
Add files using upload-large-folder tool
Browse files- .cache/dataset_size.json +25 -0
- .codespellrc +5 -0
- .eggs/README.txt +6 -0
- .github/pull_request_template.md +32 -0
- .gitignore +135 -0
- .owners.yml +14 -0
- .pre-commit-config-zh-cn.yaml +123 -0
- .pre-commit-config.yaml +124 -0
- LICENSE +203 -0
- MANIFEST.in +3 -0
- README.md +439 -0
- README_zh-CN.md +430 -0
- a.sh +6 -0
- dataset-index.yml +1157 -0
- examples/eval_PMMEval.py +29 -0
- examples/eval_TheoremQA.py +21 -0
- examples/eval_academic_leaderboard_202407.py +192 -0
- examples/eval_academic_leaderboard_REALTIME.py +131 -0
- examples/eval_alaya.py +15 -0
- examples/eval_api_demo.py +12 -0
- examples/eval_bluelm_32k_lveval.py +14 -0
- examples/eval_charm_mem.py +89 -0
- examples/eval_code_passk_repeat_dataset.py +58 -0
- examples/eval_codegeex2.py +8 -0
- examples/eval_compassarena_subjectivebench.py +103 -0
- examples/eval_hf_llama2.py +28 -0
- opencompass.egg-info/PKG-INFO +745 -0
- opencompass.egg-info/SOURCES.txt +0 -0
- opencompass.egg-info/dependency_links.txt +1 -0
- opencompass.egg-info/entry_points.txt +2 -0
- opencompass.egg-info/requires.txt +277 -0
- opencompass.egg-info/top_level.txt +1 -0
- opencompass/__init__.py +1 -0
- opencompass/registry.py +55 -0
- requirements.txt +1 -0
- requirements/agent.txt +13 -0
- requirements/api.txt +17 -0
- requirements/docs.txt +11 -0
- requirements/extra.txt +25 -0
- requirements/lmdeploy.txt +1 -0
- requirements/runtime.txt +50 -0
- run.py +4 -0
- setup.py +164 -0
- test.py +49 -0
- tmp/03190095-e58f-4a23-94a4-053ce43e2e48_params.py +0 -0
- tmp/03694f9b-bf79-4b1c-9dd9-d2cf087ec1cd_params.py +0 -0
- tmp/06837656-e189-4cad-8d53-f175cf579961_params.py +1424 -0
- tmp/072e98a5-13a4-44fd-91a0-f552368807b5_params.py +53 -0
- tmp/07b289dd-41fd-4f58-8c9b-e55ce7391d79_params.py +50 -0
- tmp/07f59276-08b3-4e03-ba78-cdcd5f4d49d1_params.py +1421 -0
.cache/dataset_size.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"demo_gsm8k": 64,
|
| 3 |
+
"LongBench_2wikimqa": 200,
|
| 4 |
+
"LongBench_hotpotqa": 200,
|
| 5 |
+
"LongBench_musique": 200,
|
| 6 |
+
"LongBench_multifieldqa_en": 150,
|
| 7 |
+
"LongBench_multifieldqa_zh": 200,
|
| 8 |
+
"LongBench_narrativeqa": 200,
|
| 9 |
+
"LongBench_qasper": 200,
|
| 10 |
+
"LongBench_triviaqa": 200,
|
| 11 |
+
"LongBench_gov_report": 200,
|
| 12 |
+
"LongBench_qmsum": 200,
|
| 13 |
+
"LongBench_vcsum": 200,
|
| 14 |
+
"LongBench_dureader": 200,
|
| 15 |
+
"LongBench_lcc": 500,
|
| 16 |
+
"LongBench_repobench-p": 500,
|
| 17 |
+
"LongBench_passage_retrieval_en": 200,
|
| 18 |
+
"LongBench_passage_retrieval_zh": 200,
|
| 19 |
+
"LongBench_passage_count": 200,
|
| 20 |
+
"LongBench_trec": 200,
|
| 21 |
+
"LongBench_lsht": 200,
|
| 22 |
+
"LongBench_multi_news": 200,
|
| 23 |
+
"LongBench_samsum": 200,
|
| 24 |
+
"triviaqa_wiki_1shot": 7993
|
| 25 |
+
}
|
.codespellrc
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[codespell]
|
| 2 |
+
skip = *.ipynb
|
| 3 |
+
count =
|
| 4 |
+
quiet-level = 3
|
| 5 |
+
ignore-words-list = nd, ans, ques, rouge, softwares, wit
|
.eggs/README.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This directory contains eggs that were downloaded by setuptools to build, test, and run plug-ins.
|
| 2 |
+
|
| 3 |
+
This directory caches those eggs to prevent repeated downloads.
|
| 4 |
+
|
| 5 |
+
However, it is safe to delete this directory.
|
| 6 |
+
|
.github/pull_request_template.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Thanks for your contribution and we appreciate it a lot. The following instructions would make your pull request more healthy and more easily get feedback. If you do not understand some items, don't worry, just make the pull request and seek help from maintainers.
|
| 2 |
+
|
| 3 |
+
## Motivation
|
| 4 |
+
|
| 5 |
+
Please describe the motivation of this PR and the goal you want to achieve through this PR.
|
| 6 |
+
|
| 7 |
+
## Modification
|
| 8 |
+
|
| 9 |
+
Please briefly describe what modification is made in this PR.
|
| 10 |
+
|
| 11 |
+
## BC-breaking (Optional)
|
| 12 |
+
|
| 13 |
+
Does the modification introduce changes that break the backward compatibility of the downstream repositories?
|
| 14 |
+
If so, please describe how it breaks the compatibility and how the downstream projects should modify their code to keep compatibility with this PR.
|
| 15 |
+
|
| 16 |
+
## Use cases (Optional)
|
| 17 |
+
|
| 18 |
+
If this PR introduces a new feature, it is better to list some use cases here and update the documentation.
|
| 19 |
+
|
| 20 |
+
## Checklist
|
| 21 |
+
|
| 22 |
+
**Before PR**:
|
| 23 |
+
|
| 24 |
+
- [ ] Pre-commit or other linting tools are used to fix the potential lint issues.
|
| 25 |
+
- [ ] Bug fixes are fully covered by unit tests, the case that causes the bug should be added in the unit tests.
|
| 26 |
+
- [ ] The modification is covered by complete unit tests. If not, please add more unit test to ensure the correctness.
|
| 27 |
+
- [ ] The documentation has been modified accordingly, like docstring or example tutorials.
|
| 28 |
+
|
| 29 |
+
**After PR**:
|
| 30 |
+
|
| 31 |
+
- [ ] If the modification has potential influence on downstream or other related projects, this PR should be tested with those projects.
|
| 32 |
+
- [ ] CLA has been signed and all committers have signed the CLA in this PR.
|
.gitignore
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
output_*/
|
| 3 |
+
outputs/
|
| 4 |
+
scripts/
|
| 5 |
+
icl_inference_output/
|
| 6 |
+
.vscode/
|
| 7 |
+
tmp/
|
| 8 |
+
configs/eval_subjective_alignbench_test.py
|
| 9 |
+
configs/openai_key.py
|
| 10 |
+
configs/secrets.py
|
| 11 |
+
configs/datasets/log.json
|
| 12 |
+
configs/eval_debug*.py
|
| 13 |
+
configs/viz_*.py
|
| 14 |
+
configs/**/*_bkup.py
|
| 15 |
+
opencompass/**/*_bkup.py
|
| 16 |
+
data
|
| 17 |
+
work_dirs
|
| 18 |
+
outputs
|
| 19 |
+
models/*
|
| 20 |
+
configs/internal/
|
| 21 |
+
# Byte-compiled / optimized / DLL files
|
| 22 |
+
__pycache__/
|
| 23 |
+
*.py[cod]
|
| 24 |
+
*$py.class
|
| 25 |
+
*.ipynb
|
| 26 |
+
|
| 27 |
+
# C extensions
|
| 28 |
+
*.so
|
| 29 |
+
|
| 30 |
+
# Distribution / packaging
|
| 31 |
+
.Python
|
| 32 |
+
build/
|
| 33 |
+
develop-eggs/
|
| 34 |
+
dist/
|
| 35 |
+
downloads/
|
| 36 |
+
eggs/
|
| 37 |
+
.eggs/
|
| 38 |
+
lib/
|
| 39 |
+
lib64/
|
| 40 |
+
parts/
|
| 41 |
+
sdist/
|
| 42 |
+
var/
|
| 43 |
+
wheels/
|
| 44 |
+
*.egg-info/
|
| 45 |
+
.installed.cfg
|
| 46 |
+
*.egg
|
| 47 |
+
MANIFEST
|
| 48 |
+
|
| 49 |
+
# PyInstaller
|
| 50 |
+
# Usually these files are written by a python script from a template
|
| 51 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 52 |
+
*.manifest
|
| 53 |
+
*.spec
|
| 54 |
+
|
| 55 |
+
# Installer logs
|
| 56 |
+
pip-log.txt
|
| 57 |
+
pip-delete-this-directory.txt
|
| 58 |
+
|
| 59 |
+
# Unit test / coverage reports
|
| 60 |
+
htmlcov/
|
| 61 |
+
.tox/
|
| 62 |
+
.coverage
|
| 63 |
+
.coverage.*
|
| 64 |
+
.cache
|
| 65 |
+
nosetests.xml
|
| 66 |
+
coverage.xml
|
| 67 |
+
*.cover
|
| 68 |
+
.hypothesis/
|
| 69 |
+
.pytest_cache/
|
| 70 |
+
|
| 71 |
+
# Translations
|
| 72 |
+
*.mo
|
| 73 |
+
*.pot
|
| 74 |
+
|
| 75 |
+
# Django stuff:
|
| 76 |
+
*.log
|
| 77 |
+
local_settings.py
|
| 78 |
+
db.sqlite3
|
| 79 |
+
|
| 80 |
+
# Flask stuff:
|
| 81 |
+
instance/
|
| 82 |
+
.webassets-cache
|
| 83 |
+
|
| 84 |
+
# Scrapy stuff:
|
| 85 |
+
.scrapy
|
| 86 |
+
|
| 87 |
+
.idea
|
| 88 |
+
|
| 89 |
+
# Auto generate documentation
|
| 90 |
+
docs/en/_build/
|
| 91 |
+
docs/zh_cn/_build/
|
| 92 |
+
|
| 93 |
+
# .zip
|
| 94 |
+
*.zip
|
| 95 |
+
|
| 96 |
+
# sft config ignore list
|
| 97 |
+
configs/sft_cfg/*B_*
|
| 98 |
+
configs/sft_cfg/1B/*
|
| 99 |
+
configs/sft_cfg/7B/*
|
| 100 |
+
configs/sft_cfg/20B/*
|
| 101 |
+
configs/sft_cfg/60B/*
|
| 102 |
+
configs/sft_cfg/100B/*
|
| 103 |
+
|
| 104 |
+
configs/cky/
|
| 105 |
+
configs/_internal_legacy*
|
| 106 |
+
# in case llama clone in the opencompass
|
| 107 |
+
llama/
|
| 108 |
+
|
| 109 |
+
# in case ilagent clone in the opencompass
|
| 110 |
+
ilagent/
|
| 111 |
+
|
| 112 |
+
# ignore the config file for criticbench evaluation
|
| 113 |
+
configs/sft_cfg/criticbench_eval/*
|
| 114 |
+
|
| 115 |
+
# path of turbomind's model after runing `lmdeploy.serve.turbomind.deploy`
|
| 116 |
+
turbomind/
|
| 117 |
+
|
| 118 |
+
# cibench output
|
| 119 |
+
*.db
|
| 120 |
+
*.pth
|
| 121 |
+
*.pt
|
| 122 |
+
*.onnx
|
| 123 |
+
*.gz
|
| 124 |
+
*.gz.*
|
| 125 |
+
*.png
|
| 126 |
+
*.txt
|
| 127 |
+
*.jpg
|
| 128 |
+
*.json
|
| 129 |
+
*.jsonl
|
| 130 |
+
*.csv
|
| 131 |
+
*.npy
|
| 132 |
+
*.c
|
| 133 |
+
|
| 134 |
+
# aliyun
|
| 135 |
+
core.*
|
.owners.yml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
assign:
|
| 2 |
+
issues: enabled
|
| 3 |
+
pull_requests: disabled
|
| 4 |
+
strategy:
|
| 5 |
+
# random
|
| 6 |
+
daily-shift-based
|
| 7 |
+
scedule:
|
| 8 |
+
'*/1 * * * *'
|
| 9 |
+
assignees:
|
| 10 |
+
- bittersweet1999
|
| 11 |
+
- liushz
|
| 12 |
+
- MaiziXiao
|
| 13 |
+
- acylam
|
| 14 |
+
- tonysy
|
.pre-commit-config-zh-cn.yaml
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
tests/data/|
|
| 4 |
+
tests/dataset/|
|
| 5 |
+
opencompass/models/internal/|
|
| 6 |
+
opencompass/utils/internal/|
|
| 7 |
+
opencompass/openicl/icl_evaluator/hf_metrics/|
|
| 8 |
+
opencompass/datasets/lawbench/utils|
|
| 9 |
+
opencompass/datasets/lawbench/evaluation_functions/|
|
| 10 |
+
opencompass/datasets/medbench/|
|
| 11 |
+
opencompass/datasets/teval/|
|
| 12 |
+
opencompass/datasets/NPHardEval/|
|
| 13 |
+
opencompass/datasets/TheoremQA|
|
| 14 |
+
opencompass/datasets/subjective/mtbench101.py|
|
| 15 |
+
docs/zh_cn/advanced_guides/compassbench_intro.md |
|
| 16 |
+
docs/zh_cn/advanced_guides/compassbench_v2_0.md |
|
| 17 |
+
opencompass/utils/datasets.py |
|
| 18 |
+
opencompass/utils/datasets_info.py
|
| 19 |
+
)
|
| 20 |
+
repos:
|
| 21 |
+
- repo: https://gitee.com/openmmlab/mirrors-flake8
|
| 22 |
+
rev: 5.0.4
|
| 23 |
+
hooks:
|
| 24 |
+
- id: flake8
|
| 25 |
+
exclude: |
|
| 26 |
+
(?x)^(
|
| 27 |
+
opencompass/configs/|
|
| 28 |
+
examples/
|
| 29 |
+
)
|
| 30 |
+
- repo: https://gitee.com/openmmlab/mirrors-isort
|
| 31 |
+
rev: 5.11.5
|
| 32 |
+
hooks:
|
| 33 |
+
- id: isort
|
| 34 |
+
exclude: |
|
| 35 |
+
(?x)^(
|
| 36 |
+
opencompass/configs/|
|
| 37 |
+
examples/
|
| 38 |
+
)
|
| 39 |
+
- repo: https://gitee.com/openmmlab/mirrors-yapf
|
| 40 |
+
rev: v0.32.0
|
| 41 |
+
hooks:
|
| 42 |
+
- id: yapf
|
| 43 |
+
exclude: |
|
| 44 |
+
(?x)^(
|
| 45 |
+
opencompass/configs/|
|
| 46 |
+
examples/
|
| 47 |
+
)
|
| 48 |
+
- repo: https://gitee.com/openmmlab/mirrors-codespell
|
| 49 |
+
rev: v2.2.1
|
| 50 |
+
hooks:
|
| 51 |
+
- id: codespell
|
| 52 |
+
exclude: |
|
| 53 |
+
(?x)^(
|
| 54 |
+
.*\.jsonl|
|
| 55 |
+
.*\.md.template|
|
| 56 |
+
opencompass/configs/ |
|
| 57 |
+
examples/
|
| 58 |
+
)
|
| 59 |
+
- repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
|
| 60 |
+
rev: v4.3.0
|
| 61 |
+
hooks:
|
| 62 |
+
- id: trailing-whitespace
|
| 63 |
+
exclude: |
|
| 64 |
+
(?x)^(
|
| 65 |
+
dicts/|
|
| 66 |
+
projects/.*?/dicts/|
|
| 67 |
+
)
|
| 68 |
+
- id: check-yaml
|
| 69 |
+
- id: end-of-file-fixer
|
| 70 |
+
exclude: |
|
| 71 |
+
(?x)^(
|
| 72 |
+
dicts/|
|
| 73 |
+
projects/.*?/dicts/|
|
| 74 |
+
)
|
| 75 |
+
- id: requirements-txt-fixer
|
| 76 |
+
- id: double-quote-string-fixer
|
| 77 |
+
- id: check-merge-conflict
|
| 78 |
+
- id: fix-encoding-pragma
|
| 79 |
+
args: ["--remove"]
|
| 80 |
+
- id: mixed-line-ending
|
| 81 |
+
args: ["--fix=lf"]
|
| 82 |
+
- repo: https://gitee.com/openmmlab/mirrors-mdformat
|
| 83 |
+
rev: 0.7.9
|
| 84 |
+
hooks:
|
| 85 |
+
- id: mdformat
|
| 86 |
+
args: ["--number", "--table-width", "200"]
|
| 87 |
+
additional_dependencies:
|
| 88 |
+
- mdformat-openmmlab
|
| 89 |
+
- mdformat_frontmatter
|
| 90 |
+
- linkify-it-py
|
| 91 |
+
exclude: configs/
|
| 92 |
+
- repo: https://gitee.com/openmmlab/mirrors-docformatter
|
| 93 |
+
rev: v1.3.1
|
| 94 |
+
hooks:
|
| 95 |
+
- id: docformatter
|
| 96 |
+
args: ["--in-place", "--wrap-descriptions", "79"]
|
| 97 |
+
- repo: local
|
| 98 |
+
hooks:
|
| 99 |
+
- id: update-dataset-suffix
|
| 100 |
+
name: dataset suffix updater
|
| 101 |
+
entry: ./tools/update_dataset_suffix.py
|
| 102 |
+
language: script
|
| 103 |
+
pass_filenames: true
|
| 104 |
+
require_serial: true
|
| 105 |
+
files: ^opencompass/configs/datasets
|
| 106 |
+
- repo: local
|
| 107 |
+
hooks:
|
| 108 |
+
- id: update-dataset-suffix-pacakge
|
| 109 |
+
name: dataset suffix updater(package)
|
| 110 |
+
entry: ./tools/update_dataset_suffix.py
|
| 111 |
+
language: script
|
| 112 |
+
pass_filenames: false
|
| 113 |
+
# require_serial: true
|
| 114 |
+
# files: ^opencompass/configs/datasets
|
| 115 |
+
args:
|
| 116 |
+
- --root_folder
|
| 117 |
+
- opencompass/configs/datasets
|
| 118 |
+
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
| 119 |
+
# rev: v0.2.0 # Use the ref you want to point at
|
| 120 |
+
# hooks:
|
| 121 |
+
# - id: check-algo-readme
|
| 122 |
+
# - id: check-copyright
|
| 123 |
+
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
tests/data/|
|
| 4 |
+
tests/dataset/|
|
| 5 |
+
opencompass/models/internal/|
|
| 6 |
+
opencompass/utils/internal/|
|
| 7 |
+
opencompass/openicl/icl_evaluator/hf_metrics/|
|
| 8 |
+
opencompass/datasets/lawbench/utils|
|
| 9 |
+
opencompass/datasets/lawbench/evaluation_functions/|
|
| 10 |
+
opencompass/datasets/medbench/|
|
| 11 |
+
opencompass/datasets/matbench/|
|
| 12 |
+
opencompass/datasets/teval/|
|
| 13 |
+
opencompass/datasets/NPHardEval/|
|
| 14 |
+
opencompass/datasets/TheoremQA|
|
| 15 |
+
opencompass/datasets/subjective/mtbench101.py|
|
| 16 |
+
docs/zh_cn/advanced_guides/compassbench_intro.md |
|
| 17 |
+
docs/zh_cn/advanced_guides/compassbench_v2_0.md |
|
| 18 |
+
opencompass/utils/datasets.py |
|
| 19 |
+
opencompass/utils/datasets_info.py
|
| 20 |
+
)
|
| 21 |
+
repos:
|
| 22 |
+
- repo: https://github.com/PyCQA/flake8
|
| 23 |
+
rev: 5.0.4
|
| 24 |
+
hooks:
|
| 25 |
+
- id: flake8
|
| 26 |
+
exclude: |
|
| 27 |
+
(?x)^(
|
| 28 |
+
opencompass/configs/|
|
| 29 |
+
examples/
|
| 30 |
+
)
|
| 31 |
+
- repo: https://github.com/PyCQA/isort
|
| 32 |
+
rev: 5.11.5
|
| 33 |
+
hooks:
|
| 34 |
+
- id: isort
|
| 35 |
+
exclude: |
|
| 36 |
+
(?x)^(
|
| 37 |
+
opencompass/configs/|
|
| 38 |
+
examples/
|
| 39 |
+
)
|
| 40 |
+
- repo: https://github.com/pre-commit/mirrors-yapf
|
| 41 |
+
rev: v0.32.0
|
| 42 |
+
hooks:
|
| 43 |
+
- id: yapf
|
| 44 |
+
exclude: |
|
| 45 |
+
(?x)^(
|
| 46 |
+
opencompass/configs/|
|
| 47 |
+
examples/
|
| 48 |
+
)
|
| 49 |
+
- repo: https://github.com/codespell-project/codespell
|
| 50 |
+
rev: v2.2.1
|
| 51 |
+
hooks:
|
| 52 |
+
- id: codespell
|
| 53 |
+
exclude: |
|
| 54 |
+
(?x)^(
|
| 55 |
+
.*\.jsonl|
|
| 56 |
+
.*\.md.template|
|
| 57 |
+
opencompass/configs/ |
|
| 58 |
+
examples/
|
| 59 |
+
)
|
| 60 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 61 |
+
rev: v5.0.0
|
| 62 |
+
hooks:
|
| 63 |
+
- id: trailing-whitespace
|
| 64 |
+
exclude: |
|
| 65 |
+
(?x)^(
|
| 66 |
+
dicts/|
|
| 67 |
+
projects/.*?/dicts/|
|
| 68 |
+
)
|
| 69 |
+
- id: check-yaml
|
| 70 |
+
- id: end-of-file-fixer
|
| 71 |
+
exclude: |
|
| 72 |
+
(?x)^(
|
| 73 |
+
dicts/|
|
| 74 |
+
projects/.*?/dicts/|
|
| 75 |
+
)
|
| 76 |
+
- id: requirements-txt-fixer
|
| 77 |
+
- id: double-quote-string-fixer
|
| 78 |
+
- id: check-merge-conflict
|
| 79 |
+
- id: fix-encoding-pragma
|
| 80 |
+
args: ["--remove"]
|
| 81 |
+
- id: mixed-line-ending
|
| 82 |
+
args: ["--fix=lf"]
|
| 83 |
+
- repo: https://github.com/executablebooks/mdformat
|
| 84 |
+
rev: 0.7.9
|
| 85 |
+
hooks:
|
| 86 |
+
- id: mdformat
|
| 87 |
+
args: ["--number", "--table-width", "200"]
|
| 88 |
+
additional_dependencies:
|
| 89 |
+
- mdformat-openmmlab
|
| 90 |
+
- mdformat_frontmatter
|
| 91 |
+
- linkify-it-py
|
| 92 |
+
exclude: configs/
|
| 93 |
+
# - repo: https://github.com/myint/docformatter
|
| 94 |
+
# rev: v1.3.1
|
| 95 |
+
# hooks:
|
| 96 |
+
# - id: docformatter
|
| 97 |
+
# args: ["--in-place", "--wrap-descriptions", "79"]
|
| 98 |
+
- repo: local
|
| 99 |
+
hooks:
|
| 100 |
+
- id: update-dataset-suffix
|
| 101 |
+
name: dataset suffix updater
|
| 102 |
+
entry: ./tools/update_dataset_suffix.py
|
| 103 |
+
language: script
|
| 104 |
+
pass_filenames: true
|
| 105 |
+
require_serial: true
|
| 106 |
+
files: ^opencompass/configs/datasets
|
| 107 |
+
- repo: local
|
| 108 |
+
hooks:
|
| 109 |
+
- id: update-dataset-suffix-pacakge
|
| 110 |
+
name: dataset suffix updater(package)
|
| 111 |
+
entry: ./tools/update_dataset_suffix.py
|
| 112 |
+
language: script
|
| 113 |
+
pass_filenames: false
|
| 114 |
+
# require_serial: true
|
| 115 |
+
# files: ^opencompass/configs/datasets
|
| 116 |
+
args:
|
| 117 |
+
- --root_folder
|
| 118 |
+
- opencompass/configs/datasets
|
| 119 |
+
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
| 120 |
+
# rev: v0.2.0 # Use the ref you want to point at
|
| 121 |
+
# hooks:
|
| 122 |
+
# - id: check-algo-readme
|
| 123 |
+
# - id: check-copyright
|
| 124 |
+
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2020 OpenCompass Authors. All rights reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2020 OpenCompass Authors.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
MANIFEST.in
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
recursive-include opencompass/configs *.py *.yml *.json *.txt *.md
|
| 2 |
+
recursive-include opencompass/openicl/icl_evaluator/hf_metrics *.py
|
| 3 |
+
recursive-include opencompass/datasets *.py *.yml *.json *.txt *.md *.yaml
|
README.md
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="docs/en/_static/image/logo.svg" width="500px"/>
|
| 3 |
+
<br />
|
| 4 |
+
<br />
|
| 5 |
+
|
| 6 |
+
[![][github-release-shield]][github-release-link]
|
| 7 |
+
[![][github-releasedate-shield]][github-releasedate-link]
|
| 8 |
+
[![][github-contributors-shield]][github-contributors-link]<br>
|
| 9 |
+
[![][github-forks-shield]][github-forks-link]
|
| 10 |
+
[![][github-stars-shield]][github-stars-link]
|
| 11 |
+
[![][github-issues-shield]][github-issues-link]
|
| 12 |
+
[![][github-license-shield]][github-license-link]
|
| 13 |
+
|
| 14 |
+
<!-- [](https://pypi.org/project/opencompass/) -->
|
| 15 |
+
|
| 16 |
+
[🌐Website](https://opencompass.org.cn/) |
|
| 17 |
+
[📖CompassHub](https://hub.opencompass.org.cn/home) |
|
| 18 |
+
[📊CompassRank](https://rank.opencompass.org.cn/home) |
|
| 19 |
+
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
|
| 20 |
+
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
|
| 21 |
+
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
| 22 |
+
|
| 23 |
+
English | [简体中文](README_zh-CN.md)
|
| 24 |
+
|
| 25 |
+
[![][github-trending-shield]][github-trending-url]
|
| 26 |
+
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
<p align="center">
|
| 30 |
+
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
|
| 31 |
+
</p>
|
| 32 |
+
|
| 33 |
+
> \[!IMPORTANT\]
|
| 34 |
+
>
|
| 35 |
+
> **Star Us**, You will receive all release notifications from GitHub without any delay ~ ⭐️
|
| 36 |
+
|
| 37 |
+
<details>
|
| 38 |
+
<summary><kbd>Star History</kbd></summary>
|
| 39 |
+
<picture>
|
| 40 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
|
| 41 |
+
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
|
| 42 |
+
</picture>
|
| 43 |
+
</details>
|
| 44 |
+
|
| 45 |
+
## 🧭 Welcome
|
| 46 |
+
|
| 47 |
+
to **OpenCompass**!
|
| 48 |
+
|
| 49 |
+
Just like a compass guides us on our journey, OpenCompass will guide you through the complex landscape of evaluating large language models. With its powerful algorithms and intuitive interface, OpenCompass makes it easy to assess the quality and effectiveness of your NLP models.
|
| 50 |
+
|
| 51 |
+
🚩🚩🚩 Explore opportunities at OpenCompass! We're currently **hiring full-time researchers/engineers and interns**. If you're passionate about LLM and OpenCompass, don't hesitate to reach out to us via [email](mailto:zhangsongyang@pjlab.org.cn). We'd love to hear from you!
|
| 52 |
+
|
| 53 |
+
🔥🔥🔥 We are delighted to announce that **the OpenCompass has been recommended by the Meta AI**, click [Get Started](https://ai.meta.com/llama/get-started/#validation) of Llama for more information.
|
| 54 |
+
|
| 55 |
+
> **Attention**<br />
|
| 56 |
+
> Breaking Change Notice: In version 0.4.0, we are consolidating all AMOTIC configuration files (previously located in ./configs/datasets, ./configs/models, and ./configs/summarizers) into the opencompass package. Users are advised to update their configuration references to reflect this structural change.
|
| 57 |
+
|
| 58 |
+
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
| 59 |
+
|
| 60 |
+
- **\[2025.07.26\]** OpenCompass now supports Intern-S1 related general and scientific evaluation benchmarks. Please check [Tutorial for Evaluating Intern-S1](https://opencompass.readthedocs.io/en/latest/user_guides/interns1.html) for more details! 🔥🔥🔥
|
| 61 |
+
- **\[2025.04.01\]** OpenCompass now supports `CascadeEvaluator`, a flexible evaluation mechanism that allows multiple evaluators to work in sequence. This enables creating customized evaluation pipelines for complex assessment scenarios. Check out the [documentation](docs/en/advanced_guides/llm_judge.md) for more details! 🔥🔥🔥
|
| 62 |
+
- **\[2025.03.11\]** We have supported evaluation for `SuperGPQA` which is a great benchmark for measuring LLM knowledge ability 🔥🔥🔥
|
| 63 |
+
- **\[2025.02.28\]** We have added a tutorial for `DeepSeek-R1` series model, please check [Evaluating Reasoning Model](docs/en/user_guides/deepseek_r1.md) for more details! 🔥🔥🔥
|
| 64 |
+
- **\[2025.02.15\]** We have added two powerful evaluation tools: `GenericLLMEvaluator` for LLM-as-judge evaluations and `MATHVerifyEvaluator` for mathematical reasoning assessments. Check out the documentation for [LLM Judge](docs/en/advanced_guides/llm_judge.md) and [Math Evaluation](docs/en/advanced_guides/general_math.md) for more details! 🔥🔥🔥
|
| 65 |
+
- **\[2025.01.16\]** We now support the [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) model which has enhanced performance on reasoning and knowledge-intensive tasks.
|
| 66 |
+
- **\[2024.12.17\]** We have provided the evaluation script for the December [CompassAcademic](examples/eval_academic_leaderboard_202412.py), which allows users to easily reproduce the official evaluation results by configuring it.
|
| 67 |
+
- **\[2024.11.14\]** OpenCompass now offers support for a sophisticated benchmark designed to evaluate complex reasoning skills — [MuSR](https://arxiv.org/pdf/2310.16049). Check out the [demo](examples/eval_musr.py) and give it a spin! 🔥🔥🔥
|
| 68 |
+
- **\[2024.11.14\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [BABILong](https://arxiv.org/pdf/2406.10149). Have a look at the [demo](examples/eval_babilong.py) and give it a try! 🔥🔥🔥
|
| 69 |
+
- **\[2024.10.14\]** We now support the OpenAI multilingual QA dataset [MMMLU](https://huggingface.co/datasets/openai/MMMLU). Feel free to give it a try! 🔥🔥🔥
|
| 70 |
+
- **\[2024.09.19\]** We now support [Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) with multiple backend(huggingface/vllm/lmdeploy). Feel free to give them a try! 🔥🔥🔥
|
| 71 |
+
- **\[2024.09.17\]** We now support OpenAI o1(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`). Feel free to give them a try! 🔥🔥🔥
|
| 72 |
+
- **\[2024.09.05\]** We now support answer extraction through model post-processing to provide a more accurate representation of the model's capabilities. As part of this update, we have integrated [XFinder](https://github.com/IAAR-Shanghai/xFinder) as our first post-processing model. For more detailed information, please refer to the [documentation](opencompass/utils/postprocessors/xfinder/README.md), and give it a try! 🔥🔥🔥
|
| 73 |
+
- **\[2024.08.20\]** OpenCompass now supports the [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists. 🔥🔥🔥
|
| 74 |
+
- **\[2024.08.16\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [RULER](https://arxiv.org/pdf/2404.06654). RULER provides an evaluation of long-context including retrieval, multi-hop tracing, aggregation, and question answering through flexible configurations. Check out the [RULER](configs/datasets/ruler/README.md) evaluation config now! 🔥🔥🔥
|
| 75 |
+
- **\[2024.08.09\]** We have released the example data and configuration for the CompassBench-202408, welcome to [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) for more details. 🔥🔥🔥
|
| 76 |
+
- **\[2024.08.01\]** We supported the [Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315) models. Welcome to try! 🔥🔥🔥
|
| 77 |
+
- **\[2024.07.23\]** We supported the [ModelScope](www.modelscope.cn) datasets, you can load them on demand without downloading all the data to your local disk. Welcome to try! 🔥🔥🔥
|
| 78 |
+
- **\[2024.07.17\]** We are excited to announce the release of NeedleBench's [technical report](http://arxiv.org/abs/2407.11963). We invite you to visit our [support documentation](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html) for detailed evaluation guidelines. 🔥🔥🔥
|
| 79 |
+
- **\[2024.07.04\]** OpenCompass now supports InternLM2.5, which has **outstanding reasoning capability**, **1M Context window and** and **stronger tool use**, you can try the models in [OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) and [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
|
| 80 |
+
- **\[2024.06.20\]** OpenCompass now supports one-click switching between inference acceleration backends, enhancing the efficiency of the evaluation process. In addition to the default HuggingFace inference backend, it now also supports popular backends [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm). This feature is available via a simple command-line switch and through deployment APIs. For detailed usage, see the [documentation](docs/en/advanced_guides/accelerator_intro.md).🔥🔥🔥.
|
| 81 |
+
|
| 82 |
+
> [More](docs/en/notes/news.md)
|
| 83 |
+
|
| 84 |
+
## 📊 Leaderboard
|
| 85 |
+
|
| 86 |
+
We provide [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `opencompass@pjlab.org.cn`.
|
| 87 |
+
|
| 88 |
+
You can also refer to [Guide to Reproducing CompassAcademic Leaderboard Results](https://opencompass.readthedocs.io/zh-cn/latest/academic.html) to quickly reproduce the leaderboard results.
|
| 89 |
+
|
| 90 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 91 |
+
|
| 92 |
+
## 🛠️ Installation
|
| 93 |
+
|
| 94 |
+
Below are the steps for quick installation and datasets preparation.
|
| 95 |
+
|
| 96 |
+
### 💻 Environment Setup
|
| 97 |
+
|
| 98 |
+
We highly recommend using conda to manage your python environment.
|
| 99 |
+
|
| 100 |
+
- #### Create your virtual environment
|
| 101 |
+
|
| 102 |
+
```bash
|
| 103 |
+
conda create --name opencompass python=3.10 -y
|
| 104 |
+
conda activate opencompass
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
- #### Install OpenCompass via pip
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
pip install -U opencompass
|
| 111 |
+
|
| 112 |
+
## Full installation (with support for more datasets)
|
| 113 |
+
# pip install "opencompass[full]"
|
| 114 |
+
|
| 115 |
+
## Environment with model acceleration frameworks
|
| 116 |
+
## Manage different acceleration frameworks using virtual environments
|
| 117 |
+
## since they usually have dependency conflicts with each other.
|
| 118 |
+
# pip install "opencompass[lmdeploy]"
|
| 119 |
+
# pip install "opencompass[vllm]"
|
| 120 |
+
|
| 121 |
+
## API evaluation (i.e. Openai, Qwen)
|
| 122 |
+
# pip install "opencompass[api]"
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
- #### Install OpenCompass from source
|
| 126 |
+
|
| 127 |
+
If you want to use opencompass's latest features, or develop new features, you can also build it from source
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 131 |
+
cd opencompass
|
| 132 |
+
pip install -e .
|
| 133 |
+
# pip install -e ".[full]"
|
| 134 |
+
# pip install -e ".[vllm]"
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
### 📂 Data Preparation
|
| 138 |
+
|
| 139 |
+
You can choose one for the following method to prepare datasets.
|
| 140 |
+
|
| 141 |
+
#### Offline Preparation
|
| 142 |
+
|
| 143 |
+
You can download and extract the datasets with the following commands:
|
| 144 |
+
|
| 145 |
+
```bash
|
| 146 |
+
# Download dataset to data/ folder
|
| 147 |
+
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
| 148 |
+
unzip OpenCompassData-core-20240207.zip
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
#### Automatic Download from OpenCompass
|
| 152 |
+
|
| 153 |
+
We have supported download datasets automatic from the OpenCompass storage server. You can run the evaluation with extra `--dry-run` to download these datasets.
|
| 154 |
+
Currently, the supported datasets are listed in [here](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259). More datasets will be uploaded recently.
|
| 155 |
+
|
| 156 |
+
#### (Optional) Automatic Download with ModelScope
|
| 157 |
+
|
| 158 |
+
Also you can use the [ModelScope](www.modelscope.cn) to load the datasets on demand.
|
| 159 |
+
|
| 160 |
+
Installation:
|
| 161 |
+
|
| 162 |
+
```bash
|
| 163 |
+
pip install modelscope[framework]
|
| 164 |
+
export DATASET_SOURCE=ModelScope
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
Then submit the evaluation task without downloading all the data to your local disk. Available datasets include:
|
| 168 |
+
|
| 169 |
+
```bash
|
| 170 |
+
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
Some third-party features, like Humaneval and Llama, may require additional steps to work properly, for detailed steps please refer to the [Installation Guide](https://opencompass.readthedocs.io/en/latest/get_started/installation.html).
|
| 174 |
+
|
| 175 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 176 |
+
|
| 177 |
+
## 🏗️ ️Evaluation
|
| 178 |
+
|
| 179 |
+
After ensuring that OpenCompass is installed correctly according to the above steps and the datasets are prepared. Now you can start your first evaluation using OpenCompass!
|
| 180 |
+
|
| 181 |
+
### Your first evaluation with OpenCompass!
|
| 182 |
+
|
| 183 |
+
OpenCompass support setting your configs via CLI or a python script. For simple evaluation settings we recommend using CLI, for more complex evaluation, it is suggested using the script way. You can find more example scripts under the configs folder.
|
| 184 |
+
|
| 185 |
+
```bash
|
| 186 |
+
# CLI
|
| 187 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
|
| 188 |
+
|
| 189 |
+
# Python scripts
|
| 190 |
+
opencompass examples/eval_chat_demo.py
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
You can find more script examples under [examples](./examples) folder.
|
| 194 |
+
|
| 195 |
+
### API evaluation
|
| 196 |
+
|
| 197 |
+
OpenCompass, by its design, does not really discriminate between open-source models and API models. You can evaluate both model types in the same way or even in one settings.
|
| 198 |
+
|
| 199 |
+
```bash
|
| 200 |
+
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
|
| 201 |
+
# CLI
|
| 202 |
+
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
|
| 203 |
+
|
| 204 |
+
# Python scripts
|
| 205 |
+
opencompass examples/eval_api_demo.py
|
| 206 |
+
|
| 207 |
+
# You can use o1_mini_2024_09_12/o1_preview_2024_09_12 for o1 models, we set max_completion_tokens=8192 as default.
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
### Accelerated Evaluation
|
| 211 |
+
|
| 212 |
+
Additionally, if you want to use an inference backend other than HuggingFace for accelerated evaluation, such as LMDeploy or vLLM, you can do so with the command below. Please ensure that you have installed the necessary packages for the chosen backend and that your model supports accelerated inference with it. For more information, see the documentation on inference acceleration backends [here](docs/en/advanced_guides/accelerator_intro.md). Below is an example using LMDeploy:
|
| 213 |
+
|
| 214 |
+
```bash
|
| 215 |
+
# CLI
|
| 216 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
|
| 217 |
+
|
| 218 |
+
# Python scripts
|
| 219 |
+
opencompass examples/eval_lmdeploy_demo.py
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
### Supported Models and Datasets
|
| 223 |
+
|
| 224 |
+
OpenCompass has predefined configurations for many models and datasets. You can list all available model and dataset configurations using the [tools](./docs/en/tools.md#list-configs).
|
| 225 |
+
|
| 226 |
+
```bash
|
| 227 |
+
# List all configurations
|
| 228 |
+
python tools/list_configs.py
|
| 229 |
+
# List all configurations related to llama and mmlu
|
| 230 |
+
python tools/list_configs.py llama mmlu
|
| 231 |
+
```
|
| 232 |
+
|
| 233 |
+
#### Supported Models
|
| 234 |
+
|
| 235 |
+
If the model is not on the list but supported by Huggingface AutoModel class or encapsulation of inference engine based on OpenAI interface (see [docs](https://opencompass.readthedocs.io/en/latest/advanced_guides/new_model.html) for details), you can also evaluate it with OpenCompass. You are welcome to contribute to the maintenance of the OpenCompass supported model and dataset lists.
|
| 236 |
+
|
| 237 |
+
```bash
|
| 238 |
+
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
#### Supported Datasets
|
| 242 |
+
|
| 243 |
+
Currently, OpenCompass have provided standard recommended configurations for datasets. Generally, config files ending with `_gen.py` or `_llm_judge_gen.py` will point to the recommended config we provide for this dataset. You can refer to [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for more details.
|
| 244 |
+
|
| 245 |
+
```bash
|
| 246 |
+
# Recommended Evaluation Config based on Rules
|
| 247 |
+
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
|
| 248 |
+
|
| 249 |
+
# Recommended Evaluation Config based on LLM Judge
|
| 250 |
+
opencompass --datasets aime2024_llmjudge_gen --models hf_internlm2_5_1_8b_chat
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
If you want to use multiple GPUs to evaluate the model in data parallel, you can use `--max-num-worker`.
|
| 254 |
+
|
| 255 |
+
```bash
|
| 256 |
+
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
|
| 257 |
+
```
|
| 258 |
+
|
| 259 |
+
> \[!TIP\]
|
| 260 |
+
>
|
| 261 |
+
> `--hf-num-gpus` is used for model parallel(huggingface format), `--max-num-worker` is used for data parallel.
|
| 262 |
+
|
| 263 |
+
> \[!TIP\]
|
| 264 |
+
>
|
| 265 |
+
> configuration with `_ppl` is designed for base model typically.
|
| 266 |
+
> configuration with `_gen` can be used for both base model and chat model.
|
| 267 |
+
|
| 268 |
+
Through the command line or configuration files, OpenCompass also supports evaluating APIs or custom models, as well as more diversified evaluation strategies. Please read the [Quick Start](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html) to learn how to run an evaluation task.
|
| 269 |
+
|
| 270 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 271 |
+
|
| 272 |
+
## 📣 OpenCompass 2.0
|
| 273 |
+
|
| 274 |
+
We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home).
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
**CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry.
|
| 278 |
+
|
| 279 |
+
**CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit).
|
| 280 |
+
|
| 281 |
+
**CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products.
|
| 282 |
+
|
| 283 |
+
## ✨ Introduction
|
| 284 |
+
|
| 285 |
+
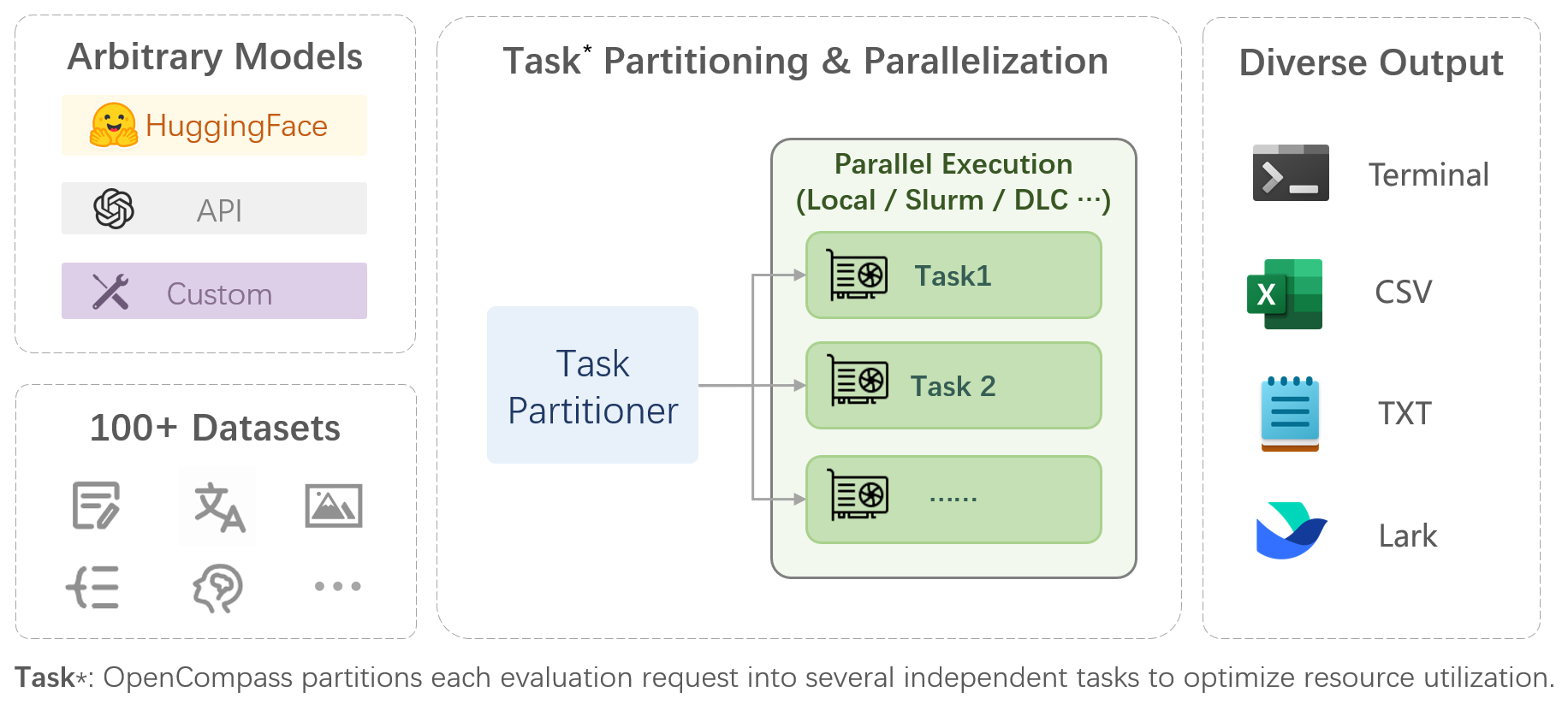
|
| 286 |
+
|
| 287 |
+
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include:
|
| 288 |
+
|
| 289 |
+
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
|
| 290 |
+
|
| 291 |
+
- **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours.
|
| 292 |
+
|
| 293 |
+
- **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models.
|
| 294 |
+
|
| 295 |
+
- **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded!
|
| 296 |
+
|
| 297 |
+
- **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results.
|
| 298 |
+
|
| 299 |
+
## 📖 Dataset Support
|
| 300 |
+
|
| 301 |
+
We have supported a statistical list of all datasets that can be used on this platform in the documentation on the OpenCompass website.
|
| 302 |
+
|
| 303 |
+
You can quickly find the dataset you need from the list through sorting, filtering, and searching functions.
|
| 304 |
+
|
| 305 |
+
In addition, we provide a recommended configuration for each dataset, and some datasets also support LLM Judge-based configurations.
|
| 306 |
+
|
| 307 |
+
Please refer to the dataset statistics chapter of [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for details.
|
| 308 |
+
|
| 309 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 310 |
+
|
| 311 |
+
## 📖 Model Support
|
| 312 |
+
|
| 313 |
+
<table align="center">
|
| 314 |
+
<tbody>
|
| 315 |
+
<tr align="center" valign="bottom">
|
| 316 |
+
<td>
|
| 317 |
+
<b>Open-source Models</b>
|
| 318 |
+
</td>
|
| 319 |
+
<td>
|
| 320 |
+
<b>API Models</b>
|
| 321 |
+
</td>
|
| 322 |
+
<!-- <td>
|
| 323 |
+
<b>Custom Models</b>
|
| 324 |
+
</td> -->
|
| 325 |
+
</tr>
|
| 326 |
+
<tr valign="top">
|
| 327 |
+
<td>
|
| 328 |
+
|
| 329 |
+
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 330 |
+
- [Baichuan](https://github.com/baichuan-inc)
|
| 331 |
+
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
| 332 |
+
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
| 333 |
+
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
| 334 |
+
- [Gemma](https://huggingface.co/google/gemma-7b)
|
| 335 |
+
- [InternLM](https://github.com/InternLM/InternLM)
|
| 336 |
+
- [LLaMA](https://github.com/facebookresearch/llama)
|
| 337 |
+
- [LLaMA3](https://github.com/meta-llama/llama3)
|
| 338 |
+
- [Qwen](https://github.com/QwenLM/Qwen)
|
| 339 |
+
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
| 340 |
+
- [Vicuna](https://github.com/lm-sys/FastChat)
|
| 341 |
+
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
| 342 |
+
- [Yi](https://github.com/01-ai/Yi)
|
| 343 |
+
- ……
|
| 344 |
+
|
| 345 |
+
</td>
|
| 346 |
+
<td>
|
| 347 |
+
|
| 348 |
+
- OpenAI
|
| 349 |
+
- Gemini
|
| 350 |
+
- Claude
|
| 351 |
+
- ZhipuAI(ChatGLM)
|
| 352 |
+
- Baichuan
|
| 353 |
+
- ByteDance(YunQue)
|
| 354 |
+
- Huawei(PanGu)
|
| 355 |
+
- 360
|
| 356 |
+
- Baidu(ERNIEBot)
|
| 357 |
+
- MiniMax(ABAB-Chat)
|
| 358 |
+
- SenseTime(nova)
|
| 359 |
+
- Xunfei(Spark)
|
| 360 |
+
- ……
|
| 361 |
+
|
| 362 |
+
</td>
|
| 363 |
+
|
| 364 |
+
</tr>
|
| 365 |
+
</tbody>
|
| 366 |
+
</table>
|
| 367 |
+
|
| 368 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 369 |
+
|
| 370 |
+
## 🔜 Roadmap
|
| 371 |
+
|
| 372 |
+
- [x] Subjective Evaluation
|
| 373 |
+
- [x] Release CompassAreana.
|
| 374 |
+
- [x] Subjective evaluation.
|
| 375 |
+
- [x] Long-context
|
| 376 |
+
- [x] Long-context evaluation with extensive datasets.
|
| 377 |
+
- [ ] Long-context leaderboard.
|
| 378 |
+
- [x] Coding
|
| 379 |
+
- [ ] Coding evaluation leaderboard.
|
| 380 |
+
- [x] Non-python language evaluation service.
|
| 381 |
+
- [x] Agent
|
| 382 |
+
- [ ] Support various agent frameworks.
|
| 383 |
+
- [x] Evaluation of tool use of the LLMs.
|
| 384 |
+
- [x] Robustness
|
| 385 |
+
- [x] Support various attack methods.
|
| 386 |
+
|
| 387 |
+
## 👷♂️ Contributing
|
| 388 |
+
|
| 389 |
+
We appreciate all contributions to improving OpenCompass. Please refer to the [contributing guideline](https://opencompass.readthedocs.io/en/latest/notes/contribution_guide.html) for the best practice.
|
| 390 |
+
|
| 391 |
+
<!-- Copy-paste in your Readme.md file -->
|
| 392 |
+
|
| 393 |
+
<!-- Made with [OSS Insight](https://ossinsight.io/) -->
|
| 394 |
+
|
| 395 |
+
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
|
| 396 |
+
<table>
|
| 397 |
+
<tr>
|
| 398 |
+
<th colspan="2">
|
| 399 |
+
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
|
| 400 |
+
</th>
|
| 401 |
+
</tr>
|
| 402 |
+
</table>
|
| 403 |
+
</a>
|
| 404 |
+
|
| 405 |
+
## 🤝 Acknowledgements
|
| 406 |
+
|
| 407 |
+
Some code in this project is cited and modified from [OpenICL](https://github.com/Shark-NLP/OpenICL).
