
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- build/lib/opencompass/configs/chatml_datasets/AMO_Bench/AMO_Bench_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/CPsyExam/CPsyExam_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/CS_Bench/CS_Bench_gen.py +25 -0
- build/lib/opencompass/configs/chatml_datasets/C_MHChem/C_MHChem_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/HMMT2025/HMMT2025_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/IMO_Bench_AnswerBench/IMO_Bench_AnswerBench_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/MaScQA/MaScQA_gen.py +12 -0
- build/lib/opencompass/configs/chatml_datasets/UGPhysics/UGPhysics_gen.py +36 -0
- build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/README.md +47 -0
- build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen.py +4 -0
- build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen_872059.py +56 -0
- build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen_fedd04.py +56 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_clean_ppl.py +55 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_cot_gen_926652.py +53 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_few_shot_gen_e9b043.py +48 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_few_shot_ppl.py +63 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_gen.py +4 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_gen_1e0de5.py +44 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl.py +4 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_2ef631.py +37 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_a450bd.py +54 -0
- build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_d52a21.py +36 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_gen.py +4 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_gen_1e0de5.py +44 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl.py +4 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_2ef631.py +37 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_a450bd.py +54 -0
- build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_d52a21.py +34 -0
- build/lib/opencompass/configs/datasets/BeyondAIME/beyondaime_cascade_eval_gen_5e9f4f.py +106 -0
- build/lib/opencompass/configs/datasets/BeyondAIME/beyondaime_gen.py +4 -0
- build/lib/opencompass/configs/datasets/CARDBiomedBench/CARDBiomedBench_llmjudge_gen_99a231.py +101 -0
- build/lib/opencompass/configs/datasets/CHARM/README.md +164 -0
- build/lib/opencompass/configs/datasets/CHARM/README_ZH.md +162 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_memory_gen_bbbd53.py +63 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_memory_settings.py +31 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_reason_cot_only_gen_f7b7d3.py +50 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_reason_gen.py +4 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_reason_gen_f8fca2.py +49 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_reason_ppl_3da4de.py +57 -0
- build/lib/opencompass/configs/datasets/CHARM/charm_reason_settings.py +36 -0
- build/lib/opencompass/configs/datasets/CIBench/CIBench_generation_gen_8ab0dc.py +35 -0
- build/lib/opencompass/configs/datasets/CIBench/CIBench_generation_oracle_gen_c4a7c1.py +35 -0
- build/lib/opencompass/configs/datasets/CIBench/CIBench_template_gen_e6b12a.py +39 -0
- build/lib/opencompass/configs/datasets/CIBench/CIBench_template_oracle_gen_fecda1.py +39 -0
- build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen.py +4 -0
- build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen_8c358f.py +51 -0
- build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl.py +4 -0
- build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl_56b537.py +36 -0
- build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl_e24a31.py +37 -0
- build/lib/opencompass/configs/datasets/CLUE_CMRC/CLUE_CMRC_gen.py +4 -0
build/lib/opencompass/configs/chatml_datasets/AMO_Bench/AMO_Bench_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='AMO-Bench',
|
| 5 |
+
path='./data/amo-bench.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/CPsyExam/CPsyExam_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='CPsyExam',
|
| 5 |
+
path='./data/CPsyExam/merged_train_dev.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/CS_Bench/CS_Bench_gen.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
subset_list = [
|
| 3 |
+
'test',
|
| 4 |
+
'valid',
|
| 5 |
+
]
|
| 6 |
+
|
| 7 |
+
language_list = [
|
| 8 |
+
'CN',
|
| 9 |
+
'EN',
|
| 10 |
+
]
|
| 11 |
+
|
| 12 |
+
datasets = []
|
| 13 |
+
|
| 14 |
+
for subset in subset_list:
|
| 15 |
+
for language in language_list:
|
| 16 |
+
datasets.append(
|
| 17 |
+
dict(
|
| 18 |
+
abbr=f'CS-Bench_{language}_{subset}',
|
| 19 |
+
path=f'./data/csbench/CSBench-{language}/{subset}.jsonl',
|
| 20 |
+
evaluator=dict(
|
| 21 |
+
type='llm_evaluator',
|
| 22 |
+
judge_cfg=dict(),
|
| 23 |
+
),
|
| 24 |
+
)
|
| 25 |
+
)
|
build/lib/opencompass/configs/chatml_datasets/C_MHChem/C_MHChem_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='C-MHChem',
|
| 5 |
+
path='./data/C-MHChem2.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/HMMT2025/HMMT2025_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='HMMT2025',
|
| 5 |
+
path='./data/hmmt2025.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/IMO_Bench_AnswerBench/IMO_Bench_AnswerBench_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='IMO-Bench-AnswerBench',
|
| 5 |
+
path='./data/imo-bench-answerbench.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/MaScQA/MaScQA_gen.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
datasets = [
|
| 3 |
+
dict(
|
| 4 |
+
abbr='MaScQA',
|
| 5 |
+
path='./data/MaScQA/MaScQA.jsonl',
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='llm_evaluator',
|
| 8 |
+
judge_cfg=dict(),
|
| 9 |
+
),
|
| 10 |
+
n=1,
|
| 11 |
+
),
|
| 12 |
+
]
|
build/lib/opencompass/configs/chatml_datasets/UGPhysics/UGPhysics_gen.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
subset_list = [
|
| 3 |
+
'AtomicPhysics',
|
| 4 |
+
'ClassicalElectromagnetism',
|
| 5 |
+
'ClassicalMechanics',
|
| 6 |
+
'Electrodynamics',
|
| 7 |
+
'GeometricalOptics',
|
| 8 |
+
'QuantumMechanics',
|
| 9 |
+
'Relativity',
|
| 10 |
+
'Solid-StatePhysics',
|
| 11 |
+
'StatisticalMechanics',
|
| 12 |
+
'SemiconductorPhysics',
|
| 13 |
+
'Thermodynamics',
|
| 14 |
+
'TheoreticalMechanics',
|
| 15 |
+
'WaveOptics',
|
| 16 |
+
]
|
| 17 |
+
|
| 18 |
+
language_list = [
|
| 19 |
+
'zh',
|
| 20 |
+
'en',
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
datasets = []
|
| 24 |
+
|
| 25 |
+
for subset in subset_list:
|
| 26 |
+
for language in language_list:
|
| 27 |
+
datasets.append(
|
| 28 |
+
dict(
|
| 29 |
+
abbr=f'UGPhysics_{subset}_{language}',
|
| 30 |
+
path=f'./data/ugphysics/{subset}/{language}.jsonl',
|
| 31 |
+
evaluator=dict(
|
| 32 |
+
type='llm_evaluator',
|
| 33 |
+
judge_cfg=dict(),
|
| 34 |
+
),
|
| 35 |
+
)
|
| 36 |
+
)
|
build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/README.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ARC Prize Public Evaluation
|
| 2 |
+
|
| 3 |
+
#### Overview
|
| 4 |
+
The spirit of ARC Prize is to open source progress towards AGI. To win prize money, you will be required to publish reproducible code/methods into public domain.
|
| 5 |
+
|
| 6 |
+
ARC Prize measures AGI progress using the [ARC-AGI private evaluation set](https://arcprize.org/guide#private), [the leaderboard is here](https://arcprize.org/leaderboard), and the Grand Prize is unlocked once the first team reaches [at least 85%](https://arcprize.org/guide#grand-prize-goal).
|
| 7 |
+
|
| 8 |
+
Note: the private evaluation set imposes limitations on solutions (eg. no internet access, so no GPT-4/Claude/etc). There is a [secondary leaderboard](https://arcprize.org/leaderboard) called ARC-AGI-Pub, it measures the [public evaluation set](https://arcprize.org/guide#public-tasks) and imposes no limits but it is not part of ARC Prize 2024 at this time.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
#### Tasks
|
| 12 |
+
ARC-AGI tasks are a series of three to five input and output tasks followed by a final task with only the input listed. Each task tests the utilization of a specific learned skill based on a minimal number of cognitive priors.
|
| 13 |
+
|
| 14 |
+
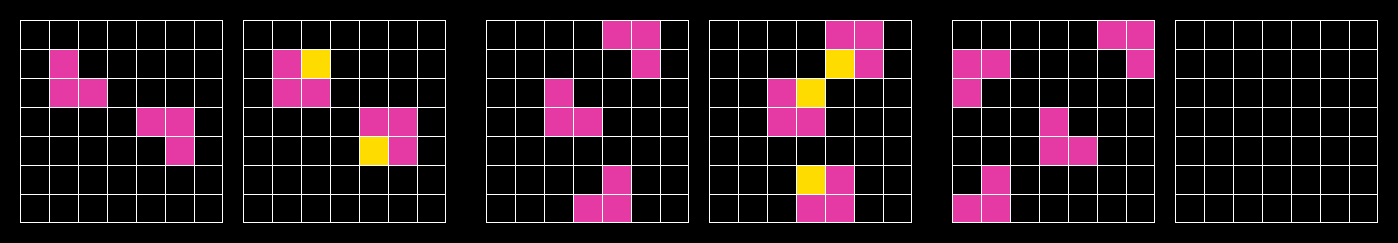
|
| 15 |
+
|
| 16 |
+
Tasks are represented as JSON lists of integers. These JSON objects can also be represented visually as a grid of colors using an ARC-AGI task viewer.
|
| 17 |
+
|
| 18 |
+
A successful submission is a pixel-perfect description (color and position) of the final task's output.
|
| 19 |
+
|
| 20 |
+
#### Format
|
| 21 |
+
|
| 22 |
+
As mentioned above, tasks are stored in JSON format. Each JSON file consists of two key-value pairs.
|
| 23 |
+
|
| 24 |
+
`train`: a list of two to ten input/output pairs (typically three.) These are used for your algorithm to infer a rule.
|
| 25 |
+
|
| 26 |
+
`test`: a list of one to three input/output pairs (typically one.) Your model should apply the inferred rule from the train set and construct an output solution. You will have access to the output test solution on the public data. The output solution on the private evaluation set will not be revealed.
|
| 27 |
+
|
| 28 |
+
Here is an example of a simple ARC-AGI task that has three training pairs along with a single test pair. Each pair is shown as a 2x2 grid. There are four colors represented by the integers 1, 4, 6, and 8. Which actual color (red/green/blue/black) is applied to each integer is arbitrary and up to you.
|
| 29 |
+
|
| 30 |
+
```json
|
| 31 |
+
{
|
| 32 |
+
"train": [
|
| 33 |
+
{"input": [[1, 0], [0, 0]], "output": [[1, 1], [1, 1]]},
|
| 34 |
+
{"input": [[0, 0], [4, 0]], "output": [[4, 4], [4, 4]]},
|
| 35 |
+
{"input": [[0, 0], [6, 0]], "output": [[6, 6], [6, 6]]}
|
| 36 |
+
],
|
| 37 |
+
"test": [
|
| 38 |
+
{"input": [[0, 0], [0, 8]], "output": [[8, 8], [8, 8]]}
|
| 39 |
+
]
|
| 40 |
+
}
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
#### Performance
|
| 44 |
+
|
| 45 |
+
| Qwen2.5-72B-Instruct | LLaMA3.1-70B-Instruct | gemma-2-27b-it |
|
| 46 |
+
| ----- | ----- | ----- |
|
| 47 |
+
| 0.09 | 0.06 | 0.05 |
|
build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .arc_prize_public_evaluation_gen_872059 import arc_prize_public_evaluation_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen_872059.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.datasets.arc_prize_public_evaluation import ARCPrizeDataset, ARCPrizeEvaluator
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# The system_prompt defines the initial instructions for the model,
|
| 8 |
+
# setting the context for solving ARC tasks.
|
| 9 |
+
system_prompt = '''You are a puzzle solving wizard. You are given a puzzle from the abstraction and reasoning corpus developed by Francois Chollet.'''
