
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- code/RL_model/verl/verl_train/docs/_static/custom.css +217 -0
- code/RL_model/verl/verl_train/docs/_static/js/resizable-sidebar.js +251 -0
- code/RL_model/verl/verl_train/docs/_static/js/runllm-widget.js +14 -0
- code/RL_model/verl/verl_train/docs/_static/logo.png +0 -0
- code/RL_model/verl/verl_train/docs/advance/agent_loop.rst +238 -0
- code/RL_model/verl/verl_train/docs/advance/async-on-policy-distill.md +242 -0
- code/RL_model/verl/verl_train/docs/advance/attention_implementation.rst +119 -0
- code/RL_model/verl/verl_train/docs/advance/checkpoint.rst +159 -0
- code/RL_model/verl/verl_train/docs/advance/dpo_extension.rst +273 -0
- code/RL_model/verl/verl_train/docs/advance/fp8.md +107 -0
- code/RL_model/verl/verl_train/docs/advance/fsdp_extension.rst +97 -0
- code/RL_model/verl/verl_train/docs/advance/fully_async.md +595 -0
- code/RL_model/verl/verl_train/docs/advance/grafana_prometheus.md +193 -0
- code/RL_model/verl/verl_train/docs/advance/megatron_extension.rst +20 -0
- code/RL_model/verl/verl_train/docs/advance/mtp.md +105 -0
- code/RL_model/verl/verl_train/docs/advance/one_step_off.md +319 -0
- code/RL_model/verl/verl_train/docs/advance/placement.rst +13 -0
- code/RL_model/verl/verl_train/docs/advance/ppo_lora.rst +208 -0
- code/RL_model/verl/verl_train/docs/advance/reward_loop.rst +301 -0
- code/RL_model/verl/verl_train/docs/advance/rollout_skip.rst +61 -0
- code/RL_model/verl/verl_train/docs/advance/rollout_trace.rst +146 -0
- code/RL_model/verl/verl_train/docs/advance/rope.rst +39 -0
- code/RL_model/verl/verl_train/docs/algo/baseline.md +73 -0
- code/RL_model/verl/verl_train/docs/algo/collabllm.md +105 -0
- code/RL_model/verl/verl_train/docs/algo/dapo.md +187 -0
- code/RL_model/verl/verl_train/docs/algo/entropy.md +115 -0
- code/RL_model/verl/verl_train/docs/algo/gpg.md +36 -0
- code/RL_model/verl/verl_train/docs/algo/grpo.md +72 -0
- code/RL_model/verl/verl_train/docs/algo/opo.md +33 -0
- code/RL_model/verl/verl_train/docs/algo/otb.md +104 -0
- code/RL_model/verl/verl_train/docs/algo/ppo.md +105 -0
- code/RL_model/verl/verl_train/docs/algo/rollout_corr.md +1313 -0
- code/RL_model/verl/verl_train/docs/algo/rollout_corr_math.md +954 -0
- code/RL_model/verl/verl_train/docs/algo/spin.md +179 -0
- code/RL_model/verl/verl_train/docs/algo/sppo.md +52 -0
- code/RL_model/verl/verl_train/docs/amd_tutorial/amd_build_dockerfile_page.rst +796 -0
- code/RL_model/verl/verl_train/docs/amd_tutorial/amd_vllm_page.rst +41 -0
- code/RL_model/verl/verl_train/docs/api/data.rst +61 -0
- code/RL_model/verl/verl_train/docs/api/single_controller.rst +30 -0
- code/RL_model/verl/verl_train/docs/api/trainer.rst +31 -0
- code/RL_model/verl/verl_train/docs/api/utils.rst +76 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_consistency.rst +50 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_profiling_en.rst +403 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_profiling_zh.rst +398 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_quick_start.rst +289 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_sglang_quick_start.rst +153 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/dockerfile_build_guidance.rst +82 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/ascend_sglang_best_practices.rst +296 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/dapo_multi_model_optimization_practice.md +324 -0
- code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/gspo_optimization_practice.md +233 -0
code/RL_model/verl/verl_train/docs/_static/custom.css
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Make the documentation use full screen width */
|
| 2 |
+
.wy-nav-content {
|
| 3 |
+
max-width: none !important;
|
| 4 |
+
width: 100% !important;
|
| 5 |
+
padding: 1.618em 3.236em !important;
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
/* Adjust the content wrapper - will be set by JavaScript */
|
| 9 |
+
.wy-nav-content-wrap {
|
| 10 |
+
margin-left: 300px;
|
| 11 |
+
transition: margin-left 0.2s ease;
|
| 12 |
+
width: auto !important;
|
| 13 |
+
position: relative !important;
|
| 14 |
+
background: white !important;
|
| 15 |
+
min-height: 100vh !important;
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
/* Make the main content area responsive */
|
| 19 |
+
.rst-content {
|
| 20 |
+
max-width: none !important;
|
| 21 |
+
width: 100% !important;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
/* Optional: Adjust table widths to prevent overflow */
|
| 25 |
+
.rst-content table.docutils {
|
| 26 |
+
width: 100% !important;
|
| 27 |
+
table-layout: auto !important;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
/* Optional: Better code block width handling */
|
| 31 |
+
.rst-content .highlight {
|
| 32 |
+
width: 100% !important;
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
/* Content area positioning already handled above */
|
| 36 |
+
|
| 37 |
+
/* Optional: Improve readability with some margin on very wide screens */
|
| 38 |
+
@media (min-width: 1400px) {
|
| 39 |
+
.wy-nav-content {
|
| 40 |
+
max-width: none !important;
|
| 41 |
+
margin: 0 auto !important;
|
| 42 |
+
}
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
/* Resizable sidebar styles */
|
| 46 |
+
.wy-nav-side {
|
| 47 |
+
position: fixed !important;
|
| 48 |
+
top: 0 !important;
|
| 49 |
+
bottom: 0 !important;
|
| 50 |
+
left: 0 !important;
|
| 51 |
+
width: 300px;
|
| 52 |
+
min-width: 200px;
|
| 53 |
+
max-width: 600px;
|
| 54 |
+
display: flex;
|
| 55 |
+
flex-direction: column;
|
| 56 |
+
z-index: 200 !important;
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
/* Ensure sidebar header (logo, search) adapts to width */
|
| 60 |
+
.wy-side-nav-search {
|
| 61 |
+
width: 100% !important;
|
| 62 |
+
box-sizing: border-box !important;
|
| 63 |
+
padding: 0.809em 0.809em !important;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
.wy-side-nav-search input[type="text"] {
|
| 67 |
+
width: 100% !important;
|
| 68 |
+
box-sizing: border-box !important;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
/* Make logo/title area responsive */
|
| 72 |
+
.wy-side-nav-search > div.version {
|
| 73 |
+
width: 100% !important;
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
.wy-side-nav-search > a {
|
| 77 |
+
width: 100% !important;
|
| 78 |
+
display: block !important;
|
| 79 |
+
white-space: nowrap !important;
|
| 80 |
+
overflow: hidden !important;
|
| 81 |
+
text-overflow: ellipsis !important;
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
/* Responsive adjustments for narrow sidebar */
|
| 85 |
+
@media (max-width: 300px) {
|
| 86 |
+
.wy-side-nav-search > a {
|
| 87 |
+
font-size: 0.9em !important;
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
.wy-side-nav-search input[type="text"] {
|
| 91 |
+
font-size: 0.8em !important;
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
/* Ensure search input doesn't overflow */
|
| 96 |
+
.wy-side-nav-search form {
|
| 97 |
+
width: 100% !important;
|
| 98 |
+
margin: 0 !important;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
/* Make search icon responsive */
|
| 102 |
+
.wy-side-nav-search .wy-dropdown {
|
| 103 |
+
width: 100% !important;
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
/* Adjust search results dropdown width */
|
| 107 |
+
.wy-side-nav-search .wy-dropdown-menu {
|
| 108 |
+
width: 100% !important;
|
| 109 |
+
max-width: none !important;
|
| 110 |
+
left: 0 !important;
|
| 111 |
+
right: 0 !important;
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
/* Resize handle is created by JavaScript */
|
| 115 |
+
|
| 116 |
+
/* Make sure the sidebar content doesn't overflow */
|
| 117 |
+
.wy-side-scroll {
|
| 118 |
+
width: 100% !important;
|
| 119 |
+
flex: 1 !important;
|
| 120 |
+
overflow-y: auto !important;
|
| 121 |
+
overflow-x: hidden !important;
|
| 122 |
+
padding-right: 10px !important;
|
| 123 |
+
box-sizing: border-box !important;
|
| 124 |
+
scroll-behavior: auto !important; /* Prevent smooth scrolling on sidebar itself */
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
/* Ensure proper scroll behavior for main content area */
|
| 128 |
+
html {
|
| 129 |
+
scroll-behavior: smooth !important;
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
/* Ensure anchor links work properly in main content */
|
| 133 |
+
.wy-nav-content-wrap {
|
| 134 |
+
scroll-behavior: smooth !important;
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
/* Fix scroll to target for anchor links */
|
| 138 |
+
.rst-content {
|
| 139 |
+
scroll-behavior: smooth !important;
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
/* Fix anchor scroll offset to account for fixed header */
|
| 143 |
+
.rst-content .section {
|
| 144 |
+
scroll-margin-top: 60px;
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
/* Fix anchor scroll offset for headers */
|
| 148 |
+
.rst-content h1, .rst-content h2, .rst-content h3, .rst-content h4, .rst-content h5, .rst-content h6 {
|
| 149 |
+
scroll-margin-top: 60px;
|
| 150 |
+
}
|
| 151 |
+
|
| 152 |
+
/* Fix anchor scroll offset for specific scroll targets */
|
| 153 |
+
.rst-content .headerlink {
|
| 154 |
+
scroll-margin-top: 60px;
|
| 155 |
+
}
|
| 156 |
+
|
| 157 |
+
/* Fix sidebar navigation styling */
|
| 158 |
+
.wy-menu-vertical {
|
| 159 |
+
width: 100% !important;
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
.wy-menu-vertical li {
|
| 163 |
+
width: 100% !important;
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
.wy-menu-vertical a {
|
| 167 |
+
width: 100% !important;
|
| 168 |
+
word-wrap: break-word !important;
|
| 169 |
+
white-space: normal !important;
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
/* Content area margin is handled by JavaScript */
|
| 173 |
+
|
| 174 |
+
/* Custom drag handle (more visible) */
|
| 175 |
+
.resize-handle {
|
| 176 |
+
position: absolute;
|
| 177 |
+
top: 0;
|
| 178 |
+
right: 0;
|
| 179 |
+
width: 8px;
|
| 180 |
+
height: 100%;
|
| 181 |
+
background: #ccc;
|
| 182 |
+
cursor: col-resize;
|
| 183 |
+
z-index: 1001;
|
| 184 |
+
opacity: 0.3;
|
| 185 |
+
transition: opacity 0.2s ease;
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
.resize-handle:hover {
|
| 189 |
+
opacity: 0.8;
|
| 190 |
+
background: #999;
|
| 191 |
+
}
|
| 192 |
+
|
| 193 |
+
.resize-handle::before {
|
| 194 |
+
content: '';
|
| 195 |
+
position: absolute;
|
| 196 |
+
top: 50%;
|
| 197 |
+
left: 50%;
|
| 198 |
+
width: 2px;
|
| 199 |
+
height: 20px;
|
| 200 |
+
background: #666;
|
| 201 |
+
transform: translate(-50%, -50%);
|
| 202 |
+
border-radius: 1px;
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
.resize-handle:hover::before {
|
| 206 |
+
background: #333;
|
| 207 |
+
}
|
| 208 |
+
|
| 209 |
+
/* Ensure smooth resizing */
|
| 210 |
+
.wy-nav-side.resizing {
|
| 211 |
+
user-select: none;
|
| 212 |
+
pointer-events: none;
|
| 213 |
+
}
|
| 214 |
+
|
| 215 |
+
.wy-nav-side.resizing .wy-side-scroll {
|
| 216 |
+
overflow: hidden;
|
| 217 |
+
}
|
code/RL_model/verl/verl_train/docs/_static/js/resizable-sidebar.js
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Resizable sidebar functionality
|
| 2 |
+
document.addEventListener('DOMContentLoaded', function() {
|
| 3 |
+
const sidebar = document.querySelector('.wy-nav-side');
|
| 4 |
+
const content = document.querySelector('.wy-nav-content-wrap');
|
| 5 |
+
|
| 6 |
+
if (!sidebar || !content) return;
|
| 7 |
+
|
| 8 |
+
// Create resize handle
|
| 9 |
+
const resizeHandle = document.createElement('div');
|
| 10 |
+
resizeHandle.className = 'resize-handle';
|
| 11 |
+
sidebar.appendChild(resizeHandle);
|
| 12 |
+
|
| 13 |
+
let isResizing = false;
|
| 14 |
+
let startX = 0;
|
| 15 |
+
let startWidth = 0;
|
| 16 |
+
|
| 17 |
+
// Get initial width
|
| 18 |
+
const getInitialWidth = () => {
|
| 19 |
+
return 300; // Default width
|
| 20 |
+
};
|
| 21 |
+
|
| 22 |
+
// Save width to localStorage
|
| 23 |
+
const saveWidth = (width) => {
|
| 24 |
+
localStorage.setItem('sidebar-width', width);
|
| 25 |
+
};
|
| 26 |
+
|
| 27 |
+
// Load width from localStorage
|
| 28 |
+
const loadWidth = () => {
|
| 29 |
+
const savedWidth = localStorage.getItem('sidebar-width');
|
| 30 |
+
if (savedWidth) {
|
| 31 |
+
const width = parseInt(savedWidth, 10);
|
| 32 |
+
if (width >= 200 && width <= 600) {
|
| 33 |
+
return width;
|
| 34 |
+
}
|
| 35 |
+
}
|
| 36 |
+
return getInitialWidth();
|
| 37 |
+
};
|
| 38 |
+
|
| 39 |
+
// Apply width to sidebar and content
|
| 40 |
+
const applyWidth = (width) => {
|
| 41 |
+
// Update sidebar width
|
| 42 |
+
sidebar.style.width = width + 'px';
|
| 43 |
+
|
| 44 |
+
// Update content margin with !important to override any CSS
|
| 45 |
+
content.style.setProperty('margin-left', width + 'px', 'important');
|
| 46 |
+
|
| 47 |
+
// Also update any other content wrapper that might exist
|
| 48 |
+
const contentInner = document.querySelector('.wy-nav-content');
|
| 49 |
+
if (contentInner) {
|
| 50 |
+
contentInner.style.setProperty('margin-left', '0px', 'important');
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
// Force reflow and repaint
|
| 54 |
+
sidebar.offsetHeight;
|
| 55 |
+
content.offsetHeight;
|
| 56 |
+
|
| 57 |
+
// Trigger window resize event to notify other components
|
| 58 |
+
window.dispatchEvent(new Event('resize'));
|
| 59 |
+
};
|
| 60 |
+
|
| 61 |
+
// Initialize with saved width
|
| 62 |
+
const initialWidth = loadWidth();
|
| 63 |
+
applyWidth(initialWidth);
|
| 64 |
+
|
| 65 |
+
// Mouse down on resize handle
|
| 66 |
+
resizeHandle.addEventListener('mousedown', (e) => {
|
| 67 |
+
isResizing = true;
|
| 68 |
+
startX = e.clientX;
|
| 69 |
+
startWidth = parseInt(window.getComputedStyle(sidebar).width, 10);
|
| 70 |
+
|
| 71 |
+
sidebar.classList.add('resizing');
|
| 72 |
+
document.body.style.cursor = 'col-resize';
|
| 73 |
+
document.body.style.userSelect = 'none';
|
| 74 |
+
|
| 75 |
+
// Add overlay to prevent iframe issues
|
| 76 |
+
const overlay = document.createElement('div');
|
| 77 |
+
overlay.style.cssText = `
|
| 78 |
+
position: fixed;
|
| 79 |
+
top: 0;
|
| 80 |
+
left: 0;
|
| 81 |
+
width: 100%;
|
| 82 |
+
height: 100%;
|
| 83 |
+
z-index: 9999;
|
| 84 |
+
cursor: col-resize;
|
| 85 |
+
`;
|
| 86 |
+
overlay.id = 'resize-overlay';
|
| 87 |
+
document.body.appendChild(overlay);
|
| 88 |
+
|
| 89 |
+
e.preventDefault();
|
| 90 |
+
});
|
| 91 |
+
|
| 92 |
+
// Mouse move
|
| 93 |
+
document.addEventListener('mousemove', (e) => {
|
| 94 |
+
if (!isResizing) return;
|
| 95 |
+
|
| 96 |
+
const width = startWidth + e.clientX - startX;
|
| 97 |
+
const clampedWidth = Math.max(200, Math.min(600, width));
|
| 98 |
+
applyWidth(clampedWidth);
|
| 99 |
+
});
|
| 100 |
+
|
| 101 |
+
// Mouse up
|
| 102 |
+
document.addEventListener('mouseup', () => {
|
| 103 |
+
if (!isResizing) return;
|
| 104 |
+
|
| 105 |
+
isResizing = false;
|
| 106 |
+
sidebar.classList.remove('resizing');
|
| 107 |
+
document.body.style.cursor = '';
|
| 108 |
+
document.body.style.userSelect = '';
|
| 109 |
+
|
| 110 |
+
// Remove overlay
|
| 111 |
+
const overlay = document.getElementById('resize-overlay');
|
| 112 |
+
if (overlay) {
|
| 113 |
+
overlay.remove();
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
// Save the current width
|
| 117 |
+
const currentWidth = parseInt(window.getComputedStyle(sidebar).width, 10);
|
| 118 |
+
saveWidth(currentWidth);
|
| 119 |
+
});
|
| 120 |
+
|
| 121 |
+
// Handle window resize - removed to prevent infinite loop
|
| 122 |
+
// The sidebar width is fixed and managed by drag functionality, no need to recalculate on window resize
|
| 123 |
+
|
| 124 |
+
// Double-click to reset to default width
|
| 125 |
+
resizeHandle.addEventListener('dblclick', () => {
|
| 126 |
+
const defaultWidth = 300;
|
| 127 |
+
applyWidth(defaultWidth);
|
| 128 |
+
saveWidth(defaultWidth);
|
| 129 |
+
});
|
| 130 |
+
});
|
| 131 |
+
|
| 132 |
+
// Fix navigation issues - Using MutationObserver for reliable initialization
|
| 133 |
+
document.addEventListener('DOMContentLoaded', function() {
|
| 134 |
+
let navigationFixed = false;
|
| 135 |
+
|
| 136 |
+
function setupNavigationFix() {
|
| 137 |
+
if (navigationFixed) return;
|
| 138 |
+
|
| 139 |
+
// Find all links in the sidebar
|
| 140 |
+
const sidebarLinks = document.querySelectorAll('.wy-menu-vertical a');
|
| 141 |
+
|
| 142 |
+
// Only proceed if we have sidebar links
|
| 143 |
+
if (sidebarLinks.length === 0) return;
|
| 144 |
+
|
| 145 |
+
console.log('Setting up navigation fix...');
|
| 146 |
+
|
| 147 |
+
sidebarLinks.forEach(function(link) {
|
| 148 |
+
const href = link.getAttribute('href');
|
| 149 |
+
|
| 150 |
+
// Clone the link to remove all existing event listeners
|
| 151 |
+
const newLink = link.cloneNode(true);
|
| 152 |
+
|
| 153 |
+
// Add our own click handler
|
| 154 |
+
newLink.addEventListener('click', function(e) {
|
| 155 |
+
console.log('Link clicked:', href);
|
| 156 |
+
|
| 157 |
+
// If it's an anchor link within the same page
|
| 158 |
+
if (href && href.startsWith('#') && href !== '#') {
|
| 159 |
+
e.preventDefault();
|
| 160 |
+
e.stopPropagation();
|
| 161 |
+
|
| 162 |
+
const targetId = href.substring(1);
|
| 163 |
+
const targetElement = document.getElementById(targetId);
|
| 164 |
+
|
| 165 |
+
if (targetElement) {
|
| 166 |
+
// Calculate offset for fixed header
|
| 167 |
+
const headerHeight = 60;
|
| 168 |
+
const elementPosition = targetElement.getBoundingClientRect().top;
|
| 169 |
+
const offsetPosition = elementPosition + window.pageYOffset - headerHeight;
|
| 170 |
+
|
| 171 |
+
window.scrollTo({
|
| 172 |
+
top: offsetPosition,
|
| 173 |
+
behavior: 'smooth'
|
| 174 |
+
});
|
| 175 |
+
|
| 176 |
+
// Update URL hash
|
| 177 |
+
if (history.pushState) {
|
| 178 |
+
history.pushState(null, null, '#' + targetId);
|
| 179 |
+
} else {
|
| 180 |
+
location.hash = '#' + targetId;
|
| 181 |
+
}
|
| 182 |
+
}
|
| 183 |
+
}
|
| 184 |
+
// For external links, navigate normally
|
| 185 |
+
else if (href && !href.startsWith('#') && !href.startsWith('javascript:')) {
|
| 186 |
+
console.log('Navigating to external link:', href);
|
| 187 |
+
window.location.href = href;
|
| 188 |
+
}
|
| 189 |
+
});
|
| 190 |
+
|
| 191 |
+
// Replace the old link with the new one
|
| 192 |
+
link.parentNode.replaceChild(newLink, link);
|
| 193 |
+
});
|
| 194 |
+
|
| 195 |
+
navigationFixed = true;
|
| 196 |
+
|
| 197 |
+
// Handle initial page load with hash
|
| 198 |
+
if (window.location.hash) {
|
| 199 |
+
// Use requestAnimationFrame for better timing
|
| 200 |
+
requestAnimationFrame(() => {
|
| 201 |
+
const targetId = window.location.hash.substring(1);
|
| 202 |
+
const targetElement = document.getElementById(targetId);
|
| 203 |
+
if (targetElement) {
|
| 204 |
+
const headerHeight = 60;
|
| 205 |
+
const elementPosition = targetElement.getBoundingClientRect().top;
|
| 206 |
+
const offsetPosition = elementPosition + window.pageYOffset - headerHeight;
|
| 207 |
+
|
| 208 |
+
window.scrollTo({
|
| 209 |
+
top: offsetPosition,
|
| 210 |
+
behavior: 'smooth'
|
| 211 |
+
});
|
| 212 |
+
}
|
| 213 |
+
});
|
| 214 |
+
}
|
| 215 |
+
}
|
| 216 |
+
|
| 217 |
+
// Try to set up navigation fix immediately
|
| 218 |
+
setupNavigationFix();
|
| 219 |
+
|
| 220 |
+
// If it didn't work, use MutationObserver to watch for when sidebar links are added
|
| 221 |
+
if (!navigationFixed) {
|
| 222 |
+
const observer = new MutationObserver(function(mutations) {
|
| 223 |
+
mutations.forEach(function(mutation) {
|
| 224 |
+
if (mutation.type === 'childList' && mutation.addedNodes.length > 0) {
|
| 225 |
+
// Check if sidebar links were added
|
| 226 |
+
const sidebarLinks = document.querySelectorAll('.wy-menu-vertical a');
|
| 227 |
+
if (sidebarLinks.length > 0) {
|
| 228 |
+
setupNavigationFix();
|
| 229 |
+
if (navigationFixed) {
|
| 230 |
+
observer.disconnect();
|
| 231 |
+
}
|
| 232 |
+
}
|
| 233 |
+
}
|
| 234 |
+
});
|
| 235 |
+
});
|
| 236 |
+
|
| 237 |
+
// Start observing the document for changes
|
| 238 |
+
observer.observe(document.body, {
|
| 239 |
+
childList: true,
|
| 240 |
+
subtree: true
|
| 241 |
+
});
|
| 242 |
+
|
| 243 |
+
// Fallback timeout in case MutationObserver doesn't work
|
| 244 |
+
setTimeout(function() {
|
| 245 |
+
if (!navigationFixed) {
|
| 246 |
+
setupNavigationFix();
|
| 247 |
+
}
|
| 248 |
+
observer.disconnect();
|
| 249 |
+
}, 5000);
|
| 250 |
+
}
|
| 251 |
+
});
|
code/RL_model/verl/verl_train/docs/_static/js/runllm-widget.js
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.addEventListener("DOMContentLoaded", function () {
|
| 2 |
+
var script = document.createElement("script");
|
| 3 |
+
script.type = "module";
|
| 4 |
+
script.id = "runllm-widget-script";
|
| 5 |
+
script.src = "https://widget.runllm.com";
|
| 6 |
+
script.setAttribute("version", "stable");
|
| 7 |
+
script.setAttribute("crossorigin", "true");
|
| 8 |
+
script.setAttribute("runllm-keyboard-shortcut", "Mod+j");
|
| 9 |
+
script.setAttribute("runllm-name", "verl Chatbot");
|
| 10 |
+
script.setAttribute("runllm-position", "TOP_RIGHT");
|
| 11 |
+
script.setAttribute("runllm-assistant-id", "679");
|
| 12 |
+
script.async = true;
|
| 13 |
+
document.head.appendChild(script);
|
| 14 |
+
});
|
code/RL_model/verl/verl_train/docs/_static/logo.png
ADDED
|
|
code/RL_model/verl/verl_train/docs/advance/agent_loop.rst
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Agent Loop
|
| 2 |
+
==========
|
| 3 |
+
|
| 4 |
+
Last updated: 07/17/2025.
|
| 5 |
+
|
| 6 |
+
.. versionadded:: 0.4.2
|
| 7 |
+
[status: alpha]
|
| 8 |
+
|
| 9 |
+
.. warning::
|
| 10 |
+
Agent Loop is ready for use, but the API may change in future releaes.
|
| 11 |
+
|
| 12 |
+
Agent Loop is designed as general interface for multi-turn rollout and agentic reinforcement learning.
|
| 13 |
+
|
| 14 |
+
**Design goal**:
|
| 15 |
+
|
| 16 |
+
- Plugable user defined agent loop
|
| 17 |
+
- Provide standard request generate api with different inference frameworks
|
| 18 |
+
- Provide request level load balance between multiple inference servers
|
| 19 |
+
|
| 20 |
+
**Non-goal**:
|
| 21 |
+
|
| 22 |
+
- How tool is defined and how to call tool
|
| 23 |
+
|
| 24 |
+
In high level overview, agent loop is given a prompt, run user defined loop: call LLM generate api, call tools, ...
|
| 25 |
+
and return the final output. The final output is then calculated reward and used as trajectory for RL training.
|
| 26 |
+
|
| 27 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/agent_loop_overview.svg?raw=true
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
API Design
|
| 31 |
+
----------
|
| 32 |
+
|
| 33 |
+
``AgentLoopBase`` class is the abstraction of agent loop, and ``run`` method is the only interface that user need to implement.
|
| 34 |
+
The run method, given prompt messages in format: [{"role": "user"}, {"content": "..."}], and additional sampling params,
|
| 35 |
+
could do whatever user wants, such as
|
| 36 |
+
|
| 37 |
+
- call LLM generate api
|
| 38 |
+
- call tools: web search, database query, code sandbox, ...
|
| 39 |
+
- environment interaction
|
| 40 |
+
- reflection
|
| 41 |
+
- ...
|
| 42 |
+
|
| 43 |
+
.. code:: python
|
| 44 |
+
|
| 45 |
+
class AgentLoopBase(ABC):
|
| 46 |
+
@abstractmethod
|
| 47 |
+
async def run(self, sampling_params: dict[str, Any], **kwargs) -> AgentLoopOutput:
|
| 48 |
+
"""Run agent loop to interact with LLM server and environment.
|
| 49 |
+
|
| 50 |
+
Args:
|
| 51 |
+
sampling_params (Dict[str, Any]): LLM sampling params.
|
| 52 |
+
**kwargs: dataset fields from `verl.utils.dataset.RLHFDataset`.
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
AgentLoopOutput: Agent loop output.
|
| 56 |
+
"""
|
| 57 |
+
raise NotImplementedError
|
| 58 |
+
|
| 59 |
+
After running user defined loop, run method should return ``AgentLoopOutput``, including prompt token ids,
|
| 60 |
+
response token ids, and response mask.
|
| 61 |
+
|
| 62 |
+
.. code:: python
|
| 63 |
+
|
| 64 |
+
class AgentLoopOutput(BaseModel):
|
| 65 |
+
"""Agent loop output."""
|
| 66 |
+
|
| 67 |
+
prompt_ids: list[int]
|
| 68 |
+
"""Prompt token ids."""
|
| 69 |
+
response_ids: list[int]
|
| 70 |
+
"""Response token ids including LLM generated token, tool response token."""
|
| 71 |
+
response_mask: list[int]
|
| 72 |
+
"""Response mask, 1 for LLM generated token, 0 for tool response token."""
|
| 73 |
+
|
| 74 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/agent_loop_output.svg?raw=true
|
| 75 |
+
|
| 76 |
+
.. note:: AgentLoopOutput only output one trajectory for a given prompt, multiple trajectories output is still under discussion.
|
| 77 |
+
|
| 78 |
+
Architecture Design
|
| 79 |
+
-------------------
|
| 80 |
+
|
| 81 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/agent_loop_architecture.png?raw=true
|
| 82 |
+
|
| 83 |
+
A single PPO step contain two phase: rollout and train. In rollout phase:
|
| 84 |
+
|
| 85 |
+
1. PPOTrainer sample a batch from dataset and call ``AgentLoopManager.generate_sequences``.
|
| 86 |
+
2. AgentLoopManager ``wake_up`` all async LLM server instances, which will sync weights between inference engine(vLLM/SGLang) and training engine(FSDP/Megatron-LM).
|
| 87 |
+
3. AgentLoopManager split batch into chunks and send each chunk to ``AgentLoopWorker``.
|
| 88 |
+
4. AgentLoopWorker receive chunk and for each prompt, spawn a user defined ``AgentLoopBase`` instance, run ``run`` coroutine until end and get ``AgentLoopOutput``.
|
| 89 |
+
|
| 90 |
+
.. tip::
|
| 91 |
+
AgentLoopWorker schedules multiple coroutines concurrently. If number of AgentLoopWorker equals batch_size, then each worker is response for one prompt.
|
| 92 |
+
|
| 93 |
+
In agent loop, when user need LLM generate response:
|
| 94 |
+
|
| 95 |
+
5. Call ``AsyncLLMServerManager.generate`` with prompt_ids.
|
| 96 |
+
6. AsyncLLMServerManager select a server instance with least request in first turn and send request to it. (In following turns, the request will be sent to the same server instance).
|
| 97 |
+
7. AsyncLLMServer receive a request, issue ipc/rpc with model_runner, and generate response. (There's slight differences between vLLM and SGLang, see below).
|
| 98 |
+
|
| 99 |
+
When all prompts in all AgentLoopWorker finish, AgentLoopManager gather results and return to PPOTrainer.
|
| 100 |
+
|
| 101 |
+
8. AgentLoopManager ``sleep`` all server instances, which will free kv cache and offload weights to CPU memory.
|
| 102 |
+
|
| 103 |
+
AsyncLLMServer
|
| 104 |
+
~~~~~~~~~~~~~~
|
| 105 |
+
|
| 106 |
+
AsyncLLMServer is the abstraction of LLM server with two types of generation api:
|
| 107 |
+
|
| 108 |
+
- `OpenAI chat completion <https://platform.openai.com/docs/api-reference/chat>`_: generate response for the given chat conversation.
|
| 109 |
+
- Token in token out: generate response ids for the given token ids.
|
| 110 |
+
|
| 111 |
+
We have officially supported vLLM and SGLang AsyncLLMServer, both of them implement the two api and are well tested.
|
| 112 |
+
Other inference engine should be easy to plug-in by implement the ``AsyncServerBase`` class.
|
| 113 |
+
|
| 114 |
+
.. code:: python
|
| 115 |
+
|
| 116 |
+
class AsyncServerBase(ABC):
|
| 117 |
+
@abstractmethod
|
| 118 |
+
async def chat_completion(self, raw_request: Request) -> JSONResponse:
|
| 119 |
+
"""OpenAI chat completion API.
|
| 120 |
+
|
| 121 |
+
Args:
|
| 122 |
+
raw_request (Request): raw json request
|
| 123 |
+
|
| 124 |
+
Returns:
|
| 125 |
+
JSONResponse: json response
|
| 126 |
+
|
| 127 |
+
API reference: https://platform.openai.com/docs/api-reference/chat/create
|
| 128 |
+
"""
|
| 129 |
+
raise NotImplementedError
|
| 130 |
+
|
| 131 |
+
@abstractmethod
|
| 132 |
+
async def generate(self, prompt_ids: list[int], sampling_params: dict[str, Any], request_id: str) -> list[int]:
|
| 133 |
+
"""Generate response ids given prompt ids.
|
| 134 |
+
|
| 135 |
+
Args:
|
| 136 |
+
prompt_ids (List[int]): prompt ids
|
| 137 |
+
sampling_params (Dict[str, Any]): sampling params
|
| 138 |
+
request_id (str): request id
|
| 139 |
+
|
| 140 |
+
Returns:
|
| 141 |
+
List[int]: response ids
|
| 142 |
+
"""
|
| 143 |
+
raise NotImplementedError
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
Chat completion vs Token in token out
|
| 147 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 148 |
+
|
| 149 |
+
.. warning::
|
| 150 |
+
The following conclusion is based on our recent experience and is still open to investigation and discussion.
|
| 151 |
+
|
| 152 |
+
Almost all agent frameworks (LangGraph, CrewAI, LlamaIndex, etc) call LLM with OpenAI chat completion api, and
|
| 153 |
+
keep chat history as messages. So user may expect that we should use the chat completion api in multi-turn rollout.
|
| 154 |
+
|
| 155 |
+
But based on our recent experience on single-turn training on DAPO and multi-turn training on `retool <https://github.com/volcengine/verl-recipe/tree/main/retool>`_,
|
| 156 |
+
we found the token_ids from apply the final messages may not equal to the token_ids by concat prompt_ids and response_ids in each turn.
|
| 157 |
+
|
| 158 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/multi_turn.png?raw=true
|
| 159 |
+
|
| 160 |
+
**Where does this inconsistency happened?**
|
| 161 |
+
|
| 162 |
+
First, the tool parser may alter the content. For example
|
| 163 |
+
|
| 164 |
+
.. code:: json
|
| 165 |
+
|
| 166 |
+
{"role": "assistant", "content": "Let me call a <tool_call>...</tool_call> and get the result"}
|
| 167 |
+
|
| 168 |
+
After tool_calls extraction, the messages is like this:
|
| 169 |
+
|
| 170 |
+
.. code:: json
|
| 171 |
+
|
| 172 |
+
{"role": "assistant", "content": "Let me call a and get the result", "tool_calls": [{"name": "foo", "arguments": "{}"}]}
|
| 173 |
+
|
| 174 |
+
Encode the extracted message back is not equal to the original LLM generated response_ids.
|
| 175 |
+
|
| 176 |
+
Second, the `decode-encode` may also lead to inconsistency: `Agent-R1 issue#30 <https://github.com/0russwest0/Agent-R1/issues/30#issuecomment-2826155367>`_.
|
| 177 |
+
|
| 178 |
+
**What is the impact of this inconsistency?**
|
| 179 |
+
|
| 180 |
+
This inconsistency is not a big problem for serving/agent system, but is critical to RL training.
|
| 181 |
+
It causes the trajectory deviate from the policy model distribution. We have observed that apply_chat_template
|
| 182 |
+
to the final chat history messages make PPO training not even converged in single-turn.
|
| 183 |
+
|
| 184 |
+
vLLM
|
| 185 |
+
^^^^
|
| 186 |
+
|
| 187 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/async_vllm.png?raw=true
|
| 188 |
+
|
| 189 |
+
For vLLM, the Async LLM Engine is running in same process as the server, and ModelRunner is running in same process as FSDP/Megatron-LM workers.
|
| 190 |
+
Async LLM Engine communicate with ModelRunner through ZeroMQ. When server receive a request, it directly call engine to generate response_ids.
|
| 191 |
+
|
| 192 |
+
SGLang
|
| 193 |
+
^^^^^^
|
| 194 |
+
|
| 195 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/async_sglang.png?raw=true
|
| 196 |
+
|
| 197 |
+
For SGLang, the Async LLM Engine is running in same process as FSDP/Megatron-LM worker-0, and it spawn multiple subprocesses as ModelRunner.
|
| 198 |
+
Also, Async LLM Engine communicate with ModelRunner through ZeroMQ. When server receive a request, it remote call the worker-0 and get response_ids.
|
| 199 |
+
|
| 200 |
+
AsyncLLMServerManager
|
| 201 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 202 |
+
|
| 203 |
+
AsyncLLMServerManager serve as proxy to multiple AsyncLLMServer instances, provides:
|
| 204 |
+
|
| 205 |
+
- load balance: select a server instance with least request in first turn and send request to it.
|
| 206 |
+
- sticky session: bind request_id to server instance, so that the same request_id will be sent to the same server instance in following turns.
|
| 207 |
+
|
| 208 |
+
AsyncLLMServerManager is passed to ``AgentLoopBase.__init__``, whenever user want to interact with LLM in agent loop,
|
| 209 |
+
they can call ``AsyncLLMServerManager.generate`` to generate response_ids.
|
| 210 |
+
|
| 211 |
+
.. code:: python
|
| 212 |
+
|
| 213 |
+
class AsyncLLMServerManager:
|
| 214 |
+
async def generate(
|
| 215 |
+
self,
|
| 216 |
+
request_id,
|
| 217 |
+
*,
|
| 218 |
+
prompt_ids: list[int],
|
| 219 |
+
sampling_params: dict[str, Any],
|
| 220 |
+
) -> list[int]:
|
| 221 |
+
"""Generate tokens from prompt ids.
|
| 222 |
+
|
| 223 |
+
Args:
|
| 224 |
+
request_id (str): request id for sticky session.
|
| 225 |
+
prompt_ids (List[int]): List of prompt token ids.
|
| 226 |
+
sampling_params (Dict[str, Any]): Sampling parameters for the chat completion.
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
List[int]: List of generated token ids.
|
| 230 |
+
"""
|
| 231 |
+
...
|
| 232 |
+
|
| 233 |
+
Next
|
| 234 |
+
----
|
| 235 |
+
|
| 236 |
+
- :doc:`Agentic RL Training<../start/agentic_rl>`: Quick start agentic RL training with gsm8k dataset.
|
| 237 |
+
- `LangGraph MathExpression <https://github.com/volcengine/verl-recipe/tree/main/langgraph_agent/example>`_: Demonstrate how to use LangGraph to build agent loop.
|
| 238 |
+
- `Retool <https://github.com/volcengine/verl-recipe/tree/main/retool>`_: End-to-end retool paper reproduction using tool agent.
|
code/RL_model/verl/verl_train/docs/advance/async-on-policy-distill.md
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Async On-Policy Knowledge Distillation Trainer
|
| 2 |
+
|
| 3 |
+
**Authors:** Brilliant Hanabi, furunding
|
| 4 |
+
|
| 5 |
+
**Last updated:** 2025-11-08
|
| 6 |
+
|
| 7 |
+
## 1. Background
|
| 8 |
+
|
| 9 |
+
On-policy knowledge distillation (KD) trains a student policy to imitate a stronger teacher using samples drawn from the student's current policy. For each on-policy rollout the teacher returns soft, top-k token distributions and the student is optimized with a token-wise sparse KL objective that focuses learning on the teacher's high-probability modes. Because training examples come from the student's own state distribution, KD reduces distributional mismatch relative to off-policy distillation or supervised fine-tuning (SFT), improving stability and sample efficiency. Compared with reinforcement learning, KD avoids high-variance reward-based optimization and complex reward design by providing dense, informative per-token targets, which typically yields faster convergence and simpler scaling. Recent empirical and implementation-focused writeups (e.g., [ThinkingMachines' blog on on-policy distillation](https://thinkingmachines.ai/blog/on-policy-distillation/)) also demonstrate that on-policy distillation can deliver high-quality behavior with substantially lower compute and data requirements than many alternative approaches.
|
| 10 |
+
|
| 11 |
+
Built on verl’s Ray-based single-controller components, we initially assembled a strictly on-policy KD pipeline where rollout generation, teacher knowledge acquisition, and policy optimization ran in lockstep. In practice, this synchronous design proved highly inefficient: the three stages had to wait for one another, creating pipeline bubbles and underutilized GPUs. To address this, we extend the asynchronous schedulers introduced by the One-Step-Off Policy pipeline to overlap these phases. This overlap preserves the same distillation objective while trading some strict on-policy guarantees for substantial gains in end-to-end throughput and hardware utilization.
|
| 12 |
+
|
| 13 |
+
## 2. Distillation Overview and Objective
|
| 14 |
+
|
| 15 |
+
This recipe centers on on-policy knowledge distillation: the student policy learns from a stronger teacher on samples generated by the current policy (on-policy). For each input prompt, the student (actor) generates responses; the teacher provides top-k token distributions, and the student is trained to match them token-wise.
|
| 16 |
+
|
| 17 |
+
Core components:
|
| 18 |
+
|
| 19 |
+
1. Teacher signal: top-k log-probabilities and token indices per valid token position.
|
| 20 |
+
2. Student objective: sparse, token-level KL divergence between student logits and teacher top-k distribution.
|
| 21 |
+
|
| 22 |
+
Objective: encourage student probabilities $Q$ to cover teacher modes $P$ using token-wise $\mathrm{KL}(P\,\|\,Q)$ computed on the teacher's top-k support.
|
| 23 |
+
|
| 24 |
+
## 3. Efficient System Design
|
| 25 |
+
|
| 26 |
+
### 3.1 Schedulers (One-Step / Two-Step Off-Policy)
|
| 27 |
+
|
| 28 |
+
The native (serial) on-policy distillation process is shown in the figure below.
|
| 29 |
+
|
| 30 |
+
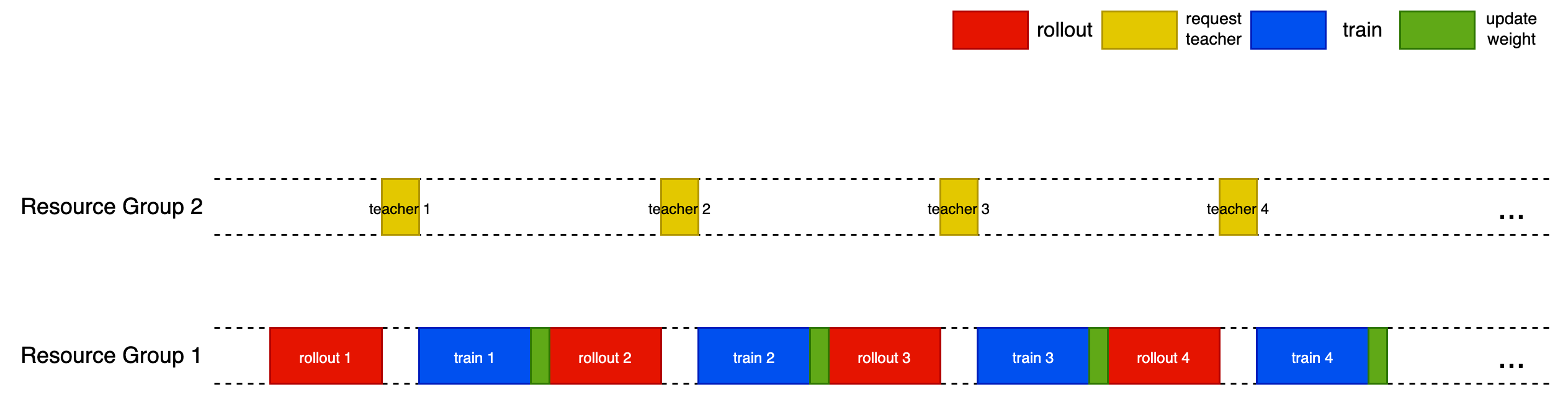
|
| 31 |
+
|
| 32 |
+
This recipe supports optional schedulers that overlap generation, teacher querying, and updates to improve throughput without changing the distillation objective.
|
| 33 |
+
|
| 34 |
+
#### 3.1.1 One-Step-Off-Policy
|
| 35 |
+
|
| 36 |
+
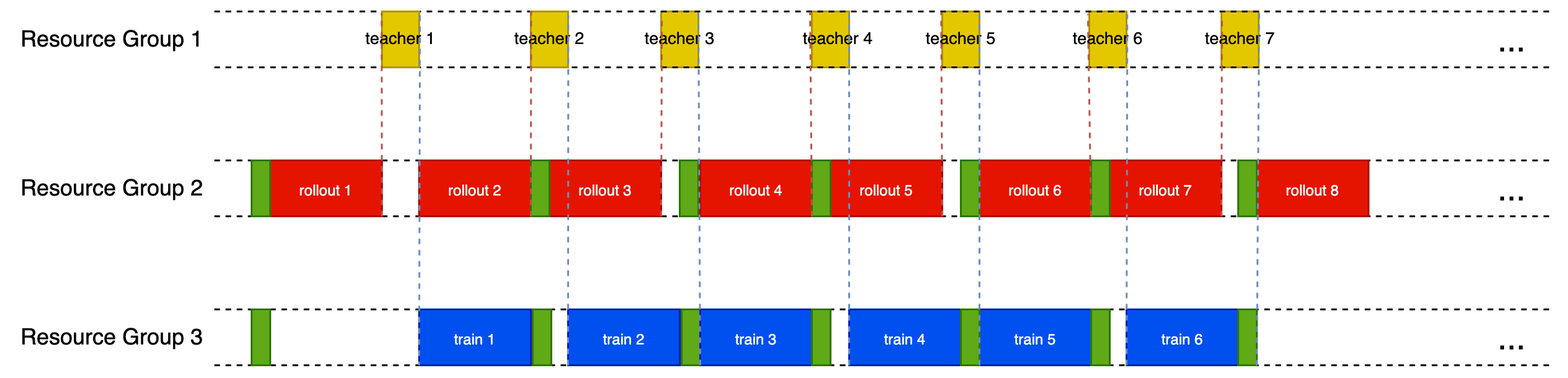
|
| 37 |
+
|
| 38 |
+
- Warm-up: 2 steps.
|
| 39 |
+
- Overlap pattern: rollout while actor update; weight sync while teacher retrieving.
|
| 40 |
+
- Timing keys: `sync_rollout_weights`, `wait_prev_gen`, `wait_prev_teacher`.
|
| 41 |
+
|
| 42 |
+
#### 3.1.2 Two-Step-Off-Policy
|
| 43 |
+
|
| 44 |
+
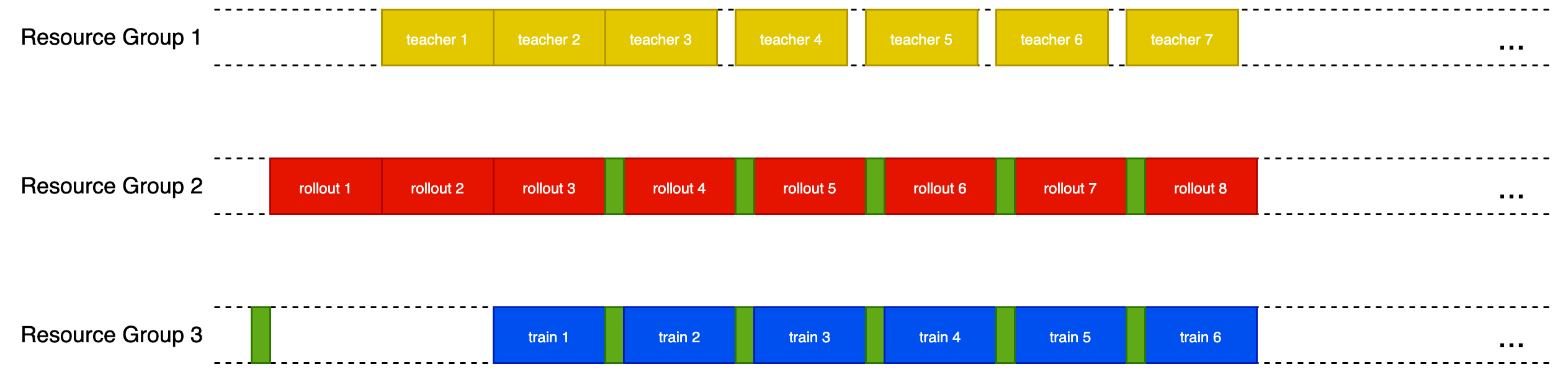
|
| 45 |
+
|
| 46 |
+
- Warm-up: 3 steps.
|
| 47 |
+
- Overlap pattern: rollout, actor update while teacher retrieving; interleave weight sync.
|
| 48 |
+
- Timing keys: `sync_rollout_weights`, `max(wait_prev_gen, wait_prev_prev_teacher)`.
|
| 49 |
+
|
| 50 |
+
Tip: Use `two_step_off` when teacher takes much more time than sync; `one_step_off` for simpler overlapping.
|
| 51 |
+
|
| 52 |
+
Practical details:
|
| 53 |
+
|
| 54 |
+
- Inputs per batch: `teacher_topk_logps`, `teacher_topk_indices`, `attention_mask` (to select valid token positions).
|
| 55 |
+
- Loss injection: last pipeline stage computes KL via a logits processor; earlier stages remain unchanged.
|
| 56 |
+
- Optional dynamic micro-batching groups sequences by density to reduce padding overhead.
|
| 57 |
+
|
| 58 |
+
The pipeline:
|
| 59 |
+
|
| 60 |
+
1. Actor parameters are synchronized to a rollout worker group (nccl broadcast) with a little bit latency.
|
| 61 |
+
2. Rollout workers (vLLM-backed) generate sequences asynchronously (`async_generate_sequences`).
|
| 62 |
+
3. Teacher client service (ZeroMQ based) returns top-k log-probabilities + token indices for each sequence (batched micro-requests), enabling KL-based guidance.
|
| 63 |
+
4. Megatron actor performs a KL divergence computation between student logits and teacher top-k distributions (custom TP-aware kernel in `megatron_kl_loss.py`).
|
| 64 |
+
5. Scheduling strategies (`one_step_off_scheduler`, `two_step_off_scheduler`) can overlap phases (optional for throughput):
|
| 65 |
+
|
| 66 |
+
### 3.2 Weights sync between actor and rollout
|
| 67 |
+
|
| 68 |
+
We initially followed the weight synchronization path from the One-Step-Off-Policy recipe (Ray collective broadcast across all actor and rollout ranks, plus Megatron-side allgather of parameter shards). In practice this became the dominant bottleneck, so we made three changes:
|
| 69 |
+
|
| 70 |
+
1. Batch-and-bulk load on the rollout side: instead of streaming tensors one-by-one (in one-step-off-policy recipe), we stage a bundle of parameter tensors and issue a single batched load into the rollout engine. In our setup this reduced the weight-loading time by roughly 3×.
|
| 71 |
+
2. Batch-and-bulk broadcast between the actor and rollout: instead of streaming tensors one-by-one (in one-step-off-policy recipe), we stage a bundle of parameter tensors and issue a single batched broadcast between the actor and rollout workers.
|
| 72 |
+
3. Replace allgather with gather-to-root in Megatron: parameter shards are gathered to actor rank 0 (rather than allgathered to everyone), and that root then serves as the single source for broadcasting to rollout ranks. On top of the previous change, 2 and 3 changes delivered an additional ~4× speedup in the synchronization phase.
|
| 73 |
+
|
| 74 |
+
## 4. High-Level Data & Control Flow
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
Driver (TaskRunner)
|
| 78 |
+
├─ Initialize Ray, tokenizer, datasets, worker groups
|
| 79 |
+
├─ Build ResourcePoolManager (actor vs rollout GPU layouts)
|
| 80 |
+
├─ Trainer.fit()
|
| 81 |
+
├─ init_workers(): build actor + rollout groups, broadcast weight metadata, create nccl collective group
|
| 82 |
+
├─ continuous_iterator(): epochs → batches
|
| 83 |
+
├─ scheduler (see Section 6)
|
| 84 |
+
• _async_gen_next_batch(): optional weight sync + non-blocking rollout
|
| 85 |
+
• _async_get_teacher_knowledge(): submit teacher requests, store future
|
| 86 |
+
├─ For each step:
|
| 87 |
+
• Sync rollout weights
|
| 88 |
+
• Retrieve (batch, gen_output, teacher_output) from futures
|
| 89 |
+
• Merge gen + teacher outputs → DataProto
|
| 90 |
+
• Compute metrics (response length stats, timing, throughput)
|
| 91 |
+
• Update actor (forward_backward_batch + KL loss + optimizer step)
|
| 92 |
+
• (Optional) save checkpoint
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
> Note: Schedulers are optional and explained later; the distillation objective is independent of how phases are overlapped.
|
| 96 |
+
|
| 97 |
+
## 5. Key Components
|
| 98 |
+
|
| 99 |
+
### 5.1 `OnPolicyDistillTrainer` (`ray_trainer.py`)
|
| 100 |
+
- Creates `GenerationBatchFuture` objects holding rollout and (later) teacher futures.
|
| 101 |
+
- Adds scheduling + teacher integration + modified metric emission (KL, timing, MFU).
|
| 102 |
+
|
| 103 |
+
### 5.2 Actor Worker (Megatron)
|
| 104 |
+
- `OnPolicyDistillActor.update_policy()` orchestrates micro-batch forward/backward.
|
| 105 |
+
- KL Loss injection via `logits_processor` during forward on pipeline last stage.
|
| 106 |
+
|
| 107 |
+
### 5.3 Rollout Worker (vLLM / SGLang)
|
| 108 |
+
- Pure inference mode (`init_model` builds model; no optimizer).
|
| 109 |
+
- `async_generate_sequences` returns a Ray future for overlapping.
|
| 110 |
+
|
| 111 |
+
### 5.4 Teacher Service (`teacher/`)
|
| 112 |
+
- Proxy + worker architecture (ZMQ REQ/REP) for batched top-k retrieval.
|
| 113 |
+
- `TeacherClient.submit()` returns a `Future`; aggregator composes micro-batches.
|
| 114 |
+
- Configurable temperature, max tokens, only-response mode.
|
| 115 |
+
|
| 116 |
+
### 5.5 KL Loss (`megatron_kl_loss.py`)
|
| 117 |
+
- Performs normalization & stable per-token probability construction across TP shards.
|
| 118 |
+
- Gradient is (student_probs - teacher_sparse_probs) scaled by upstream grad.
|
| 119 |
+
|
| 120 |
+
## 6. Configuration Highlights (`on_policy_distill_trainer.yaml`)
|
| 121 |
+
|
| 122 |
+
| Section | Purpose | Notable Keys |
|
| 123 |
+
|---------|---------|-------------|
|
| 124 |
+
| actor_rollout_ref.teacher | Teacher server | server_ip, server_port, n_server_workers |
|
| 125 |
+
| trainer | Global training control | total_epochs, save_freq, scheduler (one_step_off | two_step_off), n_gpus_per_node, nnodes |
|
| 126 |
+
| rollout | Resource split for rollout | n_gpus_per_node, nnodes |
|
| 127 |
+
|
| 128 |
+
**Remember to set `trainer.n_gpus_per_node`, `trainer.nnodes`, `rollout.n_gpus_per_node` and `rollout.nnodes` to allocate GPU resources.**
|
| 129 |
+
|
| 130 |
+
### Dynamic Batch Size
|
| 131 |
+
|
| 132 |
+
Enable by:
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
actor_rollout_ref.actor.use_dynamic_bsz=True
|
| 136 |
+
actor_rollout_ref.actor.max_token_len=6000 # cap post-group token length
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
Improves utilization under variable sequence lengths.
|
| 140 |
+
|
| 141 |
+
### Resource Guidelines
|
| 142 |
+
|
| 143 |
+
- Actor pool: `trainer.nnodes * trainer.n_gpus_per_node` GPUs.
|
| 144 |
+
- Rollout pool: `rollout.nnodes * rollout.n_gpus_per_node` GPUs.
|
| 145 |
+
- Ensure teacher server capacity ≈ `n_server_workers` to avoid stalls (monitor `wait_prev_teacher`).
|
| 146 |
+
|
| 147 |
+
## 7. Usage Examples
|
| 148 |
+
|
| 149 |
+
### 7.1 Launch Teacher Server
|
| 150 |
+
|
| 151 |
+
Before training process, you should have a teacher server to provide logp information.
|
| 152 |
+
|
| 153 |
+
We provide a toy teacher server example with vLLM. It needs `telnet` to check proxy status, and `python` command to run. So if you have not installed `telnet`, you can just delete these code in `start_server.sh`. And some OS use `python3` rather than `python`, so you also need to modify it. Also you can change the port of teacher if you meet port conflict.
|
| 154 |
+
|
| 155 |
+
There are 3 arguments can be set for vllm backend `--tp-size`, `--n-logprobs` and `--ckpt-path` in `start_server.sh` / `worker.py`. You should set before you start server.
|
| 156 |
+
|
| 157 |
+
We also provide a toy multi-node teacher server. You can start the main node using `start_server.sh` and start the slave nodes using `join_server.sh`. Still remember to set args in `join_server.sh`, especially the `$PROXY_IP` and `$PROXY_BACKEND_PORT` of main node.
|
| 158 |
+
|
| 159 |
+
When training, student will automatically use the teacher's topk (n-logprobs) to set its own topk argument at line 83 of `recipe/gkd/megatron_kl_loss.py`, so you don't need to set student's topk argument.
|
| 160 |
+
|
| 161 |
+
```bash
|
| 162 |
+
cd recipe/gkd/teacher
|
| 163 |
+
bash start_server.sh
|
| 164 |
+
# Exports ports and launches proxy + worker (default vLLM backend)
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
Verify with:
|
| 168 |
+
|
| 169 |
+
```bash
|
| 170 |
+
telnet localhost 15555
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
### 7.2 Minimal Local (Megatron + vLLM) Run
|
| 174 |
+
|
| 175 |
+
```bash
|
| 176 |
+
python3 -m recipe.gkd.main_gkd \
|
| 177 |
+
--config-path=recipe/gkd/config \
|
| 178 |
+
--config-name=on_policy_distill_trainer \
|
| 179 |
+
actor_rollout_ref.model.path=/path/to/MODEL \
|
| 180 |
+
data.train_files=/path/to/train.parquet \
|
| 181 |
+
trainer.total_epochs=2 \
|
| 182 |
+
trainer.n_gpus_per_node=4 rollout.n_gpus_per_node=2 \
|
| 183 |
+
actor_rollout_ref.teacher.server_ip=127.0.0.1 \
|
| 184 |
+
actor_rollout_ref.teacher.server_port=15555 \
|
| 185 |
+
trainer.scheduler=one_step_off
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
(Requires a running teacher server).
|
| 189 |
+
|
| 190 |
+
### 7.3 Ray Job Submission (Distilled 16B Example)
|
| 191 |
+
|
| 192 |
+
See `run_moonlight_dsv3_training.sh` for a full script including:
|
| 193 |
+
|
| 194 |
+
- Dist ckpt path setup (`dist_checkpointing_path`)
|
| 195 |
+
- Expert parallel sizing (EP / ETP)
|
| 196 |
+
- Dynamic batch sizing
|
| 197 |
+
- Two-step-off scheduling for deeper overlap.
|
| 198 |
+
|
| 199 |
+
Submit (after adjusting paths):
|
| 200 |
+
|
| 201 |
+
```bash
|
| 202 |
+
bash recipe/gkd/run_moonlight_dsv3_training.sh
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
## 8. Metrics & Monitoring
|
| 206 |
+
|
| 207 |
+
Emitted metrics include (prefixes may vary):
|
| 208 |
+
|
| 209 |
+
- Timing: `timing/wait_prev_gen`, `timing/sync_rollout_weights`, `timing/get_teacher_knowledge`, `timing/update_actor`.
|
| 210 |
+
- Sequence stats: `response_seq_len/*` (avg, max, min, counts).
|
| 211 |
+
- Performance: `perf/mfu/actor`, `perf/max_memory_allocated_gb`, `perf/cpu_memory_used_gb`.
|
| 212 |
+
- Distillation: `actor/kl_loss`, `actor/grad_norm`, `actor/lr`.
|
| 213 |
+
|
| 214 |
+
Interpretation Tips:
|
| 215 |
+
|
| 216 |
+
- High `wait_prev_teacher` → scale `n_server_workers` and allocate more teacher GPUs or reduce per-request batch size, or just use `two_step_off`.
|
| 217 |
+
- High `wait_prev_gen` with uniform lengths → allocate more rollout GPUs.
|
| 218 |
+
- High `sync_rollout_weights` → check NCCL env / network congestion and try to modify `actor_rollout_ref.rollout.update_weights_bucket_megabytes`.
|
| 219 |
+
|
| 220 |
+
## 9. Extensibility Notes
|
| 221 |
+
|
| 222 |
+
- Add new schedulers by following interface returning `(epoch, batch, gen_output, teacher_output, timing_dict)`.
|
| 223 |
+
- Integrate different distillation signals (e.g., hidden states, intermediate reasoning tokens) by extending `teacher_utils.get_teacher_knowledge` and modifying `logits_processor`.
|
| 224 |
+
|
| 225 |
+
## 10. Functional Support Summary
|
| 226 |
+
|
| 227 |
+
| Category | Supported |
|
| 228 |
+
|----------|-----------|
|
| 229 |
+
| Train engine | Megatron |
|
| 230 |
+
| Rollout engine | vLLM |
|
| 231 |
+
| Distillation signal | Teacher top-k logprobs & indices |
|
| 232 |
+
| Scheduling | one_step_off, two_step_off |
|
| 233 |
+
|
| 234 |
+
## 11. Quick Checklist Before Running
|
| 235 |
+
|
| 236 |
+
- Teacher server reachable (`telnet <ip> <port>`).
|
| 237 |
+
- `actor_rollout_ref.model.path` contains the correct Megatron/HF config artifacts.
|
| 238 |
+
- `train_files` points to a parquet dataset compatible with this recipe's dataset loader.
|
| 239 |
+
- NCCL environment vars set (see `config/runtime_env.yaml`).
|
| 240 |
+
|
| 241 |
+
---
|
| 242 |
+
Feel free to open issues or PRs to extend scheduler variants, add new distillation objectives, or broaden engine support, and more improvement.
|
code/RL_model/verl/verl_train/docs/advance/attention_implementation.rst
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. _attention-implementation-override:
|
| 2 |
+
|
| 3 |
+
Attention Implementation Override
|
| 4 |
+
==================================
|
| 5 |
+
|
| 6 |
+
Last updated: 10/31/2025.
|
| 7 |
+
|
| 8 |
+
By default, VERL's FSDP workers use ``flash_attention_2`` as the attention implementation for improved performance.
|
| 9 |
+
However, you can now override this setting to use different attention implementations based on your needs.
|
| 10 |
+
|
| 11 |
+
Supported Attention Implementations
|
| 12 |
+
-----------------------------------
|
| 13 |
+
|
| 14 |
+
The following attention implementations are supported (subject to model and hardware compatibility):
|
| 15 |
+
|
| 16 |
+
- ``flash_attention_2``: High-performance attention implementation (default)
|
| 17 |
+
- ``eager``: Standard PyTorch attention implementation
|
| 18 |
+
- ``sdpa``: Scaled Dot-Product Attention (PyTorch native)
|
| 19 |
+
|
| 20 |
+
When to Override
|
| 21 |
+
----------------
|
| 22 |
+
|
| 23 |
+
You might want to override the attention implementation in the following scenarios:
|
| 24 |
+
|
| 25 |
+
- **Debugging**: Use ``eager`` for easier debugging and better error messages
|
| 26 |
+
- **Compatibility**: Some models or hardware configurations may not support ``flash_attention_2``
|
| 27 |
+
- **Memory constraints**: Different implementations have different memory characteristics
|
| 28 |
+
- **Performance tuning**: Testing different implementations for optimal performance
|
| 29 |
+
|
| 30 |
+
Configuration Examples
|
| 31 |
+
-----------------------
|
| 32 |
+
|
| 33 |
+
PPO Training with Eager Attention
|
| 34 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 35 |
+
|
| 36 |
+
To override the attention implementation for the actor, rollout, and reference models:
|
| 37 |
+
|
| 38 |
+
.. code:: bash
|
| 39 |
+
|
| 40 |
+
python3 ppo_trainer.py \
|
| 41 |
+
+actor_rollout_ref.model.override_config.attn_implementation=eager \
|
| 42 |
+
[other parameters...]
|
| 43 |
+
|
| 44 |
+
PPO Training with SDPA Attention
|
| 45 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 46 |
+
|
| 47 |
+
.. code:: bash
|
| 48 |
+
|
| 49 |
+
python3 ppo_trainer.py \
|
| 50 |
+
+actor_rollout_ref.model.override_config.attn_implementation=sdpa \
|
| 51 |
+
[other parameters...]
|
| 52 |
+
|
| 53 |
+
Critic Model Override
|
| 54 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 55 |
+
|
| 56 |
+
For training configurations that include a critic model, you can also override its attention implementation:
|
| 57 |
+
|
| 58 |
+
.. code:: bash
|
| 59 |
+
|
| 60 |
+
python3 ppo_trainer.py \
|
| 61 |
+
+actor_rollout_ref.model.override_config.attn_implementation=eager \
|
| 62 |
+
+critic.model.override_config.attn_implementation=eager \
|
| 63 |
+
[other parameters...]
|
| 64 |
+
|
| 65 |
+
YAML Configuration
|
| 66 |
+
~~~~~~~~~~~~~~~~~~
|
| 67 |
+
|
| 68 |
+
You can also specify the attention implementation in your YAML configuration file:
|
| 69 |
+
|
| 70 |
+
.. code:: yaml
|
| 71 |
+
|
| 72 |
+
actor_rollout_ref:
|
| 73 |
+
model:
|
| 74 |
+
override_config:
|
| 75 |
+
attn_implementation: eager
|
| 76 |
+
# other overrides...
|
| 77 |
+
|
| 78 |
+
critic: # if using a critic model
|
| 79 |
+
model:
|
| 80 |
+
override_config:
|
| 81 |
+
attn_implementation: eager
|
| 82 |
+
# other overrides...
|
| 83 |
+
|
| 84 |
+
Important Notes
|
| 85 |
+
---------------
|
| 86 |
+
|
| 87 |
+
**Backward Compatibility**: If you don't specify ``attn_implementation`` in the override config,
|
| 88 |
+
VERL will continue to use ``flash_attention_2`` by default, ensuring backward compatibility with existing configurations.
|
| 89 |
+
|
| 90 |
+
**Model Support**: Not all models support all attention implementations. Ensure your model is compatible
|
| 91 |
+
with the chosen attention implementation before training.
|
| 92 |
+
|
| 93 |
+
**Performance Impact**: Different attention implementations have varying performance characteristics.
|
| 94 |
+
``flash_attention_2`` typically offers the best performance, while ``eager`` provides better debugging capabilities.
|
| 95 |
+
|
| 96 |
+
**Hardware Dependencies**: Some attention implementations (like ``flash_attention_2``) may require
|
| 97 |
+
specific hardware or CUDA versions. If you encounter compatibility issues, try using ``eager`` or ``sdpa``.
|
| 98 |
+
|
| 99 |
+
Troubleshooting
|
| 100 |
+
---------------
|
| 101 |
+
|
| 102 |
+
If you encounter errors when using a specific attention implementation:
|
| 103 |
+
|
| 104 |
+
1. **Check model compatibility**: Verify that your model supports the chosen attention implementation
|
| 105 |
+
2. **Try eager attention**: Use ``attn_implementation=eager`` as a fallback for debugging
|
| 106 |
+
3. **Check hardware requirements**: Ensure your hardware supports the attention implementation
|
| 107 |
+
4. **Review error messages**: Attention implementation errors often provide clear guidance on supported options
|
| 108 |
+
|
| 109 |
+
Example Error Resolution
|
| 110 |
+
~~~~~~~~~~~~~~~~~~~~~~~~
|
| 111 |
+
|
| 112 |
+
If you see an error like "flash_attention_2 is not supported", you can resolve it by switching to eager attention:
|
| 113 |
+
|
| 114 |
+
.. code:: bash
|
| 115 |
+
|
| 116 |
+
# Instead of the default flash_attention_2
|
| 117 |
+
python3 ppo_trainer.py +actor_rollout_ref.model.override_config.attn_implementation=eager
|
| 118 |
+
|
| 119 |
+
This override ensures your training can proceed while you investigate the flash attention compatibility issue.
|
code/RL_model/verl/verl_train/docs/advance/checkpoint.rst
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. _checkpoint-page:
|
| 2 |
+
|
| 3 |
+
Using Checkpoints to Support Fault Tolerance Training
|
| 4 |
+
=====================================================
|
| 5 |
+
|
| 6 |
+
Last updated: 06/25/2025.
|
| 7 |
+
|
| 8 |
+
There could be training errors or machine failure during the whole RLHF training process,
|
| 9 |
+
so it is recommended to enable checkpoints to minimize your loss.
|
| 10 |
+
|
| 11 |
+
The API Interface has already been listed in :ref:`config-explain-page`,
|
| 12 |
+
and we will not repeat them. But there are still some technique details
|
| 13 |
+
we hope to clarify.
|
| 14 |
+
|
| 15 |
+
.. note::
|
| 16 |
+
|
| 17 |
+
Notice that the ``checkpoint.contents`` field has no effect to FSDP checkpoint except ``hf_model``,
|
| 18 |
+
the other 3 fields are binded together to save and load. We recommend to include ``model``, ``optimizer`` and ``extra`` all.
|
| 19 |
+
|
| 20 |
+
Checkpoint Saving Directory Structure
|
| 21 |
+
-------------------------------------
|
| 22 |
+
|
| 23 |
+
Commonly, we use the ``default_local_dir`` declared in ``ppo_trainer.yaml`` or ``ppo_megatron_trainer.yml``
|
| 24 |
+
to work as preffix when saving checkpoints, which is ``checkpoints/${trainer.project_name}/${trainer.experiment_name}``.
|
| 25 |
+
|
| 26 |
+
So the inner checkpoint structure of **FSDP** is like:
|
| 27 |
+
|
| 28 |
+
.. code::
|
| 29 |
+
|
| 30 |
+
checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 31 |
+
├── global_steps_${i}
|
| 32 |
+
│ ├── actor
|
| 33 |
+
│ │ ├── huggingface # default save config and tokenizer, save huggingface model if include ``hf_model`` in checkpoint.contents
|
| 34 |
+
│ │ └── fsdp_config.json # FSDP config file, including world_size and fsdp version
|
| 35 |
+
│ │ ├── model_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 36 |
+
│ │ ├── optim_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 37 |
+
│ │ └── extra_state_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 38 |
+
│ ├── critic
|
| 39 |
+
│ │ ├── huggingface
|
| 40 |
+
│ │ └── fsdp_config.json
|
| 41 |
+
│ │ ├── model_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 42 |
+
│ │ ├── optim_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 43 |
+
│ │ └── extra_state_world_size_{self.world_size}_rank_{self.rank}.pt
|
| 44 |
+
└── latest_checkpointed_iteration.txt
|
| 45 |
+
|
| 46 |
+
All model shards, optimizers and extra states are stored together, in a sharded and distributed way.
|
| 47 |
+
|
| 48 |
+
While **Megatron** current checkpoint structure is:
|
| 49 |
+
|
| 50 |
+
.. code::
|
| 51 |
+
|
| 52 |
+
checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 53 |
+
├── global_steps_${i}
|
| 54 |
+
│ ├── actor
|
| 55 |
+
│ │ ├── huggingface # default save config and tokenizer, save huggingface model if include ``hf_mode`` in checkpoint.contents
|
| 56 |
+
│ │ └── dist_ckpt # save sharded model/optimizer/rng_states, naming the same as Megatron
|
| 57 |
+
│ └── critic
|
| 58 |
+
│ │ ├── huggingface
|
| 59 |
+
│ │ └── dist_ckpt
|
| 60 |
+
└── latest_checkpointed_iteration.txt
|
| 61 |
+
|
| 62 |
+
Convert FSDP and Megatron Checkpoints to HuggingFace Format Model
|
| 63 |
+
-----------------------------------------------------------------
|
| 64 |
+
|
| 65 |
+
We provide a tool to convert the FSDP and Megatron checkpoints to HuggingFace format model.
|
| 66 |
+
The tool is located in ``verl/model_merger``. For older versions of verl that don't include fsdp_config.json in checkpoints, you can use the legacy model merger located at ``verl/scripts/legacy_model_merger.py``.
|
| 67 |
+
|
| 68 |
+
The script supports two main sub-commands: `merge` (to convert and save checkpoints) and `test` (to validate merged checkpoints against a reference model).
|
| 69 |
+
The arguments for the `merge` sub-command are as follows:
|
| 70 |
+
|
| 71 |
+
.. code:: bash
|
| 72 |
+
|
| 73 |
+
usage: python -m verl.model_merger merge [-h] --backend {fsdp,megatron} [--local_dir LOCAL_DIR] [--tie-word-embedding] [--is-value-model] [--use_cpu_initialization] [--target_dir TARGET_DIR]
|
| 74 |
+
[--hf_upload_path HF_UPLOAD_PATH] [--private]
|
| 75 |
+
|
| 76 |
+
options:
|
| 77 |
+
-h, --help show this help message and exit
|
| 78 |
+
--backend {fsdp,megatron}
|
| 79 |
+
The backend of the model
|
| 80 |
+
--local_dir LOCAL_DIR
|
| 81 |
+
Path to the saved model checkpoints
|
| 82 |
+
--tie-word-embedding Whether to tie word embedding weights (currently only Megatron supported)
|
| 83 |
+
--is-value-model Whether the model is a value model (currently only Megatron supported)
|
| 84 |
+
--use_cpu_initialization
|
| 85 |
+
Whether to use CPU initialization for the model. This is useful for large models that cannot fit into GPU memory during initialization.
|
| 86 |
+
--target_dir TARGET_DIR
|
| 87 |
+
Directory to save the merged huggingface model
|
| 88 |
+
--hf_upload_path HF_UPLOAD_PATH
|
| 89 |
+
Hugging Face repository ID to upload the model
|
| 90 |
+
--private Whether to upload the model to a private Hugging Face repository
|
| 91 |
+
|
| 92 |
+
Example usage for merging Megatron checkpoints:
|
| 93 |
+
|
| 94 |
+
.. code:: bash
|
| 95 |
+
|
| 96 |
+
python -m verl.model_merger merge \
|
| 97 |
+
--backend megatron \
|
| 98 |
+
--tie-word-embedding \
|
| 99 |
+
--local_dir checkpoints/verl_megatron_gsm8k_examples/qwen2_5_0b5_megatron_saveload/global_step_1/actor \
|
| 100 |
+
--target_dir /path/to/merged_hf_model
|
| 101 |
+
|
| 102 |
+
Example usage for distributed merging Megatron checkpoints:
|
| 103 |
+
|
| 104 |
+
.. code:: bash
|
| 105 |
+
|
| 106 |
+
torchrun --nproc_per_node 1 --nnodes 8 --node_rank ${RANK} -m verl.model_merger merge \
|
| 107 |
+
--backend megatron \
|
| 108 |
+
--tie-word-embedding \
|
| 109 |
+
--local_dir checkpoints/verl_megatron_gsm8k_examples/qwen2_5_0b5_megatron_saveload/global_step_1/actor \
|
| 110 |
+
--target_dir /path/to/merged_hf_model
|
| 111 |
+
|
| 112 |
+
Example usage for merging FSDP checkpoints:
|
| 113 |
+
|
| 114 |
+
.. code:: bash
|
| 115 |
+
|
| 116 |
+
python -m verl.model_merger merge \
|
| 117 |
+
--backend fsdp \
|
| 118 |
+
--local_dir checkpoints/verl_fsdp_gsm8k_examples/qwen2_5_0b5_fsdp_saveload/global_step_1/actor \
|
| 119 |
+
--target_dir /path/to/merged_hf_model
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
Megatron Merger details
|
| 123 |
+
-----------------------
|
| 124 |
+
|
| 125 |
+
Current implement of decoder layers uses ``nn.ModuleList`` to store the layers,
|
| 126 |
+
and thus the model layers on every PP rank and VPP rank starts their index from 0.
|
| 127 |
+
|
| 128 |
+
There are 3 ways to correct this behavior:
|
| 129 |
+
|
| 130 |
+
1. Modify the decoder layer's state_dict, add ``offset`` to each layer's index, thus rewrite ``nn.ModuleList`` implementation.
|
| 131 |
+
2. Modify the layer index when saving checkpoint and recover them when loading checkpoint.
|
| 132 |
+
3. The Checkpoint merger do this work, calculate the actual ``offset`` from ``state_dict`` only, a little complex.
|
| 133 |
+
|
| 134 |
+
Current implementation use solution 2.
