

Commit
·
f55df64
1
Parent(s):
ab0c00b
add the link to Github
Browse files
README.md
CHANGED
|
@@ -13,9 +13,11 @@ licenses:
|
|
| 13 |
|
| 14 |
Mutual Implication Score is a symmetric measure of text semantic similarity
|
| 15 |
based on a RoBERTA model pretrained for natural language inference
|
| 16 |
-
and fine-tuned on
|
| 17 |
|
| 18 |
-
|
|
|
|
|
|
|
| 19 |
|
| 20 |
## How to use
|
| 21 |
The following snippet illustrates code usage:
|
|
@@ -35,21 +37,21 @@ print(scores)
|
|
| 35 |
|
| 36 |
## Model details
|
| 37 |
|
| 38 |
-
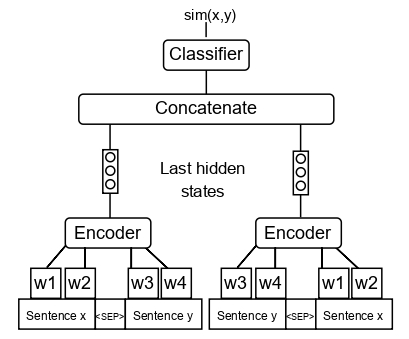
We slightly modify [RoBERTa-Large NLI](https://huggingface.co/ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli) model architecture (see the scheme below) and fine-tune it with [QQP](https://www.kaggle.com/c/quora-question-pairs)
|
| 39 |
|
| 40 |
|
| 41 |
|
| 42 |
## Performance on Text Style Transfer and Paraphrase Detection tasks
|
| 43 |
|
| 44 |
-
This measure was developed in terms of large scale comparison of different measures on text style transfer and
|
| 45 |
|
| 46 |
<img src="https://huggingface.co/SkolkovoInstitute/Mutual_Implication_Score/raw/main/corr_main.jpg" alt="drawing" width="1000"/>
|
| 47 |
|
| 48 |
The scheme above shows the correlations of measures of different classes with human judgments on paraphrase and text style transfer datasets. The text above each dataset indicates the best-performing measure. The rightmost columns show the mean performance of measures across the datasets.
|
| 49 |
|
| 50 |
-
MIS outperforms all measures on
|
| 51 |
|
| 52 |
-
To learn more refer to our article: [A large-scale computational study of content preservation measures for text style transfer and paraphrase generation](https://aclanthology.org/2022.acl-srw.23/)
|
| 53 |
|
| 54 |
## Citations
|
| 55 |
If you find this repository helpful, feel free to cite our publication:
|
|
|
|
| 13 |
|
| 14 |
Mutual Implication Score is a symmetric measure of text semantic similarity
|
| 15 |
based on a RoBERTA model pretrained for natural language inference
|
| 16 |
+
and fine-tuned on a paraphrase detection dataset.
|
| 17 |
|
| 18 |
+
The code for inference and evaluation of the model is available [here](https://github.com/skoltech-nlp/mutual_implication_score).
|
| 19 |
+
|
| 20 |
+
This measure is **particularly useful for paraphrase detection**, but can also be applied to other semantic similarity tasks, such as content similarity scoring in text style transfer.
|
| 21 |
|
| 22 |
## How to use
|
| 23 |
The following snippet illustrates code usage:
|
|
|
|
| 37 |
|
| 38 |
## Model details
|
| 39 |
|
| 40 |
+
We slightly modify the [RoBERTa-Large NLI](https://huggingface.co/ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli) model architecture (see the scheme below) and fine-tune it with [QQP](https://www.kaggle.com/c/quora-question-pairs) paraphrase dataset.
|
| 41 |
|
| 42 |

|
| 43 |
|
| 44 |
## Performance on Text Style Transfer and Paraphrase Detection tasks
|
| 45 |
|
| 46 |
+
This measure was developed in terms of large scale comparison of different measures on text style transfer and paraphrase datasets.
|
| 47 |
|
| 48 |
<img src="https://huggingface.co/SkolkovoInstitute/Mutual_Implication_Score/raw/main/corr_main.jpg" alt="drawing" width="1000"/>
|
| 49 |
|
| 50 |
The scheme above shows the correlations of measures of different classes with human judgments on paraphrase and text style transfer datasets. The text above each dataset indicates the best-performing measure. The rightmost columns show the mean performance of measures across the datasets.
|
| 51 |
|
| 52 |
+
MIS outperforms all measures on the paraphrase detection task and performs on par with top measures on the text style transfer task.
|
| 53 |
|
| 54 |
+
To learn more, refer to our article: [A large-scale computational study of content preservation measures for text style transfer and paraphrase generation](https://aclanthology.org/2022.acl-srw.23/)
|
| 55 |
|
| 56 |
## Citations
|
| 57 |
If you find this repository helpful, feel free to cite our publication:
|