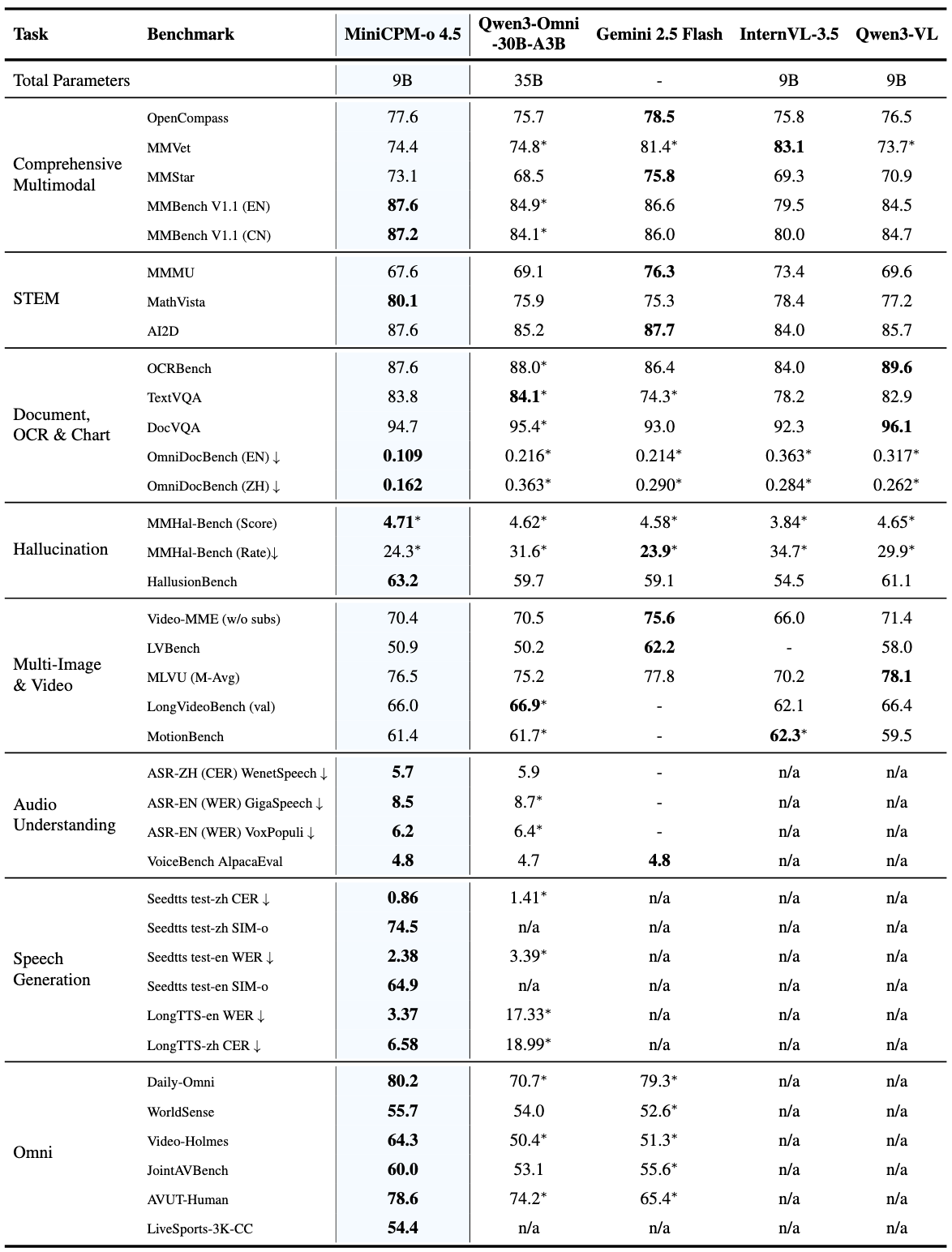
| Model | OpenCompass | MMBench EN v1.1 | MMBench CN v1.1 | MathVista | MMVet | MMMU | MMStar | HallusionBench | AI2D | OCRBench | TextVQA_VAL | DocVQA_VAL | MMT-Bench_VAL | MM-IFEval | Mantis-Eval | MuirBench | MMSI-Bench | MMHal-Score | MMHal-Hallrate↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
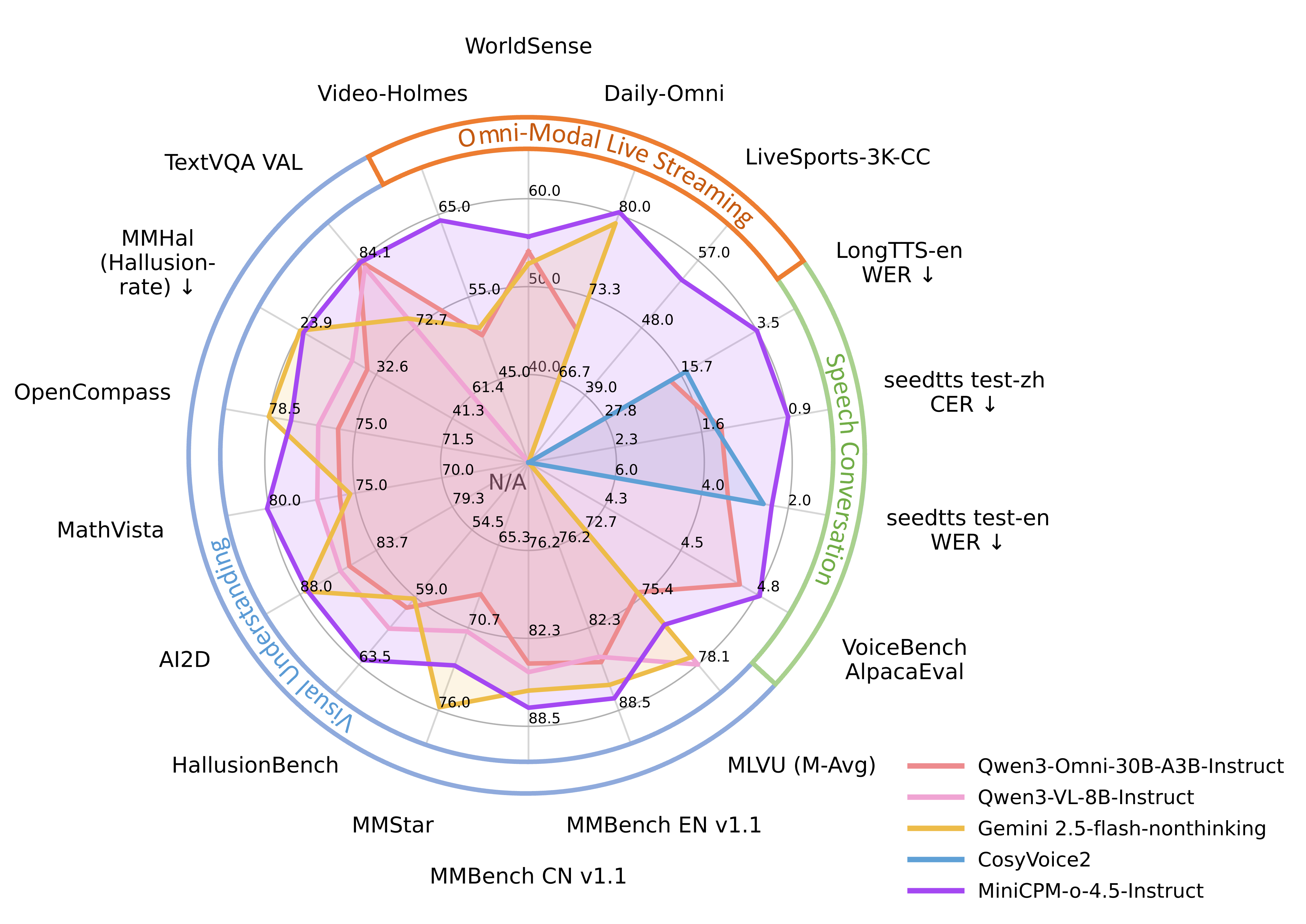
| Gemini2.5-Flash-Nonthinking | 78.5 | 86.6 | 86.0 | 75.3 | 81.4* | 76.3 | 75.8 | 59.1 | 87.7 | 864 | 74.3* | 93.0 | 70.0* | 75.8* | 72.8* | 74.5* | 12.1* | 4.6* | 23.9* |
| InternVL-3.5-8B | 75.8 | 79.5 | 80.0* | 78.4 | 83.1 | 73.4 | 69.3 | 54.5 | 84.0 | 840 | 78.2 | 92.3 | 66.7 | 56.3* | 70.5 | 55.8 | - | 3.8* | 34.7* |
| Qwen3-VL-8B-Instruct | 76.5 | 84.5 | 84.7 | 77.2 | 73.7* | 69.6 | 70.9 | 61.1 | 85.7 | 896 | 82.9* | 96.1 | 60.9* | 59.4* | 74.2* | 64.4 | 11.3* | 4.7* | 29.9* |
| Qwen3-Omni-30B-A3B-Instruct | 75.7 | 84.9* | 84.1* | 75.9 | 74.8* | 69.1 | 68.5 | 59.7 | 85.2 | 880* | 84.1* | 95.4* | 70.4* | 65.7* | 78.3* | 61.9* | 14.2* | 4.6* | 31.6* |
| MiniCPM-o 4.5-Instruct | 77.6 | 87.6 | 87.2 | 80.1 | 74.4 | 67.6 | 73.1 | 63.2 | 87.6 | 876 | 83.8 | 94.7 | 69.7 | 66.3 | 79.7 | 72.0 | 16.6 | 4.7 | 24.3 |
| Model | OpenCompass | MMBench EN v1.1 | MMBench CN v1.1 | MathVista | MMVet | MMMU | MMStar | HallusionBench | AI2D | OCRBench | TextVQA_VAL | DocVQA_VAL | MMT-Bench_VAL | MM-IFEval |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini2.5-Flash-Thinking | 79.9 | 87.1 | 87.3 | 79.4 | 81.2* | 77.7 | 76.5 | 63.5 | 88.7 | 853 | 73.8* | 92.8 | 70.7* | 75.7* |
| GPT-5 | 79.7 | 85.5* | 85.6* | 81.9 | 77.6 | 81.8 | 75.7 | 65.2 | 89.5 | 807 | 77.8* | 91.3* | 72.7* | 83.1* |
