Spaces:
Sleeping

Sleeping
File size: 19,572 Bytes
8f4b6ef 2282f4e 8f4b6ef d3f5d8a 23d4613 d3f5d8a 23d4613 d3f5d8a 052eebe 996d9f3 052eebe 484a0ad 052eebe d3f5d8a 23d4613 3d3aa6d 23d4613 3d3aa6d 052eebe 3d3aa6d 052eebe d3f5d8a 23d4613 73401e0 23d4613 73401e0 052eebe 23d4613 052eebe 23d4613 052eebe 23d4613 052eebe 23d4613 052eebe 23d4613 052eebe 73401e0 052eebe 73401e0 052eebe 23d4613 73401e0 23d4613 73401e0 052eebe 73401e0 781a300 73401e0 052eebe 73401e0 052eebe 73401e0 052eebe 73401e0 052eebe d3f5d8a 23d4613 052eebe 23d4613 d3f5d8a 23d4613 052eebe 23d4613 d177554 23d4613 052eebe 996d9f3 041e8b7 052eebe 23d4613 052eebe 23d4613 d3f5d8a 781a300 d3f5d8a 23d4613 d3f5d8a 23d4613 781a300 052eebe d3f5d8a 052eebe 781a300 23d4613 781a300 87107b2 d3f5d8a 87107b2 781a300 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 |
---
title: Futurisys ML API
emoji: 🚀
colorFrom: blue
colorTo: green
sdk: docker
pinned: false
---
# Futurisys – Déploiement d’un modèle de Machine Learning via API
## Contexte
**Futurisys** est une entreprise innovante souhaitant rendre ses modèles de machine learning
opérationnels et accessibles via une API performante.
Ce projet correspond à un **Proof of Concept (POC)** visant à déployer un modèle de machine
learning en production en appliquant les bonnes pratiques d’ingénierie logicielle: versionnage, tests, base de données et automatisation.
## Objectifs du projet
- Déployer un modèle de machine learning via une API REST
- Rendre le modèle accessible de manière fiable et documentée
- Mettre en place une architecture maintenable et évolutive
- Appliquer un workflow Git professionnel
- Préparer une base solide pour un déploiement en production
## Périmètre fonctionnel
Le projet inclut:
- Une API développée avec **FastAPI**
- L’exposition d’un modèle de machine learning via des endpoints REST
- Une base de données **PostgreSQL** pour stocker les entrées/sorties du modèle
- Des tests unitaires et fonctionnels avec **Pytest**
- Un pipeline **CI/CD** pour automatiser les tests et le déploiement
- Une documentation technique centralisée dans ce README
## Architecture du projet
L’architecture du projet repose sur une séparation claire des responsabilités afin de garantir la lisibilité, la maintenabilité et l’évolutivité de l’application.
### `Vue d’ensemble`
┌──────────────────────────────┐
│ Utilisateur │
│ (Client) │
└───────────────┬──────────────┘
│
▼
┌────────────────────────────────────────────┐
│ API FastAPI │
│ (endpoint - POST /predict) │
└┬────────────────────┬─────────────────────┬┘
| │ |
▼ ▼ ▼
┌────────────────┐ ┌──────────────┐ ┌───────────────────────────┐
│ Vérification & | | Modèle ML | | Base PostgreSQL (stockage)|
| Validation │ | - Chargement | | - Inputs |
| | | - Prédiction | | - Prédictions |
└────────────────┘ └──────────────┘ └───────────────────────────┘
▲
|
|
┌────────────────────────────────────────┐
│ CI/CD – GitHub Actions │
│ - Tests unitaires │
│ - Tests fonctionnels │
│ - Rapport de couverture │
│ - Déploiement sur HF Space │
└────────────────────────────────────────┘
### `Description du flux`
1. Un utilisateur envoie une requête `POST /predict` à l’API
2. L’API FastAPI agit comme point d’entrée:
- validation des données via **Pydantic**
- orchestration du traitement
3. Le module de prédiction:
- charge dynamiquement le modèle ML depuis **Hugging Face Hub**
- génère la prédiction et la probabilité associée
4. Les données d’entrée et les résultats sont enregistrés dans une base **PostgreSQL** afin d’assurer la traçabilité
5. La réponse est retournée au client sous forme JSON
6. Le cycle de développement, de test et de déploiement est automatisé via un pipeline **CI/CD GitHub Actions** avec déploiement sur **Hugging Face Spaces**.
Cette architecture permet une exposition fiable du modèle de Machine Learning, tout en respectant les bonnes pratiques MLOps et d’ingénierie logicielle.