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
HuggingFace to Megatron DistCheckpoint details
|
| 138 |
+
----------------------------------------------
|
| 139 |
+
|
| 140 |
+
Through ``mbridge``, we can directly save the mcore model to huggingface format during training.
|
| 141 |
+
No need to convert the model to Megatron dist-checkpoint format.
|
| 142 |
+
|
| 143 |
+
Original Checkpoint Utils
|
| 144 |
+
-------------------------
|
| 145 |
+
|
| 146 |
+
Original Checkpoint Utils refer to original checkpoint implementation in ``verl/models/[model]/megatron/checkpoint_utils``.
|
| 147 |
+
|
| 148 |
+
We only need ``[model]_loader.py`` in original checkpoint utils now, since we get rid of storing ``hf_model`` every time (which is not recommended for large model training, try only saving sharded models if you can).
|
| 149 |
+
|
| 150 |
+
.. note::
|
| 151 |
+
|
| 152 |
+
Note that ``[model]_loader`` only support environments where **storage clusters are able to connect with every calculation nodes**.
|
| 153 |
+
Because it utilizes **sharded load way to minimize the loading checkpoint overhead**.
|
| 154 |
+
Every rank loads its own data from ``state_dict`` which can be accessed by all of them.
|
| 155 |
+
While there is also no need to broadcast among DP ranks, since the saved state_dict is only produced by DP rank 0.
|
| 156 |
+
|
| 157 |
+
For users who can **only place the huggingface model on one device**, we keep the original costly implementation in ``[model]_loader_deprecated``. In this implementation, rank 0 broadcast all weights to each tp and pp rank, and then dp rank 0 broadcast to all dp ranks. There may be at risks of OOM.
|
| 158 |
+
|
| 159 |
+
To use deprecated loader, change the import package of ``load_state_dict_to_megatron_llama``.
|
code/RL_model/verl/verl_train/docs/advance/dpo_extension.rst
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Extend to other RL(HF) algorithms
|
| 2 |
+
=================================
|
| 3 |
+
|
| 4 |
+
Last updated: 02/25/2025.
|
| 5 |
+
|
| 6 |
+
We already implemented the complete training pipeline of the PPO
|
| 7 |
+
algorithms. To extend to other algorithms, we analyze the high-level
|
| 8 |
+
principle to use verl and provide a tutorial to implement the DPO
|
| 9 |
+
algorithm. Users can follow the similar paradigm to extend to other RL algorithms.
|
| 10 |
+
|
| 11 |
+
.. note:: **Key ideas**: Single process drives multi-process computation and data communication.
|
| 12 |
+
|
| 13 |
+
Overall Approach
|
| 14 |
+
----------------
|
| 15 |
+
|
| 16 |
+
Step 1: Consider what multi-machine multi-GPU computations are needed
|
| 17 |
+
for each model, such as ``generate_sequence`` , ``compute_log_prob`` and
|
| 18 |
+
``update_policy`` in the actor_rollout model. Implement distributed
|
| 19 |
+
single-process-multiple-data (SPMD) computation and encapsulate them
|
| 20 |
+
into APIs
|
| 21 |
+
|
| 22 |
+
Step 2: Based on different distributed scenarios, including FSDP and 3D
|
| 23 |
+
parallelism in Megatron-LM, implement single-process control of data
|
| 24 |
+
interaction among multi-process computations.
|
| 25 |
+
|
| 26 |
+
Step 3: Utilize the encapsulated APIs to implement the control flow
|
| 27 |
+
|
| 28 |
+
Example: Online DPO
|
| 29 |
+
-------------------
|
| 30 |
+
|
| 31 |
+
We use verl to implement a simple online DPO algorithm. The algorithm
|
| 32 |
+
flow of Online DPO is as follows:
|
| 33 |
+
|
| 34 |
+
1. There is a prompt (rollout) generator which has the same weight as
|
| 35 |
+
the actor model. After a batch of prompts are fed into the generator,
|
| 36 |
+
it generates N responses for each prompt.
|
| 37 |
+
2. Send all the prompts + responses to a verifier for scoring, which can
|
| 38 |
+
be reward model or a rule-based function. Then sort them in pairs to
|
| 39 |
+
form a training batch.
|
| 40 |
+
3. Use this training batch to train the actor model using DPO. During
|
| 41 |
+
the process, a reference policy is needed.
|
| 42 |
+
|
| 43 |
+
Step 1: What are the multi-machine multi-GPU computations
|
| 44 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 45 |
+
|
| 46 |
+
**Sample Generator**
|
| 47 |
+
|
| 48 |
+
Implementation details:
|
| 49 |
+
|
| 50 |
+
.. code:: python
|
| 51 |
+
|
| 52 |
+
from verl.single_controller.base import Worker
|
| 53 |
+
from verl.single_controller.ray import RayWorkerGroup, RayClassWithInitArgs, RayResourcePool
|
| 54 |
+
import ray
|
| 55 |
+
|
| 56 |
+
@ray.remote
|
| 57 |
+
class SampleGenerator(Worker):
|
| 58 |
+
def __init__(self, config):
|
| 59 |
+
super().__init__()
|
| 60 |
+
self.config = config
|
| 61 |
+
|
| 62 |
+
def generate_sequences(self, data):
|
| 63 |
+
pass
|
| 64 |
+
|
| 65 |
+
Here, ``SampleGenerator`` can be viewed as a multi-process pulled up by
|
| 66 |
+
``torchrun``, with each process running the same code (SPMD).
|
| 67 |
+
``SampleGenerator`` needs to implement a ``generate_sequences`` API for
|
| 68 |
+
the control flow to call. The implementation details inside can use any
|
| 69 |
+
inference engine including vllm, sglang and huggingface. Users can
|
| 70 |
+
largely reuse the code in
|
| 71 |
+
verl/verl/workers/rollout/vllm_rollout/vllm_rollout.py and we won't
|
| 72 |
+
go into details here.
|
| 73 |
+
|
| 74 |
+
**ReferencePolicy inference**
|
| 75 |
+
|
| 76 |
+
API: compute reference log probability
|
| 77 |
+
|
| 78 |
+
.. code:: python
|
| 79 |
+
|
| 80 |
+
from verl.single_controller.base import Worker
|
| 81 |
+
import ray
|
| 82 |
+
|
| 83 |
+
@ray.remote
|
| 84 |
+
class ReferencePolicy(Worker):
|
| 85 |
+
def __init__(self):
|
| 86 |
+
super().__init__()
|
| 87 |
+
self.model = Model()
|
| 88 |
+
|
| 89 |
+
def infer(self, data):
|
| 90 |
+
return self.model(data)
|
| 91 |
+
|
| 92 |
+
**Actor update**
|
| 93 |
+
|
| 94 |
+
API: Update actor model parameters
|
| 95 |
+
|
| 96 |
+
.. code:: python
|
| 97 |
+
|
| 98 |
+
from verl.single_controller.base import Worker
|
| 99 |
+
import ray
|
| 100 |
+
|
| 101 |
+
@ray.remote
|
| 102 |
+
class DPOActor(Worker):
|
| 103 |
+
def __init__(self):
|
| 104 |
+
super().__init__()
|
| 105 |
+
self.model = Model()
|
| 106 |
+
self.model = FSDP(self.model) # or other distributed strategy
|
| 107 |
+
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-3)
|
| 108 |
+
self.loss_fn = xxx
|
| 109 |
+
|
| 110 |
+
def update(self, data):
|
| 111 |
+
self.optimizer.zero_grad()
|
| 112 |
+
logits = self.model(data)
|
| 113 |
+
loss = self.loss_fn(logits)
|
| 114 |
+
loss.backward()
|
| 115 |
+
self.optimizer.step()
|
| 116 |
+
|
| 117 |
+
**Notes: How to distinguish between control processes and distributed computation processes**
|
| 118 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 119 |
+
|
| 120 |
+
- Control processes are generally functions directly decorated with
|
| 121 |
+
``@ray.remote``
|
| 122 |
+
- Computation processes are all wrapped into a ``RayWorkerGroup``.
|
| 123 |
+
|
| 124 |
+
Users can reuse most of the distribtued computation logics implemented
|
| 125 |
+
in PPO algorithm, including FSDP and Megatron-LM backend in
|
| 126 |
+
verl/verl/trainer/ppo.
|
| 127 |
+
|
| 128 |
+
Step 2: Based on different distributed scenarios, implement single-process control of multi-process data interaction
|
| 129 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 130 |
+
|
| 131 |
+
**The core problem to solve here is how a single process sends data to
|
| 132 |
+
multiple processes, drives multi-process computation, and how the
|
| 133 |
+
control process obtains the results of multi-process computation.**
|
| 134 |
+
First, we initialize the multi-process ``WorkerGroup`` in the control
|
| 135 |
+
process.
|
| 136 |
+
|
| 137 |
+
.. code:: python
|
| 138 |
+
|
| 139 |
+
@ray.remote(num_cpus=1)
|
| 140 |
+
def main_task(config):
|
| 141 |
+
# construct SampleGenerator
|
| 142 |
+
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
|
| 143 |
+
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
|
| 144 |
+
# put SampleGenerator onto resource pool
|
| 145 |
+
worker_group = RayWorkerGroup(resource_pool, ray_cls)
|
| 146 |
+
|
| 147 |
+
# construct reference policy
|
| 148 |
+
|
| 149 |
+
As we can see, in the control process, multiple processes are wrapped
|
| 150 |
+
into a ``RayWorkerGroup``. Inside this ``WorkerGroup``, there is a
|
| 151 |
+
``self._workers`` member, where each worker is a RayActor
|
| 152 |
+
(https://docs.ray.io/en/latest/ray-core/actors.html) of SampleGenerator.
|
| 153 |
+
ray_trainer.md also provide an implementation of
|
| 154 |
+
``MegatronRayWorkerGroup``.
|
| 155 |
+
|
| 156 |
+
Assuming the model is distributed using FSDP, and there is a batch of
|
| 157 |
+
data on the control process, for data parallelism, the underlying
|
| 158 |
+
calling process is:
|
| 159 |
+
|
| 160 |
+
.. code:: python
|
| 161 |
+
|
| 162 |
+
data = xxx
|
| 163 |
+
data_list = data.chunk(dp_size)
|
| 164 |
+
|
| 165 |
+
output = []
|
| 166 |
+
for d in data_list:
|
| 167 |
+
# worker_group._workers[i] is a SampleGenerator
|
| 168 |
+
output.append(worker_group._workers[i].generate_sequences.remote(d))
|
| 169 |
+
|
| 170 |
+
output = ray.get(output)
|
| 171 |
+
output = torch.cat(output)
|
| 172 |
+
|
| 173 |
+
Single process calling multiple processes involves the following 3
|
| 174 |
+
steps:
|
| 175 |
+
|
| 176 |
+
1. Split the data into DP parts on the control process.
|
| 177 |
+
2. Send the data to remote, call the remote computation through RPC, and
|
| 178 |
+
utilize multi-process computation.
|
| 179 |
+
3. Obtain the computation results of each worker on the control process
|
| 180 |
+
and merge them.
|
| 181 |
+
|
| 182 |
+
Frequently calling these 3 steps on the controller process greatly hurts
|
| 183 |
+
code readability. **In verl, we have abstracted and encapsulated these 3
|
| 184 |
+
steps, so that the worker's method + dispatch + collect can be
|
| 185 |
+
registered into the worker_group**
|
| 186 |
+
|
| 187 |
+
.. code:: python
|
| 188 |
+
|
| 189 |
+
from verl.single_controller.base.decorator import register
|
| 190 |
+
|
| 191 |
+
def dispatch_data(worker_group, data):
|
| 192 |
+
return data.chunk(worker_group.world_size)
|
| 193 |
+
|
| 194 |
+
def collect_data(worker_group, data):
|
| 195 |
+
return torch.cat(data)
|
| 196 |
+
|
| 197 |
+
dispatch_mode = {
|
| 198 |
+
'dispatch_fn': dispatch_data,
|
| 199 |
+
'collect_fn': collect_data
|
| 200 |
+
}
|
| 201 |
+
|
| 202 |
+
@register(dispatch_mode=dispatch_mode)
|
| 203 |
+
def generate_sequences(self, data):
|
| 204 |
+
pass
|
| 205 |
+
|
| 206 |
+
In this way, we can directly call the method inside the worker through
|
| 207 |
+
the ``worker_group`` on the control (driver) process (which is a single
|
| 208 |
+
process):
|
| 209 |
+
|
| 210 |
+
.. code:: python
|
| 211 |
+
|
| 212 |
+
output = worker_group.generate_sequences(data)
|
| 213 |
+
|
| 214 |
+
This single line includes data splitting, data distribution and
|
| 215 |
+
computation, and data collection.
|
| 216 |
+
|
| 217 |
+
Furthermore, the model parallelism size of each model is usually fixed,
|
| 218 |
+
including dp, tp, pp. So for these common distributed scenarios, we have
|
| 219 |
+
pre-implemented specific dispatch and collect methods,in `decorator.py <https://github.com/volcengine/verl/blob/main/verl/single_controller/base/decorator.py>`_, which can be directly used to wrap the computations.
|
| 220 |
+
|
| 221 |
+
.. code:: python
|
| 222 |
+
|
| 223 |
+
from verl.single_controller.base.decorator import register, Dispatch
|
| 224 |
+
|
| 225 |
+
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
|
| 226 |
+
def generate_sequences(self, data: DataProto) -> DataProto:
|
| 227 |
+
pass
|
| 228 |
+
|
| 229 |
+
Here it requires the data interface to be ``DataProto``. Definition of
|
| 230 |
+
``DataProto`` is in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_.
|
| 231 |
+
|
| 232 |
+
Step 3: Main training loop
|
| 233 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 234 |
+
|
| 235 |
+
With the above training flows, we can implement the algorithm's control
|
| 236 |
+
flow. It is recommended that ``main_task`` is also a ray remote process.
|
| 237 |
+
|
| 238 |
+
.. code:: python
|
| 239 |
+
|
| 240 |
+
@ray.remote(num_cpus=1)
|
| 241 |
+
def main_task(config):
|
| 242 |
+
# construct SampleGenerator
|
| 243 |
+
resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs
|
| 244 |
+
ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)
|
| 245 |
+
# put SampleGenerator onto resource pool
|
| 246 |
+
sample_gen = RayWorkerGroup(resource_pool, ray_cls)
|
| 247 |
+
|
| 248 |
+
# construct reference policy
|
| 249 |
+
ray_cls = RayClassWithInitArgs(ReferencePolicy)
|
| 250 |
+
ref_policy = RayWorkerGroup(resource_pool, ray_cls)
|
| 251 |
+
|
| 252 |
+
# construct actor
|
| 253 |
+
ray_cls = RayClassWithInitArgs(DPOActor)
|
| 254 |
+
dpo_policy = RayWorkerGroup(resource_pool, ray_cls)
|
| 255 |
+
|
| 256 |
+
dataloader = DataLoader()
|
| 257 |
+
|
| 258 |
+
for data in dataloader:
|
| 259 |
+
# generate data
|
| 260 |
+
data = sample_gen.generate_sequences(data)
|
| 261 |
+
# generate scores for each data
|
| 262 |
+
data = generate_scores(data)
|
| 263 |
+
# generate pairwise data using scores
|
| 264 |
+
data = generate_pairwise_data(data)
|
| 265 |
+
# generate ref_log_prob
|
| 266 |
+
data.batch['ref_log_prob'] = ref_policy.infer(data)
|
| 267 |
+
# update using dpo
|
| 268 |
+
dpo_policy.update(data)
|
| 269 |
+
# logging
|
| 270 |
+
|
| 271 |
+
Here, different ``WorkerGroups`` can be placed in the same resource pool or
|
| 272 |
+
in different resource pools using ``create_colocated_worker_cls``
|
| 273 |
+
similar as in `ray_trainer.py <https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py>`_.
|
code/RL_model/verl/verl_train/docs/advance/fp8.md
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FP8 rollout for verl
|
| 2 |
+
|
| 3 |
+
Last updated: 12/4/2025
|
| 4 |
+
|
| 5 |
+
This document introduces FP8 rollout in verl.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
We monkey patch several vLLM functions to enable FP8 rollout for reinforcement learning:
|
| 9 |
+
|
| 10 |
+
1. **Quantize weights**: Quantize model weights on-the-fly from higher-precision formats to FP8.
|
| 11 |
+
2. **Process weights after loading**: For vLLM, we replace the `vllm.model_executor.layers.quantization.fp8.Fp8LinearMethod.process_weights_after_loading` function to handle weight processing after quantization. For SGLang, this patch is not needed as it natively supports loading quantized weights.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Support Matrix
|
| 15 |
+
- FP8 blockwise quantization for rollout
|
| 16 |
+
- Used in Deepseek,
|
| 17 |
+
which is 1x128 quantization for activations and 128x128 quantization for model weights
|
| 18 |
+
- Dense models and MoE models
|
| 19 |
+
- Async rollout interfaces
|
| 20 |
+
- vLLM 0.10.x & vLLM 0.11 & SGlang 0.5.5
|
| 21 |
+
- FSDP and Megatron training backends
|
| 22 |
+
|
| 23 |
+
## Experiments and Outcomes
|
| 24 |
+
### Qwen3-8B-Base Dense Model
|
| 25 |
+
|
| 26 |
+
**Configuration**
|
| 27 |
+
- DAPO recipe. AIME24 online validation.
|
| 28 |
+
- vLLM(FP8 spmd rollout) + FSDP
|
| 29 |
+
- Note that SPMD rollout has been deprecated, so we removed the FP8 SPMD rollout.
|
| 30 |
+
- Prompt batch size 32, n=16.
|
| 31 |
+
- Rollout batch size: 32\*3*16
|
| 32 |
+
- Train_batch_size & ppo_mini_batch_size 32
|
| 33 |
+
- Max response length 20K
|
| 34 |
+
- Token-level TIS, C=2
|
| 35 |
+
- 8*H100
|
| 36 |
+
- vLLM 0.10.0+CUDA 12.6 vs vLLM 0.11.0+CUDA 12.9
|
| 37 |
+
|
| 38 |
+
**Accuracy**
|
| 39 |
+

|
| 41 |
+
*dark green: BF16, orange: FP8 rollout + token-level TIS, light green: FP8 rollout without TIS*
|
| 42 |
+
|
| 43 |
+
Results and observations:
|
| 44 |
+
- With TIS, FP8 rollout aligns with BF16
|
| 45 |
+
- Obvious accuracy drop when TIS is not enabled
|
| 46 |
+
- Higher mismatch kl but within acceptable range throughout the training
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
**Performance**
|
| 50 |
+
|
| 51 |
+

|
| 53 |
+
*green: BF16, orange: FP8 rollout + CUDA12.6 + DeepGemm, purple: FP8 rollout + CUDA 12.9 + DeepGemm*
|
| 54 |
+
|
| 55 |
+
Results and observations:
|
| 56 |
+
- FP8 rollout leads to around ~12% rollout speedup with CUDA 12.6 + DeepGemm
|
| 57 |
+
- When upgrading to CUDA 12.9, speedup can be up to ~18%
|
| 58 |
+
|
| 59 |
+
### Qwen3-30B-A3B-Base MoE Model
|
| 60 |
+
|
| 61 |
+
**Configuration**
|
| 62 |
+
- DAPO recipe. AIME24 online validation.
|
| 63 |
+
- FP8 async rollout, vLLM+FSDP
|
| 64 |
+
- Prompt batch size 32
|
| 65 |
+
- Rollout batch size: 32\*3*16
|
| 66 |
+
- Train_batch_size & ppo_mini_batch_size 32
|
| 67 |
+
- Max response length 20K
|
| 68 |
+
- Token-level TIS, C=2
|
| 69 |
+
- 2\*8*H100
|
| 70 |
+
- vLLM 0.10.0+CUDA 12.6
|
| 71 |
+
|
| 72 |
+
Please refer to `recipe/dapo/run_dapo_qwen3_moe_30b_vllm_fp8_rollout.sh`
|
| 73 |
+
|
| 74 |
+
**Accuracy**
|
| 75 |
+

|
| 77 |
+
*grey: BF16 + token-level TIS, red: FP8 rollout + token-level TIS*
|
| 78 |
+
|
| 79 |
+
Results and observations:
|
| 80 |
+
- Rollout & training distribution mismatch is in general higher for MoE
|
| 81 |
+
- Rollout correction required even for BF16
|
| 82 |
+
- FP8 rollout with token-level TIS aligns with BF16
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
**Performance**
|
| 86 |
+
|
| 87 |
+

|
| 89 |
+
*grey: BF16 + token-level TIS, red: FP8 rollout + token-level TIS*
|
| 90 |
+
|
| 91 |
+
Results and observations:
|
| 92 |
+
- FP8 rollout : over 35% rollout speedup
|
| 93 |
+
- Expecting more perf gain with CUDA 12.9
|
| 94 |
+
|
| 95 |
+
## Usage
|
| 96 |
+
|
| 97 |
+
FP8 can be enabled in the config file `verl/trainer/config/ppo_megatron_trainer.yaml`:
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
rollout:
|
| 101 |
+
quantization: "fp8"
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
Or it can be enabled by command line:
|
| 105 |
+
- `actor_rollout_ref.rollout.quantization=fp8`
|
| 106 |
+
|
| 107 |
+
Please refer to `recipe/dapo/run_dapo_qwen3_moe_30b_vllm_fp8_rollout.sh`
|
code/RL_model/verl/verl_train/docs/advance/fsdp_extension.rst
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Add models with the FSDP backend
|
| 3 |
+
==================================
|
| 4 |
+
|
| 5 |
+
Last updated: 02/09/2025.
|
| 6 |
+
|
| 7 |
+
Model
|
| 8 |
+
--------------------------
|
| 9 |
+
|
| 10 |
+
In principle, our FSDP backend can support any HF model and we can
|
| 11 |
+
sychronoize the actor model weight with vLLM using `hf_weight_loader.py` under `third_party/vllm`.
|
| 12 |
+
However, ``hf_weight_loader`` is will gather the full state_dict of a
|
| 13 |
+
model during synchronization, which may cause OOM. We suggest using
|
| 14 |
+
``dtensor_weight_loader`` which gather the full model parameter layer by
|
| 15 |
+
layer to reduce the peak memory usage. We already support dtensor weight
|
| 16 |
+
loader for the models below in `dtensor_weight_loader.py` under `third_party/vllm`:
|
| 17 |
+
|
| 18 |
+
- ``GPT2LMHeadModel``
|
| 19 |
+
- ``LlamaForCausalLM``
|
| 20 |
+
- ``LLaMAForCausalLM``
|
| 21 |
+
- ``MistralForCausalLM``
|
| 22 |
+
- ``InternLMForCausalLM``
|
| 23 |
+
- ``AquilaModel``
|
| 24 |
+
- ``AquilaForCausalLM``
|
| 25 |
+
- ``Phi3ForCausalLM``
|
| 26 |
+
- ``GemmaForCausalLM``
|
| 27 |
+
- ``Gemma2ForCausalLM``
|
| 28 |
+
- ``GPTBigCodeForCausalLM``
|
| 29 |
+
- ``Starcoder2ForCausalLM``
|
| 30 |
+
- ``Qwen2ForCausalLM``
|
| 31 |
+
- ``DeepseekV2ForCausalLM``
|
| 32 |
+
|
| 33 |
+
To implement ``dtensor_weight_loader`` of a model that's supported in
|
| 34 |
+
vLLM, follow the guide of gemma model below:
|
| 35 |
+
|
| 36 |
+
1. Copy the
|
| 37 |
+
``load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]])`` from the vllm model class
|
| 38 |
+
to ``dtensor_weight_loaders.py``
|
| 39 |
+
2. Modify the arguments to
|
| 40 |
+
``(actor_weights: Dict, vllm_model: nn.Module)``
|
| 41 |
+
3. Replace the ``self`` to ``vllm_model``
|
| 42 |
+
4. Add the
|
| 43 |
+
``local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)``
|
| 44 |
+
before each ``param = params_dict[name]`` and modify the following
|
| 45 |
+
weight loading using ``local_loaded_weight``.
|
| 46 |
+
5. Register the implemented dtensor weight loader to ``__MODEL_DTENSOR_WEIGHT_LOADER_REGISTRY__``.
|
| 47 |
+
|
| 48 |
+
.. code-block:: diff
|
| 49 |
+
|
| 50 |
+
- def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):
|
| 51 |
+
+ def gemma_dtensor_weight_loader(actor_weights: Dict, vllm_model: nn.Module) -> nn.Module:
|
| 52 |
+
stacked_params_mapping = [
|
| 53 |
+
# (param_name, shard_name, shard_id)
|
| 54 |
+
("qkv_proj", "q_proj", "q"),
|
| 55 |
+
("qkv_proj", "k_proj", "k"),
|
| 56 |
+
("qkv_proj", "v_proj", "v"),
|
| 57 |
+
("gate_up_proj", "gate_proj", 0),
|
| 58 |
+
("gate_up_proj", "up_proj", 1),
|
| 59 |
+
]
|
| 60 |
+
- params_dict = dict(self.named_parameters())
|
| 61 |
+
+ params_dict = dict(vllm_model.named_parameters())
|
| 62 |
+
loaded_params = set()
|
| 63 |
+
- for name, loaded_weight in weights:
|
| 64 |
+
+ for name, loaded_weight in actor_weights.items():
|
| 65 |
+
for (param_name, shard_name, shard_id) in stacked_params_mapping:
|
| 66 |
+
if shard_name not in name:
|
| 67 |
+
continue
|
| 68 |
+
name = name.replace(shard_name, param_name)
|
| 69 |
+
# Skip loading extra bias for GPTQ models.
|
| 70 |
+
if name.endswith(".bias") and name not in params_dict:
|
| 71 |
+
continue
|
| 72 |
+
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
|
| 73 |
+
param = params_dict[name]
|
| 74 |
+
weight_loader = param.weight_loader
|
| 75 |
+
- weight_loader(param, loaded_weight, shard_id)
|
| 76 |
+
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype), shard_id)
|
| 77 |
+
break
|
| 78 |
+
else:
|
| 79 |
+
# lm_head is not used in vllm as it is tied with embed_token.
|
| 80 |
+
# To prevent errors, skip loading lm_head.weight.
|
| 81 |
+
if "lm_head.weight" in name:
|
| 82 |
+
continue
|
| 83 |
+
# Skip loading extra bias for GPTQ models.
|
| 84 |
+
if name.endswith(".bias") and name not in params_dict:
|
| 85 |
+
continue
|
| 86 |
+
+ local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)
|
| 87 |
+
param = params_dict[name]
|
| 88 |
+
weight_loader = getattr(param, "weight_loader",
|
| 89 |
+
default_weight_loader)
|
| 90 |
+
- weight_loader(param, loaded_weight)
|
| 91 |
+
+ weight_loader(param, local_loaded_weight.to(dtype=param.dtype))
|
| 92 |
+
loaded_params.add(name)
|
| 93 |
+
unloaded_params = params_dict.keys() - loaded_params
|
| 94 |
+
if unloaded_params:
|
| 95 |
+
raise RuntimeError(
|
| 96 |
+
"Some weights are not initialized from checkpoints: "
|
| 97 |
+
f"{unloaded_params}")
|
code/RL_model/verl/verl_train/docs/advance/fully_async.md
ADDED
|
@@ -0,0 +1,595 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Fully Async Policy Trainer
|
| 2 |
+
|
| 3 |
+
**Author:** `https://github.com/meituan-search`
|
| 4 |
+
|
| 5 |
+
Last updated: 12/25/2025.
|
| 6 |
+
|
| 7 |
+
This document introduces a fully asynchronous PPO training system that completely decouples the Trainer and Rollouter,
|
| 8 |
+
supporting asynchronous sample generation and training.
|
| 9 |
+
Under this system, we achieved a 2.35x-2.67x performance improvement when training the Qwen2.5-7B model with 128 GPUs,
|
| 10 |
+
without significantly affecting the results.
|
| 11 |
+
|
| 12 |
+
## Introduction
|
| 13 |
+
|
| 14 |
+
### Background
|
| 15 |
+
|
| 16 |
+
The separated rollout and train architecture, compared to the colocate architecture, can allocate resources more
|
| 17 |
+
flexibly and design more flexible training logic, thereby addressing issues such as low GPU utilization and training
|
| 18 |
+
efficiency caused by long-tail problems.
|
| 19 |
+
The one_step_off_policy alleviates the problem of long rollout times and achieves some gains in training efficiency by
|
| 20 |
+
designing a separated architecture and performing asynchronous training between rollout and train for one round.
|
| 21 |
+
However, it forcibly uses data from one round of asynchronous training, which is not flexible enough and cannot
|
| 22 |
+
completely eliminate the impact of long-tail on training efficiency.
|
| 23 |
+
In other frameworks such as AReaL, Magistral, StreamRL, and AsyncFlow, asynchronous training and streaming training have
|
| 24 |
+
been implemented based on the separated architecture and have achieved gains.
|
| 25 |
+
We borrow from their methods and implemented them in VERL. The fully_async_policy supports asynchronous, streaming, and
|
| 26 |
+
partial
|
| 27 |
+
rollout training.
|
| 28 |
+
By reasonably setting parameters such as resource allocation and parameter synchronization frequency, fully_async_policy
|
| 29 |
+
can significantly improve training efficiency.
|
| 30 |
+
|
| 31 |
+
> Magistral https://arxiv.org/abs/2506.10910
|
| 32 |
+
>
|
| 33 |
+
> AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language
|
| 34 |
+
> Reasoning https://arxiv.org/abs/2505.24298
|
| 35 |
+
>
|
| 36 |
+
> StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream
|
| 37 |
+
> Generation https://arxiv.org/abs/2504.15930
|
| 38 |
+
>
|
| 39 |
+
> AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training https://arxiv.org/abs/2507.01663
|
| 40 |
+
|
| 41 |
+
### Core Contributions
|
| 42 |
+
|
| 43 |
+
- **Resource Isolation**: Unlike using hybrid_engine, Rollouter and Trainer use separate computing resources and need to
|
| 44 |
+
specify the resources they occupy separately.
|
| 45 |
+
- **Parallel Generation and Training**: While the Trainer is training, the Rollouter is generating new samples.
|
| 46 |
+
- **Multi-step Asynchronous**: Compared to one step off policy, it supports asynchronous settings from 0.x steps to
|
| 47 |
+
multiple steps, making the asynchronous solution more flexible.
|
| 48 |
+
- **NCCL Parameter Synchronization**: Based on the nccl communication primitive, refer to [checkpoint-engine](https://github.com/MoonshotAI/checkpoint-engine) to
|
| 49 |
+
achieve efficient parameter synchronization between Rollouter and Trainer.
|
| 50 |
+
- **Stream Inference and Training**: Rollouter generates data sample by sample, and data transmission uses a single
|
| 51 |
+
sample as the minimum transmission unit.
|
| 52 |
+
- **Asynchronous Training and Freshness Control**: By setting the parameter async_training.staleness_threshold, it
|
| 53 |
+
supports training with samples generated by old parameters.
|
| 54 |
+
- **PartialRollout**: The Rollouter's inference process supports partial rollout logic. During parameter
|
| 55 |
+
synchronization, by adding `sleep() and resume()` logic, it
|
| 56 |
+
saves samples from ongoing rollouts and continues using them in the next rollout, reducing the time spent waiting for
|
| 57 |
+
ongoing tasks to finish during parameter synchronization.
|
| 58 |
+
|
| 59 |
+
Currently, the supported usage mode is Megatron/FSDP+vLLM/SGLang. vLLM/SGLang must use the server mode based on AgentLoop.
|
| 60 |
+
|
| 61 |
+
## Design
|
| 62 |
+
|
| 63 |
+
The overall architecture of fully_async_policy is shown in the figure below. fully_async_policy mainly consists of four
|
| 64 |
+
parts: Rollouter, MessageQueue, Trainer, and ParameterSynchronizer.
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
1. Rollouter generates sequences sample by sample and puts the generated samples into the MessageQueue, with the
|
| 69 |
+
production speed controlled by freshness.
|
| 70 |
+
2. MessageQueue is used to temporarily store samples generated by Rollouter.
|
| 71 |
+
3. Trainer fetches samples from MessageQueue sample by sample. After fetching `require_batches*ppo_mini_batch_size`
|
| 72 |
+
samples, it will perform training. After training for async_training.trigger_parameter_sync_step rounds, it triggers
|
| 73 |
+
a parameter synchronization with Rollouter.
|
| 74 |
+
4. ParameterSynchronizer implements the NCCL synchronous parameter synchronization capability.
|
| 75 |
+
|
| 76 |
+
The source of benefits compared to the base scheme lies in the fact that in the colocate case, using more resources for
|
| 77 |
+
rollout cannot solve the idleness caused by long-tail samples.
|
| 78 |
+
After we perform resource isolation, the time for rollout and train may be longer than before (because fewer resources
|
| 79 |
+
are used),
|
| 80 |
+
but the overlap in their time consumption reduces the end-to-end time consumption.
|
| 81 |
+
|
| 82 |
+

|
| 83 |
+
|
| 84 |
+
## Usage
|
| 85 |
+
|
| 86 |
+
### Parameter Description
|
| 87 |
+
|
| 88 |
+
| super params | implication |
|
| 89 |
+
| ---------------------------------------------------------------- | ---------------------------------------------------------------------------------------------- |
|
| 90 |
+
| `trainer.nnodes` | Number of nodes for Trainer |
|
| 91 |
+
| `trainer.n_gpus_per_node` | Number of GPUs per node for Trainer |
|
| 92 |
+
| `rollout.nnodes` | Number of nodes for Rollouter |
|
| 93 |
+
| `rollout.n_gpus_per_node` | Number of GPUs per node for Rollouter |
|
| 94 |
+
| `data.train_batch_size` | In the fully async strategy, this value is not effective (default is 0) |
|
| 95 |
+
| `data.gen_batch_size` | In the fully async strategy, uses streaming sample production logic (default is 1) |
|
| 96 |
+
| `rollout.total_rollout_steps` | Total number of rollout samples |
|
| 97 |
+
| `rollout.test_freq` | How many times Rollouter updates parameters before performing a validation |
|
| 98 |
+
| `actor_rollout_ref.actor.ppo_mini_batch_size` | The ppo_mini_batch_size is a global num across all workers/gpus |
|
| 99 |
+
| `async_training.require_batches` | Number of ppo_mini_batch_size that FullyAsyncTrainer fetches at once |
|
| 100 |
+
| `async_training.trigger_parameter_sync_step` | Indicates how many local updates FullyAsyncTrainer performs before a parameter synchronization |
|
| 101 |
+
| `async_training.staleness_threshold` | Freshness control |
|
| 102 |
+
| `async_training.partial_rollout` | Whether to perform partial_rollout |
|
| 103 |
+
| `async_training.use_rollout_log_probs` | Use log_probs generated by rollout |
|
| 104 |
+
| `async_training.compute_prox_log_prob` | Whether to compute log_prob using the training model's parameters during the training phase |
|
| 105 |
+
| `async_training.checkpoint_engine.enable` | Whether to use checkpoint_engine for accelerating, default `True` |
|
| 106 |
+
| `async_training.checkpoint_engine.overlap_broadcast_and_consume` | When use checkpoint_engine, whether to overlap broadcast and load_weights, default `False` |
|
| 107 |
+
| `async_training.checkpoint_engine.device_buffer_size_M` | When use checkpoint_engine, the user-specific bucket size (MB), default `4096` |
|
| 108 |
+
| `async_training.use_trainer_do_validate` | Whether use trainer node to do validate process, default `False`|
|
| 109 |
+
|
| 110 |
+
**Further Explanation:**
|
| 111 |
+
|
| 112 |
+
- `rollout.total_rollout_steps`
|
| 113 |
+
|
| 114 |
+
Compared to colocate, the quantity can be aligned by multiplying train_batch_size and step:
|
| 115 |
+
`rollout.total_rollout_steps = data.train_batch_size * step`.
|
| 116 |
+
|
| 117 |
+
- `async_training.trigger_parameter_sync_step`
|
| 118 |
+
|
| 119 |
+
In the fully async strategy, it indicates how many local updates the Trainer performs (i.e., how many times it fetches
|
| 120 |
+
`require_batches * ppo_mini_batch_size` samples) before a parameter synchronization with Rollouter.
|
| 121 |
+
Between every two parameter synchronizations between Rollouter and Trainer, the Trainer will process
|
| 122 |
+
`trigger_parameter_sync_step* require_batches*ppo_mini_batch_size` samples.
|
| 123 |
+
To fairly compare speed with colocate, trigger_parameter_sync_step should be set to
|
| 124 |
+
`data.train_batch_size / (require_batches * ppo_mini_batch_size)`.
|
| 125 |
+
|
| 126 |
+
- `async_training.staleness_threshold`
|
| 127 |
+
|
| 128 |
+
In the fully async strategy, it indicates the maximum proportion of stale samples allowed to be used.
|
| 129 |
+
|
| 130 |
+
- staleness_threshold=0, indicates synchronous training.
|
| 131 |
+
Rollouter will generate a fixed number of samples between two parameter updates, the sample count is:
|
| 132 |
+
$$rollout\_num = (trigger\_parameter\_sync\_step*require\_batches*ppo\_mini\_batch\_size)$$
|
| 133 |
+
- staleness_threshold>0, indicates asynchronous training, can be set to a decimal for more flexible asynchronous
|
| 134 |
+
calls.
|
| 135 |
+
Rollouter will generate at most the following number of samples between two parameter updates:
|
| 136 |
+
$$rollout\_num = (1+staleness\_threshold)*(trigger\_parameter\_sync\_step*require\_batches*ppo\_mini\_batch\_size) - num\_staleness\_sample $$
|
| 137 |
+
|
| 138 |
+
num_staleness_sample represents the number of stale samples generated in excess during the last rollout.
|
| 139 |
+
|
| 140 |
+
Since it's a streaming system, rollout continues to generate and trainer continues to consume. If rollouter is slower,
|
| 141 |
+
trainer will trigger parameter synchronization earlier, and rollouter will not actually produce rollout_num samples.
|
| 142 |
+
When rollout is fast enough, setting staleness_threshold to 1 is basically equivalent to one_step_off policy.
|
| 143 |
+
To avoid too many expired samples affecting training accuracy, it is recommended to set this value to less than 1.
|
| 144 |
+
|
| 145 |
+
- `async_training.partial_rollout`
|
| 146 |
+
|
| 147 |
+
partial_rollout only actually takes effect when staleness_threshold>0.
|
| 148 |
+
|
| 149 |
+
- `async_training.use_rollout_log_probs`
|
| 150 |
+
|
| 151 |
+
In reinforcement learning algorithms, log_probs have implicit correlations with parameter versions and tokens. Due to
|
| 152 |
+
the settings of algorithms like PPO/GRPO/DAPO, when calculating importance sampling,
|
| 153 |
+
old_log_prob must use the log_probs corresponding to the rollout parameters and tokens to ensure algorithm
|
| 154 |
+
correctness. In the fully
|
| 155 |
+
async strategy, we default to old_log_prob being calculated by rollout rather than by trainer.
|
| 156 |
+
|
| 157 |
+
- `async_training.require_batches`
|
| 158 |
+
|
| 159 |
+
In streaming training, require_batches should be set to 1, indicating that training is performed after producing
|
| 160 |
+
enough ppo_mini_batch_size samples.
|
| 161 |
+
In actual testing, we found that if fewer samples are issued at once, due to the order of data distribution, it can
|
| 162 |
+
cause training instability and longer response lengths.
|
| 163 |
+
Here, we additionally provide require_batches for streaming distribution and control the number of samples
|
| 164 |
+
participating in training at once.
|
| 165 |
+
|
| 166 |
+
- `async_training.compute_prox_log_prob` (experimental)
|
| 167 |
+
|
| 168 |
+
During the training process, we observed that metrics and response lengths may become unstable in the later
|
| 169 |
+
stages of training. To mitigate this issue, we can use
|
| 170 |
+
the [Rollout Importance Sampling](https://verl.readthedocs.io/en/latest/advance/rollout_is.html)
|
| 171 |
+
technique for importance sampling. To utilize Rollout Importance Sampling, we need to compute log_prob using
|
| 172 |
+
the training engine, which requires enabling this switch.
|
| 173 |
+
Additionally, when compute_prox_log_prob and Rollout Importance Sampling are enabled under mode d
|
| 174 |
+
(async stream pipeline with partial rollout), our implementation approximates `Areal's Decoupled PPO`.
|
| 175 |
+
|
| 176 |
+
- `async_training.checkpoint_engine.enable`
|
| 177 |
+
|
| 178 |
+
Enabling the checkpoint engine generally reduces synchronization time overhead by more than 60% compared to
|
| 179 |
+
the original per-tensor parameter synchronization method. However, assembling buckets incurs additional
|
| 180 |
+
temporary GPU memory overhead.
|
| 181 |
+
|
| 182 |
+
- `async_training.checkpoint_engine.overlap_broadcast_and_consume`
|
| 183 |
+
|
| 184 |
+
Enabling pipeline between the broadcast and load_weights parameters will allocate additional GPU memory.
|
| 185 |
+
Since the main time consumption for parameter synchronization is not in the broadcast and load_weights phases,
|
| 186 |
+
but in the parameter generation phase (by megatron or FSDP), this option is off by default.
|
| 187 |
+
|
| 188 |
+
- `async_training.checkpoint_engine.device_buffer_size_M`
|
| 189 |
+
|
| 190 |
+
It controls the size of the memory buffer used for synchronization when the checkpoint-engine is enabled.
|
| 191 |
+
The actual `bucket_size` = `max(device_buffer_size_M, maximum parameter tensor size)`.
|
| 192 |
+
|
| 193 |
+
- When enable `overlap_broadcast_and_consume`, the additional device memory overhead of
|
| 194 |
+
trainer rank is `3 * bucket_size`and rollout rank is `2 * bucket_size`。
|
| 195 |
+
- When disable `overlap_broadcast_and_consume`, the additional device memory overhead of
|
| 196 |
+
trainer rank is `2 * bucket_size`and rollout rank is `1 * bucket_size`。
|
| 197 |
+
|
| 198 |
+
* `async_training.use_trainer_do_validate`
|
| 199 |
+
|
| 200 |
+
It controls whether to use the trainer's `do_validate` method for validation.
|
| 201 |
+
If set to True, the trainer will perform validation after each parameter update. It can reduce the validation time
|
| 202 |
+
overhead and trainer node idle time.
|
| 203 |
+
If set to False, the trainer will not perform validation.
|
| 204 |
+
|
| 205 |
+
### Supported Modes
|
| 206 |
+
|
| 207 |
+
1. on policy pipeline:
|
| 208 |
+
|
| 209 |
+
1. **trigger_parameter_sync_step=1, staleness_threshold=0**
|
| 210 |
+
2. Rollouter produces `require_batches*ppo_mini_batch_size` samples at once, Trainer fetches these samples for
|
| 211 |
+
training, and after training completes, Trainer and Rollouter perform a parameter synchronization;
|
| 212 |
+
3. During the rollout phase, if there are long-tail samples but few rollout samples, shorter samples cannot fill
|
| 213 |
+
idle resources, causing some resource waste.
|
| 214 |
+
4. As shown in figure a;
|
| 215 |
+
|
| 216 |
+
2. stream off policy pipeline:
|
| 217 |
+
|
| 218 |
+
1. **trigger_parameter_sync_step>1, staleness_threshold=0**
|
| 219 |
+
2. Synchronous streaming training will be performed. Rollouter produces
|
| 220 |
+
`require_batches*ppo_mini_batch_size*trigger_parameter_sync_step` samples at once, Trainer performs a local
|
| 221 |
+
training every time it fetches `require_batches*ppo_mini_batch_size` samples, and after training
|
| 222 |
+
trigger_parameter_sync_step times, Trainer and Rollouter perform a parameter synchronization;
|
| 223 |
+
3. Compared to a, since more samples are generated at once, resource idleness will be lower.
|
| 224 |
+
4. In one step training, there will be two periods of resource idleness: when fetching the first batch of samples,
|
| 225 |
+
train waits for `require_batches*ppo_mini_batch_size` samples to be produced, and during the last parameter
|
| 226 |
+
update, rollout waits for training to complete.
|
| 227 |
+
5. As shown in figure b;
|
| 228 |
+
|
| 229 |
+
3. async stream pipeline with stale samples:
|
| 230 |
+
|
| 231 |
+
1. **trigger_parameter_sync_step>=1, staleness_threshold>0, partial_rollout=False**
|
| 232 |
+
2. After each parameter update, Rollouter will plan to produce at most rollout_num samples (in practice, the number
|
| 233 |
+
of samples generated may be less than this value depending on rollout speed).
|
| 234 |
+
3. If the rollout process is relatively fast, Rollouter will generate some additional samples num_stale_samples
|
| 235 |
+
before parameter synchronization for immediate use by Trainer after synchronization.
|
| 236 |
+
When triggering parameter synchronization, if Rollouter has ongoing tasks, it will wait for the tasks to complete
|
| 237 |
+
and not add new tasks;
|
| 238 |
+
4. Compared to b, except for the first step training, subsequent training will not have the time to wait for the
|
| 239 |
+
first batch rollout to finish, but will have the time to wait for active tasks to finish.
|
| 240 |
+
5. As shown in figure c;
|
| 241 |
+
|
| 242 |
+
4. async stream pipeline with partial rollout:
|
| 243 |
+
1. **trigger_parameter_sync_step>=1, staleness_threshold>0, partial_rollout=True**
|
| 244 |
+
2. Compared to c, when triggering parameter synchronization, if Rollouter has samples being produced, it will
|
| 245 |
+
interrupt the rollout process and perform parameter synchronization. The interrupted samples will continue to be
|
| 246 |
+
generated after synchronization. This reduces the time to wait for active tasks to finish.
|
| 247 |
+
3. As shown in figure d;
|
| 248 |
+
|
| 249 |
+

|
| 250 |
+
|
| 251 |
+
### Key Metrics
|
| 252 |
+
|
| 253 |
+
| metrics | implication |
|
| 254 |
+
| ---------------------------------------------- | ------------------------------------------------------------------------------------------------------ |
|
| 255 |
+
| `trainer/idle_ratio` | Trainer idle rate |
|
| 256 |
+
| `rollouter/idle_ratio` | Rollouter idle rate |
|
| 257 |
+
| `fully_async/count/stale_samples_processed` | Total number of old samples used in training |
|
| 258 |
+
| `fully_async/count/stale_trajectory_processed` | Total number of old trajectories used in training (one sample produces rollout.n trajectories) |
|
| 259 |
+
| `fully_async/partial/total_partial_num` | Number of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 260 |
+
| `fully_async/partial/partial_ratio` | Ratio of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 261 |
+
| `fully_async/partial/max_partial_span` | Maximum parameter span of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 262 |
+
|
| 263 |
+
### Parameter Tuning Recommendations
|
| 264 |
+
|
| 265 |
+
- Resource Allocation and Adjustment:
|
| 266 |
+
|
| 267 |
+
- Reasonable resource allocation is the prerequisite for achieving good training efficiency. The ideal resource
|
| 268 |
+
allocation should make the rollout time and train time close, thereby minimizing pipeline bubbles in the entire
|
| 269 |
+
training process,
|
| 270 |
+
avoiding resource idleness, and ensuring Trainer does not use old samples. In real training scenarios, resource
|
| 271 |
+
allocation can be adjusted based on the idle time of rollout and train during actual training,
|
| 272 |
+
which can be obtained from rollouter/idle_ratio and trainer/idle_ratio. If rollouter/idle_ratio is high and
|
| 273 |
+
trainer/idle_ratio is low,
|
| 274 |
+
Trainer resources should be increased and Rollouter resources should be reduced, and vice versa.
|
| 275 |
+
|
| 276 |
+
- Key Parameters:
|
| 277 |
+
|
| 278 |
+
- staleness_threshold: Setting it too high will cause more old samples to be used, affecting model performance. It
|
| 279 |
+
is recommended to set it to less than 1.
|
| 280 |
+
- require_batches: The closer to 1, the closer to a pure streaming process, the smaller the training bubbles, and
|
| 281 |
+
the faster the acceleration effect that can be achieved in terms of speed, but it will affect the order of sample
|
| 282 |
+
processing;
|
| 283 |
+
- trigger_parameter_sync_step: The smaller the setting, the closer to on policy, but it will cause frequent
|
| 284 |
+
parameter synchronization. Long-tail samples waste resources that cannot be filled by short samples, resulting in
|
| 285 |
+
low resource utilization.
|
| 286 |
+
The larger the setting, the higher the computational efficiency, but the accuracy will be affected by off policy.
|
| 287 |
+
- rollout.test_freq: It will occupy Rollouter resources and is not recommended to be set too small.
|
| 288 |
+
|
| 289 |
+
- Mode Selection: By adjusting different parameters, the Fully Async architecture supports optimization acceleration at
|
| 290 |
+
different levels, suitable for tasks in different scenarios.
|
| 291 |
+
- For small-scale tasks that need to ensure training stability and on-policy nature, and have low speed
|
| 292 |
+
requirements, the on policy pipeline mode (Mode 1) can be tried.
|
| 293 |
+
- For scenarios that need to improve training throughput but are sensitive to staleness, the stream off policy
|
| 294 |
+
pipeline mode can be tried. That is, by
|
| 295 |
+
setting trigger_parameter_sync_step>1 to improve training efficiency, but still maintaining the synchronization
|
| 296 |
+
mechanism (staleness_threshold=0) (Mode 2).
|
| 297 |
+
- For large-scale tasks with high training speed requirements and can tolerate a certain degree of off-policy and
|
| 298 |
+
staleness, setting staleness_threshold>
|
| 299 |
+
0 and partial_rollout=True can improve training efficiency, using the async stream pipeline mode (Mode 3 or 4).
|
| 300 |
+
|
| 301 |
+
### Quick Start
|
| 302 |
+
|
| 303 |
+
```shell
|
| 304 |
+
rollout_mode="async"
|
| 305 |
+
rollout_name="vllm" # sglang or vllm
|
| 306 |
+
if [ "$rollout_mode" = "async" ]; then
|
| 307 |
+
export VLLM_USE_V1=1
|
| 308 |
+
return_raw_chat="True"
|
| 309 |
+
fi
|
| 310 |
+
|
| 311 |
+
train_prompt_bsz=0
|
| 312 |
+
gen_prompt_bsz=1
|
| 313 |
+
n_resp_per_prompt=16
|
| 314 |
+
train_prompt_mini_bsz=32
|
| 315 |
+
total_rollout_steps=$(((512*400)))
|
| 316 |
+
test_freq=10
|
| 317 |
+
staleness_threshold=0
|
| 318 |
+
trigger_parameter_sync_step=16
|
| 319 |
+
partial_rollout=False
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
python -m verl.experimental.fully_async_policy.fully_async_main \
|
| 323 |
+
train_batch_size=${train_prompt_bsz} \
|
| 324 |
+
data.gen_batch_size=${gen_prompt_bsz} \
|
| 325 |
+
data.return_raw_chat=${return_raw_chat} \
|
| 326 |
+
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \
|
| 327 |
+
actor_rollout_ref.actor.strategy=fsdp2 \
|
| 328 |
+
critic.strategy=fsdp2 \
|
| 329 |
+
actor_rollout_ref.hybrid_engine=False \
|
| 330 |
+
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \
|
| 331 |
+
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 332 |
+
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 333 |
+
actor_rollout_ref.rollout.name=${rollout_name} \
|
| 334 |
+
actor_rollout_ref.rollout.mode=${rollout_mode} \
|
| 335 |
+
actor_rollout_ref.rollout.calculate_log_probs=True \
|
| 336 |
+
trainer.nnodes="${NNODES_TRAIN}" \
|
| 337 |
+
trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \
|
| 338 |
+
rollout.nnodes="${NNODES_ROLLOUT}" \
|
| 339 |
+
rollout.n_gpus_per_node="${NGPUS_PER_NODE}" \
|
| 340 |
+
rollout.total_rollout_steps="${total_rollout_steps}" \
|
| 341 |
+
rollout.test_freq="${test_freq}" \
|
| 342 |
+
async_training.staleness_threshold="${staleness_threshold}" \
|
| 343 |
+
async_training.trigger_parameter_sync_step="${trigger_parameter_sync_step}" \
|
| 344 |
+
async_training.partial_rollout="${partial_rollout}"
|
| 345 |
+
```
|
| 346 |
+
|
| 347 |
+
## Experiments
|
| 348 |
+
|
| 349 |
+
### Asynchronous Training on 7B Model
|
| 350 |
+
|
| 351 |
+
We used Qwen2.5-Math-7B to verify the benefits of the fully async strategy under long candidates and multiple resources.
|
| 352 |
+
Using the `async stream pipeline with stale samples` strategy, we achieved about 2x performance improvement on 32 cards,
|
| 353 |
+
64 cards, and 128 cards without significantly affecting experimental results.
|
| 354 |
+
|
| 355 |
+
- Machine: H20
|
| 356 |
+
- Model: Qwen2.5-Math-7B
|
| 357 |
+
- Rollout length: max_response_length FSDP2: 28K tokens;
|
| 358 |
+
- Algorithm: DAPO
|
| 359 |
+
- Dataset: TRAIN_FILE: dapo-math-17k.parquet TEST_FILE: aime-2024.parquet
|
| 360 |
+
- Engine: vLLM + FSDP2
|
| 361 |
+
- rollout.n: 16
|
| 362 |
+
- ppo_mini_batch_size: 32
|
| 363 |
+
- test_freq: 20
|
| 364 |
+
|
| 365 |
+
- colocate sync:
|
| 366 |
+
|
| 367 |
+
- step: 400
|
| 368 |
+
- train_batch_size: 512
|
| 369 |
+
|
| 370 |
+
- fully_async_policy
|
| 371 |
+
- total_rollout_steps: 512\*400
|
| 372 |
+
- require_batches: 4
|
| 373 |
+
- trigger_parameter_sync_step: 4
|
| 374 |
+
- staleness_threshold: 0.5
|
| 375 |
+
- partial_rollout: True
|
| 376 |
+
|
| 377 |
+
| training mode | resource allocation | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 378 |
+
| :----------------: | :-----------------: | :----: | :----: | :----------: | :----------: | :--------------------: | :--------------------: | :--------------------: | :--------------------: | :-------------------------: |
|
| 379 |
+
| colocate sync | 32 | 790.10 | 357.41 | 107.71 | 269.80 | 13h 44m | 1d 3h 43m | 2d 9h 22m | 3d 17h 5m | max: 0.3313<br>last: 0.2448 |
|
| 380 |
+
| fully_async_policy | 16:16 | 294.77 | 21.26 | \ | 313.81 | 7h 58m<br>(1.72x) | 16h 21m<br>(1.70x) | 1d 0h 53m<br>(2.31x) | 1d 9h 26m<br>(2.66x) | max: 0.3302<br>last: 0.2333 |
|
| 381 |
+
| colocate sync | 64 | 365.28 | 150.72 | 70.26 | 133.41 | 10h 22m | 20h 45m | 1d 7h 6m | 1d 17h 32m | max: 0.3365<br>last: 0.2333 |
|
| 382 |
+
| fully_async_policy | 32:32 | 189.26 | 28.46 | \ | 156.98 | 4h 57m<br>(2.09x) | 10h 14m<br>(2.03x) | 16h 58m<br>(1.83x) | 21h 40m<br>(1.92x) | max: 0.3677<br>last: 0.3406 |
|
| 383 |
+
| colocate sync | 128 | 356.30 | 177.85 | 53.92 | 113.81 | 8h 36m | 17h 56m | 1d 5h 6m | 1d 16h 48m | max: 0.3573<br>last: 0.2958 |
|
| 384 |
+
| fully_async_policy | 64:64 | 150.63 | 33.14 | \ | 113.16 | 3h 13m<br>(2.67x) | 6h 46m<br>(2.65x) | 10h 53m<br>(2.67x) | 17h 22m<br>(2.35x) | max: 0.3521<br>last: 0.3094 |
|
| 385 |
+
|
| 386 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-colocate_async?nw=nwuserhouzg
|
| 387 |
+
|
| 388 |
+
### 128-card 7B Asynchronous Mode Experiment
|
| 389 |
+
|
| 390 |
+
We used Qwen2.5-Math-7B to verify the effects of various modes supported by fully async.
|
| 391 |
+
We can see that the benefit brought by streaming is approximately 1.6x, and after combining staleness and
|
| 392 |
+
partial_rollout, the benefit reaches 2.35x.
|
| 393 |
+
|
| 394 |
+
| mode | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 395 |
+
| :---------------------------------------------------------------------------------------------------: | :----: | :----: | :----------: | :----------: | :--------------------: | :--------------------: | :--------------------: | :--------------------: | :-------------------------: |
|
| 396 |
+
| colocate sync | 356.30 | 177.85 | 53.92 | 113.81 | 8h 36m | 17h 56m | 1d 5h 6m | 1d 16h 48m | max: 0.3573<br>last: 0.2958 |
|
| 397 |
+
| `stream off policy pipeline`<br>(+fully async: trigger_parameter_sync_step= 4,<br>require_batches= 4) | 231.34 | 128.47 | \ | 98.77 | 4h 25m | 9h 41m | 15h 2m | 1d 1h 53m | max: 0.2844<br>last: 0.2604 |
|
| 398 |
+
| `async stream pipeline with stale samples`<br>(+staleness_threshold=0.5) | | | | | | | | | |
|
| 399 |
+
| `async stream pipeline with partial rollout`<br>(+partial_rollout=True) | 150.63 | 33.14 | \ | 113.16 | 3h 13m | 6h 46m | 10h 53m | 17h 22m | max: 0.3521<br>last: 0.3094 |
|
| 400 |
+
|
| 401 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-stream_stale_partial?nw=nwuserhouzg
|
| 402 |
+
|
| 403 |
+
### 128-card Stale Ablation Experiment
|
| 404 |
+
|
| 405 |
+
Under the `async stream pipeline with partial rollout` mode, we verified the impact of staleness settings on training
|
| 406 |
+
efficiency.
|
| 407 |
+
We found that the larger the staleness, the more obvious the final gains.
|
| 408 |
+
We also noticed that the times for staleness values of 0.3 and 0.5 are quite close, because as the training steps
|
| 409 |
+
increase, the response length changes significantly, causing training instability.
|
| 410 |
+
Further analysis and optimization are needed for this issue.
|
| 411 |
+
|
| 412 |
+
| staleness_threshold | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 413 |
+
| :-----------------: | :----: | :----: | :----------: | :----------: | :--------------------: | :--------------------: | :--------------------: | :--------------------: | :-------------------------: |
|
| 414 |
+
| 0 | 231.34 | 128.47 | \ | 98.77 | 4h 25m | 9h 41m | 15h 2m | 1d 1h 53m | max: 0.2844<br>last: 0.2604 |
|
| 415 |
+
| 0.1 | 171.30 | 58.17 | \ | 109.12 | 3h 53m | 8h 37m | 14h 25m | 19h 59m | max: 0.3542<br>last: 0.2979 |
|
| 416 |
+
| 0.3 | 146.11 | 38.88 | \ | 103.22 | 3h 18m | 6h 49m | 11h 40m | 17h 20m | max: 0.3469<br>last: 0.2865 |
|
| 417 |
+
| 0.5 | 150.63 | 33.14 | \ | 113.16 | 3h 13m | 6h 46m | 10h 53m | 17h 22m | max: 0.3521<br>last: 0.3094 |
|
| 418 |
+
|
| 419 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-stream_stale_partial?nw=nwuserhouzg
|
| 420 |
+
|
| 421 |
+
### 128-card 7B require_batches Ablation Experiment
|
| 422 |
+
|
| 423 |
+
In multiple tests, we found that the number of samples issued each time in streaming affects the response length during
|
| 424 |
+
training, which in turn affects training time. We verified the impact on results by modifying
|
| 425 |
+
`async_training.require_batches`.
|
| 426 |
+
|
| 427 |
+
| require_batches | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | acc/mean@1 |
|
| 428 |
+
| :-------------: | :----: | :---: | :----------: | :----------: | :--------------------: | :--------------------: | :--------------------: | :-------------------------: |
|
| 429 |
+
| 1 | 203.47 | 30.88 | \ | 181.08 | 3h 31m | 8h 29m | 17h 36m | max: 0.349<br>last: 0.326 |
|
| 430 |
+
| 2 | 158.72 | 26.32 | \ | 128.08 | 3h 35m | 7h 38m | 13h 57m | max: 0.351<br>last: 0.3406 |
|
| 431 |
+
| 4 | 124.64 | 25.62 | \ | 95.06 | 3h 13m | 6h 46m | 10h 53m | max: 0.3521<br>last: 0.3521 |
|
| 432 |
+
|
| 433 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-ablation_require_batches?nw=nwuserhouzg
|
| 434 |
+
|
| 435 |
+
### 30B Model Mode Experiment
|
| 436 |
+
|
| 437 |
+
We achieved a 1.7x performance improvement with `async stream pipeline with staleness samples` strategy on the
|
| 438 |
+
Qwen3-30B-A3B-Base model compared to the colocate setup. It is worth noting that this is far from the upper limit of
|
| 439 |
+
performance gains achievable through asynchrony. Firstly, the comparative experiments used a maximum response length of
|
| 440 |
+
only 8k, which is much shorter than the 20k sequence length in previous experiments, resulting in a less pronounced
|
| 441 |
+
rollout tail effect. Secondly, we adopted a highly skewed resource allocation, with rollout using 96 GPUs and trainer
|
| 442 |
+
using 32 GPUs, which is not an optimal configuration. During the experiments, we observed that the current verl
|
| 443 |
+
implementation imposes certain constraints, such as requiring data to be evenly divisible by the number of GPUs, making
|
| 444 |
+
resource adjustment less flexible. Additionally, as asynchronous training and deployment accelerate, the performance gap
|
| 445 |
+
is gradually narrowing. Therefore, enabling more flexible resource allocation and dynamic resource adjustment in the
|
| 446 |
+
future will be our next focus.
|
| 447 |
+
|
| 448 |
+
- Machine: H20
|
| 449 |
+
- Model: Qwen3-30B-A3B-Base
|
| 450 |
+
- Rollout length: max_response_length : 8K tokens;
|
| 451 |
+
- Algorithm: GRPO
|
| 452 |
+
- Dataset: TRAIN_FILE: dapo-math-17k.parquet TEST_FILE: aime-2024.parquet
|
| 453 |
+
- Engine: vLLM + Megatron
|
| 454 |
+
- rollout.n: 16
|
| 455 |
+
- ppo_mini_batch_size: 128
|
| 456 |
+
- test_freq: 20
|
| 457 |
+
|
| 458 |
+
- colocate sync:
|
| 459 |
+
|
| 460 |
+
- step:400
|
| 461 |
+
- train_batch_size: 512
|
| 462 |
+
|
| 463 |
+
- fully_async_policy
|
| 464 |
+
- total_rollout_steps: 512\*400
|
| 465 |
+
- trigger_parameter_sync_step: 512/128 = 4
|
| 466 |
+
- staleness_threshold: 0.5
|
| 467 |
+
- partial_rollout: True
|
| 468 |
+
|
| 469 |
+
| Training Mode | Resource Allocation | Step | Gen | Old Log Prob | Ref | Update Actor | Total Time 100 Step | Total Time 200 Step | Total Time 300 Step | Total Time 400 Step | Acc/Mean@1 |
|
| 470 |
+
| ------------------ | ------------------- | ------ | ------ | ------------ | ----- | ------------ | ------------------- | ------------------- | ------------------- | ------------------- | --------------------------- |
|
| 471 |
+
| Colocate Sync | 128 | 497.89 | 348.05 | 28.73 | 20.86 | 86.27 | 13h 36m | 1d 3h 48m | 1d 19h 4m | 2d 11h 39m | max: 0.3500<br>last: 0.3208 |
|
| 472 |
+
| Fully Async Policy | 96:32 | 282.75 | 22.06 | \ | 50.05 | 206.63 | 6h 45m (2.01x) | 14h 48m (1.88x) | 1d 0h 9m (1.78x) | 1d 10h 41m (1.72x) | max: 0.3813<br>last: 0.3448 |
|
| 473 |
+
|
| 474 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-30B?nw=nwuserhouzg | | |
|
| 475 |
+
|
| 476 |
+
### checkpoint-engine Ablation Experiment
|
| 477 |
+
|
| 478 |
+
We tested the single-step parameter synchronization time of the checkpoint-engine on three models: Qwen2.5-Math-7B, Qwen3-30B-A3B, and Qwen3-235B-A22B, using default checkpoint-engine configurations. All experiments were performed on H20 machines, and the Megatron engine was used for training.
|
| 479 |
+
| model | trainer rank | rollout rank | checkpoint-engine | total sync time |
|
| 480 |
+
|:-----------------:|:--------:|:-------:|:--------------:|:--------------:|
|
| 481 |
+
| Qwen2.5-Math-7B | 4 | 4 | False | 0.12s |
|
| 482 |
+
| Qwen2.5-Math-7B | 4 | 4 | True | 0.02s |
|
| 483 |
+
| Qwen3-30B-A3B | 16 | 16 | False | 15.76s |
|
| 484 |
+
| Qwen3-30B-A3B | 16 | 16 | True | 4.38s |
|
| 485 |
+
| Qwen3-235B-A22B | 64 | 64 | False | 58.57s |
|
| 486 |
+
| Qwen3-235B-A22B | 64 | 64 | True | 23.70s |
|
| 487 |
+
|
| 488 |
+
### use_trainer_do_validate Experiment
|
| 489 |
+
|
| 490 |
+
We tested the effect of setting `use_trainer_do_validate=True` on the training process. The results show that setting
|
| 491 |
+
this parameter to True can reduce the validation time overhead and trainer node idle time.
|
| 492 |
+
We used Qwen2.5-Math-7B to verify the benefits of `use_trainer_do_validate=True` on the training process, we achieved about 2x performance improvement on validation time, and the trainer node idle time is reduced by about 40%.
|
| 493 |
+
|
| 494 |
+
* Machine: H20
|
| 495 |
+
* Model: Qwen2.5-Math-7B
|
| 496 |
+
* Rollout length: max_response_length FSDP2: 10K tokens;
|
| 497 |
+
* Algorithm: DAPO
|
| 498 |
+
* Dataset: TRAIN_FILE: dapo-math-17k.parquet TEST_FILE: aime-2024.parquet
|
| 499 |
+
* Engine: vllm+FSDP2
|
| 500 |
+
* rollout.n: 16
|
| 501 |
+
* ppo_mini_batch_size: 32
|
| 502 |
+
* test_freq: 10
|
| 503 |
+
|
| 504 |
+
* fully_async_policy
|
| 505 |
+
* total_rollout_steps: 512*400
|
| 506 |
+
* require_batches: 4
|
| 507 |
+
* trigger_parameter_sync_step: 4
|
| 508 |
+
* staleness_threshold: 0.5
|
| 509 |
+
* partial_rollout: True
|
| 510 |
+
|
| 511 |
+
| training mode | resource allocation | step | gen | old_log_prob | update_actor | validate time | total time<br>50 step | acc/mean@2 |
|
| 512 |
+
|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|
|
| 513 |
+
| colocate sync | 16 | 484.623 | 52.939 | 0 | 430.263 | 205.080 | 7h9m | 22.6 |
|
| 514 |
+
| fully_async_policy | 8:8 | 489.953 | 52.622 | 0 | 435.874 | 95.699 | 7h2m | 21.0 |
|
| 515 |
+
|
| 516 |
+
|
| 517 |
+
## Multi-Turn Tool Calling
|
| 518 |
+
|
| 519 |
+
Referencing **recipe/retool** and **ToolAgentLoop**, we implemented **AsyncPartialToolAgentLoop**, a multi-turn
|
| 520 |
+
tool-calling loop that supports partial_rollout for **fully_async_policy**.
|
| 521 |
+
|
| 522 |
+
### Core Design
|
| 523 |
+
|
| 524 |
+
`AsyncPartialToolAgentLoop` inherits from `ToolAgentLoop` and is adapted for the asynchronous training mode of
|
| 525 |
+
`fully_async_policy`. When `partial_rollout=True`, the Rollouter interrupts ongoing generation tasks before
|
| 526 |
+
synchronizing parameters with the Trainer. `AsyncPartialToolAgentLoop` is capable of:
|
| 527 |
+
|
| 528 |
+
1. **Interrupting Tasks**: Responding to an interrupt signal to save the current state. Currently, interruptions occur
|
| 529 |
+
during the `GENERATING` process or after other states have completed.
|
| 530 |
+
2. **Resuming Tasks**: Resuming execution from the saved state after parameter synchronization is complete, rather than
|
| 531 |
+
starting over.
|
| 532 |
+
|
| 533 |
+
### How to Use
|
| 534 |
+
|
| 535 |
+
RL training with multi-turn tool calling in `fully_async_policy` is similar to `recipe/retool`. It is enabled by
|
| 536 |
+
specifying `multi_turn` configurations in the config file.
|
| 537 |
+
|
| 538 |
+
1. **SFT Stage**: First, the model should undergo SFT to learn how to follow tool-calling format instructions.
|
| 539 |
+
2. **Multi-turn Configuration**: In the `fully_async_policy` training configuration, set the following parameters:
|
| 540 |
+
```yaml
|
| 541 |
+
actor_rollout_ref:
|
| 542 |
+
rollout:
|
| 543 |
+
multi_turn:
|
| 544 |
+
enable: True # AsyncPartialToolAgentLoop will be used by default in fully_async_policy mode
|
| 545 |
+
# Other multi_turn related configurations
|
| 546 |
+
```
|
| 547 |
+
3. **Async Parameters**: To improve efficiency, enable `partial_rollout` and `staleness_threshold` when using multi-turn
|
| 548 |
+
tool calling:
|
| 549 |
+
```yaml
|
| 550 |
+
async_training:
|
| 551 |
+
partial_rollout: True
|
| 552 |
+
staleness_threshold: 0.5
|
| 553 |
+
# Other async parameters
|
| 554 |
+
```
|
| 555 |
+
4. **Example**: See `recipe/fully_async_policy/shell/dapo_7b_async_retool.sh`.
|
| 556 |
+
|
| 557 |
+
### Experimental Results
|
| 558 |
+
|
| 559 |
+
To validate the performance of `fully_async_policy` on multi-turn tool-calling tasks, we compared it with the standard
|
| 560 |
+
`colocate` synchronous mode. Key parameter settings are as follows.
|
| 561 |
+
|
| 562 |
+
- **SFT Model**: Based on `Qwen2.5-7B-Instruct`, trained for 6 epochs on the `ReTool-SFT` dataset
|
| 563 |
+
- **RL Algorithm**: DAPO
|
| 564 |
+
- **Dataset**:
|
| 565 |
+
- Train: `DAPO-Math-17k`
|
| 566 |
+
- Test: `aime_2025`
|
| 567 |
+
- **Resource and Mode Comparison**:
|
| 568 |
+
- `colocate sync`: 32 H20 gpus
|
| 569 |
+
- `fully_async_policy`: 16 gpus for Trainer + 16 gpus for Rollouter
|
| 570 |
+
- **Key Configurations**:
|
| 571 |
+
1. **Tool Calling Configuration**:
|
| 572 |
+
- `multi_turn.enable: True`
|
| 573 |
+
- `multi_turn.max_user_turns: 16`
|
| 574 |
+
- `multi_turn.max_assistant_turns: 16`
|
| 575 |
+
- `multi_turn.tool_config_path: recipe/retool/sandbox_fusion_tool_config.yaml`
|
| 576 |
+
2. **`colocate sync` Configuration**:
|
| 577 |
+
- `ppo_mini_batch_size: 16`
|
| 578 |
+
- `train_batch_size: 64`
|
| 579 |
+
3. **`fully_async_policy` Configuration**:
|
| 580 |
+
- `ppo_mini_batch_size: 16`
|
| 581 |
+
- `trigger_parameter_sync_step: 4`
|
| 582 |
+
- `require_batches: 1`
|
| 583 |
+
- `staleness_threshold: 1`
|
| 584 |
+
- `partial_rollout: True`
|
| 585 |
+
|
| 586 |
+
| training mode | Resource allocation | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | aime_2025<br>acc/mean@30 |
|
| 587 |
+
| :----------------: | :-----------------: | :----: | :----: | :----------: | :----------: | :--------------------: | :--------------------: | :-------------------------: |
|
| 588 |
+
| colocate | 32 | 375.47 | 228.03 | 35.19 | 111.84 | 9h 46m | 22h 28m | start:0.1078<br>last:0.2056 |
|
| 589 |
+
| fully_async_policy | 16: 16 | 221.36 | 40.59 | \ | 179.58 | 6h 19m<br>(1.55x) | 14h 4m<br>(1.60x) | start:0.11<br>last:0.2044 |
|
| 590 |
+
|
| 591 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-multiturn-tool?nw=nwuserhouzg
|
| 592 |
+
|
| 593 |
+
## Future Plans
|
| 594 |
+
- Transfer queue integration
|
| 595 |
+
- Asynchronous parameter synchronization
|
code/RL_model/verl/verl_train/docs/advance/grafana_prometheus.md
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Use Prometheus and Grafana to Monitor Rollout
|
| 2 |
+
|
| 3 |
+
**Author:** `https://github.com/meituan-search`
|
| 4 |
+
|
| 5 |
+
Last updated: 12/05/2025.
|
| 6 |
+
|
| 7 |
+
Monitor the rollout computation process using Prometheus and Grafana when using verl to enhance system observability and facilitate further performance optimization.
|
| 8 |
+
|
| 9 |
+
We provide an additional training monitoring capability, leveraging Prometheus and Grafana to display rollout information during training and enhance system observability to facilitate further performance optimization.
|
| 10 |
+
|
| 11 |
+
The system automatically configures Prometheus to scrape metrics from rollout servers, eliminating manual configuration steps.
|
| 12 |
+
|
| 13 |
+
## Overview
|
| 14 |
+
|
| 15 |
+
The figures below show the performance of Qwen235B on the AIME2024 dataset with a response length of 20k, where the emergence of a long-tail problem is clearly observable.
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
The following figure presents the fully asynchronous training of the Qwen235B model. Here, resource idleness is distinctly noticeable, indicating that rollout resources can be reduced.
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
Through the above two examples, we also illustrate the necessity of system observability.
|
| 24 |
+
|
| 25 |
+
## Architecture Overview
|
| 26 |
+
|
| 27 |
+
The overall workflow consists of the following steps:
|
| 28 |
+
|
| 29 |
+
1. **Multi-node Ray Cluster Setup**: Start Ray cluster across multiple nodes with Grafana and Prometheus information configured in environment variables on the master node
|
| 30 |
+
2. **Start Grafana Service**: Launch Grafana on the master node for visualization of monitoring dashboards
|
| 31 |
+
3. **Start Prometheus Service**: Launch Prometheus on the master node for metrics collection and storage
|
| 32 |
+
4. **verl Async Rollout Mode**: verl uses async rollout mode to obtain rollout server ports and IP addresses
|
| 33 |
+
5. **Automatic Prometheus Configuration**: verl automatically rewrites the Prometheus configuration to add monitoring for rollout servers and notifies Prometheus to reload the configuration
|
| 34 |
+
6. **Metrics Collection**: After program execution, metrics can be viewed in Prometheus
|
| 35 |
+
7. **Dashboard Visualization**: Upload and view monitoring metrics in Grafana dashboards
|
| 36 |
+
|
| 37 |
+
## Detailed Setup Steps
|
| 38 |
+
|
| 39 |
+
### Step 1: Environment Variables and Start Ray Cluster
|
| 40 |
+
|
| 41 |
+
First, set the necessary environment variables and start the Ray service.
|
| 42 |
+
|
| 43 |
+
> Reference: [configure-manage-dashboard](https://docs.ray.io/en/latest/cluster/configure-manage-dashboard.html)
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
# Master node environment variables
|
| 47 |
+
export GF_SERVER_HTTP_PORT=3000 # Grafana service default port (customizable)
|
| 48 |
+
export PROMETHEUS_PORT=9090 # Prometheus service default port (customizable)
|
| 49 |
+
export RAY_HEAD_PORT=6379 # Ray master node port (customizable)
|
| 50 |
+
export RAY_DASHBOARD_PORT=8265 # Ray dashboard default port (customizable)
|
| 51 |
+
export GRAFANA_PATHS_DATA=/tmp/grafana # Grafana data storage directory (customizable)
|
| 52 |
+
export RAY_GRAFANA_HOST="http://${master_ip}:${GF_SERVER_HTTP_PORT}" # Ray-associated Grafana address
|
| 53 |
+
export RAY_PROMETHEUS_HOST="http://${master_ip}:${PROMETHEUS_PORT}" # Ray-associated Prometheus address
|
| 54 |
+
|
| 55 |
+
# Start Ray on master node
|
| 56 |
+
ray start --head --port=${RAY_HEAD_PORT} --dashboard-port=${RAY_DASHBOARD_PORT}
|
| 57 |
+
|
| 58 |
+
# Start Ray on worker nodes
|
| 59 |
+
ray start --address={master_addr}:${RAY_HEAD_PORT}
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
**Verification:** Visit `http://master_ip:8265` to confirm Ray has started successfully.
|
| 63 |
+
|
| 64 |
+
### Step 2: Start Grafana (Visualization Dashboard)
|
| 65 |
+
|
| 66 |
+
Grafana is used to display metrics collected by Prometheus (such as cache hit rate, throughput, etc.):
|
| 67 |
+
|
| 68 |
+
```bash
|
| 69 |
+
# Master node
|
| 70 |
+
nohup grafana-server \
|
| 71 |
+
--config /tmp/ray/session_latest/metrics/grafana/grafana.ini \
|
| 72 |
+
--homepath /usr/share/grafana \
|
| 73 |
+
web > grafana.log 2>&1 &
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
**Verification:** Visit `http://master_ip:3000` to confirm Grafana has started successfully (default credentials: `admin/admin`).
|
| 77 |
+
|
| 78 |
+
If you need to change the port, modify the `GF_SERVER_HTTP_PORT` environment variable, and grafana-server will automatically recognize it.
|
| 79 |
+
|
| 80 |
+
### Step 3: Start Prometheus (Metrics Collection)
|
| 81 |
+
|
| 82 |
+
Prometheus is responsible for scraping metrics from vLLM services and storing them as time-series data:
|
| 83 |
+
|
| 84 |
+
```bash
|
| 85 |
+
# Master node
|
| 86 |
+
nohup prometheus \
|
| 87 |
+
--config.file /tmp/ray/session_latest/metrics/prometheus/prometheus.yml \
|
| 88 |
+
--web.enable-lifecycle \
|
| 89 |
+
--web.listen-address=:${PROMETHEUS_PORT} \
|
| 90 |
+
> prometheus.log 2>&1 &
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
**Verification:** Visit `http://master_ip:9090` to confirm Prometheus service has started successfully.
|
| 94 |
+
|
| 95 |
+
### Step 4 & 5: Start verl Training
|
| 96 |
+
|
| 97 |
+
Start verl training with the following parameters configured:
|
| 98 |
+
|
| 99 |
+
**Required Configuration:**
|
| 100 |
+
|
| 101 |
+
- `actor_rollout_ref.rollout.mode="async"`
|
| 102 |
+
- `actor_rollout_ref.rollout.disable_log_stats=False`
|
| 103 |
+
- `actor_rollout_ref.rollout.prometheus.enable=True`
|
| 104 |
+
|
| 105 |
+
If use default port, this parameter can be omitted.
|
| 106 |
+
|
| 107 |
+
- `actor_rollout_ref.rollout.prometheus.port=9090`
|
| 108 |
+
|
| 109 |
+
If use default path, this parameter can be omitted.
|
| 110 |
+
|
| 111 |
+
- `actor_rollout_ref.rollout.prometheus.file="/tmp/ray/session_latest/metrics/prometheus/prometheus.yml"`
|
| 112 |
+
|
| 113 |
+
served_model_name uses `model_path.split("/")[-1]` for data statistics by default.
|
| 114 |
+
Users can also customize other aliases:
|
| 115 |
+
|
| 116 |
+
- `actor_rollout_ref.rollout.prometheus.served_model_name="Qwen3-235B"`
|
| 117 |
+
|
| 118 |
+
**Shell Script Example:**
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
WORKING_DIR=${WORKING_DIR:-"${PWD}"}
|
| 122 |
+
RUNTIME_ENV=${RUNTIME_ENV:-"${WORKING_DIR}/verl/trainer/runtime_env.yaml"}
|
| 123 |
+
|
| 124 |
+
rollout_mode="async"
|
| 125 |
+
rollout_name="vllm" # Options: sglang or vllm
|
| 126 |
+
if [ "$rollout_mode" = "async" ]; then
|
| 127 |
+
export VLLM_USE_V1=1
|
| 128 |
+
return_raw_chat="True"
|
| 129 |
+
fi
|
| 130 |
+
|
| 131 |
+
# Synchronous training
|
| 132 |
+
ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \
|
| 133 |
+
--working-dir "${WORKING_DIR}" \
|
| 134 |
+
-- python3 -m verl.trainer.main_ppo \
|
| 135 |
+
data.return_raw_chat=${return_raw_chat} \
|
| 136 |
+
actor_rollout_ref.rollout.name=${rollout_name} \
|
| 137 |
+
actor_rollout_ref.rollout.mode=${rollout_mode} \
|
| 138 |
+
actor_rollout_ref.rollout.disable_log_stats=False \
|
| 139 |
+
actor_rollout_ref.rollout.prometheus.enable=True
|
| 140 |
+
...
|
| 141 |
+
|
| 142 |
+
# Asynchronous training
|
| 143 |
+
ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \
|
| 144 |
+
--working-dir "${WORKING_DIR}" \
|
| 145 |
+
-- python3 verl.experimental.fully_async_policy.fully_async_main \
|
| 146 |
+
data.return_raw_chat=${return_raw_chat} \
|
| 147 |
+
actor_rollout_ref.rollout.name=${rollout_name} \
|
| 148 |
+
actor_rollout_ref.rollout.mode=${rollout_mode} \
|
| 149 |
+
actor_rollout_ref.rollout.disable_log_stats=False \
|
| 150 |
+
actor_rollout_ref.rollout.prometheus.enable=True
|
| 151 |
+
...
