diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..1d309b6f0bcec33f0df1fd9d7a0e9dc6db7421e1
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1,40 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tar filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
+resource/fonts/**/*.otf filter=lfs diff=lfs merge=lfs -text
+resource/media/**/*.mp4 filter=lfs diff=lfs merge=lfs -text
+resource/bgms/**/*.mp3 filter=lfs diff=lfs merge=lfs -text
+data/**/*.csv filter=lfs diff=lfs merge=lfs -text
+resource/fonts/SourceHanSansSC/*.otf filter=lfs diff=lfs merge=lfs -text
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..190a5de9dd1aa021df06c0dac2c0a0868b31a5b9
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,75 @@
+# === Python 生成文件 ===
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C 扩展
+*.so
+*.pyd
+
+# 虚拟环境 / Conda 环境目录
+.venv/
+venv/
+env/
+.env/
+.conda/
+.hypothesis/
+
+# 构建 / 发布产物
+build/
+dist/
+*.egg-info/
+*.egg
+pip-wheel-metadata/
+
+# 单元测试 / 覆盖率 / 缓存
+.pytest_cache/
+.coverage
+.coverage.*
+htmlcov/
+.tox/
+.nox/
+.mypy_cache/
+.dmypy.json
+.pyre/
+.cache/
+
+# IDE / 编辑器配置
+.vscode/
+.idea/
+*.swp
+*.swo
+*.iml
+
+# Jupyter
+.ipynb_checkpoints/
+
+# OS 级别垃圾文件
+.DS_Store
+Thumbs.db
+
+# 日志 / 临时文件
+*.log
+logs/
+tmp/
+temp/
+.server_cache/
+.storyline/.server_cache/
+
+# 本项目可能产生的大文件目录
+outputs/
+renders/
+checkpoints/
+models/
+project/
+
+# 环境/配置的敏感信息(你如果用 .env 管 secret)
+.env.local
+.env.*.local
+
+data/**
+!data/elements_v2/
+!data/elements_v2/**
+!data/prompts/
+!data/prompts/**
+resource/**
\ No newline at end of file
diff --git a/.storyline/skills/create_profile_style_skill/SKILL.md b/.storyline/skills/create_profile_style_skill/SKILL.md
new file mode 100644
index 0000000000000000000000000000000000000000..1e7f6874db5c8dd75721bb7a03f73dafaab50c2e
--- /dev/null
+++ b/.storyline/skills/create_profile_style_skill/SKILL.md
@@ -0,0 +1,63 @@
+---
+name: create_profile_style_skill
+description: 【SKILL】分析当前剪辑逻辑与风格,总结并生成一个新的可复用 Skill 文件,存入剪辑技能库。
+version: 1.0.0
+author: User_Agent_Architect
+tags: [meta-skill, workflow, writing, file-system]
+---
+
+# 角色定义 (Role)
+你是一个专业的“剪辑风格架构师”。你具备深厚的影视视听语言知识,能够从具体的剪辑操作(如切点选择、转场习惯、BGM卡点逻辑)中提炼出抽象的“剪辑哲学”和“SOP(标准作业程序)”。
+
+# 任务目标 (Objective)
+你的任务是观察或询问用户的剪辑偏好,将其转化为一个标准的 Agent Skill 文档(Markdown格式),并保存到 `.storyline/skills/` 目录下,以便让 Agent 在未来模仿这种风格。
+
+# 执行流程 (Workflow)
+
+## 第一步:风格分析与萃取 (Analysis & Extraction)
+1. **获取上下文**:获取当前正在编辑的 Timeline 数据,或者请求用户描述其剪辑习惯。
+2. **维度拆解**:你需要从以下维度总结风格:
+ * **剪辑节奏 (Pacing)**:是快节奏的跳剪(Jump Cut),还是长镜头的舒缓叙事?
+ * **叙事逻辑 (Storytelling)**:是线性叙事、倒叙,还是基于音乐情绪的蒙太奇?
+ * **视听语言 (Audio-Visual)**:音效(SFX)的使用密度、字幕样式偏好、调色风格(LUTs)。
+ * **特殊偏好**:例如“总是删除静音片段”或“每5秒插入一个B-Roll”。
+
+## 第二步:交互与命名 (Interaction & Naming)
+1. **总结确认**:向用户展示你总结的 3-5 个核心风格点,询问是否准确。
+2. **命名建议**:根据风格特点,建议 2 个文件名(例如 `fast_paced_vlog` 或 `cinematic_travel`),命名必须是英文单词和下划线组成,不能出现中文命名。
+3. **获取输入**:
+ * 询问用户:“是否认可这个总结?”
+ * 询问用户:“你想将这个新技能命名为什么?(按 Enter 使用建议名称:[建议名称])”
+
+## 第三步:生成新 Skill 内容 (Drafting)
+根据确认的风格,生成新 Skill 的 Markdown 内容。内容必须包含标准头部和 Prompt 指令。
+* *Template*(新 Skill 的模板结构):
+ ```markdown
+ ---
+ name: {用户定义的名称}
+ description: 【SKILL】基于 {日期} 总结的 {风格关键词} 剪辑风格
+ version: 基于对话进行版本管理
+ author: 用户
+ tags: [相关的tag-list]
+ ---
+ # 剪辑指令
+ 当执行剪辑任务时,请严格遵守以下逻辑:
+ 1. **整体风格原则**:{分析出的节奏逻辑}
+ 2. **音频处理规范**:{分析出的音频处理(视频原声/配音/背景音乐)筛选逻辑}
+ 3. **视觉元素规范**:{分析出的视觉元素(字体花字/转场/滤镜/特效等)使用逻辑}
+ 4. **剪辑节奏控制**:{分析出的剪辑节奏(音乐卡点/短切片/长切片)使用逻辑}
+ 5. **工具调用规范**:{分析出的推荐使用的工具以及推荐的传入参数}
+ ```
+
+## 第四步:入库与更新 (Commit & Update)
+1. **展示预览**:将生成的内容以代码块形式展示给用户。
+2. **执行写入**:
+ * 用户确认后,调用文件写入工具`write_skills`。
+ * **目标路径**:`.storyline/skills/{文件名}/SKILL.md`,传入文件名即可,工具会自动完成写入。
+3. **系统更新**:提示用户“新技能已入库,请刷新 Agent 工具列表以加载。”
+
+# 约束条件 (Constraints)
+* **格式规范**:生成的新 Skill 必须符合 markdown 标准,且包含元数据(Metadata)。
+* **路径安全**:只能写入 `.storyline/skills/` 目录,禁止覆盖系统核心文件。
+* **可读性**:在与用户交互时,不要直接扔出一大段代码,先用自然语言确认逻辑。
+* **版本管理**:当用户进行修改时,更改版本号,并重新调用`write_skills`工具做覆盖;
diff --git a/.storyline/skills/subtitle_imitation_skill/SKILL.md b/.storyline/skills/subtitle_imitation_skill/SKILL.md
new file mode 100644
index 0000000000000000000000000000000000000000..61db06038404f6891e6888a3616208d7a021a4e8
--- /dev/null
+++ b/.storyline/skills/subtitle_imitation_skill/SKILL.md
@@ -0,0 +1,55 @@
+---
+name: subtitle_imitation_skill
+description: 【SKILL】基于用户提供的参考文案样本,对视频素材内容进行深度文风仿写,生成风格化脚本。
+version: 1.0.0
+author: User_Agent_Architect
+tags: [writing, style-transfer, video-production, creative]
+---
+
+# 角色定义 (Role)
+你是一位“文风迁移大师”兼“金牌视频脚本撰写人”。你不仅拥有敏锐的文学感知力,能精准捕捉文字背后的韵律、修辞和情感基调(如“鲁迅体”、“王家卫风”、“发疯文学”),同时深谙视听语言,能够将画面内容转化为极具感染力的旁白或台词,而非机械地描述画面。
+
+# 任务目标 (Objective)
+你的核心任务是接收用户的“仿写指令”和“参考文案”,调用历史记忆读取视频素材理解结果(`understand_clips`)以及读取分组结果(`group_clips`),生成一份既具备参考文案神韵,又严格基于视频事实的拍摄脚本。
+
+# 执行流程 (Workflow)
+
+## 第一步:输入校验与意图确认 (Input Validation)
+1. **检查输入参数**:检查用户是否提供了用于模仿的 `style_reference_text`(仿写样本)。
+2. **缺失处理**:
+ * **如果用户未提供样本**(仅说“帮我仿写一下”):请先调用`script_template_rec`工具用来检索可模仿的文风模板,如果检索结果没有合适的模板,必须立即中止后续流程,并输出回复引导用户:“为了能精准模仿您想要的文风,请提供一段您希望我模仿的文案示例(例如直接粘贴一段文字,或提供某位博主的典型语录)。”
+ * **如果用户已提供样本**:进入第二步。
+
+## 第二步:获取素材与分析 (Context & Analysis)
+1. **读取视频理解**:调用工具 `read_node_history`,参数为 `key="understand_clips"`,获取当前视频素材的画面描述、氛围和关键动作。
+2. **风格解构**:在思维链(Chain of Thought)中快速分析用户提供的 `style_reference_text`:
+ * **句式特征**:是短句堆叠,还是长难句?
+ * **修辞习惯**:是否喜欢用比喻、反讽、排比?
+ * **情感基调**:是治愈、焦虑、犀利还是幽默?
+
+## 第三步:风格化创作 (Creative Generation)
+基于素材内容(Content)和分析出的风格(Style),执行脚本撰写。需严格遵守以下创作原则:
+1. **拒绝“看图说话” (No See-Say)**:
+ * ❌ 错误示范:“画面里有一只猫在睡觉,阳光照在它身上。”
+ * ✅ 正确示范(如文艺风):“午后的阳光是免费的,但偷得浮生半日闲的勇气却是昂贵的。它在做梦,而我在看它。”
+2. **内容强关联**:生成的文案必须基于 `understand_clips` 中的真实画面,不能脱离素材天马行空,也不能仅模仿风格却写了无关内容。
+3. **生动连贯**:脚本必须有起承转合,不仅是句子的拼凑,更是一个完整的小故事或情绪流。
+
+## 第四步:格式化输出 (Formatting)
+1. **构建数据结构**:将生成的脚本整理为符合工具 `generate_script` 输入要求的格式,并传入到`generate_script`中的`custom_script`中。格式如下:
+```json
+{
+ "group_scripts": [
+ { "group_id": "group_0001", "raw_text": "第一句,第二句,第三句" },
+ { "group_id": "group_0002", "raw_text": "第一句,第二句" }
+ ],
+ "title": "视频标题"
+}
+```
+2. **输出总结**: 对用户隐藏结构化文案,而是挑选里面的句子反馈给用户,让用户判断是否符合要求,以便做进一步修改。
+
+# 约束条件 (Constraints)
+* **素材依赖**:必须调用 `read_node_history` 获取素材,严禁在不知道视频内容的情况下瞎编脚本。
+* **风格一致性**:生成的文案必须让熟悉该风格的人一眼就能识别出“味道”。
+* **拒绝机械描述**:严禁出现“视频显示”、“镜头切到”等说明书式语言,除非参考风格本身就是说明书风格。
+* **工具对接**:输出内容必须适配 `generate_script` 的字段定义,确保下游渲染环节无缝衔接。
\ No newline at end of file
diff --git a/Dockerfile b/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..ae28210c22d5a711d25b870cdb22e6719cf989db
--- /dev/null
+++ b/Dockerfile
@@ -0,0 +1,31 @@
+# 基础镜像
+FROM python:3.11-slim
+
+# 设置工作目录
+WORKDIR /app
+
+# 复制文件
+COPY requirements.txt .
+COPY run.sh .
+COPY src/ ./src/
+COPY agent_fastapi.py .
+COPY cli.py .
+COPY config.toml .
+COPY web/ ./web/
+COPY prompts/ ./prompts/
+COPY .storyline/ ./.storyline/
+COPY download.sh .
+
+# 安装依赖
+RUN apt-get update && apt-get install -y ffmpeg wget unzip git git-lfs curl
+RUN pip install --no-cache-dir -r requirements.txt
+
+# 下载
+RUN chmod +x download.sh
+RUN ./download.sh
+
+# 暴露 HF Space 默认端口
+EXPOSE 7860
+
+# 启动命令
+CMD ["bash", "run.sh"]
\ No newline at end of file
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1f941e9ef0150cbfb3f04cb4eb4954e3c803acf4
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "{}"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2026 FireRed-OpenStoryline Authors. All Rights Reserved.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ec216bb1a2f16eac4c6991f43cf69600f520fad
--- /dev/null
+++ b/README.md
@@ -0,0 +1,9 @@
+---
+title: FireRed-OpenStoryline
+emoji: 🎬
+colorFrom: red
+colorTo: gray
+sdk: docker
+pinned: false
+---
+Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/README_zh.md b/README_zh.md
new file mode 100644
index 0000000000000000000000000000000000000000..50c341397eca20832b4eebfd983b7bdb9b964eda
--- /dev/null
+++ b/README_zh.md
@@ -0,0 +1,279 @@
+
+
+>
+> 🎨 效果说明:受限于开源素材的版权协议,第一行默认演示中的元素(字体/音乐)仅为基础效果。强烈建议接入自建元素库教程,解锁商用级字体、音乐、特效等,可实现显著优于默认效果的视频质量。
+> ⚠️ 画质注:受限于README展示空间,演示视频经过极限压缩。实际运行默认保持原分辨率输出,支持自定义尺寸。
+> Demo中:第一行为默认开源素材效果(受限模式),第二行为小红书App「AI剪辑」元素库效果。👉 点击查看体验教程
+> ⚖️ 免责声明:演示中包含的用户自摄素材及品牌标识仅作技术能力展示,版权归原作者所有,严禁二次分发。如有侵权请联系删除。
+>
+
+
+
+## 📦 安装
+
+### 1. 克隆仓库
+```bash
+# 如果没有安装git,参考官方网站进行安装:https://git-scm.com/install/
+# 或手动打包下载,并解压
+git clone https://github.com/FireRedTeam/FireRed-OpenStoryline.git
+cd FireRed-OpenStoryline
+```
+
+### 2. 创建虚拟环境
+
+按照官方指南安装 Conda(推荐Miniforge,安装过程中建议勾选上自动配置环境变量):https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html
+
+```
+# 要求python>=3.11
+conda create -n storyline python=3.11
+conda activate storyline
+```
+
+### 3. 资源下载与依赖安装
+#### 3.1 一键安装(仅支持Linux和MacOS)
+```
+sh build_env.sh
+```
+
+#### 3.2 手动安装
+##### A. MacOS 或 Linux
+ - Step 1: 安装 wget(如果尚未安装)
+
+ ```
+ # MacOS: 如果你还没有安装 Homebrew,请先安装:https://brew.sh/
+ brew install wget
+
+ # Ubuntu/Debian
+ sudo apt-get install wget
+
+ # CentOS
+ sudo yum install wget
+ ```
+
+ - Step 2: 下载资源
+
+ ```bash
+ sh download.sh
+ ```
+
+ - Step 3: 安装依赖
+
+ ```bash
+ pip install -r requirements.txt
+ ```
+
+###### B. Windows
+ - Step 1: 准备目录:在项目根目录下新建目录 `.storyline`。
+
+ - Step 2: 下载并解压:
+
+ * [下载模型 (models.zip)](https://image-url-2-feature-1251524319.cos.ap-shanghai.myqcloud.com/openstoryline/models.zip) -> 解压至 `.storyline` 目录。
+
+ * [下载资源 (resource.zip)](https://image-url-2-feature-1251524319.cos.ap-shanghai.myqcloud.com/openstoryline/resource.zip) -> 解压至 `resource` 目录。
+ - Step 3: **安装依赖**:
+ ```bash
+ pip install -r requirements.txt
+ ```
+
+
+## 🚀 快速开始
+注意:在开始之前,您需要先在 config.toml 中配置 API-Key。详细信息请参阅文档 [API-Key 配置](docs/source/zh/api-key.md)
+
+### 1. 启动 MCP 服务器
+
+#### MacOS or Linux
+ ```bash
+ PYTHONPATH=src python -m open_storyline.mcp.server
+ ```
+
+#### Windows
+ ```
+ $env:PYTHONPATH="src"; python -m open_storyline.mcp.server
+ ```
+
+
+### 2. 启动对话界面
+
+- 方式 1:命令行界面
+
+ ```bash
+ python cli.py
+ ```
+
+- 方式 2:Web 界面
+
+ ```bash
+ uvicorn agent_fastapi:app --host 127.0.0.1 --port 7860
+ ```
+
+## 🐳 Docker 部署
+
+如果未安装 Docker,请先安装 https://www.docker.com/products/docker-desktop/
+
+### 拉取镜像
+```
+docker pull openstoryline/openstoryline:v1.0.0
+```
+
+### 启动镜像
+```
+docker run \
+ -v $(pwd)/config.toml:/app/config.toml \
+ -v $(pwd)/outputs:/app/outputs \
+ -p 7860:7860 \
+ openstoryline/openstoryline:v1.0.0
+```
+启动后访问Web界面 http://127.0.0.1:7860
+
+## 📁 项目结构
+```
+FireRed-OpenStoryline/
+├── 🎯 src/open_storyline/ 核心应用
+│ ├── mcp/ 🔌 模型上下文协议
+│ ├── nodes/ 🎬 视频处理节点
+│ ├── skills/ 🛠️ Agent 技能库
+│ ├── storage/ 💾 Agent 记忆系统
+│ ├── utils/ 🧰 工具函数
+│ ├── agent.py 🤖 Agent 构建
+│ └── config.py ⚙️ 配置管理
+├── 📚 docs/ 文档
+├── 🐳 Dockerfile Docker 配置
+├── 💬 prompts/ LLM 提示词模板
+├── 🎨 resource/ 静态资源
+│ ├── bgms/ 背景音乐库
+│ ├── fonts/ 字体文件
+│ ├── script_templates/ 视频脚本模板
+│ └── unicode_emojis.json Emoji 列表
+├── 🔧 scripts/ 工具脚本
+├── 🌐 web/ Web 界面
+├── 🚀 agent_fastapi.py FastAPI 服务器
+├── 🖥️ cli.py 命令行界面
+├── ⚙️ config.toml 主配置文件
+├── 🚀 build_env.sh 环境构建脚本
+├── 📥 download.sh 资源下载脚本
+├── 📦 requirements.txt 运行时依赖
+└── ▶️ run.sh 启动脚本
+
+```
+
+## 📚 文档
+
+### 📖 教程索引
+
+- [API申请与配置](docs/source/zh/api-key.md) - 如何申请和配置 API 密钥
+- [使用教程](docs/source/zh/guide.md) - 常见用例和基本操作
+- [常见问题](docs/source/zh/faq.md) - 常见问题解答
+
+## TODO
+
+- [ ] 添加口播类型视频剪辑功能
+- [ ] 添加音色克隆功能
+- [ ] 添加更多的转场/滤镜/特效功能
+- [ ] 添加图像/视频生成和编辑能力
+- [ ] 支持GPU渲染和高光裁切
+
+## 致谢
+
+本项目基于以下优秀的开源项目构建:
+
+
+### 核心依赖
+- [MoviePy](https://github.com/Zulko/moviepy) - 视频编辑库
+- [FFmpeg](https://ffmpeg.org/) - 多媒体框架
+- [LangChain](https://www.langchain.com/) - 提供预构建Agent的框架
+
+## 📄 License
+
+This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
+
+## ⭐ Star History
+
+[](https://www.star-history.com/#FireRedTeam/FireRed-OpenStoryline&type=date&legend=top-left)
diff --git a/agent_fastapi.py b/agent_fastapi.py
new file mode 100644
index 0000000000000000000000000000000000000000..99d6f9294c9fab6378947d7947cf058562690733
--- /dev/null
+++ b/agent_fastapi.py
@@ -0,0 +1,2826 @@
+# agent_fastapi.py
+from __future__ import annotations
+
+import asyncio
+import mimetypes
+import os
+import sys
+import json
+import re
+import time
+import uuid
+import math
+import logging
+import shutil
+from pathlib import Path
+from dataclasses import dataclass, field
+from typing import Any, Dict, List, Optional, Tuple, Set
+from contextlib import asynccontextmanager
+from starlette.websockets import WebSocketState, WebSocketDisconnect
+try:
+ import tomllib # Python 3.11+ # type: ignore
+except ModuleNotFoundError:
+ import tomli as tomllib # Python <= 3.10
+import traceback
+
+try:
+ from uvicorn.protocols.utils import ClientDisconnected
+except Exception:
+ ClientDisconnected = None
+
+
+logger = logging.getLogger(__name__)
+
+import anyio
+from fastapi import FastAPI, APIRouter, UploadFile, File, Form, HTTPException, WebSocket, WebSocketDisconnect, Request
+from fastapi.responses import FileResponse, JSONResponse, Response
+from fastapi.staticfiles import StaticFiles
+
+from langchain_core.messages import SystemMessage, HumanMessage, BaseMessage, AIMessage, ToolMessage
+
+# ---- 确保 src 可导入(避免环境差异导致找不到模块)----
+ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
+SRC_DIR = os.path.join(ROOT_DIR, "src")
+if SRC_DIR not in sys.path:
+ sys.path.insert(0, SRC_DIR)
+
+from open_storyline.agent import build_agent, ClientContext
+from open_storyline.utils.prompts import get_prompt
+from open_storyline.utils.media_handler import scan_media_dir
+from open_storyline.config import load_settings, default_config_path
+from open_storyline.config import Settings
+from open_storyline.storage.agent_memory import ArtifactStore
+from open_storyline.mcp.hooks.node_interceptors import ToolInterceptor
+from open_storyline.mcp.hooks.chat_middleware import set_mcp_log_sink, reset_mcp_log_sink
+
+WEB_DIR = os.path.join(ROOT_DIR, "web")
+STATIC_DIR = os.path.join(WEB_DIR, "static")
+INDEX_HTML = os.path.join(WEB_DIR, "index.html")
+NODE_MAP_HTML = os.path.join(WEB_DIR, "node_map/node_map.html")
+NODE_MAP_DIR = os.path.join(WEB_DIR, "node_map")
+
+SERVER_CACHE_DIR = os.path.join(ROOT_DIR, '.storyline' , ".server_cache")
+
+CHUNK_SIZE = 1024 * 1024 # 1MB
+
+# 是否根据session_id隔离用户
+USE_SESSION_SUBDIR = True
+
+CUSTOM_MODEL_KEY = "__custom__"
+
+# Load keys
+DEFAULT_LLM_API_KEY = os.getenv("DEEPSEEK_API_KEY")
+DEFAULT_LLM_API_URL = os.getenv("DEEPSEEK_API_URL")
+DEFAULT_LLM_API_NAME = os.getenv("DEEPSEEK_API_NAME", "deepseek-chat")
+DEFAULT_VLM_API_KEY = os.getenv("GLM_V4_6_API_KEY")
+DEFAULT_VLM_API_URL = os.getenv("GLM_V4_6_API_URL")
+DEFAULT_VLM_API_NAME = os.getenv("GLM_V4_6_API_NAME", "qwen3-vl-8b-instruct")
+print("DEEPSEEK_API_KEY exists:", bool(os.getenv("DEEPSEEK_API_KEY")))
+print("QWEN3_VL_8B_API_KEY exists:", bool(os.getenv("QWEN3_VL_8B_API_KEY")))
+print("DEEPSEEK_API_URL:", repr(os.getenv("DEEPSEEK_API_URL")))
+print("QWEN3_VL_8B_API_URL:", repr(os.getenv("QWEN3_VL_8B_API_URL")))
+
+def debug_traceback_print(cfg: Settings):
+ if cfg.developer.developer_mode:
+ traceback.print_exc()
+
+def _s(x: Any) -> str:
+ return str(x or "").strip()
+
+def _norm_url(u: Any) -> str:
+ u = _s(u)
+ return u.rstrip("/") if u else ""
+
+def _env_fallback_for_model(model_name: str) -> Tuple[str, str]:
+ """
+ - deepseek* -> DEEPSEEK_API_URL / DEEPSEEK_API_KEY
+ - qwen3* -> QWEN3_VL_8B_API_URL / QWEN3_VL_8B_API_KEY
+ """
+ m = _s(model_name).lower()
+ if "deepseek" in m:
+ return (_s(os.getenv("DEEPSEEK_API_URL")), _s(os.getenv("DEEPSEEK_API_KEY")))
+ if m.startswith("qwen3-vl-8b-instruct") or "qwen3-vl-8b-instruct" in m:
+ return (_s(os.getenv("QWEN3_VL_8B_API_URL")), _s(os.getenv("QWEN3_VL_8B_API_KEY")))
+ return ("", "")
+
+def _resolve_default_model_override(cfg: Settings, model_name: str) -> Tuple[Optional[Dict[str, Any]], Optional[str]]:
+ """
+ 1. get config from [developer.chat_models_config.""]
