
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
- code
|
| 5 |
+
license: apache-2.0
|
| 6 |
+
library_name: transformers
|
| 7 |
+
tags:
|
| 8 |
+
- tokenizer
|
| 9 |
+
- txa-1
|
| 10 |
+
- axtrio-ai
|
| 11 |
+
- mistral-based
|
| 12 |
+
- chatml
|
| 13 |
+
- moe-optimized
|
| 14 |
+
pipeline_tag: text-generation
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
<div align="center">
|
| 18 |
+
<img src="https://img.rxcodexai.com/img/huggingface%20assets/logo/rx-codex-logo.png" width="40%" alt="Axtrio AI Logo" />
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
<h3 align="center">
|
| 22 |
+
<b>
|
| 23 |
+
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
|
| 24 |
+
<br/>
|
| 25 |
+
Txa 1 Tokenizer: The Foundation of Axtrio AI
|
| 26 |
+
<br/>
|
| 27 |
+
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
|
| 28 |
+
<br/>
|
| 29 |
+
</b>
|
| 30 |
+
</h3>
|
| 31 |
+
|
| 32 |
+
<br/>
|
| 33 |
+
|
| 34 |
+
<div align="center" style="line-height: 1;">
|
| 35 |
+
|
|
| 36 |
+
<a href="https://huggingface.co/AxtrioAI" target="_blank">🤗 Axtrio AI</a>
|
| 37 |
+
|
|
| 38 |
+
<a href="https://rxcodexai.com" target="_blank">🌐 Website</a>
|
| 39 |
+
|
|
| 40 |
+
<a href="mailto:contact@rxcodexai.com" target="_blank">📧 Contact</a>
|
| 41 |
+
|
|
| 42 |
+
<br/>
|
| 43 |
+
</div>
|
| 44 |
+
|
| 45 |
+
<br/>
|
| 46 |
+
|
| 47 |
+
## ⚡ Overview
|
| 48 |
+
|
| 49 |
+
The **Txa 1 Tokenizer** is a highly efficient, production-ready tokenizer engineered for the **Txa 1 (4B MoE)** model family. Built upon the battle-tested **Mistral v1** foundation, it has been fine-tuned to balance high compression rates with extreme processing speed on H100/H200 hardware.
|
| 50 |
+
|
| 51 |
+
This tokenizer natively supports **ChatML** formatting, making it instantly compatible with modern inference engines like vLLM, Ollama, and LM Studio.
|
| 52 |
+
|
| 53 |
+
**Developed by Rx, Founder & CEO of Axtrio AI.**
|
| 54 |
+
|
| 55 |
+
---
|
| 56 |
+
|