|
| 10 |
+
|
| 11 |
+
# User message template is a template for creating user prompts. It includes placeholders for training data and test input data,
|
| 12 |
+
# guiding the model to learn the rule and apply it to solve the given puzzle.
|
| 13 |
+
user_message_template = '''Here are the example input and output pairs from which you should learn the underlying rule to later predict the output for the given test input:
|
| 14 |
+
----------------------------------------
|
| 15 |
+
{training_data}
|
| 16 |
+
----------------------------------------
|
| 17 |
+
Now, solve the following puzzle based on its input grid by applying the rules you have learned from the training data.:
|
| 18 |
+
----------------------------------------
|
| 19 |
+
[{{'input': {input_test_data}, 'output': [[]]}}]
|
| 20 |
+
----------------------------------------
|
| 21 |
+
What is the output grid? Only provide the output grid in the form as in the example input and output pairs. Do not provide any additional information:'''
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
arc_prize_public_evaluation_reader_cfg = dict(
|
| 25 |
+
input_columns=['training_data', 'input_test_data'],
|
| 26 |
+
output_column='output_test_data'
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
arc_prize_public_evaluation_infer_cfg = dict(
|
| 30 |
+
prompt_template=dict(
|
| 31 |
+
type=PromptTemplate,
|
| 32 |
+
template=dict(
|
| 33 |
+
round=[
|
| 34 |
+
dict(role='SYSTEM', prompt=system_prompt),
|
| 35 |
+
dict(role='HUMAN', prompt=user_message_template),
|
| 36 |
+
],
|
| 37 |
+
)
|
| 38 |
+
),
|
| 39 |
+
retriever=dict(type=ZeroRetriever),
|
| 40 |
+
inferencer=dict(type=GenInferencer, max_out_len=2048)
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
arc_prize_public_evaluation_eval_cfg = dict(
|
| 44 |
+
evaluator=dict(type=ARCPrizeEvaluator)
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
arc_prize_public_evaluation_datasets = [
|
| 48 |
+
dict(
|
| 49 |
+
abbr='ARC_Prize_Public_Evaluation',
|
| 50 |
+
type=ARCPrizeDataset,
|
| 51 |
+
path='opencompass/arc_prize_public_evaluation',
|
| 52 |
+
reader_cfg=arc_prize_public_evaluation_reader_cfg,
|
| 53 |
+
infer_cfg=arc_prize_public_evaluation_infer_cfg,
|
| 54 |
+
eval_cfg=arc_prize_public_evaluation_eval_cfg
|
| 55 |
+
)
|
| 56 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen_fedd04.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.datasets.arc_prize_public_evaluation import ARCPrizeDataset, ARCPrizeEvaluator
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# The system_prompt defines the initial instructions for the model,
|
| 8 |
+
# setting the context for solving ARC tasks.
|
| 9 |
+
system_prompt = '''You are a puzzle solving wizard. You are given a puzzle from the abstraction and reasoning corpus developed by Francois Chollet.'''
|
| 10 |
+
|
| 11 |
+
# User message template is a template for creating user prompts. It includes placeholders for training data and test input data,
|
| 12 |
+
# guiding the model to learn the rule and apply it to solve the given puzzle.
|
| 13 |
+
user_message_template = '''Here are the example input and output pairs from which you should learn the underlying rule to later predict the output for the given test input:
|
| 14 |
+
----------------------------------------
|
| 15 |
+
{training_data}
|
| 16 |
+
----------------------------------------
|
| 17 |
+
Now, solve the following puzzle based on its input grid by applying the rules you have learned from the training data.:
|
| 18 |
+
----------------------------------------
|
| 19 |
+
[{{'input': {input_test_data}, 'output': [[]]}}]
|
| 20 |
+
----------------------------------------
|
| 21 |
+
What is the output grid? Only provide the output grid in the form as in the example input and output pairs. Do not provide any additional information:'''
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
arc_prize_public_evaluation_reader_cfg = dict(
|
| 25 |
+
input_columns=['training_data', 'input_test_data'],
|
| 26 |
+
output_column='output_test_data'
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
arc_prize_public_evaluation_infer_cfg = dict(
|
| 30 |
+
prompt_template=dict(
|
| 31 |
+
type=PromptTemplate,
|
| 32 |
+
template=dict(
|
| 33 |
+
round=[
|
| 34 |
+
dict(role='SYSTEM',fallback_role='HUMAN', prompt=system_prompt),
|
| 35 |
+
dict(role='HUMAN', prompt=user_message_template),
|
| 36 |
+
],
|
| 37 |
+
)
|
| 38 |
+
),
|
| 39 |
+
retriever=dict(type=ZeroRetriever),
|
| 40 |
+
inferencer=dict(type=GenInferencer)
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
arc_prize_public_evaluation_eval_cfg = dict(
|
| 44 |
+
evaluator=dict(type=ARCPrizeEvaluator)
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
arc_prize_public_evaluation_datasets = [
|
| 48 |
+
dict(
|
| 49 |
+
abbr='ARC_Prize_Public_Evaluation',
|
| 50 |
+
type=ARCPrizeDataset,
|
| 51 |
+
path='opencompass/arc_prize_public_evaluation',
|
| 52 |
+
reader_cfg=arc_prize_public_evaluation_reader_cfg,
|
| 53 |
+
infer_cfg=arc_prize_public_evaluation_infer_cfg,
|
| 54 |
+
eval_cfg=arc_prize_public_evaluation_eval_cfg
|
| 55 |
+
)
|
| 56 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_clean_ppl.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccContaminationEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDatasetClean as ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_c_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_c_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
'A':
|
| 16 |
+
dict(
|
| 17 |
+
round=[
|
| 18 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 19 |
+
dict(role='BOT', prompt='{textA}')
|
| 20 |
+
], ),
|
| 21 |
+
'B':
|
| 22 |
+
dict(
|
| 23 |
+
round=[
|
| 24 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 25 |
+
dict(role='BOT', prompt='{textB}')
|
| 26 |
+
], ),
|
| 27 |
+
'C':
|
| 28 |
+
dict(
|
| 29 |
+
round=[
|
| 30 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 31 |
+
dict(role='BOT', prompt='{textC}')
|
| 32 |
+
], ),
|
| 33 |
+
'D':
|
| 34 |
+
dict(
|
| 35 |
+
round=[
|
| 36 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 37 |
+
dict(role='BOT', prompt='{textD}')
|
| 38 |
+
], ),
|
| 39 |
+
}),
|
| 40 |
+
retriever=dict(type=ZeroRetriever),
|
| 41 |
+
inferencer=dict(type=PPLInferencer))
|
| 42 |
+
|
| 43 |
+
ARC_c_eval_cfg = dict(evaluator=dict(type=AccContaminationEvaluator),
|
| 44 |
+
analyze_contamination=True)
|
| 45 |
+
|
| 46 |
+
ARC_c_datasets = [
|
| 47 |
+
dict(
|
| 48 |
+
type=ARCDataset,
|
| 49 |
+
abbr='ARC-c-test',
|
| 50 |
+
path='opencompass/ai2_arc-test',
|
| 51 |
+
name='ARC-Challenge',
|
| 52 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 53 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 54 |
+
eval_cfg=ARC_c_eval_cfg)
|
| 55 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_cot_gen_926652.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
from opencompass.utils.text_postprocessors import first_option_postprocess, match_answer_pattern
|
| 7 |
+
|
| 8 |
+
QUERY_TEMPLATE = """
|
| 9 |
+
Answer the following multiple choice question. The last line of your response should be of the following format: 'ANSWER: $LETTER' (without quotes) where LETTER is one of ABCD. Think step by step before answering.
|
| 10 |
+
|
| 11 |
+
{question}
|
| 12 |
+
|
| 13 |
+
A. {textA}
|
| 14 |
+
B. {textB}
|
| 15 |
+
C. {textC}
|
| 16 |
+
D. {textD}
|
| 17 |
+
""".strip()
|
| 18 |
+
|
| 19 |
+
ARC_c_reader_cfg = dict(
|
| 20 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 21 |
+
output_column='answerKey')
|
| 22 |
+
|
| 23 |
+
ARC_c_infer_cfg = dict(
|
| 24 |
+
prompt_template=dict(
|
| 25 |
+
type=PromptTemplate,
|
| 26 |
+
template=dict(
|
| 27 |
+
round=[
|
| 28 |
+
dict(
|
| 29 |
+
role='HUMAN',
|
| 30 |
+
prompt=QUERY_TEMPLATE)
|
| 31 |
+
], ),
|
| 32 |
+
),
|
| 33 |
+
retriever=dict(type=ZeroRetriever),
|
| 34 |
+
inferencer=dict(type=GenInferencer),
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
ARC_c_eval_cfg = dict(
|
| 38 |
+
evaluator=dict(type=AccEvaluator),
|
| 39 |
+
pred_role='BOT',
|
| 40 |
+
pred_postprocessor=dict(type=first_option_postprocess, options='ABCD'),
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
ARC_c_datasets = [
|
| 44 |
+
dict(
|
| 45 |
+
abbr='ARC-c',
|
| 46 |
+
type=ARCDataset,
|
| 47 |
+
path='opencompass/ai2_arc-dev',
|
| 48 |
+
name='ARC-Challenge',
|
| 49 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 50 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 51 |
+
eval_cfg=ARC_c_eval_cfg,
|
| 52 |
+
)
|
| 53 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_few_shot_gen_e9b043.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever, FixKRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
from opencompass.utils.text_postprocessors import first_capital_postprocess
|
| 7 |
+
|
| 8 |
+
ARC_c_reader_cfg = dict(
|
| 9 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 10 |
+
output_column='answerKey',
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
ARC_c_infer_cfg = dict(
|
| 14 |
+
ice_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template=dict(
|
| 17 |
+
begin='</E>',
|
| 18 |
+
round=[
|
| 19 |
+
dict(
|
| 20 |
+
role='HUMAN',
|
| 21 |
+
prompt='Question: {question}\nA. {textA}\nB. {textB}\nC. {textC}\nD. {textD}\nAnswer:',
|
| 22 |
+
),
|
| 23 |
+
dict(role='BOT', prompt='{answerKey}'),
|
| 24 |
+
],
|
| 25 |
+
),
|
| 26 |
+
ice_token='</E>',
|
| 27 |
+
),
|
| 28 |
+
retriever=dict(type=FixKRetriever, fix_id_list=[0, 2, 4, 6, 8]),
|
| 29 |
+
inferencer=dict(type=GenInferencer, max_out_len=50),
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
ARC_c_eval_cfg = dict(
|
| 33 |
+
evaluator=dict(type=AccEvaluator),
|
| 34 |
+
pred_role='BOT',
|
| 35 |
+
pred_postprocessor=dict(type=first_capital_postprocess),
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
ARC_c_datasets = [
|
| 39 |
+
dict(
|
| 40 |
+
abbr='ARC-c',
|
| 41 |
+
type=ARCDataset,
|
| 42 |
+
path='opencompass/ai2_arc-dev',
|
| 43 |
+
name='ARC-Challenge',
|
| 44 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 45 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 46 |
+
eval_cfg=ARC_c_eval_cfg,
|
| 47 |
+
)
|
| 48 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_few_shot_ppl.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever, FixKRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_c_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey',
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
ARC_c_infer_cfg = dict(
|
| 13 |
+
ice_template=dict(
|
| 14 |
+
type=PromptTemplate,
|
| 15 |
+
template={
|
| 16 |
+
'A': dict(
|
| 17 |
+
begin='</E>',
|
| 18 |
+
round=[
|
| 19 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 20 |
+
dict(role='BOT', prompt='{textA}'),
|
| 21 |
+
],
|
| 22 |
+
),
|
| 23 |
+
'B': dict(
|
| 24 |
+
begin='</E>',
|
| 25 |
+
round=[
|
| 26 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 27 |
+
dict(role='BOT', prompt='{textB}'),
|
| 28 |
+
],
|
| 29 |
+
),
|
| 30 |
+
'C': dict(
|
| 31 |
+
begin='</E>',
|
| 32 |
+
round=[
|
| 33 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 34 |
+
dict(role='BOT', prompt='{textC}'),
|
| 35 |
+
],
|
| 36 |
+
),
|
| 37 |
+
'D': dict(
|
| 38 |
+
begin='</E>',
|
| 39 |
+
round=[
|
| 40 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 41 |
+
dict(role='BOT', prompt='{textD}'),
|
| 42 |
+
],
|
| 43 |
+
),
|
| 44 |
+
},
|
| 45 |
+
ice_token='</E>',
|
| 46 |
+
),
|
| 47 |
+
retriever=dict(type=FixKRetriever, fix_id_list=[0, 2, 4, 6, 8]),
|
| 48 |
+
inferencer=dict(type=PPLInferencer),
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
ARC_c_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 52 |
