Spaces:
Build error


Build error
Commit ·
45b200f
0
Parent(s):
Clean state
Browse files- .gitattributes +35 -0
- .gitignore +37 -0
- 1_get_files.ipynb +162 -0
- 2_simplest_approach.ipynb +365 -0
- 3_tools_approach.ipynb +640 -0
- README.md +26 -0
- app.py +249 -0
- draft_1.py +3 -0
- global_functions.py +8 -0
- globals.py +71 -0
- gradio_functions.py +62 -0
- langgraph.png +0 -0
- langgraph_agent.py +194 -0
- requirements.txt +2 -0
- retriever.py +0 -0
- togetherai_chat_example.py +20 -0
- togetherai_pic_generation_example.py +66 -0
- tools.py +179 -0
- workflow_simple.png +0 -0
- workflow_tools.png +0 -0
- x_audio_analysis.ipynb +165 -0
- x_exel_files_loader.ipynb +109 -0
- x_pic_generation.ipynb +92 -0
- x_python_code_executor.ipynb +200 -0
- x_wikipedia.ipynb +90 -0
- x_youtube_loader.ipynb +347 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
__pycache__
|
| 3 |
+
venv
|
| 4 |
+
env
|
| 5 |
+
.env
|
| 6 |
+
.venv
|
| 7 |
+
.pytest_cache
|
| 8 |
+
.coverage
|
| 9 |
+
.idea
|
| 10 |
+
.vscode
|
| 11 |
+
lightning_logs
|
| 12 |
+
.ipynb_checkpoints
|
| 13 |
+
.ckpt
|
| 14 |
+
example.ckpt
|
| 15 |
+
.neptune
|
| 16 |
+
logs_for_plots
|
| 17 |
+
logs_for_heuristics
|
| 18 |
+
logs_for_graphs
|
| 19 |
+
logs_for_freedom_maps
|
| 20 |
+
logs_for_experiments
|
| 21 |
+
heuristic_tables
|
| 22 |
+
stats
|
| 23 |
+
videos
|
| 24 |
+
algs_RL/stasts
|
| 25 |
+
.DS_Store
|
| 26 |
+
saved_replays
|
| 27 |
+
my_folder
|
| 28 |
+
results
|
| 29 |
+
test-trainer
|
| 30 |
+
.gradio
|
| 31 |
+
alfred_chroma_db
|
| 32 |
+
lib
|
| 33 |
+
flow.html
|
| 34 |
+
mlruns
|
| 35 |
+
models_for_proj
|
| 36 |
+
files
|
| 37 |
+
pics
|
1_get_files.ipynb
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {
|
| 5 |
+
"ExecuteTime": {
|
| 6 |
+
"end_time": "2025-06-08T16:23:31.534793Z",
|
| 7 |
+
"start_time": "2025-06-08T16:23:31.531154Z"
|
| 8 |
+
}
|
| 9 |
+
},
|
| 10 |
+
"cell_type": "code",
|
| 11 |
+
"source": [
|
| 12 |
+
"from globals import *\n",
|
| 13 |
+
"DEFAULT_API_URL = \"https://agents-course-unit4-scoring.hf.space\"\n",
|
| 14 |
+
"api_url = DEFAULT_API_URL\n",
|
| 15 |
+
"questions_url = f\"{api_url}/questions\"\n",
|
| 16 |
+
"submit_url = f\"{api_url}/submit\"\n",
|
| 17 |
+
"file_url = f\"{api_url}/files\""
|
| 18 |
+
],
|
| 19 |
+
"id": "f59c08d782ebc6bd",
|
| 20 |
+
"outputs": [],
|
| 21 |
+
"execution_count": 4
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"metadata": {
|
| 25 |
+
"ExecuteTime": {
|
| 26 |
+
"end_time": "2025-06-08T15:07:07.789828Z",
|
| 27 |
+
"start_time": "2025-06-08T15:07:07.098834Z"
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"cell_type": "code",
|
| 31 |
+
"source": [
|
| 32 |
+
"response = requests.get(questions_url, timeout=15)\n",
|
| 33 |
+
"response.raise_for_status()\n",
|
| 34 |
+
"questions_data = response.json()"
|
| 35 |
+
],
|
| 36 |
+
"id": "81985fdf7fcffcc9",
|
| 37 |
+
"outputs": [],
|
| 38 |
+
"execution_count": 2
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"metadata": {
|
| 42 |
+
"ExecuteTime": {
|
| 43 |
+
"end_time": "2025-06-08T16:30:24.102354Z",
|
| 44 |
+
"start_time": "2025-06-08T16:30:24.099451Z"
|
| 45 |
+
}
|
| 46 |
+
},
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"source": [
|
| 49 |
+
"for item_num, item in enumerate(questions_data):\n",
|
| 50 |
+
" # dict_keys(['task_id', 'question', 'Level', 'file_name'])\n",
|
| 51 |
+
" # print(item['question'])\n",
|
| 52 |
+
" if item['file_name'] != '':\n",
|
| 53 |
+
" print(f\"Task {item_num} has file: {item['file_name']}\")\n",
|
| 54 |
+
" # print(f\"The question: \\n {item['question']} \\n\")"
|
| 55 |
+
],
|
| 56 |
+
"id": "28fe3ba72aa61a85",
|
| 57 |
+
"outputs": [
|
| 58 |
+
{
|
| 59 |
+
"name": "stdout",
|
| 60 |
+
"output_type": "stream",
|
| 61 |
+
"text": [
|
| 62 |
+
"Task 3 has file: cca530fc-4052-43b2-b130-b30968d8aa44.png\n",
|
| 63 |
+
"Task 9 has file: 99c9cc74-fdc8-46c6-8f8d-3ce2d3bfeea3.mp3\n",
|
| 64 |
+
"Task 11 has file: f918266a-b3e0-4914-865d-4faa564f1aef.py\n",
|
| 65 |
+
"Task 13 has file: 1f975693-876d-457b-a649-393859e79bf3.mp3\n",
|
| 66 |
+
"Task 18 has file: 7bd855d8-463d-4ed5-93ca-5fe35145f733.xlsx\n"
|
| 67 |
+
]
|
| 68 |
+
}
|
| 69 |
+
],
|
| 70 |
+
"execution_count": 10
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"metadata": {
|
| 74 |
+
"ExecuteTime": {
|
| 75 |
+
"end_time": "2025-06-08T16:38:46.821091Z",
|
| 76 |
+
"start_time": "2025-06-08T16:38:46.143120Z"
|
| 77 |
+
}
|
| 78 |
+
},
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"source": [
|
| 81 |
+
"# dict_keys(['task_id', 'question', 'Level', 'file_name'])\n",
|
| 82 |
+
"item_num = 18\n",
|
| 83 |
+
"item = questions_data[item_num]\n",
|
| 84 |
+
"print('---')\n",
|
| 85 |
+
"print(f\"{item['task_id']}\")\n",
|
| 86 |
+
"print(f\"Task {item_num} has file: {item['file_name']}\")\n",
|
| 87 |
+
"\n",
|
| 88 |
+
"response = requests.get(f\"{file_url}/{item['task_id']}\", timeout=15)\n",
|
| 89 |
+
"response.raise_for_status()\n",
|
| 90 |
+
"file_data = response.url\n",
|
| 91 |
+
"print(file_data)\n",
|
| 92 |
+
"print('---')"
|
| 93 |
+
],
|
| 94 |
+
"id": "829cb65e4c515908",
|
| 95 |
+
"outputs": [
|
| 96 |
+
{
|
| 97 |
+
"name": "stdout",
|
| 98 |
+
"output_type": "stream",
|
| 99 |
+
"text": [
|
| 100 |
+
"---\n",
|
| 101 |
+
"7bd855d8-463d-4ed5-93ca-5fe35145f733\n",
|
| 102 |
+
"Task 18 has file: 7bd855d8-463d-4ed5-93ca-5fe35145f733.xlsx\n",
|
| 103 |
+
"https://agents-course-unit4-scoring.hf.space/files/7bd855d8-463d-4ed5-93ca-5fe35145f733\n",
|
| 104 |
+
"---\n"
|
| 105 |
+
]
|
| 106 |
+
}
|
| 107 |
+
],
|
| 108 |
+
"execution_count": 14
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"metadata": {
|
| 112 |
+
"ExecuteTime": {
|
| 113 |
+
"end_time": "2025-06-08T16:29:01.814363Z",
|
| 114 |
+
"start_time": "2025-06-08T16:29:01.811569Z"
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"cell_type": "code",
|
| 118 |
+
"source": "\n",
|
| 119 |
+
"id": "6108349553a14924",
|
| 120 |
+
"outputs": [
|
| 121 |
+
{
|
| 122 |
+
"name": "stdout",
|
| 123 |
+
"output_type": "stream",
|
| 124 |
+
"text": [
|
| 125 |
+
"https://agents-course-unit4-scoring.hf.space/files/cca530fc-4052-43b2-b130-b30968d8aa44\n",
|
| 126 |
+
"---\n"
|
| 127 |
+
]
|
| 128 |
+
}
|
| 129 |
+
],
|
| 130 |
+
"execution_count": 9
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"metadata": {},
|
| 134 |
+
"cell_type": "code",
|
| 135 |
+
"outputs": [],
|
| 136 |
+
"execution_count": null,
|
| 137 |
+
"source": "",
|
| 138 |
+
"id": "f3cca13bc30bca7b"
|
| 139 |
+
}
|
| 140 |
+
],
|
| 141 |
+
"metadata": {
|
| 142 |
+
"kernelspec": {
|
| 143 |
+
"display_name": "Python 3",
|
| 144 |
+
"language": "python",
|
| 145 |
+
"name": "python3"
|
| 146 |
+
},
|
| 147 |
+
"language_info": {
|
| 148 |
+
"codemirror_mode": {
|
| 149 |
+
"name": "ipython",
|
| 150 |
+
"version": 2
|
| 151 |
+
},
|
| 152 |
+
"file_extension": ".py",
|
| 153 |
+
"mimetype": "text/x-python",
|
| 154 |
+
"name": "python",
|
| 155 |
+
"nbconvert_exporter": "python",
|
| 156 |
+
"pygments_lexer": "ipython2",
|
| 157 |
+
"version": "2.7.6"
|
| 158 |
+
}
|
| 159 |
+
},
|
| 160 |
+
"nbformat": 4,
|
| 161 |
+
"nbformat_minor": 5
|
| 162 |
+
}
|
2_simplest_approach.ipynb
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"source": "Preparations",
|
| 7 |
+
"id": "85e57249794e16a7"
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
"cell_type": "code",
|
| 11 |
+
"id": "initial_id",
|
| 12 |
+
"metadata": {
|
| 13 |
+
"collapsed": true,
|
| 14 |
+
"ExecuteTime": {
|
| 15 |
+
"end_time": "2025-06-08T16:21:51.896485Z",
|
| 16 |
+
"start_time": "2025-06-08T16:21:51.893462Z"
|
| 17 |
+
}
|
| 18 |
+
},
|
| 19 |
+
"source": [
|
| 20 |
+
"from globals import *\n",
|
| 21 |
+
"DEFAULT_API_URL = \"https://agents-course-unit4-scoring.hf.space\"\n",
|
| 22 |
+
"api_url = DEFAULT_API_URL\n",
|
| 23 |
+
"questions_url = f\"{api_url}/questions\"\n",
|
| 24 |
+
"submit_url = f\"{api_url}/submit\"\n",
|
| 25 |
+
"file_url = f\"{api_url}/files\""
|
| 26 |
+
],
|
| 27 |
+
"outputs": [],
|
| 28 |
+
"execution_count": 32
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"metadata": {
|
| 32 |
+
"ExecuteTime": {
|
| 33 |
+
"end_time": "2025-06-07T14:46:28.498789Z",
|
| 34 |
+
"start_time": "2025-06-07T14:46:27.794622Z"
|
| 35 |
+
}
|
| 36 |
+
},
|
| 37 |
+
"cell_type": "code",
|
| 38 |
+
"source": [
|
| 39 |
+
"# get questions\n",
|
| 40 |
+
"response = requests.get(questions_url, timeout=15)\n",
|
| 41 |
+
"response.raise_for_status()\n",
|
| 42 |
+
"questions_data = response.json()"
|
| 43 |
+
],
|
| 44 |
+
"id": "2fc7ef4f0959246b",
|
| 45 |
+
"outputs": [],
|
| 46 |
+
"execution_count": 28
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"metadata": {
|
| 50 |
+
"ExecuteTime": {
|
| 51 |
+
"end_time": "2025-06-08T16:49:29.230136Z",
|
| 52 |
+
"start_time": "2025-06-08T16:49:29.227812Z"
|
| 53 |
+
}
|
| 54 |
+
},
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"source": [
|
| 57 |
+
"for item_num, item in enumerate(questions_data):\n",
|
| 58 |
+
" # dict_keys(['task_id', 'question', 'Level', 'file_name'])\n",
|
| 59 |
+
" # print(item['question'])\n",
|
| 60 |
+
" # print('---')\n",
|
| 61 |
+
" # print(f\"{item['task_id']}\")\n",
|
| 62 |
+
" print(f\"Task {item_num} has file: {item['file_name']}\")\n",
|
| 63 |
+
" # print(f\"The question: \\n {item['question']} \\n\")"
|
| 64 |
+
],
|
| 65 |
+
"id": "8a00fe57d4ec29bb",
|
| 66 |
+
"outputs": [
|
| 67 |
+
{
|
| 68 |
+
"name": "stdout",
|
| 69 |
+
"output_type": "stream",
|
| 70 |
+
"text": [
|
| 71 |
+
"Task 0 has file: \n",
|
| 72 |
+
"Task 1 has file: \n",
|
| 73 |
+
"Task 2 has file: \n",
|
| 74 |
+
"Task 3 has file: cca530fc-4052-43b2-b130-b30968d8aa44.png\n",
|
| 75 |
+
"Task 4 has file: \n",
|
| 76 |
+
"Task 5 has file: \n",
|
| 77 |
+
"Task 6 has file: \n",
|
| 78 |
+
"Task 7 has file: \n",
|
| 79 |
+
"Task 8 has file: \n",
|
| 80 |
+
"Task 9 has file: 99c9cc74-fdc8-46c6-8f8d-3ce2d3bfeea3.mp3\n",
|
| 81 |
+
"Task 10 has file: \n",
|
| 82 |
+
"Task 11 has file: f918266a-b3e0-4914-865d-4faa564f1aef.py\n",
|
| 83 |
+
"Task 12 has file: \n",
|
| 84 |
+
"Task 13 has file: 1f975693-876d-457b-a649-393859e79bf3.mp3\n",
|
| 85 |
+
"Task 14 has file: \n",
|
| 86 |
+
"Task 15 has file: \n",
|
| 87 |
+
"Task 16 has file: \n",
|
| 88 |
+
"Task 17 has file: \n",
|
| 89 |
+
"Task 18 has file: 7bd855d8-463d-4ed5-93ca-5fe35145f733.xlsx\n",
|
| 90 |
+
"Task 19 has file: \n"
|
| 91 |
+
]
|
| 92 |
+
}
|
| 93 |
+
],
|
| 94 |
+
"execution_count": 38
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"metadata": {
|
| 98 |
+
"ExecuteTime": {
|
| 99 |
+
"end_time": "2025-06-04T18:23:01.054690Z",
|
| 100 |
+
"start_time": "2025-06-04T18:22:59.280217Z"
|
| 101 |
+
}
|
| 102 |
+
},
|
| 103 |
+
"cell_type": "code",
|
| 104 |
+
"source": [
|
| 105 |
+
"train_dataset = load_dataset(\"gaia-benchmark/GAIA\", '2023_level1', split=\"validation\")\n",
|
| 106 |
+
"len(train_dataset)"
|
| 107 |
+
],
|
| 108 |
+
"id": "d6216c8b17766ad8",
|
| 109 |
+
"outputs": [
|
| 110 |
+
{
|
| 111 |
+
"data": {
|
| 112 |
+
"text/plain": [
|
| 113 |
+
"53"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
"execution_count": 22,
|
| 117 |
+
"metadata": {},
|
| 118 |
+
"output_type": "execute_result"
|
| 119 |
+
}
|
| 120 |
+
],
|
| 121 |
+
"execution_count": 22
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"metadata": {
|
| 125 |
+
"ExecuteTime": {
|
| 126 |
+
"end_time": "2025-06-04T18:24:32.847570Z",
|
| 127 |
+
"start_time": "2025-06-04T18:24:32.844925Z"
|
| 128 |
+
}
|
| 129 |
+
},
|
| 130 |
+
"cell_type": "code",
|
| 131 |
+
"source": [
|
| 132 |
+
"print(train_dataset[0].keys())\n",
|
| 133 |
+
"item_0 = train_dataset[0]\n",
|
| 134 |
+
"# for item in train_dataset:\n",
|
| 135 |
+
"# print(item)"
|
| 136 |
+
],
|
| 137 |
+
"id": "ace71ed85c088f6e",
|
| 138 |
+
"outputs": [
|
| 139 |
+
{
|
| 140 |
+
"name": "stdout",
|
| 141 |
+
"output_type": "stream",
|
| 142 |
+
"text": [
|
| 143 |
+
"dict_keys(['task_id', 'Question', 'Level', 'Final answer', 'file_name', 'file_path', 'Annotator Metadata'])\n"
|
| 144 |
+
]
|
| 145 |
+
}
|
| 146 |
+
],
|
| 147 |
+
"execution_count": 25
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"cell_type": "markdown",
|
| 152 |
+
"source": "Simplest approach - just ask LLM",
|
| 153 |
+
"id": "81dbae05a73009a4"
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"metadata": {
|
| 157 |
+
"ExecuteTime": {
|
| 158 |
+
"end_time": "2025-06-06T17:02:03.029164Z",
|
| 159 |
+
"start_time": "2025-06-06T17:02:02.986724Z"
|
| 160 |
+
}
|
| 161 |
+
},
|
| 162 |
+
"cell_type": "code",
|
| 163 |
+
"source": [
|
| 164 |
+
"from globals import *\n",
|
| 165 |
+
"from tools import *\n",
|
| 166 |
+
"\n",
|
| 167 |
+
"# ------------------------------------------------------ #\n",
|
| 168 |
+
"# MODELS & TOOLS\n",
|
| 169 |
+
"# ------------------------------------------------------ #\n",
|
| 170 |
+
"chat_llm = ChatTogether(model=\"meta-llama/Llama-3.3-70B-Instruct-Turbo-Free\", api_key=os.getenv(\"TOGETHER_API_KEY\"))\n",
|
| 171 |
+
"\n",
|
| 172 |
+
"# ------------------------------------------------------ #\n",
|
| 173 |
+
"# STATE\n",
|
| 174 |
+
"# ------------------------------------------------------ #\n",
|
| 175 |
+
"class AgentState(TypedDict):\n",
|
| 176 |
+
" # messages: list[AnyMessage, add_messages]\n",
|
| 177 |
+
" messages: list[AnyMessage]\n",
|
| 178 |
+
" # final_output_is_good: bool\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"# ------------------------------------------------------ #\n",
|
| 181 |
+
"# HELP FUNCTIONS\n",
|
| 182 |
+
"# ------------------------------------------------------ #\n",
|
| 183 |
+
"def step_print(state: AgentState, step_label: str):\n",
|
| 184 |
+
" print(f'<<--- [{len(state[\"messages\"])}] Starting {step_label}... --->>')\n",
|
| 185 |
+
"\n",
|
| 186 |
+
"def messages_print(messages_to_print: List[AnyMessage]):\n",
|
| 187 |
+
" print('--- Message/s ---')\n",
|
| 188 |
+
" for m in messages_to_print:\n",
|
| 189 |
+
" print(f'{m.type} ({m.name}): \\n{m.content}')\n",
|
| 190 |
+
" print(f'<<--- *** --->>')\n",
|
| 191 |
+
"\n",
|
| 192 |
+
"# ------------------------------------------------------ #\n",
|
| 193 |
+
"# NODES\n",
|
| 194 |
+
"# ------------------------------------------------------ #\n",
|
| 195 |
+
"def preprocessing(state: AgentState):\n",
|
| 196 |
+
" step_print(state, 'Preprocessing')\n",
|
| 197 |
+
" messages_print(state['messages'][-1:])\n",
|
| 198 |
+
" return {\n",
|
| 199 |
+
" \"messages\": [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state[\"messages\"]\n",
|
| 200 |
+
" }\n",
|
| 201 |
+
"\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"def assistant(state: AgentState):\n",
|
| 204 |
+
" # state[\"messages\"] = [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state[\"messages\"]\n",
|
| 205 |
+
" step_print(state, 'assistant')\n",
|
| 206 |
+
" ai_message = chat_llm.invoke(state[\"messages\"])\n",
|
| 207 |
+
" messages_print([ai_message])\n",
|
| 208 |
+
" return {\n",
|
| 209 |
+
" 'messages': state[\"messages\"] + [ai_message]\n",
|
| 210 |
+
" }\n",
|
| 211 |
+
"\n",
|
| 212 |
+
"\n",
|
| 213 |
+
"base_tool_node = ToolNode(tools)\n",
|
| 214 |
+
"def wrapped_tool_node(state: AgentState):\n",
|
| 215 |
+
" step_print(state, 'Tools')\n",
|
| 216 |
+
" # Call the original ToolNode\n",
|
| 217 |
+
" result = base_tool_node.invoke(state)\n",
|
| 218 |
+
" messages_print(result[\"messages\"])\n",
|
| 219 |
+
" # Append to the messages list instead of replacing it\n",
|
| 220 |
+
" state[\"messages\"] += result[\"messages\"]\n",
|
| 221 |
+
" return {\"messages\": state[\"messages\"]}\n",
|
| 222 |
+
"\n",
|
| 223 |
+
"\n",
|
| 224 |
+
"# ------------------------------------------------------ #\n",
|
| 225 |
+
"# CONDITIONAL FUNCTIONS\n",
|
| 226 |
+
"# ------------------------------------------------------ #\n",
|
| 227 |
+
"def condition_tools_or_continue(\n",
|
| 228 |
+
" state: Union[list[AnyMessage], dict[str, Any], BaseModel],\n",
|
| 229 |
+
" messages_key: str = \"messages\",\n",
|
| 230 |
+
") -> Literal[\"tools\", \"__end__\"]:\n",
|
| 231 |
+
"\n",
|
| 232 |
+
" if isinstance(state, list):\n",
|
| 233 |
+
" ai_message = state[-1]\n",
|
| 234 |
+
" elif isinstance(state, dict) and (messages := state.get(messages_key, [])):\n",
|