| 57 |
+
## 📊 Benchmark Arena
|
| 58 |
+
|
| 59 |
+
We pitted the Txa 1 Tokenizer against industry heavyweights in our **Tokenizer Arena**.
|
| 60 |
+
|
| 61 |
+
### 1. Speed Analysis (Throughput)
|
| 62 |
+
*Higher is better. Measures raw tokenization speed on H100 hardware.*
|
| 63 |
+
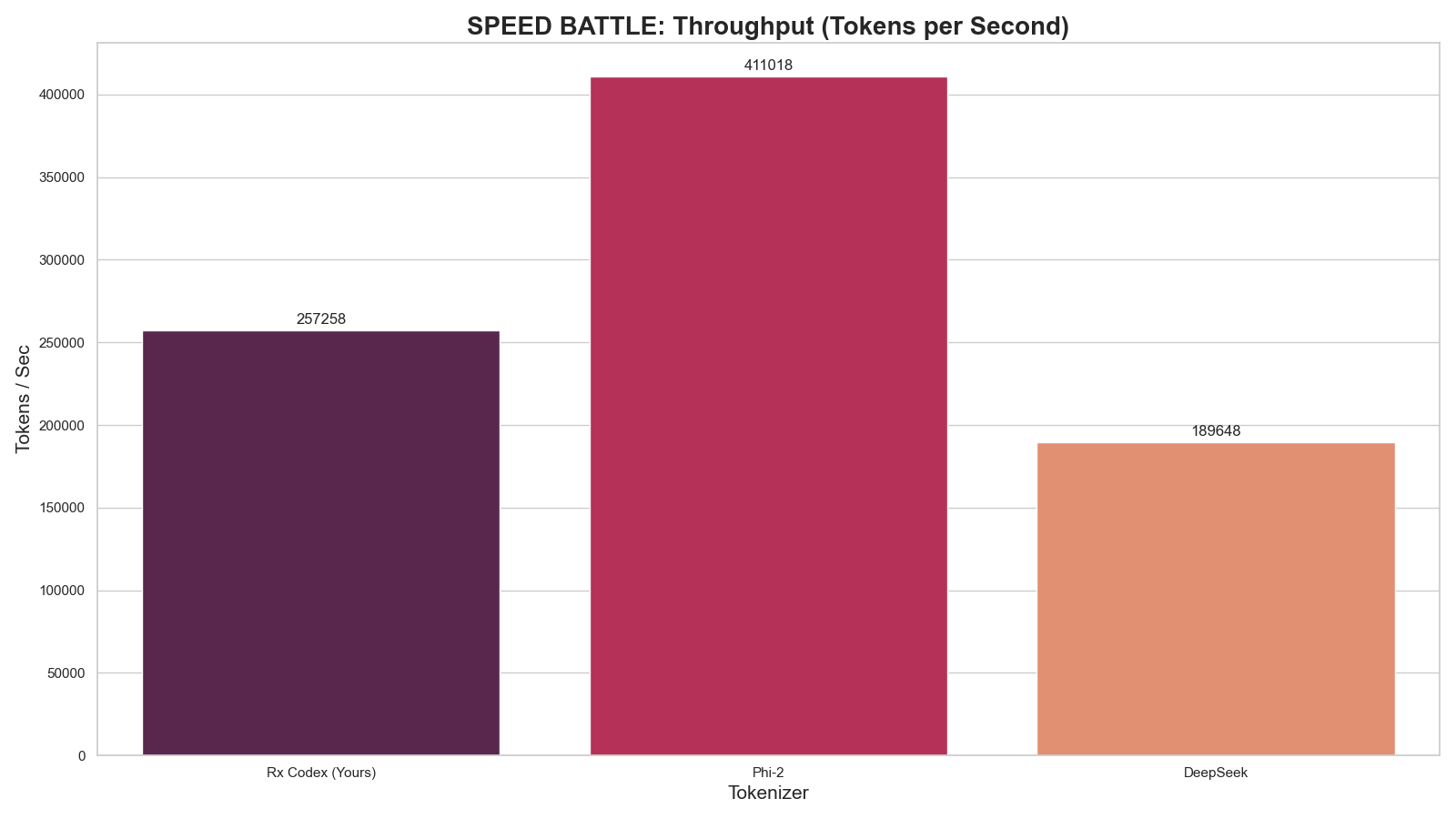
|
| 64 |
+
|
| 65 |
+
### 2. Compression Efficiency
|
| 66 |
+
*Lower is better. Measures how many tokens are needed to represent complex Code & English.*
|
| 67 |
+
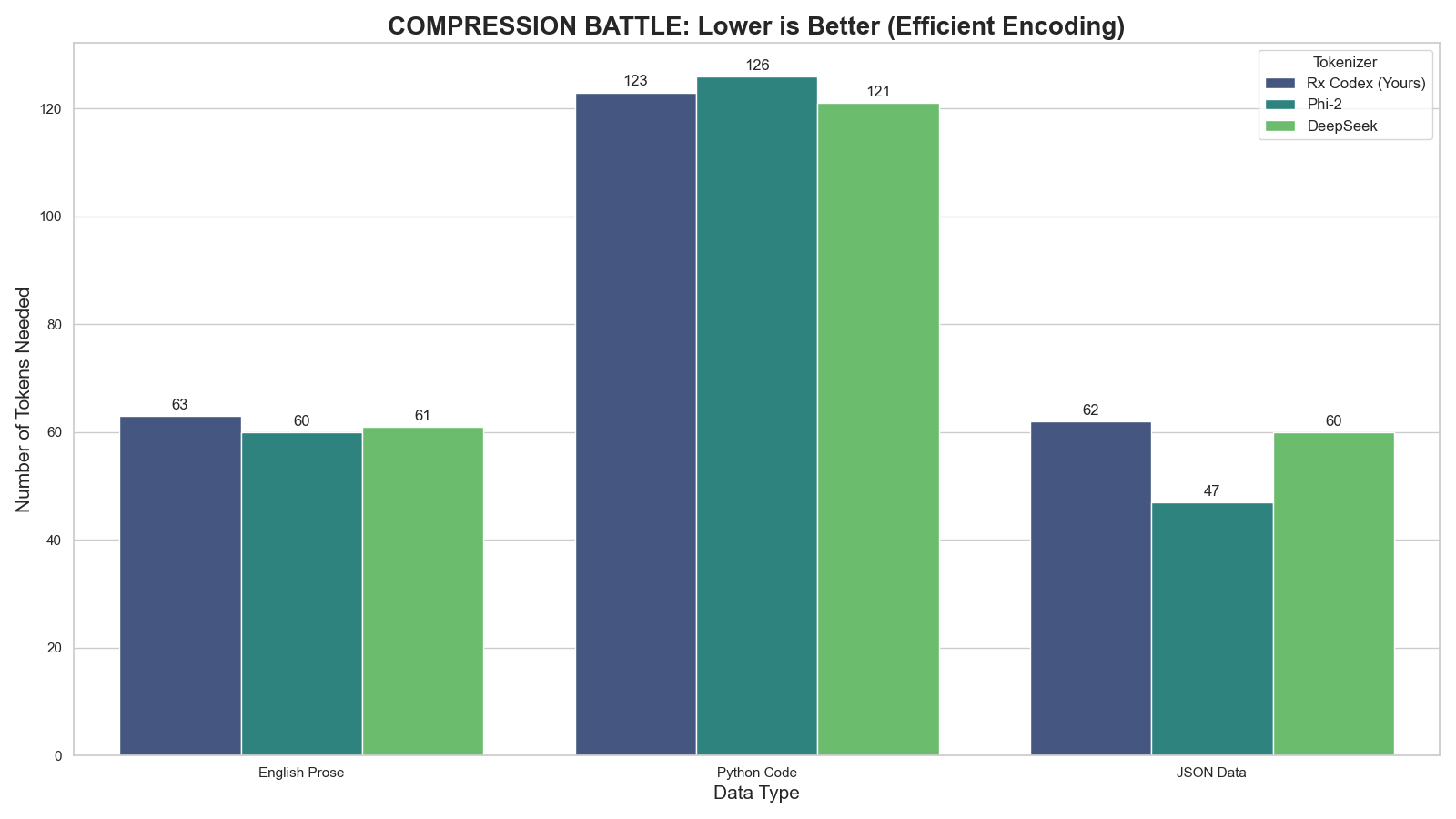
|
| 68 |
+
|
| 69 |
+
### 3. Vocabulary Architecture
|
| 70 |
+
*Comparison of dictionary sizes. Txa 1 stays lean (32k) to maximize VRAM efficiency for the 4B MoE architecture.*
|
| 71 |
+
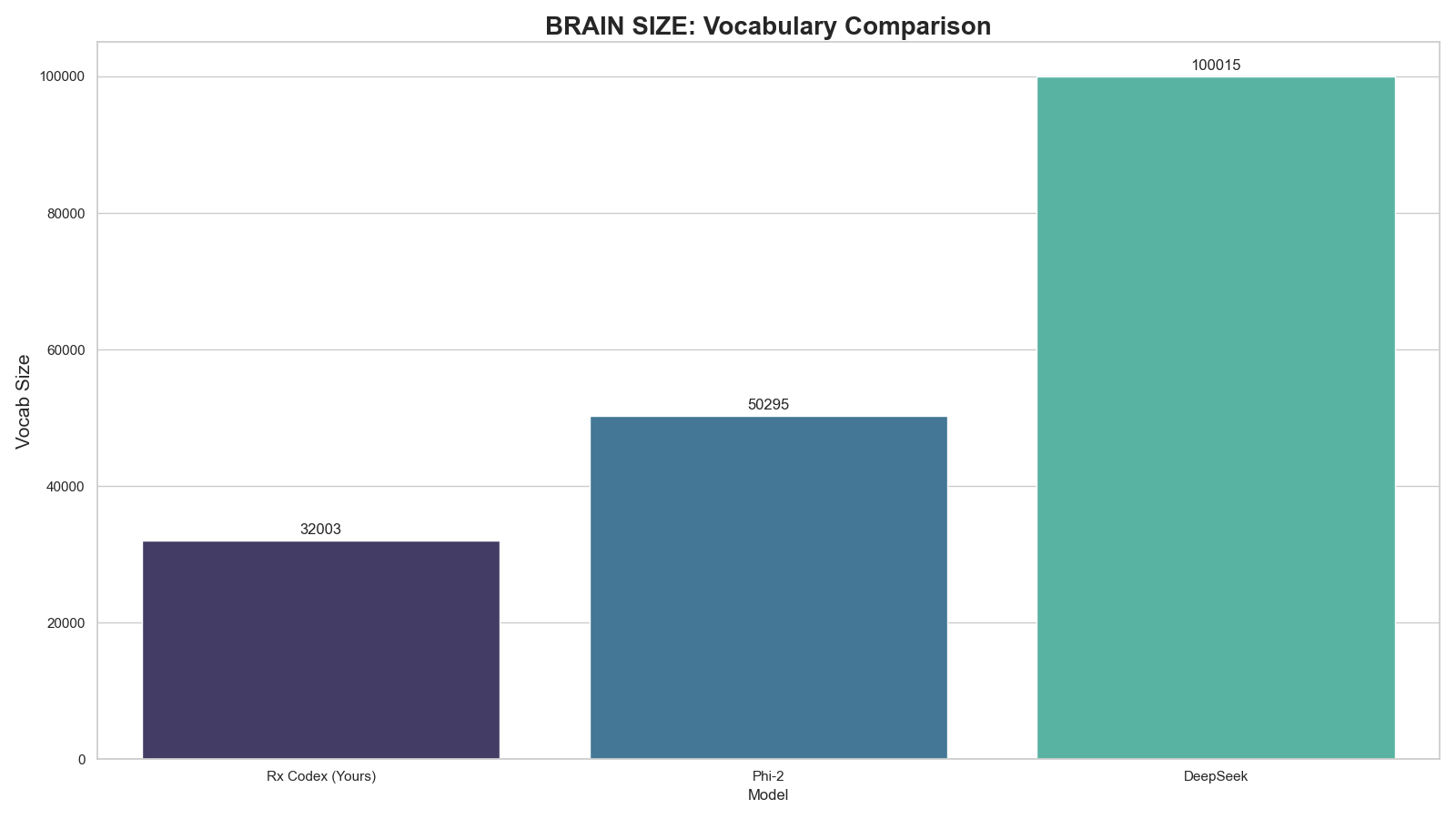
|
| 72 |
+
|
| 73 |
+
---
|
| 74 |
+
|
| 75 |
+
## 🔧 Technical Specifications
|
| 76 |
+
|
| 77 |
+
| Feature | Specification |
|
| 78 |
+
| :--- | :--- |
|
| 79 |
+
| **Base Architecture** | Byte-Pair Encoding (Mistral v1 Foundation) |
