Spaces:
Running

Running
File size: 10,351 Bytes
2752ea2 dc6a411 2752ea2 dc6a411 2752ea2 dc6a411 d5e7e0d dc6a411 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 |
---
title: Chatterbox TTS API
sdk: docker
app_port: 7860
---
# Chatterbox TTS API 服务
这是一个基于 [Chatterbox-TTS](https://github.com/resemble-ai/chatterbox) 的高性能文字转语音(TTS)服务。它提供了一个与 OpenAI TTS 兼容的 API 接口、一个支持声音克隆的增强接口,以及一个简洁的 Web 用户界面。
本项目旨在为开发者和内容创作者提供一个私有化部署、功能强大且易于集成的 TTS 解决方案。
## ✨ 功能特性
- **支持 23种语言**
- **两种 API 接口**:
1. **OpenAI 兼容接口**: `/v1/audio/speech`,可无缝对接到任何支持 OpenAI SDK 的现有工作流中。
2. **声音克隆接口**: `/v2/audio/speech_with_prompt`,通过上传一小段参考音频,即可生成具有相同音色的语音。
- **Web 用户界面**: 提供一个直观的前端页面,用于快速测试和使用 TTS 功能,无需编写任何代码。
- **灵活的输出格式**: 支持生成 `.mp3` 和 `.wav` 格式的音频。
- **跨平台支持**: 提供在 Windows, macOS 和 Linux 上的详细安装指南。
- **一键式 Windows 部署**: 为 Windows 用户提供了包含所有依赖和启动脚本的压缩包,实现开箱即用。
- **GPU 加速**: 支持 NVIDIA GPU(CUDA),并为 Windows 用户提供了一键升级脚本。
- **无缝集成**: 可作为后端服务,与 [pyVideoTrans](https://github.com/jianchang512/pyvideotrans) 等工具轻松集成。
---
## 🚀 快速开始
### 方式一:Windows 用户(推荐,一键启动)
我们为 Windows 用户准备了包含所有依赖的便携包 `win.7z`,大大简化了安装过程。
1. **下载并解压**:
- 百度网盘下载地址【内置模型共5.9G】: https://pan.baidu.com/s/12Le6rhOQnBL-sNd0uGZ91A?pwd=t55t
> 压缩包内含模型和所需环境文件,体积较大,分2个压缩卷下载,下载后全部选中解压即可,解压路径中最好不要包含中文
- 百度网盘下载地址【不含模型460MB启动后自动下载,需科学上网】: https://pan.baidu.com/s/1g3w1jFHxe_IjqgasoiVB6w?pwd=nf8v