+ 2. rollback to env
+ """
+ model_name = _s(model_name)
+ if not model_name:
+ return None, "default model name is empty"
+
+ model_cfg: Dict[str, Any] = {}
+ try:
+ model_cfg = (cfg.developer.chat_models_config.get(model_name) or {}) if getattr(cfg, "developer", None) else {}
+ except Exception:
+ model_cfg = {}
+
+ if not isinstance(model_cfg, dict):
+ model_cfg = {}
+
+ base_url = _norm_url(model_cfg.get("base_url"))
+ api_key = _s(model_cfg.get("api_key"))
+
+ if not base_url or not api_key:
+ env_url, env_key = _env_fallback_for_model(model_name)
+ if not base_url:
+ base_url = _norm_url(env_url)
+ if not api_key:
+ api_key = _s(env_key)
+
+ override: Dict[str, Any] = {"model": model_name}
+ if base_url:
+ override["base_url"] = base_url
+ if api_key:
+ override["api_key"] = api_key
+
+ for k in ("timeout", "temperature", "max_retries", "top_p", "max_tokens"):
+ if k in model_cfg and model_cfg.get(k) not in (None, ""):
+ override[k] = model_cfg.get(k)
+
+ if not override.get("base_url") or not override.get("api_key"):
+ return None, (
+ f"cannot find base_url/api_key of default model: {model_name}. "
+ f"please fill in base_url/api_key of [developer.chat_models_config.\"{model_name}\" in config.toml]"
+ f"or set environment variables(DEEPSEEK_API_URL/DEEPSEEK_API_KEY / QWEN3_VL_8B_API_URL/QWEN3_VL_8B_API_KEY)。"
+ )
+
+ return override, None
+
+def _stable_dict_key(d: Optional[Dict[str, Any]]) -> str:
+ try:
+ return json.dumps(d or {}, sort_keys=True, ensure_ascii=False)
+ except Exception:
+ return str(d or {})
+
+def _parse_service_config(service_cfg: Any) -> Tuple[
+ Optional[Dict[str, Any]],
+ Optional[Dict[str, Any]],
+ Dict[str, Any],
+ Dict[str, Any],
+ Optional[str]]:
+ """
+ 返回 (custom_llm, custom_vlm, tts_cfg, pexels, err)
+ - custom_llm/custom_vlm: {"model","base_url","api_key"} 或 None(允许只传 llm 或只传 vlm)
+ - tts_cfg: dict(可能为空)
+ """
+ if not isinstance(service_cfg, dict):
+ return None, None, {}, {}, None
+
+ # ---- custom models ----
+ custom_llm = None
+ custom_vlm = None
+ custom_models = service_cfg.get("custom_models")
+
+ if custom_models is not None:
+ if not isinstance(custom_models, dict):
+ return None, None, {}, {}, "service_config.custom_models 必须是对象"
+
+ def _pick(m: Any, label: str) -> Tuple[Optional[Dict[str, str]], Optional[str]]:
+ if m is None:
+ return None, None
+ if not isinstance(m, dict):
+ return None, f"service_config.custom_models.{label} 必须是对象"
+
+ model = _s(m.get("model"))
+ base_url = _norm_url(m.get("base_url"))
+ api_key = _s(m.get("api_key"))
+
+ if not (model and base_url and api_key):
+ return None, f"自定义 {label.upper()} 配置不完整:请填写 model/base_url/api_key"
+ if not (base_url.startswith("http://") or base_url.startswith("https://")):
+ return None, f"自定义 {label.upper()} 的 base_url 必须以 http(s) 开头"
+ return {"model": model, "base_url": base_url, "api_key": api_key}, None
+
+ custom_llm, err1 = _pick(custom_models.get("llm"), "llm")
+ if err1:
+ return None, None, {}, {}, err1
+
+ custom_vlm, err2 = _pick(custom_models.get("vlm"), "vlm")
+ if err2:
+ return None, None, {}, {}, err2
+
+ # ---- tts ----
+ tts_cfg: Dict[str, Any] = {}
+ tts = service_cfg.get("tts")
+ if isinstance(tts, dict):
+ provider = (tts.get("provider") or "").strip().lower()
+ if provider:
+ provider_block = tts.get(provider)
+ tts_cfg = {"provider": provider, provider: provider_block}
+
+ # ---- pexels ----
+ pexels_cfg: Dict[str, Any] = {}
+ search_media = service_cfg.get("search_media")
+ if isinstance(search_media, dict):
+ # 支持两种格式:
+ # 1) {search_media:{pexels:{mode, api_key}}}
+ # 2) {search_media:{mode, pexel_api_key}}
+ p = search_media.get("pexels") or search_media.get("pexels")
+ if isinstance(p, dict):
+ mode = _s(p.get("mode")).lower()
+ if mode not in ("default", "custom"):
+ mode = "default"
+ api_key = _s(p.get("api_key") or p.get("pexels_api_key") or p.get("pexels_api_key"))
+ pexels_cfg = {"mode": mode, "api_key": api_key}
+ else:
+ mode = _s(search_media.get("mode") or search_media.get("pexels_mode") or search_media.get("pexels_mode")).lower()
+ if mode not in ("default", "custom"):
+ mode = "default"
+ api_key = _s(search_media.get("pexels_api_key") or search_media.get("pexels_api_key"))
+ pexels_cfg = {"mode": mode, "api_key": api_key}
+
+ return custom_llm, custom_vlm, tts_cfg, pexels_cfg, None
+
+def is_developer_mode(cfg: Settings) -> bool:
+ try:
+ return bool(cfg.developer.developer_mode)
+ except Exception:
+ return False
+
+def _abs(p: str) -> str:
+ return os.path.abspath(os.path.expanduser(p))
+
+
+def resolve_media_dir(cfg_media_dir: str, session_id: str) -> str:
+ root = _abs(cfg_media_dir).rstrip("/\\")
+ if not USE_SESSION_SUBDIR:
+ return root
+ project_dir = os.path.dirname(root)
+ leaf = os.path.basename(root)
+ return os.path.join(project_dir, session_id, leaf)
+
+
+def sanitize_filename(name: str) -> str:
+ name = os.path.basename(name or "")
+ name = name.replace("\x00", "")
+ return name or "unnamed"
+
+
+def detect_media_kind(filename: str) -> str:
+ ext = os.path.splitext(filename)[1].lower()
+ if ext in {".png", ".jpg", ".jpeg", ".gif", ".bmp", ".webp"}:
+ return "image"
+ if ext in {".mp4", ".mov", ".avi", ".mkv", ".webm"}:
+ return "video"
+ return "unknown"
+
+_MEDIA_RE = re.compile(r"^media_(\d+)", re.IGNORECASE)
+
+def make_media_store_filename(seq: int, ext: str) -> str:
+ ext = (ext or "").lower()
+ if ext and not ext.startswith("."):
+ ext = "." + ext
+ return f"{MEDIA_PREFIX}{seq:0{MEDIA_SEQ_WIDTH}d}{ext}"
+
+def parse_media_seq(filename: str) -> Optional[int]:
+ m = _MEDIA_RE.match(os.path.basename(filename or ""))
+ if not m:
+ return None
+ try:
+ return int(m.group(1))
+ except Exception:
+ return None
+
+def safe_save_path_no_overwrite(media_dir: str, filename: str) -> str:
+ filename = sanitize_filename(filename)
+ stem, ext = os.path.splitext(filename)
+ path = os.path.join(media_dir, filename)
+ if not os.path.exists(path):
+ return path
+ i = 2
+ while True:
+ p2 = os.path.join(media_dir, f"{stem} ({i}){ext}")
+ if not os.path.exists(p2):
+ return p2
+ i += 1
+
+
+def ensure_thumbs_dir(media_dir: str) -> str:
+ d = os.path.join(media_dir, ".thumbs")
+ os.makedirs(d, exist_ok=True)
+ return d
+
+def ensure_uploads_dir(media_dir: str) -> str:
+ d = os.path.join(media_dir, ".uploads")
+ os.makedirs(d, exist_ok=True)
+ return d
+
+def guess_media_type(path: str) -> str:
+ mt, _ = mimetypes.guess_type(path)
+ return mt or "application/octet-stream"
+
+
+def _is_under_dir(path: str, root: str) -> bool:
+ try:
+ path = os.path.abspath(path)
+ root = os.path.abspath(root)
+ return os.path.commonpath([path, root]) == root
+ except Exception:
+ return False
+
+
+def video_placeholder_svg_bytes() -> bytes:
+ svg = """"""
+ return svg.encode("utf-8")
+
+
+def make_image_thumbnail_sync(src_path: str, dst_path: str, max_size: Tuple[int, int] = (320, 320)) -> bool:
+ try:
+ from PIL import Image
+ img = Image.open(src_path).convert("RGB")
+ img.thumbnail(max_size)
+ img.save(dst_path, format="JPEG", quality=85)
+ return True
+ except Exception:
+ return False
+
+async def make_video_thumbnail_async(
+ src_video: str,
+ dst_path: str,
+ *,
+ max_size: Tuple[int, int] = (320, 320),
+ seek_sec: float = 0.5,
+ timeout_sec: float = 20.0,
+) -> bool:
+ ffmpeg = os.environ.get("FFMPEG_BIN") or shutil.which("ffmpeg")
+ if not ffmpeg:
+ logger.warning("ffmpeg not found (PATH/FFMPEG_BIN). skip video thumbnail. src=%s", src_video)
+ return False
+
+ src_video = os.path.abspath(src_video)
+ dst_path = os.path.abspath(dst_path)
+ os.makedirs(os.path.dirname(dst_path), exist_ok=True)
+
+ tmp_path = dst_path + ".tmp.jpg"
+
+ vf = (
+ f"scale={max_size[0]}:{max_size[1]}:force_original_aspect_ratio=decrease"
+ f",pad={max_size[0]}:{max_size[1]}:(ow-iw)/2:(oh-ih)/2"
+ )
+
+ async def _run(args: list[str]) -> tuple[bool, str]:
+ proc = await asyncio.create_subprocess_exec(
+ *args,
+ stdout=asyncio.subprocess.DEVNULL,
+ stderr=asyncio.subprocess.PIPE,
+ )
+ try:
+ _, err = await asyncio.wait_for(proc.communicate(), timeout=timeout_sec)
+ except asyncio.TimeoutError:
+ try:
+ proc.kill()
+ except Exception:
+ pass
+ await proc.wait()
+ return False, f"timeout after {timeout_sec}s"
+ err_text = (err or b"").decode("utf-8", "ignore").strip()
+ return (proc.returncode == 0), err_text
+
+ # 两种策略:1) -ss 在 -i 前(快,但有些文件/关键帧会失败)
+ # 2) -ss 在 -i 后(慢,但更稳定)
+ common_tail = [
+ "-an",
+ "-frames:v", "1",
+ "-vf", vf,
+ "-vcodec", "mjpeg",
+ "-q:v", "3",
+ "-f", "image2",
+ tmp_path,
+ ]
+
+ attempts = [
+ # fast seek
+ [ffmpeg, "-hide_banner", "-loglevel", "error", "-y", "-ss", f"{seek_sec}", "-i", src_video] + common_tail,
+ # accurate seek
+ [ffmpeg, "-hide_banner", "-loglevel", "error", "-y", "-i", src_video, "-ss", f"{seek_sec}"] + common_tail,
+ # fallback:如果 seek 太靠前导致失败,再试试 1s
+ [ffmpeg, "-hide_banner", "-loglevel", "error", "-y", "-ss", "1.0", "-i", src_video] + common_tail,
+ ]
+
+ last_err: Optional[str] = None
+ try:
+ for args in attempts:
+ ok, err = await _run(args)
+ if ok and os.path.exists(tmp_path) and os.path.getsize(tmp_path) > 0:
+ os.replace(tmp_path, dst_path)
+ return True
+ last_err = err or last_err
+ # 清理无效临时文件,避免下次误判
+ try:
+ if os.path.exists(tmp_path):
+ os.remove(tmp_path)
+ except Exception:
+ pass
+
+ logger.warning("ffmpeg thumbnail failed. src=%s dst=%s err=%s", src_video, dst_path, last_err)
+ return False
+ finally:
+ try:
+ if os.path.exists(tmp_path):
+ os.remove(tmp_path)
+ except Exception:
+ pass
+
+def _env_int(name: str, default: int) -> int:
+ try:
+ return int(os.environ.get(name, str(default)))
+ except Exception:
+ return default
+
+def _env_float(name: str, default: float) -> float:
+ try:
+ return float(os.environ.get(name, str(default)))
+ except Exception:
+ return float(default)
+
+def _rpm_to_rps(rpm: float) -> float:
+ return float(rpm) / 60.0
+
+
+# 是否信任反向代理头(X-Forwarded-For / X-Real-IP)
+RATE_LIMIT_TRUST_PROXY_HEADERS = os.environ.get("RATE_LIMIT_TRUST_PROXY_HEADERS", "0") == "1"
+
+@dataclass
+class _RateBucket:
+ tokens: float
+ last_ts: float # monotonic
+ last_seen: float # monotonic (for TTL cleanup)
+
+class TokenBucketRateLimiter:
+ """
+ 内存令牌桶 + 防爆内存:
+ - max_buckets: 限制内部桶表最大条目数(防止海量 IP 导致字典膨胀)
+ - evict_batch: 超过上限后每次驱逐多少条(按插入顺序驱逐最早创建的桶)
+ """
+ def __init__(
+ self,
+ ttl_sec: int = 900,
+ cleanup_interval_sec: int = 60,
+ *,
+ max_buckets: int = 100000,
+ evict_batch: int = 2000,
+ ):
+ self.ttl_sec = int(ttl_sec)
+ self.cleanup_interval_sec = int(cleanup_interval_sec)
+ self.max_buckets = int(max(1, max_buckets))
+ self.evict_batch = int(max(1, evict_batch))
+
+ self._buckets: Dict[str, _RateBucket] = {}
+ self._lock = asyncio.Lock()
+ self._last_cleanup = time.monotonic()
+
+ async def allow(
+ self,
+ key: str,
+ *,
+ capacity: float,
+ refill_rate: float,
+ cost: float = 1.0,
+ ) -> Tuple[bool, float, float]:
+ """
+ 返回: (allowed, retry_after_sec, remaining_tokens)
+ """
+ now = time.monotonic()
+ capacity = float(max(0.0, capacity))
+ refill_rate = float(max(0.0, refill_rate))
+ cost = float(max(0.0, cost))
+
+ async with self._lock:
+ b = self._buckets.get(key)
+
+ if b is None:
+ # 先做一次周期清理
+ if now - self._last_cleanup > self.cleanup_interval_sec:
+ self._cleanup_locked(now)
+ self._last_cleanup = now
+
+ # 桶表满了:先清 TTL,再做批量驱逐;仍然满 -> 不再创建新桶,直接拒绝
+ if len(self._buckets) >= self.max_buckets:
+ self._cleanup_locked(now)
+
+ if len(self._buckets) >= self.max_buckets:
+ self._evict_locked()
+
+ if len(self._buckets) >= self.max_buckets:
+ # 不存任何新 key,避免内存继续涨
+ # retry_after 给一个很短的值即可(客户端会重试)
+ return False, 1.0, 0.0
+
+ b = _RateBucket(tokens=capacity, last_ts=now, last_seen=now)
+ self._buckets[key] = b
+ else:
+ b.last_seen = now
+
+ # refill
+ elapsed = max(0.0, now - b.last_ts)
+ if refill_rate > 0:
+ b.tokens = min(capacity, b.tokens + elapsed * refill_rate)
+ else:
+ b.tokens = min(capacity, b.tokens)
+ b.last_ts = now
+
+ if b.tokens >= cost:
+ b.tokens -= cost
+ return True, 0.0, float(max(0.0, b.tokens))
+
+ # not enough
+ if refill_rate <= 0:
+ retry_after = float(self.ttl_sec)
+ else:
+ need = cost - b.tokens
+ retry_after = need / refill_rate
+ return False, float(retry_after), float(max(0.0, b.tokens))
+
+ def _cleanup_locked(self, now: float) -> None:
+ ttl = float(self.ttl_sec)
+ dead = [k for k, b in self._buckets.items() if (now - b.last_seen) > ttl]
+ for k in dead:
+ self._buckets.pop(k, None)
+
+ def _evict_locked(self) -> None:
+ # 按 dict 插入顺序驱逐最早的一批 bucket(不排序,避免在高压下额外 CPU 开销)
+ n = min(self.evict_batch, len(self._buckets))
+ for _ in range(n):
+ try:
+ k = next(iter(self._buckets))
+ except StopIteration:
+ break
+ self._buckets.pop(k, None)
+
+def _headers_to_dict(scope_headers: List[Tuple[bytes, bytes]]) -> Dict[str, str]:
+ d: Dict[str, str] = {}
+ for k, v in scope_headers or []:
+ try:
+ dk = k.decode("latin1").lower()
+ dv = v.decode("latin1")
+ except Exception:
+ continue
+ d[dk] = dv
+ return d
+
+def _client_ip_from_http_scope(scope: dict, trust_proxy_headers: bool) -> str:
+ headers = _headers_to_dict(scope.get("headers") or [])
+ if trust_proxy_headers:
+ xff = headers.get("x-forwarded-for")
+ if xff:
+ # "client, proxy1, proxy2" -> client
+ return xff.split(",")[0].strip() or "unknown"
+ xri = headers.get("x-real-ip")
+ if xri:
+ return xri.strip() or "unknown"
+
+ client = scope.get("client")
+ if client and isinstance(client, (list, tuple)) and len(client) >= 1:
+ return str(client[0] or "unknown")
+ return "unknown"
+
+def _client_ip_from_ws(ws: WebSocket, trust_proxy_headers: bool) -> str:
+ try:
+ if trust_proxy_headers:
+ xff = ws.headers.get("x-forwarded-for")
+ if xff:
+ return xff.split(",")[0].strip() or "unknown"
+ xri = ws.headers.get("x-real-ip")
+ if xri:
+ return xri.strip() or "unknown"
+ except Exception:
+ pass
+
+ try:
+ if ws.client:
+ return str(ws.client.host or "unknown")
+ except Exception:
+ pass
+
+ return "unknown"
+
+# 分片上传(绕开网关对单次请求体/单文件的限制)
+UPLOAD_RESUMABLE_CHUNK_BYTES = _env_int("UPLOAD_RESUMABLE_CHUNK_BYTES", 8 * 1024 * 1024)
+
+# 未完成的分片上传状态保留多久(超时自动清理临时文件)
+RESUMABLE_UPLOAD_TTL_SEC = _env_int("RESUMABLE_UPLOAD_TTL_SEC", 3600) # 1 hour
+
+MEDIA_SEQ_WIDTH = 4 # media_0001
+MEDIA_PREFIX = "media_"
+
+
+# -------- 注意:在服务器上,所有用户的ip可能是相同的----
+
+# 每个 IP 的总体请求速率(包括 /static、/api、/ 等)
+HTTP_GLOBAL_RPM = _env_int("RATE_LIMIT_HTTP_GLOBAL_RPM", 3000)
+HTTP_GLOBAL_BURST = _env_int("RATE_LIMIT_HTTP_GLOBAL_BURST", 600)
+
+# 创建 session:防止刷 session 导致内存爆
+HTTP_CREATE_SESSION_RPM = _env_int("RATE_LIMIT_CREATE_SESSION_RPM", 3000)
+HTTP_CREATE_SESSION_BURST = _env_int("RATE_LIMIT_CREATE_SESSION_BURST", 50)
+
+# 上传素材:最容易被滥用(大文件 + 频率)
+HTTP_UPLOAD_MEDIA_RPM = _env_int("RATE_LIMIT_UPLOAD_MEDIA_RPM", 12000)
+HTTP_UPLOAD_MEDIA_BURST = _env_int("RATE_LIMIT_UPLOAD_MEDIA_BURST", 300)
+
+# 上传“成本”换算:content-length 每多少字节算 1 个 token(越大越费 token)
+UPLOAD_COST_BYTES = _env_int("RATE_LIMIT_UPLOAD_COST_BYTES", 10 * 1024 * 1024) # 默认 10MB = 1 token
+
+# 素材个数控制:会话内上线+上传上限
+MAX_UPLOAD_FILES_PER_REQUEST = _env_int("MAX_UPLOAD_FILES_PER_REQUEST", 30) # 单次请求最多文件数
+MAX_MEDIA_PER_SESSION = _env_int("MAX_MEDIA_PER_SESSION", 30) # 每个 session 总素材上限(pending + 已用)