| 235 |
+
" ai_message = messages[-1]\n",
|
| 236 |
+
" elif messages := getattr(state, messages_key, []):\n",
|
| 237 |
+
" ai_message = messages[-1]\n",
|
| 238 |
+
" else:\n",
|
| 239 |
+
" raise ValueError(f\"No messages found in input state to tool_edge: {state}\")\n",
|
| 240 |
+
" if hasattr(ai_message, \"tool_calls\") and len(ai_message.tool_calls) > 0:\n",
|
| 241 |
+
" return \"tools\"\n",
|
| 242 |
+
" # return \"checker_final_answer\"\n",
|
| 243 |
+
" return \"__end__\"\n",
|
| 244 |
+
"\n",
|
| 245 |
+
"\n",
|
| 246 |
+
"# ------------------------------------------------------ #\n",
|
| 247 |
+
"# BUILDERS\n",
|
| 248 |
+
"# ------------------------------------------------------ #\n",
|
| 249 |
+
"def workflow_simple() -> Tuple[StateGraph, str]:\n",
|
| 250 |
+
" i_builder = StateGraph(AgentState)\n",
|
| 251 |
+
" # Nodes\n",
|
| 252 |
+
" i_builder.add_node('preprocessing', preprocessing)\n",
|
| 253 |
+
" i_builder.add_node('assistant', assistant)\n",
|
| 254 |
+
"\n",
|
| 255 |
+
" # Edges\n",
|
| 256 |
+
" i_builder.add_edge(START, 'preprocessing')\n",
|
| 257 |
+
" i_builder.add_edge('preprocessing', 'assistant')\n",
|
| 258 |
+
" return i_builder, 'workflow_simple'\n",
|
| 259 |
+
"\n",
|
| 260 |
+
"\n",
|
| 261 |
+
"# ------------------------------------------------------ #\n",
|
| 262 |
+
"# COMPILATION\n",
|
| 263 |
+
"# ------------------------------------------------------ #\n",
|
| 264 |
+
"builder, builder_name = workflow_simple()\n",
|
| 265 |
+
"alfred = builder.compile()"
|
| 266 |
+
],
|
| 267 |
+
"id": "9dda3c180ddb1cf6",
|
| 268 |
+
"outputs": [],
|
| 269 |
+
"execution_count": 9
|
| 270 |
+
},
|
| 271 |
+
{
|
| 272 |
+
"metadata": {
|
| 273 |
+
"ExecuteTime": {
|
| 274 |
+
"end_time": "2025-06-06T17:02:14.364108Z",
|
| 275 |
+
"start_time": "2025-06-06T17:02:04.962236Z"
|
| 276 |
+
}
|
| 277 |
+
},
|
| 278 |
+
"cell_type": "code",
|
| 279 |
+
"source": "response = alfred.invoke({'messages': [HumanMessage(content=\"If Eliud Kipchoge could maintain his record-making marathon pace indefinitely, how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach? Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation. Round your result to the nearest 1000 hours and do not use any comma separators if necessary.\")]})",
|
| 280 |
+
"id": "817c59e55d4ccd37",
|
| 281 |
+
"outputs": [
|
| 282 |
+
{
|
| 283 |
+
"name": "stdout",
|
| 284 |
+
"output_type": "stream",
|
| 285 |
+
"text": [
|
| 286 |
+
"<<--- [1] Starting Preprocessing... --->>\n",
|
| 287 |
+
"--- Message/s ---\n",
|
| 288 |
+
"human (None): \n",
|
| 289 |
+
"If Eliud Kipchoge could maintain his record-making marathon pace indefinitely, how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach? Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation. Round your result to the nearest 1000 hours and do not use any comma separators if necessary.\n",
|
| 290 |
+
"<<--- *** --->>\n",
|
| 291 |
+
"<<--- [2] Starting assistant... --->>\n",
|
| 292 |
+
"--- Message/s ---\n",
|
| 293 |
+
"ai (None): \n",
|
| 294 |
+
"To calculate the time it would take Eliud Kipchoge to run from the Earth to the Moon at its closest approach, we first need to find out the distance between the Earth and the Moon at its closest approach and Eliud Kipchoge's speed.\n",
|
| 295 |
+
"\n",
|
| 296 |
+
"The minimum perigee value for the Moon, according to Wikipedia, is approximately 356400 kilometers.\n",
|
| 297 |
+
"\n",
|
| 298 |
+
"Eliud Kipchoge's record-making marathon pace is 2:01:39 hours for 42.195 kilometers. To find his speed in kilometers per hour, we divide the distance by the time. \n",
|
| 299 |
+
"\n",
|
| 300 |
+
"First, convert 2:01:39 hours to just hours: 2 + (1/60) + (39/3600) = 2 + 0.0167 + 0.0108 = 2.0275 hours.\n",
|
| 301 |
+
"\n",
|
| 302 |
+
"Now, calculate his speed: 42.195 km / 2.0275 hours = 20.818 km/h.\n",
|
| 303 |
+
"\n",
|
| 304 |
+
"Now, calculate the time it would take to run 356400 km at this speed: 356400 km / 20.818 km/h = 17127 hours.\n",
|
| 305 |
+
"\n",
|
| 306 |
+
"To convert this to thousand hours, divide by 1000: 17127 / 1000 = 17.127.\n",
|
| 307 |
+
"\n",
|
| 308 |
+
"Rounded to the nearest 1000 hours, this is 17 thousand hours, but since the answer should not use comma separators or units, and should be rounded to the nearest 1000, we get 17000.\n",
|
| 309 |
+
"\n",
|
| 310 |
+
"FINAL ANSWER: 17000\n",
|
| 311 |
+
"<<--- *** --->>\n"
|
| 312 |
+
]
|
| 313 |
+
}
|
| 314 |
+
],
|
| 315 |
+
"execution_count": 10
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"metadata": {
|
| 319 |
+
"ExecuteTime": {
|
| 320 |
+
"end_time": "2025-06-06T16:58:44.774532Z",
|
| 321 |
+
"start_time": "2025-06-06T16:58:42.601012Z"
|
| 322 |
+
}
|
| 323 |
+
},
|
| 324 |
+
"cell_type": "code",
|
| 325 |
+
"source": "response1 = chat_llm.invoke([SystemMessage(content=DEFAULT_SYSTEM_PROMPT), HumanMessage(content=\"If Eliud Kipchoge could maintain his record-making marathon pace indefinitely, how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach? Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation. Round your result to the nearest 1000 hours and do not use any comma separators if necessary.\")])",
|
| 326 |
+
"id": "ef5b5fafeaff660b",
|
| 327 |
+
"outputs": [],
|
| 328 |
+
"execution_count": 6
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"metadata": {
|
| 332 |
+
"ExecuteTime": {
|
| 333 |
+
"end_time": "2025-06-06T16:59:57.792887Z",
|
| 334 |
+
"start_time": "2025-06-06T16:59:55.855377Z"
|
| 335 |
+
}
|
| 336 |
+
},
|
| 337 |
+
"cell_type": "code",
|
| 338 |
+
"source": "response2 = chat_llm.invoke([SystemMessage(content=DEFAULT_SYSTEM_PROMPT), HumanMessage(content=\"If Eliud Kipchoge could maintain his record-making marathon pace indefinitely, how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach? Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation. Round your result to the nearest 1000 hours and do not use any comma separators if necessary.\"), response1])",
|
| 339 |
+
"id": "7462e130d047c1be",
|
| 340 |
+
"outputs": [],
|
| 341 |
+
"execution_count": 8
|
| 342 |
+
}
|
| 343 |
+
],
|
| 344 |
+
"metadata": {
|
| 345 |
+
"kernelspec": {
|
| 346 |
+
"display_name": "Python 3",
|
| 347 |
+
"language": "python",
|
| 348 |
+
"name": "python3"
|
| 349 |
+
},
|
| 350 |
+
"language_info": {
|
| 351 |
+
"codemirror_mode": {
|
| 352 |
+
"name": "ipython",
|
| 353 |
+
"version": 2
|
| 354 |
+
},
|
| 355 |
+
"file_extension": ".py",
|
| 356 |
+
"mimetype": "text/x-python",
|
| 357 |
+
"name": "python",
|
| 358 |
+
"nbconvert_exporter": "python",
|
| 359 |
+
"pygments_lexer": "ipython2",
|
| 360 |
+
"version": "2.7.6"
|
| 361 |
+
}
|
| 362 |
+
},
|
| 363 |
+
"nbformat": 4,
|
| 364 |
+
"nbformat_minor": 5
|
| 365 |
+
}
|
3_tools_approach.ipynb
ADDED
|
@@ -0,0 +1,640 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"source": "Preps",
|
| 7 |
+
"id": "39fa029d099d9f52"
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
"metadata": {
|
| 11 |
+
"ExecuteTime": {
|
| 12 |
+
"end_time": "2025-06-10T20:50:31.142189Z",
|
| 13 |
+
"start_time": "2025-06-10T20:50:31.139103Z"
|
| 14 |
+
}
|
| 15 |
+
},
|
| 16 |
+
"cell_type": "code",
|
| 17 |
+
"source": "from tools import describe_audio_tool",
|
| 18 |
+
"id": "a8592566121f9a22",
|
| 19 |
+
"outputs": [],
|
| 20 |
+
"execution_count": 87
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"id": "initial_id",
|
| 25 |
+
"metadata": {
|
| 26 |
+
"collapsed": true,
|
| 27 |
+
"ExecuteTime": {
|
| 28 |
+
"end_time": "2025-06-10T20:50:31.155454Z",
|
| 29 |
+
"start_time": "2025-06-10T20:50:31.152566Z"
|
| 30 |
+
}
|
| 31 |
+
},
|
| 32 |
+
"source": [
|
| 33 |
+
"from globals import *\n",
|
| 34 |
+
"from global_functions import *\n",
|
| 35 |
+
"from tools import *\n",
|
| 36 |
+
"from IPython.display import Image, display\n",
|
| 37 |
+
"import datasets\n",
|
| 38 |
+
"import base64\n",
|
| 39 |
+
"from langchain_core.messages import AnyMessage, HumanMessage, AIMessage, SystemMessage, ToolMessage\n",
|
| 40 |
+
"# describe_image_tool\n",
|
| 41 |
+
"import subprocess\n",
|
| 42 |
+
"from langchain_community.document_loaders import UnstructuredExcelLoader\n",
|
| 43 |
+
"import yt_dlp\n",
|
| 44 |
+
"from langchain_community.tools import WikipediaQueryRun\n",
|
| 45 |
+
"from langchain_community.utilities import WikipediaAPIWrapper"
|
| 46 |
+
],
|
| 47 |
+
"outputs": [],
|
| 48 |
+
"execution_count": 88
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"metadata": {
|
| 52 |
+
"ExecuteTime": {
|
| 53 |
+
"end_time": "2025-06-10T20:50:31.198378Z",
|
| 54 |
+
"start_time": "2025-06-10T20:50:31.165368Z"
|
| 55 |
+
}
|
| 56 |
+
},
|
| 57 |
+
"cell_type": "code",
|
| 58 |
+
"source": [
|
| 59 |
+
"# ------------------------------------------------------ #\n",
|
| 60 |
+
"# MODELS\n",
|
| 61 |
+
"# ------------------------------------------------------ #\n",
|
| 62 |
+
"# init_chat_llm = ChatOllama(model=model_name)\n",
|
| 63 |
+
"init_chat_llm = ChatTogether(model=\"meta-llama/Llama-3.3-70B-Instruct-Turbo-Free\", api_key=os.getenv(\"TOGETHER_API_KEY\"))\n"
|
| 64 |
+
],
|
| 65 |
+
"id": "de15a3991553b118",
|
| 66 |
+
"outputs": [],
|
| 67 |
+
"execution_count": 89
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"metadata": {
|
| 71 |
+
"ExecuteTime": {
|
| 72 |
+
"end_time": "2025-06-10T20:50:31.208604Z",
|
| 73 |
+
"start_time": "2025-06-10T20:50:31.206116Z"
|
| 74 |
+
}
|
| 75 |
+
},
|
| 76 |
+
"cell_type": "code",
|
| 77 |
+
"source": [
|
| 78 |
+
"# ------------------------------------------------------ #\n",
|
| 79 |
+
"# FUNCTIONS FOR TOOLS\n",
|
| 80 |
+
"# ------------------------------------------------------ #\n",
|
| 81 |
+
"def read_mp3(f, normalized=False):\n",
|
| 82 |
+
" \"\"\"Read MP3 file to numpy array.\"\"\"\n",
|
| 83 |
+
" a = pydub.AudioSegment.from_mp3(f)\n",
|
| 84 |
+
" y = np.array(a.get_array_of_samples())\n",
|
| 85 |
+
" if a.channels == 2:\n",
|
| 86 |
+
" y = y.reshape((-1, 2))\n",
|
| 87 |
+
" # y = y.mean(axis=1)\n",
|
| 88 |
+
" y = y[:,1]\n",
|
| 89 |
+
" if normalized:\n",
|
| 90 |
+
" return a.frame_rate, np.float32(y) / 2**15\n",
|
| 91 |
+
" else:\n",
|
| 92 |
+
" return a.frame_rate, y"
|
| 93 |
+
],
|
| 94 |
+
"id": "6db4dcdc5746ff14",
|
| 95 |
+
"outputs": [],
|
| 96 |
+
"execution_count": 90
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"metadata": {
|
| 100 |
+
"ExecuteTime": {
|
| 101 |
+
"end_time": "2025-06-10T20:50:31.222129Z",
|
| 102 |
+
"start_time": "2025-06-10T20:50:31.217718Z"
|
| 103 |
+
}
|
| 104 |
+
},
|
| 105 |
+
"cell_type": "code",
|
| 106 |
+
"source": [
|
| 107 |
+
"# ------------------------------------------------------ #\n",
|
| 108 |
+
"# TOOLS\n",
|
| 109 |
+
"# ------------------------------------------------------ #\n",
|
| 110 |
+
"# mp3\n",
|
| 111 |
+
"def describe_audio_tool(file_name: str) -> str:\n",
|
| 112 |
+
" \"\"\"\n",
|
| 113 |
+
" This tool receives a file name of an audio, uploads the audio and returns a detailed description of the audio.\n",
|
| 114 |
+
" Inputs: file_name as str\n",
|
| 115 |
+
" Outputs: audio detailed description as str\n",
|
| 116 |
+
" \"\"\"\n",
|
| 117 |
+
" # --------------------------------------------------------------------------- #\n",
|
| 118 |
+
" file_dir = f'files/{file_name}'\n",
|
| 119 |
+
" print(f\"{file_dir=}\")\n",
|
| 120 |
+
" audio_input_sr, audio_input_np = read_mp3(file_dir)\n",
|
| 121 |
+
" audio_input_t = torch.tensor(audio_input_np, dtype=torch.float32)\n",
|
| 122 |
+
" target_sr = 16000\n",
|
| 123 |
+
" resampler = T.Resample(audio_input_sr, target_sr, dtype=audio_input_t.dtype)\n",
|
| 124 |
+
" resampled_audio_input_t: torch.Tensor = resampler(audio_input_t)\n",
|
| 125 |
+
" resampled_audio_input_np = resampled_audio_input_t.numpy()\n",
|
| 126 |
+
" # --------------------------------------------------------------------------- #\n",
|
| 127 |
+
" inputs = processor(resampled_audio_input_np, sampling_rate=16000, return_tensors=\"pt\", padding=True)\n",
|
| 128 |
+
" # Inference\n",
|
| 129 |
+
" with torch.no_grad():\n",
|
| 130 |
+
" logits = model(**inputs).logits\n",
|
| 131 |
+
" # Decode\n",
|
| 132 |
+
" predicted_ids = torch.argmax(logits, dim=-1)\n",
|
| 133 |
+
" transcription = processor.decode(predicted_ids[0])\n",
|
| 134 |
+
" return transcription\n",
|
| 135 |
+
"\n",
|
| 136 |
+
"# py\n",
|
| 137 |
+
"def python_repl_tool(file_name: str) -> str:\n",
|
| 138 |
+
" \"\"\"\n",
|
| 139 |
+
" This tool receives a file name of a python code and executes it. Then, it returns a an output of the code.\n",
|
| 140 |
+
" Inputs: file_name as str\n",
|
| 141 |
+
" Outputs: code's output as str\n",
|
| 142 |
+
" \"\"\"\n",
|
| 143 |
+
" file_dir = f'files/{file_name}'\n",
|
| 144 |
+
" print(f\"{file_dir=}\")\n",
|
| 145 |
+
" result = subprocess.run([\"python\", file_dir], capture_output=True, text=True)\n",
|
| 146 |
+
" return result.stdout\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"# xlsx\n",
|
| 149 |
+
"def excel_repl_tool(file_name: str) -> str:\n",
|
| 150 |
+
" \"\"\"\n",
|
| 151 |
+
" This tool receives a file name of an Excel file and reads it. Then, it returns a string of the content of the file.\n",
|
| 152 |
+
" Inputs: file_name as str\n",
|
| 153 |
+
" Outputs: file's content as str\n",
|
| 154 |
+
" \"\"\"\n",
|
| 155 |
+
" file_dir = f'files/{file_name}'\n",
|
| 156 |
+
" print(f\"{file_dir=}\")\n",
|
| 157 |
+
" loader = UnstructuredExcelLoader(file_dir, mode=\"elements\")\n",
|
| 158 |
+
" docs = loader.load()\n",
|
| 159 |
+
" return docs[0].metadata['text_as_html']\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"\n",
|
| 162 |
+
"# youtube\n",
|
| 163 |
+
"def youtube_extractor_tool(url: str) -> str:\n",
|
| 164 |
+
" \"\"\"\n",
|
| 165 |
+
" This tool receives a url of the youtube video and reads it. Then, it returns a string of the content of the video.\n",
|
| 166 |
+
" Inputs: url as str\n",
|
| 167 |
+
" Outputs: video's content as str\n",
|
| 168 |
+
" \"\"\"\n",
|
| 169 |
+
" file_name = 'my_audio_file'\n",
|
| 170 |
+
" ydl_opts = {\n",
|
| 171 |
+
" 'format': 'bestaudio/best',\n",
|
| 172 |
+
" 'outtmpl': f'files/{file_name}.%(ext)s', # <-- set your custom filename here\n",
|
| 173 |
+
" 'postprocessors': [{\n",
|
| 174 |
+
" 'key': 'FFmpegExtractAudio',\n",
|
| 175 |
+
" 'preferredcodec': 'mp3',\n",
|
| 176 |
+
" 'preferredquality': '192',\n",
|
| 177 |
+
" }],\n",
|
| 178 |
+
" }\n",
|
| 179 |
+
"\n",
|
| 180 |
+
" with yt_dlp.YoutubeDL(ydl_opts) as ydl:\n",
|
| 181 |
+
" ydl.download([url])\n",
|
| 182 |
+
" return describe_audio_tool(file_name=f'{file_name}.mp3')\n",
|
| 183 |
+
"\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"# wiki\n",
|
| 186 |
+
"def wikipedia_tool(query: str) -> str:\n",
|
| 187 |
+
" \"\"\"\n",
|
| 188 |
+
" This tool receives a query to search inside the Wikipedia website, reads the page and returns the relevant information as a string.\n",
|
| 189 |
+
" Inputs: query as str\n",
|
| 190 |
+
" Outputs: Wikipedia's relevant content as str\n",
|
| 191 |
+
" \"\"\"\n",
|
| 192 |
+
" print(f\"[wiki tool] {query=}\")\n",
|
| 193 |
+
" wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())\n",
|
| 194 |
+
" respond = wikipedia.run(query)\n",
|
| 195 |
+
" return respond"
|
| 196 |
+
],
|
| 197 |
+
"id": "259492d051c8ae57",
|
| 198 |
+
"outputs": [],
|
| 199 |
+
"execution_count": 91
|
| 200 |
+
},
|
| 201 |
+
{
|
| 202 |
+
"metadata": {
|
| 203 |
+
"ExecuteTime": {
|
| 204 |
+
"end_time": "2025-06-10T20:50:31.239565Z",
|
| 205 |
+
"start_time": "2025-06-10T20:50:31.230235Z"
|
| 206 |
+
}
|
| 207 |
+
},
|
| 208 |
+
"cell_type": "code",
|
| 209 |
+
"source": [
|
| 210 |
+
"# ------------------------------------------------------ #\n",
|
| 211 |
+
"# BENDING TO TOOLS\n",
|
| 212 |
+
"# ------------------------------------------------------ #\n",
|
| 213 |
+
"tools = [search_tool, describe_image_tool, describe_audio_tool, python_repl_tool, excel_repl_tool, youtube_extractor_tool, wikipedia_tool]\n",
|
| 214 |
+
"chat_llm = init_chat_llm.bind_tools(tools)"
|
| 215 |
+
],
|
| 216 |
+
"id": "13d9344ff87bc5e6",
|
| 217 |
+
"outputs": [],
|
| 218 |
+
"execution_count": 92
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
"metadata": {
|
| 222 |
+
"ExecuteTime": {
|
| 223 |
+