- GitHub 下载地址【不含模型460MB启动后自动下载,需科学上网】:https://github.com/jianchang512/chatterbox-api/releases/download/0.2/1020-chatterbox-win-NO-Models.7z
2. **启动服务**:
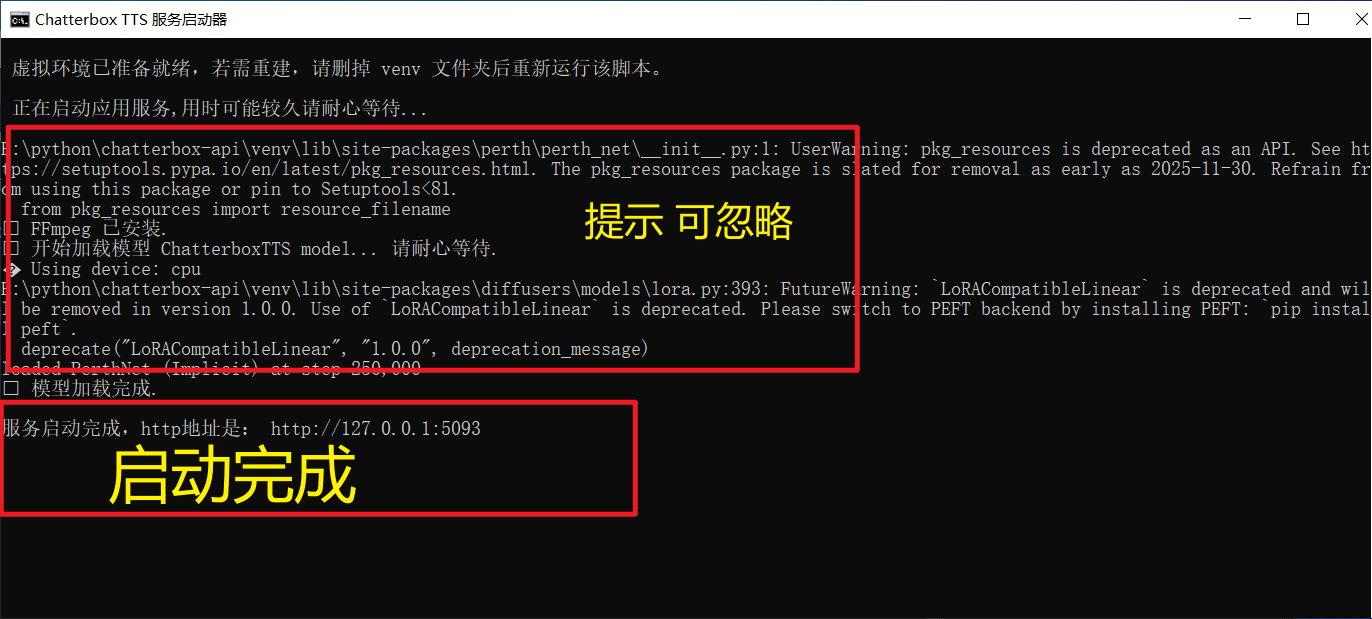
- 双击运行根目录下的 **`启动服务.bat`** 脚本。
当您在命令行窗口看到类似以下信息时,表示服务已成功启动:
```
✅ 模型加载完成.
服务启动完成,http地址是: http://127.0.0.1:5093
```
### 方式二:macOS, Linux 和手动安装用户
对于 macOS, Linux 用户,或者希望手动设置环境的 Windows 用户,请按照以下步骤操作。
> ### 纯CPU运行注意
>
> 在 Windows和Linux上,如果想CPU运行,需要修改源码,虚拟环境下/Lib/site-packages/chatterbox/mtl_tts.py`
>
> 搜索`torch.load(ckpt_dir / "ve.pt",` 改为 `torch.load(ckpt_dir / "ve.pt", map_location=device,`
>
> 搜索 `torch.load(ckpt_dir / "s3gen.pt",` 改为 `torch.load(ckpt_dir / "s3gen.pt", map_location=device,`
#### 1. 前置依赖
- **Python**: 确保已安装 Python 3.10 或更高版本。
- **ffmpeg**: 这是一个必需的音视频处理工具。
- **macOS (使用 Homebrew)**: `brew install ffmpeg`
- **Debian/Ubuntu**: `sudo apt-get update && sudo apt-get install ffmpeg`
- **Windows (手动)**: 下载 [ffmpeg](https://ffmpeg.org/download.html) ,并将其添加到系统环境变量 `PATH` 中。
#### 2. 安装步骤
```bash
# 1. 克隆项目仓库
git clone https://github.com/jianchang512/chatterbox-api.git
cd chatterbox-api
# 2. 创建并激活 Python 虚拟环境 (推荐)
python3 -m venv venv
# on Windows:
# venv\Scripts\activate
# on macOS/Linux:
source venv/bin/activate
# 3. 安装依赖
pip install -r requirements.txt
# 4. 启动服务
python app.py
```
当服务成功启动后,您将在终端看到服务地址 `http://127.0.0.1:5093`。
---
