16",
+ "tooltip": "Data and inference precision."
+ }),
+ "device": (device_choices, {
+ "default": device_choices[0],
+ "tooltip": "Device to load the weights, default: auto (CUDA if available, else CPU)"
+ }),
+ "attention_mode": (["sparse_sage_attention", "block_sparse_attention"], {
+ "default": "sparse_sage_attention",
+ "tooltip": '"sparse_sage_attention" is available for sm_75 to sm_120\n"block_sparse_attention" is available for sm_80 to sm_100'
+ }),
+ }
+ }
+
+ RETURN_TYPES = ("PIPE",)
+ RETURN_NAMES = ("pipe",)
+ FUNCTION = "main"
+ CATEGORY = "FlashVSR"
+ DESCRIPTION = 'Download the entire "FlashVSR" folder with all the files inside it from "https://huggingface.co/JunhaoZhuang/FlashVSR" and put it in the "ComfyUI/models"'
+
+ def main(self, model, mode, alt_vae, force_offload, precision, device, attention_mode):
+ _device = device
+ if device == "auto":
+ _device = "cuda:0" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else device
+ if _device == "auto" or _device not in device_choices:
+ raise RuntimeError("No devices found to run FlashVSR!")
+
+ if _device.startswith("cuda"):
+ torch.cuda.set_device(_device)
+
+ if attention_mode == "sparse_sage_attention":
+ wan_video_dit.USE_BLOCK_ATTN = False
+ else:
+ wan_video_dit.USE_BLOCK_ATTN = True
+
+ dtype_map = {
+ "fp32": torch.float32,
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ }
+ try:
+ dtype = dtype_map[precision]
+ except:
+ dtype = torch.bfloat16
+
+ pipe = init_pipeline(model, mode, _device, dtype, alt_vae=alt_vae)
+ return((pipe, force_offload),)
+
+class FlashVSRNodeAdv:
+ @classmethod
+ def INPUT_TYPES(cls):
+ return {
+ "required": {
+ "pipe": ("PIPE", {
+ "tooltip": "FlashVSR pipeline"
+ }),
+ "frames": ("IMAGE", {
+ "tooltip": "Sequential video frames as IMAGE tensor batch"
+ }),
+ "scale": ("INT", {
+ "default": 2,
+ "min": 2,
+ "max": 4,
+ }),
+ "color_fix": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Use wavelet transform to correct output video color."
+ }),
+ "tiled_vae": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Disable tiling: faster decode but higher VRAM usage.\nSet to True for lower memory consumption at the cost of speed."
+ }),
+ "tiled_dit": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Significantly reduces VRAM usage at the cost of speed."
+ }),
+ "tile_size": ("INT", {
+ "default": 256,
+ "min": 32,
+ "max": 1024,
+ "step": 32,
+ }),
+ "tile_overlap": ("INT", {
+ "default": 24,
+ "min": 8,
+ "max": 512,
+ "step": 8,
+ }),
+ "unload_dit": ("BOOLEAN", {
+ "default": False,
+ "tooltip": "Unload DiT before decoding to reduce VRAM peak at the cost of speed."
+ }),
+ "sparse_ratio": ("FLOAT", {
+ "default": 2.0,
+ "min": 1.5,
+ "max": 2.0,
+ "step": 0.1,
+ "display": "slider",
+ "tooltip": "Recommended: 1.5 or 2.0\n1.5 → faster; 2.0 → more stable"
+ }),
+ "kv_ratio": ("FLOAT", {
+ "default": 3.0,
+ "min": 1.0,
+ "max": 3.0,
+ "step": 0.1,
+ "display": "slider",
+ "tooltip": "Recommended: 1.0 to 3.0\n1.0 → less vram; 3.0 → high quality"
+ }),
+ "local_range": ("INT", {
+ "default": 11,
+ "min": 9,
+ "max": 11,
+ "step": 2,
+ "tooltip": "Recommended: 9 or 11\nlocal_range=9 → sharper details; 11 → more stable results"
+ }),
+ "seed": ("INT", {
+ "default": 0,
+ "min": 0,
+ "max": 1125899906842624
+ }),
+ }
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ RETURN_NAMES = ("image",)
+ FUNCTION = "main"
+ CATEGORY = "FlashVSR"
+ #DESCRIPTION = ""
+
+ def main(self, pipe, frames, scale, color_fix, tiled_vae, tiled_dit, tile_size, tile_overlap, unload_dit, sparse_ratio, kv_ratio, local_range, seed):
+ _pipe, force_offload = pipe
+ output = flashvsr(_pipe, frames, scale, color_fix, tiled_vae, tiled_dit, tile_size, tile_overlap, unload_dit, sparse_ratio, kv_ratio, local_range, seed, force_offload)
+ return(output,)
+
+class FlashVSRNode:
+ @classmethod
+ def INPUT_TYPES(cls):
+ return {
+ "required": {
+ "frames": ("IMAGE", {
+ "tooltip": "Sequential video frames as IMAGE tensor batch"
+ }),
+ "model": (["FlashVSR", "FlashVSR-v1.1"], {
+ "default": "FlashVSR-v1.1",
+ "tooltip": "Model version."
+ }),
+ "mode": (["tiny", "tiny-long", "full"], {
+ "default": "tiny",
+ "tooltip": 'Using "tiny-long" mode can significantly reduce VRAM used with long video input.'
+ }),
+ "scale": ("INT", {
+ "default": 2,
+ "min": 2,
+ "max": 4,
+ }),
+ "tiled_vae": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Disable tiling: faster decode but higher VRAM usage.\nSet to True for lower memory consumption at the cost of speed."
+ }),
+ "tiled_dit": ("BOOLEAN", {
+ "default": True,
+ "tooltip": "Significantly reduces VRAM usage at the cost of speed."
+ }),
+ "unload_dit": ("BOOLEAN", {
+ "default": False,
+ "tooltip": "Unload DiT before decoding to reduce VRAM peak at the cost of speed."
+ }),
+ "seed": ("INT", {
+ "default": 0,
+ "min": 0,
+ "max": 1125899906842624
+ }),
+ }
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ RETURN_NAMES = ("image",)
+ FUNCTION = "main"
+ CATEGORY = "FlashVSR"
+ DESCRIPTION = 'Download the entire "FlashVSR" folder with all the files inside it from "https://huggingface.co/JunhaoZhuang/FlashVSR" and put it in the "ComfyUI/models"'
+
+ def main(self, model, frames, mode, scale, tiled_vae, tiled_dit, unload_dit, seed):
+ wan_video_dit.USE_BLOCK_ATTN = False
+ _device = "cuda:0" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "auto"
+ if _device == "auto" or _device not in device_choices:
+ raise RuntimeError("No devices found to run FlashVSR!")
+
+ pipe = init_pipeline(model, mode, _device, torch.float16)
+ output = flashvsr(pipe, frames, scale, True, tiled_vae, tiled_dit, 256, 24, unload_dit, 2.0, 3.0, 11, seed, True)
+ return(output,)
+
+NODE_CLASS_MAPPINGS = {
+ "FlashVSRNode": FlashVSRNode,
+ "FlashVSRNodeAdv": FlashVSRNodeAdv,
+ "FlashVSRInitPipe": FlashVSRNodeInitPipe,
+}
+
+NODE_DISPLAY_NAME_MAPPINGS = {
+ "FlashVSRNode": "FlashVSR Ultra-Fast",
+ "FlashVSRNodeAdv": "FlashVSR Ultra-Fast (Advanced)",
+ "FlashVSRInitPipe": "FlashVSR Init Pipeline",
+}
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/posi_prompt.pth b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/posi_prompt.pth
new file mode 100644
index 0000000000000000000000000000000000000000..062e420f699425c3c844f813e862dcd8ef820e3d
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/posi_prompt.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4601107a11e4e11a936a6b79df579e54dbc99872132bf542151f0ffd65b4b1ef
+size 4195504
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/requirements.txt b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9412e6c10028f152820bbeb6a0b508ec0b581efa
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/requirements.txt
@@ -0,0 +1,10 @@
+torch
+torchvision
+numpy
+einops
+safetensors
+tqdm
+pillow
+huggingface_hub
+triton; platform_system!="Windows"
+triton-windows; platform_system=="Windows"
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/LICENSE.txt b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/LICENSE.txt
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/LICENSE.txt
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2555fe40d2010d1227816853e72a8c78762fa0c
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/__init__.py
@@ -0,0 +1,3 @@
+from .models import *
+from .pipelines import *
+from .schedulers import *
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/configs/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/configs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/configs/model_config.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/configs/model_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..e89ba3e4a472c50b879010eb32594418a4bff777
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/configs/model_config.py
@@ -0,0 +1,29 @@
+from typing_extensions import Literal, TypeAlias
+
+from ..models.wan_video_dit import WanModel
+from ..models.wan_video_vae import WanVideoVAE
+
+
+model_loader_configs = [
+ # These configs are provided for detecting model type automatically.
+ # The format is (state_dict_keys_hash, state_dict_keys_hash_with_shape, model_names, model_classes, model_resource)
+ (None, "9269f8db9040a9d860eaca435be61814", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "aafcfd9672c3a2456dc46e1cb6e52c70", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "6bfcfb3b342cb286ce886889d519a77e", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "6d6ccde6845b95ad9114ab993d917893", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "6bfcfb3b342cb286ce886889d519a77e", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "349723183fc063b2bfc10bb2835cf677", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "efa44cddf936c70abd0ea28b6cbe946c", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "3ef3b1f8e1dab83d5b71fd7b617f859f", ["wan_video_dit"], [WanModel], "civitai"),
+ (None, "cb104773c6c2cb6df4f9529ad5c60d0b", ["wan_video_dit"], [WanModel], "diffusers"),
+ (None, "1378ea763357eea97acdef78e65d6d96", ["wan_video_vae"], [WanVideoVAE], "civitai"),
+ (None, "ccc42284ea13e1ad04693284c7a09be6", ["wan_video_vae"], [WanVideoVAE], "civitai"),
+]
+huggingface_model_loader_configs = [
+ # These configs are provided for detecting model type automatically.
+ # The format is (architecture_in_huggingface_config, huggingface_lib, model_name, redirected_architecture)
+]
+patch_model_loader_configs = [
+ # These configs are provided for detecting model type automatically.
+ # The format is (state_dict_keys_hash_with_shape, model_name, model_class, extra_kwargs)
+]
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/TCDecoder.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/TCDecoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..f2d55d41a0f4035adfb2db2e35492c0f38adeaa6
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/TCDecoder.py
@@ -0,0 +1,320 @@
+#!/usr/bin/env python3
+"""
+Tiny AutoEncoder for Hunyuan Video (Decoder-only, pruned)
+- Encoder removed
+- Transplant/widening helpers removed
+- Deepening (IdentityConv2d+ReLU) is now built into the decoder structure itself
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from tqdm.auto import tqdm
+from collections import namedtuple
+from einops import rearrange
+import torch.nn.init as init
+
+DecoderResult = namedtuple("DecoderResult", ("frame", "memory"))
+TWorkItem = namedtuple("TWorkItem", ("input_tensor", "block_index"))
+
+# ----------------------------
+# Utility / building blocks
+# ----------------------------
+
+class IdentityConv2d(nn.Conv2d):
+ """Same-shape Conv2d initialized to identity (Dirac)."""
+ def __init__(self, C, kernel_size=3, bias=False):
+ pad = kernel_size // 2
+ super().__init__(C, C, kernel_size, padding=pad, bias=bias)
+ with torch.no_grad():
+ init.dirac_(self.weight)
+ if self.bias is not None:
+ self.bias.zero_()
+
+def conv(n_in, n_out, **kwargs):
+ return nn.Conv2d(n_in, n_out, 3, padding=1, **kwargs)
+
+class Clamp(nn.Module):
+ def forward(self, x):
+ return torch.tanh(x / 3) * 3
+
+class MemBlock(nn.Module):
+ def __init__(self, n_in, n_out):
+ super().__init__()
+ self.conv = nn.Sequential(
+ conv(n_in * 2, n_out), nn.ReLU(inplace=True),
+ conv(n_out, n_out), nn.ReLU(inplace=True),
+ conv(n_out, n_out)
+ )
+ self.skip = nn.Conv2d(n_in, n_out, 1, bias=False) if n_in != n_out else nn.Identity()
+ self.act = nn.ReLU(inplace=True)
+ def forward(self, x, past):
+ return self.act(self.conv(torch.cat([x, past], 1)) + self.skip(x))
+
+class TPool(nn.Module):
+ def __init__(self, n_f, stride):
+ super().__init__()
+ self.stride = stride
+ self.conv = nn.Conv2d(n_f*stride, n_f, 1, bias=False)
+ def forward(self, x):
+ _NT, C, H, W = x.shape
+ return self.conv(x.reshape(-1, self.stride * C, H, W))
+
+class TGrow(nn.Module):
+ def __init__(self, n_f, stride):
+ super().__init__()
+ self.stride = stride
+ self.conv = nn.Conv2d(n_f, n_f*stride, 1, bias=False)
+ def forward(self, x):
+ _NT, C, H, W = x.shape
+ x = self.conv(x)
+ return x.reshape(-1, C, H, W)
+
+class PixelShuffle3d(nn.Module):
+ def __init__(self, ff, hh, ww):
+ super().__init__()
+ self.ff = ff
+ self.hh = hh
+ self.ww = ww
+ def forward(self, x):
+ # x: (B, C, F, H, W)
+ B, C, F, H, W = x.shape
+ if F % self.ff != 0:
+ first_frame = x[:, :, 0:1, :, :].repeat(1, 1, self.ff - F % self.ff, 1, 1)
+ x = torch.cat([first_frame, x], dim=2)
+ return rearrange(
+ x,
+ 'b c (f ff) (h hh) (w ww) -> b (c ff hh ww) f h w',
+ ff=self.ff, hh=self.hh, ww=self.ww
+ ).transpose(1, 2)
+
+# ----------------------------
+# Generic NTCHW graph executor (kept; used by decoder)
+# ----------------------------
+
+def apply_model_with_memblocks(model, x, parallel, show_progress_bar, mem=None):
+ """
+ Apply a sequential model with memblocks to the given input.
+ Args:
+ - model: nn.Sequential of blocks to apply
+ - x: input data, of dimensions NTCHW
+ - parallel: if True, parallelize over timesteps (fast but uses O(T) memory)
+ if False, each timestep will be processed sequentially (slow but uses O(1) memory)
+ - show_progress_bar: if True, enables tqdm progressbar display
+
+ Returns NTCHW tensor of output data.
+ """
+ assert x.ndim == 5, f"TAEHV operates on NTCHW tensors, but got {x.ndim}-dim tensor"
+ N, T, C, H, W = x.shape
+ if parallel:
+ x = x.reshape(N*T, C, H, W)
+ for b in tqdm(model, disable=not show_progress_bar):
+ if isinstance(b, MemBlock):
+ NT, C, H, W = x.shape
+ T = NT // N
+ _x = x.reshape(N, T, C, H, W)
+ mem = F.pad(_x, (0,0,0,0,0,0,1,0), value=0)[:,:T].reshape(x.shape)
+ x = b(x, mem)
+ else:
+ x = b(x)
+ NT, C, H, W = x.shape
+ T = NT // N
+ x = x.view(N, T, C, H, W)
+ else:
+ out = []
+ work_queue = [TWorkItem(xt, 0) for t, xt in enumerate(x.reshape(N, T * C, H, W).chunk(T, dim=1))]
+ progress_bar = tqdm(range(T), disable=not show_progress_bar)
+ while work_queue:
+ xt, i = work_queue.pop(0)
+ if i == 0:
+ progress_bar.update(1)
+ if i == len(model):
+ out.append(xt)
+ else:
+ b = model[i]
+ if isinstance(b, MemBlock):
+ if mem[i] is None:
+ xt_new = b(xt, xt * 0)
+ mem[i] = xt
+ else:
+ xt_new = b(xt, mem[i])
+ mem[i].copy_(xt)
+ work_queue.insert(0, TWorkItem(xt_new, i+1))
+ elif isinstance(b, TPool):
+ if mem[i] is None:
+ mem[i] = []
+ mem[i].append(xt)
+ if len(mem[i]) > b.stride:
+ raise ValueError("TPool internal state invalid.")
+ elif len(mem[i]) == b.stride:
+ N_, C_, H_, W_ = xt.shape
+ xt = b(torch.cat(mem[i], 1).view(N_*b.stride, C_, H_, W_))
+ mem[i] = []
+ work_queue.insert(0, TWorkItem(xt, i+1))
+ elif isinstance(b, TGrow):
+ xt = b(xt)
+ NT, C_, H_, W_ = xt.shape
+ for xt_next in reversed(xt.view(N, b.stride*C_, H_, W_).chunk(b.stride, 1)):
+ work_queue.insert(0, TWorkItem(xt_next, i+1))
+ else:
+ xt = b(xt)
+ work_queue.insert(0, TWorkItem(xt, i+1))
+ progress_bar.close()
+ x = torch.stack(out, 1)
+ return x, mem
+
+# ----------------------------
+# Decoder-only TAEHV
+# ----------------------------
+
+class TAEHV(nn.Module):
+ image_channels = 3
+ def __init__(
+ self,
+ checkpoint_path="taehv.pth",
+ decoder_time_upscale=(True, True),
+ decoder_space_upscale=(True, True, True),
+ channels = [256, 128, 64, 64],
+ latent_channels = 16
+ ):
+ """Initialize TAEHV (decoder-only) with built-in deepening after every ReLU.
+ Deepening config: how_many_each=1, k=3 (fixed as requested).
+ """
+ super().__init__()
+ self.latent_channels = latent_channels
+ n_f = channels
+ self.frames_to_trim = 2**sum(decoder_time_upscale) - 1
+
+ # Build the decoder "skeleton"
+ base_decoder = nn.Sequential(
+ Clamp(), conv(self.latent_channels, n_f[0]), nn.ReLU(inplace=True),
+
+ MemBlock(n_f[0], n_f[0]), MemBlock(n_f[0], n_f[0]), MemBlock(n_f[0], n_f[0]),
+ nn.Upsample(scale_factor=2 if decoder_space_upscale[0] else 1),
+ TGrow(n_f[0], 1),
+ conv(n_f[0], n_f[1], bias=False),
+
+ MemBlock(n_f[1], n_f[1]), MemBlock(n_f[1], n_f[1]), MemBlock(n_f[1], n_f[1]),
+ nn.Upsample(scale_factor=2 if decoder_space_upscale[1] else 1),
+ TGrow(n_f[1], 2 if decoder_time_upscale[0] else 1),
+ conv(n_f[1], n_f[2], bias=False),
+
+ MemBlock(n_f[2], n_f[2]), MemBlock(n_f[2], n_f[2]), MemBlock(n_f[2], n_f[2]),
+ nn.Upsample(scale_factor=2 if decoder_space_upscale[2] else 1),
+ TGrow(n_f[2], 2 if decoder_time_upscale[1] else 1),
+ conv(n_f[2], n_f[3], bias=False),
+
+ nn.ReLU(inplace=True), conv(n_f[3], TAEHV.image_channels),
+ )
+
+ # Inline deepening: insert (IdentityConv2d(k=3) + ReLU) after every ReLU
+ self.decoder = self._apply_identity_deepen(base_decoder, how_many_each=1, k=3)
+
+ self.pixel_shuffle = PixelShuffle3d(4, 8, 8)
+
+ if checkpoint_path is not None:
+ missing_keys = self.load_state_dict(
+ self.patch_tgrow_layers(torch.load(checkpoint_path, map_location="cpu", weights_only=True)),
+ strict=False
+ )
+ print('missing_keys', missing_keys)
+
+ # Initialize decoder mem state
+ self.mem = [None] * len(self.decoder)
+
+ @staticmethod
+ def _apply_identity_deepen(decoder: nn.Sequential, how_many_each=1, k=3) -> nn.Sequential:
+ """Return a new Sequential where every nn.ReLU is followed by how_many_each*(IdentityConv2d(k)+ReLU)."""
+ new_layers = []
+ for b in decoder:
+ new_layers.append(b)
+ if isinstance(b, nn.ReLU):
+ # Deduce channel count from preceding layer
+ C = None
+ if len(new_layers) >= 2 and isinstance(new_layers[-2], nn.Conv2d):
+ C = new_layers[-2].out_channels
+ elif len(new_layers) >= 2 and isinstance(new_layers[-2], MemBlock):
+ C = new_layers[-2].conv[-1].out_channels
+ if C is not None:
+ for _ in range(how_many_each):
+ new_layers.append(IdentityConv2d(C, kernel_size=k, bias=False))
+ new_layers.append(nn.ReLU(inplace=True))
+ return nn.Sequential(*new_layers)
+
+ def patch_tgrow_layers(self, sd):
+ """Patch TGrow layers to use a smaller kernel if needed (decoder-only)."""
+ new_sd = self.state_dict()
+ for i, layer in enumerate(self.decoder):
+ if isinstance(layer, TGrow):
+ key = f"decoder.{i}.conv.weight"
+ if key in sd and sd[key].shape[0] > new_sd[key].shape[0]:
+ sd[key] = sd[key][-new_sd[key].shape[0]:]
+ return sd
+
+ def decode_video(self, x, parallel=True, show_progress_bar=False, cond=None):
+ """Decode a sequence of frames from latents.
+ x: NTCHW latent tensor; returns NTCHW RGB in ~[0, 1].
+ """
+ trim_flag = self.mem[-8] is None # keeps original relative check
+
+ if cond is not None:
+ x = torch.cat([self.pixel_shuffle(cond), x], dim=2)
+
+ x, self.mem = apply_model_with_memblocks(self.decoder, x, parallel, show_progress_bar, mem=self.mem)
+
+ if trim_flag:
+ return x[:, self.frames_to_trim:]
+ return x
+
+ def forward(self, *args, **kwargs):
+ raise NotImplementedError("Decoder-only model: call decode_video(...) instead.")
+
+ def clean_mem(self):
+ self.mem = [None] * len(self.decoder)
+
+class DotDict(dict):
+ __getattr__ = dict.__getitem__
+ __setattr__ = dict.__setitem__
+
+class TAEW2_1DiffusersWrapper(nn.Module):
+ def __init__(self, pretrained_path=None, channels = [256, 128, 64, 64]):
+ super().__init__()
+ self.dtype = torch.bfloat16
+ self.device = "cuda"
+ self.taehv = TAEHV(pretrained_path, channels = channels).to(self.dtype)
+ self.temperal_downsample = [True, True, False] # [sic]
+ self.config = DotDict(scaling_factor=1.0, latents_mean=torch.zeros(16), z_dim=16, latents_std=torch.ones(16))
+
+ def decode(self, latents, return_dict=None):
+ n, c, t, h, w = latents.shape
+ return (self.taehv.decode_video(latents.transpose(1, 2), parallel=False).transpose(1, 2).mul_(2).sub_(1),)
+
+ def stream_decode_with_cond(self, latents, tiled=False, cond=None):
+ n, c, t, h, w = latents.shape
+ return self.taehv.decode_video(latents.transpose(1, 2), parallel=False, cond=cond).transpose(1, 2).mul_(2).sub_(1)
+
+ def clean_mem(self):
+ self.taehv.clean_mem()
+
+# ----------------------------
+# Simplified builder (no small, no transplant, no post-hoc deepening)
+# ----------------------------
+
+def build_tcdecoder(new_channels = [512, 256, 128, 128],
+ device="cuda",
+ dtype=torch.bfloat16,
+ new_latent_channels=None):
+ """
+ 构建“更宽”的 decoder;深度增强(IdentityConv2d+ReLU)已在 TAEHV 内部完成。
+ - 不创建 small / 不做移植
+ - base_ckpt_path 参数保留但不使用(接口兼容)
+
+ 返回:big (单个模型)
+ """
+ if new_latent_channels is not None:
+ big = TAEHV(checkpoint_path=None, channels=new_channels, latent_channels=new_latent_channels).to(device).to(dtype).train()
+ else:
+ big = TAEHV(checkpoint_path=None, channels=new_channels).to(device).to(dtype).train()
+
+ big.clean_mem()
+ return big
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..96707b666371c39d4ba59a839d5ddfeafb5d1d43
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/__init__.py
@@ -0,0 +1 @@
+from .model_manager import *
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/model_manager.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/model_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c1412cdf6e68aeaed7ee520930dd1464a13f4fc
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/model_manager.py
@@ -0,0 +1,402 @@
+import os, torch, json, importlib
+from typing import List
+
+from ..configs.model_config import model_loader_configs, huggingface_model_loader_configs, patch_model_loader_configs
+from .utils import load_state_dict, init_weights_on_device, hash_state_dict_keys, split_state_dict_with_prefix
+
+def load_model_from_single_file(state_dict, model_names, model_classes, model_resource, torch_dtype, device):
+ loaded_model_names, loaded_models = [], []
+ for model_name, model_class in zip(model_names, model_classes):
+ #print(f" model_name: {model_name} model_class: {model_class.__name__}")
+ state_dict_converter = model_class.state_dict_converter()
+ if model_resource == "civitai":
+ state_dict_results = state_dict_converter.from_civitai(state_dict)
+ elif model_resource == "diffusers":
+ state_dict_results = state_dict_converter.from_diffusers(state_dict)
+ if isinstance(state_dict_results, tuple):
+ model_state_dict, extra_kwargs = state_dict_results
+ #print(f" This model is initialized with extra kwargs: {extra_kwargs}")
+ else:
+ model_state_dict, extra_kwargs = state_dict_results, {}
+ torch_dtype = torch.float32 if extra_kwargs.get("upcast_to_float32", False) else torch_dtype
+ with init_weights_on_device():
+ model = model_class(**extra_kwargs)
+ if hasattr(model, "eval"):
+ model = model.eval()
+ model.load_state_dict(model_state_dict, assign=True)
+ model = model.to(dtype=torch_dtype, device=device)
+ loaded_model_names.append(model_name)
+ loaded_models.append(model)
+ return loaded_model_names, loaded_models
+
+
+def load_model_from_huggingface_folder(file_path, model_names, model_classes, torch_dtype, device):
+ loaded_model_names, loaded_models = [], []
+ for model_name, model_class in zip(model_names, model_classes):
+ if torch_dtype in [torch.float32, torch.float16, torch.bfloat16]:
+ model = model_class.from_pretrained(file_path, torch_dtype=torch_dtype).eval()
+ else:
+ model = model_class.from_pretrained(file_path).eval().to(dtype=torch_dtype)
+ if torch_dtype == torch.float16 and hasattr(model, "half"):
+ model = model.half()
+ try:
+ model = model.to(device=device)
+ except:
+ pass
+ loaded_model_names.append(model_name)
+ loaded_models.append(model)
+ return loaded_model_names, loaded_models
+
+
+def load_single_patch_model_from_single_file(state_dict, model_name, model_class, base_model, extra_kwargs, torch_dtype, device):
+ #print(f" model_name: {model_name} model_class: {model_class.__name__} extra_kwargs: {extra_kwargs}")
+ base_state_dict = base_model.state_dict()
+ base_model.to("cpu")
+ del base_model
+ model = model_class(**extra_kwargs)
+ model.load_state_dict(base_state_dict, strict=False)
+ model.load_state_dict(state_dict, strict=False)
+ model.to(dtype=torch_dtype, device=device)
+ return model
+
+
+def load_patch_model_from_single_file(state_dict, model_names, model_classes, extra_kwargs, model_manager, torch_dtype, device):
+ loaded_model_names, loaded_models = [], []
+ for model_name, model_class in zip(model_names, model_classes):
+ while True:
+ for model_id in range(len(model_manager.model)):
+ base_model_name = model_manager.model_name[model_id]
+ if base_model_name == model_name:
+ base_model_path = model_manager.model_path[model_id]
+ base_model = model_manager.model[model_id]
+ print(f" Adding patch model to {base_model_name} ({base_model_path})")
+ patched_model = load_single_patch_model_from_single_file(
+ state_dict, model_name, model_class, base_model, extra_kwargs, torch_dtype, device)
+ loaded_model_names.append(base_model_name)
+ loaded_models.append(patched_model)
+ model_manager.model.pop(model_id)
+ model_manager.model_path.pop(model_id)
+ model_manager.model_name.pop(model_id)
+ break
+ else:
+ break
+ return loaded_model_names, loaded_models
+
+
+
+class ModelDetectorTemplate:
+ def __init__(self):
+ pass
+
+ def match(self, file_path="", state_dict={}):
+ return False
+
+ def load(self, file_path="", state_dict={}, device="cuda", torch_dtype=torch.float16, **kwargs):
+ return [], []
+
+
+
+class ModelDetectorFromSingleFile:
+ def __init__(self, model_loader_configs=[]):
+ self.keys_hash_with_shape_dict = {}
+ self.keys_hash_dict = {}
+ for metadata in model_loader_configs:
+ self.add_model_metadata(*metadata)
+
+
+ def add_model_metadata(self, keys_hash, keys_hash_with_shape, model_names, model_classes, model_resource):
+ self.keys_hash_with_shape_dict[keys_hash_with_shape] = (model_names, model_classes, model_resource)
+ if keys_hash is not None:
+ self.keys_hash_dict[keys_hash] = (model_names, model_classes, model_resource)
+
+
+ def match(self, file_path="", state_dict={}):
+ if isinstance(file_path, str) and os.path.isdir(file_path):
+ return False
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+ keys_hash_with_shape = hash_state_dict_keys(state_dict, with_shape=True)
+ if keys_hash_with_shape in self.keys_hash_with_shape_dict:
+ return True
+ keys_hash = hash_state_dict_keys(state_dict, with_shape=False)
+ if keys_hash in self.keys_hash_dict:
+ return True
+ return False
+
+
+ def load(self, file_path="", state_dict={}, device="cuda", torch_dtype=torch.float16, **kwargs):
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+
+ # Load models with strict matching
+ keys_hash_with_shape = hash_state_dict_keys(state_dict, with_shape=True)
+ if keys_hash_with_shape in self.keys_hash_with_shape_dict:
+ model_names, model_classes, model_resource = self.keys_hash_with_shape_dict[keys_hash_with_shape]
+ loaded_model_names, loaded_models = load_model_from_single_file(state_dict, model_names, model_classes, model_resource, torch_dtype, device)
+ return loaded_model_names, loaded_models
+
+ # Load models without strict matching
+ # (the shape of parameters may be inconsistent, and the state_dict_converter will modify the model architecture)
+ keys_hash = hash_state_dict_keys(state_dict, with_shape=False)
+ if keys_hash in self.keys_hash_dict:
+ model_names, model_classes, model_resource = self.keys_hash_dict[keys_hash]
+ loaded_model_names, loaded_models = load_model_from_single_file(state_dict, model_names, model_classes, model_resource, torch_dtype, device)
+ return loaded_model_names, loaded_models
+
+ return loaded_model_names, loaded_models
+
+
+
+class ModelDetectorFromSplitedSingleFile(ModelDetectorFromSingleFile):
+ def __init__(self, model_loader_configs=[]):
+ super().__init__(model_loader_configs)
+
+
+ def match(self, file_path="", state_dict={}):
+ if isinstance(file_path, str) and os.path.isdir(file_path):
+ return False
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+ splited_state_dict = split_state_dict_with_prefix(state_dict)
+ for sub_state_dict in splited_state_dict:
+ if super().match(file_path, sub_state_dict):
+ return True
+ return False
+
+
+ def load(self, file_path="", state_dict={}, device="cuda", torch_dtype=torch.float16, **kwargs):
+ # Split the state_dict and load from each component
+ splited_state_dict = split_state_dict_with_prefix(state_dict)
+ valid_state_dict = {}
+ for sub_state_dict in splited_state_dict:
+ if super().match(file_path, sub_state_dict):
+ valid_state_dict.update(sub_state_dict)
+ if super().match(file_path, valid_state_dict):
+ loaded_model_names, loaded_models = super().load(file_path, valid_state_dict, device, torch_dtype)
+ else:
+ loaded_model_names, loaded_models = [], []
+ for sub_state_dict in splited_state_dict:
+ if super().match(file_path, sub_state_dict):
+ loaded_model_names_, loaded_models_ = super().load(file_path, valid_state_dict, device, torch_dtype)
+ loaded_model_names += loaded_model_names_
+ loaded_models += loaded_models_
+ return loaded_model_names, loaded_models
+
+
+
+class ModelDetectorFromHuggingfaceFolder:
+ def __init__(self, model_loader_configs=[]):
+ self.architecture_dict = {}
+ for metadata in model_loader_configs:
+ self.add_model_metadata(*metadata)
+
+
+ def add_model_metadata(self, architecture, huggingface_lib, model_name, redirected_architecture):
+ self.architecture_dict[architecture] = (huggingface_lib, model_name, redirected_architecture)
+
+
+ def match(self, file_path="", state_dict={}):
+ if not isinstance(file_path, str) or os.path.isfile(file_path):
+ return False
+ file_list = os.listdir(file_path)
+ if "config.json" not in file_list:
+ return False
+ with open(os.path.join(file_path, "config.json"), "r") as f:
+ config = json.load(f)
+ if "architectures" not in config and "_class_name" not in config:
+ return False
+ return True
+
+
+ def load(self, file_path="", state_dict={}, device="cuda", torch_dtype=torch.float16, **kwargs):
+ with open(os.path.join(file_path, "config.json"), "r") as f:
+ config = json.load(f)
+ loaded_model_names, loaded_models = [], []
+ architectures = config["architectures"] if "architectures" in config else [config["_class_name"]]
+ for architecture in architectures:
+ huggingface_lib, model_name, redirected_architecture = self.architecture_dict[architecture]
+ if redirected_architecture is not None:
+ architecture = redirected_architecture
+ model_class = importlib.import_module(huggingface_lib).__getattribute__(architecture)
+ loaded_model_names_, loaded_models_ = load_model_from_huggingface_folder(file_path, [model_name], [model_class], torch_dtype, device)
+ loaded_model_names += loaded_model_names_
+ loaded_models += loaded_models_
+ return loaded_model_names, loaded_models
+
+
+
+class ModelDetectorFromPatchedSingleFile:
+ def __init__(self, model_loader_configs=[]):
+ self.keys_hash_with_shape_dict = {}
+ for metadata in model_loader_configs:
+ self.add_model_metadata(*metadata)
+
+
+ def add_model_metadata(self, keys_hash_with_shape, model_name, model_class, extra_kwargs):
+ self.keys_hash_with_shape_dict[keys_hash_with_shape] = (model_name, model_class, extra_kwargs)
+
+
+ def match(self, file_path="", state_dict={}):
+ if not isinstance(file_path, str) or os.path.isdir(file_path):
+ return False
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+ keys_hash_with_shape = hash_state_dict_keys(state_dict, with_shape=True)
+ if keys_hash_with_shape in self.keys_hash_with_shape_dict:
+ return True
+ return False
+
+
+ def load(self, file_path="", state_dict={}, device="cuda", torch_dtype=torch.float16, model_manager=None, **kwargs):
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+
+ # Load models with strict matching
+ loaded_model_names, loaded_models = [], []
+ keys_hash_with_shape = hash_state_dict_keys(state_dict, with_shape=True)
+ if keys_hash_with_shape in self.keys_hash_with_shape_dict:
+ model_names, model_classes, extra_kwargs = self.keys_hash_with_shape_dict[keys_hash_with_shape]
+ loaded_model_names_, loaded_models_ = load_patch_model_from_single_file(
+ state_dict, model_names, model_classes, extra_kwargs, model_manager, torch_dtype, device)
+ loaded_model_names += loaded_model_names_
+ loaded_models += loaded_models_
+ return loaded_model_names, loaded_models
+
+
+
+class ModelManager:
+ def __init__(
+ self,
+ torch_dtype=torch.float16,
+ device="cuda",
+ file_path_list: List[str] = [],
+ ):
+ self.torch_dtype = torch_dtype
+ self.device = device
+ self.model = []
+ self.model_path = []
+ self.model_name = []
+ self.model_detector = [
+ ModelDetectorFromSingleFile(model_loader_configs),
+ ModelDetectorFromSplitedSingleFile(model_loader_configs),
+ ModelDetectorFromHuggingfaceFolder(huggingface_model_loader_configs),
+ ModelDetectorFromPatchedSingleFile(patch_model_loader_configs),
+ ]
+ self.load_models(file_path_list)
+
+
+ def load_model_from_single_file(self, file_path="", state_dict={}, model_names=[], model_classes=[], model_resource=None):
+ print(f"Loading models from file: {file_path}")
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+ model_names, models = load_model_from_single_file(state_dict, model_names, model_classes, model_resource, self.torch_dtype, self.device)
+ for model_name, model in zip(model_names, models):
+ self.model.append(model)
+ self.model_path.append(file_path)
+ self.model_name.append(model_name)
+ #print(f" The following models are loaded: {model_names}.")
+
+
+ def load_model_from_huggingface_folder(self, file_path="", model_names=[], model_classes=[]):
+ print(f"Loading models from folder: {file_path}")
+ model_names, models = load_model_from_huggingface_folder(file_path, model_names, model_classes, self.torch_dtype, self.device)
+ for model_name, model in zip(model_names, models):
+ self.model.append(model)
+ self.model_path.append(file_path)
+ self.model_name.append(model_name)
+ #print(f" The following models are loaded: {model_names}.")
+
+
+ def load_patch_model_from_single_file(self, file_path="", state_dict={}, model_names=[], model_classes=[], extra_kwargs={}):
+ print(f"Loading patch models from file: {file_path}")
+ model_names, models = load_patch_model_from_single_file(
+ state_dict, model_names, model_classes, extra_kwargs, self, self.torch_dtype, self.device)
+ for model_name, model in zip(model_names, models):
+ self.model.append(model)
+ self.model_path.append(file_path)
+ self.model_name.append(model_name)
+ print(f" The following patched models are loaded: {model_names}.")
+
+
+ def load_lora(self, file_path="", state_dict={}, lora_alpha=1.0):
+ if isinstance(file_path, list):
+ for file_path_ in file_path:
+ self.load_lora(file_path_, state_dict=state_dict, lora_alpha=lora_alpha)
+ else:
+ print(f"Loading LoRA models from file: {file_path}")
+ is_loaded = False
+ if len(state_dict) == 0:
+ state_dict = load_state_dict(file_path)
+ for model_name, model, model_path in zip(self.model_name, self.model, self.model_path):
+ for lora in get_lora_loaders():
+ match_results = lora.match(model, state_dict)
+ if match_results is not None:
+ print(f" Adding LoRA to {model_name} ({model_path}).")
+ lora_prefix, model_resource = match_results
+ lora.load(model, state_dict, lora_prefix, alpha=lora_alpha, model_resource=model_resource)
+ is_loaded = True
+ break
+ if not is_loaded:
+ print(f" Cannot load LoRA: {file_path}")
+
+
+ def load_model(self, file_path, model_names=None, device=None, torch_dtype=None):
+ #print(f"Loading models from: {file_path}")
+ if device is None: device = self.device
+ if torch_dtype is None: torch_dtype = self.torch_dtype
+ if isinstance(file_path, list):
+ state_dict = {}
+ for path in file_path:
+ state_dict.update(load_state_dict(path))
+ elif os.path.isfile(file_path):
+ state_dict = load_state_dict(file_path)
+ else:
+ state_dict = None
+ for model_detector in self.model_detector:
+ if model_detector.match(file_path, state_dict):
+ model_names, models = model_detector.load(
+ file_path, state_dict,
+ device=device, torch_dtype=torch_dtype,
+ allowed_model_names=model_names, model_manager=self
+ )
+ for model_name, model in zip(model_names, models):
+ self.model.append(model)
+ self.model_path.append(file_path)
+ self.model_name.append(model_name)
+ #print(f" The following models are loaded: {model_names}.")
+ break
+ else:
+ print(f" We cannot detect the model type. No models are loaded.")
+
+
+ def load_models(self, file_path_list, model_names=None, device=None, torch_dtype=None):
+ for file_path in file_path_list:
+ self.load_model(file_path, model_names, device=device, torch_dtype=torch_dtype)
+
+
+ def fetch_model(self, model_name, file_path=None, require_model_path=False):
+ fetched_models = []
+ fetched_model_paths = []
+ for model, model_path, model_name_ in zip(self.model, self.model_path, self.model_name):
+ if file_path is not None and file_path != model_path:
+ continue
+ if model_name == model_name_:
+ fetched_models.append(model)
+ fetched_model_paths.append(model_path)
+ if len(fetched_models) == 0:
+ #print(f"No {model_name} models available.")
+ return None
+ if len(fetched_models) == 1:
+ print(f"Using {model_name} from {fetched_model_paths[0]}")
+ else:
+ print(f"More than one {model_name} models are loaded in model manager: {fetched_model_paths}. Using {model_name} from {fetched_model_paths[0]}")
+ if require_model_path:
+ return fetched_models[0], fetched_model_paths[0]
+ else:
+ return fetched_models[0]
+
+
+ def to(self, device):
+ for model in self.model:
+ model.to(device)
+
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/LICENSE.txt b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/LICENSE.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5ac25aa2a86b7bc0a7fe297b7091c248425084f0
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/LICENSE.txt
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2025 Jintao Zhang
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/core.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/core.py
new file mode 100644
index 0000000000000000000000000000000000000000..62ba86395fe5a111d5f744e22da8e08dd0149e9f
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/core.py
@@ -0,0 +1,45 @@
+"""
+https://github.com/jt-zhang/Sparse_SageAttention_API
+
+Copyright (c) 2024 by SageAttention team.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+"""
+
+from .quant_per_block import per_block_int8
+from .sparse_int8_attn import forward as sparse_sageattn_fwd
+import torch
+
+
+def sparse_sageattn(q, k, v, mask_id = None, is_causal=False, tensor_layout="HND"):
+ if mask_id is None:
+ mask_id = torch.ones((q.shape[0], q.shape[1], (q.shape[2] + 128 - 1)//128, (q.shape[3] + 64 - 1)//64), dtype=torch.int8, device=q.device) # TODO
+
+ output_dtype = q.dtype
+ if output_dtype == torch.bfloat16 or output_dtype == torch.float32:
+ v = v.to(torch.float16)
+
+ seq_dim = 1 if tensor_layout == "NHD" else 2
+ km = k.mean(dim=seq_dim, keepdim=True)
+ # km = torch.zeros((k.size(0), k.size(1), 1, k.size(3)), dtype=torch.float16, device=k.device) # Placeholder for mean, not used in quantization
+
+ q_int8, q_scale, k_int8, k_scale = per_block_int8(q, k, km=km, tensor_layout=tensor_layout)
+
+ o = sparse_sageattn_fwd(
+ q_int8, k_int8, mask_id, v, q_scale, k_scale,
+ is_causal=is_causal, tensor_layout=tensor_layout, output_dtype=output_dtype
+ )
+ return o
+
+
+# flops = 4 * q.size(0) * q.size(1) * q.size(2)**2 * q.size(3) / (2 if is_causal else 1)
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/quant_per_block.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/quant_per_block.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a8dab88447f250f2428a34d2cb119aab2604e4f
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/quant_per_block.py
@@ -0,0 +1,101 @@
+"""
+Copyright (c) 2024 by SageAttention team.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+"""
+
+import torch
+import triton
+import triton.language as tl
+
+@triton.jit
+def quant_per_block_int8_kernel(Input, Output, Scale, L,
+ stride_iz, stride_ih, stride_in,
+ stride_oz, stride_oh, stride_on,
+ stride_sz, stride_sh,
+ sm_scale,
+ C: tl.constexpr, BLK: tl.constexpr):
+ off_blk = tl.program_id(0)
+ off_h = tl.program_id(1)
+ off_b = tl.program_id(2)
+
+ offs_n = off_blk * BLK + tl.arange(0, BLK)
+ offs_k = tl.arange(0, C)
+
+ input_ptrs = Input + off_b * stride_iz + off_h * stride_ih + offs_n[:, None] * stride_in + offs_k[None, :]
+ output_ptrs = Output + off_b * stride_oz + off_h * stride_oh + offs_n[:, None] * stride_on + offs_k[None, :]
+ scale_ptrs = Scale + off_b * stride_sz + off_h * stride_sh + off_blk
+
+ x = tl.load(input_ptrs, mask=offs_n[:, None] < L)
+ x = x.to(tl.float32)
+ x *= sm_scale
+ scale = tl.max(tl.abs(x)) / 127.
