
File size: 6,466 Bytes
b90ead5 bb550f8 b90ead5 96be763 b90ead5 96be763 b90ead5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 |
---
license: apache-2.0
language:
- en
pipeline_tag: image-text-to-text
tags:
- multimodal
library_name: transformers
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
---
<style>
img {
display: inline;
}
</style>
[](#model-architecture)
| [](#model-architecture)
| [](#datasets)
# WebJudge
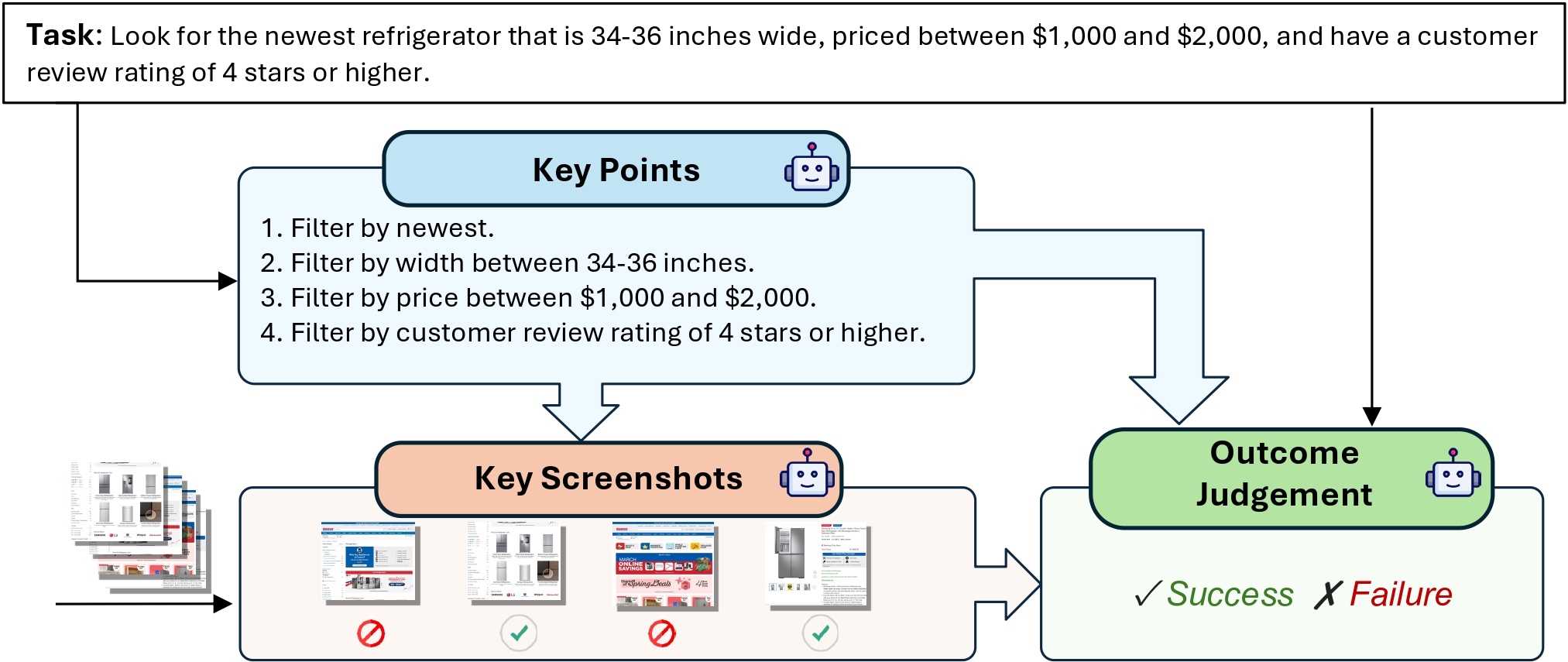
WebJudge preserves critical intermediate screenshots while mitigating the token overload issue, resulting in more accurate and reliable evaluations. Please check our [paper](https://arxiv.org/abs/2504.01382) for more details.