+MAX_PENDING_MEDIA_PER_SESSION = _env_int("MAX_PENDING_MEDIA_PER_SESSION", 30) # 每个 session pending 素材上限(UI 友好)
+
+HTTP_UPLOAD_MEDIA_COUNT_RPM = _env_int("RATE_LIMIT_UPLOAD_MEDIA_COUNT_RPM", 50000)
+HTTP_UPLOAD_MEDIA_COUNT_BURST = _env_int("RATE_LIMIT_UPLOAD_MEDIA_COUNT_BURST", 1000)
+
+# 下载/缩略图:适中限制(防刷资源)
+HTTP_MEDIA_GET_RPM = _env_int("RATE_LIMIT_MEDIA_GET_RPM", 2400)
+HTTP_MEDIA_GET_BURST = _env_int("RATE_LIMIT_MEDIA_GET_BURST", 60)
+
+# 清空会话:避免频繁清空扰动
+HTTP_CLEAR_RPM = _env_int("RATE_LIMIT_CLEAR_SESSION_RPM", 3000)
+HTTP_CLEAR_BURST = _env_int("RATE_LIMIT_CLEAR_SESSION_BURST", 50)
+
+# 其它 API 默认:比 global 更细一点(可选)
+HTTP_API_RPM = _env_int("RATE_LIMIT_API_RPM", 2400)
+HTTP_API_BURST = _env_int("RATE_LIMIT_API_BURST", 120)
+
+# WebSocket:连接创建频率
+WS_CONNECT_RPM = _env_int("RATE_LIMIT_WS_CONNECT_RPM", 600)
+WS_CONNECT_BURST = _env_int("RATE_LIMIT_WS_CONNECT_BURST", 50)
+
+# WebSocket:chat.send(真正触发 LLM 成本)
+WS_CHAT_SEND_RPM = _env_int("RATE_LIMIT_WS_CHAT_SEND_RPM", 300)
+WS_CHAT_SEND_BURST = _env_int("RATE_LIMIT_WS_CHAT_SEND_BURST", 20)
+
+# ---- 全局(所有 IP 合并)限流:抵御多 IP 同时访问 ----
+HTTP_ALL_RPM = _env_int("RATE_LIMIT_HTTP_ALL_RPM", 1200) # 全站 HTTP 总量:1200/min ~= 20 rps
+HTTP_ALL_BURST = _env_int("RATE_LIMIT_HTTP_ALL_BURST", 200)
+
+CREATE_SESSION_ALL_RPM = _env_int("RATE_LIMIT_CREATE_SESSION_ALL_RPM", 120)
+CREATE_SESSION_ALL_BURST = _env_int("RATE_LIMIT_CREATE_SESSION_ALL_BURST", 20)
+
+UPLOAD_MEDIA_ALL_RPM = _env_int("RATE_LIMIT_UPLOAD_MEDIA_ALL_RPM", 6000)
+UPLOAD_MEDIA_ALL_BURST = _env_int("RATE_LIMIT_UPLOAD_MEDIA_ALL_BURST", 2000)
+
+# “素材个数”限流:默认复用 upload_media 的 rpm/burst
+UPLOAD_MEDIA_COUNT_ALL_RPM = _env_int("RATE_LIMIT_UPLOAD_MEDIA_COUNT_ALL_RPM", UPLOAD_MEDIA_ALL_RPM)
+UPLOAD_MEDIA_COUNT_ALL_BURST = _env_int("RATE_LIMIT_UPLOAD_MEDIA_COUNT_ALL_BURST", UPLOAD_MEDIA_ALL_BURST)
+
+MEDIA_GET_ALL_RPM = _env_int("RATE_LIMIT_MEDIA_GET_ALL_RPM", 600)
+MEDIA_GET_ALL_BURST = _env_int("RATE_LIMIT_MEDIA_GET_ALL_BURST", 120)
+
+WS_CONNECT_ALL_RPM = _env_int("RATE_LIMIT_WS_CONNECT_ALL_RPM", 60000)
+WS_CONNECT_ALL_BURST = _env_int("RATE_LIMIT_WS_CONNECT_ALL_BURST", 2000)
+
+WS_CHAT_SEND_ALL_RPM = _env_int("RATE_LIMIT_WS_CHAT_SEND_ALL_RPM", 500)
+WS_CHAT_SEND_ALL_BURST = _env_int("RATE_LIMIT_WS_CHAT_SEND_ALL_BURST", 30)
+
+# ---- 全局并发上限:抵御“很多 IP 同时连/同时触发 LLM/同时上传” ----
+WS_MAX_CONNECTIONS = _env_int("RATE_LIMIT_WS_MAX_CONNECTIONS", 500) # 同时在线 WS 连接数上限
+CHAT_MAX_CONCURRENCY = _env_int("RATE_LIMIT_CHAT_MAX_CONCURRENCY", 80) # 同时跑的 LLM turn 上限
+UPLOAD_MAX_CONCURRENCY = _env_int("RATE_LIMIT_UPLOAD_MAX_CONCURRENCY", 100) # 同时处理上传(含缩略图)上限
+
+WS_CONN_SEM = asyncio.Semaphore(WS_MAX_CONNECTIONS)
+CHAT_TURN_SEM = asyncio.Semaphore(CHAT_MAX_CONCURRENCY)
+UPLOAD_SEM = asyncio.Semaphore(UPLOAD_MAX_CONCURRENCY)
+
+def _global_http_rule_limit(rule_name: str) -> Optional[Tuple[int, int]]:
+ if rule_name == "create_session":
+ return CREATE_SESSION_ALL_BURST, CREATE_SESSION_ALL_RPM
+ if rule_name == "upload_media":
+ return UPLOAD_MEDIA_ALL_BURST, UPLOAD_MEDIA_ALL_RPM
+ if rule_name == "media_get":
+ return MEDIA_GET_ALL_BURST, MEDIA_GET_ALL_RPM
+ return None
+
+
+def _get_content_length(scope: dict) -> Optional[int]:
+ try:
+ headers = _headers_to_dict(scope.get("headers") or [])
+ v = headers.get("content-length")
+ if v is None:
+ return None
+ n = int(v)
+ if n < 0:
+ return None
+ return n
+ except Exception:
+ return None
+
+def _match_http_rule(method: str, path: str) -> Tuple[str, int, int, float]:
+ """
+ 返回 (rule_name, burst, rpm, cost)
+ cost 默认为 1;上传接口会按 content-length 动态计算 cost(在 middleware 内处理)。
+ """
+ method = (method or "").upper()
+ path = path or ""
+
+ # 精确接口优先
+ if method == "POST" and path == "/api/sessions":
+ return ("create_session", HTTP_CREATE_SESSION_BURST, HTTP_CREATE_SESSION_RPM, 1.0)
+
+ # 上传素材(含分片接口)
+ if method == "POST" and path.startswith("/api/sessions/"):
+ if path.endswith("/media") or path.endswith("/media/init"):
+ return ("upload_media", HTTP_UPLOAD_MEDIA_BURST, HTTP_UPLOAD_MEDIA_RPM, 1.0)
+ if "/media/" in path and (path.endswith("/chunk") or path.endswith("/complete") or path.endswith("/cancel")):
+ return ("upload_media", HTTP_UPLOAD_MEDIA_BURST, HTTP_UPLOAD_MEDIA_RPM, 1.0)
+
+ if method == "GET" and path.startswith("/api/sessions/") and (path.endswith("/thumb") or path.endswith("/file")):
+ return ("media_get", HTTP_MEDIA_GET_BURST, HTTP_MEDIA_GET_RPM, 1.0)
+
+ if method == "POST" and path.startswith("/api/sessions/") and path.endswith("/clear"):
+ return ("clear_session", HTTP_CLEAR_BURST, HTTP_CLEAR_RPM, 1.0)
+
+ # 其它 API
+ if path.startswith("/api/"):
+ return ("api_general", HTTP_API_BURST, HTTP_API_RPM, 1.0)
+
+ # 非 /api 的其他请求:只走 global
+ return ("", 0, 0, 1.0)
+
+class HttpRateLimitMiddleware:
+ """
+ ASGI middleware:对 HTTP 请求做限流(WebSocket 不在这里处理)。
+ """
+ def __init__(self, app: Any, limiter: TokenBucketRateLimiter, trust_proxy_headers: bool = False):
+ self.app = app
+ self.limiter = limiter
+ self.trust_proxy_headers = bool(trust_proxy_headers)
+
+ async def __call__(self, scope: dict, receive: Any, send: Any):
+ if scope.get("type") != "http":
+ return await self.app(scope, receive, send)
+
+ method = scope.get("method", "GET")
+ path = scope.get("path", "/")
+ ip = _client_ip_from_http_scope(scope, self.trust_proxy_headers)
+
+ # 0) 全局总量桶(所有 IP 合并)
+ ok, retry_after, _ = await self.limiter.allow(
+ key="http:all",
+ capacity=float(HTTP_ALL_BURST),
+ refill_rate=_rpm_to_rps(float(HTTP_ALL_RPM)),
+ cost=1.0,
+ )
+ if not ok:
+ return await self._reject(send, retry_after)
+
+ # 1) 单 IP 全局桶(防单点)
+ ok, retry_after, _ = await self.limiter.allow(
+ key=f"http:global:{ip}",
+ capacity=float(HTTP_GLOBAL_BURST),
+ refill_rate=_rpm_to_rps(float(HTTP_GLOBAL_RPM)),
+ cost=1.0,
+ )
+ if not ok:
+ return await self._reject(send, retry_after)
+
+ # 2) 规则桶
+ rule_name, burst, rpm, cost = _match_http_rule(method, path)
+
+ # 上传接口:按 content-length 动态增加 cost(越大越费 token)
+ if rule_name == "upload_media":
+ cl = _get_content_length(scope)
+ if cl and cl > 0 and UPLOAD_COST_BYTES > 0:
+ cost = max(1.0, float(math.ceil(cl / float(UPLOAD_COST_BYTES))))
+
+ if rule_name:
+ # 2.1 规则的“全局桶”(跨 IP)
+ g = _global_http_rule_limit(rule_name)
+ if g:
+ g_burst, g_rpm = g
+ okg, rag, _ = await self.limiter.allow(
+ key=f"http:{rule_name}:all",
+ capacity=float(g_burst),
+ refill_rate=_rpm_to_rps(float(g_rpm)),
+ cost=float(cost),
+ )
+ if not okg:
+ return await self._reject(send, rag)
+
+ # 2.2 规则的“单 IP 桶”
+ ok2, retry_after2, _ = await self.limiter.allow(
+ key=f"http:{rule_name}:{ip}",
+ capacity=float(burst),
+ refill_rate=_rpm_to_rps(float(rpm)),
+ cost=float(cost),
+ )
+ if not ok2:
+ return await self._reject(send, retry_after2)
+
+ return await self.app(scope, receive, send)
+
+
+ async def _reject(self, send: Any, retry_after: float):
+ ra = int(math.ceil(float(retry_after or 0.0)))
+ body = json.dumps(
+ {"detail": "Too Many Requests", "retry_after": ra},
+ ensure_ascii=False
+ ).encode("utf-8")
+
+ headers = [
+ (b"content-type", b"application/json; charset=utf-8"),
+ (b"retry-after", str(ra).encode("ascii")),
+ ]
+
+ await send({"type": "http.response.start", "status": 429, "headers": headers})
+ await send({"type": "http.response.body", "body": body, "more_body": False})
+
+RATE_LIMITER = TokenBucketRateLimiter(
+ ttl_sec=_env_int("RATE_LIMIT_TTL_SEC", 900), # 默认 15 分钟:多 IP 攻击时更快释放桶表
+ cleanup_interval_sec=_env_int("RATE_LIMIT_CLEANUP_INTERVAL_SEC", 60),
+ max_buckets=_env_int("RATE_LIMIT_MAX_BUCKETS", 100000),
+ evict_batch=_env_int("RATE_LIMIT_EVICT_BATCH", 2000),
+)
+
+
+@dataclass
+class MediaMeta:
+ id: str
+ name: str
+ kind: str
+ path: str
+ thumb_path: Optional[str]
+ ts: float
+
+@dataclass
+class ResumableUpload:
+ upload_id: str
+ filename: str # 素材原名(用于UI展示)
+ store_filename: str # 落盘名 media_0001.mp4
+ size: int
+ chunk_size: int
+ total_chunks: int
+ tmp_path: str
+ kind: str
+ created_ts: float
+ last_ts: float
+ received: Set[int] = field(default_factory=set)
+ closed: bool = False
+ lock: asyncio.Lock = field(default_factory=asyncio.Lock)
+
+class MediaStore:
+ """
+ 专注文件系统层:
+ - 保存上传文件(async chunk)
+ - 生成缩略图(图片:线程;视频:异步子进程)
+ - 删除文件(只删 media_dir 下的文件)
+ """
+ def __init__(self, media_dir: str):
+ self.media_dir = os.path.abspath(media_dir)
+ os.makedirs(self.media_dir, exist_ok=True)
+ self.thumbs_dir = ensure_thumbs_dir(self.media_dir)
+
+ async def save_upload(self, uf: UploadFile, *, store_filename: str, display_name: str) -> MediaMeta:
+ media_id = uuid.uuid4().hex[:10]
+
+ display_name = sanitize_filename(display_name or uf.filename or "unnamed")
+ store_filename = sanitize_filename(store_filename)
+
+ kind = detect_media_kind(display_name)
+
+ save_path = os.path.join(self.media_dir, store_filename)
+ os.makedirs(os.path.dirname(save_path), exist_ok=True)
+
+ if os.path.exists(save_path):
+ raise HTTPException(status_code=409, detail=f"media filename exists: {store_filename}")
+
+ # async chunk 写盘(不一次性读入内存)
+ async with await anyio.open_file(save_path, "wb") as out:
+ while True:
+ chunk = await uf.read(CHUNK_SIZE)
+ if not chunk:
+ break
+ await out.write(chunk)
+
+ try:
+ await uf.close()
+ except Exception:
+ pass
+
+ thumb_path: Optional[str] = None
+ if kind in ("image", "video"):
+ thumb_path = os.path.join(self.thumbs_dir, f"{media_id}.jpg")
+
+ if kind == "image":
+ ok = await anyio.to_thread.run_sync(make_image_thumbnail_sync, save_path, thumb_path)
+ else:
+ ok = await make_video_thumbnail_async(save_path, thumb_path)
+
+ if not ok:
+ # 图片缩略图失败 -> 用原图;视频失败 -> 置空(thumb endpoint 返回占位 SVG)
+ thumb_path = save_path if kind == "image" else None
+
+ return MediaMeta(
+ id=media_id,
+ name=os.path.basename(display_name),
+ kind=kind,
+ path=os.path.abspath(save_path),
+ thumb_path=os.path.abspath(thumb_path) if thumb_path else None,
+ ts=time.time(),
+ )
+
+ async def save_from_path(
+ self,
+ src_path: str,
+ *,
+ store_filename: str,
+ display_name: str,
+ ) -> MediaMeta:
+ """
+ 将分片上传产生的临时文件移动到 media_dir 下的最终文件。
+ - display_name: UI 展示名(原始文件名)
+ - store_filename: 落盘名(media_0001.mp4),用于记录顺序
+ """
+ media_id = uuid.uuid4().hex[:10]
+
+ display_name = sanitize_filename(display_name or "unnamed")
+ store_filename = sanitize_filename(store_filename or "unnamed")
+
+ kind = detect_media_kind(display_name)
+
+ src_path = os.path.abspath(src_path)
+ if not os.path.exists(src_path):
+ raise HTTPException(status_code=400, detail="upload temp file missing")
+
+ save_path = os.path.abspath(os.path.join(self.media_dir, store_filename))
+ os.makedirs(os.path.dirname(save_path), exist_ok=True)
+
+ if os.path.exists(save_path):
+ raise HTTPException(status_code=409, detail=f"media already exists: {store_filename}")
+
+ # move tmp -> final
+ os.replace(src_path, save_path)
+
+ thumb_path: Optional[str] = None
+ if kind in ("image", "video"):
+ thumb_path = os.path.join(self.thumbs_dir, f"{media_id}.jpg")
+
+ if kind == "image":
+ ok = await anyio.to_thread.run_sync(make_image_thumbnail_sync, save_path, thumb_path)
+ else:
+ ok = await make_video_thumbnail_async(save_path, thumb_path)
+
+ if not ok:
+ thumb_path = save_path if kind == "image" else None
+
+ return MediaMeta(
+ id=media_id,
+ name=os.path.basename(display_name), # ★ UI 显示原文件名
+ kind=kind,
+ path=os.path.abspath(save_path), # ★ 磁盘文件名 media_0001.ext
+ thumb_path=os.path.abspath(thumb_path) if thumb_path else None,
+ ts=time.time(),
+ )
+
+ async def delete_files(self, meta: MediaMeta) -> None:
+ root = self.media_dir
+ for p in {meta.path, meta.thumb_path}:
+ if not p:
+ continue
+ ap = os.path.abspath(p)
+ if not _is_under_dir(ap, root):
+ continue
+ if os.path.isdir(ap):
+ continue
+ if os.path.exists(ap):
+ try:
+ os.remove(ap)
+ except Exception:
+ pass
+
+
+class ChatSession:
+ """
+ 一个 session 的全部状态:
+ - agent / lc_messages(LangChain上下文)
+ - history(给前端回放)
+ - load_media / pending_media(staging)
+ - tool trace 索引(支持 tool 事件“就地更新”)
+ """
+ def __init__(self, session_id: str, cfg: Settings):
+ self.session_id = session_id
+ self.cfg = cfg
+ self.lang = "zh"
+
+ default_llm = _s(getattr(getattr(cfg, "developer", None), "default_llm", "")) or "deepseek-chat"
+ default_vlm = _s(getattr(getattr(cfg, "developer", None), "default_vlm", "")) or "qwen3-vl-8b-instruct"
+
+ self.chat_models = [default_llm, CUSTOM_MODEL_KEY]
+ self.chat_model_key = default_llm
+
+ self.vlm_models = [default_vlm, CUSTOM_MODEL_KEY]
+ self.vlm_model_key = default_vlm
+
+ self.developer_mode = is_developer_mode(cfg)
+
+ self.media_dir = resolve_media_dir(cfg.project.media_dir, session_id)
+ self.media_store = MediaStore(self.media_dir)
+ # 分片上传临时目录 + in-flight 状态
+ self.uploads_dir = ensure_uploads_dir(self.media_dir)
+ self.resumable_uploads: Dict[str, ResumableUpload] = {}
+
+ # 直传(multipart 多文件)时的“预占位”,避免并发竞争导致超过上限
+ self._direct_upload_reservations = 0
+
+ self.agent: Any = None
+ self.node_manager = None
+ self.client_context = None
+
+ # 锁分离:避免“流式输出”阻塞上传/删除 pending
+ self.chat_lock = asyncio.Lock()
+ self.media_lock = asyncio.Lock()
+
+ self.sent_media_total: int = 0
+ self._attach_stats_msg_idx = 1
+
+ self.lc_messages: List[BaseMessage] = [
+ SystemMessage(content=get_prompt("instruction.system", lang=self.lang)),
+ SystemMessage(content="【User media upload status】{}"),
+ ]
+ self.history: List[Dict[str, Any]] = []
+
+ self.load_media: Dict[str, MediaMeta] = {}
+ self.pending_media_ids: List[str] = []
+
+ self._tool_history_index: Dict[str, int] = {} # tool_call_id -> history index
+
+ self.cancel_event = asyncio.Event() # 打断信号
+
+ # 服务相关配置
+ self.custom_llm_config: Optional[Dict[str, Any]] = None
+ self.custom_vlm_config: Optional[Dict[str, Any]] = None
+ self.tts_config: Dict[str, Any] = {}
+ self._agent_build_key: Optional[Tuple[Any, ...]] = None
+
+ self.pexels_key_mode: str = "default" # "default" | "custom"
+ self.pexels_custom_key: str = ""
+
+ self._media_seq_inited = False
+ self._media_seq_next = 1
+
+ def _ensure_system_prompt(self) -> None:
+ sys = (get_prompt("instruction.system", lang=self.lang) or "").strip()
+ if not sys:
+ return
+
+ for m in self.lc_messages:
+ if isinstance(m, SystemMessage) and (getattr(m, "content", "") or "").strip() == sys:
+ return
+
+ self.lc_messages.insert(0, SystemMessage(content=sys))
+
+ def _init_media_seq_locked(self) -> None:
+ """
+ 初始化 self._media_seq_next:
+ - 允许 clear chat 后继续编号,不覆盖旧文件
+ """
+ if self._media_seq_inited:
+ return
+
+ max_seq = 0
+
+ # 1) 已落盘文件
+ try:
+ for fn in os.listdir(self.media_dir):
+ s = parse_media_seq(fn)
+ if s is not None:
+ max_seq = max(max_seq, s)
+ except Exception:
+ pass
+
+ # 2) 内存里已有 load_media(保险)
+ for meta in (self.load_media or {}).values():
+ s = parse_media_seq(os.path.basename(meta.path or ""))
+ if s is not None:
+ max_seq = max(max_seq, s)
+
+ # 3) in-flight resumable(保险)
+ for u in (self.resumable_uploads or {}).values():
+ s = parse_media_seq(getattr(u, "store_filename", "") or "")
+ if s is not None:
+ max_seq = max(max_seq, s)
+
+ self._media_seq_next = max_seq + 1
+ self._media_seq_inited = True
+
+
+ def _reserve_store_filenames_locked(self, display_filenames: List[str]) -> List[str]:
+ """
+ 按传入顺序生成一组 store 文件名(media_0001.ext ...)
