---
license: apache-2.0
---
Metis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning
[](https://arxiv.org/pdf/2510.20519)  [](https://github.com/tatsu-lab/stanford_alpaca/blob/main/LICENSE)
[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/LICENSE)
## 💡 Overview
Current multimodal reasoning models face a critical dilemma: they often "overthink" on simple tasks (inefficiency) and suffer from general capability degradation when optimized for reasoning.
We introduce **Metis-HOME** (**H**ybrid **O**ptimized **M**ixture-of-**E**xperts), a novel framework that enables a "Hybrid Thinking" paradigm. By structuring the original dense model (Qwen2.5-VL-7B) into two distinct expert branches—a Thinking Expert for complex reasoning and a Non-Thinking Expert for rapid inference—controlled by a lightweight router, Metis-HOME effectively resolves the reasoning-vs-generalization trade-off.
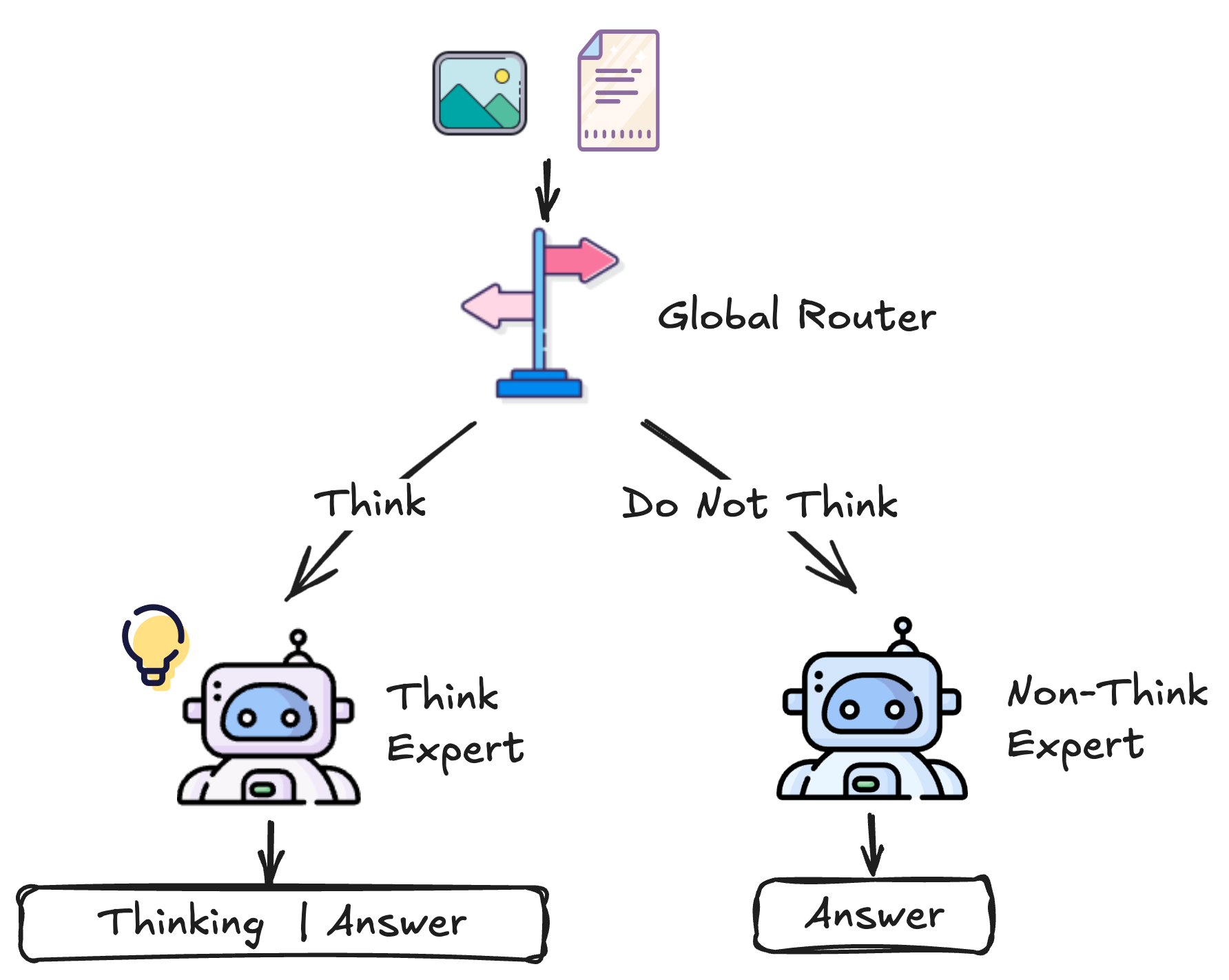
## ✨ Highlights
- 🧠 Hybrid Thinking Paradigm: Explicitly decouples "System 1" (fast, intuitive) and "System 2" (slow, deliberative) reasoning within a unified multimodal MoE architecture.
