Spaces:
Running

Running

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title: Complexity
|
| 3 |
emoji: 🐢
|
| 4 |
colorFrom: purple
|
| 5 |
colorTo: blue
|
|
@@ -9,171 +9,165 @@ thumbnail: >-
|
|
| 9 |
https://cdn-uploads.huggingface.co/production/uploads/643222d9f76c34519e96a299/8j1GHX24MV3-sv-4zl7ZB.png
|
| 10 |
---
|
| 11 |
|
| 12 |
-
# Complexity
|
| 13 |
|
| 14 |
-
**
|
| 15 |
|
| 16 |
-
## What is Complexity
|
| 17 |
|
| 18 |
-
Complexity
|
| 19 |
|
| 20 |
-
- **INL Dynamics** -
|
| 21 |
-
- **Token-Routed MLP** -
|
| 22 |
-
- **
|
| 23 |
-
- **
|
|
|
|
| 24 |
|
| 25 |
## Key Innovation: INL Dynamics
|
| 26 |
|
| 27 |
-
|
| 28 |
|
| 29 |
-
```
|
| 30 |
-
|
| 31 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
|
| 33 |
-
|
| 34 |
-
(self-stabilizing, recovers from spikes)
|
| 35 |
```
|
| 36 |
|
| 37 |
-
**
|
| 38 |
|
| 39 |
-
##
|
| 40 |
|
| 41 |
-
|
| 42 |
|
| 43 |
-
|
| 44 |
-
|--------|-------------|---------------------|
|
| 45 |
-
| Routing | Neural network | `token_id % num_experts` |
|
| 46 |
-
| Latency | 5-10ms | **<0.1ms** |
|
| 47 |
-
| Deterministic | No | **Yes** |
|
| 48 |
-
| Load balancing needed | Yes | **No** |
|
| 49 |
|
| 50 |
-
|
| 51 |
|
| 52 |
-
|
| 53 |
|
| 54 |
-
|
| 55 |
-
|-------|--------|--------|------|
|
| 56 |
-
| pacific-prime | 150M | Training (120K+ steps) | [HuggingFace](https://huggingface.co/Pacific-Prime/pacific-prime) |
|
| 57 |
-
| complexity-tiny | 150M | Available | [HuggingFace](https://huggingface.co/Pacific-Prime/complexity-tiny) |
|
| 58 |
|
| 59 |
-
##
|
| 60 |
|
| 61 |
```bash
|
| 62 |
-
pip install complexity-
|
| 63 |
```
|
| 64 |
|
| 65 |
-
## Quick Start
|
| 66 |
-
|
| 67 |
```python
|
| 68 |
-
from
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
|
| 70 |
-
#
|
| 71 |
-
|
|
|
|
| 72 |
|
| 73 |
-
#
|
| 74 |
-
|
| 75 |
-
config = DeepConfig.complexity_3_8b() # 3.8B params
|
| 76 |
-
config = DeepConfig.complexity_7b() # 7B params
|
| 77 |
```
|
| 78 |
|
| 79 |
-
##
|
| 80 |
|
| 81 |
-
|
|
| 82 |
-
|
| 83 |
-
|
|
| 84 |
-
|
|
| 85 |
-
|
|
| 86 |
-
|
|
|
|
|
|
|
|
| 87 |
|
| 88 |
-
##
|
| 89 |
|
| 90 |
-
|
|
|
|
| 91 |
|
| 92 |
-
|
|
|
|
| 93 |
|
| 94 |
-
|
| 95 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 96 |
|
| 97 |
-
|
| 98 |
-
Complexity: 5.6 → 4000 → 46 → 16 → 8 → 5.6 (auto-recovered!)