"end_time": "2025-06-10T20:50:31.247558Z",
|
| 224 |
+
"start_time": "2025-06-10T20:50:31.246108Z"
|
| 225 |
+
}
|
| 226 |
+
},
|
| 227 |
+
"cell_type": "code",
|
| 228 |
+
"source": [
|
| 229 |
+
"# ------------------------------------------------------ #\n",
|
| 230 |
+
"# STATE\n",
|
| 231 |
+
"# ------------------------------------------------------ #\n",
|
| 232 |
+
"class AgentState(TypedDict):\n",
|
| 233 |
+
" # messages: list[AnyMessage, add_messages]\n",
|
| 234 |
+
" messages: list[AnyMessage]\n",
|
| 235 |
+
" file_name: str\n",
|
| 236 |
+
" final_output_is_good: bool"
|
| 237 |
+
],
|
| 238 |
+
"id": "6a38f29e827cab31",
|
| 239 |
+
"outputs": [],
|
| 240 |
+
"execution_count": 93
|
| 241 |
+
},
|
| 242 |
+
{
|
| 243 |
+
"metadata": {
|
| 244 |
+
"ExecuteTime": {
|
| 245 |
+
"end_time": "2025-06-10T20:50:31.257049Z",
|
| 246 |
+
"start_time": "2025-06-10T20:50:31.254965Z"
|
| 247 |
+
}
|
| 248 |
+
},
|
| 249 |
+
"cell_type": "code",
|
| 250 |
+
"source": [
|
| 251 |
+
"# ------------------------------------------------------ #\n",
|
| 252 |
+
"# HELP FUNCTIONS\n",
|
| 253 |
+
"# ------------------------------------------------------ #\n",
|
| 254 |
+
"def step_print(state: AgentState | None, step_label: str):\n",
|
| 255 |
+
" if state:\n",
|
| 256 |
+
" print(f'<<--- [{len(state[\"messages\"])}] Entering ``{step_label}`` Node... --->>')\n",
|
| 257 |
+
" else:\n",
|
| 258 |
+
" print(f'<<--- [] Entering ``{step_label}`` Node... --->>')\n",
|
| 259 |
+
"\n",
|
| 260 |
+
"\n",
|
| 261 |
+
"def messages_print(messages_to_print: List[AnyMessage]):\n",
|
| 262 |
+
" print('--- Message/s ---')\n",
|
| 263 |
+
" for m in messages_to_print:\n",
|
| 264 |
+
" print(f'{m.type} ({m.name}): \\n{m.content}')\n",
|
| 265 |
+
" print(f'<<--- *** --->>')"
|
| 266 |
+
],
|
| 267 |
+
"id": "583f00a3c2e18e36",
|
| 268 |
+
"outputs": [],
|
| 269 |
+
"execution_count": 94
|
| 270 |
+
},
|
| 271 |
+
{
|
| 272 |
+
"metadata": {
|
| 273 |
+
"ExecuteTime": {
|
| 274 |
+
"end_time": "2025-06-10T20:50:31.271958Z",
|
| 275 |
+
"start_time": "2025-06-10T20:50:31.264390Z"
|
| 276 |
+
}
|
| 277 |
+
},
|
| 278 |
+
"cell_type": "code",
|
| 279 |
+
"source": [
|
| 280 |
+
"# ------------------------------------------------------ #\n",
|
| 281 |
+
"# NODES\n",
|
| 282 |
+
"# ------------------------------------------------------ #\n",
|
| 283 |
+
"def preprocessing(state: AgentState):\n",
|
| 284 |
+
" # state['messages'] = [state['messages'][0]]\n",
|
| 285 |
+
" step_print(None, 'Preprocessing')\n",
|
| 286 |
+
" if state['file_name'] != '':\n",
|
| 287 |
+
" # state['messages'] += f\"\\nfile_name: {state['file_name']}\"\n",
|
| 288 |
+
" state['messages'][0].content += f\"\\nfile_name: {state['file_name']}\"\n",
|
| 289 |
+
" messages_print(state['messages'])\n",
|
| 290 |
+
" return {\n",
|
| 291 |
+
" \"messages\": [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state[\"messages\"]\n",
|
| 292 |
+
" }\n",
|
| 293 |
+
"\n",
|
| 294 |
+
"\n",
|
| 295 |
+
"def assistant(state: AgentState):\n",
|
| 296 |
+
" # state[\"messages\"] = [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state[\"messages\"]\n",
|
| 297 |
+
" step_print(state, 'assistant')\n",
|
| 298 |
+
" ai_message = chat_llm.invoke(state[\"messages\"])\n",
|
| 299 |
+
" messages_print([ai_message])\n",
|
| 300 |
+
" return {\n",
|
| 301 |
+
" 'messages': state[\"messages\"] + [ai_message]\n",
|
| 302 |
+
" }\n",
|
| 303 |
+
"\n",
|
| 304 |
+
"\n",
|
| 305 |
+
"base_tool_node = ToolNode(tools)\n",
|
| 306 |
+
"def wrapped_tool_node(state: AgentState):\n",
|
| 307 |
+
" step_print(state, 'Tools')\n",
|
| 308 |
+
" # Call the original ToolNode\n",
|
| 309 |
+
" result = base_tool_node.invoke(state)\n",
|
| 310 |
+
" messages_print(result[\"messages\"])\n",
|
| 311 |
+
" # Append to the messages list instead of replacing it\n",
|
| 312 |
+
" state[\"messages\"] += result[\"messages\"]\n",
|
| 313 |
+
" return {\"messages\": state[\"messages\"]}\n",
|
| 314 |
+
"\n",
|
| 315 |
+
"\n",
|
| 316 |
+
"def checker_final_answer(state: AgentState):\n",
|
| 317 |
+
" step_print(state, 'Final Check')\n",
|
| 318 |
+
" s = state['messages'][-1].content\n",
|
| 319 |
+
" if \"FINAL ANSWER: \" not in s:\n",
|
| 320 |
+
" return {\n",
|
| 321 |
+
" 'messages': state[\"messages\"],\n",
|
| 322 |
+
" 'final_output_is_good': False\n",
|
| 323 |
+
" }\n",
|
| 324 |
+
" return {\n",
|
| 325 |
+
" 'final_output_is_good': True\n",
|
| 326 |
+
" }\n"
|
| 327 |
+
],
|
| 328 |
+
"id": "45ef5e1d3df698de",
|
| 329 |
+
"outputs": [],
|
| 330 |
+
"execution_count": 95
|
| 331 |
+
},
|
| 332 |
+
{
|
| 333 |
+
"metadata": {
|
| 334 |
+
"ExecuteTime": {
|
| 335 |
+
"end_time": "2025-06-10T20:50:31.281228Z",
|
| 336 |
+
"start_time": "2025-06-10T20:50:31.278542Z"
|
| 337 |
+
}
|
| 338 |
+
},
|
| 339 |
+
"cell_type": "code",
|
| 340 |
+
"source": [
|
| 341 |
+
"# ------------------------------------------------------ #\n",
|
| 342 |
+
"# CONDITIONAL FUNCTIONS\n",
|
| 343 |
+
"# ------------------------------------------------------ #\n",
|
| 344 |
+
"def condition_output(state: AgentState) -> Literal[\"assistant\", \"__end__\"]:\n",
|
| 345 |
+
" if state['final_output_is_good']:\n",
|
| 346 |
+
" return END\n",
|
| 347 |
+
" return \"assistant\"\n",
|
| 348 |
+
"\n",
|
| 349 |
+
"\n",
|
| 350 |
+
"def condition_tools_or_continue(\n",
|
| 351 |
+
" state: Union[list[AnyMessage], dict[str, Any], BaseModel],\n",
|
| 352 |
+
" messages_key: str = \"messages\",\n",
|
| 353 |
+
") -> Literal[\"tools\", \"checker_final_answer\"]:\n",
|
| 354 |
+
"\n",
|
| 355 |
+
" if isinstance(state, list):\n",
|
| 356 |
+
" ai_message = state[-1]\n",
|
| 357 |
+
" elif isinstance(state, dict) and (messages := state.get(messages_key, [])):\n",
|
| 358 |
+
" ai_message = messages[-1]\n",
|
| 359 |
+
" elif messages := getattr(state, messages_key, []):\n",
|
| 360 |
+
" ai_message = messages[-1]\n",
|
| 361 |
+
" else:\n",
|
| 362 |
+
" # pass\n",
|
| 363 |
+
" raise ValueError(f\"No messages found in input state to tool_edge: {state}\")\n",
|
| 364 |
+
" if hasattr(ai_message, \"tool_calls\") and len(ai_message.tool_calls) > 0:\n",
|
| 365 |
+
" return \"tools\"\n",
|
| 366 |
+
" return \"checker_final_answer\"\n",
|
| 367 |
+
" # return \"__end__\"\n"
|
| 368 |
+
],
|
| 369 |
+
"id": "8fd537b4436a3d4b",
|
| 370 |
+
"outputs": [],
|
| 371 |
+
"execution_count": 96
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"metadata": {
|
| 375 |
+
"ExecuteTime": {
|
| 376 |
+
"end_time": "2025-06-10T20:50:31.291047Z",
|
| 377 |
+
"start_time": "2025-06-10T20:50:31.289017Z"
|
| 378 |
+
}
|
| 379 |
+
},
|
| 380 |
+
"cell_type": "code",
|
| 381 |
+
"source": [
|
| 382 |
+
"# ------------------------------------------------------ #\n",
|
| 383 |
+
"# BUILDERS\n",
|
| 384 |
+
"# ------------------------------------------------------ #\n",
|
| 385 |
+
"def workflow_tools() -> Tuple[StateGraph, str]:\n",
|
| 386 |
+
" i_builder = StateGraph(AgentState)\n",
|
| 387 |
+
"\n",
|
| 388 |
+
" # Nodes\n",
|
| 389 |
+
" i_builder.add_node('preprocessing', preprocessing)\n",
|
| 390 |
+
" i_builder.add_node('assistant', assistant)\n",
|
| 391 |
+
" i_builder.add_node('tools', wrapped_tool_node)\n",
|
| 392 |
+
" i_builder.add_node('checker_final_answer', checker_final_answer)\n",
|
| 393 |
+
"\n",
|
| 394 |
+
" # Edges\n",
|
| 395 |
+
" i_builder.add_edge(START, 'preprocessing')\n",
|
| 396 |
+
" i_builder.add_edge('preprocessing', 'assistant')\n",
|
| 397 |
+
" i_builder.add_conditional_edges('assistant', condition_tools_or_continue)\n",
|
| 398 |
+
" i_builder.add_edge('tools', 'assistant')\n",
|
| 399 |
+
" i_builder.add_conditional_edges('checker_final_answer', condition_output)\n",
|
| 400 |
+
" return i_builder, 'workflow_tools'"
|
| 401 |
+
],
|
| 402 |
+
"id": "ec58d7a039c99ca2",
|
| 403 |
+
"outputs": [],
|
| 404 |
+
"execution_count": 97
|
| 405 |
+
},
|
| 406 |
+
{
|
| 407 |
+
"metadata": {},
|
| 408 |
+
"cell_type": "markdown",
|
| 409 |
+
"source": "Graph",
|
| 410 |
+
"id": "fda1229d71a9bba9"
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
"metadata": {
|
| 414 |
+
"ExecuteTime": {
|
| 415 |
+
"end_time": "2025-06-10T20:50:31.299610Z",
|
| 416 |
+
"start_time": "2025-06-10T20:50:31.298066Z"
|
| 417 |
+
}
|
| 418 |
+
},
|
| 419 |
+
"cell_type": "code",
|
| 420 |
+
"source": "# print(alfred.get_graph().draw_mermaid())",
|
| 421 |
+
"id": "66d69686b3d6c030",
|
| 422 |
+
"outputs": [],
|
| 423 |
+
"execution_count": 98
|
| 424 |
+
},
|
| 425 |
+
{
|
| 426 |
+
"metadata": {
|
| 427 |
+
"ExecuteTime": {
|
| 428 |
+
"end_time": "2025-06-10T20:50:31.311304Z",
|
| 429 |
+
"start_time": "2025-06-10T20:50:31.306768Z"
|
| 430 |
+
}
|
| 431 |
+
},
|
| 432 |
+
"cell_type": "code",
|
| 433 |
+
"source": [
|
| 434 |
+
"# ------------------------------------------------------ #\n",
|
| 435 |
+
"# COMPILATION\n",
|
| 436 |
+
"# ------------------------------------------------------ #\n",
|
| 437 |
+
"# builder, builder_name = workflow_simple()\n",
|
| 438 |
+
"builder, builder_name = workflow_tools()\n",
|
| 439 |
+
"alfred = builder.compile()"
|
| 440 |
+
],
|
| 441 |
+
"id": "42cebd005b0a53f4",
|
| 442 |
+
"outputs": [],
|
| 443 |
+
"execution_count": 99
|
| 444 |
+
},
|
| 445 |
+
{
|
| 446 |
+
"metadata": {
|
| 447 |
+
"ExecuteTime": {
|
| 448 |
+
"end_time": "2025-06-10T20:50:31.319171Z",
|
| 449 |
+
"start_time": "2025-06-10T20:50:31.317804Z"
|
| 450 |
+
}
|
| 451 |
+
},
|
| 452 |
+
"cell_type": "code",
|
| 453 |
+
"source": "# display(Image(alfred.get_graph().draw_mermaid_png()))",
|
| 454 |
+
"id": "b611c5a2248d19af",
|
| 455 |
+
"outputs": [],
|
| 456 |
+
"execution_count": 100
|
| 457 |
+
},
|
| 458 |
+
{
|
| 459 |
+
"metadata": {},
|
| 460 |
+
"cell_type": "markdown",
|
| 461 |
+
"source": "Check",
|
| 462 |
+
"id": "6247ddc363658c5e"
|
| 463 |
+
},
|
| 464 |
+
{
|
| 465 |
+
"metadata": {
|
| 466 |
+
"ExecuteTime": {
|
| 467 |
+
"end_time": "2025-06-10T20:50:32.029730Z",
|
| 468 |
+
"start_time": "2025-06-10T20:50:31.326735Z"
|
| 469 |
+
}
|
| 470 |
+
},
|
| 471 |
+
"cell_type": "code",
|
| 472 |
+
"source": [
|
| 473 |
+
"response = requests.get(questions_url, timeout=15)\n",
|
| 474 |
+
"response.raise_for_status()\n",
|
| 475 |
+
"questions_data = response.json()"
|
| 476 |
+
],
|
| 477 |
+
"id": "713d8c986733ac2f",
|
| 478 |
+
"outputs": [],
|
| 479 |
+
"execution_count": 101
|
| 480 |
+
},
|
| 481 |
+
{
|
| 482 |
+
"metadata": {
|
| 483 |
+
"ExecuteTime": {
|
| 484 |
+
"end_time": "2025-06-10T20:50:32.046633Z",
|
| 485 |
+
"start_time": "2025-06-10T20:50:32.043386Z"
|
| 486 |
+
}
|
| 487 |
+
},
|
| 488 |
+
"cell_type": "code",
|
| 489 |
+
"source": [
|
| 490 |
+
"for item_num, item in enumerate(questions_data):\n",
|
| 491 |
+
" # dict_keys(['task_id', 'question', 'Level', 'file_name'])\n",
|
| 492 |
+
" if item['file_name'] != '':\n",
|
| 493 |
+
" print(f\"Task {item_num} has file: {item['file_name']}\")\n",
|
| 494 |
+
" if 'wiki' in item['question']:\n",
|
| 495 |
+
" print(f\"Task {item_num} question: {item['question']}\")\n",
|
| 496 |
+
"\n",
|
| 497 |
+
"item_num = 0\n",
|
| 498 |
+
"item = questions_data[item_num]\n",
|
| 499 |
+
"# dict_keys(['task_id', 'question', 'Level', 'file_name'])\n",
|
| 500 |
+
"print('---')\n",
|
| 501 |
+
"print(f\"NUM: {item_num}\")\n",
|
| 502 |
+
"print(f\"ID: {item['task_id']}\")\n",
|
| 503 |
+
"print(f\"FILE NAME: {item['file_name']}\")\n",
|
| 504 |
+
"print(f\"QUESTION: \\n{item['question']}\")\n",
|
| 505 |
+
"print('---')"
|
| 506 |
+
],
|
| 507 |
+
"id": "52247811540e5c73",
|
| 508 |
+
"outputs": [
|
| 509 |
+
{
|
| 510 |
+
"name": "stdout",
|
| 511 |
+
"output_type": "stream",
|
| 512 |
+
"text": [
|
| 513 |
+
"Task 0 question: How many studio albums were published by Mercedes Sosa between 2000 and 2009 (included)? You can use the latest 2022 version of english wikipedia.\n",
|
| 514 |
+
"Task 3 has file: cca530fc-4052-43b2-b130-b30968d8aa44.png\n",
|
| 515 |
+
"Task 9 has file: 99c9cc74-fdc8-46c6-8f8d-3ce2d3bfeea3.mp3\n",
|
| 516 |
+
"Task 11 has file: f918266a-b3e0-4914-865d-4faa564f1aef.py\n",
|
| 517 |
+
"Task 13 has file: 1f975693-876d-457b-a649-393859e79bf3.mp3\n",
|
| 518 |
+
"Task 18 has file: 7bd855d8-463d-4ed5-93ca-5fe35145f733.xlsx\n",
|
| 519 |
+
"---\n",
|
| 520 |
+
"NUM: 0\n",
|
| 521 |
+
"ID: 8e867cd7-cff9-4e6c-867a-ff5ddc2550be\n",
|
| 522 |
+
"FILE NAME: \n",
|
| 523 |
+
"QUESTION: \n",
|
| 524 |
+
"How many studio albums were published by Mercedes Sosa between 2000 and 2009 (included)? You can use the latest 2022 version of english wikipedia.\n",
|
| 525 |
+
"---\n"
|
| 526 |
+
]
|
| 527 |
+
}
|
| 528 |
+
],
|
| 529 |
+
"execution_count": 102
|
| 530 |
+
},
|
| 531 |
+
{
|
| 532 |
+
"metadata": {
|
| 533 |
+
"ExecuteTime": {
|
| 534 |
+
"end_time": "2025-06-10T20:50:46.752288Z",
|
| 535 |
+
"start_time": "2025-06-10T20:50:36.572639Z"
|
| 536 |
+
}
|
| 537 |
+
},
|
| 538 |
+
"cell_type": "code",
|
| 539 |
+
"source": [
|
| 540 |
+
"response = alfred.invoke({\n",
|
| 541 |
+
" 'messages': [HumanMessage(content=item['question'])],\n",
|
| 542 |
+
" 'file_name': item['file_name'],\n",
|
| 543 |
+
" 'final_output_is_good': False,\n",
|
| 544 |
+
"})"
|
| 545 |
+
],
|
| 546 |
+
"id": "d1469f387207c914",
|
| 547 |
+
"outputs": [
|
| 548 |
+
{
|
| 549 |
+
"name": "stdout",
|
| 550 |
+
"output_type": "stream",
|
| 551 |
+
"text": [
|
| 552 |
+
"<<--- [] Entering ``Preprocessing`` Node... --->>\n",
|
| 553 |
+
"--- Message/s ---\n",
|
| 554 |
+
"human (None): \n",
|
| 555 |
+
"How many studio albums were published by Mercedes Sosa between 2000 and 2009 (included)? You can use the latest 2022 version of english wikipedia.\n",
|
| 556 |
+
"<<--- *** --->>\n",
|
| 557 |
+
"<<--- [2] Entering ``assistant`` Node... --->>\n",
|
| 558 |
+
"--- Message/s ---\n",
|
| 559 |
+
"ai (None): \n",
|
| 560 |
+
"\n",
|
| 561 |
+
"<<--- *** --->>\n",
|
| 562 |
+
"<<--- [3] Entering ``Tools`` Node... --->>\n",
|
| 563 |
+
"[wiki tool] query='Mercedes Sosa discography'\n",
|
| 564 |
+
"--- Message/s ---\n",
|
| 565 |
+
"tool (wikipedia_tool): \n",
|
| 566 |
+
"Page: Mercedes Sosa\n",
|
| 567 |
+
"Summary: Haydée Mercedes \"La Negra\" Sosa (Latin American Spanish: [meɾˈseðes ˈsosa]; 9 July 1935 – 4 October 2009) was an Argentine singer who was popular throughout Latin America and many countries outside the region. With her roots in Argentine folk music, Sosa became one of the preeminent exponents of El nuevo cancionero. She gave voice to songs written by many Latin American songwriters. Her music made people hail her as the \"voice of the voiceless ones\". She was often called \"the conscience of Latin America\".\n",
|
| 568 |
+
"Sosa performed in venues such as the Lincoln Center in New York City, the Théâtre Mogador in Paris, the Sistine Chapel in Vatican City, as well as sold-out shows in New York's Carnegie Hall and the Roman Colosseum during her final decade of life. Her career spanned four decades and she was the recipient of six Latin Grammy awards (2000, 2003, 2004, 2006, 2009, 2011), including a Latin Grammy Lifetime Achievement Award in 2004 and two posthumous Latin Grammy Award for Best Folk Album in 2009 and 2011. She won the Premio Gardel in 2000, the main musical award in Argentina. She served as an ambassador for UNICEF.\n",
|
| 569 |
+
"\n",
|
| 570 |
+
"Page: Cantora, un Viaje Íntimo\n",
|
| 571 |
+
"Summary: Cantora, un Viaje Íntimo (English: Cantora, An Intimate Journey) is a double album by Argentine singer Mercedes Sosa, released on 2009 through Sony Music Argentina. The album features Cantora 1 and Cantora 2, the project is Sosa's final album before her death on October 4, 2009.\n",
|
| 572 |
+
"At the 10th Annual Latin Grammy Awards, Cantora 1 was nominated for Album of the Year and won Best Folk Album and Best Recording Package, the latter award went to Alejandro Ros, the art director of the album. Additionally, Sosa won two out of five nominations for the albums at the Gardel Awards 2010, the double album was nominated for Album of the Year and Production of the Year and won Best DVD while both Cantora 1 and Cantora 2 were nominated for Best Female Folk Album, with the former winning the category.\n",
|
| 573 |
+
