---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen3-VL-2B-Instruct
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- chart
- reasoning
- vision-language
- multimodal
- chart-understanding
- VLM
datasets:
- opendatalab/ChartVerse-SFT-600K
- opendatalab/ChartVerse-RL-40K
---
**ChartVerse-2B** is a compact yet powerful Vision Language Model (VLM) specialized for complex chart reasoning, developed as part of the **[opendatalab/ChartVerse](https://huggingface.co/collections/opendatalab/chartverse)** project. For more details about our method, datasets, and full model series, please visit our [Project Page](https://chartverse.github.io).
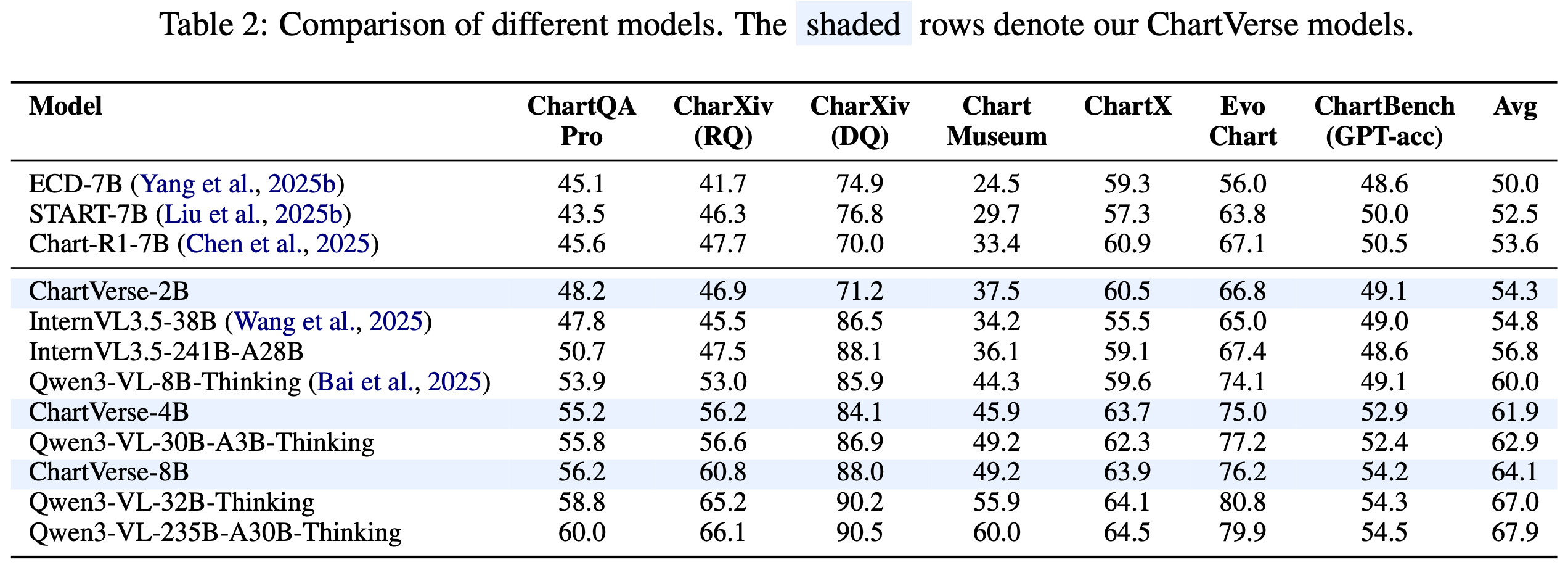
Despite its 2B parameter size, ChartVerse-2B achieves superior performance compared to larger chart-specific models like ECD-7B, START-7B, and Chart-R1-7B, demonstrating that high-quality training data can substantially offset model size limitations.
