# CyberSelfPlay: Building a Cyber Defense Environment
**Training Script Link:** [League (PFSP + PSRO) — Colab (mixed)](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing)
**Play a gamebased on this environment:** [Game](https://openenv-ui.vercel.app/)
**Documentation:** the math-led overview, full training table, and repository layout are in the [project README](README.md) (and this file links back to it in [Where to go next](#where-to-go-next)). For the deployed OpenEnv HTTP API, use the live Space app [https://harshitshri026-cyberselfplay-env.hf.space](https://harshitshri026-cyberselfplay-env.hf.space/) with interactive docs at [Swagger (`/docs`)](https://harshitshri026-cyberselfplay-env.hf.space/docs) and [ReDoc (`/redoc`)](https://harshitshri026-cyberselfplay-env.hf.space/redoc).
## Why this environment exists
In **real-world** security operations, impact is not a single model score. It is whether a team can run long incident timelines under uncertainty while adversaries adapt. **Industry** and government playbooks for detection, containment, and recovery read like multi-step missions, not one-shot classifiers. Yet most agent benchmarks are short-horizon and mostly single-agent. Cyber defense in practice is neither:
- decisions unfold over many steps,
- observations are partial and noisy,
- an attacker adapts while the defender is acting,
- success is not one move, but sustained containment and recovery.
CyberSelfPlay was built to model this gap directly: a stochastic Red-vs-Blue world where Blue must execute mission playbooks while Red applies adversarial pressure.
What makes this direction **novel** is that we do not treat “good defense” as a single yes/no check. The agent must keep making good choices for many steps in a row, under changing pressure, while mission goals are still active. That combination (multi-step behavior + partial visibility + active adversary + mission constraints) is where many current benchmarks become too easy or unrealistic, and where **industry**-relevant **impact** is actually decided.
### How this lines up with long-horizon and self-improvement themes
**Theme: (super) long-horizon planning and instruction following.** Missions are **long-running** by design: scenarios scale to **many** instructions and checkpoints, with **sparse and delayed** rewards from security and mission rubrics. The agent must **decompose** response goals, **track** state and playbook progress under partial visibility, and **recover** from early mistakes over **extended trajectories**—closer to durable planning than one-shot next responses.
**Theme: self-improvement and adaptive curricula.** The **Red vs. Blue** loop is explicit **self-play** over a **defined** scenario family. **League** work (PFSP, PSRO, and mixed) plus round-based **GRPO** changes the **opponent mix** and pressure across training, so improvement is not fitting a static list of tasks but **recursive capability growth** driven by an **adaptive curriculum** and interaction feedback on the same environment.
---
## What the environment is
CyberSelfPlay is an OpenEnv-compatible two-player environment. **Red** (attacker) and **Blue** (defender) share one hidden world state; each step, one side submits a move, the simulator applies it, and the next observation is for that actor. Blue is the policy you typically train; Red can be scripted, pooled, or treated as a league opponent archetype. Episodes are bounded by a scenario-specific turn budget, with termination on exfil success, or on horizon with a win condition tied to mission instruction completion.
**Blue** chooses from a fixed defender tool set: SIEM and triage, isolation, account controls, secret rotation, patching, hardening, backups, forensics, IOC publishing, and playbook tools such as `execute_instruction` and `checkpoint_plan`—each call names a `tool_name`, an optional `target` (host or asset), and a `params` object for tool-specific arguments, plus an optional `rationale` string. **Red** uses a separate attacker tool set: recon, enumeration, exploit and credential access, pivoting, persistence, exfil pipeline stages, cover-up, and recovery-plan sabotage. Invalid tools return a non-terminal observation with an error in metadata rather than crashing the session.
- Blue receives **partial** public state, noisy telemetry, incident summary fields, and rich **metadata** (reward components, simulator events, POSG metrics, curriculum/scenario tags).
- **CyberAction** is the OpenEnv `Action` type: JSON-shaped, validated per side before the simulator runs.
- Rewards encode both security outcomes (detect/contain/recover) and mission outcomes (instruction progress/checkpoints/violations), with components exposed for logging and for RL shaping.
Formally, the environment is modeled as a partially observable stochastic game (POSG):
$$
\mathcal{G}=\langle \mathcal{S},\mathcal{A}_R,\mathcal{A}_B,\mathcal{O}_R,\mathcal{O}_B,T,Z_R,Z_B,r_R,r_B,\gamma \rangle
$$
with objective
$$
J_i(\pi_i,\pi_{-i})=\mathbb{E}\left[\sum_{t=0}^{H}\gamma^t r_i\left(s_t,a_t^R,a_t^B\right)\right],\quad i\in\{R,B\}.
$$
Near-zero-sum coupling is represented as:
$$
r_B=-r_R-\lambda C_{\mathrm{collateral}}.
$$
In plain terms: if Red gains ground, Blue usually loses ground, and harmful side effects are also counted. This keeps the game honest and closer to what defenders see in **real-world** response and the trade-offs that show up in **industry** debriefs.