## Modèle de Machine Learning (ML)
### `Problématique`
Le modèle vise à résoudre un problème de classification binaire :
- `0`: l’employé reste dans l’entreprise
- `1`: l’employé présente un risque de départ
L’objectif métier est d’anticiper le turnover afin de permettre aux équipes RH de prioriser des actions de rétention.
### `Données et features`
Le modèle s’appuie sur un dataset RH préparé et nettoyé en amont contenant des:
- données professionnelles et contextuelles (poste, département, ancienneté, etc.)
- variables comportementales et organisationnelles
Dataset final composé de **32 features**:
```text
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1470 entries, 0 to 1469
Data columns (total 32 columns)
```
Les prétraitements incluent :
- le nettoyage et la normalisation des données brutes (3 bases distinctes brutes reçues)
- le feature engineering: enrichissement des données
- le choix des variables non redondantes (corrélation inférieure à 70% entre les features numériques & les plus correlées avec la cible)
- normalisation des variables numériques & encodage des variables catégorielles:
```python
transfo_colonnes = ColumnTransformer(
transformers=[
('num', StandardScaler(), colonnes_quantitatives),
('cat', OneHotEncoder(handle_unknown='ignore', max_categories=15, sparse_output=False), colonnes_qualitatives),
('ord', OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1), colonnes_ordinales)])
```
La table `employees_dataset` sert de référence documentaire du schéma attendu par le modèle.
### `Choix du modèle`
Le modèle retenu est un algorithme de gradient boosting (**XGBoost**) entraîné avec des hyperparamètres optimisés:
```python
# Les hyperparamètrs trouvés
Meilleurs paramètres : {'classifier__colsample_bytree': 0.8, 'classifier__gamma': 1, 'classifier__learning_rate': 0.3, 'classifier__max_depth': 3, 'classifier__min_child_weight': 5, 'classifier__n_estimators': 400, 'classifier__reg_lambda': 1, 'classifier__subsample': 0.8}
```
Ce choix est justifié par:
- de bonnes performances sur des données tabulaires
- un compromis efficace entre précision et capacité de généralisation
- un temps d’inférence compatible avec une exposition via API

### `Sérialisation et versionnage`
- Le modèle est sérialisé au format `joblib`
- Une version du modèle est associée à chaque prédiction dans la table correspondante(`v1`)
- Les artefacts ML:
- en **environnement local**, ils peuvent être présents pour les tests
- en **production**, ils sont systématiquement téléchargés depuis un espace Hugging Face Hub dédié au stockage des artefacts.
### `Performance et évaluation du modèle`
- Séparation du dataset en ensembles train / test
- Validation basée sur des métriques adaptées au contexte métier:
- **Recall (0.70)**: limiter les faux négatifs (départs non détectés)
- **F1-score (0.52 - validation croisée)**: équilibre entre précision et rappel
- **ROC-AUC (0.80 - validation croisée)**: capacité de discrimination globale du modèle
Le recall est volontairement privilégié afin de maximiser la détection des employés à risque, même au prix de quelques faux positifs.
### `Limites`
- Le modèle fournit une probabilité, ***pas une décision finale***
- Les prédictions doivent être interprétées comme une aide à la décision
- Les performances dépendent fortement de la qualité et de l’actualité des données RH
- Des biais peuvent exister si les données historiques sont déséquilibrées.
## CI/CD et Déploiement
Ce projet met en œuvre une approche CI/CD complète, séparant:
- l’intégration continue (**CI**): garantir la qualité du code
- le déploiement continu (**CD**): rendre l’API accessible publiquement
### `Intégration Continue (CI) – GitHub Actions`
À chaque **push** ou **pull request** sur les branches de travail et vers **`develop`**, le pipeline CI exécute automatiquement:
- l'installation d’un environnement Python 3.11
- l'installation des dépendances définies dans le projet
- l'exécution des tests unitaires et fonctionnels
L’objectif est de garantir la stabilité de l’API et d’éviter toute régression.
### `Déploiement Continu (CD) – Hugging Face Spaces`
Dans ce projet, Hugging Face est utilisé comme plateforme de démonstration et de mise à disposition de l’API.
Le déploiement repose sur un `Dockerfile`, qui définit:
- l’image Python utilisée (Python 3.11)
- l’installation des dépendances
- le lancement de l’API avec Uvicorn.
A noter que les ***fichiers binaires*** ne sont pas stockés dans le dépôt GiHub principal pour les raisons suivantes:
- Hugging Face bloque les push Git contenant des fichiers binaires lourds
- Git n’est pas conçu pour versionner des artefacts ML volumineux.
Pour contourner la situation, dans le projet, les artefacts sont stockés dans un Space Hugging Face dédié, séparé du code. Lors du démarrage de lAPI:
- le code télécharge dynamiquement les artefacts via huggingface_hub
- l’API peut démarrer même si les fichiers ne sont pas présents localement.