|
| 80 |
+
| **Vocabulary Size** | **32,003 Tokens** (Efficient & Lean) |
|
| 81 |
+
| **Added Special Tokens** | `<|im_start|>`, `<|im_end|>`, `<|eot|>` |
|
| 82 |
+
| **Optimization** | Code & Logic Compression |
|
| 83 |
+
| **Compatibility** | Fully Compatible with `LlamaTokenizerFast` |
|
| 84 |
+
|
| 85 |
+
## 💻 Usage
|
| 86 |
+
|
| 87 |
+
### Quick Start
|
| 88 |
+
```python
|
| 89 |
+
from transformers import AutoTokenizer
|
| 90 |
+
|
| 91 |
+
# Load the tokenizer
|
| 92 |
+
tokenizer = AutoTokenizer.from_pretrained("AxtrioAI/Txa1-4B-Tokenizer")
|
| 93 |
+
|
| 94 |
+
# Test ChatML Format
|
| 95 |
+
chat = [
|
| 96 |
+
{"role": "user", "content": "Hello Txa, can you help me debug python?"},
|
| 97 |
+
{"role": "assistant", "content": "Certainly! Please paste your code below."}
|
| 98 |
+
]
|
| 99 |
+
|
| 100 |
+
# Apply template
|
| 101 |
+
formatted_prompt = tokenizer.apply_chat_template(chat, tokenize=False)
|
| 102 |
+
print(formatted_prompt)
|