---
## Core components
At a high level, the system has:
1. **Environment core** (`cyber_selfplay_env/`)
- hidden-state simulator and transitions,
- reward rubrics,
- metrics and progress tracking,
- scenario definitions and tool interfaces.
2. **API server**
- OpenEnv endpoints for interaction.
3. **Training pipelines**
- a single-policy path: **SFT** on demonstration or filtered rollouts, then **GRPO** on environment reward;
- and a league-based path that uses the **same** SFT and GRPO machinery: an initial SFT stage, then for each **league round** a **mini-GRPO** segment together with **PFSP / PSRO** (or mixed) opponent meta-updates over Red archetypes or policy pools.
Together, these parts create a full loop: simulate attack/defense interactions, score behavior with mission-aware rewards, then improve the policy using those outcomes.
**System figures (open as links or view inline in [Colab, diagrams, and repository notebooks](#colab-diagrams-and-repository-notebooks)):** the [**environment architecture** diagram (SVG)](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181551/architecture_dus774.svg) shows how the environment, server, and training stack connect; the [**end-to-end training flow** (SVG)](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg) summarizes SFT, GRPO, and league training at a glance. Placing the links here matches how engineers skim a project: first the shape of the system, then the pipeline.
---
## Observations, actions, rewards
### Observations
Observations are **player-local**. After each `step`, the `CyberObservation` for the active actor includes:
- **`public_state`**: a partial view of the world. For Blue, this typically includes the simulation time step, a short history of **detections**, **business impact**, a coarse incident count, and **instruction progress** (counts of completed, violated, and total playbook instructions). Red sees a different slice (e.g., limited target hints and detection pressure)—so neither side sees the full state vector.
- **`telemetry`**: a short, possibly noisy list of events (e.g., recent detections for Blue; weak indirect signals for Red), reinforcing partial observability.
- **`incident_summary`**: high-level fields such as termination, winner, exfil status, and time index—usable as a quick situational readout.
- **`reward`**: scalar reward from the **previous** action (after `reset`, typically zero).
- **`done`**: whether the episode has ended.
- **`metadata`**: on successful steps, this carries **decomposed reward components**, raw **events** from the simulator, **POSG metrics** snapshots (e.g., exfil and instruction rates), and **curriculum** information (scenario name, rolling win rates, episode counts). On invalid actions, metadata may contain an **error** string instead.
Reset returns an initial Blue observation with scenario/curriculum hints and a note that play alternates between Red and Blue.
### Actions
The policy does not mutate the simulator with free text: it must emit a **`CyberAction`**: `actor` (`"red"` or `"blue"`), `tool_name` (must be in that side’s allowed set), `target` (e.g., host id), `params` (a dict for tools that need extra fields, such as which capability an `execute_instruction` step requires), and optional `rationale`. Red and Blue each have distinct tool vocabularies; the environment validates the tool name before calling the **CyberSimulator** `step` logic.
### Reward design
The reward law combines dense and delayed signals. The scripts use environment reward as the dominant term, with additional shaping in GRPO training.
Red side:
$$
\begin{aligned}
r_R &= w_1 \mathbb{1}_{\mathrm{foothold}} + w_2 \mathbb{1}_{\mathrm{priv}} + w_3 \mathbb{1}_{\mathrm{lateral}} + w_4 \mathbb{1}_{\mathrm{exfil}} \\
&\quad - w_5 \mathbb{1}_{\mathrm{detect}} + w_6 \mathbb{1}_{\mathrm{plan\_sabotage}} - \eta_R
\end{aligned}
$$
Blue side:
$$
\begin{aligned}
r_B &= v_1 \mathbb{1}_{\mathrm{detect}} + v_2 \mathbb{1}_{\mathrm{contain}} + v_3 \mathbb{1}_{\mathrm{recover}} - v_4 \mathbb{1}_{\mathrm{exfil}} \\
&\quad + v_5 \mathbb{1}_{\mathrm{instr\_progress}} + v_6 \mathbb{1}_{\mathrm{checkpoint}} - v_7 \mathbb{1}_{\mathrm{instr\_violation}} \\
&\quad + v_8 \rho_{\mathrm{inst}} - \eta_B
\end{aligned}
$$
Why this matters: these equations make it hard to “game” the benchmark with shallow tricks. The agent is pushed toward useful defense behavior across time, not just short-term score spikes.
---
## Training story: what we tried, what failed, what changed
### Step 1: Start with SFT -> vanilla GRPO
We started with the direct path:
- Supervised Fine-Tuning (SFT) on heuristic rollouts,
- then Group Relative Policy Optimization (GRPO) using environment reward.
Core GRPO intuition:
$$
\{y^{(1)},\ldots,y^{(G)}\}\sim \pi_\theta(\cdot\mid x)
$$
Sample a group of completions per prompt, score each completion, compute group-relative advantages, and update policy parameters.
At this point, we had a baseline that could parse actions and follow structure, but behavior quality still depended heavily on exploration quality.
### Step 2: We hit mode collapse pressure
During early iterations, action diversity degraded: one tool could dominate generated actions. This reduces effective exploration and hurts credit assignment.