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
### Step 6: View Metrics in Prometheus
|
| 155 |
+
|
| 156 |
+
After task execution, verify that Prometheus is correctly collecting metrics.
|
| 157 |
+
|
| 158 |
+
**Verification:** Visit the Prometheus interface at `http://master_ip:9090` and search for `vllm:` or `sglang:` to
|
| 159 |
+
confirm metrics are being reported correctly.
|
| 160 |
+
|
| 161 |
+
**Troubleshooting:**
|
| 162 |
+
|
| 163 |
+
If no metrics appear:
|
| 164 |
+
|
| 165 |
+
1. Check logs for `AgentLoopManager` to find the server port
|
| 166 |
+
2. Visit `http://master_ip:server_port/metrics` to verify server metrics are available
|
| 167 |
+
3. Confirm that `actor_rollout_ref.rollout.disable_log_stats=False` is set
|
| 168 |
+
|
| 169 |
+
### Step 7: View Metrics in Grafana
|
| 170 |
+
|
| 171 |
+
After task execution, log in to Grafana to view and customize monitoring dashboards.
|
| 172 |
+
|
| 173 |
+
**Login:** Visit `http://master_ip:3000` (default credentials: `admin/admin`)
|
| 174 |
+
|
| 175 |
+
**Import Dashboard:**
|
| 176 |
+
|
| 177 |
+
1. Select `Dashboards` → `New` → `Import` → `Upload dashboard JSON file`
|
| 178 |
+
2. Upload a pre-built dashboard JSON file
|
| 179 |
+
|
| 180 |
+
**Available Dashboards:**
|
| 181 |
+
|
| 182 |
+
- [vLLM Grafana Dashboard style 1](https://github.com/ArronHZG/verl-community/blob/main/docs/grafana/vllm_grafana.json)
|
| 183 |
+
- [vLLM Grafana Dashboard style 2](https://github.com/vllm-project/vllm/blob/main/examples/online_serving/dashboards/grafana/performance_statistics.json)
|
| 184 |
+
- [vLLM Grafana Dashboard style 2](https://github.com/vllm-project/vllm/blob/main/examples/online_serving/dashboards/grafana/query_statistics.json)
|
| 185 |
+
- [SGLang Grafana Dashboard](https://github.com/sgl-project/sglang/blob/main/examples/monitoring/grafana/dashboards/json/sglang-dashboard.json)
|
| 186 |
+
|
| 187 |
+
## Additional Resources
|
| 188 |
+
|
| 189 |
+
- [Ray Monitoring Documentation](https://docs.ray.io/en/latest/cluster/configure-manage-dashboard.html)
|
| 190 |
+
- [Prometheus Documentation](https://prometheus.io/docs/)
|
| 191 |
+
- [Grafana Documentation](https://grafana.com/docs/)
|
| 192 |
+
- [vLLM GitHub Repository](https://github.com/vllm-project/vllm)
|
| 193 |
+
- [SGLang GitHub Repository](https://github.com/sgl-project/sglang)
|
code/RL_model/verl/verl_train/docs/advance/megatron_extension.rst
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Add models with the Megatron-LM backend
|
| 2 |
+
=========================================
|
| 3 |
+
|
| 4 |
+
Last updated: 04/25/2025.
|
| 5 |
+
|
| 6 |
+
Model
|
| 7 |
+
-----------
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
If use latest verl, we have direct support of ``GPTModel`` for Megatron backend.
|
| 11 |
+
You can use the similar way of using Megatron to pretrain custom models.
|
| 12 |
+
We list the steps here:
|
| 13 |
+
|
| 14 |
+
1. Find `model_initializer.py <https://github.com/volcengine/verl/blob/main/verl/models/mcore/model_initializer.py>`_
|
| 15 |
+
2. If your model is configurable by ``TransformerLayerSpec`` , you can
|
| 16 |
+
directly use ``GPTModel``. Otherwise, Please implement a new
|
| 17 |
+
``ModelLayerSpec`` and ``ModelLayer`` here.
|
| 18 |
+
3. Use the right ``LayerSpec`` , ``TransformerConfig`` and ``HuggingfaceConfig``
|
| 19 |
+
as arguments to initialize the GPTModel.
|
| 20 |
+
4. Return the model at last.
|
code/RL_model/verl/verl_train/docs/advance/mtp.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Guide to Using MTP in SFT/RL Training and Inference
|
| 2 |
+
|
| 3 |
+
**Author**: `https://github.com/meituan-search`
|
| 4 |
+
|
| 5 |
+
Last updated: 01/30/2026
|
| 6 |
+
|
| 7 |
+
# 1. Scope of Support
|
| 8 |
+
|
| 9 |
+
Currently, RL training can be performed on mimo-7B-RL, Qwen-next, and Deepseek series models based on the MTP architecture. The support rules for training and inference engines are as follows:
|
| 10 |
+
|
| 11 |
+
- **Training Engine**: Only supports the `mbridge + megatron` combination; other training engines are not compatible at this time;
|
| 12 |
+
|
| 13 |
+
- **Inference Engine**: Compatible with all engines, but the model must be in the corresponding engine's compatibility list;
|
| 14 |
+
|
| 15 |
+
- **Dependency Versions**:
|
| 16 |
+
|
| 17 |
+
- mbridge: Use the specified branch: [https://github.com/ArronHZG/mbridge/tree/feature/verl_mtp](https://github.com/ArronHZG/mbridge/tree/feature/verl_mtp) (will be merged into the main branch in the future);
|
| 18 |
+
|
| 19 |
+
- megatron: Use the latest dev version (commit: [23e092f41ec8bc659020e401ddac9576c1cfed7e](https://github.com/NVIDIA/Megatron-LM/tree/23e092f41ec8bc659020e401ddac9576c1cfed7e)), which supports MTP + CP training methods.
|
| 20 |
+
|
| 21 |
+
- sglang: Use the specified branch: [https://github.com/ArronHZG/sglang/tree/fix_mtp_update_weights_from_tensor](https://github.com/ArronHZG/sglang/tree/fix_mtp_update_weights_from_tensor), [PR](https://github.com/sgl-project/sglang/pull/17870) , which fix the MTP update weights from tensor OOM issue.
|
| 22 |
+
|
| 23 |
+
# 2. MTP Training Configuration (Core Parameters)
|
| 24 |
+
|
| 25 |
+
The MTP training process can be flexibly controlled through the following configurations. All configurations are based on the `actor_rollout_ref.model.mtp` prefix:
|
| 26 |
+
|
| 27 |
+
| Configuration Scenario | Core Parameters | Description |
|
| 28 |
+
|------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------|
|
| 29 |
+
| Load MTP Parameters Only | `enable=True` | VRAM usage will increase, but the exported parameters include the MTP module and can be directly used for online deployment |
|
| 30 |
+
| Full-Parameter MTP Training | `enable=True`<br>`enable_train=True`<br>`mtp_loss_scaling_factor=0.1` | MTP Loss will apply to all model parameters |
|
| 31 |
+
| MTP Parameter-Only Training | `enable=True`<br>`enable_train=True`<br>`detach_encoder=True` | Freeze the Encoder layer, update only MTP module parameters, MTP Loss applies only to MTP parameters |
|
| 32 |
+
| MTP Accelerated Rollout | 1. vLLM configuration:<br>`enable=True`<br>`enable_rollout=True`<br>`method="mtp"`<br>`num_speculative_tokens=1`<br>2. SGLang configuration:<br>`enable=True`<br>`enable_rollout=True`<br>`speculative_algorithm="EAGLE"`<br>`speculative_num_steps=2`<br>`speculative_eagle_topk=2`<br>`speculative_num_draft_tokens=4` | Achieve inference acceleration during the Rollout phase based on MTP |
|
| 33 |
+
|
| 34 |
+
# 3. Experimental Results
|
| 35 |
+
|
| 36 |
+
The experiment was conducted as follows:
|
| 37 |
+
|
| 38 |
+
* model = mimo-7B-math
|
| 39 |
+
* max_response_length = 8k
|
| 40 |
+
|
| 41 |
+
Experiment chart:
|
| 42 |
+
|
| 43 |
+

|
| 45 |
+
|
| 46 |
+
The wandb link for the graph: [wandb](https://wandb.ai/hou-zg-meituan/mimo-7b-sft-mtp?nw=nwuserhouzg)
|
| 47 |
+
|
| 48 |
+
**Scenarios with No Significant Effect**
|
| 49 |
+
|
| 50 |
+
The following configurations will not have a noticeable impact on training results:
|
| 51 |
+
|
| 52 |
+
1. The base model does not carry MTP parameters;
|
| 53 |
+
|
| 54 |
+
2. The base model carries MTP parameters, but the MTP module is not trained;
|
| 55 |
+
|
| 56 |
+
3. The base model carries MTP parameters and trains MTP, with `mtp_loss_scaling_factor=0`;
|
| 57 |
+
|
| 58 |
+
4. The base model carries MTP parameters, trains MTP and detaches the encoder, with `mtp_loss_scaling_factor=0.1`.
|
| 59 |
+
|
| 60 |
+
**Scenarios with Significant Effect**
|
| 61 |
+
|
| 62 |
+
Only the following configuration will have a noticeable impact on training results:
|
| 63 |
+
|
| 64 |
+
- The base model carries MTP parameters, MTP Loss applies to all model parameters, and `mtp_loss_scaling_factor=0.1`.
|
| 65 |
+
|
| 66 |
+
**Recommended Training Method**
|
| 67 |
+
|
| 68 |
+
It is recommended to adopt the `detach_encoder=True` approach for MTP training.
|
| 69 |
+
|
| 70 |
+
# 4. Performance Notes for MTP in Rollout Inference
|
| 71 |
+
|
| 72 |
+
The effectiveness of MTP-accelerated Rollout is significantly affected by **model size** and **inference hardware**. Key reference information is as follows:
|
| 73 |
+
|
| 74 |
+
**Hardware Tensor Core Performance**
|
| 75 |
+
|
| 76 |
+
| Hardware Model | FP16 Performance (TFLOPS) |
|
| 77 |
+
|----------------|---------------------------|
|
| 78 |
+
| H20 | 148 |
|
| 79 |
+
| H800 | 1,671 |
|
| 80 |
+
| H200 | 1,979 |
|
| 81 |
+
|
| 82 |
+
**Measured Performance and Recommendations**
|
| 83 |
+
|
| 84 |
+
Taking the mimo-7B model deployed separately on H20 hardware using SGLang as an example: After enabling MTP speculative decoding, the Rollout throughput decreases by approximately 50%.
|
| 85 |
+
|
| 86 |
+
- Current priority recommendation: Do not enable MTP acceleration during the inference phase for now;
|
| 87 |
+
|
| 88 |
+
- Future planning: Further optimization of the speculative logic in the Rollout phase will be conducted to improve throughput performance.
|
| 89 |
+
|
| 90 |
+
# 5. SFT training
|
| 91 |
+
|
| 92 |
+
The SFT training with MTP is supported, using the same MTP training configuration as RL training.
|
| 93 |
+
|
| 94 |
+
An example configuration for running SFT can be found in `examples/sft/gsm8k/run_mimo_megatron_mtp.sh`
|
| 95 |
+
|
| 96 |
+
**SFT result**
|
| 97 |
+
|
| 98 |
+
The experiment was conducted using following data:
|
| 99 |
+
- model = mimo-7B-math
|
| 100 |
+
- dataset = gsm8k
|
| 101 |
+
|
| 102 |
+
The result: [wandb link](https://wandb.ai/hou-zg-meituan/mimo-7b-sft-mtp?nw=nwuserhouzg)
|
| 103 |
+
|
| 104 |
+
The presence of mtp layer has limited effect on main loss. However, when MTP layer is detached, the mtp_loss converges to a higher value.
|
| 105 |
+
|
code/RL_model/verl/verl_train/docs/advance/one_step_off.md
ADDED
|
@@ -0,0 +1,319 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: One Step Off Policy Async Trainer
|
| 2 |
+
|
| 3 |
+
**Author:** `https://github.com/meituan-search`
|
| 4 |
+
|
| 5 |
+
Last updated: 07/17/2025.
|
| 6 |
+
|
| 7 |
+
## Introduction
|
| 8 |
+
|
| 9 |
+
### Background
|
| 10 |
+
|
| 11 |
+
The current reinforcement learning training process implemented by verl is synchronous, adhering to the algorithmic
|
| 12 |
+
workflows of established methods like PPO, GRPO, and DAPO. In each step, training samples are generated by the latest
|
| 13 |
+
model, and the model is updated after training completes. While this approach aligns with off-policy reinforcement
|
| 14 |
+
learning and stabilizes RL training, but it suffers from severe efficiency issues.
|
| 15 |
+
Model updates must wait for the longest output in the generation phase to complete.
|
| 16 |
+
During the generation of long-tail samples, GPUs remain idle, resulting in significant underutilization.
|
| 17 |
+
The more severe the long-tail problem in sample generation, the lower the overall training efficiency.
|
| 18 |
+
For example, in DAPO 32B training, the Rollout phase accounts for approximately 70% of the total time,
|
| 19 |
+
and increasing resources does not reduce the Rollout duration.
|
| 20 |
+
|
| 21 |
+
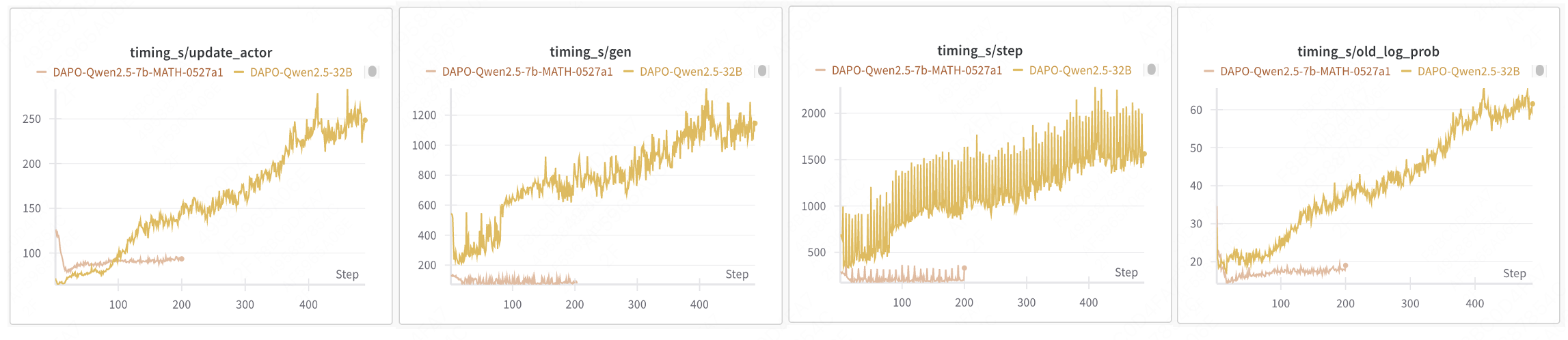
|
| 22 |
+
|
| 23 |
+
> source data: https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=nwusertongyuxuan361
|
| 24 |
+
|
| 25 |
+
### Solution
|
| 26 |
+
|
| 27 |
+
We have implemented the **One Step Off Async Trainer** to help alleviate this issue. This approach parallelizes the
|
| 28 |
+
generation and training processes, utilizing samples generated in the previous step for current training.
|
| 29 |
+
It also involves appropriately partitioning resources, allocating dedicated resources for generation while automatically
|
| 30 |
+
assigning the remainder to training. By reducing resources allocated to the generation phase, we mitigate GPU idle time
|
| 31 |
+
during long-tail sample generation. Throughout this process, generation and training parameters maintain a one-step off
|
| 32 |
+
policy.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
> reference: [AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning](https://arxiv.org/abs/2505.24298)
|
| 37 |
+
|
| 38 |
+
Our core contributions include:
|
| 39 |
+
|
| 40 |
+
1. **Parallel Generation and Training**:
|
| 41 |
+
Samples for the next batch are asynchronously generated while the current batch is being trained.
|
| 42 |
+
|
| 43 |
+
2. **Resource Isolation**:
|
| 44 |
+
Unlike `hybrid_engine`, this method requires explicit resource allocation for rollout, with remaining resources
|
| 45 |
+
automatically assigned to training.
|
| 46 |
+
|
| 47 |
+
3. **NCCL Parameter Synchronization**:
|
| 48 |
+
Employs NCCL communication primitives for seamless parameter transfer between generation and training modules.
|
| 49 |
+
|
| 50 |
+
### Experimental Results
|
| 51 |
+
|
| 52 |
+
- **Machine Configuration**: 2 nodes with 16 H20 GPUs each
|
| 53 |
+
- Generation: 4 GPUs
|
| 54 |
+
- Training: 12 GPUs
|
| 55 |
+
- **Model**: Qwen2.5-Math-7B
|
| 56 |
+
- **Rollout Configuration**:
|
| 57 |
+
- **Max Response Length**: FSDP2: 20,480 tokens; Megatron: 8,192 tokens
|
| 58 |
+
- **Algorithm**: DAPO
|
| 59 |
+
- **Rollout Engine**: vLLM
|
| 60 |
+
|
| 61 |
+
| training mode | engine | step | gen | wait_prev_gen | generate_sequences | old_log_prob | update_actor | total time | acc/best@32/mean | acc/maj@32/mean |
|
| 62 |
+
| ---------------------- | ------------- | ---- | --- | ------------- | ------------------ | ------------ | ------------ | -------------- | ---------------- | --------------- |
|
| 63 |
+
| colocate sync | VLLM+FSDP2 | 749 | 321 | - | 247 | 88 | 286 | 19h18m | 0.5948 | 0.417 |
|
| 64 |
+
| one-step-overlap async | VLLM+FSDP2 | 520 | - | 45 | 458 | 108 | 337 | 15h34m(+23%) | 0.6165 | 0.494 |
|
| 65 |
+
| colocate sync | VLLM+Megatron | 699 | 207 | - | 162 | 119 | 344 | 18h21m | 0.605 | 0.4217 |
|
| 66 |
+
| one-step-overlap async | VLLM+Megatron | 566 | - | 59 | 501 | 120 | 347 | 13h06m (+40%) | 0.6569 | 0.4038 |
|
| 67 |
+
|
| 68 |
+
- colocate sync: step ≈ gen + old_log_prob + update_actor
|
| 69 |
+
- one-step-overlap async: step ≈ wait_prev_gen + old_log_prob + update_actor
|
| 70 |
+
|
| 71 |
+
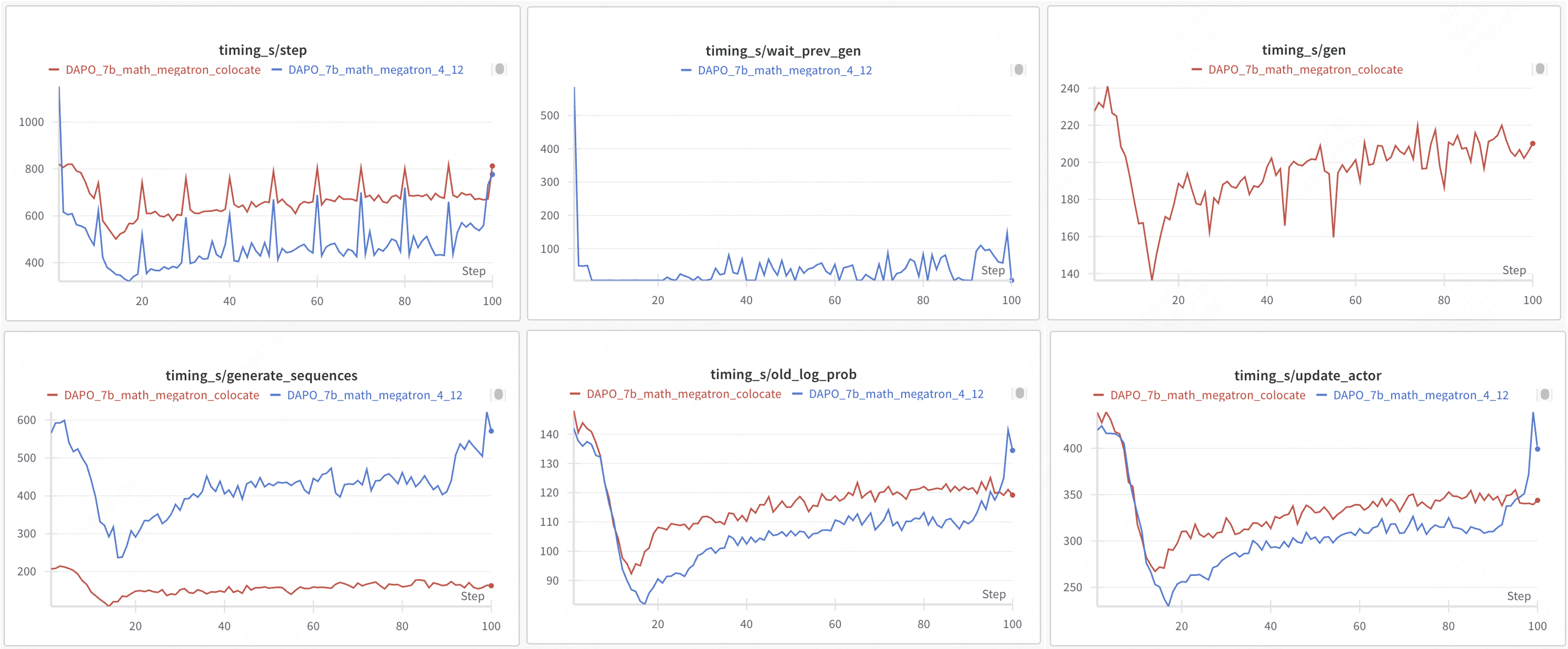
|
| 72 |
+
|
| 73 |
+
> source data: https://wandb.ai/hou-zg-meituan/one-step-off-policy?nw=nwuserhouzg
|
| 74 |
+
|
| 75 |
+
## Implementation
|
| 76 |
+
|
| 77 |
+
### One Step Off Policy Async Pipeline
|
| 78 |
+
|
| 79 |
+
Our implemented **One Step Off Policy Async Pipeline** integrates seamlessly into existing training logic at minimal
|
| 80 |
+
cost,
|
| 81 |
+
eliminating the need for additional sample storage management. The core mechanism uses `async_gen_next_batch`
|
| 82 |
+
for asynchronous rollout generation while maintaining continuous operation during epoch transitions
|
| 83 |
+
via `create_continuous_iterator`.
|
| 84 |
+
|
| 85 |
+
```python
|
| 86 |
+
# iterator generator, simplify one-step integration of the training process
|
| 87 |
+
def _create_continuous_iterator(self):
|
| 88 |
+
for epoch in range(self.config.trainer.total_epochs):
|
| 89 |
+
iterator = iter(self.train_dataloader)
|
| 90 |
+
for batch_dict in iterator:
|
| 91 |
+
yield epoch, batch_dict
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
# read next batch samples, parameters sync and launch asyn gen_seq
|
| 95 |
+
def _async_gen_next_batch(self, continuous_iterator):
|
| 96 |
+
# read train_data
|
| 97 |
+
try:
|
| 98 |
+
epoch, batch_dict = next(continuous_iterator)
|
| 99 |
+
except StopIteration:
|
| 100 |
+
return None
|
| 101 |
+
batch = DataProto.from_single_dict(batch_dict)
|
| 102 |
+
gen_batch = batch_pocess(batch)
|
| 103 |
+
# sync weights from actor to rollout
|
| 104 |
+
self.sync_rollout_weights()
|
| 105 |
+
# async generation
|
| 106 |
+
gen_batch_output = self.rollout_wg.async_generate_sequences(gen_batch)
|
| 107 |
+
# future encapsulated
|
| 108 |
+
return GenerationBatchFuture(epoch, batch, gen_batch_output)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
continuous_iterator = self._create_continuous_iterator()
|
| 112 |
+
# run rollout first to achieve one-step-off
|
| 113 |
+
batch_data_future = self._async_gen_next_batch(continuous_iterator)
|
| 114 |
+
|
| 115 |
+
while batch_data_future is not None:
|
| 116 |
+
# wait for the gen_seq result from the previous step
|
| 117 |
+
batch = batch_data_future.get()
|
| 118 |
+
# launch the next async call to generate sequences
|
| 119 |
+
batch_data_future = self._async_gen_next_batch(continuous_iterator)
|
| 120 |
+
|
| 121 |
+
# compute advantages
|
| 122 |
+
batch = critic.compute_values(batch)
|
| 123 |
+
batch = reference.compute_log_prob(batch)
|
| 124 |
+
batch = reward.compute_reward(batch)
|
| 125 |
+
batch = compute_advantages(batch)
|
| 126 |
+
|
| 127 |
+
# model update
|
| 128 |
+
critic_metrics = critic.update_critic(batch)
|
| 129 |
+
actor_metrics = actor.update_actor(batch)
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
### Parameter Synchronization
|
| 133 |
+
|
| 134 |
+
The exciting point is that our nccl based weights updating for rollout model has great performance.
|
| 135 |
+
At most of time, the latency is under 300ms, which is negligible for RLHF.
|
| 136 |
+
|
| 137 |
+
> **sync_rollout_weights**:The time for synchronizing parameters from actor to rollout is extremely fast and can almost
|
| 138 |
+
> be ignored because it is implemented with nccl.
|
| 139 |
+
|
| 140 |
+
```python
|
| 141 |
+
class ActorRolloutRefWorker:
|
| 142 |
+
# actor acquires the meta-info of model parameters for parameter sync
|
| 143 |
+
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
|
| 144 |
+
def get_actor_weights_info(self):
|
| 145 |
+
params = self._get_actor_params()
|
| 146 |
+
ret = []
|
| 147 |
+
for key, tensor in params.items():
|
| 148 |
+
ret.append((key, tensor.size(), tensor.dtype))
|
| 149 |
+
self._weights_info = ret
|
| 150 |
+
return ret
|
| 151 |
+
|
| 152 |
+
# rollout sets the meta-info of model parameters for parameter sync
|
| 153 |
+
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
|
| 154 |
+
def set_actor_weights_info(self, weights_info):
|
| 155 |
+
self._weights_info = weights_info
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class AsyncRayPPOTrainer(RayPPOTrainer):
|
| 159 |
+
def init_workers(self):
|
| 160 |
+
...
|
| 161 |
+
# rollout obtains the meta-info of model parameters from the actor for parameter sync
|
| 162 |
+
weights_info = self.actor_wg.get_actor_weights_info()[0]
|
| 163 |
+
self.rollout_wg.set_actor_weights_info(weights_info)
|
| 164 |
+
|
| 165 |
+
# Create an actor-rollout communication group for parameter sync
|
| 166 |
+
self.create_weight_sync_group
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
```python
|
| 170 |
+
# The driving process invokes the actor and rollout respectively to create a weight synchronization group based on nccl/hccl.
|
| 171 |
+
def create_weight_sync_group(self):
|
| 172 |
+
master_address = ray.get(self.actor_wg.workers[0]._get_node_ip.remote())
|
| 173 |
+
master_port = ray.get(self.actor_wg.workers[0]._get_free_port.remote())
|
| 174 |
+
world_size = len(self.actor_wg.workers + self.rollout_wg.workers)
|
| 175 |
+
self.actor_wg.create_weight_sync_group(
|
| 176 |
+
master_address,
|
| 177 |
+
master_port,
|
| 178 |
+
0,
|
| 179 |
+
world_size,
|
| 180 |
+
)
|
| 181 |
+
ray.get(
|
| 182 |
+
self.rollout_wg.create_weight_sync_group(
|
| 183 |
+
master_address,
|
| 184 |
+
master_port,
|
| 185 |
+
len(self.actor_wg.workers),
|
| 186 |
+
world_size,
|
| 187 |
+
)
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
# drive process call the actor and rollout respectively to sync parameters by nccl
|
| 191 |
+
def sync_rollout_weights(self):
|
| 192 |
+
self.actor_wg.sync_rollout_weights()
|
| 193 |
+
ray.get(self.rollout_wg.sync_rollout_weights())
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
# fsdp model parameter sync
|
| 197 |
+
@register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=False)
|
| 198 |
+
def sync_rollout_weights(self):
|
| 199 |
+
params = self._get_actor_params() if self._is_actor else None
|
| 200 |
+
if self._is_rollout:
|
| 201 |
+
inference_model = (
|
| 202 |
+
self.rollout.inference_engine.llm_engine.model_executor.driver_worker.worker.model_runner.model
|
| 203 |
+
)
|
| 204 |
+
from verl.utils.vllm.patch import patch_vllm_moe_model_weight_loader
|
| 205 |
+
patch_vllm_moe_model_weight_loader(inference_model)
|
| 206 |
+
# Model parameters are broadcast tensor-by-tensor from actor to rollout
|
| 207 |
+
for key, shape, dtype in self._weights_info:
|
| 208 |
+
tensor = torch.empty(shape, dtype=dtype, device=get_torch_device().current_device())
|
| 209 |
+
if self._is_actor:
|
| 210 |
+
assert key in params
|
| 211 |
+
origin_data = params[key]
|
| 212 |
+
if hasattr(origin_data, "full_tensor"):
|
| 213 |
+
origin_data = origin_data.full_tensor()
|
| 214 |
+
if torch.distributed.get_rank() == 0:
|
| 215 |
+
tensor.copy_(origin_data)
|
| 216 |
+
from ray.util.collective import collective
|
| 217 |
+
|
| 218 |
+
collective.broadcast(tensor, src_rank=0, group_name="actor_rollout")
|
| 219 |
+
if self._is_rollout:
|
| 220 |
+
inference_model.load_weights([(key, tensor)])
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
### PPO Correctness
|
| 224 |
+
|
| 225 |
+
To ensure the correctness of the PPO algorithm, we use rollout log_probs for PPO importance sampling.
|
| 226 |
+
For the related algorithm details, please refer to: https://verl.readthedocs.io/en/latest/algo/rollout_corr_math.html
|
| 227 |
+
The default mode is `bypass_ppo_clip`, but other modification strategies can also be explored.
|
| 228 |
+
|
| 229 |
+
### AgentLoop
|
| 230 |
+
|
| 231 |
+
In the current implementation, we no longer provide SPMD model rollout mode.
|
| 232 |
+
Instead, we have switched to AgentLoop mode, which also supports multi-turn tool calling.
|
| 233 |
+
|
| 234 |
+
## Usage
|
| 235 |
+
|
| 236 |
+
### FSDP2 Configuration Example
|
| 237 |
+
|
| 238 |
+
```shell
|
| 239 |
+
python3 -m verl.experimental.one_step_off_policy.async_main_ppo \
|
| 240 |
+
--config-path=config \
|
| 241 |
+
--config-name='one_step_off_ppo_trainer.yaml' \
|
| 242 |
+
actor_rollout_ref.actor.strategy=fsdp2 \
|
| 243 |
+
# actor and rollout are placed separately
|
| 244 |
+
actor_rollout_ref.hybrid_engine=False \
|
| 245 |
+
# actor and rollout resource
|
| 246 |
+
trainer.nnodes=1 \
|
| 247 |
+
trainer.n_gpus_per_node=6 \
|
| 248 |
+
rollout.nnodes=1 \
|
| 249 |
+
rollout.n_gpus_per_node=2
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
### Megatron Configuration Example
|
| 253 |
+
|
| 254 |
+
```shell
|
| 255 |
+
python3 -m verl.experimental.one_step_off_policy.async_main_ppo \
|
| 256 |
+
--config-path=config \
|
| 257 |
+
--config-name='one_step_off_ppo_megatron_trainer.yaml' \
|
| 258 |
+
actor_rollout_ref.actor.strategy=megatron \
|
| 259 |
+
# actor and rollout are placed separately
|
| 260 |
+
actor_rollout_ref.hybrid_engine=False \
|
| 261 |
+
# actor and rollout resource
|
| 262 |
+
trainer.nnodes=1 \
|
| 263 |
+
trainer.n_gpus_per_node=6 \
|
| 264 |
+
rollout.nnodes=1 \
|
| 265 |
+
rollout.n_gpus_per_node=2
|
| 266 |
+
```
|
| 267 |
+
|
| 268 |
+
### Configuration Guidelines
|
| 269 |
+
|
| 270 |
+
1. **Card Number Relationships**
|
| 271 |
+
Maintain either of these relationships for optimal batch distribution:
|
| 272 |
+
|
| 273 |
+
- `actor_rollout_ref.rollout.n` should be an integer divisor of:
|
| 274 |
+
`trainer.n_gpus_per_node * trainer.nnodes`
|
| 275 |
+
- `actor_rollout_ref.rollout.n * data.train_batch_size` should be evenly divisible by:
|
| 276 |
+
`trainer.n_gpus_per_node * trainer.nnodes`
|
| 277 |
+
|
| 278 |
+
> Rationale: Ensures training samples can be evenly distributed across training GPUs when using partial resources for
|
| 279 |
+
> generation.
|
| 280 |
+
|
| 281 |
+
2. **Dynamic Resource Tuning**
|
| 282 |
+
Adjust `trainer.nnodes` `trainer.n_gpus_per_node` `rollout.nnodes` `rollout.n_gpus_per_node` based on phase
|
| 283 |
+
durations:
|
| 284 |
+
- **Ideal state**: Rollout and training phases have comparable durations
|
| 285 |
+
- **Diagnostic metrics**:
|
| 286 |
+
- Monitor `wait_prev_gen` duration
|
| 287 |
+
- Analyze `sequence_length` distribution
|
| 288 |
+
- **Adjustment strategy**:
|
| 289 |
+
- High `wait_prev_gen` + uniform sequence lengths → Increase rollout resources
|
| 290 |
+
- High `wait_prev_gen` + long-tail sequences → Optimize stopping criteria (resource increase won't help)
|
| 291 |
+
> **wait_prev_gen**:The time consumed waiting for the previous rollout to end (the part that is not fully
|
| 292 |
+
> overlapped).
|
| 293 |
+
> **Resource Configuration Strategies:**
|
| 294 |
+
- **Resource-constrained scenario**: Optimize resource utilization by adjusting GPU allocation ratios,
|
| 295 |
+
keeping the number of nodes equal to allow training and rollout to share nodes;
|
| 296 |
+
- Configure `trainer.nnodes = rollout.nnodes` with
|
| 297 |
+
`trainer.n_gpus_per_node + rollout.n_gpus_per_node = physical_gpus_per_node`. Control rollout resource
|
| 298 |
+
allocation by adjusting `n_gpus_per_node`.
|
| 299 |
+
- **Resource-abundant scenario**: Optimize performance by adjusting the number of nodes,
|
| 300 |
+
keeping the number of GPUs per node equal to enable independent scaling of training and rollout
|
| 301 |
+
parallelism.
|
| 302 |
+
- Configure `trainer.n_gpus_per_node = rollout.n_gpus_per_node` and control rollout resource allocation by
|
| 303 |
+
adjusting `trainer.nnodes` and `rollout.nnodes`to achieve optimal performance.
|
| 304 |
+
> **Note**: The total number of nodes required by the system is not simply `trainer.nnodes + rollout.nnodes`. The
|
| 305 |
+
> actual calculation depends on GPU capacity:
|
| 306 |
+
>
|
| 307 |
+
> - When `trainer.n_gpus_per_node + rollout.n_gpus_per_node <= physical_gpus_per_node`,
|
| 308 |
+
> the required node count is `max(trainer.nnodes, rollout.nnodes)`
|
| 309 |
+
> - When `trainer.n_gpus_per_node + rollout.n_gpus_per_node > physical_gpus_per_node`,
|
| 310 |
+
> the required node count is `trainer.nnodes + rollout.nnodes`
|
| 311 |
+
|
| 312 |
+
## Functional Support
|
| 313 |
+
|
| 314 |
+
| Category | Support Situation |
|
| 315 |
+
| ------------------ | --------------------------------------------------------------------------------------------------------------- |
|
| 316 |
+
| train engine | FSDP2 <br/> Megatron |
|
| 317 |
+
| rollout engine | vLLM |
|
| 318 |
+
| AdvantageEstimator | GRPO <br/> GRPO_PASSK <br/> REINFORCE_PLUS_PLUS <br/> RLOO <br/> OPO <br/> REINFORCE_PLUS_PLUS_BASELINE<br/>GPG |
|
| 319 |
+
| Reward | all |
|
code/RL_model/verl/verl_train/docs/advance/placement.rst
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ray API Design Tutorial
|
| 2 |
+
=======================================
|
| 3 |
+
|
| 4 |
+
Last updated: 10/30/2024.
|
| 5 |
+
|
| 6 |
+
We provide a tutorial for our Ray API design, including:
|
| 7 |
+
|
| 8 |
+
- Ray basic concepts
|
| 9 |
+
- Resource Pool and RayWorkerGroup
|
| 10 |
+
- Data Dispatch, Execution and Collection
|
| 11 |
+
- Initialize the RayWorkerGroup and execute the distributed computation in the given Resource Pool
|
| 12 |
+
|
| 13 |
+
See details in `tutorial.ipynb <https://github.com/volcengine/verl/blob/main/examples/ray/tutorial.ipynb>`_.
|
code/RL_model/verl/verl_train/docs/advance/ppo_lora.rst
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RL(HF) algorithms with LoRA Support
|
| 2 |
+
===========================================
|
| 3 |
+
|
| 4 |
+
Last updated: 12/17/2025.
|
| 5 |
+
|
| 6 |
+
We support LoRA (Low-Rank Adaptation) for reinforcement learning algorithms such as PPO, GRPO, and others.
|
| 7 |
+
|
| 8 |
+
LoRA is a parameter-efficient fine-tuning technique that injects trainable low-rank matrices into pre-trained weights (typically linear layers). This reduces memory footprint and compute cost, making it possible to fine-tune large models with limited hardware.
|
| 9 |
+
|
| 10 |
+
The benefits this brings include:
|
| 11 |
+
|
| 12 |
+
- reinforcement learning with very large models (e.g. 70B+) with modest hardware (e.g. 8x80G GPUs),
|
| 13 |
+
- enable larger batch sizes due to reduced memory usage,
|
| 14 |
+
- simplify model transfer and deployment, as only LoRA adapters need to be saved,
|
| 15 |
+
- Combine with techniques like `SLoRA <https://arxiv.org/abs/2311.03285>`_ or `CCoE <https://arxiv.org/abs/2407.11686>`_ to serve multiple LoRA adapters efficiently
|
| 16 |
+
|
| 17 |
+
This guide explains how to enable LoRA in RL training and configure related parameters.
|
| 18 |
+
|
| 19 |
+
FSDP Backend Usage Guide
|
| 20 |
+
------------------------
|
| 21 |
+
|
| 22 |
+
.. note::
|
| 23 |
+
|
| 24 |
+
This section applies to **FSDP/FSDP2 backend only**. For Megatron backend, see the :ref:`megatron-lora` section below.
|
| 25 |
+
|
| 26 |
+
1. Lora is available in the `verl.trainer.ppo.ray_trainer.RayPPOTrainer`. Examples are provided via the `verl.trainer.main_ppo` entry point.
|
| 27 |
+
|
| 28 |
+
2. Currently, LoRA is supported via huggingface peft, only with fsdp/fsdp2 and vllm backend (sglang support coming soon).
|
| 29 |
+
|
| 30 |
+
- `strategy=fsdp` or `strategy=fsdp2`
|
| 31 |
+
- `rollout.name=vllm`
|
| 32 |
+
|
| 33 |
+
3. Required configurations for LoRA:
|
| 34 |
+
|
| 35 |
+
- `actor_rollout_ref.model.lora_rank`: int, set to a reasonable value greater than 0 (e.g., 8, 16, 32, 64)
|
| 36 |
+
- `actor_rollout_ref.model.lora_alpha`: float, the alpha term in LoRA
|
| 37 |
+
- `actor_rollout_ref.rollout.load_format="safetensors"`: required. This enables vLLM to load the base model.
|
| 38 |
+
- `actor_rollout_ref.model.target_modules`: the target modules for LoRA. Typically set to "all-linear".
|
| 39 |
+
|
| 40 |
+
4. Optional configurations for LoRA:
|
| 41 |
+
|
| 42 |
+
- `actor_rollout_ref.model.lora_adapter_path`: string, path to a pretrained LoRA adapter directory.
|
| 43 |
+
If provided, loads existing adapter instead of creating new one. Enables multi-stage training from previously saved adapters.
|
| 44 |
+
Directory need contain `adapter_model.safetensors` and `adapter_config.json`.
|
| 45 |
+
|
| 46 |
+
5. Recommend options:
|
| 47 |
+
|
| 48 |
+
- `actor_rollout_ref.model.use_shm=True`: preload the model into `/dev/shm` to improve model loading speed.
|
| 49 |
+
- `actor_rollout_ref.rollout.layered_summon=True`: this enables the actor-model to gather the FSDP shards per layers when synchronizing the LoRA Adapter to vLLM, thereby reducing GPU peak memory. Recommended if the model is very large (70B+) or the GPU memory is limited (< 48GB)
|
| 50 |
+
|
| 51 |
+
.. _megatron-lora:
|
| 52 |
+
|
| 53 |
+
Megatron Backend Usage Guide
|
| 54 |
+
----------------------------
|
| 55 |
+
|
| 56 |
+
.. warning::
|
| 57 |
+
|
| 58 |
+
The FSDP-specific config options are **NOT applicable** to Megatron backend, and they will be ignored if set. Only options listed under ``lora`` key are applicable:
|
| 59 |
+
|
| 60 |
+
- ``actor_rollout_ref.model.lora.*``
|
| 61 |
+
- ``critic.model.lora.*``
|
| 62 |
+
|
| 63 |
+
You need to install and enable Megatron-Bridge for Megatron LoRA support.
|
| 64 |
+
|
| 65 |
+
Make sure you use Megatron-Bridge later than 0.2.0, and we recommended using `this commit <https://github.com/NVIDIA-NeMo/Megatron-Bridge/commit/83a7c1134c562d8c6decd10a1f0a6e6a7a8a3a44>`_ or later for proper support, and use the following settings to enable Megatron-Bridge:
|
| 66 |
+
|
| 67 |
+
- ``actor_rollout_ref.actor.megatron.use_mbridge=True``
|
| 68 |
+
- ``actor_rollout_ref.actor.megatron.vanilla_mbridge=False``
|
| 69 |
+
|
| 70 |
+
**Key Differences from FSDP LoRA:**
|
| 71 |
+
|
| 72 |
+
1. **LoRA Implementation**: Verl Megatron backend uses Megatron-Bridge's native LoRA implementation, which differs from HuggingFace PEFT.
|
| 73 |
+
|
| 74 |
+
2. **Weight Sync / Refit Mechanism**: Currently, Megatron-Bridge can support syncing weights by either merging LoRA adapters into the base model weights before transferring to vLLM (for better inference speed but more refit time and potential precision loss), as well as loading separate adapters.
|
| 75 |
+
|
| 76 |
+
**Configuration for Megatron LoRA:**
|
| 77 |
+
|
| 78 |
+
.. code-block:: yaml
|
| 79 |
+
|
| 80 |
+
actor_rollout_ref:
|
| 81 |
+
model:
|
| 82 |
+
lora:
|
| 83 |
+
# LoRA type: "lora", "vlm_lora", "canonical_lora", or "dora"
|
| 84 |
+
type: lora
|
| 85 |
+
|
| 86 |
+
# whether to sync weights / refit by either merging LoRA adapters into the base model weights before transferring to vLLM (for better inference speed but more refit time and potential precision loss). If this is False, it will load separate adapters.
|
| 87 |
+
merge: False
|
| 88 |
+
|
| 89 |
+
# LoRA rank (Dimension of the low-rank projection space.). Set to 0 to disable LoRA
|
| 90 |
+
rank: 0
|
| 91 |
+
|
| 92 |
+
# Weighting factor for the low-rank projection. Defaults to 32
|
| 93 |
+
alpha: 32
|
| 94 |
+
|
| 95 |
+
# Dropout rate for the low-rank projection. Defaults to 0.0
|
| 96 |
+
dropout: 0.0
|
| 97 |
+
|
| 98 |
+
# A list of module names to apply LoRA to.
|
| 99 |
+
# For fused LoRA, Defaults to all linear layers ['linear_qkv', 'linear_proj', 'linear_fc1', 'linear_fc2'].
|
| 100 |
+
# For canonical LoRA: ["linear_q", "linear_k", "linear_v", "linear_proj", "linear_fc1_up", "linear_fc1_gate", "linear_fc2"]
|
| 101 |
+
# - 'linear_qkv': Apply LoRA to the fused linear layer used for query, key, and value projections in self-attention
|
| 102 |
+
# - 'linear_proj': Apply LoRA to the linear layer used for projecting the output of self-attention
|
| 103 |
+
# - 'linear_fc1': Apply LoRA to the first fully-connected layer in MLP
|
| 104 |
+
# - 'linear_fc2': Apply LoRA to the second fully-connected layer in MLP
|
| 105 |
+
# Target modules can also contain wildcards. For example, you can specify
|
| 106 |
+
# target_modules=['*.layers.0.*.linear_qkv', '*.layers.1.*.linear_qkv'] to add LoRA to only linear_qkv on the first two layers
|
| 107 |
+
#
|
| 108 |
+
# Note:
|
| 109 |
+
# For MLA (e.g., DeepSeek), you should use ["linear_kv_down_proj","linear_kv_up_proj","linear_q_down_proj","linear_q_up_proj","linear_q_proj"]
|
| 110 |
+
# Instead of "linear_qkv" or ["linear_q","linear_k","linear_v"]
|
| 111 |
+
# By default, MoE routers are excluded from LoRA adaptation, and you will need to specify "router" in target_modules to include them.
|
| 112 |
+
target_modules:
|
| 113 |
+
- linear_qkv
|
| 114 |
+
- linear_proj
|
| 115 |
+
- linear_fc1
|
| 116 |
+
- linear_fc2
|
| 117 |
+
|
| 118 |
+
# A list of module names not to apply LoRa to. It will match all nn.Linear & nn.Linear-adjacent modules whose name
|
| 119 |
+
# does not match any string in exclude_modules. If used, will require target_modules to be empty list or None
|
| 120 |
+
exclude_modules: []
|
| 121 |
+
|
| 122 |
+
# Position for applying dropout, can be 'pre' (before the low-rank projection) or 'post' (after). Defaults to 'pre'
|
| 123 |
+
dropout_position: pre
|
| 124 |
+
|
| 125 |
+
# Initialization method for the low-rank matrix A. Defaults to "xavier".
|
| 126 |
+
lora_A_init_method: xavier
|
| 127 |
+
|
| 128 |
+
# Initialization method for the low-rank matrix B. Defaults to "zero".
|
| 129 |
+
lora_B_init_method: zero
|
| 130 |
+
|
| 131 |
+
# Enables the experimental All-to-All (A2A) communication strategy. Defaults to False
|
| 132 |
+
a2a_experimental: False
|
| 133 |
+
|
| 134 |
+
# Parameter data type for LoRA weights. Default to null, which will use model's dtype.
|
| 135 |
+
dtype: null
|
| 136 |
+
|
| 137 |
+
# Path to pre-trained LoRA adapter weights (null to train from scratch)
|
| 138 |
+
adapter_path: null
|
| 139 |
+
|
| 140 |
+
# VLMLoRA additionally allows the user to specify whether the language or vision models should be frozen.
|
| 141 |
+
# For example, a common finetuning workload for multimodal models is to apply adapters to language model and fully
|
| 142 |
+
# finetune the vision model.
|
| 143 |
+
freeze_vision_model: True
|
| 144 |
+
freeze_vision_projection: True
|
| 145 |
+
freeze_language_model: True
|
| 146 |
+
|
| 147 |
+
LoRA training experiment with Qwen3-8B on 8 * H200 single node comparing FSDP and Megatron backend (script adapted from examples/grpo_trainer/run_qwen2-7b_math_megatron_lora.sh):
|
| 148 |
+
|
| 149 |
+
.. image:: https://github.com/user-attachments/assets/0482f423-01a3-4e52-a7ee-8b9cd79b7b1a
|
| 150 |
+
.. image:: https://github.com/user-attachments/assets/6ce10400-8164-47d8-90a6-c1bf002fb9e8
|
| 151 |
+
.. image:: https://github.com/user-attachments/assets/092d3a43-4eba-425e-a584-8d83c1f02de4
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
Best Practices and Notes
|
| 155 |
+
-------------------------
|
| 156 |
+
|
| 157 |
+
1. **Learning rate**: it is recommended to increase the value of learning rate by an order of magnitude.
|
| 158 |
+
|
| 159 |
+
2. **LoRA Rank**:
|
| 160 |
+
|
| 161 |
+
- Too small a rank can hurt convergence.
|
| 162 |
+
- LoRA rank recommendation from @thelongestusernameofall:
|
| 163 |
+
|
| 164 |
+
- A very small lora_rank can lead to slower convergence or worse training performance. It is recommended to set lora_rank to be>=32. Tests have shown that for a 0.5B model, with lora_rank=32,the training convergence speed and final performance are almost identical to non-LoRA training
|
| 165 |
+
- For a 32B model,with lora_rank=128,the training convergence speed and final performance are also almost identical to non-LoRA training.
|
| 166 |
+
- More comprehensive reference results are coming soon.
|
| 167 |
+
|
| 168 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/f2b80b8b26829124dd393b7a795a0640eff11644/docs/lora.jpg?raw=true
|
| 169 |
+
|
| 170 |
+
3. **FSDP-Specific:** Reference configuration for RL training with the Qwen2.5-72B model using 8 x 80GB GPUs (increase lora_rank if needed):
|
| 171 |
+
|
| 172 |
+
.. code-block::
|
| 173 |
+
|
| 174 |
+
data.train_batch_size=64 \
|
| 175 |
+
actor_rollout_ref.model.use_shm=True \
|
| 176 |
+
actor_rollout_ref.model.lora_rank=32 \
|
| 177 |
+
actor_rollout_ref.model.lora_alpha=32 \
|
| 178 |
+
actor_rollout_ref.model.target_modules=all-linear \
|
| 179 |
+
actor_rollout_ref.actor.optim.lr=3e-5 \
|
| 180 |
+
actor_rollout_ref.actor.fsdp_config.fsdp_size=8 \
|
| 181 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=True \
|
| 182 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
|
| 183 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=8 \
|
| 184 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 185 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
|
| 186 |
+
actor_rollout_ref.rollout.n=5 \
|
| 187 |
+
actor_rollout_ref.rollout.max_num_seqs=64 \
|
| 188 |
+
actor_rollout_ref.rollout.max_model_len=1536 \
|
| 189 |
+
actor_rollout_ref.rollout.max_num_batched_tokens=1536 \
|
| 190 |
+
actor_rollout_ref.rollout.load_format=safetensors \
|
| 191 |
+
actor_rollout_ref.rollout.layered_summon=True \
|
| 192 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 193 |
+
actor_rollout_ref.actor.ulysses_sequence_parallel_size=1 \
|
| 194 |
+
|
| 195 |
+
Example Scripts
|
| 196 |
+
-------------------
|
| 197 |
+
|
| 198 |
+
For end-to-end examples, refer to the scripts below:
|
| 199 |
+
|
| 200 |
+
**FSDP Examples:**
|
| 201 |
+
|
| 202 |
+
- LoRA training from scratch: examples/grpo_trainer/run_qwen2_5-3b_gsm8k_grpo_lora.sh
|
| 203 |
+
- LoRA training from adapter path: examples/grpo_trainer/run_qwen2_5-3b_gsm8k_grpo_lora_from_adapter.sh
|
| 204 |
+
|
| 205 |
+
**Megatron Examples:**
|
| 206 |
+
|
| 207 |
+
- LoRA training with Dense: examples/grpo_trainer/run_qwen2-7b_math_megatron_lora.sh
|
| 208 |
+
- LoRA training with MoE: examples/grpo_trainer/run_qwen3moe-30b_megatron_lora.sh
|
code/RL_model/verl/verl_train/docs/advance/reward_loop.rst
ADDED
|
@@ -0,0 +1,301 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Reward Loop
|
| 2 |
+
===========
|
| 3 |
+
|
| 4 |
+
.. _yyding: https://yyding1.github.io
|
| 5 |
+
|
| 6 |
+
Author: `Yuyang Ding <https://yyding1.github.io>`_
|
| 7 |
+
|
| 8 |
+
Last updated: 12/20/2025.
|
| 9 |
+
|
| 10 |
+
.. warning::
|
| 11 |
+
Reward Loop is ready for use, but the API may change in future releases.
|
| 12 |
+
User can set ``reward_model.use_reward_loop=True`` or ``False`` to control whether to enable reward loop.
|
| 13 |
+
|
| 14 |
+
Reward Loop is designed to support flexible and user-friendly reward computation, with most implementation in ``verl/experimental/reward_loop``.
|
| 15 |
+
|
| 16 |
+
Compared with the previous reward mechanism, the Reward Loop offers the following key features:
|
| 17 |
+
|
| 18 |
+
1. provides a more flexible and user-friendly design for reward-model settings, enabling hybrid reward scenarios where multiple reward sources can be seamlessly integrated.
|
| 19 |
+
2. implements asynchronous reward computation instead of the previous batch-based computation, improving efficiency for both rule-based rewards and reward-model-based scenarios.
|
| 20 |
+
|
| 21 |
+
Hybrid Reward Scenarios
|
| 22 |
+
-----------------------
|
| 23 |
+
|
| 24 |
+
Reward Loop covers all typical reward-computation scenarios.
|
| 25 |
+
|
| 26 |
+
- **Rule-based Reward**: The reward is determined by predefined rules, e.g., checking whether the predicted answer matches the ground truth via simple string matching.
|
| 27 |
+
- **Discriminative Reward Model (DisRM)**: The reward is produced by a specified discriminative reward model, such as ``Skywork/Skywork-Reward-Llama-3.1-8B-v0.2``.
|
| 28 |
+
- **Generative Reward Model (GenRM)**: The reward is obtained using a generative reward model, for example ``dyyyyyyyy/FAPO-GenRM-4B``.
|
| 29 |
+
- **Hybrid Reward Scenarios**: Reward Loop provides interfaces for plugging in reward models, allowing users to define custom reward logic based on their needs (e.g., combining rule-based methods with GenRM).
|
| 30 |
+
|
| 31 |
+
Rule-based Reward
|
| 32 |
+
~~~~~~~~~~~~~~~~~
|
| 33 |
+
|
| 34 |
+
If ``custom_reward_function`` is not provided, the reward loop will fall back to the default rule-based reward function.
|
| 35 |
+
Otherwise, only the user-defined reward function will be used. The files under ``verl/utils/reward_score/`` provide some examples.
|
| 36 |
+
|
| 37 |
+
Reward Loop supports both synchronous and asynchronous user-defined reward functions. It automatically detects the function type and executes it accordingly, ensuring that reward computation remains non-blocking and efficient.
|
| 38 |
+
|
| 39 |
+
Discriminative Reward Model (DisRM)
|
| 40 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 41 |
+
|
| 42 |
+
For scenarios involving a discriminative reward model, users should provide ``reward_model.model.path`` to specify the reward model.
|
| 43 |
+
|
| 44 |
+
The Reward Loop will pass the question and the model rollout as inputs to the reward model and obtain a reward score from its output.
|
| 45 |
+
|
| 46 |
+
Generative Reward Model (GenRM)
|
| 47 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 48 |
+
|
| 49 |
+
For generative reward model scenarios, users need to specify both ``reward_model.model.path`` and ``custom_reward_function``.
|
| 50 |
+
|
| 51 |
+
The custom reward function should implement the following components:
|
| 52 |
+
|
| 53 |
+
- Convert the question and the model rollout into a GenRM input prompt using a custom prompt template.
|
| 54 |
+
- Invoke the GenRM to perform generation with custom sampling parameters. For this purpose, the Reward Loop provides an HTTP interface (i.e., ``reward_router_address``) for interacting with GenRM.
|
| 55 |
+
- Parse the GenRM output using a custom parser and extract the reward score.
|
| 56 |
+
|
| 57 |
+
As these steps are highly customizable and task-dependent, we offer this flexibility entirely to the user-defined reward function.
|
| 58 |
+
|
| 59 |
+
Below we provide an example of a custom reward function using GenRM.
|
| 60 |
+
|
| 61 |
+
.. code:: python
|
| 62 |
+
|
| 63 |
+
async def compute_score_gsm8k(
|
| 64 |
+
data_source: str,
|
| 65 |
+
solution_str: str,
|
| 66 |
+
ground_truth: str,
|
| 67 |
+
extra_info: dict,
|
| 68 |
+
reward_router_address: str, # an HTTP router endpoint provided by Reward Loop
|
| 69 |
+
reward_model_tokenizer: PreTrainedTokenizer,
|
| 70 |
+
):
|
| 71 |
+
"""Compute the reward score."""
|
| 72 |
+
|
| 73 |
+
# Step 1: Prepare prompt and request payload
|
| 74 |
+
grm_prompt = GRM_PROMPT_TEMPLATE.format(problem=extra_info["question"], solution=solution_str)
|
| 75 |
+
messages = [{"role": "user", "content": grm_prompt}]
|
| 76 |
+
sampling_params = {"temperature": 0.7, "top_p": 0.8, "max_tokens": 4096}
|
| 77 |
+
chat_complete_request = {"messages": messages, **sampling_params}
|
| 78 |
+
|
| 79 |
+
# Step 2: Send async request to the reward model
|
| 80 |
+
# here, chat_complete sends async http request to the router address
|
| 81 |
+
result = await chat_complete(
|
| 82 |
+
router_address=reward_router_address,
|
| 83 |
+
chat_complete_request=chat_complete_request,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
# Step 3: Parse model response and extract score
|
| 87 |
+
grm_response = result.choices[0].message.content.strip()
|
| 88 |
+
try:
|
| 89 |
+
score_str = grm_response.split("\n\n")[-1].strip()
|
| 90 |
+
score = int(score_str)
|
| 91 |
+
except Exception:
|
| 92 |
+
score = 0
|
| 93 |
+
|
| 94 |
+
return {"score": score}
|
| 95 |
+
|
| 96 |
+
Hybrid Reward Scenarios
|
| 97 |
+
~~~~~~~~~~~~~~~~~~~~~~~
|
| 98 |
+
|
| 99 |
+
For more complex application settings, such as combining rule-based rewards with GenRM, or mixing rule-based rewards with DisRM, users can also achieve this by specifying the ``reward_model.model.path`` together with the ``custom_reward_function``.
|
| 100 |
+
The implementation of the customized reward function follows the same pattern as illustrated above.
|
| 101 |
+
|
| 102 |
+
A runnable and reproducible example that demonstrates how to use a rule-based reward function together with a GenRM is provided in the ``recipe/fapo`` directory for reference. Welcome to use and cite.
|
| 103 |
+
|
| 104 |
+
Architecture Design
|
| 105 |
+
-------------------
|
| 106 |
+
|
| 107 |
+
Reward Loop supports multiple execution modes for reward training:
|
| 108 |
+
|
| 109 |
+
- **Colocate Mode**: The reward model shares the same resource pool as the actor/rollout/reference models. In this setup, all rollouts must complete first, after which the reward model is awakened to perform inference.
|
| 110 |
+
- **Standalone Mode**: The reward model runs on a separate resource pool, independent from the actor/rollout/reference models. In this setup, each sample is evaluated by the reward model immediately after its rollout finishes.
|
| 111 |
+
|
| 112 |
+
.. image:: https://github.com/yyDing1/verl-materials/blob/main/reward_loop.svg?raw=true
|
| 113 |
+
|
| 114 |
+
RewardLoopWorker
|
| 115 |
+
~~~~~~~~~~~~~~~~~
|
| 116 |
+
|
| 117 |
+
The ``RewardLoopWorker`` is responsible for handling batch-level reward computation, operating in an asynchronous manner.
|
| 118 |
+
|
| 119 |
+
.. image:: https://github.com/yyDing1/verl-materials/blob/main/reward_loop_worker.svg?raw=true
|
| 120 |
+
|
| 121 |
+
For each sample, the reward is computed according to the following logic:
|
| 122 |
+
|
| 123 |
+
- if ``custom_reward_function`` is provided, we directly use user-customized reward function
|
| 124 |
+
- if ``custom_reward_function`` is not provided:
|
| 125 |
+
- **reward model is not enabled**: use default rule-based reward function
|
| 126 |
+
- **reward model is discriminative**: compute reward score using disrm
|
| 127 |
+
- **reward model is generative**: this is not permitted (user-customized reward func **must be** provided)
|
| 128 |
+
|
| 129 |
+
In most cases, we encourage users to define and use their own customized reward functions.
|
| 130 |
+
|
| 131 |
+
``RewardLoopWorker`` will initialize a ``RewardManager`` via ``_init_reward_fn()``.
|
| 132 |
+
Then the batch reward computation request of ``compute_score_batch`` will be processed asynchronously.
|
| 133 |
+
|
| 134 |
+
.. code:: python
|
| 135 |
+
|
| 136 |
+
@ray.remote
|
| 137 |
+
class RewardLoopWorker:
|
| 138 |
+
def __init__(self, config: DictConfig, reward_router_address: str = None):
|
| 139 |
+
self.config = config
|
| 140 |
+
self.reward_router_address = reward_router_address
|
| 141 |
+
self._init_reward_fn()
|
| 142 |
+
|
| 143 |
+
def _init_reward_fn(self):
|
| 144 |
+
input_tokenizer_local_path = copy_to_local(self.config.actor_rollout_ref.model.path)
|
| 145 |
+
self.input_tokenizer = hf_tokenizer(input_tokenizer_local_path, trust_remote_code=True)
|
| 146 |
+
self.reward_model_tokenizer = None
|
| 147 |
+
if self.config.reward_model.enable:
|
| 148 |
+
reward_model_tokenizer_local_path = copy_to_local(self.config.reward_model.model.path)
|
| 149 |
+
self.reward_model_tokenizer = hf_tokenizer(reward_model_tokenizer_local_path, trust_remote_code=True)
|
| 150 |
+
self.reward_fn = get_custom_reward_fn(self.config)
|
| 151 |
+
reward_manager_cls = get_reward_manager_cls(self.config.reward_model.reward_manager)
|
| 152 |
+
self.reward_loop = reward_manager_cls(
|
| 153 |
+
self.config, self.input_tokenizer, self.reward_fn, self.reward_router_address, self.reward_model_tokenizer
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
async def compute_score_batch(self, data: DataProto) -> list[dict]:
|
| 157 |
+
tasks = []
|
| 158 |
+
for i in range(len(data)):
|
| 159 |
+
tasks.append(asyncio.create_task(self.compute_score(data[i : i + 1])))
|
| 160 |
+
outputs = await asyncio.gather(*tasks)
|
| 161 |
+
return outputs
|
| 162 |
+
|
| 163 |
+
async def compute_score(self, data: DataProto) -> dict:
|
| 164 |
+
assert len(data) == 1, "RewardLoopWorker only support single data item"
|
| 165 |
+
if self.config.custom_reward_function.path is not None:
|
| 166 |
+
# directly use user-customized reward function
|
| 167 |
+
return await self.reward_loop.run_single(data)
|
| 168 |
+
else:
|
| 169 |
+
if self.config.reward_model.enable:
|
| 170 |
+
# we assume the rm is disrm
|
| 171 |
+
# genrm must set custom_reward_function
|
| 172 |
+
return await self.compute_score_disrm(data)
|
| 173 |
+
else:
|
| 174 |
+
return await self.reward_loop.run_single(data)
|
| 175 |
+
|
| 176 |
+
RewardManager
|
| 177 |
+
~~~~~~~~~~~~~
|
| 178 |
+
|
| 179 |
+
Reward Loop refactors the previous reward manager, which processed rewards sequentially on batched inputs.
|
| 180 |
+
Instead, the Reward Loop performs reward computation asynchronously and in parallel at the per-sample level.
|
| 181 |
+
|
| 182 |
+
In the ``RewardManager`` of Reward Loop, we implement a ``run_single`` function to compute the score for single sample. All the reward functions are executed by ``compute_score_fn``. The input should be a ``DataProto`` containing only one item.
|
| 183 |
+
|
| 184 |
+
.. code:: python
|
| 185 |
+
|
| 186 |
+
@register("naive")
|
| 187 |
+
class NaiveRewardManager(RewardManagerBase):
|
| 188 |
+
async def run_single(self, data: DataProto) -> dict:
|
| 189 |
+
assert len(data) == 1, "Only support single data item"
|
| 190 |
+
...
|
| 191 |
+
|
| 192 |
+
Commonly used reward managers, such as ``DAPORewardManager`` has been implemented in reward loop.
|
| 193 |
+
In addition, ``RateLimitRewardManager`` is also ready for use for external API-based reward computation scenarios like ChatGPT.
|
| 194 |
+
|
| 195 |
+
Users can also customize their own ``RewardManager``, by adding the ``@register`` decorator, inheriting from ``RewardManagerBase``, and implementing the ``run_single`` function.
|
| 196 |
+
See ``verl/experimental/reward_manager/*`` for reference.
|
| 197 |
+
|
| 198 |
+
.. code:: python
|
| 199 |
+
|
| 200 |
+
@register("user_costomized")
|
| 201 |
+
class UserCostomizedRewardManager(RewardManagerBase):
|
| 202 |
+
async def run_single(self, data: DataProto) -> dict:
|
| 203 |
+
assert len(data) == 1, "Only support single data item"
|
| 204 |
+
# your own reward manager
|
| 205 |
+
...
|
| 206 |
+
|
| 207 |
+
After defining it, users can specify their custom reward manager by setting ``reward_model.reward_manager=user_costomized``.
|
| 208 |
+
|
| 209 |
+
RewardLoopManager
|
| 210 |
+
~~~~~~~~~~~~~~~~~
|
| 211 |
+
|
| 212 |
+
To enable parallel reward computation, the Reward Loop launches multiple reward workers that handle reward computation requests concurrently.
|
| 213 |
+
|
| 214 |
+
In **standalone mode**, we directly launch one ``RewardLoopWorker`` for each ``AgentLoopWorker`` to handle reward computation independently.
|
| 215 |
+
|
| 216 |
+
In **colocate mode**, we launch a ``RewardLoopManager`` to
|
| 217 |
+
|
| 218 |
+
1. launch reward model if enabled
|
| 219 |
+
2. manage multiple ``RewardLoopWorker`` instances to parallelize reward computation.
|
| 220 |
+
|
| 221 |
+
Users can specify the number of workers by setting ``reward_model.num_workers`` in colocate mode.
|
| 222 |
+
|
| 223 |
+
.. code:: python
|
| 224 |
+
|
| 225 |
+
class RewardLoopManager:
|
| 226 |
+
"""
|
| 227 |
+
RewardLoopManager run in single controller.
|
| 228 |
+
This class will create reward loop workers and manage them.
|
| 229 |
+
RewardLoopManager will deprecate fsdp/megatron RewardModelWorker in the future.
|
| 230 |
+
"""
|
| 231 |
+
def __init__(self, config: DictConfig, rm_resource_pool: RayResourcePool = None):
|
| 232 |
+
self.config = config
|
| 233 |
+
if self.config.reward_model.enable:
|
| 234 |
+
self.reward_model_manager = RewardModelManager(config.reward_model, rm_resource_pool)
|
| 235 |
+
self.reward_router_address = self.reward_model_manager.get_router_address()
|
| 236 |
+
else:
|
| 237 |
+
self.reward_model_manager = None
|
| 238 |
+
self.reward_router_address = None
|
| 239 |
+
|
| 240 |
+
self._init_reward_loop_workers()
|
| 241 |
+
|
| 242 |
+
def _init_reward_loop_workers(self):
|
| 243 |
+
self.reward_loop_workers = []
|
| 244 |
+
num_workers = self.config.reward_model.get("num_workers", 1)
|
| 245 |
+
node_ids = [node["NodeID"] for node in ray.nodes() if node["Alive"] and node["Resources"].get("CPU", 0) > 0]
|
| 246 |
+
|
| 247 |
+
for i in range(num_workers):
|
| 248 |
+
# Round-robin scheduling over the all nodes
|
| 249 |
+
node_id = node_ids[i % len(node_ids)]
|
| 250 |
+
self.reward_loop_workers.append(
|
| 251 |
+
RewardLoopWorker.options(
|
| 252 |
+
name=f"reward_loop_worker_{i}",
|
| 253 |
+
scheduling_strategy=ray.util.scheduling_strategies.NodeAffinitySchedulingStrategy(
|
| 254 |
+
node_id=node_id,
|
| 255 |
+
soft=True,
|
| 256 |
+
),
|
| 257 |
+
).remote(self.config, self.reward_router_address)
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
def compute_rm_score(self, data: DataProto) -> DataProto:
|
| 261 |
+
"""
|
| 262 |
+
Compute reward score for the given data.
|
| 263 |
+
"""
|
| 264 |
+
...
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
RewardModelManager
|
| 268 |
+
~~~~~~~~~~~~~~~~~~
|
| 269 |
+
|
| 270 |
+
To support flexible and scalable reward model computation, Reward Loop implement a reward router that coordinates requests among multiple reward model servers.
|
| 271 |
+
|
| 272 |
+
Each reward model runs as an independent server and is registered with the router.
|
| 273 |
+
This router will forward the requests to the registered reward servers with load balancing and return the results.
|
| 274 |
+
This design allows us to expose a single unified router address to user-defined reward functions, enabling them to access various reward models seamlessly through the same interface.
|
| 275 |
+
|
| 276 |
+
.. image:: https://github.com/yyDing1/verl-materials/blob/main/reward_loop_full.svg?raw=true
|
| 277 |
+
|
| 278 |
+
.. code:: python
|
| 279 |
+
|
| 280 |
+
class RewardModelManager:
|
| 281 |
+
"""Reward model manager."""
|
| 282 |
+
|
| 283 |
+
def __init__(
|
| 284 |
+
self,
|
| 285 |
+
config: RewardModelConfig,
|
| 286 |
+
resource_pool: RayResourcePool = None,
|
| 287 |
+
):
|
| 288 |
+
"""
|
| 289 |
+
Initialize the reward model manager.
|
| 290 |
+
|
| 291 |
+
Args:
|
| 292 |
+
config (RewardModelConfig): Reward model configuration.
|
| 293 |
+
resource_pool (RayResourcePool, optional): Resource pool. Defaults to None.
|
| 294 |
+
"""
|
| 295 |
+
self.config = config
|
| 296 |
+
self.resource_pool = resource_pool
|
| 297 |
+
self._initialize_llm_servers()
|
| 298 |
+
self._initialize_router()
|
| 299 |
+
assert self.config.rollout.skip_tokenizer_init is False, "Reward model should not skip tokenizer init."
|
| 300 |
+
if self.config.rollout.free_cache_engine:
|
| 301 |
+
self.sleep()
|
code/RL_model/verl/verl_train/docs/advance/rollout_skip.rst
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RolloutSkip Function Usage Documentation
|
| 2 |
+
========================================
|
| 3 |
+
|
| 4 |
+
Last updated: 08/01/2025.
|
| 5 |
+
|
| 6 |
+
Applicable Scenarios
|
| 7 |
+
--------------------
|
| 8 |
+
|
| 9 |
+
The RolloutSkip functionality is designed to accelerate the rollout process in reinforcement learning training by caching and reusing previously generated sequences. This feature is particularly useful when:
|
| 10 |
+
|
| 11 |
+
1. You need to repeatedly run experiments with the same configuration
|
| 12 |
+
|
| 13 |
+
2. You want to save time by avoiding redundant sequence generation to come close to the optimal policy
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
API and Usage Example
|
| 17 |
+
----------------------
|
| 18 |
+
|
| 19 |
+
2.1 Trainer Adaptation
|
| 20 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 21 |
+
|
| 22 |
+
Both`RayDAPOTrainer()` (in `verl/recipe/dapo/dapo_ray_trainer.py`) and `RayPPOTrainer()`(in `verl/trainer/ppo/ray_trainer.py``) have already been adapted.
|
| 23 |
+
|
| 24 |
+
This is an example of how to patch rollout_skip in RayPPOTrainer.
|
| 25 |
+
|
| 26 |
+
.. code-block:: python
|
| 27 |
+
|
| 28 |
+
#* Import the RolloutSkip class
|
| 29 |
+
from verl.utils.rollout_skip import RolloutSkip
|
| 30 |
+
|
| 31 |
+
...
|
| 32 |
+
class RayPPOTrainer:
|
| 33 |
+
...
|
| 34 |
+
def fit(self):
|
| 35 |
+
...
|
| 36 |
+
|
| 37 |
+
#* Add code as follow:
|
| 38 |
+
rollout_skip = RolloutSkip(self.config, self.actor_rollout_wg)
|
| 39 |
+
rollout_skip.wrap_generate_sequences()
|
| 40 |
+
|
| 41 |
+
...
|
| 42 |
+
|
| 43 |
+
for epoch in range(self.config.trainer.total_epochs):
|
| 44 |
+
for batch_dict in self.train_dataloader:
|
| 45 |
+
...
|
| 46 |
+
|
| 47 |
+
2.2 Basic Configuration
|
| 48 |
+
~~~~~~~~~~~~~~~~~~~~~~~
|
| 49 |
+
|
| 50 |
+
Then, you should add the following parameters to your config to enable the RolloutSkip feature:
|
| 51 |
+
|
| 52 |
+
.. code-block:: bash
|
| 53 |
+
|
| 54 |
+
actor_rollout_ref.rollout.skip_rollout=True \
|
| 55 |
+
actor_rollout_ref.rollout.skip_dump_dir="/tmp/rollout_dump" \
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
Note:
|
| 59 |
+
|
| 60 |
+
1. The `skip_dump_dir` is the directory where the cached sequences will be stored. Ensure that this directory is writable and accessible by your training process. And make sure that `skip_dump_dir` is not relative path because ray will store the data in `/tmp/ray/session_<session_id>/` and the relative path will not be found in the worker.
|
| 61 |
+
2. The dumped data path follows this naming pattern `{experiment_name}_{project_name}_TrainGBS{train_gbs}__InferGBS{gen_gbs}__N{n}`, once you change the `experiment_name`, `project_name`, `train_gbs`, `gen_gbs`, or `n`, the cached data will be stored in a new directory.
|
code/RL_model/verl/verl_train/docs/advance/rollout_trace.rst
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Trace Function Usage Instructions
|
| 2 |
+
========================================
|
| 3 |
+
|
| 4 |
+
Last updated: 07/10/2025.
|
| 5 |
+
|
| 6 |
+
Applicable Scenarios
|
| 7 |
+
--------------------
|
| 8 |
+
|
| 9 |
+
Agentic RL involves multiple turns of conversations, tool invocations, and user interactions during the rollout process. During the Model Training process, it is necessary to track function calls, inputs, and outputs to understand the flow path of data within the application. The Trace feature helps, in complex multi-round conversations, to view the transformation of data during each interaction and the entire process leading to the final output by recording the inputs, outputs, and corresponding timestamps of functions, which is conducive to understanding the details of how the model processes data and optimizing the training results.
|
| 10 |
+
|
| 11 |
+
The Trace feature integrates commonly used Agent trace tools, including wandb weave and mlflow, which are already supported. Users can choose the appropriate trace tool according to their own needs and preferences. Here, we introduce the usage of each tool.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
Trace Parameter Configuration
|
| 15 |
+
-----------------------------
|
| 16 |
+
|
| 17 |
+
- ``actor_rollout_ref.rollout.trace.backend=mlflow|weave`` # the trace backend type
|
| 18 |
+
- ``actor_rollout_ref.rollout.trace.token2text=True`` # To show decoded text in trace view
|
| 19 |
+
- ``actor_rollout_ref.rollout.trace.max_samples_per_step_per_worker=N`` # Limit traces per worker (optional)
|
| 20 |
+
|
| 21 |
+
Limiting Trace Volume
|
| 22 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 23 |
+
|
| 24 |
+
By default, all samples are traced, which can generate large amounts of data and incur significant costs with trace backends like Weave or MLflow. To limit trace volume while maintaining representative coverage, use ``max_samples_per_step_per_worker``.
|
| 25 |
+
|
| 26 |
+
Example configuration:
|
| 27 |
+
|
| 28 |
+
.. code-block:: yaml
|
| 29 |
+
|
| 30 |
+
actor_rollout_ref:
|
| 31 |
+
rollout:
|
| 32 |
+
trace:
|
| 33 |
+
backend: weave
|
| 34 |
+
token2text: False
|
| 35 |
+
max_samples_per_step_per_worker: 5 # Each worker traces 5 random samples
|
| 36 |
+
|
| 37 |
+
Each agent loop worker independently selects up to N unique samples to trace per training step. For GRPO (``n > 1``), all rollouts for selected samples are traced. Total traces per step = max_samples_per_step_per_worker * num_workers * n.
|
| 38 |
+
|
| 39 |
+
Example: With 4 workers, max_samples_per_step_per_worker=5, and GRPO n=4, you get 4 * 5 * 4 = 80 traces per step instead of tracing all samples. Set to null (default) to trace all samples.
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Glossary
|
| 43 |
+
--------
|
| 44 |
+
|
| 45 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 46 |
+
| Object | Explaination |
|
| 47 |
+
+================+======================================================================================================+
|
| 48 |
+
| trajectory | A complete multi-turn conversation includes: |
|
| 49 |
+
| | 1. LLM output at least once |
|
| 50 |
+
| | 2. Tool Call |
|
| 51 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 52 |
+
| step | The training step corresponds to the global_steps variable in the trainer |
|
| 53 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 54 |
+
| sample_index | The identifier of the sample, defined in the extra_info.index of the dataset. It is usually a number,|
|
| 55 |
+
| | but may also be a uuid in some cases. |
|
| 56 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 57 |
+
| rollout_n | In the GROP algorithm, each sample is rolled out n times. rollout_n represents the serial number of |
|
| 58 |
+
| | the rollout. |
|
| 59 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 60 |
+
| validate | Whether the test dataset is used for evaluation? |
|
| 61 |
+
+----------------+------------------------------------------------------------------------------------------------------+
|
| 62 |
+
|
| 63 |
+
Rollout trace functions
|
| 64 |
+
-----------------------
|
| 65 |
+
|
| 66 |
+
There are 2 functions used for tracing:
|
| 67 |
+
|
| 68 |
+
1. ``rollout_trace_op``: This is a decorator function used to mark the functions to trace. In default, only few method has it, you can add it to more functions to trace more infor.
|
| 69 |
+
2. ``rollout_trace_attr``: This function is used to mark the entry of a trajectory and input some info to trace. If you add new type of agent, you may need to add it to enable trace.
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
Usage of wandb weave
|
| 73 |
+
--------------------
|
| 74 |
+
|
| 75 |
+
1.1 Basic Configuration
|
| 76 |
+
~~~~~~~~~~~~~~~~~~~~~~~
|
| 77 |
+
|
| 78 |
+
1. Set the ``WANDB_API_KEY`` environment variable
|
| 79 |
+
2. Configuration Parameters
|
| 80 |
+
|
| 81 |
+
1. ``actor_rollout_ref.rollout.trace.backend=weave``
|
| 82 |
+
2. ``trainer.logger=['console', 'wandb']``: This item is optional. Trace and logger are independent functions. When using Weave, it is recommended to also enable the wandb logger to implement both functions in one system.
|
| 83 |
+
3. ``trainer.project_name=$project_name``
|
| 84 |
+
4. ``trainer.experiment_name=$experiment_name``
|
| 85 |
+
5. ``actor_rollout_ref.rollout.mode=async``: Since trace is mainly used for agentic RL, need to enable agent toop using async mode for either vllm or sglang.
|
| 86 |
+
|
| 87 |
+
Note:
|
| 88 |
+
The Weave Free Plan comes with a default monthly network traffic allowance of 1GB. During the training process, the amount of trace data generated is substantial, reaching dozens of gigabytes per day, so it is necessary to select an appropriate wandb plan.
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
1.2 View Trace Logs
|
| 92 |
+
~~~~~~~~~~~~~~~~~~~
|
| 93 |
+
|
| 94 |
+
After executing the training, on the project page, you can see the WEAVE sidebar. Click Traces to view it.
|
| 95 |
+
|
| 96 |
+
Each Trace project corresponds to a trajectory. You can filter and select the trajectories you need to view by step, sample_index, rollout_n, and experiment_name.
|
| 97 |
+
|
| 98 |
+
After enabling token2text, prompt_text and response_text will be automatically added to the output of ToolAgentLoop.run, making it convenient to view the input and output content.
|
| 99 |
+
|
| 100 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/weave_trace_list.png?raw=true
|
| 101 |
+
|
| 102 |
+
1.3 Compare Trace Logs
|
| 103 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 104 |
+
|
| 105 |
+
Weave can select multiple trace items and then compare the differences among them.
|
| 106 |
+
|
| 107 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/weave_trace_compare.png?raw=true
|
| 108 |
+
|
| 109 |
+
Usage of mlflow
|
| 110 |
+
---------------
|
| 111 |
+
|
| 112 |
+
1. Basic Configuration
|
| 113 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 114 |
+
|
| 115 |
+
1. Set the ``MLFLOW_TRACKING_URI`` environment variable, which can be:
|
| 116 |
+
|
| 117 |
+
1. Http and https URLs corresponding to online services
|
| 118 |
+
2. Local files or directories, such as ``sqlite:////tmp/mlruns.db``, indicate that data is stored in ``/tmp/mlruns.db``. When using local files, it is necessary to initialize the file first (e.g., start the UI: ``mlflow ui --backend-store-uri sqlite:////tmp/mlruns.db``) to avoid conflicts when multiple workers create files simultaneously.
|
| 119 |
+
|
| 120 |
+
2. Configuration Parameters
|
| 121 |
+
|
| 122 |
+
1. ``actor_rollout_ref.rollout.trace.backend=mlflow``
|
| 123 |
+
2. ``trainer.logger=['console', 'mlflow']``. This item is optional. Trace and logger are independent functions. When using mlflow, it is recommended to also enable the mlflow logger to implement both functions in one system.
|
| 124 |
+
3. ``trainer.project_name=$project_name``
|
| 125 |
+
4. ``trainer.experiment_name=$experiment_name``
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
2. View Log
|
| 129 |
+
~~~~~~~~~~~
|
| 130 |
+
|
| 131 |
+
Since ``trainer.project_name`` corresponds to Experiments in mlflow, in the mlflow view, you need to select the corresponding project name, then click the "Traces" tab to view traces. Among them, ``trainer.experiment_name`` corresponds to the experiment_name of tags, and tags corresponding to step, sample_index, rollout_n, etc., are used for filtering and viewing.
|
| 132 |
+
|
| 133 |
+
For example, searching for ``"tags.step = '1'"`` can display all trajectories of step 1.
|
| 134 |
+
|
| 135 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/mlflow_trace_list.png?raw=true
|
| 136 |
+
|
| 137 |
+
Opening one of the trajectories allows you to view each function call process within it.
|
| 138 |
+
|
| 139 |
+
After enabling token2text, prompt_text and response_text will be automatically added to the output of ToolAgentLoop.run, making it convenient to view the content.
|
| 140 |
+
|
| 141 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/mlflow_trace_view.png?raw=true
|
| 142 |
+
|
| 143 |
+
Note:
|
| 144 |
+
|
| 145 |
+
1. mlflow does not support comparing multiple traces
|
| 146 |
+
2. rollout_trace can not associate the mlflow trace with the run, so the trace content cannot be seen in the mlflow run logs.
|
code/RL_model/verl/verl_train/docs/advance/rope.rst
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RoPE Scaling override
|
| 2 |
+
=======================================
|
| 3 |
+
|
| 4 |
+
Last updated: 05/14/2025.
|
| 5 |
+
|
| 6 |
+
Some models such as `Qwen/Qwen2.5-7B-Instruct <https://huggingface.co/Qwen/Qwen2.5-7B-Instruct#processing-long-texts>`_ support RoPE Scaling but don't have it defined in their config.json file.
|
| 7 |
+
For example, this model supports this configuration:
|
| 8 |
+
|
| 9 |
+
.. code:: python
|
| 10 |
+
|
| 11 |
+
{
|
| 12 |
+
...,
|
| 13 |
+
"rope_scaling": {
|
| 14 |
+
"factor": 4.0,
|
| 15 |
+
"original_max_position_embeddings": 32768,
|
| 16 |
+
"type": "yarn"
|
| 17 |
+
}
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
In order to support a longer context for such models, you must override the model configs when starting the trainer.
|
| 23 |
+
|
| 24 |
+
PPO example:
|
| 25 |
+
|
| 26 |
+
.. code:: bash
|
| 27 |
+
|
| 28 |
+
+actor_rollout_ref.model.override_config.rope_scaling.type=yarn \
|
| 29 |
+
+actor_rollout_ref.model.override_config.rope_scaling.factor=4.0 \
|
| 30 |
+
+actor_rollout_ref.model.override_config.rope_scaling.original_max_position_embeddings=32768 \
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
And for the critic model
|
| 34 |
+
|
| 35 |
+
.. code:: bash
|
| 36 |
+
|
| 37 |
+
+critic.model.override_config.rope_scaling.type=yarn \
|
| 38 |
+
+critic.model.override_config.rope_scaling.factor=4.0 \
|
| 39 |
+
+critic.model.override_config.rope_scaling.original_max_position_embeddings=32768 \
|
code/RL_model/verl/verl_train/docs/algo/baseline.md
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Algorithm Baselines
|
| 2 |
+
|
| 3 |
+
Last updated: 06/18/2025.
|
| 4 |
+
|
| 5 |
+
## Math related datasets
|
| 6 |
+
|
| 7 |
+
### GSM8k
|
| 8 |
+
|
| 9 |
+
Assuming GSM8k/math dataset is preprocessed via:
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
python3 examples/data_preprocess/*.py
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
Refer to the table below to reproduce RL training from different pre-trained checkpoints. Below is the performance on the GSM8k dataset if not specified otherwise. More comprehensive benchmark results areavailable in the recipe folder.
|
| 16 |
+
|
| 17 |
+
| Hardware | Model | Method | Test score | Details |
|
| 18 |
+
| ---------- | -------------------------------- | --------------- | ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 19 |
+
| NVIDIA GPU | google/gemma-2-2b-it | hf checkpoint | 23.9 | [Huggingface](https://huggingface.co/google/gemma-2-2b-it#benchmark-results) |
|
| 20 |
+
| NVIDIA GPU | google/gemma-2-2b-it | SFT | 52.06 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-sft-0.411.log) |
|
| 21 |
+
| NVIDIA GPU | google/gemma-2-2b-it | SFT + PPO | 64.02 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-ppo-bsz512_4-prompt1024-resp-512-0.640.log), [wandb](https://api.wandb.ai/links/verl-team/h7ux8602) |
|
| 22 |
+
| NVIDIA GPU | Qwen/Qwen2.5-0.5B-Instruct | hf checkpoint | 49.6 | [Qwen blog](https://qwen.ai/blog?id=qwen2.5-llm) |
|
| 23 |
+
| NVIDIA GPU | Qwen/Qwen2.5-0.5B-Instruct | PPO | 56.7 | [command and log](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log) |
|
| 24 |
+
| NVIDIA GPU | Qwen/Qwen2.5-0.5B-Instruct | PRIME | 58.7 | [script](https://github.com/verl-project/verl-recipe/blob/main//prime/run_prime_qwen.sh), [wandb](https://api.wandb.ai/links/zefan-wang-thu-tsinghua-university/rxd1btvb) |
|
| 25 |
+
| NVIDIA GPU | Qwen/Qwen2.5-0.5B-Instruct | GRPO-LoRA | 54.3 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz64_2-prompt512-resp1024-lorarank32-score0.543.log) |
|
| 26 |
+
| NVIDIA GPU | Qwen/Qwen2.5-1.5B-Instruct | GRPO-LoRA | 77.9 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-1.5B-bsz64_2-prompt512-resp1024-lorarank32-score0.779.log) |
|
| 27 |
+
| NVIDIA GPU | Qwen/Qwen2.5-3B-Instruct | GRPO-LoRA | 86.1 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-3B-bsz64_2-prompt512-resp1024-lorarank32-score0.861.log) |
|
| 28 |
+
| NVIDIA GPU | deepseek-ai/deepseek-llm-7b-chat | PPO (Megatron) | 69.5 [1] | [log](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/deepseek-llm-7b-chat-megatron-bsz256_4-prompt512-resp512-0.695.log), [wandb](https://wandb.ai/verl-team/verl_megatron_gsm8k_examples/runs/10fetyr3) |
|
| 29 |
+
| NVIDIA GPU | Qwen/Qwen2-7B-Instruct | GRPO | 89 | [script](https://github.com/volcengine/verl/blob/a65c9157bc0b85b64cd753de19f94e80a11bd871/examples/grpo_trainer/run_qwen2-7b_seq_balance.sh) |
|
| 30 |
+
| NVIDIA GPU | Qwen/Qwen2-7B-Instruct | GRPO (FSDP2) | 89.8 | [log](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/qwen2-7b-fsdp2.log) |
|
| 31 |
+
| NVIDIA GPU | Qwen/Qwen2-7B-Instruct | GRPO (Megatron) | 89.6 | [log](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/qwen2-7b_math_megatron.log) |
|
| 32 |
+
| NVIDIA GPU | Qwen/Qwen2.5-7B-Instruct | ReMax | 97 | [script](https://github.com/eric-haibin-lin/verl/blob/main/examples/remax_trainer/run_qwen2.5-3b_seq_balance.sh), [wandb](https://wandb.ai/liziniu1997/verl_remax_example_gsm8k/runs/vxl10pln) |
|
| 33 |
+
| NVIDIA GPU | Qwen/Qwen2.5-7B-Instruct | SPPO | 65.6 (MATH) | [SPPO script](https://github.com/volcengine/verl-recipe/tree/main/sppo/README.md) |
|
| 34 |
+
| NVIDIA GPU | Qwen/Qwen2.5-7B-Instruct | GRPO-LoRA | 93.4 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-7B-bsz64_8-prompt512-resp1024-lorarank32-score0.934.log) |
|
| 35 |
+
| NVIDIA GPU | Mixtral-8x22B-Instruct-v0.1 | Instruct model | 83.7 | [Qwen Blog](https://qwen.ai/blog?id=qwen2.5-llm) |
|
| 36 |
+
| NVIDIA GPU | Mixtral-8x22B-Instruct-v0.1 | RLOO (Megatron) | 92.3 | [wandb](https://api.wandb.ai/links/ppo_dev/sbuiuf2d) |
|
| 37 |
+
| NVIDIA GPU | Qwen/Qwen2.5-7B-Instruct | SPIN | 92 | [script](https://github.com/volcengine/verl-recipe/tree/main/spin/README.md) |
|
| 38 |
+
| NVIDIA GPU | Qwen/Qwen2-7B-Instruct | GPG | 88 | [log](https://github.com/diqiuzhuanzhuan/verldata/blob/main/run_logs/qwen2-7b_math.log), [wandb](https://wandb.ai/diqiuzhuanzhuan/verl_gpg_example_gsm8k_math/runs/ab86c4va) |
|
| 39 |
+
| NVIDIA GPU | Qwen/Qwen2-7B-Instruct | GPG (Megatron) | 88 | [log](https://github.com/diqiuzhuanzhuan/verldata/blob/main/run_logs/qwen2-7b_math_megatron.log), [wandb](https://wandb.ai/diqiuzhuanzhuan/verl_gpg_example_gsm8k_math/runs/yy8bheu8) |
|
| 40 |
+
| NVIDIA GPU | Qwen/Qwen2.5-VL-7B-Instruct | GRPO (Megatron) | 65.4 (GEO3k) | [script](https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_vl-7b-megatron.sh), [wandb](https://api.wandb.ai/links/megatron-core-moe-dev/1yngvkek) |
|
| 41 |
+
| AMD MI300 | deepseek-ai/deepseek-llm-7b-chat | PPO | 70.5 [1] | [log](https://github.com/yushengsu-thu/verl_training_log/blob/main/gsm8k/ppo_run_deepseek7b_llm.log) |
|
| 42 |
+
| AMD MI300 | deepseek-ai/deepseek-llm-7b-chat | GRPO | 71.4 [1] | [log](https://github.com/yushengsu-thu/verl_training_log/blob/main/gsm8k/grpo_run_deepseek7b_llm.log) |
|
| 43 |
+
| NVIDIA GPU | Qwen/Qwen2.5-14B-Instruct | GRPO-LoRA | 94.6 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-14B-bsz64_8-prompt512-resp1024-lorarank32-score0.946.log) |
|
| 44 |
+
| NVIDIA GPU | Qwen/Qwen2.5-32B-Instruct | GRPO-LoRA | 95.8 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-32B-bsz64_8-prompt512-resp1024-lorarank32-score0.958.log) |
|
| 45 |
+
| NVIDIA GPU | Qwen/Qwen2.5-72B-Instruct | GRPO-LoRA | 96.0 | [command and logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-72B-bs64_8-prompt512-resp1024-lorarank32-score0.960.log) |
|
| 46 |
+
|
| 47 |
+
### DAPO math-17k
|
| 48 |
+
|
| 49 |
+
- Training DAPO math-17k dataset: https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k
|
| 50 |
+
- Testing: AIME'24: https://huggingface.co/datasets/BytedTsinghua-SIA/AIME-2024
|
| 51 |
+
|
| 52 |
+
Note:
|
| 53 |
+
|
| 54 |
+
- For Qwen/Qwen2.5-Math-7B, we directly modify the max_position_embeddings to 32768 without observing performance degradation in order to train longer response length.
|
| 55 |
+
|
| 56 |
+
| Hardware | Model | Method | Test score | Details |
|
| 57 |
+
| ---------- | -------------------------- | ----------------------- | ---------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 58 |
+
| NVIDIA GPU | Qwen/Qwen2.5-Math-7B (32k) | DAPO | 36.3 | [command](https://github.com/verl-project/verl-recipe/blob/main//dapo/test_dapo_7b_math.sh), [logs](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/runs/ow47vvon?nw=nwusertongyuxuan361) |
|
| 59 |
+
| NVIDIA GPU | Qwen/Qwen2.5-7B-Instruct | DAPO + Code Interpreter | 40.0 | [command](https://github.com/verl-project/verl-recipe/blob/main//retool/run_qwen2_7b_dapo.sh) |
|
| 60 |
+
|
| 61 |
+
## Coding related datasets
|
| 62 |
+
|
| 63 |
+
Below is the result on leetcode if not specified otherwise.
|
| 64 |
+
|
| 65 |
+
| Hardware | Model | Method | Test score | Details |
|
| 66 |
+
| ---------- | ----------------------- | ------ | ---------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 67 |
+
| NVIDIA GPU | PRIME-RL/Eurus-2-7B-SFT | RPIME | 36.1 | [script](https://github.com/verl-project/verl-recipe/blob/main//prime/run_prime_qwen_code.sh), [swanlab](https://swanlab.cn/@wangzefan/prime_example/runs/7f541qhspgmy8nmhdlx35/chart) |
|
| 68 |
+
|
| 69 |
+
### Notes
|
| 70 |
+
|
| 71 |
+
[1] During evaluation, we have only extracted answers following the format `"####"`. A more flexible answer extraction, longer response length, and better prompt engineering may lead to a higher score.
|
| 72 |
+
|
| 73 |
+
[2] The default value of `actor_rollout_ref.actor.entropy_coeff` is set to `0.0` since verl 0.3.x on 2025-05-30, which is different from previous versions.
|
code/RL_model/verl/verl_train/docs/algo/collabllm.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: CollabLLM
|
| 2 |
+
|
| 3 |
+
Last updated: 09/22/2025.