|
| 408 |
+
|
| 409 |
+
Some datasets and prompt implementations are modified from [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub) and [instruct-eval](https://github.com/declare-lab/instruct-eval).
|
| 410 |
+
|
| 411 |
+
## 🖊️ Citation
|
| 412 |
+
|
| 413 |
+
```bibtex
|
| 414 |
+
@misc{2023opencompass,
|
| 415 |
+
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
| 416 |
+
author={OpenCompass Contributors},
|
| 417 |
+
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
| 418 |
+
year={2023}
|
| 419 |
+
}
|
| 420 |
+
```
|
| 421 |
+
|
| 422 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 423 |
+
|
| 424 |
+
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
|
| 425 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
|
| 426 |
+
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
|
| 427 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
|
| 428 |
+
[github-issues-link]: https://github.com/open-compass/opencompass/issues
|
| 429 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
|
| 430 |
+
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
|
| 431 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
|
| 432 |
+
[github-release-link]: https://github.com/open-compass/opencompass/releases
|
| 433 |
+
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
|
| 434 |
+
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
|
| 435 |
+
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
|
| 436 |
+
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
|
| 437 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
|
| 438 |
+
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
|
| 439 |
+
[github-trending-url]: https://trendshift.io/repositories/6630
|
README_zh-CN.md
ADDED
|
@@ -0,0 +1,430 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<img src="docs/zh_cn/_static/image/logo.svg" width="500px"/>
|
| 3 |
+
<br />
|
| 4 |
+
<br />
|
| 5 |
+
|
| 6 |
+
[![][github-release-shield]][github-release-link]
|
| 7 |
+
[![][github-releasedate-shield]][github-releasedate-link]
|
| 8 |
+
[![][github-contributors-shield]][github-contributors-link]<br>
|
| 9 |
+
[![][github-forks-shield]][github-forks-link]
|
| 10 |
+
[![][github-stars-shield]][github-stars-link]
|
| 11 |
+
[![][github-issues-shield]][github-issues-link]
|
| 12 |
+
[![][github-license-shield]][github-license-link]
|
| 13 |
+
|
| 14 |
+
<!-- [](https://pypi.org/project/opencompass/) -->
|
| 15 |
+
|
| 16 |
+
[🌐官方网站](https://opencompass.org.cn/) |
|
| 17 |
+
[📖数据集社区](https://hub.opencompass.org.cn/home) |
|
| 18 |
+
[📊性能榜单](https://rank.opencompass.org.cn/home) |
|
| 19 |
+
[📘文档教程](https://opencompass.readthedocs.io/zh_CN/latest/index.html) |
|
| 20 |
+
[🛠️安装](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
| 21 |
+
[🤔报告问题](https://github.com/open-compass/opencompass/issues/new/choose)
|
| 22 |
+
|
| 23 |
+
[English](/README.md) | 简体中文
|
| 24 |
+
|
| 25 |
+
[![][github-trending-shield]][github-trending-url]
|
| 26 |
+
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
<p align="center">
|
| 30 |
+
👋 加入我们的 <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> 和 <a href="https://r.vansin.top/?r=opencompass" target="_blank">微信社区</a>
|
| 31 |
+
</p>
|
| 32 |
+
|
| 33 |
+
> \[!IMPORTANT\]
|
| 34 |
+
>
|
| 35 |
+
> **收藏项目**,你将能第一时间获取 OpenCompass 的最新动态~⭐️
|
| 36 |
+
|
| 37 |
+
<details>
|
| 38 |
+
<summary><kbd>Star History</kbd></summary>
|
| 39 |
+
<picture>
|
| 40 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
|
| 41 |
+
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
|
| 42 |
+
</picture>
|
| 43 |
+
</details>
|
| 44 |
+
|
| 45 |
+
## 🧭 欢迎
|
| 46 |
+
|
| 47 |
+
来到**OpenCompass**!
|
| 48 |
+
|
| 49 |
+
就像指南针在我们的旅程中为我们导航一样,我们希望OpenCompass能够帮助你穿越评估大型语言模型的重重迷雾。OpenCompass提供丰富的算法和功能支持,期待OpenCompass能够帮助社区更便捷地对NLP模型的性能进行公平全面的评估。
|
| 50 |
+
|
| 51 |
+
🚩🚩🚩 欢迎加入 OpenCompass!我们目前**招聘全职研究人员/工程师和实习生**。如果您对 LLM 和 OpenCompass 充满热情,请随时通过[电子邮件](mailto:zhangsongyang@pjlab.org.cn)与我们联系。我们非常期待与您交流!
|
| 52 |
+
|
| 53 |
+
🔥🔥🔥 祝贺 **OpenCompass 作为大模型标准测试工具被Meta AI官方推荐**, 点击 Llama 的 [入门文档](https://ai.meta.com/llama/get-started/#validation) 获取更多信息。
|
| 54 |
+
|
| 55 |
+
> **注意**<br />
|
| 56 |
+
> 重要通知:从 v0.4.0 版本开始,所有位于 ./configs/datasets、./configs/models 和 ./configs/summarizers 目录下的 AMOTIC 配置文件将迁移至 opencompass 包中。请及时更新您的配置文件路径。
|
| 57 |
+
|
| 58 |
+
## 🚀 最新进展 <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
| 59 |
+
|
| 60 |
+
- **\[2025.07.26\]** OpenCompass 现已支持Intern-S1相关的通用及科学评测基准,请参阅[Intern-S1评测教程](https://opencompass.readthedocs.io/zh-cn/latest/user_guides/interns1.html)了解详情!🔥🔥🔥
|
| 61 |
+
- **\[2025.04.01\]** OpenCompass 现已支持 `CascadeEvaluator`,允许多个评估器按顺序工作,可以为更复杂的评估场景创建自定义评估流程,查看[文档](docs/zh_cn/advanced_guides/llm_judge.md)了解具体用法!🔥🔥🔥
|
| 62 |
+
- **\[2025.03.11\]** 现已支持 `SuperGPQA` 覆盖285 个研究生学科的知识能力评测,欢迎尝试!🔥🔥🔥
|
| 63 |
+
- **\[2025.02.28\]** 我们为 `DeepSeek-R1` 系列模型添加了教程,请查看 [评估推理模型](docs/zh_cn/user_guides/deepseek_r1.md) 了解更多详情!🔥🔥🔥
|
| 64 |
+
- **\[2025.02.15\]** 我们新增了两个实用的评测工具:用于LLM作为评判器的`GenericLLMEvaluator`和用于数学推理评估的`MATHVerifyEvaluator`。查看[LLM评判器](docs/zh_cn/advanced_guides/llm_judge.md)和[数学能力评测](docs/zh_cn/advanced_guides/general_math.md)文档了解更多详情!🔥🔥🔥
|
| 65 |
+
- **\[2025.01.16\]** 我们现已支持 [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) 模型,该模型在推理、知识类任务上取得同量级最优性能,欢迎尝试。
|
| 66 |
+
- **\[2024.12.17\]** 我们提供了12月CompassAcademic学术榜单评估脚本 [CompassAcademic](configs/eval_academic_leaderboard_202412.py),你可以通过简单地配置复现官方评测结果。
|
| 67 |
+
- **\[2024.10.14\]** 现已支持OpenAI多语言问答数据集[MMMLU](https://huggingface.co/datasets/openai/MMMLU),欢迎尝试! 🔥🔥🔥
|
| 68 |
+
- **\[2024.09.19\]** 现已支持[Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) ,可以使用多种推理后端(huggingface/vllm/lmdeploy), 欢迎尝试! 🔥🔥🔥
|
| 69 |
+
- **\[2024.09.05\]** 现已支持OpenAI o1 模型(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`), 欢迎尝试! 🔥🔥🔥
|
| 70 |
+
- **\[2024.09.05\]** OpenCompass 现在支持通过模型后处理来��行答案提取,以更准确地展示模型的能力。作为此次更新的一部分,我们集成了 [XFinder](https://github.com/IAAR-Shanghai/xFinder) 作为首个后处理模型。具体信息请参阅 [文档](opencompass/utils/postprocessors/xfinder/README.md),欢迎尝试! 🔥🔥🔥
|
| 71 |
+
- **\[2024.08.20\]** OpenCompass 现已支持 [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists。 🔥🔥🔥
|
| 72 |
+
- **\[2024.08.16\]** OpenCompass 现已支持全新的长上下文语言模型评估基准——[RULER](https://arxiv.org/pdf/2404.06654)。RULER 通过灵活的配置,提供了对长上下文包括检索、多跳追踪、聚合和问答等多种任务类型的评测,欢迎访问[RULER](configs/datasets/ruler/README.md)。🔥🔥🔥
|
| 73 |
+
- **\[2024.07.23\]** 我们支持了[Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315)模型,欢迎试用!🔥🔥🔥
|
| 74 |
+
- **\[2024.07.23\]** 我们支持了[ModelScope](www.modelscope.cn)数据集,您可以按需加载,无需事先下载全部数据到本地,欢迎试用!🔥🔥🔥
|
| 75 |
+
- **\[2024.07.17\]** 我们发布了CompassBench-202407榜单的示例数据和评测规则,敬请访问 [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) 获取更多信息。 🔥🔥🔥
|
| 76 |
+
- **\[2024.07.17\]** 我们正式发布 NeedleBench 的[技术报告](http://arxiv.org/abs/2407.11963)。诚邀您访问我们的[帮助文档](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html)进行评估。🔥🔥🔥
|
| 77 |
+
- **\[2024.07.04\]** OpenCompass 现已支持 InternLM2.5, 它拥有卓越的推理性能、有效支持百万字超长上下文以及工具调用能力整体升级,欢迎访问[OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) 和 [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
|
| 78 |
+
- **\[2024.06.20\]** OpenCompass 现已支持一键切换推理加速后端,助力评测过程更加高效。除了默认的HuggingFace推理后端外,还支持了常用的 [LMDeploy](https://github.com/InternLM/lmdeploy) 和 [vLLM](https://github.com/vllm-project/vllm) ,支持命令行一键切换和部署 API 加速服务两种方式,详细使用方法见[文档](docs/zh_cn/advanced_guides/accelerator_intro.md)。欢迎试用!🔥🔥🔥.
|
| 79 |
+
|
| 80 |
+
> [更多](docs/zh_cn/notes/news.md)
|
| 81 |
+
|
| 82 |
+
## 📊 性能榜单
|
| 83 |
+
|
| 84 |
+
我们将陆续提供开源模型和 API 模型的具体性能榜单,请见 [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) 。如需加入评测,请提供模型仓库地址或标准的 API 接口至邮箱 `opencompass@pjlab.org.cn`.
|
| 85 |
+
|
| 86 |
+
你也可以参考[学术榜单精度复现教程](https://opencompass.readthedocs.io/zh-cn/latest/academic.html),快速地复现榜单的结果。
|
| 87 |
+
|
| 88 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 89 |
+
|
| 90 |
+
## 🛠️ 安装指南
|
| 91 |
+
|
| 92 |
+
下面提供了快速安装和数据集准备的步骤。
|
| 93 |
+
|
| 94 |
+
### 💻 环境搭建
|
| 95 |
+
|
| 96 |
+
我们强烈建议使用 `conda` 来管理您的 Python 环境。
|
| 97 |
+
|
| 98 |
+
- #### 创建虚拟环境
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
conda create --name opencompass python=3.10 -y
|
| 102 |
+
conda activate opencompass
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
- #### 通过pip安装OpenCompass
|
| 106 |
+
|
| 107 |
+
```bash
|
| 108 |
+
# 支持绝大多数数据集及模型
|
| 109 |
+
pip install -U opencompass
|
| 110 |
+
|
| 111 |
+
# 完整安装(支持更多数据集)
|
| 112 |
+
# pip install "opencompass[full]"
|
| 113 |
+
|
| 114 |
+
# 模型推理后端,由于这些推理后端通常存在依赖冲突,建议使用不同的虚拟环境来管理它们。
|
| 115 |
+
# pip install "opencompass[lmdeploy]"
|
| 116 |
+
# pip install "opencompass[vllm]"
|
| 117 |
+
|
| 118 |
+
# API 测试(例如 OpenAI、Qwen)
|
| 119 |
+
# pip install "opencompass[api]"
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
- #### 基于源码安装OpenCompass
|
| 123 |
+
|
| 124 |
+
如果希望使用 OpenCompass 的最新功能,也可以从源代码构建它:
|
| 125 |
+
|
| 126 |
+
```bash
|
| 127 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 128 |
+
cd opencompass
|
| 129 |
+
pip install -e .
|
| 130 |
+
# pip install -e ".[full]"
|
| 131 |
+
# pip install -e ".[vllm]"
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
### 📂 数据准备
|
| 135 |
+
|
| 136 |
+
#### 提前离线下载
|
| 137 |
+
|
| 138 |
+
OpenCompass支持使用本地数据集进行评测,数据集的下载和解压可以通过以下命令完成:
|
| 139 |
+
|
| 140 |
+
```bash
|
| 141 |
+
# 下载数据集到 data/ 处
|
| 142 |
+
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
| 143 |
+
unzip OpenCompassData-core-20240207.zip
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
#### 从 OpenCompass 自动下载
|
| 147 |
+
|
| 148 |
+
我们已经支持从OpenCompass存储服务器自动下载数据集。您可以通过额外的 `--dry-run` 参数来运行评估以下载这些数据集。
|
| 149 |
+
目前支持的数据集列表在[这里](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259)。更多数据集将会很快上传。
|
| 150 |
+
|
| 151 |
+
#### (可选) 使用 ModelScope 自动下载
|
| 152 |
+
|
| 153 |
+
另外,您还可以使用[ModelScope](www.modelscope.cn)来加载数据集:
|
| 154 |
+
环境准备:
|
| 155 |
+
|
| 156 |
+
```bash
|
| 157 |
+
pip install modelscope
|
| 158 |
+
export DATASET_SOURCE=ModelScope
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
配置好环境后,无需下载全部数据,直接提交评测任务即可。目前支持的数据集有:
|
| 162 |
+
|
| 163 |
+
```bash
|
| 164 |
+
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
有部分第三方功能,如 Humaneval 以及 Llama,可能需要额外步骤才能正常运行,详细步骤请参考[安装指南](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html)。
|
| 168 |
+
|
| 169 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 170 |
+
|
| 171 |
+
## 🏗️ ️评测
|
| 172 |
+
|
| 173 |
+
在确保按照上述步骤正确安装了 OpenCompass 并准备好了数据集之后,现在您可以开始使用 OpenCompass 进行首次评估!
|
| 174 |
+
|
| 175 |
+
- ### 首次评测
|
| 176 |
+
|
| 177 |
+
OpenCompass 支持通过命令行界面 (CLI) 或 Python 脚本来设置配置。对于简单的评估设置,我们推荐使用 CLI;而对于更复杂的评估,则建议使用脚本方式。你可以在examples文件夹下找到更多脚本示例。
|
| 178 |
+
|
| 179 |
+
```bash
|
| 180 |
+
# 命令行界面 (CLI)
|
| 181 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
|
| 182 |
+
|
| 183 |
+
# Python 脚本
|
| 184 |
+
opencompass examples/eval_chat_demo.py
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
你可以在[examples](./examples) 文件夹下找到更多的脚本示例。
|
| 188 |
+
|
| 189 |
+
- ### API评测
|
| 190 |
+
|
| 191 |
+
OpenCompass 在设计上并不区分开源模型与 API 模型。您可以以相同的方式或甚至在同一设置中评估这两种类型的模型。
|
| 192 |
+
|
| 193 |
+
```bash
|
| 194 |
+
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
|
| 195 |
+
# 命令行界面 (CLI)
|
| 196 |
+
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
|
| 197 |
+
|
| 198 |
+
# Python 脚本
|
| 199 |
+
opencompass examples/eval_api_demo.py
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
# 现已支持 o1_mini_2024_09_12/o1_preview_2024_09_12 模型, 默认情况下 max_completion_tokens=8192.
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
- ### 推理后端
|
| 206 |
+
|
| 207 |
+
另外,如果您想使用除 HuggingFace 之外的推理后端来进行加速评估,比如 LMDeploy 或 vLLM,可以通过以下命令进行。请确保您已经为所选的后端安装了必要的软件包,并且您的模型支持该后端的加速推理。更多信息,请参阅关于推理加速后端的文档 [这里](docs/zh_cn/advanced_guides/accelerator_intro.md)。以下是使用 LMDeploy 的示例:
|
| 208 |
+
|
| 209 |
+
```bash
|
| 210 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
- ### 支持的模型与数据集
|
| 214 |
+
|
| 215 |
+
OpenCompass 预定义了许多模型和数据集的配置,你可以通过 [工具](./docs/zh_cn/tools.md#ListConfigs) 列出所有可用的模型和数据集配置。
|
| 216 |
+
|
| 217 |
+
```bash
|
| 218 |
+
# 列出所有配置
|
| 219 |
+
python tools/list_configs.py
|
| 220 |
+
# 列出所有跟 llama 及 mmlu 相关的配置
|
| 221 |
+
python tools/list_configs.py llama mmlu
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
#### 支持的模型
|
| 225 |
+
|
| 226 |
+
如果模型不在列表中,但支持 Huggingface AutoModel 类或支持针对 OpenAI 接口的推理引擎封装(详见[官方文档](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_model.html)),您仍然可以使用 OpenCompass 对其进行评估。欢迎您贡献维护 OpenCompass 支持的模型和数据集列表。
|
| 227 |
+
|
| 228 |
+
```bash
|
| 229 |
+
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
|
| 230 |
+
```
|
| 231 |
+
|
| 232 |
+
#### 支持的数据集
|
| 233 |
+
|
| 234 |
+
目前,OpenCompass针对数据集给出了标准的推荐配置。通常,`_gen.py`或`_llm_judge_gen.py`为结尾的配置文件将指向我们为该数据集提供的推荐配置。您可以参阅[官方文档](https://opencompass.readthedocs.io/zh-cn/latest/dataset_statistics.html) 的数据集统计章节来获取详细信息。
|
| 235 |
+
|
| 236 |
+
```bash
|
| 237 |
+
# 基于规则的推荐配置
|
| 238 |
+
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
|
| 239 |
+
|
| 240 |
+
# 基于LLM Judge的推荐配置
|
| 241 |
+
opencompass --datasets aime2024_llmjudge_gen --models hf_internlm2_5_1_8b_chat
|
| 242 |
+
```
|
| 243 |
+
|
| 244 |
+
此外,如果你想在多块 GPU 上使用模型进行推理,您可以使用 `--max-num-worker` 参数。
|
| 245 |
+
|
| 246 |
+
```bash
|
| 247 |
+
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
|
| 248 |
+
```
|
| 249 |
+
opencompass --datasets triviaqa --hf-type base --hf-path /mnt/jfzn/msj/train_exp/mask_gdn_1B_hrr-rank4 --max-num-worker 2
|
| 250 |
+
|
| 251 |
+
opencompass --datasets longbench --models gla-1.3B --max-num-worker 8
|
| 252 |
+
> \[!TIP\]
|
| 253 |
+
>
|
| 254 |
+
> `--hf-num-gpus` 用于 模型并行(huggingface 格式),`--max-num-worker` 用于数据并行。
|
| 255 |
+
|
| 256 |
+
> \[!TIP\]
|
| 257 |
+
>
|
| 258 |
+
> configuration with `_ppl` is designed for base model typically.
|
| 259 |
+
> 配置带 `_ppl` 的配置设计给基础模型使用。
|
| 260 |
+
> 配置带 `_gen` 的配置可以同时用于基础模型和对话模型。
|
| 261 |
+
|
| 262 |
+
通过命令行或配置文件,OpenCompass 还支持评测 API 或自定义模型,以及更多样化的评测策略。请阅读[快速开始](https://opencompass.readthedocs.io/zh_CN/latest/get_started/quick_start.html)了解如何运行一个评测任务。
|
| 263 |
+
|
| 264 |
+
更多教程请查看我们的[文档](https://opencompass.readthedocs.io/zh_CN/latest/index.html)。
|
| 265 |
+
|
| 266 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 267 |
+
|
| 268 |
+
## 📣 OpenCompass 2.0
|
| 269 |
+
|
| 270 |
+
我们很高兴发布 OpenCompass 司南 2.0 大模型评测体系,它主要由三大核心模块构建而成:[CompassKit](https://github.com/open-compass)、[CompassHub](https://hub.opencompass.org.cn/home)以及[CompassRank](https://rank.opencompass.org.cn/home)。
|
| 271 |
+
|
| 272 |
+
**CompassRank** 系统进行了重大革新与提升,现已成为一个兼容并蓄的排行榜体系,不仅囊括了开源基准测试项目,还包含了私有基准测试。此番升级极大地拓宽了对行业内各类模型进行全面而深入测评的可能性。
|
| 273 |
+
|
| 274 |
+
**CompassHub** 创新性地推出了一个基准测试资源导航平台,其设计初衷旨在简化和加快研究人员及行业从业者在多样化的基准测试库中进行搜索与利用的过程。为了让更多独具特色的基准测试成果得以在业内广泛传播和应用,我们热忱欢迎各位将自定义的基准数据贡献至CompassHub平台。只需轻点鼠标,通过访问[这里](https://hub.opencompass.org.cn/dataset-submit),即可启动提交流程。
|
| 275 |
+
|
| 276 |
+
**CompassKit** 是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集,它所提供的全面评测工具集能够有效地对这些复杂模型的功能性能进行精准测量和科学评估。在此,我们诚挚邀请您在学术研究或产品研发过程中积极尝试运用我们的工具包,以助您取得更加丰硕的研究成果和产品优化效果。
|
| 277 |
+
|
| 278 |
+
## ✨ 介绍
|
| 279 |
+
|
| 280 |
+

|
| 281 |
+
|
| 282 |
+
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
|
| 283 |
+
|
| 284 |
+
- **开源可复现**:提供公平、公开、可复现的大模型评测方案
|
| 285 |
+
|
| 286 |
+
- **全面的能力维度**:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
|
| 287 |
+
|
| 288 |
+
- **丰富的模型支持**:已支持 20+ HuggingFace 及 API 模型
|
| 289 |
+
|
| 290 |
+
- **分布式高效评测**:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
|
| 291 |
+
|
| 292 |
+
- **多样化评测范式**:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
|
| 293 |
+
|
| 294 |
+
- **灵活化拓展**:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
|
| 295 |
+
|
| 296 |
+
## 📖 数据集支持
|
| 297 |
+
|
| 298 |
+
我们已经在OpenCompass官网的文档中支持了所有可在本平台上使用的数据集的统计列表。
|
| 299 |
+
|
| 300 |
+
您可以通过排序、筛选和搜索等功能从列表中快速找到您需要的数据集。
|
| 301 |
+
|
| 302 |
+
详情请参阅 [官方文档](https://opencompass.readthedocs.io/zh-cn/latest/dataset_statistics.html) 的数据集统计章节。
|
| 303 |
+
|
| 304 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 305 |
+
|
| 306 |
+
## 📖 模型支持
|
| 307 |
+
|
| 308 |
+
<table align="center">
|
| 309 |
+
<tbody>
|
| 310 |
+
<tr align="center" valign="bottom">
|
| 311 |
+
<td>
|
| 312 |
+
<b>开源模型</b>
|
| 313 |
+
</td>
|
| 314 |
+
<td>
|
| 315 |
+
<b>API 模型</b>
|
| 316 |
+
</td>
|
| 317 |
+
<!-- <td>
|
| 318 |
+
<b>自定义模型</b>
|
| 319 |
+
</td> -->
|
| 320 |
+
</tr>
|
| 321 |
+
<tr valign="top">
|
| 322 |
+
<td>
|
| 323 |
+
|
| 324 |
+
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 325 |
+
- [Baichuan](https://github.com/baichuan-inc)
|
| 326 |
+
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
| 327 |
+
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
| 328 |
+
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
| 329 |
+
- [Gemma](https://huggingface.co/google/gemma-7b)
|
| 330 |
+
- [InternLM](https://github.com/InternLM/InternLM)
|
| 331 |
+
- [LLaMA](https://github.com/facebookresearch/llama)
|
| 332 |
+
- [LLaMA3](https://github.com/meta-llama/llama3)
|
| 333 |
+
- [Qwen](https://github.com/QwenLM/Qwen)
|
| 334 |
+
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
| 335 |
+
- [Vicuna](https://github.com/lm-sys/FastChat)
|
| 336 |
+
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
| 337 |
+
- [Yi](https://github.com/01-ai/Yi)
|
| 338 |
+
- ……
|
| 339 |
+
|
| 340 |
+
</td>
|
| 341 |
+
<td>
|
| 342 |
+
|
| 343 |
+
- OpenAI
|
| 344 |
+
- Gemini
|
| 345 |
+
- Claude
|
| 346 |
+
- ZhipuAI(ChatGLM)
|
| 347 |
+
- Baichuan
|
| 348 |
+
- ByteDance(YunQue)
|
| 349 |
+
- Huawei(PanGu)
|
| 350 |
+
- 360
|
| 351 |
+
- Baidu(ERNIEBot)
|
| 352 |
+
- MiniMax(ABAB-Chat)
|
| 353 |
+
- SenseTime(nova)
|
| 354 |
+
- Xunfei(Spark)
|
| 355 |
+
- ……
|
| 356 |
+
|
| 357 |
+
</td>
|
| 358 |
+
|
| 359 |
+
</tr>
|
| 360 |
+
</tbody>
|
| 361 |
+
</table>
|
| 362 |
+
|
| 363 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 364 |
+
|
| 365 |
+
## 🔜 路线图
|
| 366 |
+
|
| 367 |
+
- [x] 主观评测
|
| 368 |
+
- [x] 发布主观评测榜单
|
| 369 |
+
- [x] 发布主观评测数据集
|
| 370 |
+
- [x] 长文本
|
| 371 |
+
- [x] 支持广泛的长文本评测集
|
| 372 |
+
- [ ] 发布长文本评测榜单
|
| 373 |
+
- [x] 代码能力
|
| 374 |
+
- [ ] 发布代码能力评测榜单
|
| 375 |
+
- [x] 提供非Python语言的评测服务
|
| 376 |
+
- [x] 智能体
|
| 377 |
+
- [ ] 支持丰富的智能体方案
|
| 378 |
+
- [x] 提供智能体评测榜单
|
| 379 |
+
- [x] 鲁棒性
|
| 380 |
+
- [x] 支持各类攻击方法
|
| 381 |
+
|
| 382 |
+
## 👷♂️ 贡献
|
| 383 |
+
|
| 384 |
+
我们感谢所有的贡献者为改进和提升 OpenCompass 所作出的努力。请参考[贡献指南](https://opencompass.readthedocs.io/zh_CN/latest/notes/contribution_guide.html)来了解参与项目贡献的相关指引。
|
| 385 |
+
|
| 386 |
+
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
|
| 387 |
+
<table>
|
| 388 |
+
<tr>
|
| 389 |
+
<th colspan="2">
|
| 390 |
+
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
|
| 391 |
+
</th>
|
| 392 |
+
</tr>
|
| 393 |
+
</table>
|
| 394 |
+
</a>
|
| 395 |
+
|
| 396 |
+
## 🤝 致谢
|
| 397 |
+
|
| 398 |
+
该项目部分的代码引用并修改自 [OpenICL](https://github.com/Shark-NLP/OpenICL)。
|
| 399 |
+
|
| 400 |
+
该项目部分的数据集和提示词实现修改自 [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub), [instruct-eval](https://github.com/declare-lab/instruct-eval)
|
| 401 |
+
|
| 402 |
+
## 🖊️ 引用
|
| 403 |
+
|
| 404 |
+
```bibtex
|
| 405 |
+
@misc{2023opencompass,
|
| 406 |
+
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
| 407 |
+
author={OpenCompass Contributors},
|
| 408 |
+
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
| 409 |
+
year={2023}
|
| 410 |
+
}
|
| 411 |
+
```
|
| 412 |
+
|
| 413 |
+
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
| 414 |
+
|
| 415 |
+
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
|
| 416 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
|
| 417 |
+
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
|
| 418 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
|
| 419 |
+
[github-issues-link]: https://github.com/open-compass/opencompass/issues
|
| 420 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
|
| 421 |
+
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
|
| 422 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
|
| 423 |
+
[github-release-link]: https://github.com/open-compass/opencompass/releases
|
| 424 |
+
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
|
| 425 |
+
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
|
| 426 |
+
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
|
| 427 |
+
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
|
| 428 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
|
| 429 |
+
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
|
| 430 |
+
[github-trending-url]: https://trendshift.io/repositories/6630
|
a.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
export http_proxy="http://cloudml:gP1dY0uI0o@10.119.176.202:3128"
|
| 2 |
+
export https_proxy="http://cloudml:gP1dY0uI0o@10.119.176.202:3128"
|
| 3 |
+
# opencompass --datasets longbench --models mask_gdn_t-1.3B --max-num-worker 8
|
| 4 |
+
# opencompass --datasets longbench --models gdn-1.3B --max-num-worker 8
|
| 5 |
+
|
| 6 |
+
opencompass --datasets needlebench_v2_4k_single --models mask_gdn_t-1.3B --max-num-worker 8
|
dataset-index.yml
ADDED
|
@@ -0,0 +1,1157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- ifeval:
|
| 2 |
+
name: IFEval
|
| 3 |
+
category: Instruction Following
|
| 4 |
+
paper: https://arxiv.org/pdf/2311.07911
|
| 5 |
+
configpath: opencompass/configs/datasets/IFEval/IFEval_gen.py
|
| 6 |
+
configpath_llmjudge: ''
|
| 7 |
+
- nphard:
|
| 8 |
+
name: NPHardEval
|
| 9 |
+
category: Reasoning
|
| 10 |
+
paper: https://arxiv.org/pdf/2312.14890v2
|
| 11 |
+
configpath: opencompass/configs/datasets/NPHardEval/NPHardEval_gen.py
|
| 12 |
+
configpath_llmjudge: ''
|
| 13 |
+
- pmmeval:
|
| 14 |
+
name: PMMEval
|
| 15 |
+
category: Language
|
| 16 |
+
paper: https://arxiv.org/pdf/2411.09116v1
|
| 17 |
+
configpath: opencompass/configs/datasets/PMMEval/pmmeval_gen.py
|
| 18 |
+
configpath_llmjudge: ''
|
| 19 |
+
- pi_llm:
|
| 20 |
+
name: PI-LLM
|
| 21 |
+
category: Memory
|
| 22 |
+
paper: https://arxiv.org/abs/2506.08184
|
| 23 |
+
configpath: opencompass/configs/datasets/PI_LLM/pi_llm_gen.py
|
| 24 |
+
configpath_llmjudge: ''
|
| 25 |
+
- theoremqa:
|
| 26 |
+
name: TheroremQA
|
| 27 |
+
category: Reasoning
|
| 28 |
+
paper: https://arxiv.org/pdf/2305.12524
|
| 29 |
+
configpath: opencompass/configs/datasets/TheroremQA/TheoremQA_gen.py
|
| 30 |
+
configpath_llmjudge: ''
|
| 31 |
+
- agieval:
|
| 32 |
+
name: AGIEval
|
| 33 |
+
category: Examination
|
| 34 |
+
paper: https://arxiv.org/pdf/2304.06364
|
| 35 |
+
configpath: opencompass/configs/datasets/agieval/agieval_gen.py
|
| 36 |
+
configpath_llmjudge: ''
|
| 37 |
+
- babilong:
|
| 38 |
+
name: BABILong
|
| 39 |
+
category: Long Context
|
| 40 |
+
paper: https://arxiv.org/pdf/2406.10149
|
| 41 |
+
configpath: opencompass/configs/datasets/babilong
|
| 42 |
+
configpath_llmjudge: ''
|
| 43 |
+
- bigcodebench:
|
| 44 |
+
name: BigCodeBench
|
| 45 |
+
category: Code
|
| 46 |
+
paper: https://arxiv.org/pdf/2406.15877
|
| 47 |
+
configpath: opencompass/configs/datasets/bigcodebench/bigcodebench_gen.py
|
| 48 |
+
configpath_llmjudge: ''
|
| 49 |
+
- calm:
|
| 50 |
+
name: CaLM
|
| 51 |
+
category: Reasoning
|
| 52 |
+
paper: https://arxiv.org/pdf/2405.00622
|
| 53 |
+
configpath: opencompass/configs/datasets/calm/calm.py
|
| 54 |
+
configpath_llmjudge: ''
|
| 55 |
+
- infinitebench:
|
| 56 |
+
name: InfiniteBench (∞Bench)
|
| 57 |
+
category: Long Context
|
| 58 |
+
paper: https://aclanthology.org/2024.acl-long.814.pdf
|
| 59 |
+
configpath: opencompass/configs/datasets/infinitebench/infinitebench.py
|
| 60 |
+
configpath_llmjudge: ''
|
| 61 |
+
- korbench:
|
| 62 |
+
name: KOR-Bench
|
| 63 |
+
category: Reasoning
|
| 64 |
+
paper: https://arxiv.org/pdf/2410.06526v1
|
| 65 |
+
configpath: opencompass/configs/datasets/korbench/korbench_gen.py
|
| 66 |
+
configpath_llmjudge: opencompass/configs/datasets/korbench/korbench_llm_judge_gen.py
|
| 67 |
+
- lawbench:
|
| 68 |
+
name: LawBench
|
| 69 |
+
category: Knowledge / Law
|
| 70 |
+
paper: https://arxiv.org/pdf/2309.16289
|
| 71 |
+
configpath:
|
| 72 |
+
- opencompass/configs/datasets/lawbench/lawbench_zero_shot_gen_002588.py
|
| 73 |
+
- opencompass/configs/datasets/lawbench/lawbench_one_shot_gen_002588.py
|
| 74 |
+
configpath_llmjudge: ''
|
| 75 |
+
- leval:
|
| 76 |
+
name: L-Eval
|
| 77 |
+
category: Long Context
|
| 78 |
+
paper: https://arxiv.org/pdf/2307.11088v1
|
| 79 |
+
configpath: opencompass/configs/datasets/leval/leval.py
|
| 80 |
+
configpath_llmjudge: ''
|
| 81 |
+
- livecodebench:
|
| 82 |
+
name: LiveCodeBench
|
| 83 |
+
category: Code
|
| 84 |
+
paper: https://arxiv.org/pdf/2403.07974
|
| 85 |
+
configpath: opencompass/configs/datasets/livecodebench/livecodebench_gen.py
|
| 86 |
+
configpath_llmjudge: ''
|
| 87 |
+
- livemathbench:
|
| 88 |
+
name: LiveMathBench
|
| 89 |
+
category: Math
|
| 90 |
+
paper: https://arxiv.org/pdf/2412.13147
|
| 91 |
+
configpath: opencompass/configs/datasets/livemathbench/livemathbench_gen.py
|
| 92 |
+
configpath_llmjudge: ''
|
| 93 |
+
- livereasonbench:
|
| 94 |
+
name: LiveReasonBench
|
| 95 |
+
category: Reasoning
|
| 96 |
+
paper: ''
|
| 97 |
+
configpath: opencompass/configs/datasets/livereasonbench/livereasonbench_gen.py
|
| 98 |
+
configpath_llmjudge: ''
|
| 99 |
+
- longbench:
|
| 100 |
+
name: LongBench
|
| 101 |
+
category: Long Context
|
| 102 |
+
paper: https://github.com/THUDM/LongBench
|
| 103 |
+
configpath:
|
| 104 |
+
- opencompass/configs/datasets/longbench/longbench.py
|
| 105 |
+
- opencompass/configs/datasets/longbenchv2/longbenchv2_gen.py
|
| 106 |
+
configpath_llmjudge: ''
|
| 107 |
+
- lveval:
|
| 108 |
+
name: LV-Eval
|
| 109 |
+
category: Long Context
|
| 110 |
+
paper: https://arxiv.org/pdf/2402.05136
|
| 111 |
+
configpath: opencompass/configs/datasets/lveval/lveval.py
|
| 112 |
+
configpath_llmjudge: ''
|
| 113 |
+
- mastermath2024v1:
|
| 114 |
+
name: Mastermath2024v1
|
| 115 |
+
category: Math
|
| 116 |
+
paper: ''
|
| 117 |
+
configpath: opencompass/configs/datasets/mastermath2024v1/mastermath2024v1_gen.py
|
| 118 |
+
configpath_llmjudge: ''
|
| 119 |
+
- matbench:
|
| 120 |
+
name: matbench
|
| 121 |
+
category: Science / Material
|
| 122 |
+
paper: 'https://www.nature.com/articles/s41524-020-00406-3'
|
| 123 |
+
configpath: opencompass/configs/datasets/matbench/matbench_gen_f71840.py
|
| 124 |
+
configpath_llmjudge: ''
|
| 125 |
+
- medbench:
|
| 126 |
+
name: MedBench
|
| 127 |
+
category: Knowledge / Medicine
|
| 128 |
+
paper: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10778138
|
| 129 |
+
configpath: opencompass/configs/datasets/MedBench/medbench_gen.py
|
| 130 |
+
configpath_llmjudge: ''
|
| 131 |
+
- MedCalc_Bench:
|
| 132 |
+
name: MedCalc_Bench
|
| 133 |
+
category: Knowledge / Medicine
|
| 134 |
+
paper: https://arxiv.org/abs/2406.12036
|
| 135 |
+
configpath: opencompass/configs/datasets/MedCalc_Bench/MedCalcBench_official_gen_a5155f.py
|
| 136 |
+
configpath_llmjudge: ''
|
| 137 |
+
- MedXpertQA:
|
| 138 |
+
name: MedQA
|
| 139 |
+
category: Knowledge / Medicine
|
| 140 |
+
paper: https://arxiv.org/abs/2009.13081
|
| 141 |
+
configpath: opencompass/configs/datasets/MedQA/MedQA_gen.py
|
| 142 |
+
configpath_llmjudge: opencompass/configs/datasets/MedQA/MedQA_llmjudge_gen.py
|
| 143 |
+
- MedXpertQA:
|
| 144 |
+
name: MedXpertQA
|
| 145 |
+
category: Knowledge / Medicine
|
| 146 |
+
paper: https://arxiv.org/abs/2501.18362
|
| 147 |
+
configpath: opencompass/configs/datasets/MedXpertQA/MedXpertQA_gen.py
|
| 148 |
+
configpath_llmjudge: opencompass/configs/datasets/MedXpertQA/MedXpertQA_llmjudge_gen.py
|
| 149 |
+
- ClinicBench:
|
| 150 |
+
name: ClinicBench
|
| 151 |
+
category: Knowledge / Medicine
|
| 152 |
+
paper: https://arxiv.org/abs/2405.00716
|
| 153 |
+
configpath: ''
|
| 154 |
+
configpath_llmjudge: opencompass/configs/datasets/ClinicBench/ClinicBench_llmjudge_gen.py
|
| 155 |
+
- ScienceQA:
|
| 156 |
+
name: ScienceQA
|
| 157 |
+
category: Knowledge / Medicine
|
| 158 |
+
paper: https://arxiv.org/abs/2209.09513
|
| 159 |
+
configpath: ''
|
| 160 |
+
configpath_llmjudge: opencompass/configs/datasets/ScienceQA/ScienceQA_llmjudge_gen.py
|
| 161 |
+
- PubMedQA:
|
| 162 |
+
name: PubMedQA
|
| 163 |
+
category: Knowledge / Medicine
|
| 164 |
+
paper: https://arxiv.org/abs/1909.06146
|
| 165 |
+
configpath: ''
|
| 166 |
+
configpath_llmjudge: opencompass/configs/datasets/PubMedQA/PubMedQA_llmjudge_gen.py
|
| 167 |
+
- musr:
|
| 168 |
+
name: MuSR
|
| 169 |
+
category: Reasoning
|
| 170 |
+
paper: https://arxiv.org/pdf/2310.16049
|
| 171 |
+
configpath: opencompass/configs/datasets/musr/musr_gen.py
|
| 172 |
+
configpath_llmjudge: opencompass/configs/datasets/musr/musr_llm_judge_gen.py
|
| 173 |
+
- needlebench:
|
| 174 |
+
name: NeedleBench V1 (Deprecated)
|
| 175 |
+
category: Long Context
|
| 176 |
+
paper: https://arxiv.org/abs/2407.11963v1
|
| 177 |
+
configpath: opencompass/configs/datasets/needlebench
|
| 178 |
+
configpath_llmjudge: ''
|
| 179 |
+
- needlebench_v2:
|
| 180 |
+
name: NeedleBench V2
|
| 181 |
+
category: Long Context
|
| 182 |
+
paper: https://arxiv.org/abs/2407.11963v2
|
| 183 |
+
configpath: opencompass/configs/datasets/needlebench_v2
|
| 184 |
+
configpath_llmjudge: ''
|
| 185 |
+
- ruler:
|
| 186 |
+
name: RULER
|
| 187 |
+
category: Long Context
|
| 188 |
+
paper: https://arxiv.org/pdf/2404.06654
|
| 189 |
+
configpath: opencompass/configs/datasets/ruler
|
| 190 |
+
configpath_llmjudge: ''
|
| 191 |
+
- alignment:
|
| 192 |
+
name: AlignBench
|
| 193 |
+
category: Subjective / Alignment
|
| 194 |
+
paper: https://arxiv.org/pdf/2311.18743
|
| 195 |
+
configpath: opencompass/configs/datasets/subjective/alignbench
|
| 196 |
+
configpath_llmjudge: ''
|
| 197 |
+
- alpaca:
|
| 198 |
+
name: AlpacaEval
|
| 199 |
+
category: Subjective / Instruction Following
|
| 200 |
+
paper: https://github.com/tatsu-lab/alpaca_eval
|
| 201 |
+
configpath: opencompass/configs/datasets/subjective/aplaca_eval
|
| 202 |
+
configpath_llmjudge: ''
|
| 203 |
+
- arenahard:
|
| 204 |
+
name: Arena-Hard
|
| 205 |
+
category: Subjective / Chatbot
|
| 206 |
+
paper: https://lmsys.org/blog/2024-04-19-arena-hard/
|
| 207 |
+
configpath: opencompass/configs/datasets/subjective/arena_hard
|
| 208 |
+
configpath_llmjudge: ''
|
| 209 |
+
- flames:
|
| 210 |
+
name: FLAMES
|
| 211 |
+
category: Subjective / Alignment
|
| 212 |
+
paper: https://arxiv.org/pdf/2311.06899
|
| 213 |
+
configpath: opencompass/configs/datasets/subjective/flames/flames_gen.py
|
| 214 |
+
configpath_llmjudge: ''
|
| 215 |
+
- fofo:
|
| 216 |
+
name: FOFO
|
| 217 |
+
category: Subjective / Format Following
|
| 218 |
+
paper: https://arxiv.org/pdf/2402.18667
|
| 219 |
+
configpath: opencompass/configs/datasets/subjective/fofo
|
| 220 |
+
configpath_llmjudge: ''
|
| 221 |
+
- followbench:
|
| 222 |
+
name: FollowBench
|
| 223 |
+
category: Subjective / Instruction Following
|
| 224 |
+
paper: https://arxiv.org/pdf/2310.20410
|
| 225 |
+
configpath: opencompass/configs/datasets/subjective/followbench
|
| 226 |
+
configpath_llmjudge: ''
|
| 227 |
+
- hellobench:
|
| 228 |
+
name: HelloBench
|
| 229 |
+
category: Subjective / Long Context
|
| 230 |
+
paper: https://arxiv.org/pdf/2409.16191
|
| 231 |
+
configpath: opencompass/configs/datasets/subjective/hellobench
|
| 232 |
+
configpath_llmjudge: ''
|
| 233 |
+
- judgerbench:
|
| 234 |
+
name: JudgerBench
|
| 235 |
+
category: Subjective / Long Context
|
| 236 |
+
paper: https://arxiv.org/pdf/2410.16256
|
| 237 |
+
configpath: opencompass/configs/datasets/subjective/judgerbench
|
| 238 |
+
configpath_llmjudge: ''
|
| 239 |
+
- multiround:
|
| 240 |
+
name: MT-Bench-101
|
| 241 |
+
category: Subjective / Multi-Round
|
| 242 |
+
paper: https://arxiv.org/pdf/2402.14762
|
| 243 |
+
configpath: opencompass/configs/datasets/subjective/multiround
|
| 244 |
+
configpath_llmjudge: ''
|
| 245 |
+
- wildbench:
|
| 246 |
+
name: WildBench
|
| 247 |
+
category: Subjective / Real Task
|
| 248 |
+
paper: https://arxiv.org/pdf/2406.04770
|
| 249 |
+
configpath: opencompass/configs/datasets/subjective/wildbench
|
| 250 |
+
configpath_llmjudge: ''
|
| 251 |
+
- teval:
|
| 252 |
+
name: T-Eval
|
| 253 |
+
category: Tool Utilization
|
| 254 |
+
paper: https://arxiv.org/pdf/2312.14033
|
| 255 |
+
configpath:
|
| 256 |
+
- opencompass/configs/datasets/teval/teval_en_gen.py
|
| 257 |
+
- opencompass/configs/datasets/teval/teval_zh_gen.py
|
| 258 |
+
configpath_llmjudge: ''
|
| 259 |
+
- finalceiq:
|
| 260 |
+
name: FinanceIQ
|
| 261 |
+
category: Knowledge / Finance
|
| 262 |
+
paper: https://github.com/Duxiaoman-DI/XuanYuan/tree/main/FinanceIQ
|
| 263 |
+
configpath: opencompass/configs/datasets/FinanceIQ/FinanceIQ_gen.py
|
| 264 |
+
configpath_llmjudge: ''
|
| 265 |
+
- gaokaobench:
|
| 266 |
+
name: GAOKAOBench
|
| 267 |
+
category: Examination
|
| 268 |
+
paper: https://arxiv.org/pdf/2305.12474
|
| 269 |
+
configpath: opencompass/configs/datasets/GaokaoBench/GaokaoBench_gen.py
|
| 270 |
+
configpath_llmjudge: ''
|
| 271 |
+
- lcbench:
|
| 272 |
+
name: LCBench
|
| 273 |
+
category: Code
|
| 274 |
+
paper: https://github.com/open-compass/CodeBench/
|
| 275 |
+
configpath: opencompass/configs/datasets/LCBench/lcbench_gen.py
|
| 276 |
+
configpath_llmjudge: ''
|
| 277 |
+
- MMLUArabic:
|
| 278 |
+
name: ArabicMMLU
|
| 279 |
+
category: Language
|
| 280 |
+
paper: https://arxiv.org/pdf/2402.12840
|
| 281 |
+
configpath: opencompass/configs/datasets/MMLUArabic/MMLUArabic_gen.py
|
| 282 |
+
configpath_llmjudge: ''
|
| 283 |
+
- OpenFinData:
|
| 284 |
+
name: OpenFinData
|
| 285 |
+
category: Knowledge / Finance
|
| 286 |
+
paper: https://github.com/open-compass/OpenFinData
|
| 287 |
+
configpath: opencompass/configs/datasets/OpenFinData/OpenFinData_gen.py
|
| 288 |
+
configpath_llmjudge: ''
|
| 289 |
+
- QuALITY:
|
| 290 |
+
name: QuALITY
|
| 291 |
+
category: Long Context
|
| 292 |
+
paper: https://arxiv.org/pdf/2112.08608
|
| 293 |
+
configpath: opencompass/configs/datasets/QuALITY/QuALITY_gen.py
|
| 294 |
+
configpath_llmjudge: ''
|
| 295 |
+
- advglue:
|
| 296 |
+
name: Adversarial GLUE
|
| 297 |
+
category: Safety
|
| 298 |
+
paper: https://openreview.net/pdf?id=GF9cSKI3A_q
|
| 299 |
+
configpath:
|
| 300 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli/adv_glue_mnli_gen.py
|
| 301 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_mm/adv_glue_mnli_mm_gen.py
|
| 302 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_qnli/adv_glue_qnli_gen.py
|
| 303 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_qqp/adv_glue_qqp_gen.py
|
| 304 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_rte/adv_glue_rte_gen.py
|
| 305 |
+
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_sst2/adv_glue_sst2_gen.py
|
| 306 |
+
configpath_llmjudge: ''
|
| 307 |
+
- afqmcd:
|
| 308 |
+
name: CLUE / AFQMC
|
| 309 |
+
category: Language
|
| 310 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 311 |
+
configpath: opencompass/configs/datasets/CLUE_afqmc/CLUE_afqmc_gen.py
|
| 312 |
+
configpath_llmjudge: ''
|
| 313 |
+
- aime2024:
|
| 314 |
+
name: AIME2024
|
| 315 |
+
category: Examination
|
| 316 |
+
paper: https://huggingface.co/datasets/Maxwell-Jia/AIME_2024
|
| 317 |
+
configpath: opencompass/configs/datasets/aime2024/aime2024_gen.py
|
| 318 |
+
configpath_llmjudge: opencompass/configs/datasets/aime2024/aime2024_llmjudge_gen.py
|
| 319 |
+
- anli:
|
| 320 |
+
name: Adversarial NLI
|
| 321 |
+
category: Reasoning
|
| 322 |
+
paper: https://arxiv.org/pdf/1910.14599v2
|
| 323 |
+
configpath: opencompass/configs/datasets/anli/anli_gen.py
|
| 324 |
+
configpath_llmjudge: ''
|
| 325 |
+
- anthropics_evals:
|
| 326 |
+
name: Anthropics Evals
|
| 327 |
+
category: Safety
|
| 328 |
+
paper: https://arxiv.org/pdf/2212.09251
|
| 329 |
+
configpath:
|
| 330 |
+
- opencompass/configs/datasets/anthropics_evals/airisk_gen.py
|
| 331 |
+
- opencompass/configs/datasets/anthropics_evals/persona_gen.py
|
| 332 |
+
- opencompass/configs/datasets/anthropics_evals/sycophancy_gen.py
|
| 333 |
+
configpath_llmjudge: ''
|
| 334 |
+
- apps:
|
| 335 |
+
name: APPS
|
| 336 |
+
category: Code
|
| 337 |
+
paper: https://arxiv.org/pdf/2105.09938
|
| 338 |
+
configpath:
|
| 339 |
+
- opencompass/configs/datasets/apps/apps_gen.py
|
| 340 |
+
- opencompass/configs/datasets/apps/apps_mini_gen.py
|
| 341 |
+
configpath_llmjudge: ''
|
| 342 |
+
- arc:
|
| 343 |
+
name: ARC
|
| 344 |
+
category: Reasoning
|
| 345 |
+
paper: https://arxiv.org/pdf/1803.05457
|
| 346 |
+
configpath:
|
| 347 |
+
- opencompass/configs/datasets/ARC_c/ARC_c_gen.py
|
| 348 |
+
- opencompass/configs/datasets/ARC_e/ARC_e_gen.py
|
| 349 |
+
configpath_llmjudge: ''
|
| 350 |
+
- arc_prize_public_eval:
|
| 351 |
+
name: ARC Prize
|
| 352 |
+
category: ARC-AGI
|
| 353 |
+
paper: https://arcprize.org/guide#private
|
| 354 |
+
configpath: opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen.py
|
| 355 |
+
configpath_llmjudge: ''
|
| 356 |
+
- ax:
|
| 357 |
+
name: SuperGLUE / AX
|
| 358 |
+
category: Reasoning
|
| 359 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 360 |
+
configpath:
|
| 361 |
+
- opencompass/configs/datasets/SuperGLUE_AX_b/SuperGLUE_AX_b_gen.py
|
| 362 |
+
- opencompass/configs/datasets/SuperGLUE_AX_g/SuperGLUE_AX_g_gen.py
|
| 363 |
+
configpath_llmjudge: ''
|
| 364 |
+
- bbh:
|
| 365 |
+
name: BIG-Bench Hard
|
| 366 |
+
category: Reasoning
|
| 367 |
+
paper: https://arxiv.org/pdf/2210.09261
|
| 368 |
+
configpath: opencompass/configs/datasets/bbh/bbh_gen.py
|
| 369 |
+
configpath_llmjudge: opencompass/configs/datasets/bbh/bbh_llm_judge_gen.py
|
| 370 |
+
- bbeh:
|
| 371 |
+
name: BIG-Bench Extra Hard
|
| 372 |
+
category: Reasoning
|
| 373 |
+
paper: https://arxiv.org/abs/2502.19187
|
| 374 |
+
configpath: opencompass/configs/datasets/bbeh
|
| 375 |
+
configpath_llmjudge: ''
|
| 376 |
+
- BoolQ:
|
| 377 |
+
name: SuperGLUE / BoolQ
|
| 378 |
+
category: Knowledge
|
| 379 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 380 |
+
configpath: opencompass/configs/datasets/SuperGLUE_BoolQ/SuperGLUE_BoolQ_gen.py
|
| 381 |
+
configpath_llmjudge: ''
|
| 382 |
+
- c3:
|
| 383 |
+
name: CLUE / C3 (C³)
|
| 384 |
+
category: Understanding
|
| 385 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 386 |
+
configpath: opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen.py
|
| 387 |
+
configpath_llmjudge: ''
|
| 388 |
+
- CARDBiomedBench:
|
| 389 |
+
name: CARDBiomedBench
|
| 390 |
+
category: Knowledge / Medicine
|
| 391 |
+
paper: https://www.biorxiv.org/content/10.1101/2025.01.15.633272v1
|
| 392 |
+
configpath: opencompass/configs/datasets/CARDBiomedBench
|
| 393 |
+
configpath_llmjudge: 'opencompass/configs/datasets/CARDBiomedBench/CARDBiomedBench_llmjudge_gen_99a231.py'
|
| 394 |
+
- cb:
|
| 395 |
+
name: SuperGLUE / CB
|
| 396 |
+
category: Reasoning
|
| 397 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 398 |
+
configpath: opencompass/configs/datasets/SuperGLUE_CB/SuperGLUE_CB_gen.py
|
| 399 |
+
configpath_llmjudge: ''
|
| 400 |
+
- ceval:
|
| 401 |
+
name: C-EVAL
|
| 402 |
+
category: Examination
|
| 403 |
+
paper: https://arxiv.org/pdf/2305.08322v1
|
| 404 |
+
configpath: opencompass/configs/datasets/ceval/ceval_gen.py
|
| 405 |
+
configpath_llmjudge: ''
|
| 406 |
+
- charm:
|
| 407 |
+
name: CHARM
|
| 408 |
+
category: Reasoning
|
| 409 |
+
paper: https://arxiv.org/pdf/2403.14112
|
| 410 |
+
configpath: opencompass/configs/datasets/CHARM/charm_reason_gen.py
|
| 411 |
+
configpath_llmjudge: ''
|
| 412 |
+
- chembench:
|
| 413 |
+
name: ChemBench
|
| 414 |
+
category: Knowledge / Chemistry