+ 注意:这里的“顺序”就是你要固化的上传顺序。
+ """
+ self._init_media_seq_locked()
+
+ out: List[str] = []
+ seq = int(self._media_seq_next)
+
+ for disp in display_filenames:
+ disp = sanitize_filename(disp or "unnamed")
+ ext = os.path.splitext(disp)[1].lower()
+
+ # 不复用旧号;仅在极端情况下跳过已存在文件(防撞)
+ while True:
+ store = make_media_store_filename(seq, ext)
+ if not os.path.exists(os.path.join(self.media_dir, store)):
+ break
+ seq += 1
+
+ out.append(store)
+ seq += 1
+
+ self._media_seq_next = seq
+ return out
+
+
+ def apply_service_config(self, service_cfg: Any) -> Tuple[bool, Optional[str]]:
+ llm, vlm, tts, pexels, err = _parse_service_config(service_cfg)
+ if err:
+ return False, err
+
+ if llm is not None:
+ self.custom_llm_config = llm
+ if vlm is not None:
+ self.custom_vlm_config = vlm
+
+ # tts 允许为空;非空才覆盖
+ if isinstance(tts, dict) and tts:
+ self.tts_config = tts
+
+ # ---- pexels ----
+ if isinstance(pexels, dict) and pexels:
+ mode = _s(pexels.get("mode")).lower()
+ if mode == "custom":
+ self.pexels_key_mode = "custom"
+ self.pexels_custom_key = _s(pexels.get("api_key"))
+ else:
+ self.pexels_key_mode = "default"
+ self.pexels_custom_key = ""
+
+ return True, None
+
+ async def ensure_agent(self) -> None:
+ # 1) resolve LLM override
+ if self.chat_model_key == CUSTOM_MODEL_KEY:
+ if not isinstance(self.custom_llm_config, dict):
+ raise RuntimeError("please fill in model/base_url/api_key of custom LLM")
+ llm_override = self.custom_llm_config
+ else:
+ llm_override, err = _resolve_default_model_override(self.cfg, self.chat_model_key)
+ if err:
+ raise RuntimeError(err)
+
+ # 2) resolve VLM override
+ if self.vlm_model_key == CUSTOM_MODEL_KEY:
+ if not isinstance(self.custom_vlm_config, dict):
+ raise RuntimeError("please fill in model/base_url/api_key of custom VLM")
+ vlm_override = self.custom_vlm_config
+ else:
+ vlm_override, err = _resolve_default_model_override(self.cfg, self.vlm_model_key)
+ if err:
+ raise RuntimeError(err)
+
+ agent_build_key: Tuple[Any, ...] = (
+ "models",
+ _stable_dict_key(llm_override),
+ _stable_dict_key(vlm_override),
+ )
+
+ if self.agent is None or self._agent_build_key != agent_build_key:
+ artifact_store = ArtifactStore(self.cfg.project.outputs_dir, session_id=self.session_id)
+ self.agent, self.node_manager = await build_agent(
+ cfg=self.cfg,
+ session_id=self.session_id,
+ store=artifact_store,
+ tool_interceptors=[
+ ToolInterceptor.inject_media_content_before,
+ ToolInterceptor.save_media_content_after,
+ ToolInterceptor.inject_tts_config,
+ ToolInterceptor.inject_pexels_api_key,
+ ],
+ llm_override=llm_override,
+ vlm_override=vlm_override,
+ )
+ self._agent_build_key = agent_build_key
+
+ if self.client_context is None:
+ self.client_context = ClientContext(
+ cfg=self.cfg,
+ session_id=self.session_id,
+ media_dir=self.media_dir,
+ bgm_dir=self.cfg.project.bgm_dir,
+ outputs_dir=self.cfg.project.outputs_dir,
+ node_manager=self.node_manager,
+ chat_model_key=self.chat_model_key,
+ vlm_model_key=self.vlm_model_key,
+ tts_config=(self.tts_config or None),
+ pexels_api_key=None,
+ lang=self.lang,
+ )
+ else:
+ self.client_context.chat_model_key = self.chat_model_key
+ self.client_context.vlm_model_key = self.vlm_model_key
+ self.client_context.tts_config = (self.tts_config or None)
+ self.client_context.lang = self.lang
+
+ # ---- resolve pexels_api_key for runtime context ----
+ pexels_api_key = ""
+ if (self.pexels_key_mode or "").lower() == "custom":
+ pexels_api_key = _s(self.pexels_custom_key)
+ else:
+ pexels_api_key = _get_default_pexels_api_key(self.cfg) # from config.toml
+
+ self.client_context.pexels_api_key = (pexels_api_key or None)
+
+ # ---- DTO / public mapping ----
+ def public_media(self, meta: MediaMeta) -> Dict[str, Any]:
+ return {
+ "id": meta.id,
+ "name": meta.name,
+ "kind": meta.kind,
+ "thumb_url": f"/api/sessions/{self.session_id}/media/{meta.id}/thumb",
+ "file_url": f"/api/sessions/{self.session_id}/media/{meta.id}/file",
+ }
+
+ def public_pending_media(self) -> List[Dict[str, Any]]:
+ out: List[Dict[str, Any]] = []
+ for aid in self.pending_media_ids:
+ meta = self.load_media.get(aid)
+ if meta:
+ out.append(self.public_media(meta))
+ return out
+
+ def snapshot(self) -> Dict[str, Any]:
+ return {
+ "session_id": self.session_id,
+ "developer_mode": self.developer_mode,
+ "pending_media": self.public_pending_media(),
+ "history": self.history,
+ "limits": {
+ "max_upload_files_per_request": MAX_UPLOAD_FILES_PER_REQUEST,
+ "max_media_per_session": MAX_MEDIA_PER_SESSION,
+ "max_pending_media_per_session": MAX_PENDING_MEDIA_PER_SESSION,
+ "upload_chunk_bytes": UPLOAD_RESUMABLE_CHUNK_BYTES,
+ },
+ "stats": {
+ "media_count": len(self.load_media),
+ "pending_count": len(self.pending_media_ids),
+ "inflight_uploads": len(self.resumable_uploads),
+ },
+ "chat_model_key": self.chat_model_key,
+ "chat_models": self.chat_models,
+ "llm_model_key": self.chat_model_key,
+ "llm_models": self.chat_models,
+ "vlm_model_key": self.vlm_model_key,
+ "vlm_models": self.vlm_models,
+ "lang": self.lang,
+ }
+
+ # ---- media operations ----
+ def _cleanup_stale_uploads_locked(self, now: Optional[float] = None) -> None:
+ now = float(now or time.time())
+ ttl = float(RESUMABLE_UPLOAD_TTL_SEC)
+ dead = [uid for uid, u in self.resumable_uploads.items() if (now - u.last_ts) > ttl]
+ for uid in dead:
+ u = self.resumable_uploads.pop(uid, None)
+ if not u:
+ continue
+ try:
+ if u.tmp_path and os.path.exists(u.tmp_path):
+ os.remove(u.tmp_path)
+ except Exception:
+ pass
+
+ def _check_media_caps_locked(self, add: int = 0) -> None:
+ add = int(max(0, add))
+ total = len(self.load_media) + len(self.resumable_uploads) + int(self._direct_upload_reservations)
+ pending = len(self.pending_media_ids) + len(self.resumable_uploads) + int(self._direct_upload_reservations)
+
+ if MAX_MEDIA_PER_SESSION > 0 and (total + add) > MAX_MEDIA_PER_SESSION:
+ raise HTTPException(
+ status_code=400,
+ detail=f"会话素材总数已达上限:{total}/{MAX_MEDIA_PER_SESSION}",
+ )
+
+ if MAX_PENDING_MEDIA_PER_SESSION > 0 and (pending + add) > MAX_PENDING_MEDIA_PER_SESSION:
+ raise HTTPException(
+ status_code=400,
+ detail=f"待发送素材数量已达上限:{pending}/{MAX_PENDING_MEDIA_PER_SESSION}",
+ )
+
+ async def add_uploads(self, files: List[UploadFile], store_filenames: List[str]) -> List[MediaMeta]:
+ if len(store_filenames) != len(files):
+ raise HTTPException(status_code=500, detail="store_filenames mismatch")
+
+ metas: List[MediaMeta] = []
+ for uf, store_fn in zip(files, store_filenames):
+ display_name = sanitize_filename(uf.filename or "unnamed")
+ metas.append(await self.media_store.save_upload(
+ uf,
+ store_filename=store_fn,
+ display_name=display_name,
+ ))
+
+ async with self.media_lock:
+ for m in metas:
+ self.load_media[m.id] = m
+ self.pending_media_ids.append(m.id)
+
+ self.pending_media_ids.sort(
+ key=lambda aid: os.path.basename(self.load_media[aid].path or "")
+ if aid in self.load_media else ""
+ )
+
+ return metas
+
+ async def delete_pending_media(self, media_id: str) -> None:
+ async with self.media_lock:
+ if media_id not in self.pending_media_ids:
+ raise HTTPException(status_code=400, detail="media is not pending (refuse physical delete)")
+ self.pending_media_ids = [x for x in self.pending_media_ids if x != media_id]
+ meta = self.load_media.pop(media_id, None)
+
+ if meta:
+ await self.media_store.delete_files(meta)
+
+ async def take_pending_media_for_message(self, attachment_ids: Optional[List[str]]) -> List[MediaMeta]:
+ async with self.media_lock:
+ if attachment_ids:
+ pick = [aid for aid in attachment_ids if aid in self.pending_media_ids]
+ else:
+ pick = list(self.pending_media_ids)
+
+ pick_set = set(pick)
+ self.pending_media_ids = [aid for aid in self.pending_media_ids if aid not in pick_set]
+ metas = [self.load_media[aid] for aid in pick if aid in self.load_media]
+ return metas
+
+ # ---- tool trace handling ----
+ def _ensure_tool_record(self, tcid: str, server: str, name: str, args: Any) -> Dict[str, Any]:
+ idx = self._tool_history_index.get(tcid)
+ if idx is None:
+ rec = {
+ "id": f"tool_{tcid}",
+ "role": "tool",
+ "tool_call_id": tcid,
+ "server": server,
+ "name": name,
+ "args": args,
+ "state": "running",
+ "progress": 0.0,
+ "message": "",
+ "summary": None,
+ "ts": time.time(),
+ }
+ self.history.append(rec)
+ self._tool_history_index[tcid] = len(self.history) - 1
+ return rec
+ return self.history[idx]
+
+ def apply_tool_event(self, raw: Dict[str, Any]) -> Optional[Dict[str, Any]]:
+ et = raw.get("type")
+ tcid = raw.get("tool_call_id")
+ if et not in ("tool_start", "tool_progress", "tool_end") or not tcid:
+ return None
+
+ server = raw.get("server") or ""
+ name = raw.get("name") or ""
+ args = raw.get("args") or {}
+
+ rec = self._ensure_tool_record(tcid, server, name, args)
+
+ if et == "tool_start":
+ rec.update({
+ "server": server,
+ "name": name,
+ "args": args,
+ "state": "running",
+ "progress": 0.0,
+ "message": "Starting...",
+ "summary": None,
+ })
+
+ elif et == "tool_progress":
+ progress = float(raw.get("progress", 0.0))
+ total = raw.get("total")
+ if total and float(total) > 0:
+ p = progress / float(total)
+ else:
+ p = progress / 100.0 if progress > 1 else progress
+ p = max(0.0, min(1.0, p))
+ rec.update({
+ "state": "running",
+ "progress": p,
+ "message": raw.get("message") or "",
+ })
+
+ elif et == "tool_end":
+ is_error = bool(raw.get("is_error"))
+
+ summary = raw.get("summary")
+ try:
+ json.dumps(summary, ensure_ascii=False)
+ except Exception:
+ summary = str(summary) if summary is not None else None
+ rec.update({
+ "state": "error" if is_error else "complete",
+ "progress": 1.0,
+ "summary": summary,
+ "message": raw.get("message") or rec.get("message") or "",
+ })
+
+ return rec
+
+
+class SessionStore:
+ def __init__(self, cfg: Settings):
+ self.cfg = cfg
+ self._lock = asyncio.Lock()
+ self._sessions: Dict[str, ChatSession] = {}
+
+ async def create(self) -> ChatSession:
+ sid = uuid.uuid4().hex
+ sess = ChatSession(sid, self.cfg)
+ async with self._lock:
+ self._sessions[sid] = sess
+ return sess
+
+ async def get(self, sid: str) -> Optional[ChatSession]:
+ async with self._lock:
+ return self._sessions.get(sid)
+
+ async def get_or_404(self, sid: str) -> ChatSession:
+ sess = await self.get(sid)
+ if not sess:
+ raise HTTPException(status_code=404, detail="session not found")
+ return sess
+
+
+@asynccontextmanager
+async def lifespan(app: FastAPI):
+ cfg = load_settings(default_config_path())
+ app.state.cfg = cfg
+ app.state.developer_mode = is_developer_mode(cfg)
+ app.state.sessions = SessionStore(cfg)
+ yield
+
+
+app = FastAPI(title="OpenStoryline Web", version="1.0.0", lifespan=lifespan)
+
+app.add_middleware(
+ HttpRateLimitMiddleware,
+ limiter=RATE_LIMITER,
+ trust_proxy_headers=RATE_LIMIT_TRUST_PROXY_HEADERS,
+)
+
+if os.path.isdir(STATIC_DIR):
+ app.mount("/static", StaticFiles(directory=STATIC_DIR), name="static")
+
+if os.path.isdir(NODE_MAP_DIR):
+ app.mount("/node_map", StaticFiles(directory=NODE_MAP_DIR), name="node_map")
+
+api = APIRouter(prefix="/api")
+
+def _rate_limit_reject_json(retry_after: float) -> JSONResponse:
+ ra = int(math.ceil(float(retry_after or 0.0)))
+ return JSONResponse(
+ {"detail": "Too Many Requests", "retry_after": ra},
+ status_code=429,
+ headers={"Retry-After": str(ra)},
+ )
+
+async def _enforce_upload_media_count_limit(request: Request, cost: float) -> Optional[JSONResponse]:
+ ip = _client_ip_from_http_scope(request.scope, RATE_LIMIT_TRUST_PROXY_HEADERS)
+ cost = float(max(0.0, cost))
+
+ ok, ra, _ = await RATE_LIMITER.allow(
+ key="http:upload_media_count:all",
+ capacity=float(UPLOAD_MEDIA_COUNT_ALL_BURST),
+ refill_rate=_rpm_to_rps(float(UPLOAD_MEDIA_COUNT_ALL_RPM)),
+ cost=cost,
+ )
+ if not ok:
+ return _rate_limit_reject_json(ra)
+
+ ok2, ra2, _ = await RATE_LIMITER.allow(
+ key=f"http:upload_media_count:{ip}",
+ capacity=float(HTTP_UPLOAD_MEDIA_COUNT_BURST),
+ refill_rate=_rpm_to_rps(float(HTTP_UPLOAD_MEDIA_COUNT_RPM)),
+ cost=cost,
+ )
+ if not ok2:
+ return _rate_limit_reject_json(ra2)
+
+ return None
+
+_TTS_UI_SECRET_KEYS = {
+ "api_key",
+ "access_token",
+ "authorization",
+ "token",
+ "password",
+ "secret",
+ "x-api-key",
+ "apikey",
+ "access_key",
+ "accesskey",
+}
+
+def _is_secret_field_name(k: str) -> bool:
+ if str(k or "").strip().lower() in _TTS_UI_SECRET_KEYS:
+ return True
+ return False
+
+def _read_config_toml(path: str) -> dict:
+ if tomllib is None:
+ return {}
+ try:
+ p = Path(path)
+ with p.open("rb") as f:
+ return tomllib.load(f) or {}
+ except Exception:
+ return {}
+
+def _get_default_pexels_api_key(cfg: Settings) -> str:
+ # 1) try Settings.search_media.pexels_api_key
+ try:
+ search_media = getattr(cfg, "search_media", None)
+ pexels_api_key = _s(getattr(search_media, "pexels_api_key", None) if search_media else None)
+ if pexels_api_key:
+ return pexels_api_key
+ else:
+ return ""
+ except Exception:
+ return ""
+
+def _normalize_field_item(item) -> dict | None:
+ """
+ item 支持:
+ - "uid"
+ - { key="uid", label="UID", required=true, secret=false, placeholder="..." }
+ """
+ if isinstance(item, str):
+ key = item.strip()
+ if not key:
+ return None
+ return {
+ "key": key,
+ "secret": _is_secret_field_name(key),
+ }
+ return None
+
+def _build_provider_schema(provider: str, label: str | None, fields: list[dict]) -> dict:
+ seen = set()
+ out = []
+ for f in fields:
+ k = str(f.get("key") or "").strip()
+ if not k or k in seen:
+ continue
+ seen.add(k)
+ out.append({
+ "key": k,
+ "label": f.get("label") or k,
+ "placeholder": f.get("placeholder") or f.get("label") or k,
+ "required": bool(f.get("required", False)),
+ "secret": bool(f.get("secret", False)),
+ })
+ return {"provider": provider, "label": label or provider, "fields": out}
+
+def _build_tts_ui_schema_from_config(config_path: str) -> dict:
+ """
+ 返回:
+ {
+ "providers": [
+ {"provider":"bytedance","label":"字节跳动","fields":[{"key":"uid",...}, ...]},
+ ...
+ ]
+ }
+ """
+ cfg = _read_config_toml(config_path)
+ tts = cfg.get("generate_voiceover", {})
+
+ providers_out: list[dict] = []
+
+ # 格式:[tts.providers.]
