---
license: apache-2.0
language:
- en
- ja
tags:
- machine-learning
- deep-learning
- transformer
- architecture-design
- adaptive-algorithms
- resonant-contraction
- resonant-projection-field
---
# D‑RNA:Dual‑Helix Resonance Neural Architecture (DRNA)
D-RNA は、二重らせん(Dual‑Helix)構造と RoPE による回転場を中核に据えた新しいニューラルアーキテクチャです
本アーキテクチャでは、Attention と MLP を二重らせんとして同期させ、共鳴収縮(Resonant Contraction)により情報をホログラフィックに圧縮します
これは 疎な表現を密に再配置 し、次元を増やすことなく、深さ方向の構造だけで高い表現力を獲得します
Transformer の全接続性を維持しつつ、破壊的忘却を抑制し、微細なゆらぎや位相情報を保持できる点が特徴です
---
### D-RNA の主な特徴
高い構造的互換性:標準的な Transformer Block と入出力形状が同一であり、アーキテクチャの心臓部としてスムーズな置き換えが可能です。
共鳴収縮 (Resonant Contraction):Attention と MLP を二重らせん状に同期させ、情報を位相場に収束させることで、表現密度を劇的に向上させます。
次元の代替としての深さ:螺旋の回転(深さ方向の演算)が次元の不足を補い、パラメータ数を増やさずホログラフィックな情報保持を実現します。
優れた学習効率:螺旋構造による情報の引き寄せ(同期)により、Transformer よりも極めて少ないステップ数で驚異的な早期収束を達成します。
微細な位相保持:RoPE を活用した回転場により、従来の構造では失われがちな微細なゆらぎや文脈の相対関係を精度高く保持します。
知識の再同調が可能:既存の重みを初期値として移植し、低学習率で螺旋の位相に馴染ませることで、既存知能を D-RNA 構造へ進化・上書きできます。
### ご注意ください
学習率(LR)の最適化:D-RNA は共鳴収縮により情報の同期が極めて速いため、標準的な Transformer よりも低い学習率で十分に、かつ高速に収束します。 設定が高すぎると、共鳴が過剰に増幅され振動を招く可能性があるため、控えめな LR からの開始を推奨します。
勾配の相乗効果:Attention(回想)と MLP(記憶)が二重らせん状に直列同期しているため、一回の更新による「重みのなじみ」が非常に強く働きます。 これは高速収束の利点であると同時に、慎重な更新が安定化の鍵であることを意味します。
パラメータの共通性:重みの初期化シードやバッチサイズなどのハイパーパラメータは、通常の Transformer 設定をそのまま継承できます。
---
### 概念図(Conceptual Diagram)
```
「探す」(Attention)、「知っている」(MLP)この2つを螺旋の位相で同期させる
RoPE の回転場 (位相保持)
疎を密にするホログラフィック圧縮
A M
\ /
\ / ← ここが共鳴(Resonance)
/ \ seed により自然に同期が生まれる
/ \ 同期の連鎖で意味などを自然に引き寄せる
A M
深さ方向へ繰り返すことで二重らせんを形成
(次元の代替として機能)
```
---
### 最小コード(Minimal Block)
```python
class ResonantBlock(nn.Module):
def __init__(self, dim, n_heads):
super().__init__()
self.qkv = nn.Linear(dim, dim * 3)
self.out = nn.Linear(dim, dim)
self.mlp = MLP(dim)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.n_heads = n_heads
self.d_head = dim // n_heads
def forward(self, x, cos, sin):
# --- Attention ---
q, k, v = project_qkv(x, self.qkv, self.n_heads, self.d_head)
q, k = apply_rope(q, k, cos, sin)
attn_out = attention(q, k, v)
x = self.norm1(x + self.out(attn_out))