### `Installation et configuration`
Les prérequis:
- Python 3.11
- Poetry
- PostgreSQL (optionnel en local)
```git bash
git clone <repository_url>
cd futurisys_ml-api
poetry install
```
Les variables suivantes doivent être définies pour la connexion à la base SQL:
- `DB_USER`
- `DB_PASSWORD`
- `DB_HOST`
- `DB_PORT`
- `DB_NAME`
Elles sont chargées via un fichier `.env` non versionné.
### `Lancer l’API`
- **En local**:
```python
uvicorn App.main:app --reload
```
Documentation interactive (Swagger UI) - http://127.0.0.1:8000/docs
- **En production (Hugging Face Spaces**):
- API: https://diaure-futurisys-api-ml.hf.space
- Swagger UI: https://diaure-futurisys-api-ml.hf.space/docs
Le déploiement permet de:
- visualiser les endpoints
- tester directement l’endpoint `/predict`
- voir les schémas d’entrée et de sortie.
### `Endpoint principal`
`POST /predict`
Cet endpoint reçoit les caractéristiques d’un employé et retourne:
- une prédiction lisible (`"Reste"` ou `"Part"`)
- la probabilité associée au départ
```json
{
"Prediction": "Part",
"Probabilite_depart": 0.795678996
}
```
Les données d’entrée sont validées via **Pydantic** avec l’appel du modèle.
### `Maintenance et mise à jour du modèle`
Une mise à jour du modèle est recommandée:
- périodiquement (ex. tous les 6 à 12 mois)
- ou en cas de dérive des données.
Le processus inclut:
- la collecte de nouvelles données
- le réentraînement du modèle
- l'évaluation des performances
- la validation métier
- le déploiement d’une nouvelle version.
## Base de données et traçabilité des prédictions
### `Objectifs`
L’intégration d’une base de données PostgreSQL permet d’inscrire le projet dans une logique MLOps et de répondre à plusieurs objectifs clés:
- assurer la traçabilité complète des prédictions du modèle
- conserver l’historique des données d’entrée utilisateur
- stocker les résultats de prédiction (label, probabilité, version du modèle)
- préparer une architecture compatible avec un déploiement en production.
### `Méthodologie utilisée`
- **PostgreSQL** a été retenu pour:
- sa robustesse et sa fiabilité
- sa compatibilité native avec SQLAlchemy
- son usage courant en environnement professionnel
- **SQLAlchemy** est utilisé comme couche d’abstraction:
- gestion centralisée de la connexion à la base
- cohérence entre le schéma Python et la base SQL
Les identifiants de connexion sont stockés dans des variables d’environnement (`.env`) afin d’éviter toute exposition de secrets dans le dépôt Git.
### `Modélisation de la base de données`
La base de données repose sur trois tables distinctes, chacune ayant un rôle précis.
1. `employees_dataset - Dataset de référence`
Il contient le dataset final nettoyé et préparé lors de l'entraînement du modèle en incluant l'ensemble des **32 features** du modèle. Il sert de:
- référence de schéma
- source de validation
- base documentaire du modèle
C'est une table qui n'est jamais alimentée par l'utilisateur.
2. `inputs - Entrées utilisateur`
- Enregistre chaque requête utilisateur envoyée à l'endpoint `/predict`
- Contient exactement les features attendues par le modèle
- Structure strictement alignée avec le schéma Pydantic(`EmployeeFeatures`)
- Permet:
- l'audit des predictions
- l'analyse à posteriori
- la reproductibilité des résultats.
```python
class Input(Base):
__tablename__ = "inputs"
id = Column(Integer, primary_key=True, index=True)
genre = Column(String)
statut_marital = Column(String)
departement = Column(String)
poste = Column(String)
```
3. `predictions - Résultats du modèle`
- Continet:
- le label de prédiction
- la probabilité associée
- Reliée à `inputs` via une clé étrangère
- Garantit une trçabilité complète.
```python
class Predictions(Base):
__tablename__ = "predictions"
id = Column(Integer, primary_key=True, index=True)
input_id = Column(Integer, ForeignKey("inputs.id"))
prediction_label = Column(String)
prediction_proba = Column(Float)
model_version = Column(String)
```
SQLAlchemy crée les tables au lancement de l’API grâce au script:
```python
Base.metadata.create_all(bind=engine)
```
### `Interaction API <> Base de données`
Lors d’un appel à l’endpoint `POST /predict`:
- les données utilisateur sont validées via **Pydantic**
- les entrées sont enregistrées dans la table **inputs**
- le modèle est exécuté
- la prédiction est enregistrée dans la table **predictions**
- la réponse est retournée à l’utilisateur.