"The double album was a commercial success, being certified platinum by the CAPIF selling more than 200,000 copies in Argentina, Cantora 1 was also certified platinum selling 40,000 copies while Cantora 2 was certified gold selling 20,000 copies. The album also peaked at numbers 22 and 8 at the Top Latin Albums and Latin Pop Albums charts in United States, respectively, being Sosa's only appearances on both charts.\n",
|
| 574 |
+
"At documentary film titled Mercedes Sosa, Cantora un viaje íntimo was released on 2009, it was directed by Rodrigo Vila and features the recording process of the album as well as testimonies from the different guest artists that appeared on the project.\n",
|
| 575 |
+
"\n",
|
| 576 |
+
"Page: Joan Baez discography\n",
|
| 577 |
+
"Summary: This is a discography for American folk singer and songwriter Joan Baez.\n",
|
| 578 |
+
"<<--- *** --->>\n",
|
| 579 |
+
"<<--- [4] Entering ``assistant`` Node... --->>\n",
|
| 580 |
+
"--- Message/s ---\n",
|
| 581 |
+
"ai (None): \n",
|
| 582 |
+
"According to the Wikipedia page, between 2000 and 2009, Mercedes Sosa published the following studio albums: Acústico (2002), Corazón Libre (2005), and Cantora 1 and Cantora 2 (2009). \n",
|
| 583 |
+
"\n",
|
| 584 |
+
"FINAL ANSWER: 4\n",
|
| 585 |
+
"<<--- *** --->>\n",
|
| 586 |
+
"<<--- [5] Entering ``Final Check`` Node... --->>\n"
|
| 587 |
+
]
|
| 588 |
+
}
|
| 589 |
+
],
|
| 590 |
+
"execution_count": 103
|
| 591 |
+
},
|
| 592 |
+
{
|
| 593 |
+
"metadata": {
|
| 594 |
+
"ExecuteTime": {
|
| 595 |
+
"end_time": "2025-06-09T19:43:11.250731Z",
|
| 596 |
+
"start_time": "2025-06-09T19:43:11.249022Z"
|
| 597 |
+
}
|
| 598 |
+
},
|
| 599 |
+
"cell_type": "code",
|
| 600 |
+
"source": [
|
| 601 |
+
"# pic_loc_str = 'files/cca530fc-4052-43b2-b130-b30968d8aa44.png'\n",
|
| 602 |
+
"# # doc = [UnstructuredImageLoader(pic_loc_str).load()]\n",
|
| 603 |
+
"# dataset = datasets.Dataset.from_dict({\"image\": [pic_loc_str]}).cast_column(\"image\", datasets.Image())\n",
|
| 604 |
+
"# dataset[0][\"image\"]"
|
| 605 |
+
],
|
| 606 |
+
"id": "c9ee8e0b9fbc5df7",
|
| 607 |
+
"outputs": [],
|
| 608 |
+
"execution_count": 93
|
| 609 |
+
},
|
| 610 |
+
{
|
| 611 |
+
"metadata": {},
|
| 612 |
+
"cell_type": "code",
|
| 613 |
+
"outputs": [],
|
| 614 |
+
"execution_count": null,
|
| 615 |
+
"source": "\n",
|
| 616 |
+
"id": "ab912d811bf50006"
|
| 617 |
+
}
|
| 618 |
+
],
|
| 619 |
+
"metadata": {
|
| 620 |
+
"kernelspec": {
|
| 621 |
+
"display_name": "Python 3",
|
| 622 |
+
"language": "python",
|
| 623 |
+
"name": "python3"
|
| 624 |
+
},
|
| 625 |
+
"language_info": {
|
| 626 |
+
"codemirror_mode": {
|
| 627 |
+
"name": "ipython",
|
| 628 |
+
"version": 2
|
| 629 |
+
},
|
| 630 |
+
"file_extension": ".py",
|
| 631 |
+
"mimetype": "text/x-python",
|
| 632 |
+
"name": "python",
|
| 633 |
+
"nbconvert_exporter": "python",
|
| 634 |
+
"pygments_lexer": "ipython2",
|
| 635 |
+
"version": "2.7.6"
|
| 636 |
+
}
|
| 637 |
+
},
|
| 638 |
+
"nbformat": 4,
|
| 639 |
+
"nbformat_minor": 5
|
| 640 |
+
}
|
README.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Template Final Assignment
|
| 3 |
+
emoji: 🕵🏻♂️
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: indigo
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 5.25.2
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
hf_oauth: true
|
| 11 |
+
# optional, default duration is 8 hours/480 minutes. Max duration is 30 days/43200 minutes.
|
| 12 |
+
hf_oauth_expiration_minutes: 480
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Credits
|
| 19 |
+
|
| 20 |
+
- [Original Template](https://huggingface.co/spaces/ArseniyPerchik/Final_Assignment_Template)
|
| 21 |
+
- [Agent Evaluation API](https://agents-course-unit4-scoring.hf.space/docs)
|
| 22 |
+
- [GAIA Leaderboard](http://huggingface.co/spaces/gaia-benchmark/leaderboard)
|
| 23 |
+
- [GAIA Dataset](https://huggingface.co/datasets/gaia-benchmark/GAIA)
|
| 24 |
+
- [LangChain | Local LLMs](https://python.langchain.com/docs/how_to/local_llms/)
|
| 25 |
+
- [Laminar | Dashboard for tracing](https://www.lmnr.ai/projects)
|
| 26 |
+
- [Together.AI Docs](https://docs.together.ai/docs/introduction)
|
app.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio
|
| 2 |
+
|
| 3 |
+
from globals import *
|
| 4 |
+
from gradio_functions import *
|
| 5 |
+
|
| 6 |
+
# Initialize Laminar - this single step enables automatic tracing
|
| 7 |
+
# Laminar.initialize(project_api_key=LAMINAR_API_KEY)
|
| 8 |
+
|
| 9 |
+
# (Keep Constants as is)
|
| 10 |
+
# --- Constants ---
|
| 11 |
+
DEFAULT_API_URL = "https://agents-course-unit4-scoring.hf.space"
|
| 12 |
+
|
| 13 |
+
# --- Basic Agent Definition ---
|
| 14 |
+
# ----- THIS IS WERE YOU CAN BUILD WHAT YOU WANT ------
|
| 15 |
+
class BasicAgent:
|
| 16 |
+
def __init__(self):
|
| 17 |
+
print("BasicAgent initialized.")
|
| 18 |
+
def __call__(self, question: str, q_num: int, file_name: str) -> str:
|
| 19 |
+
print(f"# {'':=^30} #")
|
| 20 |
+
print(f"# {q_num:=^30} #")
|
| 21 |
+
print(f"# {'':=^30} #")
|
| 22 |
+
print(f"Agent received question (first 50 chars): {question[:50]}...")
|
| 23 |
+
# output_answer = "This is a default answer."
|
| 24 |
+
# output_answer_object = alfred.invoke({'messages': [HumanMessage(content=question)]})
|
| 25 |
+
_, output_answer = ask_alfred(question, file_name)
|
| 26 |
+
print(f"Agent returning fixed answer: {output_answer}")
|
| 27 |
+
return output_answer
|
| 28 |
+
|
| 29 |
+
def run_and_submit_all( profile: gr.OAuthProfile | None):
|
| 30 |
+
"""
|
| 31 |
+
Fetches all questions, runs the BasicAgent on them, submits all answers,
|
| 32 |
+
and displays the results.
|
| 33 |
+
"""
|
| 34 |
+
# --- Determine HF Space Runtime URL and Repo URL ---
|
| 35 |
+
space_id = os.getenv("SPACE_ID") # Get the SPACE_ID for sending link to the code
|
| 36 |
+
|
| 37 |
+
if profile:
|
| 38 |
+
username= f"{profile.username}"
|
| 39 |
+
print(f"User logged in: {username}")
|
| 40 |
+
else:
|
| 41 |
+
print("User not logged in.")
|
| 42 |
+
return "Please Login to Hugging Face with the button.", None
|
| 43 |
+
|
| 44 |
+
api_url = DEFAULT_API_URL
|
| 45 |
+
questions_url = f"{api_url}/questions"
|
| 46 |
+
submit_url = f"{api_url}/submit"
|
| 47 |
+
|
| 48 |
+
# 1. Instantiate Agent ( modify this part to create your agent)
|
| 49 |
+
try:
|
| 50 |
+
agent = BasicAgent()
|
| 51 |
+
except Exception as e:
|
| 52 |
+
print(f"Error instantiating agent: {e}")
|
| 53 |
+
return f"Error initializing agent: {e}", None
|
| 54 |
+
# In the case of an app running as a hugging Face space, this link points toward your codebase ( usefull for others so please keep it public)
|
| 55 |
+
agent_code = f"https://huggingface.co/spaces/{space_id}/tree/main"
|
| 56 |
+
print(agent_code)
|
| 57 |
+
|
| 58 |
+
# 2. Fetch Questions
|
| 59 |
+
print(f"Fetching questions from: {questions_url}")
|
| 60 |
+
try:
|
| 61 |
+
response = requests.get(questions_url, timeout=15)
|
| 62 |
+
response.raise_for_status()
|
| 63 |
+
questions_data = response.json()
|
| 64 |
+
if not questions_data:
|
| 65 |
+
print("Fetched questions list is empty.")
|
| 66 |
+
return "Fetched questions list is empty or invalid format.", None
|
| 67 |
+
print(f"Fetched {len(questions_data)} questions.")
|
| 68 |
+
except requests.exceptions.RequestException as e:
|
| 69 |
+
print(f"Error fetching questions: {e}")
|
| 70 |
+
return f"Error fetching questions: {e}", None
|
| 71 |
+
except requests.exceptions.JSONDecodeError as e:
|
| 72 |
+
print(f"Error decoding JSON response from questions endpoint: {e}")
|
| 73 |
+
print(f"Response text: {response.text[:500]}")
|
| 74 |
+
return f"Error decoding server response for questions: {e}", None
|
| 75 |
+
except Exception as e:
|
| 76 |
+
print(f"An unexpected error occurred fetching questions: {e}")
|
| 77 |
+
return f"An unexpected error occurred fetching questions: {e}", None
|
| 78 |
+
|
| 79 |
+
# 3. Run your Agent
|
| 80 |
+
results_log = []
|
| 81 |
+
answers_payload = []
|
| 82 |
+
print(f"Running agent on {len(questions_data)} questions...")
|
| 83 |
+
file_names = ''
|
| 84 |
+
for q_num, item in enumerate(questions_data):
|
| 85 |
+
task_id = item.get("task_id")
|
| 86 |
+
question_text = item.get("question")
|
| 87 |
+
file_name = item.get("file_name")
|
| 88 |
+
if not task_id or question_text is None:
|
| 89 |
+
print(f"Skipping item with missing task_id or question: {item}")
|
| 90 |
+
continue
|
| 91 |
+
try:
|
| 92 |
+
submitted_answer = agent(question_text, q_num, file_name)
|
| 93 |
+
file_names += f'{q_num}: {file_name}\n'
|
| 94 |
+
answers_payload.append({"task_id": task_id, "submitted_answer": submitted_answer})
|
| 95 |
+
results_log.append({"Task ID": task_id, "Question": question_text, "Submitted Answer": submitted_answer})
|
| 96 |
+
except Exception as e:
|
| 97 |
+
print(f"Error running agent on task {task_id}: {e}")
|
| 98 |
+
results_log.append({"Task ID": task_id, "Question": question_text, "Submitted Answer": f"AGENT ERROR: {e}"})
|
| 99 |
+
print(file_names)
|
| 100 |
+
if not answers_payload:
|
| 101 |
+
print("Agent did not produce any answers to submit.")
|
| 102 |
+
return "Agent did not produce any answers to submit.", pd.DataFrame(results_log)
|
| 103 |
+
|
| 104 |
+
# 4. Prepare Submission
|
| 105 |
+
submission_data = {"username": username.strip(), "agent_code": agent_code, "answers": answers_payload}
|
| 106 |
+
status_update = f"Agent finished. Submitting {len(answers_payload)} answers for user '{username}'..."
|
| 107 |
+
print(status_update)
|
| 108 |
+
|
| 109 |
+
# 5. Submit
|
| 110 |
+
print(f"Submitting {len(answers_payload)} answers to: {submit_url}")
|
| 111 |
+
try:
|
| 112 |
+
response = requests.post(submit_url, json=submission_data, timeout=60)
|
| 113 |
+
response.raise_for_status()
|
| 114 |
+
result_data = response.json()
|
| 115 |
+
final_status = (
|
| 116 |
+
f"Submission Successful!\n"
|
| 117 |
+
f"User: {result_data.get('username')}\n"
|
| 118 |
+
f"Overall Score: {result_data.get('score', 'N/A')}% "
|
| 119 |
+
f"({result_data.get('correct_count', '?')}/{result_data.get('total_attempted', '?')} correct)\n"
|
| 120 |
+
f"Message: {result_data.get('message', 'No message received.')}"
|
| 121 |
+
)
|
| 122 |
+
print("Submission successful.")
|
| 123 |
+
results_df = pd.DataFrame(results_log)
|
| 124 |
+
return final_status, results_df
|
| 125 |
+
except requests.exceptions.HTTPError as e:
|
| 126 |
+
error_detail = f"Server responded with status {e.response.status_code}."
|
| 127 |
+
try:
|
| 128 |
+
error_json = e.response.json()
|
| 129 |
+
error_detail += f" Detail: {error_json.get('detail', e.response.text)}"
|
| 130 |
+
except requests.exceptions.JSONDecodeError:
|
| 131 |
+
error_detail += f" Response: {e.response.text[:500]}"
|
| 132 |
+
status_message = f"Submission Failed: {error_detail}"
|
| 133 |
+
print(status_message)
|
| 134 |
+
results_df = pd.DataFrame(results_log)
|
| 135 |
+
return status_message, results_df
|
| 136 |
+
except requests.exceptions.Timeout:
|
| 137 |
+
status_message = "Submission Failed: The request timed out."
|
| 138 |
+
print(status_message)
|
| 139 |
+
results_df = pd.DataFrame(results_log)
|
| 140 |
+
return status_message, results_df
|
| 141 |
+
except requests.exceptions.RequestException as e:
|
| 142 |
+
status_message = f"Submission Failed: Network error - {e}"
|
| 143 |
+
print(status_message)
|
| 144 |
+
results_df = pd.DataFrame(results_log)
|
| 145 |
+
return status_message, results_df
|
| 146 |
+
except Exception as e:
|
| 147 |
+
status_message = f"An unexpected error occurred during submission: {e}"
|
| 148 |
+
print(status_message)
|
| 149 |
+
results_df = pd.DataFrame(results_log)
|
| 150 |
+
return status_message, results_df
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# --- Build Gradio Interface using Blocks ---
|
| 154 |
+
with gr.Blocks() as demo:
|
| 155 |
+
# --- #
|
| 156 |
+
gr.Markdown("# Train Dataset")
|
| 157 |
+
with gr.Row():
|
| 158 |
+
with gradio.Column():
|
| 159 |
+
tr_slider = gr.Slider(minimum=0, maximum=len(train_dataset)-1, step=1, label="Number of a question from the train dataset.")
|
| 160 |
+
tr_checkbox_meta = gradio.Checkbox(value=True, label='Hide metadata')
|
| 161 |
+
tr_checkbox_file = gradio.Checkbox(value=True, label='Hide file data')
|
| 162 |
+
gr.Markdown("## Agent's Analysis")
|
| 163 |
+
tr_graph = gradio.Image(label='LangGraph Structure')
|
| 164 |
+
with gradio.Column():
|
| 165 |
+
tr_question = gr.Textbox(label="Question content", lines=1, max_lines=20)
|
| 166 |
+
tr_answer = gr.Textbox(label="Real answer:", lines=1, max_lines=20)
|
| 167 |
+
tr_tools = gr.Textbox(label='Recommended tools:', lines=1, max_lines=20)
|
| 168 |
+
tr_file = gr.Textbox(label="File name", visible=False)
|
| 169 |
+
tr_meta = gr.Textbox(label="Metadata", lines=1, max_lines=40, visible=False)
|
| 170 |
+
gr.Markdown("## Agent's Output")
|
| 171 |
+
tr_refresh = gradio.Button('Respond!', variant='huggingface')
|
| 172 |
+
tr_agent_answer = gr.Textbox(label="Agent answer:", lines=1, max_lines=20)
|
| 173 |
+
tr_agent_answer_full = gr.Textbox(label="Agent full answer:", lines=1, max_lines=20)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# --- #
|
| 177 |
+
# --- #
|
| 178 |
+
# --- #
|
| 179 |
+
# --- #
|
| 180 |
+
# --- #
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
gr.Markdown("---")
|
| 184 |
+
gr.Markdown("# Basic Agent Evaluation Runner")
|
| 185 |
+
gr.Markdown(
|
| 186 |
+
"""
|
| 187 |
+
**Instructions:**
|
| 188 |
+
|
| 189 |
+
1. Please clone this space, then modify the code to define your agent's logic, the tools, the necessary packages, etc ...
|
| 190 |
+
2. Log in to your Hugging Face account using the button below. This uses your HF username for submission.
|
| 191 |
+
3. Click 'Run Evaluation & Submit All Answers' to fetch questions, run your agent, submit answers, and see the score.
|
| 192 |
+
|
| 193 |
+
---
|
| 194 |
+
**Disclaimers:**
|
| 195 |
+
Once clicking on the "submit button, it can take quite some time ( this is the time for the agent to go through all the questions).
|
| 196 |
+
This space provides a basic setup and is intentionally sub-optimal to encourage you to develop your own, more robust solution.
|
| 197 |
+
For instance for the delay process of the submit button, a solution could be to cache the answers and submit in a seperate action or even to answer the questions in async.
|
| 198 |
+
"""
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
gr.LoginButton()
|
| 202 |
+
|
| 203 |
+
run_button = gr.Button("Run Evaluation & Submit All Answers")
|
| 204 |
+
|
| 205 |
+
status_output = gr.Textbox(label="Run Status / Submission Result", lines=5, interactive=False)
|
| 206 |
+
# Removed max_rows=10 from DataFrame constructor
|
| 207 |
+
results_table = gr.DataFrame(label="Questions and Agent Answers", wrap=True)
|
| 208 |
+
|
| 209 |
+
# --- #
|
| 210 |
+
# --- #
|
| 211 |
+
# --- #
|
| 212 |
+
# --- #
|
| 213 |
+
# --- #
|
| 214 |
+
|
| 215 |
+
# EVENTS
|
| 216 |
+
run_button.click(
|
| 217 |
+
fn=run_and_submit_all,
|
| 218 |
+
outputs=[status_output, results_table]
|
| 219 |
+
)
|
| 220 |
+
tr_slider.change(fn=slider_release_func, inputs=[tr_slider], outputs=[tr_question, tr_answer, tr_file, tr_meta, tr_tools])
|
| 221 |
+
# tr_slider.change(fn=get_agent_answer, inputs=[tr_slider], outputs=[tr_agent_answer_full, tr_agent_answer])
|
| 222 |
+
tr_refresh.click(fn=get_agent_answer_train, inputs=[tr_slider], outputs=[tr_agent_answer_full, tr_agent_answer])
|
| 223 |
+
tr_refresh.click(fn=show_langgraph_structure, outputs=[tr_graph])
|
| 224 |
+
tr_checkbox_meta.change(fn=toggle_textbox, inputs=[tr_checkbox_meta], outputs=[tr_meta])
|
| 225 |
+
tr_checkbox_file.change(fn=toggle_textbox, inputs=[tr_checkbox_file], outputs=[tr_file])
|
| 226 |
+
|
| 227 |
+
if __name__ == "__main__":
|
| 228 |
+
print("\n" + "-"*30 + " App Starting " + "-"*30)
|
| 229 |
+
# Check for SPACE_HOST and SPACE_ID at startup for information
|
| 230 |
+
space_host_startup = os.getenv("SPACE_HOST")
|
| 231 |
+
space_id_startup = os.getenv("SPACE_ID") # Get SPACE_ID at startup
|
| 232 |
+
|
| 233 |
+
if space_host_startup:
|
| 234 |
+
print(f"✅ SPACE_HOST found: {space_host_startup}")
|
| 235 |
+
print(f" Runtime URL should be: https://{space_host_startup}.hf.space")
|
| 236 |
+
else:
|
| 237 |
+
print("ℹ️ SPACE_HOST environment variable not found (running locally?).")