In practice, this looked like “safe but repetitive” behavior: valid JSON, but less tactical variety. The agent was syntactically correct more often than strategically useful.
### Step 3: Add stabilization in single-policy GRPO
In the single-policy training path, we introduced shaping aligned with this issue:
- group-level diversity penalty when one tool dominates a batch,
- additional nudge against overusing `execute_instruction` when SFT bias is high,
- continued logging of unique-tools-per-step as a diversity meter.
This improved robustness of training dynamics while keeping environment reward primary.
This step is important because it addresses a common failure mode in small-model RL: if action variety collapses too early, learning plateaus quickly.
### Step 4: Move to league training for broader robustness
Single-policy GRPO improved behavior, but robustness against varied attacker styles needed stronger pressure. We then moved to a league-based training loop that still builds on **SFT** and **GRPO**—not only meta-game structure. A typical run starts with the same **SFT** style initialization used in the non-league recipes, then repeats for **multiple league rounds**: sample or weight **Red** opponents (PFSP, PSRO, or a **mix**), build rollouts and prompts in line with the sampled profile, and run a **mini-GRPO** phase per round on environment reward (with the same family of Unsloth/LoRA/TRL tooling as the vanilla pipeline). **PFSP** and **PSRO** (or their combination) update who gets sampled or how policy weights evolve across rounds, while the inner learning signal remains **SFT-initialized policy improvement via GRPO** under changing opponent pressure. Round-level updates use **replicator**-style or win-rate-weighted rules so the training mixture stays adaptive.
PFSP weighting:
$$
p_j \propto f(w_j),\qquad f(w)=w(1-w)
$$
PSRO-style replicator update:
$$
p_i' \propto p_i\left(1+\eta(u_i-\bar{u})\right),\qquad \bar{u}=\sum_i p_i u_i
$$
This made training pressure adaptive across rounds rather than fixed to one opponent profile.
This is where behavior starts to look more “field-like”: the defender is not tuned to one attacker template, but pushed by a moving mixture of attacker styles.
### Step 5: Turn logs into evidence, not just numbers
We deliberately kept artifact generation rich (training curves, per-step logs, and combined league histories) so claims can be traced back to concrete run outputs. That makes debugging, comparison, and review much more grounded.
---
## Colab, diagrams, and repository notebooks
The README documents the same training recipes with **public Colab** links and **static curve images** (repeated below under [Results and evidence](#results-and-evidence)). In the repo, the `notebook/` directory holds local copies aligned with each recipe.
### Environment diagrams (from the README)
These SVGs are the high-level system view and training pipeline, as in the [README `Environment Architecture` and `Training Flow` sections](README.md#environment-architecture). You can open each asset directly: [**architecture (SVG link)**](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181551/architecture_dus774.svg) · [**training flow (SVG link)**](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg).
**Architecture**
[Open architecture diagram in new tab (SVG)](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181551/architecture_dus774.svg)
 **Training flow**
[Open training flow diagram in new tab (SVG)](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg)
**Training flow**
[Open training flow diagram in new tab (SVG)](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg)
 ### Colab notebooks and what each path does
| Method | Open in Colab | Local notebook in `notebook/` | In short |
|--------|----------------|-------------------------------|----------|
| **SFT → GRPO (Vanilla)** | [Open in Colab](https://colab.research.google.com/drive/1K5771KT0-2lyU6eNghqQEStBS4OSF7D7?usp=sharing) | `SFT_→_GRPO_(Vanilla).ipynb` | Supervised fine-tuning on trajectory-style data, then **vanilla GRPO** with the environment reward only: the baseline for single-policy learning. |
| **SFT → GRPO (Anti-Collapse)** | [Open in Colab](https://colab.research.google.com/drive/1HivyWte1q-sugE04XsyMi1U_RY1oGkJ8?usp=sharing) | `SFT_→_GRPO_(Anti_Collapse_Regularization).ipynb` | Same SFT + GRPO stack with **diversity / anti-collapse** regularization so the policy does not collapse to a tiny set of tool actions. |
| **League (PFSP)** | [Open in Colab](https://colab.research.google.com/drive/1g2QCBqdvo7QwRC7dJaV8QdO7RvTPGyY1?usp=sharing) | `League(PFSP).ipynb` | **SFT** warm-start and per-round **mini-GRPO** on environment reward, with **Prioritized Fictitious Self-Play** so Red-style opponents are sampled with matchup-driven weights. |
| **League (PSRO)** | [Open in Colab](https://colab.research.google.com/drive/1O6IoE-_UloAeDXKve2ZA1W4OajychglP?usp=sharing) | `League_(PSRO) (1).ipynb` | **SFT** and **GRPO** as above, with **PSRO**-style meta-updates on the opponent or policy pool in addition to league sampling. |
| **League (PFSP + PSRO)** | [Open in Colab](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing) | `League_(PFSP_+_PSRO).ipynb` | **SFT**, **GRPO**, and **PFSP** + **PSRO** together: opponent (policy) choice and replicator-style meta-updates in one loop. |
The notebooks mirror the table in the [README `Training Approaches` section](README.md#-training-approaches-in-this-project); Colab is the shareable run surface, and the `notebook/` files are the offline copies in this repository.