|
| 4 |
+
|
| 5 |
+
> Open-Source Algorithm Implementation & Expriement Running: [Haiquan Chen](https://github.com/chenhaiq), [Shirley Wu](https://github.com/Wuyxin)
|
| 6 |
+
|
| 7 |
+
🏠 [Homepage](https://aka.ms/CollabLLM) | 📝 [Paper](https://arxiv.org/pdf/2502.00640) | 🤗 [Datasets & Models](https://huggingface.co/collabllm) | ⭐️ [Original Implementation](https://github.com/Wuyxin/collabllm)
|
| 8 |
+
|
| 9 |
+
`verl` provides a recipe for the Outstanding Paper at ICML 2025, **"CollabLLM: From Passive Responders to Active Collaborators"**. [CollabLLM](https://aka.ms/CollabLLM) is a unified fine-tuning framework that optimizes LLMs for effective and efficient multiturn collaboration with users.
|
| 10 |
+
|
| 11 |
+
**Core Idea:** Models are rewarded based on how well their responses enable effective *future* collaboration with users.
|
| 12 |
+
|
| 13 |
+
Paper Authors: [Shirley Wu](https://cs.stanford.edu/~shirwu/), [Michel Galley](https://www.microsoft.com/en-us/research/people/mgalley/), Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, [James Zou](https://www.james-zou.com/), [Jure Leskovec](https://cs.stanford.edu/people/jure/), [Jianfeng Gao](https://www.microsoft.com/en-us/research/people/jfgao/)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
## Quick Start
|
| 18 |
+
|
| 19 |
+
### 0. Environment
|
| 20 |
+
Make sure the required packages for `verl` are installed. Additionally, install `litellm` and export the required API keys. The API model will be used for user simulators and, optionally, LLM Judges (see the Configuration section below).
|
| 21 |
+
|
| 22 |
+
### 1. Prepare Your Dataset
|
| 23 |
+
|
| 24 |
+
First, process your dataset using the provided script (see example commands and usage in `process_dataset.py`):
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
python process_dataset.py --dataset <> ... --dataset_type <sft or rl>
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
**Requirements:**
|
| 32 |
+
- Input: A Hugging Face multiturn dataset. Existing datasets: `collabllm/collabllm-multiturn-$DATASET`, with `DATASET` in one of [`math-hard(-large)`, `medium(-large)`, `bigcodebench(-large)`] (*-large are the datasets used in the CollabLLM paper)
|
| 33 |
+
- Example format: See [collabllm-multiturn-math-hard](https://huggingface.co/datasets/collabllm/collabllm-multiturn-math-hard)
|
| 34 |
+
- To generate your own dataset: Use [build_dataset.py](https://github.com/Wuyxin/collabllm/blob/main/scripts/engine/build_dataset.py) from the original CollabLLM repository
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### 2. Train Your Model
|
| 38 |
+
|
| 39 |
+
**(Optional) For Supervised Fine-Tuning (SFT):**
|
| 40 |
+
```bash
|
| 41 |
+
bash train_sft_collabllm.sh
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
**For Reinforcement Learning (RL):**
|
| 45 |
+
|
| 46 |
+
```bash
|
| 47 |
+
bash train_rl_collabllm.sh
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
The RL script shows an example to train CollabLLM on `math-hard-large`.
|
| 51 |
+
|
| 52 |
+
- The config to sample future conversations are in `recipe/collabllm/config/collabllm_interaction_config.yaml`.
|
| 53 |
+
- The Multiturn-aware Reward is aggregated from these three conversational-level rewards:
|
| 54 |
+
|
| 55 |
+
```
|
| 56 |
+
+reward_model.reward_kwargs.metric_weights.accuracy=1 \
|
| 57 |
+
+reward_model.reward_kwargs.metric_weights.interactivity=1 \
|
| 58 |
+
+reward_model.reward_kwargs.metric_weights.token_amount=-0.0001 \
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
You can remove, add, or modify the weights depending on your task. A list of implemented metrics you can already add are under `recipe/collabllm/metrics`. For example, on `medium-large`, you can replace `accuracy` with `bleu_score` via
|
| 62 |
+
```
|
| 63 |
+
+reward_model.reward_kwargs.metric_weights.bleu_score=1
|
| 64 |
+
```
|
| 65 |
+
which will instead apply bleu score on the sampled future conversations.
|
| 66 |
+
|
| 67 |
+
## Algorithm
|
| 68 |
+
|
| 69 |
+
| Step | Name | Description |
|
| 70 |
+
|------|-------------------------------|-----------------------------------------------------------------------------|
|
| 71 |
+
| 1 | Model response generation | The model generates multiple responses for each prompt in a batch. |
|
| 72 |
+
| 2 | Collaborative simulation | A user simulator (e.g., GPT or Claude) samples `num_repeat_rollouts` conversations for up to `max_user_turns` additional turns. |
|
| 73 |
+
| 3 | Compute Multiturn-aware Reward | Customized conversational reward functions are applied to the sampled conversations. Rewards are aggregated, then averaged across rollouts. |
|
| 74 |
+
| 4 | Update model | The model weights are updated using the computed multiturn-aware rewards. |
|
| 75 |
+
|
| 76 |
+
---
|
| 77 |
+
|
| 78 |
+
## Configuration
|
| 79 |
+
|
| 80 |
+
The primary configuration is managed through the launch script `train_rl_collabllm.sh` and the YAML file `recipe/collabllm/config/collabllm_interaction_config.yaml`. Key configuration sections:
|
| 81 |
+
|
| 82 |
+
| Section | Key Parameters / Notes |
|
| 83 |
+
|----------------------|-----------------------------------------------------------------------------------------|
|
| 84 |
+
| `data` | Paths to training/validation files, batch sizes, sequence lengths. |
|
| 85 |
+
| `actor_rollout_ref` (common) | Base model path (used for actor + initial reference), FSDP settings, optimization (LR, scheduler). |
|
| 86 |
+
| `actor_rollout_ref` (CollabLLM-specific) | Hyperparameters under `actor_rollout_ref.rollout.multi_turn`: `max_user_turns`, `max_assistant_turns`, `num_repeat_rollouts`. |
|
| 87 |
+
| `interaction` | Defined in `collabllm_interaction_config.yaml`. Specifies user simulator and hyperparameters. Requires exported API keys. |
|
| 88 |
+
| `reward_model` | Manager set to `collabllm` by default. Modify `reward_model.reward_kwargs.metric_weights` for conversational rewards and weights. LLM Judge hyperparameters (e.g., `model`, `temperature`) go under `reward_model.reward_kwargs.llm_judge_kwargs`. |
|
| 89 |
+
| `algorithm` | GRPO-specific hyperparameters such as `actor_rollout_ref.rollout.n`. |
|
| 90 |
+
| `trainer` | Distributed training (nodes, GPUs per node), logging (WandB), checkpointing frequency. |
|
| 91 |
+
|
| 92 |
+
---
|
| 93 |
+
|
| 94 |
+
## Key Files
|
| 95 |
+
|
| 96 |
+
| File Path | Purpose |
|
| 97 |
+
|-----------|---------|
|
| 98 |
+
| `recipe/collabllm/collabllm_agent_loop.py` | Main logic to sample future conversations, using `CollabLLMInteraction` from `verl/interactions/collabllm_interaction.py`. |
|
| 99 |
+
| `verl/workers/reward_manager/collabllm.py` | Computes rewards for future conversations, leveraging `recipe/collabllm/reward_function.py` to apply each metric. |
|
| 100 |
+
|
| 101 |
+
---
|
| 102 |
+
|
| 103 |
+
## Acknowledgement
|
| 104 |
+
|
| 105 |
+
We sincerely thank the `verl` community and advisors for their contributions and guidance!
|
code/RL_model/verl/verl_train/docs/algo/dapo.md
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 06/19/2025.
|
| 4 |
+
|
| 5 |
+
> Open-Source Algorithm Implementation & Expriement Running: [Yuxuan Tong](https://tongyx361.github.io/), [Guangming Sheng](https://hk.linkedin.com/in/guangming-sheng-b50640211)
|
| 6 |
+
|
| 7 |
+
🏠 [Homepage](https://dapo-sia.github.io/) | 📝 [Paper@arXiv](https://arxiv.org/abs/2503.14476) | 🤗 [Datasets&Models@HF](https://huggingface.co/collections/BytedTsinghua-SIA/dapo-67d7f1517ee33c8aed059da0) | 🐱 [Code@GitHub](https://github.com/verl-project/verl-recipe/tree/main/dapo/recipe/dapo) | 🐱 [Repo@GitHub](https://github.com/BytedTsinghua-SIA/DAPO)
|
| 8 |
+
|
| 9 |
+
> We propose the **D**ecoupled Clip and Dynamic s**A**mpling **P**olicy **O**ptimization (DAPO) algorithm. By making our work publicly available, we provide the broader research community and society with practical access to scalable reinforcement learning, enabling all to benefit from these advancements. Our system is based on the awesome [verl](https://github.com/volcengine/verl) framework. Thanks for their great work! Applying DAPO training to Qwen2.5-32B base model proves to outperform the previous state-of-the-art DeepSeek-R1-Zero-Qwen-32B on AIME 2024, achieving **50%** accuracy with **50%** less training steps.
|
| 10 |
+
>
|
| 11 |
+
> 
|
| 12 |
+
|
| 13 |
+
## Quickstart
|
| 14 |
+
|
| 15 |
+
1. Prepare the datasets **on the Ray cluster**:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
bash prepare_dapo_data.sh # This downloads the datasets to ${HOME}/verl/data by default
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
2. Submit the job to the Ray cluster **from any machine**:
|
| 22 |
+
|
| 23 |
+
```bash
|
| 24 |
+
cd verl # Repo root
|
| 25 |
+
export RAY_ADDRESS="http://${RAY_IP:-localhost}:8265" # The Ray cluster address to connect to
|
| 26 |
+
export WORKING_DIR="${PWD}" # The local directory to package to the Ray cluster
|
| 27 |
+
# Set the runtime environment like env vars and pip packages for the Ray cluster in yaml
|
| 28 |
+
export RUNTIME_ENV="./recipe/dapo/runtime_env.yaml" # This sets environment variables for the Ray cluster
|
| 29 |
+
bash recipe/dapo/run_dapo_qwen2.5_32b.sh # or other scripts
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
## Reproduction Runs
|
| 33 |
+
|
| 34 |
+
| Setup | AIME 2024 Acc. | Hardware | Image | Commit | Environment Variables | Training Script | Training Record |
|
| 35 |
+
| -------------------------------------------- | -------------- | --------- | -------------------------------------------------------------------- | -------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------- |
|
| 36 |
+
| DAPO | 52% | 16x8xH800 | `hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.3-flashinfer0.2.2-cxx11abi0` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 37 |
+
| DAPO w/o Dynamic Sampling | 50% | 16x8xH800 | `hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.3-flashinfer0.2.2-cxx11abi0` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_wo_ds_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_wo_ds_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 38 |
+
| DAPO w/o Token-level Loss & Dynamic Sampling | 44% | 16x8xH20 | `hiyouga/verl:ngc-th2.5.1-cu120-vllm0.7.4-hotfix` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_early_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_early_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 39 |
+
|
| 40 |
+
> [!IMPORTANT]
|
| 41 |
+
>
|
| 42 |
+
> **📢 Call for Contribution!**
|
| 43 |
+
>
|
| 44 |
+
> Welcome to submit your reproduction runs and setups!
|
| 45 |
+
|
| 46 |
+
## Configuration
|
| 47 |
+
|
| 48 |
+
### Separated Clip Epsilons (-> Clip-Higher)
|
| 49 |
+
|
| 50 |
+
An example configuration:
|
| 51 |
+
|
| 52 |
+
```yaml
|
| 53 |
+
actor_rollout_ref:
|
| 54 |
+
actor:
|
| 55 |
+
clip_ratio_low: 0.2
|
| 56 |
+
clip_ratio_high: 0.28
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
`clip_ratio_low` and `clip_ratio_high` specify the $\varepsilon_{\text {low }}$ and $\varepsilon_{\text {high }}$ in the DAPO objective.
|
| 60 |
+
|
| 61 |
+
Core relevant code:
|
| 62 |
+
|
| 63 |
+
```python
|
| 64 |
+
pg_losses1 = -advantages * ratio
|
| 65 |
+
pg_losses2 = -advantages * torch.clamp(ratio, 1 - cliprange_low, 1 + cliprange_high)
|
| 66 |
+
pg_losses = torch.maximum(pg_losses1, pg_losses2)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
### Dynamic Sampling (with Group Filtering)
|
| 70 |
+
|
| 71 |
+
An example configuration:
|
| 72 |
+
|
| 73 |
+
```yaml
|
| 74 |
+
data:
|
| 75 |
+
gen_batch_size: 1536
|
| 76 |
+
train_batch_size: 512
|
| 77 |
+
algorithm:
|
| 78 |
+
filter_groups:
|
| 79 |
+
enable: True
|
| 80 |
+
metric: acc # score / seq_reward / seq_final_reward / ...
|
| 81 |
+
max_num_gen_batches: 10 # Non-positive values mean no upper limit
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
Setting `filter_groups.enable` to `True` will filter out groups whose outputs' `metric` are all the same, e.g., for `acc`, groups whose outputs' accuracies are all 1 or 0.
|
| 85 |
+
|
| 86 |
+
The trainer will repeat sampling with `gen_batch_size` until there are enough qualified groups for `train_batch_size` or reaching the upper limit specified by `max_num_gen_batches`.
|
| 87 |
+
|
| 88 |
+
Core relevant code:
|
| 89 |
+
|
| 90 |
+
```python
|
| 91 |
+
prompt_bsz = self.config.data.train_batch_size
|
| 92 |
+
if num_prompt_in_batch < prompt_bsz:
|
| 93 |
+
print(f'{num_prompt_in_batch=} < {prompt_bsz=}')
|
| 94 |
+
num_gen_batches += 1
|
| 95 |
+
max_num_gen_batches = self.config.algorithm.filter_groups.max_num_gen_batches
|
| 96 |
+
if max_num_gen_batches <= 0 or num_gen_batches < max_num_gen_batches:
|
| 97 |
+
print(f'{num_gen_batches=} < {max_num_gen_batches=}. Keep generating...')
|
| 98 |
+
continue
|
| 99 |
+
else:
|
| 100 |
+
raise ValueError(
|
| 101 |
+
f'{num_gen_batches=} >= {max_num_gen_batches=}. Generated too many. Please check your data.'
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
# Align the batch
|
| 105 |
+
traj_bsz = self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n
|
| 106 |
+
batch = batch[:traj_bsz]
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Flexible Loss Aggregation Mode (-> Token-level Loss)
|
| 110 |
+
|
| 111 |
+
An example configuration:
|
| 112 |
+
|
| 113 |
+
```yaml
|
| 114 |
+
actor_rollout_ref:
|
| 115 |
+
actor:
|
| 116 |
+
loss_agg_mode: "token-mean" # / "seq-mean-token-sum" / "seq-mean-token-mean"
|
| 117 |
+
# NOTE: "token-mean" is the default behavior
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Setting `loss_agg_mode` to `token-mean` will mean the (policy gradient) loss across all the tokens in all the sequences in a mini-batch.
|
| 121 |
+
|
| 122 |
+
Core relevant code:
|
| 123 |
+
|
| 124 |
+
```python
|
| 125 |
+
if loss_agg_mode == "token-mean":
|
| 126 |
+
loss = verl_F.masked_mean(loss_mat, loss_mask)
|
| 127 |
+
elif loss_agg_mode == "seq-mean-token-sum":
|
| 128 |
+
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) # token-sum
|
| 129 |
+
loss = torch.mean(seq_losses) # seq-mean
|
| 130 |
+
elif loss_agg_mode == "seq-mean-token-mean":
|
| 131 |
+
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / torch.sum(loss_mask, dim=-1) # token-mean
|
| 132 |
+
loss = torch.mean(seq_losses) # seq-mean
|
| 133 |
+
else:
|
| 134 |
+
raise ValueError(f"Invalid loss_agg_mode: {loss_agg_mode}")
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
### Overlong Reward Shaping
|
| 138 |
+
|
| 139 |
+
An example configuration:
|
| 140 |
+
|
| 141 |
+
```yaml
|
| 142 |
+
data:
|
| 143 |
+
max_response_length: 20480 # 16384 + 4096
|
| 144 |
+
reward_model:
|
| 145 |
+
overlong_buffer:
|
| 146 |
+
enable: True
|
| 147 |
+
len: 4096
|
| 148 |
+
penalty_factor: 1.0
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
Setting `overlong_buffer.enable` to `True` will penalize the outputs whose lengths are overlong but still within the hard context limit.
|
| 152 |
+
|
| 153 |
+
Specifically, the penalty increases linearly from `0` to `overlong_buffer.penalty_factor` when the length of the output exceeds the `max_response_length - overlong_buffer.len` by `0` to `overlong_buffer.len` tokens.
|
| 154 |
+
|
| 155 |
+
Core relevant code:
|
| 156 |
+
|
| 157 |
+
```python
|
| 158 |
+
if self.overlong_buffer_cfg.enable:
|
| 159 |
+
overlong_buffer_len = self.overlong_buffer_cfg.len
|
| 160 |
+
expected_len = self.max_resp_len - overlong_buffer_len
|
| 161 |
+
exceed_len = valid_response_length - expected_len
|
| 162 |
+
overlong_penalty_factor = self.overlong_buffer_cfg.penalty_factor
|
| 163 |
+
overlong_reward = min(-exceed_len / overlong_buffer_len * overlong_penalty_factor, 0)
|
| 164 |
+
reward += overlong_reward
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
## FAQ
|
| 168 |
+
|
| 169 |
+
### Where is the "Overlong Filtering" in the paper?
|
| 170 |
+
|
| 171 |
+
Most experiments in the paper, including the best-performant one, are run without Overlong Filtering because it's somehow overlapping with Overlong Reward Shaping in terms of properly learning from the longest outputs. So we don't implement it here.
|
| 172 |
+
|
| 173 |
+
### What's the difference between [the `recipe/dapo` directory in the `main` branch](https://github.com/volcengine/verl-recipe/tree/main/dapo) and the [`recipe/dapo` branch](https://github.com/verl-project/verl-recipe/tree/main/dapo/recipe/dapo)?
|
| 174 |
+
|
| 175 |
+
[The `recipe/dapo` branch](https://github.com/verl-project/verl-recipe/tree/main/dapo/recipe/dapo) is for **as-is reproduction** and thus won't be updated with new features.
|
| 176 |
+
|
| 177 |
+
[The `recipe/dapo` directory in the `main` branch](https://github.com/volcengine/verl-recipe/tree/main/dapo) works as an example of how to extend the latest `verl` to implement an algorithm recipe, which will be maintained with new features.
|
| 178 |
+
|
| 179 |
+
### Why can't I produce similar results after modifications?
|
| 180 |
+
|
| 181 |
+
RL infrastructures nowadays still have inherent unrobustness, on which we are still working hard to improve.
|
| 182 |
+
|
| 183 |
+
We strongly recommend to only modify one thing at a time.
|
| 184 |
+
|
| 185 |
+
We also list some known problems here:
|
| 186 |
+
|
| 187 |
+
1. Enabling CUDA graph (`enforce_eager=False`) might cause model performance degradation, whose cause is still under investigation.
|
code/RL_model/verl/verl_train/docs/algo/entropy.md
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Entropy Mechanism
|
| 2 |
+
|
| 3 |
+
Last updated: 06/27/2025.
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
<div align="center">
|
| 7 |
+
|
| 8 |
+
The Entropy Mechanism of Reinforcement Learning for Large Language Model Reasoning.
|
| 9 |
+
|
| 10 |
+
[](https://arxiv.org/pdf/2505.22617) [](https://github.com/PRIME-RL/Entropy-Mechanism-of-RL) [](https://www.alphaxiv.org/abs/2505.22617) [](https://x.com/stingning/status/1928088554166505667) [](https://x.com/charlesfornlp/status/1928089451080585283) [](https://x.com/_akhaliq/status/1928077929105268861)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
<div align="center" style="font-family: Arial, sans-serif;">
|
| 15 |
+
<p>
|
| 16 |
+
<a href="#🎉news" style="text-decoration: none; font-weight: bold;">🎉 News</a> •
|
| 17 |
+
<a href="#✨getting-started" style="text-decoration: none; font-weight: bold;">✨ Getting Started</a> •
|
| 18 |
+
<a href="#📖introduction" style="text-decoration: none; font-weight: bold;">📖 Introduction</a>
|
| 19 |
+
</p>
|
| 20 |
+
<p>
|
| 21 |
+
<a href="#🎈citation" style="text-decoration: none; font-weight: bold;">🎈 Citation</a> •
|
| 22 |
+
<a href="#🌻acknowledgement" style="text-decoration: none; font-weight: bold;">🌻 Acknowledgement</a> •
|
| 23 |
+
<a href="#📬Contact" style="text-decoration: none; font-weight: bold;">📬 Contact</a> •
|
| 24 |
+
<a href="#📈star-history" style="text-decoration: none; font-weight: bold;">📈 Star History</a>
|
| 25 |
+
</p>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## 🎉News
|
| 32 |
+
|
| 33 |
+
- **[2025/05/29]** 🎉 Ranked **#1** of the day on [Huggingface Daily Papers](https://huggingface.co/papers?date=2025-05-29).
|
| 34 |
+
- **[2025/05/29]** Released our Paper on arXiv. See [here](https://arxiv.org/pdf/2505.22617). We provide insights into the entropy mechanism of RL for LLMs and propose two simple yet effective strategies to alleviate the entropy collapse.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## ✨Getting started
|
| 39 |
+
|
| 40 |
+
After preparing the training data, for training Qwen2.5-7B on a single node, taking the KL-Cov approach as an example, you can simply run:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
cd verl
|
| 44 |
+
conda activate your_env
|
| 45 |
+
bash recipe/dapo/7b_kl_cov.sh
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
While for training Qwen2.5-32B on multi nodes, you can run the following commands:
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
cd verl
|
| 52 |
+
conda activate your_env
|
| 53 |
+
bash recipe/dapo/32b_kl_cov.sh
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
## 📖Introduction
|
| 57 |
+
|
| 58 |
+
<div align="left">
|
| 59 |
+
<img src="https://github.com/PRIME-RL/Entropy-Mechanism-of-RL/blob/main/figures/e2a.jpg?raw=true" alt="issue" style="width: 96%; height: auto;">
|
| 60 |
+
</div>
|
| 61 |
+
|
| 62 |
+
This paper addresses the entropy collapse issue in scaling reinforcement learning (RL) for large language models (LLMs), where policy entropy drops sharply during training, leading to overconfidence and performance saturation. We empirically establish a relationship between entropy ($H$) and performance ($R$): $R=−aexp(H)+b$, showing performance is bottlenecked by entropy exhaustion.
|
| 63 |
+
|
| 64 |
+
<div align="left">
|
| 65 |
+
<img src="https://github.com/PRIME-RL/Entropy-Mechanism-of-RL/blob/main/figures/cov.jpg?raw=true" alt="issue" style="width: 96%; height: auto;">
|
| 66 |
+
</div>
|
| 67 |
+
|
| 68 |
+
Theoretically, we find entropy changes are driven by the covariance between action probability and logit updates, which correlates with advantage in Policy Gradient methods. High-probability, high-advantage actions reduce entropy, while rare, high-advantage actions increase it. Empirically, the covariance term remains positive, explaining entropy’s monotonic decline. To mitigate this, we propose Clip-Cov and KL-Cov, which restrict updates for high-covariance tokens. These methods effectively prevent entropy collapse, and improve performance.
|
| 69 |
+
|
| 70 |
+
## 📃Evaluation
|
| 71 |
+
|
| 72 |
+
<div align="left">
|
| 73 |
+
<img src="https://github.com/PRIME-RL/Entropy-Mechanism-of-RL/blob/main/figures/performance_fig.jpg?raw=true" alt="issue" style="width: 96%; height: auto;">
|
| 74 |
+
</div>
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
Our method is able to maintain a considerably higher level of entropy throughout training. For example, when the baseline's entropy reaches a plateau and can no longer be consumed, the KL-Cov method still sustains an entropy level over 10 times higher. Meanwhile, the response length of the policy model steadily increases, and its performance on the test set consistently surpasses that of the baseline. This indicates that our model is able to explore more freely during training, learning better policy through RL.
|
| 78 |
+
| **Method** | **AIME24** | **AIME25** | **AMC** | **MATH-500** | **OMNI-MATH** | **OlympiadBench** | **Minerva** | **Avg.** |
|
| 79 |
+
| ----------------- | ---------: | ---------: | -------: | -----------: | ------------: | ----------------: | ----------: | -------: |
|
| 80 |
+
| *Qwen2.5-7B* | | | | | | | | |
|
| 81 |
+
| GRPO | 21.2 | 9.6 | 58.7 | 78.8 | 27.9 | 40.7 | 36.7 | 38.6 |
|
| 82 |
+
| w. Clip-higher | 18.1 | 11.5 | 56.6 | 79.2 | 29.8 | 43.3 | 40.4 | 38.8 |
|
| 83 |
+
| w. **`CLIP-Cov`** | 22.1 | **15.8** | 58.2 | 80.4 | **30.5** | **44.1** | **41.1** | 40.4 |
|
| 84 |
+
| w. **`KL-Cov`** | **22.6** | 12.9 | **61.4** | **80.8** | 29.1 | 42.6 | 38.2 | **40.6** |
|
| 85 |
+
| *Qwen2.5-32B* | | | | | | | | |
|
| 86 |
+
| GRPO | 21.8 | 16.2 | 69.7 | 84.2 | 35.2 | 43.6 | 45.5 | 45.8 |
|
| 87 |
+
| w. Clip-higher | 35.6 | 22.3 | 69.5 | 77.2 | 35.1 | 42.5 | 43.0 | 47.2 |
|
| 88 |
+
| w. **`CLIP-Cov`** | 32.3 | 22.7 | 67.2 | **87.0** | **42.0** | **57.2** | 46.0 | 50.3 |
|
| 89 |
+
| w. **`KL-Cov`** | **36.8** | **30.8** | **74.5** | 84.6 | 39.1 | 49.0 | **46.3** | **52.2** |
|
| 90 |
+
|
| 91 |
+
Our two approaches both achieve non-trivial improvements across all benchmarks. Compared to GRPO, our method outperforms it by 2.0% on average for the 7B model and by 6.4% for the 32B model. Moreover, we observe that our method yields more substantial gains on the larger Qwen2.5-32B. Specifically, our method achieves improvements of 15.0% and 14.6% compared to GRPO on the most challenging benchmarks, AIME24 and AIME25, respectively.
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## 🎈Citation
|
| 95 |
+
If you find this paper or repo helpful, please cite us.
|
| 96 |
+
|
| 97 |
+
```bibtex
|
| 98 |
+
@article{cui2025entropy,
|
| 99 |
+
title={The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models},
|
| 100 |
+
author={Cui, Ganqu and Zhang, Yuchen and Chen, Jiacheng and Yuan, Lifan and Wang, Zhi and Zuo, Yuxin and Li, Haozhan and Fan, Yuchen and Chen, Huayu and Chen, Weize and others},
|
| 101 |
+
journal={arXiv preprint arXiv:2505.22617},
|
| 102 |
+
year={2025}
|
| 103 |
+
}
|
| 104 |
+
```
|
| 105 |
+
## 🌻Acknowledgement
|
| 106 |
+
We implement our reinforcement learning algorithm extending from [verl](https://github.com/volcengine/verl). We utilize [vLLM](https://github.com/vllm-project/vllm) for inference. Our models are trained primarily on [Qwen2.5 family](https://github.com/QwenLM/Qwen2.5). Our training data is built from [DAPO-MATH](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k). Thanks for their great contributions!
|
| 107 |
+
|
| 108 |
+
## 📬 Contact
|
| 109 |
+
|
| 110 |
+
For questions, discussion, or collaboration opportunities, feel free to contact:
|
| 111 |
+
- Ganqu Cui: cuiganqu@pjlab.org.cn
|
| 112 |
+
- Yuchen Zhang: yuchen.zhang2003@gmail.com
|
| 113 |
+
- Jiacheng Chen: jackchan9345@gmail.com
|
| 114 |
+
- Ning Ding: ningding.cs@gmail.com
|
| 115 |
+
|
code/RL_model/verl/verl_train/docs/algo/gpg.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GPG: Group Policy Gradient
|
| 2 |
+
|
| 3 |
+
Last updated: 07/03/2025.
|
| 4 |
+
|
| 5 |
+
Group Policy Gradient (GPG) is a minimalist reinforcement learning (RL) method that enhances the reasoning ability of large language models without relying on supervised fine-tuning or complex tricks. GPG revisits traditional policy gradients and directly optimizes the RL objective—no surrogate losses, no KL penalties, no critic, and no reference model. Compared to GRPO, GPG is simpler, more efficient, and achieves better results on many tasks. For more details, please refer to the original paper [GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
|
| 6 |
+
](https://arxiv.org/abs/2504.02546).
|
| 7 |
+
|
| 8 |
+
## Key Components
|
| 9 |
+
- Use a corrected advantage function to improve policy gradient accuracy and training efficiency.
|
| 10 |
+
- By eliminating the critic and reference models, avoiding KL divergence constraints, significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO)
|
| 11 |
+
|
| 12 |
+
## Configuration
|
| 13 |
+
To configure GPG within the framework, use the following YAML settings.
|
| 14 |
+
|
| 15 |
+
```yaml
|
| 16 |
+
algorithm:
|
| 17 |
+
adv_estimator: gpg
|
| 18 |
+
actor_rollout_ref:
|
| 19 |
+
actor:
|
| 20 |
+
policy_loss:
|
| 21 |
+
loss_mode: "gpg"
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
## Advanced Extensions
|
| 25 |
+
GPG is a simple and strong baseline for model reasoning. Although it avoids using KL loss in its original form, you can still use KL loss to further improve the performance.
|
| 26 |
+
|
| 27 |
+
```yaml
|
| 28 |
+
algorithm:
|
| 29 |
+
adv_estimator: gpg
|
| 30 |
+
actor_rollout_ref:
|
| 31 |
+
actor:
|
| 32 |
+
use_kl_loss: True # enable kl regularization
|
| 33 |
+
kl_loss_coef: 0.01
|
| 34 |
+
policy_loss:
|
| 35 |
+
loss_mode: "gpg"
|
| 36 |
+
```
|
code/RL_model/verl/verl_train/docs/algo/grpo.md
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Group Relative Policy Optimization (GRPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 05/31/2025.
|
| 4 |
+
|
| 5 |
+
In reinforcement learning, classic algorithms like PPO rely on a "critic" model to estimate the value of actions, guiding the learning process. However, training this critic model can be resource-intensive.
|
| 6 |
+
|
| 7 |
+
GRPO simplifies this process by eliminating the need for a separate critic model. Instead, it operates as follows:
|
| 8 |
+
- Group Sampling: For a given problem, the model generates multiple possible solutions, forming a "group" of outputs.
|
| 9 |
+
- Reward Assignment: Each solution is evaluated and assigned a reward based on its correctness or quality.
|
| 10 |
+
- Baseline Calculation: The average reward of the group serves as a baseline.
|
| 11 |
+
- Policy Update: The model updates its parameters by comparing each solution's reward to the group baseline, reinforcing better-than-average solutions and discouraging worse-than-average ones.
|
| 12 |
+
|
| 13 |
+
This approach reduces computational overhead by avoiding the training of a separate value estimation model, making the learning process more efficient. For more details, refer to the original paper [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://arxiv.org/pdf/2402.03300)
|
| 14 |
+
|
| 15 |
+
## Key Components
|
| 16 |
+
|
| 17 |
+
- No Value Function (Critic-less): unlike PPO, GRPO does not train a separate value network (critic)
|
| 18 |
+
- Group Sampling (Grouped Rollouts): instead of evaluating one rollout per input, GRPO generates multiple completions (responses) from the current policy for each prompt. This set of completions is referred to as a group.
|
| 19 |
+
- Relative Rewards: within each group, completions are scored (e.g., based on correctness), and rewards are normalized relative to the group.
|
| 20 |
+
|
| 21 |
+
## Configuration
|
| 22 |
+
|
| 23 |
+
Note that all configs containing `micro_batch_size` are used to configure the maximum sample or token count per forward or backward pass to avoid GPU OOMs, whose value should not change algorithmic/convergence behavior.
|
| 24 |
+
|
| 25 |
+
Despite that many configurations start with the `ppo_` prefix, they work across different RL algorithms in verl, as the GRPO training loop is similar to that of PPO (without critic).
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
- `actor_rollout.ref.rollout.n`: For each prompt, sample n times. Default to 1. For GRPO, please set it to a value larger than 1 for group sampling.
|
| 30 |
+
|
| 31 |
+
- `data.train_batch_size`: The global batch size of prompts used to generate a set of sampled trajectories/rollouts. The number of responses/trajectories is `data.train_batch_size * actor_rollout.ref.rollout.n`
|
| 32 |
+
|
| 33 |
+
- `actor_rollout_ref.actor.ppo_mini_batch_size`: The set of sampled trajectories is split into multiple mini-batches with batch_size=ppo_mini_batch_size for PPO actor updates. The ppo_mini_batch_size is a global size across all workers.
|
| 34 |
+
|
| 35 |
+
- `actor_rollout_ref.actor.ppo_epochs`: Number of epochs for GRPO updates on one set of sampled trajectories for actor
|
| 36 |
+
|
| 37 |
+
- `actor_rollout_ref.actor.clip_ratio`: The GRPO clip range. Default to 0.2
|
| 38 |
+
|
| 39 |
+
- `algorithm.adv_estimator`: Default is gae. Please set it to grpo instead
|
| 40 |
+
|
| 41 |
+
- `actor_rollout_ref.actor.loss_agg_mode`: Default is "token-mean". Options include "token-mean", "seq-mean-token-sum", "seq-mean-token-mean". The original GRPO paper takes the sample-level loss (seq-mean-token-mean), which may be unstable in long-CoT scenarios. All GRPO example scripts provided in verl uses the default configuration "token-mean" for loss aggregation instead.
|
| 42 |
+
|
| 43 |
+
Instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss:
|
| 44 |
+
|
| 45 |
+
- `actor_rollout_ref.actor.use_kl_loss`: To use kl loss in the actor. When used, we are not applying KL in the reward function. Default is False. Please set it to True for GRPO.
|
| 46 |
+
|
| 47 |
+
- `actor_rollout_ref.actor.kl_loss_coef`: The coefficient of kl loss. Default is 0.001.
|
| 48 |
+
|
| 49 |
+
- `actor_rollout_ref.actor.kl_loss_type`: Support kl(k1), abs, mse(k2), low_var_kl(k3) and full. Appending "+" in the end (e.g., 'k1+' and 'k3+') would apply straight through to employ k2 for unbiased gradient estimation, regardless of the kl value estimation (see https://github.com/volcengine/verl/pull/2953#issuecomment-3162113848 for more details). How to calculate the kl divergence between actor and reference policy. See this blog post for detailed analysis: http://joschu.net/blog/kl-approx.html
|
| 50 |
+
|
| 51 |
+
## Advanced Extensions
|
| 52 |
+
|
| 53 |
+
### DrGRPO
|
| 54 |
+
|
| 55 |
+
[Understanding R1-Zero-Like Training: A Critical Perspective](https://arxiv.org/pdf/2503.20783) claims there's optimization bias in GRPO, which leads to artificially longer responses, especially for incorrect outputs. This inefficiency stems from the way GRPO calculates advantages using group-based reward normalization. Instead, DrGRPO aggregates token-level losses by normalizing with a global constant to eliminate length bias.
|
| 56 |
+
|
| 57 |
+
Configure the following to enable DrGRPO, with all other parameters the same as GRPO's:
|
| 58 |
+
|
| 59 |
+
- `actor_rollout_ref.actor.loss_agg_mode`: "seq-mean-token-sum-norm", which turns off seq-dim averaging
|
| 60 |
+
- `actor_rollout_ref.actor.loss_scale_factor`: (Optional) Set to a constant integer (e.g., max response length) to ensure consistent normalization throughout training. If not set, uses the current batch's response length.
|
| 61 |
+
- `actor_rollout_ref.actor.use_kl_loss`: Please set it to False for DrGRPO
|
| 62 |
+
- `algorithm.norm_adv_by_std_in_grpo`: False, which turns off standard deviation norm
|
| 63 |
+
|
| 64 |
+
## Reference Example
|
| 65 |
+
|
| 66 |
+
Qwen2.5 GRPO training log and commands: [link](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/qwen2-7b-fsdp2.log)
|
| 67 |
+
|
| 68 |
+
```bash
|
| 69 |
+
bash examples/grpo_trainer/run_qwen3-8b.sh
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
For more reference performance, please see https://verl.readthedocs.io/en/latest/algo/baseline.html
|
code/RL_model/verl/verl_train/docs/algo/opo.md
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# On-Policy RL with Optimal Reward Baseline (OPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 06/02/2025.
|
| 4 |
+
|
| 5 |
+
Loose on-policy constraints and suboptimal baselines in reinforcement learning often lead to training instability such as large policy shifts and entropy collapse. OPO addresses these challenges by using exact on-policy training with the theretically optimal reward baseline for advantage estimation. It achieves lower policy shifts and higher output entropy, encouraging more diverse and less repetitive responses.
|
| 6 |
+
|
| 7 |
+
OPO uses group sampling to generate multiple outputs for each input like GRPO. Unlike group-based algorithms which typically use the mean reward of a group as its baseline, OPO employs a theoretically optimal baseline: the length-weighted reward of the group. It also omits the standard deviation normalization. By adopting these two key components, OPO enables the training of a single policy model with the objective of maximizing only the expected reward. For more detailes, refer to the original paper [On-Policy RL with Optimal Reward Baseline](https://arxiv.org/pdf/2505.23585).
|
| 8 |
+
|
| 9 |
+
## Key Components
|
| 10 |
+
|
| 11 |
+
- Exact On-Policy Training: always generates responses from the current policy, without using any pre-generated data or off-policy data.
|
| 12 |
+
- Optimal Reward Baseline: uses a length-weighted reward of the group as the baseline for normalizing the rewards.
|
| 13 |
+
|
| 14 |
+
## Configuration
|
| 15 |
+
|
| 16 |
+
To configure OPO within the framework, use the following YAML settings. These parameters are crucial for enabling exact on-policy training and activating the optimal reward baseline.
|
| 17 |
+
|
| 18 |
+
```yaml
|
| 19 |
+
algorithm:
|
| 20 |
+
adv_estimator: opo # Use OPO for optimal reward baseline
|
| 21 |
+
data:
|
| 22 |
+
train_batch_size: 1024
|
| 23 |
+
actor_rollout_ref:
|
| 24 |
+
actor:
|
| 25 |
+
ppo_mini_batch_size: 1024 # ppo_mini_batch_size should equal to train_batch_size to enable exact on-policy training
|
| 26 |
+
entropy_coeff: 0 # disable entropy regularization
|
| 27 |
+
use_kl_loss: False # disable kl regularization
|
| 28 |
+
kl_loss_coef: 0
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Advanced Extensions
|
| 32 |
+
|
| 33 |
+
OPO can also be extended to other algorithms like RLOO and Reinforce++. It just needs to adjust their configurations to enable exact on-policy training and incorporate the optimal length-weighted reward baseline with minimal modifications to their advantage estimation functions.
|
code/RL_model/verl/verl_train/docs/algo/otb.md
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Optimal Token Baseline (OTB)
|
| 2 |
+
|
| 3 |
+
Last updated: 12/25/2025.
|
| 4 |
+
|
| 5 |
+
Optimal Token Baseline (OTB) is dynamic token-level baseline for variance reduction. It weights updates based on "Realized Energy"—essentially, how much uncertainty has accumulated up to that specific token. It downweights the noisy parts and trusts the clear signals. Read [Optimal Token Baseline blog](https://richardli.xyz/optimal-token-baseline) for more details.
|
| 6 |
+
|
| 7 |
+
## The method: OTB
|
| 8 |
+
|
| 9 |
+
- OTB builds a _dynamic_ baseline that adapts to each token by tracking the “Realized Energy”—the uncertainty that has accumulated up to that token. It downweights the noisy parts and trusts the clear signals.
|
| 10 |
+
- Unlike standard group means (which average over the padding `EOS` token ineffectively), OTB handles this naturally by computing baselines only over valid tokens.
|
| 11 |
+
|
| 12 |
+
## Logit-Gradient Proxy
|
| 13 |
+
|
| 14 |
+
- Computing true uncertainty requires expensive backward passes (calculating gradient norms per token). Instead, OTB introduces the **Logit-Gradient Proxy**: the realized energy can be estimated entirely from forward probabilities.
|
| 15 |
+
- This means zero extra backward calls and effectively no additional runtime overhead.
|
| 16 |
+
|
| 17 |
+
## Mechanics at a glance
|
| 18 |
+
|
| 19 |
+
For each prompt group of size `N`, OTB computes rewards-to-go `G_t` and cumulative variance weights `W_t`. The optimal baseline per token is
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
B*_t = (Σ_i G_t^{(i)} · W_t^{(i)}) / (Σ_i W_t^{(i)} + ε),
|
| 23 |
+
W_t = Σ_{j=1}^t (1 - 2π_j + Σπ_j²),
|
| 24 |
+
Σπ_j² = exp(logsumexp(2·logits_j) - 2·logsumexp(logits_j)).
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
The final advantage is `(G_t - B*_t) · mask_t`, so padding tokens stay at zero.
|
| 28 |
+
|
| 29 |
+
## Integration in VERL
|
| 30 |
+
|
| 31 |
+
- `AdvantageEstimator.OPTIMAL_TOKEN_BASELINE` registers `compute_optimal_token_baseline_advantage`, invoked whenever `algorithm.adv_estimator` is set to `optimal_token_baseline`.
|
| 32 |
+
- `ActorRolloutRefWorker.compute_log_prob` emits an additional tensor `sum_pi_squared` (Σπ² per token) when `actor.calculate_sum_pi_squared=True`. This requires disabling fused log-prob kernels, because they do not surface logits.
|
| 33 |
+
- Trainers assert `sum_pi_squared` exists, regroup trajectories by `non_tensor_batch["uid"]`, and run the OTB calculation. If rollout IS is active, they rescale the weights by `rollout_is_weights**2` before aggregating.
|
| 34 |
+
- In Ulysses sequence-parallel setups, the actor gathers, unpads, and returns Σπ² in the same way it handles log-probabilities, so OTB supports sharded sequence-parallel models out of the box.
|
| 35 |
+
- `sum_pi_squared_checkpointing` is available to trade compute for memory when Σπ² tensors become large (e.g., lengthy chain-of-thought reasoning).
|
| 36 |
+
|
| 37 |
+
## Configuration checklist
|
| 38 |
+
|
| 39 |
+
- `actor_rollout_ref.actor.calculate_sum_pi_squared: true` (mandatory).
|
| 40 |
+
- `actor_rollout_ref.model.use_fused_kernels: false` (required until fused kernels emit logits).
|
| 41 |
+
- `algorithm.adv_estimator: optimal_token_baseline`.
|
| 42 |
+
- Group sampling (`actor_rollout_ref.rollout.n > 1`) to unlock OTB’s variance reduction; with `n=1` the baseline collapses to returns.
|
| 43 |
+
|
| 44 |
+
Example OmegaConf overlay:
|
| 45 |
+
|
| 46 |
+
```yaml
|
| 47 |
+
algorithm:
|
| 48 |
+
adv_estimator: optimal_token_baseline
|
| 49 |
+
|
| 50 |
+
actor_rollout_ref:
|
| 51 |
+
actor:
|
| 52 |
+
calculate_sum_pi_squared: true
|
| 53 |
+
sum_pi_squared_checkpointing: false # optional memory saver
|
| 54 |
+
rollout:
|
| 55 |
+
n: 8
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
## Example script
|
| 59 |
+
|
| 60 |
+
- `examples/otb_trainer/run_qwen2_5-7b.sh`.
|
| 61 |
+
|
| 62 |
+
## Gradient Variance Proxy Metrics
|
| 63 |
+
|
| 64 |
+
All gradient-variance analysis in the Optimal Token Baseline work starts from the variance identity
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
Var(ĝ) = E[||ĝ||²] - ||E[ĝ]||²,
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
which states that the variance of any stochastic gradient equals the mean squared magnitude minus the squared norm of its expectation.
|
| 71 |
+
|
| 72 |
+
For a trajectory `τ`, the policy-gradient estimator is
|
| 73 |
+
|
| 74 |
+
```
|
| 75 |
+
ĝ(τ) = ∇ log π_θ(τ) · A(τ), A(τ) = R(τ) - B.
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
The logit-gradient proxy approximates the squared gradient norm without an extra backward pass:
|
| 79 |
+
|
| 80 |
+
```
|
| 81 |
+
||ĝ(τ)||² ≈ Ŵ(τ) · A(τ)²,
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
where `Ŵ(τ)` is the realized energy built. Given a mini-batch `{τ_i}` of size `N`, we decompose its statistics into three diagnostics:
|
| 85 |
+
|
| 86 |
+
- **Signal strength (squared norm of the mean gradient)**
|
| 87 |
+
```
|
| 88 |
+
S = || (1/N) · Σ ĝ(τ_i) ||²
|
| 89 |
+
```
|
| 90 |
+
- **Total power (signal + noise)**
|
| 91 |
+
```
|
| 92 |
+
P_total = (1/N) · Σ Ŵ(τ_i) · A(τ_i)²
|
| 93 |
+
```
|
| 94 |
+
- **Pure noise (estimated variance of the batch mean)**
|
| 95 |
+
```
|
| 96 |
+
Var_proxy = (1/(N-1)) · (P_total - S)
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
`verl/trainer/ppo/metric_utils.py#L306` implements these diagnostics via `compute_variance_proxy_metrics`, emitting
|
| 100 |
+
`variance_proxy/proxy1_signal_strength`,
|
| 101 |
+
`variance_proxy/proxy2_total_power`, and
|
| 102 |
+
`variance_proxy/proxy3_pure_noise`.
|
| 103 |
+
|
| 104 |
+
Tracking these metrics provides a forward-only, low-overhead view of gradient health for any advantage estimator that supplies `sum_pi_squared`.
|
code/RL_model/verl/verl_train/docs/algo/ppo.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Proximal Policy Optimization (PPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 06/19/2025.
|
| 4 |
+
|
| 5 |
+
Proximal Policy Optimization (PPO) is a family of policy gradient methods for reinforcement learning, proposed by OpenAI in 2017. PPO strikes a balance between simplicity, stability, and performance, making it one of the most widely used algorithms in modern RL applications, including large-scale language model fine-tuning.
|
| 6 |
+
|
| 7 |
+
Traditional policy gradient methods like REINFORCE or Vanilla Policy Gradient suffer from:
|
| 8 |
+
|
| 9 |
+
- High variance and sample inefficiency.
|
| 10 |
+
- Instability due to large policy updates.
|
| 11 |
+
|
| 12 |
+
PPO addresses this problem using a clipped surrogate objective that avoids overly large updates without requiring second-order derivatives.
|
| 13 |
+
|
| 14 |
+
For more technical details regarding PPO, we suggest reading the introduction in the [OpenAI spinning up tutorial](https://spinningup.openai.com/en/latest/algorithms/ppo.html), and the paper [Proximal Policy Optimization Algorithms](https://arxiv.org/abs/1707.06347).
|
| 15 |
+
|
| 16 |
+
## Key Components
|
| 17 |
+
|
| 18 |
+
- Actor-Critic Architecture: PPO requires both an actor model (policy) and a critic model (value function). This differs from other algorithms like GRPO and RLOO that don't require a critic model.
|
| 19 |
+
|
| 20 |
+
- Generalized Advantage Estimation (GAE): PPO uses GAE for computing advantage values, which helps reduce variance in policy gradient estimates while maintaining low bias.
|
| 21 |
+
|
| 22 |
+
- Clipped Surrogate Objective: The core of PPO is implemented through the clipped surrogate objective function that limits policy updates.
|
| 23 |
+
|
| 24 |
+
## Configuration
|
| 25 |
+
|
| 26 |
+
Note that all configs containing `micro_batch_size` are used to configure the maximum sample or token count per forward or backward pass to avoid GPU OOMs, whose value should not change algorithmic/convergence behavior.
|
| 27 |
+
|
| 28 |
+
Most critic configs are similar to those of actors. Note that the critic model is omitted from the figure below.
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
- `data.train_batch_size`: The global batch size of prompts used to generate a set of sampled trajectories/rollouts. The number of responses/trajectories is `data.train_batch_size * actor_rollout.ref.rollout.n`
|
| 33 |
+
|
| 34 |
+
- `actor_rollout_ref.actor.ppo_mini_batch_size`: The set of sampled trajectories is split into multiple mini-batches with batch_size=ppo_mini_batch_size for PPO actor updates. The ppo_mini_batch_size is a global size across all workers
|
| 35 |
+
|
| 36 |
+
- `critic.ppo_mini_batch_size`: The set of sampled trajectories is split into multiple mini-batches with batch_size=ppo_mini_batch_size for PPO critic updates. The ppo_mini_batch_size is a global size across all workers
|
| 37 |
+
|
| 38 |
+
- `actor_rollout_ref.actor.clip_ratio`: The PPO clip range. Default to 0.2
|
| 39 |
+
|
| 40 |
+
- `actor_rollout_ref.actor.ppo_epochs`: Number of epochs for PPO updates on one set of sampled trajectories for actor
|
| 41 |
+
|
| 42 |
+
- `critic.ppo_epochs`: Number of epochs for PPO updates on one set of sampled trajectories for critic. Defaults to `actor_rollout_ref.actor.ppo_epochs`
|
| 43 |
+
|
| 44 |
+
- `algorithm.gemma`: discount factor
|
| 45 |
+
|
| 46 |
+
- `algorithm.lam`: The lambda term that trades off between bias and variance in the GAE estimator
|
| 47 |
+
|
| 48 |
+
- `algorithm.adv_estimator`: Support gae, grpo, reinforce_plus_plus, reinforce_plus_plus_baseline, rloo
|
| 49 |
+
|
| 50 |
+
## Advanced Extensions
|
| 51 |
+
|
| 52 |
+
### KL Divergence Control
|
| 53 |
+
|
| 54 |
+
Options to prevent the policy from diverging too far from a reference policy. Two mechanisms are available: KL reward penalty and KL loss. For more technical details, see [Training language models to follow instructions with human feedback](https://arxiv.org/abs/2203.02155)
|
| 55 |
+
|
| 56 |
+
Options to use KL loss for KL divergence control:
|
| 57 |
+
|
| 58 |
+
- `actor_rollout_ref.actor.use_kl_loss`: to use kl loss in the actor. When used, we are not applying KL in the reward function. Default is False
|
| 59 |
+
|
| 60 |
+
- `actor_rollout_ref.actor.kl_loss_coef`: The coefficient of kl loss. Default is 0.001.
|
| 61 |
+
|
| 62 |
+
- `actor_rollout_ref.actor.kl_loss_type`: Support kl(k1), abs, mse(k2), low_var_kl(k3) and full. Appending "+" in the end (e.g., 'k1+' and 'k3+') would apply straight through to employ k2 for unbiased gradient estimation, regardless of the kl value estimation (see https://github.com/volcengine/verl/pull/2953#issuecomment-3162113848 for more details). How to calculate the kl divergence between actor and reference policy. See this blog post for detailed analysis: http://joschu.net/blog/kl-approx.html
|
| 63 |
+
|
| 64 |
+
Options to use KL penalty in the reward:
|
| 65 |
+
|
| 66 |
+
- `algorithm.use_kl_in_reward`: Whether to enable in-reward kl penalty. Default is False.
|
| 67 |
+
|
| 68 |
+
- `algorithm.kl_penalty`: Support kl(k1), abs, mse(k2), low_var_kl(k3) and full. This defines the way to calculate the kl divergence between actor and reference policy. For specific options, refer to `kl_penalty` in core_algos.py. See this blog post for detailed analysis: http://joschu.net/blog/kl-approx.html
|
| 69 |
+
|
| 70 |
+
- `algorithm.kl_ctrl.kl_coef`: The (initial) coefficient of in-reward kl_penalty. Default is 0.001.
|
| 71 |
+
- `algorithm.kl_ctrl.type`: 'fixed' for FixedKLController and 'adaptive' for AdaptiveKLController.
|
| 72 |
+
- `algorithm.kl_ctrl.horizon`: See source code of AdaptiveKLController for details.
|
| 73 |
+
- `algorithm.kl_ctrl.target_kl`: See source code of AdaptiveKLController for details.
|
| 74 |
+
|
| 75 |
+
### Dual-clip PPO
|
| 76 |
+
|
| 77 |
+
The Dual-Clip PPO introduces a approach by applying a lower bound to the policy ratio when the advantage is less than zero, when multiplied by a large raito, does not exceed a specified lower bound.
|
| 78 |
+
|
| 79 |
+

|
| 80 |
+
|
| 81 |
+
- `actor_rollout_ref.actor.clip_ratio_c`: lower bound of the value for Dual-clip PPO, defaults to 3.0
|
| 82 |
+
|
| 83 |
+
## Reference Example
|
| 84 |
+
|
| 85 |
+
Qwen2.5 training log and commands: [link](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log)
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
bash run_gemma.sh
|
| 89 |
+
trainer.n_gpus_per_node=1 \
|
| 90 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
|
| 91 |
+
trainer.logger=console \
|
| 92 |
+
critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \
|
| 93 |
+
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
|
| 94 |
+
data.train_batch_size=256 \
|
| 95 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 96 |
+
actor_rollout_ref.actor.ppo_micro_batch_size=2 \
|
| 97 |
+
critic.ppo_micro_batch_size=2
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
Reference performance with verl v0.2:
|
| 101 |
+
|
| 102 |
+
| Model | Method | Score | Link |
|
| 103 |
+
|-------------------------------|------------------|-------|------------------------------------------------------------------------------------------------|
|
| 104 |
+
| Qwen/Qwen2.5-0.5B-Instruct | pretrained model | 36.4 | [Qwen Blog](https://qwenlm.github.io/blog/qwen2.5-llm/) |
|
| 105 |
+
| Qwen/Qwen2.5-0.5B-Instruct | PPO | 56.7 | [PPO Command and Logs](https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log) |
|
code/RL_model/verl/verl_train/docs/algo/rollout_corr.md
ADDED
|
@@ -0,0 +1,1313 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Rollout Correction
|
| 2 |
+
|
| 3 |
+
**Author:** [Yingru Li](https://richardli.xyz/)
|
| 4 |
+
|
| 5 |
+
Last updated: 10/30/2025.
|
| 6 |
+
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
> **📖 Documentation Structure**
|
| 10 |
+
>
|
| 11 |
+
> - **This document** - Practical usage guide: configurations, presets, troubleshooting
|
| 12 |
+
> - **[Mathematical Formulations](rollout_corr_math.md)** - Theoretical foundations, derivations, and algorithmic details
|
| 13 |
+
>
|
| 14 |
+
> Start here for implementation, refer to the math doc for theory and design rationale.
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
This document provides a comprehensive overview of the Rollout Correction implementation in verl.
|
| 19 |
+
|
| 20 |
+
**Note on Naming**: This feature is called "Rollout Correction" to reflect the complete functionality: importance sampling (IS) weights and rejection sampling (RS). The internal variable `rollout_is_weights` retains its name as it specifically refers to the IS weights component.
|
| 21 |
+
|
| 22 |
+
### BibTeX Citation
|
| 23 |
+
|
| 24 |
+
```bibtex
|
| 25 |
+
@online{liu-li-2025-rl-collapse,
|
| 26 |
+
title = {When Speed Kills Stability: Demystifying {RL} Collapse from the Training-Inference Mismatch},
|
| 27 |
+
author = {Liu, Jiacai and Li, Yingru and Fu, Yuqian and Wang, Jiawei and Liu, Qian and Shen, Yu},
|
| 28 |
+
year = {2025},
|
| 29 |
+
month = sep,
|
| 30 |
+
url = {https://richardli.xyz/rl-collapse}
|
| 31 |
+
}
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
### Blog Series
|
| 35 |
+
|
| 36 |
+
- Main blog post: https://richardli.xyz/rl-collapse
|
| 37 |
+
- [Part 1: Why Mismatch Breaks LLM-RL](https://richardli.xyz/rl-collapse-1) (analytical framework using TV distance for bias and χ²-divergence for variance)
|
| 38 |
+
- [Part 2: The Gradient Estimator Trials](https://richardli.xyz/rl-collapse-2) (token-level vs sequence-level correction bias-variance tradeoff)
|
| 39 |
+
- [Part 3: When Math Meets Reality—Toxic Tails and Length Traps](https://richardli.xyz/rl-collapse-3) (why rejection over clipping, and geometric-level RS)
|
| 40 |
+
|
| 41 |
+
## Overview
|
| 42 |
+
|
| 43 |
+
Rollout Correction provides a unified framework to handle **general off-policy problems** in RL training. Any scenario where the data collection distribution differs from the training distribution can benefit from these methods.
|
| 44 |
+
|
| 45 |
+
**Common off-policy scenarios:**
|
| 46 |
+
|
| 47 |
+
1. **Policy Mismatch** (Implementation Differences)
|
| 48 |
+
|
| 49 |
+
- Different precision: FP8 vs FP16 vs BF16 vs FP32
|
| 50 |
+
- Different backends: vLLM vs SGLang vs FSDP vs Megatron
|
| 51 |
+
- Different implementations even with identical weights
|
| 52 |
+
|
| 53 |
+
2. **Temporal Lag** (Model Staleness)
|
| 54 |
+
|
| 55 |
+
- Rollout uses older checkpoint while training has progressed
|
| 56 |
+
- Asynchronous rollout workers with stale parameters
|
| 57 |
+
- Common in distributed/async RL systems
|
| 58 |
+
|
| 59 |
+
3. **Replay Buffers**
|
| 60 |
+
|
| 61 |
+
- Training on historical trajectories from earlier iterations
|
| 62 |
+
- Experience replay from different policy versions
|
| 63 |
+
- Data augmentation or resampling strategies
|
| 64 |
+
|
| 65 |
+
4. **Off-Policy Algorithms**
|
| 66 |
+
|
| 67 |
+
- Behavioral cloning from expert demonstrations
|
| 68 |
+
- DAPO (data from auxiliary policies)
|
| 69 |
+
- Any algorithm using trajectories from a different policy
|
| 70 |
+
|
| 71 |
+
5. **Data Quality Filtering**
|
| 72 |
+
- Reweighting or filtering collected data
|
| 73 |
+
- Preference learning with modified distributions
|
| 74 |
+
- Curriculum learning with distribution shifts
|
| 75 |
+
|
| 76 |
+
These off-policy gaps can cause training instability and policy collapse. Rollout Correction uses importance sampling (IS) weights and rejection sampling (RS) to correct for any distribution shift between data collection and training.
|
| 77 |
+
|
| 78 |
+
**Important Note on Common Implementation Mistakes:**
|
| 79 |
+
|
| 80 |
+
Many LLM-RL implementations incorrectly apply PPO by **ignoring the actual rollout policy** π_rollout and assuming the training reference policy π_old is the behavior policy. This is mathematically incorrect when π_rollout ≠ π_old (which is typical in LLM-RL due to precision/backend differences between rollout and training).
|
| 81 |
+
|
| 82 |
+
**This is not PPO's fault** - PPO itself is mathematically correct. The issue is the incorrect assumption that π_old = π_rollout in naive implementations.
|
| 83 |
+
|
| 84 |
+
This critical implementation mistake that leads to RL training collapse was identified in the blog post ["When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch"](https://richardli.xyz/rl-collapse) and motivated the development of this rollout correction framework.
|
| 85 |
+
|
| 86 |
+
**Mathematically correct approaches:**
|
| 87 |
+
|
| 88 |
+
- **Decoupled mode**: Three policies (π*rollout, π_old, π*θ) with IS correction from π_rollout to π_old
|
| 89 |
+
- **Bypass mode**: Two policies (π*rollout = π_old, π*θ) using actual rollout policy as PPO anchor
|
| 90 |
+
- **Bypass + Policy Gradient mode**: Two policies (π*rollout, π*θ) with IS/RS correction and no PPO clipping
|
| 91 |
+
|
| 92 |
+
See [Mathematical Formulations](rollout_corr_math.md#38-common-implementation-mistake) for detailed explanation.
|
| 93 |
+
|
| 94 |
+
### Key Design Principle: Separation of IS Weights and Rejection Sampling
|
| 95 |
+
|
| 96 |
+
The implementation cleanly separates two orthogonal mechanisms:
|
| 97 |
+
|
| 98 |
+
1. **IS Weights** (`rollout_is_weights`): Continuous reweighting for gradient correction
|
| 99 |
+
|
| 100 |
+
- Policy ratio: π*old/π_rollout (decoupled) or π*θ/π_rollout (bypass)
|
| 101 |
+
- **Safety-bounded**: Clamped to [exp(-20), exp(20)] ≈ [2e-9, 5e8] to prevent overflow
|
| 102 |
+
- Token level: Bounds per-token ratios
|
| 103 |
+
- Sequence level: Bounds product of ratios (broadcast to all tokens)
|
| 104 |
+
- **Truncated**: Upper clamped via `.clamp(max=rollout_is_threshold)` (TIS: Truncated Importance Sampling)
|
| 105 |
+
- **Zeroed at padding**: Multiplied by response_mask to zero out padding positions
|
| 106 |
+
- Used to weight policy gradients (variance reduction)
|
| 107 |
+
|
| 108 |
+
2. **Rejection Sampling** (`modified_response_mask`): Binary filtering for outlier exclusion
|
| 109 |
+
- Creates binary mask: 1 = keep, 0 = reject
|
| 110 |
+
- Rejects tokens/sequences with IS ratios outside [lower_threshold, upper_threshold]
|
| 111 |
+
- Modifies response_mask to exclude rejected samples from training
|
| 112 |
+
- Used for loss aggregation (rejected samples don't contribute to gradients)
|
| 113 |
+
|
| 114 |
+
This separation ensures:
|
| 115 |
+
|
| 116 |
+
- ✅ IS weights provide continuous reweighting (reduce variance)
|
| 117 |
+
- ✅ Rejection sampling provides hard filtering (remove extreme outliers)
|
| 118 |
+
- ✅ Both mechanisms can be enabled independently or together
|
| 119 |
+
- ✅ Safety bounds prevent numerical overflow in all cases
|
| 120 |
+
|
| 121 |
+
## Quick Start: Using Verified Presets
|
| 122 |
+
|
| 123 |
+
**NEW**: We now provide typed configuration with verified presets for common scenarios. These presets have been validated with tens of thousands of GPU hours across various models and training scenarios.
|
| 124 |
+
|
| 125 |
+
### Python API
|
| 126 |
+
|
| 127 |
+
```python
|
| 128 |
+
from verl.trainer.config.algorithm import RolloutCorrectionConfig
|
| 129 |
+
|
| 130 |
+
# === Decoupled PPO mode (3 policies: π_rollout, π_old, π_θ) ===
|
| 131 |
+
# IS weights correct for gap between π_old and π_rollout
|
| 132 |
+
config = RolloutCorrectionConfig.decoupled_token_is() # Token-TIS
|
| 133 |
+
config = RolloutCorrectionConfig.decoupled_seq_is() # Seq-TIS
|
| 134 |
+
config = RolloutCorrectionConfig.decoupled_seq_is_rs() # Seq-MIS
|
| 135 |
+
config = RolloutCorrectionConfig.decoupled_geo_rs() # Geo-RS (ratio mode)
|
| 136 |
+
config = RolloutCorrectionConfig.decoupled_geo_rs_token_tis() # Geo-RS + Token-TIS
|
| 137 |
+
|
| 138 |
+
# === K3 KL Estimator presets (more stable for small KL) ===
|
| 139 |
+
config = RolloutCorrectionConfig.decoupled_k3_rs() # K3-RS only
|
| 140 |
+
config = RolloutCorrectionConfig.decoupled_k3_rs_token_tis() # K3-RS + Token-TIS
|
| 141 |
+
|
| 142 |
+
# === Bypass PPO mode (2 policies: π_rollout = π_old, π_θ) - fast ===
|
| 143 |
+
# PPO ratio handles IS, so no explicit IS weights needed
|
| 144 |
+
config = RolloutCorrectionConfig.bypass_ppo_clip() # PPO-clip only
|
| 145 |
+
config = RolloutCorrectionConfig.bypass_ppo_clip_geo_rs() # PPO-clip + Geo-RS (ratio)
|
| 146 |
+
config = RolloutCorrectionConfig.bypass_ppo_clip_k3_rs() # PPO-clip + K3-RS
|
| 147 |
+
|
| 148 |
+
# === Bypass PG mode (2 policies, no PPO clipping) - fast ===
|
| 149 |
+
# IS weights computed on-the-fly as π_θ / π_rollout
|
| 150 |
+
config = RolloutCorrectionConfig.bypass_pg_is() # Seq-TIS + PG
|
| 151 |
+
config = RolloutCorrectionConfig.bypass_pg_geo_rs() # Geo-RS + PG (ratio)
|
| 152 |
+
config = RolloutCorrectionConfig.bypass_pg_geo_rs_token_tis() # Geo-RS + Token-TIS + PG
|
| 153 |
+
|
| 154 |
+
# === Other ===
|
| 155 |
+
config = RolloutCorrectionConfig.disabled() # Metrics only (no correction)
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
### YAML Configuration (Advanced)
|
| 159 |
+
|
| 160 |
+
For advanced customization or YAML-based configs:
|
| 161 |
+
|
| 162 |
+
```yaml
|
| 163 |
+
algorithm:
|
| 164 |
+
rollout_correction:
|
| 165 |
+
rollout_is: token # IS weights: "token", "sequence", or null
|
| 166 |
+
rollout_is_threshold: 2.0 # Upper threshold for IS weights
|
| 167 |
+
rollout_is_batch_normalize: false # Batch normalize IS weights to mean=1.0
|
| 168 |
+
rollout_rs: null # Rejection sampling: comma-separated canonical options (e.g. "token_k1,seq_max_k2")
|
| 169 |
+
rollout_rs_threshold: null # Threshold spec: float(s) or "lower_upper" string(s)
|
| 170 |
+
bypass_mode: false # Skip old_log_prob computation (sets π_old = π_rollout)
|
| 171 |
+
loss_type: ppo_clip # Loss type in bypass mode: "ppo_clip" (default) or "reinforce"
|
| 172 |
+
|
| 173 |
+
# REQUIRED: Enable log prob calculation
|
| 174 |
+
actor_rollout_ref:
|
| 175 |
+
rollout:
|
| 176 |
+
calculate_log_probs: true
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
## Files
|
| 180 |
+
|
| 181 |
+
### **Core Implementation**
|
| 182 |
+
|
| 183 |
+
- `verl/trainer/ppo/rollout_corr_helper.py` - Contains `compute_rollout_correction_and_rejection_mask()` and `compute_offpolicy_metrics()`
|
| 184 |
+
- `verl/trainer/ppo/core_algos.py` - Rollout Correction integration with PPO and REINFORCE modes (`compute_policy_loss_bypass_mode()`, `compute_policy_loss_reinforce()`)
|
| 185 |
+
- `verl/trainer/ppo/ray_trainer.py` - Bypass mode implementation (skips `old_log_prob` computation)
|
| 186 |
+
- `verl/workers/actor/dp_actor.py` - Mode selection logic and metrics collection
|
| 187 |
+
|
| 188 |
+
### **Configuration Files**
|
| 189 |
+
|
| 190 |
+
- `verl/trainer/config/algorithm.py` - Rollout Correction parameters in `AlgoConfig`
|
| 191 |
+
- `verl/workers/config/actor.py` - Rollout Correction parameters in `ActorConfig`
|
| 192 |
+
- `verl/trainer/config/actor/actor.yaml` - Rollout Correction configuration section
|
| 193 |
+
- `verl/trainer/config/ppo_trainer.yaml` - Algorithm config with Rollout Correction
|
| 194 |
+
|
| 195 |
+
### **Documentation**
|
| 196 |
+
|
| 197 |
+
- `docs/examples/config.rst` - Configuration parameter descriptions
|
| 198 |
+
|
| 199 |
+
### **Example Scripts**
|
| 200 |
+
|
| 201 |
+
- `recipe/dapo/run_dapo_qwen2.5_32b_rollout_corr.sh` - DAPO example with Rollout Correction
|
| 202 |
+
- `examples/rollout_correction/run_with_rollout_corr.sh` - Basic example
|
| 203 |
+
- `examples/rollout_correction/run_with_rollout_corr_multi_rs.sh` - Multi-RS example
|
| 204 |
+
|
| 205 |
+
### **Tests**
|
| 206 |
+
|
| 207 |
+
- `tests/trainer/ppo/test_rollout_corr.py` - Unit tests for IS/RS mechanisms
|
| 208 |
+
- `tests/trainer/ppo/test_rollout_corr_integration.py` - Integration tests
|
| 209 |
+
|
| 210 |
+
## Configuration Parameters
|
| 211 |
+
|
| 212 |
+
All parameters are under `algorithm.rollout_correction`:
|
| 213 |
+
|
| 214 |
+
### `rollout_is` (str or null)
|
| 215 |
+
|
| 216 |
+
Importance sampling weights aggregation level:
|
| 217 |
+
|
| 218 |
+
- `null` = No IS weights computed (metrics-only mode)
|
| 219 |
+
- `"token"`: Per-token IS weights
|
| 220 |
+
- **Decoupled mode**: ρ_t = π_old(t)/π_rollout(t)
|
| 221 |
+
- **Bypass/Pure IS mode**: ρ*t = π*θ(t)/π_rollout(t)
|
| 222 |
+
- Independent truncation per token
|
| 223 |
+
- Typical threshold: 1.5 - 5.0
|
| 224 |
+
- `"sequence"`: Per-sequence weight ρ_seq = ∏_t ρ_t
|
| 225 |
+
- Multiplicative aggregation across sequence
|
| 226 |
+
- Typical threshold: 2.0 - 10.0
|
| 227 |
+
|
| 228 |
+
All IS weights are safety-bounded to [exp(-20), exp(20)] ≈ [2e-9, 5e8]
|
| 229 |
+
|
| 230 |
+
### `rollout_is_threshold` (float)
|
| 231 |
+
|
| 232 |
+
Upper threshold for IS weight truncation. Default: `2.0`
|
| 233 |
+
|
| 234 |
+
- Truncates IS weights via `.clamp(max=rollout_is_threshold)` (TIS: Truncated Importance Sampling)
|
| 235 |
+
- Applied to IS weights for variance reduction
|
| 236 |
+
- Separate from rejection sampling (controlled by `rollout_rs` parameters)
|
| 237 |
+
|
| 238 |
+
### `rollout_is_batch_normalize` (bool)
|
| 239 |
+
|
| 240 |
+
Apply batch normalization to IS weights. Default: `False`
|
| 241 |
+
|
| 242 |
+
- `True`: Normalize IS weights to have mean=1.0 within each batch
|
| 243 |
+
- **Token-level IS**: Normalizes over all token weights
|
| 244 |
+
- **Sequence-level IS**: Normalizes over sequence means (one weight per sequence)
|
| 245 |
+
- `False`: Use raw (truncated) IS weights
|
| 246 |
+
- Reduces variance by ensuring average weight is 1.0 per batch
|
| 247 |
+
- Applied AFTER truncation to preserve truncation semantics
|
| 248 |
+
- Only affects IS weight values, not rejection sampling
|
| 249 |
+
|
| 250 |
+
### `rollout_rs` (str or null)
|
| 251 |
+
|
| 252 |
+
Rejection sampling aggregation modes. Supply a comma-separated string (spaces optional) using the canonical options implemented in `rollout_corr_helper`:
|
| 253 |
+
|
| 254 |
+
- `token_k1`: Token-level rejection with `-log r` bounds (ratio thresholds supplied as `lower_upper`). Example: `"0.6_1.4"`
|
| 255 |
+
- `token_k2`: Token-level rejection with `0.5 * (log r)^2` (upper bound only)
|
| 256 |
+
- `token_k3`: Token-level rejection with `exp(log r) - 1 - log r` (upper bound only)
|
| 257 |
+
- `seq_sum_k1`: Sequence-level rejection with sum of `-log r` (ratio bounds)
|
| 258 |
+
- `seq_sum_k2`: Sequence-level rejection with sum of `0.5 * (log r)^2` (upper bound only)
|
| 259 |
+
- `seq_sum_k3`: Sequence-level rejection with sum of `exp(log r) - 1 - log r` (upper bound only)
|
| 260 |
+
- `seq_mean_k1`: Sequence-level rejection with mean of `-log r` (ratio bounds)
|
| 261 |
+
- `seq_mean_k2`: Sequence-level rejection with mean of `0.5 * (log r)^2` (upper bound only)
|
| 262 |
+
- `seq_mean_k3`: Sequence-level rejection with mean of `exp(log r) - 1 - log r` (upper bound only)
|
| 263 |
+
- `seq_max_k2`: Sequence-level rejection with max of `0.5 * (log r)^2` (upper bound only)
|
| 264 |
+
- `seq_max_k3`: Sequence-level rejection with max of `exp(log r) - 1 - log r` (upper bound only)
|
| 265 |
+
|
| 266 |
+
### `rollout_rs_threshold` (str, float, or null)
|
| 267 |
+
|
| 268 |
+
Threshold specification for rejection sampling.
|
| 269 |
+
|
| 270 |
+
- Provide **one entry per option**, separated by commas. A single entry is broadcast to every option.
|
| 271 |
+
- **Ratio modes (`*k1`)**: Use `"lower_upper"` strings (e.g. `"0.7_1.3"`). Supplying a float implies only the upper bound; the lower bound defaults to its reciprocal.
|
| 272 |
+
- **Divergence modes (`*k2`/`*k3`)**: Supply positive upper bounds (float or numeric string).
|
| 273 |
+
- Set to `null` to disable thresholds entirely (only valid when `rollout_rs` is null).
|
| 274 |
+
|
| 275 |
+
## Understanding the Framework: Components and Combinations
|
| 276 |
+
|
| 277 |
+
The rollout correction framework is built from **orthogonal components** that can be combined flexibly. Understanding these components helps you choose the right configuration for your scenario.
|
| 278 |
+
|
| 279 |
+
### Key Components
|
| 280 |
+
|
| 281 |
+
1. **Operating Mode** (Section: [Operation Modes](#operation-modes))
|
| 282 |
+
|
| 283 |
+
- **Decoupled**: Three policies (π*rollout, π_old, π*θ) with separate π_old computation
|
| 284 |
+
- **Bypass**: Two policies (π*rollout = π_old, π*θ), skips π_old computation
|
| 285 |
+
|
| 286 |
+
2. **Loss Function** (in bypass mode, controlled by `loss_type`)
|
| 287 |
+
|
| 288 |
+
- **PPO-clip** (`loss_type="ppo_clip"`, default): PPO clipped objective (IS handled by ratio)
|
| 289 |
+
- **REINFORCE** (`loss_type="reinforce"`): Policy gradient with explicit IS weights (no clipping)
|
| 290 |
+
|
| 291 |
+
3. **IS/RS Aggregation Level**
|
| 292 |
+
- **Token**: Per-token IS weights/rejection
|
| 293 |
+
- **Sequence**: Sequence-level IS weights/rejection
|
| 294 |
+
|
| 295 |
+
See [Mathematical Formulations](rollout_corr_math.md#3-algorithmic-components-and-combinations) for detailed theory.
|
| 296 |
+
|
| 297 |
+
---
|
| 298 |
+
|
| 299 |
+
## Preset Configuration Guide
|
| 300 |
+
|
| 301 |
+
This section provides detailed guidance on choosing and using the verified presets. Each preset is a specific combination of components optimized for common scenarios.
|
| 302 |
+
|
| 303 |
+
### Understanding the Presets
|
| 304 |
+
|
| 305 |
+
#### Available Preset Methods
|
| 306 |
+
|
| 307 |
+
| Preset Method | Estimator | Mode | IS Level | RS Level | Properties |
|
| 308 |
+
| ------------------------------------------------------------------------------ | ---------------- | ------------------ | -------- | -------- | --------------------------------------- |
|
| 309 |
+
| **Decoupled PPO Mode** (3 policies: π*rollout, π_old, π*θ) |
|
| 310 |
+
| `decoupled_token_is()` | Token-TIS | Decoupled | token | - | Per-token IS weights |
|
| 311 |
+
| `decoupled_seq_is()` | Seq-TIS | Decoupled | sequence | - | Sequence-level IS weights |
|
| 312 |
+
| `decoupled_seq_is_rs()` | Seq-MIS | Decoupled | sequence | sequence | Sequence IS + sequence RS |
|
| 313 |
+
| `decoupled_geo_rs()` | Geo-RS | Decoupled | - | sequence | Geometric RS (ratio mode) |
|
| 314 |
+
| `decoupled_geo_rs_token_tis()` | Geo-RS-Token-TIS | Decoupled | token | sequence | Geometric filter + token clipped weight |
|
| 315 |
+
| **K3 KL Estimator** (more stable for small KL values) |
|
| 316 |
+
| `decoupled_k3_rs()` | K3-RS | Decoupled | - | k3 | K3 rejection, no IS weights |
|
| 317 |
+
| `decoupled_k3_rs_token_tis()` | K3-RS-Token-TIS | Decoupled | token | k3 | K3 filter + token clipped weight |
|
| 318 |
+
| **Bypass Mode (PPO-clip)** (2 policies; ratio handles IS, RS masks outliers) |
|
| 319 |
+
| `bypass_ppo_clip()` | - | Bypass (PPO-clip) | - | - | PPO-clip only |
|
| 320 |
+
| `bypass_ppo_clip_geo_rs()` | Geo-RS | Bypass (PPO-clip) | - | sequence | PPO-clip + Geo-RS (ratio) |
|
| 321 |
+
| `bypass_ppo_clip_k3_rs()` | K3-RS | Bypass (PPO-clip) | - | k3 | PPO-clip + K3-RS |
|
| 322 |
+
| **Bypass Mode (REINFORCE)** (2 policies; explicit IS weights, no PPO clipping) |
|
| 323 |
+
| `bypass_pg_is()` | Seq-TIS | Bypass (REINFORCE) | sequence | - | REINFORCE with explicit IS |
|
| 324 |
+
| `bypass_pg_geo_rs()` | Geo-RS | Bypass (REINFORCE) | - | sequence | REINFORCE with Geo-RS (ratio) |
|
| 325 |
+
| `bypass_pg_geo_rs_token_tis()` | Geo-RS-Token-TIS | Bypass (REINFORCE) | token | sequence | REINFORCE + Geo filter + token IS |
|
| 326 |
+
| **Other** |
|
| 327 |
+
| `disabled()` | - | - | - | - | Metrics only, no correction |
|
| 328 |
+
|
| 329 |
+
**Note:**
|
| 330 |
+
|
| 331 |
+
- **Bypass mode** sets π_old = π_rollout and uses `loss_type` to select the loss function:
|
| 332 |
+
- `"ppo_clip"` (default): PPO clipped objective where ratio = π_θ/π_rollout already handles IS
|
| 333 |
+
- `"reinforce"`: REINFORCE with explicit IS weights as π_θ / π_rollout
|
| 334 |
+
- Both loss types benefit from rejection sampling (RS) which masks out-of-distribution samples.
|
| 335 |
+
- Estimators (Token-TIS, Seq-TIS, Seq-MIS, Geo-RS) are compatible with Decoupled and Bypass modes.
|
| 336 |
+
|
| 337 |
+
#### Other Supported Combinations (Manual Configuration Required)
|
| 338 |
+
|
| 339 |
+
**Other supported combinations without preset methods:**
|
| 340 |
+
|
| 341 |
+
- Token IS + Token RS: Token-level IS weights + token-level RS mask
|
| 342 |
+
- Pure token RS: Token-level RS only, no IS weights
|
| 343 |
+
- Pure sequence RS: Sequence-level RS only, no IS weights
|
| 344 |
+
|
| 345 |
+
See [detailed configuration examples below](#additional-useful-configurations-not-exposed-as-presets) for manual configurations.
|
| 346 |
+
|
| 347 |
+
**Key properties:**
|
| 348 |
+
|
| 349 |
+
- Any aggregation level (token/sequence/geometric) works in either decoupled or bypass mode
|
| 350 |
+
- All combinations are fully supported by the implementation
|
| 351 |
+
- Rejection sampling is independent of IS weighting
|
| 352 |
+
- Pure RS (`bypass_pg_rs`) uses bypass + geometric RS with `loss_type="reinforce"` (no IS weights)
|
| 353 |
+
|
| 354 |
+
---
|
| 355 |
+
|
| 356 |
+
### 1. Decoupled Mode with Token-level Importance Sampling (`decoupled_token_is`)
|
| 357 |
+
|
| 358 |
+
**Configuration:**
|
| 359 |
+
|
| 360 |
+
```python
|
| 361 |
+
config = RolloutCorrectionConfig.decoupled_token_is(threshold=2.0)
|
| 362 |
+
```
|
| 363 |
+
|
| 364 |
+
**Components:**
|
| 365 |
+
|
| 366 |
+
- **Operating Mode**: Decoupled (3 policies)
|
| 367 |
+
- **Loss**: PPO with clipping (only for the second drift correction)
|
| 368 |
+
- **IS Aggregation**: Token-level
|
| 369 |
+
- **RS**: None (can be added separately)
|
| 370 |
+
|
| 371 |
+
**Equivalent YAML:**
|
| 372 |
+
|
| 373 |
+
```yaml
|
| 374 |
+
algorithm:
|
| 375 |
+
rollout_correction:
|
| 376 |
+
rollout_is: token
|
| 377 |
+
rollout_is_threshold: 2.0
|
| 378 |
+
rollout_rs: null
|
| 379 |
+
bypass_mode: false # Decoupled mode
|
| 380 |
+
```
|
| 381 |
+
|
| 382 |
+
**Properties:**
|
| 383 |
+
|
| 384 |
+
- Independent truncation per token
|
| 385 |
+
- Lower variance than sequence-level (product of ratios bounded individually)
|
| 386 |
+
- Typical threshold: 1.5 - 5.0
|
| 387 |
+
|
| 388 |
+
**Theory:** See [rollout_corr_math.md §3.3.1](rollout_corr_math.md#331-token-level-aggregation)
|
| 389 |
+
|
| 390 |
+
---
|
| 391 |
+
|
| 392 |
+
### 2. Decoupled Mode with Sequence-level Importance Sampling (`decoupled_seq_is`)
|
| 393 |
+
|
| 394 |
+
**Also known as: Seq-TIS (Sequence-Level Truncated IS)**
|
| 395 |
+
|
| 396 |
+
**Configuration:**
|
| 397 |
+
|
| 398 |
+
```python
|
| 399 |
+
config = RolloutCorrectionConfig.decoupled_seq_is(threshold=2.0)
|
| 400 |
+
```
|
| 401 |
+
|
| 402 |
+
**Components:**
|
| 403 |
+
|
| 404 |
+
- **Operating Mode**: Decoupled (3 policies)
|
| 405 |
+
- **Loss**: PPO with clipping (only for the second drift correction)
|
| 406 |
+
- **IS Aggregation**: Sequence-level (Seq-TIS)
|
| 407 |
+
- **RS**: None (can be added separately)
|
| 408 |
+
|
| 409 |
+
**Equivalent YAML:**
|
| 410 |
+
|
| 411 |
+
```yaml
|
| 412 |
+
algorithm:
|
| 413 |
+
rollout_correction:
|
| 414 |
+
rollout_is: sequence
|
| 415 |
+
rollout_is_threshold: 2.0
|
| 416 |
+
rollout_rs: null
|
| 417 |
+
bypass_mode: false # Decoupled mode
|
| 418 |
+
```
|
| 419 |
+
|
| 420 |
+
**Properties:**
|
| 421 |
+
|
| 422 |
+
- Multiplicative aggregation across sequence
|
| 423 |
+
- More sensitive to outliers than token-level
|
| 424 |
+
- Typical threshold: 2.0 - 10.0 (higher than token-level)
|
| 425 |
+
|
| 426 |
+
**Theory:** See [rollout_corr_math.md §3.3.2](rollout_corr_math.md#332-sequence-level-aggregation)
|
| 427 |
+
|
| 428 |
+
---
|
| 429 |
+
|
| 430 |
+
### 3. Decoupled Mode with Sequence-level IS + Rejection Sampling (`decoupled_seq_is_rs`)
|
| 431 |
+
|
| 432 |
+
**Also known as: Seq-MIS (Sequence-Level Masked IS)**
|
| 433 |
+
|
| 434 |
+
**Configuration:**
|
| 435 |
+
|
| 436 |
+
```python
|
| 437 |
+
config = RolloutCorrectionConfig.decoupled_seq_is_rs(is_threshold=2.0, rs_threshold="0.5_2.0")
|
| 438 |
+
```
|
| 439 |
+
|
| 440 |
+
**Components:**
|
| 441 |
+
|
| 442 |
+
- **Operating Mode**: Decoupled (3 policies)
|
| 443 |
+
- **Loss**: PPO with clipping (only for the second drift correction)
|
| 444 |
+
- **IS Aggregation**: Sequence-level (Seq-TIS)
|
| 445 |
+
- **RS**: Sequence-level rejection (Seq-MIS)
|
| 446 |
+
|
| 447 |
+
**Equivalent YAML:**
|
| 448 |
+
|
| 449 |
+
```yaml
|
| 450 |
+
algorithm:
|
| 451 |
+
rollout_correction:
|
| 452 |
+
rollout_is: sequence
|
| 453 |
+
rollout_is_threshold: 2.0
|
| 454 |
+
rollout_rs: seq_sum_k1
|
| 455 |
+
rollout_rs_threshold: 0.5_2.0
|
| 456 |
+
bypass_mode: false # Decoupled mode
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
**Properties:**
|
| 460 |
+
|
| 461 |
+
- Double mechanism: IS reweighting (Seq-TIS) + rejection filtering (Seq-MIS)
|
| 462 |
+
- Lower effective sample size (rejects outliers)
|
| 463 |
+
- For severe off-policy gaps or when the distribution tail is "toxic" (garbage/adversarial samples)
|
| 464 |
+
|
| 465 |
+
**When to use Seq-MIS over Seq-TIS:**
|
| 466 |
+
|
| 467 |
+
- **Seq-TIS (clipping only)**: Maximizes information efficiency; extracts signal from all samples. Use when data is clean and mismatch is moderate.