- 🔄 Router Mechanism: A lightweight, trainable router dynamically allocates queries based on complexity, avoiding computational waste on simple tasks like OCR or Captioning.
- 🚀 Performance:
- +6.9% improvement on reasoning benchmarks (MathVista, etc.) compared to the baseline.
- ~1% gain on general benchmarks, reversing the degradation trend observed in other reasoning-specialized models.
- 🛠️ Efficient Training: A multi-stage strategy combining Reinforcement Learning (RL) for reasoning enhancement and Mixed Supervised Fine-Tuning (SFT) for expert specialization.
## 📊 Results
### Thinking Ratio
As shown in the following figure, the **thinking ratio** analysis of Metis-HOME reveals adaptive routing behavior:
- **High ratios (78\%–98\%)** on reasoning-heavy benchmarks (*WeMath*, *MathVision*, etc.), indicating effective use of the *thinking expert* for multi-step inference.
- **Low ratios (2\%–5\%)** on general benchmarks (*MMBench*, *OCRBench*), showing preference for the *non-thinking expert*.
This aligns with our design: **deliberate reasoning for complex tasks**, **fast inference for simple ones**, optimizing computational efficiency.
 ### Benchmarks
### Benchmarks
| Model |
Reasoning |
General |
| MathVista |
MathVision |
MathVerse |
DynaMath |
WeMath |
LogicVista |
Avg. |
Avg. |
| Proprietary Models |
| Gemini-2.0-Pro |
71.3 |
48.1 |
67.3 |
43.3 |
56.5 |
53.2 |
56.6 |
73.3 |
| Gemini-2.0-Flash |
70.4 |
43.6 |
47.8 |
42.1 |