---
## Results and evidence
### Figures from training runs (same assets as the README)
Below are the **SFT / GRPO / league** curve figures linked from the README’s training table, plus the **SFT training loss** plot referenced for this write-up. Together they are the main visual evidence for convergence and per-method behavior.
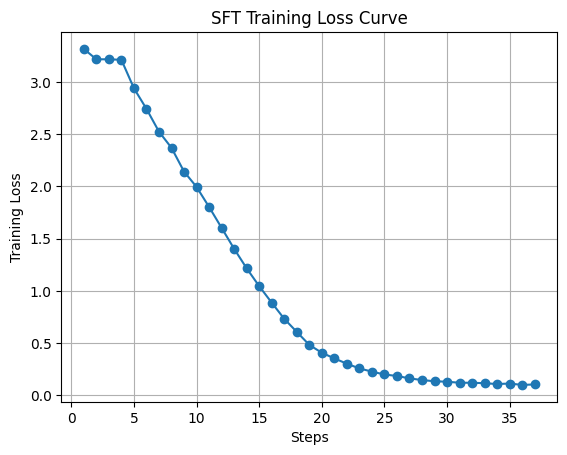
**SFT training loss (cross-entropy on expert trajectories).** The run shows a clean optimization trajectory: loss starts around **3.2–3.3**, stays almost flat for the first few steps, then falls steeply from roughly step **5** through **25**. After that the curve flattens: from about step **30** onward training loss sits near **0.1** (steps on the x-axis go up to about **37**), which indicates that the SFT stage has found a low-NLL fit on the demonstration data.
### Colab notebooks and what each path does
| Method | Open in Colab | Local notebook in `notebook/` | In short |
|--------|----------------|-------------------------------|----------|
| **SFT → GRPO (Vanilla)** | [Open in Colab](https://colab.research.google.com/drive/1K5771KT0-2lyU6eNghqQEStBS4OSF7D7?usp=sharing) | `SFT_→_GRPO_(Vanilla).ipynb` | Supervised fine-tuning on trajectory-style data, then **vanilla GRPO** with the environment reward only: the baseline for single-policy learning. |
| **SFT → GRPO (Anti-Collapse)** | [Open in Colab](https://colab.research.google.com/drive/1HivyWte1q-sugE04XsyMi1U_RY1oGkJ8?usp=sharing) | `SFT_→_GRPO_(Anti_Collapse_Regularization).ipynb` | Same SFT + GRPO stack with **diversity / anti-collapse** regularization so the policy does not collapse to a tiny set of tool actions. |
| **League (PFSP)** | [Open in Colab](https://colab.research.google.com/drive/1g2QCBqdvo7QwRC7dJaV8QdO7RvTPGyY1?usp=sharing) | `League(PFSP).ipynb` | **SFT** warm-start and per-round **mini-GRPO** on environment reward, with **Prioritized Fictitious Self-Play** so Red-style opponents are sampled with matchup-driven weights. |
| **League (PSRO)** | [Open in Colab](https://colab.research.google.com/drive/1O6IoE-_UloAeDXKve2ZA1W4OajychglP?usp=sharing) | `League_(PSRO) (1).ipynb` | **SFT** and **GRPO** as above, with **PSRO**-style meta-updates on the opponent or policy pool in addition to league sampling. |
| **League (PFSP + PSRO)** | [Open in Colab](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing) | `League_(PFSP_+_PSRO).ipynb` | **SFT**, **GRPO**, and **PFSP** + **PSRO** together: opponent (policy) choice and replicator-style meta-updates in one loop. |
The notebooks mirror the table in the [README `Training Approaches` section](README.md#-training-approaches-in-this-project); Colab is the shareable run surface, and the `notebook/` files are the offline copies in this repository.
---
## Results and evidence
### Figures from training runs (same assets as the README)
Below are the **SFT / GRPO / league** curve figures linked from the README’s training table, plus the **SFT training loss** plot referenced for this write-up. Together they are the main visual evidence for convergence and per-method behavior.
**SFT training loss (cross-entropy on expert trajectories).** The run shows a clean optimization trajectory: loss starts around **3.2–3.3**, stays almost flat for the first few steps, then falls steeply from roughly step **5** through **25**. After that the curve flattens: from about step **30** onward training loss sits near **0.1** (steps on the x-axis go up to about **37**), which indicates that the SFT stage has found a low-NLL fit on the demonstration data.