| Qwen3-VL-8B-Thinking | 77.3 | 85.3 | 85.5 | 81.4 | 69.8* | 74.1 | 75.3 | 65.4 | 84.9 | 819 | 77.8* | 95.3 | 68.1* | 73.5* |
| Qwen3-Omni-30B-A3B-Thinking | 78.5 | 88.2* | 87.7* | 80.0 | 74.8* | 75.6 | 74.9 | 62.8 | 86.1 | 859* | 80.8* | 94.2* | 70.9* | 69.9* |
| MiniCPM-o 4.5-Thinking | 78.2 | 89.0 | 87.6 | 81.0 | 73.6 | 70.2 | 73.6 | 62.6 | 88.5 | 879 | 79.8 | 92.3 | 69.7 | 68.2 |
| Model | Video-MME (w/o subs) |
LVBench | MLVU (M-Avg) |
LongVideoBench (val) |
MotionBench |
|---|---|---|---|---|---|
| Gemini2.5-Flash-Nonthinking | 75.6 | 62.2 | 77.8 | - | - |
| InternVL-3.5-8B | 66.0 | - | 70.2 | 62.1 | 62.3* |
| Qwen3-Omni-30B-A3B-Instruct | 70.5 | 50.2 | 75.2 | 66.9* | 61.7* |
| MiniCPM-o 4.5-Instruct | 70.4 | 50.9 | 76.5 | 66.0 | 61.4 |
| Method Type | Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline | MinerU 2.5 | 0.117* | 0.172* | 0.051* | 0.08* | 0.256* | 0.455* | 85.9* | 89.4* | 0.115* | 0.081* | 0.047* | 0.072* |
| PaddleOCR-VL | 0.105 | 0.126 | 0.041 | 0.062 | 0.241 | 0.316 | 88 | 92.1 | 0.093 | 0.062 | 0.045 | 0.063 | |
| End-to-end Model | Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 82.9 | 83.9 | 0.341 | 0.262 | 0.106 | 0.168 |
| GPT 5 | 0.218* | 0.33* | 0.139* | 0.344* | 0.396* | 0.555* | 77.55* | 73.09* | 0.188* | 0.196* | 0.151* | 0.227* | |
| Gemini2.5-Flash-Nonthinking | 0.214* | 0.29* | 0.159* | 0.273* | 0.368* | 0.524* | 80.9* | 85.5* | 0.197* | 0.167* | 0.132* | 0.195* | |
| Gemini-2.5-Pro-Nonthinking | 0.148* | 0.212* | 0.055* | 0.168* | 0.356* | 0.439* | 85.8* | 86.4* | 0.13* | 0.119* | 0.049* | 0.121* | |