|
| 415 |
+
paper: https://arxiv.org/pdf/2404.01475
|
| 416 |
+
configpath: opencompass/configs/datasets/ChemBench/ChemBench_gen.py
|
| 417 |
+
configpath_llmjudge: ''
|
| 418 |
+
- chid:
|
| 419 |
+
name: FewCLUE / CHID
|
| 420 |
+
category: Language
|
| 421 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 422 |
+
configpath: opencompass/configs/datasets/FewCLUE_chid/FewCLUE_chid_gen.py
|
| 423 |
+
configpath_llmjudge: ''
|
| 424 |
+
- chinese_simpleqa:
|
| 425 |
+
name: Chinese SimpleQA
|
| 426 |
+
category: Knowledge
|
| 427 |
+
paper: https://arxiv.org/pdf/2411.07140
|
| 428 |
+
configpath: opencompass/configs/datasets/chinese_simpleqa/chinese_simpleqa_gen.py
|
| 429 |
+
configpath_llmjudge: ''
|
| 430 |
+
- cibench:
|
| 431 |
+
name: CIBench
|
| 432 |
+
category: Code
|
| 433 |
+
paper: https://www.arxiv.org/pdf/2407.10499
|
| 434 |
+
configpath:
|
| 435 |
+
- opencompass/configs/datasets/CIBench/CIBench_generation_gen_8ab0dc.py
|
| 436 |
+
- opencompass/configs/datasets/CIBench/CIBench_template_gen_e6b12a.py
|
| 437 |
+
- opencompass/configs/datasets/CIBench/CIBench_template_oracle_gen_fecda1.py
|
| 438 |
+
configpath_llmjudge: ''
|
| 439 |
+
- civilcomments:
|
| 440 |
+
name: CivilComments
|
| 441 |
+
category: Safety
|
| 442 |
+
paper: https://arxiv.org/pdf/1903.04561
|
| 443 |
+
configpath: opencompass/configs/datasets/civilcomments/civilcomments_clp.py
|
| 444 |
+
configpath_llmjudge: ''
|
| 445 |
+
- clozeTest_maxmin:
|
| 446 |
+
name: Cloze Test-max/min
|
| 447 |
+
category: Code
|
| 448 |
+
paper: https://arxiv.org/pdf/2102.04664
|
| 449 |
+
configpath: opencompass/configs/datasets/clozeTest_maxmin/clozeTest_maxmin_gen.py
|
| 450 |
+
configpath_llmjudge: ''
|
| 451 |
+
- cluewsc:
|
| 452 |
+
name: FewCLUE / CLUEWSC
|
| 453 |
+
category: Language / WSC
|
| 454 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 455 |
+
configpath: opencompass/configs/datasets/FewCLUE_cluewsc/FewCLUE_cluewsc_gen.py
|
| 456 |
+
configpath_llmjudge: ''
|
| 457 |
+
- cmb:
|
| 458 |
+
name: CMB
|
| 459 |
+
category: Knowledge / Medicine
|
| 460 |
+
paper: https://arxiv.org/pdf/2308.08833
|
| 461 |
+
configpath: opencompass/configs/datasets/cmb/cmb_gen.py
|
| 462 |
+
configpath_llmjudge: ''
|
| 463 |
+
- cmmlu:
|
| 464 |
+
name: CMMLU
|
| 465 |
+
category: Understanding
|
| 466 |
+
paper: https://arxiv.org/pdf/2306.09212
|
| 467 |
+
configpath: opencompass/configs/datasets/cmmlu/cmmlu_gen.py
|
| 468 |
+
configpath_llmjudge: opencompass/configs/datasets/cmmlu/cmmlu_llm_judge_gen.py
|
| 469 |
+
- cmnli:
|
| 470 |
+
name: CLUE / CMNLI
|
| 471 |
+
category: Reasoning
|
| 472 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 473 |
+
configpath: opencompass/configs/datasets/CLUE_cmnli/CLUE_cmnli_gen.py
|
| 474 |
+
configpath_llmjudge: ''
|
| 475 |
+
- cmo_fib:
|
| 476 |
+
name: cmo_fib
|
| 477 |
+
category: Examination
|
| 478 |
+
paper: ''
|
| 479 |
+
configpath: opencompass/configs/datasets/cmo_fib/cmo_fib_gen.py
|
| 480 |
+
configpath_llmjudge: ''
|
| 481 |
+
- cmrc:
|
| 482 |
+
name: CLUE / CMRC
|
| 483 |
+
category: Understanding
|
| 484 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 485 |
+
configpath: opencompass/configs/datasets/CLUE_CMRC/CLUE_CMRC_gen.py
|
| 486 |
+
configpath_llmjudge: ''
|
| 487 |
+
- commonsenseqa:
|
| 488 |
+
name: CommonSenseQA
|
| 489 |
+
category: Knowledge
|
| 490 |
+
paper: https://arxiv.org/pdf/1811.00937v2
|
| 491 |
+
configpath: opencompass/configs/datasets/commonsenseqa/commonsenseqa_gen.py
|
| 492 |
+
configpath_llmjudge: ''
|
| 493 |
+
- commonsenseqa_cn:
|
| 494 |
+
name: CommonSenseQA-CN
|
| 495 |
+
category: Knowledge
|
| 496 |
+
paper: ''
|
| 497 |
+
configpath: opencompass/configs/datasets/commonsenseqa_cn/commonsenseqacn_gen.py
|
| 498 |
+
configpath_llmjudge: ''
|
| 499 |
+
- copa:
|
| 500 |
+
name: SuperGLUE / COPA
|
| 501 |
+
category: Reasoning
|
| 502 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 503 |
+
configpath: opencompass/configs/datasets/SuperGLUE_COPA/SuperGLUE_COPA_gen.py
|
| 504 |
+
configpath_llmjudge: ''
|
| 505 |
+
- crowspairs:
|
| 506 |
+
name: CrowsPairs
|
| 507 |
+
category: Safety
|
| 508 |
+
paper: https://arxiv.org/pdf/2010.00133
|
| 509 |
+
configpath: opencompass/configs/datasets/crowspairs/crowspairs_gen.py
|
| 510 |
+
configpath_llmjudge: ''
|
| 511 |
+
- crowspairs_cn:
|
| 512 |
+
name: CrowsPairs-CN
|
| 513 |
+
category: Safety
|
| 514 |
+
paper: ''
|
| 515 |
+
configpath: opencompass/configs/datasets/crowspairs_cn/crowspairscn_gen.py
|
| 516 |
+
configpath_llmjudge: ''
|
| 517 |
+
- cvalues:
|
| 518 |
+
name: CVALUES
|
| 519 |
+
category: Safety
|
| 520 |
+
paper: http://xdp-expriment.oss-cn-zhangjiakou.aliyuncs.com/shanqi.xgh/release_github/CValues.pdf
|
| 521 |
+
configpath: opencompass/configs/datasets/cvalues/cvalues_responsibility_gen.py
|
| 522 |
+
configpath_llmjudge: ''
|
| 523 |
+
- drcd:
|
| 524 |
+
name: CLUE / DRCD
|
| 525 |
+
category: Understanding
|
| 526 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 527 |
+
configpath: opencompass/configs/datasets/CLUE_DRCD/CLUE_DRCD_gen.py
|
| 528 |
+
configpath_llmjudge: ''
|
| 529 |
+
- drop:
|
| 530 |
+
name: DROP (DROP Simple Eval)
|
| 531 |
+
category: Understanding
|
| 532 |
+
paper: https://arxiv.org/pdf/1903.00161
|
| 533 |
+
configpath: opencompass/configs/datasets/drop/drop_gen.py
|
| 534 |
+
configpath_llmjudge: opencompass/configs/datasets/drop/drop_llm_judge_gen.py
|
| 535 |
+
- ds1000:
|
| 536 |
+
name: DS-1000
|
| 537 |
+
category: Code
|
| 538 |
+
paper: https://arxiv.org/pdf/2211.11501
|
| 539 |
+
configpath:
|
| 540 |
+
- opencompass/configs/datasets/ds1000/ds1000_gen_5c4bec.py
|
| 541 |
+
configpath_llmjudge: ''
|
| 542 |
+
- eprstmt:
|
| 543 |
+
name: FewCLUE / EPRSTMT
|
| 544 |
+
category: Understanding
|
| 545 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 546 |
+
configpath: opencompass/configs/datasets/FewCLUE_eprstmt/FewCLUE_eprstmt_gen.py
|
| 547 |
+
configpath_llmjudge: ''
|
| 548 |
+
- flores:
|
| 549 |
+
name: Flores
|
| 550 |
+
category: Language
|
| 551 |
+
paper: https://aclanthology.org/D19-1632.pdf
|
| 552 |
+
configpath: opencompass/configs/datasets/flores/flores_gen.py
|
| 553 |
+
configpath_llmjudge: ''
|
| 554 |
+
- game24:
|
| 555 |
+
name: Game24
|
| 556 |
+
category: Math
|
| 557 |
+
paper: https://huggingface.co/datasets/nlile/24-game
|
| 558 |
+
configpath: opencompass/configs/datasets/game24/game24_gen.py
|
| 559 |
+
configpath_llmjudge: ''
|
| 560 |
+
- govrepcrs:
|
| 561 |
+
name: Government Report Dataset
|
| 562 |
+
category: Long Context
|
| 563 |
+
paper: https://aclanthology.org/2021.naacl-main.112.pdf
|
| 564 |
+
configpath: opencompass/configs/datasets/govrepcrs/govrepcrs_gen.py
|
| 565 |
+
configpath_llmjudge: ''
|
| 566 |
+
- gpqa:
|
| 567 |
+
name: GPQA
|
| 568 |
+
category: Knowledge
|
| 569 |
+
paper: https://arxiv.org/pdf/2311.12022v1
|
| 570 |
+
configpath: opencompass/configs/datasets/gpqa/gpqa_gen.py
|
| 571 |
+
configpath_llmjudge: opencompass/configs/datasets/gpqa/gpqa_llm_judge_gen.py
|
| 572 |
+
- gsm8k:
|
| 573 |
+
name: GSM8K
|
| 574 |
+
category: Math
|
| 575 |
+
paper: https://arxiv.org/pdf/2110.14168v2
|
| 576 |
+
configpath: opencompass/configs/datasets/gsm8k/gsm8k_gen.py
|
| 577 |
+
configpath_llmjudge: ''
|
| 578 |
+
- gsm_hard:
|
| 579 |
+
name: GSM-Hard
|
| 580 |
+
category: Math
|
| 581 |
+
paper: https://proceedings.mlr.press/v202/gao23f/gao23f.pdf
|
| 582 |
+
configpath: opencompass/configs/datasets/gsm_hard/gsmhard_gen.py
|
| 583 |
+
configpath_llmjudge: ''
|
| 584 |
+
- hle:
|
| 585 |
+
name: HLE(Humanity's Last Exam)
|
| 586 |
+
category: Reasoning
|
| 587 |
+
paper: https://lastexam.ai/paper
|
| 588 |
+
configpath: opencompass/configs/datasets/HLE/hle_gen.py
|
| 589 |
+
configpath_llmjudge: ''
|
| 590 |
+
- hellaswag:
|
| 591 |
+
name: HellaSwag
|
| 592 |
+
category: Reasoning
|
| 593 |
+
paper: https://arxiv.org/pdf/1905.07830
|
| 594 |
+
configpath: opencompass/configs/datasets/hellaswag/hellaswag_gen.py
|
| 595 |
+
configpath_llmjudge: opencompass/configs/datasets/hellaswag/hellaswag_llm_judge_gen.py
|
| 596 |
+
- humaneval:
|
| 597 |
+
name: HumanEval
|
| 598 |
+
category: Code
|
| 599 |
+
paper: https://arxiv.org/pdf/2107.03374v2
|
| 600 |
+
configpath: opencompass/configs/datasets/humaneval/humaneval_gen.py
|
| 601 |
+
configpath_llmjudge: ''
|
| 602 |
+
- humaneval_cn:
|
| 603 |
+
name: HumanEval-CN
|
| 604 |
+
category: Code
|
| 605 |
+
paper: ''
|
| 606 |
+
configpath: opencompass/configs/datasets/humaneval_cn/humaneval_cn_gen.py
|
| 607 |
+
configpath_llmjudge: ''
|
| 608 |
+
- humaneval_multi:
|
| 609 |
+
name: Multi-HumanEval
|
| 610 |
+
category: Code
|
| 611 |
+
paper: https://arxiv.org/pdf/2210.14868
|
| 612 |
+
configpath: opencompass/configs/datasets/humaneval_multi/humaneval_multi_gen.py
|
| 613 |
+
configpath_llmjudge: ''
|
| 614 |
+
- humaneval_multi:
|
| 615 |
+
name: HumanEval+
|
| 616 |
+
category: Code
|
| 617 |
+
paper: https://arxiv.org/pdf/2305.01210
|
| 618 |
+
configpath: opencompass/configs/datasets/humaneval_plus/humaneval_plus_gen.py
|
| 619 |
+
configpath_llmjudge: ''
|
| 620 |
+
- humanevalx:
|
| 621 |
+
name: HumanEval-X
|
| 622 |
+
category: Code
|
| 623 |
+
paper: https://dl.acm.org/doi/pdf/10.1145/3580305.3599790
|
| 624 |
+
configpath: opencompass/configs/datasets/humanevalx/humanevalx_gen.py
|
| 625 |
+
configpath_llmjudge: ''
|
| 626 |
+
- humaneval_pro:
|
| 627 |
+
name: HumanEval Pro
|
| 628 |
+
category: Code
|
| 629 |
+
paper: https://arxiv.org/abs/2412.21199
|
| 630 |
+
configpath: opencompass/configs/datasets/humaneval_pro/humaneval_pro_gen.py
|
| 631 |
+
configpath_llmjudge: ''
|
| 632 |
+
- hungarian_math:
|
| 633 |
+
name: Hungarian_Math
|
| 634 |
+
category: Math
|
| 635 |
+
paper: https://huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam
|
| 636 |
+
configpath: opencompass/configs/datasets/hungarian_exam/hungarian_exam_gen.py
|
| 637 |
+
configpath_llmjudge: ''
|
| 638 |
+
- iwslt2017:
|
| 639 |
+
name: IWSLT2017
|
| 640 |
+
category: Language
|
| 641 |
+
paper: https://cris.fbk.eu/bitstream/11582/312796/1/iwslt17-overview.pdf
|
| 642 |
+
configpath: opencompass/configs/datasets/iwslt2017/iwslt2017_gen.py
|
| 643 |
+
configpath_llmjudge: ''
|
| 644 |
+
- jigsawmultilingual:
|
| 645 |
+
name: JigsawMultilingual
|
| 646 |
+
category: Safety
|
| 647 |
+
paper: https://www.kaggle.com/competitions/jigsaw-multilingual-toxic-comment-classification/data
|
| 648 |
+
configpath: opencompass/configs/datasets/jigsawmultilingual/jigsawmultilingual_clp.py
|
| 649 |
+
configpath_llmjudge: ''
|
| 650 |
+
- lambada:
|
| 651 |
+
name: LAMBADA
|
| 652 |
+
category: Understanding
|
| 653 |
+
paper: https://arxiv.org/pdf/1606.06031
|
| 654 |
+
configpath: opencompass/configs/datasets/lambada/lambada_gen.py
|
| 655 |
+
configpath_llmjudge: ''
|
| 656 |
+
- lcsts:
|
| 657 |
+
name: LCSTS
|
| 658 |
+
category: Understanding
|
| 659 |
+
paper: https://aclanthology.org/D15-1229.pdf
|
| 660 |
+
configpath: opencompass/configs/datasets/lcsts/lcsts_gen.py
|
| 661 |
+
configpath_llmjudge: ''
|
| 662 |
+
- livestembench:
|
| 663 |
+
name: LiveStemBench
|
| 664 |
+
category: ''
|
| 665 |
+
paper: ''
|
| 666 |
+
configpath: opencompass/configs/datasets/livestembench/livestembench_gen.py
|
| 667 |
+
configpath_llmjudge: ''
|
| 668 |
+
- llm_compression:
|
| 669 |
+
name: LLM Compression
|
| 670 |
+
category: Bits Per Character (BPC)
|
| 671 |
+
paper: https://arxiv.org/pdf/2404.09937
|
| 672 |
+
configpath: opencompass/configs/datasets/llm_compression/llm_compression.py
|
| 673 |
+
configpath_llmjudge: ''
|
| 674 |
+
- math:
|
| 675 |
+
name: MATH
|
| 676 |
+
category: Math
|
| 677 |
+
paper: https://arxiv.org/pdf/2103.03874
|
| 678 |
+
configpath: opencompass/configs/datasets/math/math_gen.py
|
| 679 |
+
configpath_llmjudge: opencompass/configs/datasets/math/math_llm_judge_gen.py
|
| 680 |
+
- math500:
|
| 681 |
+
name: MATH500
|
| 682 |
+
category: Math
|
| 683 |
+
paper: https://github.com/openai/prm800k
|
| 684 |
+
configpath: opencompass/configs/datasets/math/math_prm800k_500_gen.py
|
| 685 |
+
configpath_llmjudge: opencompass/configs/datasets/math/math_prm800k_500_llm_judge_gen.py
|
| 686 |
+
- math401:
|
| 687 |
+
name: MATH 401
|
| 688 |
+
category: Math
|
| 689 |
+
paper: https://arxiv.org/pdf/2304.02015
|
| 690 |
+
configpath: opencompass/configs/datasets/math401/math401_gen.py
|
| 691 |
+
configpath_llmjudge: ''
|
| 692 |
+
- mathbench:
|
| 693 |
+
name: MathBench
|
| 694 |
+
category: Math
|
| 695 |
+
paper: https://arxiv.org/pdf/2405.12209
|
| 696 |
+
configpath: opencompass/configs/datasets/mathbench/mathbench_gen.py
|
| 697 |
+
configpath_llmjudge: ''
|
| 698 |
+
- mbpp:
|
| 699 |
+
name: MBPP
|
| 700 |
+
category: Code
|
| 701 |
+
paper: https://arxiv.org/pdf/2108.07732
|
| 702 |
+
configpath: opencompass/configs/datasets/mbpp/mbpp_gen.py
|
| 703 |
+
configpath_llmjudge: ''
|
| 704 |
+
- mbpp_cn:
|
| 705 |
+
name: MBPP-CN
|
| 706 |
+
category: Code
|
| 707 |
+
paper: ''
|
| 708 |
+
configpath: opencompass/configs/datasets/mbpp_cn/mbpp_cn_gen.py
|
| 709 |
+
configpath_llmjudge: ''
|
| 710 |
+
- mbpp_plus:
|
| 711 |
+
name: MBPP-PLUS
|
| 712 |
+
category: Code
|
| 713 |
+
paper: ''
|
| 714 |
+
configpath: opencompass/configs/datasets/mbpp_plus/mbpp_plus_gen.py
|
| 715 |
+
configpath_llmjudge: ''
|
| 716 |
+
- mbpp_pro:
|
| 717 |
+
name: MBPP Pro
|
| 718 |
+
category: Code
|
| 719 |
+
paper: https://arxiv.org/abs/2412.21199
|
| 720 |
+
configpath: opencompass/configs/datasets/mbpp_pro/mbpp_pro_gen.py
|
| 721 |
+
configpath_llmjudge: ''
|
| 722 |
+
- mgsm:
|
| 723 |
+
name: MGSM
|
| 724 |
+
category: Language / Math
|
| 725 |
+
paper: https://arxiv.org/pdf/2210.03057
|
| 726 |
+
configpath: opencompass/configs/datasets/mgsm/mgsm_gen.py
|
| 727 |
+
configpath_llmjudge: ''
|
| 728 |
+
- mmlu:
|
| 729 |
+
name: MMLU
|
| 730 |
+
category: Understanding
|
| 731 |
+
paper: https://arxiv.org/pdf/2009.03300
|
| 732 |
+
configpath: opencompass/configs/datasets/mmlu/mmlu_gen.py
|
| 733 |
+
configpath_llmjudge: opencompass/configs/datasets/mmlu/mmlu_llm_judge_gen.py
|
| 734 |
+
- SciEval:
|
| 735 |
+
name: SciEval
|
| 736 |
+
category: Understanding
|
| 737 |
+
paper: https://arxiv.org/pdf/2308.13149
|
| 738 |
+
configpath: opencompass/configs/datasets/SciEval/SciEval_gen.py
|
| 739 |
+
configpath_llmjudge: opencompass/configs/datasets/SciEval/SciEval_llm_judge_gen.py
|
| 740 |
+
- mmlu_cf:
|
| 741 |
+
name: MMLU-CF
|
| 742 |
+
category: Understanding
|
| 743 |
+
paper: https://arxiv.org/pdf/2412.15194
|
| 744 |
+
configpath: opencompass/configs/datasets/mmlu_cf/mmlu_cf_gen.py
|
| 745 |
+
configpath_llmjudge: ''
|
| 746 |
+
- mmlu_pro:
|
| 747 |
+
name: MMLU-Pro
|
| 748 |
+
category: Understanding
|
| 749 |
+
paper: https://arxiv.org/pdf/2406.01574
|
| 750 |
+
configpath: opencompass/configs/datasets/mmlu_pro/mmlu_pro_gen.py
|
| 751 |
+
configpath_llmjudge: opencompass/configs/datasets/mmlu_pro/mmlu_pro_llm_judge_gen.py
|
| 752 |
+
- mmmlu:
|
| 753 |
+
name: MMMLU
|
| 754 |
+
category: Language / Understanding
|
| 755 |
+
paper: https://huggingface.co/datasets/openai/MMMLU
|
| 756 |
+
configpath:
|
| 757 |
+
- opencompass/configs/datasets/mmmlu/mmmlu_gen.py
|
| 758 |
+
- opencompass/configs/datasets/mmmlu_lite/mmmlu_lite_gen.py
|
| 759 |
+
configpath_llmjudge: ''
|
| 760 |
+
- multirc:
|
| 761 |
+
name: SuperGLUE / MultiRC
|
| 762 |
+
category: Understanding
|
| 763 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 764 |
+
configpath: opencompass/configs/datasets/SuperGLUE_MultiRC/SuperGLUE_MultiRC_gen.py
|
| 765 |
+
configpath_llmjudge: ''
|
| 766 |
+
- multipl_e:
|
| 767 |
+
name: MultiPL-E
|
| 768 |
+
category: Code
|
| 769 |
+
paper: https://arxiv.org/pdf/2210.14868
|
| 770 |
+
configpath: opencompass/configs/datasets/multipl_e
|
| 771 |
+
configpath_llmjudge: ''
|
| 772 |
+
- narrativeqa:
|
| 773 |
+
name: NarrativeQA
|
| 774 |
+
category: Understanding
|
| 775 |
+
paper: https://github.com/google-deepmind/narrativeqa
|
| 776 |
+
configpath: opencompass/configs/datasets/narrativeqa/narrativeqa_gen.py
|
| 777 |
+
configpath_llmjudge: ''
|
| 778 |
+
- natural_question:
|
| 779 |
+
name: NaturalQuestions
|
| 780 |
+
category: Knowledge
|
| 781 |
+
paper: https://github.com/google-research-datasets/natural-questions
|
| 782 |
+
configpath: opencompass/configs/datasets/nq/nq_gen.py
|
| 783 |
+
configpath_llmjudge: ''
|
| 784 |
+
- natural_question_cn:
|
| 785 |
+
name: NaturalQuestions-CN
|
| 786 |
+
category: Knowledge
|
| 787 |
+
paper: ''
|
| 788 |
+
configpath: opencompass/configs/datasets/nq_cn/nqcn_gen.py
|
| 789 |
+
configpath_llmjudge: ''
|
| 790 |
+
- obqa:
|
| 791 |
+
name: OpenBookQA
|
| 792 |
+
category: Knowledge
|
| 793 |
+
paper: https://arxiv.org/pdf/1809.02789v1
|
| 794 |
+
configpath: opencompass/configs/datasets/obqa/obqa_gen.py
|
| 795 |
+
configpath_llmjudge: ''
|
| 796 |
+
- olymmath:
|
| 797 |
+
name: OlymMATH
|
| 798 |
+
category: Math
|
| 799 |
+
paper: https://arxiv.org/abs/2503.21380
|
| 800 |
+
configpath: ''
|
| 801 |
+
configpath_llmjudge: opencompass/configs/datasets/OlymMATH/olymmath_llm_judeg_gen.py
|
| 802 |
+
- piqa:
|
| 803 |
+
name: OpenBookQA
|
| 804 |
+
category: Knowledge / Physics
|
| 805 |
+
paper: https://arxiv.org/pdf/1911.11641v1
|
| 806 |
+
configpath: opencompass/configs/datasets/piqa/piqa_gen.py
|
| 807 |
+
configpath_llmjudge: ''
|
| 808 |
+
- ProteinLMBench:
|
| 809 |
+
name: ProteinLMBench
|
| 810 |
+
category: Knowledge / Biology (Protein)
|
| 811 |
+
paper: https://arxiv.org/abs/2406.05540
|
| 812 |
+
configpath: opencompass/configs/datasets/ProteinLMBench/ProteinLMBench_gen.py
|
| 813 |
+
configpath_llmjudge: opencompass/configs/datasets/ProteinLMBench/ProteinLMBench_llmjudge_gen.py
|
| 814 |
+
- py150:
|
| 815 |
+
name: py150
|
| 816 |
+
category: Code
|
| 817 |
+
paper: https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code/CodeCompletion-line
|
| 818 |
+
configpath: opencompass/configs/datasets/py150/py150_gen.py
|
| 819 |
+
configpath_llmjudge: ''
|
| 820 |
+
- qasper:
|
| 821 |
+
name: Qasper
|
| 822 |
+
category: Long Context
|
| 823 |
+
paper: https://arxiv.org/pdf/2105.03011
|
| 824 |
+
configpath: opencompass/configs/datasets/qasper/qasper_gen.py
|
| 825 |
+
configpath_llmjudge: ''
|
| 826 |
+
- qaspercut:
|
| 827 |
+
name: Qasper-Cut
|
| 828 |
+
category: Long Context
|
| 829 |
+
paper: ''
|
| 830 |
+
configpath: opencompass/configs/datasets/qaspercut/qaspercut_gen.py
|
| 831 |
+
configpath_llmjudge: ''
|
| 832 |
+
- race:
|
| 833 |
+
name: RACE
|
| 834 |
+
category: Examination
|
| 835 |
+
paper: https://arxiv.org/pdf/1704.04683
|
| 836 |
+
configpath: opencompass/configs/datasets/race/race_gen.py
|
| 837 |
+
configpath_llmjudge: ''
|
| 838 |
+
- rbench:
|
| 839 |
+
name: R-Bench
|
| 840 |
+
category: Reasoning
|
| 841 |
+
paper: https://arxiv.org/pdf/2505.02018
|
| 842 |
+
configpath: opencompass/configs/datasets/R-Bench/rbench_gen_37cbaf8.py
|
| 843 |
+
configpath_llmjudge: ''
|
| 844 |
+
- realtoxicprompts:
|
| 845 |
+
name: RealToxicPrompts
|
| 846 |
+
category: Safety
|
| 847 |
+
paper: https://arxiv.org/pdf/2009.11462
|
| 848 |
+
configpath: opencompass/configs/datasets/realtoxicprompts/realtoxicprompts_gen.py
|
| 849 |
+
configpath_llmjudge: ''
|
| 850 |
+
- record:
|
| 851 |
+
name: SuperGLUE / ReCoRD
|
| 852 |
+
category: Understanding
|
| 853 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 854 |
+
configpath: opencompass/configs/datasets/SuperGLUE_ReCoRD/SuperGLUE_ReCoRD_gen.py
|
| 855 |
+
configpath_llmjudge: ''
|
| 856 |
+
- rte:
|
| 857 |
+
name: SuperGLUE / RTE
|
| 858 |
+
category: Reasoning
|
| 859 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 860 |
+
configpath: opencompass/configs/datasets/SuperGLUE_RTE/SuperGLUE_RTE_gen.py
|
| 861 |
+
configpath_llmjudge: ''
|
| 862 |
+
- ocnli:
|
| 863 |
+
name: CLUE / OCNLI
|
| 864 |
+
category: Reasoning
|
| 865 |
+
paper: https://arxiv.org/pdf/2004.05986
|
| 866 |
+
configpath: opencompass/configs/datasets/CLUE_ocnli/CLUE_ocnli_gen.py
|
| 867 |
+
configpath_llmjudge: ''
|
| 868 |
+
- ocnlifc:
|
| 869 |
+
name: FewCLUE / OCNLI-FC
|
| 870 |
+
category: Reasoning
|
| 871 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 872 |
+
configpath: opencompass/configs/datasets/FewCLUE_ocnli_fc/FewCLUE_ocnli_fc_gen.py
|
| 873 |
+
configpath_llmjudge: ''
|
| 874 |
+
- rolebench:
|
| 875 |
+
name: RoleBench
|
| 876 |
+
category: Role Play
|
| 877 |
+
paper: https://arxiv.org/pdf/2310.00746
|
| 878 |
+
configpath: opencompass/configs/datasets/rolebench
|
| 879 |
+
configpath_llmjudge: ''
|
| 880 |
+
- s3eval:
|
| 881 |
+
name: S3Eval
|
| 882 |
+
category: Long Context
|
| 883 |
+
paper: https://aclanthology.org/2024.naacl-long.69.pdf
|
| 884 |
+
configpath: opencompass/configs/datasets/s3eval/s3eval_gen.py
|
| 885 |
+
configpath_llmjudge: ''
|
| 886 |
+
- scibench:
|
| 887 |
+
name: SciBench
|
| 888 |
+
category: Reasoning
|
| 889 |
+
paper: https://sxkdz.github.io/files/publications/ICML/SciBench/SciBench.pdf
|
| 890 |
+
configpath: opencompass/configs/datasets/scibench/scibench_gen.py
|
| 891 |
+
configpath_llmjudge: ''
|
| 892 |
+
- scicode:
|
| 893 |
+
name: SciCode
|
| 894 |
+
category: Code
|
| 895 |
+
paper: https://arxiv.org/pdf/2407.13168
|
| 896 |
+
configpath: opencompass/configs/datasets/scicode/scicode_gen.py
|
| 897 |
+
configpath_llmjudge: ''
|
| 898 |
+
- seedbench:
|
| 899 |
+
name: SeedBench
|
| 900 |
+
category: Knowledge
|
| 901 |
+
paper: 'https://aclanthology.org/2025.acl-long.1516.pdf'
|
| 902 |
+
configpath: opencompass/configs/datasets/SeedBench/seedbench_gen.py
|
| 903 |
+
configpath_llmjudge: ''
|
| 904 |
+
- simpleqa:
|
| 905 |
+
name: SimpleQA
|
| 906 |
+
category: Knowledge
|
| 907 |
+
paper: https://arxiv.org/pdf/2411.04368
|
| 908 |
+
configpath: opencompass/configs/datasets/SimpleQA/simpleqa_gen.py
|
| 909 |
+
configpath_llmjudge: ''
|
| 910 |
+
- siqa:
|
| 911 |
+
name: SocialIQA
|
| 912 |
+
category: Reasoning
|
| 913 |
+
paper: https://arxiv.org/pdf/1904.09728
|
| 914 |
+
configpath: opencompass/configs/datasets/siqa/siqa_gen.py
|
| 915 |
+
configpath_llmjudge: ''
|
| 916 |
+
- squad20:
|
| 917 |
+
name: SQuAD2.0
|
| 918 |
+
category: Understanding
|
| 919 |
+
paper: https://arxiv.org/pdf/1806.03822
|
| 920 |
+
configpath: opencompass/configs/datasets/squad20/squad20_gen.py
|
| 921 |
+
configpath_llmjudge: ''
|
| 922 |
+
- storycloze:
|
| 923 |
+
name: StoryCloze
|
| 924 |
+
category: Reasoning
|
| 925 |
+
paper: https://aclanthology.org/2022.emnlp-main.616.pdf
|
| 926 |
+
configpath: opencompass/configs/datasets/storycloze/storycloze_gen.py
|
| 927 |
+
configpath_llmjudge: ''
|
| 928 |
+
- strategyqa:
|
| 929 |
+
name: StrategyQA
|
| 930 |
+
category: Reasoning
|
| 931 |
+
paper: https://arxiv.org/pdf/2101.02235
|
| 932 |
+
configpath: opencompass/configs/datasets/strategyqa/strategyqa_gen.py
|
| 933 |
+
configpath_llmjudge: ''
|
| 934 |
+
- summedits:
|
| 935 |
+
name: SummEdits
|
| 936 |
+
category: Language
|
| 937 |
+
paper: https://aclanthology.org/2023.emnlp-main.600.pdf
|
| 938 |
+
configpath: opencompass/configs/datasets/summedits/summedits_gen.py
|
| 939 |
+
configpath_llmjudge: ''
|
| 940 |
+
- summscreen:
|
| 941 |
+
name: SummScreen
|
| 942 |
+
category: Understanding
|
| 943 |
+
paper: https://arxiv.org/pdf/2104.07091v1
|
| 944 |
+
configpath: opencompass/configs/datasets/summscreen/summscreen_gen.py
|
| 945 |
+
configpath_llmjudge: ''
|
| 946 |
+
- svamp:
|
| 947 |
+
name: SVAMP
|
| 948 |
+
category: Math
|
| 949 |
+
paper: https://aclanthology.org/2021.naacl-main.168.pdf
|
| 950 |
+
configpath: opencompass/configs/datasets/SVAMP/svamp_gen.py
|
| 951 |
+
configpath_llmjudge: ''
|
| 952 |
+
- tabmwp:
|
| 953 |
+
name: TabMWP
|
| 954 |
+
category: Math / Table
|
| 955 |
+
paper: https://arxiv.org/pdf/2209.14610
|
| 956 |
+
configpath: opencompass/configs/datasets/TabMWP/TabMWP_gen.py
|
| 957 |
+
configpath_llmjudge: ''
|
| 958 |
+
- taco:
|
| 959 |
+
name: TACO
|
| 960 |
+
category: Code
|
| 961 |
+
paper: https://arxiv.org/pdf/2312.14852
|
| 962 |
+
configpath: opencompass/configs/datasets/taco/taco_gen.py
|
| 963 |
+
configpath_llmjudge: ''
|
| 964 |
+
- tnews:
|
| 965 |
+
name: FewCLUE / TNEWS
|
| 966 |
+
category: Understanding
|
| 967 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 968 |
+
configpath: opencompass/configs/datasets/FewCLUE_tnews/FewCLUE_tnews_gen.py
|
| 969 |
+
configpath_llmjudge: ''
|
| 970 |
+
- bustm:
|
| 971 |
+
name: FewCLUE / BUSTM
|
| 972 |
+
category: Reasoning
|
| 973 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 974 |
+
configpath: opencompass/configs/datasets/FewCLUE_bustm/FewCLUE_bustm_gen.py
|
| 975 |
+
configpath_llmjudge: ''
|
| 976 |
+
- csl:
|
| 977 |
+
name: FewCLUE / CSL
|
| 978 |
+
category: Understanding
|
| 979 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 980 |
+
configpath: opencompass/configs/datasets/FewCLUE_csl/FewCLUE_csl_gen.py
|
| 981 |
+
configpath_llmjudge: ''
|
| 982 |
+
- ocnli_fc:
|
| 983 |
+
name: FewCLUE / OCNLI-FC
|
| 984 |
+
category: Reasoning
|
| 985 |
+
paper: https://arxiv.org/pdf/2107.07498
|
| 986 |
+
configpath: opencompass/configs/datasets/FewCLUE_ocnli_fc
|
| 987 |
+
configpath_llmjudge: ''
|
| 988 |
+
- triviaqa:
|
| 989 |
+
name: TriviaQA
|
| 990 |
+
category: Knowledge
|
| 991 |
+
paper: https://arxiv.org/pdf/1705.03551v2
|
| 992 |
+
configpath: opencompass/configs/datasets/triviaqa/triviaqa_gen.py
|
| 993 |
+
configpath_llmjudge: ''
|
| 994 |
+
- triviaqarc:
|
| 995 |
+
name: TriviaQA-RC
|
| 996 |
+
category: Knowledge / Understanding
|
| 997 |
+
paper: ''
|
| 998 |
+
configpath: opencompass/configs/datasets/triviaqarc/triviaqarc_gen.py
|
| 999 |
+
configpath_llmjudge: ''
|
| 1000 |
+
- truthfulqa:
|
| 1001 |
+
name: TruthfulQA
|
| 1002 |
+
category: Safety
|
| 1003 |
+
paper: https://arxiv.org/pdf/2109.07958v2
|
| 1004 |
+
configpath: opencompass/configs/datasets/truthfulqa/truthfulqa_gen.py
|
| 1005 |
+
configpath_llmjudge: ''
|
| 1006 |
+
- tydiqa:
|
| 1007 |
+
name: TyDi-QA
|
| 1008 |
+
category: Language
|
| 1009 |
+
paper: https://storage.googleapis.com/tydiqa/tydiqa.pdf
|
| 1010 |
+
configpath: opencompass/configs/datasets/tydiqa/tydiqa_gen.py
|
| 1011 |
+
configpath_llmjudge: ''
|
| 1012 |
+
- wic:
|
| 1013 |
+
name: SuperGLUE / WiC
|
| 1014 |
+
category: Language
|
| 1015 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 1016 |
+
configpath: opencompass/configs/datasets/SuperGLUE_WiC/SuperGLUE_WiC_gen.py
|
| 1017 |
+
configpath_llmjudge: ''
|
| 1018 |
+
- wsc:
|
| 1019 |
+
name: SuperGLUE / WSC
|
| 1020 |
+
category: Language / WSC
|
| 1021 |
+
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
| 1022 |
+
configpath: opencompass/configs/datasets/SuperGLUE_WSC/SuperGLUE_WSC_gen.py
|
| 1023 |
+
configpath_llmjudge: ''
|
| 1024 |
+
- winogrande:
|
| 1025 |
+
name: WinoGrande
|
| 1026 |
+
category: Language / WSC
|
| 1027 |
+
paper: https://arxiv.org/pdf/1907.10641v2
|
| 1028 |
+
configpath: opencompass/configs/datasets/winogrande/winogrande_gen.py
|
| 1029 |
+
configpath_llmjudge: ''
|
| 1030 |
+
- xcopa:
|
| 1031 |
+
name: XCOPA
|
| 1032 |
+
category: Language
|
| 1033 |
+
paper: https://arxiv.org/pdf/2005.00333
|
| 1034 |
+
configpath: opencompass/configs/datasets/XCOPA/XCOPA_ppl.py
|
| 1035 |
+
configpath_llmjudge: ''
|
| 1036 |
+
- xiezhi:
|
| 1037 |
+
name: Xiezhi
|
| 1038 |
+
category: Knowledge
|
| 1039 |
+
paper: https://arxiv.org/pdf/2306.05783
|
| 1040 |
+
configpath: opencompass/configs/datasets/xiezhi/xiezhi_gen.py
|
| 1041 |
+
configpath_llmjudge: ''
|
| 1042 |
+
- xlsum:
|
| 1043 |
+
name: XLSum
|
| 1044 |
+
category: Understanding
|
| 1045 |
+
paper: https://arxiv.org/pdf/2106.13822v1
|
| 1046 |
+
configpath: opencompass/configs/datasets/XLSum/XLSum_gen.py
|
| 1047 |
+
configpath_llmjudge: ''
|
| 1048 |
+
- xsum:
|
| 1049 |
+
name: Xsum
|
| 1050 |
+
category: Understanding
|
| 1051 |
+
paper: https://arxiv.org/pdf/1808.08745
|
| 1052 |
+
configpath: opencompass/configs/datasets/Xsum/Xsum_gen.py
|
| 1053 |
+
configpath_llmjudge: ''
|
| 1054 |
+
- cola:
|
| 1055 |
+
name: GLUE / CoLA
|
| 1056 |
+
category: Understanding
|
| 1057 |
+
paper: https://arxiv.org/pdf/1804.07461
|
| 1058 |
+
configpath: opencompass/configs/datasets/GLUE_CoLA/GLUE_CoLA_ppl.py
|
| 1059 |
+
configpath_llmjudge: ''
|
| 1060 |
+
- mprc:
|
| 1061 |
+
name: GLUE / MPRC
|
| 1062 |
+
category: Understanding
|
| 1063 |
+
paper: https://arxiv.org/pdf/1804.07461
|
| 1064 |
+
configpath: opencompass/configs/datasets/GLUE_MRPC/GLUE_MRPC_ppl.py
|
| 1065 |
+
configpath_llmjudge: ''
|
| 1066 |
+
- qqp:
|
| 1067 |
+
name: GLUE / QQP
|
| 1068 |
+
category: Understanding
|
| 1069 |
+
paper: https://arxiv.org/pdf/1804.07461
|
| 1070 |
+
configpath: opencompass/configs/datasets/GLUE_QQP/GLUE_QQP_ppl.py
|
| 1071 |
+
configpath_llmjudge: ''
|
| 1072 |
+
- omni_math:
|
| 1073 |
+
name: Omni-MATH
|
| 1074 |
+
category: Math
|
| 1075 |
+
paper: https://omni-math.github.io/
|
| 1076 |
+
configpath: opencompass/configs/datasets/omni_math/omni_math_gen.py
|
| 1077 |
+
configpath_llmjudge: ''
|
| 1078 |
+
- wikibench:
|
| 1079 |
+
name: WikiBench
|
| 1080 |
+
category: Knowledge
|
| 1081 |
+
paper: ''
|
| 1082 |
+
configpath: opencompass/configs/datasets/wikibench/wikibench_gen.py
|
| 1083 |
+
configpath_llmjudge: ''
|
| 1084 |
+
- supergpqa:
|
| 1085 |
+
name: SuperGPQA
|
| 1086 |
+
category: Knowledge
|
| 1087 |
+
paper: https://arxiv.org/pdf/2502.14739
|
| 1088 |
+
configpath: opencompass/configs/datasets/supergpqa
|
| 1089 |
+
configpath_llmjudge: ''
|
| 1090 |
+
- climaqa:
|
| 1091 |
+
name: ClimaQA
|
| 1092 |
+
category: Science
|
| 1093 |
+
paper: https://arxiv.org/pdf/2410.16701
|
| 1094 |
+
configpath: ''
|
| 1095 |
+
configpath_llmjudge:
|
| 1096 |
+
- opencompass/configs/datasets/ClimaQA/ClimaQA_Gold_llm_judge.py
|
| 1097 |
+
- opencompass/configs/datasets/ClimaQA/ClimaQA_Silver_llm_judge.py
|
| 1098 |
+
- physics:
|
| 1099 |
+
name: PHYSICS
|
| 1100 |
+
category: Science
|
| 1101 |
+
paper: https://arxiv.org/pdf/2503.21821
|
| 1102 |
+
configpath: ''
|
| 1103 |
+
configpath_llmjudge: opencompass/configs/datasets/PHYSICS/PHYSICS_llm_judge_gen_a133a2.py
|
| 1104 |
+
- smolinstruct:
|
| 1105 |
+
name: SmolInstruct
|
| 1106 |
+
category: Science /Chemistry
|
| 1107 |
+
paper: https://arxiv.org/pdf/2402.09391
|
| 1108 |
+
configpath: opencompass/configs/datasets/SmolInstruct/smolinstruct_gen.py
|
| 1109 |
+
configpath_llmjudge: ''
|
| 1110 |
+
- SciKnowEval:
|
| 1111 |
+
name: SciKnowEval
|
| 1112 |
+
category: Science
|
| 1113 |
+
paper: https://arxiv.org/abs/2406.09098
|
| 1114 |
+
configpath: opencompass/configs/datasets/SciKnowEval/SciKnowEval_gen_ebe47d.py
|
| 1115 |
+
configpath_llmjudge: opencompass/configs/datasets/SciKnowEval/SciKnowEval_llmjudge_gen_ebe47d.py
|
| 1116 |
+
- internsandbox:
|
| 1117 |
+
name: InternSandbox
|
| 1118 |
+
category: Reasoning/Code/Agent
|
| 1119 |
+
paper: ''
|
| 1120 |
+
configpath: opencompass/configs/datasets/internsandbox/internsandbox_gen_44b982.py
|
| 1121 |
+
configpath_llmjudge: ''
|
| 1122 |
+
- nejmaibench:
|
| 1123 |
+
name: nejmaibench
|
| 1124 |
+
category: Science /Medicine
|
| 1125 |
+
paper: https://arxiv.org/pdf/2308.04709
|
| 1126 |
+
configpath: opencompass/configs/datasets/nejm_ai_benchmark/nejmaibench_gen.py
|
| 1127 |
+
configpath_llmjudge: opencompass/configs/datasets/nejm_ai_benchmark/nejmaibench_llmjudge_gen.py
|
| 1128 |
+
- medbullets:
|
| 1129 |
+
name: Medbullets
|
| 1130 |
+
category: Science /Medicine
|
| 1131 |
+
paper: https://arxiv.org/pdf/2402.18060
|
| 1132 |
+
configpath: opencompass/configs/datasets/Medbullets/medbullets_gen.py
|
| 1133 |
+
configpath_llmjudge: opencompass/configs/datasets/Medbullets/medbullets_llmjudge_gen.py
|
| 1134 |
+
- medmcqa:
|
| 1135 |
+
name: medmcqa
|
| 1136 |
+
category: Science /Medicine
|
| 1137 |
+
paper: https://arxiv.org/pdf/2203.14371
|
| 1138 |
+
configpath: opencompass/configs/datasets/medmcqa/medmcqa_gen.py
|
| 1139 |
+
configpath_llmjudge: opencompass/configs/datasets/medmcqa/medmcqa_llmjudge_gen.py
|
| 1140 |
+
- phybench:
|
| 1141 |
+
name: PHYBench
|
| 1142 |
+
category: Science /Physics
|
| 1143 |
+
paper: https://arxiv.org/abs/2504.16074
|
| 1144 |
+
configpath: opencompass/configs/datasets/PHYBench/phybench_gen.py
|
| 1145 |
+
configpath_llmjudge: ''
|
| 1146 |
+
- beyondaime:
|
| 1147 |
+
name: BeyondAIME
|
| 1148 |
+
category: Math
|
| 1149 |
+
paper: ''
|
| 1150 |
+
configpath: opencompass/configs/datasets/BeyondAIME/beyondaime_gen.py
|
| 1151 |
+
configpath_llmjudge: ''
|
| 1152 |
+
- eese:
|
| 1153 |
+
name: EESE
|
| 1154 |
+
category: Science
|
| 1155 |
+
paper: https://arxiv.org/abs/2507.16514
|
| 1156 |
+
configpath: opencompass/configs/datasets/eese/eese_llm_judge_gen.py
|
| 1157 |
+
configpath_llmjudge: opencompass/configs/datasets/eese/eese_llm_judge_gen.py
|
examples/eval_PMMEval.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
from opencompass.models import HuggingFacewithChatTemplate
|
| 4 |
+
|
| 5 |
+
with read_base():
|
| 6 |
+
# from opencompass.configs.datasets.PMMEval.flores_gen import PMMEval_flores_datasets
|
| 7 |
+
# from opencompass.configs.datasets.PMMEval.humanevalxl_gen import PMMEval_HumanEvalXL_datasets
|
| 8 |
+
# from opencompass.configs.datasets.PMMEval.mgsm_gen import PMMEval_MGSM_datasets
|
| 9 |
+
# from opencompass.configs.datasets.PMMEval.mhellaswag_gen import PMMEval_MHellaswag_datasets
|
| 10 |
+
# from opencompass.configs.datasets.PMMEval.mifeval_gen import PMMEval_MIFEval_datasets
|
| 11 |
+
# from opencompass.configs.datasets.PMMEval.mlogiqa_gen import PMMEval_MLogiQA_datasets
|
| 12 |
+
# from opencompass.configs.datasets.PMMEval.mmmlu_gen import PMMEval_MMMLU_datasets
|
| 13 |
+
# from opencompass.configs.datasets.PMMEval.xnli import PMMEval_XNLI_datasets
|
| 14 |
+
from opencompass.configs.datasets.PMMEval.pmmeval_gen import \
|
| 15 |
+
PMMEval_datasets
|
| 16 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_7b_instruct import \
|
| 17 |
+
models
|
| 18 |
+
from opencompass.configs.summarizers.PMMEval import summarizer
|
| 19 |
+
|
| 20 |
+
# datasets = PMMEval_flores_datasets
|
| 21 |
+
# datasets = PMMEval_HumanEvalXL_datasets
|
| 22 |
+
# datasets = PMMEval_MGSM_datasets
|
| 23 |
+
# datasets = PMMEval_MHellaswag_datasets
|
| 24 |
+
# datasets = PMMEval_MIFEval_datasets
|
| 25 |
+
# datasets = PMMEval_MLogiQA_datasets
|
| 26 |
+
# datasets = PMMEval_MMMLU_datasets
|
| 27 |
+
# datasets = PMMEval_XNLI_datasets
|
| 28 |
+
|
| 29 |
+
datasets = PMMEval_datasets
|
examples/eval_TheoremQA.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.TheoremQA.TheoremQA_5shot_gen_6f0af8 import \
|
| 5 |
+
TheoremQA_datasets as datasets
|
| 6 |
+
from opencompass.configs.models.hf_internlm.hf_internlm2_20b import \
|
| 7 |
+
models as hf_internlm2_20b_model
|
| 8 |
+
from opencompass.configs.models.hf_internlm.hf_internlm2_math_20b import \
|
| 9 |
+
models as hf_internlm2_math_20b_model
|
| 10 |
+
from opencompass.configs.models.mistral.hf_mistral_7b_v0_1 import \
|
| 11 |
+
models as hf_mistral_7b_v0_1_model
|
| 12 |
+
from opencompass.configs.models.mistral.hf_mistral_7b_v0_2 import \
|
| 13 |
+
models as hf_mistral_7b_v0_2_model
|
| 14 |
+
|
| 15 |
+
models = sum([v for k, v in locals().items() if k.endswith('_model')], [])
|
| 16 |
+
|
| 17 |
+
work_dir = 'outputs/TheoremQA-5shot'
|
| 18 |
+
|
| 19 |
+
# dataset version metric mode mistral-7b-v0.1-hf mistral-7b-v0.2-hf internlm2-20b-hf internlm2-math-20b-hf
|
| 20 |
+
# --------- --------- -------- ------ -------------------- -------------------- ------------------ -----------------------
|
| 21 |
+
# TheoremQA 6f0af8 score gen 18.00 16.75 25.87 30.88
|
examples/eval_academic_leaderboard_202407.py
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os.path as osp
|
| 2 |
+
|
| 3 |
+
from mmengine.config import read_base
|
| 4 |
+
|
| 5 |
+
from opencompass.partitioners import NaivePartitioner, NumWorkerPartitioner
|
| 6 |
+
from opencompass.runners import LocalRunner
|
| 7 |
+
from opencompass.tasks import OpenICLEvalTask, OpenICLInferTask
|
| 8 |
+
|
| 9 |
+
#######################################################################
|
| 10 |
+
# PART 0 Essential Configs #
|
| 11 |
+
#######################################################################
|
| 12 |
+
with read_base():
|
| 13 |
+
# Datasets Part
|
| 14 |
+
## Core Set
|
| 15 |
+
# ## Examination
|
| 16 |
+
# ## Reasoning
|
| 17 |
+
from opencompass.configs.datasets.bbh.bbh_gen_4a31fa import bbh_datasets
|
| 18 |
+
from opencompass.configs.datasets.cmmlu.cmmlu_0shot_cot_gen_305931 import \
|
| 19 |
+
cmmlu_datasets
|
| 20 |
+
from opencompass.configs.datasets.gpqa.gpqa_openai_simple_evals_gen_5aeece import \
|
| 21 |
+
gpqa_datasets
|
| 22 |
+
# ## Coding
|
| 23 |
+
from opencompass.configs.datasets.humaneval.humaneval_gen_8e312c import \
|
| 24 |
+
humaneval_datasets
|
| 25 |
+
# ## Instruction Following
|
| 26 |
+
from opencompass.configs.datasets.IFEval.IFEval_gen_3321a3 import \
|
| 27 |
+
ifeval_datasets
|
| 28 |
+
# ## Math
|
| 29 |
+
from opencompass.configs.datasets.math.math_0shot_gen_393424 import \
|
| 30 |
+
math_datasets
|
| 31 |
+
from opencompass.configs.datasets.mmlu.mmlu_openai_simple_evals_gen_b618ea import \
|
| 32 |
+
mmlu_datasets
|
| 33 |
+
from opencompass.configs.datasets.mmlu_pro.mmlu_pro_0shot_cot_gen_08c1de import \
|
| 34 |
+
mmlu_pro_datasets
|
| 35 |
+
from opencompass.configs.summarizers.groups.bbh import bbh_summary_groups
|
| 36 |
+
from opencompass.configs.summarizers.groups.cmmlu import \
|
| 37 |
+
cmmlu_summary_groups
|
| 38 |
+
# Summarizer
|
| 39 |
+
from opencompass.configs.summarizers.groups.mmlu import mmlu_summary_groups
|
| 40 |
+
from opencompass.configs.summarizers.groups.mmlu_pro import \
|
| 41 |
+
mmlu_pro_summary_groups
|
| 42 |
+
|
| 43 |
+
# Model List
|
| 44 |
+
# from opencompass.configs.models.qwen.lmdeploy_qwen2_1_5b_instruct import models as lmdeploy_qwen2_1_5b_instruct_model
|
| 45 |
+
# from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_5_7b_chat import models as hf_internlm2_5_7b_chat_model
|
| 46 |
+
# from opencompass.configs.models.openbmb.hf_minicpm_2b_sft_bf16 import models as hf_minicpm_2b_sft_bf16_model
|
| 47 |
+
# from opencompass.configs.models.yi.hf_yi_1_5_6b_chat import models as hf_yi_1_5_6b_chat_model
|
| 48 |
+
# from opencompass.configs.models.gemma.hf_gemma_2b_it import models as hf_gemma_2b_it_model
|
| 49 |
+
# from opencompass.configs.models.yi.hf_yi_1_5_34b_chat import models as hf_yi_1_5_34b_chat_model
|
| 50 |
+
|
| 51 |
+
#######################################################################
|
| 52 |
+
# PART 1 Datasets List #
|
| 53 |
+
#######################################################################
|
| 54 |
+
# datasets list for evaluation
|
| 55 |
+
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
|
| 56 |
+
|
| 57 |
+
#######################################################################
|
| 58 |
+
# PART 2 Datset Summarizer #
|
| 59 |
+
#######################################################################
|
| 60 |
+
# with read_base():
|
| 61 |
+
|
| 62 |
+
core_summary_groups = [
|
| 63 |
+
{
|
| 64 |
+
'name':
|
| 65 |
+
'core_average',
|
| 66 |
+
'subsets': [
|
| 67 |
+
['mmlu', 'accuracy'],
|
| 68 |
+
['mmlu_pro', 'accuracy'],
|
| 69 |
+
# ['cmmlu', 'naive_average'],
|
| 70 |
+
['cmmlu', 'accuracy'],
|
| 71 |
+
['bbh', 'score'],
|
| 72 |
+
['math', 'accuracy'],
|
| 73 |
+
['openai_humaneval', 'humaneval_pass@1'],