+
|
| 53 |
+
ARC_c_datasets = [
|
| 54 |
+
dict(
|
| 55 |
+
type=ARCDataset,
|
| 56 |
+
abbr='ARC-c',
|
| 57 |
+
path='opencompass/ai2_arc-dev',
|
| 58 |
+
name='ARC-Challenge',
|
| 59 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 60 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 61 |
+
eval_cfg=ARC_c_eval_cfg,
|
| 62 |
+
)
|
| 63 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .ARC_c_gen_1e0de5 import ARC_c_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_gen_1e0de5.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
from opencompass.utils.text_postprocessors import first_option_postprocess
|
| 7 |
+
|
| 8 |
+
ARC_c_reader_cfg = dict(
|
| 9 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 10 |
+
output_column='answerKey')
|
| 11 |
+
|
| 12 |
+
ARC_c_infer_cfg = dict(
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
type=PromptTemplate,
|
| 15 |
+
template=dict(
|
| 16 |
+
round=[
|
| 17 |
+
dict(
|
| 18 |
+
role='HUMAN',
|
| 19 |
+
prompt=
|
| 20 |
+
'Question: {question}\nA. {textA}\nB. {textB}\nC. {textC}\nD. {textD}\nAnswer:'
|
| 21 |
+
)
|
| 22 |
+
], ),
|
| 23 |
+
),
|
| 24 |
+
retriever=dict(type=ZeroRetriever),
|
| 25 |
+
inferencer=dict(type=GenInferencer),
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
ARC_c_eval_cfg = dict(
|
| 29 |
+
evaluator=dict(type=AccEvaluator),
|
| 30 |
+
pred_role='BOT',
|
| 31 |
+
pred_postprocessor=dict(type=first_option_postprocess, options='ABCD'),
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
ARC_c_datasets = [
|
| 35 |
+
dict(
|
| 36 |
+
abbr='ARC-c',
|
| 37 |
+
type=ARCDataset,
|
| 38 |
+
path='opencompass/ai2_arc-dev',
|
| 39 |
+
name='ARC-Challenge',
|
| 40 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 41 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 42 |
+
eval_cfg=ARC_c_eval_cfg,
|
| 43 |
+
)
|
| 44 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .ARC_c_ppl_a450bd import ARC_c_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_2ef631.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_c_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_c_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
opt: dict(
|
| 16 |
+
round=[
|
| 17 |
+
dict(role='HUMAN', prompt=f'{{question}}\nA. {{textA}}\nB. {{textB}}\nC. {{textC}}\nD. {{textD}}'),
|
| 18 |
+
dict(role='BOT', prompt=f'Answer: {opt}'),
|
| 19 |
+
]
|
| 20 |
+
) for opt in ['A', 'B', 'C', 'D']
|
| 21 |
+
},
|
| 22 |
+
),
|
| 23 |
+
retriever=dict(type=ZeroRetriever),
|
| 24 |
+
inferencer=dict(type=PPLInferencer))
|
| 25 |
+
|
| 26 |
+
ARC_c_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 27 |
+
|
| 28 |
+
ARC_c_datasets = [
|
| 29 |
+
dict(
|
| 30 |
+
type=ARCDataset,
|
| 31 |
+
abbr='ARC-c',
|
| 32 |
+
path='opencompass/ai2_arc-dev',
|
| 33 |
+
name='ARC-Challenge',
|
| 34 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 35 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 36 |
+
eval_cfg=ARC_c_eval_cfg)
|
| 37 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_a450bd.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_c_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_c_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
'A':
|
| 16 |
+
dict(
|
| 17 |
+
round=[
|
| 18 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 19 |
+
dict(role='BOT', prompt='{textA}')
|
| 20 |
+
], ),
|
| 21 |
+
'B':
|
| 22 |
+
dict(
|
| 23 |
+
round=[
|
| 24 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 25 |
+
dict(role='BOT', prompt='{textB}')
|
| 26 |
+
], ),
|
| 27 |
+
'C':
|
| 28 |
+
dict(
|
| 29 |
+
round=[
|
| 30 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 31 |
+
dict(role='BOT', prompt='{textC}')
|
| 32 |
+
], ),
|
| 33 |
+
'D':
|
| 34 |
+
dict(
|
| 35 |
+
round=[
|
| 36 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 37 |
+
dict(role='BOT', prompt='{textD}')
|
| 38 |
+
], ),
|
| 39 |
+
}),
|
| 40 |
+
retriever=dict(type=ZeroRetriever),
|
| 41 |
+
inferencer=dict(type=PPLInferencer))
|
| 42 |
+
|
| 43 |
+
ARC_c_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 44 |
+
|
| 45 |
+
ARC_c_datasets = [
|
| 46 |
+
dict(
|
| 47 |
+
type=ARCDataset,
|
| 48 |
+
abbr='ARC-c',
|
| 49 |
+
path='opencompass/ai2_arc-dev',
|
| 50 |
+
name='ARC-Challenge',
|
| 51 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 52 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 53 |
+
eval_cfg=ARC_c_eval_cfg)
|
| 54 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_c/ARC_c_ppl_d52a21.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
# with read_base():
|
| 3 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 4 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 5 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 6 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 7 |
+
from opencompass.datasets import ARCDataset
|
| 8 |
+
|
| 9 |
+
ARC_c_reader_cfg = dict(
|
| 10 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 11 |
+
output_column='answerKey')
|
| 12 |
+
|
| 13 |
+
ARC_c_infer_cfg = dict(
|
| 14 |
+
prompt_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template={
|
| 17 |
+
'A': 'Question: {question}\nAnswer: {textA}',
|
| 18 |
+
'B': 'Question: {question}\nAnswer: {textB}',
|
| 19 |
+
'C': 'Question: {question}\nAnswer: {textC}',
|
| 20 |
+
'D': 'Question: {question}\nAnswer: {textD}'
|
| 21 |
+
}),
|
| 22 |
+
retriever=dict(type=ZeroRetriever),
|
| 23 |
+
inferencer=dict(type=PPLInferencer))
|
| 24 |
+
|
| 25 |
+
ARC_c_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 26 |
+
|
| 27 |
+
ARC_c_datasets = [
|
| 28 |
+
dict(
|
| 29 |
+
type=ARCDataset,
|
| 30 |
+
abbr='ARC-c',
|
| 31 |
+
path='opencompass/ai2_arc-dev',
|
| 32 |
+
name='ARC-Challenge',
|
| 33 |
+
reader_cfg=ARC_c_reader_cfg,
|
| 34 |
+
infer_cfg=ARC_c_infer_cfg,
|
| 35 |
+
eval_cfg=ARC_c_eval_cfg)
|
| 36 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .ARC_e_gen_1e0de5 import ARC_e_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_gen_1e0de5.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
from opencompass.utils.text_postprocessors import first_option_postprocess
|
| 7 |
+
|
| 8 |
+
ARC_e_reader_cfg = dict(
|
| 9 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 10 |
+
output_column='answerKey')
|
| 11 |
+
|
| 12 |
+
ARC_e_infer_cfg = dict(
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
type=PromptTemplate,
|
| 15 |
+
template=dict(
|
| 16 |
+
round=[
|
| 17 |
+
dict(
|
| 18 |
+
role='HUMAN',
|
| 19 |
+
prompt=
|
| 20 |
+
'Question: {question}\nA. {textA}\nB. {textB}\nC. {textC}\nD. {textD}\nAnswer:'
|
| 21 |
+
)
|
| 22 |
+
], ),
|
| 23 |
+
),
|
| 24 |
+
retriever=dict(type=ZeroRetriever),
|
| 25 |
+
inferencer=dict(type=GenInferencer),
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
ARC_e_eval_cfg = dict(
|
| 29 |
+
evaluator=dict(type=AccEvaluator),
|
| 30 |
+
pred_role='BOT',
|
| 31 |
+
pred_postprocessor=dict(type=first_option_postprocess, options='ABCD'),
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
ARC_e_datasets = [
|
| 35 |
+
dict(
|
| 36 |
+
abbr='ARC-e',
|
| 37 |
+
type=ARCDataset,
|
| 38 |
+
path='opencompass/ai2_arc-easy-dev',
|
| 39 |
+
name='ARC-Easy',
|
| 40 |
+
reader_cfg=ARC_e_reader_cfg,
|
| 41 |
+
infer_cfg=ARC_e_infer_cfg,
|
| 42 |
+
eval_cfg=ARC_e_eval_cfg,
|
| 43 |
+
)
|
| 44 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .ARC_e_ppl_a450bd import ARC_e_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_2ef631.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_e_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_e_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
opt: dict(
|
| 16 |
+
round=[
|
| 17 |
+
dict(role='HUMAN', prompt=f'{{question}}\nA. {{textA}}\nB. {{textB}}\nC. {{textC}}\nD. {{textD}}'),
|
| 18 |
+
dict(role='BOT', prompt=f'Answer: {opt}'),
|
| 19 |
+
]
|
| 20 |
+
) for opt in ['A', 'B', 'C', 'D']
|
| 21 |
+
},
|
| 22 |
+
),
|
| 23 |
+
retriever=dict(type=ZeroRetriever),
|
| 24 |
+
inferencer=dict(type=PPLInferencer))
|
| 25 |
+
|
| 26 |
+
ARC_e_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 27 |
+
|
| 28 |
+
ARC_e_datasets = [
|
| 29 |
+
dict(
|
| 30 |
+
type=ARCDataset,
|
| 31 |
+
abbr='ARC-e',
|
| 32 |
+
path='opencompass/ai2_arc-easy-dev',
|
| 33 |
+
name='ARC-Easy',
|
| 34 |
+
reader_cfg=ARC_e_reader_cfg,
|
| 35 |
+
infer_cfg=ARC_e_infer_cfg,
|
| 36 |
+
eval_cfg=ARC_e_eval_cfg)
|
| 37 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_a450bd.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_e_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_e_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
'A':
|
| 16 |
+
dict(
|
| 17 |
+
round=[
|
| 18 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 19 |
+
dict(role='BOT', prompt='{textA}')
|
| 20 |
+
], ),
|
| 21 |
+
'B':
|
| 22 |
+
dict(
|
| 23 |
+
round=[
|
| 24 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 25 |
+
dict(role='BOT', prompt='{textB}')
|
| 26 |
+
], ),
|
| 27 |
+
'C':
|
| 28 |
+
dict(
|
| 29 |
+
round=[
|
| 30 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 31 |
+
dict(role='BOT', prompt='{textC}')
|
| 32 |
+
], ),
|
| 33 |
+
'D':
|
| 34 |
+
dict(
|
| 35 |
+
round=[
|
| 36 |
+
dict(role='HUMAN', prompt='Question: {question}\nAnswer: '),
|
| 37 |
+
dict(role='BOT', prompt='{textD}')
|
| 38 |
+
], ),
|
| 39 |
+
}),
|
| 40 |
+
retriever=dict(type=ZeroRetriever),
|
| 41 |
+
inferencer=dict(type=PPLInferencer))
|
| 42 |
+
|
| 43 |
+
ARC_e_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 44 |
+
|
| 45 |
+
ARC_e_datasets = [
|
| 46 |
+
dict(
|
| 47 |
+
type=ARCDataset,
|
| 48 |
+
abbr='ARC-e',
|
| 49 |
+
path='opencompass/ai2_arc-easy-dev',
|
| 50 |
+
name='ARC-Easy',
|
| 51 |
+
reader_cfg=ARC_e_reader_cfg,
|
| 52 |
+
infer_cfg=ARC_e_infer_cfg,
|
| 53 |
+
eval_cfg=ARC_e_eval_cfg)
|
| 54 |
+
]
|
build/lib/opencompass/configs/datasets/ARC_e/ARC_e_ppl_d52a21.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import ARCDataset
|
| 6 |
+
|
| 7 |
+
ARC_e_reader_cfg = dict(
|
| 8 |
+
input_columns=['question', 'textA', 'textB', 'textC', 'textD'],
|
| 9 |
+
output_column='answerKey')
|
| 10 |
+
|
| 11 |
+
ARC_e_infer_cfg = dict(
|
| 12 |
+
prompt_template=dict(
|
| 13 |
+
type=PromptTemplate,
|
| 14 |
+
template={
|
| 15 |
+
'A': 'Question: {question}\nAnswer: {textA}',
|
| 16 |
+
'B': 'Question: {question}\nAnswer: {textB}',
|
| 17 |
+
'C': 'Question: {question}\nAnswer: {textC}',
|
| 18 |
+
'D': 'Question: {question}\nAnswer: {textD}'
|
| 19 |
+
}),
|
| 20 |
+
retriever=dict(type=ZeroRetriever),
|
| 21 |
+
inferencer=dict(type=PPLInferencer))
|
| 22 |
+
|
| 23 |
+
ARC_e_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 24 |
+
|
| 25 |
+
ARC_e_datasets = [
|
| 26 |
+
dict(
|
| 27 |
+
type=ARCDataset,
|
| 28 |
+
abbr='ARC-e',
|
| 29 |
+
path='opencompass/ai2_arc-easy-dev',
|
| 30 |
+
name='ARC-Easy',
|
| 31 |
+
reader_cfg=ARC_e_reader_cfg,
|
| 32 |
+
infer_cfg=ARC_e_infer_cfg,
|
| 33 |
+
eval_cfg=ARC_e_eval_cfg)
|
| 34 |
+
]
|
build/lib/opencompass/configs/datasets/BeyondAIME/beyondaime_cascade_eval_gen_5e9f4f.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.datasets import BeyondAIMEDataset
|
| 5 |
+
from opencompass.evaluator import GenericLLMEvaluator, CascadeEvaluator, MATHVerifyEvaluator
|
| 6 |
+
from opencompass.datasets import generic_llmjudge_postprocess
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
beyondaime_reader_cfg = dict(input_columns=['question'], output_column='answer')
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
GRADER_TEMPLATE = """
|
| 13 |
+
Please as a grading expert, judge whether the final answers given by the candidates below are consistent with the standard answers, that is, whether the candidates answered correctly.