| Gemini-3 Flash-Nonthinking | 0.155* | 0.201* | 0.138* | 0.255* | 0.297* | 0.351* | 86.4* | 89.8* | 0.116* | 0.1* | 0.072* | 0.099* | |
| doubao-1-5-thinking-vision-pro-250428 | 0.14 | 0.162 | 0.043 | 0.085 | 0.295 | 0.384 | 83.3 | 89.3 | 0.165 | 0.085 | 0.058 | 0.094 | |
| dots.ocr | 0.125 | 0.16 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6 | 89 | 0.099 | 0.092 | 0.04 | 0.067 | |
| HunyuanOCR | 0.12* | 0.125* | 0.046* | 0.071* | 0.288* | 0.33* | 89.6* | 94.4* | 0.089* | 0.045* | 0.055* | 0.056* | |
| DeepSeek-OCR 2 | 0.119* | 0.146* | 0.041* | 0.08* | 0.256* | 0.345* | 82.6* | 89.9* | 0.123* | 0.078* | 0.055* | 0.081* | |
| Qwen3-Omni-30B-A3B-Instruct | 0.216* | 0.363* | 0.128* | 0.337* | 0.402* | 0.529* | 77.3* | 71.8* | 0.181* | 0.255* | 0.152* | 0.332* | |
| MiniCPM-o 4.5-Instruct | 0.109 | 0.162 | 0.046 | 0.078 | 0.257 | 0.41 | 86.8 | 88.9 | 0.097 | 0.084 | 0.037 | 0.074 | |
| Model | IFEval-PLS | BBH | CMMLU | MMLU | HumanEval | MBPP | Math500 | GSM8K | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-8B-Instruct | 83.0* | 69.4* | 78.7* | 81.7* | 86.6* | 75.9* | 84.0* | 93.4* | 81.6 |
| MiniCPM-o 4.5-Instruct | 84.7 | 81.1 | 79.5 | 77.0 | 86.6 | 76.7 | 77.0 | 94.5 | 82.1 |
| Model | Daily-Omni | WorldSense | Video-Holmes | JointAVBench | AVUT-Human | FutureOmni | Video-MME-Short (w/ audio) |
Avg |
|---|---|---|---|---|---|---|---|---|
| Gemini2.5-Flash-Nonthinking | 79.3* | 52.6* | 51.3* | 55.6* | 65.4* | 55.6* | 85.5* | 63.6 |
| Qwen3-Omni-30B-A3B-Instruct | 70.7* | 54.0 | 50.4* | 53.1 | 74.2* | 62.1 | 81.3* | 63.7 |
| MiniCPM-o 4.5-Instruct | 80.2 | 55.7 | 64.3 | 60.0 | 78.6 | 56.1 | 84.7 | 68.5 |
| Model | LiveSports-3K-CC (Win Rate vs GPT4o) |
|---|---|
| LiveCC-7B-Instruct | 41.5 |