|
| 468 |
+
- **Seq-MIS (rejection)**: Maximizes safety; acts as a hard trust region filter. Use when mismatch is severe or when high-weight samples are likely garbage rather than signal.
|
| 469 |
+
|
| 470 |
+
**Theory:** See [rollout_corr_math.md §3.4](rollout_corr_math.md#34-rejection-sampling-rs)
|
| 471 |
+
|
| 472 |
+
---
|
| 473 |
+
|
| 474 |
+
### 6. Bypass Mode with PPO-clip (`bypass_ppo_clip`)
|
| 475 |
+
|
| 476 |
+
**Configuration:**
|
| 477 |
+
|
| 478 |
+
```python
|
| 479 |
+
config = RolloutCorrectionConfig.bypass_ppo_clip()
|
| 480 |
+
```
|
| 481 |
+
|
| 482 |
+
**Components:**
|
| 483 |
+
|
| 484 |
+
- **Operating Mode**: Bypass (2 policies: π*rollout = π_old, π*θ)
|
| 485 |
+
- **Loss**: PPO-clip (IS handled by ratio, no explicit IS weights)
|
| 486 |
+
- **IS Aggregation**: None (PPO ratio handles it)
|
| 487 |
+
- **RS**: None
|
| 488 |
+
|
| 489 |
+
**Equivalent YAML:**
|
| 490 |
+
|
| 491 |
+
```yaml
|
| 492 |
+
algorithm:
|
| 493 |
+
rollout_correction:
|
| 494 |
+
rollout_is: null
|
| 495 |
+
rollout_rs: null
|
| 496 |
+
bypass_mode: true
|
| 497 |
+
loss_type: ppo_clip
|
| 498 |
+
```
|
| 499 |
+
|
| 500 |
+
**Properties:**
|
| 501 |
+
|
| 502 |
+
- PPO clipped objective in bypass mode
|
| 503 |
+
- The PPO ratio = π_θ/π_rollout already handles IS (no explicit IS weights needed)
|
| 504 |
+
- Skips `actor.compute_log_prob()` forward pass (2 policies instead of 3)
|
| 505 |
+
- No rejection sampling - use `bypass_ppo_clip_geo_rs()` for RS
|
| 506 |
+
|
| 507 |
+
**Configuration requirement:**
|
| 508 |
+
|
| 509 |
+
- Set `actor_rollout_ref.rollout.calculate_log_probs: true`
|
| 510 |
+
|
| 511 |
+
**Theory:** See [rollout_corr_math.md §3.1.2](rollout_corr_math.md#312-bypass-mode-two-policies)
|
| 512 |
+
|
| 513 |
+
---
|
| 514 |
+
|
| 515 |
+
### 7. REINFORCE with IS (`bypass_pg_is`)
|
| 516 |
+
|
| 517 |
+
**Configuration:**
|
| 518 |
+
|
| 519 |
+
```python
|
| 520 |
+
config = RolloutCorrectionConfig.bypass_pg_is(threshold=2.0)
|
| 521 |
+
```
|
| 522 |
+
|
| 523 |
+
**Components:**
|
| 524 |
+
|
| 525 |
+
- **Operating Mode**: Bypass (2 policies: π*rollout, π*θ)
|
| 526 |
+
- **Loss**: REINFORCE (policy gradient with explicit IS weights, no PPO clipping)
|
| 527 |
+
- **IS Aggregation**: Sequence-level
|
| 528 |
+
- **RS**: None
|
| 529 |
+
|
| 530 |
+
**Equivalent YAML:**
|
| 531 |
+
|
| 532 |
+
```yaml
|
| 533 |
+
algorithm:
|
| 534 |
+
rollout_correction:
|
| 535 |
+
rollout_is: sequence
|
| 536 |
+
rollout_is_threshold: 2.0
|
| 537 |
+
rollout_rs: null
|
| 538 |
+
bypass_mode: true
|
| 539 |
+
loss_type: reinforce # REINFORCE with explicit IS weights
|
| 540 |
+
```
|
| 541 |
+
|
| 542 |
+
**Properties:**
|
| 543 |
+
|
| 544 |
+
- REINFORCE loss with explicit IS weights (no PPO clipping)
|
| 545 |
+
- Single forward pass (skips old_log_prob computation)
|
| 546 |
+
- IS weights computed on-the-fly in loss function
|
| 547 |
+
|
| 548 |
+
**Theory:** See [rollout_corr_math.md §3.2.2](rollout_corr_math.md#322-policy-gradient-loss-with-isrs-correction)
|
| 549 |
+
|
| 550 |
+
---
|
| 551 |
+
|
| 552 |
+
## Additional Useful Configurations (Not Exposed as Presets)
|
| 553 |
+
|
| 554 |
+
These configurations are **fully supported** but don't have convenience preset methods yet.
|
| 555 |
+
|
| 556 |
+
### 1. Token IS + Token RS (`token_is_rs`)
|
| 557 |
+
|
| 558 |
+
Token-level IS weights with token-level RS mask.
|
| 559 |
+
|
| 560 |
+
**Python:**
|
| 561 |
+
|
| 562 |
+
```python
|
| 563 |
+
config = RolloutCorrectionConfig(
|
| 564 |
+
rollout_is="token",
|
| 565 |
+
rollout_is_threshold=2.0,
|
| 566 |
+
rollout_rs="token_k1",
|
| 567 |
+
rollout_rs_threshold=2.0,
|
| 568 |
+
)
|
| 569 |
+
```
|
| 570 |
+
|
| 571 |
+
**Properties:** Per-token IS weights + per-token RS mask.
|
| 572 |
+
|
| 573 |
+
### 2. Pure Token RS (`token_rs`)
|
| 574 |
+
|
| 575 |
+
Token-level RS only, no IS weights.
|
| 576 |
+
|
| 577 |
+
**Python:**
|
| 578 |
+
|
| 579 |
+
```python
|
| 580 |
+
config = RolloutCorrectionConfig(
|
| 581 |
+
rollout_is=None,
|
| 582 |
+
rollout_rs="token_k1",
|
| 583 |
+
rollout_rs_threshold=2.0,
|
| 584 |
+
)
|
| 585 |
+
```
|
| 586 |
+
|
| 587 |
+
**Properties:** Token-level RS mask, no IS reweighting.
|
| 588 |
+
|
| 589 |
+
### 3. Pure Sequence RS (`seq_rs`)
|
| 590 |
+
|
| 591 |
+
Sequence-level RS only, no IS weights.
|
| 592 |
+
|
| 593 |
+
**Python:**
|
| 594 |
+
|
| 595 |
+
```python
|
| 596 |
+
config = RolloutCorrectionConfig(
|
| 597 |
+
rollout_is=None,
|
| 598 |
+
rollout_rs="seq_sum_k1",
|
| 599 |
+
rollout_rs_threshold="0.5_2.0",
|
| 600 |
+
)
|
| 601 |
+
```
|
| 602 |
+
|
| 603 |
+
**Properties:** Sequence-level RS mask, no IS reweighting.
|
| 604 |
+
|
| 605 |
+
---
|
| 606 |
+
|
| 607 |
+
### Summary: How IS Weights are Processed
|
| 608 |
+
|
| 609 |
+
IS weights (`rollout_is_weights`) go through a fixed processing pipeline:
|
| 610 |
+
|
| 611 |
+
**Stage 1: Safety Bound (Prevent Overflow)**
|
| 612 |
+
|
| 613 |
+
- Token level: `exp(clamp(log_ratio, -20, 20))` per token → bounds each token to [2e-9, 5e8]
|
| 614 |
+
- Sequence level: `exp(clamp(sum(log_ratio), -20, 20))` → bounds product to [2e-9, 5e8], broadcast to all tokens
|
| 615 |
+
|
| 616 |
+
**Stage 2: Truncation (Reduce Variance)**
|
| 617 |
+
|
| 618 |
+
- `.clamp(max=rollout_is_threshold)` → caps weights at upper threshold (TIS: Truncated Importance Sampling)
|
| 619 |
+
- No lower truncation (preserves unbiasedness for small weights)
|
| 620 |
+
|
| 621 |
+
**Stage 3: Padding Zeroing (Correct Aggregation)**
|
| 622 |
+
|
| 623 |
+
- `weights * response_mask` → zeros out padding positions
|
| 624 |
+
|
| 625 |
+
**Stage 4: Optional Batch Normalization**
|
| 626 |
+
|
| 627 |
+
- If `rollout_is_batch_normalize=True`: Normalize weights to mean=1.0 within batch
|
| 628 |
+
- Applied after truncation to preserve truncation semantics
|
| 629 |
+
|
| 630 |
+
**Rejection Sampling (Separate Mechanism)**
|
| 631 |
+
|
| 632 |
+
Rejection sampling modifies `response_mask` (NOT weights) through `compute_rollout_rejection_mask()`:
|
| 633 |
+
|
| 634 |
+
- Computes safety-bounded ratios independently
|
| 635 |
+
- Creates binary mask: tokens/sequences outside [lower_threshold, upper_threshold] → 0 (rejected)
|
| 636 |
+
- Modified mask used for loss aggregation (rejected samples excluded from training)
|
| 637 |
+
|
| 638 |
+
## Operation Modes
|
| 639 |
+
|
| 640 |
+
The framework provides **two operating modes** for computing π_old, which can be combined with different loss functions.
|
| 641 |
+
|
| 642 |
+
### Operating Modes and Configuration
|
| 643 |
+
|
| 644 |
+
| Configuration | `bypass_mode` | `loss_type` | Operating Mode | Loss Function | Description |
|
| 645 |
+
| ---------------------- | ------------- | ---------------------- | -------------- | ------------- | ----------------------------------------------------------------- |
|
| 646 |
+
| **Decoupled** | `false` | N/A | Decoupled | PPO | Computes `old_log_prob` separately via `actor.compute_log_prob()` |
|
| 647 |
+
| **Bypass + PPO-clip** | `true` | `"ppo_clip"` (default) | Bypass | PPO-clip | PPO clipped objective (IS handled by ratio) |
|
| 648 |
+
| **Bypass + REINFORCE** | `true` | `"reinforce"` | Bypass | REINFORCE | Policy gradient with explicit IS weights (no PPO clipping) |
|
| 649 |
+
|
| 650 |
+
### Operating Mode Details
|
| 651 |
+
|
| 652 |
+
#### Decoupled Mode (Three Policies)
|
| 653 |
+
|
| 654 |
+
**Policy setup:**
|
| 655 |
+
|
| 656 |
+
- π_rollout: Behavior policy (data collection)
|
| 657 |
+
- π_old: Proximal policy (computed via `actor.compute_log_prob()` at start of training epoch)
|
| 658 |
+
- π_θ: Current policy (being updated)
|
| 659 |
+
|
| 660 |
+
**Configuration:** `bypass_mode = false`
|
| 661 |
+
|
| 662 |
+
**Properties:**
|
| 663 |
+
|
| 664 |
+
- ✅ Achieves batch size invariance
|
| 665 |
+
- ✅ Separately corrects Drift 1 (rollout→old) and Drift 2 (old→current)
|
| 666 |
+
- ✅ Efficient stale data utilization
|
| 667 |
+
- ❌ Extra forward pass needed (`actor.compute_log_prob()`)
|
| 668 |
+
|
| 669 |
+
**Theory:** See [rollout_corr_math.md §3.1.1](rollout_corr_math.md#311-decoupled-mode-three-policies)
|
| 670 |
+
|
| 671 |
+
#### Bypass Mode (Two Policies)
|
| 672 |
+
|
| 673 |
+
**Policy setup:**
|
| 674 |
+
|
| 675 |
+
- π_rollout: Behavior policy (data collection)
|
| 676 |
+
- π_old = π_rollout: Proximal policy equals behavior policy
|
| 677 |
+
- π_θ: Current policy (being updated)
|
| 678 |
+
|
| 679 |
+
**Configuration:** `bypass_mode = true`
|
| 680 |
+
|
| 681 |
+
**Properties:**
|
| 682 |
+
|
| 683 |
+
- ✅ Skips `actor.compute_log_prob()` call (faster)
|
| 684 |
+
- ✅ Handles off-policy correction via IS/RS (when using policy gradient with IS/RS)
|
| 685 |
+
- ✅ Uses two policies instead of three (π_rollout = π_old)
|
| 686 |
+
- ⚠️ Does not separate proximal policy from behavior policy (unlike decoupled mode)
|
| 687 |
+
|
| 688 |
+
**Theory:** See [rollout_corr_math.md §3.1.2](rollout_corr_math.md#312-bypass-mode-two-policies)
|
| 689 |
+
|
| 690 |
+
---
|
| 691 |
+
|
| 692 |
+
### IS/RS Aggregation Levels (Orthogonal to Operating Mode)
|
| 693 |
+
|
| 694 |
+
The aggregation level can be chosen **independently** of the operating mode. Any aggregation level works in either decoupled or bypass mode.
|
| 695 |
+
|
| 696 |
+
| `rollout_is` | `rollout_rs` | Behavior |
|
| 697 |
+
| ------------------------- | ------------------------------------------------------------------ | --------------------------------------------------------------------------------- |
|
| 698 |
+
| `null` | `null` | **Disabled**: No computation, no metrics, no rejection |
|
| 699 |
+
| `null` | `"token_k1"`, `"seq_sum_k1"`, `"seq_mean_k1"`, `"seq_max_k2"`, etc | **Rejection only**: Compute metrics, NO weight correction, YES rejection sampling |
|
| 700 |
+
| `"token"` or `"sequence"` | `null` | **IS weights only**: Weight correction enabled, NO rejection sampling |
|
| 701 |
+
| `"token"` or `"sequence"` | `"token_k1"`, `"seq_sum_k1"`, `"seq_mean_k1"`, `"seq_max_k2"`, etc | **Full correction**: Both weight correction and rejection sampling enabled |
|
| 702 |
+
|
| 703 |
+
### Key Insights
|
| 704 |
+
|
| 705 |
+
- ✅ Any IS/RS aggregation level (token/sequence/geometric) can be used in **either** decoupled or bypass mode
|
| 706 |
+
- ✅ You can use **rejection sampling alone** without IS weight correction (`rollout_is=null, rollout_rs="token_k1"`)
|
| 707 |
+
- ✅ You can use **IS weights alone** without outlier rejection (`rollout_is="token", rollout_rs=null`)
|
| 708 |
+
- ✅ You can use **both together** (`rollout_is="token", rollout_rs="token_k1"`)
|
| 709 |
+
- ✅ You can **monitor metrics only** without any correction by setting both to `null` but still providing rollout_log_probs
|
| 710 |
+
|
| 711 |
+
**Theory:** See [rollout_corr_math.md §3.3](rollout_corr_math.md#33-isrs-aggregation-levels) for details on aggregation levels.
|
| 712 |
+
|
| 713 |
+
### Example Workflow
|
| 714 |
+
|
| 715 |
+
**Recommended: Bypass Mode**
|
| 716 |
+
|
| 717 |
+
This workflow uses bypass mode for efficiency.
|
| 718 |
+
|
| 719 |
+
1. **Start with metrics only** to understand the off-policy gap:
|
| 720 |
+
|
| 721 |
+
```yaml
|
| 722 |
+
algorithm:
|
| 723 |
+
rollout_correction:
|
| 724 |
+
rollout_is: null
|
| 725 |
+
rollout_rs: null
|
| 726 |
+
bypass_mode: true # Bypass mode (recommended)
|
| 727 |
+
loss_type: ppo_clip # Default: PPO clipped objective
|
| 728 |
+
```
|
| 729 |
+
|
| 730 |
+
Monitor `rollout_corr/kl`, `rollout_corr/log_ppl_abs_diff`, `rollout_corr/chi2_token` to assess off-policy gap.
|
| 731 |
+
|
| 732 |
+
2. **Enable rejection sampling** if you see high outlier fractions:
|
| 733 |
+
|
| 734 |
+
```yaml
|
| 735 |
+
algorithm:
|
| 736 |
+
rollout_correction:
|
| 737 |
+
rollout_is: null
|
| 738 |
+
rollout_rs: sequence # or "geometric" for higher sensitivity
|
| 739 |
+
rollout_rs_threshold: 2.0
|
| 740 |
+
bypass_mode: true # Bypass mode
|
| 741 |
+
loss_type: ppo_clip # or "reinforce" for explicit IS weights
|
| 742 |
+
```
|
| 743 |
+
|
| 744 |
+
This excludes outliers from training without modifying gradients.
|
| 745 |
+
|
| 746 |
+
3. **Enable full IS correction** (with REINFORCE loss) once comfortable with metrics:
|
| 747 |
+
```yaml
|
| 748 |
+
algorithm:
|
| 749 |
+
rollout_correction:
|
| 750 |
+
rollout_is: sequence # Recommended: unbiased, suitable for most cases
|
| 751 |
+
rollout_is_threshold: 2.0
|
| 752 |
+
rollout_rs: sequence # or "geometric" for more aggressive filtering
|
| 753 |
+
rollout_rs_threshold: 2.0
|
| 754 |
+
bypass_mode: true # Bypass mode
|
| 755 |
+
loss_type: reinforce # REINFORCE with explicit IS weights
|
| 756 |
+
```
|
| 757 |
+
|
| 758 |
+
**Benefits of bypass mode:**
|
| 759 |
+
|
| 760 |
+
- ✅ Skips expensive `actor.compute_log_prob()` forward pass (faster)
|
| 761 |
+
- ✅ `loss_type` controls the loss function: "ppo_clip" (default) or "reinforce"
|
| 762 |
+
- ✅ PPO-clip: IS handled by ratio (no explicit weights), RS mask applied
|
| 763 |
+
- ✅ REINFORCE: Explicit IS weights computed on-the-fly (π_θ / π_rollout)
|
| 764 |
+
- ✅ Both loss types work with all IS/RS combinations
|
| 765 |
+
|
| 766 |
+
## Usage
|
| 767 |
+
|
| 768 |
+
### Basic Setup
|
| 769 |
+
|
| 770 |
+
```yaml
|
| 771 |
+
algorithm:
|
| 772 |
+
rollout_correction:
|
| 773 |
+
rollout_is: token # Enable IS weights at token level
|
| 774 |
+
rollout_is_threshold: 2.0 # Threshold for IS weights
|
| 775 |
+
rollout_rs: null # No rejection sampling
|
| 776 |
+
|
| 777 |
+
actor_rollout_ref:
|
| 778 |
+
rollout:
|
| 779 |
+
calculate_log_probs: true # Required!
|
| 780 |
+
```
|
| 781 |
+
|
| 782 |
+
### Metrics
|
| 783 |
+
|
| 784 |
+
All metrics are prefixed with `rollout_corr/` in logs. For example, `rollout_is_mean` appears as `rollout_corr/rollout_is_mean`.
|
| 785 |
+
|
| 786 |
+
These metrics cover both:
|
| 787 |
+
|
| 788 |
+
- **Diagnostic metrics**: KL divergence, perplexity differences (measuring off-policy gap)
|
| 789 |
+
- **Correction statistics**: IS weights, rejection rates (measuring correction applied)
|
| 790 |
+
|
| 791 |
+
#### **Core IS Weight Metrics**
|
| 792 |
+
|
| 793 |
+
- **`rollout_is_mean`**: Mean importance sampling weight across all valid tokens
|
| 794 |
+
|
| 795 |
+
- Value close to 1.0 indicates minimal off-policy gap
|
| 796 |
+
|
| 797 |
+
- **`rollout_is_std`**: Standard deviation of IS weights
|
| 798 |
+
|
| 799 |
+
- Higher values indicate greater variance in IS weights
|
| 800 |
+
|
| 801 |
+
- **`rollout_is_min`**: Minimum IS weight observed
|
| 802 |
+
|
| 803 |
+
- Shows the most underweighted token/sequence
|
| 804 |
+
- For sequence/geometric: computed from unclamped log-space ratios (true minimum)
|
| 805 |
+
- For token: computed from safety-bounded weights
|
| 806 |
+
|
| 807 |
+
- **`rollout_is_max`**: Maximum IS weight observed
|
| 808 |
+
- Shows the most overweighted token/sequence
|
| 809 |
+
- For sequence/geometric: computed from unclamped log-space ratios (true maximum before safety bound)
|
| 810 |
+
- For token: computed from safety-bounded weights (before threshold clamping)
|
| 811 |
+
- Compare with `rollout_is_threshold` to see truncation impact
|
| 812 |
+
|
| 813 |
+
#### **Effective Sample Size**
|
| 814 |
+
|
| 815 |
+
- **`rollout_is_eff_sample_size`**: Effective sample size after IS weighting
|
| 816 |
+
- **Formula**: `1 / mean(weights²)` where weights are normalized
|
| 817 |
+
- **Range**: 0.0 to 1.0 (as fraction of original batch)
|
| 818 |
+
- Lower values indicate weight concentration on fewer samples
|
| 819 |
+
|
| 820 |
+
#### **Threshold Exceedance Metrics**
|
| 821 |
+
|
| 822 |
+
- **`rollout_is_ratio_fraction_high`**: Fraction of weights exceeding upper threshold
|
| 823 |
+
|
| 824 |
+
- Shows how often truncation/masking occurs on high end
|
| 825 |
+
- For sequence/geometric: computed from unclamped log-space ratios (true exceedance)
|
| 826 |
+
- For token: computed from safety-bounded weights (before threshold clamping)
|
| 827 |
+
|
| 828 |
+
- **`rollout_is_ratio_fraction_low`**: Fraction of weights below lower threshold (1/upper_threshold)
|
| 829 |
+
- Diagnostic metric showing how many weights are below the reciprocal threshold
|
| 830 |
+
- For sequence/geometric: computed from unclamped log-space ratios (true exceedance)
|
| 831 |
+
- For token: computed from safety-bounded weights (before truncation)
|
| 832 |
+
|
| 833 |
+
#### **Sequence-Level Metrics** (for sequence aggregation)
|
| 834 |
+
|
| 835 |
+
- **`rollout_is_seq_mean`**: Mean IS weight at sequence level
|
| 836 |
+
|
| 837 |
+
- Should match `rollout_is_mean` for sequence-level aggregation
|
| 838 |
+
|
| 839 |
+
- **`rollout_is_seq_std`**: Standard deviation of sequence-level IS weights
|
| 840 |
+
|
| 841 |
+
- **`rollout_is_seq_min`**: Minimum sequence-level IS weight
|
| 842 |
+
|
| 843 |
+
- **`rollout_is_seq_max`**: Maximum sequence-level IS weight
|
| 844 |
+
|
| 845 |
+
- **`rollout_is_seq_max_deviation`**: Maximum absolute deviation from 1.0 at sequence level
|
| 846 |
+
|
| 847 |
+
- Shows worst-case sequence off-policy gap
|
| 848 |
+
|
| 849 |
+
- **`rollout_is_seq_fraction_high`**: Fraction of sequences exceeding upper threshold
|
| 850 |
+
|
| 851 |
+
- **`rollout_is_seq_fraction_low`**: Fraction of sequences below lower threshold
|
| 852 |
+
|
| 853 |
+
#### **Rejection Sampling Metrics** (when `rollout_rs` is enabled)
|
| 854 |
+
|
| 855 |
+
- **`rollout_rs_masked_fraction`**: Fraction of tokens rejected via rejection sampling
|
| 856 |
+
|
| 857 |
+
- **Important**: Rejection sampling modifies `response_mask` (sets rejected tokens to 0)
|
| 858 |
+
- **Separate from IS weights**: IS weights are still truncated; rejection is an independent filtering step
|
| 859 |
+
- Only present when `rollout_rs` is enabled (token/sequence/geometric)
|
| 860 |
+
|
| 861 |
+
- **`rollout_rs_seq_masked_fraction`**: Fraction of sequences with at least one rejected token
|
| 862 |
+
- Shows sequence-level impact of rejection sampling
|
| 863 |
+
- Token-level RS: sequence rejected if ANY token is outside [lower, upper]
|
| 864 |
+
- Sequence-level RS: entire sequence rejected or accepted based on sequence-level ratio
|
| 865 |
+
- Geometric RS: entire sequence rejected or accepted based on geometric mean
|
| 866 |
+
|
| 867 |
+
#### **Off-Policy Diagnostic Metrics** (Training vs Rollout Policy)
|
| 868 |
+
|
| 869 |
+
**Note on terminology:** These metrics use "training" to refer to the training reference policy and "rollout" to refer to π_rollout (the behavior policy used for data collection).
|
| 870 |
+
|
| 871 |
+
- **Decoupled mode**: "training" = π_old (computed at start of training epoch)
|
| 872 |
+
- **Bypass/Pure IS mode**: "training" = π_θ (current policy being trained)
|
| 873 |
+
|
| 874 |
+
In bypass/pure IS mode, metrics measure the drift between π_θ and π_rollout directly.
|
| 875 |
+
|
| 876 |
+
- **`training_ppl`**: Perplexity of training reference policy (π*old in decoupled mode, π*θ in bypass/pure IS mode)
|
| 877 |
+
|
| 878 |
+
- **Formula**: `exp(-mean(log_probs))`
|
| 879 |
+
- Lower values indicate higher model confidence
|
| 880 |
+
|
| 881 |
+
- **`rollout_ppl`**: Perplexity of rollout policy π_rollout (e.g., vLLM BF16)
|
| 882 |
+
|
| 883 |
+
- **`ppl_ratio`**: Ratio of training PPL to rollout PPL
|
| 884 |
+
|
| 885 |
+
- **Formula**: `exp(mean(log(training_ppl / rollout_ppl)))`
|
| 886 |
+
- **Meaning**: > 1.0 means training is less confident than rollout
|
| 887 |
+
|
| 888 |
+
- **`training_log_ppl`**: Log perplexity of training policy
|
| 889 |
+
|
| 890 |
+
- Useful for identifying trends (linear scale)
|
| 891 |
+
|
| 892 |
+
- **`rollout_log_ppl`**: Log perplexity of rollout policy
|
| 893 |
+
|
| 894 |
+
- **`log_ppl_diff`**: Mean difference in log perplexities
|
| 895 |
+
|
| 896 |
+
- **Formula**: `mean(log_ppl_rollout - log_ppl_training)`
|
| 897 |
+
- Sign indicates which policy is more confident
|
| 898 |
+
|
| 899 |
+
- **`log_ppl_abs_diff`**: Mean absolute log perplexity difference
|
| 900 |
+
|
| 901 |
+
- Magnitude of off-policy gap regardless of direction
|
| 902 |
+
|
| 903 |
+
- **`log_ppl_diff_max`**: Maximum log perplexity difference across sequences
|
| 904 |
+
|
| 905 |
+
- Identifies worst-case sequence
|
| 906 |
+
|
| 907 |
+
- **`log_ppl_diff_min`**: Minimum log perplexity difference across sequences
|
| 908 |
+
|
| 909 |
+
- **`kl`**: KL divergence KL(π_rollout || π_training)
|
| 910 |
+
|
| 911 |
+
- **Formula**: `mean(log_prob_rollout - log_prob_training)`
|
| 912 |
+
- **Note**: Can be negative (rollout is less confident)
|
| 913 |
+
|
| 914 |
+
- **`k3_kl`**: K3 divergence (equals KL(π_rollout || π_training) in expectation)
|
| 915 |
+
|
| 916 |
+
- **Formula**: `mean(exp(log_ratio) - log_ratio - 1)`
|
| 917 |
+
- More stable than direct KL (non-negative per token)
|
| 918 |
+
- Always >= 0
|
| 919 |
+
|
| 920 |
+
- **`chi2_token`**: Chi-squared divergence at token level
|
| 921 |
+
|
| 922 |
+
- **Formula**: `mean(ratio²) - 1` where ratio = π_training/π_rollout
|
| 923 |
+
- Measures second moment of IS weight distribution
|
| 924 |
+
- Always non-negative
|
| 925 |
+
|
| 926 |
+
- **`chi2_seq`**: Chi-squared divergence at sequence level
|
| 927 |
+
- **Formula**: `mean((∏_t ratio_t)²) - 1`
|
| 928 |
+
- Sequence-level second moment of IS weights
|
| 929 |
+
- More sensitive than token-level chi-squared
|
| 930 |
+
|
| 931 |
+
#### **Example: Accessing Metrics in Code**
|
| 932 |
+
|
| 933 |
+
```python
|
| 934 |
+
# Metrics are returned from compute_rollout_correction_and_rejection_mask
|
| 935 |
+
from verl.trainer.ppo.rollout_corr_helper import compute_rollout_correction_and_rejection_mask
|
| 936 |
+
|
| 937 |
+
# Returns 3 values (weights, modified_response_mask, metrics)
|
| 938 |
+
weights_proto, modified_response_mask, metrics = compute_rollout_correction_and_rejection_mask(
|
| 939 |
+
old_log_prob=training_log_probs, # from training policy
|
| 940 |
+
rollout_log_prob=rollout_log_probs, # from rollout policy
|
| 941 |
+
response_mask=response_mask,
|
| 942 |
+
rollout_is="token", # Enable IS weights at token level
|
| 943 |
+
rollout_is_threshold=2.0,
|
| 944 |
+
rollout_rs="token_k1",
|
| 945 |
+
rollout_rs_threshold="0.5_2.0",
|
| 946 |
+
)
|
| 947 |
+
|
| 948 |
+
# Extract IS weights (processed, zeroed at padding)
|
| 949 |
+
is_weights = weights_proto.batch["rollout_is_weights"]
|
| 950 |
+
|
| 951 |
+
# IS weights processing (with IS enabled at token level):
|
| 952 |
+
# 1. Safety-bounded: exp(clamp(log_ratio, -20, 20)) per token
|
| 953 |
+
# 2. Truncated: .clamp(max=2.0) to cap extreme weights
|
| 954 |
+
# 3. Zeroed at padding positions
|
| 955 |
+
# Note: Truncation is ALWAYS applied to IS weights (TIS: Truncated Importance Sampling)
|
| 956 |
+
|
| 957 |
+
# modified_response_mask has rejection applied (since rollout_rs="token_k1"):
|
| 958 |
+
# 1. RS rejection: tokens outside [0.5, 2.0] masked to 0 via response_mask
|
| 959 |
+
# Note: RS and IS are separate mechanisms - both can be enabled independently
|
| 960 |
+
|
| 961 |
+
# All metrics have 'rollout_corr/' prefix
|
| 962 |
+
print(f"Mean IS weight: {metrics['rollout_corr/rollout_is_mean']:.3f}")
|
| 963 |
+
print(f"Effective sample size: {metrics['rollout_corr/rollout_is_eff_sample_size']:.3f}")
|
| 964 |
+
print(f"RS masked fraction: {metrics['rollout_corr/rollout_rs_masked_fraction']:.3f}")
|
| 965 |
+
print(f"KL divergence: {metrics['rollout_corr/kl']:.3f}")
|
| 966 |
+
|
| 967 |
+
# Check IS weights for valid tokens (non-padding)
|
| 968 |
+
valid_weights = is_weights[response_mask.bool()]
|
| 969 |
+
print(f"\n✓ IS weights min (valid tokens): {valid_weights.min():.4f}")
|
| 970 |
+
print(f"✓ IS weights max (valid tokens): {valid_weights.max():.4f}")
|
| 971 |
+
print(f"✓ All valid IS weights > 0: {(valid_weights > 0).all()}")
|
| 972 |
+
print(f"✓ IS weights are capped at threshold: {(valid_weights <= 2.0).all()}")
|
| 973 |
+
|
| 974 |
+
# Check rejection via response_mask
|
| 975 |
+
rejected_tokens = (response_mask == 1) & (modified_response_mask == 0)
|
| 976 |
+
print(f"\n✓ Rejected {rejected_tokens.sum()} tokens via response_mask")
|
| 977 |
+
print(f"✓ Rejection sampling modifies response_mask (separate from IS weight truncation)")
|
| 978 |
+
print(f"✓ IS weights are always truncated to [0, threshold] after safety bounding")
|
| 979 |
+
|
| 980 |
+
# Check for warning conditions
|
| 981 |
+
if metrics['rollout_corr/rollout_is_mean'] < 0.5 or metrics['rollout_corr/rollout_is_mean'] > 2.0:
|
| 982 |
+
print("⚠️ Warning: Mean IS weight far from 1.0, significant off-policy gap detected")
|
| 983 |
+
|
| 984 |
+
if metrics['rollout_corr/rollout_is_eff_sample_size'] < 0.3:
|
| 985 |
+
print("⚠️ Warning: Low effective sample size, high weight concentration")
|
| 986 |
+
```
|
| 987 |
+
|
| 988 |
+
#### **Example: Monitoring Metrics During Training**
|
| 989 |
+
|
| 990 |
+
```python
|
| 991 |
+
# In your training loop
|
| 992 |
+
for epoch in range(num_epochs):
|
| 993 |
+
for batch_idx, batch in enumerate(dataloader):
|
| 994 |
+
# ... rollout phase ...
|
| 995 |
+
|
| 996 |
+
# Compute IS weights and get metrics
|
| 997 |
+
rollout_corr_config = config.algorithm.get("rollout_correction", None)
|
| 998 |
+
if rollout_corr_config is not None:
|
| 999 |
+
weights_proto, modified_response_mask, metrics = compute_rollout_correction_and_rejection_mask(
|
| 1000 |
+
old_log_prob=batch.old_log_prob,
|
| 1001 |
+
rollout_log_prob=batch.rollout_log_prob,
|
| 1002 |
+
response_mask=batch.response_mask,
|
| 1003 |
+
rollout_is=rollout_corr_config.get("rollout_is", None),
|
| 1004 |
+
rollout_is_threshold=rollout_corr_config.get("rollout_is_threshold", 2.0),
|
| 1005 |
+
rollout_rs=rollout_corr_config.get("rollout_rs", None),
|
| 1006 |
+
rollout_rs_threshold=rollout_corr_config.get("rollout_rs_threshold", None),
|
| 1007 |
+
)
|
| 1008 |
+
|
| 1009 |
+
# Log to tensorboard/wandb
|
| 1010 |
+
for metric_name, metric_value in metrics.items():
|
| 1011 |
+
logger.log_scalar(metric_name, metric_value, step=global_step)
|
| 1012 |
+
|
| 1013 |
+
# IMPORTANT: Update batch response_mask with rejection applied
|
| 1014 |
+
batch.response_mask = modified_response_mask
|
| 1015 |
+
|
| 1016 |
+
# Use IS weights in training (always safety-bounded, zeroed at padding)
|
| 1017 |
+
is_weights = weights_proto.batch["rollout_is_weights"]
|
| 1018 |
+
# ... apply weights to policy gradient ...
|
| 1019 |
+
```
|
| 1020 |
+
|
| 1021 |
+
#### **Example: Conditional Alerting Based on Metrics**
|
| 1022 |
+
|
| 1023 |
+
```python
|
| 1024 |
+
def check_rollout_correction_health(metrics, config):
|
| 1025 |
+
"""Check if Rollout Correction metrics indicate healthy training."""
|
| 1026 |
+
warnings = []
|
| 1027 |
+
|
| 1028 |
+
# Check mean IS weight
|
| 1029 |
+
mean_weight = metrics['rollout_corr/rollout_is_mean']
|
| 1030 |
+
if mean_weight < 0.5 or mean_weight > 2.0:
|
| 1031 |
+
warnings.append(f"Mean IS weight {mean_weight:.3f} is far from 1.0")
|
| 1032 |
+
|
| 1033 |
+
# Check effective sample size
|
| 1034 |
+
ess = metrics['rollout_corr/rollout_is_eff_sample_size']
|
| 1035 |
+
if ess < 0.3:
|
| 1036 |
+
warnings.append(f"Effective sample size {ess:.3f} is too low")
|
| 1037 |
+
|
| 1038 |
+
# Check standard deviation
|
| 1039 |
+
std = metrics['rollout_corr/rollout_is_std']
|
| 1040 |
+
if std > 1.0:
|
| 1041 |
+
warnings.append(f"IS weight std {std:.3f} is too high")
|
| 1042 |
+
|
| 1043 |
+
# Check KL divergence
|
| 1044 |
+
kl = metrics['rollout_corr/kl']
|
| 1045 |
+
if abs(kl) > 0.1:
|
| 1046 |
+
warnings.append(f"KL divergence {kl:.3f} indicates significant off-policy gap")
|
| 1047 |
+
|
| 1048 |
+
# Check chi-squared divergence
|
| 1049 |
+
if 'rollout_corr/chi2_token' in metrics:
|
| 1050 |
+
chi2_token = metrics['rollout_corr/chi2_token']
|
| 1051 |
+
if chi2_token > 1.0:
|
| 1052 |
+
warnings.append(f"Chi-squared divergence (token) {chi2_token:.3f} indicates severe distribution shift")
|
| 1053 |
+
|
| 1054 |
+
if warnings:
|
| 1055 |
+
print("⚠️ Rollout Correction Health Warnings:")
|
| 1056 |
+
for warning in warnings:
|
| 1057 |
+
print(f" - {warning}")
|
| 1058 |
+
return False
|
| 1059 |
+
else:
|
| 1060 |
+
print("✅ Rollout Correction metrics look healthy")
|
| 1061 |
+
return True
|
| 1062 |
+
|
| 1063 |
+
# Use in training
|
| 1064 |
+
_, _, metrics = compute_rollout_correction_and_rejection_mask(...)
|
| 1065 |
+
is_healthy = check_rollout_correction_health(metrics, config)
|
| 1066 |
+
|
| 1067 |
+
if not is_healthy:
|
| 1068 |
+
# Consider adjusting config or investigating issues
|
| 1069 |
+
print("Consider:")
|
| 1070 |
+
print(" - Tightening rollout_is_threshold")
|
| 1071 |
+
print(" - Switching to geometric aggregation level")
|
| 1072 |
+
print(" - Checking if rollout and training policies are too different")
|
| 1073 |
+
```
|
| 1074 |
+
|
| 1075 |
+
### Running Examples
|
| 1076 |
+
|
| 1077 |
+
Start with the basic token-level truncate configuration:
|
| 1078 |
+
|
| 1079 |
+
```bash
|
| 1080 |
+
bash examples/rollout_correction/run_with_rollout_corr.sh
|
| 1081 |
+
```
|
| 1082 |
+
|
| 1083 |
+
Monitor metrics for 1-2 epochs before adjusting parameters.
|
| 1084 |
+
|
| 1085 |
+
## Configuration Examples
|
| 1086 |
+
|
| 1087 |
+
### Example 1: IS Weights Only (Token Level)
|
| 1088 |
+
|
| 1089 |
+
```yaml
|
| 1090 |
+
algorithm:
|
| 1091 |
+
rollout_correction:
|
| 1092 |
+
rollout_is: token
|
| 1093 |
+
rollout_is_threshold: 2.0
|
| 1094 |
+
rollout_rs: null # No rejection sampling
|
| 1095 |
+
```
|
| 1096 |
+
|
| 1097 |
+
### Example 2: Rejection Sampling Only (No IS Weights)
|
| 1098 |
+
|
| 1099 |
+
```yaml
|
| 1100 |
+
algorithm:
|
| 1101 |
+
rollout_correction:
|
| 1102 |
+
rollout_is: null # No IS weights
|
| 1103 |
+
rollout_rs: token_k1
|
| 1104 |
+
rollout_rs_threshold: "0.5_2.0"
|
| 1105 |
+
```
|
| 1106 |
+
|
| 1107 |
+
### Example 3: Both IS and RS (Token RS)
|
| 1108 |
+
|
| 1109 |
+
```yaml
|
| 1110 |
+
algorithm:
|
| 1111 |
+
rollout_correction:
|
| 1112 |
+
rollout_is: token
|
| 1113 |
+
rollout_is_threshold: 2.0
|
| 1114 |
+
rollout_rs: token_k1
|
| 1115 |
+
rollout_rs_threshold: "0.5_2.0"
|
| 1116 |
+
```
|
| 1117 |
+
|
| 1118 |
+
### Example 5: Bypass Mode with PPO-clip (Default)
|
| 1119 |
+
|
| 1120 |
+
```yaml
|
| 1121 |
+
algorithm:
|
| 1122 |
+
rollout_correction:
|
| 1123 |
+
rollout_is: token
|
| 1124 |
+
rollout_is_threshold: 2.0
|
| 1125 |
+
rollout_rs: token_k1
|
| 1126 |
+
rollout_rs_threshold: "0.5_2.0"
|
| 1127 |
+
bypass_mode: true # Skip old_log_prob computation
|
| 1128 |
+
loss_type: ppo_clip # PPO clipped objective (default)
|
| 1129 |
+
```
|
| 1130 |
+
|
| 1131 |
+
**Skips expensive `actor.compute_log_prob()` forward pass. PPO ratio = π_θ/π_rollout handles IS.**
|
| 1132 |
+
|
| 1133 |
+
### Example 6: Bypass Mode with REINFORCE
|
| 1134 |
+
|
| 1135 |
+
```yaml
|
| 1136 |
+
algorithm:
|
| 1137 |
+
rollout_correction:
|
| 1138 |
+
rollout_is: sequence # Explicit IS correction in loss
|
| 1139 |
+
rollout_is_threshold: 2.0
|
| 1140 |
+
rollout_rs: null # Optional: can add rejection sampling
|
| 1141 |
+
bypass_mode: true
|
| 1142 |
+
loss_type: reinforce # REINFORCE with explicit IS weights
|
| 1143 |
+
```
|
| 1144 |
+
|
| 1145 |
+
**No PPO clipping, pure policy gradient with IS correction**
|
| 1146 |
+
|
| 1147 |
+
### Example 7: Bypass Mode with PPO-clip + Rejection Sampling
|
| 1148 |
+
|
| 1149 |
+
```yaml
|
| 1150 |
+
algorithm:
|
| 1151 |
+
rollout_correction:
|
| 1152 |
+
rollout_is: sequence # Computed for metrics
|
| 1153 |
+
rollout_is_threshold: 2.0
|
| 1154 |
+
rollout_rs: seq_max_k2 # Sequence max χ²/2 guard
|
| 1155 |
+
rollout_rs_threshold: 2.5
|
| 1156 |
+
bypass_mode: true
|
| 1157 |
+
loss_type: ppo_clip # PPO clipped objective (IS handled by ratio)
|
| 1158 |
+
```
|
| 1159 |
+
|
| 1160 |
+
**PPO clipping with rejection sampling. IS handled by PPO ratio (no explicit IS weights).**
|
| 1161 |
+
|
| 1162 |
+
## Troubleshooting
|
| 1163 |
+
|
| 1164 |
+
### Issue: High spread in IS weights
|
| 1165 |
+
|
| 1166 |
+
**Symptoms:** `rollout_is_std` > 1.0, `rollout_is_eff_sample_size` < 0.3
|
| 1167 |
+
|
| 1168 |
+
**Solutions:**
|
| 1169 |
+
|
| 1170 |
+
1. Switch from `sequence` to `geometric` level
|
| 1171 |
+
2. Tighten thresholds
|
| 1172 |
+
3. Verify rollout and training aren't too different
|
| 1173 |
+
|
| 1174 |
+
### Issue: Mean IS weight far from 1.0
|
| 1175 |
+
|
| 1176 |
+
**Symptoms:** `rollout_is_mean` < 0.5 or > 2.0
|
| 1177 |
+
|
| 1178 |
+
**Solutions:**
|
| 1179 |
+
|
| 1180 |
+
1. Verify `calculate_log_probs=True` is set
|
| 1181 |
+
2. Check rollout_log_probs are correctly passed
|
| 1182 |
+
3. Check for systematic distribution shift
|
| 1183 |
+
|
| 1184 |
+
### Debugging: Visualizing Metrics
|
| 1185 |
+
|
| 1186 |
+
**Example: Plot IS weight distribution**
|
| 1187 |
+
|
| 1188 |
+
```python
|
| 1189 |
+
import matplotlib.pyplot as plt
|
| 1190 |
+
import numpy as np
|
| 1191 |
+
|
| 1192 |
+
def plot_is_metrics(metrics_history):
|
| 1193 |
+
"""Plot rollout IS metrics over training steps."""
|
| 1194 |
+
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
|
| 1195 |
+
|
| 1196 |
+
# Plot 1: Mean IS weight over time
|
| 1197 |
+
axes[0, 0].plot(metrics_history['rollout_corr/rollout_is_mean'])
|
| 1198 |
+
axes[0, 0].axhline(y=1.0, color='r', linestyle='--', label='Ideal')
|
| 1199 |
+
axes[0, 0].set_title('Mean IS Weight')
|
| 1200 |
+
axes[0, 0].set_xlabel('Step')
|
| 1201 |
+
axes[0, 0].legend()
|
| 1202 |
+
|
| 1203 |
+
# Plot 2: Effective sample size
|
| 1204 |
+
axes[0, 1].plot(metrics_history['rollout_corr/rollout_is_eff_sample_size'])
|
| 1205 |
+
axes[0, 1].axhline(y=0.5, color='g', linestyle='--', label='Good')
|
| 1206 |
+
axes[0, 1].axhline(y=0.3, color='r', linestyle='--', label='Warning')
|
| 1207 |
+
axes[0, 1].set_title('Effective Sample Size')
|
| 1208 |
+
axes[0, 1].set_xlabel('Step')
|
| 1209 |
+
axes[0, 1].legend()
|
| 1210 |
+
|
| 1211 |
+
# Plot 3: KL divergence over time
|
| 1212 |
+
axes[1, 0].plot(metrics_history['rollout_corr/kl'], label='KL')
|
| 1213 |
+
axes[1, 0].plot(metrics_history['rollout_corr/k3_kl'], label='K3 KL')
|
| 1214 |
+
axes[1, 0].axhline(y=0, color='g', linestyle='--', alpha=0.3)
|
| 1215 |
+
axes[1, 0].set_title('KL Divergence')
|
| 1216 |
+
axes[1, 0].set_xlabel('Step')
|
| 1217 |
+
axes[1, 0].legend()
|
| 1218 |
+
|
| 1219 |
+
# Plot 4: PPL ratio over time
|
| 1220 |
+
axes[1, 1].plot(metrics_history['rollout_corr/ppl_ratio'])
|
| 1221 |
+
axes[1, 1].axhline(y=1.0, color='r', linestyle='--', label='Ideal')
|
| 1222 |
+
axes[1, 1].set_title('PPL Ratio (Training/Rollout)')
|
| 1223 |
+
axes[1, 1].set_xlabel('Step')
|
| 1224 |
+
axes[1, 1].legend()
|
| 1225 |
+
|
| 1226 |
+
# Plot 5: Chi-squared divergence
|
| 1227 |
+
if 'rollout_corr/chi2_token' in metrics_history:
|
| 1228 |
+
axes[1, 2].plot(metrics_history['rollout_corr/chi2_token'], label='Token-level')
|
| 1229 |
+
if 'rollout_corr/chi2_seq' in metrics_history:
|
| 1230 |
+
axes[1, 2].plot(metrics_history['rollout_corr/chi2_seq'], label='Seq-level')
|
| 1231 |
+
axes[1, 2].axhline(y=1.0, color='r', linestyle='--', label='Warning')
|
| 1232 |
+
axes[1, 2].set_title('Chi-squared Divergence')
|
| 1233 |
+
axes[1, 2].set_xlabel('Step')
|
| 1234 |
+
axes[1, 2].legend()
|
| 1235 |
+
else:
|
| 1236 |
+
axes[1, 2].axis('off')
|
| 1237 |
+
|
| 1238 |
+
plt.tight_layout()
|
| 1239 |
+
plt.savefig('rollout_is_metrics.png', dpi=150)
|
| 1240 |
+
print("Saved plot to rollout_is_metrics.png")
|
| 1241 |
+
```
|
| 1242 |
+
|
| 1243 |
+
**Example: Metric collection during training**
|
| 1244 |
+
|
| 1245 |
+
```python
|
| 1246 |
+
# Collect metrics over time
|
| 1247 |
+
metrics_history = {
|
| 1248 |
+
'rollout_corr/rollout_is_mean': [],
|
| 1249 |
+
'rollout_corr/rollout_is_eff_sample_size': [],
|
| 1250 |
+
'rollout_corr/kl': [],
|
| 1251 |
+
'rollout_corr/k3_kl': [],
|
| 1252 |
+
'rollout_corr/ppl_ratio': [],
|
| 1253 |
+
'rollout_corr/chi2_token': [],
|
| 1254 |
+
'rollout_corr/chi2_seq': [],
|
| 1255 |
+
}
|
| 1256 |
+
|
| 1257 |
+
# In training loop
|
| 1258 |
+
for step in range(num_steps):
|
| 1259 |
+
# ... compute IS weights and rejection mask ...
|
| 1260 |
+
_, _, metrics = compute_rollout_correction_and_rejection_mask(...)
|
| 1261 |
+
|
| 1262 |
+
# Store metrics
|
| 1263 |
+
for key in metrics_history.keys():
|
| 1264 |
+
if key in metrics:
|
| 1265 |
+
metrics_history[key].append(metrics[key])
|
| 1266 |
+
|
| 1267 |
+
# Plot every 100 steps
|
| 1268 |
+
if step % 100 == 0:
|
| 1269 |
+
plot_is_metrics(metrics_history)
|
| 1270 |
+
```
|
| 1271 |
+
|
| 1272 |
+
## Performance Impact
|
| 1273 |
+
|
| 1274 |
+
- **Memory overhead**: ~1% of model memory
|
| 1275 |
+
- **Computational overhead**: 1-3% depending on level
|
| 1276 |
+
- **Training stability**: Significantly improved when off-policy gap exists
|
| 1277 |
+
|
| 1278 |
+
## Testing
|
| 1279 |
+
|
| 1280 |
+
Run the test suite to verify everything works:
|
| 1281 |
+
|
| 1282 |
+
```bash
|
| 1283 |
+
# Basic unit tests
|
| 1284 |
+
python test_rollout_corr.py
|
| 1285 |
+
|
| 1286 |
+
# Integration tests (if pytest is available)
|
| 1287 |
+
pytest tests/trainer/ppo/test_rollout_corr_integration.py -v
|
| 1288 |
+
```
|
| 1289 |
+
|
| 1290 |
+
Expected output: All tests pass ✓
|
| 1291 |
+
|
| 1292 |
+
## Additional Resources
|
| 1293 |
+
|
| 1294 |
+
- **Implementation**: `verl/trainer/ppo/rollout_corr_helper.py`
|
| 1295 |
+
- **Examples**: `examples/rollout_correction/`
|
| 1296 |
+
- **DAPO Example**: `recipe/dapo/run_dapo_qwen2.5_32b_rollout_corr.sh`
|
| 1297 |
+
|
| 1298 |
+
## Summary
|
| 1299 |
+
|
| 1300 |
+
Rollout Correction provides a unified framework for handling general off-policy problems in RL:
|
| 1301 |
+
|
| 1302 |
+
- ✅ Corrects ANY distribution shift between data collection and training
|
| 1303 |
+
- ✅ Supports diverse scenarios: policy mismatch, staleness, replay buffers, off-policy algorithms
|
| 1304 |
+
- ✅ Numerical stability with safety bounds and rejection mechanisms
|
| 1305 |
+
- ✅ Comprehensive diagnostics: KL, perplexity, χ² divergence
|
| 1306 |
+
- ✅ Flexible methods from token-level to sequence-level aggregation
|
| 1307 |
+
- ✅ Memory-efficient implementation
|
| 1308 |
+
|
| 1309 |
+
## References
|
| 1310 |
+
|
| 1311 |
+
- **[Mathematical Formulations](rollout_corr_math.md)** - Detailed mathematical theory and derivations for all rollout correction methods
|
| 1312 |
+
- [When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch](https://richardli.xyz/rl-collapse) (see Blog Series above for parts 1-3)
|
| 1313 |
+
- [Your Efficient RL Framework Secretly Brings You Off-Policy RL Training](https://fengyao.notion.site/off-policy-rl)
|
code/RL_model/verl/verl_train/docs/algo/rollout_corr_math.md
ADDED
|
@@ -0,0 +1,954 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Mathematical Formulations of Rollout Correction Methods in `verl`
|
| 2 |
+
|
| 3 |
+
**Author:** [Yingru Li](https://richardli.xyz)
|
| 4 |
+
**Last updated:** 2025-11-04
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
> **📖 Documentation Structure**
|
| 9 |
+
> - **This document** - Mathematical theory: formulations, derivations, and algorithmic foundations
|
| 10 |
+
> - **[Rollout Correction Usage Guide](rollout_corr.md)** - Practical implementation: configurations, presets, troubleshooting
|
| 11 |
+
>
|
| 12 |
+
> Start here for theory and design rationale, refer to the usage guide for implementation.
|
| 13 |
+
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
### BibTeX Citation
|
| 17 |
+
|
| 18 |
+
```bibtex
|
| 19 |
+
@online{liu-li-2025-rl-collapse,
|
| 20 |
+
title = {When Speed Kills Stability: Demystifying {RL} Collapse from the Training-Inference Mismatch},
|
| 21 |
+
author = {Liu, Jiacai and Li, Yingru and Fu, Yuqian and Wang, Jiawei and Liu, Qian and Shen, Yu},
|
| 22 |
+
year = {2025},
|
| 23 |
+
month = sep,
|
| 24 |
+
url = {https://richardli.xyz/rl-collapse}
|
| 25 |
+
}
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
### Blog Series
|
| 29 |
+
|
| 30 |
+
- Main blog post: https://richardli.xyz/rl-collapse
|
| 31 |
+
- [Part 1: Why Mismatch Breaks LLM-RL](https://richardli.xyz/rl-collapse-1) (analytical framework using TV distance for bias and χ²-divergence for variance)
|
| 32 |
+
- [Part 2: The Gradient Estimator Trials](https://richardli.xyz/rl-collapse-2) (token-level vs sequence-level correction bias-variance tradeoff)
|
| 33 |
+
- [Part 3: When Math Meets Reality—Toxic Tails and Length Traps](https://richardli.xyz/rl-collapse-3) (why rejection over clipping, and geometric-level RS)
|
| 34 |
+
|
| 35 |
+
## Abstract
|
| 36 |
+
|
| 37 |
+
This document provides the definitive mathematical formulations for rollout correction methods in `verl`, following the natural progression from **REINFORCE** to **PPO** to **Decoupled PPO**.
|
| 38 |
+
|
| 39 |
+
Rollout correction provides a unified framework to handle **general off-policy problems** in RL training - any scenario where the data collection distribution differs from the training distribution.
|
| 40 |
+
|
| 41 |
+
**Applicable scenarios include:**
|
| 42 |
+
- **Policy mismatch**: Different precision (FP8 vs FP16 vs BF16 vs FP32), different backends (vLLM vs SGLang vs FSDP vs Megatron)
|
| 43 |
+
- **Temporal lag**: Model staleness, asynchronous rollout workers
|
| 44 |
+
- **Replay buffers**: Training on historical trajectories from earlier policy versions
|
| 45 |
+
- **Off-policy algorithms**: Behavioral cloning, DAPO, expert demonstrations
|
| 46 |
+
- **Data filtering**: Reweighting, preference learning, curriculum learning
|
| 47 |
+
|
| 48 |
+
---
|
| 49 |
+
|
| 50 |
+
## Table of Contents
|
| 51 |
+
|
| 52 |
+
1. [Theoretical Foundation: From REINFORCE to Decoupled PPO](#1-theoretical-foundation-from-reinforce-to-decoupled-ppo)
|
| 53 |
+
2. [Implementation in verl: The Three-Policy Framework](#2-implementation-in-verl-the-three-policy-framework)
|
| 54 |
+
3. [Algorithmic Components and Combinations](#3-algorithmic-components-and-combinations)
|
| 55 |
+
4. [Off-Policy Diagnostic Metrics](#4-off-policy-diagnostic-metrics)
|
| 56 |
+
5. [Summary and Decision Guide](#5-summary-and-decision-guide)
|
| 57 |
+
6. [Implementation References](#6-implementation-references)
|
| 58 |
+
|
| 59 |
+
---
|
| 60 |
+
|
| 61 |
+
## 1. Theoretical Foundation: From REINFORCE to Decoupled PPO
|
| 62 |
+
|
| 63 |
+
This section establishes the theoretical progression that `verl` implements.
|
| 64 |
+
|
| 65 |
+
### 1.1 REINFORCE: Policy Gradient Baseline
|
| 66 |
+
|
| 67 |
+
The REINFORCE algorithm ([Williams, 1992](https://doi.org/10.1007/BF00992696)) is the foundation of policy gradient methods.
|
| 68 |
+
|
| 69 |
+
**Vanilla REINFORCE (On-Policy)**
|
| 70 |
+
|
| 71 |
+
For trajectories $\tau = (s_0, a_0, s_1, a_1, \ldots, s_T, a_T)$ sampled from the current policy $\pi_\theta$, the policy gradient is:
|
| 72 |
+
|
| 73 |
+
$$
|
| 74 |
+
\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A_t \right]
|
| 75 |
+
$$
|
| 76 |
+
|
| 77 |
+
where $A_t$ is the advantage function at timestep $t$.
|
| 78 |
+
|
| 79 |
+
**Off-Policy REINFORCE**
|
| 80 |
+
|
| 81 |
+
When trajectories are sampled from a different behavior policy $\mu$, we apply importance sampling over the **joint trajectory distribution**:
|
| 82 |
+
|
| 83 |
+
$$
|
| 84 |
+
\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \mu} \left[ \frac{P_{\pi_\theta}(\tau)}{P_\mu(\tau)} \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A_t \right]
|
| 85 |
+
$$
|
| 86 |
+
|
| 87 |
+
where the trajectory-level importance weight is:
|
| 88 |
+
|
| 89 |
+
$$
|
| 90 |
+
\frac{P_{\pi_\theta}(\tau)}{P_\mu(\tau)} = \frac{p(s_0) \prod_{t=0}^T \pi_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t)}{p(s_0) \prod_{t=0}^T \mu(a_t|s_t) p(s_{t+1}|s_t, a_t)} = \prod_{t=0}^T \frac{\pi_\theta(a_t|s_t)}{\mu(a_t|s_t)}
|
| 91 |
+
$$
|
| 92 |
+
|
| 93 |
+
The transition dynamics $p(s_{t+1}|s_t, a_t)$ and initial state $p(s_0)$ cancel out, leaving only the product of per-step action probability ratios.
|
| 94 |
+
|
| 95 |
+
**Key properties:**
|
| 96 |
+
- **Off-policy capable**: Can learn from any behavior policy via importance sampling
|
| 97 |
+
- **No trust region**: Policy updates not constrained
|
| 98 |
+
|
| 99 |
+
**Implementation in verl:** The `bypass_pg_is` preset implements off-policy REINFORCE with truncated importance sampling.
|
| 100 |
+
|
| 101 |
+
### 1.2 PPO: Adding Trust Region Control
|
| 102 |
+
|
| 103 |
+
Proximal Policy Optimization ([Schulman et al., 2017](https://arxiv.org/abs/1707.06347)) adds a clipped surrogate objective:
|
| 104 |
+
|
| 105 |
+
$$
|
| 106 |
+
L_{\text{PPO}}(\theta) = -\mathbb{E}_{(s,a) \sim \mu} \left[ \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right]
|
| 107 |
+
$$
|
| 108 |
+
|
| 109 |
+
where $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\mu(a_t|s_t)}$ and $\epsilon$ is the clip range (typically 0.2).
|
| 110 |
+
|
| 111 |
+
**Key properties:**
|
| 112 |
+
- **Two policies**: $\mu$ (reference for clipping) and $\pi_\theta$ (being updated)
|
| 113 |
+
- **Trust region via clipping**: Limits policy update magnitude via ratio $r_t(\theta) = \frac{\pi_\theta}{\mu}$
|
| 114 |
+
|
| 115 |
+
### 1.3 Decoupled PPO: Achieving Batch Size Invariance
|
| 116 |
+
|
| 117 |
+
Decoupled PPO ([Hilton et al., 2021](https://arxiv.org/abs/2110.00641)) solves PPO's batch size sensitivity by **decoupling two roles**:
|
| 118 |
+
1. **Proximal policy** $\pi_{\text{prox}}$: The anchor policy for PPO clipping (controls policy update size)
|
| 119 |
+
2. **Behavior policy** $\mu$: The policy that collected the data (for off-policy correction via importance sampling)
|
| 120 |
+
|
| 121 |
+
**The problem**: Standard PPO controls policy update size via the ratio $\frac{\pi_\theta}{\pi_{\text{old}}}$, where $\pi_{\text{old}}$ is assumed to be both the proximal policy *and* the behavior policy. This coupling makes the algorithm sensitive to batch size because aggregating data from multiple workers or using replay buffers changes the effective behavior policy.
|
| 122 |
+
|
| 123 |
+
**The solution**: Decouple these two roles, leading to a **three-policy formulation**:
|
| 124 |
+
|
| 125 |
+
$$
|
| 126 |
+
L_{\text{DecoupledPPO}}(\theta) = -\mathbb{E}_{(s,a) \sim \mu} \left[ w_t \cdot \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right]
|
| 127 |
+
$$
|
| 128 |
+
|
| 129 |
+
where:
|
| 130 |
+
- $w_t = \frac{\pi_{\text{prox}}(a_t|s_t)}{\mu(a_t|s_t)}$: Importance sampling weight (corrects for behavior policy $\mu$). Here $\pi_{\text{prox}}$ is frozen during training, so $w_t$ is constant (no stopgrad operator needed).
|
| 131 |
+
- $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\text{prox}}(a_t|s_t)}$: PPO ratio (controls policy update size against proximal policy $\pi_{\text{prox}}$)
|
| 132 |
+
|
| 133 |
+
**Key properties**: By decoupling:
|
| 134 |
+
- **Batch size invariance**: Policy update control (via $\pi_{\text{prox}}$) is independent of data aggregation
|
| 135 |
+
- **Flexible behavior policy**: Any $\mu$ can be used (different workers, replay buffers, or stale checkpoints)
|
| 136 |
+
- **Stale data utilization**: Older trajectories can be corrected via importance sampling
|
| 137 |
+
- **Clipping preserved**: Clipping against $\pi_{\text{prox}}$ limits update magnitude
|
| 138 |
+
|
| 139 |
+
**This is the algorithm that `verl` implements via its three-policy framework.**
|
| 140 |
+
|
| 141 |
+
---
|
| 142 |
+
|
| 143 |
+
## 2. Implementation in verl: The Three-Policy Framework
|
| 144 |
+
|
| 145 |
+
The `verl` library implements decoupled PPO using three distinct policies, each serving a specific role.
|
| 146 |
+
|
| 147 |
+
### 2.1 Policy Roles and Notation
|
| 148 |
+
|
| 149 |
+
**$\pi_{\text{rollout}}$ (Behavior Policy $\mu$)**
|
| 150 |
+
The policy used for data collection. This is the behavior distribution $\mu$ from theory.
|
| 151 |
+
|
| 152 |
+
- **When created**: During rollout/data collection phase
|
| 153 |
+
- **Purpose**: Generate trajectories for training
|
| 154 |
+
- **Common sources**:
|
| 155 |
+
- Policy mismatch: Same weights, different implementation (precision, backend)
|
| 156 |
+
- Temporal lag: Stale checkpoint from async workers
|
| 157 |
+
- Replay buffer: Historical data from earlier iterations
|
| 158 |
+
- Off-policy algorithms: Expert demonstrations, auxiliary policies (DAPO)
|
| 159 |
+
- Data filtering: Reweighted or filtered data
|
| 160 |
+
- **Fixed**: Frozen during training on a batch
|
| 161 |
+
|
| 162 |
+
**$\pi_{\text{old}}$ (Proximal Policy $\pi_{\text{prox}}$)**
|
| 163 |
+
The reference policy for PPO clipping. This is the "proximal policy" from decoupled PPO theory.
|
| 164 |
+
|
| 165 |
+
- **When created**:
|
| 166 |
+
- **Decoupled mode**: Computed at start of training epoch via `actor.compute_log_prob()`
|
| 167 |
+
- **Bypass mode**: Set equal to $\pi_{\text{rollout}}$ (skips separate computation)
|
| 168 |
+
- **Purpose**:
|
| 169 |
+
- Anchor point for PPO clipping (controls policy update size)
|
| 170 |
+
- When separate from $\pi_{\text{rollout}}$: Enables batch size invariance and efficient use of stale data
|
| 171 |
+
- **Fixed**: Frozen during all PPO update epochs on the same batch
|
| 172 |
+
|
| 173 |
+
**$\pi_{\theta}$ (Current Policy)**
|
| 174 |
+
The policy being actively optimized during training.
|
| 175 |
+
|
| 176 |
+
- **Updated**: Every gradient step
|
| 177 |
+
- **Purpose**: The policy we're improving
|
| 178 |
+
|
| 179 |
+
### 2.2 Operating Modes
|
| 180 |
+
|
| 181 |
+
The three-policy framework can operate in two modes:
|
| 182 |
+
|
| 183 |
+
**Decoupled Mode (Three Policies)**
|
| 184 |
+
- Computes $\pi_{\text{old}}$ separately at the start of each training epoch
|
| 185 |
+
- **Algorithm**: Full decoupled PPO with three policies (mathematically correct)
|
| 186 |
+
- **Properties**: Achieves batch size invariance; separately corrects Drift 1 (rollout→old) and Drift 2 (old→current)
|
| 187 |
+
|
| 188 |
+
**Bypass Mode (Two Policies)**
|
| 189 |
+
- Sets $\pi_{\text{old}} = \pi_{\text{rollout}}$ (skips separate computation)
|
| 190 |
+
- **Algorithm**: Uses $\pi_{\text{rollout}}$ as both behavior policy and proximal policy (mathematically correct)
|
| 191 |
+
- **Key difference**: Proximal policy equals behavior policy, so no IS correction needed between them
|
| 192 |
+
- **Properties**: Faster (skips `actor.compute_log_prob()` call); does not achieve batch size invariance
|
| 193 |
+
|
| 194 |
+
### 2.3 Two Distribution Shifts
|
| 195 |
+
|
| 196 |
+
The three-policy framework handles two types of distribution drift:
|
| 197 |
+
|
| 198 |
+
**Drift 1: $\pi_{\text{rollout}} \to \pi_{\text{old}}$ (Off-Policy Gap)**
|
| 199 |
+
|
| 200 |
+
This is the distribution shift between the data collection policy and the training reference policy.
|
| 201 |
+
|
| 202 |
+
- **Nature**: Ranges from negligible (same checkpoint, minor differences) to severe (replay buffers, expert data)
|
| 203 |
+
- **Correction**: Importance sampling weight $w_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$
|
| 204 |
+
- **Optional**: Can be ignored (bypass mode) when negligible
|
| 205 |
+
|
| 206 |
+
**Drift 2: $\pi_{\text{old}} \to \pi_{\theta}$ (Policy Update Drift)**
|
| 207 |
+
|
| 208 |
+
This is the drift from policy parameter updates during training.
|
| 209 |
+
|
| 210 |
+
- **Nature**: Occurs as $\pi_\theta$ is updated via gradient descent
|
| 211 |
+
- **Correction**: PPO clipping on ratio $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}$
|
| 212 |
+
- **Universal**: Applies to both on-policy and off-policy training
|
| 213 |
+
|
| 214 |
+
### 2.4 Notation Summary
|
| 215 |
+
|
| 216 |
+
- $\pi_{\text{rollout}}$: Behavior policy (data collection)
|
| 217 |
+
- $\pi_{\text{old}}$: Proximal policy (PPO anchor)
|
| 218 |
+
- $\pi_{\theta}$: Current policy (being updated)
|
| 219 |
+
- $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$: Per-token IS ratio (corrects Drift 1)
|
| 220 |
+
- $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}$: PPO ratio (corrects Drift 2)
|
| 221 |
+
- $A_t$: Advantage at token $t$
|
| 222 |
+
- $T$: Set of valid tokens in a sequence
|
| 223 |
+
- $C_{\text{IS}}$: Upper threshold for IS weights (e.g., 2.0)
|
| 224 |
+
- $C_{\text{RS-upper}}$: Upper threshold for RS mask (e.g., 2.0)
|
| 225 |
+
- $C_{\text{RS-lower}}$: Lower threshold for RS mask (typically $1/C_{\text{RS-upper}}$)
|
| 226 |
+
- $\epsilon$: PPO clip range (typically 0.2)
|
| 227 |
+
|
| 228 |
+
---
|
| 229 |
+
|
| 230 |
+
## 3. Algorithmic Components and Combinations
|
| 231 |
+
|
| 232 |
+
The rollout correction framework in `verl` is built from **orthogonal components** that can be combined flexibly:
|
| 233 |
+
|
| 234 |
+
1. **Operating Mode**: How $\pi_{\text{old}}$ is computed (Decoupled vs Bypass)
|
| 235 |
+
2. **Loss Function**: PPO (with clipping) vs Pure IS (policy gradient only)
|
| 236 |
+
3. **IS/RS Aggregation Level**: Token, Sequence, or Geometric
|
| 237 |
+
|
| 238 |
+
This section explains each component and their valid combinations.
|
| 239 |
+
|
| 240 |
+
### 3.1 Operating Modes: Decoupled vs Bypass
|
| 241 |
+
|
| 242 |
+
The operating mode determines how the proximal policy $\pi_{\text{old}}$ is computed.
|
| 243 |
+
|
| 244 |
+
#### 3.1.1 Decoupled Mode (Three Policies)
|
| 245 |
+
|
| 246 |
+
**Configuration:** `bypass_mode = false`
|
| 247 |
+
|
| 248 |
+
**Policy setup:**
|
| 249 |
+
- $\pi_{\text{rollout}}$: Behavior policy (data collection)
|
| 250 |
+
- $\pi_{\text{old}}$: Proximal policy (computed via `actor.compute_log_prob()` at start of training epoch)
|
| 251 |
+
- $\pi_{\theta}$: Current policy (being updated)
|
| 252 |
+
|
| 253 |
+
**IS ratio:** $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ (corrects Drift 1: rollout→old)
|
| 254 |
+
|
| 255 |
+
**PPO ratio:** $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}$ (corrects Drift 2: old→current)
|
| 256 |
+
|
| 257 |
+
**Properties:**
|
| 258 |
+
- ✅ Achieves batch size invariance
|
| 259 |
+
- ✅ Separately corrects two distribution drifts
|
| 260 |
+
- ✅ Efficient stale data utilization
|
| 261 |
+
- ❌ Extra forward pass needed (`actor.compute_log_prob()`)
|
| 262 |
+
|
| 263 |
+
#### 3.1.2 Bypass Mode (Two Policies)
|
| 264 |
+
|
| 265 |
+
**Configuration:** `bypass_mode = true`
|
| 266 |
+
|
| 267 |
+
**Policy setup:**
|
| 268 |
+
- $\pi_{\text{rollout}}$: Behavior policy (data collection)
|
| 269 |
+
- $\pi_{\text{old}} = \pi_{\text{rollout}}$: Proximal policy equals behavior policy
|
| 270 |
+
- $\pi_{\theta}$: Current policy (being updated)
|
| 271 |
+
|
| 272 |
+
**Ratios:**
|
| 273 |
+
- **With PPO-clip loss** (`loss_type = "ppo_clip"`, default): PPO ratio $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ clips against rollout policy (IS handled by ratio)
|
| 274 |
+
- **With REINFORCE loss** (`loss_type = "reinforce"`): IS ratio $\rho_t = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ computed on-the-fly in loss function
|
| 275 |
+
|
| 276 |
+
**Properties:**
|
| 277 |
+
- ✅ Skips `actor.compute_log_prob()` call (faster)
|
| 278 |
+
- ✅ Handles off-policy correction via IS/RS (when using policy gradient with IS/RS)
|
| 279 |
+
- ✅ Uses two policies instead of three (π_rollout = π_old)
|
| 280 |
+
- ⚠️ Does not separate proximal policy from behavior policy (unlike decoupled mode)
|
| 281 |
+
|
| 282 |
+
---
|
| 283 |
+
|
| 284 |
+
### 3.2 Loss Functions: PPO vs Policy Gradient
|
| 285 |
+
|
| 286 |
+
#### 3.2.1 PPO Loss (with Clipping)
|
| 287 |
+
|
| 288 |
+
**Configuration:** `loss_type = "ppo_clip"` (default in bypass mode)
|
| 289 |
+
|
| 290 |
+
**Loss function:**
|
| 291 |
+
|
| 292 |
+
$$
|
| 293 |
+
L_{\text{PPO}}(\theta) = -\mathbb{E}_t \left[ w_t \cdot \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right]
|
| 294 |
+
$$
|
| 295 |
+
|
| 296 |
+
where:
|
| 297 |
+
- $w_t$: IS weight (depends on aggregation level, see Section 3.3). In decoupled mode, $w_t = \frac{\pi_{\text{old}}}{\pi_{\text{rollout}}}$ where $\pi_{\text{old}}$ is frozen, so $w_t$ is constant (no stopgrad needed). In bypass mode with PPO loss, no separate IS weights are typically computed.
|
| 298 |
+
- $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}$: PPO ratio
|
| 299 |
+
- $\epsilon$: Clip range (typically 0.2)
|
| 300 |
+
|
| 301 |
+
**Properties:**
|
| 302 |
+
- Trust region control via clipping
|
| 303 |
+
- Limits policy update magnitude
|
| 304 |
+
- Standard in RL training
|
| 305 |
+
|
| 306 |
+
#### 3.2.2 Policy Gradient Loss (with IS/RS Correction)
|
| 307 |
+
|
| 308 |
+
**Configuration:** `loss_type = "reinforce"` (requires `bypass_mode = true`)
|
| 309 |
+
|
| 310 |
+
**Loss function** (example with sequence-level IS):
|
| 311 |
+
|
| 312 |
+
$$
|
| 313 |
+
L_{\text{PG}}(\theta) = -\mathbb{E}_{(s,a) \sim \pi_{\text{rollout}}} \left[ \text{stopgrad}(w_{\text{seq}}(\theta)) \cdot \sum_{t \in T} \log \pi_{\theta}(a_t|s_t) \cdot A_t \right]
|
| 314 |
+
$$
|
| 315 |
+
|
| 316 |
+
where:
|
| 317 |
+
- $w_{\text{seq}}(\theta)$: Sample weight (IS or RS, see §3.3-3.4 for details)
|
| 318 |
+
- For IS: $w_{\text{seq}}(\theta) = \min\left( \prod_{t \in T} \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}, C_{\text{IS}} \right)$
|
| 319 |
+
- For RS: $w_{\text{seq}}(\theta) \in \{0, 1\}$ (binary rejection mask)
|
| 320 |
+
- **stopgrad operator**: The weight $w_{\text{seq}}(\theta)$ is computed using $\pi_\theta$ but treated as a **constant coefficient** when computing $\nabla_\theta L$. This is essential for importance sampling correctness (see theoretical justification below).
|
| 321 |
+
|
| 322 |
+
**Effective gradient:**
|
| 323 |
+
|
| 324 |
+
$$
|
| 325 |
+
\nabla_\theta L_{\text{PG}} = -\mathbb{E}_{(s,a) \sim \pi_{\text{rollout}}} \left[ \text{stopgrad}(w_{\text{seq}}(\theta)) \cdot \sum_{t \in T} \nabla_\theta \log \pi_{\theta}(a_t|s_t) \cdot A_t \right]
|
| 326 |
+
$$
|
| 327 |
+
|
| 328 |
+
**Theoretical Justification for stopgrad:**
|
| 329 |
+
|
| 330 |
+
The stopgrad operator is **mathematically required** by importance sampling theory, not an implementation detail. Here's why:
|
| 331 |
+
|
| 332 |
+
**The fundamental principle**: Importance sampling is a technique to **change the measure** (reweight samples from one distribution to estimate expectations under another), not to optimize the reweighting function itself.
|
| 333 |
+
|
| 334 |
+
**Formal derivation**:
|
| 335 |
+
|
| 336 |
+
1. **Original objective**: We want to optimize $J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[\sum_t A_t]$.
|
| 337 |
+
|
| 338 |
+
2. **Off-policy setting**: We only have samples from $\pi_{\text{rollout}}$, so we use importance sampling:
|
| 339 |
+
$$
|
| 340 |
+
J(\theta) = \mathbb{E}_{\tau \sim \pi_{\text{rollout}}} \left[ \underbrace{\frac{P_{\pi_\theta}(\tau)}{P_{\pi_{\text{rollout}}}(\tau)}}_{w(\tau;\theta)} \sum_t A_t \right]
|
| 341 |
+
$$
|
| 342 |
+
|
| 343 |
+
3. **Computing the policy gradient**: The correct gradient uses the **policy gradient theorem BEFORE importance sampling**:
|
| 344 |
+
$$
|
| 345 |
+
\begin{aligned}
|
| 346 |
+
\nabla_\theta J(\theta) &= \nabla_\theta \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_t A_t\right] \\
|
| 347 |
+
&= \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_t A_t \nabla_\theta \log \pi_\theta(a_t|s_t) \right] \quad \text{(policy gradient theorem)} \\
|
| 348 |
+
&= \mathbb{E}_{\tau \sim \pi_{\text{rollout}}} \left[ w(\tau;\theta) \sum_t A_t \nabla_\theta \log \pi_\theta(a_t|s_t) \right] \quad \text{(change of measure)}
|
| 349 |
+
\end{aligned}
|
| 350 |
+
$$
|
| 351 |
+
|
| 352 |
+
In the final line, $w(\tau;\theta)$ appears as a **multiplicative coefficient** from the change of measure, not as something we differentiate.
|
| 353 |
+
|
| 354 |
+
4. **What goes wrong without stopgrad**: If we naively compute $\nabla_\theta \left[w(\theta) \log \pi_\theta \right]$ in the loss, we get:
|
| 355 |
+
$$
|
| 356 |
+
\nabla_\theta \left[w(\theta) \log \pi_\theta \right] = \underbrace{\log \pi_\theta \cdot \nabla_\theta w(\theta)}_{\text{WRONG: bias term}} + \underbrace{w(\theta) \cdot \nabla_\theta \log \pi_\theta}_{\text{CORRECT: IS-weighted gradient}}
|
| 357 |
+
$$
|
| 358 |
+
|
| 359 |
+
The first term $\log \pi_\theta \cdot \nabla_\theta w(\theta)$ is an artifact of the computational trick (using loss times log-prob), not part of the true policy gradient. It biases the gradient estimator and optimizes a different objective than $J(\theta)$.
|
| 360 |
+
|
| 361 |
+
5. **Implementation requirement**: In PyTorch, to compute only the second term, we must use:
|
| 362 |
+
```python
|
| 363 |
+
loss = -advantages * log_prob * rollout_is_weights.detach() # stopgrad on weights
|
| 364 |
+
```
|
| 365 |
+
Without `.detach()`, autograd computes both terms, giving an incorrect gradient.
|
| 366 |
+
|
| 367 |
+
**Intuition**: The IS weight $w(\theta)$ tells us "how much to trust this sample" for estimating the gradient under $\pi_\theta$. We update $\theta$ to maximize the reweighted objective, but we don't update $\theta$ to maximize the weight itself—that would be circular reasoning (optimizing the correction factor instead of the actual objective).
|
| 368 |
+
|
| 369 |
+
**Properties:**
|
| 370 |
+
- **Algorithm**: Off-policy policy gradient with IS/RS correction
|
| 371 |
+
- **Loss types** (`loss_type` config option in bypass mode):
|
| 372 |
+
- `"ppo_clip"` (default): PPO clipped objective
|
| 373 |
+
- $L = -\mathbb{E}[\min(r \cdot A, \text{clip}(r) \cdot A)]$ where $r = \pi_\theta / \pi_{\text{rollout}}$
|
| 374 |
+
- Note: IS weights NOT applied (PPO ratio already handles it; would be double-counting)
|
| 375 |
+
- `"reinforce"`: Pure policy gradient with explicit IS weights, no PPO clipping
|
| 376 |
+
- $L = -\mathbb{E}[w \cdot \log \pi_\theta(a|s) \cdot A]$ where $w = \pi_\theta / \pi_{\text{rollout}}$
|
| 377 |
+
- **Always uses bypass mode**: Direct $\pi_\theta$ to $\pi_{\text{rollout}}$ comparison
|
| 378 |
+
- **Fast**: Single forward pass
|
| 379 |
+
|
| 380 |
+
**Implementation:** `compute_policy_loss_bypass_mode()` and `compute_policy_loss_reinforce()` in [core_algos.py](../../verl/trainer/ppo/core_algos.py)
|
| 381 |
+
|
| 382 |
+
---
|
| 383 |
+
|
| 384 |
+
### 3.3 IS/RS Aggregation Levels
|
| 385 |
+
|
| 386 |
+
The aggregation level determines how per-token probability ratios are combined into IS weights and/or rejection masks. This choice is **orthogonal to the operating mode** - you can use any aggregation level in either decoupled or bypass mode.
|
| 387 |
+
|
| 388 |
+
#### 3.3.1 Token-Level Aggregation
|
| 389 |
+
|
| 390 |
+
**IS weights:** $w_t = \min(\rho_t, C_{\text{IS}})$ where $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ (decoupled) or $\rho_t = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ (bypass/pure IS)
|
| 391 |
+
|
| 392 |
+
**Configuration:**
|
| 393 |
+
```python
|
| 394 |
+
rollout_is = "token" # IS weights
|
| 395 |
+
rollout_rs = "token_k1" # Optional: rejection sampling (ratio bounds)
|
| 396 |
+
```
|
| 397 |
+
|
| 398 |
+
**Properties:**
|
| 399 |
+
- Independent truncation per token
|
| 400 |
+
- Lower variance than sequence-level (product of ratios bounded individually)
|
| 401 |
+
- **Bias-variance tradeoff**: Token-level correction has $O(T^2 \Delta_{\max})$ bias where $T$ is sequence length and $\Delta_{\max}$ is maximum per-token policy divergence. This bias becomes significant when the rollout policy deviates substantially from the training policy. Sequence-level correction is unbiased but has higher variance.
|
| 402 |
+
- Typical threshold: 1.5 - 5.0
|
| 403 |
+
- Optional batch normalization (§3.6): Normalizes over all token weights to ensure $\mathbb{E}[\tilde{w}_t] = 1$ (reduces variance)
|
| 404 |
+
- **When to use**: Token-level works well when rollout policy stays within the trust region of training policy. When mismatch is significant, the bias becomes intolerable and sequence-level correction is preferred.
|
| 405 |
+
|
| 406 |
+
**Loss function (REINFORCE + Token IS):**
|
| 407 |
+
|
| 408 |
+
$$
|
| 409 |
+
L_{\text{REINFORCE+TIS}}(\theta) = -\mathbb{E}_t \left[ \text{stopgrad}(w_t) \cdot \log \pi_\theta(a_t|s_t) \cdot A_t \right]
|
| 410 |
+
$$
|
| 411 |
+
|
| 412 |
+
where $w_t = \min(\rho_t, C_{\text{IS}})$ are the truncated token-level IS weights. The stopgrad operator ensures that when computing $\nabla_\theta L$, the weights are treated as constants (see §3.2.2 for theoretical justification). This formulation can also be combined with PPO clipping by replacing the REINFORCE gradient with the clipped surrogate objective.