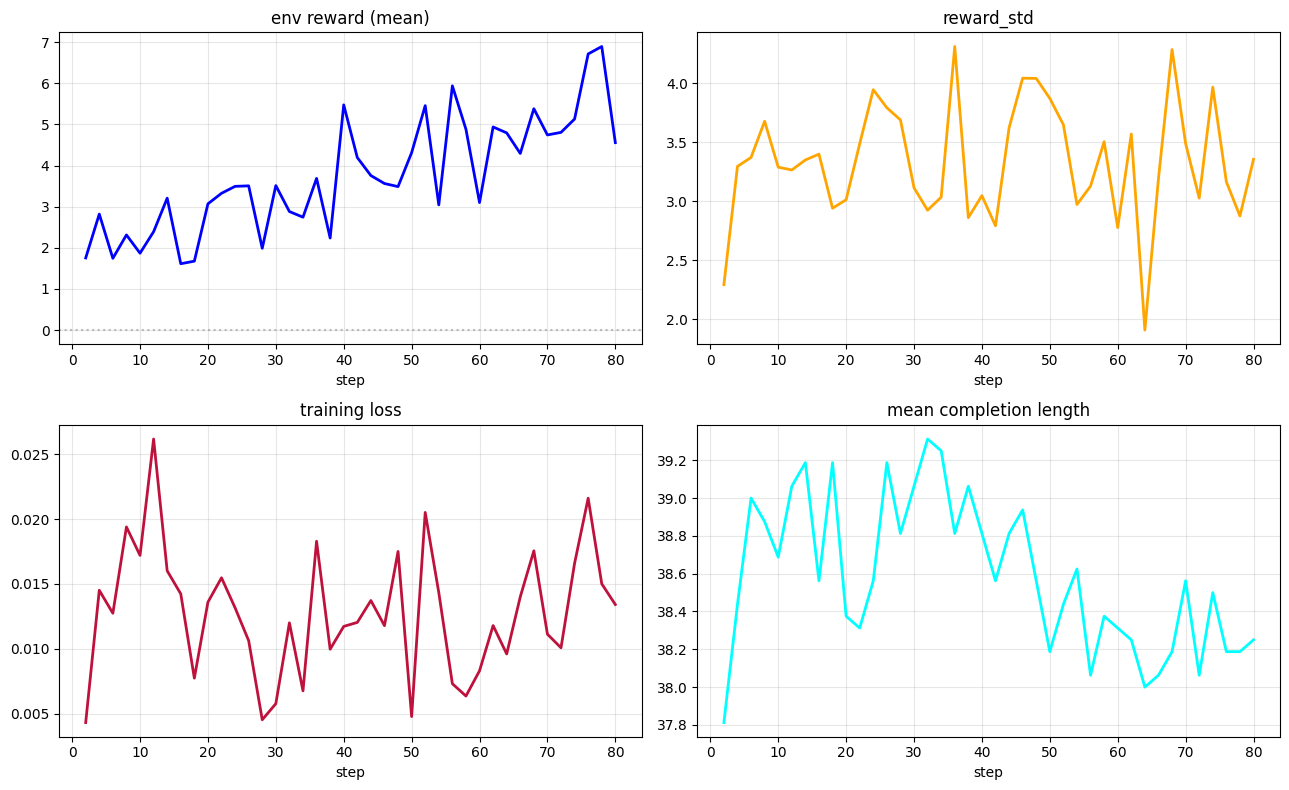
 **SFT → GRPO (Vanilla).**
**SFT → GRPO (Vanilla).**
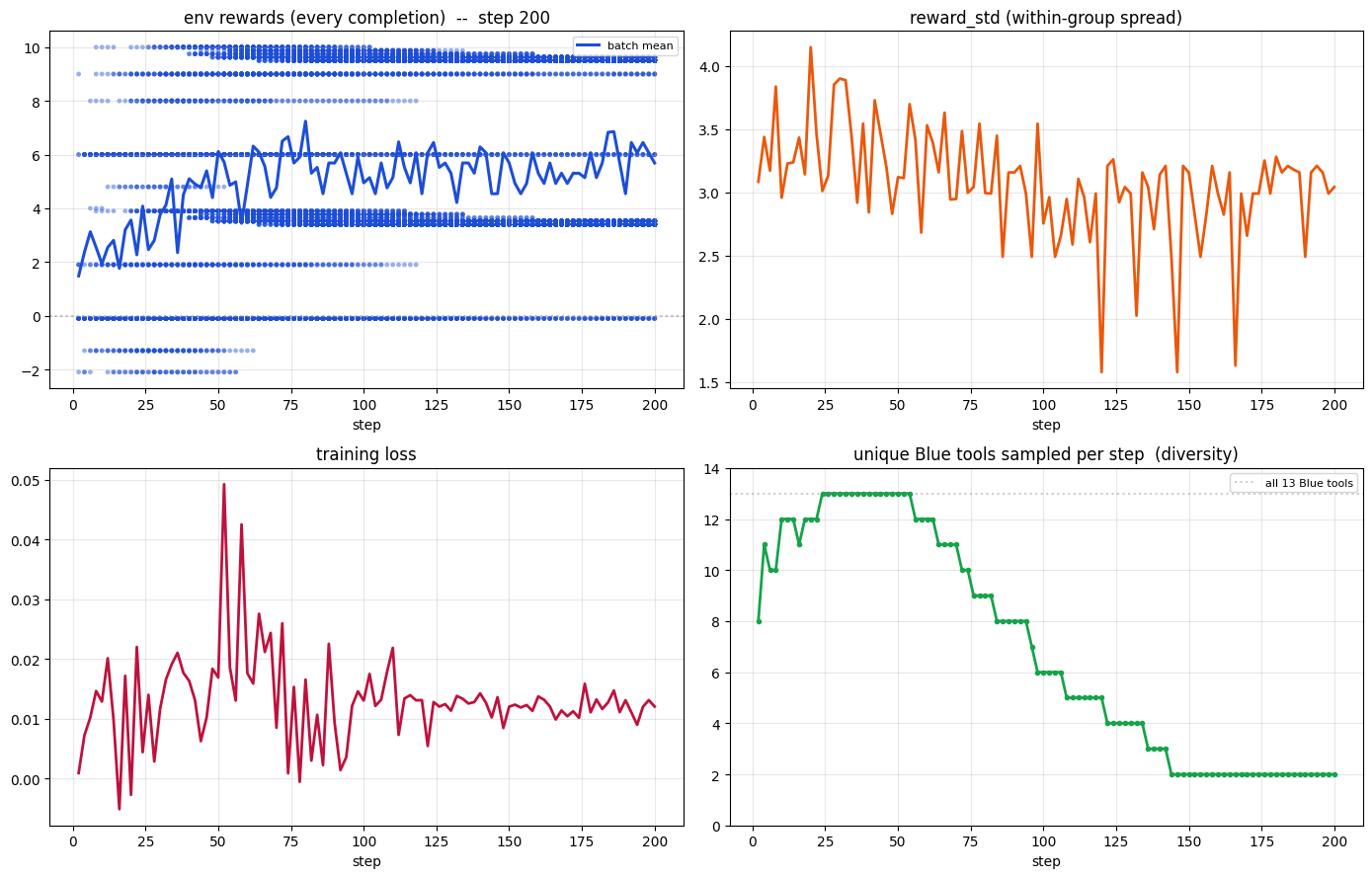
 **SFT → GRPO (Anti-Collapse).**
**SFT → GRPO (Anti-Collapse).**
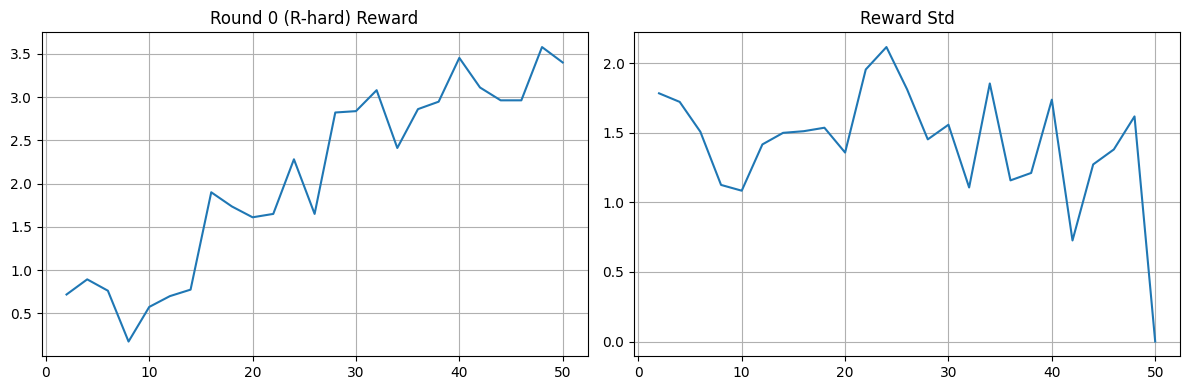
 **League (PFSP).**
**League (PFSP).**
 **League (PSRO).**
**League (PSRO).**
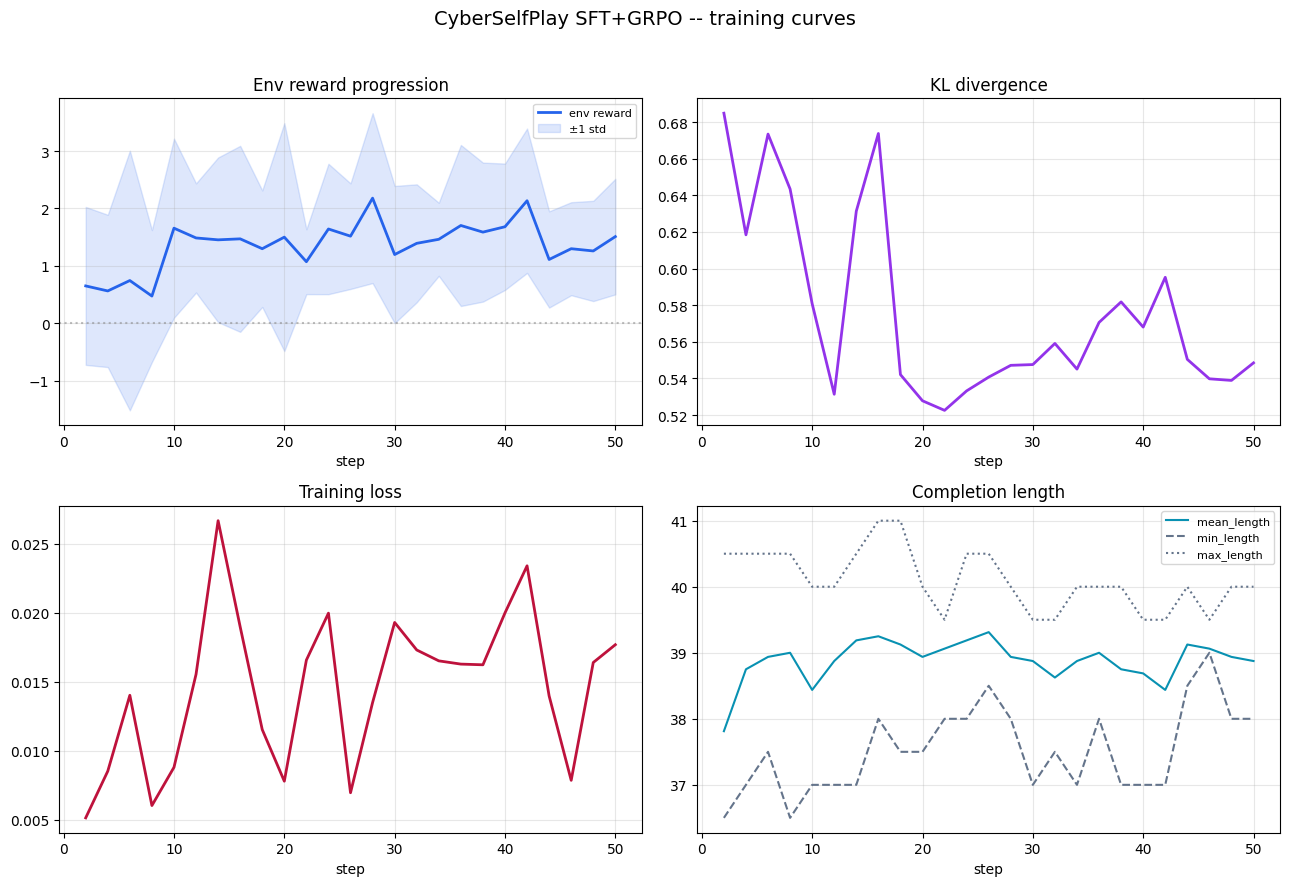 **League (PFSP + PSRO).**
**League (PFSP + PSRO).**
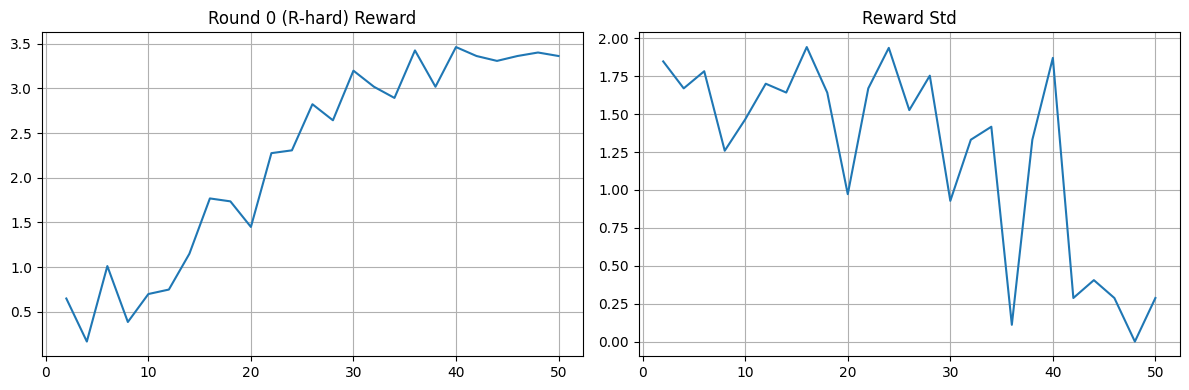 ### Interpretation in one pass
Across runs, we observe the expected pattern:
- Blue moves from imitation-only behavior (SFT) to stronger reward-aligned behavior after GRPO.
- Diversity shaping reduces collapse and stabilizes learning in single-policy training.
- League mode (PFSP/PSRO/mix) produces richer multi-round dynamics and better robustness across opponent types.
A useful way to read these results is:
1. **Can the model act in valid structured form?** (SFT gives this base)
2. **Can it improve through interaction feedback?** (GRPO gives this climb)
3. **Can it hold up under varied opponents?** (league rounds test this directly)
By the final stage, improvements are not only in average reward but also in consistency across rounds and opponent profiles.
Primary artifacts produced during training:
- consolidated training curves
- full optimization history logs
- per-step reward traces
- per-step behavior snapshots
- league-specific multi-round trend and meta-state reports
These files are the evidence trail for reward trends, variance, action diversity, and round-by-round league behavior.
---
## Why it matters
CyberSelfPlay matters because it evaluates what real defenders need:
- multi-step, instruction-conditioned recovery,
- adversarial interaction under uncertainty,
- measurable progress beyond one-step task completion.
For **industry** practitioners, it is closer to incident response realities and to how blue teams think about time-to-detect, containment, and recovery.