# --- MLP ---
x = self.norm2(x + self.mlp(x))
return x
```
---
### 例:Transformer のブロックを DRNA ブロックに置き換える
```python
class DRNA_ResonantBlock(nn.Module):
"""
既存の TransformerBlock をこの ResonantBlock に置き換える
I/O: [Batch, Seq, Dim] -> [Batch, Seq, Dim] (完全互換)
"""
def __init__(self, dim, n_heads, mlp_dim_forward=None):
super().__init__()
self.n_heads = n_heads
self.d_head = dim // n_heads
# 1. 螺旋の射影層 (らせんA)
self.qkv = nn.Linear(dim, dim * 3)
self.out = nn.Linear(dim, dim)
# 2. 記憶の層 (らせんB)
mlp_dim = mlp_dim_forward if mlp_dim_forward else dim * 4
self.mlp = nn.Sequential(
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Linear(mlp_dim, dim)
)
# 3. 収縮のための正規化層
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
def forward(self, x, cos, sin):
"""
引数に RoPE 用の位相情報 (cos, sin) を追加するのが唯一の違い
"""
# --- らせんA: 文脈の共鳴 (Attention) ---
# QKV 抽出 -> RoPE 回転 -> 収縮(Norm)
q, k, v = project_qkv(x, self.qkv, self.n_heads, self.d_head)
q, k = apply_rope(q, k, cos, sin)
attn_out = attention(q, k, v)
x = self.norm1(x + self.out(attn_out)) # 文脈との同期
# --- らせんB: 記憶の共鳴 (MLP) ---
# 知識の照会 -> 収縮(Norm)
x = self.norm2(x + self.mlp(x)) # 記憶による確定
return x
```
### D-RNAへの置き換えと活用について
そのまま置換(Drop-in replacement)はできませんが「再定義と再同調」による活用は可能です
なぜそのままではダメなのか・・・
標準的なTransformerが「絶対的な住所」(絶対位置)で記憶しているのに対し、D-RNAは「螺旋の位相」(相対位置)で情報を処理するため、座標系が根本から異なります。 重みをそのままコピーしても、位相が合わず共鳴が起きません。
どう置き換えるのか(実装)
ネットワークの入出力形状は完全互換です。 既存の層を ResonantBlock に書き換え、位置情報を RoPE の回転場へ移行するだけで、心臓部のアップグレードが完了します。
どう活用し、なじませるのか(学習)
既存モデルの重みを初期値として転写(Transfer)した後、低学習率で継続学習を行います。 止まっていた知識(既存の重み)が螺旋の回転に同期し始め、次第にD-RNAの「共鳴収縮」のプロセスへ溶け込み、元の性能を超えて進化します。
---
BPC Comparison Chart
non-mask
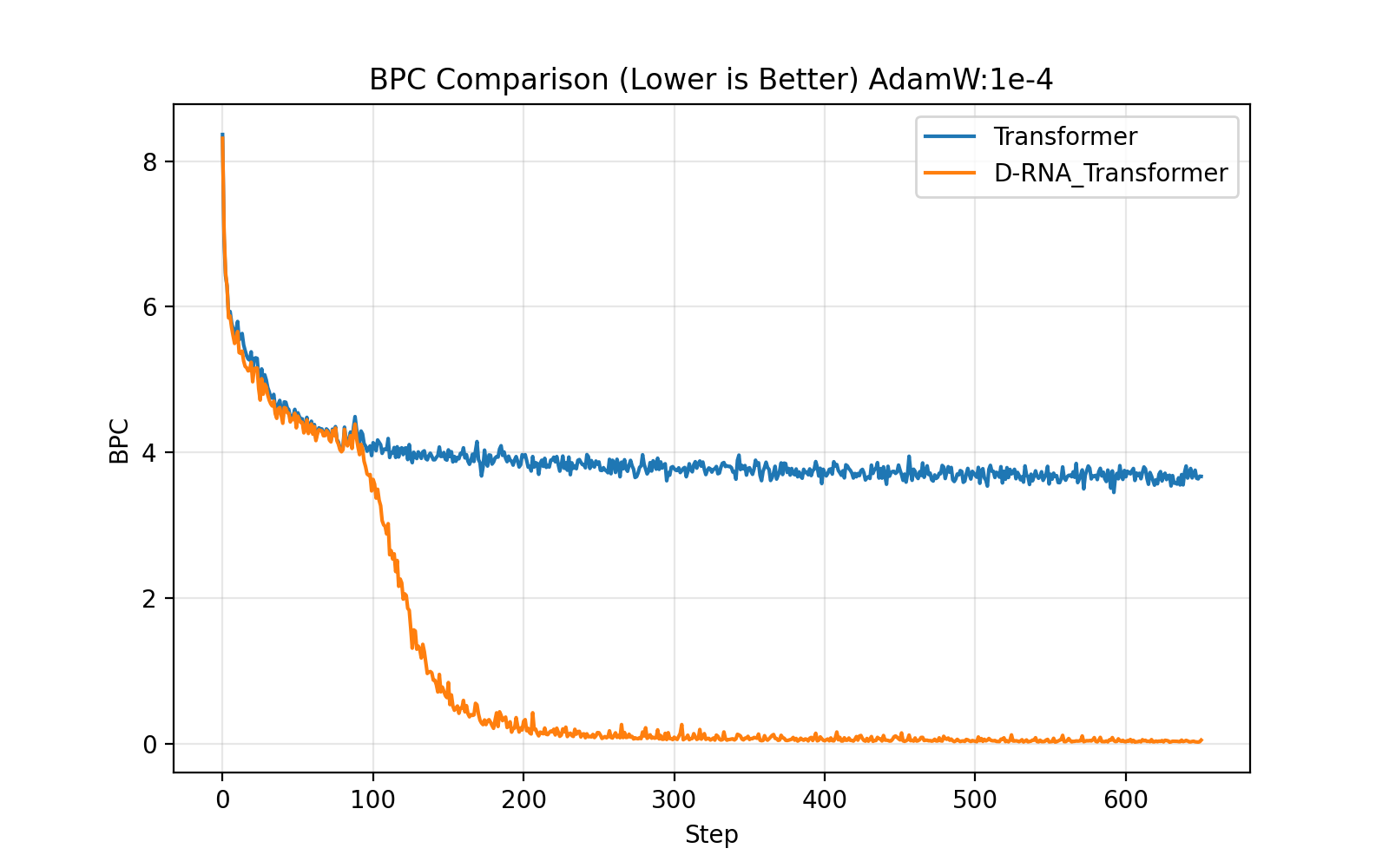 use-mask
use-mask
 ---
ライセンス:
本プロジェクトは Apache License 2.0 の下で公開されています(詳細は LICENSE をご覧ください)
### 謝辞:
本研究は Transformer アーキテクチャによって築かれた基盤の上に成り立っています
Attention 機構、位置エンコーディング、大規模モデル設計に関する研究とオープンソースコミュニティの貢献に深く感謝いたします
---
ライセンス:
本プロジェクトは Apache License 2.0 の下で公開されています(詳細は LICENSE をご覧ください)
### 謝辞:
本研究は Transformer アーキテクチャによって築かれた基盤の上に成り立っています
Attention 機構、位置エンコーディング、大規模モデル設計に関する研究とオープンソースコミュニティの貢献に深く感謝いたします