|
| 413 |
+
|
| 414 |
+
**Implementation:**
|
| 415 |
+
- IS weights: `compute_rollout_correction_weights()` in [rollout_corr_helper.py](../../verl/trainer/ppo/rollout_corr_helper.py#L325-L402)
|
| 416 |
+
- Loss: `compute_policy_loss()` in [core_algos.py](../../verl/trainer/ppo/core_algos.py#L812-L884)
|
| 417 |
+
|
| 418 |
+
#### 3.3.2 Sequence-Level Aggregation
|
| 419 |
+
|
| 420 |
+
**IS weights:** $w_{\text{seq}} = \min\left( \prod_{t \in T} \rho_t, C_{\text{IS}} \right) = \min\left( \exp\left(\sum_{t \in T} \log \rho_t\right), C_{\text{IS}} \right)$ (broadcast to all tokens)
|
| 421 |
+
|
| 422 |
+
**Configuration:**
|
| 423 |
+
```python
|
| 424 |
+
rollout_is = "sequence" # IS weights
|
| 425 |
+
rollout_rs = "seq_sum_k1" # Optional: rejection sampling
|
| 426 |
+
```
|
| 427 |
+
|
| 428 |
+
**Properties:**
|
| 429 |
+
- Multiplicative aggregation across sequence
|
| 430 |
+
- More sensitive to outliers than token-level
|
| 431 |
+
- Typical threshold: 2.0 - 10.0
|
| 432 |
+
- Optional batch normalization (§3.6): Normalizes over sequence means (one weight per sequence)
|
| 433 |
+
|
| 434 |
+
**Terminology Note:**
|
| 435 |
+
- **Seq-TIS (Sequence-Level Truncated IS)**: Clips the sequence ratio $\rho(\tau) \to \min(\rho(\tau), C)$. Maximizes information efficiency by extracting signal from all samples. Best for clean data with moderate mismatch.
|
| 436 |
+
- **Seq-MIS (Sequence-Level Masked IS)**: Rejects (masks) sequences with $\rho(\tau) > C$ instead of clipping. Acts as a hard trust region filter. Best for severe mismatch or when the distribution tail is "toxic" (contains garbage/adversarial samples rather than signal).
|
| 437 |
+
|
| 438 |
+
**Loss function (REINFORCE + Sequence IS):**
|
| 439 |
+
|
| 440 |
+
$$
|
| 441 |
+
L_{\text{REINFORCE+SeqIS}}(\theta) = -\mathbb{E}_t \left[ \text{stopgrad}(w_{\text{seq}}) \cdot \log \pi_\theta(a_t|s_t) \cdot A_t \right]
|
| 442 |
+
$$
|
| 443 |
+
|
| 444 |
+
where $w_{\text{seq}}$ is broadcast to all tokens in the sequence. The stopgrad operator ensures correct IS gradient computation (see §3.2.2). This formulation can also be combined with PPO clipping.
|
| 445 |
+
|
| 446 |
+
#### 3.3.3 Geometric Mean Aggregation (Geo-RS)
|
| 447 |
+
|
| 448 |
+
**Geometric mean ratio:** $\rho_{\text{geo}} = \exp\left( \frac{1}{|T|} \sum_{t \in T} \log \rho_t \right) = \left(\prod_{t \in T} \rho_t\right)^{1/|T|}$ (broadcast to all tokens)
|
| 449 |
+
|
| 450 |
+
**Configuration:**
|
| 451 |
+
```python
|
| 452 |
+
rollout_is = null # No IS weights, pure rejection
|
| 453 |
+
rollout_rs = "seq_mean_k1" # Geometric mean rejection sampling (ratio bounds)
|
| 454 |
+
```
|
| 455 |
+
|
| 456 |
+
**Properties:**
|
| 457 |
+
- Length-invariant (normalizes by sequence length)
|
| 458 |
+
- Ideal ratio = 1.0 (policies match)
|
| 459 |
+
- Typical bounds: `"0.999_1.001"` (~±0.1%)
|
| 460 |
+
- **Used for rejection sampling only, not IS weighting**
|
| 461 |
+
|
| 462 |
+
**The Length Trap Problem:**
|
| 463 |
+
|
| 464 |
+
Standard IS estimators have a systematic **length bias** that penalizes long sequences. The importance ratio $\rho(y)$ is multiplicative:
|
| 465 |
+
|
| 466 |
+
$$
|
| 467 |
+
\rho(y) = \prod_{t=1}^T \frac{\pi(y_t|y_{<t})}{\mu(y_t|y_{<t})}
|
| 468 |
+
$$
|
| 469 |
+
|
| 470 |
+
Assume the new policy $\pi$ differs slightly from $\mu$, with average per-token ratio $\approx 1.1$:
|
| 471 |
+
- **Short sequence (10 tokens):** $\rho \approx 1.1^{10} \approx 2.6$ → fits within threshold, **kept**
|
| 472 |
+
- **Long sequence (100 tokens):** $\rho \approx 1.1^{100} \approx 13,780$ → explodes past threshold, **rejected**
|
| 473 |
+
|
| 474 |
+
This creates **Context Collapse**: the model preferentially learns from short, shallow answers and rejects long chains of thought—even if per-step quality is identical. For reasoning models (CoT) and agents, this effectively penalizes "thinking too long."
|
| 475 |
+
|
| 476 |
+
**Geo-RS Solution:**
|
| 477 |
+
|
| 478 |
+
Geometric-level rejection normalizes by sequence length, converting the extensive property (total probability product) to an intensive property (average per-token drift):
|
| 479 |
+
|
| 480 |
+
$$
|
| 481 |
+
\rho_{\text{geo}}(y) = \rho(y)^{1/T}
|
| 482 |
+
$$
|
| 483 |
+
|
| 484 |
+
Now both sequences have the same "trust score":
|
| 485 |
+
- **Short (10 tokens):** $(1.1^{10})^{1/10} = 1.1$
|
| 486 |
+
- **Long (100 tokens):** $(1.1^{100})^{1/100} = 1.1$
|
| 487 |
+
|
| 488 |
+
**Why tight thresholds?**
|
| 489 |
+
For 100 tokens with per-token log-ratio = 0.01 each:
|
| 490 |
+
- Arithmetic product ratio: $e^{100 \times 0.01} \approx 2.7$
|
| 491 |
+
- Geometric ratio: $e^{0.01} \approx 1.010$
|
| 492 |
+
|
| 493 |
+
A ratio bound of `"0.999_1.001"` rejects sequences whose average per-token log-deviation exceeds ≈0.1%.
|
| 494 |
+
|
| 495 |
+
**Loss function (REINFORCE + Geometric RS):**
|
| 496 |
+
|
| 497 |
+
$$
|
| 498 |
+
L_{\text{GeoRS}}(\theta) = -\mathbb{E}_{(s,a) \mid \text{seq} \in \mathcal{A}_{\text{geo}}} \left[ \sum_{t \in T} \log \pi_\theta(a_t|s_t) \cdot A_t \right]
|
| 499 |
+
$$
|
| 500 |
+
|
| 501 |
+
where $\mathcal{A}_{\text{geo}} = \{ \text{seq} : C_{\text{RS-lower}} \leq \rho_{\text{geo}} \leq C_{\text{RS-upper}} \}$ is the acceptance set (rejection mask). No IS weights are used, so no stopgrad needed. This formulation can also be combined with PPO clipping.
|
| 502 |
+
|
| 503 |
+
**Combined Estimator (Geo-RS-Token-TIS):**
|
| 504 |
+
|
| 505 |
+
For best results, combine the **Geometric Filter** (length-invariant validity check) with **Token-level IS weights** (lower variance):
|
| 506 |
+
|
| 507 |
+
$$
|
| 508 |
+
\hat{g}_{\text{geo-rs-token-tis}}(y) = \underbrace{\mathbb{I}\left( C_{\text{low}} \le \rho(y)^{1/T} \le C_{\text{high}} \right)}_{\text{Geometric Filter}} \cdot \prod_t \min(\rho_t, C) \cdot f(y)
|
| 509 |
+
$$
|
| 510 |
+
|
| 511 |
+
This is implemented by combining `rollout_rs="seq_mean_k1"` with `rollout_is="token"`.
|
| 512 |
+
|
| 513 |
+
#### 3.3.4 K2 Divergence Aggregation
|
| 514 |
+
|
| 515 |
+
**Per-token statistic:**
|
| 516 |
+
|
| 517 |
+
$$
|
| 518 |
+
K2_t = \frac{1}{2} \left(\log \rho_t\right)^2
|
| 519 |
+
$$
|
| 520 |
+
|
| 521 |
+
where $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ and the implementation clips $\log \rho_t$ to $[-20, 20]$ for numerical safety.
|
| 522 |
+
|
| 523 |
+
**Sequence aggregations (share the same per-token $K2_t$):**
|
| 524 |
+
- `seq_sum_k2`: $K2_{\text{sum}} = \sum_{t \in T} K2_t$
|
| 525 |
+
- `seq_mean_k2`: $K2_{\text{mean}} = \frac{1}{|T|} \sum_{t \in T} K2_t$
|
| 526 |
+
- `seq_max_k2`: $K2_{\text{max}} = \max_{t \in T} K2_t$
|
| 527 |
+
|
| 528 |
+
**Configuration:**
|
| 529 |
+
```python
|
| 530 |
+
rollout_is = null # Optional: pair with token IS weights for lower variance
|
| 531 |
+
rollout_rs = "token_k2" # or "seq_sum_k2", "seq_mean_k2", "seq_max_k2"
|
| 532 |
+
rollout_rs_threshold = 2.0 # Positive upper bound only
|
| 533 |
+
```
|
| 534 |
+
|
| 535 |
+
**Properties:**
|
| 536 |
+
- Symmetric quadratic penalty in $\log \rho_t$; equals zero when policies match.
|
| 537 |
+
- Approximates $\tfrac{1}{2}\operatorname{Var}[\log \rho]$ for small policy drift, making it a smooth detector of mismatch.
|
| 538 |
+
- Upper-threshold only: typical ranges are 1.5-3.0 for `token_k2`, 2.0-2.5 for `seq_mean_k2`, and 2.5-4.0 for `seq_sum_k2`.
|
| 539 |
+
- `seq_max_k2` isolates single-token spikes even when the rest of the sequence is clean.
|
| 540 |
+
- Can co-exist with token-level IS weights (`rollout_is="token"`) to keep useful samples while clipping variance.
|
| 541 |
+
|
| 542 |
+
**Combined Estimator (K2-RS-Token-TIS):**
|
| 543 |
+
|
| 544 |
+
For combined filtering and weighting, let $K2_{\text{agg}}$ denote the selected aggregation (token, sum, mean, or max):
|
| 545 |
+
|
| 546 |
+
$$
|
| 547 |
+
\hat{g}_{\text{k2-rs-token-tis}}(y) = \underbrace{\mathbb{I}\left( K2_{\text{agg}}(y) \le C_{\text{k2}} \right)}_{\text{K2 Filter}} \cdot \prod_t \min(\rho_t, C) \cdot f(y)
|
| 548 |
+
$$
|
| 549 |
+
|
| 550 |
+
This is implemented via `rollout_rs="seq_mean_k2"` (or another `k2` mode) together with `rollout_is="token"`.
|
| 551 |
+
|
| 552 |
+
#### 3.3.5 K3 Divergence Aggregation
|
| 553 |
+
|
| 554 |
+
**K3 divergence at sequence level:**
|
| 555 |
+
|
| 556 |
+
$$
|
| 557 |
+
K3_{\text{seq}} = \frac{1}{|T|} \sum_{t \in T} \left( \rho_t - \log \rho_t - 1 \right)
|
| 558 |
+
$$
|
| 559 |
+
|
| 560 |
+
where $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$ is the per-token ratio.
|
| 561 |
+
|
| 562 |
+
**K3 equals the reverse KL:** In expectation, $K3 = \text{KL}(\pi_{\text{rollout}} \| \pi_{\text{old}})$. This follows from:
|
| 563 |
+
- $\mathbb{E}_{\pi_\text{rollout}}[\rho] = 1$
|
| 564 |
+
- $\mathbb{E}_{\pi_\text{rollout}}[\log \rho] = -\text{KL}(\pi_{\text{rollout}} \| \pi_{\text{old}})$
|
| 565 |
+
- Therefore: $K3 = 1 - (-\text{KL}) - 1 = \text{KL}(\pi_{\text{rollout}} \| \pi_{\text{old}})$
|
| 566 |
+
|
| 567 |
+
**Configuration:**
|
| 568 |
+
```python
|
| 569 |
+
rollout_is = null # No IS weights, pure rejection
|
| 570 |
+
rollout_rs = "seq_mean_k3" # K3 rejection sampling
|
| 571 |
+
```
|
| 572 |
+
|
| 573 |
+
**Properties:**
|
| 574 |
+
- K3 divergence is always >= 0 per token (equals 0 when ρ = 1)
|
| 575 |
+
- More stable than geometric ratio checks because each token term is non-negative
|
| 576 |
+
- Only upper threshold applies (no lower threshold since K3 >= 0)
|
| 577 |
+
- Typical threshold: 0.001 - 0.01
|
| 578 |
+
|
| 579 |
+
**Why K3 over geometric ratio?**
|
| 580 |
+
- Geometric ratio uses average log-ratio; small numerical bias can flip sign
|
| 581 |
+
- K3 = E[ρ - log ρ - 1] is non-negative per token, offering a smoother detector
|
| 582 |
+
- Both estimate the same quantity: KL(π_rollout || π_old)
|
| 583 |
+
- For small divergences, K3 ≈ 0.5 × Var(log_ratio)
|
| 584 |
+
|
| 585 |
+
**Combined Estimator (K3-RS-Token-TIS):**
|
| 586 |
+
|
| 587 |
+
For best results, combine K3 filter with token-level IS weights:
|
| 588 |
+
|
| 589 |
+
$$
|
| 590 |
+
\hat{g}_{\text{k3-rs-token-tis}}(y) = \underbrace{\mathbb{I}\left( K3_{\text{seq}} \le C_{\text{k3}} \right)}_{\text{K3 Filter}} \cdot \prod_t \min(\rho_t, C) \cdot f(y)
|
| 591 |
+
$$
|
| 592 |
+
|
| 593 |
+
This is implemented by combining `rollout_rs="k3"` with `rollout_is="token"`.
|
| 594 |
+
|
| 595 |
+
|
| 596 |
+
---
|
| 597 |
+
|
| 598 |
+
### 3.4 Batch Normalization
|
| 599 |
+
|
| 600 |
+
An optional variance reduction technique that normalizes IS weights to have mean 1.0 within each batch.
|
| 601 |
+
|
| 602 |
+
**Configuration:**
|
| 603 |
+
```python
|
| 604 |
+
rollout_is_batch_normalize = True # Default: False
|
| 605 |
+
```
|
| 606 |
+
|
| 607 |
+
**Normalization formula (aggregation-aware):**
|
| 608 |
+
|
| 609 |
+
For **token-level IS** (§3.3.1):
|
| 610 |
+
|
| 611 |
+
$$
|
| 612 |
+
\tilde{w}_t = \frac{w_t}{\frac{1}{\sum_{i,t} m_{i,t}} \sum_{i,t} w_{i,t} \cdot m_{i,t}}
|
| 613 |
+
$$
|
| 614 |
+
|
| 615 |
+
where $w_{i,t}$ are truncated token IS weights, $m_{i,t}$ is the response mask, and normalization is over **all tokens**.
|
| 616 |
+
|
| 617 |
+
For **sequence-level IS** (§3.3.2):
|
| 618 |
+
|
| 619 |
+
$$
|
| 620 |
+
\tilde{w}_i = \frac{w_i}{\frac{1}{B}\sum_{j=1}^B \bar{w}_j}
|
| 621 |
+
$$
|
| 622 |
+
|
| 623 |
+
where $\bar{w}_j = \frac{1}{T_j}\sum_{t=1}^{T_j} w_{j,t} \cdot m_{j,t}$ is the per-sequence mean (all tokens in a sequence have the same weight), and normalization is over **sequences**.
|
| 624 |
+
|
| 625 |
+
**Properties:**
|
| 626 |
+
- Applied **after** truncation to preserve truncation semantics
|
| 627 |
+
- Ensures $\mathbb{E}[\tilde{w}] = 1$ within each batch
|
| 628 |
+
- **Aggregation-aware**: Token-level normalizes over tokens; sequence-level normalizes over sequences
|
| 629 |
+
- Uses `masked_mean` to respect padding tokens
|
| 630 |
+
- Reduces gradient magnitude variance by removing random batch-level scale fluctuations
|
| 631 |
+
|
| 632 |
+
**Metrics:**
|
| 633 |
+
- `rollout_is_batch_norm_factor`: The normalization factor applied (batch mean before normalization)
|
| 634 |
+
|
| 635 |
+
**Implementation:** [rollout_corr_helper.py](../../verl/trainer/ppo/rollout_corr_helper.py#L401-L421)
|
| 636 |
+
|
| 637 |
+
---
|
| 638 |
+
|
| 639 |
+
### 3.5 Rejection Sampling (RS)
|
| 640 |
+
|
| 641 |
+
Rejection sampling can be added to **any combination** of operating mode and aggregation level. It modifies the `response_mask` to exclude outlier tokens/sequences.
|
| 642 |
+
|
| 643 |
+
**Configuration examples:**
|
| 644 |
+
```python
|
| 645 |
+
rollout_rs = "token_k1" # Token-level ratio bounds
|
| 646 |
+
rollout_rs_threshold = "0.6_1.6"
|
| 647 |
+
|
| 648 |
+
rollout_rs = "seq_sum_k1" # Sequence sum of log ratios
|
| 649 |
+
rollout_rs_threshold = "0.5_2.0"
|
| 650 |
+
|
| 651 |
+
rollout_rs = "seq_mean_k3" # Sequence mean of K3 divergence
|
| 652 |
+
rollout_rs_threshold = 0.01
|
| 653 |
+
```
|
| 654 |
+
|
| 655 |
+
**Acceptance set:**
|
| 656 |
+
- **Token-level**: $\mathcal{A}_{\text{token}} = \{ t : C_{\text{RS-lower}} \leq \rho_t \leq C_{\text{RS-upper}} \}$
|
| 657 |
+
- **Sequence-level**: $\mathcal{A}_{\text{seq}} = \{ \text{seq} : C_{\text{RS-lower}} \leq \prod_{t \in T} \rho_t \leq C_{\text{RS-upper}} \}$
|
| 658 |
+
- **Geometric**: $\mathcal{A}_{\text{geo}} = \{ \text{seq} : C_{\text{RS-lower}} \leq \rho_{\text{geo}} \leq C_{\text{RS-upper}} \}$
|
| 659 |
+
|
| 660 |
+
**Properties:**
|
| 661 |
+
- Separate from IS weighting (can use RS without IS)
|
| 662 |
+
- Reduces effective sample size
|
| 663 |
+
- Filters extreme outliers
|
| 664 |
+
|
| 665 |
+
**Implementation:** `compute_rollout_rejection_mask()` in [rollout_corr_helper.py](../../verl/trainer/ppo/rollout_corr_helper.py#L80-L188)
|
| 666 |
+
|
| 667 |
+
---
|
| 668 |
+
|
| 669 |
+
### 3.6 Combination Matrix
|
| 670 |
+
|
| 671 |
+
**Key insight:** Estimators (how IS/RS is computed) and operating modes (decoupled PPO vs bypass PG) are **orthogonal**. Any estimator can be combined with any operating mode.
|
| 672 |
+
|
| 673 |
+
#### Estimator × Operating Mode
|
| 674 |
+
|
| 675 |
+
| Estimator | Configuration | Compatible Modes |
|
| 676 |
+
|-----------|---------------|------------------|
|
| 677 |
+
| **Token-TIS** | `rollout_is="token"` | Decoupled PPO, Bypass PG |
|
| 678 |
+
| **Seq-TIS** | `rollout_is="sequence"` | Decoupled PPO, Bypass PG |
|
| 679 |
+
| **Seq-MIS** | `rollout_is="sequence"` + `rollout_rs="seq_sum_k1"` | Decoupled PPO, Bypass PG |
|
| 680 |
+
| **Geo-RS** | `rollout_rs="seq_mean_k1"` (geometric mean) | Decoupled PPO, Bypass PG |
|
| 681 |
+
| **Geo-RS-Token-TIS** | `rollout_is="token"` + `rollout_rs="seq_mean_k1"` | Decoupled PPO, Bypass PG |
|
| 682 |
+
| **K3-RS** | `rollout_rs="seq_mean_k3"` | Decoupled PPO, Bypass PG |
|
| 683 |
+
| **K3-RS-Token-TIS** | `rollout_is="token"` + `rollout_rs="seq_mean_k3"` | Decoupled PPO, Bypass PG |
|
| 684 |
+
|
| 685 |
+
**Note:** In bypass mode, `loss_type` controls the loss function. Use "ppo_clip" (default) or "reinforce".
|
| 686 |
+
|
| 687 |
+
#### Available Preset Methods
|
| 688 |
+
|
| 689 |
+
| Preset Method | Estimator | Mode | Properties |
|
| 690 |
+
|---------------|-----------|------|------------|
|
| 691 |
+
| **Decoupled PPO Mode** (3 policies: π_rollout, π_old, π_θ) |
|
| 692 |
+
| `decoupled_token_is()` | Token-TIS | Decoupled PPO | Per-token IS weights |
|
| 693 |
+
| `decoupled_seq_is()` | Seq-TIS | Decoupled PPO | Sequence-level IS weights |
|
| 694 |
+
| `decoupled_seq_is_rs()` | Seq-MIS | Decoupled PPO | Sequence IS + sequence RS |
|
| 695 |
+
| `decoupled_geo_rs()` | Geo-RS | Decoupled PPO | Geometric RS + seq\_max\_k2 guard |
|
| 696 |
+
| `decoupled_geo_rs_token_tis()` | Geo-RS-Token-TIS | Decoupled PPO | Geometric filter + token IS |
|
| 697 |
+
| **K3 KL Estimator** (more stable for small KL values) |
|
| 698 |
+
| `decoupled_k3_rs()` | K3-RS | Decoupled PPO | K3 rejection, no IS weights |
|
| 699 |
+
| `decoupled_k3_rs_token_tis()` | K3-RS-Token-TIS | Decoupled PPO | K3 filter + token clipped weight |
|
| 700 |
+
| **Bypass Mode (PPO-clip)** (ratio handles IS, RS masks outliers) |
|
| 701 |
+
| `bypass_ppo_clip()` | - | Bypass (PPO-clip) | PPO-clip only |
|
| 702 |
+
| `bypass_ppo_clip_geo_rs()` | Geo-RS | Bypass (PPO-clip) | PPO-clip + Geo-RS (ratio) |
|
| 703 |
+
| `bypass_ppo_clip_k3_rs()` | K3-RS | Bypass (PPO-clip) | PPO-clip + K3-RS |
|
| 704 |
+
| **Bypass Mode (REINFORCE)** (explicit IS weights, no PPO clipping) |
|
| 705 |
+
| `bypass_pg_is()` | Seq-TIS | Bypass (REINFORCE) | REINFORCE + Seq IS |
|
| 706 |
+
| `bypass_pg_geo_rs()` | Geo-RS | Bypass (REINFORCE) | REINFORCE + Geo-RS (ratio) |
|
| 707 |
+
| `bypass_pg_geo_rs_token_tis()` | Geo-RS-Token-TIS | Bypass (REINFORCE) | REINFORCE + Geo filter + token IS |
|
| 708 |
+
| **Other** |
|
| 709 |
+
| `disabled()` | - | - | Metrics only |
|
| 710 |
+
|
| 711 |
+
**Note:** Bypass mode sets π_old = π_rollout and uses `loss_type` to select the loss function.
|
| 712 |
+
|
| 713 |
+
#### Additional Supported Combinations (Manual Configuration)
|
| 714 |
+
|
| 715 |
+
These combinations are **fully supported** but require manual configuration:
|
| 716 |
+
|
| 717 |
+
**1. Token IS + Token RS**
|
| 718 |
+
```python
|
| 719 |
+
config = RolloutCorrectionConfig(
|
| 720 |
+
rollout_is="token",
|
| 721 |
+
rollout_is_threshold=2.0,
|
| 722 |
+
rollout_rs="token_k1",
|
| 723 |
+
rollout_rs_threshold="0.5_2.0",
|
| 724 |
+
)
|
| 725 |
+
```
|
| 726 |
+
**Properties:** Token-level IS weights + token-level RS mask.
|
| 727 |
+
|
| 728 |
+
**2. Pure Token RS**
|
| 729 |
+
```python
|
| 730 |
+
config = RolloutCorrectionConfig(
|
| 731 |
+
rollout_is=None,
|
| 732 |
+
rollout_rs="token_k1",
|
| 733 |
+
rollout_rs_threshold="0.5_2.0",
|
| 734 |
+
)
|
| 735 |
+
```
|
| 736 |
+
**Properties:** Token-level RS mask only, no IS weights.
|
| 737 |
+
|
| 738 |
+
**3. Pure Sequence RS**
|
| 739 |
+
```python
|
| 740 |
+
config = RolloutCorrectionConfig(
|
| 741 |
+
rollout_is=None,
|
| 742 |
+
rollout_rs="seq_sum_k1",
|
| 743 |
+
rollout_rs_threshold="0.5_2.0",
|
| 744 |
+
)
|
| 745 |
+
```
|
| 746 |
+
**Properties:** Sequence-level RS mask only, no IS weights.
|
| 747 |
+
|
| 748 |
+
**Key properties:**
|
| 749 |
+
- Any IS aggregation level (token/sequence) can be used in either decoupled or bypass mode
|
| 750 |
+
- Rejection sampling can be added to any combination
|
| 751 |
+
- Geometric aggregation is typically used for RS only (not IS weighting)
|
| 752 |
+
- Pure RS (`bypass_pg_rs`) uses bypass + geometric RS with `loss_type="reinforce"` for REINFORCE (no IS weights)
|
| 753 |
+
- All combinations in the table above are valid and supported by the implementation
|
| 754 |
+
|
| 755 |
+
---
|
| 756 |
+
|
| 757 |
+
### 3.7 Common Implementation Mistake
|
| 758 |
+
|
| 759 |
+
#### Incorrect LLM-RL Implementation (PPO Without Rollout Correction)
|
| 760 |
+
|
| 761 |
+
**Theory:** Naive LLM-RL implementation that incorrectly applies PPO by **ignoring the actual rollout policy** and assuming $\pi_{\text{old}} = \pi_{\text{rollout}}$.
|
| 762 |
+
|
| 763 |
+
**Note:** This incorrect implementation pattern was identified in [Liu, Li, et al. (2025)](https://richardli.xyz/rl-collapse) as a key cause of training instability in LLM-RL systems, motivating the development of this rollout correction framework.
|
| 764 |
+
|
| 765 |
+
**Loss Function:**
|
| 766 |
+
|
| 767 |
+
$$
|
| 768 |
+
L_{\text{PPO}}(\theta) = -\mathbb{E}_t \left[ \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right]
|
| 769 |
+
$$
|
| 770 |
+
|
| 771 |
+
where $r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)}$ (ignores $\pi_{\text{rollout}}$).
|
| 772 |
+
|
| 773 |
+
**Why it's wrong:**
|
| 774 |
+
- **Ignores $\pi_{\text{rollout}}$**: Uses $\pi_{\text{old}}$ as behavior policy instead of actual $\pi_{\text{rollout}}$
|
| 775 |
+
- **Policy mismatch**: In LLM-RL, rollout typically uses different precision/backend/checkpoint than training, causing $\pi_{\text{rollout}} \neq \pi_{\text{old}}$ even with same model weights
|
| 776 |
+
- **Not PPO's fault**: PPO itself is correct; the issue is the incorrect assumption
|
| 777 |
+
|
| 778 |
+
**Correct alternatives:**
|
| 779 |
+
1. **Decoupled mode**: Three policies with IS correction from $\pi_{\text{rollout}}$ to $\pi_{\text{old}}$
|
| 780 |
+
2. **Bypass mode**: Two policies using $\pi_{\text{rollout}}$ as both behavior policy and proximal policy
|
| 781 |
+
3. **Bypass + Policy Gradient mode**: Two policies with IS/RS correction and no PPO clipping
|
| 782 |
+
|
| 783 |
+
**Implementation:** `compute_policy_loss()` in [core_algos.py](../../verl/trainer/ppo/core_algos.py#L812-L884)
|
| 784 |
+
|
| 785 |
+
---
|
| 786 |
+
|
| 787 |
+
## 4. Off-Policy Diagnostic Metrics
|
| 788 |
+
|
| 789 |
+
These metrics quantify the severity of off-policy drift.
|
| 790 |
+
|
| 791 |
+
**Note on notation:** Metrics use $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$. In bypass mode, $\pi_{\text{old}} = \pi_{\text{rollout}}$, so metrics measure rollout→current drift using $\rho_t = \frac{\pi_{\theta}}{\pi_{\text{rollout}}}$ instead.
|
| 792 |
+
|
| 793 |
+
### 4.1 KL Divergence
|
| 794 |
+
|
| 795 |
+
**Direct KL estimator:**
|
| 796 |
+
|
| 797 |
+
$$
|
| 798 |
+
\text{KL}(\pi_{\text{rollout}} \| \pi_{\text{old}}) = \mathbb{E}_{t \sim \pi_{\text{rollout}}} \left[ \log \pi_{\text{rollout}}(a_t|s_t) - \log \pi_{\text{old}}(a_t|s_t) \right]
|
| 799 |
+
$$
|
| 800 |
+
|
| 801 |
+
**K3 KL estimator** (alternative formulation):
|
| 802 |
+
|
| 803 |
+
$$
|
| 804 |
+
\text{KL}_{\text{K3}} = \mathbb{E}_{t \sim \pi_{\text{rollout}}} \left[ \rho_t - \log \rho_t - 1 \right]
|
| 805 |
+
$$
|
| 806 |
+
|
| 807 |
+
where $\rho_t = \frac{\pi_{\text{old}}(a_t|s_t)}{\pi_{\text{rollout}}(a_t|s_t)}$.
|
| 808 |
+
|
| 809 |
+
### 4.2 Perplexity
|
| 810 |
+
|
| 811 |
+
**Old policy perplexity:**
|
| 812 |
+
|
| 813 |
+
$$
|
| 814 |
+
\text{PPL}_{\text{old}} = \exp\left( -\frac{1}{|T|} \sum_{t \in T} \log \pi_{\text{old}}(a_t|s_t) \right)
|
| 815 |
+
$$
|
| 816 |
+
|
| 817 |
+
**Rollout policy perplexity:**
|
| 818 |
+
|
| 819 |
+
$$
|
| 820 |
+
\text{PPL}_{\text{rollout}} = \exp\left( -\frac{1}{|T|} \sum_{t \in T} \log \pi_{\text{rollout}}(a_t|s_t) \right)
|
| 821 |
+
$$
|
| 822 |
+
|
| 823 |
+
**PPL ratio** (inverse of geometric mean IS weight):
|
| 824 |
+
|
| 825 |
+
$$
|
| 826 |
+
\text{PPL}_{\text{ratio}} = \frac{\text{PPL}_{\text{old}}}{\text{PPL}_{\text{rollout}}} = \exp\left( -\frac{1}{|T|} \sum_{t \in T} \log \rho_t \right) = \left(\prod_{t \in T} \rho_t\right)^{-1/|T|}
|
| 827 |
+
$$
|
| 828 |
+
|
| 829 |
+
**Interpretation:** Values > 1 mean $\pi_{\text{old}}$ assigns lower probability than $\pi_{\text{rollout}}$ to the observed actions (distribution shift).
|
| 830 |
+
|
| 831 |
+
### 4.3 Chi-squared Divergence
|
| 832 |
+
|
| 833 |
+
Measures the second moment of the IS weight distribution.
|
| 834 |
+
|
| 835 |
+
**Token-level:**
|
| 836 |
+
|
| 837 |
+
$$
|
| 838 |
+
\chi^2_{\text{token}} = \mathbb{E}_{t \sim \pi_{\text{rollout}}} \left[ \rho_t^2 \right] - 1
|
| 839 |
+
$$
|
| 840 |
+
|
| 841 |
+
**Sequence-level:**
|
| 842 |
+
|
| 843 |
+
$$
|
| 844 |
+
\chi^2_{\text{seq}} = \mathbb{E}_{\text{seq} \sim \pi_{\text{rollout}}} \left[ \left(\prod_{t \in T} \rho_t\right)^2 \right] - 1
|
| 845 |
+
$$
|
| 846 |
+
|
| 847 |
+
**Interpretation:**
|
| 848 |
+
- $\chi^2 = 0$: Policies are identical
|
| 849 |
+
- $\chi^2 > 0$: Higher values indicate more severe off-policy distribution shift
|
| 850 |
+
|
| 851 |
+
**Implementation:** `compute_offpolicy_metrics()` in [rollout_corr_helper.py](../../verl/trainer/ppo/rollout_corr_helper.py#L670-L776)
|
| 852 |
+
|
| 853 |
+
---
|
| 854 |
+
|
| 855 |
+
## 5. Summary and Decision Guide
|
| 856 |
+
|
| 857 |
+
### 5.1 Method Summary Table
|
| 858 |
+
|
| 859 |
+
| Method | Theory | Policies | PPO Clip | IS Correction | Correctness | Speed |
|
| 860 |
+
|--------|--------|----------|----------|---------------|-------------|-------|
|
| 861 |
+
| **Bypass Mode** (π_old = π_rollout, `loss_type` selects algorithm) |
|
| 862 |
+
| `loss_type="ppo_clip"` (default) | PPO (ratio = π_θ/π_rollout) | 2 (rollout, θ) | ✅ | RS mask only (ratio handles IS) | ✅ Correct | **Fast** |
|
| 863 |
+
| `loss_type="reinforce"` | Off-policy REINFORCE | 2 (rollout, θ) | ❌ | ✅ (explicit IS weights) | ✅ Correct | **Fast** |
|
| 864 |
+
| **Bypass Mode Presets (PPO-clip)** |
|
| 865 |
+
| `bypass_ppo_clip` | PPO only | 2 (rollout, θ) | ✅ | - | ✅ Correct | **Fast** |
|
| 866 |
+
| `bypass_ppo_clip_geo_rs` | PPO + Geo-RS | 2 (rollout, θ) | ✅ | Geo-RS mask (ratio) | ✅ Correct | **Fast** |
|
| 867 |
+
| **Bypass Mode Presets (REINFORCE)** |
|
| 868 |
+
| `bypass_pg_is` | REINFORCE + Seq-TIS | 2 (rollout, θ) | ❌ | ✅ Seq-TIS | ✅ Correct | **Fast** |
|
| 869 |
+
| `bypass_pg_geo_rs` | REINFORCE + Geo-RS | 2 (rollout, θ) | ❌ | Geo-RS only (ratio) | ✅ Correct | **Fast** |
|
| 870 |
+
| `bypass_pg_geo_rs_token_tis` | REINFORCE + Geo RS + Token IS | 2 (rollout, θ) | ❌ | ✅ Geo-RS-Token-TIS | ✅ Correct | **Fast** |
|
| 871 |
+
| **Decoupled PPO Mode** (IS weights = π_old / π_rollout) |
|
| 872 |
+
| `decoupled_token_is` | Decoupled PPO | 3 (rollout, old, θ) | ✅ | ✅ Token-TIS | ✅ Correct | Standard |
|
| 873 |
+
| `decoupled_seq_is` | Decoupled PPO | 3 (rollout, old, θ) | ✅ | ✅ Seq-TIS | ✅ Correct | Standard |
|
| 874 |
+
| `decoupled_seq_is_rs` | Decoupled PPO + RS | 3 (rollout, old, θ) | ✅ | ✅ Seq-MIS | ✅ Correct | Standard |
|
| 875 |
+
| `decoupled_geo_rs` | Decoupled PPO + Geo-RS | 3 (rollout, old, θ) | ✅ | Geo-RS only (ratio) | ✅ Correct | Standard |
|
| 876 |
+
| `decoupled_geo_rs_token_tis` | Decoupled PPO + Geo RS + Token IS | 3 (rollout, old, θ) | ✅ | ✅ Geo-RS-Token-TIS | ✅ Correct | Standard |
|
| 877 |
+
| **Incorrect (for reference)** |
|
| 878 |
+
| Naive LLM-RL | Incorrect PPO usage | 2 (old, θ) | ✅ | ❌ | ⚠️ Incorrect | Standard |
|
| 879 |
+
|
| 880 |
+
**Notes:**
|
| 881 |
+
- **Bypass mode** sets π_old = π_rollout and uses `loss_type` to select the loss function:
|
| 882 |
+
- `"ppo_clip"` (default): PPO clipped ratio (IS handled by ratio = π_θ/π_rollout, no explicit IS weights to avoid double-counting)
|
| 883 |
+
- `"reinforce"`: Explicit IS weights applied as $w \cdot \log \pi \cdot A$
|
| 884 |
+
- Both loss types benefit from rejection sampling (RS) which masks out-of-distribution samples
|
| 885 |
+
|
| 886 |
+
### 5.2 Estimator Hierarchy
|
| 887 |
+
|
| 888 |
+
These estimators define **how IS weights and rejection masks are computed**. They are orthogonal to the operating mode (decoupled PPO vs bypass policy gradient) and can be combined with either.
|
| 889 |
+
|
| 890 |
+
| Estimator | Configuration | Mechanism | Best For |
|
| 891 |
+
|-----------|---------------|-----------|----------|
|
| 892 |
+
| **Token-TIS** | `rollout_is="token"` | Clips per-token ratios | Lower variance IS with acceptable bias |
|
| 893 |
+
| **Seq-TIS** | `rollout_is="sequence"` | Clips sequence ratio $\rho(\tau) \to \min(\rho(\tau), C)$ | Clean data with moderate mismatch; unbiased |
|
| 894 |
+
| **Seq-MIS** | `rollout_is="sequence"` + `rollout_rs="seq_sum_k1"` | Rejects sequences with $\rho(\tau) > C$ | Severe mismatch; filters "toxic tail" (garbage data) |
|
| 895 |
+
| **Geo-RS** | `rollout_rs="seq_mean_k1"` | Rejects on geometric mean ratio exp(E[log(r)]) | Length-invariant trust region |
|
| 896 |
+
| **Geo-RS-Token-TIS** | `rollout_is="token"` + `rollout_rs="seq_mean_k1"` | Geometric filter + token IS weights | Ratio-based length normalization + lower variance IS |
|
| 897 |
+
| **K3-RS** | `rollout_rs="seq_mean_k3"` | Rejects on K3 KL divergence | Small KL values; smooth detector |
|
| 898 |
+
| **K3-RS-Token-TIS** | `rollout_is="token"` + `rollout_rs="seq_mean_k3"` | K3 filter + token IS weights | Small KL + lower variance IS |
|
| 899 |
+
|
| 900 |
+
**Note:** Each estimator can be used with either:
|
| 901 |
+
- **Decoupled PPO** (`bypass_mode=false`): Three policies with PPO clipping
|
| 902 |
+
- **Bypass Mode** (`bypass_mode=true`): Two policies with configurable loss type
|
| 903 |
+
- `loss_type="ppo_clip"` (default): PPO clipped objective (IS via ratio, RS mask applied)
|
| 904 |
+
- `loss_type="reinforce"`: REINFORCE with explicit IS weights
|
| 905 |
+
|
| 906 |
+
### 5.3 Method Characteristics by Scenario
|
| 907 |
+
|
| 908 |
+
**Choosing estimator by off-policy severity:**
|
| 909 |
+
- **Negligible** (same checkpoint, minor differences): No IS correction needed; use bypass mode for efficiency
|
| 910 |
+
- **Moderate** (async workers, slight staleness): Token-TIS provides per-token IS correction with lower variance
|
| 911 |
+
- **Severe** (replay buffers, old data): Seq-TIS or Seq-MIS provides sequence-level IS correction; use Seq-MIS when high-weight samples are likely garbage
|
| 912 |
+
|
| 913 |
+
**Choosing estimator by sequence length:**
|
| 914 |
+
- **Short sequences** (standard chat): Seq-TIS is optimal
|
| 915 |
+
- **Long sequences** (CoT, agents): K1-RS or K1-RS-Token-TIS to avoid Length Trap
|
| 916 |
+
|
| 917 |
+
**Choosing operating mode:**
|
| 918 |
+
- **Batch size invariance needed**: Use decoupled mode (`bypass_mode=false`)
|
| 919 |
+
- **Computational efficiency needed**: Use bypass mode (`bypass_mode=true`) to skip `old_log_prob` computation
|
| 920 |
+
- **No PPO clipping**: Use bypass mode with `loss_type="reinforce"`
|
| 921 |
+
|
| 922 |
+
### 5.4 Decoupled Mode vs Bypass Mode
|
| 923 |
+
|
| 924 |
+
**Decoupled mode** (computes `old_log_prob` separately):
|
| 925 |
+
- Implements full decoupled PPO with three policies (mathematically correct)
|
| 926 |
+
- Separately measures and corrects Drift 1 (rollout→old) and Drift 2 (old→current)
|
| 927 |
+
- Achieves batch size invariance and efficient stale data utilization
|
| 928 |
+
- Enables accurate off-policy metrics monitoring
|
| 929 |
+
|
| 930 |
+
**Bypass mode** (sets $\pi_{\text{old}} = \pi_{\text{rollout}}$):
|
| 931 |
+
- Uses $\pi_{\text{rollout}}$ as both behavior policy and proximal policy (mathematically correct)
|
| 932 |
+
- Computational efficiency: Skips separate `old_log_prob` computation
|
| 933 |
+
- Does not achieve batch size invariance (proximal policy depends on data collection)
|
| 934 |
+
|
| 935 |
+
---
|
| 936 |
+
|
| 937 |
+
## 6. Implementation References
|
| 938 |
+
|
| 939 |
+
- **[Rollout Correction Usage Guide](rollout_corr.md)** - Practical configuration and troubleshooting
|
| 940 |
+
- **Config:** [verl/trainer/config/algorithm.py](../../verl/trainer/config/algorithm.py)
|
| 941 |
+
- **IS/RS Helper:** [verl/trainer/ppo/rollout_corr_helper.py](../../verl/trainer/ppo/rollout_corr_helper.py)
|
| 942 |
+
- **PPO Loss:** [verl/trainer/ppo/core_algos.py](../../verl/trainer/ppo/core_algos.py)
|
| 943 |
+
- **Tests:** [tests/trainer/ppo/test_rollout_corr.py](../../tests/trainer/ppo/test_rollout_corr.py)
|
| 944 |
+
|
| 945 |
+
---
|
| 946 |
+
|
| 947 |
+
## References
|
| 948 |
+
|
| 949 |
+
- **Williams, R. J. (1992).** "Simple statistical gradient-following algorithms for connectionist reinforcement learning." *Machine Learning*, 8(3-4), 229-256. https://doi.org/10.1007/BF00992696
|
| 950 |
+
- **Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017).** "Proximal policy optimization algorithms." *arXiv preprint arXiv:1707.06347.* https://arxiv.org/abs/1707.06347
|
| 951 |
+
- **Hilton, J., Cobbe, K., & Schulman, J. (2021).** "Batch size-invariance for policy optimization." *arXiv preprint arXiv:2110.00641.* https://arxiv.org/abs/2110.00641
|
| 952 |
+
- Introduced decoupled PPO: separating proximal policy (for controlling policy update size) from behavior policy (for off-policy correction) to achieve batch size invariance
|
| 953 |
+
- **Liu, J., Li, Y., et al. (2025).** "When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch"
|
| 954 |
+
- Blog post: https://richardli.xyz/rl-collapse (see Blog Series above for parts 1-3)
|
code/RL_model/verl/verl_train/docs/algo/spin.md
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Self-Play Fine-Tuning (SPIN)
|
| 2 |
+
|
| 3 |
+
Last updated: 05/31/2025.
|
| 4 |
+
|
| 5 |
+
`verl` provides a recipe inspired by the paper **"Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models"** (SPIN). SPIN is a language model finetuning algorithm that enables iterative self-improvement through a self-play mechanism inspired by game theory.
|
| 6 |
+
|
| 7 |
+
**Core Idea:** Models learn by playing against themselves, reducing reliance on external preference datasets or stronger teacher models:
|
| 8 |
+
|
| 9 |
+
1. **Synthetic Data Generation:** The current model generates responses, creating its own training data from previous iterations.
|
| 10 |
+
2. **Two-Player Game Setup:** A game involving two players acted by a single LLM.
|
| 11 |
+
3. **Iterative Training:** The model progressively improves by refining its policy, with each iteration's model becoming the opponent for the next iteration.
|
| 12 |
+
|
| 13 |
+
Paper Authors: [Zixiang Chen](https://github.com/uclaml/SPIN)\*, [Yihe Deng](https://github.com/uclaml/SPIN)\*, [Huizhuo Yuan](https://scholar.google.com/citations?user=8foZzX4AAAAJ)\*, [Kaixuan Ji](https://scholar.google.com/citations?user=FOoKDukAAAAJ), [Quanquan Gu](https://web.cs.ucla.edu/~qgu/)
|
| 14 |
+
|
| 15 |
+
[[Webpage](https://uclaml.github.io/SPIN/)] [[Huggingface](https://huggingface.co/papers/2401.01335)] [[Paper](https://arxiv.org/abs/2401.01335)] [[Original Implementation](https://github.com/uclaml/SPIN)]
|
| 16 |
+
|
| 17 |
+
verl Implementation Authors: [Chendong Wang](https://cdwang96.github.io/), [Chenyang Zhao](https://github.com/zhaochenyang20)
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
## Key Function (compute_online_dpo_loss) and Related works
|
| 22 |
+
SPIN (Chen et al., 2024) proposes an iterative self-play mechanism to fine-tune language models. In each iteration, SPIN's training objective, when using a logistic loss function, is equivalent to Direct Preference Optimization (DPO) loss (Rafailov et al., 2023).
|
| 23 |
+
|
| 24 |
+
This `verl` recipe realizes SPIN's core concept by using DPO loss iteratively (Xu et al., 2023; Xiong et al., 2023; Snorkel AI, 2024). This means that in each iteration, we fine-tune the LLM using DPO loss for preference optimization. Notably, Xu et al. (2023) explored iterative preference optimization with pairwise cringe loss, while Xiong et al. (2023) discussed how to bridge theory and practice for RLHF under KL constraints using iterative training. The concept of iterative preference learning was also explored in online DPO (Guo et al., 2024), which focuses on direct alignment from online AI feedback. In online DPO, preference data is dynamically updated during training, allowing the model to learn from its own generated data.
|
| 25 |
+
|
| 26 |
+
Specifically, we developed the **`compute_online_dpo_loss`** function and built this SPIN recipe on top of it. By incorporating online preference generation, this approach enables continuously refining language models without relying on fixed external preference datasets.
|
| 27 |
+
|
| 28 |
+
**Reference Papers:**
|
| 29 |
+
* [Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models](https://arxiv.org/abs/2401.01335) (Chen et al., 2024)
|
| 30 |
+
* [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://arxiv.org/abs/2305.18290) (Rafailov et al., 2023)
|
| 31 |
+
* [Somethings are more cringe than others: Preference optimization with the pairwise cringe loss](https://arxiv.org/abs/2312.16682) (Xu et al., 2023)
|
| 32 |
+
* [Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint](https://arxiv.org/abs/2312.11456) (Xiong et al., 2023)
|
| 33 |
+
* [Snorkel-Mistral-PairRM-DPO](https://huggingface.co/snorkelai/Snorkel-Mistral-PairRM-DPO) (Snorkel AI, 2024)
|
| 34 |
+
* [Direct language model alignment from online ai feedback](https://arxiv.org/abs/2402.04792) (Guo et al., 2024)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Our Online DPO Implementation
|
| 38 |
+
|
| 39 |
+
Our `compute_online_dpo_loss` function adapts `verl`'s existing PPO infrastructure (based on `verl` v0.3.0.post1) for this iterative online DPO. Key aspects of our implementation include:
|
| 40 |
+
|
| 41 |
+
* **No Critic:** Unlike PPO, we omit the value function critic.
|
| 42 |
+
* **Dynamic Reference Model:** An explicit reference policy (`ref_policy_wg`) is used for DPO loss. This reference model's weights can be periodically updated from the actor (`ref_update_freq`), providing a dynamic baseline.
|
| 43 |
+
* **Online Preference Generation:** The `compute_onlineDPO_pref` function (in `core_algos.py`) dynamically creates chosen/rejected pairs based on a reward source (e.g., rule-based ranking for math problems).
|
| 44 |
+
* **DPO Loss Integration:** We replace PPO's policy loss with our `compute_online_dpo_loss` (in `core_algos.py`) within the actor update (`dp_actor.py`), directly optimizing the policy using the generated preferences.
|
| 45 |
+
* **Iterative Training Orchestration:** The `SpinTrainer` (in `spin_trainer.py`) manages the entire self-play loop: generation, preference labeling, optional reference model updates, and policy updates, enabling continuous self-improvement aligned with SPIN's principles.
|
| 46 |
+
|
| 47 |
+
---
|
| 48 |
+
## Algorithm
|
| 49 |
+
|
| 50 |
+
This recipe implements an Online algorithm adapted to the `verl` Reinforcement Learning framework, which provides an alternative to PPO for fine-tuning language models.
|
| 51 |
+
|
| 52 |
+
**Online Loop:** Instead of maximizing a scalar reward signal in PPO, this approach directly optimizes the policy model to align with preference data generated *online* during training:
|
| 53 |
+
|
| 54 |
+
1. **Generation:** The current model generates multiple responses for each prompt in a batch.
|
| 55 |
+
2. **Preference Labeling:** A function evaluates these generated responses to determine which one is preferred (chosen) and which is dispreferred (rejected). This can be done using a reward function or implicit ranking based on specific rules. (In this recipe, we use rule-based ranking on the math problem).
|
| 56 |
+
3. **Update:** This preference tuple (`prompt`, `chosen_response`, `rejected_response`) is used to update the actor model using `compute_online_dpo_loss`, comparing against a reference model.
|
| 57 |
+
|
| 58 |
+
**Connection with SPIN:**
|
| 59 |
+
Instead of only using a fixed target data distribution, the online generation loop in step 2 will dynamically change the target data distribution by using a certain Preference Labeling method (rule-based ranking on the math problem by selecting the better one in this recipe). This explores the direction mentioned in SPIN's paper Section 7 about "dynamically changing target data distribution" to potentially elevate LLM performance beyond the fixed human-annotated data ceiling.
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
## Reproduce the Experiment (Example Setup)
|
| 64 |
+
|
| 65 |
+
The following steps outline how to set up the environment and run the SPIN recipe, based on the provided test log using GSM8K and Qwen2.5-3B-Instruct.
|
| 66 |
+
|
| 67 |
+
1. **Setup Environment (Example using Docker):**
|
| 68 |
+
```bash
|
| 69 |
+
# Start a container with GPU access and shared memory
|
| 70 |
+
docker run -it --name spin_test --gpus all \
|
| 71 |
+
--shm-size=32g \
|
| 72 |
+
--ipc=host \
|
| 73 |
+
-v /path/to/host/.cache:/root/.cache \
|
| 74 |
+
-e HF_TOKEN=<YOUR_HUGGINGFACE_TOKEN> \
|
| 75 |
+
lmsysorg/sglang:latest \
|
| 76 |
+
/bin/bash
|
| 77 |
+
|
| 78 |
+
# Inside the container or on your host machine:
|
| 79 |
+
# Ensure /tmp is writable
|
| 80 |
+
mkdir -p /tmp
|
| 81 |
+
chmod 1777 /tmp
|
| 82 |
+
|
| 83 |
+
# Install Python 3.10 (if not present) and venv
|
| 84 |
+
sudo apt update
|
| 85 |
+
sudo apt install -y python3.10 python3.10-venv tmux
|
| 86 |
+
python3 -m ensurepip --upgrade
|
| 87 |
+
|
| 88 |
+
# Create and activate a virtual environment
|
| 89 |
+
python3 -m venv ~/.python/spin_env
|
| 90 |
+
source ~/.python/spin_env/bin/activate
|
| 91 |
+
|
| 92 |
+
# Install uv (fast package installer)
|
| 93 |
+
python3 -m pip install uv
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
2. **Install verl and Dependencies:**
|
| 97 |
+
```bash
|
| 98 |
+
# Clone the verl repository and checkout the spin branch
|
| 99 |
+
cd ~
|
| 100 |
+
git clone git@github.com:volcengine/verl.git && cd verl
|
| 101 |
+
|
| 102 |
+
# Install flash-attn (handle potential build issues)
|
| 103 |
+
python3 -m uv pip install wheel packaging
|
| 104 |
+
python3 -m uv pip install flash-attn --no-build-isolation --no-deps
|
| 105 |
+
|
| 106 |
+
# Install verl with sglang extras
|
| 107 |
+
python3 -m uv pip install -e ".[sglang]"
|
| 108 |
+
```
|
| 109 |
+
*Note: If `flash-attn` installation fails, try the manual steps again or consult its documentation.*
|
| 110 |
+
|
| 111 |
+
3. **Login & Download Data/Model:**
|
| 112 |
+
```bash
|
| 113 |
+
# Login to Weights & Biases (optional, for logging)
|
| 114 |
+
export WANDB_API_KEY=<YOUR_WANDB_API_KEY>
|
| 115 |
+
# wandb login
|
| 116 |
+
|
| 117 |
+
# Download the GSM8K dataset
|
| 118 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k # Adjusted path
|
| 119 |
+
|
| 120 |
+
# Download the base model (Example: Qwen2.5-3B-Instruct)
|
| 121 |
+
hf download Qwen/Qwen2.5-3B-Instruct --local-dir $HOME/models/Qwen2.5-3B-Instruct
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
4. **Configure:**
|
| 125 |
+
* Modify the configuration file (e.g., `config/spin_trainer.yaml` or the one specified in the run script) with correct paths to your downloaded model, data, desired hyperparameters (`dpo_beta`, learning rate, etc.), and distributed training settings (nodes, GPUs per node).
|
| 126 |
+
* Pay attention to `actor_rollout_ref.model`, `data` paths, `reward_model` config (if using one), and `trainer.ref_update_freq`.
|
| 127 |
+
|
| 128 |
+
5. **Run Training:**
|
| 129 |
+
```bash
|
| 130 |
+
# Set CUDA visible devices (adjust based on your hardware and config)
|
| 131 |
+
export CUDA_VISIBLE_DEVICES=0,1,2,3
|
| 132 |
+
|
| 133 |
+
# Launch the training script (e.g., test.sh or a custom script)
|
| 134 |
+
# Ensure test.sh points to the correct config and main script
|
| 135 |
+
bash recipe/spin/run_spin.sh
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
---
|
| 139 |
+
|
| 140 |
+
## Configuration
|
| 141 |
+
|
| 142 |
+
* The primary configuration is typically managed through a YAML file specified in the launch script (e.g., `config/spin_trainer.yaml`).
|
| 143 |
+
* Key configuration sections:
|
| 144 |
+
* `data`: Paths to training/validation prompt files, batch sizes, sequence lengths.
|
| 145 |
+
* `actor_rollout_ref`: Paths to the base model (used for actor and initial reference), FSDP settings, optimization parameters (learning rate, scheduler).
|
| 146 |
+
* `reward_model`: Configuration for the reward model used for online preference labeling (path, batch size, etc.). Can be omitted if using a simpler reward function.
|
| 147 |
+
* `algorithm`: DPO-specific hyperparameters like `dpo_beta`, `dpo_loss_type`.
|
| 148 |
+
* `trainer`: Distributed training settings (nodes, GPUs per node), logging (WandB), checkpointing frequency, and `ref_update_freq` (set > 0 to enable periodic reference model updates from the actor).
|
| 149 |
+
|
| 150 |
+
---
|
| 151 |
+
|
| 152 |
+
## Key Files
|
| 153 |
+
|
| 154 |
+
* `main_spin.py`: Main entry point using Hydra to load the config and launch the `SpinTrainer`.
|
| 155 |
+
* `spin_trainer.py`: Defines the `SpinTrainer` class, orchestrating the Online DPO training loop.
|
| 156 |
+
* `fsdp_workers.py`: Implements Ray workers (Actor, Reference) potentially using FSDP.
|
| 157 |
+
* `dp_actor.py`: Contains the actor class, including the DPO policy update logic.
|
| 158 |
+
* `core_algos.py`: Includes helper functions for `compute_online_dpo_loss` and `compute_onlineDPO_pref`.
|
| 159 |
+
* `config/spin_trainer.yaml` (or similar): Main Hydra configuration file for the recipe.
|
| 160 |
+
* `run_spin.sh` (or similar): Example bash script for launching a training run.
|
| 161 |
+
* `README.md`: This file.
|
| 162 |
+
|
| 163 |
+
---
|
| 164 |
+
|
| 165 |
+
## Acknowledgement
|
| 166 |
+
|
| 167 |
+
We sincerely thank the contribution and guidance from the `verl` community and advisors, including (adapted from SPPO):
|
| 168 |
+
|
| 169 |
+
* [Zixiang Chen](https://sites.google.com/view/zxchen)
|
| 170 |
+
* [Yuhao Yang](https://github.com/yhyang201)
|
| 171 |
+
* [Yifan Zhang](https://github.com/yifanzhang-pro)
|
| 172 |
+
* [Yongan Xiang](https://github.com/BearBiscuit05)
|
| 173 |
+
* [Junrong Lin](https://github.com/ocss884)
|
| 174 |
+
* [Yuxuan Tong](https://github.com/tongyx361)
|
| 175 |
+
* [Guangming Shen](https://github.com/PeterSH6)
|
| 176 |
+
* [Biao He](https://www.linkedin.com/in/biao-he/)
|
| 177 |
+
* [Qingquan Song](https://qingquansong.github.io/)
|
| 178 |
+
* [Chenyang Zhao](https://zhaochenyang20.github.io/Chayenne/)
|
| 179 |
+
* [Quanquan Gu](https://web.cs.ucla.edu/~qgu/)
|
code/RL_model/verl/verl_train/docs/algo/sppo.md
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Self-Play Preference Optimization (SPPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 05/28/2025.
|
| 4 |
+
|
| 5 |
+
verl provides a community recipe implementation for the paper [Self-Play Preference Optimization for Language Model Alignment](https://arxiv.org/abs/2405.00675). SPPO can significantly enhance the performance of an LLM without strong external signals such as responses or preferences from GPT-4. It can outperform the model trained with iterative direct preference optimization (DPO), among other methods. SPPO is theoretically grounded, ensuring that the LLM can converge to the von Neumann winner (i.e., Nash equilibrium) under general, potentially intransitive preference, and empirically validated through extensive evaluations on multiple datasets.
|
| 6 |
+
|
| 7 |
+
Paper Authors: [Yue Wu](https://yuewu.us/)\*, [Zhiqing Sun](https://www.cs.cmu.edu/~zhiqings/)\*, [Huizhuo Yuan](https://scholar.google.com/citations?user=8foZzX4AAAAJ)\*, [Kaixuan Ji](https://scholar.google.com/citations?user=FOoKDukAAAAJ), [Yiming Yang](https://www.cs.cmu.edu/~yiming/), [Quanquan Gu](https://web.cs.ucla.edu/~qgu/)
|
| 8 |
+
|
| 9 |
+
verl Implementation Authors: [Yuhao Yang](https://github.com/yhyang201), [Chenyang Zhao](https://github.com/zhaochenyang20)
|
| 10 |
+
|
| 11 |
+
[[Webpage](https://uclaml.github.io/SPPO/)] [[Huggingface](https://huggingface.co/papers/2405.00675)] [[Paper](https://arxiv.org/abs/2405.00675)][[Original Implementation](https://github.com/uclaml/SPPO)]
|
| 12 |
+
|
| 13 |
+
## Reproduce the Experiment
|
| 14 |
+
|
| 15 |
+
We evaluate the performance of SPPO on the MATH dataset. Starting from an initial score of 46.6 with Qwen2.5-7B-Instruct, we achieve a score of 65.6 after 20 epochs of training, placing our model approximately in the top 20 on the [MATH leaderboard](https://paperswithcode.com/sota/math-word-problem-solving-on-math). It's important to note that verl's internal evaluation metrics may not perfectly align with the official evaluation methodology for Qwen2.5-7B-Instruct. Therefore, for consistency and fair comparison, we report only the results based on verl's evaluation framework.
|
| 16 |
+
|
| 17 |
+
```
|
| 18 |
+
git clone git@github.com:volcengine/verl.git
|
| 19 |
+
cd verl
|
| 20 |
+
python3 -m uv pip install -e ".[sglang]"
|
| 21 |
+
|
| 22 |
+
export WANDB_API_KEY=<YOUR_WANDB_API_KEY>
|
| 23 |
+
|
| 24 |
+
python3 examples/data_preprocess/math_dataset.py --local_dir ~/data/math
|
| 25 |
+
hf download Qwen/Qwen2.5-7B-Instruct --local-dir $HOME/models/Qwen2.5-7B-Instruct
|
| 26 |
+
|
| 27 |
+
export CUDA_VISIBLE_DEVICES=0,1,2,3
|
| 28 |
+
bash recipe/sppo/run_qwen2.5-7b_rm.sh
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Note that the installation would occasionally fail to install flash-attn. If this happens, you can install it manually by running:
|
| 32 |
+
|
| 33 |
+
```bash
|
| 34 |
+
python3 -m uv pip install wheel
|
| 35 |
+
python3 -m uv pip install packaging
|
| 36 |
+
python3 -m uv pip install flash-attn --no-build-isolation --no-deps
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Acknowledgement
|
| 40 |
+
|
| 41 |
+
We sincerely thank the contribution and guidance from:
|
| 42 |
+
|
| 43 |
+
- [Yue Wu](https://yuewu.us/)
|
| 44 |
+
- [Chendong Wang](https://cdwang96.github.io/)
|
| 45 |
+
- [Yifan Zhang](https://github.com/yifanzhang-pro)
|
| 46 |
+
- [Yongan Xiang](https://github.com/BearBiscuit05)
|
| 47 |
+
- [Junrong Lin](https://github.com/ocss884)
|
| 48 |
+
- [Yuxuan Tong](https://github.com/tongyx361)
|
| 49 |
+
- [Guangming Shen](https://github.com/PeterSH6)
|
| 50 |
+
- [Biao He](https://www.linkedin.com/in/biao-he/)
|
| 51 |
+
- [Qingquan Song](https://qingquansong.github.io/)
|
| 52 |
+
- [Quanquan Gu](https://web.cs.ucla.edu/~qgu/)
|
code/RL_model/verl/verl_train/docs/amd_tutorial/amd_build_dockerfile_page.rst
ADDED
|
@@ -0,0 +1,796 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Getting started with AMD (ROCM Kernel)
|
| 2 |
+
=====================================================
|
| 3 |
+
|
| 4 |
+
Last updated: 07/06/2025.
|
| 5 |
+
|
| 6 |
+
Author: `Yusheng Su <https://yushengsu-thu.github.io/>`_
|
| 7 |
+
|
| 8 |
+
Setup
|
| 9 |
+
-----
|
| 10 |
+
|
| 11 |
+
If you run on AMD GPUs (MI300) with ROCM platform, you cannot use the previous quickstart to run verl. You should follow the following steps to build a docker and set ``RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES`` or ``RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES`` when starting ray in verl's RLHF training.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
docker/Dockerfile.rocm
|
| 15 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 16 |
+
|
| 17 |
+
.. code-block:: bash
|
| 18 |
+
|
| 19 |
+
FROM "rlsys/rocm-6.3.4-patch:rocm6.3.4-numa-patch_ubuntu-22.04"
|
| 20 |
+
|
| 21 |
+
SHELL ["/bin/bash", "-ceuxo", "pipefail"]
|
| 22 |
+
|
| 23 |
+
ENV MAX_JOBS=512
|
| 24 |
+
|
| 25 |
+
ENV PATH="/usr/local/python3.12/bin:$PATH"
|
| 26 |
+
RUN ln -sf /usr/bin/python3.12 /usr/bin/python && \
|
| 27 |
+
ln -sf /usr/bin/pip3.12 /usr/bin/pip
|
| 28 |
+
|
| 29 |
+
############################################
|
| 30 |
+
RUN apt-get update
|
| 31 |
+
RUN apt-get install -y pkg-config liblzma-dev
|
| 32 |
+
############################################
|
| 33 |
+
|
| 34 |
+
###########################################
|
| 35 |
+
##########Install TransformerEngine########
|
| 36 |
+
###########################################
|
| 37 |
+
WORKDIR /workspace/
|
| 38 |
+
# transformer-engine install
|
| 39 |
+
# https://github.com/ROCm/TransformerEngine
|
| 40 |
+
RUN rm -rf TransformerEngine
|
| 41 |
+
RUN git clone --recursive https://github.com/ROCm/TransformerEngine.git
|
| 42 |
+
WORKDIR /workspace/TransformerEngine
|
| 43 |
+
git checkout 236178e5
|
| 44 |
+
# git checkout bb061ade
|
| 45 |
+
# git checkout 864405c
|
| 46 |
+
ENV NVTE_FRAMEWORK=pytorch
|
| 47 |
+
ENV NVTE_ROCM_ARCH=gfx942
|
| 48 |
+
ENV NVTE_USE_HIPBLASLT=1
|
| 49 |
+
ENV NVTE_USE_ROCM=1
|
| 50 |
+
# export CMAKE_PREFIX_PATH="/opt/rocm:/opt/rocm/hip:/usr/local:/usr:${CMAKE_PREFIX_PATH:-}"
|
| 51 |
+
ENV CMAKE_PREFIX_PATH="/opt/rocm:/opt/rocm/hip:/usr/local:/usr"
|
| 52 |
+
RUN MAX_JOBS=$(MAX_JOBS) pip install . -vvv
|
| 53 |
+
WORKDIR /workspace/
|
| 54 |
+
###########################################
|
| 55 |
+
###########################################
|
| 56 |
+
###########################################
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
####################################################################################
|
| 63 |
+
################Install vllm - sglang require vllm 0.6.7 dependency#################
|
| 64 |
+
####################################################################################
|
| 65 |
+
#### Require vllm 0.6.7 - checkout 113274a0
|
| 66 |
+
WORKDIR /workspace/
|
| 67 |
+
RUN rm -rf vllm
|
| 68 |
+
RUN pip uninstall -y vllm
|
| 69 |
+
# Refer to here (down-grade vllm to 0.6.3): https://docs.vllm.ai/en/v0.6.3/getting_started/amd-installation.html
|
| 70 |
+
RUN git clone https://github.com/ROCm/vllm.git
|
| 71 |
+
# git clone https://github.com/vllm-project/vllm.git
|
| 72 |
+
WORKDIR /workspace/vllm
|
| 73 |
+
RUN git checkout 113274a0
|
| 74 |
+
ENV PYTORCH_ROCM_ARCH="gfx90a;gfx942"
|
| 75 |
+
#ENV MAX_JOBS=512
|
| 76 |
+
ENV MAX_JOBS=${MAX_JOBS}
|
| 77 |
+
RUN pip install "boto3>=1.26.0"
|
| 78 |
+
RUN pip install setuptools_scm
|
| 79 |
+
# will add src into py. You can delete the repo
|
| 80 |
+
RUN python3 setup.py install
|
| 81 |
+
WORKDIR /workspace/
|
| 82 |
+
####################################################################################
|
| 83 |
+
####################################################################################
|
| 84 |
+
####################################################################################
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
###########################################
|
| 89 |
+
############For hack docker################
|
| 90 |
+
###########################################
|
| 91 |
+
RUN pip install setuptools==75.8.0
|
| 92 |
+
###########################################
|
| 93 |
+
###########################################
|
| 94 |
+
###########################################
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
###########################################
|
| 99 |
+
############build sgalng###################
|
| 100 |
+
###########################################
|
| 101 |
+
# Set environment variables
|
| 102 |
+
ENV BASE_DIR=/sgl-workspace
|
| 103 |
+
ENV BUILD_TYPE=all
|
| 104 |
+
ENV SGL_REPO=https://github.com/sgl-project/sglang
|
| 105 |
+
ENV SGL_BRANCH=v0.4.6.post5
|
| 106 |
+
ENV TRITON_REPO=https://github.com/ROCm/triton.git
|
| 107 |
+
ENV TRITON_COMMIT=improve_fa_decode_3.0.0
|
| 108 |
+
ENV AITER_REPO=https://github.com/ROCm/aiter.git
|
| 109 |
+
ENV AITER_COMMIT=v0.1.2
|
| 110 |
+
# v0.1.2 version - commit id: 9d11f47
|
| 111 |
+
# ENV AITER_COMMIT=9d11f47
|
| 112 |
+
ENV HIP_FORCE_DEV_KERNARG=1
|
| 113 |
+
ENV HSA_NO_SCRATCH_RECLAIM=1
|
| 114 |
+
ENV SGLANG_SET_CPU_AFFINITY=1
|
| 115 |
+
ENV SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1
|
| 116 |
+
ENV NCCL_MIN_NCHANNELS=112
|
| 117 |
+
ENV MOE_PADDING=1
|
| 118 |
+
ENV VLLM_FP8_PADDING=1
|
| 119 |
+
ENV VLLM_FP8_ACT_PADDING=1
|
| 120 |
+
ENV VLLM_FP8_WEIGHT_PADDING=1
|
| 121 |
+
ENV VLLM_FP8_REDUCE_CONV=1
|
| 122 |
+
ENV TORCHINDUCTOR_MAX_AUTOTUNE=1
|
| 123 |
+
ENV TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1
|
| 124 |
+
ENV HIPCC_COMPILE_FLAGS_APPEND="--offload-arch=gfx942"
|
| 125 |
+
ENV AMDGPU_TARGETS=gfx942
|
| 126 |
+
ENV ROCM_ARCH=gfx942
|
| 127 |
+
ENV PYTORCH_ROCM_ARCH="gfx90a;gfx942"
|
| 128 |
+
# Switch to working directory
|
| 129 |
+
WORKDIR /sgl-workspace
|
| 130 |
+
# Clean and create directory
|
| 131 |
+
RUN rm -rf /sgl-workspace && mkdir -p /sgl-workspace
|
| 132 |
+
|
| 133 |
+
# Clone and build sglang
|
| 134 |
+
RUN git clone ${SGL_REPO} \
|
| 135 |
+
&& cd sglang \
|
| 136 |
+
&& git checkout ${SGL_BRANCH} || echo "Using default branch" \
|
| 137 |
+
&& cd sgl-kernel \
|
| 138 |
+
&& rm -f pyproject.toml \
|
| 139 |
+
&& mv pyproject_rocm.toml pyproject.toml \
|
| 140 |
+
&& python setup_rocm.py install \
|
| 141 |
+
&& cd .. \
|
| 142 |
+
&& if [ "$BUILD_TYPE" = "srt" ]; then \
|
| 143 |
+
python -m pip --no-cache-dir install -e "python[srt_hip]"; \
|
| 144 |
+
else \
|
| 145 |
+
python -m pip --no-cache-dir install -e "python[all_hip]"; \
|
| 146 |
+
fi \
|
| 147 |
+
&& cd /sgl-workspace \
|
| 148 |
+
&& cp -r /sgl-workspace/sglang /sglang \
|
| 149 |
+
&& python -m pip cache purge
|
| 150 |
+
|
| 151 |
+
# Install common Python packages
|
| 152 |
+
RUN pip install IPython orjson python-multipart torchao pybind11
|
| 153 |
+
# Rebuild Triton
|
| 154 |
+
RUN pip uninstall -y triton || true \
|
| 155 |
+
&& git clone ${TRITON_REPO} \
|
| 156 |
+
&& cd triton \
|
| 157 |
+
&& git checkout ${TRITON_COMMIT} \
|
| 158 |
+
&& cd python \
|
| 159 |
+
&& python3 setup.py install \
|
| 160 |
+
&& cd /sgl-workspace
|
| 161 |
+
# ENV HIPCC_COMPILE_FLAGS_APPEND="--offload-arch=gfx942 --amdgpu-lower-module-lds-strategy=1"
|
| 162 |
+
# ENV HIPCC_COMPILE_FLAGS_APPEND="--offload-arch=gfx942"
|
| 163 |
+
|
| 164 |
+
# Build aiter
|
| 165 |
+
#version: Commit 9d11f47
|
| 166 |
+
# && git checkout ${AITER_COMMIT} \
|
| 167 |
+
RUN pip uninstall -y aiter || true
|
| 168 |
+
RUN git clone ${AITER_REPO} \
|
| 169 |
+
&& cd aiter \
|
| 170 |
+
&& git checkout ${AITER_COMMIT} \
|
| 171 |
+
&& git submodule sync \
|
| 172 |
+
&& git submodule update --init --recursive \
|
| 173 |
+
&& PREBUILD_KERNELS=1 GPU_ARCHS=gfx942 python3 setup.py install \
|
| 174 |
+
&& cd /sgl-workspace
|
| 175 |
+
|
| 176 |
+
# Copy MI300X config
|
| 177 |
+
RUN find /sgl-workspace/sglang/python/sglang/srt/layers/quantization/configs/ \
|
| 178 |
+
/sgl-workspace/sglang/python/sglang/srt/layers/moe/fused_moe_triton/configs/ \
|
| 179 |
+
-type f -name '*MI300X*' | \
|
| 180 |
+
xargs -I {} sh -c 'vf_config=$(echo "$1" | sed "s/MI300X/MI300X_VF/"); cp "$1" "$vf_config"' -- {}
|
| 181 |
+
|
| 182 |
+
# Environment setup complete.
|
| 183 |
+
RUN echo "Environment setup complete."
|
| 184 |
+
|
| 185 |
+
WORKDIR /workspace/
|
| 186 |
+
###########################################
|
| 187 |
+
###########################################
|
| 188 |
+
###########################################
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
###########################################
|
| 196 |
+
###############vllm v0.8.5#################
|
| 197 |
+
###########################################
|
| 198 |
+
WORKDIR /workspace/
|
| 199 |
+
|
| 200 |
+
ENV VLLM_TARGET_DEVICE=rocm
|
| 201 |
+
ENV ROCM_PATH=/opt/rocm
|
| 202 |
+
ENV SETUPTOOLS_SCM_PRETEND_VERSION=0.8.5.dev
|
| 203 |
+
# Find the repo path in: DockerFile/Dockerfile.rocm_yang
|
| 204 |
+
# RUN git clone https://github.com/RLFoundation/vllm-patch.git
|
| 205 |
+
RUN pip uninstall -y vllm || true
|
| 206 |
+
RUN rm -rf vllm-patch
|
| 207 |
+
RUN git clone https://github.com/RLFoundation/vllm-patch.git \
|
| 208 |
+
&& cd vllm-patch \
|
| 209 |
+
&& git checkout v0.8.5-sleep-numa \
|
| 210 |
+
&& rm -rf build/ dist/ *.egg-info \
|
| 211 |
+
&& ln -sf /opt/rocm/lib/libamdhip64.so /usr/lib/libamdhip64.so \
|
| 212 |
+
&& SETUPTOOLS_SCM_PRETEND_VERSION=0.8.5.dev PYTORCH_ROCM_ARCH="gfx90a;gfx942" MAX_JOBS=${MAX_JOBS} python3 setup.py install
|
| 213 |
+
# RUN SETUPTOOLS_SCM_PRETEND_VERSION=0.8.5.dev PYTORCH_ROCM_ARCH="gfx90a;gfx942" MAX_JOBS=${MAX_JOBS} python3 setup.py develop
|
| 214 |
+
WORKDIR /workspace/
|
| 215 |
+
###########################################
|
| 216 |
+
###########################################
|
| 217 |
+
###########################################
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
#########################################
|
| 223 |
+
#### Install megatron-core###############
|
| 224 |
+
#########################################
|
| 225 |
+
RUN pip uninstall -y megatron-core && \
|
| 226 |
+
git clone https://github.com/yushengsu-thu/Megatron-LM-amd_version.git && \
|
| 227 |
+
cd Megatron-LM-amd_version && \
|
| 228 |
+
pip install -vvv -e . && \
|
| 229 |
+
cd /workspace/
|
| 230 |
+
#########################################
|
| 231 |
+
#########################################
|
| 232 |
+
#########################################
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
#######################################
|
| 238 |
+
################apex###################
|
| 239 |
+
#######################################
|
| 240 |
+
WORKDIR /workspace/
|
| 241 |
+
RUN pip uninstall -y apex && \
|
| 242 |
+
git clone git@github.com:ROCm/apex.git && \
|
| 243 |
+
cd apex && \
|
| 244 |
+
python setup.py install && \
|
| 245 |
+
cd /workspace/
|
| 246 |
+
#######################################
|
| 247 |
+
#######################################
|
| 248 |
+
#######################################
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
################################################################################
|
| 252 |
+
###########################Add torch_memory_saver###############################
|
| 253 |
+
################################################################################
|
| 254 |
+
# Set environment variables
|
| 255 |
+
ENV HIPCC_COMPILE_FLAGS_APPEND="--amdgpu-target=gfx90a;gfx942 -D__HIP_PLATFORM_AMD__"
|
| 256 |
+
ENV CFLAGS="-D__HIP_PLATFORM_AMD__"
|
| 257 |
+
ENV CXXFLAGS="-D__HIP_PLATFORM_AMD__"
|
| 258 |
+
RUN pip install "git+https://github.com/YangWang92/torch_memory_saver_numa.git@numa"
|
| 259 |
+
################################################################################
|
| 260 |
+
################################################################################
|
| 261 |
+
################################################################################
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
########################################
|
| 266 |
+
######Install ray#######################
|
| 267 |
+
########################################
|
| 268 |
+
# need to add this patch: https://github.com/ray-project/ray/pull/53531/files
|
| 269 |
+
RUN pip uninstall ray -y
|
| 270 |
+
RUN pip install "ray[data,train,tune,serve]>=2.47.0"
|
| 271 |
+
########################################
|
| 272 |
+
########################################
|
| 273 |
+
########################################
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
##########################################
|
| 277 |
+
#######Install other dependencies#########
|
| 278 |
+
##########################################
|
| 279 |
+
RUN pip install "tensordict==0.6.2" --no-deps && \
|
| 280 |
+
pip install accelerate \
|
| 281 |
+
codetiming \
|
| 282 |
+
datasets \
|
| 283 |
+
dill \
|
| 284 |
+
hydra-core \
|
| 285 |
+
liger-kernel \
|
| 286 |
+
numpy \
|
| 287 |
+
pandas \
|
| 288 |
+
peft \
|
| 289 |
+
"pyarrow>=15.0.0" \
|
| 290 |
+
pylatexenc \
|
| 291 |
+
torchdata \
|
| 292 |
+
wandb \
|
| 293 |
+
orjson \
|
| 294 |
+
pybind11
|
| 295 |
+
|
| 296 |
+
WORKDIR /workspace/
|
| 297 |
+
RUN git clone https://github.com/volcengine/verl.git && \
|
| 298 |
+
cd verl && \
|
| 299 |
+
pip install -e .
|
| 300 |
+
##########################################
|
| 301 |
+
##########################################
|
| 302 |
+
##########################################
|
| 303 |
+
|
| 304 |
+
WORKDIR /workspace/
|
| 305 |
+
CMD ["/usr/bin/bash"]
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
Build the image:
|
| 309 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 310 |
+
|
| 311 |
+
.. code-block:: bash
|
| 312 |
+
|
| 313 |
+
docker docker/build -t verl-rocm .
|
| 314 |
+
|
| 315 |
+
Run the container
|
| 316 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 317 |
+
|
| 318 |
+
Note: You can pull the docker from this DockerHub: [RLSys Foundation](https://hub.docker.com/u/yushengsuthu)
|
| 319 |
+
Pull the image:
|
| 320 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 321 |
+
|
| 322 |
+
.. code-block:: bash
|
| 323 |
+
|
| 324 |
+
docker pull rlsys/verl:verl-0.4.1_ubuntu-22.04_rocm6.3.4-numa-patch_vllm0.8.5_sglang0.4.6.post4
|
| 325 |
+
|
| 326 |
+
docker tag rlsys/verl:verl-0.4.1_ubuntu-22.04_rocm6.3.4-numa-patch_vllm0.8.5_sglang0.4.6.post4 verl-rocm:latest
|
| 327 |
+
|
| 328 |
+
Run the container
|
| 329 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
Optional: Running without root and with user permissions
|
| 333 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 334 |
+
|
| 335 |
+
.. code-block:: bash
|
| 336 |
+
|
| 337 |
+
docker run --rm -it \
|
| 338 |
+
--device /dev/dri \
|
| 339 |
+
--device /dev/kfd \
|
| 340 |
+
-p 8265:8265 \
|
| 341 |
+
--group-add video \
|
| 342 |
+
--cap-add SYS_PTRACE \
|
| 343 |
+
--security-opt seccomp=unconfined \
|
| 344 |
+
--privileged \
|
| 345 |
+
-v $HOME/.ssh:/root/.ssh \
|
| 346 |
+
-v $HOME:$HOME \
|
| 347 |
+
--shm-size 128G \
|
| 348 |
+
-w $PWD \
|
| 349 |
+
verl-rocm \
|
| 350 |
+
/bin/bash
|
| 351 |
+
|
| 352 |
+
(Optional): If you do not want to root mode and require assign yourself as the user
|
| 353 |
+
Please add ``-e HOST_UID=$(id -u)`` and ``-e HOST_GID=$(id -g)`` into the above docker launch script.
|
| 354 |
+
|
| 355 |
+
Example
|
| 356 |
+
-------
|
| 357 |
+
|
| 358 |
+
Due to to special setting in AMD (ROCM) torch,
|
| 359 |
+
1. If your ``ray>=2.45.0`` (default), you need to set ``RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES`` when starting ray in verl's RLHF training and add this [patch](https://github.com/ray-project/ray/pull/53531/files).
|
| 360 |
+
2. If your ``ray<2.45.0``, you need to set ``RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES`` when starting ray in verl's RLHF training.
|
| 361 |
+
Inference ``$ENGINE`` can be ``vllm`` or ``sglang``. We choose ``vllm`` as default in the following examples.