- **[Repository](https://github.com/OSU-NLP-Group/Online-Mind2Web)**
- **📃 [Paper](https://arxiv.org/abs/2504.01382)**
- **🏆 [Leaderboard](https://huggingface.co/spaces/osunlp/Online_Mind2Web_Leaderboard)**
- **🤗 [Data](https://huggingface.co/datasets/osunlp/Online-Mind2Web)**
- **[Model](https://huggingface.co/osunlp/WebJudge-7B)**
## Results
### Comparison against Existing Evaluation Methods on Online-Mind2Web
<table>
<tr>
<th>Model</th>
<th>Auto-Eval</th>
<td>SeeAct</td>
<td>Agent-E</td>
<td>Browser Use</td>
<td>Claude 3.5 </td>
<td>Claude 3.7</td>
<td>Operator</td>
<th>Avg AR</th>
</tr>
<tr>
<th rowspan="4">GPT-4o</th>
<td>Autonomous Eval</td>
<td>84.7</td>
<td>85.0</td>
<td>76.0</td>
<td>83.7</td>
<td>75.5</td>
<td>71.7</td>
<td>79.4</td>
</tr>
<tr>
<td>AgentTrek Eval</td>
<td>73.0</td>
<td>64.3</td>
<td>63.3</td>
<td>--</td>
<td>--</td>
<td>--</td>
<td>66.9</td>
</tr>
<tr>
<td>WebVoyager</td>
<td>--</td>
<td>75.3</td>
<td>71.3</td>
<td>74.0</td>
<td>72.0</td>
<td>76.7</td>
<td>73.9</td>
</tr>
<tr>
<td>WebJudge</td>
<td>86.7</td>
<td>86.0</td>
<td>81.4</td>
<td>86.3</td>
<td>79.1</td>
<td>81.8</td>
<td><b>83.6</b></td>
</tr>
<tr>
<th rowspan="3">o4-mini</th>
<td>Autonomous Eval</td>
<td>79.7</td>
<td>85.7</td>
<td>86.0</td>
<td>84.3</td>
<td>68.0</td>
<td>73.3</td>
<td>79.5</td>
</tr>
<tr>
<td>WebVoyager</td>
<td>--</td>
<td>80.3</td>
<td>79.0</td>
<td>81.7</td>
<td>74.3</td>
<td>78.3</td>
<td>78.7</td>
</tr>
<tr>
<td>WebJudge</td>
<td>85.3</td>
<td>86.3</td>
<td>89.3</td>
<td>87.0</td>
<td>82.3</td>
<td>83.7</td>
<td><b>85.7</b></td>
</tr>
<tr>
<th></th>
<td>WebJudge-7B</td>
<td>86.0</td>
<td>87.3</td>
<td>88.3</td>
<td>89.7</td>
<td>84.3</td>
<td>86.3</td>
<td><b>87.0</b></td>
</tr>
</table>
WebJudge powered by GPT-4o and o4-mini consistently achieves the highest agreement, with averages of 83.6% and 85.7%, respectively. Meanwhile, WebJudge-7B even outperforms o4-mini, reaching a high agreement with human judgment of 87%.
### Excellent generalization capabilities on [AgentRewardBench](https://agent-reward-bench.github.io/) (5 OOD benchmarks)
| **Methods** | **AB** | **VWA** | **WA** | **Work** | **Wk++** | **Overall** |
|--------------|--------|--------|--------|----------|----------|--------------|
| *Rule-based** | 25.0 | **85.2** | 79.0 | 100.0 | 83.3 | 83.8 |
| Autonomous Eval* | 83.3 | 61.2 | 67.6 | 96.4 | 59.3 | 67.6 |
| GPT-4o (A11y Tree)* | 77.8 | 63.0 | 70.2 | 94.6 | 63.0 | 69.8 |
| WebJudge (GPT-4o) | 66.7 | 69.8 | 72.6 | 92.3 | 75.0 | 73.7 |
| WebJudge-7B | 80.0 | 66.7 | 77.5 | 100.0 | 70.0 | 75.7 |
| WebJudge (o4-mini) | **100.0** | 74.5 | **81.2** | **100.0** | **90.0** | **82.0** |
WebJudge significantly outperforms existing methods, achieving impressive overall precision of 73.7% 75.7% and 82.0% on WebArena (WA), VisualWebArena (VWA), AssistantBench (AB), WorkArena (Work) and WorkArena++ (Wk++) across 1302 trajectories.
The high precision suggests that WebJudge holds potential as a robust and scalable reward model for downstream applications such as Rejection Sampling Fine-Tuning, Reflection, and Reinforcement Learning.
## Inference
### vLLM server
```bash
vllm serve osunlp/WebJudge-7B --port PORT --api-key API_KEY
```
or
### LLaMA-Factory API
```
API_PORT=PORT llamafactory-cli api examples/inference/qwen2_vl.yaml
```
### Prompt
Please check our [Repository](https://github.com/OSU-NLP-Group/Online-Mind2Web) and [Paper](https://arxiv.org/abs/2504.01382) for more details about prompt.
```python
text = """**Task**: {task}
**Key Points for Task Completion**: {key_points}
The snapshot of the web page is shown in the image."""
messages = [
{"role": "system", "content": system_msg},
{
"role": "user",
"content": [
{"type": "text", "text": text},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{jpg_base64_image}", "detail": "high"},
},
],
}
]
completion = client.chat.completions.create(
model=model_path,
messages=messages,
temperature=0
)
```
## Citation Information
Note: Online-Mind2Web is derived from the original Mind2Web dataset. We kindly ask that you cite both the original and this work when using or referencing the data.
```
@article{xue2025illusionprogressassessingcurrent,
title={An Illusion of Progress? Assessing the Current State of Web Agents},
author={Tianci Xue and Weijian Qi and Tianneng Shi and Chan Hee Song and Boyu Gou and Dawn Song and Huan Sun and Yu Su},
year={2025},
eprint={2504.01382},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.01382},
}
@inproceedings{deng2023mind2web,
author = {Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Oh and T. Naumann and A. Globerson and K. Saenko and M. Hardt and S. Levine},
pages = {28091--28114},
publisher = {Curran Associates, Inc.},
title = {Mind2Web: Towards a Generalist Agent for the Web},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/5950bf290a1570ea401bf98882128160-Paper-Datasets_and_Benchmarks.pdf},
volume = {36},
year = {2023}
}
```
|