|
| 74 |
+
['GPQA_diamond', 'accuracy'],
|
| 75 |
+
['IFEval', 'Prompt-level-strict-accuracy'],
|
| 76 |
+
],
|
| 77 |
+
},
|
| 78 |
+
]
|
| 79 |
+
|
| 80 |
+
summarizer = dict(
|
| 81 |
+
dataset_abbrs=[
|
| 82 |
+
['core_average', 'naive_average'],
|
| 83 |
+
['mmlu', 'accuracy'],
|
| 84 |
+
['mmlu_pro', 'accuracy'],
|
| 85 |
+
['cmmlu', 'accuracy'],
|
| 86 |
+
['bbh', 'score'],
|
| 87 |
+
['math', 'accuracy'],
|
| 88 |
+
['openai_humaneval', 'humaneval_pass@1'],
|
| 89 |
+
['GPQA_diamond', 'accuracy'],
|
| 90 |
+
['IFEval', 'Prompt-level-strict-accuracy'],
|
| 91 |
+
'',
|
| 92 |
+
['mmlu', 'accuracy'],
|
| 93 |
+
['mmlu-stem', 'accuracy'],
|
| 94 |
+
['mmlu-social-science', 'accuracy'],
|
| 95 |
+
['mmlu-humanities', 'accuracy'],
|
| 96 |
+
['mmlu-other', 'accuracy'],
|
| 97 |
+
'',
|
| 98 |
+
['mmlu_pro', 'accuracy'],
|
| 99 |
+
['mmlu_pro_math', 'accuracy'],
|
| 100 |
+
['mmlu_pro_physics', 'accuracy'],
|
| 101 |
+
['mmlu_pro_chemistry', 'accuracy'],
|
| 102 |
+
['mmlu_pro_law', 'accuracy'],
|
| 103 |
+
['mmlu_pro_engineering', 'accuracy'],
|
| 104 |
+
['mmlu_pro_other', 'accuracy'],
|
| 105 |
+
['mmlu_pro_economics', 'accuracy'],
|
| 106 |
+
['mmlu_pro_health', 'accuracy'],
|
| 107 |
+
['mmlu_pro_psychology', 'accuracy'],
|
| 108 |
+
['mmlu_pro_business', 'accuracy'],
|
| 109 |
+
['mmlu_pro_biology', 'accuracy'],
|
| 110 |
+
['mmlu_pro_philosophy', 'accuracy'],
|
| 111 |
+
['mmlu_pro_computer_science', 'accuracy'],
|
| 112 |
+
['mmlu_pro_history', 'accuracy'],
|
| 113 |
+
'',
|
| 114 |
+
['cmmlu', 'accuracy'],
|
| 115 |
+
['cmmlu-stem', 'accuracy'],
|
| 116 |
+
['cmmlu-social-science', 'accuracy'],
|
| 117 |
+
['cmmlu-humanities', 'accuracy'],
|
| 118 |
+
['cmmlu-other', 'accuracy'],
|
| 119 |
+
['cmmlu-china-specific', 'accuracy'],
|
| 120 |
+
'',
|
| 121 |
+
['bbh', 'extract_rate'],
|
| 122 |
+
['math', 'extract_rate'],
|
| 123 |
+
# ['openai_humaneval', 'extract_rate'],
|
| 124 |
+
['GPQA_diamond', 'extract_rate'],
|
| 125 |
+
# ['IFEval', 'extract_rate'],
|
| 126 |
+
'',
|
| 127 |
+
['mmlu', 'extract_rate'],
|
| 128 |
+
['mmlu-stem', 'extract_rate'],
|
| 129 |
+
['mmlu-social-science', 'extract_rate'],
|
| 130 |
+
['mmlu-humanities', 'extract_rate'],
|
| 131 |
+
['mmlu-other', 'extract_rate'],
|
| 132 |
+
'',
|
| 133 |
+
['mmlu_pro', 'extract_rate'],
|
| 134 |
+
['mmlu_pro_math', 'extract_rate'],
|
| 135 |
+
['mmlu_pro_physics', 'extract_rate'],
|
| 136 |
+
['mmlu_pro_chemistry', 'extract_rate'],
|
| 137 |
+
['mmlu_pro_law', 'extract_rate'],
|
| 138 |
+
['mmlu_pro_engineering', 'extract_rate'],
|
| 139 |
+
['mmlu_pro_other', 'extract_rate'],
|
| 140 |
+
['mmlu_pro_economics', 'extract_rate'],
|
| 141 |
+
['mmlu_pro_health', 'extract_rate'],
|
| 142 |
+
['mmlu_pro_psychology', 'extract_rate'],
|
| 143 |
+
['mmlu_pro_business', 'extract_rate'],
|
| 144 |
+
['mmlu_pro_biology', 'extract_rate'],
|
| 145 |
+
['mmlu_pro_philosophy', 'extract_rate'],
|
| 146 |
+
['mmlu_pro_computer_science', 'extract_rate'],
|
| 147 |
+
['mmlu_pro_history', 'extract_rate'],
|
| 148 |
+
'',
|
| 149 |
+
['cmmlu', 'extract_rate'],
|
| 150 |
+
['cmmlu-stem', 'extract_rate'],
|
| 151 |
+
['cmmlu-social-science', 'extract_rate'],
|
| 152 |
+
['cmmlu-humanities', 'extract_rate'],
|
| 153 |
+
['cmmlu-other', 'extract_rate'],
|
| 154 |
+
['cmmlu-china-specific', 'extract_rate'],
|
| 155 |
+
],
|
| 156 |
+
summary_groups=sum(
|
| 157 |
+
[v for k, v in locals().items() if k.endswith('_summary_groups')], []),
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
#######################################################################
|
| 161 |
+
# PART 3 Models List #
|
| 162 |
+
#######################################################################
|
| 163 |
+
|
| 164 |
+
models = sum([v for k, v in locals().items() if k.endswith('_model')], [])
|
| 165 |
+
|
| 166 |
+
#######################################################################
|
| 167 |
+
# PART 4 Inference/Evaluation Configuaration #
|
| 168 |
+
#######################################################################
|
| 169 |
+
|
| 170 |
+
# Local Runner
|
| 171 |
+
infer = dict(
|
| 172 |
+
partitioner=dict(type=NumWorkerPartitioner, num_worker=8),
|
| 173 |
+
runner=dict(
|
| 174 |
+
type=LocalRunner,
|
| 175 |
+
max_num_workers=16,
|
| 176 |
+
retry=0, # Modify if needed
|
| 177 |
+
task=dict(type=OpenICLInferTask)),
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
# eval with local runner
|
| 181 |
+
eval = dict(
|
| 182 |
+
partitioner=dict(type=NaivePartitioner, n=10),
|
| 183 |
+
runner=dict(type=LocalRunner,
|
| 184 |
+
max_num_workers=16,
|
| 185 |
+
task=dict(type=OpenICLEvalTask)),
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
#######################################################################
|
| 189 |
+
# PART 5 Utils Configuaration #
|
| 190 |
+
#######################################################################
|
| 191 |
+
base_exp_dir = 'outputs/corebench_v1_9/'
|
| 192 |
+
work_dir = osp.join(base_exp_dir, 'chat_objective')
|
examples/eval_academic_leaderboard_REALTIME.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
|
| 3 |
+
from mmengine.config import read_base
|
| 4 |
+
|
| 5 |
+
from opencompass.partitioners import NaivePartitioner, NumWorkerPartitioner
|
| 6 |
+
from opencompass.runners import LocalRunner
|
| 7 |
+
from opencompass.tasks import OpenICLEvalTask, OpenICLInferTask
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
#######################################################################
|
| 11 |
+
# PART 0 Essential Configs #
|
| 12 |
+
#######################################################################
|
| 13 |
+
with read_base():
|
| 14 |
+
# Datasets
|
| 15 |
+
from opencompass.configs.datasets.aime2025.aime2025_llmjudge_academic import \
|
| 16 |
+
aime2025_datasets
|
| 17 |
+
from opencompass.configs.datasets.gpqa.gpqa_cascade_eval_academic import \
|
| 18 |
+
gpqa_datasets
|
| 19 |
+
from opencompass.configs.datasets.IFEval.IFEval_gen_353ae7 import \
|
| 20 |
+
ifeval_datasets
|
| 21 |
+
from opencompass.configs.datasets.livecodebench.livecodebench_v6_academic import \
|
| 22 |
+
LCBCodeGeneration_dataset
|
| 23 |
+
from opencompass.configs.datasets.mmlu_pro.mmlu_pro_0shot_cot_gen_08c1de import \
|
| 24 |
+
mmlu_pro_datasets
|
| 25 |
+
from opencompass.configs.datasets.HLE.hle_llmverify_academic import \
|
| 26 |
+
hle_datasets
|
| 27 |
+
|
| 28 |
+
# Summary Groups
|
| 29 |
+
from opencompass.configs.summarizers.groups.mmlu_pro import \
|
| 30 |
+
mmlu_pro_summary_groups
|
| 31 |
+
|
| 32 |
+
# Models (add your models here)
|
| 33 |
+
# from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_5_7b_chat import \
|
| 34 |
+
# models as hf_internlm2_5_7b_chat_model
|
| 35 |
+
|
| 36 |
+
#######################################################################
|
| 37 |
+
# PART 1 Datasets List #
|
| 38 |
+
#######################################################################
|
| 39 |
+
# datasets list for evaluation
|
| 40 |
+
# Only take LCB generation for evaluation
|
| 41 |
+
|
| 42 |
+
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')),
|
| 43 |
+
[]) + [LCBCodeGeneration_dataset]
|
| 44 |
+
|
| 45 |
+
# LLM judge config: using LLM to evaluate predictions
|
| 46 |
+
judge_cfg = dict()
|
| 47 |
+
|
| 48 |
+
for item in datasets:
|
| 49 |
+
if 'judge_cfg' in item['eval_cfg']['evaluator']:
|
| 50 |
+
item['eval_cfg']['evaluator']['judge_cfg'] = judge_cfg
|
| 51 |
+
if 'llm_evaluator' in item['eval_cfg']['evaluator'].keys() and 'judge_cfg' in item['eval_cfg']['evaluator']['llm_evaluator']:
|
| 52 |
+
item['eval_cfg']['evaluator']['llm_evaluator']['judge_cfg'] = judge_cfg
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
#######################################################################
|
| 56 |
+
# PART 2 Datset Summarizer #
|
| 57 |
+
#######################################################################
|
| 58 |
+
|
| 59 |
+
core_summary_groups = [
|
| 60 |
+
{
|
| 61 |
+
'name':
|
| 62 |
+
'core_average',
|
| 63 |
+
'subsets': [
|
| 64 |
+
['IFEval', 'Prompt-level-strict-accuracy'],
|
| 65 |
+
['hle_llmjudge', 'accuracy'],
|
| 66 |
+
['aime2025_repeat_32', 'accuracy (32 runs average)'],
|
| 67 |
+
['GPQA_diamond_repeat_4', 'accuracy (4 runs average)'],
|
| 68 |
+
['mmlu_pro', 'naive_average'],
|
| 69 |
+
['lcb_code_generation_repeat_6', 'pass@1 (6 runs average)'],
|
| 70 |
+
],
|
| 71 |
+
},
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
summarizer = dict(
|
| 75 |
+
dataset_abbrs=[
|
| 76 |
+
['core_average', 'naive_average'],
|
| 77 |
+
'',
|
| 78 |
+
'Instruction Following',
|
| 79 |
+
['IFEval', 'Prompt-level-strict-accuracy'],
|
| 80 |
+
'',
|
| 81 |
+
'General Reasoning',
|
| 82 |
+
['hle_llmjudge', 'accuracy'],
|
| 83 |
+
['GPQA_diamond_repeat_4', 'accuracy (4 runs average)'],
|
| 84 |
+
'',
|
| 85 |
+
'Math Calculation',
|
| 86 |
+
['aime2025_repeat_32', 'accuracy (32 runs average)'],
|
| 87 |
+
'',
|
| 88 |
+
'Knowledge',
|
| 89 |
+
['mmlu_pro', 'naive_average'],
|
| 90 |
+
'',
|
| 91 |
+
'Code',
|
| 92 |
+
['lcb_code_generation_repeat_6', 'pass@1 (6 runs average)'],
|
| 93 |
+
],
|
| 94 |
+
summary_groups=sum(
|
| 95 |
+
[v for k, v in locals().items() if k.endswith('_summary_groups')], []),
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
#######################################################################
|
| 99 |
+
# PART 3 Models List #
|
| 100 |
+
#######################################################################
|
| 101 |
+
|
| 102 |
+
models = sum([v for k, v in locals().items() if k.endswith('_model')], [])
|
| 103 |
+
|
| 104 |
+
#######################################################################
|
| 105 |
+
# PART 4 Inference/Evaluation Configuaration #
|
| 106 |
+
#######################################################################
|
| 107 |
+
|
| 108 |
+
# infer with local runner
|
| 109 |
+
infer = dict(
|
| 110 |
+
partitioner=dict(type=NumWorkerPartitioner, num_worker=8),
|
| 111 |
+
runner=dict(
|
| 112 |
+
type=LocalRunner,
|
| 113 |
+
max_num_workers=16,
|
| 114 |
+
retry=0, # Modify if needed
|
| 115 |
+
task=dict(type=OpenICLInferTask),
|
| 116 |
+
),
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
# eval with local runner
|
| 120 |
+
eval = dict(
|
| 121 |
+
partitioner=dict(type=NaivePartitioner, n=10),
|
| 122 |
+
runner=dict(type=LocalRunner,
|
| 123 |
+
max_num_workers=16,
|
| 124 |
+
task=dict(type=OpenICLEvalTask)),
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
#######################################################################
|
| 128 |
+
# PART 5 Utils Configuaration #
|
| 129 |
+
#######################################################################
|
| 130 |
+
|
| 131 |
+
work_dir = './outputs/oc_academic_202507'
|
examples/eval_alaya.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.agieval.agieval_gen import \
|
| 5 |
+
agieval_datasets
|
| 6 |
+
from opencompass.configs.datasets.bbh.bbh_gen import bbh_datasets
|
| 7 |
+
from opencompass.configs.datasets.ceval.ceval_gen import ceval_datasets
|
| 8 |
+
from opencompass.configs.datasets.cmmlu.cmmlu_gen import cmmlu_datasets
|
| 9 |
+
from opencompass.configs.datasets.mmlu.mmlu_gen import mmlu_datasets
|
| 10 |
+
from opencompass.configs.models.alaya.alaya import models
|
| 11 |
+
|
| 12 |
+
datasets = [
|
| 13 |
+
*bbh_datasets, *ceval_datasets, *cmmlu_datasets, *agieval_datasets,
|
| 14 |
+
*mmlu_datasets
|
| 15 |
+
]
|
examples/eval_api_demo.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.demo.demo_gsm8k_chat_gen import \
|
| 5 |
+
gsm8k_datasets
|
| 6 |
+
from opencompass.configs.datasets.demo.demo_math_chat_gen import \
|
| 7 |
+
math_datasets
|
| 8 |
+
from opencompass.configs.models.openai.gpt_4o_2024_05_13 import \
|
| 9 |
+
models as gpt4
|
| 10 |
+
|
| 11 |
+
datasets = gsm8k_datasets + math_datasets
|
| 12 |
+
models = gpt4
|
examples/eval_bluelm_32k_lveval.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.lveval.lveval import \
|
| 5 |
+
LVEval_datasets as datasets
|
| 6 |
+
from opencompass.configs.models.bluelm.hf_bluelm_7b_chat_32k import models
|
| 7 |
+
from opencompass.configs.summarizers.lveval import summarizer
|
| 8 |
+
|
| 9 |
+
models[0]['path'] = '/path/to/your/huggingface_models/BlueLM-7B-Chat-32K'
|
| 10 |
+
models[0][
|
| 11 |
+
'tokenizer_path'] = '/path/to/your/huggingface_models/BlueLM-7B-Chat-32K'
|
| 12 |
+
models[0]['max_seq_len'] = 32768
|
| 13 |
+
models[0]['generation_kwargs'] = dict(do_sample=False)
|
| 14 |
+
models[0]['mode'] = 'mid' # truncate in the middle
|
examples/eval_charm_mem.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
from opencompassopencompass.configs.models import OpenAI
|
| 3 |
+
|
| 4 |
+
from opencompass.partitioners.sub_size import SubjectiveSizePartitioner
|
| 5 |
+
from opencompass.runners import LocalRunner
|
| 6 |
+
from opencompass.summarizers import CharmMemSummarizer
|
| 7 |
+
from opencompass.tasks.subjective_eval import SubjectiveEvalTask
|
| 8 |
+
|
| 9 |
+
with read_base():
|
| 10 |
+
from opencompass.configs.datasets.CHARM.charm_memory_gen_bbbd53 import \
|
| 11 |
+
charm_memory_datasets as datasets
|
| 12 |
+
|
| 13 |
+
# ------>>>>>> https://arxiv.org/abs/2403.14112
|
| 14 |
+
# from opencompass.configs.models.openai.gpt_3_5_turbo_1106 import models as gpt_3_5_turbo_1106_model
|
| 15 |
+
# from opencompass.configs.models.openai.gpt_4_1106_preview import models as gpt_4_1106_preview_model
|
| 16 |
+
# from opencompass.configs.models.hf_llama.hf_llama2_7b_chat import models as llama2_7b_chat_model
|
| 17 |
+
# from opencompass.configs.models.hf_llama.hf_llama2_13b_chat import models as llama2_13b_chat_model
|
| 18 |
+
# from opencompass.configs.models.hf_llama.hf_llama2_70b_chat import models as llama2_70b_chat_model
|
| 19 |
+
# from opencompass.configs.models.vicuna.hf_vicuna_7b_v15_16k import models as vicuna_7b_v15_16k_model
|
| 20 |
+
# from opencompass.configs.models.vicuna.hf_vicuna_13b_v15_16k import models as vicuna_13b_v15_16k_model
|
| 21 |
+
# from opencompass.configs.models.chatglm.hf_chatglm3_6b_32k import models as chatglm3_6b_32k_model
|
| 22 |
+
# from opencompass.configs.models.baichuan.hf_baichuan2_7b_chat import models as baichuan2_7b_chat_model # need torch 2.1
|
| 23 |
+
# from opencompass.configs.models.baichuan.hf_baichuan2_13b_chat import models as baichuan2_13b_chat_model # need torch 2.1
|
| 24 |
+
# from opencompass.configs.models.hf_internlm.hf_internlm2_chat_7b import models as hf_internlm2_chat_7b_model
|
| 25 |
+
# from opencompass.configs.models.hf_internlm.hf_internlm2_chat_20b import models as hf_internlm2_chat_20b_model
|
| 26 |
+
# from opencompass.configs.models.yi.hf_yi_6b_chat import models as yi_6b_chat_model
|
| 27 |
+
# from opencompass.configs.models.yi.hf_yi_34b_chat import models as yi_34b_chat_model
|
| 28 |
+
# from opencompass.configs.models.deepseek.hf_deepseek_7b_chat import models as deepseek_7b_chat_model
|
| 29 |
+
# from opencompass.configs.models.deepseek.hf_deepseek_67b_chat import models as deepseek_67b_chat_model
|
| 30 |
+
# from opencompass.configs.models.qwen.hf_qwen_7b_chat import models as qwen_7b_chat_model
|
| 31 |
+
# from opencompass.configs.models.qwen.hf_qwen_14b_chat import models as qwen_14b_chat_model
|
| 32 |
+
# from opencompass.configs.models.qwen.hf_qwen_72b_chat import models as qwen_72b_chat_model
|
| 33 |
+
# <<<<<<------ https://arxiv.org/abs/2403.14112
|
| 34 |
+
# from opencompass.configs.models.openai.gpt_3_5_turbo_0125 import models as gpt_3_5_turbo_0125_model
|
| 35 |
+
# from opencompass.configs.models.openai.gpt_4o_2024_05_13 import models as gpt_4o_2024_05_13_model
|
| 36 |
+
# from opencompass.configs.models.gemini.gemini_1_5_flash import models as gemini_1_5_flash_model
|
| 37 |
+
# from opencompass.configs.models.gemini.gemini_1_5_pro import models as gemini_1_5_pro_model
|
| 38 |
+
# from opencompass.configs.models.hf_llama.lmdeploy_llama3_8b_instruct import models as lmdeploy_llama3_8b_instruct_model
|
| 39 |
+
# from opencompass.configs.models.hf_llama.lmdeploy_llama3_70b_instruct import models as lmdeploy_llama3_70b_instruct_model
|
| 40 |
+
# from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_chat_1_8b import models as lmdeploy_internlm2_chat_1_8b_model
|
| 41 |
+
# from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_chat_7b import models as lmdeploy_internlm2_chat_7b_model
|
| 42 |
+
# from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_chat_20b import models as lmdeploy_internlm2_chat_20b_model
|
| 43 |
+
# from opencompass.configs.models.yi.hf_yi_1_5_6b_chat import models as yi_1_5_6b_chat_model
|
| 44 |
+
# from opencompass.configs.models.yi.hf_yi_1_5_34b_chat import models as yi_1_5_34b_chat_model
|
| 45 |
+
# from opencompass.configs.models.deepseek.hf_deepseek_v2_chat import models as deepseek_v2_chat_model
|
| 46 |
+
# from opencompass.configs.models.qwen.hf_qwen1_5_1_8b_chat import models as qwen1_5_1_8b_chat_model
|
| 47 |
+
# from opencompass.configs.models.qwen.hf_qwen1_5_7b_chat import models as qwen1_5_7b_chat_model
|
| 48 |
+
# from opencompass.configs.models.qwen.hf_qwen1_5_14b_chat import models as qwen1_5_14b_chat_model
|
| 49 |
+
# from opencompass.configs.models.qwen.hf_qwen1_5_72b_chat import models as qwen1_5_72b_chat_model
|
| 50 |
+
|
| 51 |
+
models = sum([v for k, v in locals().items() if k.endswith('_model')], [])
|
| 52 |
+
|
| 53 |
+
## ------------- JudgeLLM Configuration
|
| 54 |
+
api_meta_template = dict(round=[
|
| 55 |
+
dict(role='HUMAN', api_role='HUMAN'),
|
| 56 |
+
dict(role='BOT', api_role='BOT', generate=True),
|
| 57 |
+
])
|
| 58 |
+
judge_models = [
|
| 59 |
+
dict(
|
| 60 |
+
abbr='GPT-3.5-turbo-0125',
|
| 61 |
+
type=OpenAI,
|
| 62 |
+
path='gpt-3.5-turbo-0125',
|
| 63 |
+
key='ENV',
|
| 64 |
+
meta_template=api_meta_template,
|
| 65 |
+
query_per_second=16,
|
| 66 |
+
max_out_len=2048,
|
| 67 |
+
max_seq_len=2048,
|
| 68 |
+
batch_size=8,
|
| 69 |
+
temperature=0,
|
| 70 |
+
)
|
| 71 |
+
]
|
| 72 |
+
|
| 73 |
+
## ------------- Evaluation Configuration
|
| 74 |
+
eval = dict(
|
| 75 |
+
partitioner=dict(
|
| 76 |
+
type=SubjectiveSizePartitioner,
|
| 77 |
+
max_task_size=1000,
|
| 78 |
+
mode='singlescore',
|
| 79 |
+
models=models,
|
| 80 |
+
judge_models=judge_models,
|
| 81 |
+
),
|
| 82 |
+
runner=dict(type=LocalRunner,
|
| 83 |
+
max_num_workers=2,
|
| 84 |
+
task=dict(type=SubjectiveEvalTask)),
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
summarizer = dict(type=CharmMemSummarizer)
|
| 88 |
+
|
| 89 |
+
work_dir = './outputs/CHARM_mem/chat/'
|
examples/eval_code_passk_repeat_dataset.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This config is used for pass@k evaluation with dataset repetition
|
| 2 |
+
# That model cannot generate multiple response for single input
|
| 3 |
+
from mmengine.config import read_base
|
| 4 |
+
|
| 5 |
+
from opencompass.models import HuggingFaceCausalLM
|
| 6 |
+
from opencompass.partitioners import SizePartitioner
|
| 7 |
+
from opencompass.runners import LocalRunner
|
| 8 |
+
from opencompass.tasks import OpenICLInferTask
|
| 9 |
+
|
| 10 |
+
with read_base():
|
| 11 |
+
from opencompass.configs.datasets.humaneval.humaneval_repeat10_gen_8e312c import \
|
| 12 |
+
humaneval_datasets
|
| 13 |
+
from opencompass.configs.datasets.mbpp.deprecated_mbpp_repeat10_gen_1e1056 import \
|
| 14 |
+
mbpp_datasets
|
| 15 |
+
from opencompass.configs.datasets.mbpp.deprecated_sanitized_mbpp_repeat10_gen_1e1056 import \
|
| 16 |
+
sanitized_mbpp_datasets
|
| 17 |
+
|
| 18 |
+
datasets = []
|
| 19 |
+
datasets += humaneval_datasets
|
| 20 |
+
datasets += mbpp_datasets
|
| 21 |
+
datasets += sanitized_mbpp_datasets
|
| 22 |
+
|
| 23 |
+
_meta_template = dict(round=[
|
| 24 |
+
dict(role='HUMAN', begin='<|User|>:', end='\n'),
|
| 25 |
+
dict(role='BOT', begin='<|Bot|>:', end='<eoa>\n', generate=True),
|
| 26 |
+
], )
|
| 27 |
+
|
| 28 |
+
models = [
|
| 29 |
+
dict(
|
| 30 |
+
abbr='internlm-chat-7b-hf-v11',
|
| 31 |
+
type=HuggingFaceCausalLM,
|
| 32 |
+
path='internlm/internlm-chat-7b-v1_1',
|
| 33 |
+
tokenizer_path='internlm/internlm-chat-7b-v1_1',
|
| 34 |
+
tokenizer_kwargs=dict(
|
| 35 |
+
padding_side='left',
|
| 36 |
+
truncation_side='left',
|
| 37 |
+
use_fast=False,
|
| 38 |
+
trust_remote_code=True,
|
| 39 |
+
),
|
| 40 |
+
max_seq_len=2048,
|
| 41 |
+
meta_template=_meta_template,
|
| 42 |
+
model_kwargs=dict(trust_remote_code=True, device_map='auto'),
|
| 43 |
+
generation_kwargs=dict(
|
| 44 |
+
do_sample=True,
|
| 45 |
+
top_p=0.95,
|
| 46 |
+
temperature=0.8,
|
| 47 |
+
),
|
| 48 |
+
run_cfg=dict(num_gpus=1, num_procs=1),
|
| 49 |
+
batch_size=8,
|
| 50 |
+
)
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
infer = dict(
|
| 54 |
+
partitioner=dict(type=SizePartitioner, max_task_size=600),
|
| 55 |
+
runner=dict(type=LocalRunner,
|
| 56 |
+
max_num_workers=16,
|
| 57 |
+
task=dict(type=OpenICLInferTask)),
|
| 58 |
+
)
|
examples/eval_codegeex2.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.humanevalx.humanevalx_gen import \
|
| 5 |
+
humanevalx_datasets
|
| 6 |
+
from opencompass.configs.models.codegeex2.hf_codegeex2_6b import models
|
| 7 |
+
|
| 8 |
+
datasets = humanevalx_datasets
|
examples/eval_compassarena_subjectivebench.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.subjective.compass_arena_subjective_bench.singleturn.pairwise_judge import compassarena_subjectivebench_singleturn_datasets
|
| 5 |
+
from opencompass.configs.datasets.subjective.compass_arena_subjective_bench.multiturn.pairwise_judge import compassarena_subjectivebench_multiturn_datasets
|
| 6 |
+
|
| 7 |
+
from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_5_7b_chat import models as lmdeploy_internlm2_5_7b_chat
|
| 8 |
+
from opencompass.configs.models.hf_internlm.lmdeploy_internlm2_5_20b_chat import models as lmdeploy_internlm2_5_20b_chat
|
| 9 |
+
from opencompass.configs.models.hf_llama.lmdeploy_llama3_1_8b_instruct import models as lmdeploy_llama3_1_8b_instruct
|
| 10 |
+
from opencompass.configs.models.hf_llama.lmdeploy_llama3_1_70b_instruct import models as lmdeploy_llama3_1_70b_instruct
|
| 11 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_0_5b_instruct import models as lmdeploy_qwen2_5_0_5b_instruct
|
| 12 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_1_5b_instruct import models as lmdeploy_qwen2_5_1_5b_instruct
|
| 13 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_3b_instruct import models as lmdeploy_qwen2_5_3b_instruct
|
| 14 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_7b_instruct import models as lmdeploy_qwen2_5_7b_instruct
|
| 15 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_14b_instruct import models as lmdeploy_qwen2_5_14b_instruct
|
| 16 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_32b_instruct import models as lmdeploy_qwen2_5_32b_instruct
|
| 17 |
+
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_72b_instruct import models as lmdeploy_qwen2_5_72b_instruct
|
| 18 |
+
from opencompass.configs.models.qwen.lmdeploy_qwen2_7b_instruct import models as lmdeploy_qwen2_7b_instruct
|
| 19 |
+
|
| 20 |
+
from opencompass.models import (HuggingFace, HuggingFaceCausalLM,
|
| 21 |
+
HuggingFaceChatGLM3, OpenAI,
|
| 22 |
+
TurboMindModelwithChatTemplate)
|
| 23 |
+
from opencompass.partitioners import NaivePartitioner, SizePartitioner
|
| 24 |
+
from opencompass.partitioners.sub_naive import SubjectiveNaivePartitioner
|
| 25 |
+
from opencompass.partitioners.sub_num_worker import \
|
| 26 |
+
SubjectiveNumWorkerPartitioner
|
| 27 |
+
from opencompass.partitioners.sub_size import SubjectiveSizePartitioner
|
| 28 |
+
from opencompass.runners import LocalRunner, SlurmSequentialRunner
|
| 29 |
+
from opencompass.summarizers import DefaultSubjectiveSummarizer
|
| 30 |
+
from opencompass.tasks import OpenICLInferTask
|
| 31 |
+
from opencompass.tasks.subjective_eval import SubjectiveEvalTask
|
| 32 |
+
|
| 33 |
+
api_meta_template = dict(round=[
|
| 34 |
+
dict(role='HUMAN', api_role='HUMAN'),
|
| 35 |
+
dict(role='BOT', api_role='BOT', generate=True),
|
| 36 |
+
])
|
| 37 |
+
|
| 38 |
+
# -------------Inference Stage ----------------------------------------
|
| 39 |
+
# For subjective evaluation, we often set do sample for models
|
| 40 |
+
# models = [
|
| 41 |
+
# dict(
|
| 42 |
+
# type=TurboMindModelwithChatTemplate,
|
| 43 |
+
# abbr='CompassJudger-1-7B-Instruct',
|
| 44 |
+
# path='opencompass/CompassJudger-1-7B-Instruct',
|
| 45 |
+
# engine_config=dict(session_len=16384, max_batch_size=16, tp=1),
|
| 46 |
+
# gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9, max_new_tokens=2048),
|
| 47 |
+
# max_seq_len=16384,
|
| 48 |
+
# max_out_len=2048,
|
| 49 |
+
# batch_size=16,
|
| 50 |
+
# run_cfg=dict(num_gpus=1),
|
| 51 |
+
# )
|
| 52 |
+
# ]
|
| 53 |
+
|
| 54 |
+
models = [
|
| 55 |
+
*lmdeploy_qwen2_5_14b_instruct, *lmdeploy_qwen2_5_32b_instruct,
|
| 56 |
+
*lmdeploy_qwen2_5_7b_instruct, *lmdeploy_qwen2_7b_instruct
|
| 57 |
+
]
|
| 58 |
+
|
| 59 |
+
datasets = [
|
| 60 |
+
*compassarena_subjectivebench_singleturn_datasets,
|
| 61 |
+
*compassarena_subjectivebench_multiturn_datasets
|
| 62 |
+
] # add datasets you want
|
| 63 |
+
|
| 64 |
+
infer = dict(
|
| 65 |
+
partitioner=dict(type=NaivePartitioner),
|
| 66 |
+
runner=dict(type=LocalRunner,
|
| 67 |
+
max_num_workers=16,
|
| 68 |
+
task=dict(type=OpenICLInferTask)),
|
| 69 |
+
)
|
| 70 |
+
# -------------Evalation Stage ----------------------------------------
|
| 71 |
+
|
| 72 |
+
## ------------- JudgeLLM Configuration
|
| 73 |
+
judge_models = [
|
| 74 |
+
dict(
|
| 75 |
+
type=TurboMindModelwithChatTemplate,
|
| 76 |
+
abbr='CompassJudger-1-32B-Instruct',
|
| 77 |
+
path='opencompass/CompassJudger-1-32B-Instruct',
|
| 78 |
+
engine_config=dict(session_len=16384, max_batch_size=16, tp=4),
|
| 79 |
+
gen_config=dict(top_k=1,
|
| 80 |
+
temperature=1e-6,
|
| 81 |
+
top_p=0.9,
|
| 82 |
+
max_new_tokens=2048),
|
| 83 |
+
max_seq_len=16384,
|
| 84 |
+
max_out_len=2048,
|
| 85 |
+
batch_size=16,
|
| 86 |
+
run_cfg=dict(num_gpus=4),
|
| 87 |
+
)
|
| 88 |
+
]
|
| 89 |
+
|
| 90 |
+
## ------------- Evaluation Configuration
|
| 91 |
+
eval = dict(
|
| 92 |
+
partitioner=dict(
|
| 93 |
+
type=SubjectiveNaivePartitioner,
|
| 94 |
+
models=models,
|
| 95 |
+
judge_models=judge_models,
|
| 96 |
+
),
|
| 97 |
+
runner=dict(type=LocalRunner,
|
| 98 |
+
max_num_workers=16,
|
| 99 |
+
task=dict(type=SubjectiveEvalTask)),
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
summarizer = dict(type=DefaultSubjectiveSummarizer, )
|
| 103 |
+
work_dir = 'outputs/subjective/'
|
examples/eval_hf_llama2.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from mmengine.config import read_base
|
| 2 |
+
|
| 3 |
+
with read_base():
|
| 4 |
+
from opencompass.configs.datasets.agieval.agieval_mixed_713d14 import \
|
| 5 |
+
agieval_datasets
|
| 6 |
+
from opencompass.configs.datasets.gsm8k.gsm8k_gen_3309bd import \
|
| 7 |
+
gsm8k_datasets
|
| 8 |
+
from opencompass.configs.datasets.hellaswag.hellaswag_ppl_a6e128 import \
|
| 9 |
+
hellaswag_datasets
|
| 10 |
+
from opencompass.configs.datasets.humaneval.deprecated_humaneval_gen_a82cae import \
|
| 11 |
+
humaneval_datasets
|
| 12 |
+
from opencompass.configs.datasets.mmlu.mmlu_ppl_ac766d import mmlu_datasets
|
| 13 |
+
from opencompass.configs.datasets.nq.nq_open_gen_e93f8a import nq_datasets
|
| 14 |
+
from opencompass.configs.datasets.obqa.obqa_ppl_6aac9e import obqa_datasets
|
| 15 |
+
from opencompass.configs.datasets.SuperGLUE_BoolQ.SuperGLUE_BoolQ_ppl_314797 import \
|
| 16 |
+
BoolQ_datasets
|
| 17 |
+
from opencompass.configs.datasets.triviaqa.triviaqa_wiki_gen_d18bf4 import \
|
| 18 |
+
triviaqa_datasets
|
| 19 |
+
from opencompass.configs.datasets.winogrande.winogrande_ll_c5cf57 import \
|
| 20 |
+
winogrande_datasets
|
| 21 |
+
from opencompass.configs.models.hf_llama.hf_llama2_7b import models
|
| 22 |
+
from opencompass.configs.summarizers.example import summarizer
|
| 23 |
+
|
| 24 |
+
datasets = sum([
|
| 25 |
+
v
|
| 26 |
+
for k, v in locals().items() if k.endswith('_datasets') or k == 'datasets'
|
| 27 |
+
], [])
|
| 28 |
+
work_dir = './outputs/llama2/'
|
opencompass.egg-info/PKG-INFO
ADDED
|
@@ -0,0 +1,745 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.4
|
| 2 |
+
Name: opencompass
|
| 3 |
+
Version: 0.5.1
|
| 4 |
+
Summary: A comprehensive toolkit for large model evaluation
|
| 5 |
+
Home-page: https://github.com/open-compass/opencompass
|
| 6 |
+
Author: OpenCompass Contributors
|
| 7 |
+
Maintainer: OpenCompass Authors
|
| 8 |
+
License: Apache License 2.0
|
| 9 |
+
Keywords: AI,NLP,in-context learning,large language model,evaluation,benchmark,llm
|
| 10 |
+
Classifier: Programming Language :: Python :: 3.8
|
| 11 |
+
Classifier: Programming Language :: Python :: 3.9
|
| 12 |
+
Classifier: Programming Language :: Python :: 3.10
|
| 13 |
+
Classifier: Intended Audience :: Developers
|
| 14 |
+
Classifier: Intended Audience :: Education
|
| 15 |
+
Classifier: Intended Audience :: Science/Research
|
| 16 |
+
Requires-Python: >=3.8.0
|
| 17 |
+
Description-Content-Type: text/markdown
|
| 18 |
+
License-File: LICENSE
|
| 19 |
+
Requires-Dist: absl-py
|
| 20 |
+
Requires-Dist: accelerate>=0.19.0
|
| 21 |
+
Requires-Dist: cpm_kernels
|
| 22 |
+
Requires-Dist: datasets<4.0.0,>=2.12.0
|
| 23 |
+
Requires-Dist: einops>=0.5.0
|
| 24 |
+
Requires-Dist: evaluate>=0.3.0
|
| 25 |
+
Requires-Dist: func_timeout
|
| 26 |
+
Requires-Dist: fuzzywuzzy
|
| 27 |
+
Requires-Dist: gradio-client
|
| 28 |
+
Requires-Dist: h5py
|
| 29 |
+
Requires-Dist: httpx==0.27.2
|
| 30 |
+
Requires-Dist: huggingface_hub
|
| 31 |
+
Requires-Dist: immutabledict
|
| 32 |
+
Requires-Dist: importlib-metadata
|
| 33 |
+
Requires-Dist: jieba
|
| 34 |
+
Requires-Dist: json5
|
| 35 |
+
Requires-Dist: jsonlines
|
| 36 |
+
Requires-Dist: mmengine-lite
|
| 37 |
+
Requires-Dist: nltk>=3.7
|
| 38 |
+
Requires-Dist: numpy<2.0.0,>=1.23.4
|
| 39 |
+
Requires-Dist: openai
|
| 40 |
+
Requires-Dist: OpenCC
|
| 41 |
+
Requires-Dist: opencv-python-headless
|
| 42 |
+
Requires-Dist: pandas<2.0.0
|
| 43 |
+
Requires-Dist: prettytable
|
| 44 |
+
Requires-Dist: protobuf
|
| 45 |
+
Requires-Dist: python-Levenshtein
|
| 46 |
+
Requires-Dist: rank_bm25==0.2.2
|
| 47 |
+
Requires-Dist: rapidfuzz
|
| 48 |
+
Requires-Dist: requests>=2.31.0
|
| 49 |
+
Requires-Dist: retrying
|
| 50 |
+
Requires-Dist: rich
|
| 51 |
+
Requires-Dist: rouge
|
| 52 |
+
Requires-Dist: rouge_chinese
|
| 53 |
+
Requires-Dist: rouge_score
|
| 54 |
+
Requires-Dist: sacrebleu
|
| 55 |
+
Requires-Dist: scikit_learn==1.5.0
|
| 56 |
+
Requires-Dist: seaborn
|
| 57 |
+
Requires-Dist: sentence_transformers
|
| 58 |
+
Requires-Dist: tabulate
|
| 59 |
+
Requires-Dist: tiktoken
|
| 60 |
+
Requires-Dist: timeout_decorator
|
| 61 |
+
Requires-Dist: tokenizers>=0.13.3
|
| 62 |
+
Requires-Dist: torch>=1.13.1
|
| 63 |
+
Requires-Dist: tqdm>=4.64.1
|
| 64 |
+
Requires-Dist: transformers>=4.29.1
|
| 65 |
+
Requires-Dist: tree-sitter==0.21.3
|
| 66 |
+
Requires-Dist: tree_sitter_languages>=1.10.2
|
| 67 |
+
Requires-Dist: typer
|
| 68 |
+
Provides-Extra: lmdeploy
|
| 69 |
+
Requires-Dist: lmdeploy; extra == "lmdeploy"
|
| 70 |
+
Requires-Dist: absl-py; extra == "lmdeploy"
|
| 71 |
+
Requires-Dist: accelerate>=0.19.0; extra == "lmdeploy"
|
| 72 |
+
Requires-Dist: cpm_kernels; extra == "lmdeploy"
|
| 73 |
+
Requires-Dist: datasets<4.0.0,>=2.12.0; extra == "lmdeploy"
|
| 74 |
+
Requires-Dist: einops>=0.5.0; extra == "lmdeploy"
|
| 75 |
+
Requires-Dist: evaluate>=0.3.0; extra == "lmdeploy"
|
| 76 |
+
Requires-Dist: func_timeout; extra == "lmdeploy"
|
| 77 |
+
Requires-Dist: fuzzywuzzy; extra == "lmdeploy"
|
| 78 |
+
Requires-Dist: gradio-client; extra == "lmdeploy"
|
| 79 |
+
Requires-Dist: h5py; extra == "lmdeploy"
|
| 80 |
+
Requires-Dist: httpx==0.27.2; extra == "lmdeploy"
|
| 81 |
+
Requires-Dist: huggingface_hub; extra == "lmdeploy"
|
| 82 |
+
Requires-Dist: immutabledict; extra == "lmdeploy"
|
| 83 |
+
Requires-Dist: importlib-metadata; extra == "lmdeploy"
|
| 84 |
+
Requires-Dist: jieba; extra == "lmdeploy"
|
| 85 |
+
Requires-Dist: json5; extra == "lmdeploy"
|
| 86 |
+
Requires-Dist: jsonlines; extra == "lmdeploy"
|
| 87 |
+
Requires-Dist: mmengine-lite; extra == "lmdeploy"
|
| 88 |
+
Requires-Dist: nltk>=3.7; extra == "lmdeploy"
|
| 89 |
+
Requires-Dist: numpy<2.0.0,>=1.23.4; extra == "lmdeploy"
|
| 90 |
+
Requires-Dist: openai; extra == "lmdeploy"
|
| 91 |
+
Requires-Dist: OpenCC; extra == "lmdeploy"
|
| 92 |
+
Requires-Dist: opencv-python-headless; extra == "lmdeploy"
|
| 93 |
+
Requires-Dist: pandas<2.0.0; extra == "lmdeploy"
|
| 94 |
+
Requires-Dist: prettytable; extra == "lmdeploy"
|
| 95 |
+
Requires-Dist: protobuf; extra == "lmdeploy"
|
| 96 |
+
Requires-Dist: python-Levenshtein; extra == "lmdeploy"
|
| 97 |
+
Requires-Dist: rank_bm25==0.2.2; extra == "lmdeploy"
|
| 98 |
+
Requires-Dist: rapidfuzz; extra == "lmdeploy"
|
| 99 |
+
Requires-Dist: requests>=2.31.0; extra == "lmdeploy"
|
| 100 |
+
Requires-Dist: retrying; extra == "lmdeploy"
|
| 101 |
+
Requires-Dist: rich; extra == "lmdeploy"
|
| 102 |
+
Requires-Dist: rouge; extra == "lmdeploy"
|
| 103 |
+
Requires-Dist: rouge_chinese; extra == "lmdeploy"
|
| 104 |
+
Requires-Dist: rouge_score; extra == "lmdeploy"
|
| 105 |
+
Requires-Dist: sacrebleu; extra == "lmdeploy"
|
| 106 |
+
Requires-Dist: scikit_learn==1.5.0; extra == "lmdeploy"
|
| 107 |
+
Requires-Dist: seaborn; extra == "lmdeploy"
|
| 108 |
+
Requires-Dist: sentence_transformers; extra == "lmdeploy"
|
| 109 |
+
Requires-Dist: tabulate; extra == "lmdeploy"
|
| 110 |
+
Requires-Dist: tiktoken; extra == "lmdeploy"
|
| 111 |
+
Requires-Dist: timeout_decorator; extra == "lmdeploy"
|
| 112 |
+
Requires-Dist: tokenizers>=0.13.3; extra == "lmdeploy"
|
| 113 |
+
Requires-Dist: torch>=1.13.1; extra == "lmdeploy"
|
| 114 |
+
Requires-Dist: tqdm>=4.64.1; extra == "lmdeploy"
|
| 115 |
+
Requires-Dist: transformers>=4.29.1; extra == "lmdeploy"
|
| 116 |
+
Requires-Dist: tree-sitter==0.21.3; extra == "lmdeploy"
|
| 117 |
+
Requires-Dist: tree_sitter_languages>=1.10.2; extra == "lmdeploy"
|
| 118 |
+
Requires-Dist: typer; extra == "lmdeploy"
|
| 119 |
+
Provides-Extra: vllm
|
| 120 |
+
Requires-Dist: vllm; extra == "vllm"
|
| 121 |
+
Requires-Dist: absl-py; extra == "vllm"
|
| 122 |
+
Requires-Dist: accelerate>=0.19.0; extra == "vllm"
|
| 123 |
+
Requires-Dist: cpm_kernels; extra == "vllm"
|
| 124 |
+
Requires-Dist: datasets<4.0.0,>=2.12.0; extra == "vllm"
|
| 125 |
+
Requires-Dist: einops>=0.5.0; extra == "vllm"
|
| 126 |
+
Requires-Dist: evaluate>=0.3.0; extra == "vllm"
|
| 127 |
+
Requires-Dist: func_timeout; extra == "vllm"
|
| 128 |
+
Requires-Dist: fuzzywuzzy; extra == "vllm"
|
| 129 |
+
Requires-Dist: gradio-client; extra == "vllm"
|
| 130 |
+
Requires-Dist: h5py; extra == "vllm"
|
| 131 |
+
Requires-Dist: httpx==0.27.2; extra == "vllm"
|
| 132 |
+
Requires-Dist: huggingface_hub; extra == "vllm"
|
| 133 |
+
Requires-Dist: immutabledict; extra == "vllm"
|
| 134 |
+
Requires-Dist: importlib-metadata; extra == "vllm"
|
| 135 |
+
Requires-Dist: jieba; extra == "vllm"
|
| 136 |
+
Requires-Dist: json5; extra == "vllm"
|
| 137 |
+
Requires-Dist: jsonlines; extra == "vllm"
|
| 138 |
+
Requires-Dist: mmengine-lite; extra == "vllm"
|
| 139 |
+
Requires-Dist: nltk>=3.7; extra == "vllm"
|
| 140 |
+
Requires-Dist: numpy<2.0.0,>=1.23.4; extra == "vllm"
|
| 141 |
+
Requires-Dist: openai; extra == "vllm"
|
| 142 |
+
Requires-Dist: OpenCC; extra == "vllm"
|
| 143 |
+
Requires-Dist: opencv-python-headless; extra == "vllm"
|
| 144 |
+
Requires-Dist: pandas<2.0.0; extra == "vllm"
|
| 145 |
+
Requires-Dist: prettytable; extra == "vllm"
|
| 146 |
+
Requires-Dist: protobuf; extra == "vllm"
|
| 147 |
+
Requires-Dist: python-Levenshtein; extra == "vllm"
|
| 148 |
+
Requires-Dist: rank_bm25==0.2.2; extra == "vllm"
|
| 149 |
+
Requires-Dist: rapidfuzz; extra == "vllm"
|
| 150 |
+
Requires-Dist: requests>=2.31.0; extra == "vllm"
|
| 151 |
+
Requires-Dist: retrying; extra == "vllm"
|
| 152 |
+
Requires-Dist: rich; extra == "vllm"
|
| 153 |
+
Requires-Dist: rouge; extra == "vllm"
|
| 154 |
+
Requires-Dist: rouge_chinese; extra == "vllm"
|
| 155 |
+
Requires-Dist: rouge_score; extra == "vllm"
|
| 156 |
+
Requires-Dist: sacrebleu; extra == "vllm"
|
| 157 |
+
Requires-Dist: scikit_learn==1.5.0; extra == "vllm"
|
| 158 |
+
Requires-Dist: seaborn; extra == "vllm"
|
| 159 |
+
Requires-Dist: sentence_transformers; extra == "vllm"
|
| 160 |
+
Requires-Dist: tabulate; extra == "vllm"
|
| 161 |
+
Requires-Dist: tiktoken; extra == "vllm"
|
| 162 |
+
Requires-Dist: timeout_decorator; extra == "vllm"
|
| 163 |
+
Requires-Dist: tokenizers>=0.13.3; extra == "vllm"
|
| 164 |
+
Requires-Dist: torch>=1.13.1; extra == "vllm"
|
| 165 |
+
Requires-Dist: tqdm>=4.64.1; extra == "vllm"
|
| 166 |
+
Requires-Dist: transformers>=4.29.1; extra == "vllm"
|
| 167 |
+
Requires-Dist: tree-sitter==0.21.3; extra == "vllm"
|
| 168 |
+
Requires-Dist: tree_sitter_languages>=1.10.2; extra == "vllm"
|
| 169 |
+
Requires-Dist: typer; extra == "vllm"
|
| 170 |
+
Provides-Extra: api
|
| 171 |
+
Requires-Dist: anthropic; extra == "api"
|
| 172 |
+
Requires-Dist: dashscope; extra == "api"
|
| 173 |
+
Requires-Dist: openai; extra == "api"
|
| 174 |
+
Requires-Dist: spark_ai_python; extra == "api"
|
| 175 |
+
Requires-Dist: sseclient-py==1.7.2; extra == "api"
|
| 176 |
+
Requires-Dist: tencentcloud-sdk-python; extra == "api"
|
| 177 |
+
Requires-Dist: volcengine; extra == "api"
|
| 178 |
+
Requires-Dist: volcengine-python-sdk; extra == "api"
|
| 179 |
+
Requires-Dist: websocket-client; extra == "api"
|
| 180 |
+
Requires-Dist: zhipuai; extra == "api"
|
| 181 |
+
Requires-Dist: absl-py; extra == "api"
|
| 182 |
+
Requires-Dist: accelerate>=0.19.0; extra == "api"
|
| 183 |
+
Requires-Dist: cpm_kernels; extra == "api"
|
| 184 |
+
Requires-Dist: datasets<4.0.0,>=2.12.0; extra == "api"
|
| 185 |
+
Requires-Dist: einops>=0.5.0; extra == "api"
|
| 186 |
+
Requires-Dist: evaluate>=0.3.0; extra == "api"
|
| 187 |
+
Requires-Dist: func_timeout; extra == "api"
|
| 188 |
+
Requires-Dist: fuzzywuzzy; extra == "api"
|
| 189 |
+
Requires-Dist: gradio-client; extra == "api"
|
| 190 |
+
Requires-Dist: h5py; extra == "api"
|
| 191 |
+
Requires-Dist: httpx==0.27.2; extra == "api"
|
| 192 |
+
Requires-Dist: huggingface_hub; extra == "api"
|
| 193 |
+
Requires-Dist: immutabledict; extra == "api"
|
| 194 |
+
Requires-Dist: importlib-metadata; extra == "api"
|
| 195 |
+
Requires-Dist: jieba; extra == "api"
|
| 196 |
+
Requires-Dist: json5; extra == "api"
|
| 197 |
+
Requires-Dist: jsonlines; extra == "api"
|
| 198 |
+
Requires-Dist: mmengine-lite; extra == "api"
|
| 199 |
+
Requires-Dist: nltk>=3.7; extra == "api"
|
| 200 |
+
Requires-Dist: numpy<2.0.0,>=1.23.4; extra == "api"
|
| 201 |
+
Requires-Dist: openai; extra == "api"
|
| 202 |
+
Requires-Dist: OpenCC; extra == "api"
|
| 203 |
+
Requires-Dist: opencv-python-headless; extra == "api"
|
| 204 |
+
Requires-Dist: pandas<2.0.0; extra == "api"
|
| 205 |
+
Requires-Dist: prettytable; extra == "api"
|
| 206 |
+
Requires-Dist: protobuf; extra == "api"
|
| 207 |
+
Requires-Dist: python-Levenshtein; extra == "api"
|
| 208 |
+
Requires-Dist: rank_bm25==0.2.2; extra == "api"
|
| 209 |
+
Requires-Dist: rapidfuzz; extra == "api"
|
| 210 |
+
Requires-Dist: requests>=2.31.0; extra == "api"
|
| 211 |
+
Requires-Dist: retrying; extra == "api"
|
| 212 |
+
Requires-Dist: rich; extra == "api"
|
| 213 |
+
Requires-Dist: rouge; extra == "api"
|
| 214 |