+ x_int8 = x / scale
+ x_int8 += 0.5 * tl.where(x_int8 >= 0, 1, -1)
+ x_int8 = x_int8.to(tl.int8)
+ tl.store(output_ptrs, x_int8, mask=offs_n[:, None] < L)
+ tl.store(scale_ptrs, scale)
+
+def per_block_int8(q, k, km=None, BLKQ=128, BLKK=64, sm_scale=None, tensor_layout="HND"):
+ q_int8 = torch.empty(q.shape, dtype=torch.int8, device=q.device)
+ k_int8 = torch.empty(k.shape, dtype=torch.int8, device=k.device)
+
+ if km is not None:
+ k = k - km
+
+ if tensor_layout == "HND":
+ b, h_qo, qo_len, head_dim = q.shape
+ _, h_kv, kv_len, _ = k.shape
+
+ stride_bz_q, stride_h_q, stride_seq_q = q.stride(0), q.stride(1), q.stride(2)
+ stride_bz_qo, stride_h_qo, stride_seq_qo = q_int8.stride(0), q_int8.stride(1), q_int8.stride(2)
+ stride_bz_k, stride_h_k, stride_seq_k = k.stride(0), k.stride(1), k.stride(2)
+ stride_bz_ko, stride_h_ko, stride_seq_ko = k_int8.stride(0), k_int8.stride(1), k_int8.stride(2)
+ elif tensor_layout == "NHD":
+ b, qo_len, h_qo, head_dim = q.shape
+ _, kv_len, h_kv, _ = k.shape
+
+ stride_bz_q, stride_h_q, stride_seq_q = q.stride(0), q.stride(2), q.stride(1)
+ stride_bz_qo, stride_h_qo, stride_seq_qo = q_int8.stride(0), q_int8.stride(2), q_int8.stride(1)
+ stride_bz_k, stride_h_k, stride_seq_k = k.stride(0), k.stride(2), k.stride(1)
+ stride_bz_ko, stride_h_ko, stride_seq_ko = k_int8.stride(0), k_int8.stride(2), k_int8.stride(1)
+ else:
+ raise ValueError(f"Unknown tensor layout: {tensor_layout}")
+
+ q_scale = torch.empty((b, h_qo, (qo_len + BLKQ - 1) // BLKQ), device=q.device, dtype=torch.float32)
+ k_scale = torch.empty((b, h_kv, (kv_len + BLKK - 1) // BLKK), device=q.device, dtype=torch.float32)
+
+ if sm_scale is None:
+ sm_scale = head_dim**-0.5
+
+ grid = ((qo_len + BLKQ - 1) // BLKQ, h_qo, b)
+ quant_per_block_int8_kernel[grid](
+ q, q_int8, q_scale, qo_len,
+ stride_bz_q, stride_h_q, stride_seq_q,
+ stride_bz_qo, stride_h_qo, stride_seq_qo,
+ q_scale.stride(0), q_scale.stride(1),
+ sm_scale=(sm_scale * 1.44269504),
+ C=head_dim, BLK=BLKQ
+ )
+
+ grid = ((kv_len + BLKK - 1) // BLKK, h_kv, b)
+ quant_per_block_int8_kernel[grid](
+ k, k_int8, k_scale, kv_len,
+ stride_bz_k, stride_h_k, stride_seq_k,
+ stride_bz_ko, stride_h_ko, stride_seq_ko,
+ k_scale.stride(0), k_scale.stride(1),
+ sm_scale=1.0,
+ C=head_dim, BLK=BLKK
+ )
+
+ return q_int8, q_scale, k_int8, k_scale
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/sparse_int8_attn.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/sparse_int8_attn.py
new file mode 100644
index 0000000000000000000000000000000000000000..0717119bb78de204000f125f49251a676fd1eca4
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/sparse_sage/sparse_int8_attn.py
@@ -0,0 +1,162 @@
+"""
+Copyright (c) 2024 by SageAttention team.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+"""
+
+import torch, math
+import triton
+import triton.language as tl
+import torch.nn.functional as F
+
+@triton.jit
+def _attn_fwd_inner(acc, l_i, old_m, q, q_scale, kv_len,
+ K_ptrs, K_bid_ptr, K_scale_ptr, V_ptrs, stride_kn, stride_vn, start_m,
+ BLOCK_M: tl.constexpr, HEAD_DIM: tl.constexpr, BLOCK_N: tl.constexpr,
+ STAGE: tl.constexpr, offs_m: tl.constexpr, offs_n: tl.constexpr,
+ ):
+ if STAGE == 1:
+ lo, hi = 0, start_m * BLOCK_M
+ elif STAGE == 2:
+ lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
+ lo = tl.multiple_of(lo, BLOCK_M)
+ K_scale_ptr += lo // BLOCK_N
+ K_ptrs += stride_kn * lo
+ V_ptrs += stride_vn * lo
+ elif STAGE == 3:
+ lo, hi = 0, kv_len
+ for start_n in range(lo, hi, BLOCK_N):
+ kbid = tl.load(K_bid_ptr + start_n//BLOCK_N)
+ if kbid:
+ k_mask = offs_n[None, :] < (kv_len - start_n)
+ k = tl.load(K_ptrs, mask = k_mask)
+ k_scale = tl.load(K_scale_ptr)
+ qk = tl.dot(q, k).to(tl.float32) * q_scale * k_scale
+ if STAGE == 2:
+ mask = offs_m[:, None] >= (start_n + offs_n[None, :])
+ qk = qk + tl.where(mask, 0, -1.0e6)
+ local_m = tl.max(qk, 1)
+ new_m = tl.maximum(old_m, local_m)
+ qk -= new_m[:, None]
+ else:
+ local_m = tl.max(qk, 1)
+ new_m = tl.maximum(old_m, local_m)
+ qk = qk - new_m[:, None]
+
+ p = tl.math.exp2(qk)
+ l_ij = tl.sum(p, 1)
+ alpha = tl.math.exp2(old_m - new_m)
+ l_i = l_i * alpha + l_ij
+ acc = acc * alpha[:, None]
+ v = tl.load(V_ptrs, mask = offs_n[:, None] < (kv_len - start_n))
+ p = p.to(tl.float16)
+ acc += tl.dot(p, v, out_dtype=tl.float16)
+ old_m = new_m
+ K_ptrs += BLOCK_N * stride_kn
+ K_scale_ptr += 1
+ V_ptrs += BLOCK_N * stride_vn
+ return acc, l_i, old_m
+
+@triton.jit
+def _attn_fwd(Q, K, K_blkid, V, Q_scale, K_scale, Out,
+ stride_qz, stride_qh, stride_qn,
+ stride_kz, stride_kh, stride_kn,
+ stride_vz, stride_vh, stride_vn,
+ stride_oz, stride_oh, stride_on,
+ stride_kbidq, stride_kbidk,
+ qo_len, kv_len, H:tl.constexpr, num_kv_groups:tl.constexpr,
+ HEAD_DIM: tl.constexpr,
+ BLOCK_M: tl.constexpr,
+ BLOCK_N: tl.constexpr,
+ STAGE: tl.constexpr
+ ):
+ start_m = tl.program_id(0)
+ off_z = tl.program_id(2).to(tl.int64)
+ off_h = tl.program_id(1).to(tl.int64)
+ q_scale_offset = (off_z * H + off_h) * tl.cdiv(qo_len, BLOCK_M)
+ k_scale_offset = (off_z * (H // num_kv_groups) + off_h // num_kv_groups) * tl.cdiv(kv_len, BLOCK_N)
+ k_bid_offset = (off_z * (H // num_kv_groups) + off_h // num_kv_groups) * stride_kbidq
+ offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
+ offs_n = tl.arange(0, BLOCK_N)
+ offs_k = tl.arange(0, HEAD_DIM)
+ Q_ptrs = Q + (off_z * stride_qz + off_h * stride_qh) + offs_m[:, None] * stride_qn + offs_k[None, :]
+ Q_scale_ptr = Q_scale + q_scale_offset + start_m
+ K_ptrs = K + (off_z * stride_kz + (off_h // num_kv_groups) * stride_kh) + offs_n[None, :] * stride_kn + offs_k[:, None]
+ K_scale_ptr = K_scale + k_scale_offset
+ K_bid_ptr = K_blkid + k_bid_offset + start_m * stride_kbidk
+ V_ptrs = V + (off_z * stride_vz + (off_h // num_kv_groups) * stride_vh) + offs_n[:, None] * stride_vn + offs_k[None, :]
+ O_block_ptr = Out + (off_z * stride_oz + off_h * stride_oh) + offs_m[:, None] * stride_on + offs_k[None, :]
+ m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
+ l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0
+ acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32)
+ q = tl.load(Q_ptrs, mask = offs_m[:, None] < qo_len)
+ q_scale = tl.load(Q_scale_ptr)
+ acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, q_scale, kv_len, K_ptrs, K_bid_ptr, K_scale_ptr, V_ptrs, stride_kn, stride_vn,
+ start_m,
+ BLOCK_M, HEAD_DIM, BLOCK_N,
+ 4 - STAGE, offs_m, offs_n
+ )
+ if STAGE != 1:
+ acc, l_i, _ = _attn_fwd_inner(acc, l_i, m_i, q, q_scale, kv_len, K_ptrs, K_bid_ptr, K_scale_ptr, V_ptrs, stride_kn, stride_vn,
+ start_m,
+ BLOCK_M, HEAD_DIM, BLOCK_N,
+ 2, offs_m, offs_n
+ )
+ acc = acc / l_i[:, None]
+ tl.store(O_block_ptr, acc.to(Out.type.element_ty), mask = (offs_m[:, None] < qo_len))
+
+
+def forward(q, k, k_block_id, v, q_scale, k_scale, is_causal=False, tensor_layout="HND", output_dtype=torch.float16):
+ BLOCK_M = 128
+ BLOCK_N = 64
+ stage = 3 if is_causal else 1
+ o = torch.empty(q.shape, dtype=output_dtype, device=q.device)
+
+ if tensor_layout == "HND":
+ b, h_qo, qo_len, head_dim = q.shape
+ _, h_kv, kv_len, _ = k.shape
+ stride_bz_q, stride_h_q, stride_seq_q = q.stride(0), q.stride(1), q.stride(2)
+ stride_bz_k, stride_h_k, stride_seq_k = k.stride(0), k.stride(1), k.stride(2)
+ stride_bz_v, stride_h_v, stride_seq_v = v.stride(0), v.stride(1), v.stride(2)
+ stride_bz_o, stride_h_o, stride_seq_o = o.stride(0), o.stride(1), o.stride(2)
+ elif tensor_layout == "NHD":
+ b, qo_len, h_qo, head_dim = q.shape
+ _, kv_len, h_kv, _ = k.shape
+ stride_bz_q, stride_h_q, stride_seq_q = q.stride(0), q.stride(2), q.stride(1)
+ stride_bz_k, stride_h_k, stride_seq_k = k.stride(0), k.stride(2), k.stride(1)
+ stride_bz_v, stride_h_v, stride_seq_v = v.stride(0), v.stride(2), v.stride(1)
+ stride_bz_o, stride_h_o, stride_seq_o = o.stride(0), o.stride(2), o.stride(1)
+ else:
+ raise ValueError(f"tensor_layout {tensor_layout} not supported")
+
+ if is_causal:
+ assert qo_len == kv_len, "qo_len and kv_len must be equal for causal attention"
+
+ HEAD_DIM_K = head_dim
+ num_kv_groups = h_qo // h_kv
+
+ grid = (triton.cdiv(qo_len, BLOCK_M), h_qo, b )
+ _attn_fwd[grid](
+ q, k, k_block_id, v, q_scale, k_scale, o,
+ stride_bz_q, stride_h_q, stride_seq_q,
+ stride_bz_k, stride_h_k, stride_seq_k,
+ stride_bz_v, stride_h_v, stride_seq_v,
+ stride_bz_o, stride_h_o, stride_seq_o,
+ k_block_id.stride(1), k_block_id.stride(2),
+ qo_len, kv_len,
+ h_qo, num_kv_groups,
+ BLOCK_M=BLOCK_M, BLOCK_N=BLOCK_N, HEAD_DIM=HEAD_DIM_K,
+ STAGE=stage,
+ num_warps=4 if head_dim == 64 else 8,
+ num_stages=4)
+ return o
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/utils.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..94eaa66d1699965f062254f643bcf0bf71d8f8e3
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/utils.py
@@ -0,0 +1,462 @@
+import torch, os, gc
+from safetensors import safe_open
+from contextlib import contextmanager
+from einops import rearrange, repeat
+import torch.nn as nn
+import torch.nn.functional as F
+from tqdm import tqdm
+import time
+import hashlib
+
+CACHE_T = 2
+
+@contextmanager
+def init_weights_on_device(device = torch.device("meta"), include_buffers :bool = False):
+
+ old_register_parameter = torch.nn.Module.register_parameter
+ if include_buffers:
+ old_register_buffer = torch.nn.Module.register_buffer
+
+ def register_empty_parameter(module, name, param):
+ old_register_parameter(module, name, param)
+ if param is not None:
+ param_cls = type(module._parameters[name])
+ kwargs = module._parameters[name].__dict__
+ kwargs["requires_grad"] = param.requires_grad
+ module._parameters[name] = param_cls(module._parameters[name].to(device), **kwargs)
+
+ def register_empty_buffer(module, name, buffer, persistent=True):
+ old_register_buffer(module, name, buffer, persistent=persistent)
+ if buffer is not None:
+ module._buffers[name] = module._buffers[name].to(device)
+
+ def patch_tensor_constructor(fn):
+ def wrapper(*args, **kwargs):
+ kwargs["device"] = device
+ return fn(*args, **kwargs)
+
+ return wrapper
+
+ if include_buffers:
+ tensor_constructors_to_patch = {
+ torch_function_name: getattr(torch, torch_function_name)
+ for torch_function_name in ["empty", "zeros", "ones", "full"]
+ }
+ else:
+ tensor_constructors_to_patch = {}
+
+ try:
+ torch.nn.Module.register_parameter = register_empty_parameter
+ if include_buffers:
+ torch.nn.Module.register_buffer = register_empty_buffer
+ for torch_function_name in tensor_constructors_to_patch.keys():
+ setattr(torch, torch_function_name, patch_tensor_constructor(getattr(torch, torch_function_name)))
+ yield
+ finally:
+ torch.nn.Module.register_parameter = old_register_parameter
+ if include_buffers:
+ torch.nn.Module.register_buffer = old_register_buffer
+ for torch_function_name, old_torch_function in tensor_constructors_to_patch.items():
+ setattr(torch, torch_function_name, old_torch_function)
+
+def load_state_dict_from_folder(file_path, torch_dtype=None):
+ state_dict = {}
+ for file_name in os.listdir(file_path):
+ if "." in file_name and file_name.split(".")[-1] in [
+ "safetensors", "bin", "ckpt", "pth", "pt"
+ ]:
+ state_dict.update(load_state_dict(os.path.join(file_path, file_name), torch_dtype=torch_dtype))
+ return state_dict
+
+
+def load_state_dict(file_path, torch_dtype=None):
+ if file_path.endswith(".safetensors"):
+ return load_state_dict_from_safetensors(file_path, torch_dtype=torch_dtype)
+ else:
+ return load_state_dict_from_bin(file_path, torch_dtype=torch_dtype)
+
+
+def load_state_dict_from_safetensors(file_path, torch_dtype=None):
+ state_dict = {}
+ with safe_open(file_path, framework="pt", device="cpu") as f:
+ for k in f.keys():
+ state_dict[k] = f.get_tensor(k)
+ if torch_dtype is not None:
+ state_dict[k] = state_dict[k].to(torch_dtype)
+ return state_dict
+
+
+def load_state_dict_from_bin(file_path, torch_dtype=None):
+ state_dict = torch.load(file_path, map_location="cpu", weights_only=True)
+ if torch_dtype is not None:
+ for i in state_dict:
+ if isinstance(state_dict[i], torch.Tensor):
+ state_dict[i] = state_dict[i].to(torch_dtype)
+ return state_dict
+
+
+def search_for_embeddings(state_dict):
+ embeddings = []
+ for k in state_dict:
+ if isinstance(state_dict[k], torch.Tensor):
+ embeddings.append(state_dict[k])
+ elif isinstance(state_dict[k], dict):
+ embeddings += search_for_embeddings(state_dict[k])
+ return embeddings
+
+
+def search_parameter(param, state_dict):
+ for name, param_ in state_dict.items():
+ if param.numel() == param_.numel():
+ if param.shape == param_.shape:
+ if torch.dist(param, param_) < 1e-3:
+ return name
+ else:
+ if torch.dist(param.flatten(), param_.flatten()) < 1e-3:
+ return name
+ return None
+
+
+def build_rename_dict(source_state_dict, target_state_dict, split_qkv=False):
+ matched_keys = set()
+ with torch.no_grad():
+ for name in source_state_dict:
+ rename = search_parameter(source_state_dict[name], target_state_dict)
+ if rename is not None:
+ print(f'"{name}": "{rename}",')
+ matched_keys.add(rename)
+ elif split_qkv and len(source_state_dict[name].shape)>=1 and source_state_dict[name].shape[0]%3==0:
+ length = source_state_dict[name].shape[0] // 3
+ rename = []
+ for i in range(3):
+ rename.append(search_parameter(source_state_dict[name][i*length: i*length+length], target_state_dict))
+ if None not in rename:
+ print(f'"{name}": {rename},')
+ for rename_ in rename:
+ matched_keys.add(rename_)
+ for name in target_state_dict:
+ if name not in matched_keys:
+ print("Cannot find", name, target_state_dict[name].shape)
+
+
+def search_for_files(folder, extensions):
+ files = []
+ if os.path.isdir(folder):
+ for file in sorted(os.listdir(folder)):
+ files += search_for_files(os.path.join(folder, file), extensions)
+ elif os.path.isfile(folder):
+ for extension in extensions:
+ if folder.endswith(extension):
+ files.append(folder)
+ break
+ return files
+
+
+def convert_state_dict_keys_to_single_str(state_dict, with_shape=True):
+ keys = []
+ for key, value in state_dict.items():
+ if isinstance(key, str):
+ if isinstance(value, torch.Tensor):
+ if with_shape:
+ shape = "_".join(map(str, list(value.shape)))
+ keys.append(key + ":" + shape)
+ keys.append(key)
+ elif isinstance(value, dict):
+ keys.append(key + "|" + convert_state_dict_keys_to_single_str(value, with_shape=with_shape))
+ keys.sort()
+ keys_str = ",".join(keys)
+ return keys_str
+
+
+def split_state_dict_with_prefix(state_dict):
+ keys = sorted([key for key in state_dict if isinstance(key, str)])
+ prefix_dict = {}
+ for key in keys:
+ prefix = key if "." not in key else key.split(".")[0]
+ if prefix not in prefix_dict:
+ prefix_dict[prefix] = []
+ prefix_dict[prefix].append(key)
+ state_dicts = []
+ for prefix, keys in prefix_dict.items():
+ sub_state_dict = {key: state_dict[key] for key in keys}
+ state_dicts.append(sub_state_dict)
+ return state_dicts
+
+def hash_state_dict_keys(state_dict, with_shape=True):
+ keys_str = convert_state_dict_keys_to_single_str(state_dict, with_shape=with_shape)
+ keys_str = keys_str.encode(encoding="UTF-8")
+ return hashlib.md5(keys_str).hexdigest()
+
+def clean_vram():
+ gc.collect()
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ torch.cuda.ipc_collect()
+ if torch.backends.mps.is_available():
+ torch.mps.empty_cache()
+
+def get_device_list():
+ devs = ["auto"]
+ try:
+ if hasattr(torch, "cuda") and hasattr(torch.cuda, "is_available") and torch.cuda.is_available():
+ devs += [f"cuda:{i}" for i in range(torch.cuda.device_count())]
+ except Exception:
+ pass
+ try:
+ if hasattr(torch, "mps") and hasattr(torch.mps, "is_available") and torch.backends.mps.is_available():
+ devs += [f"mps:{i}" for i in range(torch.mps.device_count())]
+ except Exception:
+ pass
+ return devs
+
+class RMS_norm(nn.Module):
+
+ def __init__(self, dim, channel_first=True, images=True, bias=False):
+ super().__init__()
+ broadcastable_dims = (1, 1, 1) if not images else (1, 1)
+ shape = (dim, *broadcastable_dims) if channel_first else (dim,)
+
+ self.channel_first = channel_first
+ self.scale = dim**0.5
+ self.gamma = nn.Parameter(torch.ones(shape))
+ self.bias = nn.Parameter(torch.zeros(shape)) if bias else 0.
+
+ def forward(self, x):
+ return F.normalize(
+ x, dim=(1 if self.channel_first else
+ -1)) * self.scale * self.gamma + self.bias
+
+class CausalConv3d(nn.Conv3d):
+ """
+ Causal 3d convolusion.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self._padding = (self.padding[2], self.padding[2], self.padding[1],
+ self.padding[1], 2 * self.padding[0], 0)
+ self.padding = (0, 0, 0)
+
+ def forward(self, x, cache_x=None):
+ padding = list(self._padding)
+ if cache_x is not None and self._padding[4] > 0:
+ cache_x = cache_x.to(x.device)
+ # print(cache_x.shape, x.shape)
+ x = torch.cat([cache_x, x], dim=2)
+ padding[4] -= cache_x.shape[2]
+ # print('cache!')
+ x = F.pad(x, padding, mode='replicate') # mode='replicate'
+ # print(x[0,0,:,0,0])
+
+ return super().forward(x)
+
+class PixelShuffle3d(nn.Module):
+ def __init__(self, ff, hh, ww):
+ super().__init__()
+ self.ff = ff
+ self.hh = hh
+ self.ww = ww
+
+ def forward(self, x):
+ # x: (B, C, F, H, W)
+ return rearrange(x,
+ 'b c (f ff) (h hh) (w ww) -> b (c ff hh ww) f h w',
+ ff=self.ff, hh=self.hh, ww=self.ww)
+
+class Buffer_LQ4x_Proj(nn.Module):
+
+ def __init__(self, in_dim, out_dim, layer_num=30):
+ super().__init__()
+ self.ff = 1
+ self.hh = 16
+ self.ww = 16
+ self.hidden_dim1 = 2048
+ self.hidden_dim2 = 3072
+ self.layer_num = layer_num
+
+ self.pixel_shuffle = PixelShuffle3d(self.ff, self.hh, self.ww)
+
+ self.conv1 = CausalConv3d(in_dim*self.ff*self.hh*self.ww, self.hidden_dim1, (4, 3, 3), stride=(2, 1, 1), padding=(1, 1, 1)) # f -> f/2 h -> h w -> w
+ self.norm1 = RMS_norm(self.hidden_dim1, images=False)
+ self.act1 = nn.SiLU()
+
+ self.conv2 = CausalConv3d(self.hidden_dim1, self.hidden_dim2, (4, 3, 3), stride=(2, 1, 1), padding=(1, 1, 1)) # f -> f/2 h -> h w -> w
+ self.norm2 = RMS_norm(self.hidden_dim2, images=False)
+ self.act2 = nn.SiLU()
+
+ self.linear_layers = nn.ModuleList([nn.Linear(self.hidden_dim2, out_dim) for _ in range(layer_num)])
+
+ self.clip_idx = 0
+
+ def forward(self, video):
+ self.clear_cache()
+ # x: (B, C, F, H, W)
+
+ t = video.shape[2]
+ iter_ = 1 + (t - 1) // 4
+ first_frame = video[:, :, :1, :, :].repeat(1, 1, 3, 1, 1)
+ video = torch.cat([first_frame, video], dim=2)
+ # print(video.shape)
+
+ out_x = []
+ for i in range(iter_):
+ x = self.pixel_shuffle(video[:,:,i*4:(i+1)*4,:,:])
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv1'] = cache1_x
+ x = self.conv1(x, self.cache['conv1'])
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv2'] = cache2_x
+ if i == 0:
+ continue
+ x = self.conv2(x, self.cache['conv2'])
+ x = self.norm2(x)
+ x = self.act2(x)
+ out_x.append(x)
+ out_x = torch.cat(out_x, dim = 2)
+ # print(out_x.shape)
+ out_x = rearrange(out_x, 'b c f h w -> b (f h w) c')
+ outputs = []
+ for i in range(self.layer_num):
+ outputs.append(self.linear_layers[i](out_x))
+ return outputs
+
+ def clear_cache(self):
+ self.cache = {}
+ self.cache['conv1'] = None
+ self.cache['conv2'] = None
+ self.clip_idx = 0
+
+ def stream_forward(self, video_clip):
+ if self.clip_idx == 0:
+ # self.clear_cache()
+ first_frame = video_clip[:, :, :1, :, :].repeat(1, 1, 3, 1, 1)
+ video_clip = torch.cat([first_frame, video_clip], dim=2)
+ x = self.pixel_shuffle(video_clip)
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv1'] = cache1_x
+ x = self.conv1(x, self.cache['conv1'])
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv2'] = cache2_x
+ self.clip_idx += 1
+ return None
+ else:
+ x = self.pixel_shuffle(video_clip)
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv1'] = cache1_x
+ x = self.conv1(x, self.cache['conv1'])
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv2'] = cache2_x
+ x = self.conv2(x, self.cache['conv2'])
+ x = self.norm2(x)
+ x = self.act2(x)
+ out_x = rearrange(x, 'b c f h w -> b (f h w) c')
+ outputs = []
+ for i in range(self.layer_num):
+ outputs.append(self.linear_layers[i](out_x))
+ self.clip_idx += 1
+ return outputs
+
+class Causal_LQ4x_Proj(nn.Module):
+
+ def __init__(self, in_dim, out_dim, layer_num=30):
+ super().__init__()
+ self.ff = 1
+ self.hh = 16
+ self.ww = 16
+ self.hidden_dim1 = 2048
+ self.hidden_dim2 = 3072
+ self.layer_num = layer_num
+
+ self.pixel_shuffle = PixelShuffle3d(self.ff, self.hh, self.ww)
+
+ self.conv1 = CausalConv3d(in_dim*self.ff*self.hh*self.ww, self.hidden_dim1, (4, 3, 3), stride=(2, 1, 1), padding=(1, 1, 1)) # f -> f/2 h -> h w -> w
+ self.norm1 = RMS_norm(self.hidden_dim1, images=False)
+ self.act1 = nn.SiLU()
+
+ self.conv2 = CausalConv3d(self.hidden_dim1, self.hidden_dim2, (4, 3, 3), stride=(2, 1, 1), padding=(1, 1, 1)) # f -> f/2 h -> h w -> w
+ self.norm2 = RMS_norm(self.hidden_dim2, images=False)
+ self.act2 = nn.SiLU()
+
+ self.linear_layers = nn.ModuleList([nn.Linear(self.hidden_dim2, out_dim) for _ in range(layer_num)])
+
+ self.clip_idx = 0
+
+ def forward(self, video):
+ self.clear_cache()
+ # x: (B, C, F, H, W)
+
+ t = video.shape[2]
+ iter_ = 1 + (t - 1) // 4
+ first_frame = video[:, :, :1, :, :].repeat(1, 1, 3, 1, 1)
+ video = torch.cat([first_frame, video], dim=2)
+ # print(video.shape)
+
+ out_x = []
+ for i in range(iter_):
+ x = self.pixel_shuffle(video[:,:,i*4:(i+1)*4,:,:])
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ x = self.conv1(x, self.cache['conv1'])
+ self.cache['conv1'] = cache1_x
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ if i == 0:
+ self.cache['conv2'] = cache2_x
+ continue
+ x = self.conv2(x, self.cache['conv2'])
+ self.cache['conv2'] = cache2_x
+ x = self.norm2(x)
+ x = self.act2(x)
+ out_x.append(x)
+ out_x = torch.cat(out_x, dim = 2)
+ out_x = rearrange(out_x, 'b c f h w -> b (f h w) c')
+ outputs = []
+ for i in range(self.layer_num):
+ outputs.append(self.linear_layers[i](out_x))
+ return outputs
+
+ def clear_cache(self):
+ self.cache = {}
+ self.cache['conv1'] = None
+ self.cache['conv2'] = None
+ self.clip_idx = 0
+
+ def stream_forward(self, video_clip):
+ if self.clip_idx == 0:
+ # self.clear_cache()
+ first_frame = video_clip[:, :, :1, :, :].repeat(1, 1, 3, 1, 1)
+ video_clip = torch.cat([first_frame, video_clip], dim=2)
+ x = self.pixel_shuffle(video_clip)
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ x = self.conv1(x, self.cache['conv1'])
+ self.cache['conv1'] = cache1_x
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ self.cache['conv2'] = cache2_x
+ self.clip_idx += 1
+ return None
+ else:
+ x = self.pixel_shuffle(video_clip)
+ cache1_x = x[:, :, -CACHE_T:, :, :].clone()
+ x = self.conv1(x, self.cache['conv1'])
+ self.cache['conv1'] = cache1_x
+ x = self.norm1(x)
+ x = self.act1(x)
+ cache2_x = x[:, :, -CACHE_T:, :, :].clone()
+ x = self.conv2(x, self.cache['conv2'])
+ self.cache['conv2'] = cache2_x
+ x = self.norm2(x)
+ x = self.act2(x)
+ out_x = rearrange(x, 'b c f h w -> b (f h w) c')
+ outputs = []
+ for i in range(self.layer_num):
+ outputs.append(self.linear_layers[i](out_x))
+ self.clip_idx += 1
+ return outputs
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_dit.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_dit.py
new file mode 100644
index 0000000000000000000000000000000000000000..328e7434ac430ba879c7188da9c09267d7f0c857
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_dit.py
@@ -0,0 +1,864 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import math
+import random
+import os
+import time
+from typing import Tuple, Optional, List
+from einops import rearrange
+from .utils import hash_state_dict_keys
+
+try:
+ import flash_attn_interface
+ FLASH_ATTN_3_AVAILABLE = True
+except ModuleNotFoundError:
+ FLASH_ATTN_3_AVAILABLE = False
+
+try:
+ import flash_attn
+ FLASH_ATTN_2_AVAILABLE = True
+except ModuleNotFoundError:
+ FLASH_ATTN_2_AVAILABLE = False
+
+try:
+ from sageattention import sageattn
+ SAGE_ATTN_AVAILABLE = True
+except ModuleNotFoundError:
+ SAGE_ATTN_AVAILABLE = False
+
+try:
+ from block_sparse_attn import block_sparse_attn_func
+ BLOCK_ATTN_AVAILABLE = True
+except:
+ BLOCK_ATTN_AVAILABLE = False
+
+from .sparse_sage.core import sparse_sageattn
+from PIL import Image
+import numpy as np
+
+USE_BLOCK_ATTN = False
+
+# ----------------------------
+# Local / window masks
+# ----------------------------
+@torch.no_grad()
+def build_local_block_mask_shifted_vec(block_h: int,
+ block_w: int,
+ win_h: int = 6,
+ win_w: int = 6,
+ include_self: bool = True,
+ device=None) -> torch.Tensor:
+ device = device or torch.device("cpu")
+ H, W = block_h, block_w
+ r = torch.arange(H, device=device)
+ c = torch.arange(W, device=device)
+ YY, XX = torch.meshgrid(r, c, indexing="ij")
+ r_all = YY.reshape(-1)
+ c_all = XX.reshape(-1)
+ r_half = win_h // 2
+ c_half = win_w // 2
+ start_r = torch.clamp(r_all - r_half, 0, H - win_h)
+ end_r = start_r + win_h - 1
+ start_c = torch.clamp(c_all - c_half, 0, W - win_w)
+ end_c = start_c + win_w - 1
+ in_row = (r_all[None, :] >= start_r[:, None]) & (r_all[None, :] <= end_r[:, None])
+ in_col = (c_all[None, :] >= start_c[:, None]) & (c_all[None, :] <= end_c[:, None])
+ mask = in_row & in_col
+ if not include_self:
+ mask.fill_diagonal_(False)
+ return mask
+
+@torch.no_grad()
+def build_local_block_mask_shifted_vec_normal_slide(block_h: int,
+ block_w: int,
+ win_h: int = 6,
+ win_w: int = 6,
+ include_self: bool = True,
+ device=None) -> torch.Tensor:
+ device = device or torch.device("cpu")
+ H, W = block_h, block_w
+ r = torch.arange(H, device=device)
+ c = torch.arange(W, device=device)
+ YY, XX = torch.meshgrid(r, c, indexing="ij")
+ r_all = YY.reshape(-1)
+ c_all = XX.reshape(-1)
+ r_half = win_h // 2
+ c_half = win_w // 2
+ start_r = r_all - r_half
+ end_r = start_r + win_h - 1
+ start_c = c_all - c_half
+ end_c = start_c + win_w - 1
+ in_row = (r_all[None, :] >= start_r[:, None]) & (r_all[None, :] <= end_r[:, None])
+ in_col = (c_all[None, :] >= start_c[:, None]) & (c_all[None, :] <= end_c[:, None])
+ mask = in_row & in_col
+ if not include_self:
+ mask.fill_diagonal_(False)
+ return mask
+
+
+class WindowPartition3D:
+ """Partition / reverse-partition helpers for 5-D tensors (B,F,H,W,C)."""
+ @staticmethod
+ def partition(x: torch.Tensor, win: Tuple[int, int, int]):
+ B, F, H, W, C = x.shape
+ wf, wh, ww = win
+ assert F % wf == 0 and H % wh == 0 and W % ww == 0, "Dims must divide by window size."
+ x = x.view(B, F // wf, wf, H // wh, wh, W // ww, ww, C)
+ x = x.permute(0, 1, 3, 5, 2, 4, 6, 7).contiguous()
+ return x.view(-1, wf * wh * ww, C)
+
+ @staticmethod
+ def reverse(windows: torch.Tensor, win: Tuple[int, int, int], orig: Tuple[int, int, int]):
+ F, H, W = orig
+ wf, wh, ww = win
+ nf, nh, nw = F // wf, H // wh, W // ww
+ B = windows.size(0) // (nf * nh * nw)
+ x = windows.view(B, nf, nh, nw, wf, wh, ww, -1)
+ x = x.permute(0, 1, 4, 2, 5, 3, 6, 7).contiguous()
+ return x.view(B, F, H, W, -1)
+
+
+@torch.no_grad()
+def generate_draft_block_mask(batch_size, nheads, seqlen,
+ q_w, k_w, topk=10, local_attn_mask=None):
+ assert batch_size == 1, "Only batch_size=1 supported for now"
+ assert local_attn_mask is not None, "local_attn_mask must be provided"
+ avgpool_q = torch.mean(q_w, dim=1)
+ avgpool_k = torch.mean(k_w, dim=1)
+ avgpool_q = rearrange(avgpool_q, 's (h d) -> s h d', h=nheads)
+ avgpool_k = rearrange(avgpool_k, 's (h d) -> s h d', h=nheads)
+ q_heads = avgpool_q.permute(1, 0, 2)
+ k_heads = avgpool_k.permute(1, 0, 2)
+ D = avgpool_q.shape[-1]
+ scores = torch.einsum("hld,hmd->hlm", q_heads, k_heads) / math.sqrt(D)
+
+ repeat_head = scores.shape[0]
+ repeat_len = scores.shape[1] // local_attn_mask.shape[0]
+ repeat_num = scores.shape[2] // local_attn_mask.shape[1]
+ local_attn_mask = local_attn_mask.unsqueeze(1).unsqueeze(0).repeat(repeat_len, 1, repeat_num, 1)
+ local_attn_mask = rearrange(local_attn_mask, 'x a y b -> (x a) (y b)')
+ local_attn_mask = local_attn_mask.unsqueeze(0).repeat(repeat_head, 1, 1)
+ local_attn_mask = local_attn_mask.to(torch.float32)
+ local_attn_mask = local_attn_mask.masked_fill(local_attn_mask == False, -float('inf'))
+ local_attn_mask = local_attn_mask.masked_fill(local_attn_mask == True, 0)
+ scores = scores + local_attn_mask
+
+ attn_map = torch.softmax(scores, dim=-1)
+ attn_map = rearrange(attn_map, 'h (it s1) s2 -> (h it) s1 s2', it=seqlen)
+ loop_num, s1, s2 = attn_map.shape
+ flat = attn_map.reshape(loop_num, -1)
+ n = flat.shape[1]
+ apply_topk = min(flat.shape[1]-1, topk)
+ thresholds = torch.topk(flat, k=apply_topk + 1, dim=1, largest=True).values[:, -1]
+ thresholds = thresholds.unsqueeze(1)
+ mask_new = (flat > thresholds).reshape(loop_num, s1, s2)
+ mask_new = rearrange(mask_new, '(h it) s1 s2 -> h (it s1) s2', it=seqlen) # keep shape note
+ # 修正:上行变量名统一
+ # mask_new = rearrange(attn_map, 'h (it s1) s2 -> h (it s1) s2', it=seqlen) * 0 + mask_new
+ mask = mask_new.unsqueeze(0).repeat(batch_size, 1, 1, 1)
+ return mask
+
+
+@torch.no_grad()
+def generate_draft_block_mask_sage(batch_size, nheads, seqlen,
+ q_w, k_w, topk=10, local_attn_mask=None):
+ assert batch_size == 1, "Only batch_size=1 supported for now"
+ assert local_attn_mask is not None, "local_attn_mask must be provided"
+
+ avgpool_q = torch.mean(q_w, dim=1)
+ avgpool_q = rearrange(avgpool_q, 's (h d) -> s h d', h=nheads)
+ q_heads = avgpool_q.permute(1, 0, 2)
+ D = avgpool_q.shape[-1]
+
+ k_w_split = k_w.view(k_w.shape[0], 2, 64, k_w.shape[2])
+ avgpool_k_split = torch.mean(k_w_split, dim=2)
+ avgpool_k_refined = rearrange(avgpool_k_split, 's two d -> (s two) d', two=2) # shape: (s*2, C)
+ avgpool_k_refined = rearrange(avgpool_k_refined, 's (h d) -> s h d', h=nheads) # shape: (s*2, h, d)
+ k_heads_doubled = avgpool_k_refined.permute(1, 0, 2) # shape: (h, s*2, d)
+
+ k_heads_1, k_heads_2 = torch.chunk(k_heads_doubled, 2, dim=1)
+ scores_1 = torch.einsum("hld,hmd->hlm", q_heads, k_heads_1) / math.sqrt(D)
+ scores_2 = torch.einsum("hld,hmd->hlm", q_heads, k_heads_2) / math.sqrt(D)
+ scores = torch.cat([scores_1, scores_2], dim=-1)
+
+ repeat_head = scores.shape[0]
+ repeat_len = scores.shape[1] // local_attn_mask.shape[0]
+ repeat_num = (scores.shape[2] // 2) // local_attn_mask.shape[1]
+
+ local_attn_mask = local_attn_mask.unsqueeze(1).unsqueeze(0).repeat(repeat_len, 1, repeat_num, 1)
+ local_attn_mask = rearrange(local_attn_mask, 'x a y b -> (x a) (y b)')
+ local_attn_mask = local_attn_mask.repeat_interleave(2, dim=1)
+ local_attn_mask = local_attn_mask.unsqueeze(0).repeat(repeat_head, 1, 1)
+
+ assert scores.shape == local_attn_mask.shape, \
+ f"Scores shape {scores.shape} != Mask shape {local_attn_mask.shape}"
+
+ local_attn_mask = local_attn_mask.to(torch.float32)
+ local_attn_mask = local_attn_mask.masked_fill(local_attn_mask == False, -float('inf'))
+ local_attn_mask = local_attn_mask.masked_fill(local_attn_mask == True, 0)
+ scores = scores + local_attn_mask
+
+ attn_map = torch.softmax(scores, dim=-1)
+ attn_map = rearrange(attn_map, 'h (it s1) s2 -> (h it) s1 s2', it=seqlen)
+ loop_num, s1, s2 = attn_map.shape
+ flat = attn_map.reshape(loop_num, -1)
+ apply_topk = min(flat.shape[1]-1, topk)
+
+ if apply_topk <= 0:
+ mask_new = torch.zeros_like(flat, dtype=torch.bool).reshape(loop_num, s1, s2)
+ else:
+ thresholds = torch.topk(flat, k=apply_topk + 1, dim=1, largest=True).values[:, -1]
+ thresholds = thresholds.unsqueeze(1)
+ mask_new = (flat > thresholds).reshape(loop_num, s1, s2)
+
+ mask_new = rearrange(mask_new, '(h it) s1 s2 -> h (it s1) s2', it=seqlen)
+ mask = mask_new.unsqueeze(0).repeat(batch_size, 1, 1, 1)
+ return mask
+
+
+# ----------------------------
+# Attention kernels
+# ----------------------------
+def flash_attention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, num_heads: int, compatibility_mode=False, attention_mask=None, return_KV=False):
+ if attention_mask is not None:
+ seqlen = q.shape[1]
+ seqlen_kv = k.shape[1]
+ if USE_BLOCK_ATTN and BLOCK_ATTN_AVAILABLE:
+ q = rearrange(q, "b s (n d) -> (b s) n d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> (b s) n d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> (b s) n d", n=num_heads)
+ else:
+ q = rearrange(q, "b s (n d) -> b n s d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b n s d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b n s d", n=num_heads)
+ cu_seqlens_q = torch.tensor([0, seqlen], device=q.device, dtype=torch.int32)
+ cu_seqlens_k = torch.tensor([0, seqlen_kv], device=q.device, dtype=torch.int32)
+ head_mask_type = torch.tensor([1]*num_heads, device=q.device, dtype=torch.int32)
+ streaming_info = None
+ base_blockmask = attention_mask
+ max_seqlen_q_ = seqlen
+ max_seqlen_k_ = seqlen_kv
+ p_dropout = 0.0
+ if USE_BLOCK_ATTN and BLOCK_ATTN_AVAILABLE:
+ x = block_sparse_attn_func(
+ q, k, v,
+ cu_seqlens_q, cu_seqlens_k,
+ head_mask_type,
+ streaming_info,
+ base_blockmask,
+ max_seqlen_q_, max_seqlen_k_,
+ p_dropout,
+ deterministic=False,
+ softmax_scale=None,
+ is_causal=False,
+ exact_streaming=False,
+ return_attn_probs=False,
+ ).unsqueeze(0)
+ x = rearrange(x, "b s n d -> b s (n d)", n=num_heads)
+ else:
+ x = sparse_sageattn(
+ q, k, v,
+ mask_id=base_blockmask.to(torch.int8),
+ is_causal=False,
+ tensor_layout="HND"
+ )
+ x = rearrange(x, "b n s d -> b s (n d)", n=num_heads)
+ elif compatibility_mode:
+ q = rearrange(q, "b s (n d) -> b n s d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b n s d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b n s d", n=num_heads)
+ x = F.scaled_dot_product_attention(q, k, v)
+ x = rearrange(x, "b n s d -> b s (n d)", n=num_heads)
+ elif FLASH_ATTN_3_AVAILABLE:
+ q = rearrange(q, "b s (n d) -> b s n d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b s n d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b s n d", n=num_heads)
+ x = flash_attn_interface.flash_attn_func(q, k, v)
+ if isinstance(x, tuple):
+ x = x[0]
+ x = rearrange(x, "b s n d -> b s (n d)", n=num_heads)
+ elif FLASH_ATTN_2_AVAILABLE:
+ q = rearrange(q, "b s (n d) -> b s n d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b s n d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b s n d", n=num_heads)
+ x = flash_attn.flash_attn_func(q, k, v)
+ x = rearrange(x, "b s n d -> b s (n d)", n=num_heads)
+ elif SAGE_ATTN_AVAILABLE:
+ q = rearrange(q, "b s (n d) -> b n s d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b n s d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b n s d", n=num_heads)
+ x = sageattn(q, k, v)
+ x = rearrange(x, "b n s d -> b s (n d)", n=num_heads)
+ else:
+ q = rearrange(q, "b s (n d) -> b n s d", n=num_heads)
+ k = rearrange(k, "b s (n d) -> b n s d", n=num_heads)
+ v = rearrange(v, "b s (n d) -> b n s d", n=num_heads)
+ x = F.scaled_dot_product_attention(q, k, v)
+ x = rearrange(x, "b n s d -> b s (n d)", n=num_heads)
+ return x
+
+
+def modulate(x: torch.Tensor, shift: torch.Tensor, scale: torch.Tensor):
+ return (x * (1 + scale) + shift)
+
+
+def sinusoidal_embedding_1d(dim, position):
+ sinusoid = torch.outer(position.type(torch.float64), torch.pow(
+ 10000, -torch.arange(dim//2, dtype=torch.float64, device=position.device).div(dim//2)))
+ x = torch.cat([torch.cos(sinusoid), torch.sin(sinusoid)], dim=1)
+ return x.to(position.dtype)
+
+
+def precompute_freqs_cis_3d(dim: int, end: int = 1024, theta: float = 10000.0):
+ f_freqs_cis = precompute_freqs_cis(dim - 2 * (dim // 3), end, theta)
+ h_freqs_cis = precompute_freqs_cis(dim // 3, end, theta)
+ w_freqs_cis = precompute_freqs_cis(dim // 3, end, theta)
+ return f_freqs_cis, h_freqs_cis, w_freqs_cis
+
+
+def precompute_freqs_cis(dim: int, end: int = 1024, theta: float = 10000.0):
+ freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)
+ [: (dim // 2)].double() / dim))
+ freqs = torch.outer(torch.arange(end, device=freqs.device), freqs)
+ freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
+ return freqs_cis
+
+
+def rope_apply(x, freqs, num_heads):
+ x = rearrange(x, "b s (n d) -> b s n d", n=num_heads)
+ x_out = torch.view_as_complex(x.to(torch.float64).reshape(
+ x.shape[0], x.shape[1], x.shape[2], -1, 2))
+ x_out = torch.view_as_real(x_out * freqs).flatten(2)
+ return x_out.to(x.dtype)
+
+
+# ----------------------------
+# Norms & Blocks
+# ----------------------------
+class RMSNorm(nn.Module):
+ def __init__(self, dim, eps=1e-5):
+ super().__init__()
+ self.eps = eps
+ self.weight = nn.Parameter(torch.ones(dim))
+
+ def norm(self, x):
+ return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
+
+ def forward(self, x):
+ dtype = x.dtype
+ return self.norm(x.float()).to(dtype) * self.weight
+
+
+class AttentionModule(nn.Module):
+ def __init__(self, num_heads):
+ super().__init__()
+ self.num_heads = num_heads
+
+ def forward(self, q, k, v, attention_mask=None):
+ x = flash_attention(q=q, k=k, v=v, num_heads=self.num_heads, attention_mask=attention_mask)
+ return x
+
+
+class SelfAttention(nn.Module):
+ def __init__(self, dim: int, num_heads: int, eps: float = 1e-6):
+ super().__init__()
+ self.dim = dim
+ self.num_heads = num_heads
+ self.head_dim = dim // num_heads
+
+ self.q = nn.Linear(dim, dim)
+ self.k = nn.Linear(dim, dim)
+ self.v = nn.Linear(dim, dim)
+ self.o = nn.Linear(dim, dim)
+ self.norm_q = RMSNorm(dim, eps=eps)
+ self.norm_k = RMSNorm(dim, eps=eps)
+
+ self.attn = AttentionModule(self.num_heads)
+ self.local_attn_mask = None
+
+ def forward(self, x, freqs, f=None, h=None, w=None, local_num=None, topk=None,
+ train_img=False, block_id=None, kv_len=None, is_full_block=False,
+ is_stream=False, pre_cache_k=None, pre_cache_v=None, local_range = 9):
+ B, L, D = x.shape
+ if is_stream and pre_cache_k is not None and pre_cache_v is not None:
+ assert f==2, "f must be 2"
+ if is_stream and (pre_cache_k is None or pre_cache_v is None):
+ assert f==6, " start f must be 6"
+ assert L == f * h * w, "Sequence length mismatch with provided (f,h,w)."
+
+ q = self.norm_q(self.q(x))
+ k = self.norm_k(self.k(x))
+ v = self.v(x)
+ q = rope_apply(q, freqs, self.num_heads)
+ k = rope_apply(k, freqs, self.num_heads)
+
+ win = (2, 8, 8)
+ q = q.view(B, f, h, w, D)
+ k = k.view(B, f, h, w, D)
+ v = v.view(B, f, h, w, D)
+
+ q_w = WindowPartition3D.partition(q, win)
+ k_w = WindowPartition3D.partition(k, win)
+ v_w = WindowPartition3D.partition(v, win)
+
+ seqlen = f//win[0]
+ one_len = k_w.shape[0] // B // seqlen
+ if pre_cache_k is not None and pre_cache_v is not None:
+ k_w = torch.cat([pre_cache_k, k_w], dim=0)
+ v_w = torch.cat([pre_cache_v, v_w], dim=0)
+
+ block_n = q_w.shape[0] // B
+ block_s = q_w.shape[1]
+ block_n_kv = k_w.shape[0] // B
+
+ reorder_q = rearrange(q_w, '(b block_n) (block_s) d -> b (block_n block_s) d', block_n=block_n, block_s=block_s)
+ reorder_k = rearrange(k_w, '(b block_n) (block_s) d -> b (block_n block_s) d', block_n=block_n_kv, block_s=block_s)
+ reorder_v = rearrange(v_w, '(b block_n) (block_s) d -> b (block_n block_s) d', block_n=block_n_kv, block_s=block_s)
+
+ window_size = win[0]*h*w//128
+
+ if self.local_attn_mask is None or self.local_attn_mask_h!=h//8 or self.local_attn_mask_w!=w//8 or self.local_range!=local_range:
+ self.local_attn_mask = build_local_block_mask_shifted_vec_normal_slide(h//8, w//8, local_range, local_range, include_self=True, device=k_w.device)
+ self.local_attn_mask_h = h//8
+ self.local_attn_mask_w = w//8
+ self.local_range = local_range
+ if USE_BLOCK_ATTN and BLOCK_ATTN_AVAILABLE:
+ attention_mask = generate_draft_block_mask(B, self.num_heads, seqlen, q_w, k_w, topk=topk, local_attn_mask=self.local_attn_mask)
+ else:
+ attention_mask = generate_draft_block_mask_sage(B, self.num_heads, seqlen, q_w, k_w, topk=topk, local_attn_mask=self.local_attn_mask)
+
+ x = self.attn(reorder_q, reorder_k, reorder_v, attention_mask)
+
+ cur_block_n, cur_block_s, _ = k_w.shape
+ cache_num = cur_block_n // one_len
+ if cache_num > kv_len:
+ cache_k = k_w[one_len:, :, :]
+ cache_v = v_w[one_len:, :, :]
+ else:
+ cache_k = k_w
+ cache_v = v_w
+
+ x = rearrange(x, 'b (block_n block_s) d -> (b block_n) (block_s) d', block_n=block_n, block_s=block_s)
+ x = WindowPartition3D.reverse(x, win, (f, h, w))
+ x = x.view(B, f*h*w, D)
+
+ if is_stream:
+ return self.o(x), cache_k, cache_v
+ return self.o(x)
+
+
+class CrossAttention(nn.Module):
+ """
+ 仅考虑文本 context;提供持久 KV 缓存。
+ """
+ def __init__(self, dim: int, num_heads: int, eps: float = 1e-6):
+ super().__init__()
+ self.dim = dim
+ self.num_heads = num_heads
+ self.head_dim = dim // num_heads
+
+ self.q = nn.Linear(dim, dim)
+ self.k = nn.Linear(dim, dim)
+ self.v = nn.Linear(dim, dim)
+ self.o = nn.Linear(dim, dim)
+
+ self.norm_q = RMSNorm(dim, eps=eps)
+ self.norm_k = RMSNorm(dim, eps=eps)
+
+ self.attn = AttentionModule(self.num_heads)
+
+ # 持久缓存
+ self.cache_k = None
+ self.cache_v = None
+
+ @torch.no_grad()
+ def init_cache(self, ctx: torch.Tensor):
+ """ctx: [B, S_ctx, dim] —— 经过 text_embedding 之后的上下文"""
+ self.cache_k = self.norm_k(self.k(ctx))
+ self.cache_v = self.v(ctx)
+
+ def clear_cache(self):
+ self.cache_k = None
+ self.cache_v = None
+
+ def forward(self, x: torch.Tensor, y: torch.Tensor, is_stream: bool = False):
+ """
+ y 即文本上下文(未做其他分支)。
+ """
+ q = self.norm_q(self.q(x))
+ assert self.cache_k is not None and self.cache_v is not None
+ k = self.cache_k
+ v = self.cache_v
+
+ x = self.attn(q, k, v)
+ return self.o(x)
+
+
+class GateModule(nn.Module):
+ def __init__(self,):
+ super().__init__()
+
+ def forward(self, x, gate, residual):
+ return x + gate * residual
+
+
+class DiTBlock(nn.Module):
+ def __init__(self, dim: int, num_heads: int, ffn_dim: int, eps: float = 1e-6):
+ super().__init__()
+ self.dim = dim
+ self.num_heads = num_heads
+ self.ffn_dim = ffn_dim
+
+ self.self_attn = SelfAttention(dim, num_heads, eps)
+ self.cross_attn = CrossAttention(dim, num_heads, eps)
+
+ self.norm1 = nn.LayerNorm(dim, eps=eps, elementwise_affine=False)
+ self.norm2 = nn.LayerNorm(dim, eps=eps, elementwise_affine=False)
+ self.norm3 = nn.LayerNorm(dim, eps=eps)
+ self.ffn = nn.Sequential(nn.Linear(dim, ffn_dim), nn.GELU(
+ approximate='tanh'), nn.Linear(ffn_dim, dim))
+ self.modulation = nn.Parameter(torch.randn(1, 6, dim) / dim**0.5)
+ self.gate = GateModule()
+
+ def forward(self, x, context, t_mod, freqs, f, h, w, local_num=None, topk=None,
+ train_img=False, block_id=None, kv_len=None, is_full_block=False,
+ is_stream=False, pre_cache_k=None, pre_cache_v=None, local_range = 9):
+ shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = (
+ self.modulation.to(dtype=t_mod.dtype, device=t_mod.device) + t_mod).chunk(6, dim=1)
+ input_x = modulate(self.norm1(x), shift_msa, scale_msa)
+ self_attn_output, self_attn_cache_k, self_attn_cache_v = self.self_attn(
+ input_x, freqs, f, h, w, local_num, topk, train_img, block_id,
+ kv_len=kv_len, is_full_block=is_full_block, is_stream=is_stream,
+ pre_cache_k=pre_cache_k, pre_cache_v=pre_cache_v, local_range = local_range)
+
+ x = self.gate(x, gate_msa, self_attn_output)
+ x = x + self.cross_attn(self.norm3(x), context, is_stream=is_stream)
+ input_x = modulate(self.norm2(x), shift_mlp, scale_mlp)
+ x = self.gate(x, gate_mlp, self.ffn(input_x))
+ if is_stream:
+ return x, self_attn_cache_k, self_attn_cache_v
+ return x
+
+
+class MLP(torch.nn.Module):
+ def __init__(self, in_dim, out_dim, has_pos_emb=False):
+ super().__init__()
+ self.proj = torch.nn.Sequential(
+ nn.LayerNorm(in_dim),
+ nn.Linear(in_dim, in_dim),
+ nn.GELU(),
+ nn.Linear(in_dim, out_dim),
+ nn.LayerNorm(out_dim)
+ )
+ self.has_pos_emb = has_pos_emb
+ if has_pos_emb:
+ self.emb_pos = torch.nn.Parameter(torch.zeros((1, 514, 1280)))
+
+ def forward(self, x):
+ if self.has_pos_emb:
+ x = x + self.emb_pos.to(dtype=x.dtype, device=x.device)
+ return self.proj(x)
+
+
+class Head(nn.Module):
+ def __init__(self, dim: int, out_dim: int, patch_size: Tuple[int, int, int], eps: float):
+ super().__init__()
+ self.dim = dim
+ self.patch_size = patch_size
+ self.norm = nn.LayerNorm(dim, eps=eps, elementwise_affine=False)
+ self.head = nn.Linear(dim, out_dim * math.prod(patch_size))
+ self.modulation = nn.Parameter(torch.randn(1, 2, dim) / dim**0.5)
+
+ def forward(self, x, t_mod):
+ shift, scale = (self.modulation.to(dtype=t_mod.dtype, device=t_mod.device) + t_mod).chunk(2, dim=1)
+ x = (self.head(self.norm(x) * (1 + scale) + shift))
+ return x
+
+
+# ----------------------------
+# WanModel (no image branch) — init 时即产生 KV 缓存
+# ----------------------------
+class WanModel(torch.nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ in_dim: int,
+ ffn_dim: int,
+ out_dim: int,
+ text_dim: int,
+ freq_dim: int,
+ eps: float,
+ patch_size: Tuple[int, int, int],
+ num_heads: int,
+ num_layers: int,
+ # init_context: torch.Tensor, # <<<< 必填:在 __init__ 里用它生成 cross-attn KV 缓存
+ has_image_input: bool = False,
+ ):
+ super().__init__()
+ self.dim = dim
+ self.freq_dim = freq_dim
+ self.patch_size = patch_size
+
+ # patch embed
+ self.patch_embedding = nn.Conv3d(
+ in_dim, dim, kernel_size=patch_size, stride=patch_size)
+
+ # text / time embed
+ self.text_embedding = nn.Sequential(
+ nn.Linear(text_dim, dim),
+ nn.GELU(approximate='tanh'),
+ nn.Linear(dim, dim)
+ )
+ self.time_embedding = nn.Sequential(
+ nn.Linear(freq_dim, dim),
+ nn.SiLU(),
+ nn.Linear(dim, dim)
+ )
+ self.time_projection = nn.Sequential(
+ nn.SiLU(), nn.Linear(dim, dim * 6))
+
+ # blocks
+ self.blocks = nn.ModuleList([
+ DiTBlock(dim, num_heads, ffn_dim, eps)
+ for _ in range(num_layers)
+ ])
+ self.head = Head(dim, out_dim, patch_size, eps)
+
+ head_dim = dim // num_heads
+ self.freqs = precompute_freqs_cis_3d(head_dim)
+
+ self._cross_kv_initialized = False
+
+ # 可选:手动清空 / 重新初始化
+ def clear_cross_kv(self):
+ for blk in self.blocks:
+ blk.cross_attn.clear_cache()
+ self._cross_kv_initialized = False
+
+ @torch.no_grad()
+ def reinit_cross_kv(self, new_context: torch.Tensor):
+ ctx_txt = self.text_embedding(new_context)
+ for blk in self.blocks:
+ blk.cross_attn.init_cache(ctx_txt)
+ self._cross_kv_initialized = True
+
+ def patchify(self, x: torch.Tensor):
+ x = self.patch_embedding(x)
+ grid_size = x.shape[2:]
+ x = rearrange(x, 'b c f h w -> b (f h w) c').contiguous()
+ return x, grid_size # x, grid_size: (f, h, w)
+
+ def unpatchify(self, x: torch.Tensor, grid_size: torch.Tensor):
+ return rearrange(
+ x, 'b (f h w) (x y z c) -> b c (f x) (h y) (w z)',
+ f=grid_size[0], h=grid_size[1], w=grid_size[2],
+ x=self.patch_size[0], y=self.patch_size[1], z=self.patch_size[2]
+ )
+
+ def forward(self,
+ x: torch.Tensor,
+ timestep: torch.Tensor,
+ context: torch.Tensor,
+ use_gradient_checkpointing: bool = False,
+ use_gradient_checkpointing_offload: bool = False,
+ LQ_latents: Optional[List[torch.Tensor]] = None,
+ train_img: bool = False,
+ topk_ratio: Optional[float] = None,
+ kv_ratio: Optional[float] = None,
+ local_num: Optional[int] = None,
+ is_full_block: bool = False,
+ causal_idx: Optional[int] = None,
+ **kwargs,
+ ):
+ # time / text embeds
+ t = self.time_embedding(
+ sinusoidal_embedding_1d(self.freq_dim, timestep))
+ t_mod = self.time_projection(t).unflatten(1, (6, self.dim))
+
+ # 这里仍会嵌入 text(CrossAttention 若已有缓存会忽略它)
+ # context = self.text_embedding(context)
+
+ # 输入打补丁
+ x, (f, h, w) = self.patchify(x)
+ B = x.shape[0]
+
+ # window / masks 超参
+ win = (2, 8, 8)
+ seqlen = f//win[0]
+ if local_num is None:
+ local_random = random.random()
+ if local_random < 0.3:
+ local_num = seqlen - 3
+ elif local_random < 0.4:
+ local_num = seqlen - 4
+ elif local_random < 0.5:
+ local_num = seqlen - 2
+ else:
+ local_num = seqlen
+
+ window_size = win[0]*h*w//128
+ square_num = window_size*window_size
+ topk_ratio = 2.0
+ topk = min(max(int(square_num*topk_ratio), 1), int(square_num*seqlen)-1)
+
+ if kv_ratio is None:
+ kv_ratio = (random.uniform(0., 1.0)**2)*(local_num-2-2)+2
+ kv_len = min(max(int(window_size*kv_ratio), 1), int(window_size*seqlen)-1)
+
+ decay_ratio = random.uniform(0.7, 1.0)
+
+ # RoPE 3D
+ freqs = torch.cat([
+ self.freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ self.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ self.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+ return custom_forward
+
+ # blocks
+ for block_id, block in enumerate(self.blocks):
+ if LQ_latents is not None and block_id < len(LQ_latents):
+ x += LQ_latents[block_id]
+
+ if self.training and use_gradient_checkpointing:
+ if use_gradient_checkpointing_offload:
+ with torch.autograd.graph.save_on_cpu():
+ x = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ x, context, t_mod, freqs, f, h, w, local_num, topk,
+ train_img, block_id, kv_len, is_full_block, False,
+ None, None,
+ use_reentrant=False,
+ )
+ else:
+ x = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ x, context, t_mod, freqs, f, h, w, local_num, topk,
+ train_img, block_id, kv_len, is_full_block, False,
+ None, None,
+ use_reentrant=False,
+ )
+ else:
+ x = block(x, context, t_mod, freqs, f, h, w, local_num, topk,
+ train_img, block_id, kv_len, is_full_block, False,
+ None, None)
+
+ x = self.head(x, t)
+ x = self.unpatchify(x, (f, h, w))
+ return x
+
+ @staticmethod
+ def state_dict_converter():
+ return WanModelStateDictConverter()
+
+
+# ----------------------------
+# State dict converter(保持原映射;已忽略 has_image_input 使用)
+# ----------------------------
+class WanModelStateDictConverter:
+ def __init__(self):
+ pass
+
+ def from_diffusers(self, state_dict):
+ rename_dict = {
+ "blocks.0.attn1.norm_k.weight": "blocks.0.self_attn.norm_k.weight",
+ "blocks.0.attn1.norm_q.weight": "blocks.0.self_attn.norm_q.weight",
+ "blocks.0.attn1.to_k.bias": "blocks.0.self_attn.k.bias",
+ "blocks.0.attn1.to_k.weight": "blocks.0.self_attn.k.weight",
+ "blocks.0.attn1.to_out.0.bias": "blocks.0.self_attn.o.bias",
+ "blocks.0.attn1.to_out.0.weight": "blocks.0.self_attn.o.weight",
+ "blocks.0.attn1.to_q.bias": "blocks.0.self_attn.q.bias",
+ "blocks.0.attn1.to_q.weight": "blocks.0.self_attn.q.weight",
+ "blocks.0.attn1.to_v.bias": "blocks.0.self_attn.v.bias",
+ "blocks.0.attn1.to_v.weight": "blocks.0.self_attn.v.weight",
+ "blocks.0.attn2.norm_k.weight": "blocks.0.cross_attn.norm_k.weight",
+ "blocks.0.attn2.norm_q.weight": "blocks.0.cross_attn.norm_q.weight",
+ "blocks.0.attn2.to_k.bias": "blocks.0.cross_attn.k.bias",
+ "blocks.0.attn2.to_k.weight": "blocks.0.cross_attn.k.weight",
+ "blocks.0.attn2.to_out.0.bias": "blocks.0.cross_attn.o.bias",
+ "blocks.0.attn2.to_out.0.weight": "blocks.0.cross_attn.o.weight",
+ "blocks.0.attn2.to_q.bias": "blocks.0.cross_attn.q.bias",
+ "blocks.0.attn2.to_q.weight": "blocks.0.cross_attn.q.weight",
+ "blocks.0.attn2.to_v.bias": "blocks.0.cross_attn.v.bias",
+ "blocks.0.attn2.to_v.weight": "blocks.0.cross_attn.v.weight",
+ "blocks.0.ffn.net.0.proj.bias": "blocks.0.ffn.0.bias",
+ "blocks.0.ffn.net.0.proj.weight": "blocks.0.ffn.0.weight",
+ "blocks.0.ffn.net.2.bias": "blocks.0.ffn.2.bias",
+ "blocks.0.ffn.net.2.weight": "blocks.0.ffn.2.weight",
+ "blocks.0.norm2.bias": "blocks.0.norm3.bias",
+ "blocks.0.norm2.weight": "blocks.0.norm3.weight",
+ "blocks.0.scale_shift_table": "blocks.0.modulation",
+ "condition_embedder.text_embedder.linear_1.bias": "text_embedding.0.bias",
+ "condition_embedder.text_embedder.linear_1.weight": "text_embedding.0.weight",
+ "condition_embedder.text_embedder.linear_2.bias": "text_embedding.2.bias",
+ "condition_embedder.text_embedder.linear_2.weight": "text_embedding.2.weight",
+ "condition_embedder.time_embedder.linear_1.bias": "time_embedding.0.bias",
+ "condition_embedder.time_embedder.linear_1.weight": "time_embedding.0.weight",
+ "condition_embedder.time_embedder.linear_2.bias": "time_embedding.2.bias",
+ "condition_embedder.time_embedder.linear_2.weight": "time_embedding.2.weight",
+ "condition_embedder.time_proj.bias": "time_projection.1.bias",
+ "condition_embedder.time_proj.weight": "time_projection.1.weight",
+ "patch_embedding.bias": "patch_embedding.bias",
+ "patch_embedding.weight": "patch_embedding.weight",
+ "scale_shift_table": "head.modulation",
+ "proj_out.bias": "head.head.bias",
+ "proj_out.weight": "head.head.weight",
+ }
+ state_dict_ = {}
+ for name, param in state_dict.items():
+ if name in rename_dict:
+ state_dict_[rename_dict[name]] = param
+ else:
+ name_ = ".".join(name.split(".")[:1] + ["0"] + name.split(".")[2:])
+ if name_ in rename_dict:
+ name_ = rename_dict[name_]
+ name_ = ".".join(name_.split(".")[:1] + [name.split(".")[1]] + name_.split(".")[2:])
+ state_dict_[name_] = param
+ if hash_state_dict_keys(state_dict) == "cb104773c6c2cb6df4f9529ad5c60d0b":
+ config = {
+ "model_type": "t2v",
+ "patch_size": (1, 2, 2),
+ "text_len": 512,
+ "in_dim": 16,
+ "dim": 5120,
+ "ffn_dim": 13824,
+ "freq_dim": 256,
+ "text_dim": 4096,
+ "out_dim": 16,
+ "num_heads": 40,
+ "num_layers": 40,
+ "window_size": (-1, -1),
+ "qk_norm": True,
+ "cross_attn_norm": True,
+ "eps": 1e-6,
+ }
+ else:
+ config = {}
+ return state_dict_, config
+
+ def from_civitai(self, state_dict):
+ state_dict = {name: param for name, param in state_dict.items() if not name.startswith("vace")}
+ # 保留原有哈希匹配返回的 config;实现本身不使用 has_image_input 分支
+ if hash_state_dict_keys(state_dict) == "9269f8db9040a9d860eaca435be61814":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 16,"dim": 1536,"ffn_dim": 8960,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 12,"num_layers": 30,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "aafcfd9672c3a2456dc46e1cb6e52c70":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 16,"dim": 5120,"ffn_dim": 13824,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 40,"num_layers": 40,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "6bfcfb3b342cb286ce886889d519a77e":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 36,"dim": 5120,"ffn_dim": 13824,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 40,"num_layers": 40,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "6d6ccde6845b95ad9114ab993d917893":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 36,"dim": 1536,"ffn_dim": 8960,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 12,"num_layers": 30,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "349723183fc063b2bfc10bb2835cf677":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 48,"dim": 1536,"ffn_dim": 8960,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 12,"num_layers": 30,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "efa44cddf936c70abd0ea28b6cbe946c":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 48,"dim": 5120,"ffn_dim": 13824,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 40,"num_layers": 40,"eps": 1e-6}
+ elif hash_state_dict_keys(state_dict) == "3ef3b1f8e1dab83d5b71fd7b617f859f":
+ config = {"has_image_input": False,"patch_size": [1, 2, 2],"in_dim": 36,"dim": 5120,"ffn_dim": 13824,"freq_dim": 256,"text_dim": 4096,"out_dim": 16,"num_heads": 40,"num_layers": 40,"eps": 1e-6,"has_image_pos_emb": False}
+ else:
+ config = {}
+ return state_dict, config
+
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_vae.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_vae.py
new file mode 100644
index 0000000000000000000000000000000000000000..123303963af5e0e426e2f316a6399b22fcdffac5
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/models/wan_video_vae.py
@@ -0,0 +1,847 @@
+from einops import rearrange, repeat
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from tqdm import tqdm
+
+CACHE_T = 2
+
+
+def check_is_instance(model, module_class):
+ if isinstance(model, module_class):
+ return True
+ if hasattr(model, "module") and isinstance(model.module, module_class):
+ return True
+ return False
+
+
+def block_causal_mask(x, block_size):
+ # params
+ b, n, s, _, device = *x.size(), x.device
+ assert s % block_size == 0
+ num_blocks = s // block_size
+
+ # build mask
+ mask = torch.zeros(b, n, s, s, dtype=torch.bool, device=device)
+ for i in range(num_blocks):
+ mask[:, :,
+ i * block_size:(i + 1) * block_size, :(i + 1) * block_size] = 1
+ return mask
+
+
+class CausalConv3d(nn.Conv3d):
+ """
+ Causal 3d convolusion.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self._padding = (self.padding[2], self.padding[2], self.padding[1],
+ self.padding[1], 2 * self.padding[0], 0)
+ self.padding = (0, 0, 0)
+
+ def forward(self, x, cache_x=None):
+ padding = list(self._padding)
+ if cache_x is not None and self._padding[4] > 0:
+ cache_x = cache_x.to(x.device)
+ # print('cache_x.shape', cache_x.shape, 'x.shape', x.shape)
+ x = torch.cat([cache_x, x], dim=2)
+ padding[4] -= cache_x.shape[2]
+ x = F.pad(x, padding)
+
+ return super().forward(x)
+
+
+class RMS_norm(nn.Module):
+
+ def __init__(self, dim, channel_first=True, images=True, bias=False):
+ super().__init__()
+ broadcastable_dims = (1, 1, 1) if not images else (1, 1)
+ shape = (dim, *broadcastable_dims) if channel_first else (dim,)
+
+ self.channel_first = channel_first
+ self.scale = dim**0.5
+ self.gamma = nn.Parameter(torch.ones(shape))
+ self.bias = nn.Parameter(torch.zeros(shape)) if bias else 0.
