+ ${mainComponentName ? `<${mainComponentName} />` : '
\n
Welcome to your React App
\n
Your components have been created but need to be added here.
\n
'}
+ {/* Generated components: ${componentFiles.map(f => f.path).join(', ')} */}
+
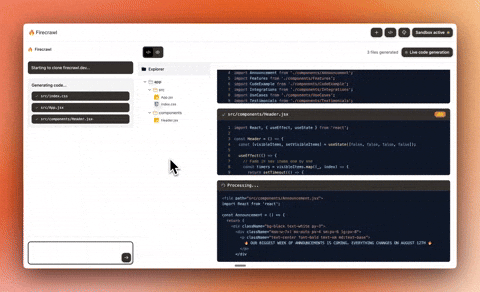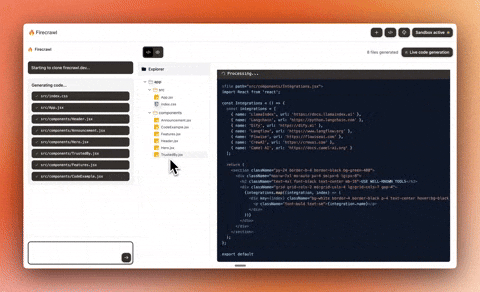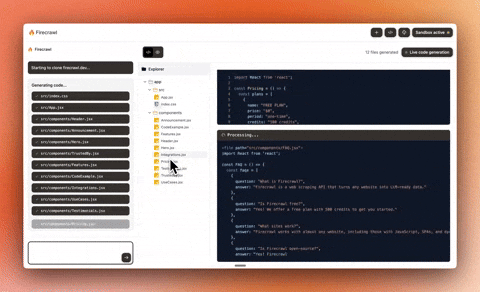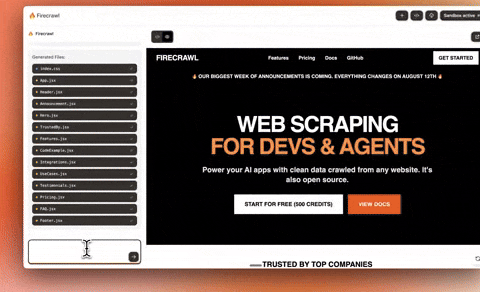 +
+## Setup
+
+1. **Clone & Install**
+```bash
+git clone https://github.com/firecrawl/open-lovable.git
+cd open-lovable
+pnpm install # or npm install / yarn install
+```
+
+2. **Add `.env.local`**
+
+```env
+# =================================================================
+# REQUIRED
+# =================================================================
+FIRECRAWL_API_KEY=your_firecrawl_api_key # https://firecrawl.dev
+
+# =================================================================
+# AI PROVIDER - Choose your LLM
+# =================================================================
+GEMINI_API_KEY=your_gemini_api_key # https://aistudio.google.com/app/apikey
+ANTHROPIC_API_KEY=your_anthropic_api_key # https://console.anthropic.com
+OPENAI_API_KEY=your_openai_api_key # https://platform.openai.com
+GROQ_API_KEY=your_groq_api_key # https://console.groq.com
+
+# =================================================================
+# FAST APPLY (Optional - for faster edits)
+# =================================================================
+MORPH_API_KEY=your_morphllm_api_key # https://morphllm.com/dashboard
+
+# =================================================================
+# SANDBOX PROVIDER - Choose ONE: Vercel (default) or E2B
+# =================================================================
+SANDBOX_PROVIDER=vercel # or 'e2b'
+
+# Option 1: Vercel Sandbox (default)
+# Choose one authentication method:
+
+# Method A: OIDC Token (recommended for development)
+# Run `vercel link` then `vercel env pull` to get VERCEL_OIDC_TOKEN automatically
+VERCEL_OIDC_TOKEN=auto_generated_by_vercel_env_pull
+
+# Method B: Personal Access Token (for production or when OIDC unavailable)
+# VERCEL_TEAM_ID=team_xxxxxxxxx # Your Vercel team ID
+# VERCEL_PROJECT_ID=prj_xxxxxxxxx # Your Vercel project ID
+# VERCEL_TOKEN=vercel_xxxxxxxxxxxx # Personal access token from Vercel dashboard
+
+# Option 2: E2B Sandbox
+# E2B_API_KEY=your_e2b_api_key # https://e2b.dev
+```
+
+3. **Run**
+```bash
+pnpm dev # or npm run dev / yarn dev
+```
+
+Open [http://localhost:3000](http://localhost:3000)
+
+## License
+
+MIT
\ No newline at end of file
diff --git a/README.md b/README.md
index 465b74986000dcab4a55bd40f03bda3df504ec97..222582cc1ff3646fc6ec6acd2473a7bd794db934 100644
--- a/README.md
+++ b/README.md
@@ -1,10 +1,10 @@
---
-title: Openoperator
-emoji: 🐠
-colorFrom: blue
-colorTo: gray
+# Trigger rebuild
+title: Open Lovable
+emoji: ❤️
+colorFrom: pink
+colorTo: blue
sdk: docker
+app_port: 3000
pinned: false
---
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/app/api/analyze-edit-intent/route.ts b/app/api/analyze-edit-intent/route.ts
new file mode 100644
index 0000000000000000000000000000000000000000..07798a03e36e1fbb9f68a93d3547c633e4547d31
--- /dev/null
+++ b/app/api/analyze-edit-intent/route.ts
@@ -0,0 +1,190 @@
+import { NextRequest, NextResponse } from 'next/server';
+import { createGroq } from '@ai-sdk/groq';
+import { createAnthropic } from '@ai-sdk/anthropic';
+import { createOpenAI } from '@ai-sdk/openai';
+import { createGoogleGenerativeAI } from '@ai-sdk/google';
+import { generateObject } from 'ai';
+import { z } from 'zod';
+// import type { FileManifest } from '@/types/file-manifest'; // Type is used implicitly through manifest parameter
+
+// Check if we're using Vercel AI Gateway
+const isUsingAIGateway = !!process.env.AI_GATEWAY_API_KEY;
+const aiGatewayBaseURL = 'https://ai-gateway.vercel.sh/v1';
+
+const groq = createGroq({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.GROQ_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : undefined,
+});
+
+const anthropic = createAnthropic({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.ANTHROPIC_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : (process.env.ANTHROPIC_BASE_URL || 'https://api.anthropic.com/v1'),