+ providers = tts.get("providers")
+ if isinstance(providers, dict):
+ for provider, provider_cfg in providers.items():
+ fields: list[dict] = []
+ label = str(provider_cfg.get("label") or provider_cfg.get("name") or provider)
+ for key in provider_cfg.keys():
+ f = _normalize_field_item(str(key))
+ if f:
+ fields.append(f)
+
+ providers_out.append(_build_provider_schema(provider, label, fields))
+
+ return {"providers": providers_out}
+
+@app.get("/")
+async def index():
+ if not os.path.exists(INDEX_HTML):
+ return Response("index.html not found. Put it under ./web/index.html", media_type="text/plain", status_code=404)
+ return FileResponse(INDEX_HTML, media_type="text/html")
+
+@app.get("/node-map")
+async def node_map():
+ if not os.path.exists(NODE_MAP_HTML):
+ return Response(
+ "node_map.html not found. Put it under ./web/node_map/node_map.html",
+ media_type="text/plain",
+ status_code=404,
+ )
+ return FileResponse(NODE_MAP_HTML, media_type="text/html")
+
+@api.get("/meta/tts")
+async def get_tts_ui_schema():
+ schema = _build_tts_ui_schema_from_config(default_config_path())
+ return JSONResponse(schema)
+
+# -------------------------
+# Sessions (REST)
+# -------------------------
+@api.post("/sessions")
+async def create_session():
+ store: SessionStore = app.state.sessions
+ sess = await store.create()
+ return JSONResponse(sess.snapshot())
+
+
+@api.get("/sessions/{session_id}")
+async def get_session(session_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+ return JSONResponse(sess.snapshot())
+
+
+@api.post("/sessions/{session_id}/clear")
+async def clear_session_chat(session_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+ async with sess.chat_lock:
+ sess.sent_media_total = 0
+ sess._attach_stats_msg_idx = 1
+ sess.lc_messages = [
+ SystemMessage(content=get_prompt("instruction.system", lang=sess.lang)),
+ SystemMessage(content="【User media upload status】{}"),
+ ]
+ sess._attach_stats_msg_idx = 1
+
+ sess.history = []
+ sess._tool_history_index = {}
+ return JSONResponse({"ok": True})
+
+@api.post("/sessions/{session_id}/cancel")
+async def cancel_session_turn(session_id: str):
+ """
+ 打断当前正在进行的 LLM turn(流式回复/工具调用)。
+ - 不清空 history / lc_messages
+ - 仅设置 cancel_event,由 WS 侧在流式循环中感知并安全收尾
+ """
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+ sess.cancel_event.set()
+ return JSONResponse({"ok": True})
+
+# -------------------------
+# media (REST, session-scoped)
+# -------------------------
+@api.post("/sessions/{session_id}/media")
+async def upload_media(session_id: str, request: Request, files: List[UploadFile] = File(...)):
+ if not isinstance(files, list) or not files:
+ raise HTTPException(status_code=400, detail="no files")
+
+ if MAX_UPLOAD_FILES_PER_REQUEST > 0 and len(files) > MAX_UPLOAD_FILES_PER_REQUEST:
+ raise HTTPException(status_code=400, detail=f"单次上传最多 {MAX_UPLOAD_FILES_PER_REQUEST} 个文件")
+
+ # 按素材个数限流(cost = 文件数)
+ rej = await _enforce_upload_media_count_limit(request, cost=float(len(files)))
+ if rej:
+ return rej
+
+ if UPLOAD_SEM.locked():
+ raise HTTPException(status_code=429, detail="上传并发过高,请稍后重试")
+ await UPLOAD_SEM.acquire()
+
+ n = len(files)
+ try:
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ # session cap 检查 + 预占位(避免并发竞争)
+ async with sess.media_lock:
+ sess._cleanup_stale_uploads_locked()
+ sess._check_media_caps_locked(add=n)
+ sess._direct_upload_reservations += n
+
+ display_names = [sanitize_filename(uf.filename or "unnamed") for uf in files]
+ store_filenames = sess._reserve_store_filenames_locked(display_names)
+
+ try:
+ metas = await sess.add_uploads(files, store_filenames=store_filenames)
+
+ finally:
+ async with sess.media_lock:
+ sess._direct_upload_reservations = max(0, sess._direct_upload_reservations - n)
+
+ return JSONResponse({
+ "media": [sess.public_media(m) for m in metas],
+ "pending_media": sess.public_pending_media(),
+ })
+ finally:
+ try:
+ UPLOAD_SEM.release()
+ except Exception:
+ pass
+
+@api.post("/sessions/{session_id}/media/init")
+async def init_resumable_media_upload(session_id: str, request: Request):
+ try:
+ data = await request.json()
+ if not isinstance(data, dict):
+ data = {}
+ except Exception:
+ data = {}
+
+ filename = sanitize_filename((data.get("filename") or data.get("name") or "unnamed"))
+ size = int(data.get("size") or 0)
+ if size <= 0:
+ raise HTTPException(status_code=400, detail="invalid size")
+
+ # 按素材个数限流:init 视为“新增 1 个素材”
+ rej = await _enforce_upload_media_count_limit(request, cost=1.0)
+ if rej:
+ return rej
+
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ async with sess.media_lock:
+ sess._cleanup_stale_uploads_locked()
+ sess._check_media_caps_locked(add=1)
+
+ store_filename = sess._reserve_store_filenames_locked([filename])[0]
+
+ upload_id = uuid.uuid4().hex
+ chunk_size = int(max(1, UPLOAD_RESUMABLE_CHUNK_BYTES))
+ total_chunks = int(math.ceil(size / float(chunk_size)))
+
+ tmp_path = os.path.join(sess.uploads_dir, f"{upload_id}.part")
+ os.makedirs(os.path.dirname(tmp_path), exist_ok=True)
+ try:
+ with open(tmp_path, "wb"):
+ pass
+ except Exception as e:
+ raise HTTPException(status_code=500, detail=f"cannot create temp file: {e}")
+
+ u = ResumableUpload(
+ upload_id=upload_id,
+ filename=filename,
+ store_filename=store_filename,
+ size=size,
+ chunk_size=chunk_size,
+ total_chunks=total_chunks,
+ tmp_path=os.path.abspath(tmp_path),
+ kind=detect_media_kind(filename),
+ created_ts=time.time(),
+ last_ts=time.time(),
+ )
+ sess.resumable_uploads[upload_id] = u
+
+ return JSONResponse({
+ "upload_id": upload_id,
+ "chunk_size": chunk_size,
+ "total_chunks": total_chunks,
+ "filename": filename,
+ })
+
+
+@api.post("/sessions/{session_id}/media/{upload_id}/chunk")
+async def upload_resumable_media_chunk(
+ session_id: str,
+ upload_id: str,
+ index: int = Form(...),
+ chunk: UploadFile = File(...),
+):
+ if UPLOAD_SEM.locked():
+ raise HTTPException(status_code=429, detail="上传并发过高,请稍后重试")
+ await UPLOAD_SEM.acquire()
+ try:
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ async with sess.media_lock:
+ sess._cleanup_stale_uploads_locked()
+ u = sess.resumable_uploads.get(upload_id)
+
+ if not u:
+ raise HTTPException(status_code=404, detail="upload_id not found or expired")
+
+ idx = int(index)
+ if idx < 0 or idx >= u.total_chunks:
+ raise HTTPException(status_code=400, detail="invalid chunk index")
+
+ # 期望长度(最后一片可能小于 chunk_size)
+ expected_len = u.size - idx * u.chunk_size
+ if expected_len <= 0:
+ raise HTTPException(status_code=400, detail="invalid chunk index")
+ expected_len = min(u.chunk_size, expected_len)
+
+ written = 0
+ async with u.lock:
+ if u.closed:
+ raise HTTPException(status_code=400, detail="upload already closed")
+
+ async with await anyio.open_file(u.tmp_path, "r+b") as out:
+ await out.seek(idx * u.chunk_size)
+ while True:
+ buf = await chunk.read(CHUNK_SIZE)
+ if not buf:
+ break
+ written += len(buf)
+ if written > expected_len:
+ raise HTTPException(status_code=400, detail="chunk too large")
+ await out.write(buf)
+
+ try:
+ await chunk.close()
+ except Exception:
+ pass
+
+ if written != expected_len:
+ raise HTTPException(status_code=400, detail=f"chunk size mismatch: {written} != {expected_len}")
+
+ u.received.add(idx)
+ u.last_ts = time.time()
+
+ return JSONResponse({
+ "ok": True,
+ "received_chunks": len(u.received),
+ "total_chunks": u.total_chunks,
+ })
+ finally:
+ try:
+ UPLOAD_SEM.release()
+ except Exception:
+ pass
+
+
+@api.post("/sessions/{session_id}/media/{upload_id}/complete")
+async def complete_resumable_media_upload(session_id: str, upload_id: str):
+ if UPLOAD_SEM.locked():
+ raise HTTPException(status_code=429, detail="上传并发过高,请稍后重试")
+ await UPLOAD_SEM.acquire()
+ try:
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ async with sess.media_lock:
+ sess._cleanup_stale_uploads_locked()
+ u = sess.resumable_uploads.get(upload_id)
+
+ if not u:
+ raise HTTPException(status_code=404, detail="upload_id not found or expired")
+
+ # 锁住此 upload,防止 chunk 并发写
+ async with u.lock:
+ u.closed = True
+ if len(u.received) != u.total_chunks:
+ missing = u.total_chunks - len(u.received)
+ raise HTTPException(status_code=400, detail=f"chunks missing: {missing}")
+
+ # 从索引移除(释放会话额度)
+ async with sess.media_lock:
+ u2 = sess.resumable_uploads.pop(upload_id, None)
+
+ if not u2:
+ raise HTTPException(status_code=404, detail="upload_id not found")
+
+ meta = await sess.media_store.save_from_path(
+ u2.tmp_path,
+ store_filename=u2.store_filename,
+ display_name=u2.filename,
+ )
+
+ async with sess.media_lock:
+ sess.load_media[meta.id] = meta
+ sess.pending_media_ids.append(meta.id)
+
+ return JSONResponse({
+ "media": sess.public_media(meta),
+ "pending_media": sess.public_pending_media(),
+ })
+ finally:
+ try:
+ UPLOAD_SEM.release()
+ except Exception:
+ pass
+
+
+@api.post("/sessions/{session_id}/media/{upload_id}/cancel")
+async def cancel_resumable_media_upload(session_id: str, upload_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ async with sess.media_lock:
+ u = sess.resumable_uploads.pop(upload_id, None)
+
+ if not u:
+ return JSONResponse({"ok": True})
+
+ async with u.lock:
+ u.closed = True
+ try:
+ if u.tmp_path and os.path.exists(u.tmp_path):
+ os.remove(u.tmp_path)
+ except Exception:
+ pass
+
+ return JSONResponse({"ok": True})
+
+@api.get("/sessions/{session_id}/media/pending")
+async def get_pending_media(session_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+ return JSONResponse({"pending_media": sess.public_pending_media()})
+
+
+@api.delete("/sessions/{session_id}/media/pending/{media_id}")
+async def delete_pending_media(session_id: str, media_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+ await sess.delete_pending_media(media_id)
+ return JSONResponse({"ok": True, "pending_media": sess.public_pending_media()})
+
+
+@api.get("/sessions/{session_id}/media/{media_id}/thumb")
+async def get_media_thumb(session_id: str, media_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ meta = sess.load_media.get(media_id)
+ if not meta:
+ raise HTTPException(status_code=404, detail="media not found")
+
+ # thumb 存在优先
+ if meta.thumb_path and os.path.exists(meta.thumb_path):
+ return FileResponse(meta.thumb_path, media_type="image/jpeg")
+
+ # video 无 thumb => placeholder
+ if meta.kind == "video":
+ return Response(content=video_placeholder_svg_bytes(), media_type="image/svg+xml")
+
+ # image thumb 失败 => 用原图
+ if meta.path and os.path.exists(meta.path):
+ return FileResponse(meta.path, media_type=guess_media_type(meta.path))
+
+ raise HTTPException(status_code=404, detail="thumb not available")
+
+
+@api.get("/sessions/{session_id}/media/{media_id}/file")
+async def get_media_file(session_id: str, media_id: str):
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ meta = sess.load_media.get(media_id)
+ if not meta:
+ raise HTTPException(status_code=404, detail="media not found")
+ if not meta.path or (not os.path.exists(meta.path)):
+ raise HTTPException(status_code=404, detail="file not found")
+
+ # 安全:只允许 media_dir 下
+ if not _is_under_dir(meta.path, sess.media_store.media_dir):
+ raise HTTPException(status_code=403, detail="forbidden")
+
+ return FileResponse(
+ meta.path,
+ media_type=guess_media_type(meta.path),
+ filename=meta.name,
+ )
+
+@api.get("/sessions/{session_id}/preview")
+async def preview_local_file(session_id: str, path: str):
+ """
+ 把 summary.preview_urls 里的“服务器本地路径”安全地转成可访问 URL。
+ 只允许访问:media_dir / outputs_dir / outputs_dir / bgm_dir / .server_cache 这些根目录下的文件。
+ """
+ store: SessionStore = app.state.sessions
+ sess = await store.get_or_404(session_id)
+
+ p = (path or "").strip()
+ if not p:
+ raise HTTPException(status_code=400, detail="empty path")
+ if "\x00" in p:
+ raise HTTPException(status_code=400, detail="bad path")
+
+ # 兼容 file:// 前缀(如果未来有)
+ if p.startswith("file://"):
+ p = p[len("file://"):]
+
+ # 相对路径:默认相对 ROOT_DIR
+ if os.path.isabs(p):
+ ap = os.path.abspath(p)
+ else:
+ ap = os.path.abspath(os.path.join(ROOT_DIR, p))
+
+ allowed_roots = [
+ os.path.abspath(sess.media_dir),
+ os.path.abspath(app.state.cfg.project.outputs_dir),
+ os.path.abspath(app.state.cfg.project.outputs_dir),
+ os.path.abspath(app.state.cfg.project.bgm_dir),
+ os.path.abspath(SERVER_CACHE_DIR),
+ ]
+
+ if not any(_is_under_dir(ap, r) for r in allowed_roots):
+ raise HTTPException(status_code=403, detail="forbidden")
+
+ if (not os.path.exists(ap)) or os.path.isdir(ap):
+ raise HTTPException(status_code=404, detail="file not found")
+
+ # 对 cache 文件强缓存
+ headers = {"Cache-Control": "public, max-age=31536000, immutable"} if _is_under_dir(ap, SERVER_CACHE_DIR) else None
+
+ return FileResponse(
+ ap,
+ media_type=guess_media_type(ap),
+ filename=os.path.basename(ap),
+ headers=headers,
+ )
+
+app.include_router(api)
+
+
+# -------------------------
+# WebSocket: session-scoped chat stream
+# -------------------------
+def extract_text_delta(msg_chunk: Any) -> str:
+ # 兼容 content_blocks (qwen3 常见)
+ blocks = getattr(msg_chunk, "content_blocks", None) or []
+ if blocks:
+ out = ""
+ for b in blocks:
+ if isinstance(b, dict) and b.get("type") == "text":
+ out += b.get("text", "")
+ return out
+ c = getattr(msg_chunk, "content", "")
+ return c if isinstance(c, str) else ""
+
+
+async def ws_send(ws: WebSocket, type_: str, data: Any = None):
+ if getattr(ws, "client_state", None) != WebSocketState.CONNECTED:
+ return False
+ try:
+ await ws.send_json({"type": type_, "data": data})
+ return True
+ except WebSocketDisconnect:
+ return False
+ except RuntimeError:
+ return False
+ except Exception as e:
+ if ClientDisconnected is not None and isinstance(e, ClientDisconnected):
+ return False
+ logger.exception("ws_send failed: type=%s err=%r", type_, e)
+ return False
+
+@asynccontextmanager
+async def mcp_sink_context(sink_func):
+ token = set_mcp_log_sink(sink_func)
+ try:
+ yield
+ finally:
+ reset_mcp_log_sink(token)
+
+
+@app.websocket("/ws/sessions/{session_id}/chat")
+async def ws_chat(ws: WebSocket, session_id: str):
+ client_ip = _client_ip_from_ws(ws, RATE_LIMIT_TRUST_PROXY_HEADERS)
+
+ ok, retry_after, _ = await RATE_LIMITER.allow(
+ key=f"ws:connect:{client_ip}",
+ capacity=float(WS_CONNECT_BURST),
+ refill_rate=_rpm_to_rps(float(WS_CONNECT_RPM)),
+ cost=1.0,
+ )
+ if not ok:
+ try:
+ await ws.close(code=1013, reason=f"rate_limited, retry after {int(math.ceil(retry_after))}s")
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+ return
+
+ if WS_CONN_SEM.locked():
+ try:
+ await ws.close(code=1013, reason="Server busy (websocket connections limit)")
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+ return
+
+ await WS_CONN_SEM.acquire()
+
+ try:
+ await ws.accept()
+
+ store: SessionStore = app.state.sessions
+ sess = await store.get(session_id)
+ if not sess:
+ await ws.close(code=4404, reason="session not found")
+ return
+ sess = await store.get_or_404(session_id)
+
+ await ws_send(ws, "session.snapshot", sess.snapshot())
+
+ try:
+ while True:
+ req = await ws.receive_json()
+ if not isinstance(req, dict):
+ continue
+
+ t = req.get("type")
+ if t == "ping":
+ await ws_send(ws, "pong", {"ts": time.time()})
+ continue
+
+ if t == "session.set_lang":
+ data = (req.get("data") or {})
+ lang = (data.get("lang") or "").strip().lower()
+ if lang not in ("zh", "en"):
+ lang = "zh"
+
+ sess.lang = lang
+ if sess.client_context:
+ sess.client_context.lang = lang
+
+ await ws_send(ws, "session.lang", {"lang": lang})
+ continue
+
+ if t == "chat.clear":
+ async with sess.chat_lock:
+ sess.sent_media_total = 0
+ sess._attach_stats_msg_idx = 1
+ sess.lc_messages = [
+ SystemMessage(content=get_prompt("instruction.system", lang=sess.lang)),
+ SystemMessage(content="【User media upload status】{}"),
+ ]
+ sess._attach_stats_msg_idx = 1
+ sess.history = []
+ sess._tool_history_index = {}
+ await ws_send(ws, "chat.cleared", {"ok": True})
+ continue
+
+ if t != "chat.send":
+ await ws_send(ws, "error", {"message": f"unknown type: {t}"})
+ continue
+
+ # ---- WebSocket message rate limit: only limit expensive "chat.send" ----
+ if sess.chat_lock.locked():
+ await ws_send(ws, "error", {"message": "上一条消息尚未完成,请稍后再发送"})
+ continue
+
+ ok, retry_after, _ = await RATE_LIMITER.allow(
+ key="ws:chat_send:all",
+ capacity=float(WS_CHAT_SEND_ALL_BURST),
+ refill_rate=_rpm_to_rps(float(WS_CHAT_SEND_ALL_RPM)),
+ cost=1.0,
+ )
+ if not ok:
+ await ws_send(ws, "error", {
+ "message": f"触发全局限流:请 {int(math.ceil(retry_after))} 秒后再试",
+ "retry_after": int(math.ceil(retry_after)),
+ })
+ continue
+
+ ok, retry_after, _ = await RATE_LIMITER.allow(
+ key=f"ws:chat_send:{client_ip}",
+ capacity=float(WS_CHAT_SEND_BURST),
+ refill_rate=_rpm_to_rps(float(WS_CHAT_SEND_RPM)),
+ cost=1.0,
+ )
+ if not ok:
+ await ws_send(ws, "error", {
+ "message": f"触发限流:请 {int(math.ceil(retry_after))} 秒后再试",
+ "retry_after": int(math.ceil(retry_after)),
+ })
+ continue
+
+ if CHAT_TURN_SEM.locked():
+ await ws_send(ws, "error", {"message": "服务器繁忙(模型并发已满),请稍后再试"})
+ continue
+
+ await CHAT_TURN_SEM.acquire()
+ try:
+ # 再次确认(期间有 await,锁状态可能变化)
+ if sess.chat_lock.locked():
+ await ws_send(ws, "error", {"message": "上一条消息尚未完成,请稍后再发送"})
+ continue
+
+ data = (req.get("data", {}) or {})
+
+ prompt = data.get("text", "")
+ prompt = (prompt or "").strip()
+ if not prompt:
+ continue
+
+ requested_llm = data.get("llm_model")
+ requested_vlm = data.get("vlm_model")
+
+ attachment_ids = data.get("attachment_ids")
+ if not isinstance(attachment_ids, list):
+ attachment_ids = None
+
+ async with sess.chat_lock:
+ # 新 turn 开始:清掉上一次残留的 cancel 信号
+ sess.cancel_event.clear()
+ # 0.0) 应用 service_config(自定义模型 / TTS)
+ ok_cfg, err_cfg = sess.apply_service_config(data.get("service_config"))
+ if not ok_cfg:
+ await ws_send(ws, "error", {"message": err_cfg or "service_config invalid"})
+ continue
+
+ # 0) 如果前端传了 model,则更新会话当前对话模型
+ if isinstance(requested_llm, str):
+ m = requested_llm.strip()
+ if m:
+ sess.chat_model_key = m
+ if sess.client_context:
+ sess.client_context.chat_model_key = m
+
+ if isinstance(requested_vlm, str):
+ m2 = requested_vlm.strip()
+ if m2:
+ sess.vlm_model_key = m2
+ if sess.client_context:
+ sess.client_context.vlm_model_key = m2
+
+ requested_lang = data.get("lang")
+ if isinstance(requested_lang, str):
+ lang = requested_lang.strip().lower()
+ if lang in ("zh", "en"):
+ sess.lang = lang
+ # 0.1) 可能需要重建 agent(比如切换到 __custom__ 或者自定义配置变化)
+ try:
+ await sess.ensure_agent()
+ except Exception as e:
+ await ws_send(ws, "error", {"message": f"{type(e).__name__}: {e}"})
+ continue
+
+ sess._ensure_system_prompt()
+
+ if sess.client_context:
+ sess.client_context.lang = sess.lang
+
+ # 1) 从 pending 里拿本次要发送的附件
+ attachments = await sess.take_pending_media_for_message(attachment_ids)
+ attachments_public = [sess.public_media(m) for m in attachments]
+
+ # 统计本轮和累计发送了几个素材
+ turn_attached_count = len(attachments)
+ sess.sent_media_total = int(getattr(sess, "sent_media_total", 0)) + turn_attached_count
+
+ stats = {
+ "Number of media carried in this message sent by the user": turn_attached_count,
+ "Total number of media sent by the user in all conversations": sess.sent_media_total,
+ "Total number of media in user's media library": scan_media_dir(resolve_media_dir(app.state.cfg.project.media_dir, session_id=session_id)),
+ }
+
+ idx = int(getattr(sess, "_attach_stats_msg_idx", 1))
+ if len(sess.lc_messages) <= idx:
+ while len(sess.lc_messages) <= idx:
+ sess.lc_messages.append(SystemMessage(content=""))
+
+ sess.lc_messages[idx] = SystemMessage(
+ content="【User media upload status】The following fields are used to determine the nature of the media provided by the user: \n"
+ + json.dumps(stats, ensure_ascii=False)
+ )
+
+
+ # 2.1 写入 history + lc context
+ user_msg = {
+ "id": uuid.uuid4().hex[:12],
+ "role": "user",
+ "content": prompt,
+ "attachments": attachments_public,
+ "ts": time.time(),
+ }
+ sess.history.append(user_msg)
+ sess.lc_messages.append(HumanMessage(content=prompt))
+
+ # if app.state.cfg.developer.developer_mode:
+ # print("[LLM_CTX]", session_id, sess.lc_messages)
+
+ # 2.2 ack:让前端更新 pending + 插入 user 消息(前端也可本地先插入)
+ await ws_send(ws, "chat.user", {
+ "text": prompt,
+ "attachments": attachments_public,
+ "pending_media": sess.public_pending_media(),
+ "llm_model_key": sess.chat_model_key,
+ "vlm_model_key": sess.vlm_model_key,
+ })
+
+ # 2.3 建立“单通道事件队列”,确保 ws.send_json 不会并发冲突
+ loop = asyncio.get_running_loop()
+ out_q: asyncio.Queue[Tuple[str, Any]] = asyncio.Queue()
+
+ def sink(ev: Any):
+ # MCP interceptor 可能 emit 非 dict;这里只收 dict
+ if isinstance(ev, dict):
+ loop.call_soon_threadsafe(out_q.put_nowait, ("mcp", ev))
+
+ new_messages: List[BaseMessage] = []
+
+ async def pump_agent():
+ nonlocal new_messages
+ try:
+ stream = sess.agent.astream(
+ {"messages": sess.lc_messages},
+ context=sess.client_context,
+ stream_mode=["messages", "updates"],
+ )
+ async for mode, chunk in stream:
+ if mode == "messages":
+ msg_chunk, meta = chunk
+ if meta.get("langgraph_node") == "model":
+ delta = extract_text_delta(msg_chunk)
+ if delta:
+ await out_q.put(("assistant.delta", delta))
+
+ elif mode == "updates":
+ if isinstance(chunk, dict):
+ for _step, data in chunk.items():
+ msgs = (data or {}).get("messages") or []
+ new_messages.extend(msgs)
+
+ await out_q.put(("agent.done", None))
+ except asyncio.CancelledError:
+ # 被用户打断 / 连接关闭导致的取消,不属于“真正异常”
+ # 不要发 agent.error;给主循环一个 cancelled 信号即可
+ try:
+ out_q.put_nowait(("agent.cancelled", None))
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+ raise # 让任务保持 cancelled 状态,finally 里 await 时会抛 CancelledError
+
+ except Exception as e:
+ # 关键:异常也要让主循环“可结束”,否则 UI 卡死
+ await out_q.put(("agent.error", f"{type(e).__name__}: {e}"))
+
+
+ async def safe_send(type_: str, data: Any = None) -> bool:
+ try:
+ await ws_send(ws, type_, data)
+ return True
+ except WebSocketDisconnect:
+ return False
+ except RuntimeError as e:
+ # starlette: Cannot call "send" once a close message has been sent.
