
dolphin-base
Browse files- dolphin-base/.gitattributes +35 -0
- dolphin-base/README.md +96 -0
- dolphin-base/bpe.model +3 -0
- dolphin-base/config.yaml +0 -0
- dolphin-base/feats_stats.npz +3 -0
dolphin-base/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
dolphin-base/README.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: automatic-speech-recognition
|
| 4 |
+
language: multilingual
|
| 5 |
+
---
|
| 6 |
+
# Dolphin
|
| 7 |
+
|
| 8 |
+
[Paper](https://arxiv.org/abs/2503.20212)
|
| 9 |
+
[Github](https://github.com/DataoceanAI/Dolphin)
|
| 10 |
+
[Huggingface](https://huggingface.co/DataoceanAI)
|
| 11 |
+
[Modelscope](https://www.modelscope.cn/organization/DataoceanAI)
|
| 12 |
+
|
| 13 |
+
Dolphin is a multilingual, multitask ASR model developed through a collaboration between Dataocean AI and Tsinghua University. It supports 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. It is trained on over 210,000 hours of data, which includes both DataoceanAI's proprietary datasets and open-source datasets. The model can perform speech recognition, voice activity detection (VAD), segmentation, and language identification (LID).
|
| 14 |
+
|
| 15 |
+
## Approach
|
| 16 |
+
|
| 17 |
+
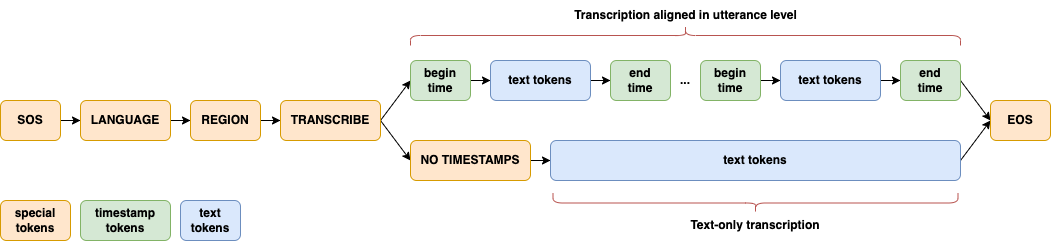
|
| 18 |
+
Dolphin largely follows the innovative design approach of [Whisper](https://github.com/openai/whisper) and [OWSM](https://github.com/espnet/espnet/tree/master/egs2/owsm_v3.1/s2t1). A joint CTC-Attention architecture is adopted, with encoder based on E-Branchformer and decoder based on standard Transformer. Several key modifications are introduced for its specific focus on ASR. Dolphin does not support translation tasks, and eliminates the use of previous text and its related tokens.
|
| 19 |
+
|
| 20 |
+
A significant enhancement in Dolphin is the introduction of a two-level language token system to better handle linguistic and regional diversity, especially in Dataocean AI dataset. The first token specifies the language (e.g., `<zh>`, `<ja>`), while the second token indicates the region (e.g., `<CN>`, `<JP>`). See details in [paper](https://arxiv.org/abs/2503.20212).
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Setup
|
| 24 |
+
Dolphin requires FFmpeg to convert audio file to WAV format. If FFmpeg is not installed on your system, please install it first:
|
| 25 |
+
|
| 26 |
+
```shell
|
| 27 |
+
# Ubuntu or Debian
|
| 28 |
+
sudo apt update && sudo apt install ffmpeg
|
| 29 |
+
|
| 30 |
+
# MacOS
|
| 31 |
+
brew install ffmpeg
|
| 32 |
+
|
| 33 |
+
# Windows
|
| 34 |
+
choco install ffmpeg
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
You can install the latest version of Dolphin using the following command:
|
| 38 |
+
```shell
|
| 39 |
+
pip install -U dataoceanai-dolphin
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
Alternatively, it can also be installed from the source:
|
| 43 |
+
```shell
|
| 44 |
+
pip install git+https://github.com/SpeechOceanTech/Dolphin.git
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Available Models and Languages
|
| 48 |
+
|
| 49 |
+
### Models
|
| 50 |
+
|
| 51 |
+
There are 4 models in Dolphin, and 2 of them are available now. See details in [paper](https://arxiv.org/abs/2503.20212).
|
| 52 |
+
|
| 53 |
+
| Model | Parameters | Average WER | Publicly Available |
|
| 54 |
+
|:------:|:----------:|:------------------:|:------------------:|
|
| 55 |
+
| base | 140 M | 33.3 | ✅ |
|
| 56 |
+
| small | 372 M | 25.2 | ✅ |
|
| 57 |
+
| medium | 910 M | 23.1 | |
|
| 58 |
+
| large | 1679 M | 21.6 | |
|
| 59 |
+
|
| 60 |
+
### Languages
|
| 61 |
+
|
| 62 |
+
Dolphin supports 40 Eastern languages and 22 Chinese dialects. For a complete list of supported languages, see [languages.md](https://github.com/DataoceanAI/Dolphin/blob/main/languages.md).
|
| 63 |
+
|
| 64 |
+
## Usage
|
| 65 |
+
|
| 66 |
+
### Command-line usage
|
| 67 |
+
|
| 68 |
+
```shell
|
| 69 |
+
dolphin audio.wav
|
| 70 |
+
|
| 71 |
+
# Download model and specify the model path
|
| 72 |
+
dolphin audio.wav --model small --model_dir /data/models/dolphin/
|
| 73 |
+
|
| 74 |
+
# Specify language and region
|
| 75 |
+
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" --region_sym "CN"
|
| 76 |
+
|
| 77 |
+
# padding speech to 30 seconds
|
| 78 |
+
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" --region_sym "CN" --padding_speech true
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
### Python usage
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
import dolphin
|
| 85 |
+
|
| 86 |
+
waveform = dolphin.load_audio("audio.wav")
|
| 87 |
+
model = dolphin.load_model("small", "/data/models/dolphin", "cuda")
|
| 88 |
+
result = model(waveform)
|
| 89 |
+
# Specify language and region
|
| 90 |
+
result = model(waveform, lang_sym="zh", region_sym="CN")
|
| 91 |
+
print(result.text)
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## License
|
| 95 |
+
|
| 96 |
+
Dolphin's code and model weights are released under the [Apache 2.0 License](https://github.com/DataoceanAI/Dolphin/blob/main/LICENSE).
|
dolphin-base/bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4b9102181ef1a2a3c42ce8fbca8a545ea4a55bce47ba7a5222951ab5bb21bb3c
|
| 3 |
+
size 854022
|
dolphin-base/config.yaml
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dolphin-base/feats_stats.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5a37d00c07d595dbc2479b31be42b3c75de422469a947ce4b7bda193c3b1de7f
|
| 3 |
+
size 1402
|