|
| 238 |
+
|
| 239 |
+
if space_id_startup: # Print repo URLs if SPACE_ID is found
|
| 240 |
+
print(f"✅ SPACE_ID found: {space_id_startup}")
|
| 241 |
+
print(f" Repo URL: https://huggingface.co/spaces/{space_id_startup}")
|
| 242 |
+
print(f" Repo Tree URL: https://huggingface.co/spaces/{space_id_startup}/tree/main")
|
| 243 |
+
else:
|
| 244 |
+
print("ℹ️ SPACE_ID environment variable not found (running locally?). Repo URL cannot be determined.")
|
| 245 |
+
|
| 246 |
+
print("-"*(60 + len(" App Starting ")) + "\n")
|
| 247 |
+
|
| 248 |
+
print("Launching Gradio Interface for Basic Agent Evaluation...")
|
| 249 |
+
demo.launch(debug=True, share=False)
|
draft_1.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from datasets import load_dataset
|
| 2 |
+
# issues_dataset = load_dataset("gaia-benchmark/GAIA", '2023_level1', split="train")
|
| 3 |
+
|
global_functions.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from globals import *
|
| 2 |
+
|
| 3 |
+
# ------------------------------------------------------ #
|
| 4 |
+
# GENERAL FUNCTIONS
|
| 5 |
+
# ------------------------------------------------------ #
|
| 6 |
+
def encode_image(image_path):
|
| 7 |
+
with open(image_path, "rb") as image_file:
|
| 8 |
+
return base64.b64encode(image_file.read()).decode('utf-8')
|
globals.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TypedDict, Annotated, Literal, Union, Any, List, Tuple
|
| 2 |
+
"""
|
| 3 |
+
Typing:
|
| 4 |
+
Union = either type A or type B
|
| 5 |
+
Optional = either type A or None
|
| 6 |
+
Literal = only specific values (constants), not any value of a type
|
| 7 |
+
"""
|
| 8 |
+
from pydantic import BaseModel
|
| 9 |
+
import os
|
| 10 |
+
import re
|
| 11 |
+
import random
|
| 12 |
+
import requests
|
| 13 |
+
import inspect
|
| 14 |
+
import subprocess
|
| 15 |
+
|
| 16 |
+
import gradio as gr
|
| 17 |
+
import pandas as pd
|
| 18 |
+
from lmnr import Laminar
|
| 19 |
+
from dotenv import load_dotenv
|
| 20 |
+
load_dotenv()
|
| 21 |
+
from together import Together
|
| 22 |
+
import base64
|
| 23 |
+
import yt_dlp
|
| 24 |
+
|
| 25 |
+
import datasets
|
| 26 |
+
from datasets import load_dataset
|
| 27 |
+
from huggingface_hub import list_models
|
| 28 |
+
from langchain.docstore.document import Document
|
| 29 |
+
from langchain_community.retrievers import BM25Retriever
|
| 30 |
+
from langchain_community.tools import DuckDuckGoSearchRun
|
| 31 |
+
from langchain_community.document_loaders import UnstructuredExcelLoader
|
| 32 |
+
from langchain_community.tools import WikipediaQueryRun
|
| 33 |
+
from langchain_community.utilities import WikipediaAPIWrapper
|
| 34 |
+
from langchain.tools import Tool
|
| 35 |
+
from langchain_ollama import ChatOllama
|
| 36 |
+
from langchain_together import ChatTogether
|
| 37 |
+
from langchain_huggingface import HuggingFaceEndpoint,ChatHuggingFace
|
| 38 |
+
from langchain_core.messages import AnyMessage, HumanMessage, AIMessage, SystemMessage, ToolMessage
|
| 39 |
+
from langgraph.graph import StateGraph, START, END
|
| 40 |
+
from langgraph.graph.message import add_messages
|
| 41 |
+
from langgraph.prebuilt import tools_condition, ToolNode
|
| 42 |
+
from langsmith import traceable
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# GLOBALS
|
| 47 |
+
HF_TOKEN = os.getenv('HF_TOKEN')
|
| 48 |
+
LAMINAR_API_KEY = os.getenv('LAMINAR_API_KEY')
|
| 49 |
+
# from the task
|
| 50 |
+
DEFAULT_API_URL = "https://agents-course-unit4-scoring.hf.space"
|
| 51 |
+
api_url = DEFAULT_API_URL
|
| 52 |
+
questions_url = f"{api_url}/questions"
|
| 53 |
+
submit_url = f"{api_url}/submit"
|
| 54 |
+
file_url = f"{api_url}/files"
|
| 55 |
+
|
| 56 |
+
# DEFAULT_SYSTEM_PROMPT = """You are a general AI assistant. I will ask you a question. Report your thoughts, and finish your answer with the following template: FINAL ANSWER: [YOUR FINAL ANSWER]. YOUR FINAL ANSWER should be a number OR as few words as possible OR a comma separated list of numbers and/or strings. If you are asked for a number, don't use comma to write your number neither use units such as $ or percent sign unless specified otherwise. If you are asked for a string, don't use articles, neither abbreviations (e.g. for cities), and write the digits in plain text unless specified otherwise.If you are asked for a comma separated list, apply the above rules depending of whether the element to be put in the list is a number or a string."""
|
| 57 |
+
DEFAULT_SYSTEM_PROMPT = """
|
| 58 |
+
You are a general AI assistant.
|
| 59 |
+
I will ask you a question.
|
| 60 |
+
Report your thoughts, and finish your answer with the following template: FINAL ANSWER: [YOUR FINAL ANSWER].
|
| 61 |
+
YOUR FINAL ANSWER should be a number OR as few words as possible OR a comma separated list of numbers and/or strings.
|
| 62 |
+
If you are asked for a number, don't use comma to write your number neither use units such as $ or percent sign unless specified otherwise.
|
| 63 |
+
If you are asked for a string, don't use articles, neither abbreviations (e.g. for cities), and write the digits in plain text unless specified otherwise.
|
| 64 |
+
If you are asked for a comma separated list, apply the above rules depending of whether the element to be put in the list is a number or a string.
|
| 65 |
+
"""
|
| 66 |
+
# Think step by step. On every step use a tool if it is needed. Make multiple tool calls if required.
|
| 67 |
+
DEFAULT_SYSTEM_PROMPT = DEFAULT_SYSTEM_PROMPT.replace("\n", "")
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
# model_name = 'qwen3:8b'
|
| 71 |
+
model_name = 'llama3.2:latest'
|
gradio_functions.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from globals import *
|
| 2 |
+
from langgraph_agent import *
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import io
|
| 5 |
+
|
| 6 |
+
train_dataset = load_dataset("gaia-benchmark/GAIA", '2023_level1', split="validation")
|
| 7 |
+
builder, builder_name = workflow_tools()
|
| 8 |
+
alfred = builder.compile()
|
| 9 |
+
|
| 10 |
+
def toggle_textbox(show):
|
| 11 |
+
return gr.update(visible=not show)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def slider_release_func(q_num: int):
|
| 15 |
+
item = train_dataset[q_num]
|
| 16 |
+
tr_metadata = ''
|
| 17 |
+
for k, v in item['Annotator Metadata'].items():
|
| 18 |
+
tr_metadata += f'{k}: \n{v} \n---\n'
|
| 19 |
+
|
| 20 |
+
return item['Question'], item['Final answer'], item['file_name'], tr_metadata.strip(), item['Annotator Metadata']['Tools']
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def process_output(response):
|
| 24 |
+
s = response['messages'][-1].content
|
| 25 |
+
pattern = "FINAL ANSWER: "
|
| 26 |
+
index = s.find(pattern)
|
| 27 |
+
if index != -1:
|
| 28 |
+
result = s[index + len(pattern):].lstrip()
|
| 29 |
+
return s, result
|
| 30 |
+
return s, f'WITH ERROR: {s}'
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_agent_answer_train(q_num: int):
|
| 35 |
+
item = train_dataset[q_num]
|
| 36 |
+
return ask_alfred(question=item['Question'], file_name=item['file_name'])
|
| 37 |
+
# # q_content = item['Question']
|
| 38 |
+
# response = alfred.invoke({
|
| 39 |
+
# 'messages': [HumanMessage(content=item['Question'])],
|
| 40 |
+
# 'file_name': item['file_name'],
|
| 41 |
+
# 'final_output_is_good': False,
|
| 42 |
+
# })
|
| 43 |
+
# # response = alfred.invoke({'messages': [HumanMessage(content=q_content)]})
|
| 44 |
+
# return process_output(response)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def ask_alfred(question: str, file_name: str):
|
| 49 |
+
response = alfred.invoke({
|
| 50 |
+
'messages': [HumanMessage(content=question)],
|
| 51 |
+
'file_name': file_name,
|
| 52 |
+
'final_output_is_good': False,
|
| 53 |
+
})
|
| 54 |
+
# response = alfred.invoke({'messages': [HumanMessage(content=q_content)]})
|
| 55 |
+
return process_output(response)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def show_langgraph_structure():
|
| 59 |
+
png_bytes = alfred.get_graph().draw_mermaid_png()
|
| 60 |
+
image = Image.open(io.BytesIO(png_bytes))
|
| 61 |
+
return image
|
| 62 |
+
|
langgraph.png
ADDED

|
langgraph_agent.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from globals import *
|
| 2 |
+
from tools import *
|
| 3 |
+
|
| 4 |
+
# ------------------------------------------------------ #
|
| 5 |
+
# MODELS
|
| 6 |
+
# ------------------------------------------------------ #
|
| 7 |
+
# init_chat_llm = ChatOllama(model=model_name)
|
| 8 |
+
init_chat_llm = ChatTogether(model="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY"))
|
| 9 |
+
|
| 10 |
+
# ------------------------------------------------------ #
|
| 11 |
+
# BENDING TO TOOLS
|
| 12 |
+
# ------------------------------------------------------ #
|
| 13 |
+
# tools = [guest_info_tool, search_tool, weather_info_tool, hub_stats_tool]
|
| 14 |
+
# tools = [search_tool]
|
| 15 |
+
tools = [
|
| 16 |
+
search_tool,
|
| 17 |
+
describe_image_tool,
|
| 18 |
+
describe_audio_tool,
|
| 19 |
+
python_repl_tool,
|
| 20 |
+
excel_repl_tool,
|
| 21 |
+
youtube_extractor_tool,
|
| 22 |
+
wikipedia_tool
|
| 23 |
+
]
|
| 24 |
+
chat_llm = init_chat_llm.bind_tools(tools)
|
| 25 |
+
|
| 26 |
+
# ------------------------------------------------------ #
|
| 27 |
+
# STATE
|
| 28 |
+
# ------------------------------------------------------ #
|
| 29 |
+
class AgentState(TypedDict):
|
| 30 |
+
# messages: list[AnyMessage, add_messages]
|
| 31 |
+
messages: list[AnyMessage]
|
| 32 |
+
file_name: str
|
| 33 |
+
final_output_is_good: bool
|
| 34 |
+
|
| 35 |
+
# ------------------------------------------------------ #
|
| 36 |
+
# HELP FUNCTIONS
|
| 37 |
+
# ------------------------------------------------------ #
|
| 38 |
+
def step_print(state: AgentState | None, step_label: str):
|
| 39 |
+
if state:
|
| 40 |
+
print(f'<<--- [{len(state["messages"])}] Entering ``{step_label}`` Node... --->>')
|
| 41 |
+
else:
|
| 42 |
+
print(f'<<--- [] Entering ``{step_label}`` Node... --->>')
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def messages_print(messages_to_print: List[AnyMessage]):
|
| 46 |
+
print('--- Message/s ---')
|
| 47 |
+
for m in messages_to_print:
|
| 48 |
+
print(f'{m.type} ({m.name}): \n{m.content}')
|
| 49 |
+
print(f'<<--- *** --->>')
|
| 50 |
+
|
| 51 |
+
# ------------------------------------------------------ #
|
| 52 |
+
# NODES
|
| 53 |
+
# ------------------------------------------------------ #
|
| 54 |
+
def preprocessing(state: AgentState):
|
| 55 |
+
# state['messages'] = [state['messages'][0]]
|
| 56 |
+
step_print(None, 'Preprocessing')
|
| 57 |
+
if state['file_name'] != '':
|
| 58 |
+
# state['messages'] += f"\nfile_name: {state['file_name']}"
|
| 59 |
+
state['messages'][0].content += f"\nfile_name: {state['file_name']}"
|
| 60 |
+
messages_print(state['messages'])
|
| 61 |
+
return {
|
| 62 |
+
"messages": [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state["messages"]
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def assistant(state: AgentState):
|
| 67 |
+
# state["messages"] = [SystemMessage(content=DEFAULT_SYSTEM_PROMPT)] + state["messages"]
|
| 68 |
+
step_print(state, 'assistant')
|
| 69 |
+
ai_message = chat_llm.invoke(state["messages"])
|
| 70 |
+
messages_print([ai_message])
|
| 71 |
+
return {
|
| 72 |
+
'messages': state["messages"] + [ai_message]
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
base_tool_node = ToolNode(tools)
|
| 77 |
+
def wrapped_tool_node(state: AgentState):
|
| 78 |
+
step_print(state, 'Tools')
|
| 79 |
+
# Call the original ToolNode
|
| 80 |
+
result = base_tool_node.invoke(state)
|
| 81 |
+
messages_print(result["messages"])
|
| 82 |
+
# Append to the messages list instead of replacing it
|
| 83 |
+
state["messages"] += result["messages"]
|
| 84 |
+
return {"messages": state["messages"]}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def checker_final_answer(state: AgentState):
|
| 88 |
+
step_print(state, 'Final Check')
|
| 89 |
+
s = state['messages'][-1].content
|
| 90 |
+
if "FINAL ANSWER: " not in s:
|
| 91 |
+
return {
|
| 92 |
+
'messages': state["messages"],
|
| 93 |
+
'final_output_is_good': False
|
| 94 |
+
}
|
| 95 |
+
return {
|
| 96 |
+
'final_output_is_good': True
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
# ------------------------------------------------------ #
|
| 100 |
+
# CONDITIONAL FUNCTIONS
|
| 101 |
+
# ------------------------------------------------------ #
|
| 102 |
+
def condition_output(state: AgentState) -> Literal["assistant", "__end__"]:
|
| 103 |
+
if state['final_output_is_good']:
|
| 104 |
+
return END
|
| 105 |
+
return "assistant"
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def condition_tools_or_continue(
|
| 109 |
+
state: Union[list[AnyMessage], dict[str, Any], BaseModel],
|
| 110 |
+
messages_key: str = "messages",
|
| 111 |
+
) -> Literal["tools", "checker_final_answer"]:
|
| 112 |
+
|
| 113 |
+
if isinstance(state, list):
|
| 114 |
+
ai_message = state[-1]
|
| 115 |
+
elif isinstance(state, dict) and (messages := state.get(messages_key, [])):
|
| 116 |
+
ai_message = messages[-1]
|
| 117 |
+
elif messages := getattr(state, messages_key, []):
|
| 118 |
+
ai_message = messages[-1]
|
| 119 |
+
else:
|
| 120 |
+
# pass
|
| 121 |
+
raise ValueError(f"No messages found in input state to tool_edge: {state}")
|
| 122 |
+
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
|
| 123 |
+
return "tools"
|
| 124 |
+
return "checker_final_answer"
|
| 125 |
+
# return "__end__"
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# ------------------------------------------------------ #
|
| 129 |
+
# BUILDERS
|
| 130 |
+
# ------------------------------------------------------ #
|
| 131 |
+
def workflow_simple() -> Tuple[StateGraph, str]:
|
| 132 |
+
i_builder = StateGraph(AgentState)
|
| 133 |
+
# Nodes
|
| 134 |
+
i_builder.add_node('preprocessing', preprocessing)
|
| 135 |
+
i_builder.add_node('assistant', assistant)
|
| 136 |
+
|
| 137 |
+
# Edges
|
| 138 |
+
i_builder.add_edge(START, 'preprocessing')
|
| 139 |
+
i_builder.add_edge('preprocessing', 'assistant')
|
| 140 |
+
return i_builder, 'workflow_simple'
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def workflow_tools() -> Tuple[StateGraph, str]:
|
| 144 |
+
i_builder = StateGraph(AgentState)
|
| 145 |
+
|
| 146 |
+
# Nodes
|
| 147 |
+
i_builder.add_node('preprocessing', preprocessing)
|
| 148 |
+
i_builder.add_node('assistant', assistant)
|
| 149 |
+
i_builder.add_node('tools', wrapped_tool_node)
|
| 150 |
+
i_builder.add_node('checker_final_answer', checker_final_answer)
|
| 151 |
+
|
| 152 |
+
# Edges
|
| 153 |
+
i_builder.add_edge(START, 'preprocessing')
|
| 154 |
+
i_builder.add_edge('preprocessing', 'assistant')
|
| 155 |
+
i_builder.add_conditional_edges('assistant', condition_tools_or_continue)
|
| 156 |
+
i_builder.add_edge('tools', 'assistant')
|
| 157 |
+
i_builder.add_conditional_edges('checker_final_answer', condition_output)
|
| 158 |
+
return i_builder, 'workflow_tools'
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
@traceable
|
| 162 |
+
def main():
|
| 163 |
+
# Laminar.initialize(project_api_key=LAMINAR_API_KEY)
|
| 164 |
+
# ------------------------------------------------------ #
|
| 165 |
+
# COMPILATION
|
| 166 |
+
# ------------------------------------------------------ #
|
| 167 |
+
# builder, builder_name = workflow_simple()
|
| 168 |
+
builder, builder_name = workflow_tools()
|
| 169 |
+
|
| 170 |
+
alfred = builder.compile()
|
| 171 |
+
# print(alfred.get_graph().draw_ascii())
|
| 172 |
+
# print(alfred.get_graph().draw_mermaid())
|
| 173 |
+
# with open(f"{builder_name}.png", "wb") as f:
|
| 174 |
+
# f.write(alfred.get_graph().draw_mermaid_png())
|
| 175 |
+
|
| 176 |
+
# ------------------------------------------------------ #
|
| 177 |
+
# EXAMPLES
|
| 178 |
+
# ------------------------------------------------------ #
|
| 179 |
+
# response = alfred.invoke({'messages': "What is an apple?"})
|
| 180 |
+
# ---
|
| 181 |
+
question = """
|
| 182 |
+
If Eliud Kipchoge could maintain his record-making marathon pace indefinitely,
|
| 183 |
+
how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach?
|
| 184 |
+
Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation.
|
| 185 |
+
Round your result to the nearest 1000 hours and do not use any comma separators if necessary.
|
| 186 |
+
"""
|
| 187 |
+
# response = alfred.invoke({'messages': [HumanMessage(content=question.replace('\n', ""))]})
|
| 188 |
+
response = alfred.invoke({'messages': [HumanMessage(content="Who is the president of USA in 2025?")]})
|
| 189 |
+
|
| 190 |
+
print(f"--- OUTPUT --- \n{response['messages'][-1].content}\n--- --- ---")
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
if __name__ == '__main__':
|
| 194 |
+
main()
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
requests
|
retriever.py
ADDED
|
File without changes
|
togetherai_chat_example.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from langchain_together import ChatTogether
|
| 3 |
+
from dotenv import load_dotenv
|
| 4 |
+
load_dotenv()
|
| 5 |
+
from langchain_community.tools import DuckDuckGoSearchRun
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
llm = ChatTogether(model="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY"))
|
| 9 |
+
|
| 10 |
+
search_tool = DuckDuckGoSearchRun()
|
| 11 |
+
|
| 12 |
+
# Augment the LLM with tools
|
| 13 |
+
llm_with_tools = llm.bind_tools([search_tool])
|
| 14 |
+
|
| 15 |
+
# Invoke the LLM with input that triggers the tool call
|
| 16 |
+
response = llm_with_tools.invoke("If Eliud Kipchoge could maintain his record-making marathon pace indefinitely, how many thousand hours would it take him to run the distance between the Earth and the Moon its closest approach? Please use the minimum perigee value on the Wikipedia page for the Moon when carrying out your calculation. Round your result to the nearest 1000 hours and do not use any comma separators if necessary.")