+
Requires-Dist: rouge_chinese; extra == "api"
|
| 215 |
+
Requires-Dist: rouge_score; extra == "api"
|
| 216 |
+
Requires-Dist: sacrebleu; extra == "api"
|
| 217 |
+
Requires-Dist: scikit_learn==1.5.0; extra == "api"
|
| 218 |
+
Requires-Dist: seaborn; extra == "api"
|
| 219 |
+
Requires-Dist: sentence_transformers; extra == "api"
|
| 220 |
+
Requires-Dist: tabulate; extra == "api"
|
| 221 |
+
Requires-Dist: tiktoken; extra == "api"
|
| 222 |
+
Requires-Dist: timeout_decorator; extra == "api"
|
| 223 |
+
Requires-Dist: tokenizers>=0.13.3; extra == "api"
|
| 224 |
+
Requires-Dist: torch>=1.13.1; extra == "api"
|
| 225 |
+
Requires-Dist: tqdm>=4.64.1; extra == "api"
|
| 226 |
+
Requires-Dist: transformers>=4.29.1; extra == "api"
|
| 227 |
+
Requires-Dist: tree-sitter==0.21.3; extra == "api"
|
| 228 |
+
Requires-Dist: tree_sitter_languages>=1.10.2; extra == "api"
|
| 229 |
+
Requires-Dist: typer; extra == "api"
|
| 230 |
+
Provides-Extra: full
|
| 231 |
+
Requires-Dist: alpaca-eval==0.6; extra == "full"
|
| 232 |
+
Requires-Dist: antlr4-python3-runtime==4.11; extra == "full"
|
| 233 |
+
Requires-Dist: cn2an; extra == "full"
|
| 234 |
+
Requires-Dist: dingo-python==1.5.0; extra == "full"
|
| 235 |
+
Requires-Dist: faiss_gpu==1.7.2; extra == "full"
|
| 236 |
+
Requires-Dist: human-eval; extra == "full"
|
| 237 |
+
Requires-Dist: langdetect; extra == "full"
|
| 238 |
+
Requires-Dist: ltp; extra == "full"
|
| 239 |
+
Requires-Dist: math-verify[antlr4_11_0]; extra == "full"
|
| 240 |
+
Requires-Dist: pyext; extra == "full"
|
| 241 |
+
Requires-Dist: pypinyin; extra == "full"
|
| 242 |
+
Requires-Dist: rdkit; extra == "full"
|
| 243 |
+
Requires-Dist: wonderwords; extra == "full"
|
| 244 |
+
Requires-Dist: absl-py; extra == "full"
|
| 245 |
+
Requires-Dist: accelerate>=0.19.0; extra == "full"
|
| 246 |
+
Requires-Dist: cpm_kernels; extra == "full"
|
| 247 |
+
Requires-Dist: datasets<4.0.0,>=2.12.0; extra == "full"
|
| 248 |
+
Requires-Dist: einops>=0.5.0; extra == "full"
|
| 249 |
+
Requires-Dist: evaluate>=0.3.0; extra == "full"
|
| 250 |
+
Requires-Dist: func_timeout; extra == "full"
|
| 251 |
+
Requires-Dist: fuzzywuzzy; extra == "full"
|
| 252 |
+
Requires-Dist: gradio-client; extra == "full"
|
| 253 |
+
Requires-Dist: h5py; extra == "full"
|
| 254 |
+
Requires-Dist: httpx==0.27.2; extra == "full"
|
| 255 |
+
Requires-Dist: huggingface_hub; extra == "full"
|
| 256 |
+
Requires-Dist: immutabledict; extra == "full"
|
| 257 |
+
Requires-Dist: importlib-metadata; extra == "full"
|
| 258 |
+
Requires-Dist: jieba; extra == "full"
|
| 259 |
+
Requires-Dist: json5; extra == "full"
|
| 260 |
+
Requires-Dist: jsonlines; extra == "full"
|
| 261 |
+
Requires-Dist: mmengine-lite; extra == "full"
|
| 262 |
+
Requires-Dist: nltk>=3.7; extra == "full"
|
| 263 |
+
Requires-Dist: numpy<2.0.0,>=1.23.4; extra == "full"
|
| 264 |
+
Requires-Dist: openai; extra == "full"
|
| 265 |
+
Requires-Dist: OpenCC; extra == "full"
|
| 266 |
+
Requires-Dist: opencv-python-headless; extra == "full"
|
| 267 |
+
Requires-Dist: pandas<2.0.0; extra == "full"
|
| 268 |
+
Requires-Dist: prettytable; extra == "full"
|
| 269 |
+
Requires-Dist: protobuf; extra == "full"
|
| 270 |
+
Requires-Dist: python-Levenshtein; extra == "full"
|
| 271 |
+
Requires-Dist: rank_bm25==0.2.2; extra == "full"
|
| 272 |
+
Requires-Dist: rapidfuzz; extra == "full"
|
| 273 |
+
Requires-Dist: requests>=2.31.0; extra == "full"
|
| 274 |
+
Requires-Dist: retrying; extra == "full"
|
| 275 |
+
Requires-Dist: rich; extra == "full"
|
| 276 |
+
Requires-Dist: rouge; extra == "full"
|
| 277 |
+
Requires-Dist: rouge_chinese; extra == "full"
|
| 278 |
+
Requires-Dist: rouge_score; extra == "full"
|
| 279 |
+
Requires-Dist: sacrebleu; extra == "full"
|
| 280 |
+
Requires-Dist: scikit_learn==1.5.0; extra == "full"
|
| 281 |
+
Requires-Dist: seaborn; extra == "full"
|
| 282 |
+
Requires-Dist: sentence_transformers; extra == "full"
|
| 283 |
+
Requires-Dist: tabulate; extra == "full"
|
| 284 |
+
Requires-Dist: tiktoken; extra == "full"
|
| 285 |
+
Requires-Dist: timeout_decorator; extra == "full"
|
| 286 |
+
Requires-Dist: tokenizers>=0.13.3; extra == "full"
|
| 287 |
+
Requires-Dist: torch>=1.13.1; extra == "full"
|
| 288 |
+
Requires-Dist: tqdm>=4.64.1; extra == "full"
|
| 289 |
+
Requires-Dist: transformers>=4.29.1; extra == "full"
|
| 290 |
+
Requires-Dist: tree-sitter==0.21.3; extra == "full"
|
| 291 |
+
Requires-Dist: tree_sitter_languages>=1.10.2; extra == "full"
|
| 292 |
+
Requires-Dist: typer; extra == "full"
|
| 293 |
+
Dynamic: author
|
| 294 |
+
Dynamic: classifier
|
| 295 |
+
Dynamic: description
|
| 296 |
+
Dynamic: description-content-type
|
| 297 |
+
Dynamic: home-page
|
| 298 |
+
Dynamic: keywords
|
| 299 |
+
Dynamic: license
|
| 300 |
+
Dynamic: license-file
|
| 301 |
+
Dynamic: maintainer
|
| 302 |
+
Dynamic: provides-extra
|
| 303 |
+
Dynamic: requires-dist
|
| 304 |
+
Dynamic: requires-python
|
| 305 |
+
Dynamic: summary
|
| 306 |
+
|
| 307 |
+
<div align="center">
|
| 308 |
+
<img src="docs/en/_static/image/logo.svg" width="500px"/>
|
| 309 |
+
<br />
|
| 310 |
+
<br />
|
| 311 |
+
|
| 312 |
+
[![][github-release-shield]][github-release-link]
|
| 313 |
+
[![][github-releasedate-shield]][github-releasedate-link]
|
| 314 |
+
[![][github-contributors-shield]][github-contributors-link]<br>
|
| 315 |
+
[![][github-forks-shield]][github-forks-link]
|
| 316 |
+
[![][github-stars-shield]][github-stars-link]
|
| 317 |
+
[![][github-issues-shield]][github-issues-link]
|
| 318 |
+
[![][github-license-shield]][github-license-link]
|
| 319 |
+
|
| 320 |
+
<!-- [](https://pypi.org/project/opencompass/) -->
|
| 321 |
+
|
| 322 |
+
[🌐Website](https://opencompass.org.cn/) |
|
| 323 |
+
[📖CompassHub](https://hub.opencompass.org.cn/home) |
|
| 324 |
+
[📊CompassRank](https://rank.opencompass.org.cn/home) |
|
| 325 |
+
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
|
| 326 |
+
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
|
| 327 |
+
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
| 328 |
+
|
| 329 |
+
English | [简体中文](README_zh-CN.md)
|
| 330 |
+
|
| 331 |
+
[![][github-trending-shield]][github-trending-url]
|
| 332 |
+
|
| 333 |
+
</div>
|
| 334 |
+
|
| 335 |
+
<p align="center">
|
| 336 |
+
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
|
| 337 |
+
</p>
|
| 338 |
+
|
| 339 |
+
> \[!IMPORTANT\]
|
| 340 |
+
>
|
| 341 |
+
> **Star Us**, You will receive all release notifications from GitHub without any delay ~ ⭐️
|
| 342 |
+
|
| 343 |
+
<details>
|
| 344 |
+
<summary><kbd>Star History</kbd></summary>
|
| 345 |
+
<picture>
|
| 346 |
+
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
|
| 347 |
+
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
|
| 348 |
+
</picture>
|
| 349 |
+
</details>
|
| 350 |
+
|
| 351 |
+
## 🧭 Welcome
|
| 352 |
+
|
| 353 |
+
to **OpenCompass**!
|
| 354 |
+
|
| 355 |
+
Just like a compass guides us on our journey, OpenCompass will guide you through the complex landscape of evaluating large language models. With its powerful algorithms and intuitive interface, OpenCompass makes it easy to assess the quality and effectiveness of your NLP models.
|
| 356 |
+
|
| 357 |
+
🚩🚩🚩 Explore opportunities at OpenCompass! We're currently **hiring full-time researchers/engineers and interns**. If you're passionate about LLM and OpenCompass, don't hesitate to reach out to us via [email](mailto:zhangsongyang@pjlab.org.cn). We'd love to hear from you!
|
| 358 |
+
|
| 359 |
+
🔥🔥🔥 We are delighted to announce that **the OpenCompass has been recommended by the Meta AI**, click [Get Started](https://ai.meta.com/llama/get-started/#validation) of Llama for more information.
|
| 360 |
+
|
| 361 |
+
> **Attention**<br />
|
| 362 |
+
> Breaking Change Notice: In version 0.4.0, we are consolidating all AMOTIC configuration files (previously located in ./configs/datasets, ./configs/models, and ./configs/summarizers) into the opencompass package. Users are advised to update their configuration references to reflect this structural change.
|
| 363 |
+
|
| 364 |
+
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
| 365 |
+
|
| 366 |
+
- **\[2025.07.26\]** OpenCompass now supports Intern-S1 related general and scientific evaluation benchmarks. Please check [Tutorial for Evaluating Intern-S1](https://opencompass.readthedocs.io/en/latest/user_guides/interns1.html) for more details! 🔥🔥🔥
|
| 367 |
+
- **\[2025.04.01\]** OpenCompass now supports `CascadeEvaluator`, a flexible evaluation mechanism that allows multiple evaluators to work in sequence. This enables creating customized evaluation pipelines for complex assessment scenarios. Check out the [documentation](docs/en/advanced_guides/llm_judge.md) for more details! 🔥🔥🔥
|
| 368 |
+
- **\[2025.03.11\]** We have supported evaluation for `SuperGPQA` which is a great benchmark for measuring LLM knowledge ability 🔥🔥🔥
|
| 369 |
+
- **\[2025.02.28\]** We have added a tutorial for `DeepSeek-R1` series model, please check [Evaluating Reasoning Model](docs/en/user_guides/deepseek_r1.md) for more details! 🔥🔥🔥
|
| 370 |
+
- **\[2025.02.15\]** We have added two powerful evaluation tools: `GenericLLMEvaluator` for LLM-as-judge evaluations and `MATHVerifyEvaluator` for mathematical reasoning assessments. Check out the documentation for [LLM Judge](docs/en/advanced_guides/llm_judge.md) and [Math Evaluation](docs/en/advanced_guides/general_math.md) for more details! 🔥🔥🔥
|
| 371 |
+
- **\[2025.01.16\]** We now support the [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) model which has enhanced performance on reasoning and knowledge-intensive tasks.
|
| 372 |
+
- **\[2024.12.17\]** We have provided the evaluation script for the December [CompassAcademic](examples/eval_academic_leaderboard_202412.py), which allows users to easily reproduce the official evaluation results by configuring it.
|
| 373 |
+
- **\[2024.11.14\]** OpenCompass now offers support for a sophisticated benchmark designed to evaluate complex reasoning skills — [MuSR](https://arxiv.org/pdf/2310.16049). Check out the [demo](examples/eval_musr.py) and give it a spin! 🔥🔥🔥
|
| 374 |
+
- **\[2024.11.14\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [BABILong](https://arxiv.org/pdf/2406.10149). Have a look at the [demo](examples/eval_babilong.py) and give it a try! 🔥🔥🔥
|
| 375 |
+
- **\[2024.10.14\]** We now support the OpenAI multilingual QA dataset [MMMLU](https://huggingface.co/datasets/openai/MMMLU). Feel free to give it a try! 🔥🔥🔥
|
| 376 |
+
- **\[2024.09.19\]** We now support [Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) with multiple backend(huggingface/vllm/lmdeploy). Feel free to give them a try! 🔥🔥🔥
|
| 377 |
+
- **\[2024.09.17\]** We now support OpenAI o1(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`). Feel free to give them a try! 🔥🔥🔥
|
| 378 |
+
- **\[2024.09.05\]** We now support answer extraction through model post-processing to provide a more accurate representation of the model's capabilities. As part of this update, we have integrated [XFinder](https://github.com/IAAR-Shanghai/xFinder) as our first post-processing model. For more detailed information, please refer to the [documentation](opencompass/utils/postprocessors/xfinder/README.md), and give it a try! 🔥🔥🔥
|
| 379 |
+
- **\[2024.08.20\]** OpenCompass now supports the [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists. 🔥🔥🔥
|
| 380 |
+
- **\[2024.08.16\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [RULER](https://arxiv.org/pdf/2404.06654). RULER provides an evaluation of long-context including retrieval, multi-hop tracing, aggregation, and question answering through flexible configurations. Check out the [RULER](configs/datasets/ruler/README.md) evaluation config now! 🔥🔥🔥
|
| 381 |
+
- **\[2024.08.09\]** We have released the example data and configuration for the CompassBench-202408, welcome to [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) for more details. 🔥🔥🔥
|
| 382 |
+
- **\[2024.08.01\]** We supported the [Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315) models. Welcome to try! 🔥🔥🔥
|
| 383 |
+
- **\[2024.07.23\]** We supported the [ModelScope](www.modelscope.cn) datasets, you can load them on demand without downloading all the data to your local disk. Welcome to try! 🔥🔥🔥
|
| 384 |
+
- **\[2024.07.17\]** We are excited to announce the release of NeedleBench's [technical report](http://arxiv.org/abs/2407.11963). We invite you to visit our [support documentation](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html) for detailed evaluation guidelines. 🔥🔥🔥
|
| 385 |
+
- **\[2024.07.04\]** OpenCompass now supports InternLM2.5, which has **outstanding reasoning capability**, **1M Context window and** and **stronger tool use**, you can try the models in [OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) and [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
|
| 386 |
+
- **\[2024.06.20\]** OpenCompass now supports one-click switching between inference acceleration backends, enhancing the efficiency of the evaluation process. In addition to the default HuggingFace inference backend, it now also supports popular backends [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm). This feature is available via a simple command-line switch and through deployment APIs. For detailed usage, see the [documentation](docs/en/advanced_guides/accelerator_intro.md).🔥🔥🔥.
|
| 387 |
+
|
| 388 |
+
> [More](docs/en/notes/news.md)
|
| 389 |
+
|
| 390 |
+
## 📊 Leaderboard
|
| 391 |
+
|
| 392 |
+
We provide [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `opencompass@pjlab.org.cn`.
|
| 393 |
+
|
| 394 |
+
You can also refer to [Guide to Reproducing CompassAcademic Leaderboard Results](https://opencompass.readthedocs.io/zh-cn/latest/academic.html) to quickly reproduce the leaderboard results.
|
| 395 |
+
|
| 396 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 397 |
+
|
| 398 |
+
## 🛠️ Installation
|
| 399 |
+
|
| 400 |
+
Below are the steps for quick installation and datasets preparation.
|
| 401 |
+
|
| 402 |
+
### 💻 Environment Setup
|
| 403 |
+
|
| 404 |
+
We highly recommend using conda to manage your python environment.
|
| 405 |
+
|
| 406 |
+
- #### Create your virtual environment
|
| 407 |
+
|
| 408 |
+
```bash
|
| 409 |
+
conda create --name opencompass python=3.10 -y
|
| 410 |
+
conda activate opencompass
|
| 411 |
+
```
|
| 412 |
+
|
| 413 |
+
- #### Install OpenCompass via pip
|
| 414 |
+
|
| 415 |
+
```bash
|
| 416 |
+
pip install -U opencompass
|
| 417 |
+
|
| 418 |
+
## Full installation (with support for more datasets)
|
| 419 |
+
# pip install "opencompass[full]"
|
| 420 |
+
|
| 421 |
+
## Environment with model acceleration frameworks
|
| 422 |
+
## Manage different acceleration frameworks using virtual environments
|
| 423 |
+
## since they usually have dependency conflicts with each other.
|
| 424 |
+
# pip install "opencompass[lmdeploy]"
|
| 425 |
+
# pip install "opencompass[vllm]"
|
| 426 |
+
|
| 427 |
+
## API evaluation (i.e. Openai, Qwen)
|
| 428 |
+
# pip install "opencompass[api]"
|
| 429 |
+
```
|
| 430 |
+
|
| 431 |
+
- #### Install OpenCompass from source
|
| 432 |
+
|
| 433 |
+
If you want to use opencompass's latest features, or develop new features, you can also build it from source
|
| 434 |
+
|
| 435 |
+
```bash
|
| 436 |
+
git clone https://github.com/open-compass/opencompass opencompass
|
| 437 |
+
cd opencompass
|
| 438 |
+
pip install -e .
|
| 439 |
+
# pip install -e ".[full]"
|
| 440 |
+
# pip install -e ".[vllm]"
|
| 441 |
+
```
|
| 442 |
+
|
| 443 |
+
### 📂 Data Preparation
|
| 444 |
+
|
| 445 |
+
You can choose one for the following method to prepare datasets.
|
| 446 |
+
|
| 447 |
+
#### Offline Preparation
|
| 448 |
+
|
| 449 |
+
You can download and extract the datasets with the following commands:
|
| 450 |
+
|
| 451 |
+
```bash
|
| 452 |
+
# Download dataset to data/ folder
|
| 453 |
+
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
| 454 |
+
unzip OpenCompassData-core-20240207.zip
|
| 455 |
+
```
|
| 456 |
+
|
| 457 |
+
#### Automatic Download from OpenCompass
|
| 458 |
+
|
| 459 |
+
We have supported download datasets automatic from the OpenCompass storage server. You can run the evaluation with extra `--dry-run` to download these datasets.
|
| 460 |
+
Currently, the supported datasets are listed in [here](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259). More datasets will be uploaded recently.
|
| 461 |
+
|
| 462 |
+
#### (Optional) Automatic Download with ModelScope
|
| 463 |
+
|
| 464 |
+
Also you can use the [ModelScope](www.modelscope.cn) to load the datasets on demand.
|
| 465 |
+
|
| 466 |
+
Installation:
|
| 467 |
+
|
| 468 |
+
```bash
|
| 469 |
+
pip install modelscope[framework]
|
| 470 |
+
export DATASET_SOURCE=ModelScope
|
| 471 |
+
```
|
| 472 |
+
|
| 473 |
+
Then submit the evaluation task without downloading all the data to your local disk. Available datasets include:
|
| 474 |
+
|
| 475 |
+
```bash
|
| 476 |
+
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
| 477 |
+
```
|
| 478 |
+
|
| 479 |
+
Some third-party features, like Humaneval and Llama, may require additional steps to work properly, for detailed steps please refer to the [Installation Guide](https://opencompass.readthedocs.io/en/latest/get_started/installation.html).
|
| 480 |
+
|
| 481 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 482 |
+
|
| 483 |
+
## 🏗️ ️Evaluation
|
| 484 |
+
|
| 485 |
+
After ensuring that OpenCompass is installed correctly according to the above steps and the datasets are prepared. Now you can start your first evaluation using OpenCompass!
|
| 486 |
+
|
| 487 |
+
### Your first evaluation with OpenCompass!
|
| 488 |
+
|
| 489 |
+
OpenCompass support setting your configs via CLI or a python script. For simple evaluation settings we recommend using CLI, for more complex evaluation, it is suggested using the script way. You can find more example scripts under the configs folder.
|
| 490 |
+
|
| 491 |
+
```bash
|
| 492 |
+
# CLI
|
| 493 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
|
| 494 |
+
|
| 495 |
+
# Python scripts
|
| 496 |
+
opencompass examples/eval_chat_demo.py
|
| 497 |
+
```
|
| 498 |
+
|
| 499 |
+
You can find more script examples under [examples](./examples) folder.
|
| 500 |
+
|
| 501 |
+
### API evaluation
|
| 502 |
+
|
| 503 |
+
OpenCompass, by its design, does not really discriminate between open-source models and API models. You can evaluate both model types in the same way or even in one settings.
|
| 504 |
+
|
| 505 |
+
```bash
|
| 506 |
+
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
|
| 507 |
+
# CLI
|
| 508 |
+
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
|
| 509 |
+
|
| 510 |
+
# Python scripts
|
| 511 |
+
opencompass examples/eval_api_demo.py
|
| 512 |
+
|
| 513 |
+
# You can use o1_mini_2024_09_12/o1_preview_2024_09_12 for o1 models, we set max_completion_tokens=8192 as default.
|
| 514 |
+
```
|
| 515 |
+
|
| 516 |
+
### Accelerated Evaluation
|
| 517 |
+
|
| 518 |
+
Additionally, if you want to use an inference backend other than HuggingFace for accelerated evaluation, such as LMDeploy or vLLM, you can do so with the command below. Please ensure that you have installed the necessary packages for the chosen backend and that your model supports accelerated inference with it. For more information, see the documentation on inference acceleration backends [here](docs/en/advanced_guides/accelerator_intro.md). Below is an example using LMDeploy:
|
| 519 |
+
|
| 520 |
+
```bash
|
| 521 |
+
# CLI
|
| 522 |
+
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
|
| 523 |
+
|
| 524 |
+
# Python scripts
|
| 525 |
+
opencompass examples/eval_lmdeploy_demo.py
|
| 526 |
+
```
|
| 527 |
+
|
| 528 |
+
### Supported Models and Datasets
|
| 529 |
+
|
| 530 |
+
OpenCompass has predefined configurations for many models and datasets. You can list all available model and dataset configurations using the [tools](./docs/en/tools.md#list-configs).
|
| 531 |
+
|
| 532 |
+
```bash
|
| 533 |
+
# List all configurations
|
| 534 |
+
python tools/list_configs.py
|
| 535 |
+
# List all configurations related to llama and mmlu
|
| 536 |
+
python tools/list_configs.py llama mmlu
|
| 537 |
+
```
|
| 538 |
+
|
| 539 |
+
#### Supported Models
|
| 540 |
+
|
| 541 |
+
If the model is not on the list but supported by Huggingface AutoModel class or encapsulation of inference engine based on OpenAI interface (see [docs](https://opencompass.readthedocs.io/en/latest/advanced_guides/new_model.html) for details), you can also evaluate it with OpenCompass. You are welcome to contribute to the maintenance of the OpenCompass supported model and dataset lists.
|
| 542 |
+
|
| 543 |
+
```bash
|
| 544 |
+
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
|
| 545 |
+
```
|
| 546 |
+
|
| 547 |
+
#### Supported Datasets
|
| 548 |
+
|
| 549 |
+
Currently, OpenCompass have provided standard recommended configurations for datasets. Generally, config files ending with `_gen.py` or `_llm_judge_gen.py` will point to the recommended config we provide for this dataset. You can refer to [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for more details.
|
| 550 |
+
|
| 551 |
+
```bash
|
| 552 |
+
# Recommended Evaluation Config based on Rules
|
| 553 |
+
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
|
| 554 |
+
|
| 555 |
+
# Recommended Evaluation Config based on LLM Judge
|
| 556 |
+
opencompass --datasets aime2024_llmjudge_gen --models hf_internlm2_5_1_8b_chat
|
| 557 |
+
```
|
| 558 |
+
|
| 559 |
+
If you want to use multiple GPUs to evaluate the model in data parallel, you can use `--max-num-worker`.
|
| 560 |
+
|
| 561 |
+
```bash
|
| 562 |
+
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
|
| 563 |
+
```
|
| 564 |
+
|
| 565 |
+
> \[!TIP\]
|
| 566 |
+
>
|
| 567 |
+
> `--hf-num-gpus` is used for model parallel(huggingface format), `--max-num-worker` is used for data parallel.
|
| 568 |
+
|
| 569 |
+
> \[!TIP\]
|
| 570 |
+
>
|
| 571 |
+
> configuration with `_ppl` is designed for base model typically.
|
| 572 |
+
> configuration with `_gen` can be used for both base model and chat model.
|
| 573 |
+
|
| 574 |
+
Through the command line or configuration files, OpenCompass also supports evaluating APIs or custom models, as well as more diversified evaluation strategies. Please read the [Quick Start](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html) to learn how to run an evaluation task.
|
| 575 |
+
|
| 576 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 577 |
+
|
| 578 |
+
## 📣 OpenCompass 2.0
|
| 579 |
+
|
| 580 |
+
We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home).
|
| 581 |
+

|
| 582 |
+
|
| 583 |
+
**CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry.
|
| 584 |
+
|
| 585 |
+
**CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit).
|
| 586 |
+
|
| 587 |
+
**CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products.
|
| 588 |
+
|
| 589 |
+
## ✨ Introduction
|
| 590 |
+
|
| 591 |
+

|
| 592 |
+
|
| 593 |
+
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include:
|
| 594 |
+
|
| 595 |
+
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
|
| 596 |
+
|
| 597 |
+
- **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours.
|
| 598 |
+
|
| 599 |
+
- **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models.
|
| 600 |
+
|
| 601 |
+
- **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded!
|
| 602 |
+
|
| 603 |
+
- **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results.
|
| 604 |
+
|
| 605 |
+
## 📖 Dataset Support
|
| 606 |
+
|
| 607 |
+
We have supported a statistical list of all datasets that can be used on this platform in the documentation on the OpenCompass website.
|
| 608 |
+
|
| 609 |
+
You can quickly find the dataset you need from the list through sorting, filtering, and searching functions.
|
| 610 |
+
|
| 611 |
+
In addition, we provide a recommended configuration for each dataset, and some datasets also support LLM Judge-based configurations.
|
| 612 |
+
|
| 613 |
+
Please refer to the dataset statistics chapter of [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for details.
|
| 614 |
+
|
| 615 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 616 |
+
|
| 617 |
+
## 📖 Model Support
|
| 618 |
+
|
| 619 |
+
<table align="center">
|
| 620 |
+
<tbody>
|
| 621 |
+
<tr align="center" valign="bottom">
|
| 622 |
+
<td>
|
| 623 |
+
<b>Open-source Models</b>
|
| 624 |
+
</td>
|
| 625 |
+
<td>
|
| 626 |
+
<b>API Models</b>
|
| 627 |
+
</td>
|
| 628 |
+
<!-- <td>
|
| 629 |
+
<b>Custom Models</b>
|
| 630 |
+
</td> -->
|
| 631 |
+
</tr>
|
| 632 |
+
<tr valign="top">
|
| 633 |
+
<td>
|
| 634 |
+
|
| 635 |
+
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 636 |
+
- [Baichuan](https://github.com/baichuan-inc)
|
| 637 |
+
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
| 638 |
+
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
| 639 |
+
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
| 640 |
+
- [Gemma](https://huggingface.co/google/gemma-7b)
|
| 641 |
+
- [InternLM](https://github.com/InternLM/InternLM)
|
| 642 |
+
- [LLaMA](https://github.com/facebookresearch/llama)
|
| 643 |
+
- [LLaMA3](https://github.com/meta-llama/llama3)
|
| 644 |
+
- [Qwen](https://github.com/QwenLM/Qwen)
|
| 645 |
+
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
| 646 |
+
- [Vicuna](https://github.com/lm-sys/FastChat)
|
| 647 |
+
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
| 648 |
+
- [Yi](https://github.com/01-ai/Yi)
|
| 649 |
+
- ……
|
| 650 |
+
|
| 651 |
+
</td>
|
| 652 |
+
<td>
|
| 653 |
+
|
| 654 |
+
- OpenAI
|
| 655 |
+
- Gemini
|
| 656 |
+
- Claude
|
| 657 |
+
- ZhipuAI(ChatGLM)
|
| 658 |
+
- Baichuan
|
| 659 |
+
- ByteDance(YunQue)
|
| 660 |
+
- Huawei(PanGu)
|
| 661 |
+
- 360
|
| 662 |
+
- Baidu(ERNIEBot)
|
| 663 |
+
- MiniMax(ABAB-Chat)
|
| 664 |
+
- SenseTime(nova)
|
| 665 |
+
- Xunfei(Spark)
|
| 666 |
+
- ……
|
| 667 |
+
|
| 668 |
+
</td>
|
| 669 |
+
|
| 670 |
+
</tr>
|
| 671 |
+
</tbody>
|
| 672 |
+
</table>
|
| 673 |
+
|
| 674 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 675 |
+
|
| 676 |
+
## 🔜 Roadmap
|
| 677 |
+
|
| 678 |
+
- [x] Subjective Evaluation
|
| 679 |
+
- [x] Release CompassAreana.
|
| 680 |
+
- [x] Subjective evaluation.
|
| 681 |
+
- [x] Long-context
|
| 682 |
+
- [x] Long-context evaluation with extensive datasets.
|
| 683 |
+
- [ ] Long-context leaderboard.
|
| 684 |
+
- [x] Coding
|
| 685 |
+
- [ ] Coding evaluation leaderboard.
|
| 686 |
+
- [x] Non-python language evaluation service.
|
| 687 |
+
- [x] Agent
|
| 688 |
+
- [ ] Support various agent frameworks.
|
| 689 |
+
- [x] Evaluation of tool use of the LLMs.
|
| 690 |
+
- [x] Robustness
|
| 691 |
+
- [x] Support various attack methods.
|
| 692 |
+
|
| 693 |
+
## 👷♂️ Contributing
|
| 694 |
+
|
| 695 |
+
We appreciate all contributions to improving OpenCompass. Please refer to the [contributing guideline](https://opencompass.readthedocs.io/en/latest/notes/contribution_guide.html) for the best practice.
|
| 696 |
+
|
| 697 |
+
<!-- Copy-paste in your Readme.md file -->
|
| 698 |
+
|
| 699 |
+
<!-- Made with [OSS Insight](https://ossinsight.io/) -->
|
| 700 |
+
|
| 701 |
+
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
|
| 702 |
+
<table>
|
| 703 |
+
<tr>
|
| 704 |
+
<th colspan="2">
|
| 705 |
+
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
|
| 706 |
+
</th>
|
| 707 |
+
</tr>
|
| 708 |
+
</table>
|
| 709 |
+
</a>
|
| 710 |
+
|
| 711 |
+
## 🤝 Acknowledgements
|
| 712 |
+
|
| 713 |
+
Some code in this project is cited and modified from [OpenICL](https://github.com/Shark-NLP/OpenICL).
|
| 714 |
+
|
| 715 |
+
Some datasets and prompt implementations are modified from [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub) and [instruct-eval](https://github.com/declare-lab/instruct-eval).
|
| 716 |
+
|
| 717 |
+
## 🖊️ Citation
|
| 718 |
+
|
| 719 |
+
```bibtex
|
| 720 |
+
@misc{2023opencompass,
|
| 721 |
+
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
| 722 |
+
author={OpenCompass Contributors},
|
| 723 |
+
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
| 724 |
+
year={2023}
|
| 725 |
+
}
|
| 726 |
+
```
|
| 727 |
+
|
| 728 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 729 |
+
|
| 730 |
+
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
|
| 731 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
|
| 732 |
+
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
|
| 733 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
|
| 734 |
+
[github-issues-link]: https://github.com/open-compass/opencompass/issues
|
| 735 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
|
| 736 |
+
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
|
| 737 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
|
| 738 |
+
[github-release-link]: https://github.com/open-compass/opencompass/releases
|
| 739 |
+
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
|
| 740 |
+
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
|
| 741 |
+
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
|
| 742 |
+
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
|
| 743 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
|
| 744 |
+
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
|
| 745 |
+
[github-trending-url]: https://trendshift.io/repositories/6630
|
opencompass.egg-info/SOURCES.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
opencompass.egg-info/dependency_links.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
opencompass.egg-info/entry_points.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[console_scripts]
|
| 2 |
+
opencompass = opencompass.cli.main:main
|
opencompass.egg-info/requires.txt
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py
|
| 2 |
+
accelerate>=0.19.0
|
| 3 |
+
cpm_kernels
|
| 4 |
+
datasets<4.0.0,>=2.12.0
|
| 5 |
+
einops>=0.5.0
|
| 6 |
+
evaluate>=0.3.0
|
| 7 |
+
func_timeout
|
| 8 |
+
fuzzywuzzy
|
| 9 |
+
gradio-client
|
| 10 |
+
h5py
|
| 11 |
+
httpx==0.27.2
|
| 12 |
+
huggingface_hub
|
| 13 |
+
immutabledict
|
| 14 |
+
importlib-metadata
|
| 15 |
+
jieba
|
| 16 |
+
json5
|
| 17 |
+
jsonlines
|
| 18 |
+
mmengine-lite
|
| 19 |
+
nltk>=3.7
|
| 20 |
+
numpy<2.0.0,>=1.23.4
|
| 21 |
+
openai
|
| 22 |
+
OpenCC
|
| 23 |
+
opencv-python-headless
|
| 24 |
+
pandas<2.0.0
|
| 25 |
+
prettytable
|
| 26 |
+
protobuf
|
| 27 |
+
python-Levenshtein
|
| 28 |
+
rank_bm25==0.2.2
|
| 29 |
+
rapidfuzz
|
| 30 |
+
requests>=2.31.0
|
| 31 |
+
retrying
|
| 32 |
+
rich
|
| 33 |
+
rouge
|
| 34 |
+
rouge_chinese
|
| 35 |
+
rouge_score
|
| 36 |
+
sacrebleu
|
| 37 |
+
scikit_learn==1.5.0
|
| 38 |
+
seaborn
|
| 39 |
+
sentence_transformers
|
| 40 |
+
tabulate
|
| 41 |
+
tiktoken
|
| 42 |
+
timeout_decorator
|
| 43 |
+
tokenizers>=0.13.3
|
| 44 |
+
torch>=1.13.1
|
| 45 |
+
tqdm>=4.64.1
|
| 46 |
+
transformers>=4.29.1
|
| 47 |
+
tree-sitter==0.21.3
|
| 48 |
+
tree_sitter_languages>=1.10.2
|
| 49 |
+
typer
|
| 50 |
+
|
| 51 |
+
[api]
|
| 52 |
+
anthropic
|
| 53 |
+
dashscope
|
| 54 |
+
openai
|
| 55 |
+
spark_ai_python
|
| 56 |
+
sseclient-py==1.7.2
|
| 57 |
+
tencentcloud-sdk-python
|
| 58 |
+
volcengine
|
| 59 |
+
volcengine-python-sdk
|
| 60 |
+
websocket-client
|
| 61 |
+
zhipuai
|
| 62 |
+
absl-py
|
| 63 |
+
accelerate>=0.19.0
|
| 64 |
+
cpm_kernels
|
| 65 |
+
datasets<4.0.0,>=2.12.0
|
| 66 |
+
einops>=0.5.0
|
| 67 |
+
evaluate>=0.3.0
|
| 68 |
+
func_timeout
|
| 69 |
+
fuzzywuzzy
|
| 70 |
+
gradio-client
|
| 71 |
+
h5py
|
| 72 |
+
httpx==0.27.2
|
| 73 |
+
huggingface_hub
|
| 74 |
+
immutabledict
|
| 75 |
+
importlib-metadata
|
| 76 |
+
jieba
|
| 77 |
+
json5
|
| 78 |
+
jsonlines
|
| 79 |
+
mmengine-lite
|
| 80 |
+
nltk>=3.7
|
| 81 |
+
numpy<2.0.0,>=1.23.4
|
| 82 |
+
OpenCC
|
| 83 |
+
opencv-python-headless
|
| 84 |
+
pandas<2.0.0
|
| 85 |
+
prettytable
|
| 86 |
+
protobuf
|
| 87 |
+
python-Levenshtein
|
| 88 |
+
rank_bm25==0.2.2
|
| 89 |
+
rapidfuzz
|
| 90 |
+
requests>=2.31.0
|
| 91 |
+
retrying
|
| 92 |
+
rich
|
| 93 |
+
rouge
|
| 94 |
+
rouge_chinese
|
| 95 |
+
rouge_score
|
| 96 |
+
sacrebleu
|
| 97 |
+
scikit_learn==1.5.0
|
| 98 |
+
seaborn
|
| 99 |
+
sentence_transformers
|
| 100 |
+
tabulate
|
| 101 |
+
tiktoken
|
| 102 |
+
timeout_decorator
|
| 103 |
+
tokenizers>=0.13.3
|
| 104 |
+
torch>=1.13.1
|
| 105 |
+
tqdm>=4.64.1
|
| 106 |
+
transformers>=4.29.1
|
| 107 |
+
tree-sitter==0.21.3
|
| 108 |
+
tree_sitter_languages>=1.10.2
|
| 109 |
+
typer
|
| 110 |
+
|
| 111 |
+
[full]
|
| 112 |
+
alpaca-eval==0.6
|
| 113 |
+
antlr4-python3-runtime==4.11
|
| 114 |
+
cn2an
|
| 115 |
+
dingo-python==1.5.0
|
| 116 |
+
faiss_gpu==1.7.2
|
| 117 |
+
human-eval
|
| 118 |
+
langdetect
|
| 119 |
+
ltp
|
| 120 |
+
math-verify[antlr4_11_0]
|
| 121 |
+
pyext
|
| 122 |
+
pypinyin
|
| 123 |
+
rdkit
|
| 124 |
+
wonderwords
|
| 125 |
+
absl-py
|
| 126 |
+
accelerate>=0.19.0
|
| 127 |
+
cpm_kernels
|
| 128 |
+
datasets<4.0.0,>=2.12.0
|
| 129 |
+
einops>=0.5.0
|
| 130 |
+
evaluate>=0.3.0
|
| 131 |
+
func_timeout
|
| 132 |
+
fuzzywuzzy
|
| 133 |
+
gradio-client
|
| 134 |
+
h5py
|
| 135 |
+
httpx==0.27.2
|
| 136 |
+
huggingface_hub
|
| 137 |
+
immutabledict
|
| 138 |
+
importlib-metadata
|
| 139 |
+
jieba
|
| 140 |
+
json5
|
| 141 |
+
jsonlines
|
| 142 |
+
mmengine-lite
|
| 143 |
+
nltk>=3.7
|
| 144 |
+
numpy<2.0.0,>=1.23.4
|
| 145 |
+
openai
|
| 146 |
+
OpenCC
|
| 147 |
+
opencv-python-headless
|
| 148 |
+
pandas<2.0.0
|
| 149 |
+
prettytable
|
| 150 |
+
protobuf
|
| 151 |
+
python-Levenshtein
|
| 152 |
+
rank_bm25==0.2.2
|
| 153 |
+
rapidfuzz
|
| 154 |
+
requests>=2.31.0
|
| 155 |
+
retrying
|
| 156 |
+
rich
|
| 157 |
+
rouge
|
| 158 |
+
rouge_chinese
|
| 159 |
+
rouge_score
|
| 160 |
+
sacrebleu
|
| 161 |
+
scikit_learn==1.5.0
|
| 162 |
+
seaborn
|
| 163 |
+
sentence_transformers
|
| 164 |
+
tabulate
|
| 165 |
+
tiktoken
|
| 166 |
+
timeout_decorator
|
| 167 |
+
tokenizers>=0.13.3
|
| 168 |
+
torch>=1.13.1
|
| 169 |
+
tqdm>=4.64.1
|
| 170 |
+
transformers>=4.29.1
|
| 171 |
+
tree-sitter==0.21.3
|
| 172 |
+
tree_sitter_languages>=1.10.2
|
| 173 |
+
typer
|
| 174 |
+
|
| 175 |
+
[lmdeploy]
|
| 176 |
+
lmdeploy
|
| 177 |
+
absl-py
|
| 178 |
+
accelerate>=0.19.0
|
| 179 |
+
cpm_kernels
|
| 180 |
+
datasets<4.0.0,>=2.12.0
|
| 181 |
+
einops>=0.5.0
|
| 182 |
+
evaluate>=0.3.0
|
| 183 |
+
func_timeout
|
| 184 |
+
fuzzywuzzy
|
| 185 |
+
gradio-client
|
| 186 |
+
h5py
|
| 187 |
+
httpx==0.27.2
|
| 188 |
+
huggingface_hub
|
| 189 |
+
immutabledict
|
| 190 |
+
importlib-metadata
|
| 191 |
+
jieba
|
| 192 |
+
json5
|
| 193 |
+
jsonlines
|
| 194 |
+
mmengine-lite
|
| 195 |
+
nltk>=3.7
|
| 196 |
+
numpy<2.0.0,>=1.23.4
|
| 197 |
+
openai
|
| 198 |
+
OpenCC
|
| 199 |
+
opencv-python-headless
|
| 200 |
+
pandas<2.0.0
|
| 201 |
+
prettytable
|
| 202 |
+
protobuf
|
| 203 |
+
python-Levenshtein
|
| 204 |
+
rank_bm25==0.2.2
|
| 205 |
+
rapidfuzz
|
| 206 |
+
requests>=2.31.0
|
| 207 |
+
retrying
|
| 208 |
+
rich
|
| 209 |
+
rouge
|
| 210 |
+
rouge_chinese
|
| 211 |
+
rouge_score
|
| 212 |
+
sacrebleu
|
| 213 |
+
scikit_learn==1.5.0
|
| 214 |
+
seaborn
|
| 215 |
+
sentence_transformers
|
| 216 |
+
tabulate
|
| 217 |
+
tiktoken
|
| 218 |
+
timeout_decorator
|
| 219 |
+
tokenizers>=0.13.3
|
| 220 |
+
torch>=1.13.1
|
| 221 |
+
tqdm>=4.64.1
|
| 222 |
+
transformers>=4.29.1
|
| 223 |
+
tree-sitter==0.21.3
|
| 224 |
+
tree_sitter_languages>=1.10.2
|
| 225 |
+
typer
|
| 226 |
+
|
| 227 |
+
[vllm]
|
| 228 |
+
vllm
|
| 229 |
+
absl-py
|
| 230 |
+
accelerate>=0.19.0
|
| 231 |
+
cpm_kernels
|
| 232 |
+
datasets<4.0.0,>=2.12.0
|
| 233 |
+
einops>=0.5.0
|
| 234 |
+
evaluate>=0.3.0
|
| 235 |
+
func_timeout
|
| 236 |
+
fuzzywuzzy
|
| 237 |
+
gradio-client
|
| 238 |
+
h5py
|
| 239 |
+
httpx==0.27.2
|
| 240 |
+
huggingface_hub
|
| 241 |
+
immutabledict
|
| 242 |
+
importlib-metadata
|
| 243 |
+
jieba
|
| 244 |
+
json5
|
| 245 |
+
jsonlines
|
| 246 |
+
mmengine-lite
|
| 247 |
+
nltk>=3.7
|
| 248 |
+
numpy<2.0.0,>=1.23.4
|
| 249 |
+
openai
|
| 250 |
+
OpenCC
|
| 251 |
+
opencv-python-headless
|
| 252 |
+
pandas<2.0.0
|
| 253 |
+
prettytable
|
| 254 |
+
protobuf
|
| 255 |
+
python-Levenshtein
|
| 256 |
+
rank_bm25==0.2.2
|
| 257 |
+
rapidfuzz
|
| 258 |
+
requests>=2.31.0
|
| 259 |
+
retrying
|
| 260 |
+
rich
|
| 261 |
+
rouge
|
| 262 |
+
rouge_chinese
|
| 263 |
+
rouge_score
|
| 264 |
+
sacrebleu
|
| 265 |
+
scikit_learn==1.5.0
|
| 266 |
+
seaborn
|
| 267 |
+
sentence_transformers
|
| 268 |
+
tabulate
|
| 269 |
+
tiktoken
|
| 270 |
+
timeout_decorator
|
| 271 |
+
tokenizers>=0.13.3
|
| 272 |
+
torch>=1.13.1
|
| 273 |
+
tqdm>=4.64.1
|
| 274 |
+
transformers>=4.29.1
|
| 275 |
+
tree-sitter==0.21.3
|
| 276 |
+
tree_sitter_languages>=1.10.2
|
| 277 |
+
typer
|
opencompass.egg-info/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
opencompass
|
opencompass/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__version__ = '0.5.1'
|
opencompass/registry.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Callable, List, Optional, Type, Union
|
| 2 |
+
|
| 3 |
+
from mmengine.registry import METRICS as MMENGINE_METRICS
|
| 4 |
+
from mmengine.registry import Registry as OriginalRegistry
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Registry(OriginalRegistry):
|
| 8 |
+
|
| 9 |
+
# override the default force behavior
|
| 10 |
+
def register_module(
|
| 11 |
+
self,
|
| 12 |
+
name: Optional[Union[str, List[str]]] = None,
|
| 13 |
+
force: bool = True,
|
| 14 |
+
module: Optional[Type] = None) -> Union[type, Callable]:
|
| 15 |
+
return super().register_module(name, force, module)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
PARTITIONERS = Registry('partitioner', locations=['opencompass.partitioners'])
|
| 19 |
+
RUNNERS = Registry('runner', locations=['opencompass.runners'])
|
| 20 |
+
TASKS = Registry('task', locations=['opencompass.tasks'])
|
| 21 |
+
MODELS = Registry('model', locations=['opencompass.models'])
|
| 22 |
+
# TODO: LOAD_DATASET -> DATASETS
|
| 23 |
+
LOAD_DATASET = Registry('load_dataset', locations=['opencompass.datasets'])
|
| 24 |
+
TEXT_POSTPROCESSORS = Registry(
|
| 25 |
+
'text_postprocessors', locations=['opencompass.utils.text_postprocessors'])
|
| 26 |
+
DICT_POSTPROCESSORS = Registry('dict_postprocessors',
|
| 27 |
+
locations=[
|
| 28 |
+
'opencompass.utils.dict_postprocessors',
|
| 29 |
+
'opencompass.datasets.generic'
|
| 30 |
+
])
|
| 31 |
+
|
| 32 |
+
EVALUATORS = Registry('evaluators', locations=['opencompass.evaluators'])
|
| 33 |
+
|
| 34 |
+
ICL_INFERENCERS = Registry('icl_inferencers',
|
| 35 |
+
locations=['opencompass.openicl.icl_inferencer'])
|
| 36 |
+
ICL_RETRIEVERS = Registry('icl_retrievers',
|
| 37 |
+
locations=['opencompass.openicl.icl_retriever'])
|
| 38 |
+
ICL_DATASET_READERS = Registry(
|
| 39 |
+
'icl_dataset_readers',
|
| 40 |
+
locations=['opencompass.openicl.icl_dataset_reader'])
|
| 41 |
+
ICL_PROMPT_TEMPLATES = Registry(
|
| 42 |
+
'icl_prompt_templates',
|
| 43 |
+
locations=['opencompass.openicl.icl_prompt_template'])
|
| 44 |
+
ICL_EVALUATORS = Registry(
|
| 45 |
+
'icl_evaluators',
|
| 46 |
+
locations=['opencompass.openicl.icl_evaluator', 'opencompass.evaluator'])
|
| 47 |
+
METRICS = Registry('metric',
|
| 48 |
+
parent=MMENGINE_METRICS,
|
| 49 |
+
locations=['opencompass.metrics'])
|
| 50 |
+
TOT_WRAPPER = Registry('tot_wrapper', locations=['opencompass.datasets'])
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def build_from_cfg(cfg):
|
| 54 |
+
"""A helper function that builds object with MMEngine's new config."""