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
PPO
|
| 366 |
+
~~~
|
| 367 |
+
|
| 368 |
+
.. code-block:: bash
|
| 369 |
+
|
| 370 |
+
YOUR_PROJECT_NAME=r1-verl-ppo-upstream
|
| 371 |
+
YOUR_RUN_NAME=r1-training_ppo-upstream
|
| 372 |
+
# export HYDRA_FULL_ERROR=1
|
| 373 |
+
|
| 374 |
+
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 375 |
+
|
| 376 |
+
# [ray] < 2.45.0
|
| 377 |
+
#export RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES=1
|
| 378 |
+
|
| 379 |
+
# [ray] >= 2.45.0
|
| 380 |
+
export RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES=1 # Patch with https://github.com/ray-project/ray/pull/52794
|
| 381 |
+
|
| 382 |
+
GPUS_PER_NODE=8
|
| 383 |
+
MODEL_PATH=Qwen/Qwen2.5-0.5B-Instruct
|
| 384 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir data/gsm8k
|
| 385 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='$MODEL_PATH')"
|
| 386 |
+
ENGINE=vllm #sglang
|
| 387 |
+
|
| 388 |
+
PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \
|
| 389 |
+
data.train_files=data/gsm8k/train.parquet \
|
| 390 |
+
data.val_files=data/gsm8k/test.parquet \
|
| 391 |
+
data.train_batch_size=256 \
|
| 392 |
+
data.val_batch_size=1312 \
|
| 393 |
+
data.max_prompt_length=512 \
|
| 394 |
+
data.max_response_length=256 \
|
| 395 |
+
actor_rollout_ref.model.path=$MODEL_PATH \
|
| 396 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 397 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 398 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
|
| 399 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
|
| 400 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
|
| 401 |
+
actor_rollout_ref.rollout.name=$ENGINE \
|
| 402 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
|
| 403 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
|
| 404 |
+
critic.optim.lr=1e-5 \
|
| 405 |
+
critic.model.path=$MODEL_PATH \
|
| 406 |
+
critic.ppo_micro_batch_size_per_gpu=4 \
|
| 407 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 408 |
+
trainer.logger=console \
|
| 409 |
+
trainer.project_name=$YOUR_PROJECT_NAME \
|
| 410 |
+
trainer.experiment_name=$YOUR_RUN_NAME \
|
| 411 |
+
trainer.val_before_train=False \
|
| 412 |
+
trainer.n_gpus_per_node=$GPUS_PER_NODE \
|
| 413 |
+
trainer.nnodes=1 \
|
| 414 |
+
trainer.save_freq=10 \
|
| 415 |
+
trainer.test_freq=10 \
|
| 416 |
+
trainer.total_epochs=15 #2>&1 | tee verl_demo.log
|
| 417 |
+
|
| 418 |
+
GRPO
|
| 419 |
+
~~~~
|
| 420 |
+
|
| 421 |
+
.. code-block:: bash
|
| 422 |
+
|
| 423 |
+
YOUR_PROJECT_NAME=r1-verl-grpo-upstream
|
| 424 |
+
YOUR_RUN_NAME=r1-training_grpo-upstream
|
| 425 |
+
# export HYDRA_FULL_ERROR=1
|
| 426 |
+
# export FSDP_VERBOSE=1
|
| 427 |
+
|
| 428 |
+
#export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 429 |
+
|
| 430 |
+
# [ray] < 2.45.0
|
| 431 |
+
#export RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES=1
|
| 432 |
+
|
| 433 |
+
# [ray] >= 2.45.0
|
| 434 |
+
export RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES=1 # Patch with https://github.com/ray-project/ray/pull/52794
|
| 435 |
+
|
| 436 |
+
GPUS_PER_NODE=8
|
| 437 |
+
MODEL_PATH=Qwen/Qwen2.5-0.5B-Instruct
|
| 438 |
+
# MODEL_PATH=Qwen/Qwen2-7B-Instruct
|
| 439 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir data/gsm8k
|
| 440 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='$MODEL_PATH')"
|
| 441 |
+
ENGINE=vllm #sglang
|
| 442 |
+
|
| 443 |
+
python3 -m verl.trainer.main_ppo \
|
| 444 |
+
algorithm.adv_estimator=grpo \
|
| 445 |
+
data.train_files=data/gsm8k/train.parquet \
|
| 446 |
+
data.val_files=data/gsm8k/test.parquet \
|
| 447 |
+
data.train_batch_size=1024 \
|
| 448 |
+
data.val_batch_size=1312 \
|
| 449 |
+
data.max_prompt_length=512 \
|
| 450 |
+
data.max_response_length=1024 \
|
| 451 |
+
actor_rollout_ref.model.path=$MODEL_PATH \
|
| 452 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 453 |
+
actor_rollout_ref.model.use_remove_padding=True \
|
| 454 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
|
| 455 |
+
actor_rollout_ref.actor.use_dynamic_bsz=True \
|
| 456 |
+
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=24000 \
|
| 457 |
+
actor_rollout_ref.actor.use_kl_loss=True \
|
| 458 |
+
actor_rollout_ref.actor.kl_loss_coef=0.001 \
|
| 459 |
+
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
|
| 460 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=Flase \
|
| 461 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=False \
|
| 462 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
|
| 463 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
|
| 464 |
+
actor_rollout_ref.rollout.name=$ENGINE \
|
| 465 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
|
| 466 |
+
actor_rollout_ref.rollout.n=5 \
|
| 467 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=False \
|
| 468 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 469 |
+
trainer.critic_warmup=0 \
|
| 470 |
+
trainer.logger=console \
|
| 471 |
+
trainer.project_name=$YOUR_PROJECT_NAME \
|
| 472 |
+
trainer.experiment_name=$YOUR_RUN_NAME \
|
| 473 |
+
trainer.n_gpus_per_node=$GPUS_PER_NODE \
|
| 474 |
+
trainer.val_before_train=False \
|
| 475 |
+
trainer.nnodes=1 \
|
| 476 |
+
trainer.save_freq=-1 \
|
| 477 |
+
trainer.test_freq=10 \
|
| 478 |
+
trainer.total_epochs=15
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
Multi-node training: slurm with Docker/Podman container
|
| 483 |
+
---------------------------------------------------------------------------------------
|
| 484 |
+
|
| 485 |
+
If you want to run multi-node training with slurm, you can use the following script.
|
| 486 |
+
|
| 487 |
+
.. note::
|
| 488 |
+
1. You need to use ``podman`` or ``docker`` in the following script. We will release the apptainer script later.
|
| 489 |
+
2. If you want to use ``podman``, you just replace ``docker`` with ``podman`` in the following script.
|
| 490 |
+
|
| 491 |
+
The script includes the following steps:
|
| 492 |
+
|
| 493 |
+
1. SLURM Configuration
|
| 494 |
+
2. Environment Setup
|
| 495 |
+
3. Docker/Podman Container Setup
|
| 496 |
+
4. Ray Cluster Initialization
|
| 497 |
+
5. Data Preprocessing
|
| 498 |
+
6. Model Setup
|
| 499 |
+
7. Training Launch
|
| 500 |
+
|
| 501 |
+
|
| 502 |
+
slurm_script.sh
|
| 503 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 504 |
+
|
| 505 |
+
.. code-block:: bash
|
| 506 |
+
|
| 507 |
+
#!/bin/bash
|
| 508 |
+
|
| 509 |
+
#SBATCH --job-name=verl-ray-on-slurm
|
| 510 |
+
#SBATCH --nodes=2
|
| 511 |
+
#SBATCH --ntasks-per-node=2
|
| 512 |
+
#SBATCH --mem=200G
|
| 513 |
+
#SBATCH --time=30-00:00:00
|
| 514 |
+
#SBATCH --gpus-per-node=8
|
| 515 |
+
#SBATCH --cpus-per-task=28
|
| 516 |
+
#SBATCH --output=../verl_log/slurm-%j.out
|
| 517 |
+
#SBATCH --error=../verl_log/slurm-%j.err
|
| 518 |
+
#SBATCH --nodelist=gpu-[0,1]
|
| 519 |
+
|
| 520 |
+
|
| 521 |
+
# load necessary modules
|
| 522 |
+
### Run this setup
|
| 523 |
+
# [Cluster]: Use docker
|
| 524 |
+
# docker pull docker.io/rocm/vllm:rocm6.2_mi300_ubuntu20.04_py3.9_vllm_0.6.4
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
##########################################################################
|
| 528 |
+
###The following setting should be set in different project and cluster###
|
| 529 |
+
##########################################################################
|
| 530 |
+
|
| 531 |
+
### Project
|
| 532 |
+
CONTAINER_NAME="multinode_verl_training"
|
| 533 |
+
IMG="verl.rocm"
|
| 534 |
+
DOCKERFILE="docker/Dockerfile.rocm"
|
| 535 |
+
# echo $PWD
|
| 536 |
+
verl_workdir="${HOME}/projects/verl_upstream"
|
| 537 |
+
export TRANSFORMERS_CACHE="${HOME}/.cache/huggingface"
|
| 538 |
+
export HF_HOME=$TRANSFORMERS_CACHE
|
| 539 |
+
|
| 540 |
+
### Cluster Network Setting
|
| 541 |
+
export NCCL_DEBUG=TRACE
|
| 542 |
+
export GPU_MAX_HW_QUEUES=2
|
| 543 |
+
export TORCH_NCCL_HIGH_PRIORITY=1
|
| 544 |
+
export NCCL_CHECKS_DISABLE=1
|
| 545 |
+
# export NCCL_IB_HCA=rdma0,rdma1,rdma2,rdma3,rdma4,rdma5,rdma6,rdma7
|
| 546 |
+
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_8,mlx5_9
|
| 547 |
+
export NCCL_IB_GID_INDEX=3
|
| 548 |
+
export NCCL_CROSS_NIC=0
|
| 549 |
+
export CUDA_DEVICE_MAX_CONNECTIONS=1
|
| 550 |
+
export NCCL_PROTO=Simple
|
| 551 |
+
export RCCL_MSCCL_ENABLE=0
|
| 552 |
+
export TOKENIZERS_PARALLELISM=false
|
| 553 |
+
export HSA_NO_SCRATCH_RECLAIM=1
|
| 554 |
+
##########################################################################
|
| 555 |
+
|
| 556 |
+
## Assign using GPUs
|
| 557 |
+
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 558 |
+
|
| 559 |
+
### For rocm and training script
|
| 560 |
+
# [ray] < 2.45.0
|
| 561 |
+
#export RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES=1
|
| 562 |
+
|
| 563 |
+
# [ray] >= 2.45.0
|
| 564 |
+
export RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES=1 # Patch with https://github.com/ray-project/ray/pull/52794
|
| 565 |
+
|
| 566 |
+
|
| 567 |
+
# Build and launch the Docker container
|
| 568 |
+
srun bash -c "
|
| 569 |
+
# Exit on any error
|
| 570 |
+
set -e
|
| 571 |
+
|
| 572 |
+
# Clean up dangling images (images with <none> tag)
|
| 573 |
+
docker image prune -f
|
| 574 |
+
|
| 575 |
+
# Need to pull the docker first
|
| 576 |
+
docker pull rlsys/verl:verl-0.4.1_ubuntu-22.04_rocm6.3.4-numa-patch_vllm0.8.5_sglang0.4.6.post4
|
| 577 |
+
|
| 578 |
+
if ! docker images --format "{{.Repository}}:{{.Tag}}" | grep -q "${IMG}"; then
|
| 579 |
+
echo \"Building ${IMG} image...\"
|
| 580 |
+
docker build -f \"${DOCKERFILE}\" -t \"${IMG}\" .
|
| 581 |
+
else
|
| 582 |
+
echo \"${IMG} image already exists, skipping build\"
|
| 583 |
+
fi
|
| 584 |
+
|
| 585 |
+
# Removing old container if exists
|
| 586 |
+
docker rm \"${CONTAINER_NAME}\" 2>/dev/null || true
|
| 587 |
+
|
| 588 |
+
# Checking network devices
|
| 589 |
+
ibdev2netdev
|
| 590 |
+
|
| 591 |
+
# Launch the docker
|
| 592 |
+
docker run --rm -d \
|
| 593 |
+
-e HYDRA_FULL_ERROR=1 \
|
| 594 |
+
-e RAY_EXPERIMENTAL_NOSET_ROCR_VISIBLE_DEVICES=1 \
|
| 595 |
+
-e RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES=1 \
|
| 596 |
+
-e NCCL_DEBUG=${NCCL_DEBUG} \
|
| 597 |
+
-e GPU_MAX_HW_QUEUES=${GPU_MAX_HW_QUEUES} \
|
| 598 |
+
-e TORCH_NCCL_HIGH_PRIORITY=${TORCH_NCCL_HIGH_PRIORITY} \
|
| 599 |
+
-e NCCL_CHECKS_DISABLE=${NCCL_CHECKS_DISABLE} \
|
| 600 |
+
-e NCCL_IB_HCA=${NCCL_IB_HCA} \
|
| 601 |
+
-e NCCL_IB_GID_INDEX=${NCCL_IB_GID_INDEX} \
|
| 602 |
+
-e NCCL_CROSS_NIC=${NCCL_CROSS_NIC} \
|
| 603 |
+
-e CUDA_DEVICE_MAX_CONNECTIONS=${CUDA_DEVICE_MAX_CONNECTIONS} \
|
| 604 |
+
-e NCCL_PROTO=${NCCL_PROTO} \
|
| 605 |
+
-e RCCL_MSCCL_ENABLE=${RCCL_MSCCL_ENABLE} \
|
| 606 |
+
-e TOKENIZERS_PARALLELISM=${TOKENIZERS_PARALLELISM} \
|
| 607 |
+
-e HSA_NO_SCRATCH_RECLAIM=${HSA_NO_SCRATCH_RECLAIM} \
|
| 608 |
+
-e TRANSFORMERS_CACHE=${TRANSFORMERS_CACHE} \
|
| 609 |
+
-e HF_HOME=${HF_HOME} \
|
| 610 |
+
--network host \
|
| 611 |
+
--device /dev/dri \
|
| 612 |
+
--device /dev/kfd \
|
| 613 |
+
--device /dev/infiniband \
|
| 614 |
+
--group-add video \
|
| 615 |
+
--cap-add SYS_PTRACE \
|
| 616 |
+
--security-opt seccomp=unconfined \
|
| 617 |
+
--privileged \
|
| 618 |
+
-v \${HOME}:\${HOME} \
|
| 619 |
+
-v \${HOME}/.ssh:/root/.ssh \
|
| 620 |
+
-w "${verl_workdir}" \
|
| 621 |
+
--shm-size 128G \
|
| 622 |
+
--name \"${CONTAINER_NAME}\" \
|
| 623 |
+
\"${IMG}\" \
|
| 624 |
+
tail -f /dev/null
|
| 625 |
+
|
| 626 |
+
echo \"Container setup completed\"
|
| 627 |
+
"
|
| 628 |
+
# (Optional): If you do not want to root mode and require assign yuorself as the user
|
| 629 |
+
# Please add `-e HOST_UID=$(id -u)` and `-e HOST_GID=$(id -g)` into the above docker launch script.
|
| 630 |
+
|
| 631 |
+
|
| 632 |
+
|
| 633 |
+
|
| 634 |
+
|
| 635 |
+
### Ray launch the nodes before training
|
| 636 |
+
|
| 637 |
+
# Getting the node names
|
| 638 |
+
nodes_array=($(scontrol show hostnames "$SLURM_JOB_NODELIST" | tr '\n' ' '))
|
| 639 |
+
|
| 640 |
+
head_node=${nodes_array[0]}
|
| 641 |
+
head_node_ip=$(srun --nodes=1 --ntasks=1 -w "$head_node" hostname --ip-address)
|
| 642 |
+
|
| 643 |
+
# if we detect a space character in the head node IP, we'll
|
| 644 |
+
# convert it to an ipv4 address. This step is optional.
|
| 645 |
+
if [[ "$head_node_ip" == *" "* ]]; then
|
| 646 |
+
IFS=' ' read -ra ADDR <<<"$head_node_ip"
|
| 647 |
+
if [[ ${#ADDR[0]} -gt 16 ]]; then
|
| 648 |
+
head_node_ip=${ADDR[1]}
|
| 649 |
+
else
|
| 650 |
+
head_node_ip=${ADDR[0]}
|
| 651 |
+
fi
|
| 652 |
+
echo "IPV6 address detected. We split the IPV4 address as $head_node_ip"
|
| 653 |
+
fi
|
| 654 |
+
|
| 655 |
+
port=6379
|
| 656 |
+
ip_head=$head_node_ip:$port
|
| 657 |
+
export ip_head
|
| 658 |
+
echo "IP Head: $ip_head"
|
| 659 |
+
|
| 660 |
+
# make sure we set environment variables before Ray initialization
|
| 661 |
+
|
| 662 |
+
# Print out all env variables
|
| 663 |
+
printenv
|
| 664 |
+
|
| 665 |
+
echo "Starting HEAD at $head_node"
|
| 666 |
+
srun --nodes=1 --ntasks=1 -w "$head_node" \
|
| 667 |
+
docker exec "${CONTAINER_NAME}" \
|
| 668 |
+
ray start --head --node-ip-address="$head_node_ip" --port=$port \
|
| 669 |
+
--dashboard-port=8266 \
|
| 670 |
+
--num-cpus "${SLURM_CPUS_PER_TASK}" --num-gpus "${SLURM_GPUS_PER_NODE}" --block &
|
| 671 |
+
# optional, though may be useful in certain versions of Ray < 1.0.
|
| 672 |
+
sleep 10
|
| 673 |
+
|
| 674 |
+
# number of nodes other than the head node
|
| 675 |
+
worker_num=$((SLURM_JOB_NUM_NODES - 1))
|
| 676 |
+
|
| 677 |
+
for ((i = 1; i <= worker_num; i++)); do
|
| 678 |
+
node_i=${nodes_array[$i]}
|
| 679 |
+
echo "Debug: Starting worker on node_i = ${node_i}"
|
| 680 |
+
if [ -z "$node_i" ]; then
|
| 681 |
+
echo "Error: Empty node name for worker $i"
|
| 682 |
+
continue
|
| 683 |
+
fi
|
| 684 |
+
echo "Starting WORKER $i at $node_i"
|
| 685 |
+
srun --nodes=1 --ntasks=1 -w "$node_i" \
|
| 686 |
+
docker exec "${CONTAINER_NAME}" \
|
| 687 |
+
ray start --address "$ip_head" --num-cpus "${SLURM_CPUS_PER_TASK}" --num-gpus "${SLURM_GPUS_PER_NODE}" --block &
|
| 688 |
+
sleep 5
|
| 689 |
+
done
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
|
| 693 |
+
|
| 694 |
+
# Ray initlization test (See whether any error in the above execution)
|
| 695 |
+
echo "Testing Ray initialization in the slurm nodes..."
|
| 696 |
+
docker exec "${CONTAINER_NAME}" python3 -c '
|
| 697 |
+
import ray
|
| 698 |
+
try:
|
| 699 |
+
ray.init(address="auto")
|
| 700 |
+
print("\n=== Ray Cluster Status ===")
|
| 701 |
+
print(f"Number of nodes: {len(ray.nodes())}")
|
| 702 |
+
for node in ray.nodes():
|
| 703 |
+
print("Node: {}, Status: {}".format(node["NodeManagerHostname"], node["Alive"]))
|
| 704 |
+
# print(f"Node: {node}")
|
| 705 |
+
ray.shutdown()
|
| 706 |
+
print("Ray initialization successful!")
|
| 707 |
+
except Exception as e:
|
| 708 |
+
print(f"Ray initialization failed: {str(e)}")
|
| 709 |
+
'
|
| 710 |
+
echo "=== Ray test completed ==="
|
| 711 |
+
######
|
| 712 |
+
|
| 713 |
+
|
| 714 |
+
|
| 715 |
+
# Run data preprocessing
|
| 716 |
+
|
| 717 |
+
echo "Starting data preprocessing..."
|
| 718 |
+
docker exec "${CONTAINER_NAME}" \
|
| 719 |
+
python3 "examples/data_preprocess/gsm8k.py" "--local_save_dir" "../data/gsm8k"
|
| 720 |
+
|
| 721 |
+
echo "Starting data preprocessing..."
|
| 722 |
+
docker exec "${CONTAINER_NAME}" \
|
| 723 |
+
python3 "examples/data_preprocess/math_dataset.py" "--local_dir" "../data/math"
|
| 724 |
+
|
| 725 |
+
train_files="../data/gsm8k/train.parquet"
|
| 726 |
+
val_files="../data/gsm8k/test.parquet"
|
| 727 |
+
|
| 728 |
+
# Download and test model
|
| 729 |
+
echo "Loading model..."
|
| 730 |
+
docker exec "${CONTAINER_NAME}" \
|
| 731 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2-7B-Instruct')"
|
| 732 |
+
MODEL_PATH="Qwen/Qwen2-7B-Instruct"
|
| 733 |
+
|
| 734 |
+
# Set model path after pipeline test
|
| 735 |
+
MODEL_PATH="Qwen/Qwen2.5-0.5B-Instruct"
|
| 736 |
+
|
| 737 |
+
echo "== Data and model loading Done =="
|
| 738 |
+
|
| 739 |
+
echo "Start to train..."
|
| 740 |
+
|
| 741 |
+
docker exec "${CONTAINER_NAME}" \
|
| 742 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2-7B-Instruct')"
|
| 743 |
+
MODEL_PATH="Qwen/Qwen2-7B-Instruct"
|
| 744 |
+
|
| 745 |
+
|
| 746 |
+
PYTHONUNBUFFERED=1 srun --overlap --nodes=${SLURM_NNODES} --ntasks=1 -w "$head_node" \
|
| 747 |
+
docker exec "${CONTAINER_NAME}" \
|
| 748 |
+
python3 -m verl.trainer.main_ppo \
|
| 749 |
+
data.train_files=$train_files \
|
| 750 |
+
data.val_files=$val_files \
|
| 751 |
+
data.train_batch_size=1024 \
|
| 752 |
+
data.max_prompt_length=1024 \
|
| 753 |
+
data.max_response_length=1024 \
|
| 754 |
+
actor_rollout_ref.model.path=$MODEL_PATH \
|
| 755 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=False \
|
| 756 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 757 |
+
actor_rollout_ref.model.use_remove_padding=True \
|
| 758 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
|
| 759 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=8 \
|
| 760 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 761 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=False \
|
| 762 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
|
| 763 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=16 \
|
| 764 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
|
| 765 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 766 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.9 \
|
| 767 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=16 \
|
| 768 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 769 |
+
critic.optim.lr=1e-5 \
|
| 770 |
+
critic.model.use_remove_padding=True \
|
| 771 |
+
critic.model.path=$MODEL_PATH \
|
| 772 |
+
critic.model.enable_gradient_checkpointing=False \
|
| 773 |
+
critic.ppo_micro_batch_size_per_gpu=8 \
|
| 774 |
+
critic.model.fsdp_config.param_offload=False \
|
| 775 |
+
critic.model.fsdp_config.optimizer_offload=False \
|
| 776 |
+
algorithm.kl_ctrl.kl_coef=0.0001 \
|
| 777 |
+
trainer.critic_warmup=0 \
|
| 778 |
+
trainer.logger='["console","wandb"]' \
|
| 779 |
+
trainer.project_name='verl_example' \
|
| 780 |
+
trainer.experiment_name='Qwen2.5-32B-Instruct_function_rm' \
|
| 781 |
+
trainer.n_gpus_per_node=${SLURM_GPUS_PER_NODE} \
|
| 782 |
+
trainer.val_before_train=False \
|
| 783 |
+
trainer.nnodes=${SLURM_NNODES} \
|
| 784 |
+
trainer.save_freq=-1 \
|
| 785 |
+
trainer.test_freq=10 \
|
| 786 |
+
trainer.total_epochs=15
|
| 787 |
+
|
| 788 |
+
|
| 789 |
+
Run slurm_script.sh
|
| 790 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 791 |
+
Just sbatch your slurm_script.sh
|
| 792 |
+
|
| 793 |
+
.. code-block:: bash
|
| 794 |
+
|
| 795 |
+
sbatch slurm_script.sh
|
| 796 |
+
|
code/RL_model/verl/verl_train/docs/amd_tutorial/amd_vllm_page.rst
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
verl performance tuning for AMD (ROCm Kernel)
|
| 2 |
+
=====================================================
|
| 3 |
+
|
| 4 |
+
Last updated: 11/13/2025.
|
| 5 |
+
|
| 6 |
+
Author: `Yang Wang <https://github.com/YangWang92/>`_, `Songlin Jiang <https://github.com/HollowMan6/>`_
|
| 7 |
+
|
| 8 |
+
Use vLLM Sleep Mode for AMD MI3xx series GPUs
|
| 9 |
+
--------------------------------------------------------------
|
| 10 |
+
|
| 11 |
+
By default, verl requires vLLM to enable sleep mode, which allows vLLM to offload GPU memory to CPU memory after rollout. This feature has been merged into the main branch of vLLM for version later than 0.11.0.
|
| 12 |
+
|
| 13 |
+
For now, you can use the vLLM main branch and build it from the source code, or you can directly install vLLM from the pre-built ROCm wheels for vLLM version later than 0.11.0 when it's available.
|
| 14 |
+
|
| 15 |
+
1. Clone the vLLM repository and build it with the following commands:
|
| 16 |
+
|
| 17 |
+
.. code-block:: bash
|
| 18 |
+
|
| 19 |
+
git clone https://github.com/vllm-project/vllm.git
|
| 20 |
+
cd vllm
|
| 21 |
+
git reset --hard 4ca5cd5740c0cd7788cdfa8b7ec6a27335607a48 # You can also use a later commit as you wish
|
| 22 |
+
python -m pip install -r requirements/rocm.txt
|
| 23 |
+
VLLM_TARGET_DEVICE=rocm ROCM_PATH=/opt/rocm/ python3 setup.py develop
|
| 24 |
+
|
| 25 |
+
2. Additionally, we recommend you to use the ROCm version later than or equal to ROCm 7.0.
|
| 26 |
+
|
| 27 |
+
After the upgrade, you can verify whether sleep mode is working by trying out `these scripts <https://github.com/EmbeddedLLM/inference-experiment/tree/main/sleep_mode>`_.
|
| 28 |
+
|
| 29 |
+
If sleep mode is working, you should see the memory usage reduce after sleep.
|
| 30 |
+
|
| 31 |
+
After applying the vLLM patch and completing the installation, you can enable sleep mode in verl to reduce memory overhead. This allows verl to offload unused GPU memory during rollout, significantly lowering the memory footprint during long-context training or multi-node reinforcement learning.
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
Enable CUDA Graph and Bypass ROCm-related issues
|
| 35 |
+
--------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
Due to potential issues with CUDA graph capture in ROCm, we've found that vLLM's CUDA graph feature cannot be enabled on multiple nodes in verl on AMD platforms with vLLM V1 mode. This leads to significantly slower rollout performance.
|
| 38 |
+
|
| 39 |
+
Our investigation shows that ROCm may trigger an unexpected crash when attempting to capture large batches with CUDA graph. One workaround is to set ``actor_rollout_ref.rollout.cudagraph_capture_sizes`` to values such as ``[1, 2, 4, 8, 16, 32, 64]`` (change depending on your GPU memory size).
|
| 40 |
+
|
| 41 |
+
Then, you can choose to enable CUDA graph by setting ``actor_rollout_ref.rollout.enforce_eager`` to ``False`` in your verl configuration file.
|
code/RL_model/verl/verl_train/docs/api/data.rst
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Data interface
|
| 2 |
+
=========================
|
| 3 |
+
|
| 4 |
+
Last updated: 05/19/2025 (API docstrings are auto-generated).
|
| 5 |
+
|
| 6 |
+
DataProto is the interface for data exchange.
|
| 7 |
+
|
| 8 |
+
The :class:`verl.DataProto` class contains two key members:
|
| 9 |
+
|
| 10 |
+
- batch: a :class:`tensordict.TensorDict` object for the actual data
|
| 11 |
+
- meta_info: a :class:`Dict` with additional meta information
|
| 12 |
+
|
| 13 |
+
TensorDict
|
| 14 |
+
~~~~~~~~~~~~
|
| 15 |
+
|
| 16 |
+
:attr:`DataProto.batch` is built on top of :class:`tensordict`, a project in the PyTorch ecosystem.
|
| 17 |
+
A TensorDict is a dict-like container for tensors. To instantiate a TensorDict, you must specify key-value pairs as well as the batch size.
|
| 18 |
+
|
| 19 |
+
.. code-block:: python
|
| 20 |
+
|
| 21 |
+
>>> import torch
|
| 22 |
+
>>> from tensordict import TensorDict
|
| 23 |
+
>>> tensordict = TensorDict({"zeros": torch.zeros(2, 3, 4), "ones": torch.ones(2, 3, 5)}, batch_size=[2,])
|
| 24 |
+
>>> tensordict["twos"] = 2 * torch.ones(2, 5, 6)
|
| 25 |
+
>>> zeros = tensordict["zeros"]
|
| 26 |
+
>>> tensordict
|
| 27 |
+
TensorDict(
|
| 28 |
+
fields={
|
| 29 |
+
ones: Tensor(shape=torch.Size([2, 3, 5]), device=cpu, dtype=torch.float32, is_shared=False),
|
| 30 |
+
twos: Tensor(shape=torch.Size([2, 5, 6]), device=cpu, dtype=torch.float32, is_shared=False),
|
| 31 |
+
zeros: Tensor(shape=torch.Size([2, 3, 4]), device=cpu, dtype=torch.float32, is_shared=False)},
|
| 32 |
+
batch_size=torch.Size([2]),
|
| 33 |
+
device=None,
|
| 34 |
+
is_shared=False)
|
| 35 |
+
|
| 36 |
+
One can also index a tensordict along its batch_size. The contents of the TensorDict can be manipulated collectively as well.
|
| 37 |
+
|
| 38 |
+
.. code-block:: python
|
| 39 |
+
|
| 40 |
+
>>> tensordict[..., :1]
|
| 41 |
+
TensorDict(
|
| 42 |
+
fields={
|
| 43 |
+
ones: Tensor(shape=torch.Size([1, 3, 5]), device=cpu, dtype=torch.float32, is_shared=False),
|
| 44 |
+
twos: Tensor(shape=torch.Size([1, 5, 6]), device=cpu, dtype=torch.float32, is_shared=False),
|
| 45 |
+
zeros: Tensor(shape=torch.Size([1, 3, 4]), device=cpu, dtype=torch.float32, is_shared=False)},
|
| 46 |
+
batch_size=torch.Size([1]),
|
| 47 |
+
device=None,
|
| 48 |
+
is_shared=False)
|
| 49 |
+
>>> tensordict = tensordict.to("cuda:0")
|
| 50 |
+
>>> tensordict = tensordict.reshape(6)
|
| 51 |
+
|
| 52 |
+
For more about :class:`tensordict.TensorDict` usage, see the official tensordict_ documentation.
|
| 53 |
+
|
| 54 |
+
.. _tensordict: https://pytorch.org/tensordict/stable/overview.html
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
Core APIs
|
| 58 |
+
~~~~~~~~~~~~~~~~~
|
| 59 |
+
|
| 60 |
+
.. autoclass:: verl.DataProto
|
| 61 |
+
:members: to, select, union, make_iterator, concat
|
code/RL_model/verl/verl_train/docs/api/single_controller.rst
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Single Controller interface
|
| 2 |
+
============================
|
| 3 |
+
|
| 4 |
+
Last updated: 05/27/2025 (API docstrings are auto-generated).
|
| 5 |
+
|
| 6 |
+
The Single Controller provides a unified interface for managing distributed workers
|
| 7 |
+
using Ray or other backends and executing functions across them.
|
| 8 |
+
It simplifies the process of dispatching tasks and collecting results, particularly
|
| 9 |
+
when dealing with data parallelism or model parallelism.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
Core APIs
|
| 13 |
+
~~~~~~~~~~~~~~~~~
|
| 14 |
+
|
| 15 |
+
.. autoclass:: verl.single_controller.Worker
|
| 16 |
+
:members: __init__, __new__, get_master_addr_port, get_cuda_visible_devices, world_size, rank
|
| 17 |
+
|
| 18 |
+
.. autoclass:: verl.single_controller.WorkerGroup
|
| 19 |
+
:members: __init__, world_size
|
| 20 |
+
|
| 21 |
+
.. autoclass:: verl.single_controller.ClassWithInitArgs
|
| 22 |
+
:members: __init__, __call__
|
| 23 |
+
|
| 24 |
+
.. autoclass:: verl.single_controller.ResourcePool
|
| 25 |
+
:members: __init__, world_size, local_world_size_list, local_rank_list
|
| 26 |
+
|
| 27 |
+
.. autoclass:: verl.single_controller.ray.RayWorkerGroup
|
| 28 |
+
:members: __init__
|
| 29 |
+
|
| 30 |
+
.. autofunction:: verl.single_controller.ray.create_colocated_worker_cls
|
code/RL_model/verl/verl_train/docs/api/trainer.rst
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Trainer Interface
|
| 2 |
+
================================
|
| 3 |
+
|
| 4 |
+
Last updated: 06/08/2025 (API docstrings are auto-generated).
|
| 5 |
+
|
| 6 |
+
Trainers drive the training loop. Introducing new trainer classes in case of new training paradiam is encouraged.
|
| 7 |
+
|
| 8 |
+
.. autosummary::
|
| 9 |
+
:nosignatures:
|
| 10 |
+
|
| 11 |
+
verl.trainer.ppo.ray_trainer.RayPPOTrainer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
Core APIs
|
| 15 |
+
~~~~~~~~~~~~~~~~~
|
| 16 |
+
|
| 17 |
+
.. autoclass:: verl.trainer.ppo.ray_trainer.RayPPOTrainer
|
| 18 |
+
:members: __init__, init_workers, fit
|
| 19 |
+
|
| 20 |
+
.. automodule:: verl.utils.tokenizer
|
| 21 |
+
:members: hf_tokenizer
|
| 22 |
+
|
| 23 |
+
.. automodule:: verl.trainer.ppo.core_algos
|
| 24 |
+
:members: agg_loss, kl_penalty, compute_policy_loss, kl_penalty
|
| 25 |
+
|
| 26 |
+
.. automodule:: verl.trainer.ppo.reward
|
| 27 |
+
:members: load_reward_manager, compute_reward, compute_reward_async
|
| 28 |
+
|
| 29 |
+
.. autoclass:: verl.workers.reward_manager.NaiveRewardManager
|
| 30 |
+
|
| 31 |
+
.. autoclass:: verl.workers.reward_manager.DAPORewardManager
|
code/RL_model/verl/verl_train/docs/api/utils.rst
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Utilities
|
| 2 |
+
============
|
| 3 |
+
|
| 4 |
+
Last updated: 05/19/2025 (API docstrings are auto-generated).
|
| 5 |
+
|
| 6 |
+
This section documents the utility functions and classes in the VERL library.
|
| 7 |
+
|
| 8 |
+
Python Functional Utilities
|
| 9 |
+
------------------------------
|
| 10 |
+
|
| 11 |
+
.. automodule:: verl.utils.py_functional
|
| 12 |
+
:members: append_to_dict
|
| 13 |
+
|
| 14 |
+
File System Utilities
|
| 15 |
+
------------------------
|
| 16 |
+
|
| 17 |
+
.. automodule:: verl.utils.fs
|
| 18 |
+
:members: copy_to_local
|
| 19 |
+
|
| 20 |
+
Tracking Utilities
|
| 21 |
+
---------------------
|
| 22 |
+
|
| 23 |
+
.. automodule:: verl.utils.tracking
|
| 24 |
+
:members: Tracking
|
| 25 |
+
|
| 26 |
+
Metrics Utilities
|
| 27 |
+
---------------------
|
| 28 |
+
|
| 29 |
+
.. automodule:: verl.utils.metric
|
| 30 |
+
:members: reduce_metrics
|
| 31 |
+
|
| 32 |
+
Checkpoint Management
|
| 33 |
+
------------------------
|
| 34 |
+
|
| 35 |
+
.. automodule:: verl.utils.checkpoint.checkpoint_manager
|
| 36 |
+
:members: find_latest_ckpt_path
|
| 37 |
+
|
| 38 |
+
.. automodule:: verl.utils.checkpoint.fsdp_checkpoint_manager
|
| 39 |
+
:members: FSDPCheckpointManager
|
| 40 |
+
|
| 41 |
+
Dataset Utilities
|
| 42 |
+
---------------------
|
| 43 |
+
|
| 44 |
+
.. automodule:: verl.utils.dataset.rl_dataset
|
| 45 |
+
:members: RLHFDataset, collate_fn
|
| 46 |
+
|
| 47 |
+
Torch Functional Utilities
|
| 48 |
+
-----------------------------
|
| 49 |
+
|
| 50 |
+
.. automodule:: verl.utils.torch_functional
|
| 51 |
+
:members: get_constant_schedule_with_warmup, masked_whiten, masked_mean, logprobs_from_logits
|
| 52 |
+
|
| 53 |
+
Sequence Length Balancing
|
| 54 |
+
----------------------------
|
| 55 |
+
|
| 56 |
+
.. automodule:: verl.utils.seqlen_balancing
|
| 57 |
+
:members: get_reverse_idx, rearrange_micro_batches
|
| 58 |
+
|
| 59 |
+
Ulysses Utilities
|
| 60 |
+
--------------------
|
| 61 |
+
|
| 62 |
+
.. automodule:: verl.utils.ulysses
|
| 63 |
+
:members: gather_outputs_and_unpad, ulysses_pad_and_slice_inputs
|
| 64 |
+
|
| 65 |
+
FSDP Utilities
|
| 66 |
+
------------------
|
| 67 |
+
|
| 68 |
+
.. automodule:: verl.utils.fsdp_utils
|
| 69 |
+
:members: get_fsdp_wrap_policy, get_init_weight_context_manager, init_fn, load_fsdp_model_to_gpu, load_fsdp_optimizer, offload_fsdp_model_to_cpu, offload_fsdp_optimizer,
|
| 70 |
+
|
| 71 |
+
Debug Utilities
|
| 72 |
+
-------------------
|
| 73 |
+
|
| 74 |
+
.. automodule:: verl.utils.profiler
|
| 75 |
+
:members: log_gpu_memory_usage, GPUMemoryLogger
|
| 76 |
+
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_consistency.rst
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Align the Inference results of the verl and vLLM frameworks on Ascend devices(zh)
|
| 2 |
+
====================================
|
| 3 |
+
|
| 4 |
+
在昇腾设备上对齐verl和vLLM两个框架下的推理结果。
|
| 5 |
+
|
| 6 |
+
Last updated: 11/17/2025.
|
| 7 |
+
|
| 8 |
+
这是一份在昇腾设备上对齐verl和vLLM两个框架下推理结果的教程。
|
| 9 |
+
|
| 10 |
+
环境变量配置
|
| 11 |
+
~~~~~~~~~~~~
|
| 12 |
+
|
| 13 |
+
在多卡通信情况下:
|
| 14 |
+
|
| 15 |
+
- HCCL通信下(默认场景):
|
| 16 |
+
|
| 17 |
+
- export CLOSE_MATMUL_K_SHIFT=1
|
| 18 |
+
- export ATB_MATMUL_SHUFFLE_K_ENABLE=0
|
| 19 |
+
- export HCCL_DETERMINISTIC="true"
|
| 20 |
+
- export VLLM_ENABLE_V1_MULTIPROCESSING=0
|
| 21 |
+
|
| 22 |
+
- LCCL通信下(通过export HCCL_OP_EXPANSION_MODE="AIV"使能):
|
| 23 |
+
|
| 24 |
+
- export CLOSE_MATMUL_K_SHIFT=1
|
| 25 |
+
- export ATB_MATMUL_SHUFFLE_K_ENABLE=0
|
| 26 |
+
- export LCCL_DETERMINISTIC=1
|
| 27 |
+
- export ATB_LLM_LCOC_ENABLE=0
|
| 28 |
+
- export VLLM_ENABLE_V1_MULTIPROCESSING=0
|
| 29 |
+
|
| 30 |
+
在单卡无通信情况下:
|
| 31 |
+
|
| 32 |
+
- HCCL和LCCL通信下:
|
| 33 |
+
|
| 34 |
+
- export CLOSE_MATMUL_K_SHIFT=1
|
| 35 |
+
- export ATB_MATMUL_SHUFFLE_K_ENABLE=0
|
| 36 |
+
- export VLLM_ENABLE_V1_MULTIPROCESSING=0
|
| 37 |
+
|
| 38 |
+
vLLM初始化参数
|
| 39 |
+
~~~~~~~~~~~~
|
| 40 |
+
|
| 41 |
+
需要对 SamplingParams 参数里单独设置seed, 保持vLLM和verl推理结果一致, 举例修改如下:
|
| 42 |
+
|
| 43 |
+
.. code:: yaml
|
| 44 |
+
|
| 45 |
+
sampling_params = SamplingParams(n=1,
|
| 46 |
+
logprobs=0, # can be set to 0 and let actor to recompute
|
| 47 |
+
max_tokens=config.response_length,
|
| 48 |
+
repetition_penalty=config.get("repetition_penalty", 1.0),
|
| 49 |
+
seed=1234)
|
| 50 |
+
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_profiling_en.rst
ADDED
|
@@ -0,0 +1,403 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Performance data collection based on FSDP or MindSpeed(Megatron) on Ascend devices(en)
|
| 2 |
+
==========================================================================================
|
| 3 |
+
|
| 4 |
+
Last updated: 12/20/2025.
|
| 5 |
+
|
| 6 |
+
This is a tutorial for data collection using the GRPO or DAPO algorithm
|
| 7 |
+
based on FSDP or MindSpeed(Megatron) on Ascend devices.
|
| 8 |
+
|
| 9 |
+
Configuration
|
| 10 |
+
-------------
|
| 11 |
+
|
| 12 |
+
Leverage two levels of configuration to control data collection:
|
| 13 |
+
|
| 14 |
+
- **Global profiler control**: Use parameters in ``verl/trainer/config/ppo_trainer.yaml`` (FSDP) or ``verl/trainer/config/ppo_megatron_trainer.yaml`` (MindSpeed) to control the collection mode and steps.
|
| 15 |
+
- **Role profile control**: Use parameters in each role's ``profile`` field to control various parameters.
|
| 16 |
+
|
| 17 |
+
Global collection control
|
| 18 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 19 |
+
|
| 20 |
+
Use parameters in ppo_trainer.yaml to control the collection mode
|
| 21 |
+
and steps.
|
| 22 |
+
|
| 23 |
+
- global_profiler: Control the ranks and mode of profiling
|
| 24 |
+
|
| 25 |
+
- tool: The profiling tool to use, options are nsys, npu, torch,
|
| 26 |
+
torch_memory.
|
| 27 |
+
- steps: This parameter can be set as a list that has
|
| 28 |
+
collection steps, such as [2, 4], which means it will collect steps 2
|
| 29 |
+
and 4. If set to null, no collection occurs.
|
| 30 |
+
- save_path: The path to save the collected data. Default is
|
| 31 |
+
"outputs/profile".
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
Role collection control
|
| 35 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 36 |
+
|
| 37 |
+
In each role's ``profiler`` field, you can control the collection mode for that role.
|
| 38 |
+
|
| 39 |
+
- enable: Whether to enable profiling for this role.
|
| 40 |
+
- all_ranks: Whether to collect data from all ranks.
|
| 41 |
+
- ranks: A list of ranks to collect data from. If empty, no data is collected.
|
| 42 |
+
- tool_config: Configuration for the profiling tool used by this role.
|
| 43 |
+
|
| 44 |
+
Use parameters in each role's ``profiler.tool_config.npu`` to control npu profiler behavior:
|
| 45 |
+
|
| 46 |
+
- level: Collection level—options are level_none, level0, level1, and
|
| 47 |
+
level2
|
| 48 |
+
|
| 49 |
+
- level_none: Disables all level-based data collection (turns off profiler_level).
|
| 50 |
+
- level0: Collect high-level application data, underlying NPU data, and operator execution details on NPU. After balancing data volume and analytical capability, Level 0 is recommended as the default configuration.
|
| 51 |
+
- level1: Extends level0 by adding CANN-layer AscendCL data and AI Core performance metrics on NPU.
|
| 52 |
+
- level2: Extends level1 by adding CANN-layer Runtime data and AI CPU metrics.
|
| 53 |
+
|
| 54 |
+
- contents: A list of options to control the collection content, such as
|
| 55 |
+
npu, cpu, memory, shapes, module, stack.
|
| 56 |
+
|
| 57 |
+
- npu: Whether to collect device-side performance data.
|
| 58 |
+
- cpu: Whether to collect host-side performance data.
|
| 59 |
+
- memory: Whether to enable memory analysis.
|
| 60 |
+
- shapes: Whether to record tensor shapes.
|
| 61 |
+
- module: Whether to record framework-layer Python call stack information. It is recommended to use 'module' instead of 'stack' for recording call stack information, as it costs less performance overhead.
|
| 62 |
+
- stack: Whether to record operator call stack information.
|
| 63 |
+
|
| 64 |
+
- analysis: Enables automatic data parsing.
|
| 65 |
+
- discrete: Whether to enable discrete mode.
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
Examples
|
| 69 |
+
--------
|
| 70 |
+
|
| 71 |
+
Disabling collection
|
| 72 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 73 |
+
|
| 74 |
+
.. code:: yaml
|
| 75 |
+
|
| 76 |
+
global_profiler:
|
| 77 |
+
steps: null # disable profile
|
| 78 |
+
|
| 79 |
+
End-to-End collection
|
| 80 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 81 |
+
|
| 82 |
+
.. code:: yaml
|
| 83 |
+
|
| 84 |
+
global_profiler:
|
| 85 |
+
steps: [1, 2, 5]
|
| 86 |
+
save_path: ./outputs/profile
|
| 87 |
+
actor_rollout_ref:
|
| 88 |
+
actor: # Set actor role profiler collection configuration parameters
|
| 89 |
+
profiler:
|
| 90 |
+
enable: True
|
| 91 |
+
all_ranks: True
|
| 92 |
+
tool_config:
|
| 93 |
+
npu:
|
| 94 |
+
discrete: False
|
| 95 |
+
contents: [npu, cpu] # Control collection list, default cpu, npu, can configure memory, shapes, module, etc.
|
| 96 |
+
# rollout & ref follow actor settings
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
Discrete Mode Collection
|
| 100 |
+
~~~~~~~~~~~~~~~~~~~~~~~~
|
| 101 |
+
|
| 102 |
+
.. code:: yaml
|
| 103 |
+
|
| 104 |
+
global_profiler:
|
| 105 |
+
steps: [1, 2, 5]
|
| 106 |
+
save_path: ./outputs/profile
|
| 107 |
+
actor_rollout_ref:
|
| 108 |
+
actor:
|
| 109 |
+
profiler:
|
| 110 |
+
enable: True # Set to True to profile training
|
| 111 |
+
all_ranks: False
|
| 112 |
+
ranks: [0] # Global Rank 0
|
| 113 |
+
tool_config:
|
| 114 |
+
npu:
|
| 115 |
+
discrete: True
|
| 116 |
+
contents: [npu, cpu]
|
| 117 |
+
rollout:
|
| 118 |
+
profiler:
|
| 119 |
+
enable: True # Set to True to profile inference
|
| 120 |
+
all_ranks: False
|
| 121 |
+
ranks: [0] # In Agent Loop mode, this is the Replica Rank (e.g., 0-th instance)
|
| 122 |
+
tool_config:
|
| 123 |
+
npu:
|
| 124 |
+
discrete: True # Must be enabled in Agent Loop mode
|
| 125 |
+
# ref follow actor settings
|
| 126 |
+
|
| 127 |
+
**Agent Loop Scenario Description**:
|
| 128 |
+
|
| 129 |
+
When Rollout runs in `Agent Loop <../advance/agent_loop.rst>`_ mode, performance data for the Rollout phase **must be collected using discrete mode**. At this time, the Profiler is triggered by the inference engine backend.
|
| 130 |
+
|
| 131 |
+
1. **Rank Meaning**: ``ranks`` in the Rollout config refers to the **Replica Rank** (instance index), not the global rank.
|
| 132 |
+
2. **Inference Engine Setup**:
|
| 133 |
+
|
| 134 |
+
- **vLLM Engine**
|
| 135 |
+
- **Must be configured via environment variables**:
|
| 136 |
+
- ``VLLM_TORCH_PROFILER_DIR``: Directory to save traces (**Required**).
|
| 137 |
+
- ``VLLM_TORCH_PROFILER_WITH_STACK``: Control stack tracing (1: on, 0: off, default: on).
|
| 138 |
+
- ``VLLM_TORCH_PROFILER_RECORD_SHAPES``: Set to 1 to record shapes of operator inputs.
|
| 139 |
+
- ``VLLM_TORCH_PROFILER_WITH_PROFILE_MEMORY``: Set to 1 to track tensor memory allocation/free.
|
| 140 |
+
- ``VLLM_TORCH_PROFILER_WITH_FLOPS``: Set to 1 to estimate FLOPS.
|
| 141 |
+
- *Note: vLLM ignores the save_path and contents in yaml.*
|
| 142 |
+
|
| 143 |
+
- **SGLang Engine**
|
| 144 |
+
- **Zero Configuration**. Automatically reads configuration from ``ppo_trainer.yaml``.
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
Visualization
|
| 148 |
+
-------------
|
| 149 |
+
|
| 150 |
+
Collected data is stored in the user-defined save_path and can be
|
| 151 |
+
visualized by using the `MindStudio Insight <https://www.hiascend.com/document/detail/zh/mindstudio/80RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0002.html>`_ tool.
|
| 152 |
+
|
| 153 |
+
Additionally, in a Linux environment, the MindStudio Insight tool is provided in the form of a `JupyterLab Plugin <https://www.hiascend.com/document/detail/zh/mindstudio/82RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0130.html>`_ ,offering a more intuitive and highly interactive user interface. The advantages of the JupyterLab plugin are as follows:
|
| 154 |
+
|
| 155 |
+
- Seamless integration: Supports running the MindStudio Insight tool directly within the Jupyter environment, eliminating the need to switch platforms or copy data from the server, enabling data to be collected and used immediately.
|
| 156 |
+
- Fast startup: Allows MindStudio Insight to be launched quickly via the JupyterLab command line or graphical interface.
|
| 157 |
+
- Smooth operation: In a Linux environment, launching MindStudio Insight through JupyterLab effectively alleviates performance lag compared to the full-package communication mode, significantly improving the user experience.
|
| 158 |
+
- Remote access: Supports remotely launching MindStudio Insight. Users can connect to the service via a local browser for direct visual analysis, reducing the difficulty of uploading and downloading data during large-model training or inference.
|
| 159 |
+
|
| 160 |
+
If the analysis parameter is set to False, offline parsing is required after data collection:
|
| 161 |
+
|
| 162 |
+
.. code:: python
|
| 163 |
+
|
| 164 |
+
import torch_npu
|
| 165 |
+
# Set profiler_path to the parent directory of the "localhost.localdomain_<PID>_<timestamp>_ascend_pt" folder
|
| 166 |
+
torch_npu.profiler.profiler.analyse(profiler_path=profiler_path)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
Advanced Guide: Fine-grained Collection
|
| 170 |
+
---------------------------------------
|
| 171 |
+
|
| 172 |
+
Background and Challenges
|
| 173 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 174 |
+
|
| 175 |
+
Although the configuration-based collection method mentioned above is convenient, it faces challenges in training scenarios with **long sequences (Long Context)** or **large global batch sizes (Large Global Batch Size)**. Within a complete training step (Step), model computation exhibits high-frequency and repetitive characteristics:
|
| 176 |
+
|
| 177 |
+
1. **Rollout phase**: Sequence generation (Generate Sequence) is an autoregressive process involving thousands of forward computations of the Decoder model.
|
| 178 |
+
2. **Training phase**: To control peak memory usage, verl typically adopts a Micro-Batch strategy, dividing large data streams into multiple micro-batches for computation.
|
| 179 |
+
|
| 180 |
+
- **compute_log_prob (Actor/Ref)**: Involves multiple rounds of pure forward propagation.
|
| 181 |
+
- **update_policy (Actor/Critic)**: Involves multiple rounds of forward and backward propagation.
|
| 182 |
+
|
| 183 |
+
This characteristic leads to massive and repetitive operator records from full profiling. As shown in the image below:
|
| 184 |
+
|
| 185 |
+
.. image:: https://raw.githubusercontent.com/mengchengTang/verl-data/master/verl_ascend_profiler.png
|
| 186 |
+
|
| 187 |
+
Even with ``discrete`` mode enabled, performance data files for a single stage can still reach several TB, leading to **parsing failures** or **visualization tool lag**.
|
| 188 |
+
|
| 189 |
+
Solution: Critical Path Sampling
|
| 190 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 191 |
+
|
| 192 |
+
To solve the above problems, we can adopt a **critical path sampling** strategy: Based on the API interface provided by `torch_npu.profiler <https://www.hiascend.com/document/detail/zh/canncommercial/80RC2/devaids/auxiliarydevtool/atlasprofiling_16_0038.html>`_, directly modify Python source code to collect only representative data segments (such as specific Decode Steps or the first Micro-Batch).
|
| 193 |
+
|
| 194 |
+
**Important Notes**
|
| 195 |
+
|
| 196 |
+
1. This chapter involves direct source code modification. It is recommended to back up files before modification and restore them after debugging.
|
| 197 |
+
2. When using code instrumentation for collection, be sure to **disable global collection** (``global_profiler: steps: null``) in ``ppo_trainer.yaml`` or ``ppo_megatron_trainer.yaml`` to avoid Profiler conflicts.
|
| 198 |
+
|
| 199 |
+
1. Fine-grained Collection in Rollout Phase
|
| 200 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 201 |
+
|
| 202 |
+
For vLLM or SGLang inference engines, we can control the ``schedule`` parameter to collect model forward propagation performance data for specific tokens.
|
| 203 |
+
|
| 204 |
+
**vLLM Engine**
|
| 205 |
+
|
| 206 |
+
- **Reference Version**: vLLM v0.11.0, vLLM-Ascend v0.11.0rc1
|
| 207 |
+
- **Modified File**: ``vllm-ascend/vllm_ascend/worker/worker_v1.py``
|
| 208 |
+
|
| 209 |
+
.. code-block:: diff
|
| 210 |
+
|
| 211 |
+
class NPUWorker(WorkerBase):
|
| 212 |
+
|
| 213 |
+
def __init__(self, *args, **kwargs):
|
| 214 |
+
# ... existing code ...
|
| 215 |
+
|
| 216 |
+
+ # Initialize profiler
|
| 217 |
+
+ import torch_npu
|
| 218 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(
|
| 219 |
+
+ profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
|
| 220 |
+
+ export_type=torch_npu.profiler.ExportType.Db, # You can choose torch_npu.profiler.ExportType.Text format
|
| 221 |
+
+ )
|
| 222 |
+
+ self.profiler_npu = torch_npu.profiler.profile(
|
| 223 |
+
+ activities=[torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU],
|
| 224 |
+
+ with_modules=False, # Collect call stack
|
| 225 |
+
+ profile_memory=False, # Collect memory
|
| 226 |
+
+ experimental_config=experimental_config,
|
| 227 |
+
+ # Skip first step, warmup one step, collect 3 steps, repeat 1 time. If you want to collect decode steps 30~70, set schedule=torch_npu.profiler.schedule(wait=29, warmup=1, active=30, repeat=1)
|
| 228 |
+
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
|
| 229 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/vllm_profile", analyse_flag=True) # Data save path and whether to parse online
|
| 230 |
+
+ )
|
| 231 |
+
+ self.profiler_npu.start()
|
| 232 |
+
|
| 233 |
+
# ... existing code ...
|
| 234 |
+
|
| 235 |
+
def execute_model(self, scheduler_output=None, intermediate_tensors=None, **kwargs):
|
| 236 |
+
# ... existing code ...
|
| 237 |
+
output = self.model_runner.execute_model(scheduler_output,
|
| 238 |
+
intermediate_tensors)
|
| 239 |
+
|
| 240 |
+
+ self.profiler_npu.step() # Drive schedule to collect partial decode steps
|
| 241 |
+
|
| 242 |
+
# ... existing code ...
|
| 243 |
+
|
| 244 |
+
**SGLang Engine**
|
| 245 |
+
|
| 246 |
+
- **Reference Version**: SGLang master branch
|
| 247 |
+
- **Modified File**: ``sglang/python/sglang/srt/model_executor/model_runner.py``
|
| 248 |
+
|
| 249 |
+
.. code-block:: diff
|
| 250 |
+
|
| 251 |
+
# ... existing imports ...
|
| 252 |
+
+ import torch_npu
|
| 253 |
+
|
| 254 |
+
class ModelRunner:
|
| 255 |
+
|
| 256 |
+
def __init__(self, *args, **kwargs):
|
| 257 |
+
# ... existing init code ...
|
| 258 |
+
|
| 259 |
+
+ # Initialize profiler (same configuration as above, omitted)
|
| 260 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 261 |
+
+ self.profiler_npu = torch_npu.profiler.profile(
|
| 262 |
+
+ # ...
|
| 263 |
+
+ # Skip first step, warmup one step, collect 3 steps, repeat 1 time.
|
| 264 |
+
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
|
| 265 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/sglang_profile", analyse_flag=True)
|
| 266 |
+
+ )
|
| 267 |
+
+ self.profiler_npu.start()
|
| 268 |
+
|
| 269 |
+
def forward(self, forward_batch, **kwargs):
|
| 270 |
+
# ... existing code ...
|
| 271 |
+
|
| 272 |
+
+ self.profiler_npu.step() # Drive schedule to collect partial decode steps
|
| 273 |
+
return output
|
| 274 |
+
|
| 275 |
+
2. Fine-grained Collection in compute_log_prob (Actor & Ref) Phase
|
| 276 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 277 |
+
|
| 278 |
+
This phase computes probability distributions for new and old policies.
|
| 279 |
+
|
| 280 |
+
**FSDP Backend**
|
| 281 |
+
|
| 282 |
+
The FSDP backend allows fine-grained control at the Micro-Batch level.
|
| 283 |
+
|
| 284 |
+
- **Modified File**: ``verl/workers/actor/dp_actor.py``
|
| 285 |
+
|
| 286 |
+
.. code-block:: diff
|
| 287 |
+
|
| 288 |
+
# ... import dependencies ...
|
| 289 |
+
+ import torch_npu
|
| 290 |
+
|
| 291 |
+
class DataParallelPPOActor(BasePPOActor):
|
| 292 |
+
|
| 293 |
+
def compute_log_prob(self, data: DataProto, calculate_entropy=False) -> torch.Tensor:
|
| 294 |
+
|
| 295 |
+
+ role = "Ref" if self.actor_optimizer is None else "Actor"
|
| 296 |
+
+ # Prepare profiler (same configuration as above, omitted)
|
| 297 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 298 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 299 |
+
+ # ...
|
| 300 |
+
+ # wait=0, warmup=0, active=1: directly collect first micro-batch
|
| 301 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 302 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(f"./outputs/{role}_compute_log_prob", analyse_flag=True)
|
| 303 |
+
+ )
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
+ # This function is shared by ref and actor, set role flag to distinguish. If you want to collect actor_compute_log_prob, set if role=="Actor":
|
| 307 |
+
+ if role=="Ref":
|
| 308 |
+
+ self.prof_npu.start()
|
| 309 |
+
|
| 310 |
+
for micro_batch in micro_batches:
|
| 311 |
+
|
| 312 |
+
# ... original computation logic ...
|
| 313 |
+
with torch.no_grad():
|
| 314 |
+
entropy, log_probs = self._forward_micro_batch(...)
|
| 315 |
+
|
| 316 |
+
+ # Drive schedule to collect micro batch
|
| 317 |
+
+ if role=="Ref":
|
| 318 |
+
+ self.prof_npu.step()
|
| 319 |
+
|
| 320 |
+
# ...
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
**Megatron Backend**
|
| 324 |
+
|
| 325 |
+
The Micro-Batch scheduling in the Megatron backend is managed internally by the framework and does not currently support fine-grained collection at the Micro-Batch level through simple code instrumentation. It is recommended to use global configuration for collection.
|
| 326 |
+
|
| 327 |
+
3. Fine-grained Collection in update_policy (Actor & Critic) Phase
|
| 328 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 329 |
+
|
| 330 |
+
The Update phase includes forward and backward propagation.
|
| 331 |
+
|
| 332 |
+
**FSDP Backend**
|
| 333 |
+
|
| 334 |
+
The FSDP backend supports collection at both Mini-Batch and Micro-Batch granularities.
|
| 335 |
+
|
| 336 |
+
- **Modified File**: ``verl/workers/actor/dp_actor.py``
|
| 337 |
+
|
| 338 |
+
.. code-block:: diff
|
| 339 |
+
|
| 340 |
+
# ... import dependencies ...
|
| 341 |
+
+ import torch_npu
|
| 342 |
+
|
| 343 |
+
class DataParallelPPOActor(BasePPOActor):
|
| 344 |
+
|
| 345 |
+
def update_policy(self, data: DataProto):
|
| 346 |
+
|
| 347 |
+
+ # Prepare profiler (same configuration as above, omitted)
|
| 348 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 349 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 350 |
+
+ # ...
|
| 351 |
+
+ # Only collect first Mini Batch (including all Micro-Batch computations and one optimizer update)
|
| 352 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 353 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/fsdp_actor_update_profile", analyse_flag=True)
|
| 354 |
+
+ )
|
| 355 |
+
+ self.prof_npu.start()
|
| 356 |
+
|
| 357 |
+
# ... PPO Epochs loop ...
|
| 358 |
+
for _ in range(self.config.ppo_epochs):
|
| 359 |
+
# ... Mini Batch loop ...
|
| 360 |
+
for batch_idx, mini_batch in enumerate(mini_batches):
|
| 361 |
+
# ... mini_batches split ...
|
| 362 |
+
|
| 363 |
+
for i, micro_batch in enumerate(micro_batches):
|
| 364 |
+
# ... Original Forward & Backward logic ...
|
| 365 |
+
# ... loss.backward() ...
|
| 366 |
+
pass
|
| 367 |
+
|
| 368 |
+
grad_norm = self._optimizer_step()
|
| 369 |
+
|
| 370 |
+
+ # Drive schedule to collect mini batch, if you want micro batch collection, move self.prof_npu.step() inside the micro_batch loop
|
| 371 |
+
+ self.prof_npu.step()
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
**Megatron Backend**
|
| 375 |
+
|
| 376 |
+
The Megatron backend supports collection at the Mini-Batch granularity.
|
| 377 |
+
|
| 378 |
+
- **Modified File**: ``verl/workers/actor/megatron_actor.py``
|
| 379 |
+
|
| 380 |
+
.. code-block:: diff
|
| 381 |
+
|
| 382 |
+
class MegatronPPOActor(BasePPOActor):
|
| 383 |
+
|
| 384 |
+
def update_policy(self, dataloader: Iterable[DataProto]) -> dict:
|
| 385 |
+
# ...
|
| 386 |
+
+ # Prepare profiler (same configuration as above, omitted)
|
| 387 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 388 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 389 |
+
+ # ...
|
| 390 |
+
+ # Only collect computation of first Mini Batch (including all Micro-Batches) and one optimizer update
|
| 391 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 392 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/megatron_actor_update_profile", analyse_flag=True)
|
| 393 |
+
+ )
|
| 394 |
+
+ self.prof_npu.start()
|
| 395 |
+
|
| 396 |
+
for data in dataloader:
|
| 397 |
+
# ... internally calls self.forward_backward_batch for computation ...
|
| 398 |
+
# ... metric_micro_batch = self.forward_backward_batch(...)
|
| 399 |
+
|
| 400 |
+
# ... self.actor_optimizer.step() ...
|
| 401 |
+
|
| 402 |
+
+ # Drive schedule to collect mini batch
|
| 403 |
+
+ self.prof_npu.step()
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_profiling_zh.rst
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Performance data collection based on FSDP or MindSpeed(Megatron) on Ascend devices(zh)
|
| 2 |
+
==================================================================================
|
| 3 |
+
|
| 4 |
+
在昇腾设备上基于 FSDP 或 MindSpeed (Megatron) 后端进行性能数据采集
|
| 5 |
+
----------------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
Last updated: 12/20/2025.
|
| 8 |
+
|
| 9 |
+
这是一份在昇腾设备上基于FSDP或MindSpeed(Megatron)后端,使用GRPO或DAPO算法进行数据采集的教程。
|
| 10 |
+
|
| 11 |
+
配置
|
| 12 |
+
----
|
| 13 |
+
|
| 14 |
+
使用两级profile设置来控制数据采集
|
| 15 |
+
|
| 16 |
+
- 全局采集控制:使用verl/trainer/config/ppo_trainer.yaml(FSDP),或verl/trainer/config/ppo_megatron_trainer.yaml(MindSpeed)中的配置项控制采集的模式和步数。
|
| 17 |
+
- 角色profile控制:通过每个角色中的配置项控制等参数。
|
| 18 |
+
|
| 19 |
+
全局采集控制
|
| 20 |
+
~~~~~~~~~~~~
|
| 21 |
+
|
| 22 |
+
通过 ppo_trainer.yaml 中的参数控制采集步数和模式:
|
| 23 |
+
|
| 24 |
+
- global_profiler: 控制采集的rank和模式
|
| 25 |
+
|
| 26 |
+
- tool: 使用的采集工具,选项有 nsys、npu、torch、torch_memory。
|
| 27 |
+
- steps: 此参数可以设置为包含采集步数的列表,例如 [2, 4],表示将采集第2步和第4步。如果设置为 null,则不进行采集。
|
| 28 |
+
- save_path: 保存采集数据的路径。默认值为 "outputs/profile"。
|
| 29 |
+
|
| 30 |
+
角色profiler控制
|
| 31 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 32 |
+
|
| 33 |
+
在每个角色的 ``profiler`` 字段中,您可以控制该角色的采集模式。
|
| 34 |
+
|
| 35 |
+
- enable: 是否为此角色启用性能分析。
|
| 36 |
+
- all_ranks: 是否从所有rank收集数据。
|
| 37 |
+
- ranks: 要收集数据的rank列表。如果为空,则不收集数据。
|
| 38 |
+
- tool_config: 此角色使用的性能分析工具的配置。
|
| 39 |
+
|
| 40 |
+
通过每个角色的 ``profiler.tool_config.npu`` 中的参数控制具体采集行为:
|
| 41 |
+
|
| 42 |
+
- level: 采集级别—选项有 level_none、level0、level1 和 level2
|
| 43 |
+
|
| 44 |
+
- level_none: 禁用所有基于级别的数据采集(关闭 profiler_level)。
|
| 45 |
+
- level0: 采集高级应用数据、底层NPU数据和NPU上的算子执行详情。在权衡数据量和分析能力后,level0是推荐的默认配置。
|
| 46 |
+
- level1: 在level0基础上增加CANN层AscendCL数据和NPU上的AI Core性能指标。
|
| 47 |
+
- level2: 在level1基础上增加CANN层Runtime数据和AI CPU指标。
|
| 48 |
+
|
| 49 |
+
- contents: 控制采集内容的选项列表,例如
|
| 50 |
+
npu、cpu、memory、shapes、module、stack。
|
| 51 |
+
|
| 52 |
+
- npu: 是否采集设备端性能数据。
|
| 53 |
+
- cpu: 是否采集主机端性能数据。
|
| 54 |
+
- memory: 是否启用内存分析。
|
| 55 |
+
- shapes: 是否记录张量形状。
|
| 56 |
+
- module: 是否记录框架层Python调用栈信息。相较于stack,更推荐使用module记录调用栈信息,因其产生的性能膨胀更低。
|
| 57 |
+
- stack: 是否记录算子调用栈信息。
|
| 58 |
+
|
| 59 |
+
- analysis: 启用自动数据解析。
|
| 60 |
+
- discrete: 使用离散模式。
|
| 61 |
+
|
| 62 |
+
示例
|
| 63 |
+
----
|
| 64 |
+
|
| 65 |
+
禁用采集
|
| 66 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 67 |
+
|
| 68 |
+
.. code:: yaml
|
| 69 |
+
|
| 70 |
+
global_profiler:
|
| 71 |
+
steps: null # disable profile
|
| 72 |
+
|
| 73 |
+
端到端采集
|
| 74 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 75 |
+
|
| 76 |
+
.. code:: yaml
|
| 77 |
+
|
| 78 |
+
global_profiler:
|
| 79 |
+
steps: [1, 2, 5]
|
| 80 |
+
save_path: ./outputs/profile
|
| 81 |
+
actor_rollout_ref:
|
| 82 |
+
actor: # 设置 actor role 的 profiler 采集配置参数
|
| 83 |
+
profiler:
|
| 84 |
+
enable: True
|
| 85 |
+
all_ranks: True
|
| 86 |
+
tool_config:
|
| 87 |
+
npu:
|
| 88 |
+
discrete: False
|
| 89 |
+
contents: [npu, cpu] # 控制采集列表,默认cpu、npu,可配置memory、shapes、module等
|
| 90 |
+
|
| 91 |
+
# rollout & ref follow actor settings
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
离散模式采集
|
| 95 |
+
~~~~~~~~~~~~~~~~~~~~~~~~
|
| 96 |
+
|
| 97 |
+
.. code:: yaml
|
| 98 |
+
|
| 99 |
+
global_profiler:
|
| 100 |
+
steps: [1, 2, 5]
|
| 101 |
+
save_path: ./outputs/profile
|
| 102 |
+
actor_rollout_ref:
|
| 103 |
+
actor:
|
| 104 |
+
profiler:
|
| 105 |
+
enable: True # 设置为 True 以采集训练阶段
|
| 106 |
+
all_ranks: False
|
| 107 |
+
ranks: [0] # 全局 Rank 0
|
| 108 |
+
tool_config:
|
| 109 |
+
npu:
|
| 110 |
+
discrete: True
|
| 111 |
+
contents: [npu, cpu]
|
| 112 |
+
rollout:
|
| 113 |
+
profiler:
|
| 114 |
+
enable: True # 设置为 True 以采集推理阶段
|
| 115 |
+
all_ranks: False
|
| 116 |
+
ranks: [0] # 在 Agent Loop 模式下,此处指推理实例的 Replica Rank (例如第 0 个实例)
|
| 117 |
+
tool_config:
|
| 118 |
+
npu:
|
| 119 |
+
discrete: True # Agent Loop 模式下必须开启离散模式
|
| 120 |
+
# ref follow actor settings
|
| 121 |
+
|
| 122 |
+
**Agent Loop 场景说明**:
|
| 123 |
+
|
| 124 |
+
当 Rollout 运行在 `Agent Loop <../advance/agent_loop.rst>`_ 模式时,Rollout 阶段的性能数据 **必须使用离散模式** 采集。此时 Profiler 由推理引擎后端触发,配置要求如下:
|
| 125 |
+
|
| 126 |
+
1. **Rank 含义**:Rollout 配置中的 ``ranks`` 指代 **Replica Rank**(实例索引),而非全局 Rank。
|
| 127 |
+
2. **推理引擎配置**:
|
| 128 |
+
|
| 129 |
+
- **vLLM 引擎**
|
| 130 |
+
- **必须通过环境变量配置**:
|
| 131 |
+
- ``VLLM_TORCH_PROFILER_DIR``: 设置数据保存路径(**必选**)。
|
| 132 |
+
- ``VLLM_TORCH_PROFILER_WITH_STACK``: 是否记录调用栈 (1开启, 0关闭,默认开启)。
|
| 133 |
+
- ``VLLM_TORCH_PROFILER_RECORD_SHAPES``: 设置为 1 以记录形状。
|
| 134 |
+
- ``VLLM_TORCH_PROFILER_WITH_PROFILE_MEMORY``: 设置为 1 以记录内存。
|
| 135 |
+
- ``VLLM_TORCH_PROFILER_WITH_FLOPS``: 设置为 1 以估算 FLOPS。
|
| 136 |
+
- *注意:vLLM 会忽略 yaml 中的 save_path 和 contents。*
|
| 137 |
+
|
| 138 |
+
- **SGLang 引擎**
|
| 139 |
+
- **零配置**。自动读取 ``ppo_trainer.yaml`` 中的配置。
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
可视化
|
| 143 |
+
------
|
| 144 |
+
|
| 145 |
+
采集后的数据存放在用户设置的save_path下,可通过 `MindStudio Insight <https://www.hiascend.com/document/detail/zh/mindstudio/80RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0002.html>`_ 工具进行可视化。
|
| 146 |
+
|
| 147 |
+
另外在Linux环境下,MindStudio Insight工具提供了 `JupyterLab插件 <https://www.hiascend.com/document/detail/zh/mindstudio/82RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0130.html>`_ 形态,提供更直观和交互式强的操作界面。JupyterLab插件优势如下:
|
| 148 |
+
|
| 149 |
+
- 无缝集成:支持在Jupyter环境中直接运行MindStudio Insight工具,无需切换平台,无需拷贝服务器上的数据,实现数据即采即用。
|
| 150 |
+
- 快速启动:通过JupyterLab的命令行或图形界面,可快速启动MindStudio Insight工具。
|
| 151 |
+
- 运行流畅:在Linux环境下,通过JupyterLab环境启动MindStudio Insight,相较于整包通信,有效解决了运行卡顿问题,操作体验显著提升。
|
| 152 |
+
- 远程访问:支持远程启动MindStudio Insight,可通过本地浏览器远程连接服务直接进行可视化分析,缓解了大模型训练或推理数据上传和下载的困难。
|
| 153 |
+
|
| 154 |
+
如果analysis参数设置为False,采集之后需要进行离线解析:
|
| 155 |
+
|
| 156 |
+
.. code:: python
|
| 157 |
+
|
| 158 |
+
import torch_npu
|
| 159 |
+
# profiler_path请设置为"localhost.localdomain_<PID>_<timestamp>_ascend_pt"目录的上一级目录
|
| 160 |
+
torch_npu.profiler.profiler.analyse(profiler_path=profiler_path)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
进阶指南:精细化采集
|
| 164 |
+
--------------------
|
| 165 |
+
|
| 166 |
+
背景与挑战
|
| 167 |
+
~~~~~~~~~~
|
| 168 |
+
|
| 169 |
+
上述基于配置文件的采集方式虽然便捷,但在 **长序列 (Long Context)** 或 **大全局批量 (Large Global Batch Size)** 的训练场景中面临挑战。
|
| 170 |
+
在一个完整的训练步 (Step) 内,模型计算呈现出高频次、重复性的特征:
|
| 171 |
+
|
| 172 |
+
1. Rollout 阶段:序列生成 (Generate Sequence) 是一个自回归过程,涉及成千上万次 Decoder 模型的前向计算。
|
| 173 |
+
2. Training 阶段:为了控制显存峰值,verl 通常采用 Micro-Batch 策略,将庞大的数据流切分为多个微批次进行计算。
|
| 174 |
+
|
| 175 |
+
- compute_log_prob (Actor/Ref):涉及多轮纯前向传播。
|
| 176 |
+
- update_policy (Actor/Critic):涉及多轮前向与反向传播。
|
| 177 |
+
|
| 178 |
+
这种特性会导致全量 Profiling 产生海量且重复的算子记录。如下图所示:
|
| 179 |
+
|
| 180 |
+
.. image:: https://raw.githubusercontent.com/mengchengTang/verl-data/master/verl_ascend_profiler.png
|
| 181 |
+
|
| 182 |
+
即使使用了 ``discrete`` 模式,单个阶段的性能数据文件仍可能达到数 TB,导致 **解析失败** 或 **可视化工具卡顿** 。
|
| 183 |
+
|
| 184 |
+
解决方案:关键路径采样
|
| 185 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 186 |
+
|
| 187 |
+
为了解决上述问题,我们可以采用 **关键路径采样** 策略:基于 `torch_npu.profiler <https://www.hiascend.com/document/detail/zh/canncommercial/80RC2/devaids/auxiliarydevtool/atlasprofiling_16_0038.html>`_ 提供的API接口,直接修改 Python 源码,仅采集具有代表性的数据片段(如特定 Decode Step 或首个 Micro-Batch)。
|
| 188 |
+
|
| 189 |
+
**重要提示**
|
| 190 |
+
|
| 191 |
+
1. 本章节涉及直接修改源码。建议修改前备份文件,调试完成后恢复。
|
| 192 |
+
2. 使用代码插桩采集时,请务必在 ``ppo_trainer.yaml`` 或 ``ppo_megatron_trainer.yaml`` 中**禁用全局采集** (``global_profiler: steps: null``),以避免 Profiler 冲突。
|
| 193 |
+
|
| 194 |
+
1. Rollout 阶段精细化采集
|
| 195 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 196 |
+
|
| 197 |
+
对于 vLLM 或 SGLang 推理引擎,我们可以通过控制 ``schedule`` 参数来控制采集模型在特定token的前向传播性能数据。
|
| 198 |
+
|
| 199 |
+
**vLLM 引擎**
|
| 200 |
+
|
| 201 |
+
- **参考版本**:vLLM v0.11.0, vLLM-Ascend v0.11.0rc1
|
| 202 |
+
- **修改文件**:``vllm-ascend/vllm_ascend/worker/worker_v1.py``
|
| 203 |
+
|
| 204 |
+
.. code-block:: diff
|
| 205 |
+
|
| 206 |
+
class NPUWorker(WorkerBase):
|
| 207 |
+
|
| 208 |
+
def __init__(self, *args, **kwargs):
|
| 209 |
+
# ... existing code ...
|
| 210 |
+
|
| 211 |
+
+ # Initialize profiler
|
| 212 |
+
+ import torch_npu
|
| 213 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(
|
| 214 |
+
+ profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
|
| 215 |
+
+ export_type=torch_npu.profiler.ExportType.Db, # 可选择torch_npu.profiler.ExportType.Text格式
|
| 216 |
+
+ )
|
| 217 |
+
+ self.profiler_npu = torch_npu.profiler.profile(
|
| 218 |
+
+ activities=[torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU],
|
| 219 |
+
+ with_modules=False, # 采集调用栈
|
| 220 |
+
+ profile_memory=False, # 采集内存
|
| 221 |
+
+ experimental_config=experimental_config,
|
| 222 |
+
+ # 跳过第一步,warmup一步,采集3步,重复1次。如果想采集第30~70个decode step,可以设置为schedule=torch_npu.profiler.schedule(wait=29, warmup=1, active=30, repeat=1)
|
| 223 |
+
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
|
| 224 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/vllm_profile", analyse_flag=True) # 采集数据保存路径,是否在线解析
|
| 225 |
+
+ )
|
| 226 |
+
+ self.profiler_npu.start()
|
| 227 |
+
|
| 228 |
+
# ... existing code ...
|
| 229 |
+
|
| 230 |
+
def execute_model(self, scheduler_output=None, intermediate_tensors=None, **kwargs):
|
| 231 |
+
# ... existing code ...
|
| 232 |
+
output = self.model_runner.execute_model(scheduler_output,
|
| 233 |
+
intermediate_tensors)
|
| 234 |
+
|
| 235 |
+
+ self.profiler_npu.step() # 驱动 schedule,对部分decode step进行采集
|
| 236 |
+
|
| 237 |
+
# ... existing code ...
|
| 238 |
+
|
| 239 |
+
**SGLang 引擎**
|
| 240 |
+
|
| 241 |
+
- **参考版本**:SGLang master 分支
|
| 242 |
+
- **修改文件**:``sglang/python/sglang/srt/model_executor/model_runner.py``
|
| 243 |
+
|
| 244 |
+
.. code-block:: diff
|
| 245 |
+
|
| 246 |
+
# ... existing imports ...
|
| 247 |
+
+ import torch_npu
|
| 248 |
+
|
| 249 |
+
class ModelRunner:
|
| 250 |
+
|
| 251 |
+
def __init__(self, *args, **kwargs):
|
| 252 |
+
# ... existing init code ...
|
| 253 |
+
|
| 254 |
+
+ # Initialize profiler (配置同上,略)
|
| 255 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 256 |
+
+ self.profiler_npu = torch_npu.profiler.profile(
|
| 257 |
+
+ # ...
|
| 258 |
+
+ # 跳过第一步,warmup一步,采集3步,重复1次。
|
| 259 |
+
+ schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
|
| 260 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/sglang_profile", analyse_flag=True)
|
| 261 |
+
+ )
|
| 262 |
+
+ self.profiler_npu.start()
|
| 263 |
+
|
| 264 |
+
def forward(self, forward_batch, **kwargs):
|
| 265 |
+
# ... existing code ...
|
| 266 |
+
|
| 267 |
+
+ self.profiler_npu.step() # 驱动 schedule,对部分decode step进行采集
|
| 268 |
+
return output
|
| 269 |
+
|
| 270 |
+
2. compute_log_prob (Actor & Ref) 阶段精细化采集
|
| 271 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 272 |
+
|
| 273 |
+
该阶段计算新旧策略的概率分布。
|
| 274 |
+
|
| 275 |
+
**FSDP 后端**
|
| 276 |
+
|
| 277 |
+
FSDP 后端允许在 Micro-Batch 级别进行精细控制。
|
| 278 |
+
|
| 279 |
+
- **修改文件**:``verl/workers/actor/dp_actor.py``
|
| 280 |
+
|
| 281 |
+
.. code-block:: diff
|
| 282 |
+
|
| 283 |
+
# ... 引入依赖 ...
|
| 284 |
+
+ import torch_npu
|
| 285 |
+
|
| 286 |
+
class DataParallelPPOActor(BasePPOActor):
|
| 287 |
+
|
| 288 |
+
def compute_log_prob(self, data: DataProto, calculate_entropy=False) -> torch.Tensor:
|
| 289 |
+
|
| 290 |
+
+ role = "Ref" if self.actor_optimizer is None else "Actor"
|
| 291 |
+
+ # 准备 profiler (配置同上,略)
|
| 292 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 293 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 294 |
+
+ # ...
|
| 295 |
+
+ # wait=0, warmup=0, active=1: 直接采集第一个 micro-batch
|
| 296 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 297 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(f"./outputs/{role}_compute_log_prob", analyse_flag=True)
|
| 298 |
+
+ )
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
+ # 此函数ref和actor共用,设置role标志位来区分。如果想采集actor_compute_log_prob,可设置if role=="Actor":
|
| 302 |
+
+ if role=="Ref":
|
| 303 |
+
+ self.prof_npu.start()
|
| 304 |
+
|
| 305 |
+
for micro_batch in micro_batches:
|
| 306 |
+
|
| 307 |
+
# ... 原始计算逻辑 ...
|
| 308 |
+
with torch.no_grad():
|
| 309 |
+
entropy, log_probs = self._forward_micro_batch(...)
|
| 310 |
+
|
| 311 |
+
+ # 驱动 schedule,对micro batch进行采集
|
| 312 |
+
+ if role=="Ref":
|
| 313 |
+
+ self.prof_npu.step()
|
| 314 |
+
|
| 315 |
+
# ...
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
**Megatron 后端**
|
| 319 |
+
|
| 320 |
+
Megatron 后端的 Micro-Batch 调度由框架内部管理,暂不支持通过简单的代码插桩进行 Micro-Batch 级别的精细化采集。建议使用全局配置进行采集。
|
| 321 |
+
|
| 322 |
+
3. update_policy (Actor & Critic) 阶段精细化采集
|
| 323 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 324 |
+
|
| 325 |
+
Update 阶段包含前向和反向传播。
|
| 326 |
+
|
| 327 |
+
**FSDP 后端**
|
| 328 |
+
|
| 329 |
+
FSDP 后端支持设置对 Mini-Batch 和 Micro-Batch 的粒度进行采集。
|
| 330 |
+
|
| 331 |
+
- **修改文件**:``verl/workers/actor/dp_actor.py``
|
| 332 |
+
|
| 333 |
+
.. code-block:: diff
|
| 334 |
+
|
| 335 |
+
# ... 引入依赖 ...
|
| 336 |
+
+ import torch_npu
|
| 337 |
+
|
| 338 |
+
class DataParallelPPOActor(BasePPOActor):
|
| 339 |
+
|
| 340 |
+
def update_policy(self, data: DataProto):
|
| 341 |
+
|
| 342 |
+
+ # 准备 profiler (配置同上,略)
|
| 343 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 344 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 345 |
+
+ # ...
|
| 346 |
+
+ # 仅采集第一个 Mini Batch(包含所有 Micro-Batch 的计算和一次优化器更新)
|
| 347 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 348 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/fsdp_actor_update_profile", analyse_flag=True)
|
| 349 |
+
+ )
|
| 350 |
+
+ self.prof_npu.start()
|
| 351 |
+
|
| 352 |
+
# ... PPO Epochs 循环 ...
|
| 353 |
+
for _ in range(self.config.ppo_epochs):
|
| 354 |
+
# ... Mini Batch 循环 ...
|
| 355 |
+
for batch_idx, mini_batch in enumerate(mini_batches):
|
| 356 |
+
# ... mini_batches 切分 ...
|
| 357 |
+
|
| 358 |
+
for i, micro_batch in enumerate(micro_batches):
|
| 359 |
+
# ... 原始 Forward & Backward 逻辑 ...
|
| 360 |
+
# ... loss.backward() ...
|
| 361 |
+
pass
|
| 362 |
+
|
| 363 |
+
grad_norm = self._optimizer_step()
|
| 364 |
+
|
| 365 |
+
+ # 驱动 schedule,对mini batch进行采集,如果想对micro batch进行,则将self.prof_npu.step()移动到micro_batch的循环内
|
| 366 |
+
+ self.prof_npu.step()
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
**Megatron 后端**
|
| 370 |
+
|
| 371 |
+
Megatron 后端支持以 Mini-Batch 的粒度进行采集。
|
| 372 |
+
|
| 373 |
+
- **修改文件**:``verl/workers/actor/megatron_actor.py``
|
| 374 |
+
|
| 375 |
+
.. code-block:: diff
|
| 376 |
+
|
| 377 |
+
class MegatronPPOActor(BasePPOActor):
|
| 378 |
+
|
| 379 |
+
def update_policy(self, dataloader: Iterable[DataProto]) -> dict:
|
| 380 |
+
# ...
|
| 381 |
+
+ # 准备 profiler (配置同上,略)
|
| 382 |
+
+ experimental_config = torch_npu.profiler._ExperimentalConfig(...)
|
| 383 |
+
+ self.prof_npu = torch_npu.profiler.profile(
|
| 384 |
+
+ # ...
|
| 385 |
+
+ # 仅采集第一个 Mini Batch 的计算(含所有 Micro-Batch)和一次优化器更新
|
| 386 |
+
+ schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1),
|
| 387 |
+
+ on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./outputs/megatron_actor_update_profile", analyse_flag=True)
|
| 388 |
+
+ )
|
| 389 |
+
+ self.prof_npu.start()
|
| 390 |
+
|
| 391 |
+
for data in dataloader:
|
| 392 |
+
# ... 内部会调用 self.forward_backward_batch 进行计算 ...
|
| 393 |
+
# ... metric_micro_batch = self.forward_backward_batch(...)
|
| 394 |
+
|
| 395 |
+
# ... self.actor_optimizer.step() ...
|
| 396 |
+
|
| 397 |
+
+ # 驱动 schedule,对mini batch进行采集
|
| 398 |
+
+ self.prof_npu.step()
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_quick_start.rst
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ascend Quickstart
|
| 2 |
+
===================================
|
| 3 |
+
|
| 4 |
+
Last updated: 12/11/2025.
|
| 5 |
+
|
| 6 |
+
我们在 verl 上增加对华为昇腾设备的支持。
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
关键更新
|
| 10 |
+
----------------------------------
|
| 11 |
+
|
| 12 |
+
2025/12/11:verl 存量场景目前支持自动识别 NPU 设备类型, GPU 脚本在昇腾上运行,原则上不再需要显式设置 trainer.device=npu 参数,新增特性通过设置 trainer.device 仍可优先使用,逐步适配自动识别能力。
|
| 13 |
+
|
| 14 |
+
[说明] 自动识别 NPU 设备类型的前提,是运行程序所在环境包含 torch_npu 软件包。如不包含该软件包,仍需显式指定 trainer.device=npu 参数。
|
| 15 |
+
|
| 16 |
+
硬件支持
|
| 17 |
+
-----------------------------------
|
| 18 |
+
|
| 19 |
+
Atlas 200T A2 Box16
|
| 20 |
+
|
| 21 |
+
Atlas 900 A2 PODc
|
| 22 |
+
|
| 23 |
+
Atlas 800T A3
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
安装流程
|
| 27 |
+
-----------------------------------
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
DockerFile镜像构建 & 使用
|
| 31 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 32 |
+
|
| 33 |
+
如需要通过 DockerFile 构建镜像,或希望使用基于 verl 构建的镜像,请参考 `文档 <https://github.com/volcengine/verl/tree/main/docs/ascend_tutorial/dockerfile_build_guidance.rst>`_ 。
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
安装基础环境
|
| 37 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 38 |
+
|
| 39 |
+
1. 基础环境涉及以下软件包,请参考 `文档 <https://gitcode.com/Ascend/pytorch>`_ 安装。
|
| 40 |
+
|
| 41 |
+
+---------------+----------------------+
|
| 42 |
+
| software | version |
|
| 43 |
+
+---------------+----------------------+
|
| 44 |
+
| Python | >= 3.10, <3.12 |
|
| 45 |
+
+---------------+----------------------+
|
| 46 |
+
| CANN | == 8.3.RC1 |
|
| 47 |
+
+---------------+----------------------+
|
| 48 |
+
| torch | == 2.7.1 |
|
| 49 |
+
+---------------+----------------------+
|
| 50 |
+
| torch_npu | == 2.7.1 |
|
| 51 |
+
+---------------+----------------------+
|
| 52 |
+
|
| 53 |
+
2. (可选)在 x86 平台安装时,pip 需要配置额外的源,指令如下:
|
| 54 |
+
|
| 55 |
+
.. code-block:: bash
|
| 56 |
+
|
| 57 |
+
pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/"
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
安装其他软件包
|
| 61 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 62 |
+
|
| 63 |
+
基础环境准备完毕后,需要通过指令安装以下软件包:
|
| 64 |
+
|
| 65 |
+
+---------------+----------------------+
|
| 66 |
+
| torchvision | == 0.22.1 |
|
| 67 |
+
+---------------+----------------------+
|
| 68 |
+
| triton-ascend | == 3.2.0rc4 |
|
| 69 |
+
+---------------+----------------------+
|
| 70 |
+
| transformers | latest release |
|
| 71 |
+
+---------------+----------------------+
|
| 72 |
+
|
| 73 |
+
安装指令:
|
| 74 |
+
|
| 75 |
+
.. code-block:: bash
|
| 76 |
+
|
| 77 |
+
# 安装torchvision,版本需要和torch匹配
|
| 78 |
+
pip install torchvision==0.22.1
|
| 79 |
+
|
| 80 |
+
# 清理环境上可能存在的历史triton/triton-ascend软件包残留
|
| 81 |
+
pip uninstall -y triton triton-ascend
|
| 82 |
+
|
| 83 |
+
# 安装triton-ascend,不需要单独安装triton
|
| 84 |
+
pip install triton-ascend==3.2.0rc4
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
安装 vllm & vllm-ascend
|
| 88 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 89 |
+
|
| 90 |
+
1. 需确保CANN ascend-toolkit 和 nnal 环境变量被激活,对于CANN默认安装路径 /usr/local/Ascend 而言,激活指令如下:
|
| 91 |
+
|
| 92 |
+
.. code-block::
|
| 93 |
+
|
| 94 |
+
source /usr/local/Ascend/ascend-toolkit/set_env.sh
|
| 95 |
+
source /usr/local/Ascend/nnal/atb/set_env.sh
|
| 96 |
+
|
| 97 |
+
2. vllm 源码安装指令:
|
| 98 |
+
|
| 99 |
+
.. code-block:: bash
|
| 100 |
+
|
| 101 |
+
git clone --depth 1 --branch v0.11.0 https://github.com/vllm-project/vllm.git
|
| 102 |
+
cd vllm && VLLM_TARGET_DEVICE=empty pip install -v -e . && cd ..
|
| 103 |
+
|
| 104 |
+
3. vllm-ascend 源码安装指令:
|
| 105 |
+
|
| 106 |
+
.. code-block:: bash
|
| 107 |
+
|
| 108 |
+
git clone --depth 1 --branch v0.11.0rc1 https://github.com/vllm-project/vllm-ascend.git
|
| 109 |
+
cd vllm-ascend && pip install -v -e . && cd ..