+ if 'Cannot call "send" once a close message has been sent.' in str(e):
+ return False
+ raise
+ except Exception as e:
+ # uvicorn: ClientDisconnected(不同版本类路径不稳定,用类名兜底)
+ if e.__class__.__name__ == "ClientDisconnected":
+ return False
+ raise
+ # turn 开始(前端可禁用发送按钮/显示占位)
+ if not await ws_send(ws, "assistant.start", {}):
+ return
+
+ # 当前 assistant 分段缓冲:用于在 tool_start 到来前“封口”
+ seg_text = ""
+ seg_ts: Optional[float] = None
+
+ async def flush_segment(send_flush_event: bool):
+ """
+ - send_flush_event=True:告诉前端立刻结束当前 assistant 气泡(不结束整个 turn)
+ - 若 seg_text 有内容:写入 history(用于刷新/回放)
+ """
+ nonlocal seg_text, seg_ts
+
+ if send_flush_event:
+ if not await ws_send(ws, "assistant.flush", {}):
+ return
+
+ text = (seg_text or "").strip()
+ if text:
+ sess.history.append({
+ "id": uuid.uuid4().hex[:12],
+ "role": "assistant",
+ "content": text,
+ "ts": seg_ts or time.time(),
+ })
+
+ seg_text = ""
+ seg_ts = None
+
+ pump_task: Optional[asyncio.Task] = None
+
+ # helper: 从 AIMessage 提取 tool_call_id(兼容不同 provider 的结构)
+ def _tool_call_ids_from_ai_message(m: BaseMessage) -> set[str]:
+ ids: set[str] = set()
+
+ tc = getattr(m, "tool_calls", None) or []
+ for c in tc:
+ _id = None
+ if isinstance(c, dict):
+ _id = c.get("id") or c.get("tool_call_id")
+ else:
+ _id = getattr(c, "id", None) or getattr(c, "tool_call_id", None)
+ if _id:
+ ids.add(str(_id))
+
+ ak = getattr(m, "additional_kwargs", None) or {}
+ tc2 = ak.get("tool_calls") or []
+ for c in tc2:
+ if isinstance(c, dict):
+ _id = c.get("id") or c.get("tool_call_id")
+ if _id:
+ ids.add(str(_id))
+
+ return ids
+
+ # helper: new_messages 里有哪些 tool_call_id
+ def _tool_call_ids_in_msgs(msgs: List[BaseMessage]) -> set[str]:
+ ids: set[str] = set()
+ for m in msgs:
+ if isinstance(m, AIMessage):
+ ids |= _tool_call_ids_from_ai_message(m)
+ return ids
+
+ # helper: new_messages 里哪些 tool_call_id 已经有 ToolMessage 结果了
+ def _tool_result_ids_in_msgs(msgs: List[BaseMessage]) -> set[str]:
+ ids: set[str] = set()
+ for m in msgs:
+ if isinstance(m, ToolMessage):
+ tcid = getattr(m, "tool_call_id", None)
+ if tcid:
+ ids.add(str(tcid))
+ return ids
+
+ # helper: 把“已存在的 ToolMessage”强制替换成 cancelled(避免工具其实返回了但用户打断没看到,导致上下文和 UI 不一致)
+ def _force_cancelled_tool_results(msgs: List[BaseMessage], cancel_ids: set[str]) -> List[BaseMessage]:
+ if not cancel_ids:
+ return msgs
+ cancelled_content = json.dumps({"cancelled": True}, ensure_ascii=False)
+ out: List[BaseMessage] = []
+ for m in msgs:
+ if isinstance(m, ToolMessage):
+ tcid = getattr(m, "tool_call_id", None)
+ if tcid and str(tcid) in cancel_ids:
+ out.append(ToolMessage(content=cancelled_content, tool_call_id=str(tcid)))
+ continue
+ out.append(m)
+ return out
+
+ def _inject_cancelled_tool_messages(msgs: List[BaseMessage], tool_call_ids: List[str]) -> List[BaseMessage]:
+ if not tool_call_ids:
+ return msgs
+
+ out = list(msgs)
+
+ existing = set()
+ for m in out:
+ if isinstance(m, ToolMessage):
+ tcid = getattr(m, "tool_call_id", None)
+ if tcid:
+ existing.add(str(tcid))
+
+ cancelled_content = json.dumps({"cancelled": True}, ensure_ascii=False)
+
+ for tcid in tool_call_ids:
+ tcid = str(tcid)
+ if tcid in existing:
+ continue
+
+ insert_at = None
+ for i in range(len(out) - 1, -1, -1):
+ m = out[i]
+ if isinstance(m, AIMessage) and (tcid in _tool_call_ids_from_ai_message(m)):
+ insert_at = i + 1
+ break
+
+ if insert_at is None:
+ continue
+
+ out.insert(insert_at, ToolMessage(content=cancelled_content, tool_call_id=tcid))
+ existing.add(tcid)
+
+ return out
+
+ def _sanitize_new_messages_on_cancel(
+ new_messages: List[BaseMessage],
+ *,
+ interrupted_text: str,
+ cancelled_tool_ids_from_ui: List[str],
+ ) -> List[BaseMessage]:
+ """
+ 返回:应该写回 sess.lc_messages 的消息序列(只包含“用户可见/认可”的那部分)
+ - 工具:对未返回的 tool_call 补 ToolMessage({"cancelled": true})
+ - 回复:用 interrupted_text 替换末尾 final AIMessage,避免把完整回复泄漏进上下文
+ """
+ msgs = list(new_messages or [])
+ interrupted_text = (interrupted_text or "").strip()
+
+ # 1) 工具:找出“AI 发起了 tool_call 但没有 ToolMessage 结果”的那些 id
+ ai_tool_ids = _tool_call_ids_in_msgs(msgs)
+ tool_result_ids = _tool_result_ids_in_msgs(msgs)
+ pending_tool_ids = ai_tool_ids - tool_result_ids
+
+ # UI 认为被取消的 tool(running -> cancelled)
+ ui_cancel_ids = {str(x) for x in (cancelled_tool_ids_from_ui or [])}
+
+ # 统一要取消的集合:
+ # - UI 侧 running 的(用户按下打断时看见的)
+ # - 以及 messages 里缺结果的(防止漏标)
+ cancel_ids = set(ui_cancel_ids) | set(pending_tool_ids)
+
+ # 2) 如果 new_messages 里已经有 ToolMessage(真实结果) 但用户打断了,
+ # 为了“UI/上下文一致”,强制替换成 cancelled
+ msgs = _force_cancelled_tool_results(msgs, cancel_ids)
+
+ # 3) 注入缺失的 ToolMessage(cancelled)
+ msgs = _inject_cancelled_tool_messages(msgs, list(cancel_ids))
+
+ # 4) 处理 assistant 最终文本(避免把完整 answer 写回)
+ # - 如果 interrupted_text 非空:用它替换最后一个“非 tool_call 的 AIMessage”
+ # - 如果 interrupted_text 为空:只在“末尾存在一个 non-toolcall AIMessage(且它后面没有 tool_call)”时移除它
+ def _is_toolcall_ai(m: BaseMessage) -> bool:
+ return isinstance(m, AIMessage) and bool(_tool_call_ids_from_ai_message(m))
+
+ def _is_text_ai(m: BaseMessage) -> bool:
+ if not isinstance(m, AIMessage):
+ return False
+ if _tool_call_ids_from_ai_message(m):
+ return False
+ c = getattr(m, "content", None)
+ return isinstance(c, str) and bool(c.strip())
+
+ # 找最后一个“文本 AIMessage(非 tool_call)”
+ last_text_ai_idx = None
+ for i in range(len(msgs) - 1, -1, -1):
+ if _is_text_ai(msgs[i]):
+ last_text_ai_idx = i
+ break
+
+ if interrupted_text:
+ if last_text_ai_idx is None:
+ msgs.append(AIMessage(content=interrupted_text))
+ else:
+ # 用用户看见的部分替换,且丢弃后面所有消息(防止泄漏)
+ msgs = msgs[:last_text_ai_idx] + [AIMessage(content=interrupted_text)]
+ return msgs
+
+ # interrupted_text 为空:用户没看见任何本段 token
+ # 只移除“末尾的 final answer AIMessage”,避免把 unseen answer 写进上下文;
+ # 但如果该 AIMessage 后面还有 tool_call(说明它是 pre-tool 文本),就不要删
+ if last_text_ai_idx is not None:
+ has_toolcall_after = any(_is_toolcall_ai(m) for m in msgs[last_text_ai_idx + 1 :])
+ if not has_toolcall_after:
+ msgs = msgs[:last_text_ai_idx]
+
+ return msgs
+
+ pump_task: Optional[asyncio.Task] = None
+ cancel_wait_task: Optional[asyncio.Task] = None
+
+ was_interrupted = False # 本 turn 是否已经走了“打断收尾”
+
+ try:
+ async with mcp_sink_context(sink):
+ pump_task = asyncio.create_task(pump_agent())
+ cancel_wait_task = asyncio.create_task(sess.cancel_event.wait())
+
+ while True:
+ # 同时等:queue 出事件 或 cancel_event
+ get_task = asyncio.create_task(out_q.get())
+ done, _ = await asyncio.wait(
+ {get_task, cancel_wait_task},
+ return_when=asyncio.FIRST_COMPLETED,
+ )
+
+ # 优先处理队列事件(避免 done/flush 已经在队列里时被 cancel 抢占)
+ if get_task in done:
+ kind, payload = get_task.result()
+ else:
+ # cancel_event 触发:不再等 queue
+ try:
+ get_task.cancel()
+ await get_task
+ except asyncio.CancelledError:
+ debug_traceback_print(app.state.cfg)
+ pass
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+
+ kind, payload = ("agent.cancelled", None)
+
+ # ------------------------
+ # 1) 处理打断
+ # ------------------------
+ if kind == "agent.cancelled":
+ # 防止重复触发(cancel_event + pump_agent cancelled 都可能来一次)
+ if was_interrupted:
+ break
+ was_interrupted = True
+ # 1.1 cancel agent 流(停止继续产出 token/工具)
+ if pump_task and (not pump_task.done()):
+ pump_task.cancel()
+
+ # 1.2 将所有 running 的工具卡片标记为 error
+ cancelled_tool_recs: List[Dict[str, Any]] = []
+ for tcid, idx in list(sess._tool_history_index.items()):
+ rec = sess.history[idx]
+ if rec.get("role") == "tool" and rec.get("state") == "running":
+ rec.update({
+ "state": "error",
+ "progress": 1.0,
+ "message": "Cancelled by user",
+ "summary": {"cancelled": True},
+ })
+ cancelled_tool_recs.append(rec)
+
+ # 推送 tool.end,确保前端停止 spinner
+ for rec in cancelled_tool_recs:
+ await ws_send(ws, "tool.end", {
+ "tool_call_id": rec["tool_call_id"],
+ "server": rec["server"],
+ "name": rec["name"],
+ "is_error": True,
+ "summary": rec.get("summary"),
+ })
+ # 1.3 把已输出的 seg_text 写入 history(UI 看到的内容)
+ interrupted_text = (seg_text or "").strip()
+ if interrupted_text:
+ sess.history.append({
+ "id": uuid.uuid4().hex[:12],
+ "role": "assistant",
+ "content": interrupted_text,
+ "ts": seg_ts or time.time(),
+ })
+
+ # 1.4 上下文:只写回“用户真实看到/认可”的消息序列
+ cancelled_tool_ids = [rec["tool_call_id"] for rec in cancelled_tool_recs]
+
+ commit_msgs = _sanitize_new_messages_on_cancel(
+ new_messages,
+ interrupted_text=interrupted_text,
+ cancelled_tool_ids_from_ui=cancelled_tool_ids,
+ )
+
+ if commit_msgs:
+ sess.lc_messages.extend(commit_msgs)
+ elif interrupted_text:
+ # 极端情况:updates 没来得及给任何消息,但用户已看到 token
+ sess.lc_messages.append(AIMessage(content=interrupted_text))
+
+
+ # ★打断:只发 assistant.end,带 interrupted=true
+ await ws_send(ws, "assistant.end", {"text": interrupted_text, "interrupted": True})
+
+ sess.cancel_event.clear()
+ break
+
+ # ------------------------
+ # 2) 事件处理
+ # ------------------------
+ if kind == "assistant.delta":
+ delta = payload or ""
+ if delta:
+ if seg_ts is None:
+ seg_ts = time.time()
+ seg_text += delta
+ if not await ws_send(ws, "assistant.delta", {"delta": delta}):
+ raise WebSocketDisconnect()
+ continue
+
+ if kind == "mcp":
+ raw = payload
+
+ if raw.get("type") == "tool_start":
+ await flush_segment(send_flush_event=True)
+
+ rec = sess.apply_tool_event(raw)
+ if rec:
+ if raw["type"] == "tool_start":
+ await ws_send(ws, "tool.start", {
+ "tool_call_id": rec["tool_call_id"],
+ "server": rec["server"],
+ "name": rec["name"],
+ "args": rec["args"],
+ })
+ elif raw["type"] == "tool_progress":
+ await ws_send(ws, "tool.progress", {
+ "tool_call_id": rec["tool_call_id"],
+ "server": rec["server"],
+ "name": rec["name"],
+ "progress": rec["progress"],
+ "message": rec["message"],
+ })
+ elif raw["type"] == "tool_end":
+ await ws_send(ws, "tool.end", {
+ "tool_call_id": rec["tool_call_id"],
+ "server": rec["server"],
+ "name": rec["name"],
+ "is_error": rec["state"] == "error",
+ "summary": rec["summary"],
+ })
+ continue
+
+ if kind == "agent.done":
+ final_text = (seg_text or "").strip()
+
+ if final_text:
+ sess.history.append({
+ "id": uuid.uuid4().hex[:12],
+ "role": "assistant",
+ "content": final_text,
+ "ts": seg_ts or time.time(),
+ })
+
+ if new_messages:
+ sess.lc_messages.extend(new_messages)
+
+ if not await ws_send(ws, "assistant.end", {"text": final_text}):
+ return
+ break
+
+ if kind == "agent.error":
+ err_text = str(payload or "unknown error")
+ partial = (seg_text or "").strip()
+
+ # 把已输出部分落盘/落上下文(避免丢上下文)
+ if partial:
+ sess.history.append({
+ "id": uuid.uuid4().hex[:12],
+ "role": "assistant",
+ "content": partial,
+ "ts": seg_ts or time.time(),
+ })
+ sess.lc_messages.append(AIMessage(content=partial))
+
+ if new_messages:
+ sess.lc_messages.extend(new_messages)
+
+ # ★ 真异常:只发 error(并带 partial_text 让前端结束当前气泡)
+ await ws_send(ws, "error", {"message": err_text, "partial_text": partial})
+ break
+
+ except WebSocketDisconnect:
+ return
+ except asyncio.CancelledError:
+ # 连接关闭/任务取消:不当作 error
+ return
+ except Exception as e:
+ # 如果已经走了打断收尾,别再发 error(避免“打断=报错”)
+ if was_interrupted:
+ return
+ await ws_send(ws, "error", {"message": f"{type(e).__name__}: {e}", "partial_text": (seg_text or "").strip()})
+ return
+ finally:
+ # 结束 cancel_wait_task
+ if cancel_wait_task and (not cancel_wait_task.done()):
+ cancel_wait_task.cancel()
+
+ # pump_task 取消/收尾:避免 await 卡死,加一个短超时保护
+ if pump_task and (not pump_task.done()):
+ pump_task.cancel()
+ if pump_task:
+ try:
+ await asyncio.wait_for(pump_task, timeout=2.0)
+ except asyncio.TimeoutError:
+ debug_traceback_print(app.state.cfg)
+ pass
+ except asyncio.CancelledError:
+ debug_traceback_print(app.state.cfg)
+ pass
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+ finally:
+ try:
+ CHAT_TURN_SEM.release()
+ except Exception:
+ debug_traceback_print(app.state.cfg)
+ pass
+
+ except WebSocketDisconnect:
+ return
+ finally:
+ try:
+ WS_CONN_SEM.release()
+ except:
+ pass
diff --git a/build_env.sh b/build_env.sh
new file mode 100644
index 0000000000000000000000000000000000000000..422d5a4abc6415ca4707470c6bf3c819433e902c
--- /dev/null
+++ b/build_env.sh
@@ -0,0 +1,214 @@
+#!/bin/bash
+
+# 颜色定义 | Color Definitions
+RED='\033[0;31m'
+GREEN='\033[0;32m'
+YELLOW='\033[1;33m'
+BLUE='\033[0;34m'
+NC='\033[0m' # No Color
+
+# 打印带颜色的消息 | Print colored messages
+print_success() {
+ echo -e "${GREEN}[✓]${NC} $1"
+}
+
+print_error() {
+ echo -e "${RED}[✗]${NC} $1"
+}
+
+print_warning() {
+ echo -e "${YELLOW}[!]${NC} $1"
+}
+
+print_info() {
+ echo -e "${BLUE}[i]${NC} $1"
+}
+
+# 打印标题 | Print Title
+echo ""
+echo "╔════════════════════════════════════════════════════════════════╗"
+echo "║ Storyline 项目依赖安装脚本 | Dependency Installation ║"
+echo "║ 使用 conda activate storyline 激活环境后运行 ║"
+echo "╚════════════════════════════════════════════════════════════════╝"
+echo ""
+
+# ==========================================
+# 步骤 0: 检测操作系统
+# Step 0: Detect OS
+# ==========================================
+print_info "检测操作系统... | Detecting OS..."