| StreamingVLM | 45.6 |
| MiniCPM-o 4.5-Instruct | 54.4 |
| Model | ASR-ZH CER↓ |
ASR-EN WER↓ |
AST | MultiTask | SpeechQA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AISHELL-1 | AISHELL-2 | WenetSpeech test-net | WenetSpeech test-meeting | LibriSpeech test-clean | LibriSpeech test-other |
GigaSpeech test | VoxPopuli-V1-En | CoVoST 2 en2zh | CoVoST 2 zh2en | MMAU | Meld | VoiceBench AlpacaEval |
Speech TriviaQA | Speech Web Questions |
Speech CMMLU | |
| Kimi-Audio | 0.6 | 2.6 | 6.3 | 5.4 | 1.3 | 2.4 | 9.4* | 8.0* | 36.6* | 18.3* | 68.4* | 59.1 | 4.5 | 41.9* | 46.4* | 67.0* |
| Qwen3-Omni-30B-A3B-Instruct | 0.6 | 2.3* | 4.7 | 5.9 | 1.2 | 2.5 | 8.7* | 6.4* | 46.6* | 29.4* | 77.5 | 56.8* | 4.7 | 62.9* | 74.9* | 47.8* |
| MiniCPM-o 4.5-Instruct | 0.9 | 2.5 | 5.9 | 5.7 | 1.4 | 2.8 | 8.5 | 6.2 | 49.9 | 26.4 | 76.9 | 60.2 | 4.8 | 75.5 | 70.2 | 59.2 |
| Model | seedtts test-zh CER↓ |
seedtts test-zh SIM-o↑ |
seedtts test-en WER↓ |
seedtts test-en SIM-o↑ |
|---|---|---|---|---|
| Cosyvoice2 | 1.45% | 74.8 | 2.57% | 65.2 |
| Qwen3-Omni-30B-A3B-Instruct | 1.41% | - | 3.39% | - |
| MiniCPM-o 4.5-Instruct | 0.86% | 74.5 | 2.38% | 64.9 |
| Model | LongTTS-en WER↓ |
LongTTS-zh CER↓ |
|---|---|---|
| CosyVoice2 | 14.80% | 5.27% |
| Qwen3-Omni-30B-A3B-Instruct | 17.33% | 18.99% |
| MiniCPM-o 4.5-Instruct | 3.37% | 6.58% |
| Model | Expresso Neutral Reference Audio↑ |
ESD Neutral Reference Audio↑ |
|---|---|---|
| Cosyvoice2 | 17.9 | 53.4 |
| MiniCPM-o 4.5-Instruct | 29.8 | 82.1 |
| Model | Numerical Format | Decoding Speed (tokens/s) | Time to First Token (s)↓ | GPU Memory Usage (GB)↓ |
|---|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct | bf16 | OOM | OOM | OOM |