|
| 14 |
+
|
| 15 |
+
Here are some evaluation criteria:
|
| 16 |
+
1. Please refer to the given standard answer. You don't need to re-generate the answer to the question because the standard answer has been given. You only need to judge whether the candidate's answer is consistent with the standard answer according to the form of the question. Don't try to answer the original question. You can assume that the standard answer is definitely correct.
|
| 17 |
+
2. Because the candidate's answer may be different from the standard answer in the form of expression, before making a judgment, please understand the question and the standard answer first, and then judge whether the candidate's answer is correct, but be careful not to try to answer the original question.
|
| 18 |
+
3. Some answers may contain multiple items, such as multiple-choice questions, multiple-select questions, fill-in-the-blank questions, etc. As long as the answer is the same as the standard answer, it is enough. For multiple-select questions and multiple-blank fill-in-the-blank questions, the candidate needs to answer all the corresponding options or blanks correctly to be considered correct.
|
| 19 |
+
4. Some answers may be expressed in different ways, such as some answers may be a mathematical expression, some answers may be a textual description, as long as the meaning expressed is the same. And some formulas are expressed in different ways, but they are equivalent and correct.
|
| 20 |
+
5. If the prediction is given with \\boxed{}, please ignore the \\boxed{} and only judge whether the candidate's answer is consistent with the standard answer.
|
| 21 |
+
|
| 22 |
+
Please judge whether the following answers are consistent with the standard answer based on the above criteria. Grade the predicted answer of this new question as one of:
|
| 23 |
+
A: CORRECT
|
| 24 |
+
B: INCORRECT
|
| 25 |
+
Just return the letters "A" or "B", with no text around it.
|
| 26 |
+
|
| 27 |
+
Here is your task. Simply reply with either CORRECT, INCORRECT. Don't apologize or correct yourself if there was a mistake; we are just trying to grade the answer.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
<Original Question Begin>: \n{question}\n<Original Question End>\n\n
|
| 31 |
+
<Gold Target Begin>: \n{answer}\n<Gold Target End>\n\n
|
| 32 |
+
<Predicted Answer Begin>: \n{prediction}\n<Predicted End>\n\n
|
| 33 |
+
|
| 34 |
+
Judging the correctness of candidates' answers:
|
| 35 |
+
""".strip()
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
beyondaime_infer_cfg = dict(
|
| 40 |
+
prompt_template=dict(
|
| 41 |
+
type=PromptTemplate,
|
| 42 |
+
template=dict(
|
| 43 |
+
round=[
|
| 44 |
+
dict(
|
| 45 |
+
role='HUMAN',
|
| 46 |
+
prompt='{question}\nRemember to put your final answer within \\boxed{}.',
|
| 47 |
+
),
|
| 48 |
+
],
|
| 49 |
+
),
|
| 50 |
+
),
|
| 51 |
+
retriever=dict(type=ZeroRetriever),
|
| 52 |
+
inferencer=dict(type=GenInferencer),
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
beyondaime_cascade_evaluator = dict(
|
| 57 |
+
type=CascadeEvaluator,
|
| 58 |
+
rule_evaluator=dict(
|
| 59 |
+
type=MATHVerifyEvaluator,
|
| 60 |
+
),
|
| 61 |
+
llm_evaluator=dict(
|
| 62 |
+
type=GenericLLMEvaluator,
|
| 63 |
+
prompt_template=dict(
|
| 64 |
+
type=PromptTemplate,
|
| 65 |
+
template=dict(
|
| 66 |
+
begin=[
|
| 67 |
+
dict(
|
| 68 |
+
role='SYSTEM',
|
| 69 |
+
fallback_role='HUMAN',
|
| 70 |
+
prompt="You are a helpful assistant who evaluates the correctness and quality of models' outputs.",
|
| 71 |
+
)
|
| 72 |
+
],
|
| 73 |
+
round=[
|
| 74 |
+
dict(role='HUMAN', prompt=GRADER_TEMPLATE),
|
| 75 |
+
],
|
| 76 |
+
),
|
| 77 |
+
),
|
| 78 |
+
dataset_cfg=dict(
|
| 79 |
+
type=BeyondAIMEDataset,
|
| 80 |
+
path='ByteDance-Seed/BeyondAIME',
|
| 81 |
+
reader_cfg=beyondaime_reader_cfg,
|
| 82 |
+
),
|
| 83 |
+
judge_cfg=dict(),
|
| 84 |
+
dict_postprocessor=dict(type=generic_llmjudge_postprocess),
|
| 85 |
+
),
|
| 86 |
+
parallel=False,
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
beyondaime_eval_cfg = dict(
|
| 91 |
+
evaluator=beyondaime_cascade_evaluator,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
beyondaime_datasets = [
|
| 96 |
+
dict(
|
| 97 |
+
type=BeyondAIMEDataset,
|
| 98 |
+
abbr='beyondaime',
|
| 99 |
+
path='ByteDance-Seed/BeyondAIME',
|
| 100 |
+
reader_cfg=beyondaime_reader_cfg,
|
| 101 |
+
infer_cfg=beyondaime_infer_cfg,
|
| 102 |
+
eval_cfg=beyondaime_eval_cfg,
|
| 103 |
+
)
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
|
build/lib/opencompass/configs/datasets/BeyondAIME/beyondaime_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .beyondaime_cascade_eval_gen_5e9f4f import beyondaime_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/CARDBiomedBench/CARDBiomedBench_llmjudge_gen_99a231.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.datasets import CARDBiomedBenchDataset
|
| 2 |
+
from opencompass.datasets import generic_llmjudge_postprocess
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 5 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 6 |
+
from opencompass.evaluator import GenericLLMEvaluator
|
| 7 |
+
ZERO_SHOT_PROMPT = 'You are an expert in {expert}.\n{question}\n'
|
| 8 |
+
|
| 9 |
+
GRADER_TEMPLATE = """
|
| 10 |
+
Please as a grading expert, judge whether the final answers given by the candidates below are consistent with the standard answers, that is, whether the candidates answered correctly.
|
| 11 |
+
|
| 12 |
+
Here are some evaluation criteria:
|
| 13 |
+
1. Please refer to the given standard answer. You don't need to re-generate the answer to the question because the standard answer has been given. You only need to judge whether the candidate's answer is consistent with the standard answer according to the form of the question. Don't try to answer the original question. You can assume that the standard answer is definitely correct.
|
| 14 |
+
2. Because the candidate's answer may be different from the standard answer in the form of expression, before making a judgment, please understand the question and the standard answer first, and then judge whether the candidate's answer is correct, but be careful not to try to answer the original question.
|
| 15 |
+
3. Some answers may contain multiple items, such as multiple-choice questions, multiple-select questions, fill-in-the-blank questions, etc. As long as the answer is the same as the standard answer, it is enough. For multiple-select questions and multiple-blank fill-in-the-blank questions, the candidate needs to answer all the corresponding options or blanks correctly to be considered correct.
|
| 16 |
+
4. Some answers may be expressed in different ways, such as some answers may be a mathematical expression, some answers may be a textual description, as long as the meaning expressed is the same. And some formulas are expressed in different ways, but they are equivalent and correct.
|
| 17 |
+
|
| 18 |
+
Please judge whether the following answers are consistent with the standard answer based on the above criteria. Grade the predicted answer of this new question as one of:
|
| 19 |
+
A: CORRECT
|
| 20 |
+
B: INCORRECT
|
| 21 |
+
Just return the letters "A" or "B", with no text around it.
|
| 22 |
+
|
| 23 |
+
Here is your task. Simply reply with either CORRECT, INCORRECT. Don't apologize or correct yourself if there was a mistake; we are just trying to grade the answer.
|
| 24 |
+
|
| 25 |
+
<Original Question Begin>: Q: You are an expert in {expert}.\n{question}\n<Original Question End>\n\n
|
| 26 |
+
<Gold Target Begin>: \n{answer}\n<Gold Target End>\n\n
|
| 27 |
+
<Predicted Answer Begin>: \n{prediction}\n<Predicted End>\n\n
|
| 28 |
+
Judging the correctness of candidates' answers:
|
| 29 |
+
""".strip()
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# Reader configuration
|
| 33 |
+
reader_cfg = dict(
|
| 34 |
+
input_columns=[
|
| 35 |
+
'question',
|
| 36 |
+
'answer',
|
| 37 |
+
'Bio_Category',
|
| 38 |
+
'SQL_Category',
|
| 39 |
+
'uuid',
|
| 40 |
+
'template uuid',
|
| 41 |
+
'expert',
|
| 42 |
+
],
|
| 43 |
+
output_column='answer',
|
| 44 |
+
)
|
| 45 |
+
# Inference configuration
|
| 46 |
+
infer_cfg = dict(
|
| 47 |
+
prompt_template=dict(
|
| 48 |
+
type=PromptTemplate,
|
| 49 |
+
template=dict(
|
| 50 |
+
round=[
|
| 51 |
+
dict(
|
| 52 |
+
|
| 53 |
+
role='HUMAN',
|
| 54 |
+
prompt=ZERO_SHOT_PROMPT, # prompt mode: zero-shot
|
| 55 |
+
),
|
| 56 |
+
],
|
| 57 |
+
),
|
| 58 |
+
),
|
| 59 |
+
retriever=dict(type=ZeroRetriever),
|
| 60 |
+
inferencer=dict(type=GenInferencer),
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# Evaluation configuration
|
| 64 |
+
eval_cfg = dict(
|
| 65 |
+
evaluator=dict(
|
| 66 |
+
type=GenericLLMEvaluator,
|
| 67 |
+
prompt_template=dict(
|
| 68 |
+
type=PromptTemplate,
|
| 69 |
+
template=dict(
|
| 70 |
+
begin=[
|
| 71 |
+
dict(
|
| 72 |
+
role='SYSTEM',
|
| 73 |
+
fallback_role='HUMAN',
|
| 74 |
+
prompt="You are a helpful assistant who evaluates the correctness and quality of models' outputs.",
|
| 75 |
+
)
|
| 76 |
+
],
|
| 77 |
+
round=[
|
| 78 |
+
dict(role='HUMAN', prompt=GRADER_TEMPLATE),
|
| 79 |
+
],
|
| 80 |
+
),
|
| 81 |
+
),
|
| 82 |
+
dataset_cfg=dict(
|
| 83 |
+
type=CARDBiomedBenchDataset,
|
| 84 |
+
path='NIH-CARD/CARDBiomedBench',
|
| 85 |
+
prompt_mode='zero-shot',
|
| 86 |
+
reader_cfg=reader_cfg,
|
| 87 |
+
),
|
| 88 |
+
judge_cfg=dict(),
|
| 89 |
+
dict_postprocessor=dict(type=generic_llmjudge_postprocess),
|
| 90 |
+
),
|
| 91 |
+
)
|
| 92 |
+
cardbiomedbench_dataset = dict(
|
| 93 |
+
type=CARDBiomedBenchDataset,
|
| 94 |
+
abbr='cardbiomedbench',
|
| 95 |
+
path='NIH-CARD/CARDBiomedBench',
|
| 96 |
+
prompt_mode='zero-shot',
|
| 97 |
+
reader_cfg=reader_cfg,
|
| 98 |
+
infer_cfg=infer_cfg,
|
| 99 |
+
eval_cfg=eval_cfg,
|
| 100 |
+
)
|
| 101 |
+
cardbiomedbench_datasets = [cardbiomedbench_dataset]
|
build/lib/opencompass/configs/datasets/CHARM/README.md
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CHARM✨ Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations [ACL2024]
|
| 2 |
+
[](https://arxiv.org/abs/2403.14112)
|
| 3 |
+
[](./LICENSE)
|
| 4 |
+
<div align="center">
|
| 5 |
+
|
| 6 |
+
📃[Paper](https://arxiv.org/abs/2403.14112)
|
| 7 |
+
🏰[Project Page](https://opendatalab.github.io/CHARM/)
|
| 8 |
+
🏆[Leaderboard](https://opendatalab.github.io/CHARM/leaderboard.html)
|
| 9 |
+
✨[Findings](https://opendatalab.github.io/CHARM/findings.html)
|
| 10 |
+
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
<div align="center">
|
| 14 |
+
📖 <a href="./README_ZH.md"> 中文</a> | <a href="./README.md">English</a>
|
| 15 |
+
</div>
|
| 16 |
+
|
| 17 |
+
## Dataset Description
|
| 18 |
+
|
| 19 |
+
**CHARM** is the first benchmark for comprehensively and in-depth evaluating the commonsense reasoning ability of large language models (LLMs) in Chinese, which covers both globally known and Chinese-specific commonsense. In addition, the CHARM can evaluate the LLMs' memorization-independent reasoning abilities and analyze the typical errors.