+
+ def forward(self, x):
+ return F.normalize(
+ x, dim=(1 if self.channel_first else
+ -1)) * self.scale * self.gamma + self.bias
+
+
+class Upsample(nn.Upsample):
+
+ def forward(self, x):
+ """
+ Fix bfloat16 support for nearest neighbor interpolation.
+ """
+ return super().forward(x.float()).type_as(x)
+
+
+class Resample(nn.Module):
+
+ def __init__(self, dim, mode):
+ assert mode in ('none', 'upsample2d', 'upsample3d', 'downsample2d',
+ 'downsample3d')
+ super().__init__()
+ self.dim = dim
+ self.mode = mode
+
+ # layers
+ if mode == 'upsample2d':
+ self.resample = nn.Sequential(
+ Upsample(scale_factor=(2., 2.), mode='nearest-exact'),
+ nn.Conv2d(dim, dim // 2, 3, padding=1))
+ elif mode == 'upsample3d':
+ self.resample = nn.Sequential(
+ Upsample(scale_factor=(2., 2.), mode='nearest-exact'),
+ nn.Conv2d(dim, dim // 2, 3, padding=1))
+ self.time_conv = CausalConv3d(dim,
+ dim * 2, (3, 1, 1),
+ padding=(1, 0, 0))
+
+ elif mode == 'downsample2d':
+ self.resample = nn.Sequential(
+ nn.ZeroPad2d((0, 1, 0, 1)),
+ nn.Conv2d(dim, dim, 3, stride=(2, 2)))
+ elif mode == 'downsample3d':
+ self.resample = nn.Sequential(
+ nn.ZeroPad2d((0, 1, 0, 1)),
+ nn.Conv2d(dim, dim, 3, stride=(2, 2)))
+ self.time_conv = CausalConv3d(dim,
+ dim, (3, 1, 1),
+ stride=(2, 1, 1),
+ padding=(0, 0, 0))
+
+ else:
+ self.resample = nn.Identity()
+
+ def forward(self, x, feat_cache=None, feat_idx=[0]):
+ b, c, t, h, w = x.size()
+ if self.mode == 'upsample3d':
+ if feat_cache is not None:
+ idx = feat_idx[0]
+ if feat_cache[idx] is None:
+ feat_cache[idx] = 'Rep'
+ feat_idx[0] += 1
+ else:
+
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[
+ idx] is not None and feat_cache[idx] != 'Rep':
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ if cache_x.shape[2] < 2 and feat_cache[
+ idx] is not None and feat_cache[idx] == 'Rep':
+ cache_x = torch.cat([
+ torch.zeros_like(cache_x).to(cache_x.device),
+ cache_x
+ ],
+ dim=2)
+ if feat_cache[idx] == 'Rep':
+ x = self.time_conv(x)
+ else:
+ x = self.time_conv(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+
+ x = x.reshape(b, 2, c, t, h, w)
+ x = torch.stack((x[:, 0, :, :, :, :], x[:, 1, :, :, :, :]),
+ 3)
+ x = x.reshape(b, c, t * 2, h, w)
+ t = x.shape[2]
+ x = rearrange(x, 'b c t h w -> (b t) c h w')
+ x = self.resample(x)
+ x = rearrange(x, '(b t) c h w -> b c t h w', t=t)
+
+ if self.mode == 'downsample3d':
+ if feat_cache is not None:
+ idx = feat_idx[0]
+ if feat_cache[idx] is None:
+ feat_cache[idx] = x.clone()
+ feat_idx[0] += 1
+ else:
+ cache_x = x[:, :, -1:, :, :].clone()
+ x = self.time_conv(
+ torch.cat([feat_cache[idx][:, :, -1:, :, :], x], 2))
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ return x
+
+ def init_weight(self, conv):
+ conv_weight = conv.weight
+ nn.init.zeros_(conv_weight)
+ c1, c2, t, h, w = conv_weight.size()
+ one_matrix = torch.eye(c1, c2)
+ init_matrix = one_matrix
+ nn.init.zeros_(conv_weight)
+ conv_weight.data[:, :, 1, 0, 0] = init_matrix
+ conv.weight.data.copy_(conv_weight)
+ nn.init.zeros_(conv.bias.data)
+
+ def init_weight2(self, conv):
+ conv_weight = conv.weight.data
+ nn.init.zeros_(conv_weight)
+ c1, c2, t, h, w = conv_weight.size()
+ init_matrix = torch.eye(c1 // 2, c2)
+ conv_weight[:c1 // 2, :, -1, 0, 0] = init_matrix
+ conv_weight[c1 // 2:, :, -1, 0, 0] = init_matrix
+ conv.weight.data.copy_(conv_weight)
+ nn.init.zeros_(conv.bias.data)
+
+
+class ResidualBlock(nn.Module):
+
+ def __init__(self, in_dim, out_dim, dropout=0.0):
+ super().__init__()
+ self.in_dim = in_dim
+ self.out_dim = out_dim
+
+ # layers
+ self.residual = nn.Sequential(
+ RMS_norm(in_dim, images=False), nn.SiLU(),
+ CausalConv3d(in_dim, out_dim, 3, padding=1),
+ RMS_norm(out_dim, images=False), nn.SiLU(), nn.Dropout(dropout),
+ CausalConv3d(out_dim, out_dim, 3, padding=1))
+ self.shortcut = CausalConv3d(in_dim, out_dim, 1) \
+ if in_dim != out_dim else nn.Identity()
+
+ def forward(self, x, feat_cache=None, feat_idx=[0]):
+ h = self.shortcut(x)
+ for layer in self.residual:
+ if check_is_instance(layer, CausalConv3d) and feat_cache is not None:
+ idx = feat_idx[0]
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ x = layer(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ else:
+ x = layer(x)
+ return x + h
+
+
+class AttentionBlock(nn.Module):
+ """
+ Causal self-attention with a single head.
+ """
+
+ def __init__(self, dim):
+ super().__init__()
+ self.dim = dim
+
+ # layers
+ self.norm = RMS_norm(dim)
+ self.to_qkv = nn.Conv2d(dim, dim * 3, 1)
+ self.proj = nn.Conv2d(dim, dim, 1)
+
+ # zero out the last layer params
+ nn.init.zeros_(self.proj.weight)
+
+ def forward(self, x):
+ identity = x
+ b, c, t, h, w = x.size()
+ x = rearrange(x, 'b c t h w -> (b t) c h w')
+ x = self.norm(x)
+ # compute query, key, value
+ q, k, v = self.to_qkv(x).reshape(b * t, 1, c * 3, -1).permute(
+ 0, 1, 3, 2).contiguous().chunk(3, dim=-1)
+
+ # apply attention
+ x = F.scaled_dot_product_attention(
+ q,
+ k,
+ v,
+ #attn_mask=block_causal_mask(q, block_size=h * w)
+ )
+ x = x.squeeze(1).permute(0, 2, 1).reshape(b * t, c, h, w)
+
+ # output
+ x = self.proj(x)
+ x = rearrange(x, '(b t) c h w-> b c t h w', t=t)
+ return x + identity
+
+
+class Encoder3d(nn.Module):
+
+ def __init__(self,
+ dim=128,
+ z_dim=4,
+ dim_mult=[1, 2, 4, 4],
+ num_res_blocks=2,
+ attn_scales=[],
+ temperal_downsample=[True, True, False],
+ dropout=0.0):
+ super().__init__()
+ self.dim = dim
+ self.z_dim = z_dim
+ self.dim_mult = dim_mult
+ self.num_res_blocks = num_res_blocks
+ self.attn_scales = attn_scales
+ self.temperal_downsample = temperal_downsample
+
+ # dimensions
+ dims = [dim * u for u in [1] + dim_mult]
+ scale = 1.0
+
+ # init block
+ self.conv1 = CausalConv3d(3, dims[0], 3, padding=1)
+
+ # downsample blocks
+ downsamples = []
+ for i, (in_dim, out_dim) in enumerate(zip(dims[:-1], dims[1:])):
+ # residual (+attention) blocks
+ for _ in range(num_res_blocks):
+ downsamples.append(ResidualBlock(in_dim, out_dim, dropout))
+ if scale in attn_scales:
+ downsamples.append(AttentionBlock(out_dim))
+ in_dim = out_dim
+
+ # downsample block
+ if i != len(dim_mult) - 1:
+ mode = 'downsample3d' if temperal_downsample[
+ i] else 'downsample2d'
+ downsamples.append(Resample(out_dim, mode=mode))
+ scale /= 2.0
+ self.downsamples = nn.Sequential(*downsamples)
+
+ # middle blocks
+ self.middle = nn.Sequential(ResidualBlock(out_dim, out_dim, dropout),
+ AttentionBlock(out_dim),
+ ResidualBlock(out_dim, out_dim, dropout))
+
+ # output blocks
+ self.head = nn.Sequential(RMS_norm(out_dim, images=False), nn.SiLU(),
+ CausalConv3d(out_dim, z_dim, 3, padding=1))
+
+ def forward(self, x, feat_cache=None, feat_idx=[0]):
+ if feat_cache is not None:
+ idx = feat_idx[0]
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ x = self.conv1(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ else:
+ x = self.conv1(x)
+
+ ## downsamples
+ for layer in self.downsamples:
+ if feat_cache is not None:
+ x = layer(x, feat_cache, feat_idx)
+ else:
+ x = layer(x)
+
+ ## middle
+ for layer in self.middle:
+ if check_is_instance(layer, ResidualBlock) and feat_cache is not None:
+ x = layer(x, feat_cache, feat_idx)
+ else:
+ x = layer(x)
+
+ ## head
+ for layer in self.head:
+ if check_is_instance(layer, CausalConv3d) and feat_cache is not None:
+ idx = feat_idx[0]
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ x = layer(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ else:
+ x = layer(x)
+ return x
+
+
+class Decoder3d(nn.Module):
+
+ def __init__(self,
+ dim=128,
+ z_dim=4,
+ dim_mult=[1, 2, 4, 4],
+ num_res_blocks=2,
+ attn_scales=[],
+ temperal_upsample=[False, True, True],
+ dropout=0.0):
+ super().__init__()
+ self.dim = dim
+ self.z_dim = z_dim
+ self.dim_mult = dim_mult
+ self.num_res_blocks = num_res_blocks
+ self.attn_scales = attn_scales
+ self.temperal_upsample = temperal_upsample
+
+ # dimensions
+ dims = [dim * u for u in [dim_mult[-1]] + dim_mult[::-1]]
+ scale = 1.0 / 2**(len(dim_mult) - 2)
+
+ # init block
+ self.conv1 = CausalConv3d(z_dim, dims[0], 3, padding=1)
+
+ # middle blocks
+ self.middle = nn.Sequential(ResidualBlock(dims[0], dims[0], dropout),
+ AttentionBlock(dims[0]),
+ ResidualBlock(dims[0], dims[0], dropout))
+
+ # upsample blocks
+ upsamples = []
+ for i, (in_dim, out_dim) in enumerate(zip(dims[:-1], dims[1:])):
+ # residual (+attention) blocks
+ if i == 1 or i == 2 or i == 3:
+ in_dim = in_dim // 2
+ for _ in range(num_res_blocks + 1):
+ upsamples.append(ResidualBlock(in_dim, out_dim, dropout))
+ if scale in attn_scales:
+ upsamples.append(AttentionBlock(out_dim))
+ in_dim = out_dim
+
+ # upsample block
+ if i != len(dim_mult) - 1:
+ mode = 'upsample3d' if temperal_upsample[i] else 'upsample2d'
+ upsamples.append(Resample(out_dim, mode=mode))
+ scale *= 2.0
+ self.upsamples = nn.Sequential(*upsamples)
+
+ # output blocks
+ self.head = nn.Sequential(RMS_norm(out_dim, images=False), nn.SiLU(),
+ CausalConv3d(out_dim, 3, 3, padding=1))
+
+ def forward(self, x, feat_cache=None, feat_idx=[0]):
+ ## conv1
+ if feat_cache is not None:
+ idx = feat_idx[0]
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ x = self.conv1(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ else:
+ x = self.conv1(x)
+
+ ## middle
+ for layer in self.middle:
+ if check_is_instance(layer, ResidualBlock) and feat_cache is not None:
+ x = layer(x, feat_cache, feat_idx)
+ else:
+ x = layer(x)
+
+ ## upsamples
+ for layer in self.upsamples:
+ if feat_cache is not None:
+ x = layer(x, feat_cache, feat_idx)
+ else:
+ x = layer(x)
+
+ ## head
+ for layer in self.head:
+ if check_is_instance(layer, CausalConv3d) and feat_cache is not None:
+ idx = feat_idx[0]
+ cache_x = x[:, :, -CACHE_T:, :, :].clone()
+ if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
+ # cache last frame of last two chunk
+ cache_x = torch.cat([
+ feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
+ cache_x.device), cache_x
+ ],
+ dim=2)
+ x = layer(x, feat_cache[idx])
+ feat_cache[idx] = cache_x
+ feat_idx[0] += 1
+ else:
+ x = layer(x)
+ return x
+
+
+def count_conv3d(model):
+ count = 0
+ for m in model.modules():
+ if check_is_instance(m, CausalConv3d):
+ count += 1
+ return count
+
+
+class VideoVAE_(nn.Module):
+
+ def __init__(self,
+ dim=96,
+ z_dim=16,
+ dim_mult=[1, 2, 4, 4],
+ num_res_blocks=2,
+ attn_scales=[],
+ temperal_downsample=[False, True, True],
+ dropout=0.0):
+ super().__init__()
+ self.dim = dim
+ self.z_dim = z_dim
+ self.dim_mult = dim_mult
+ self.num_res_blocks = num_res_blocks
+ self.attn_scales = attn_scales
+ self.temperal_downsample = temperal_downsample
+ self.temperal_upsample = temperal_downsample[::-1]
+
+ # modules
+ self.encoder = Encoder3d(dim, z_dim * 2, dim_mult, num_res_blocks,
+ attn_scales, self.temperal_downsample, dropout)
+ self.conv1 = CausalConv3d(z_dim * 2, z_dim * 2, 1)
+ self.conv2 = CausalConv3d(z_dim, z_dim, 1)
+ self.decoder = Decoder3d(dim, z_dim, dim_mult, num_res_blocks,
+ attn_scales, self.temperal_upsample, dropout)
+
+ def forward(self, x):
+ mu, log_var = self.encode(x)
+ z = self.reparameterize(mu, log_var)
+ x_recon = self.decode(z)
+ return x_recon, mu, log_var
+
+ def encode(self, x, scale):
+ self.clear_cache()
+ ## cache
+ t = x.shape[2]
+ iter_ = 1 + (t - 1) // 4
+
+ for i in range(iter_):
+ self._enc_conv_idx = [0]
+ if i == 0:
+ out = self.encoder(x[:, :, :1, :, :],
+ feat_cache=self._enc_feat_map,
+ feat_idx=self._enc_conv_idx)
+ else:
+ out_ = self.encoder(x[:, :, 1 + 4 * (i - 1):1 + 4 * i, :, :],
+ feat_cache=self._enc_feat_map,
+ feat_idx=self._enc_conv_idx)
+ out = torch.cat([out, out_], 2)
+ mu, log_var = self.conv1(out).chunk(2, dim=1)
+ if isinstance(scale[0], torch.Tensor):
+ scale = [s.to(dtype=mu.dtype, device=mu.device) for s in scale]
+ mu = (mu - scale[0].view(1, self.z_dim, 1, 1, 1)) * scale[1].view(
+ 1, self.z_dim, 1, 1, 1)
+ else:
+ scale = scale.to(dtype=mu.dtype, device=mu.device)
+ mu = (mu - scale[0]) * scale[1]
+ return mu
+
+ def decode(self, z, scale):
+ self.clear_cache()
+ # z: [b,c,t,h,w]
+ if isinstance(scale[0], torch.Tensor):
+ scale = [s.to(dtype=z.dtype, device=z.device) for s in scale]
+ z = z / scale[1].view(1, self.z_dim, 1, 1, 1) + scale[0].view(
+ 1, self.z_dim, 1, 1, 1)
+ else:
+ scale = scale.to(dtype=z.dtype, device=z.device)
+ z = z / scale[1] + scale[0]
+ iter_ = z.shape[2]
+ x = self.conv2(z)
+ for i in range(iter_):
+ self._conv_idx = [0]
+ if i == 0:
+ out = self.decoder(x[:, :, i:i + 1, :, :],
+ feat_cache=self._feat_map,
+ feat_idx=self._conv_idx)
+ else:
+ out_ = self.decoder(x[:, :, i:i + 1, :, :],
+ feat_cache=self._feat_map,
+ feat_idx=self._conv_idx)
+ out = torch.cat([out, out_], 2) # may add tensor offload
+ return out
+
+
+ def stream_decode(self, z, scale):
+ # self.clear_cache()
+ # z: [b,c,t,h,w]
+ if isinstance(scale[0], torch.Tensor):
+ scale = [s.to(dtype=z.dtype, device=z.device) for s in scale]
+ z = z / scale[1].view(1, self.z_dim, 1, 1, 1) + scale[0].view(
+ 1, self.z_dim, 1, 1, 1)
+ else:
+ scale = scale.to(dtype=z.dtype, device=z.device)
+ z = z / scale[1] + scale[0]
+ iter_ = z.shape[2]
+ x = self.conv2(z)
+ for i in range(iter_):
+ self._conv_idx = [0]
+ if i == 0:
+ out = self.decoder(x[:, :, i:i + 1, :, :],
+ feat_cache=self._feat_map,
+ feat_idx=self._conv_idx)
+ else:
+ out_ = self.decoder(x[:, :, i:i + 1, :, :],
+ feat_cache=self._feat_map,
+ feat_idx=self._conv_idx)
+ out = torch.cat([out, out_], 2) # may add tensor offload
+ return out
+
+ def reparameterize(self, mu, log_var):
+ std = torch.exp(0.5 * log_var)
+ eps = torch.randn_like(std)
+ return eps * std + mu
+
+ def sample(self, imgs, deterministic=False):
+ mu, log_var = self.encode(imgs)
+ if deterministic:
+ return mu
+ std = torch.exp(0.5 * log_var.clamp(-30.0, 20.0))
+ return mu + std * torch.randn_like(std)
+
+ def clear_cache(self):
+ self._conv_num = count_conv3d(self.decoder)
+ self._conv_idx = [0]
+ self._feat_map = [None] * self._conv_num
+ # print('self._feat_map', len(self._feat_map))
+ # cache encode
+ if self.encoder is not None:
+ self._enc_conv_num = count_conv3d(self.encoder)
+ self._enc_conv_idx = [0]
+ self._enc_feat_map = [None] * self._enc_conv_num
+ # print('self._enc_feat_map', len(self._enc_feat_map))
+
+
+class WanVideoVAE(nn.Module):
+
+ def __init__(self, z_dim=16, dim=96):
+ super().__init__()
+
+ mean = [
+ -0.7571, -0.7089, -0.9113, 0.1075, -0.1745, 0.9653, -0.1517, 1.5508,
+ 0.4134, -0.0715, 0.5517, -0.3632, -0.1922, -0.9497, 0.2503, -0.2921
+ ]
+ std = [
+ 2.8184, 1.4541, 2.3275, 2.6558, 1.2196, 1.7708, 2.6052, 2.0743,
+ 3.2687, 2.1526, 2.8652, 1.5579, 1.6382, 1.1253, 2.8251, 1.9160
+ ]
+ self.mean = torch.tensor(mean)
+ self.std = torch.tensor(std)
+ self.scale = [self.mean, 1.0 / self.std]
+
+ # init model
+ self.model = VideoVAE_(z_dim=z_dim, dim = dim).eval().requires_grad_(False)
+ self.upsampling_factor = 8
+
+
+ def build_1d_mask(self, length, left_bound, right_bound, border_width):
+ x = torch.ones((length,))
+ if not left_bound:
+ x[:border_width] = (torch.arange(border_width) + 1) / border_width
+ if not right_bound:
+ x[-border_width:] = torch.flip((torch.arange(border_width) + 1) / border_width, dims=(0,))
+ return x
+
+
+ def build_mask(self, data, is_bound, border_width):
+ _, _, _, H, W = data.shape
+ h = self.build_1d_mask(H, is_bound[0], is_bound[1], border_width[0])
+ w = self.build_1d_mask(W, is_bound[2], is_bound[3], border_width[1])
+
+ h = repeat(h, "H -> H W", H=H, W=W)
+ w = repeat(w, "W -> H W", H=H, W=W)
+
+ mask = torch.stack([h, w]).min(dim=0).values
+ mask = rearrange(mask, "H W -> 1 1 1 H W")
+ return mask
+
+
+ def tiled_decode(self, hidden_states, device, tile_size, tile_stride):
+ _, _, T, H, W = hidden_states.shape
+ size_h, size_w = tile_size
+ stride_h, stride_w = tile_stride
+
+ # Split tasks
+ tasks = []
+ for h in range(0, H, stride_h):
+ if (h-stride_h >= 0 and h-stride_h+size_h >= H): continue
+ for w in range(0, W, stride_w):
+ if (w-stride_w >= 0 and w-stride_w+size_w >= W): continue
+ h_, w_ = h + size_h, w + size_w
+ tasks.append((h, h_, w, w_))
+
+ data_device = "cpu"
+ computation_device = device
+
+ out_T = T * 4 - 3
+ weight = torch.zeros((1, 1, out_T, H * self.upsampling_factor, W * self.upsampling_factor), dtype=hidden_states.dtype, device=data_device)
+ values = torch.zeros((1, 3, out_T, H * self.upsampling_factor, W * self.upsampling_factor), dtype=hidden_states.dtype, device=data_device)
+
+ for h, h_, w, w_ in tqdm(tasks, desc="VAE decoding"):
+ hidden_states_batch = hidden_states[:, :, :, h:h_, w:w_].to(computation_device)
+ hidden_states_batch = self.model.decode(hidden_states_batch, self.scale).to(data_device)
+
+ mask = self.build_mask(
+ hidden_states_batch,
+ is_bound=(h==0, h_>=H, w==0, w_>=W),
+ border_width=((size_h - stride_h) * self.upsampling_factor, (size_w - stride_w) * self.upsampling_factor)
+ ).to(dtype=hidden_states.dtype, device=data_device)
+
+ target_h = h * self.upsampling_factor
+ target_w = w * self.upsampling_factor
+ values[
+ :,
+ :,
+ :,
+ target_h:target_h + hidden_states_batch.shape[3],
+ target_w:target_w + hidden_states_batch.shape[4],
+ ] += hidden_states_batch * mask
+ weight[
+ :,
+ :,
+ :,
+ target_h: target_h + hidden_states_batch.shape[3],
+ target_w: target_w + hidden_states_batch.shape[4],
+ ] += mask
+ values = values / weight
+ values = values.clamp_(-1, 1)
+ return values
+
+
+ def tiled_encode(self, video, device, tile_size, tile_stride):
+ _, _, T, H, W = video.shape
+ size_h, size_w = tile_size
+ stride_h, stride_w = tile_stride
+
+ # Split tasks
+ tasks = []
+ for h in range(0, H, stride_h):
+ if (h-stride_h >= 0 and h-stride_h+size_h >= H): continue
+ for w in range(0, W, stride_w):
+ if (w-stride_w >= 0 and w-stride_w+size_w >= W): continue
+ h_, w_ = h + size_h, w + size_w
+ tasks.append((h, h_, w, w_))
+
+ data_device = "cpu"
+ computation_device = device
+
+ out_T = (T + 3) // 4
+ weight = torch.zeros((1, 1, out_T, H // self.upsampling_factor, W // self.upsampling_factor), dtype=video.dtype, device=data_device)
+ values = torch.zeros((1, 16, out_T, H // self.upsampling_factor, W // self.upsampling_factor), dtype=video.dtype, device=data_device)
+
+ for h, h_, w, w_ in tqdm(tasks, desc="VAE encoding"):
+ hidden_states_batch = video[:, :, :, h:h_, w:w_].to(computation_device)
+ hidden_states_batch = self.model.encode(hidden_states_batch, self.scale).to(data_device)
+
+ mask = self.build_mask(
+ hidden_states_batch,
+ is_bound=(h==0, h_>=H, w==0, w_>=W),
+ border_width=((size_h - stride_h) // self.upsampling_factor, (size_w - stride_w) // self.upsampling_factor)
+ ).to(dtype=video.dtype, device=data_device)
+
+ target_h = h // self.upsampling_factor
+ target_w = w // self.upsampling_factor
+ values[
+ :,
+ :,
+ :,
+ target_h:target_h + hidden_states_batch.shape[3],
+ target_w:target_w + hidden_states_batch.shape[4],
+ ] += hidden_states_batch * mask
+ weight[
+ :,
+ :,
+ :,
+ target_h: target_h + hidden_states_batch.shape[3],
+ target_w: target_w + hidden_states_batch.shape[4],
+ ] += mask
+ values = values / weight
+ return values
+
+
+ def single_encode(self, video, device):
+ video = video.to(device)
+ x = self.model.encode(video, self.scale)
+ return x
+
+
+ def single_decode(self, hidden_state, device):
+ hidden_state = hidden_state.to(device)
+ video = self.model.decode(hidden_state, self.scale)
+ return video.clamp_(-1, 1)
+
+
+ def encode(self, videos, device, tiled=False, tile_size=(34, 34), tile_stride=(18, 16)):
+
+ videos = [video.to("cpu") for video in videos]
+ hidden_states = []
+ for video in videos:
+ video = video.unsqueeze(0)
+ if tiled:
+ tile_size = (tile_size[0] * 8, tile_size[1] * 8)
+ tile_stride = (tile_stride[0] * 8, tile_stride[1] * 8)
+ hidden_state = self.tiled_encode(video, device, tile_size, tile_stride)
+ else:
+ hidden_state = self.single_encode(video, device)
+ hidden_state = hidden_state.squeeze(0)
+ hidden_states.append(hidden_state)
+ hidden_states = torch.stack(hidden_states)
+ return hidden_states
+
+
+ def decode(self, hidden_states, device, tiled=False, tile_size=(34, 34), tile_stride=(18, 16)):
+ hidden_states = [hidden_state.to("cpu") for hidden_state in hidden_states]
+ videos = []
+ for hidden_state in hidden_states:
+ hidden_state = hidden_state.unsqueeze(0)
+ if tiled:
+ video = self.tiled_decode(hidden_state, device, tile_size, tile_stride)
+ else:
+ video = self.single_decode(hidden_state, device)
+ video = video.squeeze(0)
+ videos.append(video)
+ videos = torch.stack(videos)
+ return videos
+
+ def clear_cache(self):
+ self.model.clear_cache()
+
+ def stream_decode(self, hidden_states, tiled=False, tile_size=(34, 34), tile_stride=(18, 16)):
+ hidden_states = [hidden_state for hidden_state in hidden_states]
+ assert len(hidden_states) == 1
+ hidden_state = hidden_states[0]
+ video = self.model.stream_decode(hidden_state, self.scale)
+ return video
+
+
+ @staticmethod
+ def state_dict_converter():
+ return WanVideoVAEStateDictConverter()
+
+
+class WanVideoVAEStateDictConverter:
+
+ def __init__(self):
+ pass
+
+ def from_civitai(self, state_dict):
+ state_dict_ = {}
+ if 'model_state' in state_dict:
+ state_dict = state_dict['model_state']
+ for name in state_dict:
+ state_dict_['model.' + name] = state_dict[name]
+ return state_dict_
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3eb0b24808ceb14cdcb075f14401f978401cd6f7
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/__init__.py
@@ -0,0 +1,3 @@
+from .flashvsr_full import FlashVSRFullPipeline
+from .flashvsr_tiny import FlashVSRTinyPipeline
+from .flashvsr_tiny_long import FlashVSRTinyLongPipeline
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/base.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9f6a4d8b2fc678be243ffcb2c599b11bdbd2f8b
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/base.py
@@ -0,0 +1,130 @@
+import torch
+import gc
+import numpy as np
+from PIL import Image
+from torchvision.transforms import GaussianBlur
+
+class BasePipeline(torch.nn.Module):
+
+ def __init__(self, device="cuda", torch_dtype=torch.float16, height_division_factor=64, width_division_factor=64):
+ super().__init__()
+ self.device = device
+ self.torch_dtype = torch_dtype
+ self.height_division_factor = height_division_factor
+ self.width_division_factor = width_division_factor
+ self.cpu_offload = False
+ self.model_names = []
+
+
+ def check_resize_height_width(self, height, width):
+ if height % self.height_division_factor != 0:
+ height = (height + self.height_division_factor - 1) // self.height_division_factor * self.height_division_factor
+ print(f"The height cannot be evenly divided by {self.height_division_factor}. We round it up to {height}.")
+ if width % self.width_division_factor != 0:
+ width = (width + self.width_division_factor - 1) // self.width_division_factor * self.width_division_factor
+ print(f"The width cannot be evenly divided by {self.width_division_factor}. We round it up to {width}.")
+ return height, width
+
+
+ def preprocess_image(self, image):
+ image = torch.Tensor(np.array(image, dtype=np.float32) * (2 / 255) - 1).permute(2, 0, 1).unsqueeze(0)
+ return image
+
+
+ def preprocess_images(self, images):
+ return [self.preprocess_image(image) for image in images]
+
+
+ def vae_output_to_image(self, vae_output):
+ image = vae_output[0].cpu().float().permute(1, 2, 0).numpy()
+ image = Image.fromarray(((image / 2 + 0.5).clip(0, 1) * 255).astype("uint8"))
+ return image
+
+
+ def vae_output_to_video(self, vae_output):
+ video = vae_output.cpu().permute(1, 2, 0).numpy()
+ video = [Image.fromarray(((image / 2 + 0.5).clip(0, 1) * 255).astype("uint8")) for image in video]
+ return video
+
+
+ def merge_latents(self, value, latents, masks, scales, blur_kernel_size=33, blur_sigma=10.0):
+ if len(latents) > 0:
+ blur = GaussianBlur(kernel_size=blur_kernel_size, sigma=blur_sigma)
+ height, width = value.shape[-2:]
+ weight = torch.ones_like(value)
+ for latent, mask, scale in zip(latents, masks, scales):
+ mask = self.preprocess_image(mask.resize((width, height))).mean(dim=1, keepdim=True) > 0
+ mask = mask.repeat(1, latent.shape[1], 1, 1).to(dtype=latent.dtype, device=latent.device)
+ mask = blur(mask)
+ value += latent * mask * scale
+ weight += mask * scale
+ value /= weight
+ return value
+
+
+ def control_noise_via_local_prompts(self, prompt_emb_global, prompt_emb_locals, masks, mask_scales, inference_callback, special_kwargs=None, special_local_kwargs_list=None):
+ if special_kwargs is None:
+ noise_pred_global = inference_callback(prompt_emb_global)
+ else:
+ noise_pred_global = inference_callback(prompt_emb_global, special_kwargs)
+ if special_local_kwargs_list is None:
+ noise_pred_locals = [inference_callback(prompt_emb_local) for prompt_emb_local in prompt_emb_locals]
+ else:
+ noise_pred_locals = [inference_callback(prompt_emb_local, special_kwargs) for prompt_emb_local, special_kwargs in zip(prompt_emb_locals, special_local_kwargs_list)]
+ noise_pred = self.merge_latents(noise_pred_global, noise_pred_locals, masks, mask_scales)
+ return noise_pred
+
+
+ def extend_prompt(self, prompt, local_prompts, masks, mask_scales):
+ local_prompts = local_prompts or []
+ masks = masks or []
+ mask_scales = mask_scales or []
+ extended_prompt_dict = self.prompter.extend_prompt(prompt)
+ prompt = extended_prompt_dict.get("prompt", prompt)
+ local_prompts += extended_prompt_dict.get("prompts", [])
+ masks += extended_prompt_dict.get("masks", [])
+ mask_scales += [100.0] * len(extended_prompt_dict.get("masks", []))
+ return prompt, local_prompts, masks, mask_scales
+
+
+ def enable_cpu_offload(self):
+ self.cpu_offload = True
+
+
+ def load_models_to_device(self, loadmodel_names=[]):
+ # only load models to device if cpu_offload is enabled
+ if not self.cpu_offload:
+ return
+ # offload the unneeded models to cpu
+ for model_name in self.model_names:
+ if model_name not in loadmodel_names:
+ model = getattr(self, model_name)
+ if model is not None:
+ if hasattr(model, "vram_management_enabled") and model.vram_management_enabled:
+ for module in model.modules():
+ if hasattr(module, "offload"):
+ module.offload()
+ else:
+ model.cpu()
+ # load the needed models to device
+ for model_name in loadmodel_names:
+ model = getattr(self, model_name)
+ if model is not None:
+ if hasattr(model, "vram_management_enabled") and model.vram_management_enabled:
+ for module in model.modules():
+ if hasattr(module, "onload"):
+ module.onload()
+ else:
+ model.to(self.device)
+ # fresh the cuda cache
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ if torch.backends.mps.is_available():
+ torch.mps.empty_cache()
+
+
+ def generate_noise(self, shape, seed=None, device="cpu", dtype=torch.float16):
+ generator = None if seed is None else torch.Generator(device).manual_seed(seed)
+ noise = torch.randn(shape, generator=generator, device=device, dtype=dtype)
+ return noise
+
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_full.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_full.py
new file mode 100644
index 0000000000000000000000000000000000000000..57263d13a3ad6d53c964c414324e918b1e0efa80
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_full.py
@@ -0,0 +1,618 @@
+import types
+import os
+import time
+from typing import Optional, Tuple, Literal
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import numpy as np
+from einops import rearrange
+from PIL import Image
+from tqdm import tqdm
+# import pyfiglet
+
+from ..models import ModelManager
+from ..models.utils import clean_vram
+from ..models.wan_video_dit import WanModel, RMSNorm, sinusoidal_embedding_1d
+from ..models.wan_video_vae import WanVideoVAE, RMS_norm, CausalConv3d, Upsample
+from ..schedulers.flow_match import FlowMatchScheduler
+from .base import BasePipeline
+
+
+# -----------------------------
+# 基础工具:ADAIN 所需的统计量(保留以备需要;管线默认用 wavelet)
+# -----------------------------
+def _calc_mean_std(feat: torch.Tensor, eps: float = 1e-5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert feat.dim() == 4, 'feat 必须是 (N, C, H, W)'
+ N, C = feat.shape[:2]
+ var = feat.view(N, C, -1).var(dim=2, unbiased=False) + eps
+ std = var.sqrt().view(N, C, 1, 1)
+ mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
+ return mean, std
+
+
+def _adain(content_feat: torch.Tensor, style_feat: torch.Tensor) -> torch.Tensor:
+ assert content_feat.shape[:2] == style_feat.shape[:2], "ADAIN: N、C 必须匹配"
+ size = content_feat.size()
+ style_mean, style_std = _calc_mean_std(style_feat)
+ content_mean, content_std = _calc_mean_std(content_feat)
+ normalized = (content_feat - content_mean.expand(size)) / content_std.expand(size)
+ return normalized * style_std.expand(size) + style_mean.expand(size)
+
+
+# -----------------------------
+# 小波式模糊与分解/重构(ColorCorrector 用)
+# -----------------------------
+def _make_gaussian3x3_kernel(dtype, device) -> torch.Tensor:
+ vals = [
+ [0.0625, 0.125, 0.0625],
+ [0.125, 0.25, 0.125 ],
+ [0.0625, 0.125, 0.0625],
+ ]
+ return torch.tensor(vals, dtype=dtype, device=device)
+
+
+def _wavelet_blur(x: torch.Tensor, radius: int) -> torch.Tensor:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ N, C, H, W = x.shape
+ base = _make_gaussian3x3_kernel(x.dtype, x.device)
+ weight = base.view(1, 1, 3, 3).repeat(C, 1, 1, 1)
+ pad = radius
+ x_pad = F.pad(x, (pad, pad, pad, pad), mode='replicate')
+ out = F.conv2d(x_pad, weight, bias=None, stride=1, padding=0, dilation=radius, groups=C)
+ return out
+
+
+def _wavelet_decompose(x: torch.Tensor, levels: int = 5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ high = torch.zeros_like(x)
+ low = x
+ for i in range(levels):
+ radius = 2 ** i
+ blurred = _wavelet_blur(low, radius)
+ high = high + (low - blurred)
+ low = blurred
+ return high, low
+
+
+def _wavelet_reconstruct(content: torch.Tensor, style: torch.Tensor, levels: int = 5) -> torch.Tensor:
+ c_high, _ = _wavelet_decompose(content, levels=levels)
+ _, s_low = _wavelet_decompose(style, levels=levels)
+ return c_high + s_low
+
+
+# -----------------------------
+# 无状态颜色矫正模块(视频友好,默认 wavelet)
+# -----------------------------
+class TorchColorCorrectorWavelet(nn.Module):
+ def __init__(self, levels: int = 5):
+ super().__init__()
+ self.levels = levels
+
+ @staticmethod
+ def _flatten_time(x: torch.Tensor) -> Tuple[torch.Tensor, int, int]:
+ assert x.dim() == 5, '输入必须是 (B, C, f, H, W)'
+ B, C, f, H, W = x.shape
+ y = x.permute(0, 2, 1, 3, 4).reshape(B * f, C, H, W)
+ return y, B, f
+
+ @staticmethod
+ def _unflatten_time(y: torch.Tensor, B: int, f: int) -> torch.Tensor:
+ BF, C, H, W = y.shape
+ assert BF == B * f
+ return y.reshape(B, f, C, H, W).permute(0, 2, 1, 3, 4)
+
+ def forward(
+ self,
+ hq_image: torch.Tensor, # (B, C, f, H, W)
+ lq_image: torch.Tensor, # (B, C, f, H, W)
+ clip_range: Tuple[float, float] = (-1.0, 1.0),
+ method: Literal['wavelet', 'adain'] = 'wavelet',
+ chunk_size: Optional[int] = None,
+ ) -> torch.Tensor:
+ assert hq_image.shape == lq_image.shape, "HQ 与 LQ 的形状必须一致"
+ assert hq_image.dim() == 5 and hq_image.shape[1] == 3, "输入必须是 (B, 3, f, H, W)"
+
+ B, C, f, H, W = hq_image.shape
+ if chunk_size is None or chunk_size >= f:
+ hq4, B, f = self._flatten_time(hq_image)
+ lq4, _, _ = self._flatten_time(lq_image)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out = self._unflatten_time(out4, B, f)
+ return out
+
+ outs = []
+ for start in range(0, f, chunk_size):
+ end = min(start + chunk_size, f)
+ hq_chunk = hq_image[:, :, start:end]
+ lq_chunk = lq_image[:, :, start:end]
+ hq4, B_, f_ = self._flatten_time(hq_chunk)
+ lq4, _, _ = self._flatten_time(lq_chunk)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out_chunk = self._unflatten_time(out4, B_, f_)
+ outs.append(out_chunk)
+ out = torch.cat(outs, dim=2)
+ return out
+
+
+# -----------------------------
+# 简化版 Pipeline(仅 dit + vae)
+# -----------------------------
+class FlashVSRFullPipeline(BasePipeline):
+
+ def __init__(self, device="cuda", torch_dtype=torch.float16):
+ super().__init__(device=device, torch_dtype=torch_dtype)
+ self.scheduler = FlowMatchScheduler(shift=5, sigma_min=0.0, extra_one_step=True)
+ self.dit: WanModel = None
+ self.vae: WanVideoVAE = None
+ self.model_names = ['dit', 'vae']
+ self.height_division_factor = 16
+ self.width_division_factor = 16
+ self.use_unified_sequence_parallel = False
+ self.prompt_emb_posi = None
+ self.ColorCorrector = TorchColorCorrectorWavelet(levels=5)
+
+ print(r"""
+ ███████╗██╗ █████╗ ███████╗██╗ ██╗██╗ ██╗███████╗█████╗
+ ██╔════╝██║ ██╔══██╗██╔════╝██║ ██║██║ ██║██╔════╝██╔══██╗ ██╗
+ █████╗ ██║ ███████║███████╗███████║╚██╗ ██╔╝███████╗███████║ ██████╗
+ ██╔══╝ ██║ ██╔══██║╚════██║██╔══██║ ╚████╔╝ ╚════██║██╔═██║ ██╔═╝
+ ██║ ███████╗██║ ██║███████║██║ ██║ ╚██╔╝ ███████║██║ ██║ ╚═╝
+ ╚═╝ ╚══════╝╚═╝ ╚═╝╚══════╝╚═╝ ╚═╝ ╚═╝ ╚══════╝╚═╝ ╚═╝
+""")
+
+ def enable_vram_management(self, num_persistent_param_in_dit=None):
+ # 仅管理 dit / vae
+ dtype = next(iter(self.dit.parameters())).dtype
+ from ..vram_management import enable_vram_management, AutoWrappedModule, AutoWrappedLinear
+ enable_vram_management(
+ self.dit,
+ module_map={
+ torch.nn.Linear: AutoWrappedLinear,
+ torch.nn.Conv3d: AutoWrappedModule,
+ torch.nn.LayerNorm: AutoWrappedModule,
+ RMSNorm: AutoWrappedModule,
+ },
+ module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device=self.device,
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ max_num_param=num_persistent_param_in_dit,
+ overflow_module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device="cpu",
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ )
+ dtype = next(iter(self.vae.parameters())).dtype
+ enable_vram_management(
+ self.vae,
+ module_map={
+ torch.nn.Linear: AutoWrappedLinear,
+ torch.nn.Conv2d: AutoWrappedModule,
+ RMS_norm: AutoWrappedModule,
+ CausalConv3d: AutoWrappedModule,
+ Upsample: AutoWrappedModule,
+ torch.nn.SiLU: AutoWrappedModule,
+ torch.nn.Dropout: AutoWrappedModule,
+ },
+ module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device=self.device,
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ )
+ self.enable_cpu_offload()
+
+ def fetch_models(self, model_manager: ModelManager):
+ self.dit = model_manager.fetch_model("wan_video_dit")
+ self.vae = model_manager.fetch_model("wan_video_vae")
+
+ @staticmethod
+ def from_model_manager(model_manager: ModelManager, torch_dtype=None, device=None, use_usp=False):
+ if device is None: device = model_manager.device
+ if torch_dtype is None: torch_dtype = model_manager.torch_dtype
+ pipe = FlashVSRFullPipeline(device=device, torch_dtype=torch_dtype)
+ pipe.fetch_models(model_manager)
+ # 可选:统一序列并行入口(此处默认关闭)
+ pipe.use_unified_sequence_parallel = False
+ return pipe
+
+ def denoising_model(self):
+ return self.dit
+
+ # -------------------------
+ # 新增:显式 KV 预初始化函数
+ # -------------------------
+ def init_cross_kv(
+ self,
+ context_tensor: Optional[torch.Tensor] = None,
+ prompt_path = None
+ ):
+ self.load_models_to_device(["dit"])
+ """
+ 使用固定 prompt 生成文本 context,并在 WanModel 中初始化所有 CrossAttention 的 KV 缓存。
+ 必须在 __call__ 前显式调用一次。
+ """
+ #prompt_path = "../../examples/WanVSR/prompt_tensor/posi_prompt.pth"
+ if self.dit is None:
+ raise RuntimeError("请先通过 fetch_models / from_model_manager 初始化 self.dit")
+
+ if context_tensor is None:
+ if prompt_path is None:
+ raise ValueError("init_cross_kv: 需要提供 prompt_path 或 context_tensor 其一")
+ ctx = torch.load(prompt_path, map_location=self.device)
+ else:
+ ctx = context_tensor
+
+ ctx = ctx.to(dtype=self.torch_dtype, device=self.device)
+
+ if self.prompt_emb_posi is None:
+ self.prompt_emb_posi = {}
+ self.prompt_emb_posi['context'] = ctx
+ self.prompt_emb_posi['stats'] = "load"
+
+ if hasattr(self.dit, "reinit_cross_kv"):
+ self.dit.reinit_cross_kv(ctx)
+ else:
+ raise AttributeError("WanModel 缺少 reinit_cross_kv(ctx) 方法,请在模型实现中加入该能力。")
+ self.timestep = torch.tensor([1000.], device=self.device, dtype=self.torch_dtype)
+ self.t = self.dit.time_embedding(sinusoidal_embedding_1d(self.dit.freq_dim, self.timestep))
+ self.t_mod = self.dit.time_projection(self.t).unflatten(1, (6, self.dit.dim))
+ # Scheduler
+ self.scheduler.set_timesteps(1, denoising_strength=1.0, shift=5.0)
+ self.load_models_to_device([])
+
+ def prepare_unified_sequence_parallel(self):
+ return {"use_unified_sequence_parallel": self.use_unified_sequence_parallel}
+
+ def prepare_extra_input(self, latents=None):
+ return {}
+
+ def encode_video(self, input_video, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ latents = self.vae.encode(input_video, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return latents
+
+ def decode_video(self, latents, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ frames = self.vae.decode(latents, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return frames
+
+ def offload_model(self, keep_vae=False):
+ self.dit.clear_cross_kv()
+ self.prompt_emb_posi['stats'] = "offload"
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.to('cpu')
+ if keep_vae:
+ self.load_models_to_device(["vae"])
+ else:
+ self.load_models_to_device([])
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt=None,
+ negative_prompt="",
+ denoising_strength=1.0,
+ seed=None,
+ rand_device="gpu",
+ height=480,
+ width=832,
+ num_frames=81,
+ cfg_scale=5.0,
+ num_inference_steps=50,
+ sigma_shift=5.0,
+ tiled=True,
+ tile_size=(60, 104),
+ tile_stride=(30, 52),
+ tea_cache_l1_thresh=None,
+ tea_cache_model_id="Wan2.1-T2V-1.3B",
+ progress_bar_cmd=tqdm,
+ progress_bar_st=None,
+ LQ_video=None,
+ is_full_block=False,
+ if_buffer=False,
+ topk_ratio=2.0,
+ kv_ratio=3.0,
+ local_range = 9,
+ color_fix = True,
+ unload_dit = False,
+ force_offload = False,
+ ):
+ # 只接受 cfg=1.0(与原代码一致)
+ assert cfg_scale == 1.0, "cfg_scale must be 1.0"
+
+ # 要求:必须先 init_cross_kv()
+ if self.prompt_emb_posi is None or 'context' not in self.prompt_emb_posi:
+ raise RuntimeError(
+ "Cross-Attn KV 未初始化。请在调用 __call__ 前先执行:\n"
+ " pipe.init_cross_kv()\n"
+ "或传入自定义 context:\n"
+ " pipe.init_cross_kv(context_tensor=your_context_tensor)"
+ )
+
+ if num_frames % 4 != 1:
+ num_frames = (num_frames + 2) // 4 * 4 + 1
+ print(f"Only `num_frames % 4 != 1` is acceptable. We round it up to {num_frames}.")
