
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,94 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: llama2
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
library_name: peft
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
license: llama2
|
| 7 |
---
|
| 8 |
+
|
| 9 |
+
# ML1 Previews- 34b
|
| 10 |
+
|
| 11 |
+
This repository contains the previews for the ML1 model - [Reddit Post](https://www.reddit.com/r/LocalLLaMA/comments/16ul4sw/ml1_34b70b_phi_115_reproduction_on_llama2/)
|
| 12 |
+
|
| 13 |
+
## Checkpoints
|
| 14 |
+
1. `15%` - Complete
|
| 15 |
+
* [Link]()
|
| 16 |
+
3. `30%` - IP
|
| 17 |
+
4. ...
|
| 18 |
+
|
| 19 |
+
<!-- 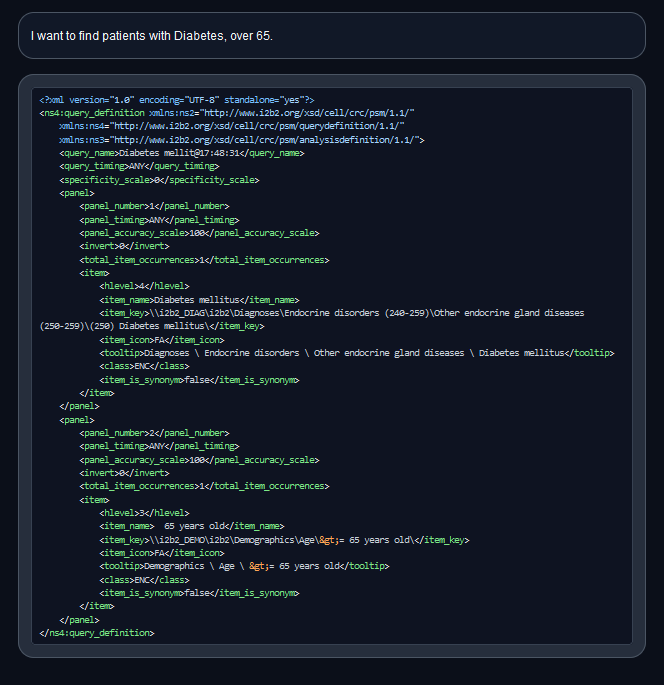 -->
|
| 20 |
+
|
| 21 |
+
## Model Description
|
| 22 |
+
|
| 23 |
+
The goal is to develop a series of models that can express superior performance given high quality data. To achieve this, I plan to experiment with the lovely dataset produced by [/u/docsoc1](https://www.reddit.com/user/docsoc1). Huge shout out to him/her! If you'd like to view that dataset, the link is below.
|
| 24 |
+
|
| 25 |
+
Dataset: [emrgnt-cmplxty/sciphi-textbooks-are-all-you-need](https://huggingface.co/datasets/emrgnt-cmplxty/sciphi-textbooks-are-all-you-need)
|
| 26 |
+
|
| 27 |
+
## Prompt Format
|
| 28 |
+
|
| 29 |
+
The model is trained using the alpaca format. Please see [here](https://github.com/tatsu-lab/stanford_alpaca#data-release) or below for that format:
|
| 30 |
+
|
| 31 |
+
```text
|
| 32 |
+
Below is an instruction that describes a task. Write a response that appropriately completes the request.
|
| 33 |
+
|
| 34 |
+
### Instruction:
|
| 35 |
+
{instruction}
|
| 36 |
+
|
| 37 |
+
### Response:
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
### Architecture
|
| 41 |
+
`nmitchko/ML1-34b-previews` is a large language model repository of LoRA checkpoints specifically fine-tuned to add text-book synthesized data in the style of Phi 1/1.5.
|
| 42 |
+
It is based on [`codellama-34b-hf`](https://huggingface.co/codellama/CodeLlama-34b-hf) at 34 billion parameters.
|
| 43 |
+
|
| 44 |
+
The primary goal of this model is to improve research accuracy with the i2b2 tool.
|
| 45 |
+
It was trained using [LoRA](https://arxiv.org/abs/2106.09685), specifically [QLora Multi GPU](https://github.com/ChrisHayduk/qlora-multi-gpu), to reduce memory footprint.
|
| 46 |
+
|
| 47 |
+
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
|
| 48 |
+
|
| 49 |
+
### Requirements
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
bitsandbytes>=0.41.0
|
| 53 |
+
peft@main
|
| 54 |
+
transformers@main
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
Steps to load this model:
|
| 58 |
+
1. Load base model (codellama-34b-hf) using transformers
|
| 59 |
+
2. Download a checkpoint folder (checkpoint-1)
|
| 60 |
+
3. Apply LoRA using peft
|
| 61 |
+
|
| 62 |
+
## Training Parameters
|
| 63 |
+
|
| 64 |
+
The model is currently training on [emrgnt-cmplxty/sciphi-textbooks-are-all-you-need](https://huggingface.co/datasets/emrgnt-cmplxty/sciphi-textbooks-are-all-you-need)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
`emrgnt-cmplxty/sciphi-textbooks-are-all-you-need` contains textbook synthesized data.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
| Item | Amount | Units |
|
| 71 |
+
|---------------|--------|-------|
|
| 72 |
+
| LoRA Rank | 64 | ~ |
|
| 73 |
+
| LoRA Alpha | 16 | ~ |
|
| 74 |
+
| Learning Rate | 1e-4 | SI |
|
| 75 |
+
| Dropout | 5 | % |
|
| 76 |
+
|
| 77 |
+
## Training procedure
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
The following `bitsandbytes` quantization config was used during training:
|
| 81 |
+
- quant_method: QuantizationMethod.BITS_AND_BYTES
|
| 82 |
+
- load_in_8bit: False
|
| 83 |
+
- load_in_4bit: True
|
| 84 |
+
- llm_int8_threshold: 6.0
|
| 85 |
+
- llm_int8_skip_modules: None
|
| 86 |
+
- llm_int8_enable_fp32_cpu_offload: False
|
| 87 |
+
- llm_int8_has_fp16_weight: False
|
| 88 |
+
- bnb_4bit_quant_type: nf4
|
| 89 |
+
- bnb_4bit_use_double_quant: True
|
| 90 |
+
- bnb_4bit_compute_dtype: bfloat16
|
| 91 |
+
|
| 92 |
+
### Framework versions
|
| 93 |
+
|
| 94 |
+
- PEFT 0.6.0.dev0
|