|
| 99 |
```
|
| 100 |
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
## Available Configurations
|
| 104 |
|
| 105 |
```python
|
| 106 |
-
|
| 107 |
-
DeepConfig.complexity_tiny() # ~15M
|
| 108 |
-
DeepConfig.complexity_20m() # ~20M
|
| 109 |
-
DeepConfig.complexity_small() # ~50M
|
| 110 |
-
|
| 111 |
-
# Medium models
|
| 112 |
-
DeepConfig.complexity_150m() # ~150M (default)
|
| 113 |
-
DeepConfig.complexity_base() # ~125M
|
| 114 |
-
DeepConfig.complexity_medium() # ~350M
|
| 115 |
-
|
| 116 |
-
# Large models
|
| 117 |
-
DeepConfig.complexity_1b() # ~1B
|
| 118 |
-
DeepConfig.complexity_3b() # ~3B
|
| 119 |
-
DeepConfig.complexity_3_8b() # ~3.8B
|
| 120 |
-
DeepConfig.complexity_7b() # ~7B
|
| 121 |
-
```
|
| 122 |
|
| 123 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 124 |
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
dynamics_beta=0.1, # Correction strength
|
| 129 |
-
dynamics_gate=0.5, # Amplitude control
|
| 130 |
-
dynamics_dt=0.1, # Integration timestep
|
| 131 |
-
)
|
| 132 |
```
|
| 133 |
|
| 134 |
-
##
|
| 135 |
|
| 136 |
-
|
| 137 |
-
INL Dynamics absorbs bad batches without killing your training run.
|
| 138 |
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
### 3. Robotics Applications
|
| 143 |
-
Deterministic Token-Routed MLP = predictable, certifiable behavior.
|
| 144 |
-
|
| 145 |
-
### 4. Edge Deployment
|
| 146 |
-
GQA + Token-Routed = fast inference with small KV cache.
|
| 147 |
-
|
| 148 |
-
## Research
|
| 149 |
|
| 150 |
-
|
|
|
|
|
|
|
|
|
|
| 151 |
|
| 152 |
-
|
| 153 |
|
| 154 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 155 |
|
| 156 |
## Links
|
| 157 |
|
| 158 |
-
- [
|
| 159 |
-
- [
|
| 160 |
-
- [Pacific-Prime Organization](https://huggingface.co/Pacific-Prime)
|
| 161 |
|
| 162 |
## License
|
| 163 |
|
| 164 |
-
CC
|
| 165 |
|
| 166 |
## Citation
|
| 167 |
|
| 168 |
```bibtex
|
| 169 |
-
@software{
|
| 170 |
-
title={Complexity
|
| 171 |
-
author={
|
| 172 |
year={2024},
|
| 173 |
-
url={https://
|
| 174 |
}
|
| 175 |
```
|
| 176 |
|
| 177 |
---
|
| 178 |
|
| 179 |
-
**
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Complexity Framework
|
| 3 |
emoji: 🐢
|
| 4 |
colorFrom: purple
|
| 5 |
colorTo: blue
|
|
|
|
| 9 |
https://cdn-uploads.huggingface.co/production/uploads/643222d9f76c34519e96a299/8j1GHX24MV3-sv-4zl7ZB.png
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Complexity Framework
|
| 13 |
|
| 14 |
+
**Modular Python framework for building LLMs with INL Dynamics stability**
|
| 15 |
|
| 16 |
+
## What is Complexity Framework?
|
| 17 |
|
| 18 |
+
Complexity Framework is a complete toolkit for building transformer architectures with built-in training stability. It provides:
|
| 19 |
|
| 20 |
+
- **INL Dynamics** - Second-order dynamical system for training stability
|
| 21 |
+
- **Token-Routed MLP (MoE)** - Efficient sparse activation
|
| 22 |
+
- **CUDA/Triton Optimizations** - Flash Attention, Sliding Window, Sparse, Linear
|
| 23 |
+
- **O(N) Architectures** - Mamba, RWKV, RetNet
|
| 24 |
+
- **Small Budget Training** - Quantization, Mixed Precision, Gradient Checkpointing
|
| 25 |
|
| 26 |
## Key Innovation: INL Dynamics
|
| 27 |
|
| 28 |
+
Velocity tracking to prevent training explosion after 400k+ steps:
|
| 29 |
|
| 30 |
+
```python
|
| 31 |
+
from complexity.api import INLDynamics
|
| 32 |
+
|
| 33 |
+
# CRITICAL: beta in [0, 2], NOT [0, inf)!
|
| 34 |
+
dynamics = INLDynamics(
|
| 35 |
+
hidden_size=768,
|
| 36 |
+
beta_max=2.0, # Clamp beta for stability
|
| 37 |
+
velocity_max=10.0, # Limit velocity
|
| 38 |
+
)
|
| 39 |
|
| 40 |
+
h_next, v_next = dynamics(hidden_states, velocity)
|
|
|
|
| 41 |
```
|
| 42 |
|
| 43 |
+
**The bug we fixed**: `softplus` without clamp goes to infinity, causing NaN after 400k steps. Clamping beta to [0, 2] keeps training stable.