+
+ # Tiler 参数
+ tiler_kwargs = {"tiled": tiled, "tile_size": tile_size, "tile_stride": tile_stride}
+
+ # 初始化噪声
+ if if_buffer:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ else:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4 + 1, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ # noise = noise.to(dtype=self.torch_dtype, device=self.device)
+ latents = noise
+
+ process_total_num = (num_frames - 1) // 8 - 2
+ is_stream = True
+
+ if self.prompt_emb_posi['stats'] == "offload":
+ self.init_cross_kv(context_tensor=self.prompt_emb_posi['context'])
+ self.load_models_to_device(["dit", "vae"])
+ self.dit.LQ_proj_in.to(self.device)
+
+ # 清理可能存在的 LQ_proj_in cache
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ latents_total = []
+ self.vae.clear_cache()
+
+ with torch.no_grad():
+ for cur_process_idx in progress_bar_cmd(range(process_total_num)):
+ if cur_process_idx == 0:
+ pre_cache_k = [None] * len(self.dit.blocks)
+ pre_cache_v = [None] * len(self.dit.blocks)
+ LQ_latents = None
+ inner_loop_num = 7
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, max(0, inner_idx*4-3):(inner_idx+1)*4-3, :, :]
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ cur_latents = latents[:, :, :6, :, :]
+ else:
+ LQ_latents = None
+ inner_loop_num = 2
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, cur_process_idx*8+17+inner_idx*4:cur_process_idx*8+21+inner_idx*4, :, :]
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ cur_latents = latents[:, :, 4+cur_process_idx*2:6+cur_process_idx*2, :, :]
+
+ # 推理(无 motion_controller / vace)
+ noise_pred_posi, pre_cache_k, pre_cache_v = model_fn_wan_video(
+ self.dit,
+ x=cur_latents,
+ timestep=self.timestep,
+ context=None,
+ tea_cache=None,
+ use_unified_sequence_parallel=False,
+ LQ_latents=LQ_latents,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k,
+ pre_cache_v=pre_cache_v,
+ topk_ratio=topk_ratio,
+ kv_ratio=kv_ratio,
+ cur_process_idx=cur_process_idx,
+ t_mod=self.t_mod,
+ t=self.t,
+ local_range = local_range,
+ )
+
+ # 更新 latent
+ cur_latents = cur_latents - noise_pred_posi
+ latents_total.append(cur_latents)
+
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ if unload_dit and hasattr(self, 'dit') and not next(self.dit.parameters()).is_cpu:
+ print("[FlashVSR] Offloading DiT to the CPU to free up VRAM...")
+ self.offload_model(keep_vae=True)
+
+ latents = torch.cat(latents_total, dim=2)
+
+ # Decode
+ print("[FlashVSR] Starting VAE decoding...")
+ frames = self.decode_video(latents, **tiler_kwargs)
+
+ self.vae.clear_cache()
+ if force_offload:
+ self.offload_model()
+
+ # 颜色校正(wavelet)
+ try:
+ if color_fix:
+ frames = self.ColorCorrector(
+ frames.to(device=LQ_video.device),
+ LQ_video[:, :, :frames.shape[2], :, :],
+ clip_range=(-1, 1),
+ chunk_size=16,
+ method='adain'
+ )
+ except:
+ pass
+
+ return frames[0]
+
+
+# -----------------------------
+# TeaCache(保留原逻辑;此处默认不启用)
+# -----------------------------
+class TeaCache:
+ def __init__(self, num_inference_steps, rel_l1_thresh, model_id):
+ self.num_inference_steps = num_inference_steps
+ self.step = 0
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = None
+ self.rel_l1_thresh = rel_l1_thresh
+ self.previous_residual = None
+ self.previous_hidden_states = None
+
+ self.coefficients_dict = {
+ "Wan2.1-T2V-1.3B": [-5.21862437e+04, 9.23041404e+03, -5.28275948e+02, 1.36987616e+01, -4.99875664e-02],
+ "Wan2.1-T2V-14B": [-3.03318725e+05, 4.90537029e+04, -2.65530556e+03, 5.87365115e+01, -3.15583525e-01],
+ "Wan2.1-I2V-14B-480P": [2.57151496e+05, -3.54229917e+04, 1.40286849e+03, -1.35890334e+01, 1.32517977e-01],
+ "Wan2.1-I2V-14B-720P": [8.10705460e+03, 2.13393892e+03, -3.72934672e+02, 1.66203073e+01, -4.17769401e-02],
+ }
+ if model_id not in self.coefficients_dict:
+ supported_model_ids = ", ".join([i for i in self.coefficients_dict])
+ raise ValueError(f"{model_id} is not a supported TeaCache model id. Please choose a valid model id in ({supported_model_ids}).")
+ self.coefficients = self.coefficients_dict[model_id]
+
+ def check(self, dit: WanModel, x, t_mod):
+ modulated_inp = t_mod.clone()
+ if self.step == 0 or self.step == self.num_inference_steps - 1:
+ should_calc = True
+ self.accumulated_rel_l1_distance = 0
+ else:
+ coefficients = self.coefficients
+ rescale_func = np.poly1d(coefficients)
+ self.accumulated_rel_l1_distance += rescale_func(((modulated_inp-self.previous_modulated_input).abs().mean() / self.previous_modulated_input.abs().mean()).cpu().item())
+ should_calc = not (self.accumulated_rel_l1_distance < self.rel_l1_thresh)
+ if should_calc:
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = modulated_inp
+ self.step = (self.step + 1) % self.num_inference_steps
+ if should_calc:
+ self.previous_hidden_states = x.clone()
+ return not should_calc
+
+ def store(self, hidden_states):
+ self.previous_residual = hidden_states - self.previous_hidden_states
+ self.previous_hidden_states = None
+
+ def update(self, hidden_states):
+ hidden_states = hidden_states + self.previous_residual
+ return hidden_states
+
+
+# -----------------------------
+# 简化版模型前向封装(无 vace / 无 motion_controller)
+# -----------------------------
+def model_fn_wan_video(
+ dit: WanModel,
+ x: torch.Tensor,
+ timestep: torch.Tensor,
+ context: torch.Tensor,
+ tea_cache: Optional[TeaCache] = None,
+ use_unified_sequence_parallel: bool = False,
+ LQ_latents: Optional[torch.Tensor] = None,
+ is_full_block: bool = False,
+ is_stream: bool = False,
+ pre_cache_k: Optional[list[torch.Tensor]] = None,
+ pre_cache_v: Optional[list[torch.Tensor]] = None,
+ topk_ratio: float = 2.0,
+ kv_ratio: float = 3.0,
+ cur_process_idx: int = 0,
+ t_mod : torch.Tensor = None,
+ t : torch.Tensor = None,
+ local_range: int = 9,
+ **kwargs,
+):
+ # patchify
+ x, (f, h, w) = dit.patchify(x)
+
+ win = (2, 8, 8)
+ seqlen = f // win[0]
+ local_num = seqlen
+ window_size = win[0] * h * w // 128
+ square_num = window_size * window_size
+ topk = int(square_num * topk_ratio) - 1
+ kv_len = int(kv_ratio)
+
+ # RoPE 位置(分段)
+ if cur_process_idx == 0:
+ freqs = torch.cat([
+ dit.freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+ else:
+ freqs = torch.cat([
+ dit.freqs[0][4 + cur_process_idx*2:4 + cur_process_idx*2 + f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+
+ # TeaCache(默认不启用)
+ tea_cache_update = tea_cache.check(dit, x, t_mod) if tea_cache is not None else False
+
+ # 统一序列并行(此处默认关闭)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import (get_sequence_parallel_rank,
+ get_sequence_parallel_world_size,
+ get_sp_group)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = torch.chunk(x, get_sequence_parallel_world_size(), dim=1)[get_sequence_parallel_rank()]
+
+ # Block 堆叠
+ if tea_cache_update:
+ x = tea_cache.update(x)
+ else:
+ for block_id, block in enumerate(dit.blocks):
+ if LQ_latents is not None and block_id < len(LQ_latents):
+ x = x + LQ_latents[block_id]
+ x, last_pre_cache_k, last_pre_cache_v = block(
+ x, context, t_mod, freqs, f, h, w,
+ local_num, topk,
+ block_id=block_id,
+ kv_len=kv_len,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k[block_id] if pre_cache_k is not None else None,
+ pre_cache_v=pre_cache_v[block_id] if pre_cache_v is not None else None,
+ local_range = local_range,
+ )
+ if pre_cache_k is not None: pre_cache_k[block_id] = last_pre_cache_k
+ if pre_cache_v is not None: pre_cache_v[block_id] = last_pre_cache_v
+
+ x = dit.head(x, t)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import get_sp_group
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = get_sp_group().all_gather(x, dim=1)
+ x = dit.unpatchify(x, (f, h, w))
+ return x, pre_cache_k, pre_cache_v
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny.py
new file mode 100644
index 0000000000000000000000000000000000000000..52fe12716aea308108b12993f071b8698278bc37
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny.py
@@ -0,0 +1,615 @@
+import types
+import os
+import time
+from typing import Optional, Tuple, Literal
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import numpy as np
+from einops import rearrange
+from PIL import Image
+from tqdm import tqdm
+# import pyfiglet
+
+from ..models import ModelManager
+from ..models.utils import clean_vram
+from ..models.wan_video_dit import WanModel, RMSNorm, sinusoidal_embedding_1d
+from ..models.wan_video_vae import WanVideoVAE, RMS_norm, CausalConv3d, Upsample
+from ..schedulers.flow_match import FlowMatchScheduler
+from .base import BasePipeline
+
+
+# -----------------------------
+# 基础工具:ADAIN 所需的统计量(保留以备需要;管线默认用 wavelet)
+# -----------------------------
+def _calc_mean_std(feat: torch.Tensor, eps: float = 1e-5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert feat.dim() == 4, 'feat 必须是 (N, C, H, W)'
+ N, C = feat.shape[:2]
+ var = feat.view(N, C, -1).var(dim=2, unbiased=False) + eps
+ std = var.sqrt().view(N, C, 1, 1)
+ mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
+ return mean, std
+
+
+def _adain(content_feat: torch.Tensor, style_feat: torch.Tensor) -> torch.Tensor:
+ assert content_feat.shape[:2] == style_feat.shape[:2], "ADAIN: N、C 必须匹配"
+ size = content_feat.size()
+ style_mean, style_std = _calc_mean_std(style_feat)
+ content_mean, content_std = _calc_mean_std(content_feat)
+ normalized = (content_feat - content_mean.expand(size)) / content_std.expand(size)
+ return normalized * style_std.expand(size) + style_mean.expand(size)
+
+
+# -----------------------------
+# 小波式模糊与分解/重构(ColorCorrector 用)
+# -----------------------------
+def _make_gaussian3x3_kernel(dtype, device) -> torch.Tensor:
+ vals = [
+ [0.0625, 0.125, 0.0625],
+ [0.125, 0.25, 0.125 ],
+ [0.0625, 0.125, 0.0625],
+ ]
+ return torch.tensor(vals, dtype=dtype, device=device)
+
+
+def _wavelet_blur(x: torch.Tensor, radius: int) -> torch.Tensor:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ N, C, H, W = x.shape
+ base = _make_gaussian3x3_kernel(x.dtype, x.device)
+ weight = base.view(1, 1, 3, 3).repeat(C, 1, 1, 1)
+ pad = radius
+ x_pad = F.pad(x, (pad, pad, pad, pad), mode='replicate')
+ out = F.conv2d(x_pad, weight, bias=None, stride=1, padding=0, dilation=radius, groups=C)
+ return out
+
+
+def _wavelet_decompose(x: torch.Tensor, levels: int = 5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ high = torch.zeros_like(x)
+ low = x
+ for i in range(levels):
+ radius = 2 ** i
+ blurred = _wavelet_blur(low, radius)
+ high = high + (low - blurred)
+ low = blurred
+ return high, low
+
+
+def _wavelet_reconstruct(content: torch.Tensor, style: torch.Tensor, levels: int = 5) -> torch.Tensor:
+ c_high, _ = _wavelet_decompose(content, levels=levels)
+ _, s_low = _wavelet_decompose(style, levels=levels)
+ return c_high + s_low
+
+
+# -----------------------------
+# 无状态颜色矫正模块(视频友好,默认 wavelet)
+# -----------------------------
+class TorchColorCorrectorWavelet(nn.Module):
+ def __init__(self, levels: int = 5):
+ super().__init__()
+ self.levels = levels
+
+ @staticmethod
+ def _flatten_time(x: torch.Tensor) -> Tuple[torch.Tensor, int, int]:
+ assert x.dim() == 5, '输入必须是 (B, C, f, H, W)'
+ B, C, f, H, W = x.shape
+ y = x.permute(0, 2, 1, 3, 4).reshape(B * f, C, H, W)
+ return y, B, f
+
+ @staticmethod
+ def _unflatten_time(y: torch.Tensor, B: int, f: int) -> torch.Tensor:
+ BF, C, H, W = y.shape
+ assert BF == B * f
+ return y.reshape(B, f, C, H, W).permute(0, 2, 1, 3, 4)
+
+ def forward(
+ self,
+ hq_image: torch.Tensor, # (B, C, f, H, W)
+ lq_image: torch.Tensor, # (B, C, f, H, W)
+ clip_range: Tuple[float, float] = (-1.0, 1.0),
+ method: Literal['wavelet', 'adain'] = 'wavelet',
+ chunk_size: Optional[int] = None,
+ ) -> torch.Tensor:
+ assert hq_image.shape == lq_image.shape, "HQ 与 LQ 的形状必须一致"
+ assert hq_image.dim() == 5 and hq_image.shape[1] == 3, "输入必须是 (B, 3, f, H, W)"
+
+ B, C, f, H, W = hq_image.shape
+ if chunk_size is None or chunk_size >= f:
+ hq4, B, f = self._flatten_time(hq_image)
+ lq4, _, _ = self._flatten_time(lq_image)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out = self._unflatten_time(out4, B, f)
+ return out
+
+ outs = []
+ for start in range(0, f, chunk_size):
+ end = min(start + chunk_size, f)
+ hq_chunk = hq_image[:, :, start:end]
+ lq_chunk = lq_image[:, :, start:end]
+ hq4, B_, f_ = self._flatten_time(hq_chunk)
+ lq4, _, _ = self._flatten_time(lq_chunk)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out_chunk = self._unflatten_time(out4, B_, f_)
+ outs.append(out_chunk)
+ out = torch.cat(outs, dim=2)
+ return out
+
+
+# -----------------------------
+# 简化版 Pipeline(仅 dit + vae)
+# -----------------------------
+class FlashVSRTinyPipeline(BasePipeline):
+
+ def __init__(self, device="cuda", torch_dtype=torch.float16):
+ super().__init__(device=device, torch_dtype=torch_dtype)
+ self.scheduler = FlowMatchScheduler(shift=5, sigma_min=0.0, extra_one_step=True)
+ self.dit: WanModel = None
+ self.vae: WanVideoVAE = None
+ self.model_names = ['dit', 'vae']
+ self.height_division_factor = 16
+ self.width_division_factor = 16
+ self.use_unified_sequence_parallel = False
+ self.prompt_emb_posi = None
+ self.ColorCorrector = TorchColorCorrectorWavelet(levels=5)
+
+ print(r"""
+ ███████╗██╗ █████╗ ███████╗██╗ ██╗██╗ ██╗███████╗█████╗
+ ██╔════╝██║ ██╔══██╗██╔════╝██║ ██║██║ ██║██╔════╝██╔══██╗ ██╗
+ █████╗ ██║ ███████║███████╗███████║╚██╗ ██╔╝███████╗███████║ ██████╗
+ ██╔══╝ ██║ ██╔══██║╚════██║██╔══██║ ╚████╔╝ ╚════██║██╔═██║ ██╔═╝
+ ██║ ███████╗██║ ██║███████║██║ ██║ ╚██╔╝ ███████║██║ ██║ ╚═╝
+ ╚═╝ ╚══════╝╚═╝ ╚═╝╚══════╝╚═╝ ╚═╝ ╚═╝ ╚══════╝╚═╝ ╚═╝
+""")
+
+ def enable_vram_management(self, num_persistent_param_in_dit=None):
+ # 仅管理 dit / vae
+ dtype = next(iter(self.dit.parameters())).dtype
+ from ..vram_management import enable_vram_management, AutoWrappedModule, AutoWrappedLinear
+ enable_vram_management(
+ self.dit,
+ module_map={
+ torch.nn.Linear: AutoWrappedLinear,
+ torch.nn.Conv3d: AutoWrappedModule,
+ torch.nn.LayerNorm: AutoWrappedModule,
+ RMSNorm: AutoWrappedModule,
+ },
+ module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device=self.device,
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ max_num_param=num_persistent_param_in_dit,
+ overflow_module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device="cpu",
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ )
+ self.enable_cpu_offload()
+
+ def fetch_models(self, model_manager: ModelManager):
+ self.dit = model_manager.fetch_model("wan_video_dit")
+ self.vae = model_manager.fetch_model("wan_video_vae")
+
+ @staticmethod
+ def from_model_manager(model_manager: ModelManager, torch_dtype=None, device=None, use_usp=False):
+ if device is None: device = model_manager.device
+ if torch_dtype is None: torch_dtype = model_manager.torch_dtype
+ pipe = FlashVSRTinyPipeline(device=device, torch_dtype=torch_dtype)
+ pipe.fetch_models(model_manager)
+ # 可选:统一序列并行入口(此处默认关闭)
+ pipe.use_unified_sequence_parallel = False
+ return pipe
+
+ def denoising_model(self):
+ return self.dit
+
+ # -------------------------
+ # 新增:显式 KV 预初始化函数
+ # -------------------------
+ def init_cross_kv(
+ self,
+ context_tensor: Optional[torch.Tensor] = None,
+ prompt_path = None,
+ ):
+ self.load_models_to_device(["dit"])
+ """
+ 使用固定 prompt 生成文本 context,并在 WanModel 中初始化所有 CrossAttention 的 KV 缓存。
+ 必须在 __call__ 前显式调用一次。
+ """
+ #prompt_path = "../../examples/WanVSR/prompt_tensor/posi_prompt.pth"
+
+ if self.dit is None:
+ raise RuntimeError("请先通过 fetch_models / from_model_manager 初始化 self.dit")
+
+ if context_tensor is None:
+ if prompt_path is None:
+ raise ValueError("init_cross_kv: 需要提供 prompt_path 或 context_tensor 其一")
+ ctx = torch.load(prompt_path, map_location=self.device)
+ else:
+ ctx = context_tensor
+
+ ctx = ctx.to(dtype=self.torch_dtype, device=self.device)
+
+ if self.prompt_emb_posi is None:
+ self.prompt_emb_posi = {}
+ self.prompt_emb_posi['context'] = ctx
+ self.prompt_emb_posi['stats'] = "load"
+
+ if hasattr(self.dit, "reinit_cross_kv"):
+ self.dit.reinit_cross_kv(ctx)
+ else:
+ raise AttributeError("WanModel 缺少 reinit_cross_kv(ctx) 方法,请在模型实现中加入该能力。")
+ self.timestep = torch.tensor([1000.], device=self.device, dtype=self.torch_dtype)
+ self.t = self.dit.time_embedding(sinusoidal_embedding_1d(self.dit.freq_dim, self.timestep))
+ self.t_mod = self.dit.time_projection(self.t).unflatten(1, (6, self.dit.dim))
+ # Scheduler
+ self.scheduler.set_timesteps(1, denoising_strength=1.0, shift=5.0)
+ self.load_models_to_device([])
+
+ def prepare_unified_sequence_parallel(self):
+ return {"use_unified_sequence_parallel": self.use_unified_sequence_parallel}
+
+ def prepare_extra_input(self, latents=None):
+ return {}
+
+ def encode_video(self, input_video, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ latents = self.vae.encode(input_video, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return latents
+
+ def _decode_video(self, latents, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ frames = self.vae.decode(latents, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return frames
+
+ def decode_video(self, latents, cond=None, **kwargs):
+ frames = self.TCDecoder.decode_video(
+ latents.transpose(1, 2), # TCDecoder 需要 (B, F, C, H, W)
+ parallel=False,
+ show_progress_bar=False,
+ cond=cond
+ ).transpose(1, 2).mul_(2).sub_(1) # 转回 (B, C, F, H, W) 格式,范围 -1 to 1
+
+ return frames
+
+ def offload_model(self, keep_vae=False):
+ self.dit.clear_cross_kv()
+ self.prompt_emb_posi['stats'] = "offload"
+ self.load_models_to_device([])
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.to('cpu')
+ if not keep_vae:
+ self.TCDecoder.to('cpu')
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt=None,
+ negative_prompt="",
+ denoising_strength=1.0,
+ seed=None,
+ rand_device="gpu",
+ height=480,
+ width=832,
+ num_frames=81,
+ cfg_scale=5.0,
+ num_inference_steps=50,
+ sigma_shift=5.0,
+ tiled=True,
+ tile_size=(60, 104),
+ tile_stride=(30, 52),
+ tea_cache_l1_thresh=None,
+ tea_cache_model_id="Wan2.1-T2V-1.3B",
+ progress_bar_cmd=tqdm,
+ progress_bar_st=None,
+ LQ_video=None,
+ is_full_block=False,
+ if_buffer=False,
+ topk_ratio=2.0,
+ kv_ratio=3.0,
+ local_range = 9,
+ color_fix = True,
+ unload_dit = False,
+ force_offload = False,
+ ):
+ # 只接受 cfg=1.0(与原代码一致)
+ assert cfg_scale == 1.0, "cfg_scale must be 1.0"
+
+ # 要求:必须先 init_cross_kv()
+ if self.prompt_emb_posi is None or 'context' not in self.prompt_emb_posi:
+ raise RuntimeError(
+ "Cross-Attn KV 未初始化。请在调用 __call__ 前先执行:\n"
+ " pipe.init_cross_kv()\n"
+ "或传入自定义 context:\n"
+ " pipe.init_cross_kv(context_tensor=your_context_tensor)"
+ )
+
+ # 尺寸修正
+ height, width = self.check_resize_height_width(height, width)
+ if num_frames % 4 != 1:
+ num_frames = (num_frames + 2) // 4 * 4 + 1
+ print(f"Only `num_frames % 4 != 1` is acceptable. We round it up to {num_frames}.")
+
+ # Tiler 参数
+ tiler_kwargs = {"tiled": tiled, "tile_size": tile_size, "tile_stride": tile_stride}
+
+ # 初始化噪声
+ if if_buffer:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ else:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4 + 1, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ # noise = noise.to(dtype=self.torch_dtype, device=self.device)
+ latents = noise
+
+ process_total_num = (num_frames - 1) // 8 - 2
+ is_stream = True
+
+ if self.prompt_emb_posi['stats'] == "offload":
+ self.init_cross_kv(context_tensor=self.prompt_emb_posi['context'])
+ self.load_models_to_device(["dit"])
+ self.dit.LQ_proj_in.to(self.device)
+ self.TCDecoder.to(self.device)
+
+ # 清理可能存在的 LQ_proj_in cache
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ latents_total = []
+ self.TCDecoder.clean_mem()
+ LQ_pre_idx = 0
+ LQ_cur_idx = 0
+
+ with torch.no_grad():
+ for cur_process_idx in progress_bar_cmd(range(process_total_num)):
+ if cur_process_idx == 0:
+ pre_cache_k = [None] * len(self.dit.blocks)
+ pre_cache_v = [None] * len(self.dit.blocks)
+ LQ_latents = None
+ inner_loop_num = 7
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, max(0, inner_idx*4-3):(inner_idx+1)*4-3, :, :]
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ LQ_cur_idx = (inner_loop_num-1)*4-3
+ cur_latents = latents[:, :, :6, :, :]
+ else:
+ LQ_latents = None
+ inner_loop_num = 2
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, cur_process_idx*8+17+inner_idx*4:cur_process_idx*8+21+inner_idx*4, :, :]
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ LQ_cur_idx = cur_process_idx*8+21+(inner_loop_num-2)*4
+ cur_latents = latents[:, :, 4+cur_process_idx*2:6+cur_process_idx*2, :, :]
+
+ # 推理(无 motion_controller / vace)
+ noise_pred_posi, pre_cache_k, pre_cache_v = model_fn_wan_video(
+ self.dit,
+ x=cur_latents,
+ timestep=self.timestep,
+ context=None,
+ tea_cache=None,
+ use_unified_sequence_parallel=False,
+ LQ_latents=LQ_latents,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k,
+ pre_cache_v=pre_cache_v,
+ topk_ratio=topk_ratio,
+ kv_ratio=kv_ratio,
+ cur_process_idx=cur_process_idx,
+ t_mod=self.t_mod,
+ t=self.t,
+ local_range = local_range,
+ )
+
+ # 更新 latent
+ cur_latents = cur_latents - noise_pred_posi
+ latents_total.append(cur_latents)
+ LQ_pre_idx = LQ_cur_idx
+
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ if unload_dit and hasattr(self, 'dit') and not next(self.dit.parameters()).is_cpu:
+ print("[FlashVSR] Offloading DiT to the CPU to free up VRAM...")
+ self.offload_model(keep_vae=True)
+
+ latents = torch.cat(latents_total, dim=2)
+
+ # Decode
+ print("[FlashVSR] Starting VAE decoding...")
+ frames = self.TCDecoder.decode_video(latents.transpose(1, 2),parallel=False, show_progress_bar=False, cond=LQ_video[:,:,:LQ_cur_idx,:,:]).transpose(1, 2).mul_(2).sub_(1)
+
+ self.TCDecoder.clean_mem()
+ if force_offload:
+ self.offload_model()
+
+ # 颜色校正(wavelet)
+ try:
+ if color_fix:
+ frames = self.ColorCorrector(
+ frames.to(device=LQ_video.device),
+ LQ_video[:, :, :frames.shape[2], :, :],
+ clip_range=(-1, 1),
+ chunk_size=16,
+ method='adain'
+ )
+ except:
+ pass
+
+ return frames[0]
+
+
+# -----------------------------
+# TeaCache(保留原逻辑;此处默认不启用)
+# -----------------------------
+class TeaCache:
+ def __init__(self, num_inference_steps, rel_l1_thresh, model_id):
+ self.num_inference_steps = num_inference_steps
+ self.step = 0
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = None
+ self.rel_l1_thresh = rel_l1_thresh
+ self.previous_residual = None
+ self.previous_hidden_states = None
+
+ self.coefficients_dict = {
+ "Wan2.1-T2V-1.3B": [-5.21862437e+04, 9.23041404e+03, -5.28275948e+02, 1.36987616e+01, -4.99875664e-02],
+ "Wan2.1-T2V-14B": [-3.03318725e+05, 4.90537029e+04, -2.65530556e+03, 5.87365115e+01, -3.15583525e-01],
+ "Wan2.1-I2V-14B-480P": [2.57151496e+05, -3.54229917e+04, 1.40286849e+03, -1.35890334e+01, 1.32517977e-01],
+ "Wan2.1-I2V-14B-720P": [8.10705460e+03, 2.13393892e+03, -3.72934672e+02, 1.66203073e+01, -4.17769401e-02],
+ }
+ if model_id not in self.coefficients_dict:
+ supported_model_ids = ", ".join([i for i in self.coefficients_dict])
+ raise ValueError(f"{model_id} is not a supported TeaCache model id. Please choose a valid model id in ({supported_model_ids}).")
+ self.coefficients = self.coefficients_dict[model_id]
+
+ def check(self, dit: WanModel, x, t_mod):
+ modulated_inp = t_mod.clone()
+ if self.step == 0 or self.step == self.num_inference_steps - 1:
+ should_calc = True
+ self.accumulated_rel_l1_distance = 0
+ else:
+ coefficients = self.coefficients
+ rescale_func = np.poly1d(coefficients)
+ self.accumulated_rel_l1_distance += rescale_func(((modulated_inp-self.previous_modulated_input).abs().mean() / self.previous_modulated_input.abs().mean()).cpu().item())
+ should_calc = not (self.accumulated_rel_l1_distance < self.rel_l1_thresh)
+ if should_calc:
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = modulated_inp
+ self.step = (self.step + 1) % self.num_inference_steps
+ if should_calc:
+ self.previous_hidden_states = x.clone()
+ return not should_calc
+
+ def store(self, hidden_states):
+ self.previous_residual = hidden_states - self.previous_hidden_states
+ self.previous_hidden_states = None
+
+ def update(self, hidden_states):
+ hidden_states = hidden_states + self.previous_residual
+ return hidden_states
+
+
+# -----------------------------
+# 简化版模型前向封装(无 vace / 无 motion_controller)
+# -----------------------------
+def model_fn_wan_video(
+ dit: WanModel,
+ x: torch.Tensor,
+ timestep: torch.Tensor,
+ context: torch.Tensor,
+ tea_cache: Optional[TeaCache] = None,
+ use_unified_sequence_parallel: bool = False,
+ LQ_latents: Optional[torch.Tensor] = None,
+ is_full_block: bool = False,
+ is_stream: bool = False,
+ pre_cache_k: Optional[list[torch.Tensor]] = None,
+ pre_cache_v: Optional[list[torch.Tensor]] = None,
+ topk_ratio: float = 2.0,
+ kv_ratio: float = 3.0,
+ cur_process_idx: int = 0,
+ t_mod : torch.Tensor = None,
+ t : torch.Tensor = None,
+ local_range: int = 9,
+ **kwargs,
+):
+ # patchify
+ x, (f, h, w) = dit.patchify(x)
+
+ win = (2, 8, 8)
+ seqlen = f // win[0]
+ local_num = seqlen
+ window_size = win[0] * h * w // 128
+ square_num = window_size * window_size
+ topk = int(square_num * topk_ratio) - 1
+ kv_len = int(kv_ratio)
+
+ # RoPE 位置(分段)
+ if cur_process_idx == 0:
+ freqs = torch.cat([
+ dit.freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+ else:
+ freqs = torch.cat([
+ dit.freqs[0][4 + cur_process_idx*2:4 + cur_process_idx*2 + f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+
+ # TeaCache(默认不启用)
+ tea_cache_update = tea_cache.check(dit, x, t_mod) if tea_cache is not None else False
+
+ # 统一序列并行(此处默认关闭)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import (get_sequence_parallel_rank,
+ get_sequence_parallel_world_size,
+ get_sp_group)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = torch.chunk(x, get_sequence_parallel_world_size(), dim=1)[get_sequence_parallel_rank()]
+
+ # Block 堆叠
+ if tea_cache_update:
+ x = tea_cache.update(x)
+ else:
+ for block_id, block in enumerate(dit.blocks):
+ if LQ_latents is not None and block_id < len(LQ_latents):
+ x = x + LQ_latents[block_id]
+ x, last_pre_cache_k, last_pre_cache_v = block(
+ x, context, t_mod, freqs, f, h, w,
+ local_num, topk,
+ block_id=block_id,
+ kv_len=kv_len,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k[block_id] if pre_cache_k is not None else None,
+ pre_cache_v=pre_cache_v[block_id] if pre_cache_v is not None else None,
+ local_range = local_range,
+ )
+ if pre_cache_k is not None: pre_cache_k[block_id] = last_pre_cache_k
+ if pre_cache_v is not None: pre_cache_v[block_id] = last_pre_cache_v
+
+ x = dit.head(x, t)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import get_sp_group
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = get_sp_group().all_gather(x, dim=1)
+ x = dit.unpatchify(x, (f, h, w))
+ return x, pre_cache_k, pre_cache_v
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny_long.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny_long.py
new file mode 100644
index 0000000000000000000000000000000000000000..c927ef262550a556fd49e8d3e21e400d4233d0e6
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/pipelines/flashvsr_tiny_long.py
@@ -0,0 +1,620 @@
+import types
+import os
+import time
+from typing import Optional, Tuple, Literal
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import numpy as np
+from einops import rearrange
+from PIL import Image
+from tqdm import tqdm
+# import pyfiglet
+
+from ..models import ModelManager
+from ..models.utils import clean_vram
+from ..models.wan_video_dit import WanModel, RMSNorm, sinusoidal_embedding_1d
+from ..models.wan_video_vae import WanVideoVAE, RMS_norm, CausalConv3d, Upsample
+from ..schedulers.flow_match import FlowMatchScheduler
+from .base import BasePipeline
+
+
+# -----------------------------
+# 基础工具:ADAIN 所需的统计量(保留以备需要;管线默认用 wavelet)
+# -----------------------------
+def _calc_mean_std(feat: torch.Tensor, eps: float = 1e-5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert feat.dim() == 4, 'feat 必须是 (N, C, H, W)'
+ N, C = feat.shape[:2]
+ var = feat.view(N, C, -1).var(dim=2, unbiased=False) + eps
+ std = var.sqrt().view(N, C, 1, 1)
+ mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
+ return mean, std
+
+
+def _adain(content_feat: torch.Tensor, style_feat: torch.Tensor) -> torch.Tensor:
+ assert content_feat.shape[:2] == style_feat.shape[:2], "ADAIN: N、C 必须匹配"
+ size = content_feat.size()
+ style_mean, style_std = _calc_mean_std(style_feat)
+ content_mean, content_std = _calc_mean_std(content_feat)
+ normalized = (content_feat - content_mean.expand(size)) / content_std.expand(size)
+ return normalized * style_std.expand(size) + style_mean.expand(size)
+
+
+# -----------------------------
+# 小波式模糊与分解/重构(ColorCorrector 用)
+# -----------------------------
+def _make_gaussian3x3_kernel(dtype, device) -> torch.Tensor:
+ vals = [
+ [0.0625, 0.125, 0.0625],
+ [0.125, 0.25, 0.125 ],
+ [0.0625, 0.125, 0.0625],
+ ]
+ return torch.tensor(vals, dtype=dtype, device=device)
+
+
+def _wavelet_blur(x: torch.Tensor, radius: int) -> torch.Tensor:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ N, C, H, W = x.shape
+ base = _make_gaussian3x3_kernel(x.dtype, x.device)
+ weight = base.view(1, 1, 3, 3).repeat(C, 1, 1, 1)
+ pad = radius
+ x_pad = F.pad(x, (pad, pad, pad, pad), mode='replicate')
+ out = F.conv2d(x_pad, weight, bias=None, stride=1, padding=0, dilation=radius, groups=C)
+ return out
+
+
+def _wavelet_decompose(x: torch.Tensor, levels: int = 5) -> Tuple[torch.Tensor, torch.Tensor]:
+ assert x.dim() == 4, 'x 必须是 (N, C, H, W)'
+ high = torch.zeros_like(x)
+ low = x
+ for i in range(levels):
+ radius = 2 ** i
+ blurred = _wavelet_blur(low, radius)
+ high = high + (low - blurred)
+ low = blurred
+ return high, low
+
+
+def _wavelet_reconstruct(content: torch.Tensor, style: torch.Tensor, levels: int = 5) -> torch.Tensor:
+ c_high, _ = _wavelet_decompose(content, levels=levels)
+ _, s_low = _wavelet_decompose(style, levels=levels)
+ return c_high + s_low
+
+
+# -----------------------------
+# 无状态颜色矫正模块(视频友好,默认 wavelet)
+# -----------------------------
+class TorchColorCorrectorWavelet(nn.Module):
+ def __init__(self, levels: int = 5):
+ super().__init__()
+ self.levels = levels
+
+ @staticmethod
+ def _flatten_time(x: torch.Tensor) -> Tuple[torch.Tensor, int, int]:
+ assert x.dim() == 5, '输入必须是 (B, C, f, H, W)'
+ B, C, f, H, W = x.shape
+ y = x.permute(0, 2, 1, 3, 4).reshape(B * f, C, H, W)
+ return y, B, f
+
+ @staticmethod
+ def _unflatten_time(y: torch.Tensor, B: int, f: int) -> torch.Tensor:
+ BF, C, H, W = y.shape
+ assert BF == B * f
+ return y.reshape(B, f, C, H, W).permute(0, 2, 1, 3, 4)
+
+ def forward(
+ self,
+ hq_image: torch.Tensor, # (B, C, f, H, W)
+ lq_image: torch.Tensor, # (B, C, f, H, W)
+ clip_range: Tuple[float, float] = (-1.0, 1.0),
+ method: Literal['wavelet', 'adain'] = 'wavelet',
+ chunk_size: Optional[int] = None,
+ ) -> torch.Tensor:
+ assert hq_image.shape == lq_image.shape, "HQ 与 LQ 的形状必须一致"
+ assert hq_image.dim() == 5 and hq_image.shape[1] == 3, "输入必须是 (B, 3, f, H, W)"
+
+ B, C, f, H, W = hq_image.shape
+ if chunk_size is None or chunk_size >= f:
+ hq4, B, f = self._flatten_time(hq_image)
+ lq4, _, _ = self._flatten_time(lq_image)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out = self._unflatten_time(out4, B, f)
+ return out
+
+ outs = []
+ for start in range(0, f, chunk_size):
+ end = min(start + chunk_size, f)
+ hq_chunk = hq_image[:, :, start:end]
+ lq_chunk = lq_image[:, :, start:end]
+ hq4, B_, f_ = self._flatten_time(hq_chunk)
+ lq4, _, _ = self._flatten_time(lq_chunk)
+ if method == 'wavelet':
+ out4 = _wavelet_reconstruct(hq4, lq4, levels=self.levels)
+ elif method == 'adain':
+ out4 = _adain(hq4, lq4)
+ else:
+ raise ValueError(f"未知 method: {method}")
+ out4 = torch.clamp(out4, *clip_range)
+ out_chunk = self._unflatten_time(out4, B_, f_)
+ outs.append(out_chunk)
+ out = torch.cat(outs, dim=2)
+ return out
+
+
+# -----------------------------
+# 简化版 Pipeline(仅 dit + vae)
+# -----------------------------
+class FlashVSRTinyLongPipeline(BasePipeline):
+
+ def __init__(self, device="cuda", torch_dtype=torch.float16):
+ super().__init__(device=device, torch_dtype=torch_dtype)
+ self.scheduler = FlowMatchScheduler(shift=5, sigma_min=0.0, extra_one_step=True)
+ self.dit: WanModel = None
+ self.vae: WanVideoVAE = None
+ self.model_names = ['dit', 'vae']
+ self.height_division_factor = 16
+ self.width_division_factor = 16
+ self.use_unified_sequence_parallel = False
+ self.prompt_emb_posi = None
+ self.ColorCorrector = TorchColorCorrectorWavelet(levels=5)
+
+ print(r"""
+ ███████╗██╗ █████╗ ███████╗██╗ ██╗██╗ ██╗███████╗█████╗
+ ██╔════╝██║ ██╔══██╗██╔════╝██║ ██║██║ ██║██╔════╝██╔══██╗ ██╗
+ █████╗ ██║ ███████║███████╗███████║╚██╗ ██╔╝███████╗███████║ ██████╗
+ ██╔══╝ ██║ ██╔══██║╚════██║██╔══██║ ╚████╔╝ ╚════██║██╔═██║ ██╔═╝
+ ██║ ███████╗██║ ██║███████║██║ ██║ ╚██╔╝ ███████║██║ ██║ ╚═╝
+ ╚═╝ ╚══════╝╚═╝ ╚═╝╚══════╝╚═╝ ╚═╝ ╚═╝ ╚══════╝╚═╝ ╚═╝
+""")
+
+ def enable_vram_management(self, num_persistent_param_in_dit=None):
+ # 仅管理 dit / vae
+ dtype = next(iter(self.dit.parameters())).dtype
+ from ..vram_management import enable_vram_management, AutoWrappedModule, AutoWrappedLinear
+ enable_vram_management(
+ self.dit,
+ module_map={
+ torch.nn.Linear: AutoWrappedLinear,
+ torch.nn.Conv3d: AutoWrappedModule,
+ torch.nn.LayerNorm: AutoWrappedModule,
+ RMSNorm: AutoWrappedModule,
+ },
+ module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device=self.device,
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ max_num_param=num_persistent_param_in_dit,
+ overflow_module_config=dict(
+ offload_dtype=dtype,
+ offload_device="cpu",
+ onload_dtype=dtype,
+ onload_device="cpu",
+ computation_dtype=self.torch_dtype,
+ computation_device=self.device,
+ ),
+ )
+ self.enable_cpu_offload()
+
+ def fetch_models(self, model_manager: ModelManager):
+ self.dit = model_manager.fetch_model("wan_video_dit")
+ self.vae = model_manager.fetch_model("wan_video_vae")
+
+ @staticmethod
+ def from_model_manager(model_manager: ModelManager, torch_dtype=None, device=None, use_usp=False):
+ if device is None: device = model_manager.device
+ if torch_dtype is None: torch_dtype = model_manager.torch_dtype
+ pipe = FlashVSRTinyLongPipeline(device=device, torch_dtype=torch_dtype)
+ pipe.fetch_models(model_manager)
+ # 可选:统一序列并行入口(此处默认关闭)
+ pipe.use_unified_sequence_parallel = False
+ return pipe
+
+ def denoising_model(self):
+ return self.dit
+
+ # -------------------------
+ # 新增:显式 KV 预初始化函数
+ # -------------------------
+ def init_cross_kv(
+ self,
+ context_tensor: Optional[torch.Tensor] = None,
+ prompt_path = None,
+ ):
+ self.load_models_to_device(["dit"])
+ """
+ 使用固定 prompt 生成文本 context,并在 WanModel 中初始化所有 CrossAttention 的 KV 缓存。
+ 必须在 __call__ 前显式调用一次。
+ """
+ #prompt_path = "../../examples/WanVSR/prompt_tensor/posi_prompt.pth"
+
+ if self.dit is None:
+ raise RuntimeError("请先通过 fetch_models / from_model_manager 初始化 self.dit")
+
+ if context_tensor is None:
+ if prompt_path is None:
+ raise ValueError("init_cross_kv: 需要提供 prompt_path 或 context_tensor 其一")
+ ctx = torch.load(prompt_path, map_location=self.device)
+ else:
+ ctx = context_tensor
+
+ ctx = ctx.to(dtype=self.torch_dtype, device=self.device)
+
+ if self.prompt_emb_posi is None:
+ self.prompt_emb_posi = {}
+ self.prompt_emb_posi['context'] = ctx
+ self.prompt_emb_posi['stats'] = "load"
+
+ if hasattr(self.dit, "reinit_cross_kv"):
+ self.dit.reinit_cross_kv(ctx)
+ else:
+ raise AttributeError("WanModel 缺少 reinit_cross_kv(ctx) 方法,请在模型实现中加入该能力。")
+ self.timestep = torch.tensor([1000.], device=self.device, dtype=self.torch_dtype)
+ self.t = self.dit.time_embedding(sinusoidal_embedding_1d(self.dit.freq_dim, self.timestep))
+ self.t_mod = self.dit.time_projection(self.t).unflatten(1, (6, self.dit.dim))
+ # Scheduler
+ self.scheduler.set_timesteps(1, denoising_strength=1.0, shift=5.0)
+ self.load_models_to_device([])
+
+ def prepare_unified_sequence_parallel(self):
+ return {"use_unified_sequence_parallel": self.use_unified_sequence_parallel}
+
+ def prepare_extra_input(self, latents=None):
+ return {}
+
+ def encode_video(self, input_video, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ latents = self.vae.encode(input_video, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return latents
+
+ def _decode_video(self, latents, tiled=True, tile_size=(34, 34), tile_stride=(18, 16)):
+ frames = self.vae.decode(latents, device=self.device, tiled=tiled, tile_size=tile_size, tile_stride=tile_stride)
+ return frames
+
+ def decode_video(self, latents, cond=None, **kwargs):
+ frames = self.TCDecoder.decode_video(
+ latents.transpose(1, 2), # TCDecoder 需要 (B, F, C, H, W)
+ parallel=False,
+ show_progress_bar=False,
+ cond=cond
+ ).transpose(1, 2).mul_(2).sub_(1) # 转回 (B, C, F, H, W) 格式,范围 -1 to 1
+
+ return frames
+
+ def offload_model(self, keep_vae=False):
+ self.dit.clear_cross_kv()
+ self.prompt_emb_posi['stats'] = "offload"
+ self.load_models_to_device([])
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.to('cpu')
+ if not keep_vae:
+ self.TCDecoder.to('cpu')
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt=None,
+ negative_prompt="",
+ denoising_strength=1.0,
+ seed=None,
+ rand_device="gpu",
+ height=480,
+ width=832,
+ num_frames=81,
+ cfg_scale=5.0,
+ num_inference_steps=50,
+ sigma_shift=5.0,
+ tiled=True,
+ tile_size=(60, 104),
+ tile_stride=(30, 52),
+ tea_cache_l1_thresh=None,
+ tea_cache_model_id="Wan2.1-T2V-1.3B",
+ progress_bar_cmd=tqdm,
+ progress_bar_st=None,
+ LQ_video=None,
+ is_full_block=False,
+ if_buffer=False,
+ topk_ratio=2.0,
+ kv_ratio=3.0,
+ local_range = 9,
+ color_fix = True,
+ unload_dit = False,
+ force_offload = False,
+ ):
+ # 只接受 cfg=1.0(与原代码一致)
+ assert cfg_scale == 1.0, "cfg_scale must be 1.0"
+
+ # 要求:必须先 init_cross_kv()
+ if self.prompt_emb_posi is None or 'context' not in self.prompt_emb_posi:
+ raise RuntimeError(
+ "Cross-Attn KV 未初始化。请在调用 __call__ 前先执行:\n"
+ " pipe.init_cross_kv()\n"
+ "或传入自定义 context:\n"
+ " pipe.init_cross_kv(context_tensor=your_context_tensor)"
+ )
+
+ # 尺寸修正
+ height, width = self.check_resize_height_width(height, width)
+ if num_frames % 4 != 1:
+ num_frames = (num_frames + 2) // 4 * 4 + 1
+ print(f"Only `num_frames % 4 != 1` is acceptable. We round it up to {num_frames}.")
+
+ # Tiler 参数
+ tiler_kwargs = {"tiled": tiled, "tile_size": tile_size, "tile_stride": tile_stride}
+
+ # 初始化噪声
+ if if_buffer:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ else:
+ noise = self.generate_noise((1, 16, (num_frames - 1) // 4 + 1, height//8, width//8), seed=seed, device=self.device, dtype=self.torch_dtype)
+ # noise = noise.to(dtype=self.torch_dtype, device=self.device)
+ latents = noise
+
+ process_total_num = (num_frames - 1) // 8 - 2
+ is_stream = True
+
+ if self.prompt_emb_posi['stats'] == "offload":
+ self.init_cross_kv(context_tensor=self.prompt_emb_posi['context'])
+ self.load_models_to_device(["dit"])
+ self.dit.LQ_proj_in.to(self.device)
+ self.TCDecoder.to(self.device)
+
+ # 清理可能存在的 LQ_proj_in cache
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ frames_total = []
+ LQ_pre_idx = 0
+ LQ_cur_idx = 0
+ self.TCDecoder.clean_mem()
+
+ with torch.no_grad():
+ for cur_process_idx in progress_bar_cmd(range(process_total_num)):
+ if cur_process_idx == 0:
+ pre_cache_k = [None] * len(self.dit.blocks)
+ pre_cache_v = [None] * len(self.dit.blocks)
+ LQ_latents = None
+ inner_loop_num = 7
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, max(0, inner_idx*4-3):(inner_idx+1)*4-3, :, :].to(self.device)
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ LQ_cur_idx = (inner_loop_num-1)*4-3
+ cur_latents = latents[:, :, :6, :, :]
+ else:
+ LQ_latents = None
+ inner_loop_num = 2
+ for inner_idx in range(inner_loop_num):
+ cur = self.denoising_model().LQ_proj_in.stream_forward(
+ LQ_video[:, :, cur_process_idx*8+17+inner_idx*4:cur_process_idx*8+21+inner_idx*4, :, :].to(self.device)
+ ) if LQ_video is not None else None
+ if cur is None:
+ continue
+ if LQ_latents is None:
+ LQ_latents = cur
+ else:
+ for layer_idx in range(len(LQ_latents)):
+ LQ_latents[layer_idx] = torch.cat([LQ_latents[layer_idx], cur[layer_idx]], dim=1)
+ LQ_cur_idx = cur_process_idx*8+21+(inner_loop_num-2)*4
+ cur_latents = latents[:, :, 4+cur_process_idx*2:6+cur_process_idx*2, :, :]
+
+ # 推理(无 motion_controller / vace)
+ noise_pred_posi, pre_cache_k, pre_cache_v = model_fn_wan_video(
+ self.dit,
+ x=cur_latents,
+ timestep=self.timestep,
+ context=None,
+ tea_cache=None,
+ use_unified_sequence_parallel=False,
+ LQ_latents=LQ_latents,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k,
+ pre_cache_v=pre_cache_v,
+ topk_ratio=topk_ratio,
+ kv_ratio=kv_ratio,
+ cur_process_idx=cur_process_idx,
+ t_mod=self.t_mod,
+ t=self.t,
+ local_range = local_range,
+ )
+
+ # 更新 latent
+ cur_latents = cur_latents - noise_pred_posi
+
+ # Decode
+ cur_LQ_frame = LQ_video[:,:,LQ_pre_idx:LQ_cur_idx,:,:].to(self.device)
+ cur_frames = self.TCDecoder.decode_video(
+ cur_latents.transpose(1, 2),
+ parallel=False,
+ show_progress_bar=False,
+ cond=cur_LQ_frame).transpose(1, 2).mul_(2).sub_(1)
+
+ # 颜色校正(wavelet)
+ try:
+ if color_fix:
+ cur_frames = self.ColorCorrector(
+ cur_frames.to(device=self.device),
+ cur_LQ_frame,
+ clip_range=(-1, 1),
+ chunk_size=None,
+ method='adain'
+ )
+ except:
+ pass
+
+ frames_total.append(cur_frames.to('cpu'))
+ LQ_pre_idx = LQ_cur_idx
+
+ if unload_dit:
+ del noise_pred_posi, cur_frames, cur_latents, cur_LQ_frame
+ clean_vram()
+
+ if hasattr(self.dit, "LQ_proj_in"):
+ self.dit.LQ_proj_in.clear_cache()
+
+ self.TCDecoder.clean_mem()
+ if force_offload:
+ self.offload_model()
+
+ frames = torch.cat(frames_total, dim=2)
+
+ return frames[0]
+
+
+# -----------------------------
+# TeaCache(保留原逻辑;此处默认不启用)
+# -----------------------------
+class TeaCache:
+ def __init__(self, num_inference_steps, rel_l1_thresh, model_id):
+ self.num_inference_steps = num_inference_steps
+ self.step = 0
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = None
+ self.rel_l1_thresh = rel_l1_thresh
+ self.previous_residual = None
+ self.previous_hidden_states = None
+
+ self.coefficients_dict = {
+ "Wan2.1-T2V-1.3B": [-5.21862437e+04, 9.23041404e+03, -5.28275948e+02, 1.36987616e+01, -4.99875664e-02],
+ "Wan2.1-T2V-14B": [-3.03318725e+05, 4.90537029e+04, -2.65530556e+03, 5.87365115e+01, -3.15583525e-01],
+ "Wan2.1-I2V-14B-480P": [2.57151496e+05, -3.54229917e+04, 1.40286849e+03, -1.35890334e+01, 1.32517977e-01],
+ "Wan2.1-I2V-14B-720P": [8.10705460e+03, 2.13393892e+03, -3.72934672e+02, 1.66203073e+01, -4.17769401e-02],
+ }
+ if model_id not in self.coefficients_dict:
+ supported_model_ids = ", ".join([i for i in self.coefficients_dict])
+ raise ValueError(f"{model_id} is not a supported TeaCache model id. Please choose a valid model id in ({supported_model_ids}).")