## ☁️ 部署到 Hugging Face Spaces(免费 CPU,API 对外)
1. 新建 Space,选择 `Docker`。
2. 直接上传本仓库代码(`chatterbox-api` 目录内容)到 Space。
3. Space 构建完成后即可访问:
- Web UI: `https://<your-space>.hf.space/`
- OpenAI 兼容 API: `https://<your-space>.hf.space/v1/audio/speech`
- 声音克隆 API: `https://<your-space>.hf.space/v2/audio/speech_with_prompt`
如果你是用一键脚本部署(同 `whisperx-api` 的方式),直接用 `chatterbox-api/chouxiang/deploy.py`,并在 `chatterbox-api/chouxiang/.env` 里设置:
- `DEFAULT_STEPS=200`(CPU 建议 100–300,越小越快)
- `TORCH_NUM_THREADS=2`
- `TORCH_NUM_INTEROP_THREADS=1`
## ⚡ 升级到 GPU 版本 (可选)
如果您的电脑配备了支持 CUDA 的 NVIDIA 显卡,并已正确安装 [NVIDIA 驱动](https://www.nvidia.com/Download/index.aspx) 和 [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit-archive),您可以升级到 GPU 版本以获得显著的性能提升。
### Windows 用户 (一键升级)
1. 请先确保您已经成功运行过一次 `启动服务.bat`,以完成基础环境的安装。
2. 双击运行 **`安装N卡GPU支持.bat`** 脚本。
3. 脚本会自动卸载 CPU 版本的 PyTorch,并安装与 CUDA 12.8 兼容的 GPU 版本。
### Linux 手动升级
在激活虚拟环境后,执行以下命令:
```bash
# 1. 卸载现有的 CPU 版本 PyTorch
pip uninstall -y torch torchaudio
# 2. 安装与您的 CUDA 版本匹配的 PyTorch
# 以下命令适用于 CUDA 12.6,请根据您的 CUDA 版本从 PyTorch 官网获取正确的命令
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu126
```
*您可以访问 [PyTorch 官网](https://pytorch.org/get-started/locally/) 来获取适合您系统的安装命令。*
升级后,重新启动服务,您将在启动日志中看到 `Using device: cuda`。
---
## 📖 使用指南
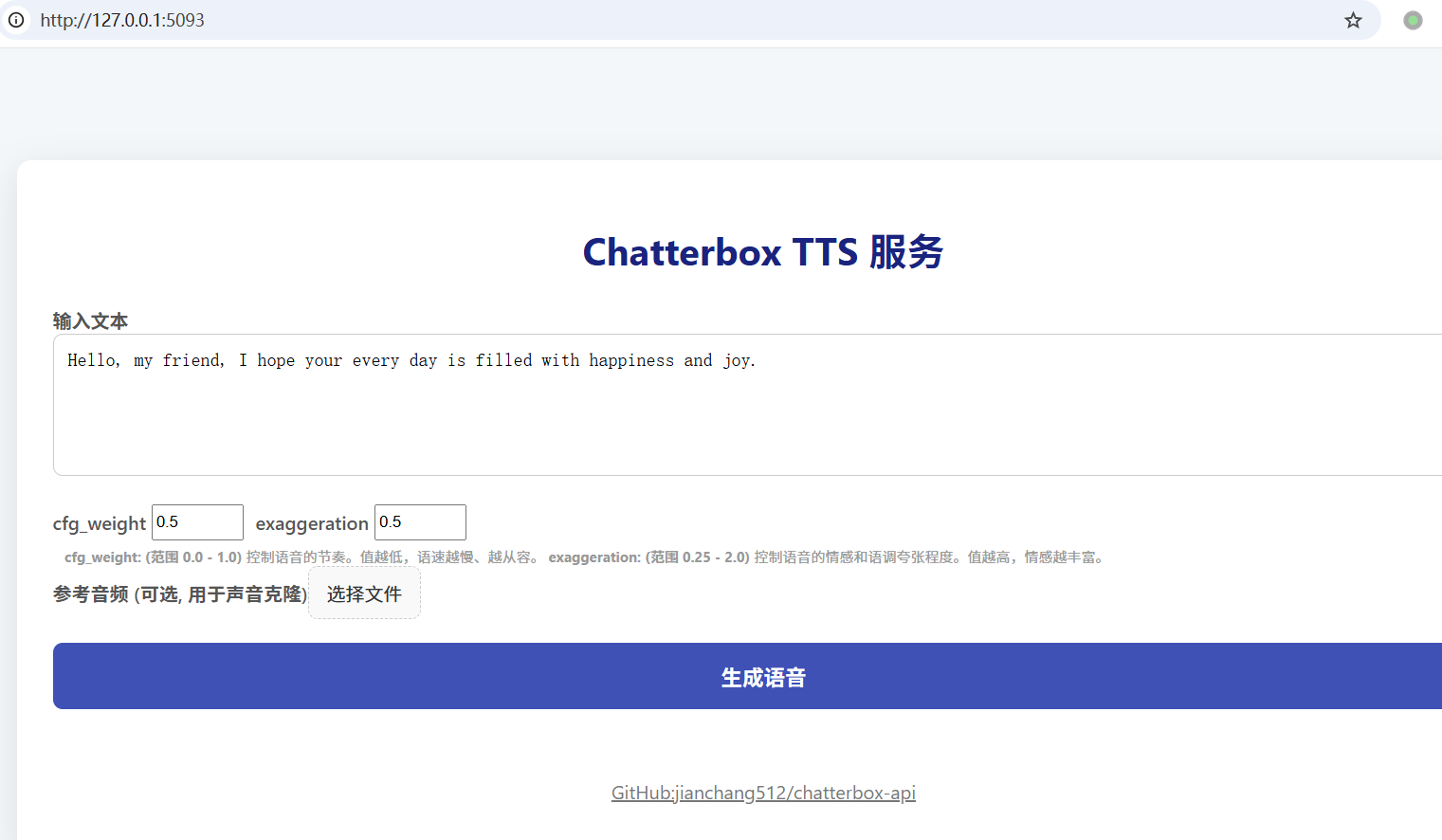
### 1. Web 界面
服务启动后,在浏览器中打开 **`http://127.0.0.1:5093`** 即可访问 Web UI。