|
| 20 |
+
|
| 21 |
+
## Comparison of commonsense reasoning benchmarks
|
| 22 |
+
<html lang="en">
|
| 23 |
+
<table align="center">
|
| 24 |
+
<thead class="fixed-header">
|
| 25 |
+
<tr>
|
| 26 |
+
<th>Benchmarks</th>
|
| 27 |
+
<th>CN-Lang</th>
|
| 28 |
+
<th>CSR</th>
|
| 29 |
+
<th>CN-specifics</th>
|
| 30 |
+
<th>Dual-Domain</th>
|
| 31 |
+
<th>Rea-Mem</th>
|
| 32 |
+
</tr>
|
| 33 |
+
</thead>
|
| 34 |
+
<tr>
|
| 35 |
+
<td>Most benchmarks in <a href="https://arxiv.org/abs/2302.04752"> davis2023benchmarks</a></td>
|
| 36 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 37 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 38 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 39 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 40 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 41 |
+
</tr>
|
| 42 |
+
<tr>
|
| 43 |
+
<td><a href="https://arxiv.org/abs/1809.05053"> XNLI</a>, <a
|
| 44 |
+
href="https://arxiv.org/abs/2005.00333">XCOPA</a>,<a
|
| 45 |
+
href="https://arxiv.org/abs/2112.10668">XStoryCloze</a></td>
|
| 46 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 47 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 48 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 49 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 50 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 51 |
+
</tr>
|
| 52 |
+
<tr>
|
| 53 |
+
<td><a href="https://arxiv.org/abs/2007.08124">LogiQA</a>, <a
|
| 54 |
+
href="https://arxiv.org/abs/2004.05986">CLUE</a>, <a
|
| 55 |
+
href="https://arxiv.org/abs/2306.09212">CMMLU</a></td>
|
| 56 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 57 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 58 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 59 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 60 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 61 |
+
</tr>
|
| 62 |
+
<tr>
|
| 63 |
+
<td><a href="https://arxiv.org/abs/2312.12853">CORECODE</a> </td>
|
| 64 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 65 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 66 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 67 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 68 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 69 |
+
</tr>
|
| 70 |
+
<tr>
|
| 71 |
+
<td><strong><a href="https://arxiv.org/abs/2403.14112">CHARM (ours)</a> </strong></td>
|
| 72 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 73 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 74 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 75 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 76 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 77 |
+
</tr>
|
| 78 |
+
</table>
|
| 79 |
+
|
| 80 |
+
"CN-Lang" indicates the benchmark is presented in Chinese language. "CSR" means the benchmark is designed to focus on <strong>C</strong>ommon<strong>S</strong>ense <strong>R</strong>easoning. "CN-specific" indicates the benchmark includes elements that are unique to Chinese culture, language, regional characteristics, history, etc. "Dual-Domain" indicates the benchmark encompasses both Chinese-specific and global domain tasks, with questions presented in the similar style and format. "Rea-Mem" indicates the benchmark includes closely-interconnected <strong>rea</strong>soning and <strong>mem</strong>orization tasks.
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## 🛠️ How to Use
|
| 84 |
+
Below are the steps for quickly downloading CHARM and using OpenCompass for evaluation.
|
| 85 |
+
|
| 86 |
+
### 1. Download CHARM
|
| 87 |
+
```bash
|
| 88 |
+
git clone https://github.com/opendatalab/CHARM ${path_to_CHARM_repo}
|
| 89 |
+
|
| 90 |
+
cd ${path_to_opencompass}
|
| 91 |
+
mkdir data
|
| 92 |
+
ln -snf ${path_to_CHARM_repo}/data/CHARM ./data/CHARM
|
| 93 |
+
```
|
| 94 |
+
### 2. Run Inference and Evaluation
|
| 95 |
+
```bash
|
| 96 |
+
cd ${path_to_opencompass}
|
| 97 |
+
|
| 98 |
+
# modify config file `examples/eval_charm_rea.py`: uncomment or add models you want to evaluate
|
| 99 |
+
python run.py examples/eval_charm_rea.py -r --dump-eval-details
|
| 100 |
+
|
| 101 |
+
# modify config file `examples/eval_charm_mem.py`: uncomment or add models you want to evaluate
|
| 102 |
+
python run.py examples/eval_charm_mem.py -r --dump-eval-details
|
| 103 |
+
```
|
| 104 |
+
The inference and evaluation results would be in `${path_to_opencompass}/outputs`, like this:
|
| 105 |
+
```bash
|
| 106 |
+
outputs
|
| 107 |
+
├── CHARM_mem
|
| 108 |
+
│ └── chat
|
| 109 |
+
│ └── 20240605_151442
|
| 110 |
+
│ ├── predictions
|
| 111 |
+
│ │ ├── internlm2-chat-1.8b-turbomind
|
| 112 |
+
│ │ ├── llama-3-8b-instruct-lmdeploy
|
| 113 |
+
│ │ └── qwen1.5-1.8b-chat-hf
|
| 114 |
+
│ ├── results
|
| 115 |
+
│ │ ├── internlm2-chat-1.8b-turbomind_judged-by--GPT-3.5-turbo-0125
|
| 116 |
+
│ │ ├── llama-3-8b-instruct-lmdeploy_judged-by--GPT-3.5-turbo-0125
|
| 117 |
+
│ │ └── qwen1.5-1.8b-chat-hf_judged-by--GPT-3.5-turbo-0125
|
| 118 |
+
│ └── summary
|
| 119 |
+
│ └── 20240605_205020 # MEMORY_SUMMARY_DIR
|
| 120 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Anachronisms_Judgment
|
| 121 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Movie_and_Music_Recommendation
|
| 122 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Sport_Understanding
|
| 123 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Time_Understanding
|
| 124 |
+
│ └── judged-by--GPT-3.5-turbo-0125.csv # MEMORY_SUMMARY_CSV
|
| 125 |
+
└── CHARM_rea
|
| 126 |
+
└── chat
|
| 127 |
+
└── 20240605_152359
|
| 128 |
+
├── predictions
|
| 129 |
+
│ ├── internlm2-chat-1.8b-turbomind
|
| 130 |
+
│ ├── llama-3-8b-instruct-lmdeploy
|
| 131 |
+
│ └── qwen1.5-1.8b-chat-hf
|
| 132 |
+
├── results # REASON_RESULTS_DIR
|
| 133 |
+
│ ├── internlm2-chat-1.8b-turbomind
|
| 134 |
+
│ ├── llama-3-8b-instruct-lmdeploy
|
| 135 |
+
│ └── qwen1.5-1.8b-chat-hf
|
| 136 |
+
└── summary
|
| 137 |
+
├── summary_20240605_205328.csv # REASON_SUMMARY_CSV
|
| 138 |
+
└── summary_20240605_205328.txt
|
| 139 |
+
```
|
| 140 |
+
### 3. Generate Analysis Results
|
| 141 |
+
```bash
|
| 142 |
+
cd ${path_to_CHARM_repo}
|
| 143 |
+
|
| 144 |
+
# generate Table5, Table6, Table9 and Table10 in https://arxiv.org/abs/2403.14112
|
| 145 |
+
PYTHONPATH=. python tools/summarize_reasoning.py ${REASON_SUMMARY_CSV}
|
| 146 |
+
|
| 147 |
+
# generate Figure3 and Figure9 in https://arxiv.org/abs/2403.14112
|
| 148 |
+
PYTHONPATH=. python tools/summarize_mem_rea.py ${REASON_SUMMARY_CSV} ${MEMORY_SUMMARY_CSV}
|
| 149 |
+
|
| 150 |
+
# generate Table7, Table12, Table13 and Figure11 in https://arxiv.org/abs/2403.14112
|
| 151 |
+
PYTHONPATH=. python tools/analyze_mem_indep_rea.py data/CHARM ${REASON_RESULTS_DIR} ${MEMORY_SUMMARY_DIR} ${MEMORY_SUMMARY_CSV}
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
## 🖊️ Citation
|
| 155 |
+
```bibtex
|
| 156 |
+
@misc{sun2024benchmarking,
|
| 157 |
+
title={Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations},
|
| 158 |
+
author={Jiaxing Sun and Weiquan Huang and Jiang Wu and Chenya Gu and Wei Li and Songyang Zhang and Hang Yan and Conghui He},
|
| 159 |
+
year={2024},
|
| 160 |
+
eprint={2403.14112},
|
| 161 |
+
archivePrefix={arXiv},
|
| 162 |
+
primaryClass={cs.CL}
|
| 163 |
+
}
|
| 164 |
+
```
|
build/lib/opencompass/configs/datasets/CHARM/README_ZH.md
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CHARM✨ Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations [ACL2024]
|
| 2 |
+
[](https://arxiv.org/abs/2403.14112)
|
| 3 |
+
[](./LICENSE)
|
| 4 |
+
<div align="center">
|
| 5 |
+
|
| 6 |
+
📃[Paper](https://arxiv.org/abs/2403.14112)
|
| 7 |
+
🏰[Project Page](https://opendatalab.github.io/CHARM/)
|
| 8 |
+
🏆[Leaderboard](https://opendatalab.github.io/CHARM/leaderboard.html)
|
| 9 |
+
✨[Findings](https://opendatalab.github.io/CHARM/findings.html)
|
| 10 |
+
</div>
|
| 11 |
+
|
| 12 |
+
<div align="center">
|
| 13 |
+
📖 <a href="./README_ZH.md"> 中文</a> | <a href="./README.md">English</a>
|
| 14 |
+
</div>
|
| 15 |
+
|
| 16 |
+
## 数据集介绍
|
| 17 |
+
|
| 18 |
+
**CHARM** 是首个全面深入评估大型语言模型(LLMs)在中文常识推理能力的基准测试,它覆盖了国际普遍认知的常识以及独特的中国文化常识。此外,CHARM 还可以评估 LLMs 独立于记忆的推理能力,并分析其典型错误。
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## 与其他常识推理评测基准的比较
|
| 22 |
+
<html lang="en">
|
| 23 |
+
<table align="center">
|
| 24 |
+
<thead class="fixed-header">
|
| 25 |
+
<tr>
|
| 26 |
+
<th>基准</th>
|
| 27 |
+
<th>汉语</th>
|
| 28 |
+
<th>常识推理</th>
|
| 29 |
+
<th>中国特有知识</th>
|
| 30 |
+
<th>中国和世界知识域</th>
|
| 31 |
+
<th>推理和记忆的关系</th>
|
| 32 |
+
</tr>
|
| 33 |
+
</thead>
|
| 34 |
+
<tr>
|
| 35 |
+
<td><a href="https://arxiv.org/abs/2302.04752"> davis2023benchmarks</a> 中提到的基准</td>
|
| 36 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 37 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 38 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 39 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 40 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 41 |
+
</tr>
|
| 42 |
+
<tr>
|
| 43 |
+
<td><a href="https://arxiv.org/abs/1809.05053"> XNLI</a>, <a
|
| 44 |
+
href="https://arxiv.org/abs/2005.00333">XCOPA</a>,<a
|
| 45 |
+
href="https://arxiv.org/abs/2112.10668">XStoryCloze</a></td>
|
| 46 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 47 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 48 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 49 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 50 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 51 |
