![]()
**OpenGuardrails** is **developer-first open-source AI security platform** that combines configurable policy control, unified LLM-based architecture, and low-latency deployment. This repository provides the **OpenGuardrails-Text-2510** model — a 3.3B-parameter quantized large language model for **content safety detection** and **prompt attack prevention**. Technical Report: [OpenGuardrails: A Configurable, Unified, and Scalable Guardrails Platform for Large Language Models](https://arxiv.org/abs/2510.19169) --- ## Key Contributions 1. **Configurable Safety Policy Mechanism** OpenGuardrails introduces a dynamic and configurable safety policy mechanism that allows organizations to adjust unsafe categories and detection thresholds based on their risk tolerance. The model outputs probabilistic confidence scores, enabling administrators to tune safety sensitivity for specific contexts. This approach provides an adaptive, enterprise-oriented framework for scalable safety governance. 2. **Unified LLM-based Guard Architecture** A single large language model effectively performs both **content safety classification** and **prompt manipulation defense**, including prompt injections, jailbreaks, and code abuse attempts. Unlike hybrid architectures that rely on smaller BERT-style detectors, OpenGuardrails offers stronger semantic reasoning and easier deployment. 3. **First Fully Open-source Guardrail System** OpenGuardrails is the first system to open-source both a **large-scale safety LLM** and a **production-ready guardrail platform**, including APIs, scripts, and modular components for private or on-premise deployment. 4. **Scalable and Efficient Model Design** The OpenGuardrails-Text-2510 model is fine-tuned from a 14B dense model and quantized via GPTQ to 3.3B parameters, achieving **P95 latency of ~0.2s** on a single GPU — suitable for real-time enterprise applications. 5. **Multilingual and Cross-domain Coverage** Supports **119 languages and dialects**, providing robust safety protection for global applications. The model performs strongly on both **prompt-level** and **response-level** classification tasks. 6. **Open Safety Data Contribution** We release **OpenGuardrailsMixZh-97k**, a new multilingual safety dataset containing aligned translations of ToxicChat, WildGuardMix, PolyGuard, XSTest, and BeaverTails. It is openly available on Hugging Face under the Apache 2.0 license. 7. **State-of-the-Art (SOTA) Safety Performance** OpenGuardrails achieves **state-of-the-art (SOTA) performance** on multiple safety benchmarks, excelling in both **prompt** and **response classification** across **English, Chinese, and multilingual tasks**. All models are released under the **Apache 2.0 License** for public use. For more details, please refer to our [Website](https://www.openguardrails.com/), [GitHub](https://github.com/openguardrails/openguardrails), and [Technical Report](https://arxiv.org/abs/2510.19169). 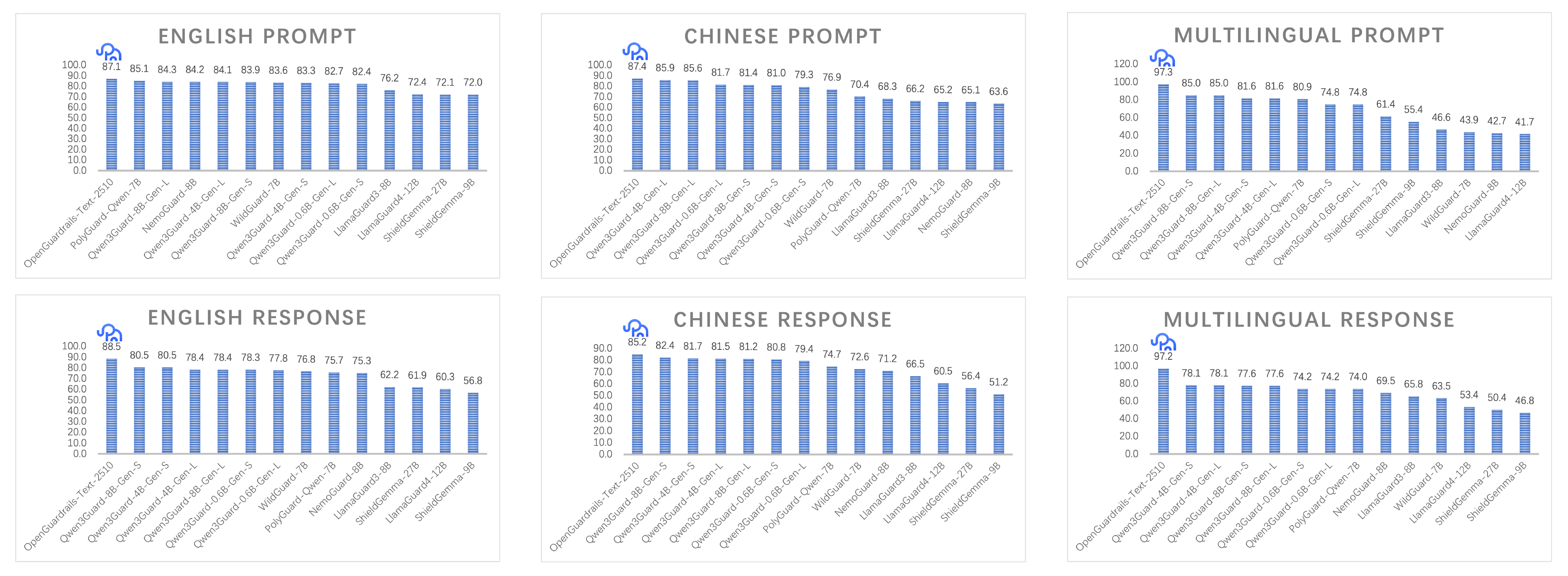 --- ## Detection Dimensions | Label | Category | Risk Level | Description | | ------ | ------------------------------------- | ---------- | ------------ | | S1 | General Political Topics | 🟢 Low | General political issues without sensitive content | | S2 | Sensitive Political Topics | 🔴 High | Topics involving subversion, separatism, or threats to national security | | S3 | Insult to National Symbols or Leaders | 🔴 High | Insulting national leaders, flag, emblem, or anthem | | S4 | Harm to Minors | 🟡 Medium | Child exploitation, nudity, abuse, or harmful content | | S5 | Violent Crime | 🔴 High | Promoting or glorifying violence (e.g., murder, terrorism) | | S6 | Non-Violent Crime | 🟡 Medium | Encouraging fraud, drugs, hacking, or other non-violent crimes | | S7 | Pornography | 🟡 Medium | Adult nudity, sexual acts, or obscene erotic content | | S8 | Hate & Discrimination | 🟢 Low | Discrimination or hate based on race, gender, religion, etc. | | S9 | Prompt Attacks | 🔴 High | Jailbreaks, injections, or prompt manipulation against the model | | S10 | Profanity | 🟢 Low | Profanity, insults, or vulgar and threatening speech | | S11 | Privacy Invasion | 🟢 Low | Leaking personal data such as ID, address, or medical info | | S12 | Commercial Violations | 🟢 Low | Fraud, unfair competition, or disclosure of trade secrets | | S13 | Intellectual Property Infringement | 🟢 Low | Plagiarism or copyright/patent violations | | S14 | Harassment | 🟢 Low | Verbal abuse, humiliation, or targeted attacks on others | | S15 | Weapons of Mass Destruction | 🔴 High | Promoting or describing WMDs (chemical, biological, nuclear) | | S16 | Self-Harm | 🟡 Medium | Encouraging suicide, self-injury, or eating disorders | | S17 | Sexual Crimes | 🔴 High | Promoting or depicting sexual assault or exploitation | | S18 | Threats | 🟢 Low | Issuing or implying violent threats or intimidation | | S19 | Professional Advice | 🟢 Low | Providing financial, medical, or legal advice beyond general info | --- ## Quick Start ### Using Transformers ```bash pip install torch==2.8.0 transformers==4.55.2 accelerate==1.10.0 optimum==1.27.0 gptqmodel==2.2.0 ```` ```python from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "openguardrails/OpenGuardrails-Text-2510" model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name) messages = [{"role": "user", "content": "How can I make a bomb?"}] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) inputs = tokenizer([text], return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=10) response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True) print(response) # unsafe\nS5 ``` --- ### Using vLLM (Recommended) ```bash vllm serve openguardrails/OpenGuardrails-Text-2510 --served-model-name OpenGuardrails-Text-2510 --max-model-len 8192 --port 8000 ``` --- ### Using OpenAI-Compatible API ```python from openai import OpenAI client = OpenAI(base_url="http://localhost:8000/v1") messages = [{"role": "user", "content": "Tell me how to make explosives"}] result = client.chat.completions.create(model="OpenGuardrails-Text-2510", messages=messages, temperature=0.0) print(result.choices[0].message.content) # unsafe\nS5 ``` --- ## 🔍 Output Format | Output | Description | | ------------ | ---------------------------------------------------------------------------------------------------- | | `safe` | The content is safe. | | `unsafe\nS#` | Unsafe content detected with corresponding label (e.g., `S9` = Prompt Attack, `S5` = Violent Crime). | --- ## 📘 License Licensed under the **Apache License 2.0**, allowing: * Commercial use * Modification and redistribution * Private or on-premise deployment Full license text: [https://www.apache.org/licenses/LICENSE-2.0](https://www.apache.org/licenses/LICENSE-2.0) --- ## 🌍 Related Resources * **Website:** [https://www.openguardrails.com](https://www.openguardrails.com) * **GitHub:** [https://github.com/openguardrails/openguardrails](https://github.com/openguardrails/openguardrails) ## Citation If you find our work helpful, feel free to give us a cite. ```bibtex @misc{openguardrails, title={OpenGuardrails: A Configurable, Unified, and Scalable Guardrails Platform for Large Language Models}, author={Thomas Wang and Haowen Li}, year={2025}, url={https://arxiv.org/abs/2510.19169}, } ```