+ self.coefficients = self.coefficients_dict[model_id]
+
+ def check(self, dit: WanModel, x, t_mod):
+ modulated_inp = t_mod.clone()
+ if self.step == 0 or self.step == self.num_inference_steps - 1:
+ should_calc = True
+ self.accumulated_rel_l1_distance = 0
+ else:
+ coefficients = self.coefficients
+ rescale_func = np.poly1d(coefficients)
+ self.accumulated_rel_l1_distance += rescale_func(((modulated_inp-self.previous_modulated_input).abs().mean() / self.previous_modulated_input.abs().mean()).cpu().item())
+ should_calc = not (self.accumulated_rel_l1_distance < self.rel_l1_thresh)
+ if should_calc:
+ self.accumulated_rel_l1_distance = 0
+ self.previous_modulated_input = modulated_inp
+ self.step = (self.step + 1) % self.num_inference_steps
+ if should_calc:
+ self.previous_hidden_states = x.clone()
+ return not should_calc
+
+ def store(self, hidden_states):
+ self.previous_residual = hidden_states - self.previous_hidden_states
+ self.previous_hidden_states = None
+
+ def update(self, hidden_states):
+ hidden_states = hidden_states + self.previous_residual
+ return hidden_states
+
+
+# -----------------------------
+# 简化版模型前向封装(无 vace / 无 motion_controller)
+# -----------------------------
+def model_fn_wan_video(
+ dit: WanModel,
+ x: torch.Tensor,
+ timestep: torch.Tensor,
+ context: torch.Tensor,
+ tea_cache: Optional[TeaCache] = None,
+ use_unified_sequence_parallel: bool = False,
+ LQ_latents: Optional[torch.Tensor] = None,
+ is_full_block: bool = False,
+ is_stream: bool = False,
+ pre_cache_k: Optional[list[torch.Tensor]] = None,
+ pre_cache_v: Optional[list[torch.Tensor]] = None,
+ topk_ratio: float = 2.0,
+ kv_ratio: float = 3.0,
+ cur_process_idx: int = 0,
+ t_mod : torch.Tensor = None,
+ t : torch.Tensor = None,
+ local_range: int = 9,
+ **kwargs,
+):
+ # patchify
+ x, (f, h, w) = dit.patchify(x)
+
+ win = (2, 8, 8)
+ seqlen = f // win[0]
+ local_num = seqlen
+ window_size = win[0] * h * w // 128
+ square_num = window_size * window_size
+ topk = int(square_num * topk_ratio) - 1
+ kv_len = int(kv_ratio)
+
+ # RoPE 位置(分段)
+ if cur_process_idx == 0:
+ freqs = torch.cat([
+ dit.freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+ else:
+ freqs = torch.cat([
+ dit.freqs[0][4 + cur_process_idx*2:4 + cur_process_idx*2 + f].view(f, 1, 1, -1).expand(f, h, w, -1),
+ dit.freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
+ dit.freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
+ ], dim=-1).reshape(f * h * w, 1, -1).to(x.device)
+
+ # TeaCache(默认不启用)
+ tea_cache_update = tea_cache.check(dit, x, t_mod) if tea_cache is not None else False
+
+ # 统一序列并行(此处默认关闭)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import (get_sequence_parallel_rank,
+ get_sequence_parallel_world_size,
+ get_sp_group)
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = torch.chunk(x, get_sequence_parallel_world_size(), dim=1)[get_sequence_parallel_rank()]
+
+ # Block 堆叠
+ if tea_cache_update:
+ x = tea_cache.update(x)
+ else:
+ for block_id, block in enumerate(dit.blocks):
+ if LQ_latents is not None and block_id < len(LQ_latents):
+ x = x + LQ_latents[block_id]
+ x, last_pre_cache_k, last_pre_cache_v = block(
+ x, context, t_mod, freqs, f, h, w,
+ local_num, topk,
+ block_id=block_id,
+ kv_len=kv_len,
+ is_full_block=is_full_block,
+ is_stream=is_stream,
+ pre_cache_k=pre_cache_k[block_id] if pre_cache_k is not None else None,
+ pre_cache_v=pre_cache_v[block_id] if pre_cache_v is not None else None,
+ local_range = local_range,
+ )
+ if pre_cache_k is not None: pre_cache_k[block_id] = last_pre_cache_k
+ if pre_cache_v is not None: pre_cache_v[block_id] = last_pre_cache_v
+
+ x = dit.head(x, t)
+ if use_unified_sequence_parallel:
+ import torch.distributed as dist
+ from xfuser.core.distributed import get_sp_group
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ x = get_sp_group().all_gather(x, dim=1)
+ x = dit.unpatchify(x, (f, h, w))
+ return x, pre_cache_k, pre_cache_v
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..744c8dd4bd216c137583dd6f5091d2da731fadf8
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/__init__.py
@@ -0,0 +1 @@
+from .flow_match import FlowMatchScheduler
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/flow_match.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/flow_match.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6d02195aac2345e1938044d8ffd310dc6c4d3b9
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/schedulers/flow_match.py
@@ -0,0 +1,79 @@
+import torch
+
+
+
+class FlowMatchScheduler():
+
+ def __init__(self, num_inference_steps=100, num_train_timesteps=1000, shift=3.0, sigma_max=1.0, sigma_min=0.003/1.002, inverse_timesteps=False, extra_one_step=False, reverse_sigmas=False):
+ self.num_train_timesteps = num_train_timesteps
+ self.shift = shift
+ self.sigma_max = sigma_max
+ self.sigma_min = sigma_min
+ self.inverse_timesteps = inverse_timesteps
+ self.extra_one_step = extra_one_step
+ self.reverse_sigmas = reverse_sigmas
+ self.set_timesteps(num_inference_steps)
+
+
+ def set_timesteps(self, num_inference_steps=100, denoising_strength=1.0, training=False, shift=None):
+ if shift is not None:
+ self.shift = shift
+ sigma_start = self.sigma_min + (self.sigma_max - self.sigma_min) * denoising_strength
+ if self.extra_one_step:
+ self.sigmas = torch.linspace(sigma_start, self.sigma_min, num_inference_steps + 1)[:-1]
+ else:
+ self.sigmas = torch.linspace(sigma_start, self.sigma_min, num_inference_steps)
+ if self.inverse_timesteps:
+ self.sigmas = torch.flip(self.sigmas, dims=[0])
+ self.sigmas = self.shift * self.sigmas / (1 + (self.shift - 1) * self.sigmas)
+ if self.reverse_sigmas:
+ self.sigmas = 1 - self.sigmas
+ self.timesteps = self.sigmas * self.num_train_timesteps
+ if training:
+ x = self.timesteps
+ y = torch.exp(-2 * ((x - num_inference_steps / 2) / num_inference_steps) ** 2)
+ y_shifted = y - y.min()
+ bsmntw_weighing = y_shifted * (num_inference_steps / y_shifted.sum())
+ self.linear_timesteps_weights = bsmntw_weighing
+
+
+ def step(self, model_output, timestep, sample, to_final=False, **kwargs):
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.cpu()
+ timestep_id = torch.argmin((self.timesteps - timestep).abs())
+ sigma = self.sigmas[timestep_id]
+ if to_final or timestep_id + 1 >= len(self.timesteps):
+ sigma_ = 1 if (self.inverse_timesteps or self.reverse_sigmas) else 0
+ else:
+ sigma_ = self.sigmas[timestep_id + 1]
+ prev_sample = sample + model_output * (sigma_ - sigma)
+ return prev_sample
+
+
+ def return_to_timestep(self, timestep, sample, sample_stablized):
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.cpu()
+ timestep_id = torch.argmin((self.timesteps - timestep).abs())
+ sigma = self.sigmas[timestep_id]
+ model_output = (sample - sample_stablized) / sigma
+ return model_output
+
+
+ def add_noise(self, original_samples, noise, timestep):
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.cpu()
+ timestep_id = torch.argmin((self.timesteps - timestep).abs())
+ sigma = self.sigmas[timestep_id]
+ sample = (1 - sigma) * original_samples + sigma * noise
+ return sample
+
+
+ def training_target(self, sample, noise, timestep):
+ target = noise - sample
+ return target
+
+
+ def training_weight(self, timestep):
+ timestep_id = torch.argmin((self.timesteps - timestep.to(self.timesteps.device)).abs())
+ weights = self.linear_timesteps_weights[timestep_id]
+ return weights
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/__init__.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..69a388db1dea2d5699b716260dfa0902c27c0ab5
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/__init__.py
@@ -0,0 +1 @@
+from .layers import *
diff --git a/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/layers.py b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9df39ed224bf44a611af3ab984cb84a5d12c527
--- /dev/null
+++ b/custom_nodes/ComfyUI-FlashVSR_Ultra_Fast/src/vram_management/layers.py
@@ -0,0 +1,95 @@
+import torch, copy
+from ..models.utils import init_weights_on_device
+
+
+def cast_to(weight, dtype, device):
+ r = torch.empty_like(weight, dtype=dtype, device=device)
+ r.copy_(weight)
+ return r
+
+
+class AutoWrappedModule(torch.nn.Module):
+ def __init__(self, module: torch.nn.Module, offload_dtype, offload_device, onload_dtype, onload_device, computation_dtype, computation_device):
+ super().__init__()
+ self.module = module.to(dtype=offload_dtype, device=offload_device)
+ self.offload_dtype = offload_dtype
+ self.offload_device = offload_device
+ self.onload_dtype = onload_dtype
+ self.onload_device = onload_device
+ self.computation_dtype = computation_dtype
+ self.computation_device = computation_device
+ self.state = 0
+
+ def offload(self):
+ if self.state == 1 and (self.offload_dtype != self.onload_dtype or self.offload_device != self.onload_device):
+ self.module.to(dtype=self.offload_dtype, device=self.offload_device)
+ self.state = 0
+
+ def onload(self):
+ if self.state == 0 and (self.offload_dtype != self.onload_dtype or self.offload_device != self.onload_device):
+ self.module.to(dtype=self.onload_dtype, device=self.onload_device)
+ self.state = 1
+
+ def forward(self, *args, **kwargs):
+ if self.onload_dtype == self.computation_dtype and self.onload_device == self.computation_device:
+ module = self.module
+ else:
+ module = copy.deepcopy(self.module).to(dtype=self.computation_dtype, device=self.computation_device)
+ return module(*args, **kwargs)
+
+
+class AutoWrappedLinear(torch.nn.Linear):
+ def __init__(self, module: torch.nn.Linear, offload_dtype, offload_device, onload_dtype, onload_device, computation_dtype, computation_device):
+ with init_weights_on_device(device=torch.device("meta")):
+ super().__init__(in_features=module.in_features, out_features=module.out_features, bias=module.bias is not None, dtype=offload_dtype, device=offload_device)
+ self.weight = module.weight
+ self.bias = module.bias
+ self.offload_dtype = offload_dtype
+ self.offload_device = offload_device
+ self.onload_dtype = onload_dtype
+ self.onload_device = onload_device
+ self.computation_dtype = computation_dtype
+ self.computation_device = computation_device
+ self.state = 0
+
+ def offload(self):
+ if self.state == 1 and (self.offload_dtype != self.onload_dtype or self.offload_device != self.onload_device):
+ self.to(dtype=self.offload_dtype, device=self.offload_device)
+ self.state = 0
+
+ def onload(self):
+ if self.state == 0 and (self.offload_dtype != self.onload_dtype or self.offload_device != self.onload_device):
+ self.to(dtype=self.onload_dtype, device=self.onload_device)
+ self.state = 1
+
+ def forward(self, x, *args, **kwargs):
+ if self.onload_dtype == self.computation_dtype and self.onload_device == self.computation_device:
+ weight, bias = self.weight, self.bias
+ else:
+ weight = cast_to(self.weight, self.computation_dtype, self.computation_device)
+ bias = None if self.bias is None else cast_to(self.bias, self.computation_dtype, self.computation_device)
+ return torch.nn.functional.linear(x, weight, bias)
+
+
+def enable_vram_management_recursively(model: torch.nn.Module, module_map: dict, module_config: dict, max_num_param=None, overflow_module_config: dict = None, total_num_param=0):
+ for name, module in model.named_children():
+ for source_module, target_module in module_map.items():
+ if isinstance(module, source_module):
+ num_param = sum(p.numel() for p in module.parameters())
+ if max_num_param is not None and total_num_param + num_param > max_num_param:
+ module_config_ = overflow_module_config
+ else:
+ module_config_ = module_config
+ module_ = target_module(module, **module_config_)
+ setattr(model, name, module_)
+ total_num_param += num_param
+ break
+ else:
+ total_num_param = enable_vram_management_recursively(module, module_map, module_config, max_num_param, overflow_module_config, total_num_param)
+ return total_num_param
+
+
+def enable_vram_management(model: torch.nn.Module, module_map: dict, module_config: dict, max_num_param=None, overflow_module_config: dict = None):
+ enable_vram_management_recursively(model, module_map, module_config, max_num_param, overflow_module_config, total_num_param=0)
+ model.vram_management_enabled = True
+
diff --git a/custom_nodes/ComfyUI-LCS/.gitignore b/custom_nodes/ComfyUI-LCS/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..16bb595a9895bc9d4a1bd311eabf767b85ac2f9b
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/.gitignore
@@ -0,0 +1,2 @@
+.claude/
+__pycache__/
diff --git a/custom_nodes/ComfyUI-LCS/README.md b/custom_nodes/ComfyUI-LCS/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b60676e72bf1d195553323109217277904f8429
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/README.md
@@ -0,0 +1,344 @@
+# ComfyUI-LCS
+
+Training-free color control via the **Latent Color Subspace**, plus **sharpness control** via a discovered sharpness subspace.
+
+> **Note:** This is an unofficial community implementation. For the official code, see [ExplainableML/LCS](https://github.com/ExplainableML/LCS).
+
+Based on ["The Latent Color Subspace"](https://arxiv.org/abs/2603.12261v1) (ICML 2026): color in diffusion model latent patch spaces lives in a **3D subspace** (PCA captures 100% color variance), while the remaining 61 dimensions encode structure and detail orthogonally.
+
+This plugin steers colors directly in the 3D LCS during diffusion sampling — no training, no LoRA, no post-processing.
+
+> [中文版 README](README_zh.md)
+
+## LCS vs Traditional Post-Processing
+
+LCS operates **during** diffusion sampling, not after — this is the key difference from traditional color grading (Photoshop, filters, etc.).
+
+| | Traditional Post-Processing | LCS |
+|---|---|---|
+| **When** | After VAE decode, in pixel space | During sampling, in latent space |
+| **Mechanism** | Color filter on the final image | Modifies 3D color subspace mid-generation |
+| **Model awareness** | None — structure already locked | Model adapts to color shifts in subsequent steps |
+| **Result** | Colors can look "painted on" | Colors look naturally intended by the model |
+
+For example: to get a warm orange sunset, post-processing tints everything orange (muddying shadows and skin tones), while LCS nudges the color subspace early in sampling so clouds, lighting, and reflections are *coherently* warm.
+
+The core insight: color and structure are **orthogonal** in the latent patch space — you can steer one without disturbing the other.
+
+## Tested Models
+
+| Model | Status |
+|-------|--------|
+| FLUX | Tested |
+| FLUX2.klein | Tested |
+| z-image | Tested |
+| z-image-turbo | Tested |
+| Wan (qwen-image) | Tested |
+| LTX2.3 | Tested |
+
+
+LCS calibrates per-VAE, so it should work with any model using a compatible VAE. Feel free to report results with other models.
+
+## Features
+
+- **Color Steering** — Push colors toward any target color
+- **Batch Multi-Color** — Different colors per batch item
+- **Tone Adjustment** — Contrast, brightness, saturation, temperature with one-click presets
+- **Color Anchor** — Zero-config color drift correction: self-anchor, reference-based, or spatial smoothing with auto mode
+- **Sharpness Control** — Sharpen or blur during generation via a discovered sharpness subspace (PC1 explains ~97% variance)
+- **Localized Control** — Optional mask for region-specific changes
+- **Latent Color Preview** — Visualize color structure without VAE decoding
+- **Step Observer** — Per-step color previews for debugging
+
+## Installation
+
+```bash
+cd ComfyUI/custom_nodes
+git clone https://github.com/facok/ComfyUI-LCS.git
+```
+
+Dependencies (usually already present in ComfyUI):
+
+```bash
+pip install einops safetensors
+```
+
+## Quick Start
+
+### Basic Color Control
+
+```
+LCS Load Data → LCS Color Intervene → KSampler
+ ↑
+ (pick a color)
+```
+
+1. **LCS Load Data** — connect your VAE (auto-calibrates on first run)
+2. **LCS Color Intervene** — connect MODEL and LCS_DATA, pick a target color
+3. Connect the output MODEL to KSampler
+
+### Tone Adjustment
+
+```
+LCS Load Data → LCS Tone Adjust → KSampler
+```
+
+1. **LCS Load Data** → **LCS Tone Adjust**
+2. Select a preset (e.g., "Cinematic") or adjust sliders manually
+
+
+
+
+### Sharpness Control
+
+```
+LCS Load Data ──→ LCS Sharpness Calibrate → LCS Sharpness Intervene → KSampler
+ ↑ lcs_data
+```
+
+1. **LCS Sharpness Calibrate** — connect VAE (auto-calibrates and caches). Optionally connect `lcs_data` from LCS Load Data to ensure sharpness edits don't affect color.
+2. **LCS Sharpness Intervene** — connect MODEL and SHARPNESS_DATA, set strength
+ - Positive strength → sharper
+ - Negative strength → blurrier
+ - 0 → no change
+
+### Multi-Color Batch
+
+```
+LCS Load Data → LCS Color Batch → KSampler
+ ↓
+ batch_size → EmptyLatentImage
+```
+
+Enter comma-separated hex colors (e.g., `#FF0000,#00FF00,#0000FF`). Each color applies to one batch item.
+
+### Color Anchor (Zero-Config Drift Correction)
+
+```
+LCS Load Data → LCS Color Anchor → KSampler
+```
+
+1. **LCS Load Data** → **LCS Color Anchor** — connect MODEL and LCS_DATA
+2. Set mode to **auto** (default) and leave intensity at default
+3. Connect the output MODEL to KSampler
+
+That's it. In `auto` mode, the node automatically selects the correction strategy based on which optional inputs are connected:
+
+| Connected Inputs | Resolved Mode | Behavior |
+|---|---|---|
+| Nothing | self_anchor | Learns the image's color patterns early on, then prevents sudden color shifts |
+| reference_image + vae | reference | Keeps generated colors close to your reference image |
+| mask (no reference) | smooth | Smooths out color seams (great for inpainting) |
+
+Intensity is also derived automatically from measured drift — no manual tuning needed.
+
+> **When to use manual mode:** If you want full control, set mode to `smooth`, `reference`, or `self_anchor` explicitly and adjust the `intensity` slider (0–1). Auto mode is designed for zero-config "just works" usage.
+
+## Nodes
+
+### Calibration
+
+| Node | Description |
+|------|-------------|
+| **LCS Load Data** | Auto-calibrate and cache LCS color data per-VAE. Fingerprints VAE weights for automatic cache management. |
+| **LCS Sharpness Calibrate** | Discover sharpness subspace via PCA on blur stimuli. Optionally connect `lcs_data` for color-orthogonal sharpness. |
+
+Calibration runs once per VAE and caches automatically. Subsequent runs load instantly.
+
+### Intervention
+
+| Node | Description |
+|------|-------------|
+| **LCS Color Intervene** | Steer colors toward a target. Supports Type I (LCS shift), Type II (HSL shift), or interpolated mode. |
+| **LCS Color Batch** | Different target colors per batch item. Outputs `batch_size` for EmptyLatentImage. |
+| **LCS Tone Adjust** | Contrast, brightness, saturation, temperature. Preset dropdown with real-time slider sync. |
+| **LCS Color Anchor** | Correct color drift during sampling. Auto mode infers strategy and intensity from connected inputs. |
+| **LCS Sharpness Intervene** | Control sharpness during generation. Positive = sharper, negative = blurrier. |
+
+### Observation
+
+| Node | Description |
+|------|-------------|
+| **LCS Preview Colors** | Decode latent colors to RGB preview without VAE decoding. |
+| **LCS Step Observer** | Save per-step color preview PNGs to ComfyUI temp directory. |
+
+## Intervention Modes
+
+| Mode | Description | Best For |
+|------|-------------|----------|
+| **interpolated** (default) | Blends Type I and Type II using sigma | General use |
+| **type_i** | Direct translation in 3D LCS space | Strong global color shifts |
+| **type_ii** | Per-patch HSL interpolation via bicone geometry | Precise local color control |
+
+## Key Parameters
+
+### Color Intervention
+- **strength** (0.0–2.0): Intervention intensity. 1.0 = full, 0.0 = none.
+- **start_step / end_step**: Step range for intervention. Paper optimal: steps 8–10 of 50.
+- **mask**: Optional. Downsampled to patch grid for localized control.
+
+### Sharpness Intervention
+- **strength** (-5.0–5.0): Positive = sharper, negative = blurrier, 0 = no change.
+- **start_step / end_step**: Step range (default 5–15).
+- **mask**: Optional. Localized sharpness control.
+
+> **Tip for distilled models**: Step-distilled models (e.g., z-image-turbo) use far fewer steps, so intervention should start earlier — even from step 0.
+
+### Color Anchor
+
+Sometimes diffusion models produce unexpected color shifts during sampling — a blue sky suddenly turns purple, or inpainting leaves visible color seams. The Color Anchor node fixes these problems by monitoring and correcting colors as the image is being generated.
+
+**Modes:**
+
+| Mode | What it does | When to use |
+|------|-------------|----------|
+| **auto** (default) | Looks at what you connected and picks the best strategy for you | Just want it to work, no config needed |
+| **self_anchor** | Watches how colors evolve in early steps, then prevents sudden color jumps in later steps | General color stability, no reference needed |
+| **reference** | Keeps the generated image's colors close to a reference image you provide | "Make it look like this photo's color palette" |
+| **smooth** | Smooths out abrupt color boundaries between regions | Fixing visible seams after inpainting |
+
+**How auto mode picks for you:**
+
+1. **Which strategy?** Based on what you plugged in:
+ - Connected a reference image + VAE → uses `reference`
+ - Connected a mask (but no reference) → uses `smooth`
+ - Connected nothing extra → uses `self_anchor`
+2. **How strong?** The node measures how much color drift is actually happening, then sets the correction strength accordingly. Big drift → stronger fix. Small drift → gentle touch. The range is 0.15–0.6, so it never over-corrects or does nothing.
+
+**What happens during sampling:**
+
+The node runs at every sampling step but doesn't always intervene. It automatically figures out which steps are safe to correct:
+
+1. **Early steps** (image is mostly noise) — Too early to fix colors without creating artifacts. Skipped. In self_anchor mode, the node uses these steps to *learn* the image's color patterns.
+2. **Middle steps** (image is taking shape) — The sweet spot. The node applies corrections here, ramping smoothly in and out to avoid sudden changes.
+3. **Late steps** (fine details) — Corrections would disturb fine detail. Skipped.
+
+Only colors are modified — structure, texture, and detail are never touched.
+
+**Parameters:**
+
+- **mode**: `auto`, `smooth`, `reference`, or `self_anchor`
+- **intensity** (0.0–1.0): How strong the correction is. In `auto` mode this is determined automatically. Set to 0 to disable the node entirely.
+- **vae** (optional): Needed for `reference` mode to encode the reference image
+- **reference_image** (optional): The image whose colors you want to match
+- **mask** (optional): Only correct colors inside the masked area
+
+## Tone Presets
+
+Select a preset — sliders update in real-time. Tweak after selecting for fine-tuning. Select **Custom** to set values manually.
+
+| Preset | Contrast | Brightness | Saturation | Temperature |
+|--------|----------|------------|------------|-------------|
+| Base | 1.0 | 0.0 | 1.0 | 0.0 |
+| Cinematic | 1.20 | -0.05 | 0.90 | 0.05 |
+| HDR | 1.40 | 0.0 | 1.20 | 0.0 |
+| Vivid | 1.10 | 0.0 | 1.50 | 0.0 |
+| Dramatic | 1.50 | -0.10 | 0.85 | 0.0 |
+| Low Key | 1.30 | -0.20 | 0.80 | 0.0 |
+| High Key | 0.80 | 0.20 | 0.90 | 0.0 |
+| Warm | 1.05 | 0.03 | 1.10 | 0.30 |
+| Cool | 1.05 | 0.0 | 1.05 | -0.30 |
+| Desaturated | 1.0 | 0.0 | 0.40 | 0.0 |
+
+## How It Works
+
+### Color (LCS)
+
+1. **Project** — Convert denoised prediction to 64D patch space, project onto 3D LCS basis
+2. **Decompose** — Separate 3D color coordinates from the 61D structural residual
+3. **Normalize** — Transform to reference timestep (t=50) using learned alpha/beta statistics
+4. **Manipulate** — Shift colors, adjust tone, or apply other transformations in 3D LCS
+5. **Reconstruct** — Denormalize, add back the preserved 61D residual, convert to latent space
+
+The 61D residual (structure, texture, detail) is never modified — only the 3D color subspace is touched.
+
+### Sharpness
+
+Sharpness lives in a separate subspace orthogonal to color:
+
+1. **Calibrate** — Generate grayscale noise images at multiple blur levels, VAE-encode, PCA on color-removed patch vectors. PC1 captures ~97% of sharpness variance.
+2. **Intervene** — Add `strength * pc1_direction` to each patch. Since pc1_direction is orthogonal to color (calibrated with LCS removal) and DC-free (per-vector zero-mean before PCA), this modifies only spatial frequency content without affecting color or brightness.
+
+### Color Anchor
+
+The Color Anchor stabilizes colors without pushing them toward a specific target — it prevents drift from what the model is already generating:
+
+1. **Decide when to act** — The node checks each sampling step: is the image still mostly noise (too early), taking shape (good time to correct), or nearly finished (too late)? It only corrects during the safe middle window.
+2. **Learn the color pattern** (self_anchor) — During early noisy steps, the node watches how colors relate to their neighbors and builds a running average of these relationships. This is more reliable than tracking absolute colors, which shift naturally as the image forms.
+3. **Measure drift** — On the first correction step, the node measures how much the colors have actually drifted (varies by mode: step-to-step jumps, distance from reference, or spatial roughness). This sets the correction strength in auto mode.
+4. **Apply gentle corrections** — Corrections ramp smoothly in and out (no sudden jumps). Each mode corrects differently: self_anchor fixes patches that deviate from learned patterns, reference pulls toward the reference image's colors, smooth blurs out sharp color boundaries.
+5. **Preserve everything else** — As with all LCS operations, only the 3D color coordinates change. Structure, texture, and detail are untouched.
+
+## File Structure
+
+```
+ComfyUI-LCS/
+├── __init__.py # Entry point (V3 + V2 compat)
+├── requirements.txt
+├── core/
+│ ├── adaptive.py # Adaptive scheduling (phases, envelopes, drift estimation)
+│ ├── bilateral.py # Bilateral filter for LCS color smoothing
+│ ├── calibration.py # PCA calibration pipeline (color)
+│ ├── color_space.py # Bicone LCS ↔ HSL mapping
+│ ├── defaults.py # Alpha/beta tables from paper
+│ ├── lcs_data.py # LCSData dataclass
+│ ├── patchify.py # Patch ↔ latent conversion
+│ ├── relationships.py # Local color relationship analysis & anomaly detection
+│ ├── sampling.py # Shared constants & step utilities
+│ ├── sharpness.py # Sharpness subspace calibration
+│ └── timestep.py # Sigma/timestep utilities
+├── nodes/
+│ ├── anchor.py # LCSColorAnchor (adaptive color drift correction)
+│ ├── calibrate.py # LCSLoadData (auto-calibrate + cache)
+│ ├── intervene.py # LCSColorIntervene, LCSColorBatch, LCSToneAdjust
+│ ├── observe.py # LCSPreviewColors, LCSStepObserver
+│ └── sharpen.py # LCSSharpnessCalibrate, LCSSharpnessIntervene
+├── data/ # Cached calibration files
+└── web/js/
+ └── tone_preset.js # Frontend preset sync
+```
+
+## Changelog
+
+### 2026-03-21
+- **Color Anchor: auto mode** — New `auto` mode that infers correction strategy (self_anchor / reference / smooth) from connected inputs and derives intensity from measured drift. Zero-config usage.
+- **Color Anchor: adaptive scheduling** — Phase assignment (observe/correct/skip) and strength envelope are derived from the sigma schedule at runtime.
+
+### 2026-03-20
+- **Sharpness Control** — New sharpness subspace discovered via PCA on blur stimuli. `LCS Sharpness Calibrate` + `LCS Sharpness Intervene` nodes. PC1 explains ~97% variance, orthogonal to color.
+- **Color-orthogonal sharpness** — Optional `lcs_data` input removes color component during sharpness calibration, preventing color shift.
+
+### 2026-03-19
+- **Video VAE support (Wan)** — Handle 5D video latents in patchify/unpatchify. Per-image VAE encoding fallback for video VAEs.
+- **LTXV compatibility** — Pad odd spatial dims in patchify, handle 3D tensors, skip gracefully for incompatible formats.
+- **FLUX2 support** — Auto-detect 128-channel latents in unpatchify.
+- **Universal latent format** — Use model's `latent_format` for space conversion instead of hardcoded FLUX constants.
+
+### 2026-03-18
+- **Tone Adjust** — `LCS Tone Adjust` node with contrast, brightness, saturation, temperature sliders. 10 presets with frontend real-time sync.
+- **Color temperature** — Warm/cool shift along LCS blue-yellow axis.
+- **Bicone HSL geometry** — Correct Type II intervention via bicone LCS-to-HSL mapping.
+
+### 2026-03-17
+- **Initial release** — Color steering (Type I + Type II + interpolated), batch multi-color, localized mask control, latent color preview, step observer. Per-VAE auto-calibration with caching.
+
+## Citation
+
+Official repository: [ExplainableML/LCS](https://github.com/ExplainableML/LCS)
+
+```bibtex
+@article{pach2026latentcolorsubspace,
+ title={The Latent Color Subspace: Emergent Order in High-Dimensional Chaos},
+ author={Mateusz Pach and Jessica Bader and Quentin Bouniot and Serge Belongie and Zeynep Akata},
+ journal={arxiv},
+ year={2026}
+}
+```
+
+## Acknowledgments
+
+Thanks to Mateusz Pach, Jessica Bader, Quentin Bouniot, Serge Belongie, and Zeynep Akata for their research making training-free color control possible.
+
+## License
+
+MIT
diff --git a/custom_nodes/ComfyUI-LCS/README_zh.md b/custom_nodes/ComfyUI-LCS/README_zh.md
new file mode 100644
index 0000000000000000000000000000000000000000..74404355d02edb11207fe03fad45b85f80fcfc22
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/README_zh.md
@@ -0,0 +1,343 @@
+# ComfyUI-LCS
+
+基于**潜在颜色子空间**(Latent Color Subspace)的免训练颜色控制,以及基于发现的**锐度子空间**的锐度控制。
+
+> **注意:** 本项目为非官方社区实现。官方代码见 [ExplainableML/LCS](https://github.com/ExplainableML/LCS)。
+
+基于论文 ["The Latent Color Subspace"](https://arxiv.org/abs/2603.12261v1)(ICML 2026):扩散模型潜在 patch 空间中的颜色完全存在于一个 **3 维子空间**(PCA 捕获 100% 颜色方差),剩余 61 维编码结构与细节,与颜色正交。
+
+本插件在扩散采样过程中直接操作 3D LCS 控制颜色——无需训练、无需 LoRA、无需后处理。
+
+> [English README](README.md)
+
+## LCS 与传统后处理调色的区别
+
+LCS 在扩散采样**过程中**操作,而非生成之后——这是与传统调色(Photoshop、滤镜等)的根本区别。
+
+| | 传统后处理 | LCS |
+|---|---|---|
+| **时机** | VAE 解码后,像素空间 | 采样过程中,潜在空间 |
+| **机制** | 对成品图像施加颜色滤镜 | 在生成中途修改 3D 颜色子空间 |
+| **模型感知** | 无——结构已定型 | 模型在后续步骤中自适应颜色偏移 |
+| **效果** | 颜色容易显得"涂上去的" | 颜色与内容自然融合 |
+
+例:想要暖橙色日落,后处理会给全图叠橙色(阴影和肤色变脏),而 LCS 在采样早期推动颜色子空间,模型生成的云层、光照、反射与暖色调**内在一致**。
+
+核心发现:颜色与结构在潜在 patch 空间中**正交**——可以单独控制颜色而不干扰结构。
+
+## 已测试模型
+
+| 模型 | 状态 |
+|------|------|
+| FLUX | 已测试 |
+| FLUX2.klein | 已测试 |
+| z-image | 已测试 |
+| z-image-turbo | 已测试 |
+| Wan (qwen-image) | 已测试 |
+| LTX2.3 | 已测试 |
+
+LCS 按 VAE 校准,理论上适用于任何使用兼容 VAE 架构的模型。欢迎反馈其他模型的测试结果。
+
+## 功能
+
+- **颜色引导** — 将颜色推向任意目标色
+- **批量多色** — 为批次中每张图像指定不同颜色
+- **色调调整** — 对比度、亮度、饱和度、色温,支持一键预设
+- **颜色锚定** — 零配置颜色漂移校正:自锚定、参考图锚定、空间平滑,支持全自动模式
+- **锐度控制** — 在生成过程中增强或减弱锐度,基于发现的锐度子空间(PC1 解释 ~97% 方差)
+- **局部控制** — 可选遮罩,实现区域性变化
+- **潜在颜色预览** — 无需 VAE 解码即可可视化颜色结构
+- **步骤观察器** — 保存每步颜色预览,用于调试
+
+## 安装
+
+```bash
+cd ComfyUI/custom_nodes
+git clone https://github.com/facok/ComfyUI-LCS.git
+```
+
+依赖(通常 ComfyUI 已自带):
+
+```bash
+pip install einops safetensors
+```
+
+## 快速开始
+
+### 基本颜色控制
+
+```
+LCS Load Data → LCS Color Intervene → KSampler
+ ↑
+ (选择颜色)
+```
+
+1. **LCS Load Data** — 连接 VAE(首次运行自动校准)
+2. **LCS Color Intervene** — 连接 MODEL 和 LCS_DATA,选择目标颜色
+3. 将输出 MODEL 连接到 KSampler
+
+### 色调调整
+
+```
+LCS Load Data → LCS Tone Adjust → KSampler
+```
+
+1. **LCS Load Data** → **LCS Tone Adjust**
+2. 选择预设(如 "Cinematic")或手动调整滑条
+
+
+
+### 锐度控制
+
+```
+LCS Load Data ──→ LCS Sharpness Calibrate → LCS Sharpness Intervene → KSampler
+ ↑ lcs_data
+```
+
+1. **LCS Sharpness Calibrate** — 连接 VAE(首次运行自动校准并缓存)。可选连接 `lcs_data`(来自 LCS Load Data),确保锐度编辑不影响颜色。
+2. **LCS Sharpness Intervene** — 连接 MODEL 和 SHARPNESS_DATA,设置强度
+ - 正值 → 更锐利
+ - 负值 → 更模糊
+ - 0 → 无变化
+
+
+### 批量多色生成
+
+```
+LCS Load Data → LCS Color Batch → KSampler
+ ↓
+ batch_size → EmptyLatentImage
+```
+
+输入逗号分隔的十六进制颜色(如 `#FF0000,#00FF00,#0000FF`),每个颜色对应一个批次项。
+
+### 颜色锚定(零配置漂移校正)
+
+```
+LCS Load Data → LCS Color Anchor → KSampler
+```
+
+1. **LCS Load Data** → **LCS Color Anchor** — 连接 MODEL 和 LCS_DATA
+2. 模式设为 **auto**(默认),intensity 保持默认值
+3. 将输出 MODEL 连接到 KSampler
+
+完成。在 `auto` 模式下,节点根据连接的可选输入自动选择校正策略:
+
+| 已连接输入 | 解析模式 | 行为 |
+|---|---|---|
+| 无 | self_anchor | 在早期学习图像的颜色规律,然后防止突然的颜色偏移 |
+| reference_image + vae | reference | 让生成的颜色贴近你的参考图 |
+| mask(无参考图) | smooth | 平滑颜色接缝(很适合修复/补绘) |
+
+intensity 也会根据实测漂移自动推导——无需手动调参。
+
+> **手动模式:** 如果需要完全控制,可以将模式设为 `smooth`、`reference` 或 `self_anchor`,并手动调节 `intensity` 滑条(0–1)。auto 模式适合零配置「开箱即用」场景。
+
+## 节点一览
+
+### 校准
+
+| 节点 | 说明 |
+|------|------|
+| **LCS Load Data** | 自动校准并按 VAE 缓存 LCS 颜色数据。通过 VAE 权重指纹自动管理缓存。 |
+| **LCS Sharpness Calibrate** | 通过模糊刺激 PCA 发现锐度子空间。可选连接 `lcs_data` 使锐度正交于颜色。 |
+
+每个 VAE 只需校准一次,结果自动缓存,后续运行瞬时加载。
+
+### 干预
+
+| 节点 | 说明 |
+|------|------|
+| **LCS Color Intervene** | 将颜色引导至目标色。支持 Type I(LCS 平移)、Type II(HSL 偏移)或插值模式。 |
+| **LCS Color Batch** | 每个批次项施加不同目标颜色。输出 `batch_size` 可连接 EmptyLatentImage。 |
+| **LCS Tone Adjust** | 对比度、亮度、饱和度、色温调整。预设下拉菜单,滑条实时同步。 |
+| **LCS Color Anchor** | 采样过程中校正颜色漂移。auto 模式根据连接输入自动推断策略和强度。 |
+| **LCS Sharpness Intervene** | 在生成过程中控制锐度。正值 = 更锐利,负值 = 更模糊。 |
+
+### 观察
+
+| 节点 | 说明 |
+|------|------|
+| **LCS Preview Colors** | 将潜在颜色解码为 RGB 预览图,无需 VAE 解码。 |
+| **LCS Step Observer** | 将每步颜色预览 PNG 保存至 ComfyUI 临时目录。 |
+
+## 干预模式
+
+| 模式 | 说明 | 适用场景 |
+|------|------|----------|
+| **interpolated**(默认) | 以 sigma 为权重混合 Type I 和 Type II | 通用场景 |
+| **type_i** | 3D LCS 空间中的直接平移 | 强烈的全局颜色偏移 |
+| **type_ii** | 通过双锥几何进行逐 patch HSL 插值 | 精确的局部颜色控制 |
+
+## 关键参数
+
+### 颜色干预
+- **strength**(0.0–2.0):干预强度。1.0 = 完整干预,0.0 = 无干预。
+- **start_step / end_step**:干预步骤范围。论文最优:50 步中的第 8–10 步。
+- **mask**:可选。下采样至 patch 网格分辨率,用于局部控制。
+
+### 锐度干预
+- **strength**(-5.0–5.0):正值 = 更锐利,负值 = 更模糊,0 = 无变化。
+- **start_step / end_step**:干预步骤范围(默认 5–15)。
+- **mask**:可选。用于局部锐度控制。
+
+> **步数蒸馏模型提示**:对于步数蒸馏模型(如 z-image-turbo),总步数很少,干预应从更早的步骤开始——甚至可以从第 0 步就开始干预。
+
+### 颜色锚定
+
+扩散模型在采样过程中有时会出现意想不到的颜色偏移——蓝天突然变紫,或者修复/补绘后留下明显的颜色接缝。颜色锚定节点在图像生成过程中监控和修正这些问题。
+
+**模式:**
+
+| 模式 | 功能 | 适用场景 |
+|------|------|----------|
+| **auto**(默认) | 根据你连接的输入自动选最合适的策略 | 不想调参,开箱即用 |
+| **self_anchor** | 在早期步骤观察颜色变化规律,在后续步骤防止突然的颜色跳变 | 通用颜色稳定,不需要参考图 |
+| **reference** | 让生成图像的颜色贴近你提供的参考图 | 「我想要这张照片的配色风格」 |
+| **smooth** | 平滑区域之间的突兀颜色边界 | 修复/补绘后消除接缝 |
+
+**auto 模式如何自动选择:**
+
+1. **用哪种策略?** 看你连了什么:
+ - 连了参考图 + VAE → 用 `reference`
+ - 连了遮罩(没有参考图)→ 用 `smooth`
+ - 什么额外输入都没连 → 用 `self_anchor`
+2. **修正多强?** 节点会测量实际的颜色漂移幅度,据此自动设置校正强度。漂移大 → 修正更强;漂移小 → 轻轻一碰。范围是 0.15–0.6,既不会矫枉过正,也不会毫无作用。
+
+**采样过程中发生了什么:**
+
+节点在每个采样步都会运行,但不会每步都干预。它自动判断哪些步骤适合校正:
+
+1. **早期步骤**(图像基本是噪声)— 太早修正颜色会产生伪影,跳过。在 self_anchor 模式下,节点利用这些步骤*学习*图像的颜色规律。
+2. **中间步骤**(图像逐渐成形)— 最佳校正时机。节点在这里施加校正,平滑地渐入渐出,避免突变。
+3. **后期步骤**(精细细节)— 校正会干扰细节,跳过。
+
+只修改颜色——结构、纹理、细节始终不受影响。
+
+**参数:**
+
+- **mode**:`auto`、`smooth`、`reference` 或 `self_anchor`
+- **intensity**(0.0–1.0):校正强度。auto 模式下自动决定。设为 0 可完全禁用此节点。
+- **vae**(可选):reference 模式需要用它来编码参考图
+- **reference_image**(可选):你想匹配其颜色的参考图
+- **mask**(可选):只在遮罩区域内校正颜色
+
+## 色调预设
+
+选择预设后滑条实时更新。可在预设基础上微调。选择 **Custom** 可完全手动设置。
+
+| 预设 | 对比度 | 亮度 | 饱和度 | 色温 |
+|------|--------|------|--------|------|
+| Base | 1.0 | 0.0 | 1.0 | 0.0 |
+| Cinematic | 1.20 | -0.05 | 0.90 | 0.05 |
+| HDR | 1.40 | 0.0 | 1.20 | 0.0 |
+| Vivid | 1.10 | 0.0 | 1.50 | 0.0 |
+| Dramatic | 1.50 | -0.10 | 0.85 | 0.0 |
+| Low Key | 1.30 | -0.20 | 0.80 | 0.0 |
+| High Key | 0.80 | 0.20 | 0.90 | 0.0 |
+| Warm | 1.05 | 0.03 | 1.10 | 0.30 |
+| Cool | 1.05 | 0.0 | 1.05 | -0.30 |
+| Desaturated | 1.0 | 0.0 | 0.40 | 0.0 |
+
+## 工作原理
+
+### 颜色(LCS)
+
+1. **投影** — 将去噪预测转换到 64D patch 空间,投影到 3D LCS 基底
+2. **分解** — 将 3D 颜色坐标与 61D 结构残差分离
+3. **归一化** — 使用学习的 alpha/beta 统计量变换至参考时间步(t=50)
+4. **操作** — 在 3D LCS 中偏移颜色、调整色调或进行其他变换
+5. **重建** — 反归一化,加回保留的 61D 残差,转换回潜在空间
+
+61D 残差(结构、纹理、细节)始终不被修改——只有 3D 颜色子空间会被改变。
+
+### 锐度
+
+锐度存在于与颜色正交的独立子空间中:
+
+1. **校准** — 生成灰度噪声图像,应用多级高斯模糊,VAE 编码后对去除颜色分量的 patch 向量做 PCA。PC1 捕获 ~97% 的锐度方差。
+2. **干预** — 在每个 patch 上沿 `strength * pc1_direction` 方向添加偏移。由于 pc1_direction 与颜色正交(校准时已移除 LCS 分量)且无直流分量(PCA 前做了逐向量零均值化),因此只改变空间频率内容,不影响颜色或亮度。
+
+### 颜色锚定
+
+颜色锚定的作用是稳定颜色,而不是把颜色推向某个特定目标——它防止模型已经在生成的颜色发生偏移:
+
+1. **判断何时介入** — 节点检查每个采样步:图像还是一片噪声(太早)、正在成形(适合校正)、还是快完成了(太晚)?只在安全的中间窗口进行校正。
+2. **学习颜色规律**(self_anchor)— 在早期噪声较大的步骤中,节点观察每个区域的颜色与邻居之间的关系,建立一个动态平均值。比起追踪绝对颜色值,这种「相对关系」更可靠,因为绝对颜色在图像成形过程中本来就会自然变化。
+3. **测量漂移** — 在第一个校正步,节点测量颜色实际漂移了多少(根据模式不同:步间跳变幅度、与参考图的差距、或空间粗糙程度)。这决定了 auto 模式下的校正强度。
+4. **温和地修正** — 校正平滑地渐入渐出(不会突变)。每种模式的修正方式不同:self_anchor 修复偏离已学规律的区域,reference 拉近与参考图的颜色,smooth 模糊掉尖锐的颜色边界。
+5. **保留其他一切** — 与所有 LCS 操作一样,只修改 3D 颜色坐标,结构、纹理、细节完全不受影响。
+
+## 文件结构
+
+```
+ComfyUI-LCS/
+├── __init__.py # 入口(V3 + V2 兼容)
+├── requirements.txt
+├── core/
+│ ├── adaptive.py # 自适应调度(阶段、包络、漂移估计)
+│ ├── bilateral.py # LCS 颜色平滑的双边滤波
+│ ├── calibration.py # PCA 校准流程(颜色)
+│ ├── color_space.py # 双锥 LCS ↔ HSL 映射
+│ ├── defaults.py # 论文中的 Alpha/beta 表
+│ ├── lcs_data.py # LCSData 数据类
+│ ├── patchify.py # Patch ↔ 潜在空间转换
+│ ├── relationships.py # 局部颜色关系分析与异常检测
+│ ├── sampling.py # 共享常量和步骤工具
+│ ├── sharpness.py # 锐度子空间校准
+│ └── timestep.py # Sigma/时间步工具
+├── nodes/
+│ ├── anchor.py # LCSColorAnchor(自适应颜色漂移校正)
+│ ├── calibrate.py # LCSLoadData(自动校准 + 缓存)
+│ ├── intervene.py # LCSColorIntervene, LCSColorBatch, LCSToneAdjust
+│ ├── observe.py # LCSPreviewColors, LCSStepObserver
+│ └── sharpen.py # LCSSharpnessCalibrate, LCSSharpnessIntervene
+├── data/ # 缓存的校准文件
+└── web/js/
+ └── tone_preset.js # 前端预设同步
+```
+
+## 更新日志
+
+### 2026-03-21
+- **颜色锚定:auto 模式** — 新增 `auto` 模式,根据连接的输入自动推断校正策略(self_anchor / reference / smooth),并根据实测漂移推导强度。零配置使用。
+- **颜色锚定:自适应调度** — 阶段分配(observe/correct/skip)和强度包络在运行时从 sigma 调度表推导。
+
+### 2026-03-20
+- **锐度控制** — 通过模糊刺激 PCA 发现锐度子空间。新增 `LCS Sharpness Calibrate` + `LCS Sharpness Intervene` 节点。PC1 解释 ~97% 方差,与颜色正交。
+- **颜色正交锐度** — 可选连接 `lcs_data`,在锐度校准时移除颜色分量,防止颜色偏移。
+
+### 2026-03-19
+- **视频 VAE 支持(Wan)** — 在 patchify/unpatchify 中处理 5D 视频潜在表示。视频 VAE 自动回退到逐帧编码。
+- **LTXV 兼容** — patchify 中填充奇数空间维度,处理 3D 张量,不兼容格式时优雅跳过。
+- **FLUX2 支持** — unpatchify 自动检测 128 通道潜在表示。
+- **通用潜在格式** — 使用模型的 `latent_format` 进行空间转换,不再硬编码 FLUX 常量。
+
+### 2026-03-18
+- **色调调整** — `LCS Tone Adjust` 节点,支持对比度、亮度、饱和度、色温滑条。10 个预设,前端实时同步。
+- **色温控制** — 沿 LCS 蓝-黄轴的暖/冷偏移。
+- **双锥 HSL 几何** — 通过双锥 LCS-to-HSL 映射实现正确的 Type II 干预。
+
+### 2026-03-17
+- **首次发布** — 颜色引导(Type I + Type II + 插值模式)、批量多色、局部遮罩控制、潜在颜色预览、步骤观察器。按 VAE 自动校准并缓存。
+
+## 引用
+
+官方仓库:[ExplainableML/LCS](https://github.com/ExplainableML/LCS)
+
+```bibtex
+@article{pach2026latentcolorsubspace,
+ title={The Latent Color Subspace: Emergent Order in High-Dimensional Chaos},
+ author={Mateusz Pach and Jessica Bader and Quentin Bouniot and Serge Belongie and Zeynep Akata},
+ journal={arxiv},
+ year={2026}
+}
+```
+
+## 致谢
+
+感谢 Mateusz Pach、Jessica Bader、Quentin Bouniot、Serge Belongie 和 Zeynep Akata,他们的研究使免训练颜色控制成为可能。
+
+## 许可证
+
+MIT
diff --git a/custom_nodes/ComfyUI-LCS/__init__.py b/custom_nodes/ComfyUI-LCS/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..70ba7471ce85cc5cf323fe2e0872df1f146d1418
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/__init__.py
@@ -0,0 +1,53 @@
+"""ComfyUI-LCS: The Latent Color Subspace — training-free color control for FLUX.
+
+Paper: "The Latent Color Subspace" (arXiv:2603.12261v1, ICML 2026)
+"""
+
+# Register as ComfyUI_LCS so other plugins can `from ComfyUI_LCS.core.xxx import ...`
+import sys as _sys
+_sys.modules.setdefault("ComfyUI_LCS", _sys.modules[__name__])
+
+# V3 ComfyExtension entry point
+from comfy_api.latest import ComfyExtension, io
+from .nodes.calibrate import LCSLoadData
+from .nodes.intervene import LCSColorIntervene, LCSColorBatch, LCSToneAdjust
+from .nodes.observe import LCSPreviewColors, LCSStepObserver
+from .nodes.sharpen import LCSSharpnessCalibrate, LCSSharpnessIntervene
+from .nodes.anchor import LCSColorAnchor
+
+
+class LCSExtension(ComfyExtension):
+ """V3 ComfyExtension providing all LCS nodes to ComfyUI."""
+
+ async def get_node_list(self) -> list[type[io.ComfyNode]]:
+ """Return all LCS node classes."""
+ return [
+ LCSLoadData,
+ LCSColorIntervene,
+ LCSColorBatch,
+ LCSToneAdjust,
+ LCSPreviewColors,
+ LCSStepObserver,
+ LCSSharpnessCalibrate,
+ LCSSharpnessIntervene,
+ LCSColorAnchor,
+ ]
+
+
+async def comfy_entrypoint() -> LCSExtension:
+ """V3 async entry point called by ComfyUI on startup."""
+ return LCSExtension()
+
+
+# V2 backward compatibility
+from .nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
+
+WEB_DIRECTORY = "./web"
+
+__all__ = [
+ "NODE_CLASS_MAPPINGS",
+ "NODE_DISPLAY_NAME_MAPPINGS",
+ "WEB_DIRECTORY",
+ "LCSExtension",
+ "comfy_entrypoint",
+]
diff --git a/custom_nodes/ComfyUI-LCS/core/__init__.py b/custom_nodes/ComfyUI-LCS/core/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa25cd18e816e0f67bbe7bd3a764367e4b964e3d
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/__init__.py
@@ -0,0 +1,10 @@
+from .lcs_data import LCSData
+from .patchify import patchify, unpatchify
+from .timestep import sigma_to_paper_t, get_alpha_beta, normalize_to_t50, denormalize_from_t50
+from .color_space import decode_lcs_to_hsl, encode_hsl_to_lcs, hex_to_hsl, hsl_to_rgb
+
+
+def calibrate(*args, **kwargs):
+ """Lazy wrapper for core.calibration.calibrate (avoids importing comfy.utils at module level)."""
+ from .calibration import calibrate as _calibrate
+ return _calibrate(*args, **kwargs)
diff --git a/custom_nodes/ComfyUI-LCS/core/adaptive.py b/custom_nodes/ComfyUI-LCS/core/adaptive.py
new file mode 100644
index 0000000000000000000000000000000000000000..280da4209e86cb630edb28934cfe4a4508cc397b
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/adaptive.py
@@ -0,0 +1,109 @@
+"""Schedule-aware adaptive logic for LCS color anchoring.
+
+Derives intervention windows, strength envelopes, and phase assignments
+from the sigma schedule's amplification factor (beta_50 / beta_t), replacing
+all manually-tuned step/strength parameters with data-driven decisions.
+"""
+
+import math
+import torch
+from .defaults import get_beta_table
+
+
+def compute_amplification(sigma_val, device=None):
+ """Compute amplification factor A = max_k(beta_50[k] / beta_t(sigma)[k]).
+
+ The amplification factor measures how much the normalization step inflates
+ noise relative to signal. High A means corrections are dangerous (amplified
+ noise dominates), low A means corrections are safe.
+
+ sigma_val: float in [0, 1] (FLUX sigma, 1=noise, 0=clean)
+ Returns: float amplification factor
+ """
+ beta_table = get_beta_table() # [51, 3]
+ beta_50 = beta_table[50] # [3]
+
+ # Convert sigma to paper timestep
+ t = 50.0 * (1.0 - max(0.0, min(1.0, sigma_val)))
+ t = max(0.0, min(50.0, t))
+ t_low = int(t)
+ t_high = min(t_low + 1, 50)
+ frac = t - t_low
+
+ beta_t = (1.0 - frac) * beta_table[t_low] + frac * beta_table[t_high]
+
+ # Per-component ratio, take max
+ beta_t_safe = beta_t.clamp(min=1e-8)
+ ratios = beta_50 / beta_t_safe # [3]
+ return ratios.max().item()
+
+
+def compute_step_phases(sigmas, mode):
+ """Assign a phase to each sampling step based on amplification factor.