- **输入文本**: 在文本框中输入您想要转换的文字。
- **调整参数**:
- `cfg_weight`: (范围 0.0 - 1.0) 控制语音的节奏。值越低,语速越慢、越从容。对于快节奏的参考音频,可适当降低此值(如 0.3)。
- `exaggeration`: (范围 0.25 - 2.0) 控制语音的情感和语调夸张程度。值越高,情感越丰富,语速也可能越快。
- **声音克隆**: 点击 "选择文件" 上传一段参考音频(如 .mp3, .wav)。如果提供了参考音频,服务将使用克隆接口。
- **生成语音**: 点击 "生成语音" 按钮,稍等片刻即可在线试听和下载生成的 MP3 文件。
### 2. API 调用
#### 接口 1: OpenAI 兼容接口 (`/v1/audio/speech`)
此接口无需参考音频,可使用 OpenAI SDK 直接调用。
**Python 示例 (`openai` SDK):**
```python
from openai import OpenAI
import os
# 将客户端指向我们的本地服务
client = OpenAI(
base_url="http://127.0.0.1:5093/v1",
api_key="not-needed" # API密钥不是必需的,但SDK要求提供
)
response = client.audio.speech.create(
model="chatterbox-tts", # 此参数会被忽略
voice="en", #
speed=0.5, # 对应 cfg_weight 参数
input="Hello, this is a test from the OpenAI compatible API.",
instructions="0.5" # (可选) 对应 exaggeration 参数, 注意需要是字符串
response_format="mp3" # 可选 'mp3' 或 'wav'
)
# 将音频流保存到文件
response.stream_to_file("output_api1.mp3")
print("音频已保存到 output_api1.mp3")
```
#### 接口 2: 声音克隆接口 (`/v2/audio/speech_with_prompt`)
此接口需要通过 `multipart/form-data` 格式同时上传文本和参考音频文件。
**Python 示例 (`requests` 库):**
```python
import requests
API_URL = "http://127.0.0.1:5093/v2/audio/speech_with_prompt"
REFERENCE_AUDIO = "path/to/your/reference.mp3" # 替换为您的参考音频路径
form_data = {
'input': 'This voice should sound like the reference audio.',
'cfg_weight': '0.5',