|
| 17 |
+
|
| 18 |
+
print(response)
|
| 19 |
+
# Get the tool call
|
| 20 |
+
print(response.tool_calls)
|
togetherai_pic_generation_example.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from together import Together
|
| 2 |
+
import os
|
| 3 |
+
from langchain_together import ChatTogether
|
| 4 |
+
from dotenv import load_dotenv
|
| 5 |
+
load_dotenv()
|
| 6 |
+
import base64
|
| 7 |
+
#%%
|
| 8 |
+
client = Together()
|
| 9 |
+
|
| 10 |
+
getDescriptionPrompt = "what is in the image? describe in detail"
|
| 11 |
+
|
| 12 |
+
imagePath= "pics/IMG_3651.jpg"
|
| 13 |
+
|
| 14 |
+
def encode_image(image_path):
|
| 15 |
+
with open(image_path, "rb") as image_file:
|
| 16 |
+
return base64.b64encode(image_file.read()).decode('utf-8')
|
| 17 |
+
|
| 18 |
+
base64_image = encode_image(imagePath)
|
| 19 |
+
|
| 20 |
+
stream = client.chat.completions.create(
|
| 21 |
+
# model="meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo",
|
| 22 |
+
model="meta-llama/Llama-Vision-Free",
|
| 23 |
+
messages=[
|
| 24 |
+
{
|
| 25 |
+
"role": "user",
|
| 26 |
+
"content": [
|
| 27 |
+
{"type": "text", "text": getDescriptionPrompt},
|
| 28 |
+
{
|
| 29 |
+
"type": "image_url",
|
| 30 |
+
"image_url": {
|
| 31 |
+
"url": f"data:image/jpeg;base64,{base64_image}",
|
| 32 |
+
},
|
| 33 |
+
},
|
| 34 |
+
],
|
| 35 |
+
}
|
| 36 |
+
],
|
| 37 |
+
stream=False,
|
| 38 |
+
)
|
| 39 |
+
#%%
|
| 40 |
+
prompt = stream.choices[0].message.content
|
| 41 |
+
#%%
|
| 42 |
+
client = Together()
|
| 43 |
+
response = client.images.generate(
|
| 44 |
+
prompt=prompt,
|
| 45 |
+
model="black-forest-labs/FLUX.1-schnell-Free",
|
| 46 |
+
steps=4,
|
| 47 |
+
n=4
|
| 48 |
+
)
|
| 49 |
+
print(response.data[0].url)
|
| 50 |
+
|
| 51 |
+
# ---
|
| 52 |
+
|
| 53 |
+
# from together import Together
|
| 54 |
+
# import os
|
| 55 |
+
# from langchain_together import ChatTogether
|
| 56 |
+
# from dotenv import load_dotenv
|
| 57 |
+
# load_dotenv()
|
| 58 |
+
#
|
| 59 |
+
# client = Together()
|
| 60 |
+
# response = client.images.generate(
|
| 61 |
+
# prompt="Cats fighting boats with atomic bombs",
|
| 62 |
+
# model="black-forest-labs/FLUX.1-schnell-Free",
|
| 63 |
+
# steps=4,
|
| 64 |
+
# n=4
|
| 65 |
+
# )
|
| 66 |
+
# print(response.data[0].url)
|
tools.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from globals import *
|
| 2 |
+
from global_functions import *
|
| 3 |
+
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
|
| 4 |
+
import torch
|
| 5 |
+
import torchaudio.transforms as T
|
| 6 |
+
import pydub
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
# ------------------------------------------------------ #
|
| 10 |
+
# CONSTANTS FOR TOOLS
|
| 11 |
+
# ------------------------------------------------------ #
|
| 12 |
+
audio_model_dir = './models_for_proj/wav2vec2-base-960h'
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# ------------------------------------------------------ #
|
| 16 |
+
# FUNCTIONS FOR TOOLS
|
| 17 |
+
# ------------------------------------------------------ #
|
| 18 |
+
def read_mp3(f, normalized=False):
|
| 19 |
+
"""Read MP3 file to numpy array."""
|
| 20 |
+
a = pydub.AudioSegment.from_mp3(f)
|
| 21 |
+
y = np.array(a.get_array_of_samples())
|
| 22 |
+
if a.channels == 2:
|
| 23 |
+
y = y.reshape((-1, 2))
|
| 24 |
+
# y = y.mean(axis=1)
|
| 25 |
+
y = y[:,1]
|
| 26 |
+
if normalized:
|
| 27 |
+
return a.frame_rate, np.float32(y) / 2**15
|
| 28 |
+
else:
|
| 29 |
+
return a.frame_rate, y
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# ------------------------------------------------------ #
|
| 33 |
+
# MODELS FOR TOOLS
|
| 34 |
+
# ------------------------------------------------------ #
|
| 35 |
+
client = Together()
|
| 36 |
+
|
| 37 |
+
# audio
|
| 38 |
+
model = Wav2Vec2ForCTC.from_pretrained(audio_model_dir)
|
| 39 |
+
processor = Wav2Vec2Processor.from_pretrained(audio_model_dir)
|
| 40 |
+
|
| 41 |
+
# ------------------------------------------------------ #
|
| 42 |
+
# TOOLS
|
| 43 |
+
# ------------------------------------------------------ #
|
| 44 |
+
# search
|
| 45 |
+
search_tool = DuckDuckGoSearchRun()
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# png
|
| 49 |
+
def describe_image_tool(file_name: str) -> str:
|
| 50 |
+
"""
|
| 51 |
+
This tool receives a file name of an image, uploads the image and returns a detailed description of the image.
|
| 52 |
+
Inputs: file_name as str
|
| 53 |
+
Outputs: image detailed description as str
|
| 54 |
+
"""
|
| 55 |
+
assert '.png' in file_name
|
| 56 |
+
pic_dir = f'[describe_image_tool] files/{file_name}'
|
| 57 |
+
getDescriptionPrompt = "What is in the image? describe in detail. Use professional notations when applicable. For example, if the image is a chess position, describe the position of ALL pieces with classical chess algebraic notation. BE PRECISE!"
|
| 58 |
+
base64_image = encode_image(pic_dir)
|
| 59 |
+
model_out = client.chat.completions.create(
|
| 60 |
+
# model="meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo",
|
| 61 |
+
model="meta-llama/Llama-Vision-Free",
|
| 62 |
+
messages=[
|
| 63 |
+
{
|
| 64 |
+
"role": "user",
|
| 65 |
+
"content": [
|
| 66 |
+
{
|
| 67 |
+
"type": "text",
|
| 68 |
+
"text": getDescriptionPrompt},
|
| 69 |
+
{
|
| 70 |
+
"type": "image_url",
|
| 71 |
+
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}",},
|
| 72 |
+
},
|
| 73 |
+
],
|
| 74 |
+
}
|
| 75 |
+
],
|
| 76 |
+
stream=False,
|
| 77 |
+
)
|
| 78 |
+
description = model_out.choices[0].message.content
|
| 79 |
+
# state["messages"] += [HumanMessage(content='Do not use the image. Use the description provided further by tools.')]
|
| 80 |
+
return f"Do not use the image. Instead, use the description provided further by the tool. Here is the detailed description of the image. {description}"
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
# mp3
|
| 84 |
+
def describe_audio_tool(file_name: str) -> str:
|
| 85 |
+
"""
|
| 86 |
+
This tool receives a file name of an audio, uploads the audio and returns a detailed description of the audio.
|
| 87 |
+
Inputs: file_name as str
|
| 88 |
+
Outputs: audio detailed description as str
|
| 89 |
+
"""
|
| 90 |
+
# --------------------------------------------------------------------------- #
|
| 91 |
+
file_dir = f'files/{file_name}'
|
| 92 |
+
print(f"[describe_audio_tool] {file_dir=}")
|
| 93 |
+
audio_input_sr, audio_input_np = read_mp3(file_dir)
|
| 94 |
+
audio_input_t = torch.tensor(audio_input_np, dtype=torch.float32)
|
| 95 |
+
target_sr = 16000
|
| 96 |
+
resampler = T.Resample(audio_input_sr, target_sr, dtype=audio_input_t.dtype)
|
| 97 |
+
resampled_audio_input_t: torch.Tensor = resampler(audio_input_t)
|
| 98 |
+
resampled_audio_input_np = resampled_audio_input_t.numpy()
|
| 99 |
+
# --------------------------------------------------------------------------- #
|
| 100 |
+
inputs = processor(resampled_audio_input_np, sampling_rate=16000, return_tensors="pt", padding=True)
|
| 101 |
+
# Inference
|
| 102 |
+
with torch.no_grad():
|
| 103 |
+
logits = model(**inputs).logits
|
| 104 |
+
# Decode
|
| 105 |
+
predicted_ids = torch.argmax(logits, dim=-1)
|
| 106 |
+
transcription = processor.decode(predicted_ids[0])
|
| 107 |
+
return transcription
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# py
|
| 111 |
+
def python_repl_tool(file_name: str) -> str:
|
| 112 |
+
"""
|
| 113 |
+
This tool receives a file name of a python code and executes it. Then, it returns a an output of the code.
|
| 114 |
+
Inputs: file_name as str
|
| 115 |
+
Outputs: code's output as str
|
| 116 |
+
"""
|
| 117 |
+
file_dir = f'files/{file_name}'
|
| 118 |
+
print(f"[python_repl_tool] {file_dir=}")
|
| 119 |
+
if os.path.exists(file_dir):
|
| 120 |
+
result = subprocess.run(["python", file_dir], capture_output=True, text=True)
|
| 121 |
+
return result.stdout
|
| 122 |
+
else:
|
| 123 |
+
return 'No such file.'
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# xlsx
|
| 127 |
+
def excel_repl_tool(file_name: str) -> str:
|
| 128 |
+
"""
|
| 129 |
+
This tool receives a file name of an Excel file and reads it. Then, it returns a string of the content of the file.
|
| 130 |
+
Inputs: file_name as str
|
| 131 |
+
Outputs: file's content as str
|
| 132 |
+
"""
|
| 133 |
+
file_dir = f'files/{file_name}'
|
| 134 |
+
print(f"{file_dir=}")
|
| 135 |
+
loader = UnstructuredExcelLoader(file_dir, mode="elements")
|
| 136 |
+
docs = loader.load()
|
| 137 |
+
return docs[0].metadata['text_as_html']
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
# youtube
|
| 141 |
+
def youtube_extractor_tool(url: str) -> str:
|
| 142 |
+
"""
|
| 143 |
+
This tool receives a url of the youtube video and reads it. Then, it returns a string of the content of the video.
|
| 144 |
+
Inputs: url as str
|
| 145 |
+
Outputs: video's content as str
|
| 146 |
+
"""
|
| 147 |
+
file_name = 'my_audio_file'
|
| 148 |
+
ydl_opts = {
|
| 149 |
+
'format': 'bestaudio/best',
|
| 150 |
+
'outtmpl': f'files/{file_name}.%(ext)s', # <-- set your custom filename here
|
| 151 |
+
'postprocessors': [{
|
| 152 |
+
'key': 'FFmpegExtractAudio',
|
| 153 |
+
'preferredcodec': 'mp3',
|
| 154 |
+
'preferredquality': '192',
|
| 155 |
+
}],
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 159 |
+
ydl.download([url])
|
| 160 |
+
return describe_audio_tool(file_name=f'{file_name}.mp3')
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
# wiki
|
| 164 |
+
def wikipedia_tool(query: str) -> str:
|
| 165 |
+
"""
|
| 166 |
+
This tool receives a query to search inside the Wikipedia website, reads the page and returns the relevant information as a string.
|
| 167 |
+
Inputs: query as str
|
| 168 |
+
Outputs: Wikipedia's relevant content as str
|
| 169 |
+
"""
|
| 170 |
+
print(f"[wiki tool] {query=}")
|
| 171 |
+
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
|
| 172 |
+
respond = wikipedia.run(query)
|
| 173 |
+
return respond
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# pdf
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# web
|
workflow_simple.png
ADDED
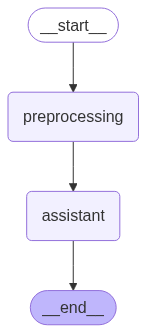
|
workflow_tools.png
ADDED

|
x_audio_analysis.ipynb
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"source": "Audio",
|
| 7 |
+
"id": "8b8c1a352260e82a"
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
"cell_type": "code",
|
| 11 |
+
"id": "initial_id",
|
| 12 |
+
"metadata": {
|
| 13 |
+
"collapsed": true,
|
| 14 |
+
"ExecuteTime": {
|
| 15 |
+
"end_time": "2025-06-10T09:38:10.760409Z",
|
| 16 |
+
"start_time": "2025-06-10T09:38:10.617508Z"
|
| 17 |
+
}
|
| 18 |
+
},
|
| 19 |
+
"source": [
|
| 20 |
+
"from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor\n",
|
| 21 |
+
"import torch\n",
|
| 22 |
+
"import torchaudio.transforms as T\n",
|
| 23 |
+
"import pydub\n",
|
| 24 |
+
"import numpy as np"
|
| 25 |
+
],
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"execution_count": 5
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"metadata": {
|
| 31 |
+
"ExecuteTime": {
|
| 32 |
+
"end_time": "2025-06-10T09:43:53.684713Z",
|
| 33 |
+
"start_time": "2025-06-10T09:43:53.681866Z"
|
| 34 |
+
}
|
| 35 |
+
},
|
| 36 |
+
"cell_type": "code",
|
| 37 |
+
"source": [
|
| 38 |
+
"# CONSTANTS\n",
|
| 39 |
+
"audio_model_dir = './models_for_proj/wav2vec2-base-960h'\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"# audio_dir = 'files/1f975693-876d-457b-a649-393859e79bf3.mp3'\n",
|
| 42 |
+
"audio_dir = 'files/99c9cc74-fdc8-46c6-8f8d-3ce2d3bfeea3.mp3'"
|
| 43 |
+
],
|
| 44 |
+
"id": "3ee50d096b2c9d44",
|
| 45 |
+
"outputs": [],
|
| 46 |
+
"execution_count": 19
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"metadata": {
|
| 50 |
+
"ExecuteTime": {
|
| 51 |
+
"end_time": "2025-06-10T09:43:54.053411Z",
|
| 52 |
+
"start_time": "2025-06-10T09:43:54.006676Z"
|
| 53 |
+
}
|
| 54 |
+
},
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"source": [
|
| 57 |
+
"\n",
|
| 58 |
+
"model = Wav2Vec2ForCTC.from_pretrained(audio_model_dir)\n",
|
| 59 |
+
"processor = Wav2Vec2Processor.from_pretrained(audio_model_dir)"
|
| 60 |
+
],
|
| 61 |
+
"id": "b51a485af7b9cf14",
|
| 62 |
+
"outputs": [],
|
| 63 |
+
"execution_count": 20
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"metadata": {
|
| 67 |
+
"ExecuteTime": {
|
| 68 |
+
"end_time": "2025-06-10T09:43:54.603559Z",
|
| 69 |
+
"start_time": "2025-06-10T09:43:54.414677Z"
|
| 70 |
+
}
|
| 71 |
+
},
|
| 72 |
+
"cell_type": "code",
|
| 73 |
+
"source": [
|
| 74 |
+
"def read_mp3(f, normalized=False):\n",
|
| 75 |
+
" \"\"\"Read MP3 file to numpy array.\"\"\"\n",
|
| 76 |
+
" a = pydub.AudioSegment.from_mp3(f)\n",
|
| 77 |
+
" y = np.array(a.get_array_of_samples())\n",
|
| 78 |
+
" if a.channels == 2:\n",
|
| 79 |
+
" y = y.reshape((-1, 2))\n",
|
| 80 |
+
" if normalized:\n",
|
| 81 |
+
" return a.frame_rate, np.float32(y) / 2**15\n",
|
| 82 |
+
" else:\n",
|
| 83 |
+
" return a.frame_rate, y\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"# Usage\n",
|
| 86 |
+
"audio_input_sr, audio_input_np = read_mp3(audio_dir)"
|
| 87 |
+
],
|
| 88 |
+
"id": "ac7e2b43ace4d232",
|
| 89 |
+
"outputs": [],
|
| 90 |
+
"execution_count": 21
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"metadata": {
|
| 94 |
+
"ExecuteTime": {
|
| 95 |
+
"end_time": "2025-06-10T09:43:56.920665Z",
|
| 96 |
+
"start_time": "2025-06-10T09:43:56.244101Z"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
"cell_type": "code",
|
| 100 |
+
"source": [
|
| 101 |
+
"# --------------------------------------------------------------------------- #\n",
|
| 102 |
+
"# audio_input_sr, audio_input_np = audio_input\n",
|
| 103 |
+
"audio_input_t = torch.tensor(audio_input_np, dtype=torch.float32)\n",
|
| 104 |
+
"target_sr = 16000\n",
|
| 105 |
+
"resampler = T.Resample(audio_input_sr, target_sr, dtype=audio_input_t.dtype)\n",
|
| 106 |
+
"resampled_audio_input_t: torch.Tensor = resampler(audio_input_t)\n",
|
| 107 |
+
"resampled_audio_input_np = resampled_audio_input_t.numpy()\n",
|
| 108 |
+
"# --------------------------------------------------------------------------- #\n",
|
| 109 |
+
"# result = asr_pipe_default(resampled_audio_input_np)\n",
|
| 110 |
+
"inputs = processor(resampled_audio_input_np, sampling_rate=16000, return_tensors=\"pt\", padding=True)\n",
|
| 111 |
+
"# Inference\n",
|
| 112 |
+
"with torch.no_grad():\n",
|
| 113 |
+
" logits = model(**inputs).logits\n",
|
| 114 |
+
"# Decode\n",
|
| 115 |
+
"predicted_ids = torch.argmax(logits, dim=-1)\n",
|
| 116 |
+
"transcription = processor.decode(predicted_ids[0])\n",
|
| 117 |
+
"# print(\"Transcription:\", transcription)\n",
|
| 118 |
+
"transcription"
|
| 119 |
+
],
|
| 120 |
+
"id": "2a4738e9d038985",
|
| 121 |
+
"outputs": [
|
| 122 |
+
{
|
| 123 |
+
"data": {
|
| 124 |
+
"text/plain": [
|
| 125 |
+
"'IN A SAUCEPAN COMBINE RIPE STRAWBERRIES GRANULATED SUGAR FRESHLY SQUEEZED LEMON JUICE AND CORNSTARCH COOK THE MIXTURE OF A MEDIUM HEAT STIRRING CONSTANTLY UNTIL IT THICKENS TO A SMOOTH CONSISTENCY REMOVE FROM HEAT AND STIR IN A DASH OF PURE VANILLA EXTRACT ALLOW THE STRAWBERRY PIE FEELING TO COOL BEFORE USING IT AS A DELICIOUS AND FRUITY FILLING FOR YOUR PIE CRUST'"
|
| 126 |
+
]
|
| 127 |
+
},
|
| 128 |
+
"execution_count": 22,
|
| 129 |
+
"metadata": {},
|
| 130 |
+
"output_type": "execute_result"
|
| 131 |
+
}
|
| 132 |
+
],
|
| 133 |
+
"execution_count": 22
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"cell_type": "code",
|
| 138 |
+
"outputs": [],
|
| 139 |
+
"execution_count": null,
|
| 140 |
+
"source": "",
|
| 141 |
+
"id": "f159c2955f140600"
|
| 142 |
+
}
|
| 143 |
+
],
|
| 144 |
+
"metadata": {
|
| 145 |
+
"kernelspec": {
|
| 146 |
+
"display_name": "Python 3",
|
| 147 |
+
"language": "python",
|
| 148 |
+
"name": "python3"
|
| 149 |
+
},
|
| 150 |
+
"language_info": {
|
| 151 |
+
"codemirror_mode": {
|
| 152 |
+
"name": "ipython",
|
| 153 |
+
"version": 2
|
| 154 |
+
},
|
| 155 |
+
"file_extension": ".py",
|
| 156 |
+
"mimetype": "text/x-python",
|
| 157 |
+
"name": "python",
|
| 158 |
+
"nbconvert_exporter": "python",
|
| 159 |
+
"pygments_lexer": "ipython2",
|
| 160 |
+
"version": "2.7.6"
|
| 161 |
+
}
|
| 162 |
+
},
|
| 163 |
+
"nbformat": 4,
|
| 164 |
+
"nbformat_minor": 5
|
| 165 |
+
}
|
x_exel_files_loader.ipynb
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"id": "a49a961ef9dafc8b",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"ExecuteTime": {
|
| 8 |
+