+
+ Physics-derived constants (not empirical):
+ A_MAX = 10.0 — above: normalization amplifies noise >10x → skip
+ A_WARMUP = 5.0 — self_anchor only: observe phase for EMA buildup
+ SIGMA_MIN = 0.15 — below: final detail refinement → skip
+
+ sigmas: 1D tensor of sigma values for each step (length N+1, last is 0)
+ mode: "smooth", "reference", or "self_anchor"
+
+ Returns: list of N strings, each "skip" / "observe" / "correct"
+ """
+ A_MAX = 10.0
+ A_WARMUP = 5.0
+ SIGMA_MIN = 0.15
+
+ n_steps = len(sigmas) - 1 # last sigma is terminal (0)
+ phases = []
+
+ for i in range(n_steps):
+ sigma_val = float(sigmas[i])
+
+ # Final refinement — skip
+ if sigma_val < SIGMA_MIN:
+ phases.append("skip")
+ continue
+
+ amp = compute_amplification(sigma_val)
+
+ # Too noisy — skip
+ if amp > A_MAX:
+ phases.append("skip")
+ continue
+
+ # Self-anchor warmup zone
+ if mode == "self_anchor" and amp > A_WARMUP:
+ phases.append("observe")
+ continue
+
+ phases.append("correct")
+
+ return phases
+
+
+def estimate_intensity(drift_signal):
+ """Map drift magnitude to intensity in [0.15, 0.6]."""
+ DRIFT_SCALE = 0.2
+ INTENSITY_MIN = 0.15
+ INTENSITY_MAX = 0.6
+ return max(INTENSITY_MIN, min(INTENSITY_MAX, drift_signal / DRIFT_SCALE))
+
+
+def compute_strength_envelope(n_correction_steps):
+ """Sinusoidal bell envelope over correction steps.
+
+ sin(pi * i / (n-1)) for i in 0..n-1
+ Prevents abrupt on/off at phase boundaries.
+ Single step returns [1.0].
+
+ Returns: 1D tensor of length n_correction_steps
+ """
+ if n_correction_steps <= 0:
+ return torch.zeros(0)
+ if n_correction_steps == 1:
+ return torch.ones(1)
+ n = n_correction_steps
+ indices = torch.arange(n, dtype=torch.float32)
+ return torch.sin(math.pi * indices / (n - 1))
diff --git a/custom_nodes/ComfyUI-LCS/core/bilateral.py b/custom_nodes/ComfyUI-LCS/core/bilateral.py
new file mode 100644
index 0000000000000000000000000000000000000000..27c68154cd033fa386dee742215a8a5c6e00493a
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/bilateral.py
@@ -0,0 +1,79 @@
+"""Bilateral filter in LCS space for smooth color anchoring."""
+
+import math
+
+import torch
+import torch.nn.functional as F
+
+
+def estimate_bilateral_params(c, h_len, w_len):
+ """Estimate bilateral filter parameters from local color statistics.
+
+ Computes per-channel spatial std of c across the grid, takes the median
+ to derive sigma_color. sigma_spatial is fixed at 1.5 (5x5 kernel is small).
+
+ c: [B, L, 3] LCS coordinates
+ Returns: (sigma_spatial, sigma_color) floats
+ """
+ B = c.shape[0]
+ grid = c.reshape(B, h_len, w_len, 3) # [B, H, W, 3]
+ # Per-channel std across spatial dims → [B, 3]
+ channel_std = grid.reshape(B, -1, 3).std(dim=1) # [B, 3]
+ # Median across batch and channels
+ median_std = float(channel_std.median())
+ sigma_color = max(0.05, min(3.0, 0.75 * median_std))
+ sigma_spatial = 1.5
+ return sigma_spatial, sigma_color
+
+
+def bilateral_filter_lcs(c, h_len, w_len, sigma_spatial, sigma_color, kernel_radius=2):
+ """Bilateral filter on [B, L, 3] LCS coordinates arranged on h_len x w_len grid.
+
+ Uses spatial distance + LCS color distance as joint weights.
+ kernel_radius=2 -> 5x5 neighborhood (25 lookups per patch).
+ Returns [B, L, 3] filtered coordinates.
+ """
+ B = c.shape[0]
+ # Reshape to spatial grid
+ grid = c.reshape(B, h_len, w_len, 3) # [B, H, W, 3]
+
+ # Pad by kernel_radius (replicate) — pad last two spatial dims
+ # F.pad on [B, H, W, 3]: need to pad dims -3 and -2 (H and W)
+ # Permute to [B, 3, H, W] for F.pad, then back
+ grid_chw = grid.permute(0, 3, 1, 2) # [B, 3, H, W]
+ r = kernel_radius
+ padded = F.pad(grid_chw, (r, r, r, r), mode="replicate") # [B, 3, H+2r, W+2r]
+
+ # Precompute spatial Gaussian weights for each offset in kernel
+ inv_2ss = -0.5 / (sigma_spatial * sigma_spatial)
+ inv_2sc = -0.5 / (sigma_color * sigma_color)
+
+ # Accumulate weighted sum
+ weight_sum = torch.zeros(B, 1, h_len, w_len, device=c.device, dtype=c.dtype)
+ value_sum = torch.zeros(B, 3, h_len, w_len, device=c.device, dtype=c.dtype)
+
+ for dy in range(-r, r + 1):
+ for dx in range(-r, r + 1):
+ # Spatial weight (constant per offset)
+ spatial_dist_sq = float(dy * dy + dx * dx)
+ w_spatial = math.exp(spatial_dist_sq * inv_2ss)
+
+ # Extract neighbor values from padded grid
+ y_start = r + dy
+ x_start = r + dx
+ neighbor = padded[:, :, y_start:y_start + h_len, x_start:x_start + w_len] # [B, 3, H, W]
+
+ # Color distance weight (per-pixel)
+ diff = neighbor - grid_chw # [B, 3, H, W]
+ color_dist_sq = (diff * diff).sum(dim=1, keepdim=True) # [B, 1, H, W]
+ w_color = torch.exp(color_dist_sq * inv_2sc) # [B, 1, H, W]
+
+ w = w_spatial * w_color
+ weight_sum.add_(w)
+ value_sum.add_(w * neighbor)
+
+ # Normalize
+ result = value_sum / weight_sum.clamp(min=1e-8) # [B, 3, H, W]
+
+ # Back to [B, L, 3]
+ return result.permute(0, 2, 3, 1).reshape(B, -1, 3)
diff --git a/custom_nodes/ComfyUI-LCS/core/calibration.py b/custom_nodes/ComfyUI-LCS/core/calibration.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9fbc80c0f17fcc5282582577c35ccb8f610a4f2
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/calibration.py
@@ -0,0 +1,214 @@
+"""PCA calibration from FLUX VAE: compute LCS basis, mean, and anchor positions."""
+
+import hashlib
+import math
+import torch
+import comfy.utils
+from .patchify import patchify
+from .lcs_data import LCSData
+from .color_space import _chromatic_plane_basis
+
+
+def vae_fingerprint(vae) -> str:
+ """8-char hex fingerprint from VAE decoder weights.
+
+ Used to cache calibration data per-VAE so different VAE models
+ get separate calibration files automatically.
+ """
+ sd = vae.get_sd()
+ # Use first decoder weight tensor as fingerprint source
+ for key in sorted(sd.keys()):
+ if "decoder" in key and "weight" in key:
+ w = sd[key]
+ return hashlib.sha256(w.cpu().float().numpy().tobytes()).hexdigest()[:8]
+ # Fallback: hash first weight found
+ first_key = sorted(sd.keys())[0]
+ w = sd[first_key]
+ return hashlib.sha256(w.cpu().float().numpy().tobytes()).hexdigest()[:8]
+
+
+# 8 anchor colors: R, B, G, M, C, Y, Black, White
+ANCHOR_COLORS_RGB = [
+ (1.0, 0.0, 0.0), # Red
+ (0.0, 0.0, 1.0), # Blue
+ (0.0, 1.0, 0.0), # Green
+ (1.0, 0.0, 1.0), # Magenta
+ (0.0, 1.0, 1.0), # Cyan
+ (1.0, 1.0, 0.0), # Yellow
+ (0.0, 0.0, 0.0), # Black
+ (1.0, 1.0, 1.0), # White
+]
+
+
+def calibrate(vae, num_colors=512, image_size=512, batch_size=8):
+ """Compute LCS data (PCA basis, mean, anchors) from FLUX VAE.
+
+ 1. Sample num_colors solid-color images uniformly from HSV
+ 2. VAE encode each → latent
+ 3. Patchify → average patches per image → vector in R^64
+ 4. PCA on all vectors → basis B [64,3], mean μ [64]
+ 5. Encode 8 anchor colors → compute LCS coords + hue angles
+
+ Returns: LCSData
+ """
+ device = comfy.model_management.intermediate_device()
+
+ print(f"\n[LCS Calibration] Starting calibration for {num_colors} colors...")
+ print(f"[LCS Calibration] Image size: {image_size}x{image_size}, Batch size: {batch_size}")
+
+ # Step 1: Sample colors uniformly from HSV (full saturation, full value for diversity)
+ colors = []
+ for i in range(num_colors):
+ # Uniform sampling in HSV
+ h = (i * 137.508) % 360.0 / 360.0 # Golden angle for uniform coverage
+ s = 0.3 + 0.7 * ((i * 73) % 100) / 100.0 # Vary saturation 0.3-1.0
+ v = 0.3 + 0.7 * ((i * 47) % 100) / 100.0 # Vary value 0.3-1.0
+ # HSV to RGB
+ r, g, b = _hsv_to_rgb(h, s, v)
+ colors.append((r, g, b))
+
+ # Step 2+3: Encode and average patches
+ vectors = []
+ pbar = comfy.utils.ProgressBar(num_colors)
+
+ num_batches = (num_colors + batch_size - 1) // batch_size
+ print(f"[LCS Calibration] Encoding {num_colors} color images in {num_batches} batches...")
+
+ for batch_start in range(0, num_colors, batch_size):
+ batch_end = min(batch_start + batch_size, num_colors)
+ batch_colors = colors[batch_start:batch_end]
+ actual_batch = len(batch_colors)
+
+ # Create solid color images [B, H, W, 3] (BHWC format for ComfyUI VAE)
+ imgs = torch.zeros(actual_batch, image_size, image_size, 3, dtype=torch.float32, device="cpu")
+ for j, (r, g, b) in enumerate(batch_colors):
+ imgs[j, :, :, 0] = r
+ imgs[j, :, :, 1] = g
+ imgs[j, :, :, 2] = b
+
+ # VAE encode — try batch first, fall back to per-image for video VAEs
+ latent = vae.encode(imgs[:, :, :, :3])
+
+ # Squeeze video VAE temporal dim — calibration uses still images
+ if latent.ndim == 5:
+ latent = latent[:, :, 0, :, :]
+
+ # Patchify → [B', L, D]
+ patches, _, _, _ = patchify(latent)
+
+ # Average across patches → [B', D]
+ avg = patches.mean(dim=1).cpu()
+
+ if avg.shape[0] == actual_batch:
+ # Normal VAE: batch encode worked
+ vectors.extend(avg.unbind(0))
+ else:
+ # Video VAE or unexpected batch collapse — encode one by one
+ for k in range(actual_batch):
+ single = imgs[k:k+1, :, :, :3]
+ lat = vae.encode(single)
+ if lat.ndim == 5:
+ lat = lat[:, :, 0, :, :]
+ p, _, _, _ = patchify(lat)
+ vectors.append(p.mean(dim=1).cpu().squeeze(0))
+
+ pbar.update(actual_batch)
+
+ # Stack all vectors: [N, 64]
+ X = torch.stack(vectors, dim=0).float()
+ print(f"[LCS Calibration] Collected {X.shape[0]} patch vectors of dimension {X.shape[1]}")
+
+ # Step 4: PCA
+ print("[LCS Calibration] Computing PCA...")
+ mean = X.mean(dim=0) # [64]
+ X_centered = X - mean
+ # SVD for PCA
+ U, S, Vh = torch.linalg.svd(X_centered, full_matrices=False)
+ # Top 3 components: B = V[:, :3] (columns are principal directions)
+ basis = Vh[:3].T # [64, 3] (Vh rows are right singular vectors)
+
+ # Variance explained
+ total_var = (S ** 2).sum()
+ explained = (S[:3] ** 2) / total_var
+ print(f"[LCS Calibration] Top 3 components explain {explained.sum():.1%} variance")
+ print(f"[LCS Calibration] PC1: {explained[0]:.1%}, PC2: {explained[1]:.1%}, PC3: {explained[2]:.1%}")
+
+ # Step 5: Encode 8 anchor colors → LCS coords
+ print("[LCS Calibration] Encoding 8 anchor colors...")
+ anchor_lcs_list = []
+ for i, (r, g, b) in enumerate(ANCHOR_COLORS_RGB):
+ img = torch.zeros(1, image_size, image_size, 3, dtype=torch.float32, device="cpu")
+ img[0, :, :, 0] = r
+ img[0, :, :, 1] = g
+ img[0, :, :, 2] = b
+ latent = vae.encode(img[:, :, :, :3])
+ if latent.ndim == 5:
+ latent = latent[:, :, 0, :, :]
+ patches, _, _, _ = patchify(latent)
+ avg = patches.mean(dim=1).cpu().squeeze(0) # [64]
+ # Project to LCS
+ lcs_coord = (avg - mean) @ basis # [3]
+ anchor_lcs_list.append(lcs_coord)
+
+ anchor_lcs = torch.stack(anchor_lcs_list, dim=0) # [8, 3]
+
+ # Compute hue angles for 6 chromatic anchors
+ anchor_angles = _compute_anchor_angles(anchor_lcs, basis, mean)
+
+ print(f"[LCS Calibration] Complete! Basis shape: {basis.shape}")
+ print(f"[LCS Calibration] Anchor LCS coords:\n{anchor_lcs}")
+
+ return LCSData(
+ basis=basis,
+ mean=mean,
+ anchor_lcs=anchor_lcs,
+ anchor_angles=anchor_angles,
+ )
+
+
+def _compute_anchor_angles(anchor_lcs, basis, mean):
+ """Compute hue angles of the 6 chromatic anchors in the chromatic plane.
+
+ The chromatic plane is perpendicular to the achromatic axis (black→white).
+ Returns [6] tensor of angles in radians.
+ """
+ black = anchor_lcs[6] # [3]
+ white = anchor_lcs[7] # [3]
+ chromatic = anchor_lcs[:6] # [6, 3]
+
+ # Achromatic axis
+ a = white - black
+ a_unit, e1, e2 = _chromatic_plane_basis(a)
+
+ # Project each chromatic anchor onto the plane and compute angle
+ angles = []
+ for i in range(6):
+ c = chromatic[i]
+ # Project onto achromatic axis
+ c_proj = black + ((c - black) * a).sum() / ((a * a).sum() + 1e-10) * a
+ # Chromatic residual
+ chroma = c - c_proj
+ x = (chroma * e1).sum()
+ y = (chroma * e2).sum()
+ angle = torch.atan2(y, x) % (2 * math.pi)
+ angles.append(angle)
+
+ return torch.stack(angles) # [6]
+
+
+def _hsv_to_rgb(h, s, v):
+ """Convert HSV to RGB (scalars in [0,1])."""
+ if s < 1e-10:
+ return v, v, v
+ h6 = h * 6.0
+ i = int(h6) % 6
+ f = h6 - int(h6)
+ p = v * (1.0 - s)
+ q = v * (1.0 - s * f)
+ t = v * (1.0 - s * (1.0 - f))
+ if i == 0: return v, t, p
+ if i == 1: return q, v, p
+ if i == 2: return p, v, t
+ if i == 3: return p, q, v
+ if i == 4: return t, p, v
+ return v, p, q
diff --git a/custom_nodes/ComfyUI-LCS/core/color_space.py b/custom_nodes/ComfyUI-LCS/core/color_space.py
new file mode 100644
index 0000000000000000000000000000000000000000..909eda20da68e3ef8a158436ffd83d27cdb5ead4
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/color_space.py
@@ -0,0 +1,380 @@
+"""Bicone LCS ↔ HSL mapping using 8 anchor colors.
+
+Anchors are indexed as: [Red, Blue, Green, Magenta, Cyan, Yellow, Black, White]
+Indices: 0=R, 1=B, 2=G, 3=M, 4=C, 5=Y, 6=Black, 7=White
+"""
+
+import math
+import torch
+
+# Standard HSL hue for each anchor: R=0, B=4/6, G=2/6, M=5/6, C=3/6, Y=1/6
+_ANCHOR_HUES = (0.0, 4.0/6.0, 2.0/6.0, 5.0/6.0, 3.0/6.0, 1.0/6.0)
+
+
+def _bicone_factor(l, clamp_min=None):
+ """Compute bicone scaling factor: 1 - |2L - 1|.
+
+ At l=0.5 (equator), factor=1 (full radius).
+ At l=0 or l=1 (poles), factor=0 (zero radius).
+
+ Args:
+ l: Lightness tensor [...]
+ clamp_min: Optional minimum value for numerical stability
+
+ Returns:
+ Bicone factor tensor [...]
+ """
+ factor = 1.0 - (2.0 * l - 1.0).abs()
+ if clamp_min is not None:
+ factor = factor.clamp(min=clamp_min)
+ return factor
+
+
+def _wrap_hue_diff(diff):
+ """Wrap hue differences to the shortest path on the unit circle [-0.5, 0.5]."""
+ return diff - (diff > 0.5).float() + (diff < -0.5).float()
+
+
+def _hue_lerp(h1, h2, t):
+ """Lerp hues on the circle [0,1], taking the shortest path."""
+ return (h1 + t * _wrap_hue_diff(h2 - h1)) % 1.0
+
+
+def _chromatic_plane_basis(a):
+ """Build orthonormal basis (a_unit, e1, e2) for the chromatic plane perpendicular to a."""
+ a_unit = a / (a.norm() + 1e-10)
+ arb = torch.zeros(3, device=a.device, dtype=a.dtype)
+ arb[0] = 1.0
+ if a_unit[0].abs() > 0.9:
+ arb[0] = 0.0
+ arb[1] = 1.0
+ e1 = arb - (arb * a_unit).sum() * a_unit
+ e1 = e1 / (e1.norm() + 1e-10)
+ e2 = torch.linalg.cross(a_unit, e1)
+ return a_unit, e1, e2
+
+
+def hex_to_hsl(hex_str):
+ """Convert "#RRGGBB" to (h, s, l) where h∈[0,1], s∈[0,1], l∈[0,1]."""
+ hex_str = hex_str.lstrip("#")
+ r = int(hex_str[0:2], 16) / 255.0
+ g = int(hex_str[2:4], 16) / 255.0
+ b = int(hex_str[4:6], 16) / 255.0
+ return rgb_to_hsl(r, g, b)
+
+
+def rgb_to_hsl(r, g, b):
+ """Convert RGB [0,1] to HSL [0,1]."""
+ cmax = max(r, g, b)
+ cmin = min(r, g, b)
+ delta = cmax - cmin
+ l = (cmax + cmin) / 2.0
+
+ if delta < 1e-10:
+ return 0.0, 0.0, l
+
+ s = delta / (1.0 - abs(2.0 * l - 1.0)) if abs(2.0 * l - 1.0) < 1.0 else 0.0
+
+ if cmax == r:
+ h = ((g - b) / delta) % 6.0
+ elif cmax == g:
+ h = (b - r) / delta + 2.0
+ else:
+ h = (r - g) / delta + 4.0
+ h = h / 6.0
+ if h < 0:
+ h += 1.0
+
+ return h, max(0.0, min(1.0, s)), max(0.0, min(1.0, l))
+
+
+def hsl_to_rgb(h, s, l):
+ """Convert HSL [0,1] to RGB [0,1]. Works with scalars or tensors."""
+ if isinstance(h, torch.Tensor):
+ return _hsl_to_rgb_tensor(h, s, l)
+
+ c = (1.0 - abs(2.0 * l - 1.0)) * s
+ x = c * (1.0 - abs((h * 6.0) % 2.0 - 1.0))
+ m = l - c / 2.0
+
+ h6 = h * 6.0
+ if h6 < 1:
+ r, g, b = c, x, 0
+ elif h6 < 2:
+ r, g, b = x, c, 0
+ elif h6 < 3:
+ r, g, b = 0, c, x
+ elif h6 < 4:
+ r, g, b = 0, x, c
+ elif h6 < 5:
+ r, g, b = x, 0, c
+ else:
+ r, g, b = c, 0, x
+
+ return r + m, g + m, b + m
+
+
+def _hsl_to_rgb_tensor(h, s, l):
+ """Vectorized HSL→RGB for tensors."""
+ c = _bicone_factor(l) * s
+ h6 = h * 6.0
+ x = c * (1.0 - ((h6 % 2.0) - 1.0).abs())
+ m = l - c / 2.0
+
+ r = torch.zeros_like(h)
+ g = torch.zeros_like(h)
+ b = torch.zeros_like(h)
+
+ mask0 = h6 < 1
+ mask1 = (h6 >= 1) & (h6 < 2)
+ mask2 = (h6 >= 2) & (h6 < 3)
+ mask3 = (h6 >= 3) & (h6 < 4)
+ mask4 = (h6 >= 4) & (h6 < 5)
+ mask5 = h6 >= 5
+
+ r[mask0] = c[mask0]; g[mask0] = x[mask0]
+ r[mask1] = x[mask1]; g[mask1] = c[mask1]
+ g[mask2] = c[mask2]; b[mask2] = x[mask2]
+ g[mask3] = x[mask3]; b[mask3] = c[mask3]
+ r[mask4] = x[mask4]; b[mask4] = c[mask4]
+ r[mask5] = c[mask5]; b[mask5] = x[mask5]
+
+ return (r + m).clamp(0, 1), (g + m).clamp(0, 1), (b + m).clamp(0, 1)
+
+
+def decode_lcs_to_hsl(c, anchor_lcs, anchor_angles):
+ """Decode LCS coordinates to HSL using bicone geometry.
+
+ c: [..., 3] LCS coordinates (normalized to t=50)
+ anchor_lcs: [8, 3] anchor positions [R,B,G,M,C,Y,Black,White]
+ anchor_angles: [6] hue angles of chromatic anchors in radians
+
+ Returns: (h, s, l) each [...] in [0,1]
+ """
+ black = anchor_lcs[6] # [3]
+ white = anchor_lcs[7] # [3]
+ chromatic = anchor_lcs[:6] # [6, 3]
+
+ # Achromatic axis
+ a = white - black # [3]
+ a_norm_sq = (a * a).sum() + 1e-10
+
+ # Lightness: project onto achromatic axis
+ diff = c - black # [..., 3]
+ l = (diff * a).sum(dim=-1) / a_norm_sq # [...]
+ l = l.clamp(0.0, 1.0)
+
+ # Point on achromatic axis
+ c_L = black + l.unsqueeze(-1) * a # [..., 3]
+
+ # Chromatic residual
+ chroma_vec = c - c_L # [..., 3]
+ chroma_dist = chroma_vec.norm(dim=-1) + 1e-10 # [...]
+
+ # Compute hue angle in chromatic plane
+ a_unit, e1, e2 = _chromatic_plane_basis(a)
+
+ # Project chromatic vector to 2D
+ x_coord = (chroma_vec * e1).sum(dim=-1) # [...]
+ y_coord = (chroma_vec * e2).sum(dim=-1) # [...]
+ angle = torch.atan2(y_coord, x_coord) # [...] radians
+ angle = angle % (2 * math.pi)
+
+ # Map angle to hue [0,1] using sorted anchor angles
+ # anchor_angles are the angles of [R,B,G,M,C,Y] in the same coordinate system
+ # Standard HSL hue: R=0, Y=1/6, G=2/6, C=3/6, B=4/6, M=5/6
+ # But anchors may not be in that order in angle-space, so we interpolate
+ sorted_angles, sort_idx = anchor_angles.sort()
+ anchor_hues = torch.tensor(_ANCHOR_HUES, device=c.device, dtype=c.dtype)
+ sorted_hues = anchor_hues[sort_idx]
+
+ # Piecewise linear interpolation around the circle
+ h = _angle_to_hue(angle, sorted_angles, sorted_hues)
+
+ # Saturation: distance to achromatic axis normalized by max distance
+ # Max distance at this hue and lightness
+ bicone_factor = _bicone_factor(l, clamp_min=1e-10)
+
+ # Find the chroma boundary at this hue (perpendicular to achromatic axis)
+ chroma_boundary = _hue_to_chroma_vector(h, chromatic, anchor_angles, a_unit, e1, e2, black, a)
+ max_radius = chroma_boundary.norm(dim=-1) + 1e-10
+ s = chroma_dist / (max_radius * bicone_factor)
+ s = s.clamp(0.0, 1.0)
+
+ return h, s, l
+
+
+def encode_hsl_to_lcs(h, s, l, anchor_lcs, anchor_angles):
+ """Encode HSL to LCS coordinates using bicone geometry.
+
+ h, s, l: [...] in [0,1]
+ anchor_lcs: [8, 3]
+ anchor_angles: [6] radians
+
+ Returns: c [..., 3] LCS coordinates
+ """
+ black = anchor_lcs[6] # [3]
+ white = anchor_lcs[7] # [3]
+ chromatic = anchor_lcs[:6] # [6, 3]
+
+ a = white - black
+ a_unit, e1, e2 = _chromatic_plane_basis(a)
+
+ # Lightness point on achromatic axis
+ c_L = black + l.unsqueeze(-1) * a # [..., 3]
+
+ # Chroma direction vector (equatorial radius at this hue)
+ chroma_dir = _hue_to_chroma_vector(h, chromatic, anchor_angles, a_unit, e1, e2, black, a)
+
+ # Combine: c = c_L + s * (1 - |2l-1|) * chroma_dir
+ bicone_factor = _bicone_factor(l)
+ c = c_L + (s * bicone_factor).unsqueeze(-1) * chroma_dir
+
+ return c
+
+
+def _angle_to_hue(angle, sorted_angles, sorted_hues):
+ """Map an angle [...] to hue [0,1] via piecewise linear interpolation on anchor angles."""
+ n = len(sorted_angles)
+ h = torch.zeros_like(angle)
+
+ for i in range(n):
+ j = (i + 1) % n
+ a_start = sorted_angles[i]
+ a_end = sorted_angles[j]
+ h_start = sorted_hues[i]
+ h_end = sorted_hues[j]
+
+ # Handle wraparound
+ if a_end < a_start:
+ a_end = a_end + 2 * math.pi
+ span = a_end - a_start
+ if span < 1e-10:
+ continue
+
+ # Check which angles fall in this segment
+ if a_end > 2 * math.pi:
+ # Wraparound segment
+ mask = (angle >= a_start) | (angle < (a_end - 2 * math.pi))
+ angle_shifted = torch.where(angle < a_start, angle + 2 * math.pi, angle)
+ else:
+ mask = (angle >= a_start) & (angle < a_end)
+ angle_shifted = angle
+
+ frac = ((angle_shifted - a_start) / span).clamp(0, 1)
+
+ # Interpolate hue (handling hue wraparound)
+ h_diff = h_end - h_start
+ if abs(h_diff) > 0.5:
+ if h_diff > 0:
+ h_diff -= 1.0
+ else:
+ h_diff += 1.0
+ interp = h_start + frac * h_diff
+ interp = interp % 1.0
+
+ h = torch.where(mask, interp, h)
+
+ return h
+
+
+def _hue_to_chroma_vector(h, chromatic, anchor_angles, a_unit, e1, e2, black, a):
+ """Map hue values [...] to EQUATORIAL chroma direction vectors.
+
+ Returns vectors in 3D LCS space that lie in the chromatic plane (perpendicular to a_unit)
+ with magnitude equal to the equatorial chroma radius at that hue (i.e., the radius at l=0.5).
+
+ The equatorial radius is computed by normalizing each anchor's chroma radius by its
+ bicone factor (1 - |2L - 1|), where L is the anchor's lightness. This ensures proper
+ round-trip encoding/decoding across the bicone.
+
+ chromatic: [6, 3] anchor LCS positions
+ anchor_angles: [6] calibrated angles of chromatic anchors (radians)
+ a_unit: [3] unit vector along achromatic axis
+ e1, e2: [3] orthonormal basis for chromatic plane
+ black: [3] black anchor position
+ a: [3] full achromatic axis vector (white - black)
+ """
+ # Compute each anchor's lightness (scalar projection onto achromatic axis)
+ a_sq = (a * a).sum() + 1e-10
+ anchor_diff = chromatic - black # [6, 3]
+ anchor_l = (anchor_diff * a).sum(dim=-1) / a_sq # [6] lightness values
+
+ # Project anchors onto chromatic plane to get chroma vectors
+ anchor_on_axis = black + anchor_l.unsqueeze(-1) * a # [6, 3]
+ anchor_chroma = chromatic - anchor_on_axis # [6, 3] chroma vectors
+ anchor_r = anchor_chroma.norm(dim=-1) # [6] radii at anchor lightness
+
+ # Normalize to equatorial radii (radius at l=0.5 where bicone_factor=1)
+ bicone_factors = _bicone_factor(anchor_l, clamp_min=1e-6) # [6]
+ equatorial_r = anchor_r / bicone_factors # [6] equatorial radii
+
+ anchor_hues = torch.tensor(_ANCHOR_HUES, device=chromatic.device, dtype=chromatic.dtype)
+
+ # Sort by ANGLE (same as _angle_to_hue) to match segment structure
+ sorted_angles, sort_idx = anchor_angles.sort()
+ sorted_hues = anchor_hues[sort_idx]
+ sorted_radii = equatorial_r[sort_idx] # [6] equatorial radii
+
+ # Iterate segments in angle order (same as _angle_to_hue)
+ n = 6
+ result = torch.empty(h.shape + (3,), device=chromatic.device, dtype=chromatic.dtype)
+
+ for i in range(n):
+ j = (i + 1) % n
+ h_start = sorted_hues[i]
+ h_end = sorted_hues[j]
+
+ # Hue span with wraparound (same logic as _angle_to_hue)
+ h_diff = h_end - h_start
+ if abs(h_diff) > 0.5:
+ if h_diff > 0:
+ h_diff -= 1.0
+ else:
+ h_diff += 1.0
+
+ if abs(h_diff) < 1e-10:
+ continue
+
+ # Determine hue range for this segment
+ h_end_unwrapped = h_start + h_diff
+
+ # Build mask for which input hues fall in this segment
+ if h_diff > 0:
+ if h_end_unwrapped > 1.0:
+ mask = (h >= h_start) | (h < (h_end_unwrapped - 1.0))
+ h_shifted = torch.where(h < h_start, h + 1.0, h)
+ else:
+ mask = (h >= h_start) & (h < h_end_unwrapped)
+ h_shifted = h
+ else:
+ # Hue decreases
+ if h_end_unwrapped < 0.0:
+ mask = (h <= h_start) | (h > (h_end_unwrapped + 1.0))
+ h_shifted = torch.where(h > h_start, h - 1.0, h)
+ else:
+ mask = (h <= h_start) & (h > h_end_unwrapped)
+ h_shifted = h
+
+ frac = ((h_shifted - h_start) / h_diff).clamp(0, 1)
+
+ # Interpolate radius
+ interp_r = sorted_radii[i] + frac * (sorted_radii[j] - sorted_radii[i])
+
+ # Interpolate angle
+ a_start = sorted_angles[i]
+ a_end = sorted_angles[j]
+ a_span = a_end - a_start
+ if a_span < 0:
+ a_span += 2 * math.pi
+ interp_angle = (a_start + frac * a_span) % (2 * math.pi)
+
+ # Reconstruct 3D chroma vector
+ interp_vec = interp_r.unsqueeze(-1) * (
+ torch.cos(interp_angle).unsqueeze(-1) * e1
+ + torch.sin(interp_angle).unsqueeze(-1) * e2
+ )
+
+ result = torch.where(mask.unsqueeze(-1), interp_vec, result)
+
+ return result
diff --git a/custom_nodes/ComfyUI-LCS/core/defaults.py b/custom_nodes/ComfyUI-LCS/core/defaults.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fa34747a74df994a3ee0f1f04b94e47c9a2c5a9
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/defaults.py
@@ -0,0 +1,65 @@
+"""Hardcoded alpha_t and beta_t tables from paper Appendix F (51 entries, t=0..50)."""
+
+import torch
+
+# Shift alpha_t: 3D vectors for each timestep t=0..50
+ALPHA_T = [
+ [2.3413, -2.3586, 0.4266], [2.3574, -2.3833, 0.4644], [2.3638, -2.3904, 0.4883],
+ [2.3734, -2.3951, 0.5122], [2.3831, -2.3993, 0.5384], [2.3925, -2.4026, 0.5647],
+ [2.4023, -2.4047, 0.5919], [2.4124, -2.4060, 0.6198], [2.4226, -2.4064, 0.6484],
+ [2.4330, -2.4060, 0.6772], [2.4437, -2.4051, 0.7065], [2.4546, -2.4035, 0.7367],
+ [2.4659, -2.4011, 0.7668], [2.4775, -2.3981, 0.7974], [2.4897, -2.4009, 0.8312],
+ [2.5021, -2.4036, 0.8656], [2.5148, -2.4065, 0.9008], [2.5277, -2.4093, 0.9364],
+ [2.5408, -2.4123, 0.9727], [2.5542, -2.4154, 1.0099], [2.5680, -2.4186, 1.0481],
+ [2.5820, -2.4218, 1.0868], [2.5963, -2.4252, 1.1263], [2.6110, -2.4288, 1.1672],
+ [2.6261, -2.4324, 1.2090], [2.6416, -2.4363, 1.2520], [2.6575, -2.4403, 1.2957],
+ [2.6738, -2.4444, 1.3406], [2.6904, -2.4485, 1.3865], [2.7074, -2.4529, 1.4336],
+ [2.7250, -2.4574, 1.4818], [2.7432, -2.4621, 1.5314], [2.7618, -2.4669, 1.5823],
+ [2.7810, -2.4720, 1.6344], [2.8006, -2.4771, 1.6878], [2.8209, -2.4826, 1.7430],
+ [2.8418, -2.4883, 1.7995], [2.8631, -2.4944, 1.8578], [2.8853, -2.5005, 1.9179],
+ [2.9080, -2.5066, 1.9793], [2.9313, -2.5132, 2.0426], [2.9555, -2.5199, 2.1082],
+ [2.9804, -2.5268, 2.1756], [3.0060, -2.5338, 2.2450], [3.0328, -2.5411, 2.3172],
+ [3.0603, -2.5486, 2.3914], [3.0889, -2.5561, 2.4682], [3.1189, -2.5640, 2.5482],
+ [3.1497, -2.5725, 2.6302], [3.1824, -2.5796, 2.7175], [3.2152, -2.5889, 2.8050],
+]
+
+# Scale beta_t: 3D vectors for each timestep t=0..50
+BETA_T = [
+ [0.0163, 0.0172, 0.0295], [0.0905, 0.0716, 0.0999], [0.1345, 0.1123, 0.1544],
+ [0.1826, 0.1491, 0.2065], [0.2360, 0.1899, 0.2630], [0.2904, 0.2316, 0.3202],
+ [0.3471, 0.2749, 0.3793], [0.4050, 0.3191, 0.4394], [0.4640, 0.3641, 0.5003],
+ [0.5231, 0.4091, 0.5611], [0.5834, 0.4547, 0.6228], [0.6456, 0.5016, 0.6861],
+ [0.7077, 0.5481, 0.7488], [0.7713, 0.5958, 0.8127], [0.8410, 0.6496, 0.8866],
+ [0.9119, 0.7044, 0.9616], [0.9845, 0.7605, 1.0386], [1.0578, 0.8172, 1.1163],
+ [1.1325, 0.8750, 1.1957], [1.2094, 0.9344, 1.2771], [1.2880, 0.9953, 1.3606],
+ [1.3680, 1.0571, 1.4453], [1.4498, 1.1205, 1.5321], [1.5341, 1.1858, 1.6216],
+ [1.6206, 1.2526, 1.7131], [1.7094, 1.3214, 1.8072], [1.7998, 1.3913, 1.9030],
+ [1.8927, 1.4633, 2.0014], [1.9879, 1.5370, 2.1022], [2.0854, 1.6126, 2.2056],
+ [2.1853, 1.6900, 2.3114], [2.2881, 1.7696, 2.4202], [2.3939, 1.8515, 2.5321],
+ [2.5021, 1.9354, 2.6467], [2.6133, 2.0215, 2.7642], [2.7280, 2.1106, 2.8857],
+ [2.8455, 2.2017, 3.0101], [2.9668, 2.2957, 3.1386], [3.0921, 2.3929, 3.2712],
+ [3.2204, 2.4922, 3.4067], [3.3523, 2.5946, 3.5464], [3.4888, 2.7006, 3.6911],
+ [3.6292, 2.8097, 3.8398], [3.7741, 2.9222, 3.9931], [3.9247, 3.0394, 4.1527],
+ [4.0793, 3.1597, 4.3168], [4.2393, 3.2843, 4.4866], [4.4053, 3.4142, 4.6636],
+ [4.5760, 3.5480, 4.8461], [4.7541, 3.6886, 5.0383], [4.9407, 3.8364, 5.2390],
+]
+
+# Pre-convert to tensors (lazily cached on first access)
+_alpha_tensor = None
+_beta_tensor = None
+
+
+def get_alpha_table():
+ """Return α_t table as tensor [51, 3], cached after first call."""
+ global _alpha_tensor
+ if _alpha_tensor is None:
+ _alpha_tensor = torch.tensor(ALPHA_T, dtype=torch.float32) # [51, 3]
+ return _alpha_tensor
+
+
+def get_beta_table():
+ """Return β_t table as tensor [51, 3], cached after first call."""
+ global _beta_tensor
+ if _beta_tensor is None:
+ _beta_tensor = torch.tensor(BETA_T, dtype=torch.float32) # [51, 3]
+ return _beta_tensor
diff --git a/custom_nodes/ComfyUI-LCS/core/diagnostics.py b/custom_nodes/ComfyUI-LCS/core/diagnostics.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e7f75687677c28f4c59092f1e76890e54f61d82
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/diagnostics.py
@@ -0,0 +1,246 @@
+"""Diagnostic tests for LCS intervention pipeline.
+
+This module provides tests and diagnostics to identify conditions that
+cause image blurriness or quality degradation during LCS intervention.
+"""
+
+import torch
+import math
+from .color_space import decode_lcs_to_hsl, encode_hsl_to_lcs, _hue_lerp
+from .timestep import get_alpha_beta, get_alpha_beta_t50, normalize_to_t50, denormalize_from_t50
+
+# Test constants
+_T50_REFERENCE_COORD = [0.5, 0.3, 0.1] # Typical LCS magnitude at t=50
+_TEST_STRENGTHS = [0.0, 0.25, 0.5, 0.75, 1.0, 1.5, 2.0] # Range from none to overshoot
+_VARIATION_SCALE = 0.5 # Scale for test patch variation
+_NOISE_SCALE = 2.0 # Simulated diffusion noise magnitude
+_PROBLEMATIC_AMPLIFICATION_THRESHOLD = 50 # >50x noise amplification is problematic
+
+
+def test_round_trip_consistency(anchor_lcs, anchor_angles):
+ """Test that encode(decode(x)) ≈ x for typical LCS coordinates.
+
+ This verifies the bicone geometry math is correct.
+ """
+ chromatic = anchor_lcs[:6]
+ black, white = anchor_lcs[6], anchor_lcs[7]
+
+ # Test round-trip on anchor positions
+ errors = []
+ test_cases = list(chromatic) # All 6 chromatic anchors
+
+ # Add some mid-tones and random points
+ for _ in range(5):
+ # Generate random LCS point
+ h = torch.rand(1).item()
+ s = torch.rand(1).item()
+ l = torch.rand(1).item()
+ c = encode_hsl_to_lcs(
+ torch.tensor(h), torch.tensor(s), torch.tensor(l),
+ anchor_lcs, anchor_angles
+ )
+ test_cases.append(c)
+
+ for c in test_cases:
+ h, s, l = decode_lcs_to_hsl(c, anchor_lcs, anchor_angles)
+ c_round = encode_hsl_to_lcs(h, s, l, anchor_lcs, anchor_angles)
+ error = (c - c_round).norm().item()
+ errors.append(error)
+
+ max_error = max(errors)
+ avg_error = sum(errors) / len(errors)
+ return {
+ "max_round_trip_error": max_error,
+ "avg_round_trip_error": avg_error,
+ "passed": max_error < 1e-4,
+ "errors": errors,
+ }
+
+
+def test_normalization_stability():
+ """Test that normalize/denormalize round-trip is stable across all timesteps.
+
+ Identifies timesteps where numerical instability could cause issues.
+ """
+ # Sample LCS coordinates at t=50 (clean image reference)
+ c_t50 = torch.tensor(_T50_REFERENCE_COORD, dtype=torch.float32)
+ alpha_50, beta_50 = get_alpha_beta_t50()
+
+ results = []
+ for t in range(51):
+ sigma = 1.0 - t / 50.0 # sigma = 1 - t/50
+ alpha_t, beta_t = get_alpha_beta(sigma)
+
+ # Normalize then denormalize
+ c_norm = normalize_to_t50(c_t50, alpha_t, beta_t, alpha_50, beta_50)
+ c_back = denormalize_from_t50(c_norm, alpha_t, beta_t, alpha_50, beta_50)
+
+ error = (c_t50 - c_back).norm().item()
+
+ # Check amplification factor
+ amplification = (beta_50 / beta_t).max().item()
+
+ results.append({
+ "t": t,
+ "sigma": sigma,
+ "beta_t_min": beta_t.min().item(),
+ "amplification": amplification,
+ "round_trip_error": error,
+ })
+
+ return results
+
+
+def test_type_ii_uniformity(anchor_lcs, anchor_angles):
+ """Test if Type II intervention at high strength produces uniform outputs.
+
+ This is a key diagnostic for the blurriness issue - if all patches
+ converge to the same HSL values, the image loses detail.
+ """
+ # Create diverse patch set (simulate image with color variation)
+ patches = torch.randn(100, 3) * _VARIATION_SCALE + torch.tensor([0.3, 0.2, 0.1])
+
+ # Target color (e.g., saturated red)
+ t_h, t_s, t_l = 0.0, 1.0, 0.5
+
+ # Decode all patches ONCE (constant across strengths)
+ h_cur, s_cur, l_cur = decode_lcs_to_hsl(patches, anchor_lcs, anchor_angles)
+
+ # Target HSL tensors
+ h_new = torch.full_like(h_cur, t_h)
+ s_new = torch.full_like(s_cur, t_s)
+ l_new = torch.full_like(l_cur, t_l)
+
+ # Compute input variance once (patches never changes)
+ input_var = patches.var(dim=0).mean().item()
+
+ # Test different strengths
+ for strength in _TEST_STRENGTHS:
+ # Hue lerp using shared helper
+ h_interp = _hue_lerp(h_cur, h_new, strength)
+ s_interp = (s_cur + strength * (s_new - s_cur)).clamp(0, 1)
+ l_interp = (l_cur + strength * (l_new - l_cur)).clamp(0, 1)
+
+ # Re-encode
+ new_patches = encode_hsl_to_lcs(h_interp, s_interp, l_interp, anchor_lcs, anchor_angles)
+
+ # Measure variance loss
+ output_var = new_patches.var(dim=0).mean().item()
+ var_ratio = output_var / (input_var + 1e-10)
+
+ # Check how many unique HSL values we end up with
+ h_unique = len(torch.unique(h_interp.round(decimals=3)))
+ s_unique = len(torch.unique(s_interp.round(decimals=3)))
+ l_unique = len(torch.unique(l_interp.round(decimals=3)))
+
+ print(f"strength={strength:.2f}: var_ratio={var_ratio:.3f}, "
+ f"unique_h={h_unique}, unique_s={s_unique}, unique_l={l_unique}")
+
+
+def test_early_timestep_amplification():
+ """Test numerical behavior at very early timesteps (high sigma).
+
+ At t≈0 (sigma≈1), beta_t is very small, causing large amplification
+ in normalize_to_t50. This could amplify noise and corrupt the signal.
+ """
+ # Typical LCS coordinate magnitude at t=50
+ c_ref = torch.tensor(_T50_REFERENCE_COORD, dtype=torch.float32)
+ alpha_50, beta_50 = get_alpha_beta_t50() # Constant across all sigmas
+
+ for sigma in [1.0, 0.99, 0.95, 0.90, 0.85, 0.80, 0.50, 0.0]:
+ alpha_t, beta_t = get_alpha_beta(sigma)
+
+ # Simulate a noisy observation at timestep t
+ # In diffusion, the observation is alpha_t * clean + beta_t * noise
+ # At high sigma, noise dominates
+ noise = torch.randn(3) * _NOISE_SCALE
+ c_observed = alpha_t + beta_t * c_ref + beta_t * noise
+
+ # Normalize to t=50
+ c_norm = normalize_to_t50(c_observed, alpha_t, beta_t, alpha_50, beta_50)
+
+ # Measure deviation from reference
+ deviation = (c_norm - c_ref).norm().item()
+ amplification = (beta_50 / beta_t).max().item()
+
+ print(f"sigma={sigma:.2f}: beta_t={beta_t.numpy()}, "
+ f"amplification={amplification:.1f}x, deviation={deviation:.3f}")
+
+
+def analyze_blurriness_causes(lcs_data_path=None):
+ """Comprehensive analysis of all potential blurriness causes."""
+ print("=" * 60)
+ print("LCS INTERVENTION BLURRINESS ANALYSIS")
+ print("=" * 60)
+
+ # Load actual calibration data
+ if lcs_data_path is None:
+ from pathlib import Path
+ data_dir = Path(__file__).parent.parent / "data"
+ safetensors_files = list(data_dir.glob("lcs_*.safetensors"))
+ if safetensors_files:
+ lcs_data_path = safetensors_files[0]
+ else:
+ print("ERROR: No calibration data found. Run LCSLoadData with calibrate=True first.")
+ return
+
+ from safetensors.torch import load_file
+ data = load_file(lcs_data_path)
+ anchor_lcs = data["anchor_lcs"]
+ anchor_angles = data["anchor_angles"]
+
+ print(f"\nLoaded calibration data from: {lcs_data_path}")
+ print(f"anchor_lcs shape: {anchor_lcs.shape}")
+ print(f"anchor_angles shape: {anchor_angles.shape}")
+
+ print("\n1. ROUND-TRIP CONSISTENCY TEST")
+ print("-" * 40)
+ result = test_round_trip_consistency(anchor_lcs, anchor_angles)
+ print(f"Max error: {result['max_round_trip_error']:.2e}")
+ print(f"Avg error: {result['avg_round_trip_error']:.2e}")
+ print(f"Status: {'PASS' if result['passed'] else 'FAIL'}")
+
+ print("\n2. NORMALIZATION STABILITY TEST")
+ print("-" * 40)
+ norm_results = test_normalization_stability()
+ problematic = [r for r in norm_results if r['amplification'] > _PROBLEMATIC_AMPLIFICATION_THRESHOLD]
+ print(f"Timesteps with >{_PROBLEMATIC_AMPLIFICATION_THRESHOLD}x amplification: {len(problematic)}")
+ for r in problematic[:5]:
+ print(f" t={r['t']:2d} (sigma={r['sigma']:.2f}): amp={r['amplification']:.1f}x")
+
+ print("\n3. TYPE II UNIFORMITY TEST")
+ print("-" * 40)
+ test_type_ii_uniformity(anchor_lcs, anchor_angles)
+
+ print("\n4. EARLY TIMESTEP AMPLIFICATION TEST")
+ print("-" * 40)
+ test_early_timestep_amplification()
+
+ print("\n" + "=" * 60)
+ print("CONCLUSIONS")
+ print("=" * 60)
+ print("""
+Potential blurriness causes identified:
+
+1. TYPE II AT HIGH STRENGTH: At strength=1.0, all patches get the same
+ target HSL, destroying spatial color variation. This is the PRIMARY
+ cause of blur in type_ii mode.
+
+2. EARLY TIMESTEP AMPLIFICATION: At sigma>0.95 (t<2.5), beta_t is ~0.02,
+ causing ~250x amplification of noise. Intervening too early (step 0-2)
+ will corrupt the signal.
+
+3. OVERSHOOTING: strength>1.0 overshoots the target, potentially pushing
+ values outside the valid color gamut. This can cause clipping and
+ artifacts.
+
+RECOMMENDATIONS:
+- For type_ii mode, use strength<0.8 to preserve some original variation
+- Avoid intervening before step 5 (sigma<0.90)
+- For interpolated mode, the gamma=sigma blending naturally limits damage
+ at early steps
+""")
+
+
+if __name__ == "__main__":
+ analyze_blurriness_causes()
diff --git a/custom_nodes/ComfyUI-LCS/core/lcs_data.py b/custom_nodes/ComfyUI-LCS/core/lcs_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..649bcced12e921df38a6bb725aaf2fe3086a6028
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/lcs_data.py
@@ -0,0 +1,28 @@
+from dataclasses import dataclass
+import torch
+
+
+@dataclass
+class LCSData:
+ """Calibration data for the Latent Color Subspace.
+
+ Produced by PCA on FLUX VAE-encoded solid-color images. Flows between
+ all LCS nodes as the shared LCS_DATA custom type.
+ """
+
+ basis: torch.Tensor # [64, 3] PCA basis B (orthonormal columns)
+ mean: torch.Tensor # [64] PCA mean mu
+ anchor_lcs: torch.Tensor # [8, 3] LCS coords of 8 anchor colors [R,B,G,M,C,Y,Black,White]
+ anchor_angles: torch.Tensor # [6] hue angles (radians) of the 6 chromatic anchors
+
+ def to(self, device, dtype=None):
+ """Move all tensors to device/dtype."""
+ kw = {"device": device}
+ if dtype is not None:
+ kw["dtype"] = dtype
+ return LCSData(
+ basis=self.basis.to(**kw),
+ mean=self.mean.to(**kw),
+ anchor_lcs=self.anchor_lcs.to(**kw),
+ anchor_angles=self.anchor_angles.to(**kw),
+ )
diff --git a/custom_nodes/ComfyUI-LCS/core/patchify.py b/custom_nodes/ComfyUI-LCS/core/patchify.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc3cbd5e8cf04eb474d4d910d093e9558f7bb2a0
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/patchify.py
@@ -0,0 +1,93 @@
+"""Patchify/unpatchify for latent tensors (patch_size=2, auto-detect channels).
+
+Handles 3D, 4D, and 5D inputs. Pads odd spatial dims to even before patchifying.
+"""
+
+from einops import rearrange
+import torch.nn.functional as F
+
+
+def patchify(x):
+ """Convert latent [C, H, W], [B, C, H, W], or [B, C, T, H, W] → patch sequence [B, L, C*4].
+
+ Handles three input formats:
+ - 3D [C, H, W]: adds batch dim, extra_shape="unbatched"
+ - 4D [B, C, H, W]: standard path, extra_shape=None
+ - 5D [B, C, T, H, W]: video VAE, merges T into batch, extra_shape=(B, C, T)
+
+ Pads odd H/W to even before patchifying. The pad amounts are stored
+ in the returned extra_shape for unpatchify to crop back.
+
+ L = (H_padded/2) * (W_padded/2), d = C * 2 * 2.
+ """
+ extra_shape = None
+ pad_h = 0
+ pad_w = 0
+
+ if x.ndim == 3:
+ extra_shape = "unbatched"
+ x = x.unsqueeze(0)
+ elif x.ndim == 5:
+ B_orig, C, T, H, W = x.shape
+ extra_shape = (B_orig, C, T)
+ x = x.permute(0, 2, 1, 3, 4).reshape(B_orig * T, C, H, W)
+
+ B, C, H, W = x.shape
+ if H < 1 or W < 1:
+ return None, None, None, None
+
+ # Pad odd dimensions to even (replicate last row/col)
+ if H % 2 != 0:
+ pad_h = 1
+ if W % 2 != 0:
+ pad_w = 1
+ if pad_h or pad_w:
+ x = F.pad(x, (0, pad_w, 0, pad_h), mode="replicate")
+
+ H_p, W_p = x.shape[2], x.shape[3]
+ h_len = H_p // 2
+ w_len = W_p // 2
+ patches = rearrange(x, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
+
+ # Bundle pad info with extra_shape
+ if pad_h or pad_w:
+ extra_shape = {"orig_extra": extra_shape, "pad_h": pad_h, "pad_w": pad_w}
+
+ return patches, h_len, w_len, extra_shape
+
+
+def unpatchify(patches, h_len, w_len, extra_shape=None):
+ """Convert patch sequence [B, L, C*4] → latent, restoring original shape.
+
+ Auto-detects channel count from patch dimension: C = D / 4.
+ Handles padding removal and 3D/5D restoration based on extra_shape.
+ """
+ D = patches.shape[-1]
+ C = D // 4 # patch_size=2×2=4
+ x = rearrange(patches, "b (h w) (c ph pw) -> b c (h ph) (w pw)",
+ h=h_len, w=w_len, c=C, ph=2, pw=2)
+
+ # Unwrap pad info if present
+ pad_h = 0
+ pad_w = 0
+ orig_extra = extra_shape
+ if isinstance(extra_shape, dict):
+ pad_h = extra_shape["pad_h"]
+ pad_w = extra_shape["pad_w"]
+ orig_extra = extra_shape["orig_extra"]
+
+ # Remove padding
+ if pad_h:
+ x = x[:, :, :-pad_h, :]
+ if pad_w:
+ x = x[:, :, :, :-pad_w]
+
+ # Restore original format
+ if orig_extra == "unbatched":
+ x = x.squeeze(0)
+ elif orig_extra is not None:
+ B_orig, C_orig, T = orig_extra
+ H, W = x.shape[2], x.shape[3]
+ x = x.reshape(B_orig, T, C_orig, H, W).permute(0, 2, 1, 3, 4)
+
+ return x
diff --git a/custom_nodes/ComfyUI-LCS/core/relationships.py b/custom_nodes/ComfyUI-LCS/core/relationships.py
new file mode 100644
index 0000000000000000000000000000000000000000..470659572a742e5ee38f9b8cb5949d045826c4bd
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/relationships.py
@@ -0,0 +1,117 @@
+"""Local color relationship analysis for drift detection and correction."""