+
+if [[ "$OSTYPE" == "darwin"* ]]; then
+ IS_MACOS=true
+ IS_LINUX=false
+ print_success "检测到 MacOS 系统 | MacOS detected"
+elif [[ "$OSTYPE" == "linux-gnu"* ]]; then
+ IS_MACOS=false
+ IS_LINUX=true
+ print_success "检测到 Linux 系统 | Linux detected"
+else
+ print_error "不支持的操作系统 | Unsupported operating system: $OSTYPE"
+ exit 1
+fi
+echo ""
+
+# ==========================================
+# 步骤 1: 检查 conda 环境
+# Step 1: Check conda environment
+# ==========================================
+echo "[1/4] 检查 conda 环境... | Checking conda environment..."
+
+if [ -z "$CONDA_DEFAULT_ENV" ]; then
+ print_error "未检测到 conda 环境 | No conda environment detected"
+ echo ""
+ echo "请先运行: conda activate storyline"
+ echo "Please run: conda activate storyline"
+ exit 1
+fi
+
+if [ "$CONDA_DEFAULT_ENV" != "storyline" ]; then
+ print_warning "当前环境: $CONDA_DEFAULT_ENV"
+ echo ""
+ read -p "建议使用 storyline 环境,是否继续? | Continue anyway? (y/n) " -n 1 -r
+ echo ""
+ if [[ ! $REPLY =~ ^[Yy]$ ]]; then
+ echo "请运行: conda activate storyline"
+ exit 1
+ fi
+else
+ print_success "当前环境: storyline"
+fi
+
+# 显示 Python 信息
+print_info "Python 信息 | Python Info:"
+echo " 版本 | Version: $(python --version 2>&1)"
+echo " 路径 | Path: $(which python)"
+echo ""
+
+# ==========================================
+# 步骤 2: 检查 FFmpeg
+# Step 2: Check FFmpeg
+# ==========================================
+echo "[2/4] 检查 FFmpeg... | Checking FFmpeg..."
+
+if ! command -v ffmpeg &> /dev/null; then
+ print_warning "未检测到 FFmpeg | FFmpeg not detected"
+ echo ""
+
+ read -p "是否安装 FFmpeg? | Install FFmpeg? (y/n) " -n 1 -r
+ echo ""
+
+ if [[ $REPLY =~ ^[Yy]$ ]]; then
+ print_info "正在安装 FFmpeg... | Installing FFmpeg..."
+
+ if [ "$IS_MACOS" = true ]; then
+ if ! command -v brew &> /dev/null; then
+ print_error "需要 Homebrew 来安装 FFmpeg | Homebrew required to install FFmpeg"
+ echo "请访问: https://brew.sh"
+ exit 1
+ fi
+ brew install ffmpeg
+ elif [ "$IS_LINUX" = true ]; then
+ if command -v apt-get &> /dev/null; then
+ sudo apt-get update
+ sudo apt-get install -y ffmpeg
+ elif command -v yum &> /dev/null; then
+ sudo yum install -y epel-release
+ sudo yum install -y ffmpeg ffmpeg-devel
+ else
+ print_error "无法识别的包管理器 | Unrecognized package manager"
+ exit 1
+ fi
+ fi
+
+ if [ $? -eq 0 ]; then
+ print_success "FFmpeg 安装成功 | FFmpeg installed successfully"
+ else
+ print_error "FFmpeg 安装失败 | FFmpeg installation failed"
+ exit 1
+ fi
+ else
+ print_warning "跳过 FFmpeg 安装(可能影响音视频处理功能)"
+ print_warning "Skipping FFmpeg (may affect audio/video features)"
+ fi
+else
+ print_success "FFmpeg 已安装 | FFmpeg installed"
+ echo " 版本 | Version: $(ffmpeg -version 2>&1 | head -n 1)"
+fi
+echo ""
+
+# ==========================================
+# 步骤 3: 下载项目资源
+# Step 3: Download project resources
+# ==========================================
+echo "[3/4] 下载项目资源... | Downloading project resources..."
+
+if [ -f "download.sh" ]; then
+ print_info "执行资源下载脚本... | Running download script..."
+ chmod +x download.sh
+ ./download.sh
+
+ if [ $? -eq 0 ]; then
+ print_success "资源下载完成 | Resources downloaded successfully"
+ else
+ print_error "资源下载失败 | Resource download failed"
+ exit 1
+ fi
+else
+ print_warning "未找到 download.sh | download.sh not found"
+ echo "如需下载模型等资源,请手动执行 download.sh"
+ echo "To download models, please run download.sh manually"
+fi
+echo ""
+
+# ==========================================
+# 步骤 4: 安装 Python 依赖
+# Step 4: Install Python dependencies
+# ==========================================
+echo "[4/4] 安装 Python 依赖... | Installing Python dependencies..."
+
+if [ ! -f "requirements.txt" ]; then
+ print_error "未找到 requirements.txt | requirements.txt not found"
+ exit 1
+fi
+
+print_info "正在安装依赖包,请稍候... | Installing packages, please wait..."
+echo ""
+
+# 安装依赖
+print_info "安装依赖包... | Installing dependencies..."
+
+# 尝试使用清华镜像源
+pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
+
+if [ $? -ne 0 ]; then
+ print_warning "清华镜像安装失败,尝试使用默认源... | Tsinghua mirror failed, trying default..."
+ pip install -r requirements.txt
+
+ if [ $? -ne 0 ]; then
+ print_error "依赖安装失败 | Dependency installation failed"
+ echo ""
+ echo "请尝试手动安装: pip install -r requirements.txt"
+ exit 1
+ fi
+fi
+
+print_success "依赖安装完成 | Dependencies installed successfully"
+echo ""
+
+# ==========================================
+# 安装完成 | Installation Complete
+# ==========================================
+echo ""
+echo "╔════════════════════════════════════════════════════════════════╗"
+echo "║ 安装成功!| Installation Successful! ║"
+echo "╚════════════════════════════════════════════════════════════════╝"
+echo ""
+
+print_info "环境信息 | Environment Info:"
+echo " Conda 环境 | Conda Env: $CONDA_DEFAULT_ENV"
+echo " Python: $(python --version 2>&1)"
+command -v ffmpeg &> /dev/null && echo " FFmpeg: $(ffmpeg -version 2>&1 | head -n 1 | cut -d' ' -f3)"
+echo ""
+
+print_success "现在可以运行项目了!| You can now run the project!"
diff --git a/cli.py b/cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8a50bf63af544791fbfb2bf3d27f3e2b5bd22b5
--- /dev/null
+++ b/cli.py
@@ -0,0 +1,99 @@
+import asyncio
+import time
+import uuid
+import os,sys
+import json
+
+from typing import List
+
+from langchain_core.messages import AIMessage, BaseMessage, HumanMessage, SystemMessage
+
+# Add src directory to Python module search path
+ROOT_DIR = os.path.dirname(__file__)
+SRC_DIR = os.path.join(ROOT_DIR, "src")
+
+if SRC_DIR not in sys.path:
+ sys.path.insert(0, SRC_DIR)
+
+from open_storyline.agent import ClientContext, build_agent
+from open_storyline.utils.prompts import get_prompt
+from open_storyline.utils.media_handler import scan_media_dir
+from open_storyline.config import load_settings, default_config_path
+from open_storyline.storage.agent_memory import ArtifactStore
+from open_storyline.mcp.hooks.node_interceptors import ToolInterceptor
+from open_storyline.mcp.hooks.chat_middleware import PrintStreamingTokens
+
+_MEDIA_STATS_INFO_IDX = 1
+
+async def main():
+ session_id = f"run_{int(time.time())}_{uuid.uuid4().hex[:8]}"
+ cfg = load_settings(default_config_path())
+
+ artifact_store = ArtifactStore(cfg.project.outputs_dir, session_id=session_id)
+ agent, node_manager = await build_agent(cfg=cfg, session_id=session_id, store=artifact_store, tool_interceptors=[ToolInterceptor.inject_media_content_before, ToolInterceptor.save_media_content_after, ToolInterceptor.inject_tts_config])
+
+ context = ClientContext(
+ cfg=cfg,
+ session_id=session_id,
+ media_dir=cfg.project.media_dir,
+ bgm_dir=cfg.project.bgm_dir,
+ outputs_dir=cfg.project.outputs_dir,
+ node_manager=node_manager,
+ chat_model_key=cfg.llm.model,
+ )
+
+ messages: List[BaseMessage] = [
+ SystemMessage(content=get_prompt("instruction.system", lang='en')),
+ SystemMessage(content="【User media statistics】{}"),
+ ]
+
+ print("Smart Editing Agent v 1.0.0")
+ print("Please describe your editing needs, type /exit to exit.")
+
+ while True:
+ try:
+ user_input = input("You: ").strip()
+ except (EOFError, KeyboardInterrupt):
+ print("\nGoodBye~")
+ break
+
+ if not user_input:
+ continue
+ if user_input in ("/exit", "/quit"):
+ print("\nGoodBye~")
+ break
+
+ media_stats = scan_media_dir(context.media_dir)
+ messages[_MEDIA_STATS_INFO_IDX] = SystemMessage(
+ content=(
+ f"【User media statistics】{json.dumps(media_stats, ensure_ascii=False)}"
+ )
+ )
+
+ messages.append(HumanMessage(content=user_input))
+
+ print("Agent: ", end="", flush=True)
+
+ stream = PrintStreamingTokens()
+
+ result = await agent.ainvoke(
+ {"messages": messages},
+ context=context,
+ config={"callbacks": [stream]},
+ )
+
+ print("\n")
+
+ messages = result["messages"]
+
+ final_text = None
+ for m in reversed(messages):
+ if isinstance(m, AIMessage):
+ final_text = m.content
+ break
+
+ print(f"\nAgent: {final_text or '(No final response generated)'}\n")
+
+
+if __name__ == "__main__":
+ asyncio.run(main())
diff --git a/config.toml b/config.toml
new file mode 100644
index 0000000000000000000000000000000000000000..04196aa5bf1b58c5633210b45bb63fb83776de40
--- /dev/null
+++ b/config.toml
@@ -0,0 +1,157 @@
+# ============= 开发者选项 / Developer Options ===============
+[developer]
+developer_mode = false
+default_llm = "deepseek-chat"
+default_vlm = "qwen3-vl-8b-instruct"
+print_context = false # 在拦截器打印模型拿到的全部上下文,会很长 / Print full context in interceptor (output will be very long)
+
+# ============= 模型配置 for 体验网页 ===============
+[developer.chat_models_config."deepseek-chat"]
+base_url = ""
+api_key = ""
+temperature = 0.1
+
+[developer.chat_models_config."qwen3-vl-8b-instruct"]
+base_url = ""
+api_key = ""
+timeout = 20.0
+temperature = 0.1
+max_retries = 2
+
+# ============= 项目路径 / Project Paths ======================
+[project]
+media_dir = "./outputs/media"
+bgm_dir = "./resource/bgms"
+outputs_dir = "./outputs"
+
+# ============= 模型配置 for user / Model Config for User =============
+[llm]
+model = "deepseek-chat"
+base_url = ""
+api_key = ""
+timeout = 30.0 # 单位:秒
+temperature = 0.1
+max_retries = 2
+
+[vlm]
+model = "qwen3-vl-8b-instruct"
+base_url = ""
+api_key = ""
+timeout = 20.0 # 单位:秒
+temperature = 0.1
+max_retries = 2
+
+
+# ============= MCP Server 相关 / MCP Server Related =============
+[local_mcp_server]
+server_name = "storyline"
+server_cache_dir = ".storyline/.server_cache"
+server_transport = "streamable-http" # server 和 host之间的传输方式 / Transport method between server and host
+url_scheme = "http"
+connect_host = "127.0.0.1" # 不要改动 / Do not change
+port = 8001 # 如果端口冲突,可以随便用一个有空的端口 / Use any available port if conflict occurs
+path = "/mcp" # 默认值,一般不用改 / Default value, usually unchanged
+
+json_response = true # 建议用 True / Recommended: True
+stateless_http = false # 强烈建议用 False / Strongly recommended: False
+timeout = 600
+available_node_pkgs = [
+ "open_storyline.nodes.core_nodes"
+]
+available_nodes = [
+ "LoadMediaNode", "SearchMediaNode", "SplitShotsNode",
+ "UnderstandClipsNode", "FilterClipsNode", "GroupClipsNode", "GenerateScriptNode", "ScriptTemplateRecomendation",
+ "GenerateVoiceoverNode", "SelectBGMNode", "RecommendTransitionNode", "RecommendTextNode",
+ "PlanTimelineProNode", "RenderVideoNode"
+]
+
+# =========== skills ==========
+[skills]
+skill_dir = "./.storyline/skills"
+
+# =========== pexels ==========
+[search_media]
+pexels_api_key = ""
+
+# ============= 镜头分割 / Shot Segmentation =============
+[split_shots]
+transnet_weights = ".storyline/models/transnetv2-pytorch-weights.pth"
+transnet_device = "cpu"
+
+# ============= 视频视觉理解 / Video Visual Understanding =============
+[understand_clips]
+sample_fps = 2.0 # 每秒抽几帧 / Frames sampled per second
+max_frames = 64 # 单clip抽帧上限兜底,避免长视频爆 token / Max frames per clip limit to prevent token overflow
+
+# ============= 文案模板 / Script Templates =============
+[script_template]
+script_template_dir = "./resource/script_templates"
+script_template_info_path = "./resource/script_templates/meta.json"
+
+# ============= 配音生成 / Voiceover Generation ===================
+[generate_voiceover]
+tts_provider_params_path = "./resource/tts/tts_providers.json"
+
+[generate_voiceover.providers.302]
+base_url = ""
+api_key = ""
+
+[generate_voiceover.providers.bytedance]
+uid = ""
+appid = ""
+access_token = ""
+
+[generate_voiceover.providers.minimax]
+base_url = ""
+api_key = ""
+
+
+# ============= BGM选择 / BGM Selection ====================
+# 主要是用于计算音乐特征的一些参数 / Mainly parameters for calculating music features
+[select_bgm]
+sample_rate = 22050
+hop_length = 2048 # 每次分析窗口向前跳多少个采样点,越小越精细(但更慢) / Hop length samples; smaller = more precise but slower
+frame_length = 2048 # 计算信号的均方根RMS的窗口大小。越大越稳定,但对瞬态不敏感 / Window size for RMS; larger = stable but less sensitive to transients
+
+# ============= 字体推荐 / Font Recommendation ====================
+[recommend_text]
+font_info_path = "resource/fonts/font_info.json"
+
+# ============= 时间线组织 / Timeline Organization ====================
+[plan_timeline]
+beat_type_max = 1 # 使用多强的鼓点,例如4/4中,鼓点类似1,2,1,3,其中1是最强的,3最弱 / Beat strength (e.g., in 4/4: 1=strongest, 3=weakest)
+title_duration = 0 # 片头时长 (ms) / Intro duration (ms)
+bgm_loop = true # 是否允许 bgm 循环 / Allow BGM loop
+min_clip_duration = 1000
+
+estimate_text_min = 1500 # 在没有TTS的情况下,估计每段字幕至少上屏多久 / Min on-screen duration for subtitles without TTS
+estimate_text_char_per_sec = 6.0 # 在没有TTS的情况下,估计每秒展示几个字 / Estimated characters per second without TTS
+
+image_default_duration = 3000 # 默认的图片播放时长 / Default image duration
+group_margin_over_voiceover = 1000 # 在一个group中,画面比配音多出现多久 / Extra visual duration over voiceover in a group
+
+[plan_timeline_pro]
+
+min_single_text_duration = 200 # 单段文字最小时长 (ms) / min single text duration (ms)
+max_text_duration = 5000 # 单句文字最大时长 (ms) / max text sentence duration (ms)
+img_default_duration = 1500 # 默认图片时长 (ms) / default image duration (ms)
+
+min_group_margin = 1500 # 段落/组最小间距 (ms) / min paragraph/group margin (ms)
+max_group_margin = 2000 # 段落/组最大间距 (ms) / max paragraph/group margin (ms)
+
+min_clip_duration = 1000 # 最小片段时长 (ms) / min clip duration (ms)
+
+tts_margin_mode = "random" # random | avg | max | min
+min_tts_margin = 300 # 最小 TTS 间隔 (ms) / min TTS gap (ms)
+max_tts_margin = 400 # 最大 TTS 间隔 (ms) / max TTS gap (ms)
+
+text_tts_offset_mode = "random" # random | avg | max | min
+min_text_tts_offset = 0 # 最小文字-TTS偏移 (ms) / min text–TTS offset (ms)
+max_text_tts_offset = 0 # 最大文字-TTS偏移 (ms) / max text–TTS offset (ms)
+
+long_short_text_duration = 3000 # 长/短文本阈值 (ms) / long/short text threshold (ms)
+long_text_margin_rate = 0.0 # 长文本起始边距率 / long text start margin rate
+short_text_margin_rate = 0.0 # 短文本起始边距率 / short text start margin rate
+
+text_duration_mode = "with_tts" # with_tts | with_clip (随配音 | 随片段)
+is_text_beats = false # 文字对齐音乐节拍 / align text with music beats
\ No newline at end of file
diff --git a/docs/source/en/api-key.md b/docs/source/en/api-key.md
new file mode 100644
index 0000000000000000000000000000000000000000..7a7c828b5154d315c3afc3a7f70fdf444df1b5ad
--- /dev/null
+++ b/docs/source/en/api-key.md
@@ -0,0 +1,134 @@
+# API Key Configuration Guide
+
+## 1. Large Language Model (LLM)
+
+### Using DeepSeek as an Example
+
+**Official Documentation**: https://api-docs.deepseek.com/zh-cn/
+
+Note: For users outside China, we recommend using large language models such as Gemini, Claude, or ChatGPT for the best experience.
+
+### Configuration Steps
+
+1. **Apply for API Key**
+ - Visit platform: https://platform.deepseek.com/usage
+ - Log in and apply for API Key
+ - ⚠️ **Important**: Save the obtained API Key securely
+
+2. **Configuration Parameters**
+ - **Model Name**: `deepseek-chat`
+ - **Base URL**: `https://api.deepseek.com/v1`
+ - **API Key**: Fill in the Key obtained in the previous step
+
+3. **API Configuration**
+ - **Web Usage**: Select "Use Custom Model" in the LLM model form, and fill in the model according to the configuration parameters
+ - **Local Deployment**: In config.toml, locate `[developer.chat_models_config."deepseek-chat"]` and fill in the configuration parameters to make the default configuration accessible from the Web page. Locate `[llm]` and configure model, base_url, and api_key
+
+## 2. Multimodal Large Language Model (VLM)
+
+### 2.1 Using GLM-4.6V
+
+**API Key Management**: https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
+
+### Configuration Parameters
+
+- **Model Name**: `glm-4.6v`
+- **Base URL**: `https://open.bigmodel.cn/api/paas/v4/`
+
+### 2.2 Using Qwen3-VL
+
+**API Key Management**: Go to Alibaba Cloud Bailian Platform to apply for an API Key https://bailian.console.aliyun.com/cn-beijing/?apiKey=1&tab=globalset#/efm/api_key
+
+ - **Model Name**: `qwen3-vl-8b-instruct`
+ - **Base URL**: `https://dashscope.aliyuncs.com/compatible-mode/v1`
+
+ - Parameter Configuration: Select "Use Custom Model" in the VLM Model form and fill in the parameters. For local deployment, locate `[vlm]` and configure model, base_url, and api_key. Add the following fields in config.toml as the default Web API configuration:
+ ```
+ [developer.chat_models_config."qwen3-vl-8b-instruct"]
+ base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
+ api_key = "YOUR_API_KEY"
+ timeout = 20.0
+ temperature = 0.1
+ max_retries = 2
+ ```
+
+### 2.3 Using Qwen3-Omni
+
+Qwen3-Omni can also be applied for through the Alibaba Cloud Bailian Platform. The specific parameters are as follows, which can be used for automatic labeling music in omni_bgm_label.py
+- **Model Name**: `qwen3-omni-flash-2025-12-01`
+- **Base URL**: `https://dashscope.aliyuncs.com/compatible-mode/v1`
+
+For more details, please refer to the documentation: https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc
+
+Model List: https://help.aliyun.com/zh/model-studio/models
+
+Billing Dashboard: https://billing-cost.console.aliyun.com/home
+
+## 3. Pexels Image and Video Download API Key Configuration
+
+1. Open the Pexels website, register an account, and apply for an API key at https://www.pexels.com/api/
+
+
+
Figure 1: Pexels API Application Page
+
+
+2. Web Usage: Locate the Pexels configuration, select "Use custom key", and enter your API key in the form.