47.4 |
52.3 |
50.6 |
72.6 |
| Claude 3.7 Sonnet |
66.8 |
41.9 |
46.7 |
39.7 |
49.3 |
58.2 |
50.4 |
70.1 |
| ChatGPT-4o |
60.0 |
31.2 |
40.6 |
34.5 |
45.8 |
52.8 |
44.2 |
72.0 |
| Open-source Models |
| LLaVA-OneVision-72B |
67.1 |
25.3 |
27.2 |
15.6 |
32.0 |
40.9 |
34.7 |
68.0 |
| Kimi-VL-A3B-Instruct |
66.0 |
21.8 |
34.1 |
18.0 |
32.3 |
42.7 |
35.8 |
69.1 |
| InternVL3-8B |
70.5 |
30.0 |
38.5 |
25.7 |
39.5 |
44.5 |
41.4 |
73.6 |
| VL-Rethinker-7B |
75.5 |
29.3 |
47.2 |
25.4 |
37.8 |
47.0 |
43.7 |
68.3 |
| Metis-RISE-7B |
75.8 |
28.7 |
51.0 |
27.7 |
45.2 |
49.7 |
46.4 |
68.4 |
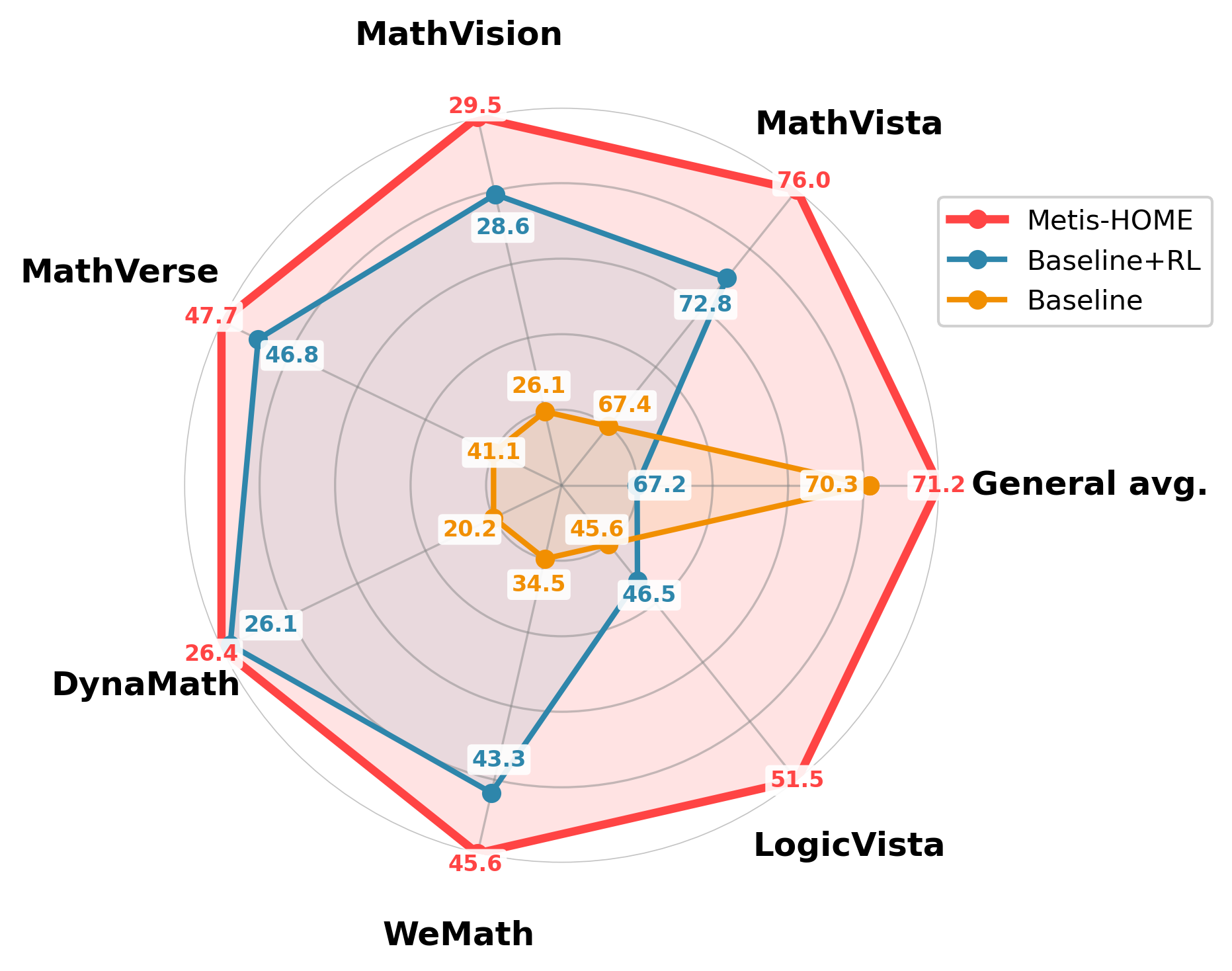
| Baseline |
67.4 |
26.2 |
41.1 |
20.2 |
34.5 |
45.6 |
39.2 |
70.3 |
| Baseline+RL |
72.8 |
28.7 |
46.8 |
26.2 |
43.3 |
46.5 |
44.0 |
67.2 |
| Metis-HOME |
76.0 |
29.5 |
47.7 |
26.4 |
45.6 |
51.5 |
46.1 |
71.2 |
## 🔍 Usage Example
You can use the demo inference script in the `examples` folder:
```bash
python examples/demo_inference.py
```
## 📌 Acknowledgement
We sincerely appreciate [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) and [MM-EUREKA](https://github.com/ModalMinds/MM-EUREKA) for providing reference training framework.
## 📖 Citation
```bibtex
@article{lan2025metis,
title={Metis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning},
author={Lan, Xiaohan and Liu, Fanfan and Qiu, Haibo and Yang, Siqi and Ruan, Delian and Shi, Peng and Ma, Lin},
journal={arXiv preprint arXiv:2510.20519},
year={2025}
}
```