'exaggeration': '0.5',
'response_format': 'mp3' # 可选 'mp3' 或 'wav'
}
with open(REFERENCE_AUDIO, 'rb') as audio_file:
files = {'audio_prompt': audio_file}
response = requests.post(API_URL, data=form_data, files=files)
if response.ok:
with open("output_api2.mp3", "wb") as f:
f.write(response.content)
print("克隆音频已保存到 output_api2.mp3")
else:
print("请求失败:", response.text)
```
### 3. 在 pyVideoTrans 中使用
本项目可以作为强大的 TTS 后端,为 [pyVideoTrans](https://github.com/jianchang512/pyvideotrans) 提供高质量的英文配音。
1. **启动本项目**: 确保 Chatterbox TTS API 服务正在本地运行 (`http://127.0.0.1:5093`)。
2. **更新 pyVideoTrans**: 确保您的 pyVideoTrans 版本升级到 `v3.73` 或更高。
3. **配置 pyVideoTrans**:
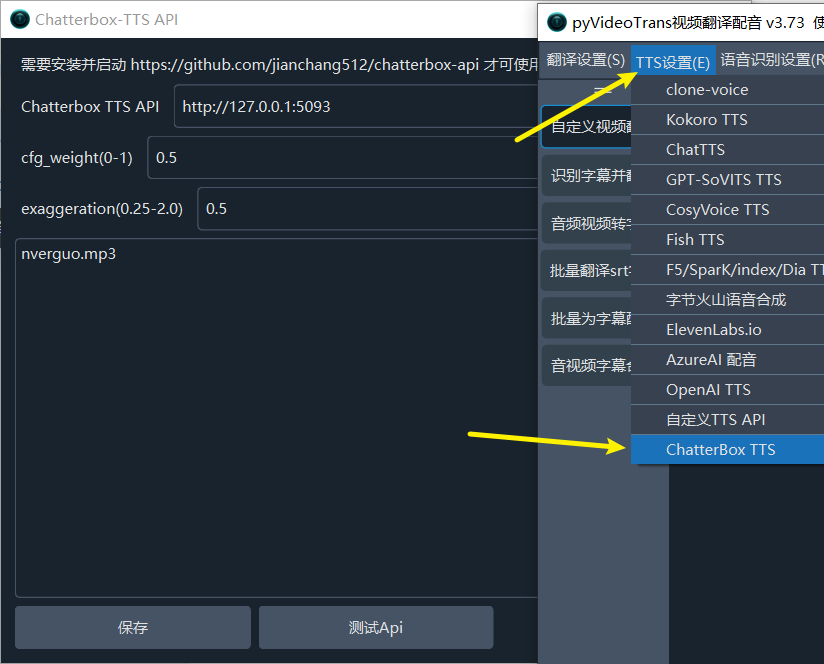
- 在 pyVideoTrans 菜单中,进入 `TTS设置` -> `Chatterbox TTS`。
- **API 地址**: 填写本服务的地址,默认为 `http://127.0.0.1:5093`。
- **参考音频** (可选): 如果您想使用声音克隆,请在此处填写参考音频的文件名(例如 `my_voice.wav`)。请确保该音频文件已放置在 pyVideoTrans 根目录下的 `chatterbox` 文件夹内。
- **调整参数**: 根据需要调整 `cfg_weight` 和 `exaggeration` 以获得最佳效果。
**参数调整建议**:
- **通用场景 (TTS, 语音助手)**: 默认设置 (`cfg_weight=0.5`, `exaggeration=0.5`) 适用于大多数情况。
- **快语速参考音频**: 如果参考音频的语速较快,可以尝试将 `cfg_weight` 降低到 `0.3` 左右,以改善生成语音的节奏。
- **富有表现力/戏剧性演讲**: 尝试较低的 `cfg_weight` (如 `0.3`) 和较高的 `exaggeration` (如 `0.7` 或更高)。通常提高 `exaggeration` 会加快语速,降低 `cfg_weight` 有助于平衡,使节奏更从容、更清晰。
---
## 致谢
[Chatterbox-TTS](https://github.com/resemble-ai/chatterbox)
|