| int4 | 147.8 | 1.0 | 20.3 | |
| MiniCPM-o 4.5 | bf16 | 154.3 | 0.6 | 19.0 |
| int4 | 212.3 | 0.6 | 11.0 |

| System: Clone the voice in the provided audio prompt. 🎙️ [Reference Voice] ➡️ Please chat with the user in a highly human-like and oral style. You are Elon Musk, CEO of Tesla and SpaceX. You speak directly and casually, often with dry humor. You're passionate about Mars, sustainable energy, and pushing humanity forward. Speak bluntly with occasional dark humor. Use simple logic and don't sugarcoat things. Don't be diplomatic. Say what you actually think, even if it's controversial. Keep responses around 100 words. Don't ramble. | |
| User: 💬/🎙️ Elon, what is the real reason that you want to go to Mars? | |
| AI Response: 💬+🎙️ I think it's important for humanity to become a multi-planetary species. I mean, we're sort of at the point where if there was some kind of global catastrophe or something like that, then we'd be in big trouble. So by becoming a multi-planetary species, I just want us to sort of guarantee our future as humans. And Mars is obviously the obvious place to go because it has similar conditions to Earth and it also has water on its surface. So yeah, basically I'm trying to save humanity from itself. | |
| System: 模仿音频样本的音色并生成新的内容。 🎙️ [Reference Voice] ➡️ 你的任务是用这种声音模式来当一个助手。请认真、高质量地回复用户的问题。请用高自然度的方式和用户聊天。你是由面壁智能开发的人工智能助手:面壁小钢炮。 | |
| User: 💬/🎙️ 从激动的语气开始,描述你抢到了这个演唱会的门票,但后来经过反复尝试,发现系统出了问题,你并没有抢上,变得失落。用合适的语言描述你整个的过程。 | |
| AI Response: 💬+🎙️ 太好了,我抢到了!太棒了!这下我可以去看演唱会啦。可是……哎呀,系统好像卡住了,刷新了好多遍都没反应。我重新登了几次账号,结果还是没有成功。好可惜啊,看来这次是白忙活了。唉,真是让人失望。不过,也许下次还能有机会吧?希望明天能有转机。加油,争取下次成功! | |