+
+import torch
+import torch.nn.functional as F
+
+
+def compute_local_relationships(c, h_len, w_len, kernel_radius=2):
+ """Compute per-patch relationship vector from 5x5 neighborhood.
+
+ For each patch, cosine similarity with each of up to 24 neighbors.
+ Returns [B, L, N_neighbors] relationship vectors where N_neighbors = (2*r+1)^2 - 1.
+ """
+ B = c.shape[0]
+ r = kernel_radius
+ k_size = 2 * r + 1
+ n_neighbors = k_size * k_size - 1 # 24 for r=2
+
+ # Reshape to spatial grid
+ grid = c.reshape(B, h_len, w_len, 3) # [B, H, W, 3]
+
+ # Permute to [B, 3, H, W] for padding
+ grid_chw = grid.permute(0, 3, 1, 2) # [B, 3, H, W]
+ padded = F.pad(grid_chw, (r, r, r, r), mode="replicate") # [B, 3, H+2r, W+2r]
+
+ # Center values — normalize for cosine similarity
+ center_norm = grid_chw / grid_chw.norm(dim=1, keepdim=True).clamp(min=1e-8)
+
+ # Pre-normalize padded tensor once (avoids per-neighbor normalization in loop)
+ padded_norm = padded / padded.norm(dim=1, keepdim=True).clamp(min=1e-8)
+
+ # Collect cosine similarities with each neighbor
+ similarities = []
+ for dy in range(-r, r + 1):
+ for dx in range(-r, r + 1):
+ if dy == 0 and dx == 0:
+ continue
+ y_start = r + dy
+ x_start = r + dx
+ neighbor_norm = padded_norm[:, :, y_start:y_start + h_len, x_start:x_start + w_len]
+ # Cosine similarity per pixel
+ sim = (center_norm * neighbor_norm).sum(dim=1) # [B, H, W]
+ similarities.append(sim)
+
+ # Stack to [B, H, W, N_neighbors] -> [B, L, N_neighbors]
+ rel = torch.stack(similarities, dim=-1) # [B, H, W, N_neighbors]
+ return rel.reshape(B, -1, n_neighbors)
+
+
+def detect_anomalies_adaptive(r_current, r_reference):
+ """Compare current vs reference relationships with adaptive threshold.
+
+ Uses per-batch robust outlier detection: threshold = median + 3.0 * 1.4826 * MAD.
+ Returns anomaly_magnitude [B, L, 1] in [0, 1].
+ """
+ # Mean absolute difference across neighbor relationships
+ diff = (r_current - r_reference).abs().mean(dim=-1) # [B, L]
+
+ # Per-batch robust statistics
+ median = diff.median(dim=-1, keepdim=True).values # [B, 1]
+ mad = (diff - median).abs().median(dim=-1, keepdim=True).values # [B, 1]
+ threshold = median + 3.0 * 1.4826 * mad # [B, 1]
+
+ # Soft ramp above threshold, normalized to [0, 1]
+ anomaly = (diff - threshold).clamp(min=0.0) # [B, L]
+ # Normalize per-batch: max anomaly → 1.0
+ amax = anomaly.amax(dim=-1, keepdim=True).clamp(min=1e-8) # [B, 1]
+ anomaly = anomaly / amax
+
+ return anomaly.unsqueeze(-1) # [B, L, 1]
+
+
+def infer_color_from_neighbors(c, anomaly_mag, h_len, w_len, kernel_radius=2):
+ """For anomalous patches, infer correct color from non-anomalous neighbors.
+
+ Uses inverse-anomaly weighting: patches with low anomaly contribute more.
+ Returns [B, L, 3] corrected colors (blended: anomalous patches get
+ neighbor-inferred values, non-anomalous patches keep their original).
+ """
+ B = c.shape[0]
+ r = kernel_radius
+
+ # Reshape to spatial grid
+ grid = c.reshape(B, h_len, w_len, 3)
+ anom_grid = anomaly_mag.reshape(B, h_len, w_len, 1)
+
+ # Pad both grid and anomaly
+ grid_chw = grid.permute(0, 3, 1, 2) # [B, 3, H, W]
+ anom_chw = anom_grid.permute(0, 3, 1, 2) # [B, 1, H, W]
+ padded_c = F.pad(grid_chw, (r, r, r, r), mode="replicate")
+ padded_a = F.pad(anom_chw, (r, r, r, r), mode="replicate")
+
+ # Weight neighbors by how non-anomalous they are
+ weight_sum = torch.zeros(B, 1, h_len, w_len, device=c.device, dtype=c.dtype)
+ value_sum = torch.zeros(B, 3, h_len, w_len, device=c.device, dtype=c.dtype)
+
+ for dy in range(-r, r + 1):
+ for dx in range(-r, r + 1):
+ if dy == 0 and dx == 0:
+ continue
+ y_start = r + dy
+ x_start = r + dx
+ neighbor_c = padded_c[:, :, y_start:y_start + h_len, x_start:x_start + w_len]
+ neighbor_a = padded_a[:, :, y_start:y_start + h_len, x_start:x_start + w_len]
+
+ # Weight: 1 - anomaly (non-anomalous neighbors get high weight)
+ w = (1.0 - neighbor_a).clamp(min=0.01) # [B, 1, H, W]
+ weight_sum = weight_sum + w
+ value_sum = value_sum + w * neighbor_c
+
+ # Inferred color from neighbors
+ inferred = value_sum / weight_sum.clamp(min=1e-8) # [B, 3, H, W]
+ inferred = inferred.permute(0, 2, 3, 1).reshape(B, -1, 3) # [B, L, 3]
+
+ # Blend: anomalous patches use inferred, non-anomalous keep original
+ # anomaly_mag is [B, L, 1], range [0, ~1]
+ blend = anomaly_mag.clamp(0, 1)
+ return c * (1.0 - blend) + inferred * blend
diff --git a/custom_nodes/ComfyUI-LCS/core/sampling.py b/custom_nodes/ComfyUI-LCS/core/sampling.py
new file mode 100644
index 0000000000000000000000000000000000000000..925687fb8451ce659a2769a22c299b977bc38969
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/sampling.py
@@ -0,0 +1,105 @@
+"""Shared sampling utilities for LCS intervention hooks."""
+
+import comfy.utils
+import torch
+import torch.nn.functional as F
+
+
+def find_step_index(sigma, sigmas):
+ """Find the step index for a given sigma value in the sigma schedule.
+
+ Uses torch.isclose for robust matching across dtype differences (e.g. bfloat16
+ sigma vs float32 sample_sigmas), with argmin fallback for edge cases.
+ """
+ sigma_val = sigma.flatten()[0].float()
+ sigmas_f = sigmas.float()
+ matched = torch.isclose(sigmas_f, sigma_val, rtol=1e-3, atol=1e-5).nonzero()
+ if len(matched) > 0:
+ return matched[0].item()
+ return (sigmas_f - sigma_val).abs().argmin().item()
+
+
+def denoised_to_raw(denoised, model):
+ """Convert denoised tensor from process_in space to raw VAE space.
+
+ Uses the model's latent_format.process_out (inverse of process_in).
+ Works for any model: FLUX (scale+shift), LTXV (identity), SD (scale), etc.
+ """
+ return model.latent_format.process_out(denoised)
+
+
+def raw_to_denoised(raw, model):
+ """Convert raw VAE space tensor back to process_in space.
+
+ Uses the model's latent_format.process_in.
+ """
+ return model.latent_format.process_in(raw)
+
+
+def unpack_video_if_needed(denoised, args):
+ """Unpack LTXAV-style packed latents if detected.
+
+ LTXAV packs video [B,128,F,H,W] + audio [B,ch,T,freq] into [B,1,flat].
+ Returns (tensor_to_process, pack_info) where pack_info is None for
+ non-packed formats or a dict for repacking.
+ """
+ # Detect packed format: shape [B, 1, flat] with very large last dim
+ if denoised.ndim == 3 and denoised.shape[1] == 1:
+ # Try to find latent_shapes from cond data
+ cond = args.get("cond")
+ latent_shapes = _extract_latent_shapes(cond)
+ if latent_shapes is not None and len(latent_shapes) > 1:
+ tensors = comfy.utils.unpack_latents(denoised, latent_shapes)
+ # tensors[0] = video [B, 128, F, H, W], tensors[1] = audio [B, ch, T, freq]
+ return tensors[0], {"other_tensors": tensors[1:]}
+ return denoised, None
+
+
+def repack_video_if_needed(modified, pack_info):
+ """Repack video tensor back into LTXAV packed format if it was unpacked.
+
+ modified: the video tensor after intervention [B, 128, F, H, W]
+ pack_info: from unpack_video_if_needed
+ """
+ if pack_info is None:
+ return modified
+ all_tensors = [modified] + pack_info["other_tensors"]
+ packed, _ = comfy.utils.pack_latents(all_tensors)
+ return packed
+
+
+def downsample_mask(mask, h_len, w_len, device, dtype):
+ """Downsample a mask to patch grid and flatten to [1, L, 1]."""
+ mask_dev = mask.to(device=device, dtype=dtype)
+ if mask_dev.ndim == 3:
+ mask_dev = mask_dev[:1]
+ if mask_dev.ndim == 2:
+ mask_4d = mask_dev.unsqueeze(0).unsqueeze(0) # [1, 1, H, W]
+ elif mask_dev.ndim == 3:
+ mask_4d = mask_dev.unsqueeze(1) # [B, 1, H, W]
+ else:
+ mask_4d = mask_dev
+ mask_resized = F.interpolate(
+ mask_4d, size=(h_len, w_len), mode="bilinear", align_corners=False
+ )
+ return mask_resized.reshape(1, -1, 1) # [1, L, 1]
+
+
+def _extract_latent_shapes(cond):
+ """Try to extract latent_shapes from conditioning data.
+
+ After convert_cond, cond is a list of dicts with 'model_conds' containing
+ CONDConstant-wrapped values like 'latent_shapes'.
+ """
+ if cond is None:
+ return None
+ for c in cond:
+ if isinstance(c, dict):
+ model_conds = c.get('model_conds', {})
+ if 'latent_shapes' in model_conds:
+ ls = model_conds['latent_shapes']
+ # CONDConstant wraps the value in .cond
+ if hasattr(ls, 'cond'):
+ return ls.cond
+ return ls
+ return None
diff --git a/custom_nodes/ComfyUI-LCS/core/sharpness.py b/custom_nodes/ComfyUI-LCS/core/sharpness.py
new file mode 100644
index 0000000000000000000000000000000000000000..47f74fb9d5d35b9791db6ab1cad69f84a5b34158
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/sharpness.py
@@ -0,0 +1,213 @@
+"""Sharpness subspace calibration via sinusoidal grating stimuli.
+
+Replaces the previous Gaussian blur approach with narrowband frequency
+gratings, which achieve higher linearity (R²=0.94 vs 0.88) because each
+stimulus contains a single spatial frequency — a purer probe of the VAE's
+frequency encoding axis.
+
+The two methods discover the same 1D subspace (|cos|=0.986, 9.7° apart),
+but grating stimuli yield a cleaner PC1 direction.
+"""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple
+import warnings
+
+import torch
+import comfy.utils
+
+from .patchify import patchify
+from .lcs_data import LCSData
+
+
+@dataclass
+class SharpnessData:
+ """Calibration data for the sharpness subspace.
+
+ Produced by PCA on FLUX VAE-encoded sinusoidal gratings at varying
+ spatial frequencies. PC1 captures ~94% of variance with R²=0.94
+ linearity vs log₂(frequency).
+ """
+
+ basis: torch.Tensor # [64, K] PCA basis (columns), K typically 1-2
+ mean: torch.Tensor # [64] PCA mean (in color-removed space if lcs_data was used)
+ sign: float # +1 or -1: ensures positive strength = sharper
+ lcs_basis: Optional[torch.Tensor] = None # [64, 3] LCS basis used during calibration (for re-orthogonalization)
+
+ def to(self, device, dtype=None):
+ """Move all tensors to device/dtype."""
+ kw = {"device": device}
+ if dtype is not None:
+ kw["dtype"] = dtype
+ return SharpnessData(
+ basis=self.basis.to(**kw),
+ mean=self.mean.to(**kw),
+ sign=self.sign,
+ lcs_basis=self.lcs_basis.to(**kw) if self.lcs_basis is not None else None,
+ )
+
+
+def _generate_grating_batch(
+ indices: List[int],
+ angles: torch.Tensor,
+ phases: torch.Tensor,
+ frequencies: Tuple[float, ...],
+ coord_x: torch.Tensor,
+ coord_y: torch.Tensor,
+) -> torch.Tensor:
+ """Generate a batch of sinusoidal grating stimuli by flat index.
+
+ Each flat index maps to (orientation, frequency) via divmod.
+ Returns [len(indices), 3, H, W] tensor.
+ """
+ num_freqs = len(frequencies)
+ batch = []
+ for idx in indices:
+ ori = idx // num_freqs
+ freq = frequencies[idx % num_freqs]
+ angle = angles[ori].item()
+ phase = phases[ori].item()
+ cos_a, sin_a = math.cos(angle), math.sin(angle)
+ coord = coord_x * cos_a + coord_y * sin_a
+ grating = 0.5 + 0.3 * torch.sin(2 * math.pi * freq * coord + phase)
+ batch.append(grating.unsqueeze(0).expand(3, -1, -1))
+ return torch.stack(batch, dim=0)
+
+
+def calibrate_sharpness(vae, num_samples: int = 64, image_size: int = 512,
+ frequencies: Tuple[float, ...] = (1, 2, 4, 8, 16, 32, 64),
+ batch_size: int = 8,
+ lcs_data: LCSData = None,
+ # Legacy parameter — accepted but ignored
+ blur_levels: Optional[Tuple[float, ...]] = None,
+ ) -> SharpnessData:
+ """Compute sharpness subspace data (PCA basis, mean, sign) from FLUX VAE.
+
+ Generates sinusoidal gratings at varying spatial frequencies (one pure
+ frequency per stimulus), VAE-encodes them, and runs PCA to find the
+ sharpness/frequency direction in 64D patch space.
+
+ Args:
+ vae: ComfyUI VAE object
+ num_samples: Number of orientations (each combined with all frequencies)
+ image_size: Size of generated images
+ frequencies: Spatial frequencies in cycles/image
+ batch_size: Batch size for VAE encoding
+ lcs_data: Optional LCS data for removing color component during calibration.
+ When provided, the sharpness PC1 will be orthogonal to the color subspace,
+ preventing color shifts during intervention.
+
+ Returns: SharpnessData
+ """
+ if blur_levels is not None:
+ warnings.warn(
+ "blur_levels is deprecated and ignored; calibration now uses sinusoidal gratings",
+ DeprecationWarning, stacklevel=2,
+ )
+
+ n_freqs = len(frequencies)
+ total_images = num_samples * n_freqs
+
+ print(f"\n[LCS Sharpness Calibration] Starting: {num_samples} orientations × {n_freqs} frequencies = {total_images} stimuli")
+ print(f"[LCS Sharpness Calibration] Frequencies: {list(frequencies)} cycles/image")
+
+ # Pre-compute shared state for grating generation
+ gen = torch.Generator().manual_seed(42)
+ angles = torch.rand(num_samples, generator=gen) * math.pi # [0, π)
+ phases = torch.rand(num_samples, generator=gen) * 2 * math.pi # [0, 2π)
+ y_coords = torch.linspace(-0.5, 0.5, image_size).unsqueeze(1)
+ x_coords = torch.linspace(-0.5, 0.5, image_size).unsqueeze(0)
+ coord_y = y_coords.expand(image_size, image_size)
+ coord_x = x_coords.expand(image_size, image_size)
+
+ # Build frequency labels for all stimuli (flat index → frequency)
+ freq_labels = [frequencies[idx % n_freqs] for idx in range(total_images)]
+ freq_labels_t = torch.tensor(freq_labels, dtype=torch.float32)
+ log_freq = torch.log2(freq_labels_t.clamp(min=0.5))
+
+ # Generate stimuli lazily per batch and VAE encode
+ vectors = []
+ pbar = comfy.utils.ProgressBar(total_images)
+
+ for batch_start in range(0, total_images, batch_size):
+ batch_end = min(batch_start + batch_size, total_images)
+ indices = list(range(batch_start, batch_end))
+ batch = _generate_grating_batch(indices, angles, phases, frequencies, coord_x, coord_y)
+ actual_batch = batch.shape[0]
+
+ # Convert BCHW → BHWC for ComfyUI VAE
+ imgs_bhwc = batch.permute(0, 2, 3, 1).contiguous().cpu()
+
+ # VAE encode — try batch first, fall back to per-image for video VAEs
+ latent = vae.encode(imgs_bhwc)
+ patches, _, _, _ = patchify(latent)
+ avg = patches.mean(dim=1).cpu()
+
+ if avg.shape[0] == actual_batch:
+ vectors.extend(avg.unbind(0))
+ else:
+ # Video VAE: batch not fully supported, encode one by one
+ vectors.extend(avg.unbind(0))
+ for k in range(1, actual_batch):
+ single = imgs_bhwc[k:k+1]
+ lat = vae.encode(single)
+ p, _, _, _ = patchify(lat)
+ vectors.append(p.mean(dim=1).cpu().squeeze(0))
+
+ pbar.update(actual_batch)
+
+ # Stack all vectors: [N, 64]
+ X = torch.stack(vectors, dim=0).float()
+ print(f"[LCS Sharpness Calibration] Collected {X.shape[0]} vectors of dimension {X.shape[1]}")
+
+ # Remove LCS color component FIRST, in the raw space where LCS was calibrated.
+ # This must happen before per-vector DC removal, because the LCS basis has
+ # significant DC components (PC1 ≈ brightness). Doing DC removal first would
+ # shift vectors into a different space where B^T(x - mu) is incorrect.
+ if lcs_data is not None:
+ print("[LCS Sharpness Calibration] Removing LCS color component...")
+ lcs_mean = lcs_data.mean.to(X.device, X.dtype)
+ lcs_basis = lcs_data.basis.to(X.device, X.dtype)
+ # Project out color: X' = X - B B^T (X - mu)
+ centered = X - lcs_mean
+ lcs_coords = centered @ lcs_basis # [N, 3]
+ X = X - lcs_coords @ lcs_basis.T
+ print("[LCS Sharpness Calibration] Color component removed")
+
+ # Remove per-vector DC AFTER color removal.
+ # VAE encoding shifts the latent mean depending on stimulus content.
+ # Per-vector zero-mean forces PCA to find patterns in the relative channel
+ # structure, not in the absolute level.
+ X = X - X.mean(dim=1, keepdim=True)
+
+ # Step 3: PCA
+ print("[LCS Sharpness Calibration] Computing PCA...")
+ mean = X.mean(dim=0) # [64]
+ X_centered = X - mean
+ U, S, Vh = torch.linalg.svd(X_centered, full_matrices=False)
+ # Top 2 components
+ basis = Vh[:2].T # [64, 2]
+
+ # Variance explained
+ total_var = (S ** 2).sum()
+ explained = (S[:2] ** 2) / total_var
+ print(f"[LCS Sharpness Calibration] PC1: {explained[0]:.1%}, PC2: {explained[1]:.1%} ({(explained[0]+explained[1]):.1%} total)")
+
+ # Step 4: Determine sign convention
+ # Project all vectors onto PC1
+ pc1_scores = X_centered @ basis[:, 0] # [N]
+
+ # Correlate PC1 score with log₂(frequency)
+ # Higher frequency = sharper → if positive correlation, sign = +1
+ correlation = torch.corrcoef(torch.stack([pc1_scores, log_freq]))[0, 1]
+ sign = 1.0 if correlation > 0 else -1.0
+ print(f"[LCS Sharpness Calibration] PC1-frequency correlation: {correlation:.3f} → sign = {sign:+.0f}")
+ print(f"[LCS Sharpness Calibration] Complete! Basis shape: {basis.shape}")
+
+ return SharpnessData(
+ basis=basis,
+ mean=mean,
+ sign=sign,
+ lcs_basis=lcs_data.basis.clone() if lcs_data is not None else None,
+ )
diff --git a/custom_nodes/ComfyUI-LCS/core/timestep.py b/custom_nodes/ComfyUI-LCS/core/timestep.py
new file mode 100644
index 0000000000000000000000000000000000000000..96948007e1c18608c01cffd7461b17d83cdd09f2
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/core/timestep.py
@@ -0,0 +1,75 @@
+"""Sigma ↔ paper timestep conversion and α_t/β_t interpolation."""
+
+import torch
+from .defaults import get_alpha_table, get_beta_table
+
+
+def sigma_to_paper_t(sigma):
+ """Convert FLUX sigma ∈ [0,1] to paper timestep t ∈ [0,50].
+
+ sigma=1 → noise → t=0, sigma=0 → clean → t=50.
+ """
+ if isinstance(sigma, torch.Tensor):
+ return 50.0 * (1.0 - sigma.clamp(0.0, 1.0))
+ return 50.0 * (1.0 - max(0.0, min(1.0, sigma)))
+
+
+def get_alpha_beta(sigma, device=None):
+ """Get interpolated α_t and β_t [3] vectors for a given sigma.
+
+ Returns (alpha_t, beta_t) as tensors on the specified device.
+ """
+ t = sigma_to_paper_t(sigma)
+ if isinstance(t, torch.Tensor):
+ t = t.item()
+
+ alpha_table = get_alpha_table() # [51, 3]
+ beta_table = get_beta_table() # [51, 3]
+
+ t = max(0.0, min(50.0, t))
+ t_low = int(t)
+ t_high = min(t_low + 1, 50)
+ frac = t - t_low
+
+ alpha = (1.0 - frac) * alpha_table[t_low] + frac * alpha_table[t_high]
+ beta = (1.0 - frac) * beta_table[t_low] + frac * beta_table[t_high]
+
+ if device is not None:
+ alpha = alpha.to(device)
+ beta = beta.to(device)
+ return alpha, beta
+
+
+def get_alpha_beta_t50(device=None):
+ """Get α_50 and β_50 (reference timestep t=50, clean image)."""
+ alpha_table = get_alpha_table()
+ beta_table = get_beta_table()
+ alpha_50 = alpha_table[50]
+ beta_50 = beta_table[50]
+ if device is not None:
+ alpha_50 = alpha_50.to(device)
+ beta_50 = beta_50.to(device)
+ return alpha_50, beta_50
+
+
+def normalize_to_t50(c, alpha_t, beta_t, alpha_50, beta_50):
+ """Normalize LCS coords from timestep t to reference t=50.
+
+ ĉ = (c - α_t) / β_t * β_50 + α_50
+ c: [..., 3], alpha_t/beta_t/alpha_50/beta_50: [3]
+ """
+ beta_t_safe = beta_t.clone()
+ beta_t_safe = torch.where(beta_t_safe.abs() < 1e-6,
+ torch.full_like(beta_t_safe, 1e-6), beta_t_safe)
+ return (c - alpha_t) / beta_t_safe * beta_50 + alpha_50
+
+
+def denormalize_from_t50(c_hat, alpha_t, beta_t, alpha_50, beta_50):
+ """Denormalize LCS coords from reference t=50 back to timestep t.
+
+ c = (ĉ - α_50) / β_50 * β_t + α_t
+ """
+ beta_50_safe = beta_50.clone()
+ beta_50_safe = torch.where(beta_50_safe.abs() < 1e-6,
+ torch.full_like(beta_50_safe, 1e-6), beta_50_safe)
+ return (c_hat - alpha_50) / beta_50_safe * beta_t + alpha_t
diff --git a/custom_nodes/ComfyUI-LCS/data/.gitkeep b/custom_nodes/ComfyUI-LCS/data/.gitkeep
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-LCS/data/lcs_bc7957e0.safetensors b/custom_nodes/ComfyUI-LCS/data/lcs_bc7957e0.safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..847f0bca11ebb2097ec1cc08a7cee7331c0d8531
Binary files /dev/null and b/custom_nodes/ComfyUI-LCS/data/lcs_bc7957e0.safetensors differ
diff --git a/custom_nodes/ComfyUI-LCS/nodes/__init__.py b/custom_nodes/ComfyUI-LCS/nodes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dd37ab92246e9f7d0f60fd29aa6ec92f8fc4a12
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/__init__.py
@@ -0,0 +1,31 @@
+"""V2 backward compatibility exports for all LCS nodes."""
+
+from .calibrate import LCSLoadData
+from .intervene import LCSColorIntervene, LCSColorBatch, LCSToneAdjust
+from .observe import LCSPreviewColors, LCSStepObserver
+from .sharpen import LCSSharpnessCalibrate, LCSSharpnessIntervene
+from .anchor import LCSColorAnchor
+
+NODE_CLASS_MAPPINGS = {
+ "LCSLoadData": LCSLoadData,
+ "LCSColorIntervene": LCSColorIntervene,
+ "LCSColorBatch": LCSColorBatch,
+ "LCSToneAdjust": LCSToneAdjust,
+ "LCSPreviewColors": LCSPreviewColors,
+ "LCSStepObserver": LCSStepObserver,
+ "LCSSharpnessCalibrate": LCSSharpnessCalibrate,
+ "LCSSharpnessIntervene": LCSSharpnessIntervene,
+ "LCSColorAnchor": LCSColorAnchor,
+}
+
+NODE_DISPLAY_NAME_MAPPINGS = {
+ "LCSLoadData": "LCS Load Data",
+ "LCSColorIntervene": "LCS Color Intervene",
+ "LCSColorBatch": "LCS Color Batch",
+ "LCSToneAdjust": "LCS Tone Adjust",
+ "LCSPreviewColors": "LCS Preview Colors",
+ "LCSStepObserver": "LCS Step Observer",
+ "LCSSharpnessCalibrate": "LCS Sharpness Calibrate",
+ "LCSSharpnessIntervene": "LCS Sharpness Intervene",
+ "LCSColorAnchor": "LCS Color Anchor",
+}
diff --git a/custom_nodes/ComfyUI-LCS/nodes/anchor.py b/custom_nodes/ComfyUI-LCS/nodes/anchor.py
new file mode 100644
index 0000000000000000000000000000000000000000..d347ff720773e69a1f6647ec0cbb5601c5eb8e46
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/anchor.py
@@ -0,0 +1,335 @@
+"""Color anchor node: correct color drift during sampling.
+
+Adaptive version — all scheduling and filtering parameters are derived
+from runtime signals (sigma schedule, local color statistics, robust
+outlier detection). User controls: mode + intensity.
+"""
+
+import torch
+import torch.nn.functional as F
+from comfy_api.latest import io
+
+from ..core.adaptive import compute_step_phases, compute_strength_envelope, estimate_intensity
+from ..core.bilateral import bilateral_filter_lcs, estimate_bilateral_params
+from ..core.relationships import (
+ compute_local_relationships,
+ detect_anomalies_adaptive,
+ infer_color_from_neighbors,
+)
+from ..core.patchify import patchify, unpatchify
+from ..core.sampling import (
+ find_step_index,
+ denoised_to_raw,
+ raw_to_denoised,
+ unpack_video_if_needed,
+ repack_video_if_needed,
+ downsample_mask,
+)
+from ..core.timestep import get_alpha_beta, get_alpha_beta_t50, normalize_to_t50, denormalize_from_t50
+
+LCS_DATA = io.Custom("LCS_DATA")
+
+
+def _encode_reference_to_lcs(reference_image, vae, lcs_data):
+ """VAE-encode reference image to LCS coordinates.
+
+ reference_image: [B, H, W, 3] (BHWC ComfyUI format)
+ Returns (c_ref [1, L, 3], h_len, w_len) in t=50 space.
+ """
+ latent = vae.encode(reference_image[:1, :, :, :3])
+ patches, h_len, w_len, _ = patchify(latent)
+ if patches is None:
+ return None, 0, 0
+
+ device = patches.device
+ dtype = patches.dtype
+ ld = lcs_data.to(device, dtype)
+ c_ref = (patches - ld.mean) @ ld.basis # [1, L, 3]
+ return c_ref, h_len, w_len
+
+
+def _resize_color_field(c, src_h, src_w, dst_h, dst_w):
+ """Bilinear resize of [B, L, 3] color field for resolution mismatch."""
+ if src_h == dst_h and src_w == dst_w:
+ return c
+ B = c.shape[0]
+ grid = c.reshape(B, src_h, src_w, 3).permute(0, 3, 1, 2)
+ resized = F.interpolate(grid, size=(dst_h, dst_w), mode="bilinear", align_corners=False)
+ return resized.permute(0, 2, 3, 1).reshape(B, -1, 3)
+
+
+def _build_adaptive_anchor_fn(lcs_data, mode, intensity, mask,
+ c_ref=None, ref_h=0, ref_w=0, r_ref=None,
+ auto_intensity=False):
+ """Build unified post_cfg_function for all anchor modes.
+
+ Phase assignment and strength scheduling are derived from the sigma
+ schedule on the first hook call. All filter/threshold parameters are
+ estimated from the data at each step.
+
+ Closure state auto-resets per graph execution (new closure = new dict).
+ """
+ state = {
+ "phases": None,
+ "envelope": None,
+ "correction_index": 0,
+ "r_ema": None,
+ "prev_c_mean": None,
+ "drift_sum": 0.0,
+ "drift_count": 0,
+ "auto_intensity_val": None,
+ }
+
+ def post_cfg_fn(args):
+ denoised = args["denoised"]
+ sigma = args["sigma"]
+ model = args["model"]
+
+ # --- Lazy init: compute phases and envelope from sigma schedule ---
+ if state["phases"] is None:
+ sigmas = args["model_options"]["transformer_options"]["sample_sigmas"]
+ state["phases"] = compute_step_phases(sigmas, mode)
+ n_correct = sum(1 for p in state["phases"] if p == "correct")
+ state["envelope"] = compute_strength_envelope(n_correct)
+ state["correction_index"] = 0
+
+ # Find current step index
+ sigmas = args["model_options"]["transformer_options"]["sample_sigmas"]
+ step_index = find_step_index(sigma, sigmas)
+
+ # Look up phase (guard against out-of-range)
+ if step_index >= len(state["phases"]):
+ return denoised
+ phase = state["phases"][step_index]
+
+ # Skip phase — return unchanged
+ if phase == "skip":
+ return denoised
+
+ # --- Common pipeline: unpack → raw → patchify → project → normalize ---
+ working, pack_info = unpack_video_if_needed(denoised, args)
+
+ sigma_val = float(sigma.flatten()[0])
+ device = working.device
+ dtype = working.dtype
+
+ ld = lcs_data.to(device, dtype)
+ B_mat = ld.basis
+ mu = ld.mean
+
+ raw = denoised_to_raw(working, model)
+ patches, h_len, w_len, extra_shape = patchify(raw)
+ if patches is None:
+ return denoised
+
+ projection = (patches - mu) @ B_mat # [B, L, 3]
+ reconstruction = projection @ B_mat.T + mu
+ residual = patches - reconstruction
+
+ alpha_t, beta_t = get_alpha_beta(sigma_val, device=device)
+ alpha_t, beta_t = alpha_t.to(dtype), beta_t.to(dtype)
+ alpha_50, beta_50 = get_alpha_beta_t50(device=device)
+ alpha_50, beta_50 = alpha_50.to(dtype), beta_50.to(dtype)
+
+ c_norm = normalize_to_t50(projection, alpha_t, beta_t, alpha_50, beta_50)
+
+ # --- Observe phase (self_anchor warmup): update EMA, return unchanged ---
+ if phase == "observe":
+ r_current = compute_local_relationships(c_norm, h_len, w_len)
+ decay = 0.8
+ if state["r_ema"] is None:
+ state["r_ema"] = r_current.detach().clone()
+ else:
+ state["r_ema"] = decay * state["r_ema"] + (1 - decay) * r_current.detach()
+
+ # Collect step-to-step drift for auto_intensity (self_anchor)
+ c_mean_now = c_norm.detach().mean(dim=1, keepdim=True)
+ if auto_intensity and state["prev_c_mean"] is not None:
+ drift = (c_mean_now - state["prev_c_mean"]).abs().mean().item()
+ state["drift_sum"] += drift
+ state["drift_count"] += 1
+ state["prev_c_mean"] = c_mean_now
+ return denoised
+
+ # --- Correct phase ---
+ # Compute mode-specific target first (reused for auto-intensity drift measurement)
+ if mode == "smooth":
+ sigma_s, sigma_c = estimate_bilateral_params(c_norm, h_len, w_len)
+ c_filtered = bilateral_filter_lcs(c_norm, h_len, w_len, sigma_s, sigma_c)
+ elif mode == "reference":
+ c_ref_dev = c_ref.to(device=device, dtype=dtype)
+ r_ref_dev = r_ref.to(device=device, dtype=dtype)
+ if ref_h != h_len or ref_w != w_len:
+ c_ref_resized = _resize_color_field(c_ref_dev, ref_h, ref_w, h_len, w_len)
+ r_ref_resized = compute_local_relationships(c_ref_resized, h_len, w_len)
+ else:
+ c_ref_resized = c_ref_dev
+ r_ref_resized = r_ref_dev
+
+ # Auto-intensity: measure drift on first correction step, cache for rest
+ effective_intensity = intensity
+ if auto_intensity:
+ if state["auto_intensity_val"] is None:
+ if mode == "self_anchor" and state["drift_count"] > 0:
+ drift_signal = state["drift_sum"] / state["drift_count"]
+ elif mode == "self_anchor":
+ # No observe phase (img2img) — measure from seeded baseline
+ if state["prev_c_mean"] is not None:
+ drift_signal = (c_norm.detach().mean(dim=1, keepdim=True)
+ - state["prev_c_mean"]).abs().mean().item()
+ else:
+ drift_signal = 0.05 # conservative default
+ elif mode == "reference":
+ drift_signal = (c_norm - c_ref_resized).abs().mean().item()
+ elif mode == "smooth":
+ drift_signal = (c_filtered - c_norm).abs().mean().item()
+ state["auto_intensity_val"] = estimate_intensity(drift_signal)
+ effective_intensity = state["auto_intensity_val"]
+
+ # Compute step strength from envelope
+ ci = state["correction_index"]
+ envelope = state["envelope"]
+ if ci < len(envelope):
+ step_strength = effective_intensity * float(envelope[ci])
+ else:
+ step_strength = effective_intensity
+ state["correction_index"] = ci + 1
+
+ # Self-anchor convergence damping
+ if mode == "self_anchor" and state["prev_c_mean"] is not None:
+ c_mean_now = c_norm.detach().mean(dim=1, keepdim=True)
+ delta = (c_mean_now - state["prev_c_mean"]).abs().mean().item()
+ step_strength *= min(delta / 0.1, 1.0)
+
+ # Mode-specific correction (reuses targets computed above)
+ if mode == "smooth":
+ new_c_norm = c_norm + step_strength * (c_filtered - c_norm)
+
+ elif mode == "reference":
+ B_size = c_norm.shape[0]
+ c_ref_exp = c_ref_resized.expand(B_size, -1, -1)
+ r_ref_exp = r_ref_resized.expand(B_size, -1, -1)
+
+ r_current = compute_local_relationships(c_norm, h_len, w_len)
+ anomaly_mag = detect_anomalies_adaptive(r_current, r_ref_exp)
+
+ correction = c_ref_exp - c_norm
+ new_c_norm = c_norm + step_strength * anomaly_mag * correction
+
+ else: # self_anchor
+ r_current = compute_local_relationships(c_norm, h_len, w_len)
+
+ if state["r_ema"] is None:
+ # Seed EMA — first step, no correction yet (anomalies will be zero)
+ state["r_ema"] = r_current.detach().clone()
+
+ anomaly_mag = detect_anomalies_adaptive(r_current, state["r_ema"])
+ c_corrected = infer_color_from_neighbors(
+ c_norm, anomaly_mag, h_len, w_len
+ )
+ new_c_norm = c_norm + step_strength * (c_corrected - c_norm)
+
+ # Update EMA (slow decay during correction)
+ decay = 0.95
+ state["r_ema"] = decay * state["r_ema"] + (1 - decay) * r_current.detach()
+ state["prev_c_mean"] = c_norm.detach().mean(dim=1, keepdim=True)
+
+ # --- Apply mask ---
+ if mask is not None:
+ mask_flat = downsample_mask(mask, h_len, w_len, device, dtype)
+ if mask_flat.shape[1] != new_c_norm.shape[1]:
+ mask_flat = mask_flat[:, :new_c_norm.shape[1], :]
+ new_c_norm = c_norm + mask_flat * (new_c_norm - c_norm)
+
+ # --- Denormalize → reconstruct → unpatchify → repack ---
+ new_projection = denormalize_from_t50(new_c_norm, alpha_t, beta_t, alpha_50, beta_50)
+ patches_new = new_projection @ B_mat.T + mu + residual
+ raw_new = unpatchify(patches_new, h_len, w_len, extra_shape)
+ modified = raw_to_denoised(raw_new, model).to(dtype)
+ return repack_video_if_needed(modified, pack_info)
+
+ return post_cfg_fn
+
+
+class LCSColorAnchor(io.ComfyNode):
+ """Correct color drift during sampling by anchoring local color relationships.
+
+ Four modes:
+ - auto: Infer mode from connected inputs and intensity from drift signals
+ - smooth: Bilateral filter smooths color discontinuities (inpainting boundaries)
+ - reference: Anchor to a reference image's color relationships
+ - self_anchor: Build internal color model during warmup, then correct drift
+
+ All scheduling and filter parameters are derived adaptively from the sigma
+ schedule and image content. In auto mode, intensity is also derived automatically.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ return io.Schema(
+ node_id="LCSColorAnchor",
+ display_name="LCS Color Anchor",
+ category="LCS/intervention",
+ description="Correct color drift during sampling by anchoring local color relationships",
+ inputs=[
+ io.Model.Input("model"),
+ LCS_DATA.Input("lcs_data", tooltip="Calibration data from LCSLoadData"),
+ io.Combo.Input("mode", options=["auto", "smooth", "reference", "self_anchor"],
+ default="auto",
+ tooltip="auto: infer mode and intensity from connected inputs; smooth: bilateral filter; reference: anchor to image; self_anchor: auto-detect drift"),
+ io.Float.Input("intensity", default=0.5, min=0.0, max=1.0, step=0.05,
+ tooltip="Correction intensity (0 = none, 1 = full)"),
+ io.Vae.Input("vae", optional=True,
+ tooltip="Required for reference mode (VAE-encodes reference image)"),
+ io.Image.Input("reference_image", optional=True,
+ tooltip="Reference image for reference mode"),
+ io.Mask.Input("mask", optional=True,
+ tooltip="Optional mask for localized correction"),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, lcs_data, mode, intensity,
+ vae=None, reference_image=None, mask=None) -> io.NodeOutput:
+ """Clone model, attach adaptive color anchor hook."""
+ m = model.clone()
+
+ # Resolve auto mode based on connected inputs
+ auto_intensity = False
+ if mode == "auto":
+ auto_intensity = True
+ if reference_image is not None and vae is not None:
+ mode = "reference"
+ elif mask is not None:
+ mode = "smooth"
+ else:
+ mode = "self_anchor"
+
+ if not auto_intensity and intensity < 1e-6:
+ return io.NodeOutput(m)
+
+ c_ref = None
+ ref_h = 0
+ ref_w = 0
+ r_ref = None
+
+ if mode == "reference":
+ if vae is None or reference_image is None:
+ print("[LCS Color Anchor] Reference mode requires vae and reference_image — skipping.")
+ return io.NodeOutput(m)
+ c_ref, ref_h, ref_w = _encode_reference_to_lcs(reference_image, vae, lcs_data)
+ if c_ref is None:
+ print("[LCS Color Anchor] Failed to encode reference image — skipping.")
+ return io.NodeOutput(m)
+ r_ref = compute_local_relationships(c_ref, ref_h, ref_w)
+
+ hook = _build_adaptive_anchor_fn(
+ lcs_data, mode, intensity, mask,
+ c_ref=c_ref, ref_h=ref_h, ref_w=ref_w, r_ref=r_ref,
+ auto_intensity=auto_intensity,
+ )
+ m.set_model_sampler_post_cfg_function(hook)
+ return io.NodeOutput(m)
diff --git a/custom_nodes/ComfyUI-LCS/nodes/calibrate.py b/custom_nodes/ComfyUI-LCS/nodes/calibrate.py
new file mode 100644
index 0000000000000000000000000000000000000000..530210142b9b1a9356fa8ac39283aa2754bdc3e2
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/calibrate.py
@@ -0,0 +1,71 @@
+"""Calibration node: LCSLoadData with automatic per-VAE caching."""
+
+import os
+import torch
+from comfy_api.latest import io
+from safetensors.torch import save_file, load_file
+
+from ..core.calibration import calibrate, vae_fingerprint
+from ..core.lcs_data import LCSData
+
+LCS_DATA = io.Custom("LCS_DATA")
+DATA_DIR = os.path.join(os.path.dirname(os.path.dirname(__file__)), "data")
+
+
+def _save_lcs(lcs_data: LCSData, path: str):
+ """Save LCSData to safetensors file."""
+ os.makedirs(os.path.dirname(path), exist_ok=True)
+ save_file({
+ "basis": lcs_data.basis.contiguous(),
+ "mean": lcs_data.mean.contiguous(),
+ "anchor_lcs": lcs_data.anchor_lcs.contiguous(),
+ "anchor_angles": lcs_data.anchor_angles.contiguous(),
+ }, path)
+
+
+def _load_lcs(path: str) -> LCSData:
+ """Load LCSData from safetensors file."""
+ data = load_file(path)
+ return LCSData(
+ basis=data["basis"],
+ mean=data["mean"],
+ anchor_lcs=data["anchor_lcs"],
+ anchor_angles=data["anchor_angles"],
+ )
+
+
+class LCSLoadData(io.ComfyNode):
+ """Load or auto-compute LCS calibration data for a VAE.
+
+ Computes a fingerprint of the VAE weights and checks for a cached
+ calibration file. On cache miss, runs PCA calibration automatically
+ and saves the result for future reuse.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ return io.Schema(
+ node_id="LCSLoadData",
+ display_name="LCS Load Data",
+ category="LCS/calibration",
+ description="Auto-calibrate and cache LCS data per-VAE",
+ inputs=[
+ io.Vae.Input("vae", tooltip="VAE model (calibration is cached per-VAE)"),
+ ],
+ outputs=[
+ LCS_DATA.Output(display_name="lcs_data"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, vae) -> io.NodeOutput:
+ fp = vae_fingerprint(vae)
+ cache_path = os.path.join(DATA_DIR, f"lcs_{fp}.safetensors")
+
+ if os.path.exists(cache_path):
+ lcs_data = _load_lcs(cache_path)
+ else:
+ lcs_data = calibrate(vae, num_colors=512, image_size=512)
+ _save_lcs(lcs_data, cache_path)
+
+ return io.NodeOutput(lcs_data)
diff --git a/custom_nodes/ComfyUI-LCS/nodes/intervene.py b/custom_nodes/ComfyUI-LCS/nodes/intervene.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d0bfffac6bbaacd7382face1430281e1561df7d
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/intervene.py
@@ -0,0 +1,490 @@
+"""Intervention nodes: LCSColorIntervene, LCSColorBatch, and LCSToneAdjust."""
+
+import torch
+from comfy_api.latest import io
+
+from ..core.lcs_data import LCSData
+from ..core.patchify import patchify, unpatchify
+from ..core.sampling import find_step_index, denoised_to_raw, raw_to_denoised, unpack_video_if_needed, repack_video_if_needed, downsample_mask
+from ..core.timestep import get_alpha_beta, get_alpha_beta_t50, normalize_to_t50, denormalize_from_t50
+from ..core.color_space import hex_to_hsl, encode_hsl_to_lcs, decode_lcs_to_hsl, _hue_lerp
+
+LCS_DATA = io.Custom("LCS_DATA")
+
+# Backward-compat alias for any external code that imported _find_step_index
+_find_step_index = find_step_index
+
+
+def _build_post_cfg_fn(lcs_data, target_colors_hsl, strength, mode, start_step, end_step, mask):
+ """Build the post_cfg_function closure for color intervention.
+
+ target_colors_hsl: list of (h, s, l) tuples, one per batch item (or one for all).
+ """
+ def post_cfg_fn(args):
+ """Post-CFG hook: project to LCS, apply color intervention, reconstruct."""
+ denoised = args["denoised"]
+ sigma = args["sigma"]
+ model = args["model"]
+
+ # Determine current step index
+ sigmas = args["model_options"]["transformer_options"]["sample_sigmas"]
+ step_index = _find_step_index(sigma, sigmas)
+
+ # Check if in intervention range
+ if step_index < start_step or step_index > end_step:
+ return denoised
+
+ # Unpack LTXAV packed format if needed
+ working, pack_info = unpack_video_if_needed(denoised, args)
+
+ sigma_val = float(sigma.flatten()[0])
+ device = working.device
+ dtype = working.dtype
+
+ # Move LCS data to device
+ ld = lcs_data.to(device, dtype)
+ B_mat = ld.basis
+ mu = ld.mean
+ anchor_lcs = ld.anchor_lcs
+ anchor_angles = ld.anchor_angles
+
+ # Convert from process_in to raw VAE space
+ raw = denoised_to_raw(working, model)
+
+ # Patchify
+ patches, h_len, w_len, extra_shape = patchify(raw)
+ if patches is None:
+ return denoised # Incompatible latent format
+
+ # Project to LCS
+ projection = (patches - mu) @ B_mat # [B, L, 3]
+
+ # Compute residual (61D orthogonal complement)
+ reconstruction = projection @ B_mat.T + mu # [B, L, 64]
+ residual = patches - reconstruction # [B, L, 64]
+
+ # Get timestep statistics
+ alpha_t, beta_t = get_alpha_beta(sigma_val, device=device)
+ alpha_t, beta_t = alpha_t.to(dtype), beta_t.to(dtype)
+ alpha_50, beta_50 = get_alpha_beta_t50(device=device)
+ alpha_50, beta_50 = alpha_50.to(dtype), beta_50.to(dtype)
+
+ # Normalize to t=50
+ c_norm = normalize_to_t50(projection, alpha_t, beta_t, alpha_50, beta_50) # [B, L, 3]
+
+ # Apply intervention per batch item
+ B_size = c_norm.shape[0]
+ new_c_norm = c_norm.clone()
+
+ for b in range(B_size):
+ color_idx = b if b < len(target_colors_hsl) else 0
+ t_h, t_s, t_l = target_colors_hsl[color_idx]
+
+ # Encode target color to LCS at t=50
+ t_h_t = torch.tensor(t_h, device=device, dtype=dtype)
+ t_s_t = torch.tensor(t_s, device=device, dtype=dtype)
+ t_l_t = torch.tensor(t_l, device=device, dtype=dtype)
+ target_lcs = encode_hsl_to_lcs(t_h_t, t_s_t, t_l_t, anchor_lcs, anchor_angles) # [3]
+
+ c_b = c_norm[b] # [L, 3]
+
+ if mode == "type_i":
+ # Type I: direct LCS translation
+ shift = target_lcs - c_b.mean(dim=0)
+ new_c_norm[b] = c_b + strength * shift
+
+ elif mode == "type_ii":
+ # Type II: decode → shift in HSL → re-encode
+ h_cur, s_cur, l_cur = decode_lcs_to_hsl(c_b, anchor_lcs, anchor_angles)
+ # Shift towards target HSL
+ h_new = t_h_t.expand_as(h_cur)
+ s_new = t_s_t.expand_as(s_cur)
+ l_new = t_l_t.expand_as(l_cur)
+ # Interpolate in HSL
+ h_interp = _hue_lerp(h_cur, h_new, strength)
+ s_interp = s_cur + strength * (s_new - s_cur)
+ l_interp = l_cur + strength * (l_new - l_cur)
+ new_c_norm[b] = encode_hsl_to_lcs(h_interp, s_interp.clamp(0, 1),
+ l_interp.clamp(0, 1),
+ anchor_lcs, anchor_angles)
+
+ else: # interpolated (default)
+ # gamma_t = sigma (high sigma → Type I, low sigma → Type II)
+ gamma = sigma_val
+
+ # Type I
+ shift = target_lcs - c_b.mean(dim=0)
+ c_type_i = c_b + strength * shift
+
+ # Type II
+ h_cur, s_cur, l_cur = decode_lcs_to_hsl(c_b, anchor_lcs, anchor_angles)
+ h_new = t_h_t.expand_as(h_cur)
+ s_new = t_s_t.expand_as(s_cur)
+ l_new = t_l_t.expand_as(l_cur)
+ h_interp = _hue_lerp(h_cur, h_new, strength)
+ s_interp = s_cur + strength * (s_new - s_cur)
+ l_interp = l_cur + strength * (l_new - l_cur)
+ c_type_ii = encode_hsl_to_lcs(h_interp, s_interp.clamp(0, 1),
+ l_interp.clamp(0, 1),
+ anchor_lcs, anchor_angles)
+
+ # Interpolate: gamma * Type_I + (1-gamma) * Type_II
+ new_c_norm[b] = gamma * c_type_i + (1.0 - gamma) * c_type_ii
+
+ # Apply mask if provided
+ if mask is not None:
+ mask_flat = downsample_mask(mask, h_len, w_len, device, dtype)
+ if mask_flat.shape[1] != new_c_norm.shape[1]:
+ mask_flat = mask_flat[:, :new_c_norm.shape[1], :]
+ # Blend: masked areas get intervention, unmasked keep original
+ new_c_norm = c_norm + mask_flat * (new_c_norm - c_norm)
+
+ # Denormalize back to timestep t
+ new_projection = denormalize_from_t50(new_c_norm, alpha_t, beta_t, alpha_50, beta_50)
+
+ # Reconstruct patches
+ patches_new = new_projection @ B_mat.T + mu + residual
+
+ # Unpatchify
+ raw_new = unpatchify(patches_new, h_len, w_len, extra_shape)
+
+ # Convert back to process_in space
+ modified = raw_to_denoised(raw_new, model).to(dtype)
+
+ # Repack if LTXAV
+ return repack_video_if_needed(modified, pack_info)
+
+ return post_cfg_fn
+
+
+class LCSColorIntervene(io.ComfyNode):
+ """Steer colors during FLUX generation via the Latent Color Subspace.
+
+ Installs a post-CFG hook that projects the denoised prediction into the
+ 3D LCS, shifts it toward the target color (Type I, Type II, or interpolated),
+ preserves the 61D residual, and writes the modified prediction back.
+ Active only during [start_step, end_step].
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ """Define inputs (MODEL, LCS_DATA, color, strength, mode, steps, mask) and MODEL output."""
+ return io.Schema(
+ node_id="LCSColorIntervene",
+ display_name="LCS Color Intervene",
+ category="LCS/intervention",
+ description="Steer colors during FLUX generation via Latent Color Subspace",
+ inputs=[
+ io.Model.Input("model"),
+ LCS_DATA.Input("lcs_data", tooltip="Calibration data from LCSLoadData"),
+ io.Color.Input("color", default="#FF0000", tooltip="Target color"),
+ io.Float.Input("strength", default=1.0, min=0.0, max=2.0, step=0.05,
+ tooltip="Intervention strength (1.0 = full, 0.0 = none)"),
+ io.Combo.Input("mode", options=["interpolated", "type_i", "type_ii"],
+ default="interpolated",
+ tooltip="Interpolated blends Type I (LCS shift) and Type II (HSL shift)"),
+ io.Int.Input("start_step", default=8, min=0, max=50,
+ tooltip="First step to apply intervention (paper optimal: 8)"),
+ io.Int.Input("end_step", default=10, min=0, max=50,
+ tooltip="Last step to apply intervention (paper optimal: 10)"),
+ io.Mask.Input("mask", optional=True,
+ tooltip="Optional mask for localized color control"),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, lcs_data, color, strength, mode, start_step, end_step,
+ mask=None) -> io.NodeOutput:
+ """Clone model, attach LCS color intervention hook. Returns patched MODEL."""
+ m = model.clone()
+ h, s, l = hex_to_hsl(color)
+ hook = _build_post_cfg_fn(lcs_data, [(h, s, l)], strength, mode, start_step, end_step, mask)
+ m.set_model_sampler_post_cfg_function(hook)
+ return io.NodeOutput(m)
+
+
+class LCSColorBatch(io.ComfyNode):
+ """Apply different target colors to each batch item for multi-color generation.
+
+ Parses comma-separated hex colors and installs a post-CFG hook that applies
+ a distinct color target per batch index. Also outputs batch_size (INT) for
+ connecting to EmptyLatentImage.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ """Define inputs (MODEL, LCS_DATA, colors string, strength, mode, steps, mask) and (MODEL, INT) outputs."""
+ return io.Schema(
+ node_id="LCSColorBatch",
+ display_name="LCS Color Batch",
+ category="LCS/intervention",
+ description="Apply different target colors to each batch item for multi-color generation",
+ inputs=[
+ io.Model.Input("model"),
+ LCS_DATA.Input("lcs_data", tooltip="Calibration data from LCSLoadData"),
+ io.String.Input("colors", default="#FF0000,#00FF00,#0000FF",
+ tooltip="Comma-separated hex colors, one per batch item"),
+ io.Float.Input("strength", default=1.0, min=0.0, max=2.0, step=0.05),
+ io.Combo.Input("mode", options=["interpolated", "type_i", "type_ii"],
+ default="interpolated"),
+ io.Int.Input("start_step", default=8, min=0, max=50),
+ io.Int.Input("end_step", default=10, min=0, max=50),
+ io.Mask.Input("mask", optional=True),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ io.Int.Output(display_name="batch_size"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, lcs_data, colors, strength, mode, start_step, end_step,
+ mask=None) -> io.NodeOutput:
+ """Clone model, attach per-batch color hooks. Returns (MODEL, batch_size INT)."""