+});
+
+const openai = createOpenAI({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.OPENAI_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : process.env.OPENAI_BASE_URL,
+});
+
+const googleGenerativeAI = createGoogleGenerativeAI({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.GEMINI_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : undefined,
+});
+
+// Schema for the AI's search plan - not file selection!
+const searchPlanSchema = z.object({
+ editType: z.enum([
+ 'UPDATE_COMPONENT',
+ 'ADD_FEATURE',
+ 'FIX_ISSUE',
+ 'UPDATE_STYLE',
+ 'REFACTOR',
+ 'ADD_DEPENDENCY',
+ 'REMOVE_ELEMENT'
+ ]).describe('The type of edit being requested'),
+
+ reasoning: z.string().describe('Explanation of the search strategy'),
+
+ searchTerms: z.array(z.string()).describe('Specific text to search for (case-insensitive). Be VERY specific - exact button text, class names, etc.'),
+
+ regexPatterns: z.array(z.string()).optional().describe('Regex patterns for finding code structures (e.g., "className=[\\"\\\'].*header.*[\\"\\\']")'),
+
+ fileTypesToSearch: z.array(z.string()).default(['.jsx', '.tsx', '.js', '.ts']).describe('File extensions to search'),
+
+ expectedMatches: z.number().min(1).max(10).default(1).describe('Expected number of matches (helps validate search worked)'),
+
+ fallbackSearch: z.object({
+ terms: z.array(z.string()),
+ patterns: z.array(z.string()).optional()
+ }).optional().describe('Backup search if primary fails')
+});
+
+export async function POST(request: NextRequest) {
+ try {
+ const { prompt, manifest, model = 'openai/gpt-oss-20b' } = await request.json();
+
+ console.log('[analyze-edit-intent] Request received');
+ console.log('[analyze-edit-intent] Prompt:', prompt);
+ console.log('[analyze-edit-intent] Model:', model);
+ console.log('[analyze-edit-intent] Manifest files count:', manifest?.files ? Object.keys(manifest.files).length : 0);
+
+ if (!prompt || !manifest) {
+ return NextResponse.json({
+ error: 'prompt and manifest are required'
+ }, { status: 400 });
+ }
+
+ // Create a summary of available files for the AI
+ const validFiles = Object.entries(manifest.files as Record
+
+## Setup
+
+1. **Clone & Install**
+```bash
+git clone https://github.com/firecrawl/open-lovable.git
+cd open-lovable
+pnpm install # or npm install / yarn install
+```
+
+2. **Add `.env.local`**
+
+```env
+# =================================================================
+# REQUIRED
+# =================================================================
+FIRECRAWL_API_KEY=your_firecrawl_api_key # https://firecrawl.dev
+
+# =================================================================
+# AI PROVIDER - Choose your LLM
+# =================================================================
+GEMINI_API_KEY=your_gemini_api_key # https://aistudio.google.com/app/apikey
+ANTHROPIC_API_KEY=your_anthropic_api_key # https://console.anthropic.com
+OPENAI_API_KEY=your_openai_api_key # https://platform.openai.com
+GROQ_API_KEY=your_groq_api_key # https://console.groq.com
+
+# =================================================================
+# FAST APPLY (Optional - for faster edits)
+# =================================================================
+MORPH_API_KEY=your_morphllm_api_key # https://morphllm.com/dashboard
+
+# =================================================================
+# SANDBOX PROVIDER - Choose ONE: Vercel (default) or E2B
+# =================================================================
+SANDBOX_PROVIDER=vercel # or 'e2b'
+
+# Option 1: Vercel Sandbox (default)
+# Choose one authentication method:
+
+# Method A: OIDC Token (recommended for development)
+# Run `vercel link` then `vercel env pull` to get VERCEL_OIDC_TOKEN automatically
+VERCEL_OIDC_TOKEN=auto_generated_by_vercel_env_pull
+
+# Method B: Personal Access Token (for production or when OIDC unavailable)
+# VERCEL_TEAM_ID=team_xxxxxxxxx # Your Vercel team ID
+# VERCEL_PROJECT_ID=prj_xxxxxxxxx # Your Vercel project ID
+# VERCEL_TOKEN=vercel_xxxxxxxxxxxx # Personal access token from Vercel dashboard