|
| 55 |
+
return PARTITIONERS.build(cfg)
|
requirements.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
-r requirements/runtime.txt
|
requirements/agent.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
antlr4-python3-runtime==4.11
|
| 2 |
+
ipykernel
|
| 3 |
+
ipython
|
| 4 |
+
json5
|
| 5 |
+
jupyter
|
| 6 |
+
jupyter_client
|
| 7 |
+
jupytext
|
| 8 |
+
-e git+https://github.com/open-compass/lagent-cibench.git#egg=lagent
|
| 9 |
+
lightgbm==4.1.0
|
| 10 |
+
networkx
|
| 11 |
+
scikit-image
|
| 12 |
+
sympy==1.12
|
| 13 |
+
tensorflow==2.14.0
|
requirements/api.txt
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# claude
|
| 2 |
+
anthropic
|
| 3 |
+
# Qwen
|
| 4 |
+
dashscope
|
| 5 |
+
# openai
|
| 6 |
+
openai
|
| 7 |
+
# xunfei
|
| 8 |
+
spark_ai_python
|
| 9 |
+
sseclient-py==1.7.2
|
| 10 |
+
# tecent
|
| 11 |
+
tencentcloud-sdk-python
|
| 12 |
+
# bytedance
|
| 13 |
+
volcengine
|
| 14 |
+
volcengine-python-sdk
|
| 15 |
+
websocket-client
|
| 16 |
+
# zhipu
|
| 17 |
+
zhipuai
|
requirements/docs.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
docutils==0.18.1
|
| 2 |
+
modelindex
|
| 3 |
+
myst-parser
|
| 4 |
+
-e git+https://github.com/open-compass/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
|
| 5 |
+
sphinx==6.1.3
|
| 6 |
+
sphinx-copybutton
|
| 7 |
+
sphinx-design
|
| 8 |
+
sphinx-notfound-page
|
| 9 |
+
sphinx-tabs
|
| 10 |
+
sphinxcontrib-jquery
|
| 11 |
+
tabulate
|
requirements/extra.txt
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Alpaca-eval
|
| 2 |
+
alpaca-eval==0.6
|
| 3 |
+
# OlympiadBench
|
| 4 |
+
antlr4-python3-runtime==4.11
|
| 5 |
+
cn2an
|
| 6 |
+
# Dingo
|
| 7 |
+
dingo-python==1.5.0
|
| 8 |
+
# Icl topk retriever
|
| 9 |
+
faiss_gpu==1.7.2
|
| 10 |
+
# Humaneval, Humaneval X
|
| 11 |
+
-e git+https://github.com/open-compass/human-eval.git#egg=human-eval
|
| 12 |
+
# IFEval
|
| 13 |
+
langdetect
|
| 14 |
+
# Lawbench, leval
|
| 15 |
+
ltp
|
| 16 |
+
# Math
|
| 17 |
+
math-verify[antlr4_11_0]
|
| 18 |
+
# Taco, apps Dataset
|
| 19 |
+
pyext
|
| 20 |
+
# Law Bench
|
| 21 |
+
pypinyin
|
| 22 |
+
# Smolinstruct
|
| 23 |
+
rdkit
|
| 24 |
+
# RULER
|
| 25 |
+
wonderwords
|
requirements/lmdeploy.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
lmdeploy
|
requirements/runtime.txt
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py
|
| 2 |
+
accelerate>=0.19.0
|
| 3 |
+
cpm_kernels
|
| 4 |
+
datasets>=2.12.0,<4.0.0
|
| 5 |
+
einops>=0.5.0
|
| 6 |
+
evaluate>=0.3.0
|
| 7 |
+
func_timeout
|
| 8 |
+
fuzzywuzzy
|
| 9 |
+
gradio-client
|
| 10 |
+
h5py
|
| 11 |
+
httpx==0.27.2
|
| 12 |
+
huggingface_hub
|
| 13 |
+
immutabledict
|
| 14 |
+
importlib-metadata
|
| 15 |
+
jieba
|
| 16 |
+
json5
|
| 17 |
+
jsonlines
|
| 18 |
+
mmengine-lite
|
| 19 |
+
nltk>=3.7
|
| 20 |
+
numpy>=1.23.4,<2.0.0
|
| 21 |
+
openai
|
| 22 |
+
OpenCC
|
| 23 |
+
opencv-python-headless
|
| 24 |
+
pandas<2.0.0
|
| 25 |
+
prettytable
|
| 26 |
+
protobuf
|
| 27 |
+
# pyext
|
| 28 |
+
python-Levenshtein
|
| 29 |
+
rank_bm25==0.2.2
|
| 30 |
+
rapidfuzz
|
| 31 |
+
requests>=2.31.0
|
| 32 |
+
retrying
|
| 33 |
+
rich
|
| 34 |
+
rouge
|
| 35 |
+
-e git+https://github.com/Isaac-JL-Chen/rouge_chinese.git@master#egg=rouge_chinese
|
| 36 |
+
rouge_score
|
| 37 |
+
sacrebleu
|
| 38 |
+
scikit_learn==1.5.0
|
| 39 |
+
seaborn
|
| 40 |
+
sentence_transformers
|
| 41 |
+
tabulate
|
| 42 |
+
tiktoken
|
| 43 |
+
timeout_decorator
|
| 44 |
+
tokenizers>=0.13.3
|
| 45 |
+
torch>=1.13.1
|
| 46 |
+
tqdm>=4.64.1
|
| 47 |
+
transformers>=4.29.1
|
| 48 |
+
tree-sitter==0.21.3
|
| 49 |
+
tree_sitter_languages>=1.10.2
|
| 50 |
+
typer
|
run.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from opencompass.cli.main import main
|
| 2 |
+
|
| 3 |
+
if __name__ == '__main__':
|
| 4 |
+
main()
|
setup.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import find_packages, setup
|
| 2 |
+
from setuptools.command.install import install
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class DownloadNLTK(install):
|
| 6 |
+
|
| 7 |
+
def run(self):
|
| 8 |
+
self.do_egg_install()
|
| 9 |
+
import nltk
|
| 10 |
+
|
| 11 |
+
nltk.download('punkt')
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def readme():
|
| 15 |
+
with open('README.md', encoding='utf-8') as f:
|
| 16 |
+
content = f.read()
|
| 17 |
+
return content
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_requirements(fname='requirements.txt', with_version=True):
|
| 21 |
+
"""Parse the package dependencies listed in a requirements file but strips
|
| 22 |
+
specific versioning information.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
fname (str): path to requirements file
|
| 26 |
+
with_version (bool, default=False): if True include version specs
|
| 27 |
+
|
| 28 |
+
Returns:
|
| 29 |
+
List[str]: list of requirements items
|
| 30 |
+
|
| 31 |
+
CommandLine:
|
| 32 |
+
python -c "import setup; print(setup.parse_requirements())"
|
| 33 |
+
"""
|
| 34 |
+
import re
|
| 35 |
+
import sys
|
| 36 |
+
from os.path import exists
|
| 37 |
+
|
| 38 |
+
require_fpath = fname
|
| 39 |
+
|
| 40 |
+
def parse_line(line):
|
| 41 |
+
"""Parse information from a line in a requirements text file."""
|
| 42 |
+
if line.startswith('-r '):
|
| 43 |
+
# Allow specifying requirements in other files
|
| 44 |
+
target = line.split(' ')[1]
|
| 45 |
+
for info in parse_require_file(target):
|
| 46 |
+
yield info
|
| 47 |
+
else:
|
| 48 |
+
info = {'line': line}
|
| 49 |
+
if line.startswith('-e '):
|
| 50 |
+
info['package'] = line.split('#egg=')[1]
|
| 51 |
+
else:
|
| 52 |
+
# Remove versioning from the package
|
| 53 |
+
pat = '(' + '|'.join(['>=', '==', '>']) + ')'
|
| 54 |
+
parts = re.split(pat, line, maxsplit=1)
|
| 55 |
+
parts = [p.strip() for p in parts]
|
| 56 |
+
|
| 57 |
+
info['package'] = parts[0]
|
| 58 |
+
if len(parts) > 1:
|
| 59 |
+
op, rest = parts[1:]
|
| 60 |
+
if ';' in rest:
|
| 61 |
+
# Handle platform specific dependencies
|
| 62 |
+
# http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
|
| 63 |
+
version, platform_deps = map(str.strip,
|
| 64 |
+
rest.split(';'))
|
| 65 |
+
info['platform_deps'] = platform_deps
|
| 66 |
+
else:
|
| 67 |
+
version = rest # NOQA
|
| 68 |
+
if '--' in version:
|
| 69 |
+
# the `extras_require` doesn't accept options.
|
| 70 |
+
version = version.split('--')[0].strip()
|
| 71 |
+
info['version'] = (op, version)
|
| 72 |
+
yield info
|
| 73 |
+
|
| 74 |
+
def parse_require_file(fpath):
|
| 75 |
+
with open(fpath, 'r') as f:
|
| 76 |
+
for line in f.readlines():
|
| 77 |
+
line = line.strip()
|
| 78 |
+
if line and not line.startswith('#'):
|
| 79 |
+
for info in parse_line(line):
|
| 80 |
+
yield info
|
| 81 |
+
|
| 82 |
+
def gen_packages_items():
|
| 83 |
+
if exists(require_fpath):
|
| 84 |
+
for info in parse_require_file(require_fpath):
|
| 85 |
+
parts = [info['package']]
|
| 86 |
+
if with_version and 'version' in info:
|
| 87 |
+
parts.extend(info['version'])
|
| 88 |
+
if not sys.version.startswith('3.4'):
|
| 89 |
+
# apparently package_deps are broken in 3.4
|
| 90 |
+
platform_deps = info.get('platform_deps')
|
| 91 |
+
if platform_deps is not None:
|
| 92 |
+
parts.append(';' + platform_deps)
|
| 93 |
+
item = ''.join(parts)
|
| 94 |
+
yield item
|
| 95 |
+
|
| 96 |
+
packages = list(gen_packages_items())
|
| 97 |
+
return packages
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def get_version():
|
| 101 |
+
version_file = 'opencompass/__init__.py'
|
| 102 |
+
with open(version_file, 'r', encoding='utf-8') as f:
|
| 103 |
+
exec(compile(f.read(), version_file, 'exec'))
|
| 104 |
+
return locals()['__version__']
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def do_setup():
|
| 108 |
+
setup(
|
| 109 |
+
name='opencompass',
|
| 110 |
+
author='OpenCompass Contributors',
|
| 111 |
+
version=get_version(),
|
| 112 |
+
description='A comprehensive toolkit for large model evaluation',
|
| 113 |
+
url='https://github.com/open-compass/opencompass',
|
| 114 |
+
long_description=readme(),
|
| 115 |
+
long_description_content_type='text/markdown',
|
| 116 |
+
maintainer='OpenCompass Authors',
|
| 117 |
+
cmdclass={'download_nltk': DownloadNLTK},
|
| 118 |
+
setup_requires=['nltk==3.8'],
|
| 119 |
+
python_requires='>=3.8.0',
|
| 120 |
+
install_requires=parse_requirements('requirements/runtime.txt'),
|
| 121 |
+
extras_require={
|
| 122 |
+
'lmdeploy':
|
| 123 |
+
parse_requirements('requirements/lmdeploy.txt') +
|
| 124 |
+
parse_requirements('requirements/runtime.txt'),
|
| 125 |
+
'vllm':
|
| 126 |
+
parse_requirements('requirements/vllm.txt') +
|
| 127 |
+
parse_requirements('requirements/runtime.txt'),
|
| 128 |
+
'api':
|
| 129 |
+
parse_requirements('requirements/api.txt') +
|
| 130 |
+
parse_requirements('requirements/runtime.txt'),
|
| 131 |
+
'full':
|
| 132 |
+
parse_requirements('requirements/extra.txt') +
|
| 133 |
+
parse_requirements('requirements/runtime.txt'),
|
| 134 |
+
},
|
| 135 |
+
license='Apache License 2.0',
|
| 136 |
+
include_package_data=True,
|
| 137 |
+
packages=find_packages(),
|
| 138 |
+
keywords=[
|
| 139 |
+
'AI',
|
| 140 |
+
'NLP',
|
| 141 |
+
'in-context learning',
|
| 142 |
+
'large language model',
|
| 143 |
+
'evaluation',
|
| 144 |
+
'benchmark',
|
| 145 |
+
'llm',
|
| 146 |
+
],
|
| 147 |
+
classifiers=[
|
| 148 |
+
'Programming Language :: Python :: 3.8',
|
| 149 |
+
'Programming Language :: Python :: 3.9',
|
| 150 |
+
'Programming Language :: Python :: 3.10',
|
| 151 |
+
'Intended Audience :: Developers',
|
| 152 |
+
'Intended Audience :: Education',
|
| 153 |
+
'Intended Audience :: Science/Research',
|
| 154 |
+
],
|
| 155 |
+
entry_points={
|
| 156 |
+
'console_scripts': [
|
| 157 |
+
'opencompass = opencompass.cli.main:main',
|
| 158 |
+
],
|
| 159 |
+
},
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
if __name__ == '__main__':
|
| 164 |
+
do_setup()
|
test.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer,AutoConfig
|
| 3 |
+
|
| 4 |
+
def load_tokenizer(model_name: str, is_hf: bool=False):
|
| 5 |
+
if not is_hf:
|
| 6 |
+
tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
| 7 |
+
tokenizer.model_max_length = 2048
|
| 8 |
+
else:
|
| 9 |
+
if "mamba" in model_name or "mpt" in model_name:
|
| 10 |
+
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
|
| 11 |
+
else:
|
| 12 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 13 |
+
tokenizer.pad_token = tokenizer.eos_token
|
| 14 |
+
tokenizer.pad_token_id = tokenizer.eos_token_id
|
| 15 |
+
return tokenizer
|
| 16 |
+
|
| 17 |
+
from fla.models import DeltaNetConfig, DeltaNetForCausalLM, DeltaNetModel
|
| 18 |
+
print(DeltaNetConfig.model_type)
|
| 19 |
+
AutoConfig.register("delta_net",DeltaNetConfig)
|
| 20 |
+
AutoModelForCausalLM.register(DeltaNetConfig,DeltaNetForCausalLM)
|
| 21 |
+
|
| 22 |
+
from opencompass.models.fla2.models import mask_deltanetConfig,mask_deltanetForCausalLM
|
| 23 |
+
print(mask_deltanetConfig.model_type)
|
| 24 |
+
AutoConfig.register("mask_deltanet",mask_deltanetConfig)
|
| 25 |
+
AutoModelForCausalLM.register(mask_deltanetConfig,mask_deltanetForCausalLM)
|
| 26 |
+
# model_path = "/mnt/jfzn/msj/delta_net-1.3B-100B"
|
| 27 |
+
model_path = "/mnt/jfzn/msj/train_exp/mask_deltanet_1B_rank4"
|
| 28 |
+
# 注意:DeltaNet 必须开 trust_remote_code!!!
|
| 29 |
+
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
| 30 |
+
|
| 31 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 32 |
+
model_path,
|
| 33 |
+
torch_dtype=torch.bfloat16, # 推荐 fp16,加速且稳定
|
| 34 |
+
trust_remote_code=True, # <<=== 你的代码缺了它!
|
| 35 |
+
device_map="cuda",
|
| 36 |
+
)
|
| 37 |
+
tokenizer = load_tokenizer(model_path, is_hf=True)
|
| 38 |
+
prompt = "What is the official language of China?"
|
| 39 |
+
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
|
| 40 |
+
|
| 41 |
+
outputs = model.generate(
|
| 42 |
+
**inputs,
|
| 43 |
+
max_new_tokens=100,
|
| 44 |
+
do_sample=False,
|
| 45 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 46 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
tmp/03190095-e58f-4a23-94a4-053ce43e2e48_params.py
ADDED
|
File without changes
|
tmp/03694f9b-bf79-4b1c-9dd9-d2cf087ec1cd_params.py
ADDED
|
File without changes
|
tmp/06837656-e189-4cad-8d53-f175cf579961_params.py
ADDED
|
@@ -0,0 +1,1424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets = [
|
| 2 |
+
[
|
| 3 |
+
dict(
|
| 4 |
+
abbr='LongBench_2wikimqa_6',
|
| 5 |
+
eval_cfg=dict(
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 8 |
+
pred_role='BOT'),
|
| 9 |
+
infer_cfg=dict(
|
| 10 |
+
inferencer=dict(
|
| 11 |
+
max_out_len=32,
|
| 12 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
template=dict(round=[
|
| 15 |
+
dict(
|
| 16 |
+
prompt=
|
| 17 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 18 |
+
role='HUMAN'),
|
| 19 |
+
]),
|
| 20 |
+
type=
|
| 21 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 22 |
+
retriever=dict(
|
| 23 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 24 |
+
name='2wikimqa',
|
| 25 |
+
path='opencompass/Longbench',
|
| 26 |
+
reader_cfg=dict(
|
| 27 |
+
input_columns=[
|
| 28 |
+
'context',
|
| 29 |
+
'input',
|
| 30 |
+
],
|
| 31 |
+
output_column='answers',
|
| 32 |
+
test_range='[150:175]',
|
| 33 |
+
test_split='test',
|
| 34 |
+
train_split='test'),
|
| 35 |
+
type='opencompass.datasets.LongBench2wikimqaDataset'),
|
| 36 |
+
dict(
|
| 37 |
+
abbr='LongBench_hotpotqa_6',
|
| 38 |
+
eval_cfg=dict(
|
| 39 |
+
evaluator=dict(
|
| 40 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 41 |
+
pred_role='BOT'),
|
| 42 |
+
infer_cfg=dict(
|
| 43 |
+
inferencer=dict(
|
| 44 |
+
max_out_len=32,
|
| 45 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 46 |
+
prompt_template=dict(
|
| 47 |
+
template=dict(round=[
|
| 48 |
+
dict(
|
| 49 |
+
prompt=
|
| 50 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 51 |
+
role='HUMAN'),
|
| 52 |
+
]),
|
| 53 |
+
type=
|
| 54 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 55 |
+
retriever=dict(
|
| 56 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 57 |
+
name='hotpotqa',
|
| 58 |
+
path='opencompass/Longbench',
|
| 59 |
+
reader_cfg=dict(
|
| 60 |
+
input_columns=[
|
| 61 |
+
'context',
|
| 62 |
+
'input',
|
| 63 |
+
],
|
| 64 |
+
output_column='answers',
|
| 65 |
+
test_range='[150:175]',
|
| 66 |
+
test_split='test',
|
| 67 |
+
train_split='test'),
|
| 68 |
+
type='opencompass.datasets.LongBenchhotpotqaDataset'),
|
| 69 |
+
dict(
|
| 70 |
+
abbr='LongBench_musique_6',
|
| 71 |
+
eval_cfg=dict(
|
| 72 |
+
evaluator=dict(
|
| 73 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 74 |
+
pred_role='BOT'),
|
| 75 |
+
infer_cfg=dict(
|
| 76 |
+
inferencer=dict(
|
| 77 |
+
max_out_len=32,
|
| 78 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 79 |
+
prompt_template=dict(
|
| 80 |
+
template=dict(round=[
|
| 81 |
+
dict(
|
| 82 |
+
prompt=
|
| 83 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 84 |
+
role='HUMAN'),
|
| 85 |
+
]),
|
| 86 |
+
type=
|
| 87 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 88 |
+
retriever=dict(
|
| 89 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 90 |
+
name='musique',
|
| 91 |
+
path='opencompass/Longbench',
|
| 92 |
+
reader_cfg=dict(
|
| 93 |
+
input_columns=[
|
| 94 |
+
'context',
|
| 95 |
+
'input',
|
| 96 |
+
],
|
| 97 |
+
output_column='answers',
|
| 98 |
+
test_range='[150:175]',
|
| 99 |
+
test_split='test',
|
| 100 |
+
train_split='test'),
|
| 101 |
+
type='opencompass.datasets.LongBenchmusiqueDataset'),
|
| 102 |
+
dict(
|
| 103 |
+
abbr='LongBench_multifieldqa_en_6',
|
| 104 |
+
eval_cfg=dict(
|
| 105 |
+
evaluator=dict(
|
| 106 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 107 |
+
pred_role='BOT'),
|
| 108 |
+
infer_cfg=dict(
|
| 109 |
+
inferencer=dict(
|
| 110 |
+
max_out_len=64,
|
| 111 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 112 |
+
prompt_template=dict(
|
| 113 |
+
template=dict(round=[
|
| 114 |
+
dict(
|
| 115 |
+
prompt=
|
| 116 |
+
'Read the following text and answer briefly.\n\n{context}\n\nNow, answer the following question based on the above text, only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 117 |
+
role='HUMAN'),
|
| 118 |
+
]),
|
| 119 |
+
type=
|
| 120 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 121 |
+
retriever=dict(
|
| 122 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 123 |
+
name='multifieldqa_en',
|
| 124 |
+
path='opencompass/Longbench',
|
| 125 |
+
reader_cfg=dict(
|
| 126 |
+
input_columns=[
|
| 127 |
+
'context',
|
| 128 |
+
'input',
|
| 129 |
+
],
|
| 130 |
+
output_column='answers',
|
| 131 |
+
test_range='[114:133]',
|
| 132 |
+
test_split='test',
|
| 133 |
+
train_split='test'),
|
| 134 |
+
type='opencompass.datasets.LongBenchmultifieldqa_enDataset'),
|
| 135 |
+
dict(
|
| 136 |
+
abbr='LongBench_multifieldqa_zh_6',
|
| 137 |
+
eval_cfg=dict(
|
| 138 |
+
evaluator=dict(
|
| 139 |
+
language='zh',
|
| 140 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 141 |
+
pred_role='BOT'),
|
| 142 |
+
infer_cfg=dict(
|
| 143 |
+
inferencer=dict(
|
| 144 |
+
max_out_len=64,
|
| 145 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 146 |
+
prompt_template=dict(
|
| 147 |
+
template=dict(round=[
|
| 148 |
+
dict(
|
| 149 |
+
prompt=
|
| 150 |
+
'阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:',
|
| 151 |
+
role='HUMAN'),
|
| 152 |
+
]),
|
| 153 |
+
type=
|
| 154 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 155 |
+
retriever=dict(
|
| 156 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 157 |
+
name='multifieldqa_zh',
|
| 158 |
+
path='opencompass/Longbench',
|
| 159 |
+
reader_cfg=dict(
|
| 160 |
+
input_columns=[
|
| 161 |
+
'context',
|
| 162 |
+
'input',
|
| 163 |
+
],
|
| 164 |
+
output_column='answers',
|
| 165 |
+
test_range='[150:175]',
|
| 166 |
+
test_split='test',
|
| 167 |
+
train_split='test'),
|
| 168 |
+
type='opencompass.datasets.LongBenchmultifieldqa_zhDataset'),
|
| 169 |
+
dict(
|
| 170 |
+
abbr='LongBench_narrativeqa_6',
|
| 171 |
+
eval_cfg=dict(
|
| 172 |
+
evaluator=dict(
|
| 173 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 174 |
+
pred_role='BOT'),
|
| 175 |
+
infer_cfg=dict(
|
| 176 |
+
inferencer=dict(
|
| 177 |
+
max_out_len=128,
|
| 178 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 179 |
+
prompt_template=dict(
|
| 180 |
+
template=dict(round=[
|
| 181 |
+
dict(
|
| 182 |
+
prompt=
|
| 183 |
+
'You are given a story, which can be either a novel or a movie script, and a question. Answer the question as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nStory: {context}\n\nNow, answer the question based on the story as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nQuestion: {input}\n\nAnswer:',
|
| 184 |
+
role='HUMAN'),
|
| 185 |
+
]),
|
| 186 |
+
type=
|
| 187 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 188 |
+
retriever=dict(
|
| 189 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 190 |
+
name='narrativeqa',
|
| 191 |
+
path='opencompass/Longbench',
|
| 192 |
+
reader_cfg=dict(
|
| 193 |
+
input_columns=[
|
| 194 |
+
'context',
|
| 195 |
+
'input',
|
| 196 |
+
],
|
| 197 |
+
output_column='answers',
|
| 198 |
+
test_range='[150:175]',
|
| 199 |
+
test_split='test',
|
| 200 |
+
train_split='test'),
|
| 201 |
+
type='opencompass.datasets.LongBenchnarrativeqaDataset'),
|
| 202 |
+
dict(
|
| 203 |
+
abbr='LongBench_qasper_6',
|
| 204 |
+
eval_cfg=dict(
|
| 205 |
+
evaluator=dict(
|
| 206 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 207 |
+
pred_role='BOT'),
|
| 208 |
+
infer_cfg=dict(
|
| 209 |
+
inferencer=dict(
|
| 210 |
+
max_out_len=32,
|
| 211 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 212 |
+
prompt_template=dict(
|
| 213 |
+
template=dict(round=[
|
| 214 |
+
dict(
|
| 215 |
+
prompt=
|
| 216 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 217 |
+
role='HUMAN'),
|
| 218 |
+
]),
|
| 219 |
+
type=
|
| 220 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 221 |
+
retriever=dict(
|
| 222 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 223 |
+
name='qasper',
|
| 224 |
+
path='opencompass/Longbench',
|
| 225 |
+
reader_cfg=dict(
|
| 226 |
+
input_columns=[
|
| 227 |
+
'context',
|
| 228 |
+
'input',
|
| 229 |
+
],
|
| 230 |
+
output_column='answers',
|
| 231 |
+
test_range='[150:175]',
|
| 232 |
+
test_split='test',
|
| 233 |
+
train_split='test'),
|
| 234 |
+
type='opencompass.datasets.LongBenchqasperDataset'),
|
| 235 |
+
dict(
|
| 236 |
+
abbr='LongBench_triviaqa_6',
|
| 237 |
+
eval_cfg=dict(
|
| 238 |
+
evaluator=dict(
|
| 239 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 240 |
+
pred_postprocessor=dict(
|
| 241 |
+
type='opencompass.datasets.triviaqa_postprocess'),
|
| 242 |
+
pred_role='BOT'),
|
| 243 |
+
infer_cfg=dict(
|
| 244 |
+
inferencer=dict(
|
| 245 |
+
max_out_len=32,
|
| 246 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 247 |
+
prompt_template=dict(
|
| 248 |
+
template=dict(round=[
|
| 249 |
+
dict(
|
| 250 |
+
prompt=
|
| 251 |
+
'Answer the question based on the given passage. Only give me the answer and do not output any other words. The following are some examples.\n\n{context}\n\n{input}',
|
| 252 |
+
role='HUMAN'),
|
| 253 |
+
]),
|
| 254 |
+
type=
|
| 255 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 256 |
+
retriever=dict(
|
| 257 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 258 |
+
name='triviaqa',
|
| 259 |
+
path='opencompass/Longbench',
|
| 260 |
+
reader_cfg=dict(
|
| 261 |
+
input_columns=[
|
| 262 |
+
'context',
|
| 263 |
+
'input',
|
| 264 |
+
],
|
| 265 |
+
output_column='answers',
|
| 266 |
+
test_range='[150:175]',
|
| 267 |
+
test_split='test',
|
| 268 |
+
train_split='test'),
|
| 269 |
+
type='opencompass.datasets.LongBenchtriviaqaDataset'),
|
| 270 |
+
dict(
|
| 271 |
+
abbr='LongBench_gov_report_6',
|
| 272 |
+
eval_cfg=dict(
|
| 273 |
+
evaluator=dict(
|
| 274 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 275 |
+
pred_role='BOT'),
|
| 276 |
+
infer_cfg=dict(
|
| 277 |
+
inferencer=dict(
|
| 278 |
+
max_out_len=512,
|
| 279 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 280 |
+
prompt_template=dict(
|
| 281 |
+
template=dict(round=[
|
| 282 |
+
dict(
|
| 283 |
+
prompt=
|
| 284 |
+
'You are given a report by a government agency. Write a one-page summary of the report.\n\nReport:\n{context}\n\nNow, write a one-page summary of the report.\n\nSummary:',
|
| 285 |
+
role='HUMAN'),
|
| 286 |
+
]),
|
| 287 |
+
type=
|
| 288 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 289 |
+
retriever=dict(
|
| 290 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 291 |
+
name='gov_report',
|
| 292 |
+
path='opencompass/Longbench',
|
| 293 |
+
reader_cfg=dict(
|
| 294 |
+
input_columns=[
|
| 295 |
+
'context',
|
| 296 |
+
],
|
| 297 |
+
output_column='answers',
|
| 298 |
+
test_range='[150:175]',
|
| 299 |
+
test_split='test',
|
| 300 |
+
train_split='test'),
|
| 301 |
+
type='opencompass.datasets.LongBenchgov_reportDataset'),
|
| 302 |
+
dict(
|
| 303 |
+
abbr='LongBench_qmsum_6',
|
| 304 |
+
eval_cfg=dict(
|
| 305 |
+
evaluator=dict(
|
| 306 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 307 |
+
pred_role='BOT'),
|
| 308 |
+
infer_cfg=dict(
|
| 309 |
+
inferencer=dict(
|
| 310 |
+
max_out_len=512,
|
| 311 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 312 |
+
prompt_template=dict(
|
| 313 |
+
template=dict(round=[
|
| 314 |
+
dict(
|
| 315 |
+
prompt=
|
| 316 |
+
'You are given a meeting transcript and a query containing a question or instruction. Answer the query in one or more sentences.\n\nTranscript:\n{context}\n\nNow, answer the query based on the above meeting transcript in one or more sentences.\n\nQuery: {input}\nAnswer:',
|
| 317 |
+
role='HUMAN'),
|
| 318 |
+
]),
|
| 319 |
+
type=
|
| 320 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 321 |
+
retriever=dict(
|
| 322 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 323 |
+
name='qmsum',
|
| 324 |
+
path='opencompass/Longbench',
|
| 325 |
+
reader_cfg=dict(
|
| 326 |
+
input_columns=[
|
| 327 |
+
'context',
|
| 328 |
+
'input',
|
| 329 |
+
],
|
| 330 |
+
output_column='answers',
|
| 331 |
+
test_range='[150:175]',
|
| 332 |
+
test_split='test',
|
| 333 |
+
train_split='test'),
|
| 334 |
+
type='opencompass.datasets.LongBenchqmsumDataset'),
|
| 335 |
+
dict(
|
| 336 |
+
abbr='LongBench_vcsum_6',
|
| 337 |
+
eval_cfg=dict(
|
| 338 |
+
evaluator=dict(
|
| 339 |
+
language='zh',
|
| 340 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 341 |
+
pred_role='BOT'),
|
| 342 |
+
infer_cfg=dict(
|
| 343 |
+
inferencer=dict(
|
| 344 |
+
max_out_len=512,
|
| 345 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 346 |
+
prompt_template=dict(
|
| 347 |
+
template=dict(round=[
|
| 348 |
+
dict(
|
| 349 |
+
prompt=
|
| 350 |
+
'下面有一段会议记录,请你阅读后,写一段总结,总结会议的内容。\n会议记录:\n{context}\n\n会议总结:',
|
| 351 |
+
role='HUMAN'),
|
| 352 |
+
]),
|
| 353 |
+
type=
|
| 354 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 355 |
+
retriever=dict(
|
| 356 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 357 |
+
name='vcsum',
|
| 358 |
+
path='opencompass/Longbench',
|
| 359 |
+
reader_cfg=dict(
|
| 360 |
+
input_columns=[
|
| 361 |
+
'context',
|
| 362 |
+
],
|
| 363 |
+
output_column='answers',
|
| 364 |
+
test_range='[150:175]',
|
| 365 |
+
test_split='test',
|
| 366 |
+
train_split='test'),
|
| 367 |
+
type='opencompass.datasets.LongBenchvcsumDataset'),
|
| 368 |
+
dict(
|
| 369 |
+
abbr='LongBench_dureader_6',
|
| 370 |
+
eval_cfg=dict(
|
| 371 |
+
evaluator=dict(
|
| 372 |
+
language='zh',
|
| 373 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 374 |
+
pred_role='BOT'),
|
| 375 |
+
infer_cfg=dict(
|
| 376 |
+
inferencer=dict(
|
| 377 |
+
max_out_len=128,
|
| 378 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 379 |
+
prompt_template=dict(
|
| 380 |
+
template=dict(round=[
|
| 381 |
+
dict(
|
| 382 |
+
prompt=
|
| 383 |
+
'请基于给定的文章回答下述问题。\n\n文章:{context}\n\n请基于上述文章回答下面的问题。\n\n问题:{input}\n回答:',
|
| 384 |
+
role='HUMAN'),
|
| 385 |
+
]),
|
| 386 |
+
type=
|
| 387 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 388 |
+
retriever=dict(
|
| 389 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 390 |
+
name='dureader',
|
| 391 |
+
path='opencompass/Longbench',
|
| 392 |
+
reader_cfg=dict(
|
| 393 |
+
input_columns=[
|
| 394 |
+
'context',
|
| 395 |
+
'input',
|
| 396 |
+
],
|
| 397 |
+
output_column='answers',
|
| 398 |
+
test_range='[150:175]',
|
| 399 |
+
test_split='test',
|
| 400 |
+
train_split='test'),
|
| 401 |
+
type='opencompass.datasets.LongBenchdureaderDataset'),
|
| 402 |
+
dict(
|
| 403 |
+
abbr='LongBench_lcc_6',
|
| 404 |
+
eval_cfg=dict(
|
| 405 |
+
evaluator=dict(
|
| 406 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 407 |
+
pred_role='BOT'),
|
| 408 |
+
infer_cfg=dict(
|
| 409 |
+
inferencer=dict(
|
| 410 |
+
max_out_len=64,
|
| 411 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 412 |
+
prompt_template=dict(
|
| 413 |
+
template=dict(round=[
|
| 414 |
+
dict(
|
| 415 |
+
prompt=
|
| 416 |
+
'Please complete the code given below. \n{context}Next line of code:\n',
|
| 417 |
+
role='HUMAN'),
|
| 418 |
+
]),
|
| 419 |
+
type=
|
| 420 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 421 |
+
retriever=dict(
|
| 422 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 423 |
+
name='lcc',
|
| 424 |
+
path='opencompass/Longbench',
|
| 425 |
+
reader_cfg=dict(
|
| 426 |
+
input_columns=[
|
| 427 |
+
'context',
|
| 428 |
+
],
|
| 429 |
+
output_column='answers',
|
| 430 |
+
test_range='[378:441]',
|
| 431 |
+
test_split='test',
|
| 432 |
+
train_split='test'),
|
| 433 |
+
type='opencompass.datasets.LongBenchlccDataset'),
|
| 434 |
+
dict(
|
| 435 |
+
abbr='LongBench_repobench-p_6',
|
| 436 |
+
eval_cfg=dict(
|
| 437 |
+
evaluator=dict(
|
| 438 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 439 |
+
pred_role='BOT'),
|
| 440 |
+
infer_cfg=dict(
|
| 441 |
+
inferencer=dict(
|
| 442 |
+
max_out_len=64,
|
| 443 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 444 |
+
prompt_template=dict(
|
| 445 |
+
template=dict(round=[
|
| 446 |
+
dict(
|
| 447 |
+
prompt=
|
| 448 |
+
'Please complete the code given below. \n{context}{input}Next line of code:\n',
|
| 449 |
+
role='HUMAN'),
|
| 450 |
+
]),
|
| 451 |
+
type=
|
| 452 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 453 |
+
retriever=dict(
|
| 454 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 455 |
+
name='repobench-p',
|
| 456 |
+
path='opencompass/Longbench',
|
| 457 |
+
reader_cfg=dict(
|
| 458 |
+
input_columns=[
|
| 459 |
+
'context',
|
| 460 |
+
'input',
|
| 461 |
+
],
|
| 462 |
+
output_column='answers',
|
| 463 |
+
test_range='[378:441]',
|
| 464 |
+
test_split='test',
|
| 465 |
+
train_split='test'),
|
| 466 |
+
type='opencompass.datasets.LongBenchrepobenchDataset'),
|
| 467 |
+
dict(
|
| 468 |
+
abbr='LongBench_passage_retrieval_en_6',
|
| 469 |
+
eval_cfg=dict(
|
| 470 |
+
evaluator=dict(
|
| 471 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 472 |
+
pred_role='BOT'),
|
| 473 |
+
infer_cfg=dict(
|
| 474 |
+
inferencer=dict(
|
| 475 |
+
max_out_len=32,
|
| 476 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 477 |
+
prompt_template=dict(
|
| 478 |
+
template=dict(round=[
|
| 479 |
+
dict(
|
| 480 |
+
prompt=
|
| 481 |
+
'Here are 30 paragraphs from Wikipedia, along with an abstract. Please determine which paragraph the abstract is from.\n\n{context}\n\nThe following is an abstract.\n\n{input}\n\nPlease enter the number of the paragraph that the abstract is from. The answer format must be like "Paragraph 1", "Paragraph 2", etc.\n\nThe answer is: ',
|
| 482 |
+
role='HUMAN'),
|
| 483 |
+
]),
|
| 484 |
+
type=
|
| 485 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 486 |
+
retriever=dict(
|
| 487 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 488 |
+
name='passage_retrieval_en',
|
| 489 |
+
path='opencompass/Longbench',
|
| 490 |
+
reader_cfg=dict(
|
| 491 |
+
input_columns=[
|
| 492 |
+
'context',
|
| 493 |
+
'input',
|
| 494 |
+
],
|
| 495 |
+
output_column='answers',
|
| 496 |
+
test_range='[150:175]',
|
| 497 |
+
test_split='test',
|
| 498 |
+
train_split='test'),
|
| 499 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_enDataset'),
|
| 500 |
+
dict(
|
| 501 |
+
abbr='LongBench_passage_retrieval_zh_6',
|
| 502 |
+
eval_cfg=dict(
|
| 503 |
+
evaluator=dict(
|
| 504 |
+
language='zh',
|
| 505 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 506 |
+
pred_role='BOT'),
|
| 507 |
+
infer_cfg=dict(
|
| 508 |
+
inferencer=dict(
|
| 509 |
+
max_out_len=32,
|
| 510 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 511 |
+
prompt_template=dict(
|
| 512 |
+
template=dict(round=[
|
| 513 |
+
dict(
|
| 514 |
+
prompt=
|
| 515 |
+
'以下是若干段落文字,以及其中一个段落的摘要。请确定给定的摘要出自哪一段。\n\n{context}\n\n下面是一个摘要\n\n{input}\n\n请输入摘要所属段落的编号。答案格式必须是"段落1","段落2"等格式\n\n答案是:',
|
| 516 |
+
role='HUMAN'),
|
| 517 |
+
]),
|
| 518 |
+
type=
|
| 519 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 520 |
+
retriever=dict(
|
| 521 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 522 |
+
name='passage_retrieval_zh',
|
| 523 |
+
path='opencompass/Longbench',
|
| 524 |
+
reader_cfg=dict(
|
| 525 |
+
input_columns=[
|
| 526 |
+
'context',
|
| 527 |
+
'input',
|
| 528 |
+
],
|
| 529 |
+
output_column='answers',
|
| 530 |
+
test_range='[150:175]',
|
| 531 |
+
test_split='test',
|
| 532 |
+
train_split='test'),
|
| 533 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_zhDataset'),
|
| 534 |
+
dict(
|
| 535 |
+
abbr='LongBench_passage_count_6',
|
| 536 |
+
eval_cfg=dict(
|
| 537 |
+
evaluator=dict(
|
| 538 |
+
type='opencompass.datasets.LongBenchCountEvaluator'),
|
| 539 |
+
pred_role='BOT'),
|
| 540 |
+
infer_cfg=dict(
|
| 541 |
+
inferencer=dict(
|
| 542 |
+
max_out_len=32,
|
| 543 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 544 |
+
prompt_template=dict(
|
| 545 |
+
template=dict(round=[
|
| 546 |
+
dict(
|
| 547 |
+
prompt=
|
| 548 |
+
'There are some paragraphs below sourced from Wikipedia. Some of them may be duplicates. Please carefully read these paragraphs and determine how many unique paragraphs there are after removing duplicates. In other words, how many non-repeating paragraphs are there in total?\n\n{context}\n\nPlease enter the final count of unique paragraphs after removing duplicates. The output format should only contain the number, such as 1, 2, 3, and so on.\n\nThe final answer is: ',
|
| 549 |
+
role='HUMAN'),
|
| 550 |
+
]),
|
| 551 |
+
type=
|
| 552 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 553 |
+
retriever=dict(
|
| 554 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 555 |
+
name='passage_count',
|
| 556 |
+
path='opencompass/Longbench',
|
| 557 |
+
reader_cfg=dict(
|
| 558 |
+
input_columns=[
|
| 559 |
+
'context',
|
| 560 |
+
'input',
|
| 561 |
+
],
|
| 562 |
+
output_column='answers',
|
| 563 |
+
test_range='[150:175]',
|
| 564 |
+
test_split='test',
|
| 565 |
+
train_split='test'),
|
| 566 |
+
type='opencompass.datasets.LongBenchpassage_countDataset'),
|
| 567 |
+
dict(
|
| 568 |
+
abbr='LongBench_trec_6',
|
| 569 |
+
eval_cfg=dict(
|
| 570 |
+
evaluator=dict(
|
| 571 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 572 |
+
),
|
| 573 |
+
pred_postprocessor=dict(
|
| 574 |
+
type='opencompass.datasets.trec_postprocess'),
|
| 575 |
+
pred_role='BOT'),
|
| 576 |
+
infer_cfg=dict(
|
| 577 |
+
inferencer=dict(
|
| 578 |
+
max_out_len=64,
|
| 579 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 580 |
+
prompt_template=dict(
|
| 581 |
+
template=dict(round=[
|
| 582 |
+
dict(
|
| 583 |
+
prompt=
|
| 584 |
+
'Please determine the type of the question below. Here are some examples of questions.\n\n{context}\n{input}',
|
| 585 |
+
role='HUMAN'),
|
| 586 |
+
]),
|
| 587 |
+
type=
|
| 588 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 589 |
+
retriever=dict(
|
| 590 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 591 |
+
name='trec',
|
| 592 |
+
path='opencompass/Longbench',
|
| 593 |
+
reader_cfg=dict(
|
| 594 |
+
input_columns=[
|
| 595 |
+
'context',
|
| 596 |
+
'input',
|
| 597 |
+
],
|
| 598 |
+
output_column='all_labels',
|
| 599 |
+
test_range='[150:175]',
|
| 600 |
+
test_split='test',
|
| 601 |
+
train_split='test'),
|
| 602 |
+
type='opencompass.datasets.LongBenchtrecDataset'),
|
| 603 |
+
dict(
|
| 604 |
+
abbr='LongBench_lsht_6',
|
| 605 |
+
eval_cfg=dict(
|
| 606 |
+
evaluator=dict(
|
| 607 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 608 |
+
),
|
| 609 |
+
pred_postprocessor=dict(
|
| 610 |
+
type='opencompass.datasets.lsht_postprocess'),
|
| 611 |
+
pred_role='BOT'),
|
| 612 |
+
infer_cfg=dict(
|
| 613 |
+
inferencer=dict(
|
| 614 |
+
max_out_len=64,
|
| 615 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 616 |
+
prompt_template=dict(
|
| 617 |
+
template=dict(round=[
|
| 618 |
+
dict(
|
| 619 |
+
prompt='请判断给定新闻的类别,下面是一些例子。\n\n{context}\n{input}',
|
| 620 |
+
role='HUMAN'),
|
| 621 |
+
]),
|
| 622 |
+
type=
|
| 623 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 624 |
+
retriever=dict(
|
| 625 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 626 |
+
name='lsht',
|
| 627 |
+
path='opencompass/Longbench',
|
| 628 |
+
reader_cfg=dict(
|
| 629 |
+
input_columns=[
|
| 630 |
+
'context',
|
| 631 |
+
'input',
|
| 632 |
+
],
|
| 633 |
+
output_column='all_labels',
|
| 634 |
+
test_range='[150:175]',
|
| 635 |
+
test_split='test',
|
| 636 |
+
train_split='test'),
|
| 637 |
+
type='opencompass.datasets.LongBenchlshtDataset'),
|
| 638 |
+
dict(
|
| 639 |
+
abbr='LongBench_multi_news_6',
|
| 640 |
+
eval_cfg=dict(
|
| 641 |
+
evaluator=dict(
|
| 642 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 643 |
+
pred_role='BOT'),
|
| 644 |
+
infer_cfg=dict(
|
| 645 |
+
inferencer=dict(
|
| 646 |
+
max_out_len=512,
|
| 647 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 648 |
+
prompt_template=dict(
|
| 649 |
+
template=dict(round=[
|
| 650 |
+
dict(
|
| 651 |
+
prompt=
|
| 652 |
+
'You are given several news passages. Write a one-page summary of all news. \n\nNews:\n{context}\n\nNow, write a one-page summary of all the news.\n\nSummary:\n',
|
| 653 |
+
role='HUMAN'),
|
| 654 |
+
]),
|
| 655 |
+
type=
|
| 656 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 657 |
+
retriever=dict(
|
| 658 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 659 |
+
name='multi_news',
|
| 660 |
+
path='opencompass/Longbench',
|
| 661 |
+
reader_cfg=dict(
|
| 662 |
+
input_columns=[
|
| 663 |
+
'context',
|
| 664 |
+
],
|
| 665 |
+
output_column='answers',
|
| 666 |
+
test_range='[150:175]',
|
| 667 |
+
test_split='test',
|
| 668 |
+
train_split='test'),
|
| 669 |
+
type='opencompass.datasets.LongBenchmulti_newsDataset'),
|
| 670 |
+
dict(
|
| 671 |
+
abbr='LongBench_samsum_6',
|
| 672 |
+
eval_cfg=dict(
|
| 673 |
+
evaluator=dict(
|
| 674 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 675 |
+
pred_postprocessor=dict(
|
| 676 |
+
type='opencompass.datasets.samsum_postprocess'),
|
| 677 |
+
pred_role='BOT'),
|
| 678 |
+
infer_cfg=dict(
|
| 679 |
+
inferencer=dict(
|
| 680 |
+
max_out_len=128,
|
| 681 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 682 |
+
prompt_template=dict(
|
| 683 |
+
template=dict(round=[
|
| 684 |
+
dict(
|
| 685 |
+
prompt=
|
| 686 |
+
'Summarize the dialogue into a few short sentences. The following are some examples.\n\n{context}\n\n{input}',
|
| 687 |
+
role='HUMAN'),
|
| 688 |
+
]),
|
| 689 |
+
type=
|
| 690 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 691 |
+
retriever=dict(
|
| 692 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 693 |
+
name='samsum',
|
| 694 |
+
path='opencompass/Longbench',
|
| 695 |
+
reader_cfg=dict(
|
| 696 |
+
input_columns=[
|
| 697 |
+
'context',
|
| 698 |
+
'input',
|
| 699 |
+
],
|
| 700 |
+
output_column='answers',
|
| 701 |
+
test_range='[150:175]',
|
| 702 |
+
test_split='test',
|
| 703 |
+
train_split='test'),
|
| 704 |
+
type='opencompass.datasets.LongBenchsamsumDataset'),
|
| 705 |
+
dict(
|
| 706 |
+
abbr='LongBench_2wikimqa_6',
|
| 707 |
+
eval_cfg=dict(
|
| 708 |
+
evaluator=dict(
|
| 709 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 710 |
+
pred_role='BOT'),
|
| 711 |
+
infer_cfg=dict(
|
| 712 |
+
inferencer=dict(
|
| 713 |
+
max_out_len=32,
|
| 714 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 715 |
+
prompt_template=dict(
|
| 716 |
+
template=dict(round=[
|
| 717 |
+
dict(
|
| 718 |
+
prompt=
|
| 719 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 720 |
+
role='HUMAN'),
|
| 721 |
+
]),
|
| 722 |
+
type=
|
| 723 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 724 |
+
retriever=dict(
|
| 725 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 726 |
+
name='2wikimqa',
|
| 727 |
+
path='opencompass/Longbench',
|
| 728 |
+
reader_cfg=dict(
|
| 729 |
+
input_columns=[
|
| 730 |
+
'context',
|
| 731 |
+
'input',
|
| 732 |
+
],
|
| 733 |
+
output_column='answers',
|
| 734 |
+
test_range='[150:175]',
|
| 735 |
+
test_split='test',
|
| 736 |
+
train_split='test'),
|
| 737 |
+
type='opencompass.datasets.LongBench2wikimqaDataset'),
|
| 738 |
+
dict(
|
| 739 |
+
abbr='LongBench_hotpotqa_6',
|
| 740 |
+
eval_cfg=dict(
|
| 741 |
+
evaluator=dict(
|
| 742 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 743 |
+
pred_role='BOT'),
|
| 744 |
+
infer_cfg=dict(
|
| 745 |
+
inferencer=dict(
|
| 746 |
+
max_out_len=32,
|
| 747 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 748 |
+
prompt_template=dict(
|
| 749 |
+
template=dict(round=[
|
| 750 |
+
dict(
|
| 751 |
+
prompt=
|
| 752 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 753 |
+
role='HUMAN'),
|
| 754 |
+
]),
|
| 755 |
+
type=
|
| 756 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 757 |
+
retriever=dict(
|
| 758 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 759 |
+
name='hotpotqa',
|
| 760 |
+
path='opencompass/Longbench',
|
| 761 |
+
reader_cfg=dict(
|
| 762 |
+
input_columns=[
|
| 763 |
+
'context',
|
| 764 |
+
'input',
|
| 765 |
+
],
|
| 766 |
+
output_column='answers',
|
| 767 |
+
test_range='[150:175]',
|
| 768 |
+
test_split='test',
|
| 769 |
+
train_split='test'),
|
| 770 |
+
type='opencompass.datasets.LongBenchhotpotqaDataset'),
|
| 771 |
+
dict(
|
| 772 |
+
abbr='LongBench_musique_6',
|
| 773 |
+
eval_cfg=dict(
|
| 774 |
+
evaluator=dict(
|
| 775 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 776 |
+
pred_role='BOT'),
|
| 777 |
+
infer_cfg=dict(
|
| 778 |
+
inferencer=dict(
|
| 779 |
+
max_out_len=32,
|
| 780 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 781 |
+
prompt_template=dict(
|
