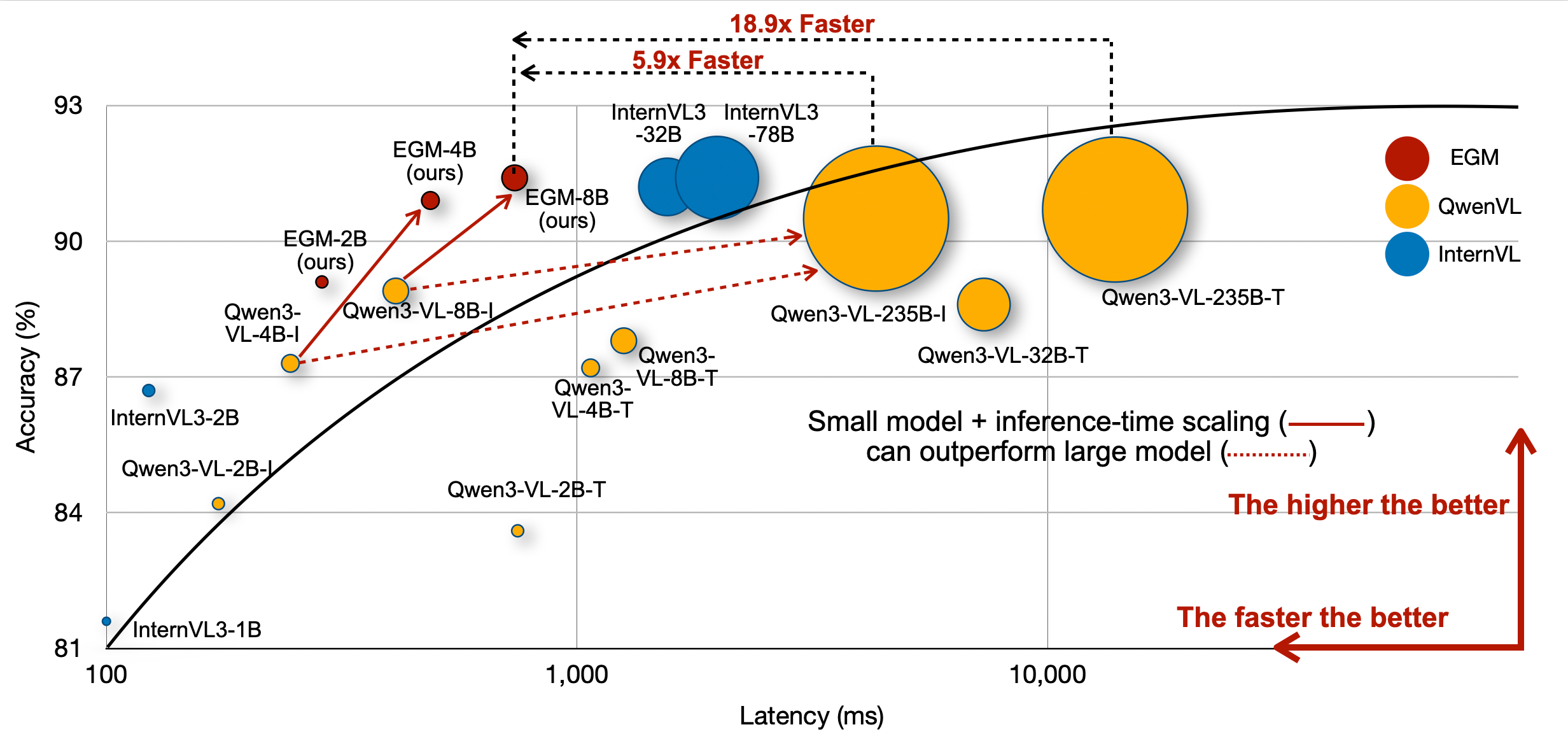
---
license: apache-2.0
language:
- en
library_name: transformers
base_model:
- Qwen/Qwen3-VL-8B-Thinking
pipeline_tag: image-text-to-text
tags:
- visual-grounding
- multimodal
- qwen3-vl
- supervised-fine-tuning
---
# EGM-Qwen3-VL-8B-SFT
[Project Page]
[Code]
## Model Summary
**EGM-Qwen3-VL-8B-SFT** is the supervised fine-tuning (SFT) checkpoint from the first stage of the [EGM (Efficient Visual Grounding Language Models)](https://nvlabs.github.io/EGM) training pipeline. It is built on top of [Qwen3-VL-8B-Thinking](https://huggingface.co/Qwen/Qwen3-VL-8B-Thinking).
This is an **intermediate checkpoint** intended for further reinforcement learning training. For the final model with best performance, see [nvidia/EGM-8B](https://huggingface.co/nvidia/EGM-8B).
## Training Details
### SFT Stage
In the SFT stage, a proprietary VLM generates detailed chain-of-thought reasoning steps for visual grounding training data. The base Qwen3-VL-8B-Thinking model is then fine-tuned on this reasoning-augmented data to learn structured visual grounding with explicit reasoning.
This SFT checkpoint serves as the initialization for the subsequent RL stage (GRPO), which yields the final [EGM-8B](https://huggingface.co/nvidia/EGM-8B) model.
### How to Use for RL Training
```bash
pip install -U huggingface_hub
huggingface-cli download nvidia/EGM-8B-SFT --local-dir ./models/EGM-8B-SFT
```
Then follow the installation instructions in the [EGM repository](https://github.com/NVlabs/EGM#installation), prepare the RL data and start training:
```bash
export BASE_DIR=$(pwd)
export MODEL_PATH="${BASE_DIR}/models/EGM-8B-SFT"
export OUTPUT_DIR="${BASE_DIR}/checkpoint/"
export DATA_DIR="${BASE_DIR}/data/EGM_Datasets/processed_rl_data/"
cd verl
bash scripts/grounding_qwen.sh
```
See the [EGM repository](https://github.com/NVlabs/EGM#rl-training) for full RL training instructions.
## Model Architecture
| Component | Details |
|---|---|
| Architecture | Qwen3VLForConditionalGeneration |
| Precision | bfloat16 |
| Text Hidden Size | 4096 |
| Text Layers | 36 |
| Attention Heads | 32 (8 KV heads) |
| Text Intermediate Size | 12,288 |
| Vision Hidden Size | 1152 |
| Vision Layers | 27 |
| Patch Size | 16 x 16 |
| Max Position Embeddings | 262,144 |
| Vocabulary Size | 151,936 |
## Related Models
| Model | Description |
|---|---|
| [nvidia/EGM-8B](https://huggingface.co/nvidia/EGM-8B) | Final RL-trained model (best performance) |
| [nvidia/EGM-4B-SFT](https://huggingface.co/nvidia/EGM-4B-SFT) | SFT checkpoint for the 4B variant |
| [nvidia/EGM-4B](https://huggingface.co/nvidia/EGM-4B) | Final RL-trained 4B model |
## Citation
```bibtex
@article{zhan2026EGM,
author = {Zhan, Guanqi and Li, Changye and Liu, Zhijian and Lu, Yao and Wu, Yi and Han, Song and Zhu, Ligeng},
title = {EGM: Efficient Visual Grounding Language Models},
booktitle = {arXiv},
year = {2026}
}
```
## Acknowledgment
This repository benefits from [Qwen3-VL](https://github.com/QwenLM/Qwen3-VL), [InternVL](https://github.com/OpenGVLab/InternVL), [verl](https://github.com/volcengine/verl) and [verl-internvl](https://github.com/Weiyun1025/verl-internvl).