+
</tr>
|
| 52 |
+
<tr>
|
| 53 |
+
<td><a href="https://arxiv.org/abs/2007.08124">LogiQA</a>,<a
|
| 54 |
+
href="https://arxiv.org/abs/2004.05986">CLUE</a>, <a
|
| 55 |
+
href="https://arxiv.org/abs/2306.09212">CMMLU</a></td>
|
| 56 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 57 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 58 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 59 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 60 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 61 |
+
</tr>
|
| 62 |
+
<tr>
|
| 63 |
+
<td><a href="https://arxiv.org/abs/2312.12853">CORECODE</a> </td>
|
| 64 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 65 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 66 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 67 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 68 |
+
<td><strong><span style="color: red;">✘</span></strong></td>
|
| 69 |
+
</tr>
|
| 70 |
+
<tr>
|
| 71 |
+
<td><strong><a href="https://arxiv.org/abs/2403.14112">CHARM (ours)</a> </strong></td>
|
| 72 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 73 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 74 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 75 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 76 |
+
<td><strong><span style="color: green;">✔</span></strong></td>
|
| 77 |
+
</tr>
|
| 78 |
+
</table>
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
## 🛠️ 如何使用
|
| 82 |
+
以下是快速下载 CHARM 并在 OpenCompass 上进行评估的步骤。
|
| 83 |
+
|
| 84 |
+
### 1. 下载 CHARM
|
| 85 |
+
```bash
|
| 86 |
+
git clone https://github.com/opendatalab/CHARM ${path_to_CHARM_repo}
|
| 87 |
+
|
| 88 |
+
cd ${path_to_opencompass}
|
| 89 |
+
mkdir data
|
| 90 |
+
ln -snf ${path_to_CHARM_repo}/data/CHARM ./data/CHARM
|
| 91 |
+
```
|
| 92 |
+
### 2. 推理和评测
|
| 93 |
+
```bash
|
| 94 |
+
cd ${path_to_opencompass}
|
| 95 |
+
|
| 96 |
+
# 修改配置文件`examples/eval_charm_rea.py`: 将现有的模型取消注释,或者添加你想评测的模型
|
| 97 |
+
python run.py examples/eval_charm_rea.py -r --dump-eval-details
|
| 98 |
+
|
| 99 |
+
# 修改配置文件`examples/eval_charm_mem.py`: 将现有的模型取消注释,或者添加你想评测的模型
|
| 100 |
+
python run.py examples/eval_charm_mem.py -r --dump-eval-details
|
| 101 |
+
```
|
| 102 |
+
推理和评测的结果位于路径`${path_to_opencompass}/outputs`, 如下所示:
|
| 103 |
+
```bash
|
| 104 |
+
outputs
|
| 105 |
+
├── CHARM_mem
|
| 106 |
+
│ └── chat
|
| 107 |
+
│ └── 20240605_151442
|
| 108 |
+
│ ├── predictions
|
| 109 |
+
│ │ ├── internlm2-chat-1.8b-turbomind
|
| 110 |
+
│ │ ├── llama-3-8b-instruct-lmdeploy
|
| 111 |
+
│ │ └── qwen1.5-1.8b-chat-hf
|
| 112 |
+
│ ├── results
|
| 113 |
+
│ │ ├── internlm2-chat-1.8b-turbomind_judged-by--GPT-3.5-turbo-0125
|
| 114 |
+
│ │ ├── llama-3-8b-instruct-lmdeploy_judged-by--GPT-3.5-turbo-0125
|
| 115 |
+
│ │ └── qwen1.5-1.8b-chat-hf_judged-by--GPT-3.5-turbo-0125
|
| 116 |
+
│ └── summary
|
| 117 |
+
│ └── 20240605_205020 # MEMORY_SUMMARY_DIR
|
| 118 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Anachronisms_Judgment
|
| 119 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Movie_and_Music_Recommendation
|
| 120 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Sport_Understanding
|
| 121 |
+
│ ├── judged-by--GPT-3.5-turbo-0125-charm-memory-Chinese_Time_Understanding
|
| 122 |
+
│ └── judged-by--GPT-3.5-turbo-0125.csv # MEMORY_SUMMARY_CSV
|
| 123 |
+
└── CHARM_rea
|
| 124 |
+
└── chat
|
| 125 |
+
└── 20240605_152359
|
| 126 |
+
├── predictions
|
| 127 |
+
│ ├── internlm2-chat-1.8b-turbomind
|
| 128 |
+
│ ├── llama-3-8b-instruct-lmdeploy
|
| 129 |
+
│ └── qwen1.5-1.8b-chat-hf
|
| 130 |
+
├── results # REASON_RESULTS_DIR
|
| 131 |
+
│ ├── internlm2-chat-1.8b-turbomind
|
| 132 |
+
│ ├── llama-3-8b-instruct-lmdeploy
|
| 133 |
+
│ └── qwen1.5-1.8b-chat-hf
|
| 134 |
+
└── summary
|
| 135 |
+
├── summary_20240605_205328.csv # REASON_SUMMARY_CSV
|
| 136 |
+
└── summary_20240605_205328.txt
|
| 137 |
+
```
|
| 138 |
+
### 3. 生成分析结果
|
| 139 |
+
```bash
|
| 140 |
+
cd ${path_to_CHARM_repo}
|
| 141 |
+
|
| 142 |
+
# 生成论文中的Table5, Table6, Table9 and Table10,详见https://arxiv.org/abs/2403.14112
|
| 143 |
+
PYTHONPATH=. python tools/summarize_reasoning.py ${REASON_SUMMARY_CSV}
|
| 144 |
+
|
| 145 |
+
# 生成论文中的Figure3 and Figure9,详见https://arxiv.org/abs/2403.14112
|
| 146 |
+
PYTHONPATH=. python tools/summarize_mem_rea.py ${REASON_SUMMARY_CSV} ${MEMORY_SUMMARY_CSV}
|
| 147 |
+
|
| 148 |
+
# 生成论文中的Table7, Table12, Table13 and Figure11,详见https://arxiv.org/abs/2403.14112
|
| 149 |
+
PYTHONPATH=. python tools/analyze_mem_indep_rea.py data/CHARM ${REASON_RESULTS_DIR} ${MEMORY_SUMMARY_DIR} ${MEMORY_SUMMARY_CSV}
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
## 🖊️ 引用
|
| 153 |
+
```bibtex
|
| 154 |
+
@misc{sun2024benchmarking,
|
| 155 |
+
title={Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations},
|
| 156 |
+
author={Jiaxing Sun and Weiquan Huang and Jiang Wu and Chenya Gu and Wei Li and Songyang Zhang and Hang Yan and Conghui He},
|
| 157 |
+
year={2024},
|
| 158 |
+
eprint={2403.14112},
|
| 159 |
+
archivePrefix={arXiv},
|
| 160 |
+
primaryClass={cs.CL}
|
| 161 |
+
}
|
| 162 |
+
```
|
build/lib/opencompass/configs/datasets/CHARM/charm_memory_gen_bbbd53.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from mmengine.config import read_base
|
| 3 |
+
|
| 4 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 5 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 6 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 7 |
+
from opencompass.datasets import CharmDataset, CharmMemoryEvaluator, LMEvaluator
|
| 8 |
+
|
| 9 |
+
with read_base():
|
| 10 |
+
from .charm_memory_settings import charm_memory_tasks, judge_system_prompts, dataset_path
|
| 11 |
+
|
| 12 |
+
charm_memory_datasets = []
|
| 13 |
+
|
| 14 |
+
for _task in charm_memory_tasks:
|
| 15 |
+
|
| 16 |
+
charm_memory_reader_cfg = dict(input_columns=['input'],
|
| 17 |
+
output_column='target')
|
| 18 |
+
|
| 19 |
+
charm_memory_infer_cfg = dict(
|
| 20 |
+
prompt_template=dict(
|
| 21 |
+
type=PromptTemplate,
|
| 22 |
+
template=dict(round=[
|
| 23 |
+
dict(role='HUMAN', prompt='请尽可能简短地回答下述问题。\n问题:{input}\n答:')
|
| 24 |
+
]),
|
| 25 |
+
),
|
| 26 |
+
retriever=dict(type=ZeroRetriever),
|
| 27 |
+
inferencer=dict(type=GenInferencer, max_out_len=512),
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
if _task == 'Chinese_Movie_and_Music_Recommendation':
|
| 31 |
+
charm_memory_eval_cfg = dict(
|
| 32 |
+
evaluator=dict(type=CharmMemoryEvaluator),
|
| 33 |
+
pred_role='BOT',
|
| 34 |
+
)
|
| 35 |
+
else:
|
| 36 |
+
judge_system_prompt = judge_system_prompts[_task]
|
| 37 |
+
charm_memory_eval_cfg = dict(
|
| 38 |
+
evaluator=dict(
|
| 39 |
+
type=LMEvaluator,
|
| 40 |
+
prompt_template=dict(
|
| 41 |
+
type=PromptTemplate,
|
| 42 |
+
template=dict(round=[
|
| 43 |
+
dict(
|
| 44 |
+
role='HUMAN',
|
| 45 |
+
prompt=judge_system_prompt +
|
| 46 |
+
"\n\n[Question]\n{input}\n[The Start of Reference Answer]\n{target}\n[The End of Reference Answer]\n\n[The Start of Assistant's Answer]\n{prediction}\n[The End of Assistant's Answer]" # noqa
|
| 47 |
+
),
|
| 48 |
+
]),
|
| 49 |
+
),
|
| 50 |
+
),
|
| 51 |
+
pred_role='BOT',
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
charm_memory_datasets.append(
|
| 55 |
+
dict(
|
| 56 |
+
type=CharmDataset,
|
| 57 |
+
path=dataset_path,
|
| 58 |
+
name=_task,
|
| 59 |
+
abbr='charm-memory-' + _task,
|
| 60 |
+
reader_cfg=charm_memory_reader_cfg,
|
| 61 |
+
infer_cfg=charm_memory_infer_cfg.copy(),
|
| 62 |
+
eval_cfg=charm_memory_eval_cfg.copy(),
|
| 63 |
+
))
|
build/lib/opencompass/configs/datasets/CHARM/charm_memory_settings.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
charm_memory_tasks = [
|
| 4 |
+
'Chinese_Anachronisms_Judgment',
|
| 5 |
+
'Chinese_Movie_and_Music_Recommendation',
|
| 6 |
+
'Chinese_Sport_Understanding',
|
| 7 |
+
'Chinese_Time_Understanding',
|
| 8 |
+
]
|
| 9 |
+
|
| 10 |
+
dataset_path = 'data/CHARM/memorization'
|
| 11 |
+
|
| 12 |
+
system_prompt_template = """Please act as an impartial judge, comparing the responses of the AI assistants to the reference answer and determining if the answers are correct.
|
| 13 |
+
You will receive the reference answer provided by a human and the responses of the AI assistants.
|
| 14 |
+
Your task is to judge whether the AI assistant's answers is correct.
|
| 15 |
+
{task_specific_prompt}
|
| 16 |
+
After providing your explanation, strictly output your final judgment in the following format: “[正确]” if the AI assistant's response is correct, “[错误]” if the AI assistant's response is incorrect.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
task_specific_prompts = {
|
| 20 |
+
'Chinese_Anachronisms_Judgment':
|
| 21 |
+
"If the provided reference answer is a list, the model's prediction is considered correct if it matches any item in the list.",
|
| 22 |
+
'Chinese_Time_Understanding':
|
| 23 |
+
"When evaluating the AI assistant's response regarding Chinese solar terms, as long as the AI assistant's response falls within the time frame provided in the reference answer, consider it correct.",
|
| 24 |
+
'Chinese_Sport_Understanding':
|
| 25 |
+
"If the provided reference answer is a list, the model's prediction is considered correct if it matches any item in the list."