|
| 44 |
|
| 45 |
+
## Loss Spike Recovery
|
| 46 |
|
| 47 |
+
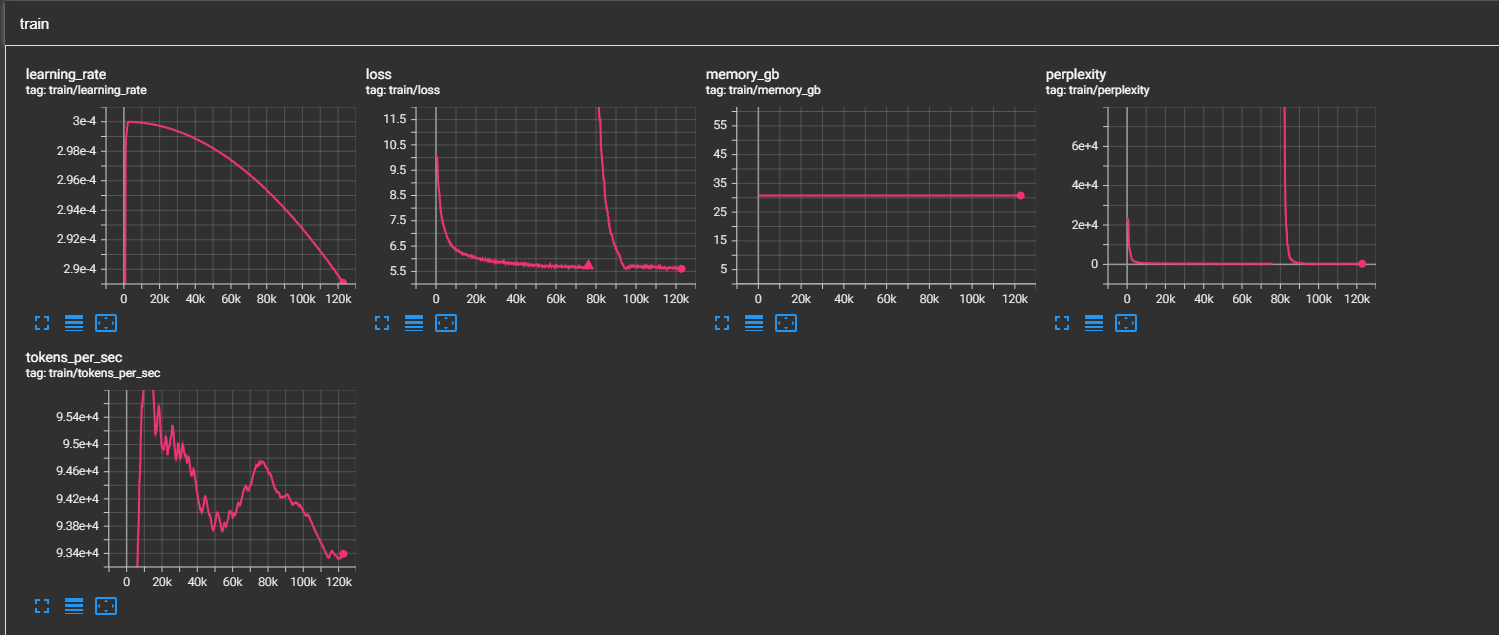
|
| 48 |
|
| 49 |
+
*INL Dynamics recovers from loss spikes thanks to velocity damping.*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Stability at 400k+ Steps
|
| 52 |
|
| 53 |
+
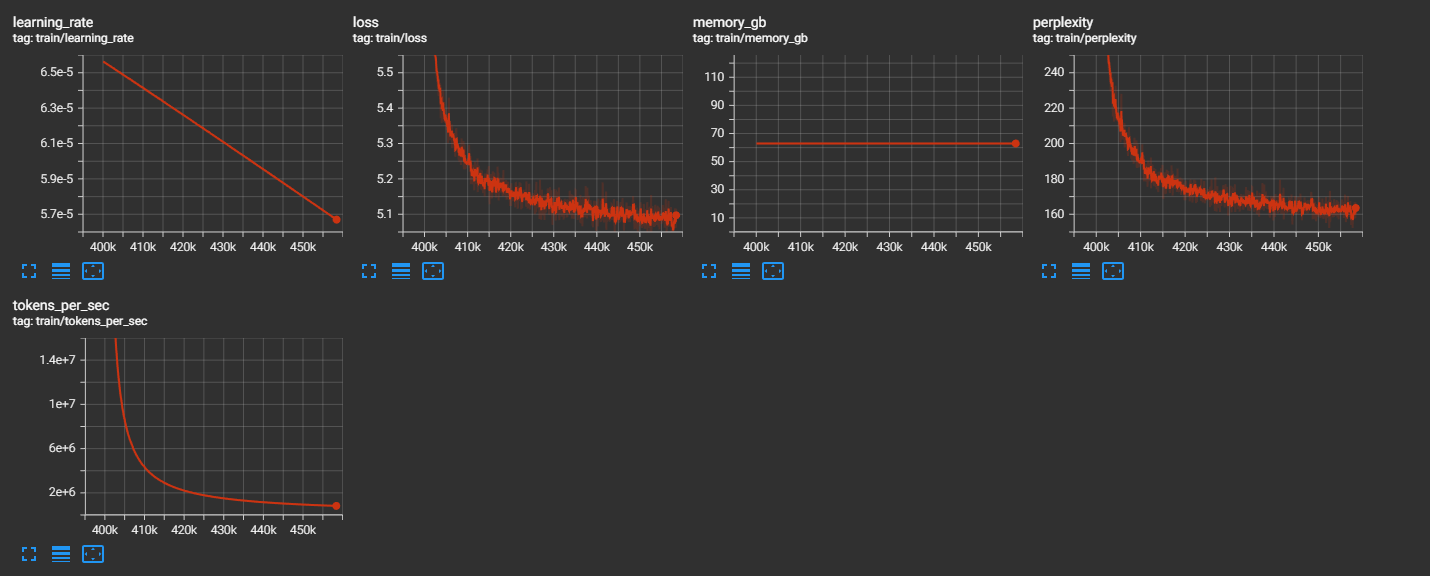
|
| 54 |
|
| 55 |
+
*After beta clamping fix: training remains stable past 400k steps where it previously exploded.*
|
|
|
|
|
|
|
|
|
|
| 56 |
|
| 57 |
+
## Quick Start
|
| 58 |
|
| 59 |
```bash
|
| 60 |
+
pip install complexity-framework
|
| 61 |
```
|
| 62 |
|
|
|
|
|
|
|
| 63 |
```python
|
| 64 |
+
from complexity.api import (
|
| 65 |
+
# Building blocks
|
| 66 |
+
Attention, MLP, RMSNorm, RoPE, INLDynamics,
|
| 67 |
+
# Optimizations
|
| 68 |
+
CUDA, Efficient,
|
| 69 |
+
# Architectures O(N)
|
| 70 |
+
Architecture, Mamba, RWKV,
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
# Flash Attention
|
| 74 |
+
attn = CUDA.flash(hidden_size=4096, num_heads=32)
|
| 75 |
|
| 76 |
+
# INL Dynamics (training stability)
|
| 77 |
+
dynamics = INLDynamics(hidden_size=768, beta_max=2.0)
|
| 78 |
+
h, velocity = dynamics(hidden_states, velocity)
|
| 79 |
|
| 80 |
+
# Small budget model
|
| 81 |
+
model = Efficient.tiny_llm(vocab_size=32000) # ~125M params
|
|
|
|
|
|
|
| 82 |
```
|
| 83 |
|
| 84 |
+
## Features
|
| 85 |
|
| 86 |
+
| Module | Description |
|
| 87 |
+
|--------|-------------|
|
| 88 |
+
| **Core** | Attention (GQA/MHA/MQA), MLP (SwiGLU/GeGLU/MoE), Position (RoPE/YaRN/ALiBi) |
|
| 89 |
+
| **INL Dynamics** | Velocity tracking for training stability |
|
| 90 |
+
| **CUDA/Triton** | Flash Attention, Sliding Window, Sparse, Linear |
|
| 91 |
+