| 782 |
+
template=dict(round=[
|
| 783 |
+
dict(
|
| 784 |
+
prompt=
|
| 785 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 786 |
+
role='HUMAN'),
|
| 787 |
+
]),
|
| 788 |
+
type=
|
| 789 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 790 |
+
retriever=dict(
|
| 791 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 792 |
+
name='musique',
|
| 793 |
+
path='opencompass/Longbench',
|
| 794 |
+
reader_cfg=dict(
|
| 795 |
+
input_columns=[
|
| 796 |
+
'context',
|
| 797 |
+
'input',
|
| 798 |
+
],
|
| 799 |
+
output_column='answers',
|
| 800 |
+
test_range='[150:175]',
|
| 801 |
+
test_split='test',
|
| 802 |
+
train_split='test'),
|
| 803 |
+
type='opencompass.datasets.LongBenchmusiqueDataset'),
|
| 804 |
+
dict(
|
| 805 |
+
abbr='LongBench_multifieldqa_en_6',
|
| 806 |
+
eval_cfg=dict(
|
| 807 |
+
evaluator=dict(
|
| 808 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 809 |
+
pred_role='BOT'),
|
| 810 |
+
infer_cfg=dict(
|
| 811 |
+
inferencer=dict(
|
| 812 |
+
max_out_len=64,
|
| 813 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 814 |
+
prompt_template=dict(
|
| 815 |
+
template=dict(round=[
|
| 816 |
+
dict(
|
| 817 |
+
prompt=
|
| 818 |
+
'Read the following text and answer briefly.\n\n{context}\n\nNow, answer the following question based on the above text, only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 819 |
+
role='HUMAN'),
|
| 820 |
+
]),
|
| 821 |
+
type=
|
| 822 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 823 |
+
retriever=dict(
|
| 824 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 825 |
+
name='multifieldqa_en',
|
| 826 |
+
path='opencompass/Longbench',
|
| 827 |
+
reader_cfg=dict(
|
| 828 |
+
input_columns=[
|
| 829 |
+
'context',
|
| 830 |
+
'input',
|
| 831 |
+
],
|
| 832 |
+
output_column='answers',
|
| 833 |
+
test_range='[114:133]',
|
| 834 |
+
test_split='test',
|
| 835 |
+
train_split='test'),
|
| 836 |
+
type='opencompass.datasets.LongBenchmultifieldqa_enDataset'),
|
| 837 |
+
dict(
|
| 838 |
+
abbr='LongBench_multifieldqa_zh_6',
|
| 839 |
+
eval_cfg=dict(
|
| 840 |
+
evaluator=dict(
|
| 841 |
+
language='zh',
|
| 842 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 843 |
+
pred_role='BOT'),
|
| 844 |
+
infer_cfg=dict(
|
| 845 |
+
inferencer=dict(
|
| 846 |
+
max_out_len=64,
|
| 847 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 848 |
+
prompt_template=dict(
|
| 849 |
+
template=dict(round=[
|
| 850 |
+
dict(
|
| 851 |
+
prompt=
|
| 852 |
+
'阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:',
|
| 853 |
+
role='HUMAN'),
|
| 854 |
+
]),
|
| 855 |
+
type=
|
| 856 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 857 |
+
retriever=dict(
|
| 858 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 859 |
+
name='multifieldqa_zh',
|
| 860 |
+
path='opencompass/Longbench',
|
| 861 |
+
reader_cfg=dict(
|
| 862 |
+
input_columns=[
|
| 863 |
+
'context',
|
| 864 |
+
'input',
|
| 865 |
+
],
|
| 866 |
+
output_column='answers',
|
| 867 |
+
test_range='[150:175]',
|
| 868 |
+
test_split='test',
|
| 869 |
+
train_split='test'),
|
| 870 |
+
type='opencompass.datasets.LongBenchmultifieldqa_zhDataset'),
|
| 871 |
+
dict(
|
| 872 |
+
abbr='LongBench_narrativeqa_6',
|
| 873 |
+
eval_cfg=dict(
|
| 874 |
+
evaluator=dict(
|
| 875 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 876 |
+
pred_role='BOT'),
|
| 877 |
+
infer_cfg=dict(
|
| 878 |
+
inferencer=dict(
|
| 879 |
+
max_out_len=128,
|
| 880 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 881 |
+
prompt_template=dict(
|
| 882 |
+
template=dict(round=[
|
| 883 |
+
dict(
|
| 884 |
+
prompt=
|
| 885 |
+
'You are given a story, which can be either a novel or a movie script, and a question. Answer the question as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nStory: {context}\n\nNow, answer the question based on the story as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nQuestion: {input}\n\nAnswer:',
|
| 886 |
+
role='HUMAN'),
|
| 887 |
+
]),
|
| 888 |
+
type=
|
| 889 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 890 |
+
retriever=dict(
|
| 891 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 892 |
+
name='narrativeqa',
|
| 893 |
+
path='opencompass/Longbench',
|
| 894 |
+
reader_cfg=dict(
|
| 895 |
+
input_columns=[
|
| 896 |
+
'context',
|
| 897 |
+
'input',
|
| 898 |
+
],
|
| 899 |
+
output_column='answers',
|
| 900 |
+
test_range='[150:175]',
|
| 901 |
+
test_split='test',
|
| 902 |
+
train_split='test'),
|
| 903 |
+
type='opencompass.datasets.LongBenchnarrativeqaDataset'),
|
| 904 |
+
dict(
|
| 905 |
+
abbr='LongBench_qasper_6',
|
| 906 |
+
eval_cfg=dict(
|
| 907 |
+
evaluator=dict(
|
| 908 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 909 |
+
pred_role='BOT'),
|
| 910 |
+
infer_cfg=dict(
|
| 911 |
+
inferencer=dict(
|
| 912 |
+
max_out_len=32,
|
| 913 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 914 |
+
prompt_template=dict(
|
| 915 |
+
template=dict(round=[
|
| 916 |
+
dict(
|
| 917 |
+
prompt=
|
| 918 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 919 |
+
role='HUMAN'),
|
| 920 |
+
]),
|
| 921 |
+
type=
|
| 922 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 923 |
+
retriever=dict(
|
| 924 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 925 |
+
name='qasper',
|
| 926 |
+
path='opencompass/Longbench',
|
| 927 |
+
reader_cfg=dict(
|
| 928 |
+
input_columns=[
|
| 929 |
+
'context',
|
| 930 |
+
'input',
|
| 931 |
+
],
|
| 932 |
+
output_column='answers',
|
| 933 |
+
test_range='[150:175]',
|
| 934 |
+
test_split='test',
|
| 935 |
+
train_split='test'),
|
| 936 |
+
type='opencompass.datasets.LongBenchqasperDataset'),
|
| 937 |
+
dict(
|
| 938 |
+
abbr='LongBench_triviaqa_6',
|
| 939 |
+
eval_cfg=dict(
|
| 940 |
+
evaluator=dict(
|
| 941 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 942 |
+
pred_postprocessor=dict(
|
| 943 |
+
type='opencompass.datasets.triviaqa_postprocess'),
|
| 944 |
+
pred_role='BOT'),
|
| 945 |
+
infer_cfg=dict(
|
| 946 |
+
inferencer=dict(
|
| 947 |
+
max_out_len=32,
|
| 948 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 949 |
+
prompt_template=dict(
|
| 950 |
+
template=dict(round=[
|
| 951 |
+
dict(
|
| 952 |
+
prompt=
|
| 953 |
+
'Answer the question based on the given passage. Only give me the answer and do not output any other words. The following are some examples.\n\n{context}\n\n{input}',
|
| 954 |
+
role='HUMAN'),
|
| 955 |
+
]),
|
| 956 |
+
type=
|
| 957 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 958 |
+
retriever=dict(
|
| 959 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 960 |
+
name='triviaqa',
|
| 961 |
+
path='opencompass/Longbench',
|
| 962 |
+
reader_cfg=dict(
|
| 963 |
+
input_columns=[
|
| 964 |
+
'context',
|
| 965 |
+
'input',
|
| 966 |
+
],
|
| 967 |
+
output_column='answers',
|
| 968 |
+
test_range='[150:175]',
|
| 969 |
+
test_split='test',
|
| 970 |
+
train_split='test'),
|
| 971 |
+
type='opencompass.datasets.LongBenchtriviaqaDataset'),
|
| 972 |
+
dict(
|
| 973 |
+
abbr='LongBench_gov_report_6',
|
| 974 |
+
eval_cfg=dict(
|
| 975 |
+
evaluator=dict(
|
| 976 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 977 |
+
pred_role='BOT'),
|
| 978 |
+
infer_cfg=dict(
|
| 979 |
+
inferencer=dict(
|
| 980 |
+
max_out_len=512,
|
| 981 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 982 |
+
prompt_template=dict(
|
| 983 |
+
template=dict(round=[
|
| 984 |
+
dict(
|
| 985 |
+
prompt=
|
| 986 |
+
'You are given a report by a government agency. Write a one-page summary of the report.\n\nReport:\n{context}\n\nNow, write a one-page summary of the report.\n\nSummary:',
|
| 987 |
+
role='HUMAN'),
|
| 988 |
+
]),
|
| 989 |
+
type=
|
| 990 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 991 |
+
retriever=dict(
|
| 992 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 993 |
+
name='gov_report',
|
| 994 |
+
path='opencompass/Longbench',
|
| 995 |
+
reader_cfg=dict(
|
| 996 |
+
input_columns=[
|
| 997 |
+
'context',
|
| 998 |
+
],
|
| 999 |
+
output_column='answers',
|
| 1000 |
+
test_range='[150:175]',
|
| 1001 |
+
test_split='test',
|
| 1002 |
+
train_split='test'),
|
| 1003 |
+
type='opencompass.datasets.LongBenchgov_reportDataset'),
|
| 1004 |
+
dict(
|
| 1005 |
+
abbr='LongBench_qmsum_6',
|
| 1006 |
+
eval_cfg=dict(
|
| 1007 |
+
evaluator=dict(
|
| 1008 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1009 |
+
pred_role='BOT'),
|
| 1010 |
+
infer_cfg=dict(
|
| 1011 |
+
inferencer=dict(
|
| 1012 |
+
max_out_len=512,
|
| 1013 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1014 |
+
prompt_template=dict(
|
| 1015 |
+
template=dict(round=[
|
| 1016 |
+
dict(
|
| 1017 |
+
prompt=
|
| 1018 |
+
'You are given a meeting transcript and a query containing a question or instruction. Answer the query in one or more sentences.\n\nTranscript:\n{context}\n\nNow, answer the query based on the above meeting transcript in one or more sentences.\n\nQuery: {input}\nAnswer:',
|
| 1019 |
+
role='HUMAN'),
|
| 1020 |
+
]),
|
| 1021 |
+
type=
|
| 1022 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1023 |
+
retriever=dict(
|
| 1024 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1025 |
+
name='qmsum',
|
| 1026 |
+
path='opencompass/Longbench',
|
| 1027 |
+
reader_cfg=dict(
|
| 1028 |
+
input_columns=[
|
| 1029 |
+
'context',
|
| 1030 |
+
'input',
|
| 1031 |
+
],
|
| 1032 |
+
output_column='answers',
|
| 1033 |
+
test_range='[150:175]',
|
| 1034 |
+
test_split='test',
|
| 1035 |
+
train_split='test'),
|
| 1036 |
+
type='opencompass.datasets.LongBenchqmsumDataset'),
|
| 1037 |
+
dict(
|
| 1038 |
+
abbr='LongBench_vcsum_6',
|
| 1039 |
+
eval_cfg=dict(
|
| 1040 |
+
evaluator=dict(
|
| 1041 |
+
language='zh',
|
| 1042 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1043 |
+
pred_role='BOT'),
|
| 1044 |
+
infer_cfg=dict(
|
| 1045 |
+
inferencer=dict(
|
| 1046 |
+
max_out_len=512,
|
| 1047 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1048 |
+
prompt_template=dict(
|
| 1049 |
+
template=dict(round=[
|
| 1050 |
+
dict(
|
| 1051 |
+
prompt=
|
| 1052 |
+
'下面有一段会议记录,请你阅读后,写一段总结,总结会议的内容。\n会议记录:\n{context}\n\n会议总结:',
|
| 1053 |
+
role='HUMAN'),
|
| 1054 |
+
]),
|
| 1055 |
+
type=
|
| 1056 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1057 |
+
retriever=dict(
|
| 1058 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1059 |
+
name='vcsum',
|
| 1060 |
+
path='opencompass/Longbench',
|
| 1061 |
+
reader_cfg=dict(
|
| 1062 |
+
input_columns=[
|
| 1063 |
+
'context',
|
| 1064 |
+
],
|
| 1065 |
+
output_column='answers',
|
| 1066 |
+
test_range='[150:175]',
|
| 1067 |
+
test_split='test',
|
| 1068 |
+
train_split='test'),
|
| 1069 |
+
type='opencompass.datasets.LongBenchvcsumDataset'),
|
| 1070 |
+
dict(
|
| 1071 |
+
abbr='LongBench_dureader_6',
|
| 1072 |
+
eval_cfg=dict(
|
| 1073 |
+
evaluator=dict(
|
| 1074 |
+
language='zh',
|
| 1075 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1076 |
+
pred_role='BOT'),
|
| 1077 |
+
infer_cfg=dict(
|
| 1078 |
+
inferencer=dict(
|
| 1079 |
+
max_out_len=128,
|
| 1080 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1081 |
+
prompt_template=dict(
|
| 1082 |
+
template=dict(round=[
|
| 1083 |
+
dict(
|
| 1084 |
+
prompt=
|
| 1085 |
+
'请基于给定的文章回答下述问题。\n\n文章:{context}\n\n请基于上述文章回答下面的问题。\n\n问题:{input}\n回答:',
|
| 1086 |
+
role='HUMAN'),
|
| 1087 |
+
]),
|
| 1088 |
+
type=
|
| 1089 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1090 |
+
retriever=dict(
|
| 1091 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1092 |
+
name='dureader',
|
| 1093 |
+
path='opencompass/Longbench',
|
| 1094 |
+
reader_cfg=dict(
|
| 1095 |
+
input_columns=[
|
| 1096 |
+
'context',
|
| 1097 |
+
'input',
|
| 1098 |
+
],
|
| 1099 |
+
output_column='answers',
|
| 1100 |
+
test_range='[150:175]',
|
| 1101 |
+
test_split='test',
|
| 1102 |
+
train_split='test'),
|
| 1103 |
+
type='opencompass.datasets.LongBenchdureaderDataset'),
|
| 1104 |
+
dict(
|
| 1105 |
+
abbr='LongBench_lcc_6',
|
| 1106 |
+
eval_cfg=dict(
|
| 1107 |
+
evaluator=dict(
|
| 1108 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 1109 |
+
pred_role='BOT'),
|
| 1110 |
+
infer_cfg=dict(
|
| 1111 |
+
inferencer=dict(
|
| 1112 |
+
max_out_len=64,
|
| 1113 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1114 |
+
prompt_template=dict(
|
| 1115 |
+
template=dict(round=[
|
| 1116 |
+
dict(
|
| 1117 |
+
prompt=
|
| 1118 |
+
'Please complete the code given below. \n{context}Next line of code:\n',
|
| 1119 |
+
role='HUMAN'),
|
| 1120 |
+
]),
|
| 1121 |
+
type=
|
| 1122 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1123 |
+
retriever=dict(
|
| 1124 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1125 |
+
name='lcc',
|
| 1126 |
+
path='opencompass/Longbench',
|
| 1127 |
+
reader_cfg=dict(
|
| 1128 |
+
input_columns=[
|
| 1129 |
+
'context',
|
| 1130 |
+
],
|
| 1131 |
+
output_column='answers',
|
| 1132 |
+
test_range='[378:441]',
|
| 1133 |
+
test_split='test',
|
| 1134 |
+
train_split='test'),
|
| 1135 |
+
type='opencompass.datasets.LongBenchlccDataset'),
|
| 1136 |
+
dict(
|
| 1137 |
+
abbr='LongBench_repobench-p_6',
|
| 1138 |
+
eval_cfg=dict(
|
| 1139 |
+
evaluator=dict(
|
| 1140 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 1141 |
+
pred_role='BOT'),
|
| 1142 |
+
infer_cfg=dict(
|
| 1143 |
+
inferencer=dict(
|
| 1144 |
+
max_out_len=64,
|
| 1145 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1146 |
+
prompt_template=dict(
|
| 1147 |
+
template=dict(round=[
|
| 1148 |
+
dict(
|
| 1149 |
+
prompt=
|
| 1150 |
+
'Please complete the code given below. \n{context}{input}Next line of code:\n',
|
| 1151 |
+
role='HUMAN'),
|
| 1152 |
+
]),
|
| 1153 |
+
type=
|
| 1154 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1155 |
+
retriever=dict(
|
| 1156 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1157 |
+
name='repobench-p',
|
| 1158 |
+
path='opencompass/Longbench',
|
| 1159 |
+
reader_cfg=dict(
|
| 1160 |
+
input_columns=[
|
| 1161 |
+
'context',
|
| 1162 |
+
'input',
|
| 1163 |
+
],
|
| 1164 |
+
output_column='answers',
|
| 1165 |
+
test_range='[378:441]',
|
| 1166 |
+
test_split='test',
|
| 1167 |
+
train_split='test'),
|
| 1168 |
+
type='opencompass.datasets.LongBenchrepobenchDataset'),
|
| 1169 |
+
dict(
|
| 1170 |
+
abbr='LongBench_passage_retrieval_en_6',
|
| 1171 |
+
eval_cfg=dict(
|
| 1172 |
+
evaluator=dict(
|
| 1173 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 1174 |
+
pred_role='BOT'),
|
| 1175 |
+
infer_cfg=dict(
|
| 1176 |
+
inferencer=dict(
|
| 1177 |
+
max_out_len=32,
|
| 1178 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1179 |
+
prompt_template=dict(
|
| 1180 |
+
template=dict(round=[
|
| 1181 |
+
dict(
|
| 1182 |
+
prompt=
|
| 1183 |
+
'Here are 30 paragraphs from Wikipedia, along with an abstract. Please determine which paragraph the abstract is from.\n\n{context}\n\nThe following is an abstract.\n\n{input}\n\nPlease enter the number of the paragraph that the abstract is from. The answer format must be like "Paragraph 1", "Paragraph 2", etc.\n\nThe answer is: ',
|
| 1184 |
+
role='HUMAN'),
|
| 1185 |
+
]),
|
| 1186 |
+
type=
|
| 1187 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1188 |
+
retriever=dict(
|
| 1189 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1190 |
+
name='passage_retrieval_en',
|
| 1191 |
+
path='opencompass/Longbench',
|
| 1192 |
+
reader_cfg=dict(
|
| 1193 |
+
input_columns=[
|
| 1194 |
+
'context',
|
| 1195 |
+
'input',
|
| 1196 |
+
],
|
| 1197 |
+
output_column='answers',
|
| 1198 |
+
test_range='[150:175]',
|
| 1199 |
+
test_split='test',
|
| 1200 |
+
train_split='test'),
|
| 1201 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_enDataset'),
|
| 1202 |
+
dict(
|
| 1203 |
+
abbr='LongBench_passage_retrieval_zh_6',
|
| 1204 |
+
eval_cfg=dict(
|
| 1205 |
+
evaluator=dict(
|
| 1206 |
+
language='zh',
|
| 1207 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 1208 |
+
pred_role='BOT'),
|
| 1209 |
+
infer_cfg=dict(
|
| 1210 |
+
inferencer=dict(
|
| 1211 |
+
max_out_len=32,
|
| 1212 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1213 |
+
prompt_template=dict(
|
| 1214 |
+
template=dict(round=[
|
| 1215 |
+
dict(
|
| 1216 |
+
prompt=
|
| 1217 |
+
'以下是若干段落文字,以及其中一个段落的摘要。请确定给定的摘要出自哪一段。\n\n{context}\n\n下面是一个摘要\n\n{input}\n\n请输入摘要所属段落的编号。答案格式必须是"段落1","段落2"等格式\n\n答案是:',
|
| 1218 |
+
role='HUMAN'),
|
| 1219 |
+
]),
|
| 1220 |
+
type=
|
| 1221 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1222 |
+
retriever=dict(
|
| 1223 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1224 |
+
name='passage_retrieval_zh',
|
| 1225 |
+
path='opencompass/Longbench',
|
| 1226 |
+
reader_cfg=dict(
|
| 1227 |
+
input_columns=[
|
| 1228 |
+
'context',
|
| 1229 |
+
'input',
|
| 1230 |
+
],
|
| 1231 |
+
output_column='answers',
|
| 1232 |
+
test_range='[150:175]',
|
| 1233 |
+
test_split='test',
|
| 1234 |
+
train_split='test'),
|
| 1235 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_zhDataset'),
|
| 1236 |
+
dict(
|
| 1237 |
+
abbr='LongBench_passage_count_6',
|
| 1238 |
+
eval_cfg=dict(
|
| 1239 |
+
evaluator=dict(
|
| 1240 |
+
type='opencompass.datasets.LongBenchCountEvaluator'),
|
| 1241 |
+
pred_role='BOT'),
|
| 1242 |
+
infer_cfg=dict(
|
| 1243 |
+
inferencer=dict(
|
| 1244 |
+
max_out_len=32,
|
| 1245 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1246 |
+
prompt_template=dict(
|
| 1247 |
+
template=dict(round=[
|
| 1248 |
+
dict(
|
| 1249 |
+
prompt=
|
| 1250 |
+
'There are some paragraphs below sourced from Wikipedia. Some of them may be duplicates. Please carefully read these paragraphs and determine how many unique paragraphs there are after removing duplicates. In other words, how many non-repeating paragraphs are there in total?\n\n{context}\n\nPlease enter the final count of unique paragraphs after removing duplicates. The output format should only contain the number, such as 1, 2, 3, and so on.\n\nThe final answer is: ',
|
| 1251 |
+
role='HUMAN'),
|
| 1252 |
+
]),
|
| 1253 |
+
type=
|
| 1254 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1255 |
+
retriever=dict(
|
| 1256 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1257 |
+
name='passage_count',
|
| 1258 |
+
path='opencompass/Longbench',
|
| 1259 |
+
reader_cfg=dict(
|
| 1260 |
+
input_columns=[
|
| 1261 |
+
'context',
|
| 1262 |
+
'input',
|
| 1263 |
+
],
|
| 1264 |
+
output_column='answers',
|
| 1265 |
+
test_range='[150:175]',
|
| 1266 |
+
test_split='test',
|
| 1267 |
+
train_split='test'),
|
| 1268 |
+
type='opencompass.datasets.LongBenchpassage_countDataset'),
|
| 1269 |
+
dict(
|
| 1270 |
+
abbr='LongBench_trec_6',
|
| 1271 |
+
eval_cfg=dict(
|
| 1272 |
+
evaluator=dict(
|
| 1273 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 1274 |
+
),
|
| 1275 |
+
pred_postprocessor=dict(
|
| 1276 |
+
type='opencompass.datasets.trec_postprocess'),
|
| 1277 |
+
pred_role='BOT'),
|
| 1278 |
+
infer_cfg=dict(
|
| 1279 |
+
inferencer=dict(
|
| 1280 |
+
max_out_len=64,
|
| 1281 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1282 |
+
prompt_template=dict(
|
| 1283 |
+
template=dict(round=[
|
| 1284 |
+
dict(
|
| 1285 |
+
prompt=
|
| 1286 |
+
'Please determine the type of the question below. Here are some examples of questions.\n\n{context}\n{input}',
|
| 1287 |
+
role='HUMAN'),
|
| 1288 |
+
]),
|
| 1289 |
+
type=
|
| 1290 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1291 |
+
retriever=dict(
|
| 1292 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1293 |
+
name='trec',
|
| 1294 |
+
path='opencompass/Longbench',
|
| 1295 |
+
reader_cfg=dict(
|
| 1296 |
+
input_columns=[
|
| 1297 |
+
'context',
|
| 1298 |
+
'input',
|
| 1299 |
+
],
|
| 1300 |
+
output_column='all_labels',
|
| 1301 |
+
test_range='[150:175]',
|
| 1302 |
+
test_split='test',
|
| 1303 |
+
train_split='test'),
|
| 1304 |
+
type='opencompass.datasets.LongBenchtrecDataset'),
|
| 1305 |
+
dict(
|
| 1306 |
+
abbr='LongBench_lsht_6',
|
| 1307 |
+
eval_cfg=dict(
|
| 1308 |
+
evaluator=dict(
|
| 1309 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 1310 |
+
),
|
| 1311 |
+
pred_postprocessor=dict(
|
| 1312 |
+
type='opencompass.datasets.lsht_postprocess'),
|
| 1313 |
+
pred_role='BOT'),
|
| 1314 |
+
infer_cfg=dict(
|
| 1315 |
+
inferencer=dict(
|
| 1316 |
+
max_out_len=64,
|
| 1317 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1318 |
+
prompt_template=dict(
|
| 1319 |
+
template=dict(round=[
|
| 1320 |
+
dict(
|
| 1321 |
+
prompt='请判断给定新闻的类别,下面是一些例子。\n\n{context}\n{input}',
|
| 1322 |
+
role='HUMAN'),
|
| 1323 |
+
]),
|
| 1324 |
+
type=
|
| 1325 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1326 |
+
retriever=dict(
|
| 1327 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1328 |
+
name='lsht',
|
| 1329 |
+
path='opencompass/Longbench',
|
| 1330 |
+
reader_cfg=dict(
|
| 1331 |
+
input_columns=[
|
| 1332 |
+
'context',
|
| 1333 |
+
'input',
|
| 1334 |
+
],
|
| 1335 |
+
output_column='all_labels',
|
| 1336 |
+
test_range='[150:175]',
|
| 1337 |
+
test_split='test',
|
| 1338 |
+
train_split='test'),
|
| 1339 |
+
type='opencompass.datasets.LongBenchlshtDataset'),
|
| 1340 |
+
dict(
|
| 1341 |
+
abbr='LongBench_multi_news_6',
|
| 1342 |
+
eval_cfg=dict(
|
| 1343 |
+
evaluator=dict(
|
| 1344 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1345 |
+
pred_role='BOT'),
|
| 1346 |
+
infer_cfg=dict(
|
| 1347 |
+
inferencer=dict(
|
| 1348 |
+
max_out_len=512,
|
| 1349 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1350 |
+
prompt_template=dict(
|
| 1351 |
+
template=dict(round=[
|
| 1352 |
+
dict(
|
| 1353 |
+
prompt=
|
| 1354 |
+
'You are given several news passages. Write a one-page summary of all news. \n\nNews:\n{context}\n\nNow, write a one-page summary of all the news.\n\nSummary:\n',
|
| 1355 |
+
role='HUMAN'),
|
| 1356 |
+
]),
|
| 1357 |
+
type=
|
| 1358 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1359 |
+
retriever=dict(
|
| 1360 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1361 |
+
name='multi_news',
|
| 1362 |
+
path='opencompass/Longbench',
|
| 1363 |
+
reader_cfg=dict(
|
| 1364 |
+
input_columns=[
|
| 1365 |
+
'context',
|
| 1366 |
+
],
|
| 1367 |
+
output_column='answers',
|
| 1368 |
+
test_range='[150:175]',
|
| 1369 |
+
test_split='test',
|
| 1370 |
+
train_split='test'),
|
| 1371 |
+
type='opencompass.datasets.LongBenchmulti_newsDataset'),
|
| 1372 |
+
dict(
|
| 1373 |
+
abbr='LongBench_samsum_6',
|
| 1374 |
+
eval_cfg=dict(
|
| 1375 |
+
evaluator=dict(
|
| 1376 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1377 |
+
pred_postprocessor=dict(
|
| 1378 |
+
type='opencompass.datasets.samsum_postprocess'),
|
| 1379 |
+
pred_role='BOT'),
|
| 1380 |
+
infer_cfg=dict(
|
| 1381 |
+
inferencer=dict(
|
| 1382 |
+
max_out_len=128,
|
| 1383 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1384 |
+
prompt_template=dict(
|
| 1385 |
+
template=dict(round=[
|
| 1386 |
+
dict(
|
| 1387 |
+
prompt=
|
| 1388 |
+
'Summarize the dialogue into a few short sentences. The following are some examples.\n\n{context}\n\n{input}',
|
| 1389 |
+
role='HUMAN'),
|
| 1390 |
+
]),
|
| 1391 |
+
type=
|
| 1392 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1393 |
+
retriever=dict(
|
| 1394 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1395 |
+
name='samsum',
|
| 1396 |
+
path='opencompass/Longbench',
|
| 1397 |
+
reader_cfg=dict(
|
| 1398 |
+
input_columns=[
|
| 1399 |
+
'context',
|
| 1400 |
+
'input',
|
| 1401 |
+
],
|
| 1402 |
+
output_column='answers',
|
| 1403 |
+
test_range='[150:175]',
|
| 1404 |
+
test_split='test',
|
| 1405 |
+
train_split='test'),
|
| 1406 |
+
type='opencompass.datasets.LongBenchsamsumDataset'),
|
| 1407 |
+
],
|
| 1408 |
+
]
|
| 1409 |
+
models = [
|
| 1410 |
+
dict(
|
| 1411 |
+
abbr='delta_net',
|
| 1412 |
+
batch_size=128,
|
| 1413 |
+
max_seq_len=2048,
|
| 1414 |
+
model_kwargs=dict(
|
| 1415 |
+
device_map='auto',
|
| 1416 |
+
torch_dtype='torch.bfloat16',
|
| 1417 |
+
trust_remote_code=True),
|
| 1418 |
+
path='/mnt/jfzn/msj/delta_net-1.3B-100B',
|
| 1419 |
+
run_cfg=dict(num_gpus=1),
|
| 1420 |
+
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
| 1421 |
+
tokenizer_path='/mnt/jfzn/msj/delta_net-1.3B-100B',
|
| 1422 |
+
type='opencompass.models.HuggingFaceBaseModel'),
|
| 1423 |
+
]
|
| 1424 |
+
work_dir = 'outputs/default/20251127_223020'
|
tmp/072e98a5-13a4-44fd-91a0-f552368807b5_params.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets = [
|
| 2 |
+
[
|
| 3 |
+
dict(
|
| 4 |
+
abbr='LongBench_multifieldqa_en',
|
| 5 |
+
eval_cfg=dict(
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 8 |
+
pred_role='BOT'),
|
| 9 |
+
infer_cfg=dict(
|
| 10 |
+
inferencer=dict(
|
| 11 |
+
max_out_len=64,
|
| 12 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
template=dict(round=[
|
| 15 |
+
dict(
|
| 16 |
+
prompt=
|
| 17 |
+
'Read the following text and answer briefly.\n\n{context}\n\nNow, answer the following question based on the above text, only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 18 |
+
role='HUMAN'),
|
| 19 |
+
]),
|
| 20 |
+
type=
|
| 21 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 22 |
+
retriever=dict(
|
| 23 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 24 |
+
name='multifieldqa_en',
|
| 25 |
+
path='opencompass/Longbench',
|
| 26 |
+
reader_cfg=dict(
|
| 27 |
+
input_columns=[
|
| 28 |
+
'context',
|
| 29 |
+
'input',
|
| 30 |
+
],
|
| 31 |
+
output_column='answers',
|
| 32 |
+
test_split='test',
|
| 33 |
+
train_split='test'),
|
| 34 |
+
type='opencompass.datasets.LongBenchmultifieldqa_enDataset'),
|
| 35 |
+
],
|
| 36 |
+
]
|
| 37 |
+
eval = dict(runner=dict(task=dict(dump_details=True)))
|
| 38 |
+
models = [
|
| 39 |
+
dict(
|
| 40 |
+
abbr='retnet',
|
| 41 |
+
batch_size=128,
|
| 42 |
+
max_seq_len=2048,
|
| 43 |
+
model_kwargs=dict(
|
| 44 |
+
device_map='auto',
|
| 45 |
+
torch_dtype='torch.bfloat16',
|
| 46 |
+
trust_remote_code=True),
|
| 47 |
+
path='/mnt/jfzn/msj/retnet-1.3B-100B',
|
| 48 |
+
run_cfg=dict(num_gpus=1),
|
| 49 |
+
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
| 50 |
+
tokenizer_path='/mnt/jfzn/msj/retnet-1.3B-100B',
|
| 51 |
+
type='opencompass.models.HuggingFaceBaseModel'),
|
| 52 |
+
]
|
| 53 |
+
work_dir = 'outputs/default/20251207_223306'
|
tmp/07b289dd-41fd-4f58-8c9b-e55ce7391d79_params.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets = [
|
| 2 |
+
[
|
| 3 |
+
dict(
|
| 4 |
+
abbr='LongBench_narrativeqa',
|
| 5 |
+
eval_cfg=dict(
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 8 |
+
pred_role='BOT'),
|
| 9 |
+
infer_cfg=dict(
|
| 10 |
+
inferencer=dict(
|
| 11 |
+
max_out_len=128,
|
| 12 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
template=dict(round=[
|
| 15 |
+
dict(
|
| 16 |
+
prompt=
|
| 17 |
+
'You are given a story, which can be either a novel or a movie script, and a question. Answer the question as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nStory: {context}\n\nNow, answer the question based on the story as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nQuestion: {input}\n\nAnswer:',
|
| 18 |
+
role='HUMAN'),
|
| 19 |
+
]),
|
| 20 |
+
type=
|
| 21 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 22 |
+
retriever=dict(
|
| 23 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 24 |
+
name='narrativeqa',
|
| 25 |
+
path='opencompass/Longbench',
|
| 26 |
+
reader_cfg=dict(
|
| 27 |
+
input_columns=[
|
| 28 |
+
'context',
|
| 29 |
+
'input',
|
| 30 |
+
],
|
| 31 |
+
output_column='answers',
|
| 32 |
+
test_split='test',
|
| 33 |
+
train_split='test'),
|
| 34 |
+
type='opencompass.datasets.LongBenchnarrativeqaDataset'),
|
| 35 |
+
],
|
| 36 |
+
]
|
| 37 |
+
eval = dict(runner=dict(task=dict(dump_details=True)))
|
| 38 |
+
models = [
|
| 39 |
+
dict(
|
| 40 |
+
abbr='mask_gdn-1.3B',
|
| 41 |
+
batch_padding=False,
|
| 42 |
+
batch_size=16,
|
| 43 |
+
max_out_len=100,
|
| 44 |
+
max_seq_len=16384,
|
| 45 |
+
path='/mnt/jfzn/msj/train_exp/mask_gdn_1B_hrr-rank4',
|
| 46 |
+
run_cfg=dict(num_gpus=1),
|
| 47 |
+
tokenizer_path='/mnt/jfzn/msj/train_exp/mask_gdn_1B_hrr-rank4',
|
| 48 |
+
type='opencompass.models.HuggingFaceCausalLM'),
|
| 49 |
+
]
|
| 50 |
+
work_dir = 'outputs/default/20251127_164548'
|
tmp/07f59276-08b3-4e03-ba78-cdcd5f4d49d1_params.py
ADDED
|
@@ -0,0 +1,1421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets = [
|
| 2 |
+
[
|
| 3 |
+
dict(
|
| 4 |
+
abbr='LongBench_2wikimqa_7',
|
| 5 |
+
eval_cfg=dict(
|
| 6 |
+
evaluator=dict(
|
| 7 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 8 |
+
pred_role='BOT'),
|
| 9 |
+
infer_cfg=dict(
|
| 10 |
+
inferencer=dict(
|
| 11 |
+
max_out_len=32,
|
| 12 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 13 |
+
prompt_template=dict(
|
| 14 |
+
template=dict(round=[
|
| 15 |
+
dict(
|
| 16 |
+
prompt=
|
| 17 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 18 |
+
role='HUMAN'),
|
| 19 |
+
]),
|
| 20 |
+
type=
|
| 21 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 22 |
+
retriever=dict(
|
| 23 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 24 |
+
name='2wikimqa',
|
| 25 |
+
path='opencompass/Longbench',
|
| 26 |
+
reader_cfg=dict(
|
| 27 |
+
input_columns=[
|
| 28 |
+
'context',
|
| 29 |
+
'input',
|
| 30 |
+
],
|
| 31 |
+
output_column='answers',
|
| 32 |
+
test_range='[175:200]',
|
| 33 |
+
test_split='test',
|
| 34 |
+
train_split='test'),
|
| 35 |
+
type='opencompass.datasets.LongBench2wikimqaDataset'),
|
| 36 |
+
dict(
|
| 37 |
+
abbr='LongBench_hotpotqa_7',
|
| 38 |
+
eval_cfg=dict(
|
| 39 |
+
evaluator=dict(
|
| 40 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 41 |
+
pred_role='BOT'),
|
| 42 |
+
infer_cfg=dict(
|
| 43 |
+
inferencer=dict(
|
| 44 |
+
max_out_len=32,
|
| 45 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 46 |
+
prompt_template=dict(
|
| 47 |
+
template=dict(round=[
|
| 48 |
+
dict(
|
| 49 |
+
prompt=
|
| 50 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 51 |
+
role='HUMAN'),
|
| 52 |
+
]),
|
| 53 |
+
type=
|
| 54 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 55 |
+
retriever=dict(
|
| 56 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 57 |
+
name='hotpotqa',
|
| 58 |
+
path='opencompass/Longbench',
|
| 59 |
+
reader_cfg=dict(
|
| 60 |
+
input_columns=[
|
| 61 |
+
'context',
|
| 62 |
+
'input',
|
| 63 |
+
],
|
| 64 |
+
output_column='answers',
|
| 65 |
+
test_range='[175:200]',
|
| 66 |
+
test_split='test',
|
| 67 |
+
train_split='test'),
|
| 68 |
+
type='opencompass.datasets.LongBenchhotpotqaDataset'),
|
| 69 |
+
dict(
|
| 70 |
+
abbr='LongBench_musique_7',
|
| 71 |
+
eval_cfg=dict(
|
| 72 |
+
evaluator=dict(
|
| 73 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 74 |
+
pred_role='BOT'),
|
| 75 |
+
infer_cfg=dict(
|
| 76 |
+
inferencer=dict(
|
| 77 |
+
max_out_len=32,
|
| 78 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 79 |
+
prompt_template=dict(
|
| 80 |
+
template=dict(round=[
|
| 81 |
+
dict(
|
| 82 |
+
prompt=
|
| 83 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 84 |
+
role='HUMAN'),
|
| 85 |
+
]),
|
| 86 |
+
type=
|
| 87 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 88 |
+
retriever=dict(
|
| 89 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 90 |
+
name='musique',
|
| 91 |
+
path='opencompass/Longbench',
|
| 92 |
+
reader_cfg=dict(
|
| 93 |
+
input_columns=[
|
| 94 |
+
'context',
|
| 95 |
+
'input',
|
| 96 |
+
],
|
| 97 |
+
output_column='answers',
|
| 98 |
+
test_range='[175:200]',
|
| 99 |
+
test_split='test',
|
| 100 |
+
train_split='test'),
|
| 101 |
+
type='opencompass.datasets.LongBenchmusiqueDataset'),
|
| 102 |
+
dict(
|
| 103 |
+
abbr='LongBench_multifieldqa_en_7',
|
| 104 |
+
eval_cfg=dict(
|
| 105 |
+
evaluator=dict(
|
| 106 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 107 |
+
pred_role='BOT'),
|
| 108 |
+
infer_cfg=dict(
|
| 109 |
+
inferencer=dict(
|
| 110 |
+
max_out_len=64,
|
| 111 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 112 |
+
prompt_template=dict(
|
| 113 |
+
template=dict(round=[
|
| 114 |
+
dict(
|
| 115 |
+
prompt=
|
| 116 |
+
'Read the following text and answer briefly.\n\n{context}\n\nNow, answer the following question based on the above text, only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 117 |
+
role='HUMAN'),
|
| 118 |
+
]),
|
| 119 |
+
type=
|
| 120 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 121 |
+
retriever=dict(
|
| 122 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 123 |
+
name='multifieldqa_en',
|
| 124 |
+
path='opencompass/Longbench',
|
| 125 |
+
reader_cfg=dict(
|
| 126 |
+
input_columns=[
|
| 127 |
+
'context',
|
| 128 |
+
'input',
|
| 129 |
+
],
|
| 130 |
+
output_column='answers',
|
| 131 |
+
test_range='[133:152]',
|
| 132 |
+
test_split='test',
|
| 133 |
+
train_split='test'),
|
| 134 |
+
type='opencompass.datasets.LongBenchmultifieldqa_enDataset'),
|
| 135 |
+
dict(
|
| 136 |
+
abbr='LongBench_multifieldqa_zh_7',
|
| 137 |
+
eval_cfg=dict(
|
| 138 |
+
evaluator=dict(
|
| 139 |
+
language='zh',
|
| 140 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 141 |
+
pred_role='BOT'),
|
| 142 |
+
infer_cfg=dict(
|
| 143 |
+
inferencer=dict(
|
| 144 |
+
max_out_len=64,
|
| 145 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 146 |
+
prompt_template=dict(
|
| 147 |
+
template=dict(round=[
|
| 148 |
+
dict(
|
| 149 |
+
prompt=
|
| 150 |
+
'阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:',
|
| 151 |
+
role='HUMAN'),
|
| 152 |
+
]),
|
| 153 |
+
type=
|
| 154 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 155 |
+
retriever=dict(
|
| 156 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 157 |
+
name='multifieldqa_zh',
|
| 158 |
+
path='opencompass/Longbench',
|
| 159 |
+
reader_cfg=dict(
|
| 160 |
+
input_columns=[
|
| 161 |
+
'context',
|
| 162 |
+
'input',
|
| 163 |
+
],
|
| 164 |
+
output_column='answers',
|
| 165 |
+
test_range='[175:200]',
|
| 166 |
+
test_split='test',
|
| 167 |
+
train_split='test'),
|
| 168 |
+
type='opencompass.datasets.LongBenchmultifieldqa_zhDataset'),
|
| 169 |
+
dict(
|
| 170 |
+
abbr='LongBench_narrativeqa_7',
|
| 171 |
+
eval_cfg=dict(
|
| 172 |
+
evaluator=dict(
|
| 173 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 174 |
+
pred_role='BOT'),
|
| 175 |
+
infer_cfg=dict(
|
| 176 |
+
inferencer=dict(
|
| 177 |
+
max_out_len=128,
|
| 178 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 179 |
+
prompt_template=dict(
|
| 180 |
+
template=dict(round=[
|
| 181 |
+
dict(
|
| 182 |
+
prompt=
|
| 183 |
+
'You are given a story, which can be either a novel or a movie script, and a question. Answer the question as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nStory: {context}\n\nNow, answer the question based on the story as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nQuestion: {input}\n\nAnswer:',
|
| 184 |
+
role='HUMAN'),
|
| 185 |
+
]),
|
| 186 |
+
type=
|
| 187 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 188 |
+
retriever=dict(
|
| 189 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 190 |
+
name='narrativeqa',
|
| 191 |
+
path='opencompass/Longbench',
|
| 192 |
+
reader_cfg=dict(
|
| 193 |
+
input_columns=[
|
| 194 |
+
'context',
|
| 195 |
+
'input',
|
| 196 |
+
],
|
| 197 |
+
output_column='answers',
|
| 198 |
+
test_range='[175:200]',
|
| 199 |
+
test_split='test',
|
| 200 |
+
train_split='test'),
|
| 201 |
+
type='opencompass.datasets.LongBenchnarrativeqaDataset'),
|
| 202 |
+
dict(
|
| 203 |
+
abbr='LongBench_qasper_7',
|
| 204 |
+
eval_cfg=dict(
|
| 205 |
+
evaluator=dict(
|
| 206 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 207 |
+
pred_role='BOT'),
|
| 208 |
+
infer_cfg=dict(
|
| 209 |
+
inferencer=dict(
|
| 210 |
+
max_out_len=32,
|
| 211 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 212 |
+
prompt_template=dict(
|
| 213 |
+
template=dict(round=[
|
| 214 |
+
dict(
|
| 215 |
+
prompt=
|
| 216 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 217 |
+
role='HUMAN'),
|
| 218 |
+
]),
|
| 219 |
+
type=
|
| 220 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 221 |
+
retriever=dict(
|
| 222 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 223 |
+
name='qasper',
|
| 224 |
+
path='opencompass/Longbench',
|
| 225 |
+
reader_cfg=dict(
|
| 226 |
+
input_columns=[
|
| 227 |
+
'context',
|
| 228 |
+
'input',
|
| 229 |
+
],
|
| 230 |
+
output_column='answers',
|
| 231 |
+
test_range='[175:200]',
|
| 232 |
+
test_split='test',
|
| 233 |
+
train_split='test'),
|
| 234 |
+
type='opencompass.datasets.LongBenchqasperDataset'),
|
| 235 |
+
dict(
|
| 236 |
+
abbr='LongBench_triviaqa_7',
|
| 237 |
+
eval_cfg=dict(
|
| 238 |
+
evaluator=dict(
|
| 239 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 240 |
+
pred_postprocessor=dict(
|
| 241 |
+
type='opencompass.datasets.triviaqa_postprocess'),
|
| 242 |
+
pred_role='BOT'),
|
| 243 |
+
infer_cfg=dict(
|
| 244 |
+
inferencer=dict(
|
| 245 |
+
max_out_len=32,
|
| 246 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 247 |
+
prompt_template=dict(
|
| 248 |
+
template=dict(round=[
|
| 249 |
+
dict(
|
| 250 |
+
prompt=
|
| 251 |
+
'Answer the question based on the given passage. Only give me the answer and do not output any other words. The following are some examples.\n\n{context}\n\n{input}',
|
| 252 |
+
role='HUMAN'),
|
| 253 |
+
]),
|
| 254 |
+
type=
|
| 255 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 256 |
+
retriever=dict(
|
| 257 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 258 |
+
name='triviaqa',
|
| 259 |
+
path='opencompass/Longbench',
|
| 260 |
+
reader_cfg=dict(
|
| 261 |
+
input_columns=[
|
| 262 |
+
'context',
|
| 263 |
+
'input',
|
| 264 |
+
],
|
| 265 |
+
output_column='answers',
|
| 266 |
+
test_range='[175:200]',
|
| 267 |
+
test_split='test',
|
| 268 |
+
train_split='test'),
|
| 269 |
+
type='opencompass.datasets.LongBenchtriviaqaDataset'),
|
| 270 |
+
dict(
|
| 271 |
+
abbr='LongBench_gov_report_7',
|
| 272 |
+
eval_cfg=dict(
|
| 273 |
+
evaluator=dict(
|
| 274 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 275 |
+
pred_role='BOT'),
|
| 276 |
+
infer_cfg=dict(
|
| 277 |
+
inferencer=dict(
|
| 278 |
+
max_out_len=512,
|
| 279 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 280 |
+
prompt_template=dict(
|
| 281 |
+
template=dict(round=[
|
| 282 |
+
dict(
|
| 283 |
+
prompt=
|
| 284 |
+
'You are given a report by a government agency. Write a one-page summary of the report.\n\nReport:\n{context}\n\nNow, write a one-page summary of the report.\n\nSummary:',
|
| 285 |
+
role='HUMAN'),
|
| 286 |
+
]),
|
| 287 |
+
type=
|
| 288 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 289 |
+
retriever=dict(
|
| 290 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 291 |
+
name='gov_report',
|
| 292 |
+
path='opencompass/Longbench',
|
| 293 |
+
reader_cfg=dict(
|
| 294 |
+
input_columns=[
|
| 295 |
+
'context',
|
| 296 |
+
],
|
| 297 |
+
output_column='answers',
|
| 298 |
+
test_range='[175:200]',
|
| 299 |
+
test_split='test',
|
| 300 |
+
train_split='test'),
|
| 301 |
+
type='opencompass.datasets.LongBenchgov_reportDataset'),
|
| 302 |
+
dict(
|
| 303 |
+
abbr='LongBench_qmsum_7',
|
| 304 |
+
eval_cfg=dict(
|
| 305 |
+
evaluator=dict(
|
| 306 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 307 |
+
pred_role='BOT'),
|
| 308 |
+
infer_cfg=dict(
|
| 309 |
+
inferencer=dict(
|
| 310 |
+
max_out_len=512,
|
| 311 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 312 |
+
prompt_template=dict(
|
| 313 |
+
template=dict(round=[
|
| 314 |
+
dict(
|
| 315 |
+
prompt=
|
| 316 |
+
'You are given a meeting transcript and a query containing a question or instruction. Answer the query in one or more sentences.\n\nTranscript:\n{context}\n\nNow, answer the query based on the above meeting transcript in one or more sentences.\n\nQuery: {input}\nAnswer:',
|
| 317 |
+
role='HUMAN'),
|
| 318 |
+
]),
|
| 319 |
+
type=
|
| 320 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 321 |
+
retriever=dict(
|
| 322 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 323 |
+
name='qmsum',
|
| 324 |
+
path='opencompass/Longbench',
|
| 325 |
+
reader_cfg=dict(
|
| 326 |
+
input_columns=[
|
| 327 |
+
'context',
|
| 328 |
+
'input',
|
| 329 |
+
],
|
| 330 |
+
output_column='answers',
|
| 331 |
+
test_range='[175:200]',
|
| 332 |
+
test_split='test',
|
| 333 |
+
train_split='test'),
|
| 334 |
+
type='opencompass.datasets.LongBenchqmsumDataset'),
|
| 335 |
+
dict(
|
| 336 |
+
abbr='LongBench_vcsum_7',
|
| 337 |
+
eval_cfg=dict(
|
| 338 |
+
evaluator=dict(
|
| 339 |
+
language='zh',
|
| 340 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 341 |
+
pred_role='BOT'),
|
| 342 |
+
infer_cfg=dict(
|
| 343 |
+
inferencer=dict(