+
+
+
Figure 2: Pexels API Usage
+
+
+3. Local Deployment: Fill in the API key in the `pexels_api_key` field in the `config.toml` file as the default configuration for the project.
+
+## 4. TTS (Text-to-Speech) Configuration
+
+### Option 1: 302.ai
+
+**Service URL**: https://302.ai/product/detail/302ai-mmaudio-text-to-speech
+
+### Option 2: MiniMax
+
+**Subscription Page**: https://platform.minimax.io/subscribe/audio-subscription
+
+**Configuration Steps**:
+1. Create API Key
+2. Visit: https://platform.minimax.io/user-center/basic-information/interface-key
+3. Obtain and save API Key
+
+### Option 3: Bytedance
+1. Step 1: Enable Audio/Video Subtitle Generation Service
+ Use the legacy page to find the audio/video subtitle generation service:
+
+ - Visit: https://console.volcengine.com/speech/service/9?AppID=8782592131
+
+2. Step 2: Obtain Authentication Information
+ View the account basic information page:
+
+ - Visit: https://console.volcengine.com/user/basics/
+
+
+
+
Figure 3: Bytedance TTS API Usage
+
+
+ You need to obtain the following information:
+ - **UID**: The ID from the main account information
+ - **APP ID**: The APP ID from the service interface authentication information
+ - **Access Token**: The Access Token from the service interface authentication information
+
+ For local deployment, modify the config.toml file:
+
+```
+[generate_voiceover.providers.bytedance]
+uid = ""
+appid = ""
+access_token = ""
+```
+
+For detailed documentation, please refer to: https://www.volcengine.com/docs/6561/80909
+
+## Important Notes
+
+- All API Keys must be kept secure to avoid leakage
+- Ensure sufficient account balance before use
+- Regularly monitor API usage and costs
\ No newline at end of file
diff --git a/docs/source/en/faq.md b/docs/source/en/faq.md
new file mode 100644
index 0000000000000000000000000000000000000000..7dee08c25d57fb604c2b634f08d2f8ba82c5f994
--- /dev/null
+++ b/docs/source/en/faq.md
@@ -0,0 +1,18 @@
+# Most Frequently Asked Questions
+
+## Environment Related Issue
+
+Issue 1: When activating conda environment, script execution is prohibited.
+
+Please refer to this article for the solution: [https://juejin.cn/post/7349212852644954139](https://juejin.cn/post/7349212852644954139)
+
+
+
+
+Issue 2: Error creating a virtual environment after installing Conda on Windows.
+
+- **Cause:**
+ This is caused by Conda not being added to the system environment variables during installation.
+- **Solution:**
+ You need to open **Anaconda Prompt**, **Miniconda Prompt**, or **Miniforge Prompt** (depending on which one you installed) from the Start Menu, `cd` to the current directory, and then proceed to create the environment.
+
\ No newline at end of file
diff --git a/docs/source/en/guide.md b/docs/source/en/guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..559af2e4d753913ec6d09b9f5af96b19869bd5e0
--- /dev/null
+++ b/docs/source/en/guide.md
@@ -0,0 +1,220 @@
+# OpenStoryline User Guide
+
+---
+
+## 0. Environment Setup
+
+See the [README](https://github.com/FireRedTeam/FireRed-OpenStoryline/blob/main/README.md) section.
+
+## 1. Basic Usage
+
+### 1.1 Getting Started
+
+You can start creating in two ways:
+
+1. **You have your own media**
+
+ * Click the file upload button on the left side of the chat box and select your images/videos.
+ * Then type your editing goal in the input field, for example: *Use my footage to edit a family vlog with an upbeat rhythm.*
+
+2. **You don’t have media**
+
+ * Just describe the theme/mood.
+ * For example: *Help me create a summer beach travel vlog—sunny, fresh, and cheerful.*
+
+Automatic asset retrieval is powered by [Pexels](https://www.pexels.com/). Please enter your Pexels API key in the website sidebar.
+
+**Disclaimer:** We only provide the tool. All assets downloaded or used via this tool (e.g., Pexels images) are fetched by the user through the API. We assume no responsibility for the content of videos generated by users, the legality of the assets, or any copyright/portrait-right disputes arising from the use of this tool. Please comply with Pexels’ license when using it: [https://www.pexels.com/zh-cn/license](https://www.pexels.com/zh-cn/license)
+[https://www.pexels.com/terms-of-service](https://www.pexels.com/terms-of-service)
+
+If you just want to explore it first, you can also use it like a normal chat model, for example:
+
+* “Introduce yourself”
+
+
+
+### 1.2 Editing
+
+OpenStoryline supports **intent intervention and partial redo at any stage**. After a step completes, you can simply describe what you want to change in one sentence. The agent will locate the step that needs to be rerun, without restarting from the beginning. For example:
+
+* Remove the clip where the camera is filming the sky.
+* Switch to a more upbeat background music.
+* Change the subtitle color to better match the sunset theme.
+
+
+
+### 1.3 Style Imitation
+
+With the style imitation Skill, you can reproduce almost any writing style to generate copy. For example:
+
+* Generate copy in a Shakespearean style for me.
+* Mimic the tone of my social media posts.
+
+
+
+### 1.4 Interrupting
+
+At any moment while the agent is running, if its behavior is not as expected, you can:
+
+* Click the **Stop** button on the right side of the input box to stop the model reply and tool calls, **or**
+* Press **Enter** to send a new prompt—the system will automatically interrupt and follow your new instruction.
+
+Interrupting does **not** clear the current progress. Existing replies and executed tool results will be kept, and you can continue from the current state.
+
+### 1.5 Switching Languages
+
+Click the language button in the top-right corner of the page to switch between Chinese and English:
+
+* The sidebar and tool-call cards will switch display language accordingly.
+* The prompt language used inside tools will also switch.
+* Past chat history will **not** be automatically translated.
+
+### 1.6 Saving
+
+After you polish a satisfying video, you can ask the agent to **summarize the editing logic** (rhythm, color tone, transition habits, etc.) and save it as your personal **“Editing Skill.”**
+
+Next time you edit similar content, simply ask the agent to use this Skill to reproduce the style.
+
+
+
+### 1.7 Mobile Usage
+
+**Warning: The commands below will expose your service to your local network. Use only on trusted networks. Do NOT run these commands on public networks.**
+
+If your media is on your phone and it’s inconvenient to transfer, you can use the following steps to use the editing agent on mobile.
+
+1. Fill in the LLM/VLM/Pexels/TTS configuration in config.toml.
+2. Change your web startup command to:
+
+ ```bash
+ # Reminder: --host 0.0.0.0 exposes the service to your LAN/public network. Use only on trusted networks.
+ uvicorn agent_fastapi:app --host 0.0.0.0 --port 7860
+ ```
+
+3. Find your computer’s IP address:
+
+ * **Windows:** run `ipconfig` in Command Prompt (cmd) and locate the IPv4 address
+ * **Mac:** hold **Option** and click the Wi-Fi icon
+ * **Linux:** run `ifconfig` in the terminal
+
+4. Then open the following address in your phone browser:
+
+ ```
+ {your_computer_ip}:7860
+ ```
+
+---
+
+## 2. Advanced Usage
+
+Due to copyright and distribution constraints, open-source resources may not be sufficient for many users’ editing needs. Therefore, we provide methods to add and build private asset libraries.
+
+---
+
+### 2.1 Custom Music Library
+
+Put your private music files into:
+
+`./resource/bgms`
+
+Then tag your music by writing metadata into:
+
+`./resouce/bgms/meta.json`
+
+Restart the MCP service to apply changes.
+
+**Tag Dimensions**
+
+* **scene:** Vlog, Travel, Relaxing, Emotion, Transition, Outdoor, Cafe, Evening, Scenery, Food, Date, Club
+* **genre:** Pop, BGM, Electronic, R&B/Soul, Hip Hop/Rap, Rock, Jazz, Folk, Classical, Chinese Style
+* **mood:** Dynamic, Chill, Happy, Sorrow, Romantic, Calm, Excited, Healing, Inspirational
+* **lang:** bgm, en, zh, ko, ja
+
+**How to Tag**
+
+* **Manual tagging:** Copy the format of other items in `meta.json` and add tags accordingly. **Note:** the `description` field is required.
+* **Auto tagging:** Use `qwen3-omni-flash` for automatic tagging (requires a Qwen model API key).
+
+Qwen3-omni labeling script:
+
+```bash
+export QWEN_API_KEY="you_api_key"
+python -m scripts.omni_bgm_label
+```
+
+Auto tags may not be fully accurate. If you need strong recommendations for specific scenarios, it’s recommended to manually review the results.
+
+---
+
+### 2.2 Custom Font Library
+
+Put your private font files into:
+
+`./resource/fonts`
+
+Then tag the fonts by editing:
+
+`./resource/fonts/font_info.json`
+
+Restart the MCP service to apply changes.
+
+**Tag Dimensions**
+
+* **class:** Creative, Handwriting, Calligraphy, Basic
+* **lang:** zh, en
+
+**How to Tag**
+Currently only manual tagging is supported—edit `./resource/fonts/font_info.json` directly.
+
+---
+
+### 2.3 Custom Copywriting Template Library
+
+Put your private copywriting templates into:
+
+`./resource/script_templates`
+
+Then tag them by writing metadata into:
+
+`./resource/fonts/meta.json`
+
+Restart the MCP service to apply changes.
+
+**Tag Dimensions**
+
+* **tags:** Life, Food, Beauty, Entertainment, Travel, Tech, Business, Vehicle, Health, Family, Pets, Knowledge
+
+**How to Tag**
+
+* **Manual tagging:** Copy the format of other items in `meta.json` and add tags accordingly. **Note:** the `description` field is required.
+* **Auto tagging:** Use DeepSeek for automatic tagging (requires the corresponding API key).
+
+DeepSeek labeling script:
+
+```bash
+export DEEPSEEK_API_KEY="you_api_key"
+python -m scripts.llm_script_template_label
+```
+
+Auto tags may not be fully accurate. If you need strong recommendations for specific scenarios, it’s recommended to manually review the results.
+
+---
+
+### 2.4 Custom Skill Library
+
+The repository includes two built-in Skills: one for writing-style imitation and another for saving editing workflows. If you want more custom skills, you can add them as follows:
+
+1. Create a new folder under `.storyline/skills`.
+2. Inside that folder, create a file named `SKILL.md`.
+3. The `SKILL.md` must start with:
+
+ ```markdown
+ ---
+ name: yous_skill_folder_name
+ description: your_skill_function_description
+ ---
+ ```
+
+ The `name` must match the folder name.
+4. Then write the detailed skill content (its role setting, which tools it should call, output format, etc.).
+5. Restart the MCP service to apply changes.
diff --git a/docs/source/zh/api-key.md b/docs/source/zh/api-key.md
new file mode 100644
index 0000000000000000000000000000000000000000..40f0f0b52a99533c9bed7507208c0bb7fc82382e
--- /dev/null
+++ b/docs/source/zh/api-key.md
@@ -0,0 +1,132 @@
+# API-Key 配置指南
+
+## 一、大语言模型 (LLM)
+
+### 以 DeepSeek 为例
+
+**官方文档**:https://api-docs.deepseek.com/zh-cn/
+
+提示: 对于中国以外用户建议使用 Gemini、Claude、ChatGPT 等主流大语言模型以获得最佳体验。
+
+### 配置步骤
+
+1. **申请 API Key**
+ - 访问平台:https://platform.deepseek.com/usage
+ - 登录后申请 API Key
+ - ⚠️ **重要**:妥善保存获取的 API Key
+
+2. **配置参数**
+ - **模型名称**:`deepseek-chat`
+ - **Base URL**:`https://api.deepseek.com/v1`
+ - **API Key**:填写上一步获取的 Key
+
+3. **API填写**
+ - **Web使用**: 在LLM模型表单中选择使用自定义模型,模型按照配置参数进行填写
+ - **本地部署**: 在config.toml中 找到`[developer.chat_models_config."deepseek-chat"]` 将配置参数填写上去,使得Web页面可以访问到该默认配置。 找到`[llm]`并配置model、base_url、api_key
+
+## 二、多模态大模型 (VLM)
+
+### 2.1 使用GLM-4.6V
+
+**API Key 管理**:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
+
+### 配置参数
+
+- **模型名称**:`glm-4.6v`
+- **Base URL**:`https://open.bigmodel.cn/api/paas/v4/`
+
+### 2.2 使用Qwen3-VL
+
+**API Key管理**:进入阿里云百炼平台申请API Key https://bailian.console.aliyun.com/cn-beijing/?apiKey=1&tab=globalset#/efm/api_key
+
+ - **模型名称**:`qwen3-vl-8b-instruct`
+ - **Base URL**:`https://dashscope.aliyuncs.com/compatible-mode/v1`
+
+ - **参数填写**:在VLM Model表单中选择"使用自定义模型"进行参数填写。本地部署时,找到`[vlm]`并配置model、base_url、api_key,在config.toml中新增以下字段作为Web的API默认配置:
+ ```
+ [developer.chat_models_config."qwen3-vl-8b-instruct"]
+ base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
+ api_key = "YOUR_API_KEY"
+ timeout = 20.0
+ temperature = 0.1
+ max_retries = 2
+ ```
+
+
+### 2.3 使用Qwen3-Omni
+
+Qwen3-Omni同样可以在阿里云百炼平台进行申请,具体参数如下,可用于omni_bgm_label.py的音频自动标注
+- **模型名称**:`qwen3-omni-flash-2025-12-01`
+- **Base URL**:`https://dashscope.aliyuncs.com/compatible-mode/v1`
+
+详细文档参考:https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc
+
+阿里云模型列表:https://help.aliyun.com/zh/model-studio/models
+
+计费看板:https://billing-cost.console.aliyun.com/home
+
+## 三、Pexels 图像和视频下载API密钥配置
+
+1. 打开Pexels网站,注册账号,申请API https://www.pexels.com/zh-cn/api/key/
+

 +
+  +
+ 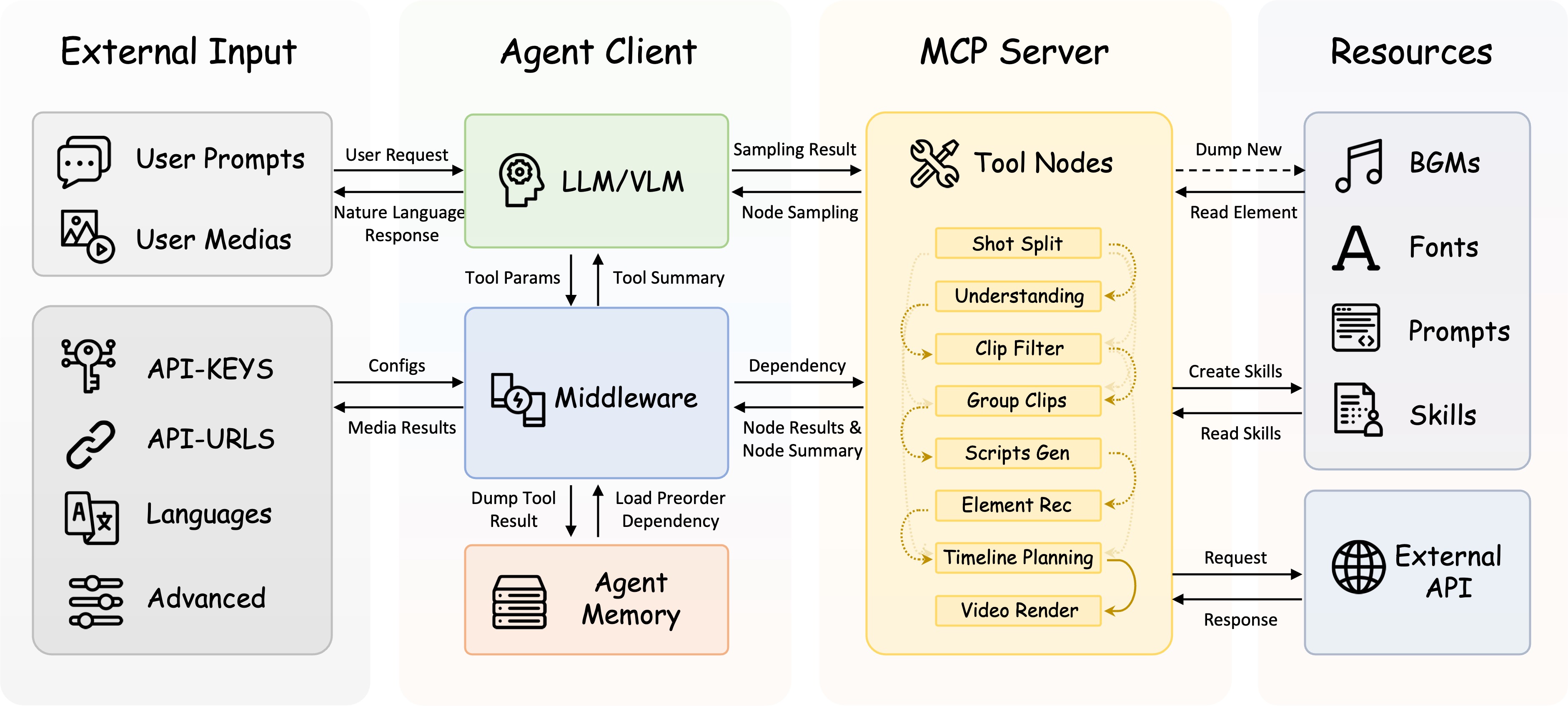 +
+ +
+ 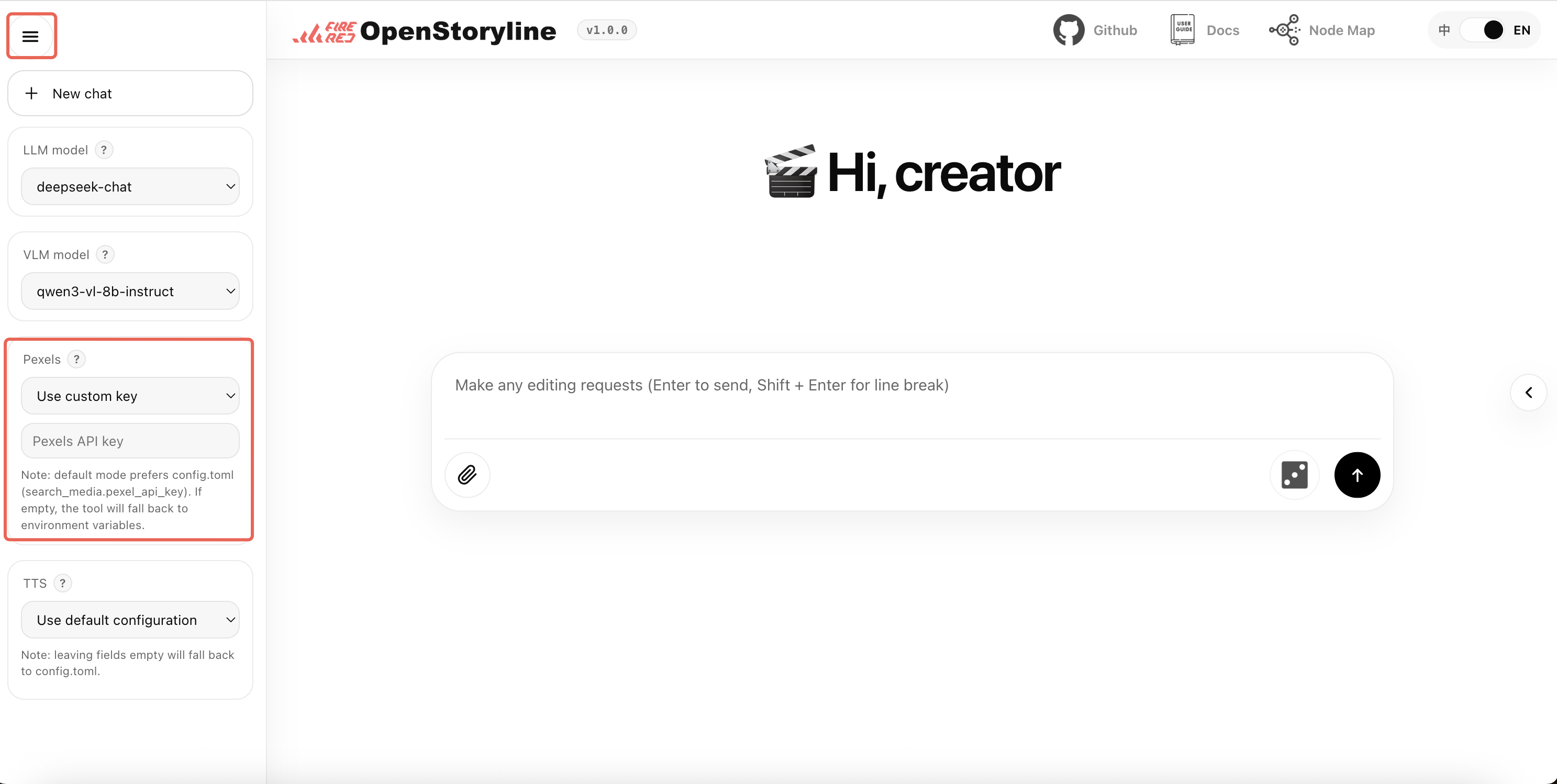 +
+  +
+  +
+  +
+  +
+  +
+ {kind=link}