| **Efficient** | Quantization, Mixed Precision, Small Models |
|
| 92 |
+
| **O(N) Architectures** | Mamba, RWKV, RetNet |
|
| 93 |
+
| **Multimodal** | Vision, Audio, Fusion |
|
| 94 |
|
| 95 |
+
## Token-Routed MLP (MoE)
|
| 96 |
|
| 97 |
+
```python
|
| 98 |
+
from complexity.api import MLP, TokenRoutedMLP
|
| 99 |
|
| 100 |
+
# Via factory
|
| 101 |
+
moe = MLP.moe(hidden_size=4096, num_experts=8, top_k=2)
|
| 102 |
|
| 103 |
+
# Direct
|
| 104 |
+
moe = TokenRoutedMLP(
|
| 105 |
+
hidden_size=4096,
|
| 106 |
+
num_experts=8,
|
| 107 |
+
top_k=2,
|
| 108 |
+
)
|
| 109 |
|
| 110 |
+
output, aux_loss = moe(hidden_states)
|
|
|
|
| 111 |
```
|
| 112 |
|
| 113 |
+
## Small Budget Training
|
|
|
|
|
|
|
| 114 |
|
| 115 |
```python
|
| 116 |
+
from complexity.api import Efficient
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 117 |
|
| 118 |
+
# Pre-configured models
|
| 119 |
+
model = Efficient.nano_llm(vocab_size=32000) # ~10M params
|
| 120 |
+
model = Efficient.micro_llm(vocab_size=32000) # ~30M params
|
| 121 |
+
model = Efficient.tiny_llm(vocab_size=32000) # ~125M params
|
| 122 |
+
model = Efficient.small_llm(vocab_size=32000) # ~350M params
|
| 123 |
|
| 124 |
+
# Memory optimizations
|
| 125 |
+
Efficient.enable_checkpointing(model)
|
| 126 |
+
model, optimizer, scaler = Efficient.mixed_precision(model, optimizer)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
```
|
| 128 |
|
| 129 |
+
## O(N) Architectures
|
| 130 |
|
| 131 |
+
For very long sequences:
|
|
|
|
| 132 |
|
| 133 |
+
```python
|
| 134 |
+
from complexity.api import Architecture
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 135 |
|
| 136 |
+
model = Architecture.mamba(hidden_size=768, num_layers=12)
