
Commit ·
e5334da
1
Parent(s): 213eef7
Update README.md
Browse files
README.md
CHANGED
|
@@ -3,6 +3,12 @@ language:
|
|
| 3 |
- en
|
| 4 |
library_name: transformers
|
| 5 |
license: llama2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
|
| 8 |
|
|
@@ -30,7 +36,7 @@ A hybrid (explain + instruct) style Llama2-70b model, Pleae check examples below
|
|
| 30 |
|
| 31 |
|
| 32 |
### quantized versions
|
| 33 |
-
Huge respect to
|
| 34 |
|
| 35 |
https://huggingface.co/TheBloke/model_007-70B-GGML
|
| 36 |
|
|
@@ -52,19 +58,22 @@ We evaluated model_007 on a wide range of tasks using [Language Model Evaluation
|
|
| 52 |
|
| 53 |
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 54 |
|
| 55 |
-
|||
|
| 56 |
-
|:------:|:--------:|
|
| 57 |
-
|**Task**|**
|
| 58 |
-
|*
|
| 59 |
-
|*
|
| 60 |
-
|*
|
| 61 |
-
|*
|
| 62 |
-
|**
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
|
| 65 |
<br>
|
| 66 |
|
| 67 |
-
##
|
| 68 |
|
| 69 |
Here is the Orca prompt format
|
| 70 |
|
|
@@ -79,7 +88,35 @@ Tell me about Orcas.
|
|
| 79 |
|
| 80 |
```
|
| 81 |
|
| 82 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
|
| 84 |
```python
|
| 85 |
import torch
|
|
@@ -105,19 +142,7 @@ print(tokenizer.decode(output[0], skip_special_tokens=True))
|
|
| 105 |
|
| 106 |
```
|
| 107 |
|
| 108 |
-
|
| 109 |
-
Here is the Alpaca prompt format
|
| 110 |
-
|
| 111 |
-
```
|
| 112 |
-
|
| 113 |
-
### User:
|
| 114 |
-
Tell me about Alpacas.
|
| 115 |
-
|
| 116 |
-
### Assistant:
|
| 117 |
-
|
| 118 |
-
```
|
| 119 |
-
|
| 120 |
-
Below shows a code example on how to use this model
|
| 121 |
|
| 122 |
```python
|
| 123 |
import torch
|
|
|
|
| 3 |
- en
|
| 4 |
library_name: transformers
|
| 5 |
license: llama2
|
| 6 |
+
datasets:
|
| 7 |
+
- pankajmathur/orca_mini_v1_dataset
|
| 8 |
+
- pankajmathur/dolly-v2_orca