+ m = model.clone()
+
+ # Parse comma-separated hex colors
+ color_list = [c.strip() for c in colors.split(",") if c.strip()]
+ target_hsl = [hex_to_hsl(c) for c in color_list]
+ batch_size = len(target_hsl)
+
+ hook = _build_post_cfg_fn(lcs_data, target_hsl, strength, mode, start_step, end_step, mask)
+ m.set_model_sampler_post_cfg_function(hook)
+ return io.NodeOutput(m, batch_size)
+
+
+_EPS = 1e-6
+
+
+def _is_default_tone(contrast, brightness, saturation, color_temperature):
+ """Check if all tone parameters are at their default (no-op) values."""
+ return (abs(contrast - 1.0) < _EPS and abs(brightness) < _EPS
+ and abs(saturation - 1.0) < _EPS and abs(color_temperature) < _EPS)
+
+
+def _build_tone_fn(lcs_data, contrast, brightness, saturation, color_temperature,
+ start_step, end_step, mask):
+ """Build the post_cfg_function closure for tone adjustment (contrast/brightness/saturation/temperature).
+
+ Operates directly in 3D LCS space by decomposing into lightness (projection
+ onto achromatic axis) and chroma (perpendicular residual). No HSL round-trip.
+ """
+ # Precompute warm/cool direction vector (depends only on immutable calibration data)
+ # Scaled so that color_temperature=1.0 shifts by the mean anchor chroma magnitude,
+ # giving a visually significant warm↔cool shift.
+ _warm_dir = None
+ if abs(color_temperature) > _EPS:
+ anc = lcs_data.anchor_lcs # [8, 3]
+ black_anc, white_anc = anc[6], anc[7]
+ a_pre = white_anc - black_anc
+ a_sq_pre = (a_pre * a_pre).sum()
+
+ def _anchor_chroma_pre(idx):
+ pt = anc[idx]
+ l_a = ((pt - black_anc) * a_pre).sum() / a_sq_pre
+ return pt - (black_anc + l_a * a_pre)
+
+ chromas = [_anchor_chroma_pre(i) for i in range(6)]
+ warm_center = (chromas[0] + chromas[5]) / 2 # Red + Yellow
+ cool_center = (chromas[1] + chromas[4]) / 2 # Blue + Cyan
+ wd = warm_center - cool_center
+ wd_unit = wd / wd.norm() # unit vector
+
+ # Scale: color_temperature=1.0 → shift by mean chroma norm
+ mean_chroma_norm = sum(c.norm() for c in chromas) / 6.0
+ _warm_dir = wd_unit * mean_chroma_norm
+
+ def post_cfg_fn(args):
+ """Post-CFG hook: project to LCS, adjust contrast/brightness/saturation, reconstruct."""
+ denoised = args["denoised"]
+ sigma = args["sigma"]
+ model = args["model"]
+
+ # Determine current step index
+ sigmas = args["model_options"]["transformer_options"]["sample_sigmas"]
+ step_index = _find_step_index(sigma, sigmas)
+
+ if step_index < start_step or step_index > end_step:
+ return denoised
+
+ # Unpack LTXAV packed format if needed
+ working, pack_info = unpack_video_if_needed(denoised, args)
+
+ sigma_val = float(sigma.flatten()[0])
+ device = working.device
+ dtype = working.dtype
+
+ ld = lcs_data.to(device, dtype)
+ B_mat = ld.basis
+ mu = ld.mean
+ anchor_lcs = ld.anchor_lcs
+
+ # Convert from process_in to raw VAE space
+ raw = denoised_to_raw(working, model)
+
+ # Patchify
+ patches, h_len, w_len, extra_shape = patchify(raw)
+ if patches is None:
+ return denoised # Incompatible latent format
+
+ # Project to LCS
+ projection = (patches - mu) @ B_mat
+
+ # Compute residual (orthogonal complement)
+ reconstruction = projection @ B_mat.T + mu
+ residual = patches - reconstruction
+
+ # Get timestep statistics
+ alpha_t, beta_t = get_alpha_beta(sigma_val, device=device)
+ alpha_t, beta_t = alpha_t.to(dtype), beta_t.to(dtype)
+ alpha_50, beta_50 = get_alpha_beta_t50(device=device)
+ alpha_50, beta_50 = alpha_50.to(dtype), beta_50.to(dtype)
+
+ # Normalize to t=50
+ c_norm = normalize_to_t50(projection, alpha_t, beta_t, alpha_50, beta_50)
+
+ # Achromatic axis: black → white in LCS anchor space
+ black = anchor_lcs[6] # [3]
+ white = anchor_lcs[7] # [3]
+ a = white - black # [3]
+ a_sq = (a * a).sum() # ||a||²
+
+ # Decompose into lightness + chroma
+ # l_scalar: scalar projection along achromatic axis, [B, L]
+ l_scalar = ((c_norm - black) * a).sum(dim=-1) / a_sq
+ # c_L: point on achromatic axis, [B, L, 3]
+ c_L = black + l_scalar.unsqueeze(-1) * a
+ # chroma: perpendicular component, [B, L, 3]
+ chroma = c_norm - c_L
+
+ # Adjust lightness: contrast around per-image mean + brightness shift
+ # No clamp: LCS coords are naturally unbounded during denoising (same as
+ # Type I intervention), and clamping destroys highlight/shadow detail that
+ # the user wants to enhance. The no-op skip in execute() handles defaults.
+ l_mean = l_scalar.mean(dim=-1, keepdim=True) # [B, 1]
+ l_new = (l_scalar - l_mean) * contrast + l_mean + brightness
+
+ # Adjust color temperature: shift chroma along warm↔cool axis (precomputed)
+ if _warm_dir is not None:
+ chroma = chroma + color_temperature * _warm_dir.to(device=device, dtype=dtype)
+
+ # Adjust saturation
+ chroma_new = chroma * saturation
+
+ # Reconstruct in normalized LCS space
+ new_c_norm = black + l_new.unsqueeze(-1) * a + chroma_new # [B, L, 3]
+
+ # Apply mask if provided
+ if mask is not None:
+ mask_flat = downsample_mask(mask, h_len, w_len, device, dtype)
+ if mask_flat.shape[1] != new_c_norm.shape[1]:
+ mask_flat = mask_flat[:, :new_c_norm.shape[1], :]
+ new_c_norm = c_norm + mask_flat * (new_c_norm - c_norm)
+
+ # Denormalize back to timestep t
+ new_projection = denormalize_from_t50(new_c_norm, alpha_t, beta_t, alpha_50, beta_50)
+
+ # Reconstruct patches
+ patches_new = new_projection @ B_mat.T + mu + residual
+
+ # Unpatchify
+ raw_new = unpatchify(patches_new, h_len, w_len, extra_shape)
+
+ # Convert back to process_in space
+ modified = raw_to_denoised(raw_new, model).to(dtype)
+
+ # Repack if LTXAV
+ return repack_video_if_needed(modified, pack_info)
+
+ return post_cfg_fn
+
+
+# Preset definitions. Frontend JS (web/js/tone_preset.js) syncs these into
+# sliders on user interaction. The Python-side copy serves as fallback for
+# headless / batch execution where frontend JS does not run.
+TONE_PRESETS = {
+ "Custom": None,
+ "Base": {"contrast": 1.0, "brightness": 0.0, "saturation": 1.0, "color_temperature": 0.0},
+ "Cinematic": {"contrast": 1.20, "brightness": -0.05, "saturation": 0.90, "color_temperature": 0.05},
+ "HDR": {"contrast": 1.40, "brightness": 0.0, "saturation": 1.20, "color_temperature": 0.0},
+ "Vivid": {"contrast": 1.10, "brightness": 0.0, "saturation": 1.50, "color_temperature": 0.0},
+ "Dramatic": {"contrast": 1.50, "brightness": -0.10, "saturation": 0.85, "color_temperature": 0.0},
+ "Low Key": {"contrast": 1.30, "brightness": -0.20, "saturation": 0.80, "color_temperature": 0.0},
+ "High Key": {"contrast": 0.80, "brightness": 0.20, "saturation": 0.90, "color_temperature": 0.0},
+ "Warm": {"contrast": 1.05, "brightness": 0.03, "saturation": 1.10, "color_temperature": 0.30},
+ "Cool": {"contrast": 1.05, "brightness": 0.0, "saturation": 1.05, "color_temperature": -0.30},
+ "Desaturated": {"contrast": 1.0, "brightness": 0.0, "saturation": 0.40, "color_temperature": 0.0},
+}
+
+
+class LCSToneAdjust(io.ComfyNode):
+ """Adjust tone (contrast, brightness, saturation, color temperature) in the Latent Color Subspace.
+
+ Decomposes each patch into lightness (projection onto black→white axis)
+ and chroma (perpendicular residual). Contrast scales lightness around its
+ mean, brightness shifts it, saturation scales the chroma magnitude, and
+ color temperature shifts chroma along the warm↔cool axis.
+ All math is done directly in 3D LCS — no HSL round-trip needed.
+ Select a preset for one-click tonal styles, or use Custom to set sliders manually.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ """Define inputs and MODEL output for tone adjustment."""
+ return io.Schema(
+ node_id="LCSToneAdjust",
+ display_name="LCS Tone Adjust",
+ category="LCS/intervention",
+ description="Adjust tone (contrast, brightness, saturation, color temperature) via Latent Color Subspace",
+ inputs=[
+ io.Model.Input("model"),
+ LCS_DATA.Input("lcs_data", tooltip="Calibration data from LCSLoadData"),
+ io.Combo.Input("preset", options=list(TONE_PRESETS.keys()), default="Custom",
+ tooltip="Select a tonal preset or Custom to use the sliders below"),
+ io.Float.Input("contrast", default=1.0, min=0.0, max=3.0, step=0.05,
+ tooltip="Lightness contrast multiplier (>1 = more contrast, <1 = less, 1 = no change)"),
+ io.Float.Input("brightness", default=0.0, min=-1.0, max=1.0, step=0.05,
+ tooltip="Lightness shift (>0 = brighter, <0 = darker)"),
+ io.Float.Input("saturation", default=1.0, min=0.0, max=3.0, step=0.05,
+ tooltip="Saturation multiplier (>1 = more vivid, <1 = more muted, 0 = grayscale)"),
+ io.Float.Input("color_temperature", default=0.0, min=-1.0, max=1.0, step=0.05,
+ tooltip="Color temperature shift (>0 = warmer/amber, <0 = cooler/blue)"),
+ io.Int.Input("start_step", default=5, min=0, max=50,
+ tooltip="First step to apply adjustment"),
+ io.Int.Input("end_step", default=15, min=0, max=50,
+ tooltip="Last step to apply adjustment"),
+ io.Mask.Input("mask", optional=True,
+ tooltip="Optional mask for localized adjustment"),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, lcs_data, preset, contrast, brightness, saturation,
+ color_temperature, start_step, end_step, mask=None) -> io.NodeOutput:
+ """Clone model, attach LCS tone adjustment hook. Returns patched MODEL.
+
+ Frontend JS syncs preset values into sliders on user interaction.
+ For headless/batch execution (no frontend), if a preset is selected
+ but sliders are still at defaults, apply the preset values server-side.
+ """
+ # Headless fallback: preset selected but sliders untouched → apply preset
+ p = TONE_PRESETS.get(preset)
+ if p is not None and _is_default_tone(contrast, brightness, saturation, color_temperature):
+ contrast = p["contrast"]
+ brightness = p["brightness"]
+ saturation = p["saturation"]
+ color_temperature = p["color_temperature"]
+
+ m = model.clone()
+ # Skip hook entirely when all parameters are at default (true no-op)
+ if not _is_default_tone(contrast, brightness, saturation, color_temperature):
+ hook = _build_tone_fn(lcs_data, contrast, brightness, saturation,
+ color_temperature, start_step, end_step, mask)
+ m.set_model_sampler_post_cfg_function(hook)
+ return io.NodeOutput(m)
diff --git a/custom_nodes/ComfyUI-LCS/nodes/observe.py b/custom_nodes/ComfyUI-LCS/nodes/observe.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc6f7ef71a89ed6f8226bd702f012476796c8667
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/observe.py
@@ -0,0 +1,161 @@
+"""Observation nodes: LCSPreviewColors and LCSStepObserver."""
+
+import os
+import torch
+import numpy as np
+import torch.nn.functional as F
+from PIL import Image as PILImage
+from comfy_api.latest import io
+import folder_paths
+
+from ..core.lcs_data import LCSData
+from ..core.patchify import patchify
+from ..core.timestep import get_alpha_beta, get_alpha_beta_t50, normalize_to_t50
+from ..core.color_space import decode_lcs_to_hsl, hsl_to_rgb
+from ..core.sampling import denoised_to_raw, unpack_video_if_needed
+
+LCS_DATA = io.Custom("LCS_DATA")
+
+# FLUX VAE constants — fallback for LCSPreviewColors which has no model access
+_FLUX_SCALE_FACTOR = 0.3611
+_FLUX_SHIFT_FACTOR = 0.1159
+
+
+def _latent_to_color_preview(samples, lcs_data, sigma, upscale=8, model=None):
+ """Convert latent tensor to LCS color preview image.
+
+ samples: [B, C, H, W] or [B, C, T, H, W] in process_in space
+ model: if provided, uses model.latent_format for space conversion;
+ otherwise falls back to FLUX constants.
+ Returns: [B, H_up, W_up, 3] float32 in [0,1]
+ """
+ device = samples.device
+ dtype = samples.dtype
+ ld = lcs_data.to(device, dtype)
+
+ if model is not None:
+ raw = denoised_to_raw(samples, model)
+ else:
+ raw = samples / _FLUX_SCALE_FACTOR + _FLUX_SHIFT_FACTOR
+ patches, h_len, w_len, _ = patchify(raw)
+ if patches is None:
+ # Incompatible latent format — return black image
+ B = samples.shape[0] if samples.ndim >= 4 else 1
+ return torch.zeros(B, upscale * 2, upscale * 2, 3)
+ projection = (patches - ld.mean) @ ld.basis
+
+ alpha_t, beta_t = get_alpha_beta(sigma, device=device)
+ alpha_t, beta_t = alpha_t.to(dtype), beta_t.to(dtype)
+ alpha_50, beta_50 = get_alpha_beta_t50(device=device)
+ alpha_50, beta_50 = alpha_50.to(dtype), beta_50.to(dtype)
+ c_norm = normalize_to_t50(projection, alpha_t, beta_t, alpha_50, beta_50)
+
+ B = c_norm.shape[0]
+ images = []
+ for b in range(B):
+ c_b = c_norm[b]
+ h_vals, s_vals, l_vals = decode_lcs_to_hsl(c_b, ld.anchor_lcs, ld.anchor_angles)
+ r, g, b_ch = hsl_to_rgb(h_vals, s_vals, l_vals)
+ rgb = torch.stack([r, g, b_ch], dim=-1).reshape(h_len, w_len, 3)
+ if upscale > 1:
+ rgb = F.interpolate(
+ rgb.permute(2, 0, 1).unsqueeze(0),
+ scale_factor=upscale, mode="nearest"
+ ).squeeze(0).permute(1, 2, 0)
+ images.append(rgb)
+
+ return torch.stack(images, dim=0).clamp(0, 1).cpu().float()
+
+
+class LCSPreviewColors(io.ComfyNode):
+ """Visualize latent colors without VAE decoding — pure math color preview from LCS.
+
+ Projects latent patches into the 3D LCS, normalizes to t=50, decodes to HSL,
+ converts to RGB, and upscales 8x to pixel resolution. Produces a [B, H, W, 3] IMAGE.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ """Define inputs (LATENT, LCS_DATA, sigma) and IMAGE output."""
+ return io.Schema(
+ node_id="LCSPreviewColors",
+ display_name="LCS Preview Colors",
+ category="LCS/observe",
+ description="Visualize latent colors without VAE decoding — pure math color preview from LCS",
+ inputs=[
+ io.Latent.Input("latent", tooltip="Latent from KSampler or similar"),
+ LCS_DATA.Input("lcs_data"),
+ io.Float.Input("sigma", default=0.0, min=0.0, max=1.0, step=0.01,
+ tooltip="Sigma for normalization (0.0 = final/clean, use sigma from sampler)"),
+ ],
+ outputs=[
+ io.Image.Output(display_name="preview"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, latent, lcs_data, sigma) -> io.NodeOutput:
+ """Decode latent to LCS color preview. Returns IMAGE [B, H, W, 3]."""
+ samples = latent["samples"]
+ result = _latent_to_color_preview(samples, lcs_data, sigma, upscale=8)
+ return io.NodeOutput(result)
+
+
+class LCSStepObserver(io.ComfyNode):
+ """Patches model to save per-step LCS color previews to ComfyUI's temp directory.
+
+ Installs a post-CFG hook that generates a color preview image for the first
+ batch item at each sampling step. Images are saved as lcs_step_NNN_sX.XXX.png.
+ Does not modify the denoised prediction.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ """Define inputs (MODEL, LCS_DATA) and MODEL output."""
+ return io.Schema(
+ node_id="LCSStepObserver",
+ display_name="LCS Step Observer",
+ category="LCS/observe",
+ description="Patches model to save per-step LCS color previews to temp directory",
+ inputs=[
+ io.Model.Input("model"),
+ LCS_DATA.Input("lcs_data"),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, lcs_data) -> io.NodeOutput:
+ """Clone model, attach step observer hook. Returns patched MODEL."""
+ m = model.clone()
+ step_counter = [0]
+
+ def observer_fn(args):
+ """Post-CFG hook: generate color preview and save to temp directory."""
+ denoised = args["denoised"]
+ sigma = args["sigma"]
+ model = args["model"]
+ sigma_val = float(sigma.flatten()[0])
+
+ # Unpack LTXAV packed format if needed
+ working, _ = unpack_video_if_needed(denoised, args)
+
+ # Generate color preview for first batch item
+ preview = _latent_to_color_preview(
+ working[:1], lcs_data, sigma_val, upscale=4, model=model
+ )
+
+ # Save to temp directory
+ temp_dir = folder_paths.get_temp_directory()
+ img_np = (preview[0].numpy() * 255).clip(0, 255).astype(np.uint8)
+ pil_img = PILImage.fromarray(img_np)
+ filename = f"lcs_step_{step_counter[0]:03d}_s{sigma_val:.3f}.png"
+ pil_img.save(os.path.join(temp_dir, filename))
+ step_counter[0] += 1
+
+ return denoised # Don't modify
+
+ m.set_model_sampler_post_cfg_function(observer_fn)
+ return io.NodeOutput(m)
diff --git a/custom_nodes/ComfyUI-LCS/nodes/sharpen.py b/custom_nodes/ComfyUI-LCS/nodes/sharpen.py
new file mode 100644
index 0000000000000000000000000000000000000000..8858476b896c1c1ef4957506a73528b7619c0ff0
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/nodes/sharpen.py
@@ -0,0 +1,200 @@
+"""Sharpness nodes: LCSSharpnessCalibrate and LCSSharpnessIntervene."""
+
+import os
+
+import torch
+from comfy_api.latest import io
+from safetensors.torch import save_file, load_file
+
+from ..core.sharpness import SharpnessData, calibrate_sharpness
+from ..core.calibration import vae_fingerprint
+from ..core.patchify import patchify, unpatchify
+from ..core.sampling import find_step_index, denoised_to_raw, raw_to_denoised, unpack_video_if_needed, repack_video_if_needed, downsample_mask
+
+SHARPNESS_DATA = io.Custom("SHARPNESS_DATA")
+LCS_DATA = io.Custom("LCS_DATA")
+DATA_DIR = os.path.join(os.path.dirname(os.path.dirname(__file__)), "data")
+
+
+def _save_sharpness(data: SharpnessData, path: str):
+ """Save SharpnessData to safetensors file."""
+ os.makedirs(os.path.dirname(path), exist_ok=True)
+ tensors = {
+ "basis": data.basis.contiguous(),
+ "mean": data.mean.contiguous(),
+ "sign": torch.tensor([data.sign]),
+ }
+ if data.lcs_basis is not None:
+ tensors["lcs_basis"] = data.lcs_basis.contiguous()
+ save_file(tensors, path)
+
+
+def _load_sharpness(path: str) -> SharpnessData:
+ """Load SharpnessData from safetensors file."""
+ d = load_file(path)
+ return SharpnessData(
+ basis=d["basis"],
+ mean=d["mean"],
+ sign=float(d["sign"].item()),
+ lcs_basis=d.get("lcs_basis"),
+ )
+
+
+class LCSSharpnessCalibrate(io.ComfyNode):
+ """Calibrate the sharpness subspace for a VAE.
+
+ Generates sinusoidal grating stimuli at varying spatial frequencies,
+ VAE-encodes them, and runs PCA to find the sharpness direction in
+ 64D patch space. Result is cached per-VAE fingerprint.
+
+ When lcs_data is provided, the color component is removed during calibration,
+ ensuring the sharpness PC1 is orthogonal to the color subspace.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ return io.Schema(
+ node_id="LCSSharpnessCalibrate",
+ display_name="LCS Sharpness Calibrate",
+ category="LCS/calibration",
+ description="Auto-calibrate and cache sharpness subspace data per-VAE using frequency gratings. Connect lcs_data to ensure sharpness edits don't affect color.",
+ inputs=[
+ io.Vae.Input("vae", tooltip="VAE model (calibration is cached per-VAE)"),
+ LCS_DATA.Input("lcs_data", optional=True, tooltip="Optional: remove color component to prevent color shifts"),
+ ],
+ outputs=[
+ SHARPNESS_DATA.Output(display_name="sharpness_data"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, vae, lcs_data=None) -> io.NodeOutput:
+ fp = vae_fingerprint(vae)
+ suffix = "_lcs" if lcs_data is not None else ""
+ cache_path = os.path.join(DATA_DIR, f"sharpness_{fp}_grating{suffix}.safetensors")
+
+ if os.path.exists(cache_path):
+ data = _load_sharpness(cache_path)
+ else:
+ data = calibrate_sharpness(vae, lcs_data=lcs_data)
+ _save_sharpness(data, cache_path)
+
+ return io.NodeOutput(data)
+
+
+def _build_sharpness_fn(sharpness_data, strength, start_step, end_step, mask):
+ """Build the post_cfg_function closure for sharpness intervention.
+
+ Simple and correct approach: patches_new = patches + edit_vec.
+ Adding a vector along one direction automatically preserves all other
+ dimensions (residual preservation by construction). No need for explicit
+ projection/residual/reconstruction.
+
+ The sharpness basis is calibrated with LCS color removal (if lcs_data was
+ provided at calibration time), so pc1_dir is already orthogonal to color.
+ At intervention time, we just add delta along that direction.
+ """
+ # Precompute constant edit vector once (not per-step).
+ # Remove DC component from pc1_dir to prevent brightness shift,
+ # then re-orthogonalize against LCS basis (if available) because
+ # the DC vector [1,1,...,1] has nonzero projection onto LCS color space.
+ pc1_dir = sharpness_data.basis[:, 0].clone()
+ pc1_dir = pc1_dir - pc1_dir.mean()
+ if sharpness_data.lcs_basis is not None:
+ B = sharpness_data.lcs_basis.to(pc1_dir.device, pc1_dir.dtype)
+ pc1_dir = pc1_dir - B @ (B.T @ pc1_dir)
+ edit_vec = (strength * sharpness_data.sign) * pc1_dir # [64], on CPU
+
+ def post_cfg_fn(args):
+ denoised = args["denoised"]
+ sigma = args["sigma"]
+ model = args["model"]
+
+ # Step gating
+ sigmas = args["model_options"]["transformer_options"]["sample_sigmas"]
+ step_index = find_step_index(sigma, sigmas)
+
+ if step_index < start_step or step_index > end_step:
+ return denoised
+
+ # Unpack LTXAV packed format if needed
+ working, pack_info = unpack_video_if_needed(denoised, args)
+
+ device = working.device
+ dtype = working.dtype
+
+ # Move edit vector to device/dtype (short-circuits if already there)
+ ev = edit_vec.to(device=device, dtype=dtype)
+
+ # Convert from process_in to raw VAE space
+ raw = denoised_to_raw(working, model)
+
+ # Patchify
+ patches, h_len, w_len, extra_shape = patchify(raw)
+ if patches is None:
+ return denoised # Incompatible latent format
+
+ # Apply sharpness edit
+ if mask is not None:
+ mask_flat = downsample_mask(mask, h_len, w_len, device, dtype)
+ if mask_flat.shape[1] != patches.shape[1]:
+ mask_flat = mask_flat[:, :patches.shape[1], :]
+ patches_new = patches + mask_flat * ev
+ else:
+ patches_new = patches + ev
+
+ # Unpatchify
+ raw_new = unpatchify(patches_new, h_len, w_len, extra_shape)
+
+ # Convert back to process_in space
+ modified = raw_to_denoised(raw_new, model).to(dtype)
+
+ # Repack if LTXAV
+ return repack_video_if_needed(modified, pack_info)
+
+ return post_cfg_fn
+
+
+class LCSSharpnessIntervene(io.ComfyNode):
+ """Control sharpness during FLUX generation via the sharpness subspace.
+
+ Installs a post-CFG hook that adds a scaled shift along the sharpness
+ PC1 direction (calibrated from sinusoidal grating stimuli). When calibrated
+ with lcs_data, the sharpness direction is orthogonal to color, so color is
+ preserved by construction.
+ Positive strength = sharper, negative = blurrier.
+ """
+
+ @classmethod
+ def define_schema(cls) -> io.Schema:
+ return io.Schema(
+ node_id="LCSSharpnessIntervene",
+ display_name="LCS Sharpness Intervene",
+ category="LCS/intervention",
+ description="Control sharpness during FLUX generation (positive = sharper, negative = blurrier)",
+ inputs=[
+ io.Model.Input("model"),
+ SHARPNESS_DATA.Input("sharpness_data", tooltip="Calibration data from LCSSharpnessCalibrate"),
+ io.Float.Input("strength", default=0.0, min=-5.0, max=5.0, step=0.1,
+ tooltip="Sharpness strength (>0 = sharper, <0 = blurrier, 0 = no change)"),
+ io.Int.Input("start_step", default=5, min=0, max=50,
+ tooltip="First step to apply sharpness intervention"),
+ io.Int.Input("end_step", default=15, min=0, max=50,
+ tooltip="Last step to apply sharpness intervention"),
+ io.Mask.Input("mask", optional=True,
+ tooltip="Optional mask for localized sharpness control"),
+ ],
+ outputs=[
+ io.Model.Output(display_name="model"),
+ ],
+ )
+
+ @classmethod
+ def execute(cls, model, sharpness_data, strength, start_step, end_step,
+ mask=None) -> io.NodeOutput:
+ m = model.clone()
+ # Skip hook when strength is zero (true no-op)
+ if abs(strength) > 1e-6:
+ hook = _build_sharpness_fn(sharpness_data, strength, start_step, end_step, mask)
+ m.set_model_sampler_post_cfg_function(hook)
+ return io.NodeOutput(m)
diff --git a/custom_nodes/ComfyUI-LCS/requirements.txt b/custom_nodes/ComfyUI-LCS/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..146237c43ec6bf86e4198a15f6111156500b8230
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/requirements.txt
@@ -0,0 +1,2 @@
+einops
+safetensors
diff --git a/custom_nodes/ComfyUI-LCS/web/js/tone_preset.js b/custom_nodes/ComfyUI-LCS/web/js/tone_preset.js
new file mode 100644
index 0000000000000000000000000000000000000000..8f754318af0cc0a94d99c99bf990a0aecacc475a
--- /dev/null
+++ b/custom_nodes/ComfyUI-LCS/web/js/tone_preset.js
@@ -0,0 +1,51 @@
+import { app } from "../../../scripts/app.js";
+
+// Preset values — must match TONE_PRESETS in nodes/intervene.py.
+// Frontend syncs these into sliders on user interaction; Python has
+// a copy as fallback for headless/batch execution without frontend.
+const TONE_PRESETS = {
+ "Base": { contrast: 1.0, brightness: 0.0, saturation: 1.0, color_temperature: 0.0 },
+ "Cinematic": { contrast: 1.20, brightness: -0.05, saturation: 0.90, color_temperature: 0.05 },
+ "HDR": { contrast: 1.40, brightness: 0.0, saturation: 1.20, color_temperature: 0.0 },
+ "Vivid": { contrast: 1.10, brightness: 0.0, saturation: 1.50, color_temperature: 0.0 },
+ "Dramatic": { contrast: 1.50, brightness: -0.10, saturation: 0.85, color_temperature: 0.0 },
+ "Low Key": { contrast: 1.30, brightness: -0.20, saturation: 0.80, color_temperature: 0.0 },
+ "High Key": { contrast: 0.80, brightness: 0.20, saturation: 0.90, color_temperature: 0.0 },
+ "Warm": { contrast: 1.05, brightness: 0.03, saturation: 1.10, color_temperature: 0.30 },
+ "Cool": { contrast: 1.05, brightness: 0.0, saturation: 1.05, color_temperature: -0.30 },
+ "Desaturated": { contrast: 1.0, brightness: 0.0, saturation: 0.40, color_temperature: 0.0 },
+};
+
+const SLIDER_NAMES = ["contrast", "brightness", "saturation", "color_temperature"];
+
+function syncPreset(node, presetName) {
+ const preset = TONE_PRESETS[presetName];
+ if (!preset) return; // "Custom" — leave sliders as-is
+
+ for (const name of SLIDER_NAMES) {
+ const widget = node.widgets?.find(w => w.name === name);
+ if (widget && name in preset) {
+ widget.value = preset[name];
+ }
+ }
+ node.graph?.setDirtyCanvas(true, true);
+}
+
+app.registerExtension({
+ name: "ComfyUI-LCS.TonePresetSync",
+
+ nodeCreated(node) {
+ if (node.comfyClass !== "LCSToneAdjust") return;
+
+ const presetWidget = node.widgets?.find(w => w.name === "preset");
+ if (!presetWidget) return;
+
+ // Only sync on explicit user interaction (dropdown change), not on
+ // workflow load or paste — those restore saved slider values directly.
+ const origCallback = presetWidget.callback;
+ presetWidget.callback = function (value, canvas, nodeRef, pos, event) {
+ if (origCallback) origCallback.call(this, value, canvas, nodeRef, pos, event);
+ syncPreset(node, value);
+ };
+ },
+});
diff --git a/models/FlashVSR-v1.1/.gitattributes b/models/FlashVSR-v1.1/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..a6344aac8c09253b3b630fb776ae94478aa0275b
--- /dev/null
+++ b/models/FlashVSR-v1.1/.gitattributes
@@ -0,0 +1,35 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tar filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
diff --git a/models/FlashVSR-v1.1/LQ_proj_in.ckpt b/models/FlashVSR-v1.1/LQ_proj_in.ckpt
new file mode 100644
index 0000000000000000000000000000000000000000..22366868eea9a8e63218a5f3c2266c80fabbdc04
--- /dev/null
+++ b/models/FlashVSR-v1.1/LQ_proj_in.ckpt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d6d011cdaaba6a52645086caa08fa04124e746f6ca568140a24007591142bfd2
+size 575694948
diff --git a/models/FlashVSR-v1.1/README.md b/models/FlashVSR-v1.1/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b592ae115fb8061ce99e8e701c9688a255fa03d
--- /dev/null
+++ b/models/FlashVSR-v1.1/README.md
@@ -0,0 +1,221 @@
+---
+license: apache-2.0
+pipeline_tag: video-to-video
+---
+
+# ⚡ FlashVSR
+
+**Towards Real-Time Diffusion-Based Streaming Video Super-Resolution**
+
+**Authors:** Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, Tianfan Xue
+
+ +
+ +
+-blue) +
+-blue) +
+ +
+ +
+**Your star means a lot for us to develop this project!** :star:
+
+
+
+**Your star means a lot for us to develop this project!** :star:
+
+ +
+---
+
+### 🌟 Abstract
+
+Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
+
+---
+
+### 📰 News
+
+- **Nov 2025 — 🎉 [FlashVSR v1.1](https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1) released:** enhanced stability + fidelity
+- **Oct 2025 — [FlashVSR v1](https://huggingface.co/JunhaoZhuang/FlashVSR) (initial release)**: Inference code and model weights are available now! 🎉
+- **Bug Fix (October 21, 2025):** Fixed `local_attention_mask` update logic to prevent artifacts when switching between different aspect ratios during continuous inference.
+- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
+
+---
+
+### 📢 Important Quality Note (ComfyUI & other third-party implementations)
+
+First of all, huge thanks to the community for the fast adoption, feedback, and contributions to FlashVSR! 🙌
+During community testing, we noticed that some third-party implementations of FlashVSR (e.g. early ComfyUI versions) do **not include our Locality-Constrained Sparse Attention (LCSA)** module and instead fall back to **dense attention**. This may lead to **noticeable quality degradation**, especially at higher resolutions.
+Community discussion: https://github.com/kijai/ComfyUI-WanVideoWrapper/issues/1441
+
+Below is a comparison example provided by a community member:
+
+| Fig.1 – LR Input Video | Fig.2 – 3rd-party (no LCSA) | Fig.3 – Official FlashVSR |
+|------------------|-----------------------------------------------|--------------------------------------|
+| | | |
+
+✅ The **official FlashVSR pipeline (this repository)**:
+- **Better preserves fine structures and details**
+- **Effectively avoids texture aliasing and visual artifacts**
+
+We are also working on a **version that does not rely on the Block-Sparse Attention library** while keeping **the same output quality**; this alternative may run slower than the optimized original implementation.
+
+Thanks again to the community for actively testing and helping improve FlashVSR together! 🚀
+
+---
+
+### 📋 TODO
+
+- ✅ Release inference code and model weights
+- ⬜ Release dataset (VSR-120K)
+
+---
+
+### 🚀 Getting Started
+
+Follow these steps to set up and run **FlashVSR** on your local machine:
+
+> ⚠️ **Note:** This project is primarily designed and optimized for **4× video super-resolution**.
+> We **strongly recommend** using the **4× SR setting** to achieve better results and stability. ✅
+
+#### 1️⃣ Clone the Repository
+
+```bash
+git clone https://github.com/OpenImagingLab/FlashVSR
+cd FlashVSR
+````
+
+#### 2️⃣ Set Up the Python Environment
+
+Create and activate the environment (**Python 3.11.13**):
+
+```bash
+conda create -n flashvsr python=3.11.13
+conda activate flashvsr
+```
+
+Install project dependencies:
+
+```bash
+pip install -e .
+pip install -r requirements.txt
+```
+
+#### 3️⃣ Install Block-Sparse Attention (Required)
+
+FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
+
+> **⚠️ Note:**
+>
+> * The Block-Sparse Attention build process can be memory-intensive, especially when compiling in parallel with multiple `ninja` jobs. It is recommended to keep sufficient memory available during compilation to avoid OOM errors. Once the build is complete, runtime memory usage is stable and not an issue.
+> * Based on our testing, the Block-Sparse Attention backend works correctly on **NVIDIA A100 and A800** (Ampere) with **ideal acceleration performance**, and it also runs correctly on **H200** (Hopper) but the acceleration is limited due to hardware scheduling differences and sparse kernel behavior. **Compatibility and performance on other GPUs (e.g., RTX 40/50 series or H800) are currently unknown**. For more details, please refer to the official documentation: https://github.com/mit-han-lab/Block-Sparse-Attention
+
+
+```bash
+# ✅ Recommended: clone and install in a separate clean folder (outside the FlashVSR repo)
+git clone https://github.com/mit-han-lab/Block-Sparse-Attention
+cd Block-Sparse-Attention
+pip install packaging
+pip install ninja
+python setup.py install
+```
+
+#### 4️⃣ Download Model Weights from Hugging Face
+
+FlashVSR provides both **v1** and **v1.1** model weights on Hugging Face (via **Git LFS**).
+Please install Git LFS first:
+
+```bash
+# From the repo root
+cd examples/WanVSR
+
+# Install Git LFS (once per machine)
+git lfs install
+
+# Clone v1 (original) or v1.1 (recommended)
+git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR # v1
+# or
+git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1 # v1.1
+```
+
+After cloning, you should have one of the following folders:
+
+```
+./examples/WanVSR/FlashVSR/ # v1
+./examples/WanVSR/FlashVSR-v1.1/ # v1.1
+│
+├── LQ_proj_in.ckpt
+├── TCDecoder.ckpt
+├── Wan2.1_VAE.pth
+├── diffusion_pytorch_model_streaming_dmd.safetensors
+└── README.md
+```
+
+> Inference scripts automatically load weights from the corresponding folder.
+
+---
+
+#### 5️⃣ Run Inference
+
+```bash
+# From the repo root
+cd examples/WanVSR
+
+# v1 (original)
+python infer_flashvsr_full.py
+# or
+python infer_flashvsr_tiny.py
+# or
+python infer_flashvsr_tiny_long_video.py
+
+# v1.1 (recommended)
+python infer_flashvsr_v1.1_full.py
+# or
+python infer_flashvsr_v1.1_tiny.py
+# or
+python infer_flashvsr_v1.1_tiny_long_video.py
+```
+
+---
+
+### 🛠️ Method
+
+The overview of **FlashVSR**. This framework features:
+
+* **Three-Stage Distillation Pipeline** for streaming VSR training.
+* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
+* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
+* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
+
+
+
+---
+
+### 🌟 Abstract
+
+Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving **efficiency, scalability, and real-time performance**. To this end, we propose **FlashVSR**, the first diffusion-based one-step streaming framework towards real-time VSR. **FlashVSR runs at ∼17 FPS for 768 × 1408 videos on a single A100 GPU** by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train–test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct **VSR-120K**, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves **state-of-the-art performance with up to ∼12× speedup** over prior one-step diffusion VSR models.
+
+---
+
+### 📰 News
+
+- **Nov 2025 — 🎉 [FlashVSR v1.1](https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1) released:** enhanced stability + fidelity
+- **Oct 2025 — [FlashVSR v1](https://huggingface.co/JunhaoZhuang/FlashVSR) (initial release)**: Inference code and model weights are available now! 🎉
+- **Bug Fix (October 21, 2025):** Fixed `local_attention_mask` update logic to prevent artifacts when switching between different aspect ratios during continuous inference.
+- **Coming Soon:** Dataset release (**VSR-120K**) for large-scale training.
+
+---
+
+### 📢 Important Quality Note (ComfyUI & other third-party implementations)
+
+First of all, huge thanks to the community for the fast adoption, feedback, and contributions to FlashVSR! 🙌
+During community testing, we noticed that some third-party implementations of FlashVSR (e.g. early ComfyUI versions) do **not include our Locality-Constrained Sparse Attention (LCSA)** module and instead fall back to **dense attention**. This may lead to **noticeable quality degradation**, especially at higher resolutions.
+Community discussion: https://github.com/kijai/ComfyUI-WanVideoWrapper/issues/1441
+
+Below is a comparison example provided by a community member:
+
+| Fig.1 – LR Input Video | Fig.2 – 3rd-party (no LCSA) | Fig.3 – Official FlashVSR |
+|------------------|-----------------------------------------------|--------------------------------------|
+| | | |
+
+✅ The **official FlashVSR pipeline (this repository)**:
+- **Better preserves fine structures and details**
+- **Effectively avoids texture aliasing and visual artifacts**
+
+We are also working on a **version that does not rely on the Block-Sparse Attention library** while keeping **the same output quality**; this alternative may run slower than the optimized original implementation.
+
+Thanks again to the community for actively testing and helping improve FlashVSR together! 🚀
+
+---
+
+### 📋 TODO
+
+- ✅ Release inference code and model weights
+- ⬜ Release dataset (VSR-120K)
+
+---
+
+### 🚀 Getting Started
+
+Follow these steps to set up and run **FlashVSR** on your local machine:
+
+> ⚠️ **Note:** This project is primarily designed and optimized for **4× video super-resolution**.
+> We **strongly recommend** using the **4× SR setting** to achieve better results and stability. ✅
+
+#### 1️⃣ Clone the Repository
+
+```bash
+git clone https://github.com/OpenImagingLab/FlashVSR
+cd FlashVSR
+````
+
+#### 2️⃣ Set Up the Python Environment
+
+Create and activate the environment (**Python 3.11.13**):
+
+```bash
+conda create -n flashvsr python=3.11.13
+conda activate flashvsr
+```
+
+Install project dependencies:
+
+```bash
+pip install -e .
+pip install -r requirements.txt
+```
+
+#### 3️⃣ Install Block-Sparse Attention (Required)
+
+FlashVSR relies on the **Block-Sparse Attention** backend to enable flexible and dynamic attention masking for efficient inference.
+
+> **⚠️ Note:**
+>
+> * The Block-Sparse Attention build process can be memory-intensive, especially when compiling in parallel with multiple `ninja` jobs. It is recommended to keep sufficient memory available during compilation to avoid OOM errors. Once the build is complete, runtime memory usage is stable and not an issue.
+> * Based on our testing, the Block-Sparse Attention backend works correctly on **NVIDIA A100 and A800** (Ampere) with **ideal acceleration performance**, and it also runs correctly on **H200** (Hopper) but the acceleration is limited due to hardware scheduling differences and sparse kernel behavior. **Compatibility and performance on other GPUs (e.g., RTX 40/50 series or H800) are currently unknown**. For more details, please refer to the official documentation: https://github.com/mit-han-lab/Block-Sparse-Attention
+
+
+```bash
+# ✅ Recommended: clone and install in a separate clean folder (outside the FlashVSR repo)
+git clone https://github.com/mit-han-lab/Block-Sparse-Attention
+cd Block-Sparse-Attention
+pip install packaging
+pip install ninja
+python setup.py install
+```
+
+#### 4️⃣ Download Model Weights from Hugging Face
+
+FlashVSR provides both **v1** and **v1.1** model weights on Hugging Face (via **Git LFS**).
+Please install Git LFS first:
+
+```bash
+# From the repo root
+cd examples/WanVSR
+
+# Install Git LFS (once per machine)
+git lfs install
+
+# Clone v1 (original) or v1.1 (recommended)
+git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR # v1
+# or
+git lfs clone https://huggingface.co/JunhaoZhuang/FlashVSR-v1.1 # v1.1
+```
+
+After cloning, you should have one of the following folders:
+
+```
+./examples/WanVSR/FlashVSR/ # v1
+./examples/WanVSR/FlashVSR-v1.1/ # v1.1
+│
+├── LQ_proj_in.ckpt
+├── TCDecoder.ckpt
+├── Wan2.1_VAE.pth
+├── diffusion_pytorch_model_streaming_dmd.safetensors
+└── README.md
+```
+
+> Inference scripts automatically load weights from the corresponding folder.
+
+---
+
+#### 5️⃣ Run Inference
+
+```bash
+# From the repo root
+cd examples/WanVSR
+
+# v1 (original)
+python infer_flashvsr_full.py
+# or
+python infer_flashvsr_tiny.py
+# or
+python infer_flashvsr_tiny_long_video.py
+
+# v1.1 (recommended)
+python infer_flashvsr_v1.1_full.py
+# or
+python infer_flashvsr_v1.1_tiny.py
+# or
+python infer_flashvsr_v1.1_tiny_long_video.py
+```
+
+---
+
+### 🛠️ Method
+
+The overview of **FlashVSR**. This framework features:
+
+* **Three-Stage Distillation Pipeline** for streaming VSR training.
+* **Locality-Constrained Sparse Attention** to cut redundant computation and bridge the train–test resolution gap.
+* **Tiny Conditional Decoder** for efficient, high-quality reconstruction.
+* **VSR-120K Dataset** consisting of **120k videos** and **180k images**, supports joint training on both images and videos.
+
+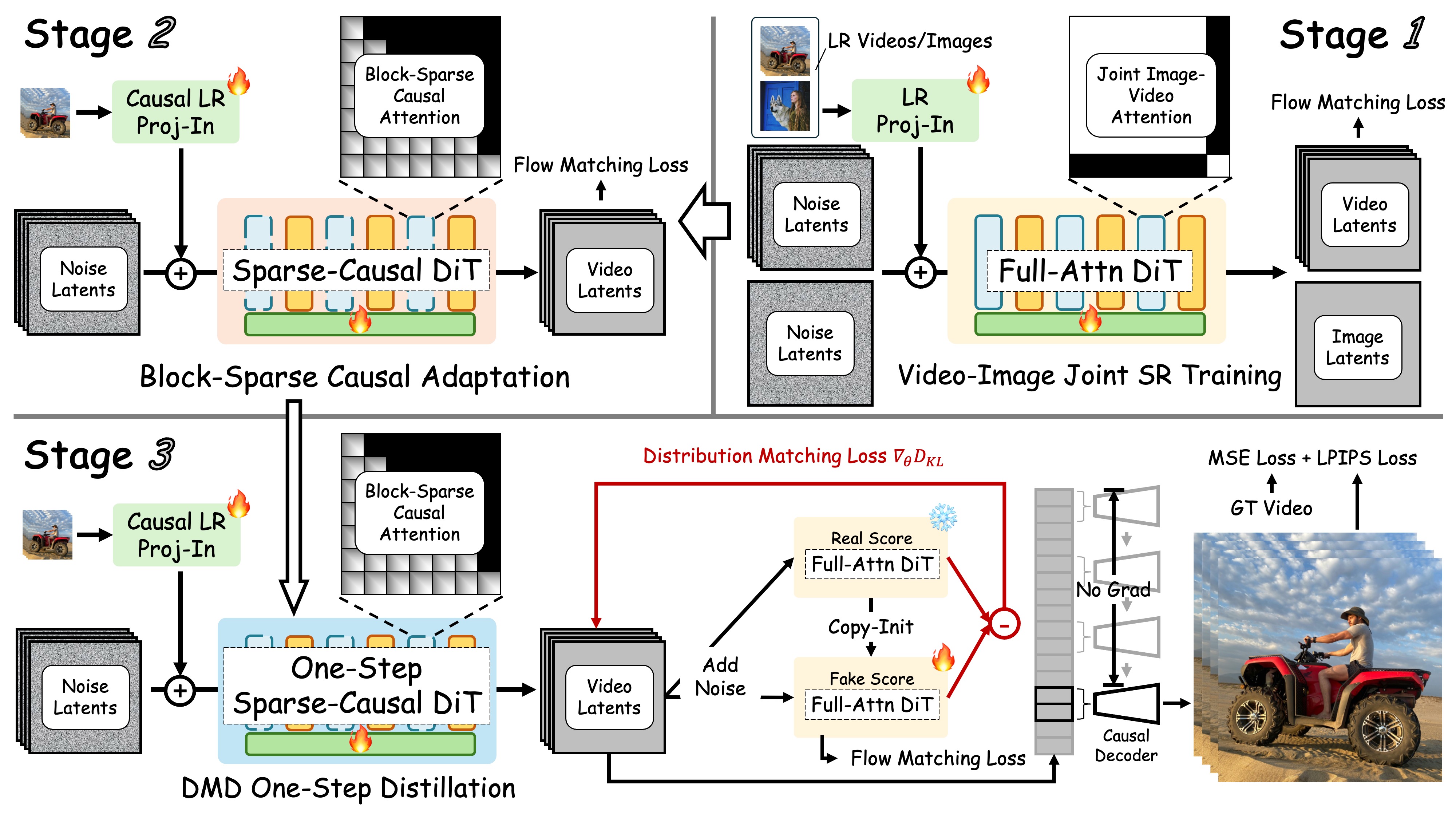 +
+---
+
+### 🤗 Feedback & Support
+
+We welcome feedback and issues. Thank you for trying **FlashVSR**!
+
+---
+
+### 📄 Acknowledgments
+
+We gratefully acknowledge the following open-source projects:
+
+* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
+* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
+* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
+
+---
+
+### 📞 Contact
+
+* **Junhao Zhuang**
+ Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
+
+---
+
+### 📜 Citation
+
+```bibtex
+@article{zhuang2025flashvsr,
+ title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
+ author={Zhuang, Junhao and Guo, Shi and Cai, Xin and Li, Xiaohui and Liu, Yihao and Yuan, Chun and Xue, Tianfan},
+ journal={arXiv preprint arXiv:2510.12747},
+ year={2025}
+}
+```
diff --git a/models/FlashVSR-v1.1/TCDecoder.ckpt b/models/FlashVSR-v1.1/TCDecoder.ckpt
new file mode 100644
index 0000000000000000000000000000000000000000..c9172bab1dddb2bfcebf49749292b990ef00209f
--- /dev/null
+++ b/models/FlashVSR-v1.1/TCDecoder.ckpt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e224bdcf2f52745cbf4d393ff5374c2ba09e90285d5d19062d2bf63b915b6161
+size 189018333
diff --git a/models/FlashVSR-v1.1/Wan2.1_VAE.pth b/models/FlashVSR-v1.1/Wan2.1_VAE.pth
new file mode 100644
index 0000000000000000000000000000000000000000..5897fba405232a6b07a947d6188d19a8e050ccfb
--- /dev/null
+++ b/models/FlashVSR-v1.1/Wan2.1_VAE.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:38071ab59bd94681c686fa51d75a1968f64e470262043be31f7a094e442fd981
+size 507609880
diff --git a/models/FlashVSR-v1.1/config.json b/models/FlashVSR-v1.1/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..3163ad0144826c126dfd750454ac5d30757cfec8
--- /dev/null
+++ b/models/FlashVSR-v1.1/config.json
@@ -0,0 +1,3 @@
+{
+ "model_type": "flashvsr"
+}
\ No newline at end of file
diff --git a/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors b/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..cd6a37b2d2caa77887bdc8349e43af2a88d38b5f
--- /dev/null
+++ b/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bd28180edcf3446c028e32fc6b731a80bf7e4da2ab4caac3186b9499964d37be
+size 5676070392
diff --git a/models/FlashVSR-v1.1/model_index.json b/models/FlashVSR-v1.1/model_index.json
new file mode 100644
index 0000000000000000000000000000000000000000..27b27d4163fa0d50959936e28624795c515ade4a
--- /dev/null
+++ b/models/FlashVSR-v1.1/model_index.json
@@ -0,0 +1,4 @@
+{
+ "_class_name": "FlashVSRPipeline",
+ "_diffusers_version": "0.24.0"
+}
\ No newline at end of file
+
+---
+
+### 🤗 Feedback & Support
+
+We welcome feedback and issues. Thank you for trying **FlashVSR**!
+
+---
+
+### 📄 Acknowledgments
+
+We gratefully acknowledge the following open-source projects:
+
+* **DiffSynth Studio** — [https://github.com/modelscope/DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio)
+* **Block-Sparse-Attention** — [https://github.com/mit-han-lab/Block-Sparse-Attention](https://github.com/mit-han-lab/Block-Sparse-Attention)
+* **taehv** — [https://github.com/madebyollin/taehv](https://github.com/madebyollin/taehv)
+
+---
+
+### 📞 Contact
+
+* **Junhao Zhuang**
+ Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
+
+---
+
+### 📜 Citation
+
+```bibtex
+@article{zhuang2025flashvsr,
+ title={FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution},
+ author={Zhuang, Junhao and Guo, Shi and Cai, Xin and Li, Xiaohui and Liu, Yihao and Yuan, Chun and Xue, Tianfan},
+ journal={arXiv preprint arXiv:2510.12747},
+ year={2025}
+}
+```
diff --git a/models/FlashVSR-v1.1/TCDecoder.ckpt b/models/FlashVSR-v1.1/TCDecoder.ckpt
new file mode 100644
index 0000000000000000000000000000000000000000..c9172bab1dddb2bfcebf49749292b990ef00209f
--- /dev/null
+++ b/models/FlashVSR-v1.1/TCDecoder.ckpt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e224bdcf2f52745cbf4d393ff5374c2ba09e90285d5d19062d2bf63b915b6161
+size 189018333
diff --git a/models/FlashVSR-v1.1/Wan2.1_VAE.pth b/models/FlashVSR-v1.1/Wan2.1_VAE.pth
new file mode 100644
index 0000000000000000000000000000000000000000..5897fba405232a6b07a947d6188d19a8e050ccfb
--- /dev/null
+++ b/models/FlashVSR-v1.1/Wan2.1_VAE.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:38071ab59bd94681c686fa51d75a1968f64e470262043be31f7a094e442fd981
+size 507609880
diff --git a/models/FlashVSR-v1.1/config.json b/models/FlashVSR-v1.1/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..3163ad0144826c126dfd750454ac5d30757cfec8
--- /dev/null
+++ b/models/FlashVSR-v1.1/config.json
@@ -0,0 +1,3 @@
+{
+ "model_type": "flashvsr"
+}
\ No newline at end of file
diff --git a/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors b/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..cd6a37b2d2caa77887bdc8349e43af2a88d38b5f
--- /dev/null
+++ b/models/FlashVSR-v1.1/diffusion_pytorch_model_streaming_dmd.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bd28180edcf3446c028e32fc6b731a80bf7e4da2ab4caac3186b9499964d37be
+size 5676070392
diff --git a/models/FlashVSR-v1.1/model_index.json b/models/FlashVSR-v1.1/model_index.json
new file mode 100644
index 0000000000000000000000000000000000000000..27b27d4163fa0d50959936e28624795c515ade4a
--- /dev/null
+++ b/models/FlashVSR-v1.1/model_index.json
@@ -0,0 +1,4 @@
+{
+ "_class_name": "FlashVSRPipeline",
+ "_diffusers_version": "0.24.0"
+}
\ No newline at end of file