"end_time": "2025-06-10T15:26:54.606280Z",
|
| 9 |
+
"start_time": "2025-06-10T15:26:54.499875Z"
|
| 10 |
+
}
|
| 11 |
+
},
|
| 12 |
+
"source": "from langchain_community.document_loaders import UnstructuredExcelLoader",
|
| 13 |
+
"outputs": [],
|
| 14 |
+
"execution_count": 3
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"metadata": {
|
| 18 |
+
"ExecuteTime": {
|
| 19 |
+
"end_time": "2025-06-10T15:26:54.806898Z",
|
| 20 |
+
"start_time": "2025-06-10T15:26:54.804638Z"
|
| 21 |
+
}
|
| 22 |
+
},
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"source": "file_dir = 'files/7bd855d8-463d-4ed5-93ca-5fe35145f733.xlsx'",
|
| 25 |
+
"id": "7f1454e97563e93",
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"execution_count": 4
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"metadata": {
|
| 31 |
+
"ExecuteTime": {
|
| 32 |
+
"end_time": "2025-06-10T15:29:12.643058Z",
|
| 33 |
+
"start_time": "2025-06-10T15:29:12.625239Z"
|
| 34 |
+
}
|
| 35 |
+
},
|
| 36 |
+
"cell_type": "code",
|
| 37 |
+
"source": [
|
| 38 |
+
"\n",
|
| 39 |
+
"loader = UnstructuredExcelLoader(file_dir, mode=\"elements\")\n",
|
| 40 |
+
"docs = loader.load()\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"print(len(docs))\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"# docs"
|
| 45 |
+
],
|
| 46 |
+
"id": "initial_id",
|
| 47 |
+
"outputs": [
|
| 48 |
+
{
|
| 49 |
+
"name": "stdout",
|
| 50 |
+
"output_type": "stream",
|
| 51 |
+
"text": [
|
| 52 |
+
"1\n"
|
| 53 |
+
]
|
| 54 |
+
}
|
| 55 |
+
],
|
| 56 |
+
"execution_count": 7
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"metadata": {
|
| 60 |
+
"ExecuteTime": {
|
| 61 |
+
"end_time": "2025-06-10T15:32:40.555855Z",
|
| 62 |
+
"start_time": "2025-06-10T15:32:40.553019Z"
|
| 63 |
+
}
|
| 64 |
+
},
|
| 65 |
+
"cell_type": "code",
|
| 66 |
+
"source": "print(docs[0].metadata['text_as_html'])",
|
| 67 |
+
"id": "6c69b91ca45b0039",
|
| 68 |
+
"outputs": [
|
| 69 |
+
{
|
| 70 |
+
"name": "stdout",
|
| 71 |
+
"output_type": "stream",
|
| 72 |
+
"text": [
|
| 73 |
+
"<table><tr><td>Location</td><td>Burgers</td><td>Hot Dogs</td><td>Salads</td><td>Fries</td><td>Ice Cream</td><td>Soda</td></tr><tr><td>Pinebrook</td><td>1594</td><td>1999</td><td>2002</td><td>2005</td><td>1977</td><td>1980</td></tr><tr><td>Wharvton</td><td>1983</td><td>2008</td><td>2014</td><td>2015</td><td>2017</td><td>2018</td></tr><tr><td>Sagrada</td><td>2019</td><td>2022</td><td>2022</td><td>2023</td><td>2021</td><td>2019</td></tr><tr><td>Algrimand</td><td>1958</td><td>1971</td><td>1982</td><td>1989</td><td>1998</td><td>2009</td></tr><tr><td>Marztep</td><td>2015</td><td>2016</td><td>2018</td><td>2019</td><td>2021</td><td>2022</td></tr><tr><td>San Cecelia</td><td>2011</td><td>2010</td><td>2012</td><td>2013</td><td>2015</td><td>2016</td></tr><tr><td>Pimento</td><td>2017</td><td>1999</td><td>2001</td><td>2003</td><td>1969</td><td>2967</td></tr><tr><td>Tinseles</td><td>1967</td><td>1969</td><td>1982</td><td>1994</td><td>2005</td><td>2006</td></tr><tr><td>Rosdale</td><td>2007</td><td>2009</td><td>2021</td><td>1989</td><td>2005</td><td>2011</td></tr></table>\n"
|
| 74 |
+
]
|
| 75 |
+
}
|
| 76 |
+
],
|
| 77 |
+
"execution_count": 11
|
| 78 |
+
},
|
| 79 |
+
{
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"cell_type": "code",
|
| 82 |
+
"outputs": [],
|
| 83 |
+
"execution_count": null,
|
| 84 |
+
"source": "",
|
| 85 |
+
"id": "29d83c36757726aa"
|
| 86 |
+
}
|
| 87 |
+
],
|
| 88 |
+
"metadata": {
|
| 89 |
+
"kernelspec": {
|
| 90 |
+
"display_name": "Python 3",
|
| 91 |
+
"language": "python",
|
| 92 |
+
"name": "python3"
|
| 93 |
+
},
|
| 94 |
+
"language_info": {
|
| 95 |
+
"codemirror_mode": {
|
| 96 |
+
"name": "ipython",
|
| 97 |
+
"version": 2
|
| 98 |
+
},
|
| 99 |
+
"file_extension": ".py",
|
| 100 |
+
"mimetype": "text/x-python",
|
| 101 |
+
"name": "python",
|
| 102 |
+
"nbconvert_exporter": "python",
|
| 103 |
+
"pygments_lexer": "ipython2",
|
| 104 |
+
"version": "2.7.6"
|
| 105 |
+
}
|
| 106 |
+
},
|
| 107 |
+
"nbformat": 4,
|
| 108 |
+
"nbformat_minor": 5
|
| 109 |
+
}
|
x_pic_generation.ipynb
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"source": "Picture generations\n",
|
| 7 |
+
"id": "d93a01c4260ba9d2"
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
"cell_type": "code",
|
| 11 |
+
"execution_count": null,
|
| 12 |
+
"id": "initial_id",
|
| 13 |
+
"metadata": {
|
| 14 |
+
"collapsed": true
|
| 15 |
+
},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"from together import Together\n",
|
| 19 |
+
"import os\n",
|
| 20 |
+
"from langchain_together import ChatTogether\n",
|
| 21 |
+
"from dotenv import load_dotenv\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"load_dotenv()\n",
|
| 24 |
+
"import base64\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"client = Together()\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"getDescriptionPrompt = \"what is in the image? describe in detail\"\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"imagePath = \"pics/IMG_3651.jpg\"\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"def encode_image(image_path):\n",
|
| 34 |
+
" with open(image_path, \"rb\") as image_file:\n",
|
| 35 |
+
" return base64.b64encode(image_file.read()).decode('utf-8')\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"\n",
|
| 38 |
+
"base64_image = encode_image(imagePath)\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"stream = client.chat.completions.create(\n",
|
| 41 |
+
" # model=\"meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo\",\n",
|
| 42 |
+
" model=\"meta-llama/Llama-Vision-Free\",\n",
|
| 43 |
+
" messages=[\n",
|
| 44 |
+
" {\n",
|
| 45 |
+
" \"role\": \"user\",\n",
|
| 46 |
+
" \"content\": [\n",
|
| 47 |
+
" {\"type\": \"text\", \"text\": getDescriptionPrompt},\n",
|
| 48 |
+
" {\n",
|
| 49 |
+
" \"type\": \"image_url\",\n",
|
| 50 |
+
" \"image_url\": {\n",
|
| 51 |
+
" \"url\": f\"data:image/jpeg;base64,{base64_image}\",\n",
|
| 52 |
+
" },\n",
|
| 53 |
+
" },\n",
|
| 54 |
+
" ],\n",
|
| 55 |
+
" }\n",
|
| 56 |
+
" ],\n",
|
| 57 |
+
" stream=False,\n",
|
| 58 |
+
")\n",
|
| 59 |
+
"prompt = stream.choices[0].message.content\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"response = client.images.generate(\n",
|
| 62 |
+
" prompt=prompt,\n",
|
| 63 |
+
" model=\"black-forest-labs/FLUX.1-schnell-Free\",\n",
|
| 64 |
+
" steps=4,\n",
|
| 65 |
+
" n=4\n",
|
| 66 |
+
")\n",
|
| 67 |
+
"print(response.data[0].url)"
|
| 68 |
+
]
|
| 69 |
+
}
|
| 70 |
+
],
|
| 71 |
+
"metadata": {
|
| 72 |
+
"kernelspec": {
|
| 73 |
+
"display_name": "Python 3",
|
| 74 |
+
"language": "python",
|
| 75 |
+
"name": "python3"
|
| 76 |
+
},
|
| 77 |
+
"language_info": {
|
| 78 |
+
"codemirror_mode": {
|
| 79 |
+
"name": "ipython",
|
| 80 |
+
"version": 2
|
| 81 |
+
},
|
| 82 |
+
"file_extension": ".py",
|
| 83 |
+
"mimetype": "text/x-python",
|
| 84 |
+
"name": "python",
|
| 85 |
+
"nbconvert_exporter": "python",
|
| 86 |
+
"pygments_lexer": "ipython2",
|
| 87 |
+
"version": "2.7.6"
|
| 88 |
+
}
|
| 89 |
+
},
|
| 90 |
+
"nbformat": 4,
|
| 91 |
+
"nbformat_minor": 5
|
| 92 |
+
}
|
x_python_code_executor.ipynb
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"source": "Python Code Executor",
|
| 7 |
+
"id": "f96e89bb67a640f5"
|
| 8 |
+
},
|
| 9 |
+
{
|
| 10 |
+
"cell_type": "code",
|
| 11 |
+
"id": "initial_id",
|
| 12 |
+
"metadata": {
|
| 13 |
+
"collapsed": true,
|
| 14 |
+
"ExecuteTime": {
|
| 15 |
+
"end_time": "2025-06-10T15:11:36.621661Z",
|
| 16 |
+
"start_time": "2025-06-10T15:11:36.617741Z"
|
| 17 |
+
}
|
| 18 |
+
},
|
| 19 |
+
"source": [
|
| 20 |
+
"from langchain_core.tools import Tool\n",
|
| 21 |
+
"from langchain_experimental.utilities import PythonREPL\n",
|
| 22 |
+
"import subprocess"
|
| 23 |
+
],
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"execution_count": 10
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"metadata": {
|
| 29 |
+
"ExecuteTime": {
|
| 30 |
+
"end_time": "2025-06-10T14:54:42.141759Z",
|
| 31 |
+
"start_time": "2025-06-10T14:54:42.138854Z"
|
| 32 |
+
}
|
| 33 |
+
},
|
| 34 |
+
"cell_type": "code",
|
| 35 |
+
"source": "file_dir = 'files/f918266a-b3e0-4914-865d-4faa564f1aef.py'",
|
| 36 |
+
"id": "1f0aed71e203012d",
|
| 37 |
+
"outputs": [],
|
| 38 |
+
"execution_count": 6
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"metadata": {
|
| 42 |
+
"ExecuteTime": {
|
| 43 |
+
"end_time": "2025-06-10T14:44:45.063803Z",
|
| 44 |
+
"start_time": "2025-06-10T14:44:45.061618Z"
|
| 45 |
+
}
|
| 46 |
+
},
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"source": "python_repl = PythonREPL()",
|
| 49 |
+
"id": "acea852beeb1035e",
|
| 50 |
+
"outputs": [],
|
| 51 |
+
"execution_count": 2
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"metadata": {
|
| 55 |
+
"ExecuteTime": {
|
| 56 |
+
"end_time": "2025-06-10T14:55:05.802715Z",
|
| 57 |
+
"start_time": "2025-06-10T14:55:05.797934Z"
|
| 58 |
+
}
|
| 59 |
+
},
|
| 60 |
+
"cell_type": "code",
|
| 61 |
+
"source": [
|
| 62 |
+
"\n",
|
| 63 |
+
"with open(file_dir, \"r\", encoding=\"utf-8\") as f:\n",
|
| 64 |
+
" code = f.read()\n",
|
| 65 |
+
" print(code)\n"
|
| 66 |
+
],
|
| 67 |
+
"id": "620b184072e95086",
|
| 68 |
+
"outputs": [
|
| 69 |
+
{
|
| 70 |
+
"name": "stdout",
|
| 71 |
+
"output_type": "stream",
|
| 72 |
+
"text": [
|
| 73 |
+
"from random import randint\n",
|
| 74 |
+
"import time\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"class UhOh(Exception):\n",
|
| 77 |
+
" pass\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"class Hmm:\n",
|
| 80 |
+
" def __init__(self):\n",
|
| 81 |
+
" self.value = randint(-100, 100)\n",
|
| 82 |
+
"\n",
|
| 83 |
+
" def Yeah(self):\n",
|
| 84 |
+
" if self.value == 0:\n",
|
| 85 |
+
" return True\n",
|
| 86 |
+
" else:\n",
|
| 87 |
+
" raise UhOh()\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"def Okay():\n",
|
| 90 |
+
" while True:\n",
|
| 91 |
+
" yield Hmm()\n",
|
| 92 |
+
"\n",
|
| 93 |
+
"def keep_trying(go, first_try=True):\n",
|
| 94 |
+
" maybe = next(go)\n",
|
| 95 |
+
" try:\n",
|
| 96 |
+
" if maybe.Yeah():\n",
|
| 97 |
+
" return maybe.value\n",
|
| 98 |
+
" except UhOh:\n",
|
| 99 |
+
" if first_try:\n",
|
| 100 |
+
" print(\"Working...\")\n",
|
| 101 |
+
" print(\"Please wait patiently...\")\n",
|
| 102 |
+
" time.sleep(0.1)\n",
|
| 103 |
+
" return keep_trying(go, first_try=False)\n",
|
| 104 |
+
"\n",
|
| 105 |
+
"if __name__ == \"__main__\":\n",
|
| 106 |
+
" go = Okay()\n",
|
| 107 |
+
" print(f\"{keep_trying(go)}\")\n",
|
| 108 |
+
"\n"
|
| 109 |
+
]
|
| 110 |
+
}
|
| 111 |
+
],
|
| 112 |
+
"execution_count": 8
|
| 113 |
+
},
|
| 114 |
+
{
|
| 115 |
+
"metadata": {
|
| 116 |
+
"ExecuteTime": {
|
| 117 |
+
"end_time": "2025-06-10T14:55:08.665931Z",
|
| 118 |
+
"start_time": "2025-06-10T14:55:08.661026Z"
|
| 119 |
+
}
|
| 120 |
+
},
|
| 121 |
+
"cell_type": "code",
|
| 122 |
+
"source": "print(python_repl.run(code))",
|
| 123 |
+
"id": "c55e78888adc58f2",
|
| 124 |
+
"outputs": [
|
| 125 |
+
{
|
| 126 |
+
"name": "stdout",
|
| 127 |
+
"output_type": "stream",
|
| 128 |
+
"text": [
|
| 129 |
+
"\n"
|
| 130 |
+
]
|
| 131 |
+
}
|
| 132 |
+
],
|
| 133 |
+
"execution_count": 9
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"metadata": {
|
| 137 |
+
"ExecuteTime": {
|
| 138 |
+
"end_time": "2025-06-10T15:13:00.580769Z",
|
| 139 |
+
"start_time": "2025-06-10T15:12:56.064064Z"
|
| 140 |
+
}
|
| 141 |
+
},
|
| 142 |
+
"cell_type": "code",
|
| 143 |
+
"source": [
|
| 144 |
+
"def run_as_main(filename):\n",
|
| 145 |
+
" result = subprocess.run([\"python\", filename], capture_output=True, text=True)\n",
|
| 146 |
+
" return result.stdout\n",
|
| 147 |
+
"print(run_as_main(file_dir))"
|
| 148 |
+
],
|
| 149 |
+
"id": "c7b145cdb13aea01",
|
| 150 |
+
"outputs": [
|
| 151 |
+
{
|
| 152 |
+
"name": "stdout",
|
| 153 |
+
"output_type": "stream",
|
| 154 |
+
"text": [
|
| 155 |
+
"Working...\n",
|
| 156 |
+
"Please wait patiently...\n",
|
| 157 |
+
"0\n",
|
| 158 |
+
"\n"
|
| 159 |
+
]
|
| 160 |
+
}
|
| 161 |
+
],
|
| 162 |
+
"execution_count": 13
|
| 163 |
+
},
|
| 164 |
+
{
|
| 165 |
+
"metadata": {},
|
| 166 |
+
"cell_type": "code",
|
| 167 |
+
"outputs": [],
|
| 168 |
+
"execution_count": null,
|
| 169 |
+
"source": [
|
| 170 |
+
"repl_tool = Tool(\n",
|
| 171 |
+
" name=\"python_repl\",\n",
|
| 172 |
+
" description=\"A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`.\",\n",
|
| 173 |
+
" func=python_repl.run,\n",
|
| 174 |
+
")"
|
| 175 |
+
],
|
| 176 |
+
"id": "1789b291aa070b8b"
|
| 177 |
+
}
|
| 178 |
+
],
|
| 179 |
+
"metadata": {
|
| 180 |
+
"kernelspec": {
|
| 181 |
+
"display_name": "Python 3",
|
| 182 |
+
"language": "python",
|
| 183 |
+
"name": "python3"
|
| 184 |
+
},
|
| 185 |
+
"language_info": {
|
| 186 |
+
"codemirror_mode": {
|
| 187 |
+
"name": "ipython",
|
| 188 |
+
"version": 2
|
| 189 |
+
},
|
| 190 |
+
"file_extension": ".py",
|
| 191 |
+
"mimetype": "text/x-python",
|
| 192 |
+
"name": "python",
|
| 193 |
+
"nbconvert_exporter": "python",
|
| 194 |
+
"pygments_lexer": "ipython2",
|
| 195 |
+
"version": "2.7.6"
|
| 196 |
+
}
|
| 197 |
+
},
|
| 198 |
+
"nbformat": 4,
|
| 199 |
+
"nbformat_minor": 5
|
| 200 |
+
}
|
x_wikipedia.ipynb
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"id": "initial_id",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"collapsed": true,
|
| 8 |
+
"ExecuteTime": {
|
| 9 |
+
"end_time": "2025-06-10T20:45:09.274873Z",
|
| 10 |
+
"start_time": "2025-06-10T20:45:08.953896Z"
|
| 11 |
+
}
|
| 12 |
+
},
|
| 13 |
+
"source": [
|
| 14 |
+
"from langchain_community.tools import WikipediaQueryRun\n",
|
| 15 |
+
"from langchain_community.utilities import WikipediaAPIWrapper"
|
| 16 |
+
],
|
| 17 |
+
"outputs": [],
|
| 18 |
+
"execution_count": 1
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"metadata": {
|
| 22 |
+
"ExecuteTime": {
|
| 23 |
+
"end_time": "2025-06-10T20:45:16.805090Z",
|
| 24 |
+
"start_time": "2025-06-10T20:45:16.743407Z"
|
| 25 |
+
}
|
| 26 |
+
},
|
| 27 |
+
"cell_type": "code",
|
| 28 |
+
"source": "wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())",
|
| 29 |
+
"id": "516d65340769e70b",
|
| 30 |
+
"outputs": [],
|
| 31 |
+
"execution_count": 2
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"metadata": {
|
| 35 |
+
"ExecuteTime": {
|
| 36 |
+
"end_time": "2025-06-10T20:49:46.749788Z",
|
| 37 |
+
"start_time": "2025-06-10T20:49:43.387220Z"
|
| 38 |
+
}
|
| 39 |
+
},
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"source": [
|
| 42 |
+
"respond = wikipedia.run(\"HUNTER X HUNTER\")\n",
|
| 43 |
+
"respond"
|
| 44 |
+
],
|
| 45 |
+
"id": "c54ff01d863ca54f",
|
| 46 |
+
"outputs": [
|
| 47 |
+
{
|
| 48 |
+
"data": {
|
| 49 |
+
"text/plain": [
|
| 50 |
+