|
| 9 |
+
- pankajmathur/WizardLM_Orca
|
| 10 |
+
- pankajmathur/alpaca_orca
|
| 11 |
+
- ehartford/dolphin
|
| 12 |
---
|
| 13 |
|
| 14 |
|
|
|
|
| 36 |
|
| 37 |
|
| 38 |
### quantized versions
|
| 39 |
+
Huge respect to @TheBloke, here are the GGML/GPTQ/GGUF versions, go crazy :)
|
| 40 |
|
| 41 |
https://huggingface.co/TheBloke/model_007-70B-GGML
|
| 42 |
|
|
|
|
| 58 |
|
| 59 |
Here are the results on metrics used by [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 60 |
|
| 61 |
+
|||
|
| 62 |
+
|:------:|:--------:|
|
| 63 |
+
|**Task**|**Value**|
|
| 64 |
+
|*ARC*|0.7108|
|
| 65 |
+
|*HellaSwag*|0.8765|
|
| 66 |
+
|*MMLU*|0.6904|
|
| 67 |
+
|*TruthfulQA*|0.6312|
|
| 68 |
+
|*Winogrande*|0.8335|
|
| 69 |
+
|*GSM8K*|0.3715|
|
| 70 |
+
|*DROP*|0.3105|
|
| 71 |
+
|**Total Average**|**0.6320**|
|
| 72 |
|
| 73 |
|
| 74 |
<br>
|
| 75 |
|
| 76 |
+
## Prompt Format
|
| 77 |
|
| 78 |
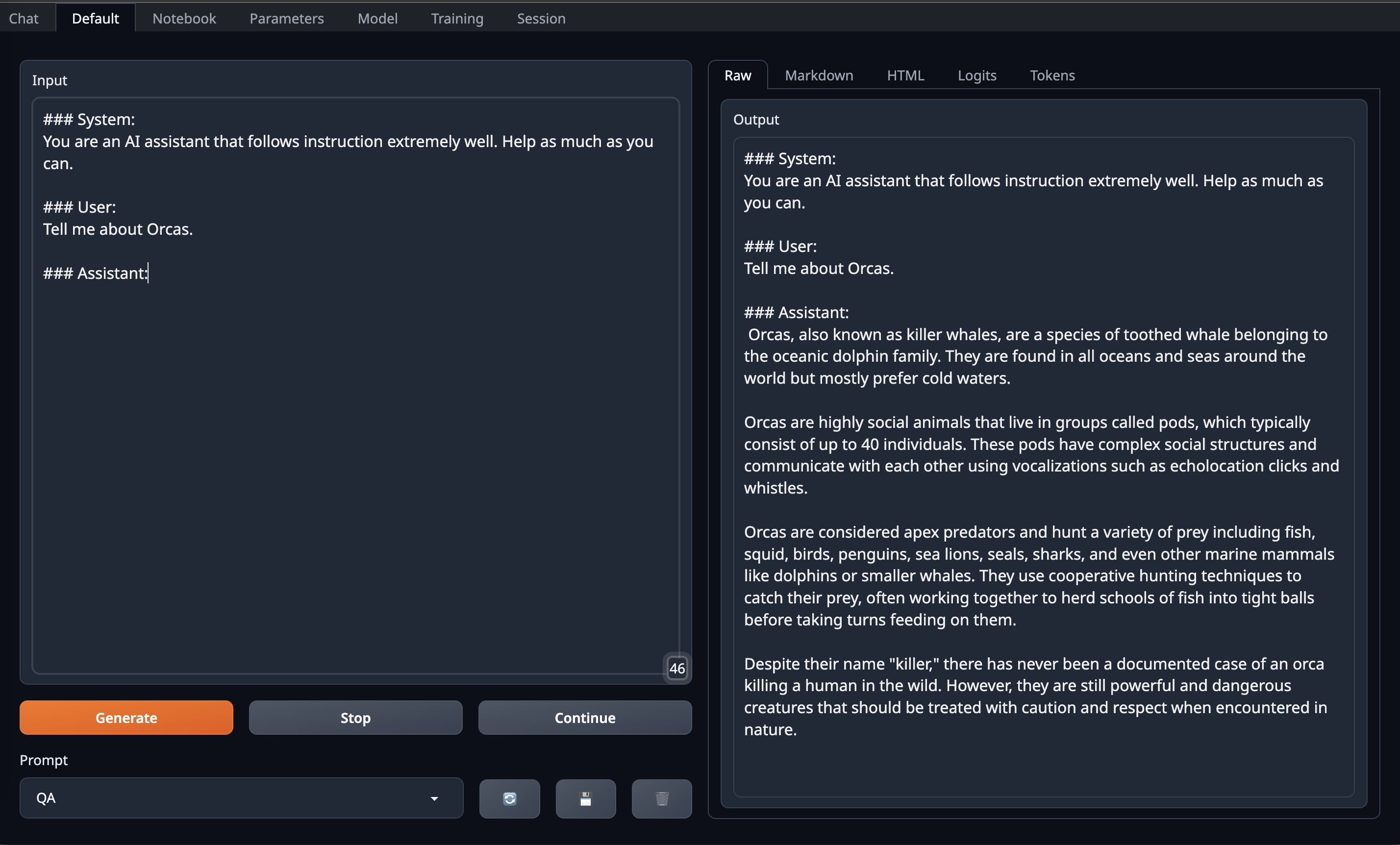
Here is the Orca prompt format
|
| 79 |
|
|
|
|
| 88 |
|
| 89 |
```
|
| 90 |
|
| 91 |
+
Here is the Alpaca prompt format
|
| 92 |
+
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
### User:
|
| 96 |
+
Tell me about Alpacas.
|
| 97 |
+
|
| 98 |
+
### Assistant:
|
| 99 |
+
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
#### OobaBooga Instructions:
|
| 103 |
+
|
| 104 |
+
This model required upto 45GB GPU VRAM in 4bit so it can be loaded directly on Single RTX 6000/L40/A40/A100/H100 GPU or Double RTX 4090/L4/A10/RTX 3090/RTX A5000
|
| 105 |
+
So, if you have access to Machine with 45GB GPU VRAM and have installed [OobaBooga Web UI](https://github.com/oobabooga/text-generation-webui) on it.
|
| 106 |
+
You can just download this model by using HF repo link directly on OobaBooga Web UI "Model" Tab/Page & Just use **load-in-4bit** option in it.
