---
license: mit
tags:
- audio tokenizer
library_name: transformers
pipeline_tag: feature-extraction
---
# VibeVoice Acoustic Tokenizer
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking.
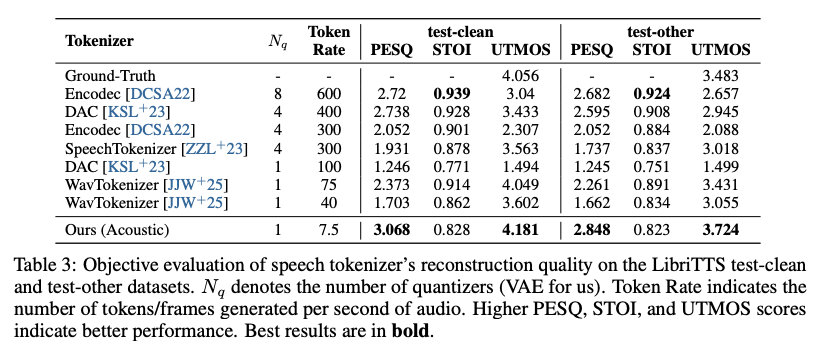
A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details.
The speech tokenizer is a key component for both VibeVoice [TTS](https://huggingface.co/microsoft/VibeVoice-1.5B) and [ASR](https://huggingface.co/microsoft/VibeVoice-ASR).
➡️ **Technical Report:** [VibeVoice Technical Report](https://arxiv.org/abs/2508.19205)
➡️ **Project Page:** [microsoft/VibeVoice](https://microsoft.github.io/VibeVoice)
# Models
| Model | Context Length | Length (min) | Weight |
|-------|----------------|----------|----------|
| VibeVoice-Realtime-0.5B | 8K | ~10 min | [HF link](https://huggingface.co/microsoft/VibeVoice-Realtime-0.5B) |
| VibeVoice-1.5B | 64K | ~90 min | [HF link](https://huggingface.co/microsoft/VibeVoice-1.5B) |
| VibeVoice-ASR | 64K | ~60 min | [HF link](https://huggingface.co/microsoft/VibeVoice-ASR) |
| VibeVoice-AcousticTokenizer | - | - | This model |
# Usage
## Setup
Until the VibeVoice acoustic tokenizer is part of an official Transformers release, it can be used by installing from the source code:
```python
pip install git+https://github.com/huggingface/transformers.git
```
## Example
Encoding and decoding
```python
import torch
from scipy.io import wavfile
from transformers import AutoFeatureExtractor, VibeVoiceAcousticTokenizerModel
from transformers.audio_utils import load_audio_librosa
model_id = "microsoft/VibeVoice-AcousticTokenizer"
# load model
feature_extractor = AutoFeatureExtractor.from_pretrained(model_id)
model = VibeVoiceAcousticTokenizerModel.from_pretrained(model_id, device_map="auto")
print("Model loaded on device:", model.device)
print("Model dtype:", model.dtype)
# load audio
audio = load_audio_librosa(
"https://huggingface.co/datasets/bezzam/vibevoice_samples/resolve/main/voices/en-Alice_woman.wav",
sampling_rate=feature_extractor.sampling_rate,
)
# preprocess audio
inputs = feature_extractor(
audio,
sampling_rate=feature_extractor.sampling_rate,
pad_to_multiple_of=3200,
).to(model.device, model.dtype)
print("Input audio shape:", inputs.input_values.shape)
# Input audio shape: torch.Size([1, 1, 224000])
with torch.no_grad():
# set VAE sampling to False for deterministic output
encoded_outputs = model.encode(inputs.input_values, sample=False)
print("Latent shape:", encoded_outputs.latents.shape)
# Latent shape: torch.Size([1, 70, 64])
decoded_outputs = model.decode(**encoded_outputs)
print("Reconstructed audio shape:", decoded_outputs.audio.shape)
# Reconstructed audio shape: torch.Size([1, 1, 224000])
# Save audio
output_fp = "vibevoice_acoustic_tokenizer_reconstructed.wav"
wavfile.write(output_fp, feature_extractor.sampling_rate, decoded_outputs.audio.squeeze().float().cpu().numpy())
print(f"Reconstructed audio saved to : {output_fp}")
```
**Original audio**
**Encoded/decoded audio**
Streaming
For streaming ASR or TTS, where cached states need to be tracked, the `use_cache` parameter can be used when encoding or decoding audio:
```python
import torch
from scipy.io import wavfile
from transformers import AutoFeatureExtractor, VibeVoiceAcousticTokenizerModel
from transformers.audio_utils import load_audio_librosa
model_id = "microsoft/VibeVoice-AcousticTokenizer"
# load model
feature_extractor = AutoFeatureExtractor.from_pretrained(model_id)
model = VibeVoiceAcousticTokenizerModel.from_pretrained(model_id, device_map="auto")
print("Model loaded on device:", model.device)
print("Model dtype:", model.dtype)
# load audio
audio = load_audio_librosa(
"https://huggingface.co/datasets/bezzam/vibevoice_samples/resolve/main/voices/en-Alice_woman.wav",
sampling_rate=feature_extractor.sampling_rate,
)
# preprocess audio
inputs = feature_extractor(
audio,
sampling_rate=feature_extractor.sampling_rate,
pad_to_multiple_of=3200,
).to(model.device, model.dtype)
print("Input audio shape:", inputs.input_values.shape)
# Input audio shape: torch.Size([1, 1, 224000])
# chache will be initialized after a first pass
encoder_cache = None
decoder_cache = None
with torch.no_grad():
# set VAE sampling to False for deterministic output
encoded_outputs = model.encode(inputs.input_values, sample=False, padding_cache=encoder_cache, use_cache=True)
print("Latent shape:", encoded_outputs.latents.shape)
# Latent shape: torch.Size([1, 70, 64])
decoded_outputs = model.decode(encoded_outputs.latents, padding_cache=decoder_cache, use_cache=True)
print("Reconstructed audio shape:", decoded_outputs.audio.shape)
# Reconstructed audio shape: torch.Size([1, 1, 224000])
# `padding_cache` can be extracted from the outputs for subsequent passes
encoder_cache = encoded_outputs.padding_cache
print("Number of cached encoder layers:", len(encoder_cache.per_layer_in_channels))
# Number of cached encoder layers: 34
decoder_cache = decoded_outputs.padding_cache
print("Number of cached decoder layers:", len(decoder_cache.per_layer_in_channels))
# Number of cached decoder layers: 34
# Save audio
output_fp = "vibevoice_acoustic_tokenizer_reconstructed.wav"
wavfile.write(output_fp, feature_extractor.sampling_rate, decoded_outputs.audio.squeeze().float().cpu().numpy())
print(f"Reconstructed audio saved to : {output_fp}")
```