For researchers, it offers a reproducible testbed for strategic, multi-step agent behavior, with a **novel** mix of instruction following, tools, and adversarial pressure in one environment.
For teams building defensive copilots or autonomous responders, this kind of environment gives a safer place to test policy behavior before production deployment.
For evaluation-focused work, it provides a bridge between toy tasks and operationally meaningful multi-step scenarios.
---
## Why this submission can stand out
- It tackles a **real-world**-tilted setting that combines multi-step behavior, partial observability, adversarial play, and mission objectives in one benchmark, which is an unusual and **impact**-relevant target for the field.
- It does not stop at one training recipe; it shows a full progression from baseline to stabilized training to league pressure, with clear **industry**-minded artifacts (curves, logs, league history).
- It includes mathematical grounding, system-level structure, and diagram-level **novelty** in how the stack is presented (see [architecture](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181551/architecture_dus774.svg) and [training flow](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg) links in [Core components](#core-components) and [diagrams](#environment-diagrams-from-the-readme)), plus artifact-level evidence in one coherent package.
- The narrative from “initial approach -> failure mode -> fix -> stronger method” is explicit and reproducible, which is what teams need to trust deployment-related claims.
---
## Where to go next
- **Project README** (formal POSG, rewards, training math, and full method table): [README.md](README.md)
- **Hugging Face Space (live environment):** [CyberSelfPlay on Hugging Face](https://huggingface.co/spaces/HarshitShri026) — running API: [harshitshri026-cyberselfplay-env.hf.space](https://harshitshri026-cyberselfplay-env.hf.space/), [Swagger `/docs`](https://harshitshri026-cyberselfplay-env.hf.space/docs), [ReDoc `/redoc`](https://harshitshri026-cyberselfplay-env.hf.space/redoc)
The README and this blog point to each other so you can move between the specification-style overview and the narrative plus figures here.
### Interpretation in one pass
Across runs, we observe the expected pattern:
- Blue moves from imitation-only behavior (SFT) to stronger reward-aligned behavior after GRPO.
- Diversity shaping reduces collapse and stabilizes learning in single-policy training.
- League mode (PFSP/PSRO/mix) produces richer multi-round dynamics and better robustness across opponent types.
A useful way to read these results is:
1. **Can the model act in valid structured form?** (SFT gives this base)
2. **Can it improve through interaction feedback?** (GRPO gives this climb)
3. **Can it hold up under varied opponents?** (league rounds test this directly)
By the final stage, improvements are not only in average reward but also in consistency across rounds and opponent profiles.
Primary artifacts produced during training:
- consolidated training curves
- full optimization history logs
- per-step reward traces
- per-step behavior snapshots
- league-specific multi-round trend and meta-state reports
These files are the evidence trail for reward trends, variance, action diversity, and round-by-round league behavior.
---
## Why it matters
CyberSelfPlay matters because it evaluates what real defenders need:
- multi-step, instruction-conditioned recovery,
- adversarial interaction under uncertainty,
- measurable progress beyond one-step task completion.
For **industry** practitioners, it is closer to incident response realities and to how blue teams think about time-to-detect, containment, and recovery.
For researchers, it offers a reproducible testbed for strategic, multi-step agent behavior, with a **novel** mix of instruction following, tools, and adversarial pressure in one environment.
For teams building defensive copilots or autonomous responders, this kind of environment gives a safer place to test policy behavior before production deployment.
For evaluation-focused work, it provides a bridge between toy tasks and operationally meaningful multi-step scenarios.
---
## Why this submission can stand out
- It tackles a **real-world**-tilted setting that combines multi-step behavior, partial observability, adversarial play, and mission objectives in one benchmark, which is an unusual and **impact**-relevant target for the field.
- It does not stop at one training recipe; it shows a full progression from baseline to stabilized training to league pressure, with clear **industry**-minded artifacts (curves, logs, league history).
- It includes mathematical grounding, system-level structure, and diagram-level **novelty** in how the stack is presented (see [architecture](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181551/architecture_dus774.svg) and [training flow](https://res.cloudinary.com/dgyebzm4w/image/upload/v1777181108/training-flow_a3xupo.svg) links in [Core components](#core-components) and [diagrams](#environment-diagrams-from-the-readme)), plus artifact-level evidence in one coherent package.
- The narrative from “initial approach -> failure mode -> fix -> stronger method” is explicit and reproducible, which is what teams need to trust deployment-related claims.
---
## Where to go next
- **Project README** (formal POSG, rewards, training math, and full method table): [README.md](README.md)
- **Hugging Face Space (live environment):** [CyberSelfPlay on Hugging Face](https://huggingface.co/spaces/HarshitShri026) — running API: [harshitshri026-cyberselfplay-env.hf.space](https://harshitshri026-cyberselfplay-env.hf.space/), [Swagger `/docs`](https://harshitshri026-cyberselfplay-env.hf.space/docs), [ReDoc `/redoc`](https://harshitshri026-cyberselfplay-env.hf.space/redoc)
The README and this blog point to each other so you can move between the specification-style overview and the narrative plus figures here.