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
安装 MindSpeed
|
| 113 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 114 |
+
|
| 115 |
+
MindSpeed 源码安装指令:
|
| 116 |
+
|
| 117 |
+
.. code-block:: bash
|
| 118 |
+
|
| 119 |
+
# 下载 MindSpeed,切换到指定commit-id,并下载 Megatron-LM
|
| 120 |
+
git clone https://gitcode.com/Ascend/MindSpeed.git
|
| 121 |
+
cd MindSpeed && git checkout f2b0977e && cd ..
|
| 122 |
+
git clone --depth 1 --branch core_v0.12.1 https://github.com/NVIDIA/Megatron-LM.git
|
| 123 |
+
|
| 124 |
+
# 安装 MindSpeed & Megatron
|
| 125 |
+
pip install -e MindSpeed
|
| 126 |
+
|
| 127 |
+
# 将 Megatron-LM 源码路径配置到 PYTHONPATH 环境变量中
|
| 128 |
+
export PYTHONPATH=$PYTHONPATH:"$(pwd)/Megatron-LM"
|
| 129 |
+
|
| 130 |
+
# (可选)如希望 shell 关闭,或系统重启后,PYTHONPATH 环境变量仍然生效,建议将它添加到 .bashrc 配置文件中
|
| 131 |
+
echo "export PYTHONPATH=$PYTHONPATH:\"$(pwd)/Megatron-LM\"" >> ~/.bashrc
|
| 132 |
+
|
| 133 |
+
# 安装 mbridge
|
| 134 |
+
pip install mbridge
|
| 135 |
+
|
| 136 |
+
MindSpeed 对应 Megatron-LM 后端使用场景,使用方式如下:
|
| 137 |
+
|
| 138 |
+
1. 使能 verl worker 模型 ``strategy`` 配置为 ``megatron`` ,例如 ``actor_rollout_ref.actor.strategy=megatron``。
|
| 139 |
+
|
| 140 |
+
2. MindSpeed 自定义入参可通过 ``override_transformer_config`` 参数传入,例如对 actor 模型开启 FA 特性可使用 ``+actor_rollout_ref.actor.megatron.override_transformer_config.use_flash_attn=True``。
|
| 141 |
+
|
| 142 |
+
3. 更多特性信息可参考 `MindSpeed & verl 文档 <https://gitcode.com/Ascend/MindSpeed/blob/master/docs/user-guide/verl.md>`_ 。
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
安装verl
|
| 146 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 147 |
+
|
| 148 |
+
.. code-block:: bash
|
| 149 |
+
|
| 150 |
+
git clone --depth 1 https://github.com/volcengine/verl.git
|
| 151 |
+
cd verl && pip install -r requirements-npu.txt && pip install -v -e . && cd ..
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
昇腾暂不支持生态库说明
|
| 155 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 156 |
+
|
| 157 |
+
verl 中昇腾暂不支持生态库如下:
|
| 158 |
+
|
| 159 |
+
+---------------+----------------+
|
| 160 |
+
| software | description |
|
| 161 |
+
+---------------+----------------+
|
| 162 |
+
| flash_attn | not supported |
|
| 163 |
+
+---------------+----------------+
|
| 164 |
+
| liger-kernel | not supported |
|
| 165 |
+
+---------------+----------------+
|
| 166 |
+
|
| 167 |
+
1. 不支持通过 flash_attn 使能 flash attention 加速,支持通过 transformers 使用。
|
| 168 |
+
2. 不支持 liger-kernel 使能。
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
快速开始
|
| 172 |
+
-----------------------------------
|
| 173 |
+
正式使用前,建议您通过对Qwen2.5-0.5B GRPO的训练尝试以检验环境准备和安装的正确性。
|
| 174 |
+
|
| 175 |
+
1.下载数据集并将数据集预处理为parquet格式,以便包含计算RL奖励所需的必要字段
|
| 176 |
+
|
| 177 |
+
.. code-block:: bash
|
| 178 |
+
|
| 179 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k
|
| 180 |
+
|
| 181 |
+
2.执行训练
|
| 182 |
+
|
| 183 |
+
.. code-block:: bash
|
| 184 |
+
|
| 185 |
+
set -x
|
| 186 |
+
|
| 187 |
+
export VLLM_ATTENTION_BACKEND=XFORMERS
|
| 188 |
+
|
| 189 |
+
python3 -m verl.trainer.main_ppo \
|
| 190 |
+
algorithm.adv_estimator=grpo \
|
| 191 |
+
data.train_files=$HOME/data/gsm8k/train.parquet \
|
| 192 |
+
data.val_files=$HOME/data/gsm8k/test.parquet \
|
| 193 |
+
data.train_batch_size=128 \
|
| 194 |
+
data.max_prompt_length=512 \
|
| 195 |
+
data.max_response_length=128 \
|
| 196 |
+
data.filter_overlong_prompts=True \
|
| 197 |
+
data.truncation='error' \
|
| 198 |
+
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
|
| 199 |
+
actor_rollout_ref.actor.optim.lr=5e-7 \
|
| 200 |
+
actor_rollout_ref.model.use_remove_padding=False \
|
| 201 |
+
actor_rollout_ref.actor.entropy_coeff=0.001 \
|
| 202 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 203 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=20 \
|
| 204 |
+
actor_rollout_ref.actor.use_kl_loss=True \
|
| 205 |
+
actor_rollout_ref.actor.kl_loss_coef=0.001 \
|
| 206 |
+
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
|
| 207 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 208 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=False \
|
| 209 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
|
| 210 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=40 \
|
| 211 |
+
actor_rollout_ref.rollout.enable_chunked_prefill=False \
|
| 212 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
|
| 213 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 214 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
|
| 215 |
+
actor_rollout_ref.rollout.n=5 \
|
| 216 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=40 \
|
| 217 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 218 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 219 |
+
trainer.critic_warmup=0 \
|
| 220 |
+
trainer.logger=console \
|
| 221 |
+
trainer.project_name='verl_grpo_example_gsm8k' \
|
| 222 |
+
trainer.experiment_name='qwen2_7b_function_rm' \
|
| 223 |
+
trainer.n_gpus_per_node=8 \
|
| 224 |
+
trainer.nnodes=1 \
|
| 225 |
+
trainer.save_freq=-1 \
|
| 226 |
+
trainer.test_freq=5 \
|
| 227 |
+
trainer.total_epochs=1 $@
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
算法支持现状
|
| 232 |
+
-----------------------------------
|
| 233 |
+
|
| 234 |
+
**表1** RL类算法
|
| 235 |
+
|
| 236 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 237 |
+
| algorithm | model | download link | actor.strategy | rollout.name | shell location | hardware |
|
| 238 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 239 |
+
| GRPO | Qwen2.5-7B-instruct |`7B <https://huggingface.co/Qwen/Qwen2.5-7B-Instruct>`_ | FSDP | vllm-ascend |`qwen2_5_7b_grpo_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_7b_grpo_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 240 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 241 |
+
| GRPO | Qwen2.5-32B-instruct |`32B <https://huggingface.co/Qwen/Qwen2.5-32B-Instruct>`_ | FSDP | vllm-ascend |`qwen2_5_32b_grpo_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_32b_grpo_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 242 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 243 |
+
| GRPO | Qwen2.5-VL-3B-instruct |`3B <https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct>`_ | FSDP | vllm-ascend |`qwen2_5_vl_3b_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_vl_3b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 244 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 245 |
+
| GRPO | Qwen2.5-VL-7B-instruct |`7B <https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct>`_ | FSDP | vllm-ascend |`qwen2_5_vl_7b_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_vl_7b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 246 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 247 |
+
| GRPO | Qwen2.5-VL-32B-instruct |`32B <https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct>`_ | FSDP | vllm-ascend |`qwen2_5_vl_32b_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen2_5_vl_32b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 248 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 249 |
+
| GRPO | Qwen3-4B |`4B <https://huggingface.co/Qwen/Qwen3-4B>`_ | FSDP | vllm-ascend |`qwen3-4B_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen3_4b_grpo_vllm_1k_npu.sh>`_ | Atlas 800T A3 |
|
| 250 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 251 |
+
| GRPO | Qwen3-8B |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP | vllm-ascend |`qwen3_8b_vllm_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen3-8b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 252 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 253 |
+
| GRPO | Qwen3-8B |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP | sglang |`qwen3_8b_sglang_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen3_8b_grpo_sglang_32k_spmd_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 254 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 255 |
+
| GRPO | Qwen3-32B |`32B <https://huggingface.co/Qwen/Qwen3-32B>`_ | FSDP | vllm-ascend |`qwen3-32B_npu <https://github.com/volcengine/verl/blob/main/examples/grpo_trainer/run_qwen3-32b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 256 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 257 |
+
| GRPO | DeepSeekv3-671B |`671B <https://huggingface.co/deepseek-ai/DeepSeek-V3>`_ | Megatron | vllm-ascend |`deepseek_v3_megatron_npu <https://github.com/verl-project/verl-recipe/blob/main//r1_ascend/run_deepseekv3_671b_grpo_megatron_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 258 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 259 |
+
| DAPO | Qwen2.5-7B-instruct |`7B <https://huggingface.co/Qwen/Qwen2.5-7B-Instruct>`_ | FSDP | vllm-ascend |`qwen2.5_7b_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen2.5_7b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 260 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 261 |
+
| DAPO | Qwen2.5-32B |`32B <https://huggingface.co/Qwen/Qwen2.5-32B>`_ | FSDP | vllm-ascend |`qwen2.5_32b_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen2.5_32b_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 262 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 263 |
+
| DAPO | Qwen3-8B-base |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP | vllm-ascend |`qwen3_8b_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen3_8b_base_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 264 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 265 |
+
| DAPO | Qwen3-14B-base |`14B <https://huggingface.co/Qwen/Qwen3-14B>`_ | FSDP | vllm-ascend |`qwen3_14b_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen3_14b_base_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 266 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 267 |
+
| DAPO | Qwen3-30B-A3B-base |`30B <https://huggingface.co/Qwen/Qwen3-30B-A3B>`_ | FSDP | vllm-ascend |`qwen3_30b_fsdp_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen3_moe_30b_base_fsdp_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 268 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 269 |
+
| DAPO | Qwen3-30B-A3B-base |`30B <https://huggingface.co/Qwen/Qwen3-30B-A3B>`_ | Megatron | vllm-ascend |`qwen3_30b_megatron_npu <https://github.com/verl-project/verl-recipe/blob/main//dapo/run_dapo_qwen3_moe_30b_megatron_npu.sh>`_ | Atlas 200T A2 Box16 |
|
| 270 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 271 |
+
| PPO | Qwen3-8B |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP | vllm-ascend |`qwen3_8b_ppo_npu <https://github.com/volcengine/verl/blob/main/examples/ppo_trainer/run_qwen3-8b_npu.sh>`_ | Atlas 900 A2 PODc |
|
| 272 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 273 |
+
| One_Step_Off_Policy | Qwen3-8B |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP2 | vllm-ascend |`qwen3_8b_fsdp2_npu <https://github.com/verl-project/verl-recipe/blob/main//one_step_off_policy/shell/grpo_qwen3_8b_gsm8k_fsdp2_8_8_npu.sh>`_ | Atlas 800T A3 |
|
| 274 |
+
+-----------------------+-------------------------+------------------------------------------------------------------+-------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+--------------------------+
|
| 275 |
+
|
| 276 |
+
**表2** SFT类算法
|
| 277 |
+
|
| 278 |
+
+-----------+-------------------------+------------------------------------------------------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+----------------------+
|
| 279 |
+
| algorithm | model | download link | actor.strategy | shell location | hardware |
|
| 280 |
+
+-----------+-------------------------+------------------------------------------------------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+----------------------+
|
| 281 |
+
| SFT-PEFT | Qwen3-8B |`8B <https://huggingface.co/Qwen/Qwen3-8B>`_ | FSDP |`sft_peft_sp2_npu <https://github.com/volcengine/verl/blob/main/examples/sft/gsm8k/run_qwen3_8b_sft_peft_sp2_npu.sh>`_ | Atlas 900 A2 PODc |
|
| 282 |
+
+-----------+-------------------------+-------------------------+----------------------------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+----------------------+
|
| 283 |
+
| ReTool-SFT| Qwen2-7B-instruct |`7B <https://huggingface.co/Qwen/Qwen2-7B-Instruct>`_ | FSDP |`qwen2_7b_sft_npu <https://github.com/verl-project/verl-recipe/blob/main/retool/run_qwen2_7b_sft_npu.sh>`_ | Atlas 900 A2 PODc |
|
| 284 |
+
+-----------+-------------------------+-------------------------+----------------------------------------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------+----------------------+
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
声明
|
| 288 |
+
-----------------------------------
|
| 289 |
+
verl中提供的ascend支持代码、Dockerfile、镜像皆为参考样例,如在生产环境中使用请通过官方正式途径沟通,谢谢。
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/ascend_sglang_quick_start.rst
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ascend Quickstart with SGLang Backend
|
| 2 |
+
===================================
|
| 3 |
+
|
| 4 |
+
Last updated: 01/27/2026.
|
| 5 |
+
|
| 6 |
+
我们在 verl 上增加对华为昇腾设备的支持。
|
| 7 |
+
|
| 8 |
+
硬件支持
|
| 9 |
+
-----------------------------------
|
| 10 |
+
|
| 11 |
+
Atlas 200T A2 Box16
|
| 12 |
+
|
| 13 |
+
Atlas 900 A2 PODc
|
| 14 |
+
|
| 15 |
+
Atlas 800T A3
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
安装
|
| 19 |
+
-----------------------------------
|
| 20 |
+
关键支持版本
|
| 21 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 22 |
+
|
| 23 |
+
+-----------+-----------------+
|
| 24 |
+
| software | version |
|
| 25 |
+
+===========+=================+
|
| 26 |
+
| Python | == 3.11 |
|
| 27 |
+
+-----------+-----------------+
|
| 28 |
+
| HDK | >= 25.3.RC1 |
|
| 29 |
+
+-----------+-----------------+
|
| 30 |
+
| CANN | >= 8.3.RC1 |
|
| 31 |
+
+-----------+-----------------+
|
| 32 |
+
| torch | >= 2.7.1 |
|
| 33 |
+
+-----------+-----------------+
|
| 34 |
+
| torch_npu | >= 2.7.1.post2 |
|
| 35 |
+
+-----------+-----------------+
|
| 36 |
+
| sglang | v0.5.8 |
|
| 37 |
+
+-----------+-----------------+
|
| 38 |
+
|
| 39 |
+
从 Docker 镜像进行安装
|
| 40 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 41 |
+
我们提供了DockerFile进行构建,详见 `dockerfile_build_guidance <https://github.com/verl-project/verl/blob/main/docs/ascend_tutorial/dockerfile_build_guidance.rst>`_ ,请根据设备自行选择对应构建文件
|
| 42 |
+
|
| 43 |
+
从自定义环境安装
|
| 44 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 45 |
+
|
| 46 |
+
**1. 安装HDK&CANN依赖并激活**
|
| 47 |
+
|
| 48 |
+
异构计算架构CANN(Compute Architecture for Neural Networks)是昇腾针对AI场景推出的异构计算架构, 为了使训练和推理引擎能够利用更好、更快的硬件支持, 我们需要安装以下 `先决条件 <https://www.hiascend.com/document/detail/zh/canncommercial/83RC1/softwareinst/instg/instg_quick.html?Mode=PmIns&InstallType=netconda&OS=openEuler&Software=cannToolKit>`_
|
| 49 |
+
|
| 50 |
+
+-----------+-------------+
|
| 51 |
+
| HDK | >= 25.3.RC1 |
|
| 52 |
+
+-----------+-------------+
|
| 53 |
+
| CANN | >= 8.3.RC1 |
|
| 54 |
+
+-----------+-------------+
|
| 55 |
+
安装完成后请激活环境
|
| 56 |
+
|
| 57 |
+
.. code-block:: bash
|
| 58 |
+
|
| 59 |
+
source /usr/local/Ascend/ascend-toolkit/set_env.sh
|
| 60 |
+
source /usr/local/Ascend/nnal/atb/set_env.sh
|
| 61 |
+
|
| 62 |
+
**2. 创建conda环境**
|
| 63 |
+
|
| 64 |
+
.. code-block:: bash
|
| 65 |
+
|
| 66 |
+
# create conda env
|
| 67 |
+
conda create -n verl-sglang python==3.11
|
| 68 |
+
conda activate verl-sglang
|
| 69 |
+
|
| 70 |
+
**3. 然后,执行我们在 verl 中提供的脚本** `install_sglang_mcore_npu.sh <https://github.com/verl-project/verl/blob/main/scripts/install_sglang_mcore_npu.sh>`_
|
| 71 |
+
|
| 72 |
+
如果在此步骤中遇到错误,请检查脚本并手动按照脚本中的步骤操作。
|
| 73 |
+
|
| 74 |
+
.. code-block:: bash
|
| 75 |
+
|
| 76 |
+
git clone https://github.com/volcengine/verl.git
|
| 77 |
+
# Make sure you have activated verl conda env
|
| 78 |
+
# NPU_DEVICE=A3 or A2 depends on your device
|
| 79 |
+
NPU_DEVICE=A3 bash verl/scripts/install_sglang_mcore_npu.sh
|
| 80 |
+
|
| 81 |
+
**4. 安装verl**
|
| 82 |
+
|
| 83 |
+
.. code-block:: bash
|
| 84 |
+
|
| 85 |
+
cd verl
|
| 86 |
+
pip install --no-deps -e .
|
| 87 |
+
pip install -r requirements-npu.txt
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
快速开始
|
| 91 |
+
-----------------------------------
|
| 92 |
+
|
| 93 |
+
**1.当前NPU sglang脚本一览**
|
| 94 |
+
|
| 95 |
+
.. _Qwen3-30B: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3moe-30b_sglang_megatron_npu.sh
|
| 96 |
+
.. _Qwen2.5-32B: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen2-32b_sglang_fsdp_npu.sh
|
| 97 |
+
.. _Qwen3-8B-1k: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3_8b_grpo_sglang_1k_spmd_npu.sh
|
| 98 |
+
.. _Qwen3-8B-32k: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3_8b_grpo_sglang_32k_spmd_npu.sh
|
| 99 |
+
|
| 100 |
+
+-----------------+----------------+----------+-------------------+
|
| 101 |
+
| 模型 | 推荐NPU型号 | 节点数量 | 训推后端 |
|
| 102 |
+
+=================+================+==========+===================+
|
| 103 |
+
| `Qwen3-30B`_ | Atlas 800T A3 | 1 | SGLang + Megatron |
|
| 104 |
+
+-----------------+----------------+----------+-------------------+
|
| 105 |
+
| `Qwen2.5-32B`_ | Atlas 900 A2 | 2 | SGLang + FSDP |
|
| 106 |
+
+-----------------+----------------+----------+-------------------+
|
| 107 |
+
| `Qwen3-8B-1k`_ | Atlas A3/A2 | 1 | SGLang + FSDP |
|
| 108 |
+
+-----------------+----------------+----------+-------------------+
|
| 109 |
+
| `Qwen3-8B-32k`_ | Atlas A3/A2 | 1 | SGLang + FSDP |
|
| 110 |
+
+-----------------+----------------+----------+-------------------+
|
| 111 |
+
|
| 112 |
+
**2.最佳实践**
|
| 113 |
+
|
| 114 |
+
我们提供基于verl+sglang `Qwen3-30B`_ 以及 `Qwen2.5-32B`_ 的 `最佳实践 <https://github.com/verl-project/verl/blob/main/docs/ascend_tutorial/examples/ascend_sglang_best_practices.rst>`_ 作为参考
|
| 115 |
+
|
| 116 |
+
**3.环境变量与参数**
|
| 117 |
+
|
| 118 |
+
当前NPU上支持sglang后端必须添加以下环境变量
|
| 119 |
+
|
| 120 |
+
.. code-block:: bash
|
| 121 |
+
|
| 122 |
+
#支持NPU单卡多进程 https://www.hiascend.com/document/detail/zh/canncommercial/850/commlib/hcclug/hcclug_000091.html
|
| 123 |
+
export HCCL_HOST_SOCKET_PORT_RANGE=60000-60050
|
| 124 |
+
export HCCL_NPU_SOCKET_PORT_RANGE=61000-61050
|
| 125 |
+
#规避ray在device侧调用无法根据is_npu_available接口识别设备可用性
|
| 126 |
+
export RAY_EXPERIMENTAL_NOSET_ASCEND_RT_VISIBLE_DEVICES=1
|
| 127 |
+
#根据当前设备和需要卡数定义
|
| 128 |
+
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
|
| 129 |
+
#使能推理EP时���要
|
| 130 |
+
export SGLANG_DEEPEP_BF16_DISPATCH=1
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
当前verl已解析推理常见参数, 详见 `async_sglang_server.py <https://github.com/verl-project/verl/blob/main/verl/workers/rollout/sglang_rollout/async_sglang_server.py>`_ 中 ServerArgs初始化传参,其他 `sglang参数 <https://github.com/sgl-project/sglang/blob/main/docs/advanced_features/server_arguments.md>`_ 均可通过engine_kwargs 进行参数传递
|
| 135 |
+
|
| 136 |
+
vllm后端推理脚本转换为sglang, 需要添加修改以下参数
|
| 137 |
+
|
| 138 |
+
.. code-block:: bash
|
| 139 |
+
|
| 140 |
+
#必须
|
| 141 |
+
actor_rollout_ref.rollout.name=sglang
|
| 142 |
+
+actor_rollout_ref.rollout.engine_kwargs.sglang.attention_backend="ascend"
|
| 143 |
+
#可选
|
| 144 |
+
#使能推理EP,详细使用方法见 https://github.com/sgl-project/sgl-kernel-npu/blob/main/python/deep_ep/README_CN.md
|
| 145 |
+
++actor_rollout_ref.rollout.engine_kwargs.sglang.deepep_mode="auto"
|
| 146 |
+
++actor_rollout_ref.rollout.engine_kwargs.sglang.moe_a2a_backend="deepep"
|
| 147 |
+
#Moe模型多DP时必须设置为True
|
| 148 |
+
+actor_rollout_ref.rollout.engine_kwargs.sglang.enable_dp_attention=False
|
| 149 |
+
#chunked_prefill默认关闭
|
| 150 |
+
+actor_rollout_ref.rollout.engine_kwargs.sglang.chunked_prefill_size=-1
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/dockerfile_build_guidance.rst
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ascend Dockerfile Build Guidance
|
| 2 |
+
===================================
|
| 3 |
+
|
| 4 |
+
Last updated: 12/4/2025.
|
| 5 |
+
|
| 6 |
+
我们在verl上增加对华为昇腾镜像构建的支持。
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
镜像硬件支持
|
| 10 |
+
-----------------------------------
|
| 11 |
+
|
| 12 |
+
Atlas 200T A2 Box16
|
| 13 |
+
|
| 14 |
+
Atlas 900 A2 PODc
|
| 15 |
+
|
| 16 |
+
Atlas 800T A3
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
镜像内各组件版本信息清单
|
| 20 |
+
----------------
|
| 21 |
+
|
| 22 |
+
================= ============
|
| 23 |
+
组件 版本
|
| 24 |
+
================= ============
|
| 25 |
+
基础镜像 Ubuntu 22.04
|
| 26 |
+
Python 3.11
|
| 27 |
+
CANN 8.3.RC1
|
| 28 |
+
torch 2.7.1
|
| 29 |
+
torch_npu 2.7.1
|
| 30 |
+
torchvision 0.22.1
|
| 31 |
+
vLLM 0.11.0
|
| 32 |
+
vLLM-ascend 0.11.0rc1
|
| 33 |
+
Megatron-LM v0.12.1
|
| 34 |
+
MindSpeed (f2b0977e)
|
| 35 |
+
triton-ascend 3.2.0rc4
|
| 36 |
+
mbridge latest version
|
| 37 |
+
SGLang v0.5.8
|
| 38 |
+
sgl-kernel-npu (46b73de)
|
| 39 |
+
================= ============
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Dockerfile构建镜像脚本清单
|
| 43 |
+
---------------------------
|
| 44 |
+
|
| 45 |
+
============== ============== ============== ==============================================================
|
| 46 |
+
设备类型 基础镜像版本 推理后端 参考文件
|
| 47 |
+
============== ============== ============== ==============================================================
|
| 48 |
+
A2 8.2.RC1 vLLM `Dockerfile.ascend_8.2.rc1_a2 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend_8.2.rc1_a2>`_
|
| 49 |
+
A2 8.3.RC1 vLLM `Dockerfile.ascend_8.3.rc1_a2 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend_8.3.rc1_a2>`_
|
| 50 |
+
A2 8.3.RC1 SGLang `Dockerfile.ascend.sglang_8.3.rc1_a2 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend.sglang_8.3.rc1_a2>`_
|
| 51 |
+
A3 8.2.RC1 vLLM `Dockerfile.ascend_8.2.rc1_a3 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend_8.2.rc1_a3>`_
|
| 52 |
+
A3 8.3.RC1 vLLM `Dockerfile.ascend_8.3.rc1_a3 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend_8.3.rc1_a3>`_
|
| 53 |
+
A3 8.3.RC1 SGLang `Dockerfile.ascend.sglang_8.3.rc1_a3 <https://github.com/volcengine/verl/blob/main/docker/ascend/Dockerfile.ascend.sglang_8.3.rc1_a3>`_
|
| 54 |
+
============== ============== ============== ==============================================================
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
镜像构建命令示例
|
| 58 |
+
--------------------
|
| 59 |
+
|
| 60 |
+
.. code:: bash
|
| 61 |
+
|
| 62 |
+
# Navigate to the directory containing the Dockerfile
|
| 63 |
+
cd {verl-root-path}/docker/ascend
|
| 64 |
+
|
| 65 |
+
# Build the image
|
| 66 |
+
# vLLM
|
| 67 |
+
docker build -f Dockerfile.ascend_8.3.rc1_a2 -t verl-ascend:8.3.rc1-a2 .
|
| 68 |
+
# SGLang
|
| 69 |
+
docker build -f Dockerfile.ascend_8.3.rc1_a2 -t verl-ascend-sglang:8.3.rc1-a2 .
|
| 70 |
+
|
| 71 |
+
公开镜像地址
|
| 72 |
+
--------------------
|
| 73 |
+
|
| 74 |
+
昇腾在 `quay.io/ascend/verl <https://quay.io/repository/ascend/verl?tab=tags&tag=latest>`_ 中托管每日构建的 A2/A3 镜像,基于上述 Dockerfile 构建。
|
| 75 |
+
|
| 76 |
+
每日构建镜像名格式:verl-{CANN版本}-{NPU设备类型}-{操作系统版本}-{python版本}-latest
|
| 77 |
+
|
| 78 |
+
verl release版本镜像名格式:verl-{CANN版本}-{NPU设备类型}-{操作系统版本}-{python版本}-{verl release版本号}
|
| 79 |
+
|
| 80 |
+
声明
|
| 81 |
+
--------------------
|
| 82 |
+
verl中提供的ascend相关Dockerfile、镜像皆为参考样例,可用于尝鲜体验,如在生产环境中使用请通过官方正式途径沟通,谢谢。
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/ascend_sglang_best_practices.rst
ADDED
|
@@ -0,0 +1,296 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ascend SGLang Best Practice
|
| 2 |
+
===================================
|
| 3 |
+
|
| 4 |
+
Last updated: 01/27/2026.
|
| 5 |
+
|
| 6 |
+
.. _Qwen3-30B: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3moe-30b_sglang_megatron_npu.sh
|
| 7 |
+
.. _Qwen2.5-32B: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen2-32b_sglang_fsdp_npu.sh
|
| 8 |
+
引言
|
| 9 |
+
----------------------------------
|
| 10 |
+
|
| 11 |
+
SGLang 是当前主流的高性能开源推理引擎, 昇腾已经全面原生支持该推理引擎在verl中使用,
|
| 12 |
+
仅需简单的构建流程,开发者即可完成环境构建,本文将提供两个经典用例来帮助开发者了解以下内容:
|
| 13 |
+
|
| 14 |
+
1. 环境构建
|
| 15 |
+
2. 模型训练与评估
|
| 16 |
+
3. 性能采集
|
| 17 |
+
|
| 18 |
+
两个用例模型脚本以及其需要的硬件条件各自如下:
|
| 19 |
+
|
| 20 |
+
+----------------------+---------------------+----------+------------------------+
|
| 21 |
+
| 模型 | NPU型号 | 节点数量 | 训推后端 |
|
| 22 |
+
+======================+=====================+==========+========================+
|
| 23 |
+
| `Qwen3-30B`_ | Atlas 800T A3 | 1 | SGLang + Megatron |
|
| 24 |
+
+----------------------+---------------------+----------+------------------------+
|
| 25 |
+
| `Qwen2.5-32B`_ | Atlas 900 A2 | 2 | SGLang + FSDP |
|
| 26 |
+
+----------------------+---------------------+----------+------------------------+
|
| 27 |
+
|
| 28 |
+
环境构建
|
| 29 |
+
-----------------------------------
|
| 30 |
+
我们在quickstart中提供了两种构建环境的方法, 1.从镜像文件DockerFile进行构建 2.从自定义Conda环境进行构建
|
| 31 |
+
|
| 32 |
+
在本实践中, 我们额外指定verl 的commit id 以避免引入其他问题
|
| 33 |
+
|
| 34 |
+
.. code-block:: bash
|
| 35 |
+
|
| 36 |
+
cd verl
|
| 37 |
+
git checkout 772c224
|
| 38 |
+
模型训练与评估
|
| 39 |
+
-----------------------------------
|
| 40 |
+
1.模型数据准备
|
| 41 |
+
^^^^^^^^^^^
|
| 42 |
+
`Qwen3-30B`_
|
| 43 |
+
^^^^^^^^^^^
|
| 44 |
+
**下载模型权重**
|
| 45 |
+
|
| 46 |
+
--local-dir: 模型保存路径
|
| 47 |
+
|
| 48 |
+
.. code-block:: bash
|
| 49 |
+
|
| 50 |
+
export HF_ENDPOINT=https://hf-mirror.com
|
| 51 |
+
hf download --resume-download Qwen/Qwen3-30B-A3B --local-dir /path/to/local_dir
|
| 52 |
+
|
| 53 |
+
**下载数据集**
|
| 54 |
+
|
| 55 |
+
.. code-block:: bash
|
| 56 |
+
|
| 57 |
+
git clone https://www.modelscope.cn/datasets/AI-ModelScope/DAPO-Math-17k.git
|
| 58 |
+
|
| 59 |
+
**HuggingFace To Megatron权重转换(可选)**
|
| 60 |
+
|
| 61 |
+
.. code-block:: bash
|
| 62 |
+
|
| 63 |
+
python scripts/converter_hf_to_mcore.py \
|
| 64 |
+
--hf_model_path Qwen/Qwen3-30B-A3B \
|
| 65 |
+
--output_path Qwen/Qwen3-30B-A3B-mcore \
|
| 66 |
+
--use_cpu_initialization # Only work for MoE models
|
| 67 |
+
*注:verl当前已支持mbridge进行灵活的hf和mcore之间的权重转换,可以修改以下相关参数直接加载hf权重*
|
| 68 |
+
|
| 69 |
+
.. code-block:: bash
|
| 70 |
+
|
| 71 |
+
actor_rollout_ref.actor.megatron.use_dist_checkpointing=False
|
| 72 |
+
actor_rollout_ref.actor.megatron.use_mbridge=True
|
| 73 |
+
|
| 74 |
+
`Qwen2.5-32B`_
|
| 75 |
+
^^^^^^^^^^^
|
| 76 |
+
**下载模型权重**
|
| 77 |
+
|
| 78 |
+
--local-dir: 模型保存路径
|
| 79 |
+
|
| 80 |
+
.. code-block:: bash
|
| 81 |
+
|
| 82 |
+
export HF_ENDPOINT=https://hf-mirror.com
|
| 83 |
+
hf download --resume-download Qwen/Qwen2.5-32B --local-dir /path/to/local_dir
|
| 84 |
+
|
| 85 |
+
**下载及处理数据集**
|
| 86 |
+
|
| 87 |
+
.. code-block:: bash
|
| 88 |
+
|
| 89 |
+
wget https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset/resolve/main/deepscaler.json
|
| 90 |
+
python recipe/r1_ascend/json_to_parquet.py --output_dir ./data/deepscaler --json_path path/to/deepscaler.json --train_data_ratio 0.9
|
| 91 |
+
|
| 92 |
+
2.训练
|
| 93 |
+
^^^^^^^^^^^
|
| 94 |
+
根据开发者实际路径配置情况修改模型训练脚本中的以下参数
|
| 95 |
+
|
| 96 |
+
.. code-block:: bash
|
| 97 |
+
|
| 98 |
+
# Model Weights Paths
|
| 99 |
+
MODEL_PATH=Qwen/Qwen3-30B-A3B
|
| 100 |
+
MCORE_MODEL_PATH=Qwen/Qwen3-30B-A3B-mcore
|
| 101 |
+
RAY_DATA_HOME=${RAY_DATA_HOME:-"${HOME}/verl"}
|
| 102 |
+
CKPTS_DIR=${CKPTS_DIR:-"${RAY_DATA_HOME}/ckpts/${project_name}/${exp_name}"}
|
| 103 |
+
|
| 104 |
+
# File System Paths
|
| 105 |
+
TRAIN_FILE=$RAY_DATA_HOME/dataset/dapo-math-17k.parquet
|
| 106 |
+
TEST_FILE=$RAY_DATA_HOME/dataset/aime-2024.parquet
|
| 107 |
+
|
| 108 |
+
#保存频率,-1默认不保存,如需评测请修改此参数
|
| 109 |
+
trainer.save_freq=-1
|
| 110 |
+
|
| 111 |
+
对于单机任务 `Qwen3-30B`_ , 可以直接bash执行verl仓上示例脚本
|
| 112 |
+
|
| 113 |
+
.. code-block:: bash
|
| 114 |
+
|
| 115 |
+
bash examples/grpo_trainer/run_qwen3moe-30b_sglang_megatron_npu.sh
|
| 116 |
+
对于多节点任务 `Qwen2.5-32B`_ ,我们推荐使用以下脚本进行大规模多节点训练拉起
|
| 117 |
+
|
| 118 |
+
.. code-block:: bash
|
| 119 |
+
|
| 120 |
+
pkill -9 python
|
| 121 |
+
ray stop --force
|
| 122 |
+
rm -rf /tmp/ray
|
| 123 |
+
export RAY_DEDUP_LOGS=0
|
| 124 |
+
export HYDRA_FULL_ERROR=1
|
| 125 |
+
# TASK_QUEUE_ENABLE,下发优化,图模式设置为1,非图模式设置为2
|
| 126 |
+
export TASK_QUEUE_ENABLE=1
|
| 127 |
+
export HCCL_ASYNC_ERROR_HANDLING=0
|
| 128 |
+
export HCCL_EXEC_TIMEOUT=3600
|
| 129 |
+
export HCCL_CONNECT_TIMEOUT=3600
|
| 130 |
+
|
| 131 |
+
export HCCL_HOST_SOCKET_PORT_RANGE=60000-60050
|
| 132 |
+
export HCCL_NPU_SOCKET_PORT_RANGE=61000-61050
|
| 133 |
+
export RAY_EXPERIMENTAL_NOSET_ASCEND_RT_VISIBLE_DEVICES=1
|
| 134 |
+
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8
|
| 135 |
+
# 修改为当前需要跑的用例路径
|
| 136 |
+
DEFAULT_SH="./run_*.sh"
|
| 137 |
+
echo "Use $DEFAULT_SH"
|
| 138 |
+
|
| 139 |
+
ulimit -n 32768
|
| 140 |
+
mkdir logs
|
| 141 |
+
|
| 142 |
+
NNODES=2
|
| 143 |
+
NPUS_PER_NODE=8
|
| 144 |
+
# 修改为对应主节点IP
|
| 145 |
+
MASTER_ADDR="IP FOR MASTER NODE"
|
| 146 |
+
# 修改为当前节点的通信网卡
|
| 147 |
+
SOCKET_IFNAME="Your SOCKET IFNAME"
|
| 148 |
+
export HCCL_SOCKET_IFNAME="SOCKET IFNAME FOR CURRENT NODE"
|
| 149 |
+
export GLOO_SOCKET_IFNAME="SOCKET IFNAME FOR CURRENT NODE"
|
| 150 |
+
# 获取当前IP
|
| 151 |
+
CURRENT_IP=$(ifconfig $SOCKET_IFNAME | grep -Eo 'inet (addr:)?([0-9]{1,3}\.){3}[0-9]{1,3}' | awk '{print $NF}')
|
| 152 |
+
if [ "$MASTER_ADDR" = "$CURRENT_IP" ]; then
|
| 153 |
+
# 主节点启动
|
| 154 |
+
ray start --head --port 6766 --dashboard-host=$MASTER_ADDR --node-ip-address=$CURRENT_IP --dashboard-port=8260 --resources='{"NPU": '$NPUS_PER_NODE'}'
|
| 155 |
+
|
| 156 |
+
while true; do
|
| 157 |
+
ray_status_output=$(ray status)
|
| 158 |
+
npu_count=$(echo "$ray_status_output" | grep -oP '(?<=/)\d+\.\d+(?=\s*NPU)' | head -n 1)
|
| 159 |
+
npu_count_int=$(echo "$npu_count" | awk '{print int($1)}')
|
| 160 |
+
device_count=$((npu_count_int / $NPUS_PER_NODE))
|
| 161 |
+
|
| 162 |
+
# 判断device_count 是否与 NNODES 相等
|
| 163 |
+
if [ "$device_count" -eq "$NNODES" ]; then
|
| 164 |
+
echo "Ray cluster is ready with $device_count devices (from $npu_count NPU resources), starting Python script."
|
| 165 |
+
ray status
|
| 166 |
+
bash $DEFAULT_SH
|
| 167 |
+
break
|
| 168 |
+
else
|
| 169 |
+
echo "Waiting for Ray to allocate $NNODES devices. Current device count: $device_count"
|
| 170 |
+
sleep 5
|
| 171 |
+
fi
|
| 172 |
+
done
|
| 173 |
+
else
|
| 174 |
+
# 子节点尝试往主节点注册 ray 直到成功
|
| 175 |
+
while true; do
|
| 176 |
+
# 尝试连接 ray 集群
|
| 177 |
+
ray start --address="$MASTER_ADDR:6766" --resources='{"NPU": '$NPUS_PER_NODE'}' --node-ip-address=$CURRENT_IP
|
| 178 |
+
|
| 179 |
+
# 检查连接是否成功
|
| 180 |
+
ray status
|
| 181 |
+
if [ $? -eq 0 ]; then
|
| 182 |
+
echo "Successfully connected to the Ray cluster!"
|
| 183 |
+
break
|
| 184 |
+
else
|
| 185 |
+
echo "Failed to connect to the Ray cluster. Retrying in 5 seconds..."
|
| 186 |
+
sleep 5
|
| 187 |
+
fi
|
| 188 |
+
done
|
| 189 |
+
fi
|
| 190 |
+
|
| 191 |
+
sleep 600
|
| 192 |
+
|
| 193 |
+
DEFAULT_SH:修改为训练所用配置 sh 文件路径。在此案例中修改为 `Qwen2.5-32B`_ 路径。
|
| 194 |
+
|
| 195 |
+
NNODES 和 NPUS_PER_NODE:修改为使用节点数量和每个节点 NPU 数量。在此案例中分别为2和8。
|
| 196 |
+
|
| 197 |
+
MASTER_ADDR:修改为对应主节点 IP。即所有节点的 MASTER_ADDR 应该相同。
|
| 198 |
+
|
| 199 |
+
SOCKET_IFNAME, HCCL_SOCKET_IFNAME, GLOO_SOCKET_IFNAME: 修改为对应通信网卡,通信网卡可以通过以下命令获取:
|
| 200 |
+
|
| 201 |
+
.. code-block:: bash
|
| 202 |
+
|
| 203 |
+
ifconfig |grep "$(hostname -I |awk '{print $1}'|awk -F '.' '{print $0}')" -B 1|awk -F ':' '{print$1}' | head -1 | tail -1
|
| 204 |
+
|
| 205 |
+
3.模型评估
|
| 206 |
+
^^^^^^^^^^^
|
| 207 |
+
|
| 208 |
+
不同模型步骤一致,仅以Qwen3-30b为例列举
|
| 209 |
+
|
| 210 |
+
我们通过 AISBenchmark 评估模型,该工具支持vllm/sglang多种推理后端的评估
|
| 211 |
+
|
| 212 |
+
**安装方法**
|
| 213 |
+
|
| 214 |
+
.. code-block:: bash
|
| 215 |
+
|
| 216 |
+
git clone https://gitee.com/aisbench/benchmark.git
|
| 217 |
+
cd benchmark
|
| 218 |
+
pip install -e .
|
| 219 |
+
|
| 220 |
+
**下载评估数据集**
|
| 221 |
+
|
| 222 |
+
.. code-block:: bash
|
| 223 |
+
|
| 224 |
+
cd path/to/benchmark/ais_bench/datasets
|
| 225 |
+
wget http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/math.zip
|
| 226 |
+
unzip math.zip
|
| 227 |
+
rm math.zip
|
| 228 |
+
|
| 229 |
+
**修改AISBench配置代码使能sglang推理评测**
|
| 230 |
+
|
| 231 |
+
打开 benchmark/ais_bench/benchmark/configs/models/vllm_api/vllm_api_stream_chat.py 文件,这是推理配置文件
|
| 232 |
+
|
| 233 |
+
.. code-block:: bash
|
| 234 |
+
|
| 235 |
+
from ais_bench.benchmark.models import VLLMCustomAPIChatStream
|
| 236 |
+
from ais_bench.benchmark.utils.model_postprocessors import extract_non_reasoning_content
|
| 237 |
+
from ais_bench.benchmark.clients import OpenAIChatStreamClient, OpenAIChatStreamSglangClient
|
| 238 |
+
|
| 239 |
+
models = [
|
| 240 |
+
dict(
|
| 241 |
+
attr="service",
|
| 242 |
+
type=VLLMCustomAPIChatStream,
|
| 243 |
+
abbr='sgl-api-stream-chat',
|
| 244 |
+
path="/path/to/Qwen3-30B", # 修改为 Qwen3-30B 模型路径
|
| 245 |
+
model="qwen3-30b",
|
| 246 |
+
request_rate = 0,
|
| 247 |
+
max_seq_len=2048,
|
| 248 |
+
retry = 2,
|
| 249 |
+
host_ip = "localhost", # 推理服务的IP
|
| 250 |
+
host_port = 8005, # 推理服务的端口
|
| 251 |
+
max_out_len = 8192, # 最大输出tokens长度
|
| 252 |
+
batch_size=48, # 推理的最大并发数
|
| 253 |
+
trust_remote_code=False,
|
| 254 |
+
custom_client=dict(type=OpenAIChatStreamSglangClient), #使用sglang客户端
|
| 255 |
+
generation_kwargs = dict(
|
| 256 |
+
temperature = 0,
|
| 257 |
+
seed = 1234,
|
| 258 |
+
),
|
| 259 |
+
pred_postprocessor=dict(type=extract_non_reasoning_content)
|
| 260 |
+
)
|
| 261 |
+
]
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
**启动sglang_server服务**
|
| 265 |
+
|
| 266 |
+
.. code-block:: bash
|
| 267 |
+
|
| 268 |
+
python -m sglang.launch_server --model-path "/path/to/Qwen3-30B" --tp-size 4 --dp-size 1 --port 8005
|
| 269 |
+
|
| 270 |
+
**启动sglang_client评测**
|
| 271 |
+
|
| 272 |
+
.. code-block:: bash
|
| 273 |
+
|
| 274 |
+
ais_bench --models vllm_api_stream_chat --datasets math500_gen_0_shot_cot_chat_prompt
|
| 275 |
+
|
| 276 |
+
**评测结果**
|
| 277 |
+
|
| 278 |
+
经过训练,模型在Math-500上的评分显著上升
|
| 279 |
+
|
| 280 |
+
+------+----------------------+---------+----------+------+----------------------+
|
| 281 |
+
| iter | dataset | version | metric | mode | sgl-api-stream-chat |
|
| 282 |
+
+======+======================+=========+==========+======+======================+
|
| 283 |
+
| 0 | math_prm800k_500 | c4b6f0 | accuracy | gen | 84.4 |
|
| 284 |
+
+------+----------------------+---------+----------+------+----------------------+
|
| 285 |
+
| 150 | math_prm800k_500 | c4b6f0 | accuracy | gen | 91.7 |
|
| 286 |
+
+------+----------------------+---------+----------+------+----------------------+
|
| 287 |
+
|
| 288 |
+
性能采集
|
| 289 |
+
-----------------------------------
|
| 290 |
+
关于NPU profiling的详细文档请参考 `ascend_profiling_zh <https://github.com/volcengine/verl/blob/main/docs/ascend_tutorial/ascend_profiling_zh.rst>`_
|
| 291 |
+
|
| 292 |
+
在 `Qwen3-30B`_ 的脚本中提供了基本的采集性能选项PROF_CONFIG,默认设置 global_profiler.steps=null 关闭采集, 开发者可根据实际需要进行参数修改
|
| 293 |
+
|
| 294 |
+
采集完成后,开发者可以使用 `MindStudio Insight <https://www.hiascend.com/document/detail/zh/mindstudio/830/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0002.html>`_ 进行数据解析
|
| 295 |
+
|
| 296 |
+
注: verl框架侧进行采集全量 Profiling 产生海量且重复的算子记录,可以根据文档修改代码仅采集关键阶段
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/dapo_multi_model_optimization_practice.md
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DAPO 介绍
|
| 2 |
+
|
| 3 |
+
Last updated: 01/27/2026.
|
| 4 |
+
|
| 5 |
+
DAPO的论文可以参考:[DAPO](https://arxiv.org/pdf/2503.14476),其中包含以下几个关键技术。
|
| 6 |
+
|
| 7 |
+
* **Clip-Higher**: 通过对重要性采样比的上限剪裁促进了系统的多样性并避免了熵坍缩(Entropy Collapse)。
|
| 8 |
+
* **Dynamic Sampling**: 提高了训练效率和稳定性。DAPO出了一种执行动态采样的策略,并过滤掉准确率等于1和0的提示组,从而保持批次间具有有效梯度的提示数量一致。
|
| 9 |
+
* **Token-level Policy Gradient Loss**: 在长链思维强化学习 (long-CoT RL) 场景中至关重要。
|
| 10 |
+
* **Overlong Reward Shaping**: 减少奖励噪声并稳定了训练。
|
| 11 |
+
|
| 12 |
+
在verl中,可以进行如下设置,从而进行DAPO算法的运行。
|
| 13 |
+
|
| 14 |
+
- **奖励模型的管理策略为 DAPO**
|
| 15 |
+
在dapo算法中,必须配置成dapo。
|
| 16 |
+
|
| 17 |
+
```
|
| 18 |
+
reward_model.reward_manager=dapo
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
- **Clip-Higher 更高裁剪 **
|
| 22 |
+
`clip_ratio_low` 和 `clip_ratio_high` 用于指定 DAPO 目标函数中的 $\varepsilon_{\text {low }}$ 和 $\varepsilon_{\text {high }}$。
|
| 23 |
+
|
| 24 |
+
```
|
| 25 |
+
clip_ratio_low=0.2 # 裁剪比例下限,默认值为0.2
|
| 26 |
+
clip_ratio_high=0.28 # 裁剪比例上限,默认值为0.28
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
- **动态采样的相关配置 **
|
| 30 |
+
将 `filter_groups.enable` 设置为 `True` 会过滤掉输出 `metric` 完全相同的组,例如对于 `acc` 指标,过滤掉输出准确率全部为 1 或 0 的组。
|
| 31 |
+
训练器会使用 `gen_batch_size` 进行重复采样,直到生成足够数量的符合条件的组,或者达到 `max_num_gen_batches` 所指定的上限为止。
|
| 32 |
+
|
| 33 |
+
```
|
| 34 |
+
data.gen_batch_size=${gen_prompt_bsz}
|
| 35 |
+
algorithm.filter_groups.enable=${enable_filter_groups} # 动态采样开关
|
| 36 |
+
algorithm.filter_groups.metric=${filter_groups_metric} # 使用准确率作为过滤标准
|
| 37 |
+
algorithm.filter_groups.max_num_gen_batches=${max_num_gen_batches} # 最大生成批次数量,最多重复生成数据的次数
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
- **Token-level Loss **
|
| 41 |
+
将 `loss_agg_mode` 设置为 `token-mean` 意味着计算一个批次中所有序列内所有 token 的(策略梯度)损失的平均值。
|
| 42 |
+
|
| 43 |
+
```
|
| 44 |
+
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode}
|
| 45 |
+
#注意:“token-mean”是默认行为。
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
- **奖励模型对超长回答的惩罚配置 **
|
| 49 |
+
将 `overlong_buffer.enable` 设置为 `True` 将对输出长度过长但仍未超过硬上下文限制的输出进行惩罚。具体来说,当输出的长度超过 `max_response_length - overlong_buffer.len` 且超出 `0` 到 `overlong_buffer.len` 个 token 时,惩罚值会从 `0` 线性增加到 `overlong_buffer.penalty_factor`。
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
reward_model.overlong_buffer.enable=${enable_overlong_buffer} # 启用超长缓冲区惩罚,开启对超长输出的惩罚机制
|
| 53 |
+
reward_model.overlong_buffer.len=${overlong_buffer_len} # 缓冲区长度,定义缓冲区的toke,最大惩罚强度
|
| 54 |
+
reward_model.overlong_buffer.penalty_factor=${overlong_penalty_factor} #惩罚因子,最大惩罚强度
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
相关参数涉及的代码可以参考:[Recipe: Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)](https://github.com/verl-project/verl-recipe/blob/main/dapo/README.md)
|
| 58 |
+
|
| 59 |
+
# 硬件要求
|
| 60 |
+
|
| 61 |
+
当前支持Atlas 800T A3 与 Atlas 900 A3 SuperPoD。完成跑完本次最佳实践需要 2台Atlas 800T A3。关键软件版本可以参考:[Ascend Quickstart](https://github.com/volcengine/verl/blob/main/docs/ascend_tutorial/ascend_quick_start.rst)
|
| 62 |
+
|
| 63 |
+
# 模型训练
|
| 64 |
+
|
| 65 |
+
## 数据集准备
|
| 66 |
+
|
| 67 |
+
Geometry3k 数据集是由加利福尼亚大学洛杉矶分校与浙江大学联合研发的几何领域专用数据集,核心面向视觉问答(VQA)任务展开研究与模型训练。该数据集总计包含 3002 个样本,采用图像和文本两种模态数据形式构建,其中文本模态涵盖各类几何问题描述,图像则以可视化图表呈现问题中的几何图形信息,包括三角形、圆形、四边形等基础几何形状,以及不同图形间的位置、嵌套、相交等关联关系。可以从Hugging Face库下载对应的原始数据集:[Geometry3k ](https://huggingface.co/datasets/hiyouga/geometry3k)
|
| 68 |
+
|
| 69 |
+
```python
|
| 70 |
+
# 下载原始数据并预处理
|
| 71 |
+
python ./examples/data_preprocess/geo3k.py --local_dir=./data/geo3k
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
## 权重下载
|
| 75 |
+
|
| 76 |
+
从Hugging Face库下载对应的模型权重:[Qwen3-VL-30B-A3B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct/tree/main
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
## 全局变量导入
|
| 80 |
+
|
| 81 |
+
- 为了确保 Ray 进程能够正常回收内存,需要安装并使能 jemalloc 库进行内存管理,用于更好管理内存,避免长跑过程中内存 OOM。
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
# 根据实际安装路径设置 jemalloc 环境变量
|
| 85 |
+
export LD_PRELOAD=/usr/local/lib/libjemalloc.so.2
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
- 某些模型是通过 vllm ascend 进行优化的。但在某些情况下,优化后的模型可能并不适用。此时,将此值设置为 0 即可禁用优化后的模型。
|
| 89 |
+
|
| 90 |
+
```
|
| 91 |
+
export USE_OPTIMIZED_MODEL=0
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
- 启用vLLM V1
|
| 95 |
+
|
| 96 |
+
```
|
| 97 |
+
export VLLM_USE_V1=1
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
昇腾多卡通信的兜底��置,延长连接超时时间,避免集群环境下训练启动因连接慢而失败
|
| 101 |
+
|
| 102 |
+
```
|
| 103 |
+
export HCCL_CONNECT_TIMEOUT=5400
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
- 控制 vLLM 在昇腾芯片上是否启用NZ优化
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
export VLLM_ASCEND_ENABLE_NZ=0
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
- 根据使用机器的情况,修改相关配置, 例如双机机 A2 可设置`trainer.nnodes`为 1 、`trainer.n_gpus_per_node`为8
|
| 113 |
+
|
| 114 |
+
## 训练脚本
|
| 115 |
+
|
| 116 |
+
基于以上修改,提供了示例配置文件,创建 run_dapo_qwen3_vl_30b.sh 文件。
|
| 117 |
+
|
| 118 |
+
```bash
|
| 119 |
+
set -xeuo pipefail
|
| 120 |
+
|
| 121 |
+
export VLLM_USE_V1=1
|
| 122 |
+
export HCCL_CONNECT_TIMEOUT=5400
|
| 123 |
+
export VLLM_ASCEND_ENABLE_NZ=0
|
| 124 |
+
export LD_PRELOAD=/usr/local/lib/libjemalloc.so.2
|
| 125 |
+
# Some models are optimized by vllm ascend. While in some case, e.g. rlhf training,
|
| 126 |
+
# the optimized model may not be suitable. In this case, set this value to 0 to disable the optimized model.
|
| 127 |
+
export USE_OPTIMIZED_MODEL=0
|
| 128 |
+
|
| 129 |
+
project_name='DAPO'
|
| 130 |
+
exp_name='DAPO-Qwen3-vl-30B'
|
| 131 |
+
|
| 132 |
+
adv_estimator=grpo
|
| 133 |
+
|
| 134 |
+
use_kl_in_reward=False
|
| 135 |
+
kl_coef=0.0
|
| 136 |
+
use_kl_loss=False
|
| 137 |
+
kl_loss_coef=0.0
|
| 138 |
+
|
| 139 |
+
clip_ratio_low=0.2
|
| 140 |
+
clip_ratio_high=0.28
|
| 141 |
+
|
| 142 |
+
max_prompt_length=1024
|
| 143 |
+
max_response_length=2048
|
| 144 |
+
enable_overlong_buffer=False
|
| 145 |
+
overlong_buffer_len=$((1024 * 2))
|
| 146 |
+
overlong_penalty_factor=1.0
|
| 147 |
+
|
| 148 |
+
loss_agg_mode="token-mean"
|
| 149 |
+
|
| 150 |
+
enable_filter_groups=True
|
| 151 |
+
filter_groups_metric=acc
|
| 152 |
+
max_num_gen_batches=4
|
| 153 |
+
train_prompt_bsz=64
|
| 154 |
+
gen_prompt_bsz=$((train_prompt_bsz * 3))
|
| 155 |
+
n_resp_per_prompt=8
|
| 156 |
+
train_prompt_mini_bsz=16
|
| 157 |
+
|
| 158 |
+
# Ray
|
| 159 |
+
PWD=./
|
| 160 |
+
RAY_ADDRESS=${RAY_ADDRESS:-"http://localhost:8265"}
|
| 161 |
+
WORKING_DIR=${WORKING_DIR:-"${PWD}"}
|
| 162 |
+
RUNTIME_ENV=${RUNTIME_ENV:-"${WORKING_DIR}/verl/trainer/runtime_env.yaml"}
|
| 163 |
+
|
| 164 |
+
# Paths
|
| 165 |
+
RAY_DATA_HOME=${RAY_DATA_HOME:-"${HOME}/verl"}
|
| 166 |
+
MODEL_PATH=${MODEL_PATH:-"${RAY_DATA_HOME}/models/Qwen3-VL-30B-A3B-Instruct"}
|
| 167 |
+
CKPTS_DIR=${CKPTS_DIR:-"${RAY_DATA_HOME}/ckpts/${project_name}/${exp_name}"}
|
| 168 |
+
TRAIN_FILE=${TRAIN_FILE:-"${RAY_DATA_HOME}/data/geo3k/train.parquet"}
|
| 169 |
+
TEST_FILE=${TEST_FILE:-"${RAY_DATA_HOME}/data/geo3k/test.parquet"}
|
| 170 |
+
|
| 171 |
+
# Algorithm
|
| 172 |
+
temperature=1.0
|
| 173 |
+
top_p=1.0
|
| 174 |
+
top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
|
| 175 |
+
val_top_p=0.7
|
| 176 |
+
|
| 177 |
+
# Performance Related Parameter
|
| 178 |
+
sp_size=8
|
| 179 |
+
use_dynamic_bsz=True
|
| 180 |
+
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) / sp_size))
|
| 181 |
+
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) / sp_size))
|
| 182 |
+
gen_tp=8
|
| 183 |
+
fsdp_size=16
|
| 184 |
+
|
| 185 |
+
ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \
|
| 186 |
+
--working-dir "${WORKING_DIR}" \
|
| 187 |
+
--address "${RAY_ADDRESS}" \
|
| 188 |
+
-- python3 -m recipe.dapo.main_dapo \
|
| 189 |
+
data.train_files="${TRAIN_FILE}" \
|
| 190 |
+
data.val_files="${TEST_FILE}" \
|
| 191 |
+
data.prompt_key=prompt \
|
| 192 |
+
data.truncation='left' \
|
| 193 |
+
data.max_prompt_length=${max_prompt_length} \
|
| 194 |
+
data.max_response_length=${max_response_length} \
|
| 195 |
+
data.gen_batch_size=${gen_prompt_bsz} \
|
| 196 |
+
data.train_batch_size=${train_prompt_bsz} \
|
| 197 |
+
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \
|
| 198 |
+
algorithm.adv_estimator=${adv_estimator} \
|
| 199 |
+
algorithm.use_kl_in_reward=${use_kl_in_reward} \
|
| 200 |
+
algorithm.kl_ctrl.kl_coef=${kl_coef} \
|
| 201 |
+
actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \
|
| 202 |
+
actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \
|
| 203 |
+
actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \
|
| 204 |
+
actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \
|
| 205 |
+
actor_rollout_ref.actor.clip_ratio_c=10.0 \
|
| 206 |
+
algorithm.filter_groups.enable=${enable_filter_groups} \
|
| 207 |
+
algorithm.filter_groups.max_num_gen_batches=${max_num_gen_batches} \
|
| 208 |
+
algorithm.filter_groups.metric=${filter_groups_metric} \
|
| 209 |
+
actor_rollout_ref.model.use_remove_padding=True \
|
| 210 |
+
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \
|
| 211 |
+
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 212 |
+
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 213 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=2 \
|
| 214 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=2 \
|
| 215 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=2 \
|
| 216 |
+
actor_rollout_ref.model.path="${MODEL_PATH}" \
|
| 217 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 218 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 219 |
+
actor_rollout_ref.actor.optim.lr_warmup_steps=10 \
|
| 220 |
+
actor_rollout_ref.actor.optim.weight_decay=0.1 \
|
| 221 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz} \
|
| 222 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=False \
|
| 223 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
|
| 224 |
+
actor_rollout_ref.actor.use_torch_compile=False \
|
| 225 |
+
actor_rollout_ref.actor.entropy_coeff=0 \
|
| 226 |
+
actor_rollout_ref.actor.grad_clip=1.0 \
|
| 227 |
+
actor_rollout_ref.rollout.enforce_eager=True \
|
| 228 |
+
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \
|
| 229 |
+
actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \
|
| 230 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.70 \
|
| 231 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
|
| 232 |
+
actor_rollout_ref.rollout.enable_chunked_prefill=True \
|
| 233 |
+
actor_rollout_ref.rollout.temperature=${temperature} \
|
| 234 |
+
actor_rollout_ref.rollout.top_p=${top_p} \
|
| 235 |
+
actor_rollout_ref.rollout.top_k="${top_k}" \
|
| 236 |
+
actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \
|
| 237 |
+
actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \
|
| 238 |
+
actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \
|
| 239 |
+
actor_rollout_ref.rollout.val_kwargs.do_sample=True \
|
| 240 |
+
actor_rollout_ref.rollout.val_kwargs.n=1 \
|
| 241 |
+
actor_rollout_ref.rollout.expert_parallel_size=8 \
|
| 242 |
+
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \
|
| 243 |
+
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
|
| 244 |
+
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
|
| 245 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 246 |
+
+actor_rollout_ref.rollout.engine_kwargs.vllm.disable_mm_preprocessor_cache=True \
|
| 247 |
+
actor_rollout_ref.actor.strategy=fsdp2 \
|
| 248 |
+
actor_rollout_ref.ref.strategy=fsdp2 \
|
| 249 |
+
critic.strategy=fsdp2 \
|
| 250 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 251 |
+
actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \
|
| 252 |
+
actor_rollout_ref.actor.fsdp_config.fsdp_size=${fsdp_size} \
|
| 253 |
+
reward_model.reward_manager=dapo \
|
| 254 |
+
reward_model.overlong_buffer.enable=${enable_overlong_buffer} \
|
| 255 |
+
reward_model.overlong_buffer.len=${overlong_buffer_len} \
|
| 256 |
+
reward_model.overlong_buffer.penalty_factor=${overlong_penalty_factor} \
|
| 257 |
+
trainer.logger=console \
|
| 258 |
+
trainer.project_name="${project_name}" \
|
| 259 |
+
trainer.experiment_name="${exp_name}" \
|
| 260 |
+
trainer.n_gpus_per_node=8 \
|
| 261 |
+
trainer.nnodes=2 \
|
| 262 |
+
trainer.val_before_train=True \
|
| 263 |
+
trainer.test_freq=1 \
|
| 264 |
+
trainer.save_freq=20 \
|
| 265 |
+
trainer.resume_mode=auto \
|
| 266 |
+
trainer.device=npu \
|
| 267 |
+
trainer.total_epochs=30 \
|
| 268 |
+
trainer.total_training_steps=100 \
|
| 269 |
+
trainer.default_local_dir="${CKPTS_DIR}"
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
# 优化参考
|
| 273 |
+
|
| 274 |
+
- **启动动态批次大小**
|
| 275 |
+
根据单 GPU 的最大 Token 总数(ppo_max_token_len_per_gpu)动态调整批次大小
|
| 276 |
+
|
| 277 |
+
```
|
| 278 |
+
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz}
|
| 279 |
+
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz}
|
| 280 |
+
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz}
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
- **单个 GPU 能处理的最大 Token 总数**
|
| 284 |
+
当`use_dynamic_bsz=True`时,单 GPU 在一个微批次中能处理的最大 Token 数量
|
| 285 |
+
|
| 286 |
+
```
|
| 287 |
+
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len}
|
| 288 |
+
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len}
|
| 289 |
+
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len}
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
- **单个 GPU 微批次大小**
|
| 293 |
+
当`use_dynamic_bsz=True`时,框架会以该值为初始批次大小,再根据`ppo_max_token_len_per_gpu`向上 / 向下调整
|
| 294 |
+
|
| 295 |
+
```
|
| 296 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=2
|
| 297 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=2
|
| 298 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=2
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
- **启用 FSDP2 框架**
|
| 302 |
+
“将模型参数、梯度、优化器状态分片存储在不同 GPU 上”,避免单卡加载全量模型导致显存溢出。
|
| 303 |
+
|
| 304 |
+
```
|
| 305 |
+
# 启用 FSDP2 框架
|
| 306 |
+
actor_rollout_ref.actor.strategy=fsdp2
|
| 307 |
+
actor_rollout_ref.ref.strategy=fsdp2
|
| 308 |
+
critic.strategy=fsdp2
|
| 309 |
+
|
| 310 |
+
# 仅用于 FSDP2:前向传播后重新分片以减少内存占用。
|
| 311 |
+
actor_rollout_ref.actor.fsdp_config.reshard_after_forward=True
|
| 312 |
+
# 仅用于 FSDP2:是否在模型前向传播后重新分片以节省内存。
|
| 313 |
+
actor_rollout_ref.ref.fsdp_config.reshard_after_forward=True
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
- **启用专家并行配置**
|
| 317 |
+
指定有多少个 GPU用于并行计算不同的专家网络
|
| 318 |
+
|
| 319 |
+
```
|
| 320 |
+
# MoE 架构 Actor 模型的专家并行配置
|
| 321 |
+
actor_rollout_ref.rollout.expert_parallel_size=8
|
| 322 |
+
```
|
| 323 |
+
|
| 324 |
+
|
code/RL_model/verl/verl_train/docs/ascend_tutorial/examples/gspo_optimization_practice.md
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## NPU Qwen3-32B GSPO Optimization Practice
|
| 2 |
+
|
| 3 |
+
Last updated: 01/27/2026.
|
| 4 |
+
|
| 5 |
+
本文章对应脚本地址:[qwen3_32b_gspo_npu](https://github.com/volcengine/verl/blob/main/examples/gspo_trainer/run_qwen3_32b_gspo_npu.sh)
|
| 6 |
+
|
| 7 |
+
### 算法适配
|
| 8 |
+
|
| 9 |
+
GSPO通过将优化颗粒度从**token级**提升到**sequence级**,规避了GRPO会遇到的**方差急剧增大**导致训练不稳定的情况,增加了训练的稳定性,同时该算法也在一定程度上提升了算法的收敛速度。
|
| 10 |
+
|
| 11 |
+
想要成功在verl仓库中成功调用到GSPO算法,需要进行如下的必要配置
|
| 12 |
+
|
| 13 |
+
~~~python
|
| 14 |
+
# 核心算法配置
|
| 15 |
+
algorithm.adv_estimator=grpo \ # 使用GRPO优势估计器
|
| 16 |
+
algorithm.use_kl_in_reward=False \ # 不在奖励中添加KL惩罚
|
| 17 |
+
# GSPO策略损失模式
|
| 18 |
+
actor_rollout_ref.actor.policy_loss.loss_mode=gspo \ # 启用GSPO策略损失
|
| 19 |
+
# 极小裁剪范围(GSPO特色)
|
| 20 |
+
actor_rollout_ref.actor.clip_ratio_low=0.0003 \ # 裁剪下界,论文推荐值
|
| 21 |
+
actor_rollout_ref.actor.clip_ratio_high=0.0004 \ # 裁剪上界,论文推荐值
|
| 22 |
+
# KL配置(GSPO不使用KL loss)
|
| 23 |
+
actor_rollout_ref.actor.use_kl_loss=False \ # 禁用KL损失
|
| 24 |
+
actor_rollout_ref.actor.kl_loss_coef=0.0 \ # KL损失系数设为0
|
| 25 |
+
# 序列级损失聚合模式(GSPO核心)
|
| 26 |
+
actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-mean \ # 序列级平均,GSPO论文推荐
|
| 27 |
+
# 批次配置
|
| 28 |
+
actor_rollout_ref.rollout.n=16 \ # 每个prompt生成16个响应(组采样)
|
| 29 |
+
~~~
|
| 30 |
+
|
| 31 |
+
一般选择入口函数为`verl.trainer.main_ppo`
|
| 32 |
+
|
| 33 |
+
### 性能调优
|
| 34 |
+
|
| 35 |
+
优化从训练、推理、调度和其他四个方面入手。
|
| 36 |
+
|
| 37 |
+
#### 训练
|
| 38 |
+
|
| 39 |
+
##### 动态bsz
|
| 40 |
+
|
| 41 |
+
~~~bash
|
| 42 |
+
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) / sp_size))
|
| 43 |
+
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) / sp_size))
|
| 44 |
+
~~~
|
| 45 |
+
|
| 46 |
+
**这个优化点主要调整上面这两个参数,不过需要注意这两个参数调整的太大会导致OOM**
|
| 47 |
+
|
| 48 |
+
**主要调整**`actor_ppo_max_token_len`,调大了会降低训练的耗时,调整`infer_ppo_max_token_len`没有明显的收益,可以不动
|
| 49 |
+
|
| 50 |
+
**这两个参数的作用介绍如下:**
|
| 51 |
+
|
| 52 |
+
**这两个参数用于控制动态批处理(dynamic batch size)模式下每个GPU处理的最大token数量**
|
| 53 |
+
|
| 54 |
+
- **`actor_ppo_max_token_len`**: Actor模型在PPO更新(前向+反向传播)时每个GPU能处理的最大token数
|
| 55 |
+
- **`infer_ppo_max_token_len`**: 推理阶段(Reference policy和Rollout)计算log概率时每个GPU能处理的最大token数
|
| 56 |
+
|
| 57 |
+
#### 推理
|
| 58 |
+
|
| 59 |
+
##### ACLgraph+FULL_DECODE_ONLY
|
| 60 |
+
|
| 61 |
+
推理算子下发方面的优化,平均能有`15%~20%`左右的性能收益。
|
| 62 |
+
|
| 63 |
+
先看单开**ACLgraph**,如下:
|
| 64 |
+
|
| 65 |
+
~~~bash
|
| 66 |
+
# 开启ACLgraph+FULL_DECODE_ONLY(注意:当设置此参数为False时,TASK_QUEUE_ENABLE必须设置为1,不然会报错)
|
| 67 |
+
actor_rollout_ref.rollout.enforce_eager=False
|
| 68 |
+
actor_rollout_ref.rollout.engine_kwargs.vllm.compilation_config.cudagraph_capture_sizes='[8,16,32,64,128]' \
|
| 69 |
+
actor_rollout_ref.rollout.engine_kwargs.vllm.compilation_config.cudagraph_mode='FULL_DECODE_ONLY' \
|
| 70 |
+
~~~
|
| 71 |
+
|
| 72 |
+
`FULL_DECODE_ONLY`开启成功后有如下输出:
|
| 73 |
+
|
| 74 |
+

|
| 75 |
+
|
| 76 |
+
**`cudagraph_capture_sizes`参数设置指南**
|
| 77 |
+
|
| 78 |
+
cudagraph_capture_sizes设置的值对应的是批大小,这里的批大小不是配置里的DP域对应的那个批次大小,这里是相较于vllm来说的批大小,单位为**token**
|
| 79 |
+
|
| 80 |
+
默认生成的算法如下,可做参考
|
| 81 |
+
|
| 82 |
+

|
| 83 |
+
|
| 84 |
+
##### 推理后端切换
|
| 85 |
+
|
| 86 |
+
使用方式:`export VLLM_ATTENTION_BACKEND=XFORMERS`
|
| 87 |
+
|
| 88 |
+

|
| 89 |
+
|
| 90 |
+
注:需要注意某些后端在一些比较老的vllm-ascend版本内并不支持
|
| 91 |
+
|
| 92 |
+
##### 使能vllm v1版本
|
| 93 |
+
|
| 94 |
+
使用方式:`export VLLM_USE_V1=1`
|
| 95 |
+
|
| 96 |
+
可以常开,一般都是正收益。
|
| 97 |
+
|
| 98 |
+
#### 调度
|
| 99 |
+
|
| 100 |
+
##### AIV
|
| 101 |
+
|
| 102 |
+
打开方式:设置`export HCCL_OP_EXPANSION_MODE="AIV"`
|
| 103 |
+
|
| 104 |
+
HCCL_OP_EXPANSION_MODE环境变量用于配置通信算法的编排展开位置,支持如下取值:
|
| 105 |
+
|
| 106 |
+
- AI_CPU:代表通信算法的编排展开位置在Device侧的AI CPU计算单元。
|
| 107 |
+
- AIV:代表通信算法的编排展开位置在Device侧的Vector Core计算单元。
|
| 108 |
+
- HOST:代表通信算法的编排展开位置为Host侧CPU,Device侧根据硬件型号自动选择相应的调度器。
|
| 109 |
+
- HOST_TS:代表通信算法的编排展开位置为Host侧CPU,Host向Device的Task Scheduler下发任务,Device的Task Scheduler进行任务调度执行。
|
| 110 |
+
|
| 111 |
+
下面介绍两种展开机制
|
| 112 |
+
|
| 113 |
+
###### HOST展开
|
| 114 |
+
|
| 115 |
+
<img src="https://github.com/wucong25/verl-data/blob/main/ascend_task_queue1.png" alt="image-20260113194257095" style="zoom:50%;" />
|
| 116 |
+
|
| 117 |
+
- 软件栈工作在hostcpu,通信算法展开一个个task
|
| 118 |
+
- 每个task调用runtime接口���下发到device的rtsqueue
|
| 119 |
+
- STARS从rstqueue上顺序拿取task
|
| 120 |
+
- 根据task类型分别调用掉SDMA和RDMA引擎。
|
| 121 |
+
**单算子瓶颈**:hostbound 每个task提交是2~5us,一个通信算子有几百个task,单算子场景不会在device上缓存,下发一个执行一个
|
| 122 |
+
|
| 123 |
+
###### AICpu机制展开
|
| 124 |
+
|
| 125 |
+
<img src="https://github.com/wucong25/verl-data/blob/main/ascend_task_queue3.png" alt="image-20260113194333218" style="zoom:50%;" />
|
| 126 |
+
|
| 127 |
+
- host侧不下发一个个task,把通信算子作为一个个kernel,放在通信算子kernel的队列上去。
|
| 128 |
+
- STARS调度kernel队列流上的kernel,把kernel放到AiCPU上去执行。
|
| 129 |
+
- AICPU调用函数(kernel),用一个线程执行kernel 函数,在函数内把通信task展开,把task放到rstqueue上,STARS调用。
|
| 130 |
+
- 降低host和aicpu交互,由几百次降低为一次。
|
| 131 |
+
- task的提交在AICPU上提交,做了提交的部分合并。
|
| 132 |
+
|
| 133 |
+
##### TASK_QUEUE_ENABLE
|
| 134 |
+
|
| 135 |
+
**使用方式:**`export TASK_QUEUE_ENABLE=2`
|
| 136 |
+
|
| 137 |
+
TASK_QUEUE_ENABLE,下发优化,图模式设置为1(即开启图模式的时候这个要设置为1),非图模式设置为2
|
| 138 |
+
|
| 139 |
+
示意图:
|
| 140 |
+
|
| 141 |
+

|
| 142 |
+
|
| 143 |
+
##### 绑核优化
|
| 144 |
+
|
| 145 |
+
**使用方式:**`export CPU_AFFINITY_CONF=1`
|
| 146 |
+
|
| 147 |
+
详细设置原理可看:https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0059.html
|
| 148 |
+
|
| 149 |
+
#### 其他
|
| 150 |
+
|
| 151 |
+
以下内容汇总了若干全局环境变量的调优配置。由于这些参数在训练阶段与推理阶段往往都能带来正向收益,且目前尚缺乏足够精细的消融实验来严格区分它们各自对训练或推理的贡献占比,故统一归拢在此,供后续持续监控与进一步拆解分析。
|
| 152 |
+
|
| 153 |
+
##### 使能jemalloc
|
| 154 |
+
|
| 155 |
+
使用方式(注意需要先安装jemalloc库):`export LD_PRELOAD=/usr/local/lib/libjemalloc.so.2`
|
| 156 |
+
|
| 157 |
+
**安装使用教程:**[MindSpeed-RL/docs/install_guide.md · Ascend/MindSpeed-RL - AtomGit | GitCode](https://gitcode.com/Ascend/MindSpeed-RL/blob/master/docs/install_guide.md#高性能内存库-jemalloc-安装)
|
| 158 |
+
|
| 159 |
+
##### 多流复用
|
| 160 |
+
|
| 161 |
+
内存方面有优化
|
| 162 |
+
|
| 163 |
+
使能方式:`export MULTI_STREAM_MEMORY_REUSE=1`
|
| 164 |
+
|
| 165 |
+
原理介绍:https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0040.html
|
| 166 |
+
|
| 167 |
+
##### VLLM_ASCEND_ENABLE_FLASHCOMM
|
| 168 |
+
|
| 169 |
+
使用方式:`export VLLM_ASCEND_ENABLE_FLASHCOMM=1`
|
| 170 |
+
|
| 171 |
+
启用昇腾 NPU 特有的FLASHCOMM高速通信优化技术
|
| 172 |
+
|
| 173 |
+
地址:https://vllm-ascend.readthedocs.io/zh-cn/latest/user_guide/release_notes.html
|
| 174 |
+
|
| 175 |
+
##### VLLM_ASCEND_ENABLE_DENSE_OPTIMIZE
|
| 176 |
+
|
| 177 |
+
使用方式:`export VLLM_ASCEND_ENABLE_DENSE_OPTIMIZE=1`
|
| 178 |
+
|
| 179 |
+
启用昇腾 NPU针对大模型推理的稠密计算优化
|
| 180 |
+
|
| 181 |
+
地址:https://vllm-ascend.readthedocs.io/zh-cn/latest/user_guide/release_notes.html
|
| 182 |
+
|
| 183 |
+
##### VLLM_ASCEND_ENABLE_PREFETCH_MLP
|
| 184 |
+
|
| 185 |
+
使用方式:`export VLLM_ASCEND_ENABLE_PREFETCH_MLP=1`
|
| 186 |
+
|
| 187 |
+
启用 MLP 层的权重预取机制
|
| 188 |
+
|
| 189 |
+
<img src="https://github.com/wucong25/verl-data/blob/main/ascend_prefetch.png" alt="image-20251124173132677" style="zoom:50%;" />
|
| 190 |
+
|
| 191 |
+
##### verl框架参数设置
|
| 192 |
+
|
| 193 |
+
主要是内存方面的一些设置开关(注意,这个里面的优化都或多或少会导致吞吐量有一定程度的劣化)
|
| 194 |
+
|
| 195 |
+
~~~bash
|
| 196 |
+
# 梯度检查点 (Gradient Checkpointing)
|
| 197 |
+
# 作用: 通过重新计算激活值来节省显存,以计算换内存。在前向传播时不保存中间激活值,反向传播时重新计算,可以显著降低显存占用,允许使用更大的batch size。
|
| 198 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 199 |
+
|
| 200 |
+
# 参数卸载 (Parameter Offload)
|
| 201 |
+
# 作用: 将模型参数卸载到CPU内存,训练时再加载回GPU。
|
| 202 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=${offload} # True
|
| 203 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=${offload} # True
|
| 204 |
+
|
| 205 |
+
# 优化器状态卸载 (Optimizer Offload)
|
| 206 |
+
# 作用: 将优化器状态(如Adam的动量)卸载到CPU。优化器状态通常占用大量显存(对于Adam,每个参数需要额外8字节),卸载可以节省显存。
|
| 207 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} # True
|
| 208 |
+
|
| 209 |
+
# 释放推理引擎缓存 (Free Cache Engine)
|
| 210 |
+
# 作用: 在训练阶段释放推理引擎的KV cache和权重。这是3D-HybridEngine的核心优化,允许在同一GPU上交替进行推理和训练,显著降低显存需求。
|
| 211 |
+
actor_rollout_ref.rollout.free_cache_engine=True
|
| 212 |
+
|
| 213 |
+
# 熵计算优化
|
| 214 |
+
# entropy_checkpointing: 在训练时对熵计算启用重计算,降低显存峰值
|
| 215 |
+
# entropy_from_logits_with_chunking: 分块处理logits张量(如2048 tokens一组),避免一次性加载整个[bsz*seq_len, vocab]张量
|
| 216 |
+
actor_rollout_ref.actor.entropy_checkpointing=True
|
| 217 |
+
actor_rollout_ref.ref.entropy_checkpointing=True
|
| 218 |
+
actor_rollout_ref.actor.entropy_from_logits_with_chunking=True
|
| 219 |
+
actor_rollout_ref.ref.entropy_from_logits_with_chunking=True
|
| 220 |
+
|
| 221 |
+
# 推理引擎显存配置
|
| 222 |
+
# gpu_memory_utilization: 控制vLLM使用的GPU显存比例(0.90 = 90%)
|
| 223 |
+
# enforce_eager=False: 启用CUDA graphs加速推理,但会占用额外显存
|
| 224 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.90
|
| 225 |
+
actor_rollout_ref.rollout.enforce_eager=False
|
| 226 |
+
~~~
|
| 227 |
+
|
| 228 |
+
### NPU调优参考文章
|
| 229 |
+
|
| 230 |
+
环境变量相关:[环境变量列表-Ascend Extension for PyTorch6.0.0-昇腾社区](https://www.hiascend.com/document/detail/zh/Pytorch/600/apiref/Envvariables/Envir_001.html)
|
| 231 |
+
|
| 232 |
+
社区性能调优教程:[性能调优流程-Ascend Extension for PyTorch6.0.0-昇腾社区](https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0001.html)
|
| 233 |
+
|