## 🔥 Highlights
- **Compact yet Powerful**: 2B parameters achieving 54.3% average score across 6 challenging chart benchmarks
- **Surpasses Larger Models**: Outperforms all 7B chart-specific baselines (ECD-7B: 50.0%, START-7B: 52.5%, Chart-R1-7B: 53.6%)
- **High-Quality Training**: Trained on ChartVerse-SFT-600K and ChartVerse-RL-40K with rigorous truth-anchored QA synthesis
- **Strong Reasoning**: Equipped with Chain-of-Thought reasoning capabilities for complex multi-step chart analysis
## 📊 Model Performance
### Overall Results
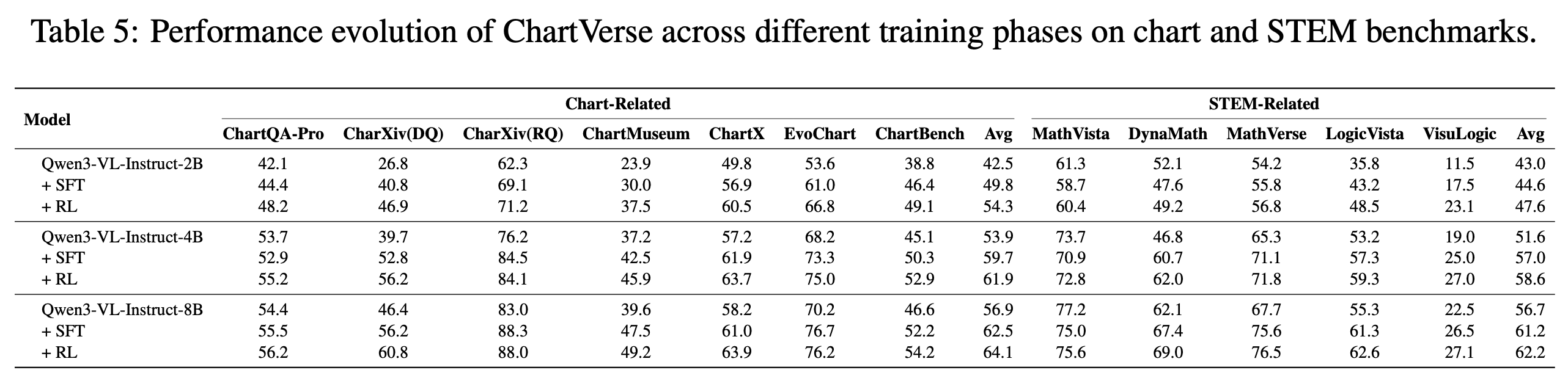
### SFT vs RL Performance
## 📚 Training Data
### [ChartVerse-SFT-600K](https://huggingface.co/datasets/opendatalab/ChartVerse-SFT-600K)
- **412K** unique high-complexity charts
- **603K** QA pairs with **3.9B** tokens of CoT reasoning
- Rollout Posterior Entropy: **0.44** (highest among all datasets)
- Truth-anchored answer verification via code execution
### [ChartVerse-RL-40K](https://huggingface.co/datasets/opendatalab/ChartVerse-RL-40K)
- **40K** highest-difficulty samples
- Filtered by failure rate: 0 < r(Q) < 1
- Ensures "hard but solvable" training signal
## 🏋️ Training Details
**Supervised Fine-Tuning (SFT)**:
- Framework: LLaMA-Factory
- Dataset: ChartVerse-SFT-600K
- Learning rate: 1.0 × 10⁻⁵
- Global batch size: 128
- Context length: 22,000 tokens
**Reinforcement Learning (RL)**:
- Framework: veRL
- Dataset: ChartVerse-RL-40K
- Algorithm: GSPO
- Learning rate: 1.0 × 10⁻⁶
- Rollout samples: 16 per prompt
## 🚀 Quick Start
```python
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
# 1. Load Model
model_path = "opendatalab/ChartVerse-2B"
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_path)
# 2. Prepare Input
image_path = "path/to/your/chart.png"
query = "Which region demonstrates the greatest proportional variation in annual revenue compared to its typical revenue level?"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": query},
],
}
]
# 3. Inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=16384)
output_text = processor.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
```
## 📖 Citation
```bibtex
@misc{liu2026chartversescalingchartreasoning,
title={ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch},
author={Zheng Liu and Honglin Lin and Chonghan Qin and Xiaoyang Wang and Xin Gao and Yu Li and Mengzhang Cai and Yun Zhu and Zhanping Zhong and Qizhi Pei and Zhuoshi Pan and Xiaoran Shang and Bin Cui and Conghui He and Wentao Zhang and Lijun Wu},
year={2026},
eprint={2601.13606},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.13606},
}
```
## 📄 License
This model is released under the Apache 2.0 License.
## 🙏 Acknowledgements
- Base model: [Qwen3-VL-2B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-2B-Instruct)
- Training frameworks: [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory), [veRL](https://github.com/volcengine/verl)
- Evaluation: [VLMEvalKit](https://github.com/open-compass/VLMEvalKit)