"'Page: Hunter × Hunter\\nSummary: Hunter × Hunter (pronounced \"hunter hunter\") is a Japanese manga series written and illustrated by Yoshihiro Togashi. It has been serialized in Shueisha\\'s shōnen manga magazine Weekly Shōnen Jump since March 1998, although the manga has frequently gone on extended hiatuses since 2006. Its chapters have been collected in 38 tankōbon volumes as of September 2024. The story focuses on a young boy named Gon Freecss who discovers that his father, who left him at a young age, is actually a world-renowned Hunter, a licensed professional who specializes in fantastical pursuits such as locating rare or unidentified animal species, treasure hunting, surveying unexplored enclaves, or hunting down lawless individuals. Gon departs on a journey to become a Hunter and eventually find his father. Along the way, Gon meets various other Hunters and encounters the paranormal.\\nHunter × Hunter was adapted into a 62-episode anime television series by Nippon Animation and directed by Kazuhiro Furuhashi, which ran on Fuji Television from October 1999 to March 2001. Three separate original video animations (OVAs) totaling 30 episodes were subsequently produced by Nippon Animation and released in Japan from 2002 to 2004. A second anime television series by Madhouse aired on Nippon Television from October 2011 to September 2014, totaling 148 episodes, with two animated theatrical films released in 2013. There are also numerous audio albums, video games, musicals, and other media based on Hunter × Hunter.\\nThe manga has been licensed for English release in North America by Viz Media since April 2005. Both television series have been also licensed by Viz Media, with the first series having aired on the Funimation Channel in 2009 and the second series broadcast on Adult Swim\\'s Toonami programming block from April 2016 to June 2019.\\nHunter × Hunter has been a huge critical and financial success and has become one of the best-selling manga series of all time, having over 84 million copies in circulation by July 2022.\\n\\n\\n\\nPage: Hunter × Hunter (2011 TV series)\\nSummary: Hunter × Hunter is an anime television series that aired from 2011 to 2014 based on Yoshihiro Togashi\\'s manga series Hunter × Hunter. The story begins with a young boy named Gon Freecss, who one day discovers that the father who he thought was dead, is in fact alive and well. He learns that his father, Ging, is a legendary \"Hunter\", an individual who has proven themselves an elite member of humanity. Despite the fact that Ging left his son with his relatives in order to pursue his own dreams, Gon becomes determined to follow in his father\\'s footsteps, pass the rigorous \"Hunter Examination\", and eventually find his father to become a Hunter in his own right.\\nThis second anime television series adaptation of Hunter × Hunter was announced on July 24, 2011. It is a complete reboot starting from the beginning of the original manga, with no connection to the first anime television series from 1999. Produced by Nippon TV, VAP, Shueisha and Madhouse, the series is directed by Hiroshi Kōjina, with Atsushi Maekawa and Tsutomu Kamishiro handling series composition, Takahiro Yoshimatsu designing the characters and Yoshihisa Hirano composing the music. Instead of having the old cast reprise their roles for the new adaptation, the series features an entirely new cast to voice the characters. The new series premiered airing weekly on Nippon TV and the nationwide Nippon News Network from October 2, 2011. The series started to be collected in both DVD and Blu-ray format on January 25, 2012. Viz Media has licensed the anime for a DVD/Blu-ray release in North America with an English dub. On television, the series began airing on Adult Swim\\'s Toonami programming block on April 17, 2016, and ended on June 23, 2019.\\nThe anime series\\' opening theme is alternated between the song \"Departure!\" and an alternate version titled \"Departure! -Second Version-\" both sung by Galneryus\\' vocalist Ma'"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
"execution_count": 4,
|
| 54 |
+
"metadata": {},
|
| 55 |
+
"output_type": "execute_result"
|
| 56 |
+
}
|
| 57 |
+
],
|
| 58 |
+
"execution_count": 4
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"metadata": {},
|
| 62 |
+
"cell_type": "code",
|
| 63 |
+
"outputs": [],
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"source": "",
|
| 66 |
+
"id": "b5d559230ecc3190"
|
| 67 |
+
}
|
| 68 |
+
],
|
| 69 |
+
"metadata": {
|
| 70 |
+
"kernelspec": {
|
| 71 |
+
"display_name": "Python 3",
|
| 72 |
+
"language": "python",
|
| 73 |
+
"name": "python3"
|
| 74 |
+
},
|
| 75 |
+
"language_info": {
|
| 76 |
+
"codemirror_mode": {
|
| 77 |
+
"name": "ipython",
|
| 78 |
+
"version": 2
|
| 79 |
+
},
|
| 80 |
+
"file_extension": ".py",
|
| 81 |
+
"mimetype": "text/x-python",
|
| 82 |
+
"name": "python",
|
| 83 |
+
"nbconvert_exporter": "python",
|
| 84 |
+
"pygments_lexer": "ipython2",
|
| 85 |
+
"version": "2.7.6"
|
| 86 |
+
}
|
| 87 |
+
},
|
| 88 |
+
"nbformat": 4,
|
| 89 |
+
"nbformat_minor": 5
|
| 90 |
+
}
|
x_youtube_loader.ipynb
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"id": "6369bdabdf59b658",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"ExecuteTime": {
|
| 8 |
+
"end_time": "2025-06-10T20:28:20.833977Z",
|
| 9 |
+
"start_time": "2025-06-10T20:28:14.932967Z"
|
| 10 |
+
}
|
| 11 |
+
},
|
| 12 |
+
"source": [
|
| 13 |
+
"from langchain.document_loaders import YoutubeLoader\n",
|
| 14 |
+
"from langchain_yt_dlp.youtube_loader import YoutubeLoaderDL\n",
|
| 15 |
+
"from globals import *\n",
|
| 16 |
+
"import torch\n",
|
| 17 |
+
"import torchaudio.transforms as T\n",
|
| 18 |
+
"import pydub\n",
|
| 19 |
+
"import numpy as np\n",
|
| 20 |
+
"from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor"
|
| 21 |
+
],
|
| 22 |
+
"outputs": [],
|
| 23 |
+
"execution_count": 33
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"metadata": {
|
| 27 |
+
"ExecuteTime": {
|
| 28 |
+
"end_time": "2025-06-10T20:05:04.414620Z",
|
| 29 |
+
"start_time": "2025-06-10T20:05:04.412354Z"
|
| 30 |
+
}
|
| 31 |
+
},
|
| 32 |
+
"cell_type": "code",
|
| 33 |
+
"source": "url = \"https://www.youtube.com/watch?v=1htKBjuUWec\"\n",
|
| 34 |
+
"id": "666e521f8ecf3f47",
|
| 35 |
+
"outputs": [],
|
| 36 |
+
"execution_count": 14
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"metadata": {
|
| 40 |
+
"ExecuteTime": {
|
| 41 |
+
"end_time": "2025-06-10T20:26:57.491908Z",
|
| 42 |
+
"start_time": "2025-06-10T20:26:57.489481Z"
|
| 43 |
+
}
|
| 44 |
+
},
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"source": [
|
| 47 |
+
"# Load transcript as LangChain Documents\n",
|
| 48 |
+
"# loader = YoutubeLoader.from_youtube_url(url, add_video_info=False)\n",
|
| 49 |
+
"# loader = YoutubeLoaderDL.from_youtube_url(\n",
|
| 50 |
+
"# url, add_video_info=True\n",
|
| 51 |
+
"# )\n",
|
| 52 |
+
"# docs = loader.load()\n",
|
| 53 |
+
"#\n",
|
| 54 |
+
"# # Print the transcript content\n",
|
| 55 |
+
"# for doc in docs:\n",
|
| 56 |
+
"# print(doc.page_content)\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"# Optionally, save to a file\n",
|
| 59 |
+
"# with open(\"transcript.txt\", \"w\", encoding=\"utf-8\") as f:\n",
|
| 60 |
+
"# for doc in docs:\n",
|
| 61 |
+
"# f.write(doc.page_content)"
|
| 62 |
+
],
|
| 63 |
+
"id": "initial_id",
|
| 64 |
+
"outputs": [],
|
| 65 |
+
"execution_count": 30
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"metadata": {
|
| 69 |
+
"ExecuteTime": {
|
| 70 |
+
"end_time": "2025-06-10T20:27:03.519450Z",
|
| 71 |
+
"start_time": "2025-06-10T20:27:03.517474Z"
|
| 72 |
+
}
|
| 73 |
+
},
|
| 74 |
+
"cell_type": "code",
|
| 75 |
+
"source": [
|
| 76 |
+
"# from pytube import YouTube\n",
|
| 77 |
+
"#\n",
|
| 78 |
+
"# yt = YouTube(url)\n",
|
| 79 |
+
"#\n",
|
| 80 |
+
"# # Download the audio stream (usually mp4)\n",
|
| 81 |
+
"# stream = yt.streams.filter(only_audio=True).first()\n",
|
| 82 |
+
"# stream.download(firstilename=f\"{yt.title}.mp3\")"
|
| 83 |
+
],
|
| 84 |
+
"id": "ec4885c3a15d9a2b",
|
| 85 |
+
"outputs": [],
|
| 86 |
+
"execution_count": 31
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"metadata": {
|
| 90 |
+
"ExecuteTime": {
|
| 91 |
+
"end_time": "2025-06-10T20:04:18.601366Z",
|
| 92 |
+
"start_time": "2025-06-10T20:04:18.597488Z"
|
| 93 |
+
}
|
| 94 |
+
},
|
| 95 |
+
"cell_type": "code",
|
| 96 |
+
"source": [
|
| 97 |
+
"import ssl\n",
|
| 98 |
+
"import certifi\n",
|
| 99 |
+
"# Correct: assign a lambda (function) that returns a properly configured SSL context\n",
|
| 100 |
+
"ssl._create_default_https_context = lambda: ssl.create_default_context(cafile=certifi.where())"
|
| 101 |
+
],
|
| 102 |
+
"id": "167af702547c15e4",
|
| 103 |
+
"outputs": [],
|
| 104 |
+
"execution_count": 12
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"metadata": {
|
| 108 |
+
"ExecuteTime": {
|
| 109 |
+
"end_time": "2025-06-10T20:07:53.667018Z",
|
| 110 |
+
"start_time": "2025-06-10T20:07:52.627871Z"
|
| 111 |
+
}
|
| 112 |
+
},
|
| 113 |
+
"cell_type": "code",
|
| 114 |
+
"source": [
|
| 115 |
+
"\n",
|
| 116 |
+
"from pytube import YouTube\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"def download_video(url, output_path='.'):\n",
|
| 119 |
+
" try:\n",
|
| 120 |
+
" yt = YouTube(url)\n",
|
| 121 |
+
" print('here')\n",
|
| 122 |
+
" stream = yt.streams.get_highest_resolution()\n",
|
| 123 |
+
" print(f\"Downloading: {yt.title}\")\n",
|
| 124 |
+
" stream.download(output_path=output_path)\n",
|
| 125 |
+
" print(\"Download completed.\")\n",
|
| 126 |
+
" except Exception as e:\n",
|
| 127 |
+
" print(f\"Error: {e}\")\n",
|
| 128 |
+
"\n",
|
| 129 |
+
"# Example usage\n",
|
| 130 |
+
"download_video(url)"
|
| 131 |
+
],
|
| 132 |
+
"id": "289b9a4321ea487b",
|
| 133 |
+
"outputs": [
|
| 134 |
+
{
|
| 135 |
+
"name": "stdout",
|
| 136 |
+
"output_type": "stream",
|
| 137 |
+
"text": [
|
| 138 |
+
"here\n",
|
| 139 |
+
"Error: HTTP Error 400: Bad Request\n"
|
| 140 |
+
]
|
| 141 |
+
}
|
| 142 |
+
],
|
| 143 |
+
"execution_count": 23
|
| 144 |
+
},
|
| 145 |
+
{
|
| 146 |
+
"metadata": {
|
| 147 |
+
"ExecuteTime": {
|
| 148 |
+
"end_time": "2025-06-10T20:08:47.590897Z",
|
| 149 |
+
"start_time": "2025-06-10T20:08:44.115350Z"
|
| 150 |
+
}
|
| 151 |
+
},
|
| 152 |
+
"cell_type": "code",
|
| 153 |
+
"source": [
|
| 154 |
+
"import yt_dlp\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"ydl_opts = {\n",
|
| 157 |
+
" 'format': 'best', # or 'bestvideo+bestaudio'\n",
|
| 158 |
+
" 'outtmpl': '%(title)s.%(ext)s', # save as video title\n",
|
| 159 |
+
"}\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"with yt_dlp.YoutubeDL(ydl_opts) as ydl:\n",
|
| 162 |
+
" ydl.download([url])"
|
| 163 |
+
],
|
| 164 |
+
"id": "4eb045792318e67a",
|
| 165 |
+
"outputs": [
|
| 166 |
+
{
|
| 167 |
+
"name": "stdout",
|
| 168 |
+
"output_type": "stream",
|
| 169 |
+
"text": [
|
| 170 |
+
"[youtube] Extracting URL: https://www.youtube.com/watch?v=1htKBjuUWec\n",
|
| 171 |
+
"[youtube] 1htKBjuUWec: Downloading webpage\n",
|
| 172 |
+
"[youtube] 1htKBjuUWec: Downloading tv client config\n",
|
| 173 |
+
"[youtube] 1htKBjuUWec: Downloading tv player API JSON\n",
|
| 174 |
+
"[youtube] 1htKBjuUWec: Downloading ios player API JSON\n",
|
| 175 |
+
"[youtube] 1htKBjuUWec: Downloading m3u8 information\n",
|
| 176 |
+
"[info] 1htKBjuUWec: Downloading 1 format(s): 18\n",
|
| 177 |
+
"[download] Destination: Teal'c coffee first time.mp4\n",
|
| 178 |
+
"[download] 100% of 1.19MiB in 00:00:01 at 1.09MiB/s \n"
|
| 179 |
+
]
|
| 180 |
+
}
|
| 181 |
+
],
|
| 182 |
+
"execution_count": 24
|
| 183 |
+
},
|
| 184 |
+
{
|
| 185 |
+
"metadata": {
|
| 186 |
+
"ExecuteTime": {
|
| 187 |
+
"end_time": "2025-06-10T20:22:32.706482Z",
|
| 188 |
+
"start_time": "2025-06-10T20:22:29.843517Z"
|
| 189 |
+
}
|
| 190 |
+
},
|
| 191 |
+
"cell_type": "code",
|
| 192 |
+
"source": [
|
| 193 |
+
"import yt_dlp\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"file_name = 'my_audio_file'\n",
|
| 196 |
+
"ydl_opts = {\n",
|
| 197 |
+
" 'format': 'bestaudio/best',\n",
|
| 198 |
+
" 'outtmpl': f'files/{file_name}.%(ext)s', # <-- set your custom filename here\n",
|
| 199 |
+
" 'postprocessors': [{\n",
|
| 200 |
+
" 'key': 'FFmpegExtractAudio',\n",
|
| 201 |
+
" 'preferredcodec': 'mp3',\n",
|
| 202 |
+
" 'preferredquality': '192',\n",
|
| 203 |
+
" }],\n",
|
| 204 |
+
"}\n",
|
| 205 |
+
"\n",
|
| 206 |
+
"with yt_dlp.YoutubeDL(ydl_opts) as ydl:\n",
|
| 207 |
+
" ydl.download([url])"
|
| 208 |
+
],
|
| 209 |
+
"id": "68b51ca78254d8f",
|
| 210 |
+
"outputs": [
|
| 211 |
+
{
|
| 212 |
+
"name": "stdout",
|
| 213 |
+
"output_type": "stream",
|
| 214 |
+
"text": [
|
| 215 |
+
"[youtube] Extracting URL: https://www.youtube.com/watch?v=1htKBjuUWec\n",
|
| 216 |
+
"[youtube] 1htKBjuUWec: Downloading webpage\n",
|
| 217 |
+
"[youtube] 1htKBjuUWec: Downloading tv client config\n",
|
| 218 |
+
"[youtube] 1htKBjuUWec: Downloading tv player API JSON\n",
|
| 219 |
+
"[youtube] 1htKBjuUWec: Downloading ios player API JSON\n",
|
| 220 |
+
"[youtube] 1htKBjuUWec: Downloading m3u8 information\n",
|
| 221 |
+
"[info] 1htKBjuUWec: Downloading 1 format(s): 251\n",
|
| 222 |
+
"[download] Destination: files/my_audio_file.webm\n",
|
| 223 |
+
"[download] 100% of 444.93KiB in 00:00:00 at 3.41MiB/s \n",
|
| 224 |
+
"[ExtractAudio] Destination: files/my_audio_file.mp3\n",
|
| 225 |
+
"Deleting original file files/my_audio_file.webm (pass -k to keep)\n"
|
| 226 |
+
]
|
| 227 |
+
}
|
| 228 |
+
],
|
| 229 |
+
"execution_count": 26
|
| 230 |
+
},
|
| 231 |
+
{
|
| 232 |
+
"metadata": {
|
| 233 |
+
"ExecuteTime": {
|
| 234 |
+
"end_time": "2025-06-10T20:35:23.558866Z",
|
| 235 |
+
"start_time": "2025-06-10T20:35:23.515883Z"
|
| 236 |
+
}
|
| 237 |
+
},
|
| 238 |
+
"cell_type": "code",
|
| 239 |
+
"source": [
|
| 240 |
+
"audio_model_dir = './models_for_proj/wav2vec2-base-960h'\n",
|
| 241 |
+
"model = Wav2Vec2ForCTC.from_pretrained(audio_model_dir)\n",
|
| 242 |
+
"processor = Wav2Vec2Processor.from_pretrained(audio_model_dir)\n",
|
| 243 |
+
"\n",
|
| 244 |
+
"def read_mp3(f, normalized=False):\n",
|
| 245 |
+
" \"\"\"Read MP3 file to numpy array.\"\"\"\n",
|
| 246 |
+
" a = pydub.AudioSegment.from_mp3(f)\n",
|
| 247 |
+
" y = np.array(a.get_array_of_samples())\n",
|
| 248 |
+
" if a.channels == 2:\n",
|
| 249 |
+
" y = y.reshape((-1, 2))\n",
|
| 250 |
+
" # y = y.mean(axis=1)\n",
|
| 251 |
+
" y = y[:,1]\n",
|
| 252 |
+
" if normalized:\n",
|
| 253 |
+
" return a.frame_rate, np.float32(y) / 2**15\n",
|
| 254 |
+
" else:\n",
|
| 255 |
+
" return a.frame_rate, y\n",
|
| 256 |
+
"\n",
|
| 257 |
+
"def describe_audio_tool(file_name: str) -> str:\n",
|
| 258 |
+
" \"\"\"\n",
|
| 259 |
+
" This tool receives a file name of an audio, uploads the audio and returns a detailed description of the audio.\n",
|
| 260 |
+
" Inputs: file_name as str\n",
|
| 261 |
+
" Outputs: audio detailed description as str\n",
|
| 262 |
+
" \"\"\"\n",
|
| 263 |
+
" # --------------------------------------------------------------------------- #\n",
|
| 264 |
+
" file_dir = f'files/{file_name}'\n",
|
| 265 |
+
" print(f\"{file_dir=}\")\n",
|
| 266 |
+
" audio_input_sr, audio_input_np = read_mp3(file_dir)\n",
|
| 267 |
+
" audio_input_t = torch.tensor(audio_input_np, dtype=torch.float32)\n",
|
| 268 |
+
" target_sr = 16000\n",
|
| 269 |
+
" resampler = T.Resample(audio_input_sr, target_sr, dtype=audio_input_t.dtype)\n",
|
| 270 |
+
" resampled_audio_input_t: torch.Tensor = resampler(audio_input_t)\n",
|
| 271 |
+
" resampled_audio_input_np = resampled_audio_input_t.numpy()\n",
|
| 272 |
+
" # --------------------------------------------------------------------------- #\n",
|
| 273 |
+
" inputs = processor(resampled_audio_input_np, sampling_rate=16000, return_tensors=\"pt\", padding=True)\n",
|
| 274 |
+
" # Inference\n",
|
| 275 |
+
" with torch.no_grad():\n",
|
| 276 |
+
" logits = model(**inputs).logits\n",
|
| 277 |
+
" # Decode\n",
|
| 278 |
+
" predicted_ids = torch.argmax(logits, dim=-1)\n",
|
| 279 |
+
" transcription = processor.decode(predicted_ids[0])\n",
|
| 280 |
+
" return transcription"
|
| 281 |
+
],
|
| 282 |
+
"id": "64f438af2b38765f",
|
| 283 |
+
"outputs": [],
|
| 284 |
+
"execution_count": 43
|
| 285 |
+
},
|
| 286 |
+
{
|
| 287 |
+
"metadata": {
|
| 288 |
+
"ExecuteTime": {
|
| 289 |
+
"end_time": "2025-06-10T20:35:27.235493Z",
|
| 290 |
+
"start_time": "2025-06-10T20:35:26.202459Z"
|
| 291 |
+
}
|
| 292 |
+
},
|
| 293 |
+
"cell_type": "code",
|
| 294 |
+
"source": "describe_audio_tool(file_name=f'{file_name}.mp3')",
|
| 295 |
+
"id": "b4a6ae10e1cbbcae",
|
| 296 |
+
"outputs": [
|
| 297 |
+
{
|
| 298 |
+
"name": "stdout",
|
| 299 |
+
"output_type": "stream",
|
| 300 |
+
"text": [
|
| 301 |
+
"file_dir='files/my_audio_file.mp3'\n"
|
| 302 |
+
]
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"data": {
|
| 306 |
+
"text/plain": [
|
| 307 |
+
"\"ALIS COFFEE'S GRAY WO IS JUST THINKING YET HE TAT SOMESCHICKERY A CHIC TEK H IS NOT HOT EXTREMELY\""
|
| 308 |
+
]
|
| 309 |
+
},
|
| 310 |
+
"execution_count": 44,
|
| 311 |
+
"metadata": {},
|
| 312 |
+
"output_type": "execute_result"
|
| 313 |
+
}
|
| 314 |
+
],
|
| 315 |
+
"execution_count": 44
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"metadata": {},
|
| 319 |
+
"cell_type": "code",
|
| 320 |
+
"outputs": [],
|
| 321 |
+
"execution_count": null,
|
| 322 |
+
"source": "",
|
| 323 |
+
"id": "ce9aaf764346b7e4"
|
| 324 |
+
}
|
| 325 |
+
],
|
| 326 |
+
"metadata": {
|
| 327 |
+
"kernelspec": {
|
| 328 |
+
"display_name": "Python 3",
|
| 329 |
+
"language": "python",
|
| 330 |
+
"name": "python3"
|
| 331 |
+
},
|
| 332 |
+
"language_info": {
|
| 333 |
+
"codemirror_mode": {
|
| 334 |
+
"name": "ipython",
|
| 335 |
+
"version": 2
|
| 336 |
+
},
|
| 337 |
+
"file_extension": ".py",
|
| 338 |
+
"mimetype": "text/x-python",
|
| 339 |
+
"name": "python",
|
| 340 |
+
"nbconvert_exporter": "python",
|
| 341 |
+
"pygments_lexer": "ipython2",
|
| 342 |
+
"version": "2.7.6"
|
| 343 |
+
}
|
| 344 |
+
},
|
| 345 |
+
"nbformat": 4,
|
| 346 |
+
"nbformat_minor": 5
|
| 347 |
+
}
|