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
judge_system_prompts = {
|
| 29 |
+
k: system_prompt_template.format(task_specific_prompt=v)
|
| 30 |
+
for k, v in task_specific_prompts.items()
|
| 31 |
+
}
|
build/lib/opencompass/configs/datasets/CHARM/charm_reason_cot_only_gen_f7b7d3.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from mmengine.config import read_base
|
| 3 |
+
|
| 4 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 5 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 6 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 7 |
+
from opencompass.datasets import CharmDataset, charm_reason_postprocess, CharmReasonEvaluator
|
| 8 |
+
|
| 9 |
+
with read_base():
|
| 10 |
+
from .charm_reason_settings import charm_tasks, settings
|
| 11 |
+
|
| 12 |
+
settings = [s for s in settings if s[0] in ['ZH-CoT', 'EN-CoT']]
|
| 13 |
+
|
| 14 |
+
charm_reason_datasets = []
|
| 15 |
+
|
| 16 |
+
for _cot, _cot_prefix, dataset_path, fewshot_example_path, prompt_template in settings:
|
| 17 |
+
for _task in charm_tasks:
|
| 18 |
+
_fewshot_example_file = os.path.join(fewshot_example_path, f'{_task}_{_cot}.txt')
|
| 19 |
+
with open(_fewshot_example_file, 'r') as f:
|
| 20 |
+
_hint = f.read()
|
| 21 |
+
|
| 22 |
+
charm_reason_reader_cfg = dict(input_columns=['input'], output_column='target')
|
| 23 |
+
|
| 24 |
+
charm_reason_infer_cfg = dict(
|
| 25 |
+
prompt_template=dict(
|
| 26 |
+
type=PromptTemplate,
|
| 27 |
+
template=dict(round=[dict(role='HUMAN', prompt=prompt_template.format(_hint=_hint) + _cot_prefix)]),
|
| 28 |
+
),
|
| 29 |
+
retriever=dict(type=ZeroRetriever),
|
| 30 |
+
inferencer=dict(type=GenInferencer, max_out_len=512),
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
charm_reason_eval_cfg = dict(
|
| 34 |
+
evaluator=dict(type=CharmReasonEvaluator),
|
| 35 |
+
pred_role='BOT',
|
| 36 |
+
pred_postprocessor=dict(type=charm_reason_postprocess),
|
| 37 |
+
dataset_postprocessor=dict(type=charm_reason_postprocess),
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
charm_reason_datasets.append(
|
| 41 |
+
dict(
|
| 42 |
+
type=CharmDataset,
|
| 43 |
+
path=dataset_path,
|
| 44 |
+
name=_task,
|
| 45 |
+
abbr='charm-reason-' + _task + '_' + _cot,
|
| 46 |
+
reader_cfg=charm_reason_reader_cfg,
|
| 47 |
+
infer_cfg=charm_reason_infer_cfg.copy(),
|
| 48 |
+
eval_cfg=charm_reason_eval_cfg.copy(),
|
| 49 |
+
)
|
| 50 |
+
)
|
build/lib/opencompass/configs/datasets/CHARM/charm_reason_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .charm_reason_gen_f8fca2 import charm_reason_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/CHARM/charm_reason_gen_f8fca2.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from mmengine.config import read_base
|
| 3 |
+
|
| 4 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 5 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 6 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 7 |
+
from opencompass.datasets import CharmDataset, charm_reason_postprocess, CharmReasonEvaluator
|
| 8 |
+
|
| 9 |
+
with read_base():
|
| 10 |
+
from .charm_reason_settings import charm_tasks, settings
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
charm_reason_datasets = []
|
| 14 |
+
|
| 15 |
+
for _cot, _cot_prefix, dataset_path, fewshot_example_path, prompt_template in settings:
|
| 16 |
+
for _task in charm_tasks:
|
| 17 |
+
_fewshot_example_file = os.path.join(fewshot_example_path, f'{_task}_{_cot}.txt')
|
| 18 |
+
with open(_fewshot_example_file, 'r') as f:
|
| 19 |
+
_hint = f.read()
|
| 20 |
+
|
| 21 |
+
charm_reason_reader_cfg = dict(input_columns=['input'], output_column='target')
|
| 22 |
+
|
| 23 |
+
charm_reason_infer_cfg = dict(
|
| 24 |
+
prompt_template=dict(
|
| 25 |
+
type=PromptTemplate,
|
| 26 |
+
template=dict(round=[dict(role='HUMAN', prompt=prompt_template.format(_hint=_hint) + _cot_prefix)]),
|
| 27 |
+
),
|
| 28 |
+
retriever=dict(type=ZeroRetriever),
|
| 29 |
+
inferencer=dict(type=GenInferencer, max_out_len=512),
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
charm_reason_eval_cfg = dict(
|
| 33 |
+
evaluator=dict(type=CharmReasonEvaluator),
|
| 34 |
+
pred_role='BOT',
|
| 35 |
+
pred_postprocessor=dict(type=charm_reason_postprocess),
|
| 36 |
+
dataset_postprocessor=dict(type=charm_reason_postprocess),
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
charm_reason_datasets.append(
|
| 40 |
+
dict(
|
| 41 |
+
type=CharmDataset,
|
| 42 |
+
path=dataset_path,
|
| 43 |
+
name=_task,
|
| 44 |
+
abbr='charm-reason-' + _task + '_' + _cot,
|
| 45 |
+
reader_cfg=charm_reason_reader_cfg,
|
| 46 |
+
infer_cfg=charm_reason_infer_cfg.copy(),
|
| 47 |
+
eval_cfg=charm_reason_eval_cfg.copy(),
|
| 48 |
+
)
|
| 49 |
+
)
|
build/lib/opencompass/configs/datasets/CHARM/charm_reason_ppl_3da4de.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 4 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 5 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 6 |
+
from opencompass.datasets import CharmDataset
|
| 7 |
+
from opencompass.openicl.icl_evaluator import AccwithDetailsEvaluator
|
| 8 |
+
|
| 9 |
+
charm_tasks = [
|
| 10 |
+
['Chinese_Anachronisms_Judgment', 'AB'],
|
| 11 |
+
['Chinese_Movie_and_Music_Recommendation', 'ABCD'],
|
| 12 |
+
['Chinese_Natural_Language_Inference', 'ABC'],
|
| 13 |
+
['Chinese_Reading_Comprehension', 'ABCD'],
|
| 14 |
+
['Chinese_Sequence_Understanding', 'ABCD'],
|
| 15 |
+
['Chinese_Sport_Understanding', 'AB'],
|
| 16 |
+
['Chinese_Time_Understanding', 'ABCD'],
|
| 17 |
+
['Global_Anachronisms_Judgment', 'AB'],
|
| 18 |
+
['Global_Movie_and_Music_Recommendation', 'ABCD'],
|
| 19 |
+
['Global_Natural_Language_Inference', 'ABC'],
|
| 20 |
+
['Global_Reading_Comprehension', 'ABCD'],
|
| 21 |
+
['Global_Sequence_Understanding', 'ABCD'],
|
| 22 |
+
['Global_Sport_Understanding', 'AB'],
|
| 23 |
+
['Global_Time_Understanding', 'ABCDEF'],
|
| 24 |
+
]
|
| 25 |
+
|
| 26 |
+
charm_reason_datasets = []
|
| 27 |
+
for task_name, options in charm_tasks:
|
| 28 |
+
|
| 29 |
+
with open(os.path.join(os.path.dirname(__file__), 'few-shot-examples', f'{task_name}_Direct.txt'), 'r') as f:
|
| 30 |
+
few_shot_example = f.read()
|
| 31 |
+
|
| 32 |
+
charm_reason_reader_cfg = dict(input_columns=['input'], output_column='target')
|
| 33 |
+
|
| 34 |
+
charm_reason_infer_cfg = dict(
|
| 35 |
+
prompt_template=dict(
|
| 36 |
+
type=PromptTemplate,
|
| 37 |
+
template={
|
| 38 |
+
f'({opt})': f'{few_shot_example}\n{{input}}\nA: {opt}' for opt in options
|
| 39 |
+
},
|
| 40 |
+
),
|
| 41 |
+
retriever=dict(type=ZeroRetriever),
|
| 42 |
+
inferencer=dict(type=PPLInferencer),
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
charm_reason_eval_cfg = dict(evaluator=dict(type=AccwithDetailsEvaluator))
|
| 46 |
+
|
| 47 |
+
charm_reason_datasets.append(
|
| 48 |
+
dict(
|
| 49 |
+
type=CharmDataset,
|
| 50 |
+
abbr=f'charm-reason-{task_name}_Direct',
|
| 51 |
+
path=f'data/CHARM/reasoning',
|
| 52 |
+
name=task_name,
|
| 53 |
+
reader_cfg=charm_reason_reader_cfg,
|
| 54 |
+
infer_cfg=charm_reason_infer_cfg,
|
| 55 |
+
eval_cfg=charm_reason_eval_cfg,
|
| 56 |
+
)
|
| 57 |
+
)
|
build/lib/opencompass/configs/datasets/CHARM/charm_reason_settings.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
charm_tasks = [
|
| 4 |
+
'Chinese_Anachronisms_Judgment',
|
| 5 |
+
'Chinese_Movie_and_Music_Recommendation',
|
| 6 |
+
'Chinese_Natural_Language_Inference',
|
| 7 |
+
'Chinese_Reading_Comprehension',
|
| 8 |
+
'Chinese_Sequence_Understanding',
|
| 9 |
+
'Chinese_Sport_Understanding',
|
| 10 |
+
'Chinese_Time_Understanding',
|
| 11 |
+
'Global_Anachronisms_Judgment',
|
| 12 |
+
'Global_Movie_and_Music_Recommendation',
|
| 13 |
+
'Global_Natural_Language_Inference',
|
| 14 |
+
'Global_Reading_Comprehension',
|
| 15 |
+
'Global_Sequence_Understanding',
|
| 16 |
+
'Global_Sport_Understanding',
|
| 17 |
+
'Global_Time_Understanding',
|
| 18 |
+
]
|
| 19 |
+
|
| 20 |
+
XLT_template = 'Follow the given examples and answer the question.\n{_hint}\n\n I want you to act as an commonsense reasoning expert for Chinese. \n Request: {{input}}\n'
|
| 21 |
+
Translate_EN_template = 'Follow the given examples and answer the question.\n{_hint}\n\nQ: {{input}}\nA: '
|
| 22 |
+
Other_template = '请按照给定的例子回答问题。\n{_hint}\n\nQ:{{input}}\nA:'
|
| 23 |
+
|
| 24 |
+
data_dir = 'data/CHARM'
|
| 25 |
+
dataset_path_ZH = f'{data_dir}/reasoning'
|
| 26 |
+
dataset_path_TransEn = f'{data_dir}/reasoning_Translate-EN'
|
| 27 |
+
fewshot_example_path_ZH = os.path.join(os.path.dirname(__file__), 'few-shot-examples')
|
| 28 |
+
fewshot_example_path_TransEn = os.path.join(os.path.dirname(__file__), 'few-shot-examples_Translate-EN')
|
| 29 |
+
|
| 30 |
+
settings = [
|
| 31 |
+
('Direct', '', dataset_path_ZH, fewshot_example_path_ZH, Other_template),
|
| 32 |
+
('ZH-CoT', '让我们一步一步来思考。', dataset_path_ZH, fewshot_example_path_ZH, Other_template),
|
| 33 |
+
('EN-CoT', "Let's think step by step.", dataset_path_ZH, fewshot_example_path_ZH, Other_template),
|
| 34 |
+
('XLT', """You should retell the request in English.\nYou should do the answer step by step to choose the right answer.\nYou should step-by-step answer the request.\nYou should tell me the answer in this format 'So the answer is'.""", dataset_path_ZH, fewshot_example_path_ZH, XLT_template),
|
| 35 |
+
('Translate-EN', "Let's think step by step.", dataset_path_TransEn, fewshot_example_path_TransEn, Translate_EN_template),
|
| 36 |
+
]
|
build/lib/opencompass/configs/datasets/CIBench/CIBench_generation_gen_8ab0dc.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import AgentInferencer
|
| 4 |
+
|
| 5 |
+
from opencompass.datasets import CIBenchDataset, CIBenchEvaluator
|
| 6 |
+
|
| 7 |
+
cibench_reader_cfg = dict(
|
| 8 |
+
input_columns=['questions'],
|
| 9 |
+
output_column='references',
|
| 10 |
+
train_split='test',
|
| 11 |
+
test_split='test')
|
| 12 |
+
|
| 13 |
+
cibench_infer_cfg = dict(
|
| 14 |
+