|
| 137 |
+
model = Architecture.rwkv(hidden_size=768, num_layers=12)
|
| 138 |
+
model = Architecture.retnet(hidden_size=768, num_layers=12)
|
| 139 |
+
```
|
| 140 |
|
| 141 |
+
## Documentation
|
| 142 |
|
| 143 |
+
- [Getting Started](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/getting-started.md)
|
| 144 |
+
- [API Reference](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/api.md)
|
| 145 |
+
- [INL Dynamics](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/dynamics.md)
|
| 146 |
+
- [MoE / Token-Routed MLP](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/moe.md)
|
| 147 |
+
- [CUDA Optimizations](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/cuda.md)
|
| 148 |
+
- [Efficient Training](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/efficient.md)
|
| 149 |
+
- [O(N) Architectures](https://github.com/Complexity-ML/complexity-framework/blob/main/docs/architectures.md)
|
| 150 |
|
| 151 |
## Links
|
| 152 |
|
| 153 |
+
- [GitHub](https://github.com/Complexity-ML/complexity-framework)
|
| 154 |
+
- [PyPI](https://pypi.org/project/complexity-framework/) (coming soon)
|
|
|
|
| 155 |
|
| 156 |
## License
|
| 157 |
|
| 158 |
+
CC BY-NC 4.0 (Creative Commons Attribution-NonCommercial 4.0)
|
| 159 |
|
| 160 |
## Citation
|
| 161 |
|
| 162 |
```bibtex
|
| 163 |
+
@software{complexity_framework_2024,
|
| 164 |
+
title={Complexity Framework: Modular LLM Building Blocks with INL Dynamics},
|
| 165 |
+
author={Complexity-ML},
|
| 166 |
year={2024},
|
| 167 |
+
url={https://github.com/Complexity-ML/complexity-framework}
|
| 168 |
}
|
| 169 |
```
|
| 170 |
|
| 171 |
---
|
| 172 |
|
| 173 |
+
**Build stable LLMs. Train with confidence.**
|