## Tests et Qualité
### `Objectifs des tests`
Les tests ont été conçus pour:
- valider le bon fonctionnement des composants critiques (chargement du modèle, validation des données, etc)
- garantir que l’API répond correctement dans des scénarios réels
- détecter rapidement les régressions lors du développement
- assurer la reproductibilité des résultats
- fournir des indicateurs de qualité (couverture de tests)
L’ensemble des tests est exécuté automatiquement dans le pipeline CI à chaque push ou pull request.
### `Types de tests exécutés`
- **Tests unitaires** qui sont des tests rapides qui permettent de détecter immédiatement les erreurs de logique. Ils se concentrent sur les composants isolés du projet comme:
- la vérification du chargement du modèle et du mapping des classes sans levée d'erreurs (`model_loading.py`)
- la validation des données via Pydantic et test de l'endpoint de bout en bout(`test_api.py`)
- **Tests fonctionnels** qui évaluent l’application dans son ensemble en simulant un usage réel de l’API et garantissant son bon comportement en production:
- contrôle du fonctionnement de l'API en mode CI lorsque la base est désactivée CI (`test_db_disabled.py`)
- test tout le pipeline de prédiction (`test_predict_endpoint.py`)
- test spécifique de l'endpoint `/predict` et vérification de la cohérence de la réponse.
**Exécution locale** des tests:
```python
poetry run pytest
poetry run pytest tests.units
poetry run pytest tests.fonctionnel
```
### `Rapport de couverture`
Généré automatiquement dans GitHub Actions, c'est un apport qui mesure la proportion de code éxécutée par les tests en indiquant:
- quelles lignes ont été exécutées
- quelles lignes ne l'ont pas été
- le pourcentage global de couverture.
Il a pour rôle:
- d'évaluer la qualité de la suite de tests
- d'identifier les zones non testées
- de réduire les risques de régression
- de garantir la fiabilité du code avant déploiement.
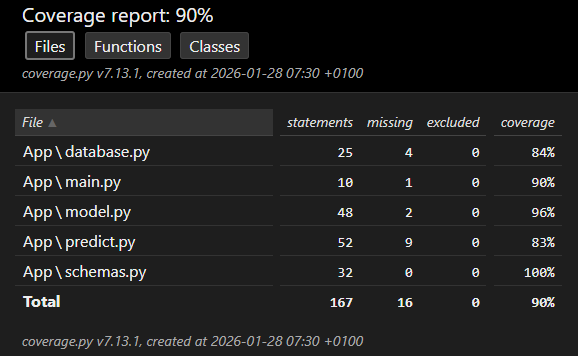
## Stack technique
- **Langage**: Python
- **API**: FastAPI
- **Machine Learning**: scikit-learn
- **Base de données**: PostgreSQL
- **Tests**: Pytest, pytest-cov
- **CI/CD**: GitHub Actions, Hugging Face
- **Versionnage**: Git / GitHub
## Structure du projet
```text
futurisys_ml-api/
├── github/workflows
│ ├── ci.yml # Description des évènement déclenchants des tests
├── app/ # Code applicatif principal
│ ├── database.py # Point de connexion à la base PostgreSQL
│ ├── main.py # Point d’entrée de l’API
│ ├── model.py # Définition des tables de la database
│ ├── predict.py # Application du modèle
│ ├── schemas.py # Validation des données (Pydantic)
│ ── model/ # Elements du modèle
│ ├── mapping_classes.json # Correspondances des classes
│ ├── modele_final_xgb.joblib # Modèle final avec hyperparamètres
|
├── scripts/ # Scripts bd (BD, données)
│ ├── create_tables.py # Créaton des tables définies dans model.py
│ ├── dataset_final.csv # Data final
│ ├── insert_dataset.py # Code chargement de la table dataset_final
|
├── tests/ # Tests unitaires, fonctionnels
│ ├── test_sanity.py # Test de vérification rapide
│ ├── test_api.py # Tests API supplémentaires
│ ├── test_sanity.py # Test de vérification rapide
|
│ ── fonctionnel/ # Tests fonctionnels
│ ├── sample_payload.py # Test automatisé de l'API via Pytest
│ ├── test_api.py # Tests API supplémentaires
│ ├── test_sanity.py # Test de vérification rapide
|
│ ── units/ # Tests unitaires
│ ├── test_model_loading.py # Test automatisé de l'API via Pytest
|
├── .env # Stockage des variables sensibles et de configuration
├── .gitignore # Nettoyage du dépôt
├── Dockerfile # Reproduction du dépôt
├── poetry.lock # Nettoyage du dépôt
├── pyproject.toml # Librairies dépendances ML
├── README.md # Présentation du projet
└── requirements.txt # Librairies dépendances API
```
|