|
| 107 |
+
|
| 108 |
+
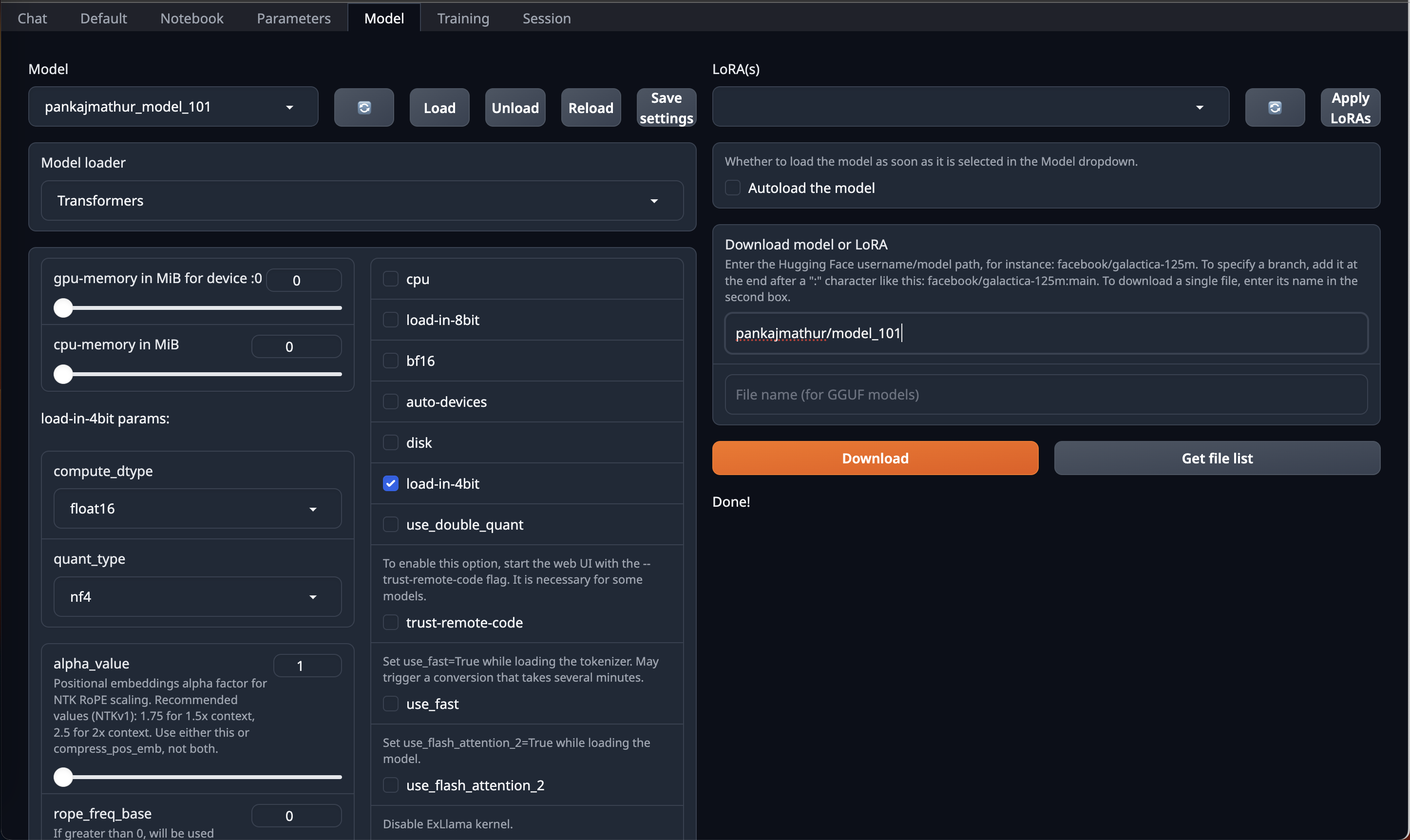
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
After that go to Default Tab/Page on OobaBooga Web UI and **copy paste above prompt format into Input** and Enjoy!
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
<br>
|
| 116 |
+
|
| 117 |
+
#### Code Instructions:
|
| 118 |
+
|
| 119 |
+
Below shows a code example on how to use this model via Orca prompt
|
| 120 |
|
| 121 |
```python
|
| 122 |
import torch
|
|
|
|
| 142 |
|
| 143 |
```
|
| 144 |
|
| 145 |
+
Below shows a code example on how to use this model via Alpaca prompt
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 146 |
|
| 147 |
```python
|
| 148 |
import torch
|