|
| 344 |
+
max_out_len=512,
|
| 345 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 346 |
+
prompt_template=dict(
|
| 347 |
+
template=dict(round=[
|
| 348 |
+
dict(
|
| 349 |
+
prompt=
|
| 350 |
+
'下面有一段会议记录,请你阅读后,写一段总结,总结会议的内容。\n会议记录:\n{context}\n\n会议总结:',
|
| 351 |
+
role='HUMAN'),
|
| 352 |
+
]),
|
| 353 |
+
type=
|
| 354 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 355 |
+
retriever=dict(
|
| 356 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 357 |
+
name='vcsum',
|
| 358 |
+
path='opencompass/Longbench',
|
| 359 |
+
reader_cfg=dict(
|
| 360 |
+
input_columns=[
|
| 361 |
+
'context',
|
| 362 |
+
],
|
| 363 |
+
output_column='answers',
|
| 364 |
+
test_range='[175:200]',
|
| 365 |
+
test_split='test',
|
| 366 |
+
train_split='test'),
|
| 367 |
+
type='opencompass.datasets.LongBenchvcsumDataset'),
|
| 368 |
+
dict(
|
| 369 |
+
abbr='LongBench_dureader_7',
|
| 370 |
+
eval_cfg=dict(
|
| 371 |
+
evaluator=dict(
|
| 372 |
+
language='zh',
|
| 373 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 374 |
+
pred_role='BOT'),
|
| 375 |
+
infer_cfg=dict(
|
| 376 |
+
inferencer=dict(
|
| 377 |
+
max_out_len=128,
|
| 378 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 379 |
+
prompt_template=dict(
|
| 380 |
+
template=dict(round=[
|
| 381 |
+
dict(
|
| 382 |
+
prompt=
|
| 383 |
+
'请基于给定的文章回答下述问题。\n\n文章:{context}\n\n请基于上述文章回答下面的问题。\n\n问题:{input}\n回答:',
|
| 384 |
+
role='HUMAN'),
|
| 385 |
+
]),
|
| 386 |
+
type=
|
| 387 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 388 |
+
retriever=dict(
|
| 389 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 390 |
+
name='dureader',
|
| 391 |
+
path='opencompass/Longbench',
|
| 392 |
+
reader_cfg=dict(
|
| 393 |
+
input_columns=[
|
| 394 |
+
'context',
|
| 395 |
+
'input',
|
| 396 |
+
],
|
| 397 |
+
output_column='answers',
|
| 398 |
+
test_range='[175:200]',
|
| 399 |
+
test_split='test',
|
| 400 |
+
train_split='test'),
|
| 401 |
+
type='opencompass.datasets.LongBenchdureaderDataset'),
|
| 402 |
+
dict(
|
| 403 |
+
abbr='LongBench_lcc_7',
|
| 404 |
+
eval_cfg=dict(
|
| 405 |
+
evaluator=dict(
|
| 406 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 407 |
+
pred_role='BOT'),
|
| 408 |
+
infer_cfg=dict(
|
| 409 |
+
inferencer=dict(
|
| 410 |
+
max_out_len=64,
|
| 411 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 412 |
+
prompt_template=dict(
|
| 413 |
+
template=dict(round=[
|
| 414 |
+
dict(
|
| 415 |
+
prompt=
|
| 416 |
+
'Please complete the code given below. \n{context}Next line of code:\n',
|
| 417 |
+
role='HUMAN'),
|
| 418 |
+
]),
|
| 419 |
+
type=
|
| 420 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 421 |
+
retriever=dict(
|
| 422 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 423 |
+
name='lcc',
|
| 424 |
+
path='opencompass/Longbench',
|
| 425 |
+
reader_cfg=dict(
|
| 426 |
+
input_columns=[
|
| 427 |
+
'context',
|
| 428 |
+
],
|
| 429 |
+
output_column='answers',
|
| 430 |
+
test_range='[441:504]',
|
| 431 |
+
test_split='test',
|
| 432 |
+
train_split='test'),
|
| 433 |
+
type='opencompass.datasets.LongBenchlccDataset'),
|
| 434 |
+
dict(
|
| 435 |
+
abbr='LongBench_repobench-p_7',
|
| 436 |
+
eval_cfg=dict(
|
| 437 |
+
evaluator=dict(
|
| 438 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 439 |
+
pred_role='BOT'),
|
| 440 |
+
infer_cfg=dict(
|
| 441 |
+
inferencer=dict(
|
| 442 |
+
max_out_len=64,
|
| 443 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 444 |
+
prompt_template=dict(
|
| 445 |
+
template=dict(round=[
|
| 446 |
+
dict(
|
| 447 |
+
prompt=
|
| 448 |
+
'Please complete the code given below. \n{context}{input}Next line of code:\n',
|
| 449 |
+
role='HUMAN'),
|
| 450 |
+
]),
|
| 451 |
+
type=
|
| 452 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 453 |
+
retriever=dict(
|
| 454 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 455 |
+
name='repobench-p',
|
| 456 |
+
path='opencompass/Longbench',
|
| 457 |
+
reader_cfg=dict(
|
| 458 |
+
input_columns=[
|
| 459 |
+
'context',
|
| 460 |
+
'input',
|
| 461 |
+
],
|
| 462 |
+
output_column='answers',
|
| 463 |
+
test_range='[441:504]',
|
| 464 |
+
test_split='test',
|
| 465 |
+
train_split='test'),
|
| 466 |
+
type='opencompass.datasets.LongBenchrepobenchDataset'),
|
| 467 |
+
dict(
|
| 468 |
+
abbr='LongBench_passage_retrieval_en_7',
|
| 469 |
+
eval_cfg=dict(
|
| 470 |
+
evaluator=dict(
|
| 471 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 472 |
+
pred_role='BOT'),
|
| 473 |
+
infer_cfg=dict(
|
| 474 |
+
inferencer=dict(
|
| 475 |
+
max_out_len=32,
|
| 476 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 477 |
+
prompt_template=dict(
|
| 478 |
+
template=dict(round=[
|
| 479 |
+
dict(
|
| 480 |
+
prompt=
|
| 481 |
+
'Here are 30 paragraphs from Wikipedia, along with an abstract. Please determine which paragraph the abstract is from.\n\n{context}\n\nThe following is an abstract.\n\n{input}\n\nPlease enter the number of the paragraph that the abstract is from. The answer format must be like "Paragraph 1", "Paragraph 2", etc.\n\nThe answer is: ',
|
| 482 |
+
role='HUMAN'),
|
| 483 |
+
]),
|
| 484 |
+
type=
|
| 485 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 486 |
+
retriever=dict(
|
| 487 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 488 |
+
name='passage_retrieval_en',
|
| 489 |
+
path='opencompass/Longbench',
|
| 490 |
+
reader_cfg=dict(
|
| 491 |
+
input_columns=[
|
| 492 |
+
'context',
|
| 493 |
+
'input',
|
| 494 |
+
],
|
| 495 |
+
output_column='answers',
|
| 496 |
+
test_range='[175:200]',
|
| 497 |
+
test_split='test',
|
| 498 |
+
train_split='test'),
|
| 499 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_enDataset'),
|
| 500 |
+
dict(
|
| 501 |
+
abbr='LongBench_passage_retrieval_zh_7',
|
| 502 |
+
eval_cfg=dict(
|
| 503 |
+
evaluator=dict(
|
| 504 |
+
language='zh',
|
| 505 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 506 |
+
pred_role='BOT'),
|
| 507 |
+
infer_cfg=dict(
|
| 508 |
+
inferencer=dict(
|
| 509 |
+
max_out_len=32,
|
| 510 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 511 |
+
prompt_template=dict(
|
| 512 |
+
template=dict(round=[
|
| 513 |
+
dict(
|
| 514 |
+
prompt=
|
| 515 |
+
'以下是若干段落文字,以及其中一个段落的摘要。请确定给定的摘要出自哪一段。\n\n{context}\n\n下面是一个摘要\n\n{input}\n\n请输入摘要所属段落的编号。答案格式必须是"段落1","段落2"等格式\n\n答案是:',
|
| 516 |
+
role='HUMAN'),
|
| 517 |
+
]),
|
| 518 |
+
type=
|
| 519 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 520 |
+
retriever=dict(
|
| 521 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 522 |
+
name='passage_retrieval_zh',
|
| 523 |
+
path='opencompass/Longbench',
|
| 524 |
+
reader_cfg=dict(
|
| 525 |
+
input_columns=[
|
| 526 |
+
'context',
|
| 527 |
+
'input',
|
| 528 |
+
],
|
| 529 |
+
output_column='answers',
|
| 530 |
+
test_range='[175:200]',
|
| 531 |
+
test_split='test',
|
| 532 |
+
train_split='test'),
|
| 533 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_zhDataset'),
|
| 534 |
+
dict(
|
| 535 |
+
abbr='LongBench_passage_count_7',
|
| 536 |
+
eval_cfg=dict(
|
| 537 |
+
evaluator=dict(
|
| 538 |
+
type='opencompass.datasets.LongBenchCountEvaluator'),
|
| 539 |
+
pred_role='BOT'),
|
| 540 |
+
infer_cfg=dict(
|
| 541 |
+
inferencer=dict(
|
| 542 |
+
max_out_len=32,
|
| 543 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 544 |
+
prompt_template=dict(
|
| 545 |
+
template=dict(round=[
|
| 546 |
+
dict(
|
| 547 |
+
prompt=
|
| 548 |
+
'There are some paragraphs below sourced from Wikipedia. Some of them may be duplicates. Please carefully read these paragraphs and determine how many unique paragraphs there are after removing duplicates. In other words, how many non-repeating paragraphs are there in total?\n\n{context}\n\nPlease enter the final count of unique paragraphs after removing duplicates. The output format should only contain the number, such as 1, 2, 3, and so on.\n\nThe final answer is: ',
|
| 549 |
+
role='HUMAN'),
|
| 550 |
+
]),
|
| 551 |
+
type=
|
| 552 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 553 |
+
retriever=dict(
|
| 554 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 555 |
+
name='passage_count',
|
| 556 |
+
path='opencompass/Longbench',
|
| 557 |
+
reader_cfg=dict(
|
| 558 |
+
input_columns=[
|
| 559 |
+
'context',
|
| 560 |
+
'input',
|
| 561 |
+
],
|
| 562 |
+
output_column='answers',
|
| 563 |
+
test_range='[175:200]',
|
| 564 |
+
test_split='test',
|
| 565 |
+
train_split='test'),
|
| 566 |
+
type='opencompass.datasets.LongBenchpassage_countDataset'),
|
| 567 |
+
dict(
|
| 568 |
+
abbr='LongBench_trec_7',
|
| 569 |
+
eval_cfg=dict(
|
| 570 |
+
evaluator=dict(
|
| 571 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 572 |
+
),
|
| 573 |
+
pred_postprocessor=dict(
|
| 574 |
+
type='opencompass.datasets.trec_postprocess'),
|
| 575 |
+
pred_role='BOT'),
|
| 576 |
+
infer_cfg=dict(
|
| 577 |
+
inferencer=dict(
|
| 578 |
+
max_out_len=64,
|
| 579 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 580 |
+
prompt_template=dict(
|
| 581 |
+
template=dict(round=[
|
| 582 |
+
dict(
|
| 583 |
+
prompt=
|
| 584 |
+
'Please determine the type of the question below. Here are some examples of questions.\n\n{context}\n{input}',
|
| 585 |
+
role='HUMAN'),
|
| 586 |
+
]),
|
| 587 |
+
type=
|
| 588 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 589 |
+
retriever=dict(
|
| 590 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 591 |
+
name='trec',
|
| 592 |
+
path='opencompass/Longbench',
|
| 593 |
+
reader_cfg=dict(
|
| 594 |
+
input_columns=[
|
| 595 |
+
'context',
|
| 596 |
+
'input',
|
| 597 |
+
],
|
| 598 |
+
output_column='all_labels',
|
| 599 |
+
test_range='[175:200]',
|
| 600 |
+
test_split='test',
|
| 601 |
+
train_split='test'),
|
| 602 |
+
type='opencompass.datasets.LongBenchtrecDataset'),
|
| 603 |
+
dict(
|
| 604 |
+
abbr='LongBench_lsht_7',
|
| 605 |
+
eval_cfg=dict(
|
| 606 |
+
evaluator=dict(
|
| 607 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 608 |
+
),
|
| 609 |
+
pred_postprocessor=dict(
|
| 610 |
+
type='opencompass.datasets.lsht_postprocess'),
|
| 611 |
+
pred_role='BOT'),
|
| 612 |
+
infer_cfg=dict(
|
| 613 |
+
inferencer=dict(
|
| 614 |
+
max_out_len=64,
|
| 615 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 616 |
+
prompt_template=dict(
|
| 617 |
+
template=dict(round=[
|
| 618 |
+
dict(
|
| 619 |
+
prompt='请判断给定新闻的类别,下面是一些例子。\n\n{context}\n{input}',
|
| 620 |
+
role='HUMAN'),
|
| 621 |
+
]),
|
| 622 |
+
type=
|
| 623 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 624 |
+
retriever=dict(
|
| 625 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 626 |
+
name='lsht',
|
| 627 |
+
path='opencompass/Longbench',
|
| 628 |
+
reader_cfg=dict(
|
| 629 |
+
input_columns=[
|
| 630 |
+
'context',
|
| 631 |
+
'input',
|
| 632 |
+
],
|
| 633 |
+
output_column='all_labels',
|
| 634 |
+
test_range='[175:200]',
|
| 635 |
+
test_split='test',
|
| 636 |
+
train_split='test'),
|
| 637 |
+
type='opencompass.datasets.LongBenchlshtDataset'),
|
| 638 |
+
dict(
|
| 639 |
+
abbr='LongBench_multi_news_7',
|
| 640 |
+
eval_cfg=dict(
|
| 641 |
+
evaluator=dict(
|
| 642 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 643 |
+
pred_role='BOT'),
|
| 644 |
+
infer_cfg=dict(
|
| 645 |
+
inferencer=dict(
|
| 646 |
+
max_out_len=512,
|
| 647 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 648 |
+
prompt_template=dict(
|
| 649 |
+
template=dict(round=[
|
| 650 |
+
dict(
|
| 651 |
+
prompt=
|
| 652 |
+
'You are given several news passages. Write a one-page summary of all news. \n\nNews:\n{context}\n\nNow, write a one-page summary of all the news.\n\nSummary:\n',
|
| 653 |
+
role='HUMAN'),
|
| 654 |
+
]),
|
| 655 |
+
type=
|
| 656 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 657 |
+
retriever=dict(
|
| 658 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 659 |
+
name='multi_news',
|
| 660 |
+
path='opencompass/Longbench',
|
| 661 |
+
reader_cfg=dict(
|
| 662 |
+
input_columns=[
|
| 663 |
+
'context',
|
| 664 |
+
],
|
| 665 |
+
output_column='answers',
|
| 666 |
+
test_range='[175:200]',
|
| 667 |
+
test_split='test',
|
| 668 |
+
train_split='test'),
|
| 669 |
+
type='opencompass.datasets.LongBenchmulti_newsDataset'),
|
| 670 |
+
dict(
|
| 671 |
+
abbr='LongBench_samsum_7',
|
| 672 |
+
eval_cfg=dict(
|
| 673 |
+
evaluator=dict(
|
| 674 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 675 |
+
pred_postprocessor=dict(
|
| 676 |
+
type='opencompass.datasets.samsum_postprocess'),
|
| 677 |
+
pred_role='BOT'),
|
| 678 |
+
infer_cfg=dict(
|
| 679 |
+
inferencer=dict(
|
| 680 |
+
max_out_len=128,
|
| 681 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 682 |
+
prompt_template=dict(
|
| 683 |
+
template=dict(round=[
|
| 684 |
+
dict(
|
| 685 |
+
prompt=
|
| 686 |
+
'Summarize the dialogue into a few short sentences. The following are some examples.\n\n{context}\n\n{input}',
|
| 687 |
+
role='HUMAN'),
|
| 688 |
+
]),
|
| 689 |
+
type=
|
| 690 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 691 |
+
retriever=dict(
|
| 692 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 693 |
+
name='samsum',
|
| 694 |
+
path='opencompass/Longbench',
|
| 695 |
+
reader_cfg=dict(
|
| 696 |
+
input_columns=[
|
| 697 |
+
'context',
|
| 698 |
+
'input',
|
| 699 |
+
],
|
| 700 |
+
output_column='answers',
|
| 701 |
+
test_range='[175:200]',
|
| 702 |
+
test_split='test',
|
| 703 |
+
train_split='test'),
|
| 704 |
+
type='opencompass.datasets.LongBenchsamsumDataset'),
|
| 705 |
+
dict(
|
| 706 |
+
abbr='LongBench_2wikimqa_7',
|
| 707 |
+
eval_cfg=dict(
|
| 708 |
+
evaluator=dict(
|
| 709 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 710 |
+
pred_role='BOT'),
|
| 711 |
+
infer_cfg=dict(
|
| 712 |
+
inferencer=dict(
|
| 713 |
+
max_out_len=32,
|
| 714 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 715 |
+
prompt_template=dict(
|
| 716 |
+
template=dict(round=[
|
| 717 |
+
dict(
|
| 718 |
+
prompt=
|
| 719 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 720 |
+
role='HUMAN'),
|
| 721 |
+
]),
|
| 722 |
+
type=
|
| 723 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 724 |
+
retriever=dict(
|
| 725 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 726 |
+
name='2wikimqa',
|
| 727 |
+
path='opencompass/Longbench',
|
| 728 |
+
reader_cfg=dict(
|
| 729 |
+
input_columns=[
|
| 730 |
+
'context',
|
| 731 |
+
'input',
|
| 732 |
+
],
|
| 733 |
+
output_column='answers',
|
| 734 |
+
test_range='[175:200]',
|
| 735 |
+
test_split='test',
|
| 736 |
+
train_split='test'),
|
| 737 |
+
type='opencompass.datasets.LongBench2wikimqaDataset'),
|
| 738 |
+
dict(
|
| 739 |
+
abbr='LongBench_hotpotqa_7',
|
| 740 |
+
eval_cfg=dict(
|
| 741 |
+
evaluator=dict(
|
| 742 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 743 |
+
pred_role='BOT'),
|
| 744 |
+
infer_cfg=dict(
|
| 745 |
+
inferencer=dict(
|
| 746 |
+
max_out_len=32,
|
| 747 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 748 |
+
prompt_template=dict(
|
| 749 |
+
template=dict(round=[
|
| 750 |
+
dict(
|
| 751 |
+
prompt=
|
| 752 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 753 |
+
role='HUMAN'),
|
| 754 |
+
]),
|
| 755 |
+
type=
|
| 756 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 757 |
+
retriever=dict(
|
| 758 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 759 |
+
name='hotpotqa',
|
| 760 |
+
path='opencompass/Longbench',
|
| 761 |
+
reader_cfg=dict(
|
| 762 |
+
input_columns=[
|
| 763 |
+
'context',
|
| 764 |
+
'input',
|
| 765 |
+
],
|
| 766 |
+
output_column='answers',
|
| 767 |
+
test_range='[175:200]',
|
| 768 |
+
test_split='test',
|
| 769 |
+
train_split='test'),
|
| 770 |
+
type='opencompass.datasets.LongBenchhotpotqaDataset'),
|
| 771 |
+
dict(
|
| 772 |
+
abbr='LongBench_musique_7',
|
| 773 |
+
eval_cfg=dict(
|
| 774 |
+
evaluator=dict(
|
| 775 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 776 |
+
pred_role='BOT'),
|
| 777 |
+
infer_cfg=dict(
|
| 778 |
+
inferencer=dict(
|
| 779 |
+
max_out_len=32,
|
| 780 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 781 |
+
prompt_template=dict(
|
| 782 |
+
template=dict(round=[
|
| 783 |
+
dict(
|
| 784 |
+
prompt=
|
| 785 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 786 |
+
role='HUMAN'),
|
| 787 |
+
]),
|
| 788 |
+
type=
|
| 789 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 790 |
+
retriever=dict(
|
| 791 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 792 |
+
name='musique',
|
| 793 |
+
path='opencompass/Longbench',
|
| 794 |
+
reader_cfg=dict(
|
| 795 |
+
input_columns=[
|
| 796 |
+
'context',
|
| 797 |
+
'input',
|
| 798 |
+
],
|
| 799 |
+
output_column='answers',
|
| 800 |
+
test_range='[175:200]',
|
| 801 |
+
test_split='test',
|
| 802 |
+
train_split='test'),
|
| 803 |
+
type='opencompass.datasets.LongBenchmusiqueDataset'),
|
| 804 |
+
dict(
|
| 805 |
+
abbr='LongBench_multifieldqa_en_7',
|
| 806 |
+
eval_cfg=dict(
|
| 807 |
+
evaluator=dict(
|
| 808 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 809 |
+
pred_role='BOT'),
|
| 810 |
+
infer_cfg=dict(
|
| 811 |
+
inferencer=dict(
|
| 812 |
+
max_out_len=64,
|
| 813 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 814 |
+
prompt_template=dict(
|
| 815 |
+
template=dict(round=[
|
| 816 |
+
dict(
|
| 817 |
+
prompt=
|
| 818 |
+
'Read the following text and answer briefly.\n\n{context}\n\nNow, answer the following question based on the above text, only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 819 |
+
role='HUMAN'),
|
| 820 |
+
]),
|
| 821 |
+
type=
|
| 822 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 823 |
+
retriever=dict(
|
| 824 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 825 |
+
name='multifieldqa_en',
|
| 826 |
+
path='opencompass/Longbench',
|
| 827 |
+
reader_cfg=dict(
|
| 828 |
+
input_columns=[
|
| 829 |
+
'context',
|
| 830 |
+
'input',
|
| 831 |
+
],
|
| 832 |
+
output_column='answers',
|
| 833 |
+
test_range='[133:152]',
|
| 834 |
+
test_split='test',
|
| 835 |
+
train_split='test'),
|
| 836 |
+
type='opencompass.datasets.LongBenchmultifieldqa_enDataset'),
|
| 837 |
+
dict(
|
| 838 |
+
abbr='LongBench_multifieldqa_zh_7',
|
| 839 |
+
eval_cfg=dict(
|
| 840 |
+
evaluator=dict(
|
| 841 |
+
language='zh',
|
| 842 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 843 |
+
pred_role='BOT'),
|
| 844 |
+
infer_cfg=dict(
|
| 845 |
+
inferencer=dict(
|
| 846 |
+
max_out_len=64,
|
| 847 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 848 |
+
prompt_template=dict(
|
| 849 |
+
template=dict(round=[
|
| 850 |
+
dict(
|
| 851 |
+
prompt=
|
| 852 |
+
'阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:',
|
| 853 |
+
role='HUMAN'),
|
| 854 |
+
]),
|
| 855 |
+
type=
|
| 856 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 857 |
+
retriever=dict(
|
| 858 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 859 |
+
name='multifieldqa_zh',
|
| 860 |
+
path='opencompass/Longbench',
|
| 861 |
+
reader_cfg=dict(
|
| 862 |
+
input_columns=[
|
| 863 |
+
'context',
|
| 864 |
+
'input',
|
| 865 |
+
],
|
| 866 |
+
output_column='answers',
|
| 867 |
+
test_range='[175:200]',
|
| 868 |
+
test_split='test',
|
| 869 |
+
train_split='test'),
|
| 870 |
+
type='opencompass.datasets.LongBenchmultifieldqa_zhDataset'),
|
| 871 |
+
dict(
|
| 872 |
+
abbr='LongBench_narrativeqa_7',
|
| 873 |
+
eval_cfg=dict(
|
| 874 |
+
evaluator=dict(
|
| 875 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 876 |
+
pred_role='BOT'),
|
| 877 |
+
infer_cfg=dict(
|
| 878 |
+
inferencer=dict(
|
| 879 |
+
max_out_len=128,
|
| 880 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 881 |
+
prompt_template=dict(
|
| 882 |
+
template=dict(round=[
|
| 883 |
+
dict(
|
| 884 |
+
prompt=
|
| 885 |
+
'You are given a story, which can be either a novel or a movie script, and a question. Answer the question as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nStory: {context}\n\nNow, answer the question based on the story as concisely as you can, using a single phrase if possible. Do not provide any explanation.\n\nQuestion: {input}\n\nAnswer:',
|
| 886 |
+
role='HUMAN'),
|
| 887 |
+
]),
|
| 888 |
+
type=
|
| 889 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 890 |
+
retriever=dict(
|
| 891 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 892 |
+
name='narrativeqa',
|
| 893 |
+
path='opencompass/Longbench',
|
| 894 |
+
reader_cfg=dict(
|
| 895 |
+
input_columns=[
|
| 896 |
+
'context',
|
| 897 |
+
'input',
|
| 898 |
+
],
|
| 899 |
+
output_column='answers',
|
| 900 |
+
test_range='[175:200]',
|
| 901 |
+
test_split='test',
|
| 902 |
+
train_split='test'),
|
| 903 |
+
type='opencompass.datasets.LongBenchnarrativeqaDataset'),
|
| 904 |
+
dict(
|
| 905 |
+
abbr='LongBench_qasper_7',
|
| 906 |
+
eval_cfg=dict(
|
| 907 |
+
evaluator=dict(
|
| 908 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 909 |
+
pred_role='BOT'),
|
| 910 |
+
infer_cfg=dict(
|
| 911 |
+
inferencer=dict(
|
| 912 |
+
max_out_len=32,
|
| 913 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 914 |
+
prompt_template=dict(
|
| 915 |
+
template=dict(round=[
|
| 916 |
+
dict(
|
| 917 |
+
prompt=
|
| 918 |
+
'Answer the question based on the given passages. Only give me the answer and do not output any other words.\n\nThe following are given passages.\n{context}\n\nAnswer the question based on the given passages. Only give me the answer and do not output any other words.\n\nQuestion: {input}\nAnswer:',
|
| 919 |
+
role='HUMAN'),
|
| 920 |
+
]),
|
| 921 |
+
type=
|
| 922 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 923 |
+
retriever=dict(
|
| 924 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 925 |
+
name='qasper',
|
| 926 |
+
path='opencompass/Longbench',
|
| 927 |
+
reader_cfg=dict(
|
| 928 |
+
input_columns=[
|
| 929 |
+
'context',
|
| 930 |
+
'input',
|
| 931 |
+
],
|
| 932 |
+
output_column='answers',
|
| 933 |
+
test_range='[175:200]',
|
| 934 |
+
test_split='test',
|
| 935 |
+
train_split='test'),
|
| 936 |
+
type='opencompass.datasets.LongBenchqasperDataset'),
|
| 937 |
+
dict(
|
| 938 |
+
abbr='LongBench_triviaqa_7',
|
| 939 |
+
eval_cfg=dict(
|
| 940 |
+
evaluator=dict(
|
| 941 |
+
type='opencompass.datasets.LongBenchF1Evaluator'),
|
| 942 |
+
pred_postprocessor=dict(
|
| 943 |
+
type='opencompass.datasets.triviaqa_postprocess'),
|
| 944 |
+
pred_role='BOT'),
|
| 945 |
+
infer_cfg=dict(
|
| 946 |
+
inferencer=dict(
|
| 947 |
+
max_out_len=32,
|
| 948 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 949 |
+
prompt_template=dict(
|
| 950 |
+
template=dict(round=[
|
| 951 |
+
dict(
|
| 952 |
+
prompt=
|
| 953 |
+
'Answer the question based on the given passage. Only give me the answer and do not output any other words. The following are some examples.\n\n{context}\n\n{input}',
|
| 954 |
+
role='HUMAN'),
|
| 955 |
+
]),
|
| 956 |
+
type=
|
| 957 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 958 |
+
retriever=dict(
|
| 959 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 960 |
+
name='triviaqa',
|
| 961 |
+
path='opencompass/Longbench',
|
| 962 |
+
reader_cfg=dict(
|
| 963 |
+
input_columns=[
|
| 964 |
+
'context',
|
| 965 |
+
'input',
|
| 966 |
+
],
|
| 967 |
+
output_column='answers',
|
| 968 |
+
test_range='[175:200]',
|
| 969 |
+
test_split='test',
|
| 970 |
+
train_split='test'),
|
| 971 |
+
type='opencompass.datasets.LongBenchtriviaqaDataset'),
|
| 972 |
+
dict(
|
| 973 |
+
abbr='LongBench_gov_report_7',
|
| 974 |
+
eval_cfg=dict(
|
| 975 |
+
evaluator=dict(
|
| 976 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 977 |
+
pred_role='BOT'),
|
| 978 |
+
infer_cfg=dict(
|
| 979 |
+
inferencer=dict(
|
| 980 |
+
max_out_len=512,
|
| 981 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 982 |
+
prompt_template=dict(
|
| 983 |
+
template=dict(round=[
|
| 984 |
+
dict(
|
| 985 |
+
prompt=
|
| 986 |
+
'You are given a report by a government agency. Write a one-page summary of the report.\n\nReport:\n{context}\n\nNow, write a one-page summary of the report.\n\nSummary:',
|
| 987 |
+
role='HUMAN'),
|
| 988 |
+
]),
|
| 989 |
+
type=
|
| 990 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 991 |
+
retriever=dict(
|
| 992 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 993 |
+
name='gov_report',
|
| 994 |
+
path='opencompass/Longbench',
|
| 995 |
+
reader_cfg=dict(
|
| 996 |
+
input_columns=[
|
| 997 |
+
'context',
|
| 998 |
+
],
|
| 999 |
+
output_column='answers',
|
| 1000 |
+
test_range='[175:200]',
|
| 1001 |
+
test_split='test',
|
| 1002 |
+
train_split='test'),
|
| 1003 |
+
type='opencompass.datasets.LongBenchgov_reportDataset'),
|
| 1004 |
+
dict(
|
| 1005 |
+
abbr='LongBench_qmsum_7',
|
| 1006 |
+
eval_cfg=dict(
|
| 1007 |
+
evaluator=dict(
|
| 1008 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1009 |
+
pred_role='BOT'),
|
| 1010 |
+
infer_cfg=dict(
|
| 1011 |
+
inferencer=dict(
|
| 1012 |
+
max_out_len=512,
|
| 1013 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1014 |
+
prompt_template=dict(
|
| 1015 |
+
template=dict(round=[
|
| 1016 |
+
dict(
|
| 1017 |
+
prompt=
|
| 1018 |
+
'You are given a meeting transcript and a query containing a question or instruction. Answer the query in one or more sentences.\n\nTranscript:\n{context}\n\nNow, answer the query based on the above meeting transcript in one or more sentences.\n\nQuery: {input}\nAnswer:',
|
| 1019 |
+
role='HUMAN'),
|
| 1020 |
+
]),
|
| 1021 |
+
type=
|
| 1022 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1023 |
+
retriever=dict(
|
| 1024 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1025 |
+
name='qmsum',
|
| 1026 |
+
path='opencompass/Longbench',
|
| 1027 |
+
reader_cfg=dict(
|
| 1028 |
+
input_columns=[
|
| 1029 |
+
'context',
|
| 1030 |
+
'input',
|
| 1031 |
+
],
|
| 1032 |
+
output_column='answers',
|
| 1033 |
+
test_range='[175:200]',
|
| 1034 |
+
test_split='test',
|
| 1035 |
+
train_split='test'),
|
| 1036 |
+
type='opencompass.datasets.LongBenchqmsumDataset'),
|
| 1037 |
+
dict(
|
| 1038 |
+
abbr='LongBench_vcsum_7',
|
| 1039 |
+
eval_cfg=dict(
|
| 1040 |
+
evaluator=dict(
|
| 1041 |
+
language='zh',
|
| 1042 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1043 |
+
pred_role='BOT'),
|
| 1044 |
+
infer_cfg=dict(
|
| 1045 |
+
inferencer=dict(
|
| 1046 |
+
max_out_len=512,
|
| 1047 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1048 |
+
prompt_template=dict(
|
| 1049 |
+
template=dict(round=[
|
| 1050 |
+
dict(
|
| 1051 |
+
prompt=
|
| 1052 |
+
'下面有一段会议记录,请你阅读后,写一段总结,总结会议的内容。\n会议记录:\n{context}\n\n会议总结:',
|
| 1053 |
+
role='HUMAN'),
|
| 1054 |
+
]),
|
| 1055 |
+
type=
|
| 1056 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1057 |
+
retriever=dict(
|
| 1058 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1059 |
+
name='vcsum',
|
| 1060 |
+
path='opencompass/Longbench',
|
| 1061 |
+
reader_cfg=dict(
|
| 1062 |
+
input_columns=[
|
| 1063 |
+
'context',
|
| 1064 |
+
],
|
| 1065 |
+
output_column='answers',
|
| 1066 |
+
test_range='[175:200]',
|
| 1067 |
+
test_split='test',
|
| 1068 |
+
train_split='test'),
|
| 1069 |
+
type='opencompass.datasets.LongBenchvcsumDataset'),
|
| 1070 |
+
dict(
|
| 1071 |
+
abbr='LongBench_dureader_7',
|
| 1072 |
+
eval_cfg=dict(
|
| 1073 |
+
evaluator=dict(
|
| 1074 |
+
language='zh',
|
| 1075 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1076 |
+
pred_role='BOT'),
|
| 1077 |
+
infer_cfg=dict(
|
| 1078 |
+
inferencer=dict(
|
| 1079 |
+
max_out_len=128,
|
| 1080 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1081 |
+
prompt_template=dict(
|
| 1082 |
+
template=dict(round=[
|
| 1083 |
+
dict(
|
| 1084 |
+
prompt=
|
| 1085 |
+
'请基于给定的文章回答下述问题。\n\n文章:{context}\n\n请基于上述文章回答下面的问题。\n\n问题:{input}\n回答:',
|
| 1086 |
+
role='HUMAN'),
|
| 1087 |
+
]),
|
| 1088 |
+
type=
|
| 1089 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1090 |
+
retriever=dict(
|
| 1091 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1092 |
+
name='dureader',
|
| 1093 |
+
path='opencompass/Longbench',
|
| 1094 |
+
reader_cfg=dict(
|
| 1095 |
+
input_columns=[
|
| 1096 |
+
'context',
|
| 1097 |
+
'input',
|
| 1098 |
+
],
|
| 1099 |
+
output_column='answers',
|
| 1100 |
+
test_range='[175:200]',
|
| 1101 |
+
test_split='test',
|
| 1102 |
+
train_split='test'),
|
| 1103 |
+
type='opencompass.datasets.LongBenchdureaderDataset'),
|
| 1104 |
+
dict(
|
| 1105 |
+
abbr='LongBench_lcc_7',
|
| 1106 |
+
eval_cfg=dict(
|
| 1107 |
+
evaluator=dict(
|
| 1108 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 1109 |
+
pred_role='BOT'),
|
| 1110 |
+
infer_cfg=dict(
|
| 1111 |
+
inferencer=dict(
|
| 1112 |
+
max_out_len=64,
|
| 1113 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1114 |
+
prompt_template=dict(
|
| 1115 |
+
template=dict(round=[
|
| 1116 |
+
dict(
|
| 1117 |
+
prompt=
|
| 1118 |
+
'Please complete the code given below. \n{context}Next line of code:\n',
|
| 1119 |
+
role='HUMAN'),
|
| 1120 |
+
]),
|
| 1121 |
+
type=
|
| 1122 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1123 |
+
retriever=dict(
|
| 1124 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1125 |
+
name='lcc',
|
| 1126 |
+
path='opencompass/Longbench',
|
| 1127 |
+
reader_cfg=dict(
|
| 1128 |
+
input_columns=[
|
| 1129 |
+
'context',
|
| 1130 |
+
],
|
| 1131 |
+
output_column='answers',
|
| 1132 |
+
test_range='[441:504]',
|
| 1133 |
+
test_split='test',
|
| 1134 |
+
train_split='test'),
|
| 1135 |
+
type='opencompass.datasets.LongBenchlccDataset'),
|
| 1136 |
+
dict(
|
| 1137 |
+
abbr='LongBench_repobench-p_7',
|
| 1138 |
+
eval_cfg=dict(
|
| 1139 |
+
evaluator=dict(
|
| 1140 |
+
type='opencompass.datasets.LongBenchCodeSimEvaluator'),
|
| 1141 |
+
pred_role='BOT'),
|
| 1142 |
+
infer_cfg=dict(
|
| 1143 |
+
inferencer=dict(
|
| 1144 |
+
max_out_len=64,
|
| 1145 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1146 |
+
prompt_template=dict(
|
| 1147 |
+
template=dict(round=[
|
| 1148 |
+
dict(
|
| 1149 |
+
prompt=
|
| 1150 |
+
'Please complete the code given below. \n{context}{input}Next line of code:\n',
|
| 1151 |
+
role='HUMAN'),
|
| 1152 |
+
]),
|
| 1153 |
+
type=
|
| 1154 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1155 |
+
retriever=dict(
|
| 1156 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1157 |
+
name='repobench-p',
|
| 1158 |
+
path='opencompass/Longbench',
|
| 1159 |
+
reader_cfg=dict(
|
| 1160 |
+
input_columns=[
|
| 1161 |
+
'context',
|
| 1162 |
+
'input',
|
| 1163 |
+
],
|
| 1164 |
+
output_column='answers',
|
| 1165 |
+
test_range='[441:504]',
|
| 1166 |
+
test_split='test',
|
| 1167 |
+
train_split='test'),
|
| 1168 |
+
type='opencompass.datasets.LongBenchrepobenchDataset'),
|
| 1169 |
+
dict(
|
| 1170 |
+
abbr='LongBench_passage_retrieval_en_7',
|
| 1171 |
+
eval_cfg=dict(
|
| 1172 |
+
evaluator=dict(
|
| 1173 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 1174 |
+
pred_role='BOT'),
|
| 1175 |
+
infer_cfg=dict(
|
| 1176 |
+
inferencer=dict(
|
| 1177 |
+
max_out_len=32,
|
| 1178 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1179 |
+
prompt_template=dict(
|
| 1180 |
+
template=dict(round=[
|
| 1181 |
+
dict(
|
| 1182 |
+
prompt=
|
| 1183 |
+
'Here are 30 paragraphs from Wikipedia, along with an abstract. Please determine which paragraph the abstract is from.\n\n{context}\n\nThe following is an abstract.\n\n{input}\n\nPlease enter the number of the paragraph that the abstract is from. The answer format must be like "Paragraph 1", "Paragraph 2", etc.\n\nThe answer is: ',
|
| 1184 |
+
role='HUMAN'),
|
| 1185 |
+
]),
|
| 1186 |
+
type=
|
| 1187 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1188 |
+
retriever=dict(
|
| 1189 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1190 |
+
name='passage_retrieval_en',
|
| 1191 |
+
path='opencompass/Longbench',
|
| 1192 |
+
reader_cfg=dict(
|
| 1193 |
+
input_columns=[
|
| 1194 |
+
'context',
|
| 1195 |
+
'input',
|
| 1196 |
+
],
|
| 1197 |
+
output_column='answers',
|
| 1198 |
+
test_range='[175:200]',
|
| 1199 |
+
test_split='test',
|
| 1200 |
+
train_split='test'),
|
| 1201 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_enDataset'),
|
| 1202 |
+
dict(
|
| 1203 |
+
abbr='LongBench_passage_retrieval_zh_7',
|
| 1204 |
+
eval_cfg=dict(
|
| 1205 |
+
evaluator=dict(
|
| 1206 |
+
language='zh',
|
| 1207 |
+
type='opencompass.datasets.LongBenchRetrievalEvaluator'),
|
| 1208 |
+
pred_role='BOT'),
|
| 1209 |
+
infer_cfg=dict(
|
| 1210 |
+
inferencer=dict(
|
| 1211 |
+
max_out_len=32,
|
| 1212 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1213 |
+
prompt_template=dict(
|
| 1214 |
+
template=dict(round=[
|
| 1215 |
+
dict(
|
| 1216 |
+
prompt=
|
| 1217 |
+
'以下是若干段落文字,以及其中一个段落的摘要。请确定给定的摘要出自哪一段。\n\n{context}\n\n下面是一个摘要\n\n{input}\n\n请输入摘要所属段落的编号。答案格式必须是"段落1","段落2"等格式\n\n答案是:',
|
| 1218 |
+
role='HUMAN'),
|
| 1219 |
+
]),
|
| 1220 |
+
type=
|
| 1221 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1222 |
+
retriever=dict(
|
| 1223 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1224 |
+
name='passage_retrieval_zh',
|
| 1225 |
+
path='opencompass/Longbench',
|
| 1226 |
+
reader_cfg=dict(
|
| 1227 |
+
input_columns=[
|
| 1228 |
+
'context',
|
| 1229 |
+
'input',
|
| 1230 |
+
],
|
| 1231 |
+
output_column='answers',
|
| 1232 |
+
test_range='[175:200]',
|
| 1233 |
+
test_split='test',
|
| 1234 |
+
train_split='test'),
|
| 1235 |
+
type='opencompass.datasets.LongBenchpassage_retrieval_zhDataset'),
|
| 1236 |
+
dict(
|
| 1237 |
+
abbr='LongBench_passage_count_7',
|
| 1238 |
+
eval_cfg=dict(
|
| 1239 |
+
evaluator=dict(
|
| 1240 |
+
type='opencompass.datasets.LongBenchCountEvaluator'),
|
| 1241 |
+
pred_role='BOT'),
|
| 1242 |
+
infer_cfg=dict(
|
| 1243 |
+
inferencer=dict(
|
| 1244 |
+
max_out_len=32,
|
| 1245 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1246 |
+
prompt_template=dict(
|
| 1247 |
+
template=dict(round=[
|
| 1248 |
+
dict(
|
| 1249 |
+
prompt=
|
| 1250 |
+
'There are some paragraphs below sourced from Wikipedia. Some of them may be duplicates. Please carefully read these paragraphs and determine how many unique paragraphs there are after removing duplicates. In other words, how many non-repeating paragraphs are there in total?\n\n{context}\n\nPlease enter the final count of unique paragraphs after removing duplicates. The output format should only contain the number, such as 1, 2, 3, and so on.\n\nThe final answer is: ',
|
| 1251 |
+
role='HUMAN'),
|
| 1252 |
+
]),
|
| 1253 |
+
type=
|
| 1254 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1255 |
+
retriever=dict(
|
| 1256 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1257 |
+
name='passage_count',
|
| 1258 |
+
path='opencompass/Longbench',
|
| 1259 |
+
reader_cfg=dict(
|
| 1260 |
+
input_columns=[
|
| 1261 |
+
'context',
|
| 1262 |
+
'input',
|
| 1263 |
+
],
|
| 1264 |
+
output_column='answers',
|
| 1265 |
+
test_range='[175:200]',
|
| 1266 |
+
test_split='test',
|
| 1267 |
+
train_split='test'),
|
| 1268 |
+
type='opencompass.datasets.LongBenchpassage_countDataset'),
|
| 1269 |
+
dict(
|
| 1270 |
+
abbr='LongBench_trec_7',
|
| 1271 |
+
eval_cfg=dict(
|
| 1272 |
+
evaluator=dict(
|
| 1273 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 1274 |
+
),
|
| 1275 |
+
pred_postprocessor=dict(
|
| 1276 |
+
type='opencompass.datasets.trec_postprocess'),
|
| 1277 |
+
pred_role='BOT'),
|
| 1278 |
+
infer_cfg=dict(
|
| 1279 |
+
inferencer=dict(
|
| 1280 |
+
max_out_len=64,
|
| 1281 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1282 |
+
prompt_template=dict(
|
| 1283 |
+
template=dict(round=[
|
| 1284 |
+
dict(
|
| 1285 |
+
prompt=
|
| 1286 |
+
'Please determine the type of the question below. Here are some examples of questions.\n\n{context}\n{input}',
|
| 1287 |
+
role='HUMAN'),
|
| 1288 |
+
]),
|
| 1289 |
+
type=
|
| 1290 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1291 |
+
retriever=dict(
|
| 1292 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1293 |
+
name='trec',
|
| 1294 |
+
path='opencompass/Longbench',
|
| 1295 |
+
reader_cfg=dict(
|
| 1296 |
+
input_columns=[
|
| 1297 |
+
'context',
|
| 1298 |
+
'input',
|
| 1299 |
+
],
|
| 1300 |
+
output_column='all_labels',
|
| 1301 |
+
test_range='[175:200]',
|
| 1302 |
+
test_split='test',
|
| 1303 |
+
train_split='test'),
|
| 1304 |
+
type='opencompass.datasets.LongBenchtrecDataset'),
|
| 1305 |
+
dict(
|
| 1306 |
+
abbr='LongBench_lsht_7',
|
| 1307 |
+
eval_cfg=dict(
|
| 1308 |
+
evaluator=dict(
|
| 1309 |
+
type='opencompass.datasets.LongBenchClassificationEvaluator'
|
| 1310 |
+
),
|
| 1311 |
+
pred_postprocessor=dict(
|
| 1312 |
+
type='opencompass.datasets.lsht_postprocess'),
|
| 1313 |
+
pred_role='BOT'),
|
| 1314 |
+
infer_cfg=dict(
|
| 1315 |
+
inferencer=dict(
|
| 1316 |
+
max_out_len=64,
|
| 1317 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1318 |
+
prompt_template=dict(
|
| 1319 |
+
template=dict(round=[
|
| 1320 |
+
dict(
|
| 1321 |
+
prompt='请判断给定新闻的类别,下面是一些例子。\n\n{context}\n{input}',
|
| 1322 |
+
role='HUMAN'),
|
| 1323 |
+
]),
|
| 1324 |
+
type=
|
| 1325 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1326 |
+
retriever=dict(
|
| 1327 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1328 |
+
name='lsht',
|
| 1329 |
+
path='opencompass/Longbench',
|
| 1330 |
+
reader_cfg=dict(
|
| 1331 |
+
input_columns=[
|
| 1332 |
+
'context',
|
| 1333 |
+
'input',
|
| 1334 |
+
],
|
| 1335 |
+
output_column='all_labels',
|
| 1336 |
+
test_range='[175:200]',
|
| 1337 |
+
test_split='test',
|
| 1338 |
+
train_split='test'),
|
| 1339 |
+
type='opencompass.datasets.LongBenchlshtDataset'),
|
| 1340 |
+
dict(
|
| 1341 |
+
abbr='LongBench_multi_news_7',
|
| 1342 |
+
eval_cfg=dict(
|
| 1343 |
+
evaluator=dict(
|
| 1344 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1345 |
+
pred_role='BOT'),
|
| 1346 |
+
infer_cfg=dict(
|
| 1347 |
+
inferencer=dict(
|
| 1348 |
+
max_out_len=512,
|
| 1349 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1350 |
+
prompt_template=dict(
|
| 1351 |
+
template=dict(round=[
|
| 1352 |
+
dict(
|
| 1353 |
+
prompt=
|
| 1354 |
+
'You are given several news passages. Write a one-page summary of all news. \n\nNews:\n{context}\n\nNow, write a one-page summary of all the news.\n\nSummary:\n',
|
| 1355 |
+
role='HUMAN'),
|
| 1356 |
+
]),
|
| 1357 |
+
type=
|
| 1358 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1359 |
+
retriever=dict(
|
| 1360 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1361 |
+
name='multi_news',
|
| 1362 |
+
path='opencompass/Longbench',
|
| 1363 |
+
reader_cfg=dict(
|
| 1364 |
+
input_columns=[
|
| 1365 |
+
'context',
|
| 1366 |
+
],
|
| 1367 |
+
output_column='answers',
|
| 1368 |
+
test_range='[175:200]',
|
| 1369 |
+
test_split='test',
|
| 1370 |
+
train_split='test'),
|
| 1371 |
+
type='opencompass.datasets.LongBenchmulti_newsDataset'),
|
| 1372 |
+
dict(
|
| 1373 |
+
abbr='LongBench_samsum_7',
|
| 1374 |
+
eval_cfg=dict(
|
| 1375 |
+
evaluator=dict(
|
| 1376 |
+
type='opencompass.datasets.LongBenchRougeEvaluator'),
|
| 1377 |
+
pred_postprocessor=dict(
|
| 1378 |
+
type='opencompass.datasets.samsum_postprocess'),
|
| 1379 |
+
pred_role='BOT'),
|
| 1380 |
+
infer_cfg=dict(
|
| 1381 |
+
inferencer=dict(
|
| 1382 |
+
max_out_len=128,
|
| 1383 |
+
type='opencompass.openicl.icl_inferencer.GenInferencer'),
|
| 1384 |
+
prompt_template=dict(
|
| 1385 |
+
template=dict(round=[
|
| 1386 |
+
dict(
|
| 1387 |
+
prompt=
|
| 1388 |
+
'Summarize the dialogue into a few short sentences. The following are some examples.\n\n{context}\n\n{input}',
|
| 1389 |
+
role='HUMAN'),
|
| 1390 |
+
]),
|
| 1391 |
+
type=
|
| 1392 |
+
'opencompass.openicl.icl_prompt_template.PromptTemplate'),
|
| 1393 |
+
retriever=dict(
|
| 1394 |
+
type='opencompass.openicl.icl_retriever.ZeroRetriever')),
|
| 1395 |
+
name='samsum',
|
| 1396 |
+
path='opencompass/Longbench',
|
| 1397 |
+
reader_cfg=dict(
|
| 1398 |
+
input_columns=[
|
| 1399 |
+
'context',
|
| 1400 |
+
'input',
|
| 1401 |
+
],
|
| 1402 |
+
output_column='answers',
|
| 1403 |
+
test_range='[175:200]',
|
| 1404 |
+
test_split='test',
|
| 1405 |
+
train_split='test'),
|
| 1406 |
+
type='opencompass.datasets.LongBenchsamsumDataset'),
|
| 1407 |
+
],
|
| 1408 |
+
]
|
| 1409 |
+
models = [
|
| 1410 |
+
dict(
|
| 1411 |
+
abbr='mask_gdn-1.3B',
|
| 1412 |
+
batch_padding=False,
|
| 1413 |
+
batch_size=16,
|
| 1414 |
+
max_out_len=100,
|
| 1415 |
+
max_seq_len=16384,
|
| 1416 |
+
path='/mnt/jfzn/msj/train_exp/mask_gdn_1B_hrr-rank4',
|
| 1417 |
+
run_cfg=dict(num_gpus=1),
|
| 1418 |
+
tokenizer_path='/mnt/jfzn/msj/train_exp/mask_gdn_1B_hrr-rank4',
|
| 1419 |
+
type='opencompass.models.HuggingFaceCausalLM'),
|
| 1420 |
+
]
|
| 1421 |
+
work_dir = 'outputs/default/20251127_164744'
|