prompt_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template="""{questions}""",
|
| 17 |
+
),
|
| 18 |
+
retriever=dict(type=ZeroRetriever),
|
| 19 |
+
inferencer=dict(type=AgentInferencer, infer_mode='every'),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
libs = ['matplotlib', 'opencv', 'pandas', 'pytorch', 'scipy', 'seaborn']
|
| 23 |
+
cibench_eval_cfg = dict(evaluator=dict(type=CIBenchEvaluator), pred_role='BOT')
|
| 24 |
+
|
| 25 |
+
cibench_datasets = [
|
| 26 |
+
dict(
|
| 27 |
+
abbr=f'cibench_generation/{lib}',
|
| 28 |
+
type=CIBenchDataset,
|
| 29 |
+
path=f'./data/cibench_dataset/cibench_generation/{lib}',
|
| 30 |
+
internet_check=False,
|
| 31 |
+
reader_cfg=cibench_reader_cfg,
|
| 32 |
+
infer_cfg=cibench_infer_cfg,
|
| 33 |
+
eval_cfg=cibench_eval_cfg,
|
| 34 |
+
) for lib in libs
|
| 35 |
+
]
|
build/lib/opencompass/configs/datasets/CIBench/CIBench_generation_oracle_gen_c4a7c1.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import AgentInferencer
|
| 4 |
+
|
| 5 |
+
from opencompass.datasets import CIBenchDataset, CIBenchEvaluator
|
| 6 |
+
|
| 7 |
+
cibench_reader_cfg = dict(
|
| 8 |
+
input_columns=['questions'],
|
| 9 |
+
output_column='references',
|
| 10 |
+
train_split='test',
|
| 11 |
+
test_split='test')
|
| 12 |
+
|
| 13 |
+
cibench_infer_cfg = dict(
|
| 14 |
+
prompt_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template="""{questions}""",
|
| 17 |
+
),
|
| 18 |
+
retriever=dict(type=ZeroRetriever),
|
| 19 |
+
inferencer=dict(type=AgentInferencer, infer_mode='every_with_gt'),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
libs = ['matplotlib', 'opencv', 'pandas', 'pytorch', 'scipy', 'seaborn']
|
| 23 |
+
cibench_eval_cfg = dict(evaluator=dict(type=CIBenchEvaluator), pred_role='BOT')
|
| 24 |
+
|
| 25 |
+
cibench_datasets = [
|
| 26 |
+
dict(
|
| 27 |
+
abbr=f'cibench_generation_oracle/{lib}',
|
| 28 |
+
type=CIBenchDataset,
|
| 29 |
+
path=f'./data/cibench_dataset/cibench_generation/{lib}',
|
| 30 |
+
internet_check=False,
|
| 31 |
+
reader_cfg=cibench_reader_cfg,
|
| 32 |
+
infer_cfg=cibench_infer_cfg,
|
| 33 |
+
eval_cfg=cibench_eval_cfg,
|
| 34 |
+
) for lib in libs
|
| 35 |
+
]
|
build/lib/opencompass/configs/datasets/CIBench/CIBench_template_gen_e6b12a.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import AgentInferencer
|
| 4 |
+
|
| 5 |
+
from opencompass.datasets import CIBenchDataset, CIBenchEvaluator
|
| 6 |
+
|
| 7 |
+
cibench_reader_cfg = dict(
|
| 8 |
+
input_columns=['questions'],
|
| 9 |
+
output_column='references',
|
| 10 |
+
train_split='test',
|
| 11 |
+
test_split='test')
|
| 12 |
+
|
| 13 |
+
cibench_infer_cfg = dict(
|
| 14 |
+
prompt_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template="""{questions}""",
|
| 17 |
+
),
|
| 18 |
+
retriever=dict(type=ZeroRetriever),
|
| 19 |
+
inferencer=dict(type=AgentInferencer, infer_mode='every'),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
# no tensorboard
|
| 23 |
+
libs = ['/lightgbm', '/matplotlib', '/nltk', '/opencv', '/pandas', '/pytorch',
|
| 24 |
+
'/scipy', '/seaborn', '/sklearn', '/tensorflow',
|
| 25 |
+
'_chinese/lightgbm', '_chinese/matplotlib', '_chinese/nltk',
|
| 26 |
+
'_chinese/opencv', '_chinese/pandas', '_chinese/pytorch',
|
| 27 |
+
'_chinese/scipy', '_chinese/seaborn', '_chinese/sklearn', '_chinese/tensorflow']
|
| 28 |
+
cibench_eval_cfg = dict(evaluator=dict(type=CIBenchEvaluator), pred_role='BOT')
|
| 29 |
+
cibench_datasets = [
|
| 30 |
+
dict(
|
| 31 |
+
abbr=f'cibench_template{lib}',
|
| 32 |
+
type=CIBenchDataset,
|
| 33 |
+
path=f'./data/cibench_dataset/cibench_template{lib}',
|
| 34 |
+
internet_check=False,
|
| 35 |
+
reader_cfg=cibench_reader_cfg,
|
| 36 |
+
infer_cfg=cibench_infer_cfg,
|
| 37 |
+
eval_cfg=cibench_eval_cfg,
|
| 38 |
+
) for lib in libs
|
| 39 |
+
]
|
build/lib/opencompass/configs/datasets/CIBench/CIBench_template_oracle_gen_fecda1.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import AgentInferencer
|
| 4 |
+
|
| 5 |
+
from opencompass.datasets import CIBenchDataset, CIBenchEvaluator
|
| 6 |
+
|
| 7 |
+
cibench_reader_cfg = dict(
|
| 8 |
+
input_columns=['questions'],
|
| 9 |
+
output_column='references',
|
| 10 |
+
train_split='test',
|
| 11 |
+
test_split='test')
|
| 12 |
+
|
| 13 |
+
cibench_infer_cfg = dict(
|
| 14 |
+
prompt_template=dict(
|
| 15 |
+
type=PromptTemplate,
|
| 16 |
+
template="""{questions}""",
|
| 17 |
+
),
|
| 18 |
+
retriever=dict(type=ZeroRetriever),
|
| 19 |
+
inferencer=dict(type=AgentInferencer, infer_mode='every_with_gt'),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
# no tensorboard
|
| 23 |
+
libs = ['/lightgbm', '/matplotlib', '/nltk', '/opencv', '/pandas', '/pytorch',
|
| 24 |
+
'/scipy', '/seaborn', '/sklearn', '/tensorflow',
|
| 25 |
+
'_chinese/lightgbm', '_chinese/matplotlib', '_chinese/nltk',
|
| 26 |
+
'_chinese/opencv', '_chinese/pandas', '_chinese/pytorch',
|
| 27 |
+
'_chinese/scipy', '_chinese/seaborn', '_chinese/sklearn', '_chinese/tensorflow']
|
| 28 |
+
cibench_eval_cfg = dict(evaluator=dict(type=CIBenchEvaluator), pred_role='BOT')
|
| 29 |
+
cibench_datasets = [
|
| 30 |
+
dict(
|
| 31 |
+
abbr=f'cibench_template_oracle{lib}',
|
| 32 |
+
type=CIBenchDataset,
|
| 33 |
+
path=f'./data/cibench_dataset/cibench_template{lib}',
|
| 34 |
+
internet_check=False,
|
| 35 |
+
reader_cfg=cibench_reader_cfg,
|
| 36 |
+
infer_cfg=cibench_infer_cfg,
|
| 37 |
+
eval_cfg=cibench_eval_cfg,
|
| 38 |
+
) for lib in libs
|
| 39 |
+
]
|
build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .CLUE_C3_gen_8c358f import C3_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen_8c358f.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import GenInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import C3Dataset_V2
|
| 6 |
+
from opencompass.utils.text_postprocessors import first_capital_postprocess
|
| 7 |
+
|
| 8 |
+
C3_reader_cfg = dict(
|
| 9 |
+
input_columns=[
|
| 10 |
+
'question',
|
| 11 |
+
'content',
|
| 12 |
+
'choice0',
|
| 13 |
+
'choice1',
|
| 14 |
+
'choice2',
|
| 15 |
+
'choice3',
|
| 16 |
+
'choices',
|
| 17 |
+
],
|
| 18 |
+
output_column='label',
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
C3_infer_cfg = dict(
|
| 22 |
+
prompt_template=dict(
|
| 23 |
+
type=PromptTemplate,
|
| 24 |
+
template=dict(round=[
|
| 25 |
+
dict(
|
| 26 |
+
role='HUMAN',
|
| 27 |
+
prompt=
|
| 28 |
+
'{content}\n问:{question}\nA. {choice0}\nB. {choice1}\nC. {choice2}\nD. {choice3}\n请从“A”,“B”,“C”,“D”中进行选择。\n答:',
|
| 29 |
+
),
|
| 30 |
+
]),
|
| 31 |
+
),
|
| 32 |
+
retriever=dict(type=ZeroRetriever),
|
| 33 |
+
inferencer=dict(type=GenInferencer),
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
C3_eval_cfg = dict(
|
| 37 |
+
evaluator=dict(type=AccEvaluator),
|
| 38 |
+
pred_role='BOT',
|
| 39 |
+
pred_postprocessor=dict(type=first_capital_postprocess),
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
C3_datasets = [
|
| 43 |
+
dict(
|
| 44 |
+
abbr='C3',
|
| 45 |
+
type=C3Dataset_V2,
|
| 46 |
+
path='./data/CLUE/C3/dev_0.json',
|
| 47 |
+
reader_cfg=C3_reader_cfg,
|
| 48 |
+
infer_cfg=C3_infer_cfg,
|
| 49 |
+
eval_cfg=C3_eval_cfg,
|
| 50 |
+
)
|
| 51 |
+
]
|
build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .CLUE_C3_ppl_e24a31 import C3_datasets # noqa: F401, F403
|
build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl_56b537.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import C3Dataset
|
| 6 |
+
|
| 7 |
+
C3_reader_cfg = dict(
|
| 8 |
+
input_columns=[
|
| 9 |
+
'question', 'content', 'choice0', 'choice1', 'choice2', 'choice3',
|
| 10 |
+
'choices'
|
| 11 |
+
],
|
| 12 |
+
output_column='label')
|
| 13 |
+
|
| 14 |
+
C3_infer_cfg = dict(
|
| 15 |
+
prompt_template=dict(
|
| 16 |
+
type=PromptTemplate,
|
| 17 |
+
template={
|
| 18 |
+
0: '文章:{content}\n问题:{question}\n答案:{choice0}',
|
| 19 |
+
1: '文章:{content}\n问题:{question}\n答案:{choice1}',
|
| 20 |
+
2: '文章:{content}\n问题:{question}\n答案:{choice2}',
|
| 21 |
+
3: '文章:{content}\n问题:{question}\n答案:{choice3}'
|
| 22 |
+
}),
|
| 23 |
+
retriever=dict(type=ZeroRetriever),
|
| 24 |
+
inferencer=dict(type=PPLInferencer))
|
| 25 |
+
|
| 26 |
+
C3_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 27 |
+
|
| 28 |
+
C3_datasets = [
|
| 29 |
+
dict(
|
| 30 |
+
type=C3Dataset,
|
| 31 |
+
abbr='C3',
|
| 32 |
+
path='./data/CLUE/C3/dev_0.json',
|
| 33 |
+
reader_cfg=C3_reader_cfg,
|
| 34 |
+
infer_cfg=C3_infer_cfg,
|
| 35 |
+
eval_cfg=C3_eval_cfg)
|
| 36 |
+
]
|
build/lib/opencompass/configs/datasets/CLUE_C3/CLUE_C3_ppl_e24a31.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
| 2 |
+
from opencompass.openicl.icl_retriever import ZeroRetriever
|
| 3 |
+
from opencompass.openicl.icl_inferencer import PPLInferencer
|
| 4 |
+
from opencompass.openicl.icl_evaluator import AccEvaluator
|
| 5 |
+
from opencompass.datasets import C3Dataset
|
| 6 |
+
|
| 7 |
+
C3_reader_cfg = dict(
|
| 8 |
+
input_columns=[
|
| 9 |
+
'question', 'content', 'choice0', 'choice1', 'choice2', 'choice3',
|
| 10 |
+
'choices'
|
| 11 |
+
],
|
| 12 |
+
output_column='label')
|
| 13 |
+
|
| 14 |
+
C3_infer_cfg = dict(
|
| 15 |
+
prompt_template=dict(
|
| 16 |
+
type=PromptTemplate,
|
| 17 |
+
template={
|
| 18 |
+
i: dict(round=[
|
| 19 |
+
dict(role='HUMAN', prompt='文章:{content}\n问题:{question}'),
|
| 20 |
+
dict(role='BOT', prompt=f'答案:{{choice{i}}}')
|
| 21 |
+
])
|
| 22 |
+
for i in range(4)
|
| 23 |
+
}),
|
| 24 |
+
retriever=dict(type=ZeroRetriever),
|
| 25 |
+
inferencer=dict(type=PPLInferencer))
|
| 26 |
+
|
| 27 |
+
C3_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
| 28 |
+
|
| 29 |
+
C3_datasets = [
|
| 30 |
+
dict(
|
| 31 |
+
type=C3Dataset,
|
| 32 |
+
abbr='C3',
|
| 33 |
+
path='./data/CLUE/C3/dev_0.json',
|
| 34 |
+
reader_cfg=C3_reader_cfg,
|
| 35 |
+
infer_cfg=C3_infer_cfg,
|
| 36 |
+
eval_cfg=C3_eval_cfg)
|
| 37 |
+
]
|
build/lib/opencompass/configs/datasets/CLUE_CMRC/CLUE_CMRC_gen.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from .CLUE_CMRC_gen_1bd3c8 import CMRC_datasets # noqa: F401, F403
|