+
+# Option 2: E2B Sandbox
+# E2B_API_KEY=your_e2b_api_key # https://e2b.dev
+```
+
+3. **Run**
+```bash
+pnpm dev # or npm run dev / yarn dev
+```
+
+Open [http://localhost:3000](http://localhost:3000)
+
+## License
+
+MIT
\ No newline at end of file
diff --git a/README.md b/README.md
index 465b74986000dcab4a55bd40f03bda3df504ec97..222582cc1ff3646fc6ec6acd2473a7bd794db934 100644
--- a/README.md
+++ b/README.md
@@ -1,10 +1,10 @@
---
-title: Openoperator
-emoji: 🐠
-colorFrom: blue
-colorTo: gray
+# Trigger rebuild
+title: Open Lovable
+emoji: ❤️
+colorFrom: pink
+colorTo: blue
sdk: docker
+app_port: 3000
pinned: false
---
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/app/api/analyze-edit-intent/route.ts b/app/api/analyze-edit-intent/route.ts
new file mode 100644
index 0000000000000000000000000000000000000000..07798a03e36e1fbb9f68a93d3547c633e4547d31
--- /dev/null
+++ b/app/api/analyze-edit-intent/route.ts
@@ -0,0 +1,190 @@
+import { NextRequest, NextResponse } from 'next/server';
+import { createGroq } from '@ai-sdk/groq';
+import { createAnthropic } from '@ai-sdk/anthropic';
+import { createOpenAI } from '@ai-sdk/openai';
+import { createGoogleGenerativeAI } from '@ai-sdk/google';
+import { generateObject } from 'ai';
+import { z } from 'zod';
+// import type { FileManifest } from '@/types/file-manifest'; // Type is used implicitly through manifest parameter
+
+// Check if we're using Vercel AI Gateway
+const isUsingAIGateway = !!process.env.AI_GATEWAY_API_KEY;
+const aiGatewayBaseURL = 'https://ai-gateway.vercel.sh/v1';
+
+const groq = createGroq({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.GROQ_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : undefined,
+});
+
+const anthropic = createAnthropic({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.ANTHROPIC_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : (process.env.ANTHROPIC_BASE_URL || 'https://api.anthropic.com/v1'),
+});
+
+const openai = createOpenAI({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.OPENAI_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : process.env.OPENAI_BASE_URL,
+});
+
+const googleGenerativeAI = createGoogleGenerativeAI({
+ apiKey: process.env.AI_GATEWAY_API_KEY ?? process.env.GEMINI_API_KEY,
+ baseURL: isUsingAIGateway ? aiGatewayBaseURL : undefined,
+});
+
+// Schema for the AI's search plan - not file selection!
+const searchPlanSchema = z.object({
+ editType: z.enum([
+ 'UPDATE_COMPONENT',
+ 'ADD_FEATURE',
+ 'FIX_ISSUE',
+ 'UPDATE_STYLE',
+ 'REFACTOR',
+ 'ADD_DEPENDENCY',
+ 'REMOVE_ELEMENT'
+ ]).describe('The type of edit being requested'),
+
+ reasoning: z.string().describe('Explanation of the search strategy'),
+
+ searchTerms: z.array(z.string()).describe('Specific text to search for (case-insensitive). Be VERY specific - exact button text, class names, etc.'),
+
+ regexPatterns: z.array(z.string()).optional().describe('Regex patterns for finding code structures (e.g., "className=[\\"\\\'].*header.*[\\"\\\']")'),
+
+ fileTypesToSearch: z.array(z.string()).default(['.jsx', '.tsx', '.js', '.ts']).describe('File extensions to search'),
+
+ expectedMatches: z.number().min(1).max(10).default(1).describe('Expected number of matches (helps validate search worked)'),
+
+ fallbackSearch: z.object({
+ terms: z.array(z.string()),
+ patterns: z.array(z.string()).optional()
+ }).optional().describe('Backup search if primary fails')
+});
+
+export async function POST(request: NextRequest) {
+ try {
+ const { prompt, manifest, model = 'openai/gpt-oss-20b' } = await request.json();
+
+ console.log('[analyze-edit-intent] Request received');
+ console.log('[analyze-edit-intent] Prompt:', prompt);
+ console.log('[analyze-edit-intent] Model:', model);
+ console.log('[analyze-edit-intent] Manifest files count:', manifest?.files ? Object.keys(manifest.files).length : 0);
+
+ if (!prompt || !manifest) {
+ return NextResponse.json({
+ error: 'prompt and manifest are required'
+ }, { status: 400 });
+ }
+
+ // Create a summary of available files for the AI
+ const validFiles = Object.entries(manifest.files as Record